
An Open-Source Wireless Sensor Node Platform with Active Node-Level Reliability for Monitoring Applications


Abstract
:1. Introduction
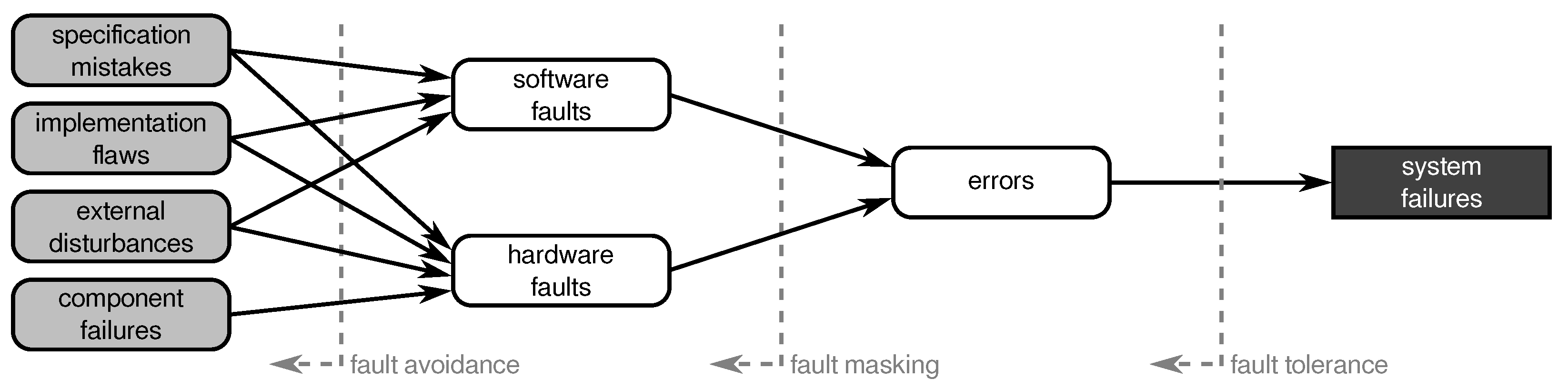
1.1. Faults Pose a Serious Threat
- low-cost components,
- limited resources (especially energy), and
- the often harsh environmental conditions.
- an outlier detection in the sensor data,
- a dense deployment to identify deviations between the measurements reported by neighboring nodes, or
- simple node-level diagnostics such as a monitoring of the battery voltage.
1.2. Active Node-Level Reliability
1.3. Contribution, Methodology and Outline
- a literature review on recent sensor node platforms,
- a taxonomy for faults in WSNs,
- a practical evaluation of the fault indicator concept proposed in [4], and
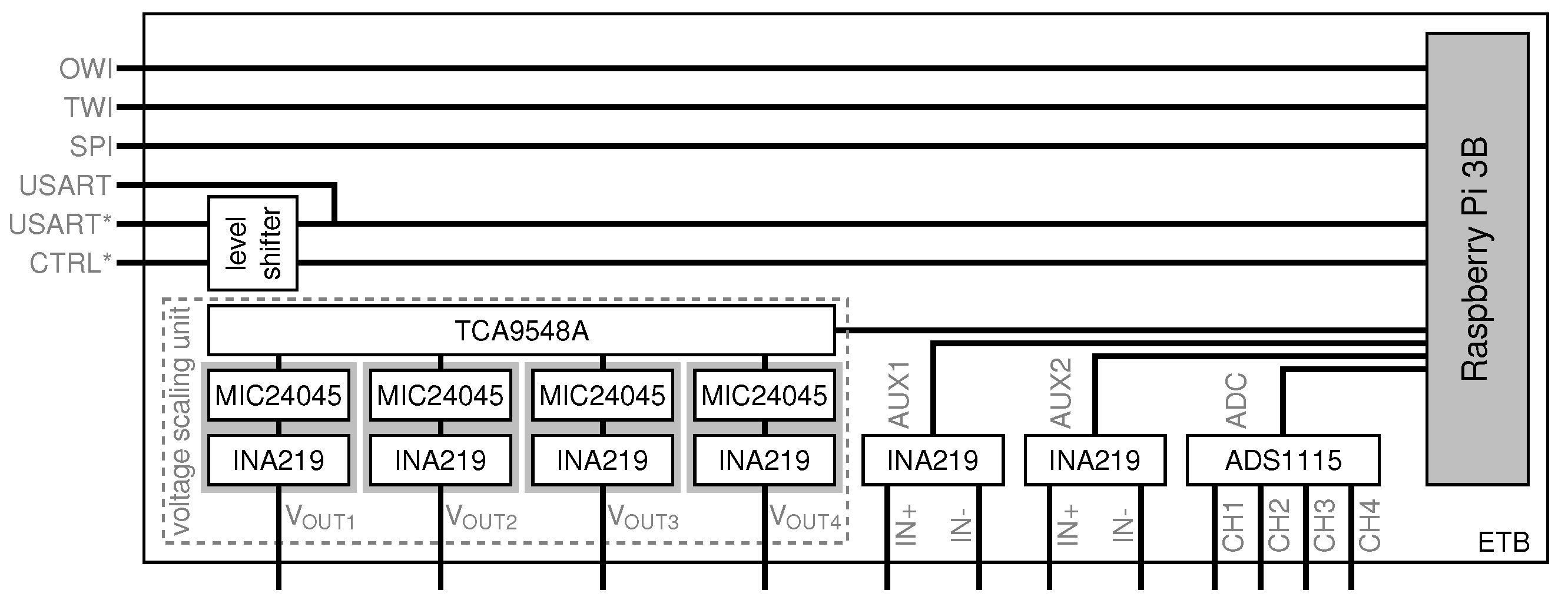
- the presentation of our embedded testbench (ETB), a Raspberry Pi hardware add-on that enables the analysis and profiling of embedded systems like sensor nodes.
- an indoor deployment (i.e., normal operation in a controlled environment),
- an outdoor deployment (i.e., normal operation in an uncontrolled environment), and
- a lab setup running automated experiments with configurable environmental conditions such as the ambient temperature or the supply voltage, thus, forcing the sensor node in a form of impaired operation in a controlled environment.
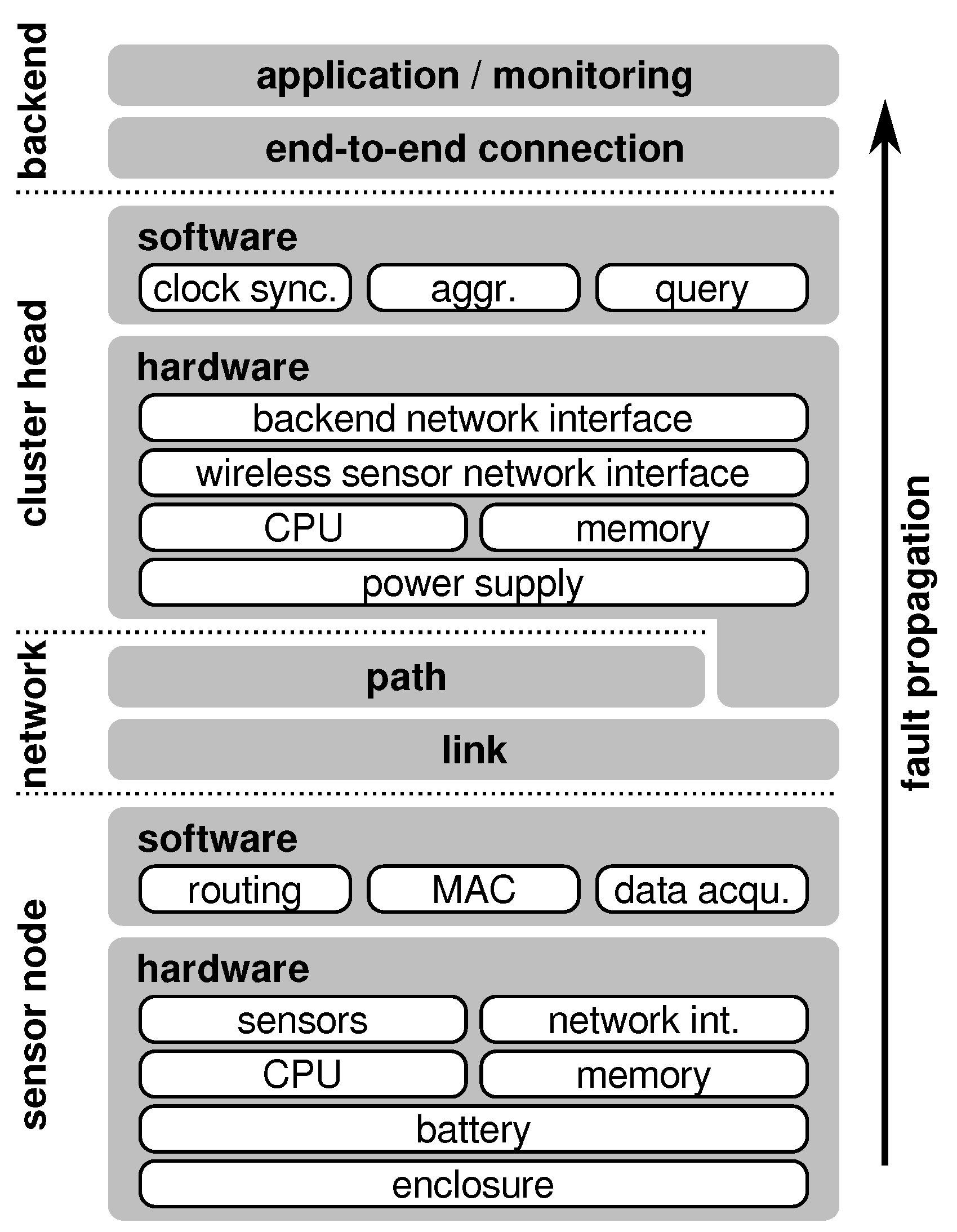
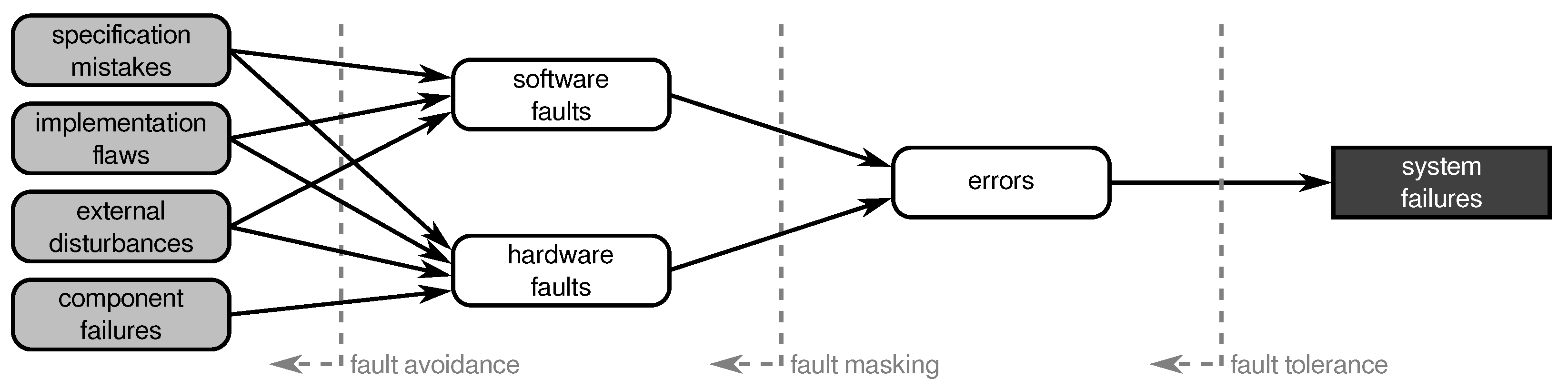
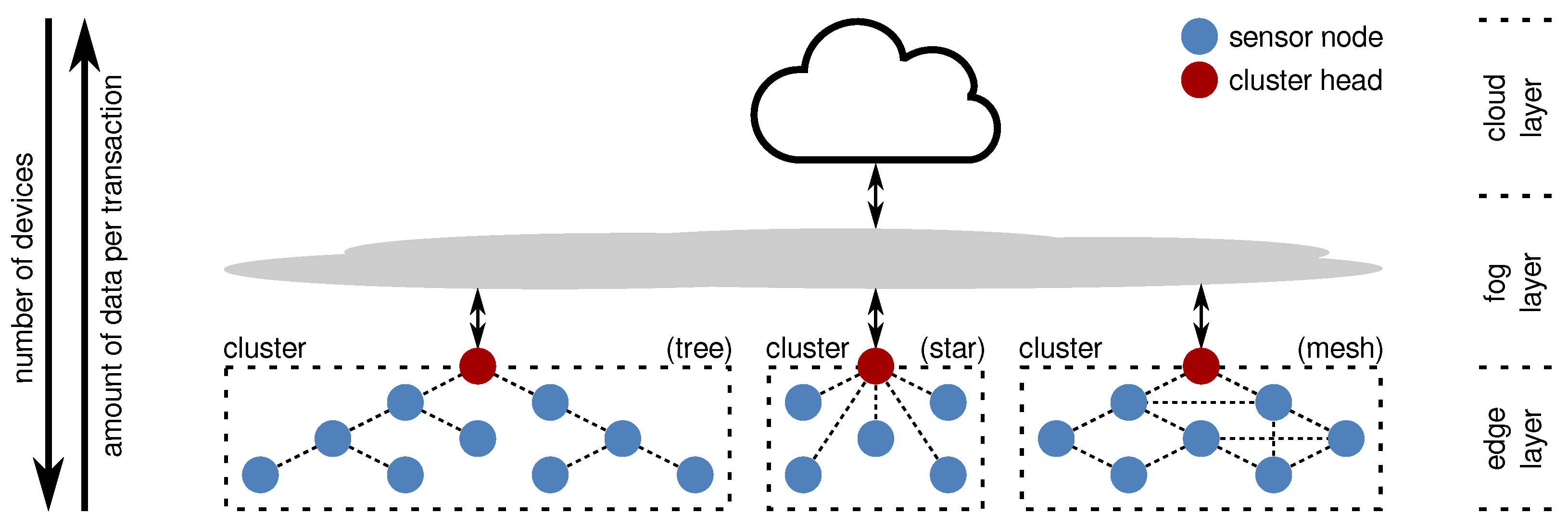
2. Faults in Wireless Sensor Networks
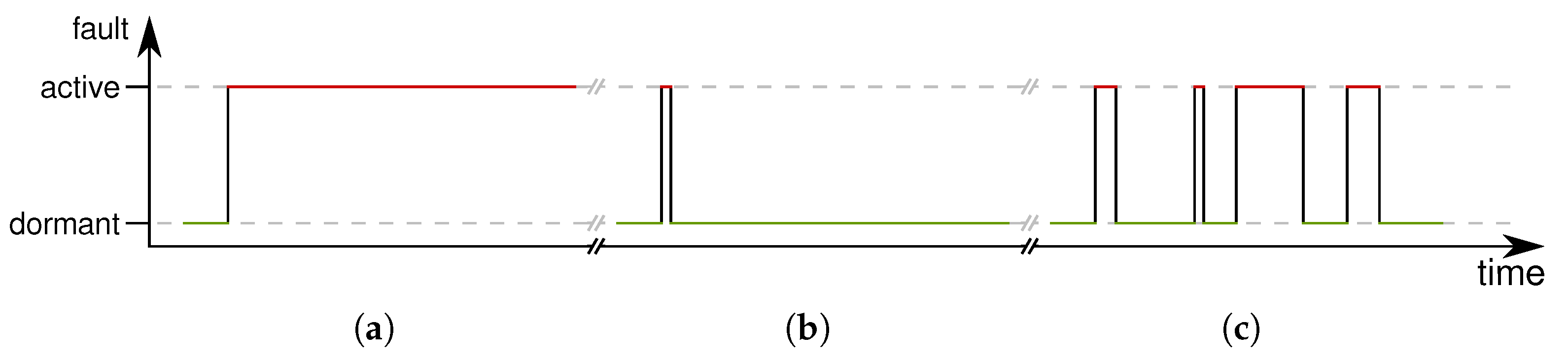
2.1. Terminology
- system-level fault tolerance,
- network-level fault tolerance, and
- node-level fault tolerance.
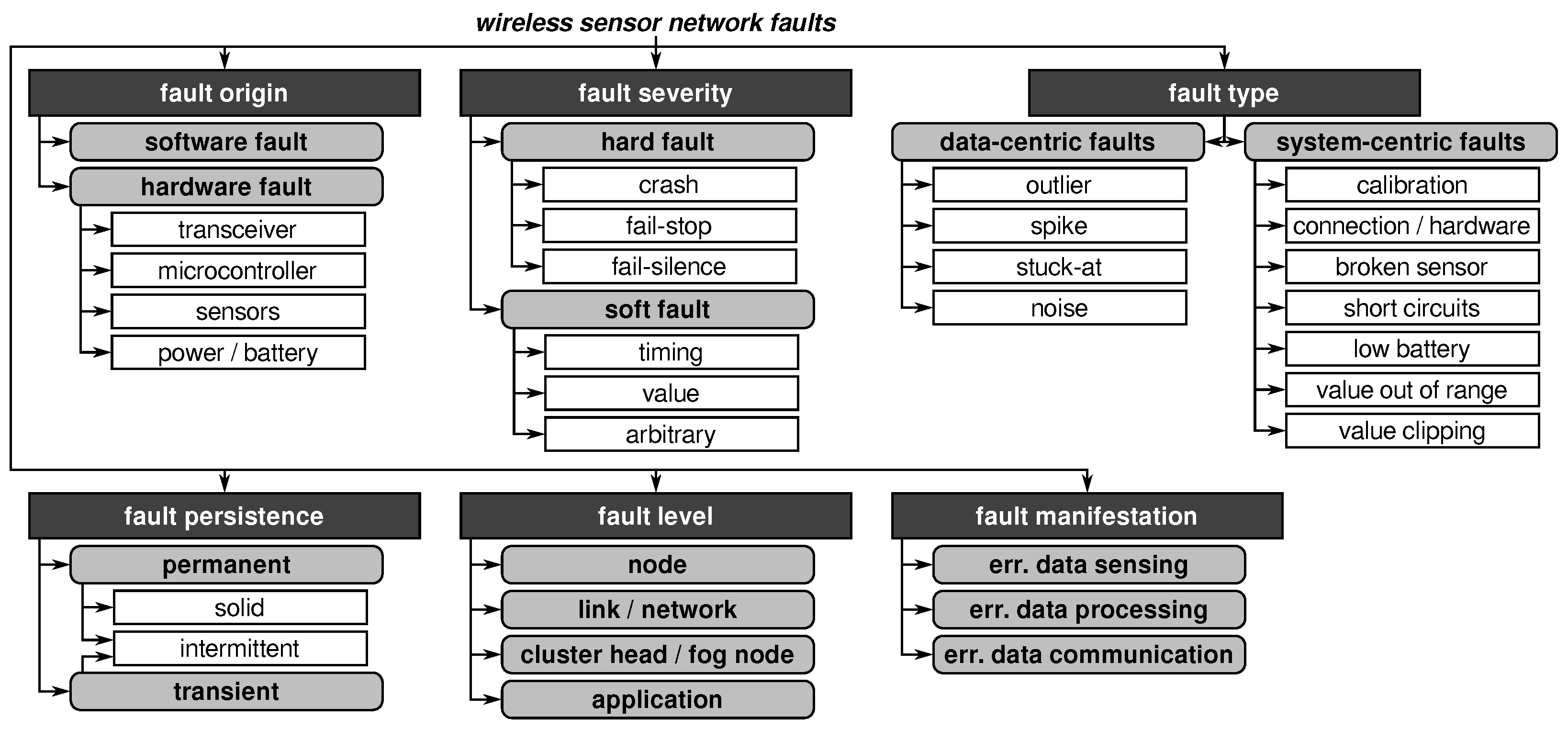
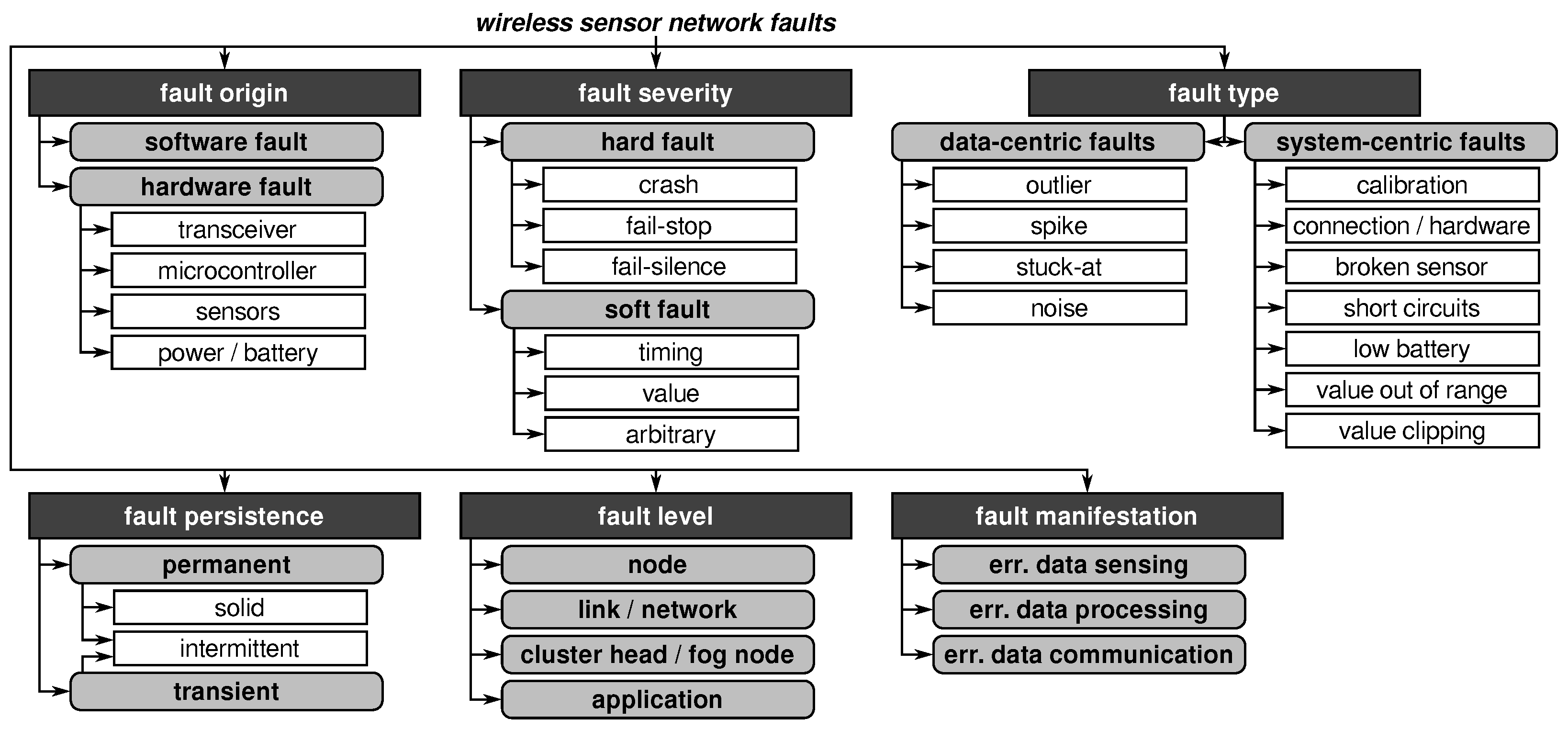
2.2. Wireless Sensor Network Fault Taxonomy
2.2.1. Fault Origin
2.2.2. Fault Severity
2.2.3. Fault Type
2.2.4. Fault Persistence
2.2.5. Fault Level
2.2.6. Fault Manifestation
- the measurement of certain physical quantities (i.e., data sensing),
- the (pre)processing of the acquired data (i.e., data processing), and
- the forwarding of these data via the network (i.e., data communication).
2.3. Faults vs. Anomalies
“Unless ground truth is known or given by something with high confidence, the term fault can only refer to a deviation from the expected model of the phenomenon.”
2.4. Fault Detection in WSNs
- sensor data analysis (see Section 2.4.1),
- group detection (see Section 2.4.2), and
- local self-diagnosis (see Section 2.4.3).
2.4.1. Sensor Data Analysis
- (i)
- statistics-based,
- (ii)
- rule-based,
- (iii)
- time series analysis-based, or
- (iv)
- learning-based methods.
2.4.2. Group Detection
- (i)
- the sensor nodes are deployed densely (i.e., the difference in the measurements of two error-free sensor nodes is negligibly small),
- (ii)
- faults occur rarely and without systemic dependencies (i.e., the number of faulty nodes is much smaller than the number of non-faulty nodes), and
- (iii)
- faults significantly alter the sensor data (i.e., a faulty sensor reading significantly deviates from proper readings of its local neighbors).
2.4.3. Local Self-Diagnosis
3. Sensor Node Platforms
- (i)
- to build sensor nodes from scratch (custom nodes),
- (ii)
- to utilize a generic embedded platform (semi-custom nodes), or
- (iii)
- to use an available sensor node platform (commercial or academic nodes).
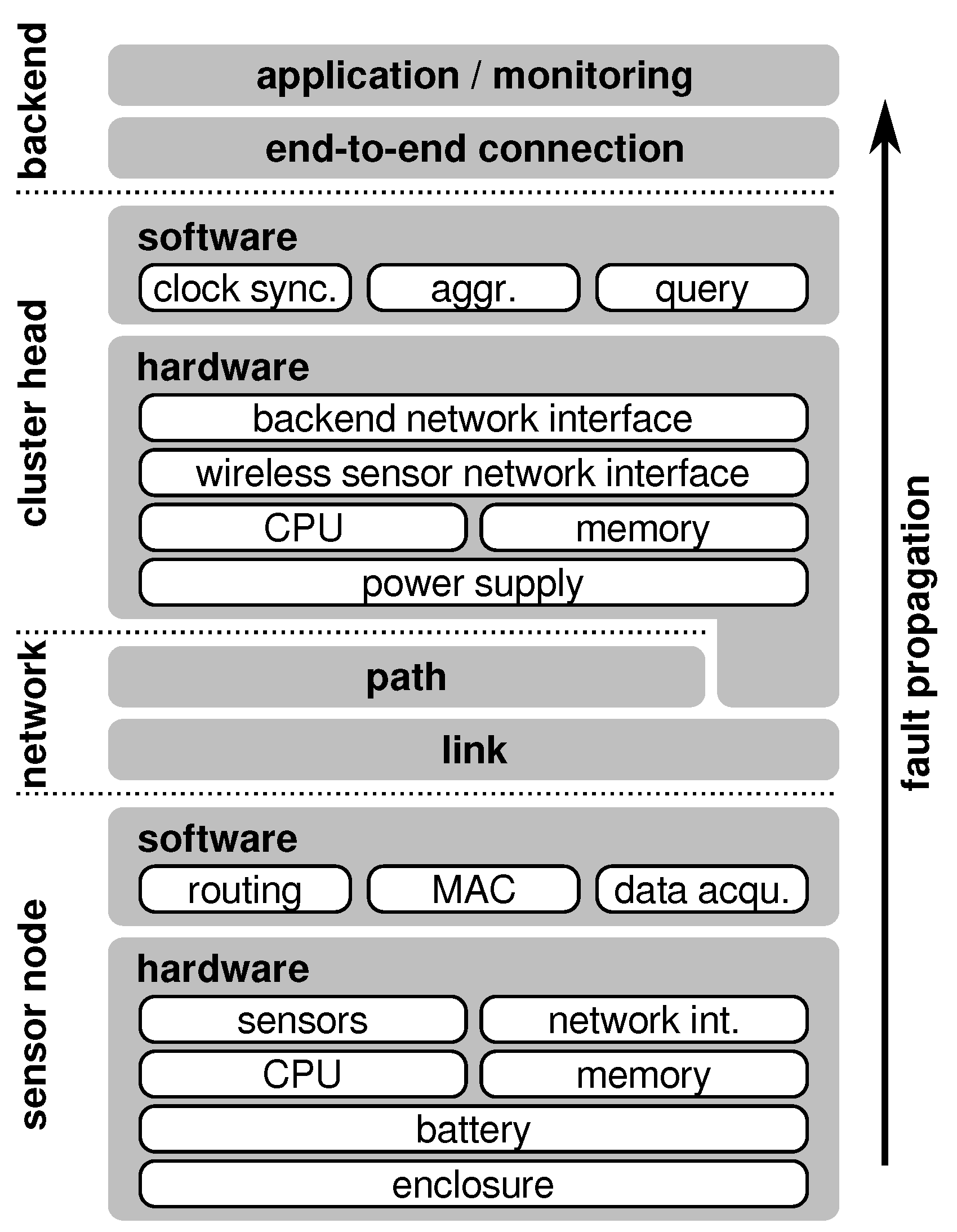
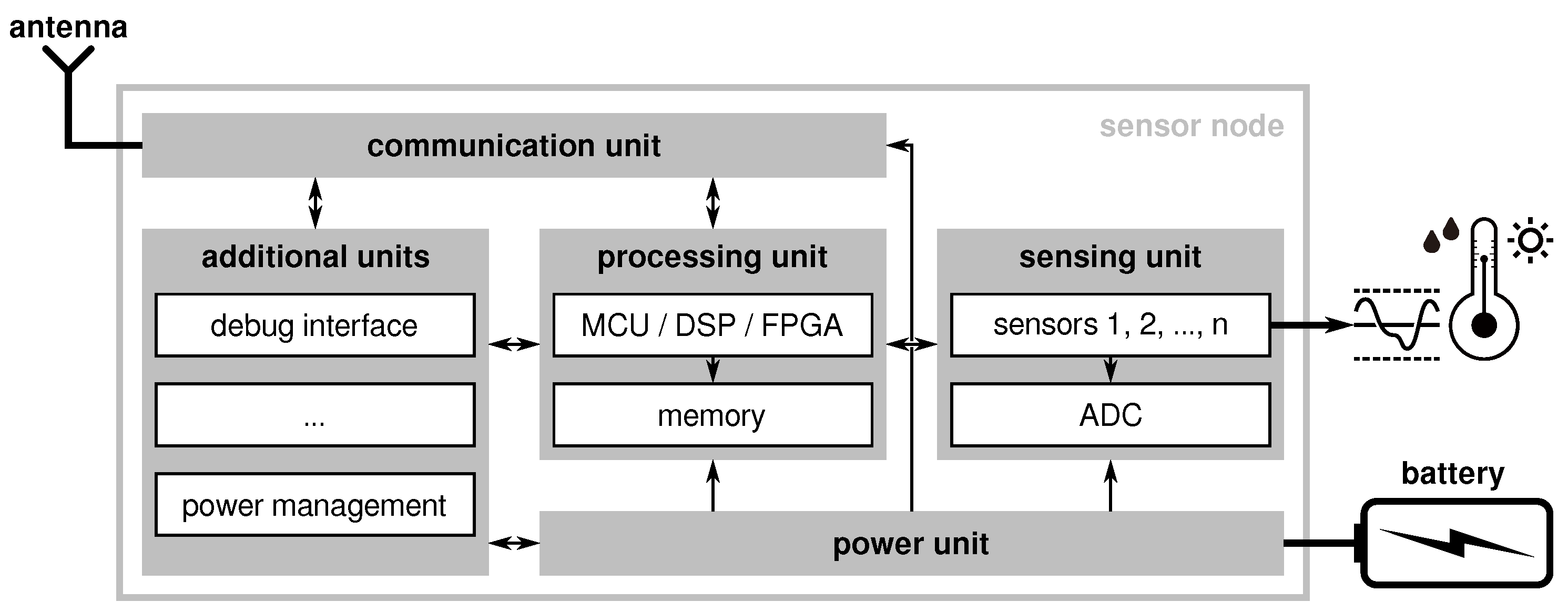
3.1. Basic Components
- (i)
- a set of sensors,
- (ii)
- a processing unit (optionally with external memory),
- (iii)
- a radio transceiver, and
- (iv)
- a power unit with a power source (i.e., a battery).
3.2. Related Sensor Node Platforms
- “WSN” OR “wireless sensor network” OR “sensor network” OR “sensor”
- “node” OR “mote” OR “board” OR “platform”
- “design” OR “development” OR “implementation” OR “concept”
- “reliability” OR “resilience” OR “fault tolerance” OR “fault diagnosis”
-
![Sensors 21 07613 i001]()
- refers to nodes using a DC/DC converter,
-
![Sensors 21 07613 i002]()
- denotes nodes using a linear regulator (e.g., low-dropout regulator (LDO)), and
-
![Sensors 21 07613 i003]()
- highlights nodes that have the battery directly connected to the core supply rail.
-
![Sensors 21 07613 i001]()
- means that all related information is publicly available,
-
![Sensors 21 07613 i002]()
- refers to nodes where only parts are available (mostly the software), and
-
![Sensors 21 07613 i003]()
- shows that no information has been made publicly available.
3.2.1. Energy-Efficient Sensor Nodes
- (i)
- the duration of the active and the sleep phases (i.e., duty-cycling) and
- (ii)
- the power consumption in both phases (i.e., energy-efficient hardware).
3.2.2. Self-Diagnostic Sensor Nodes
- the secondary MCU can be impaired by faults, too, and
- checking the primary MCU’s ALU only is insufficient to ensure reliability.
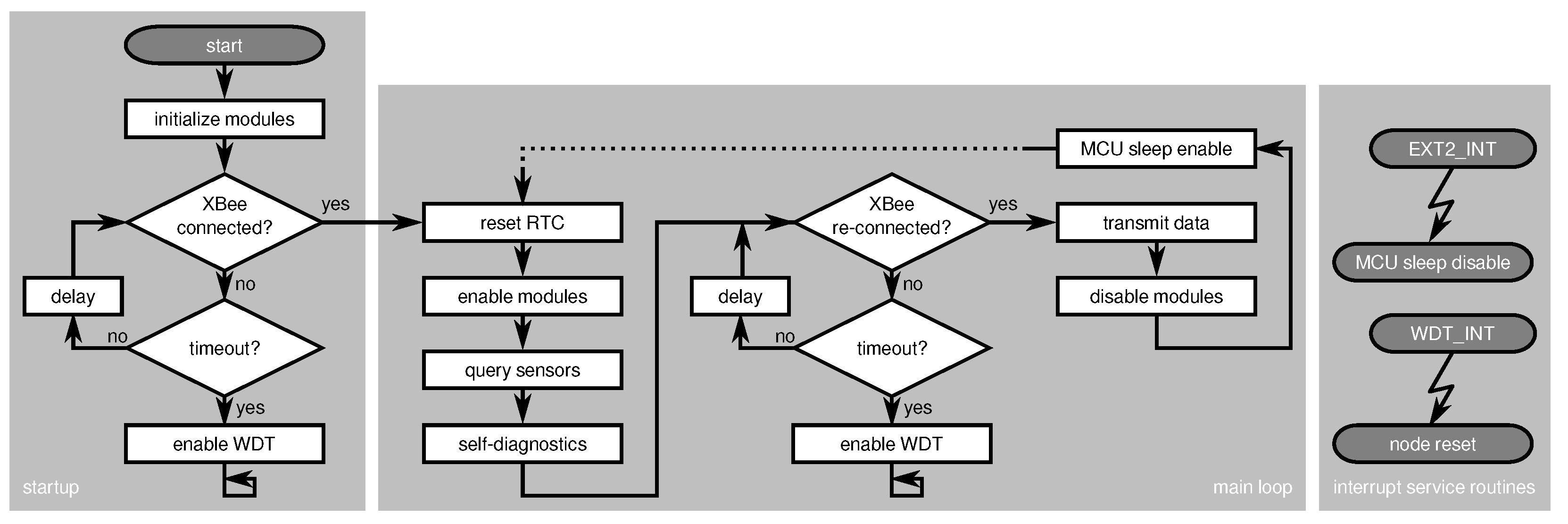
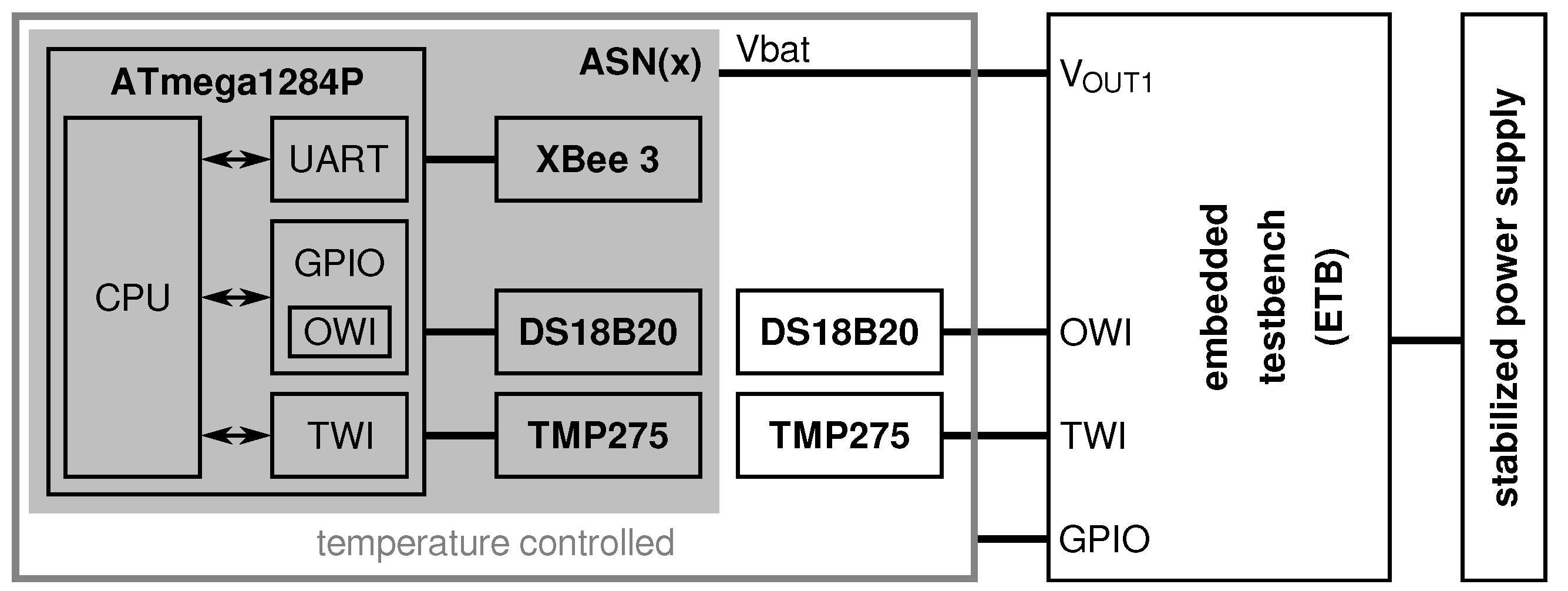
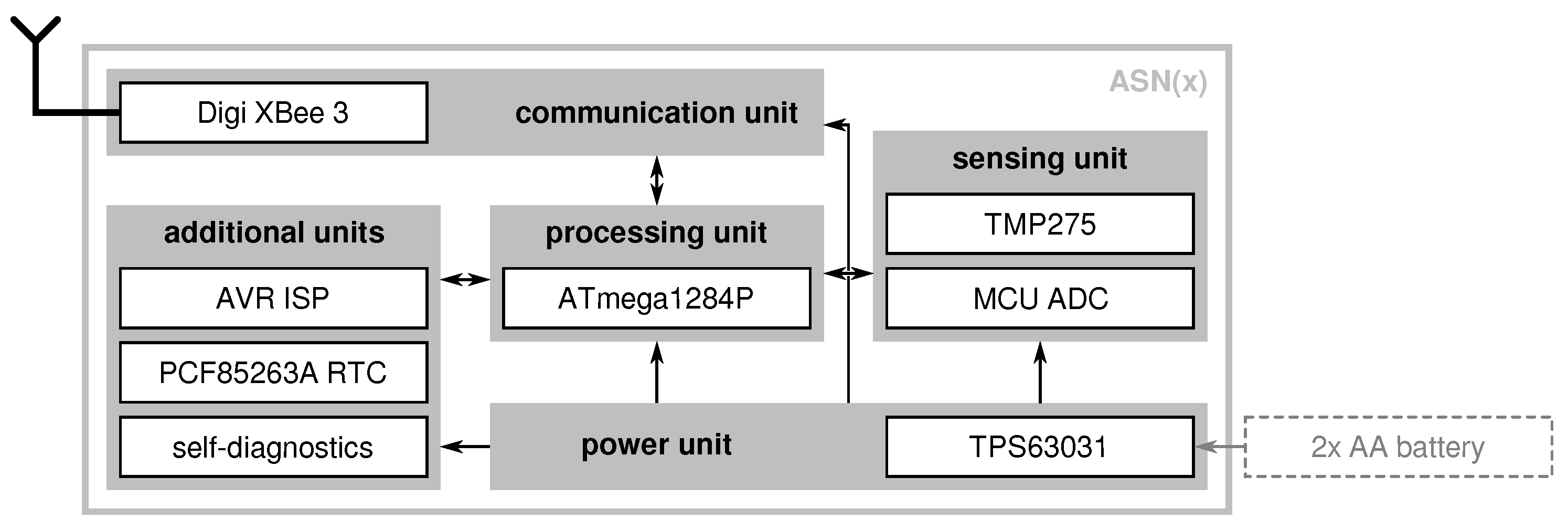
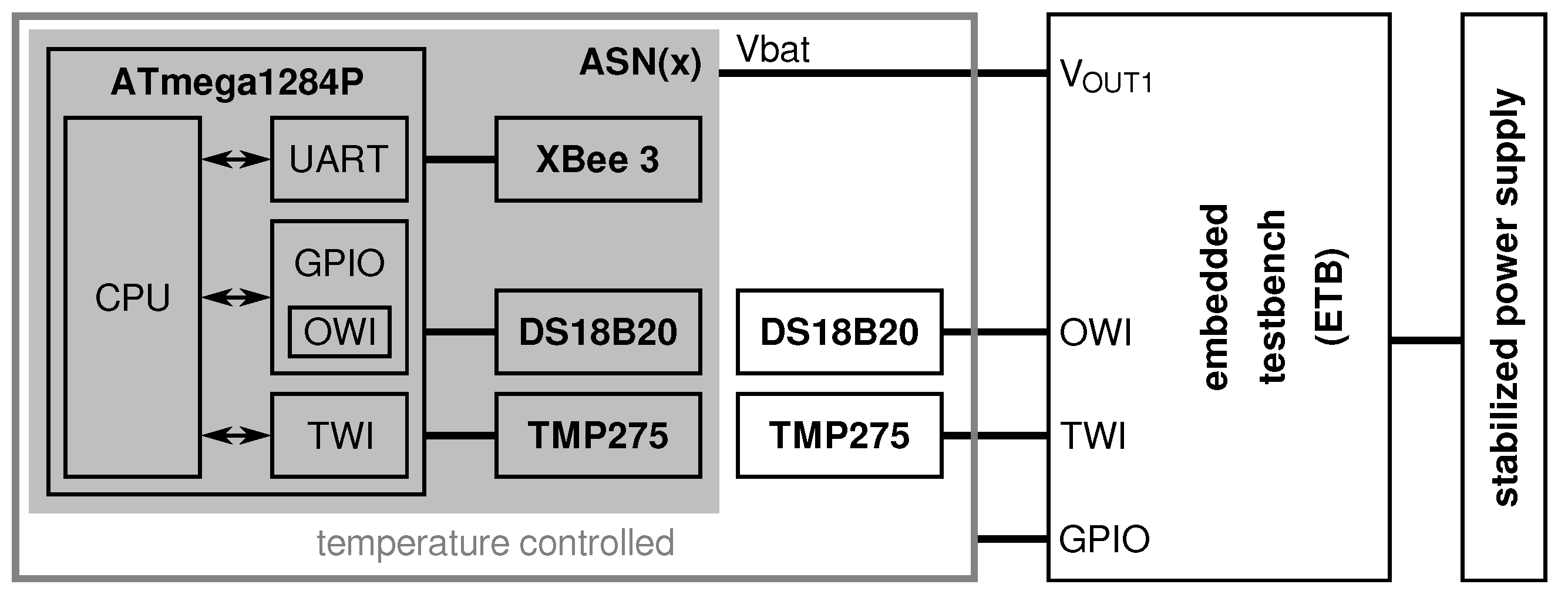
4. ASN(x)—An AVR-Based Sensor Node with Xbee Radio
- enables active node-level reliability by incorporating self-check capabilities,
- offers an energy-efficient operation especially suitable for monitoring applications,
- is versatile regarding its usage (i.e., modular expandability),
- is based on current components that are highly available on the market,
- is comparably cheap (about $50 per node including the radio), and
- is completely open-source published on Github under the MIT license.
- a processing unit (see Section 4.1),
- a sensing unit (see Section 4.2),
- a power unit (see Section 4.3), and
- a transceiver unit (see Section 4.4).
4.1. Processing Unit
4.2. Sensing Unit
4.3. Power Unit
4.4. Transceiver Unit
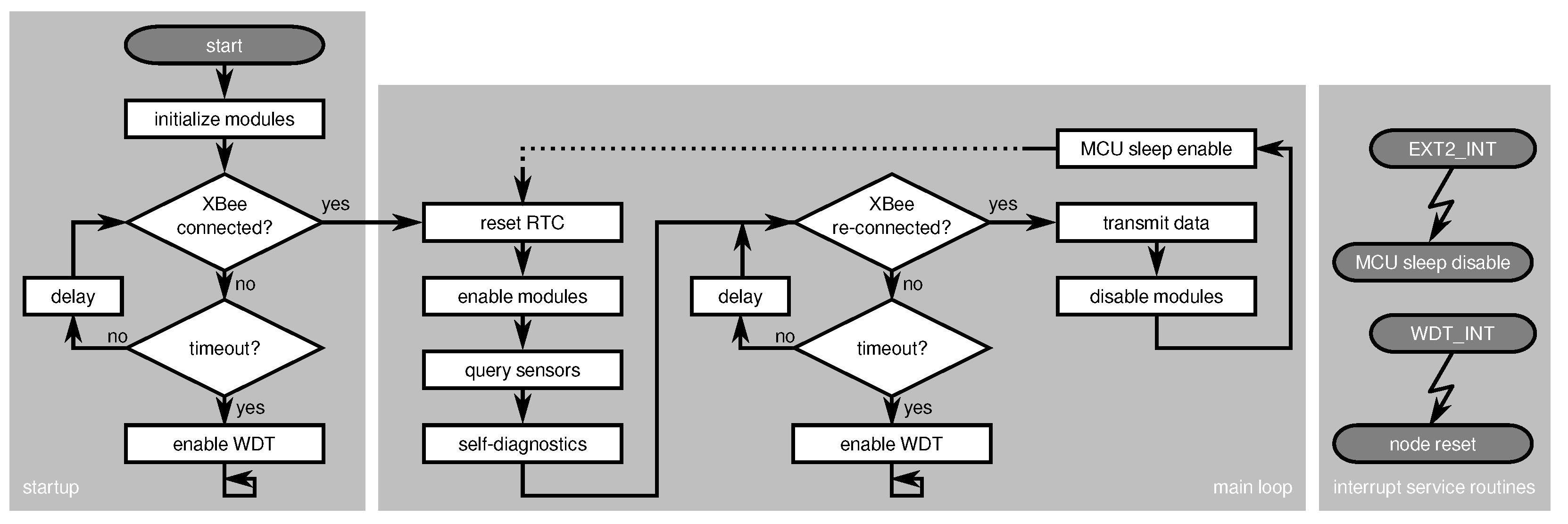
4.5. Node-Level Indicators
4.5.1. Node Temperature Monitor
4.5.2. Supply Voltage Monitor
4.5.3. Battery Voltage Monitor
4.5.4. Active Runtime Monitor
4.5.5. Reset Monitor
- bit 0: power-on reset,
- bit 1: external reset (via the reset pin),
- bit 2: brown-out reset (in case the brown-out detection is enabled), and
- bit 3: watchdog reset.
4.5.6. Software Incident Counter
4.5.7. ADC Self-Check
4.5.8. USART Self-Check
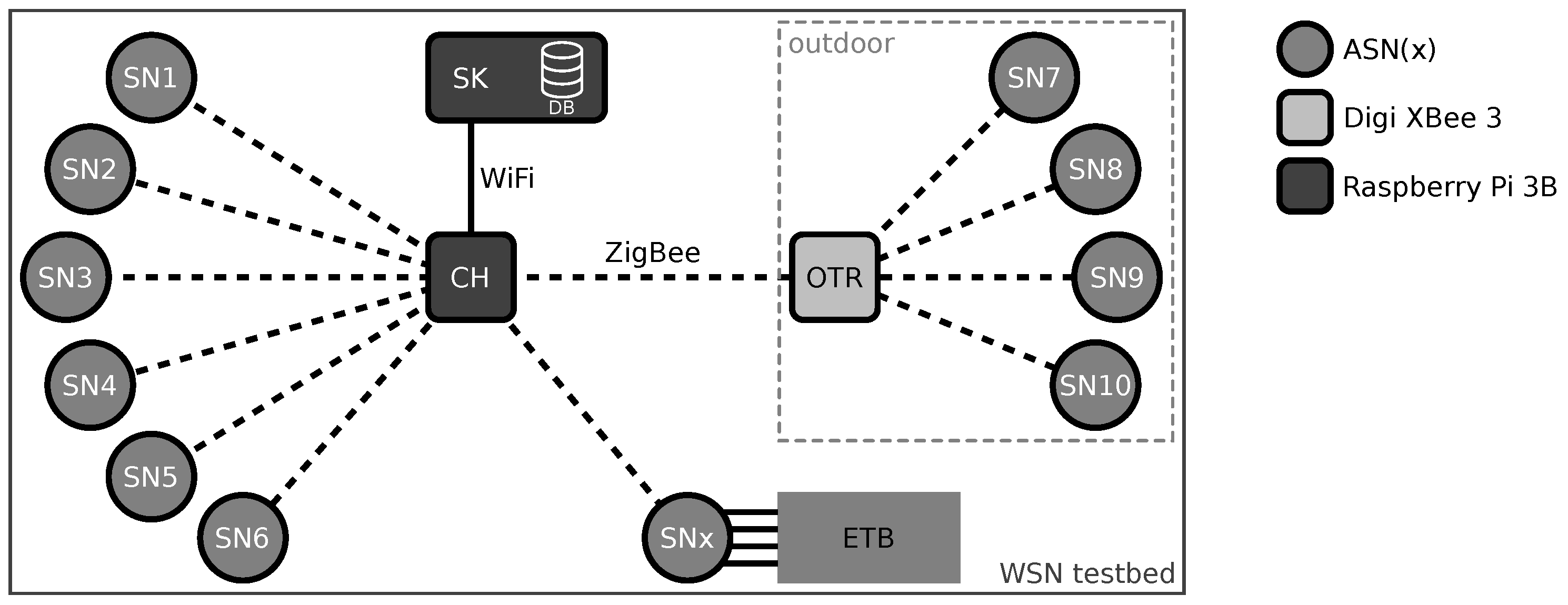
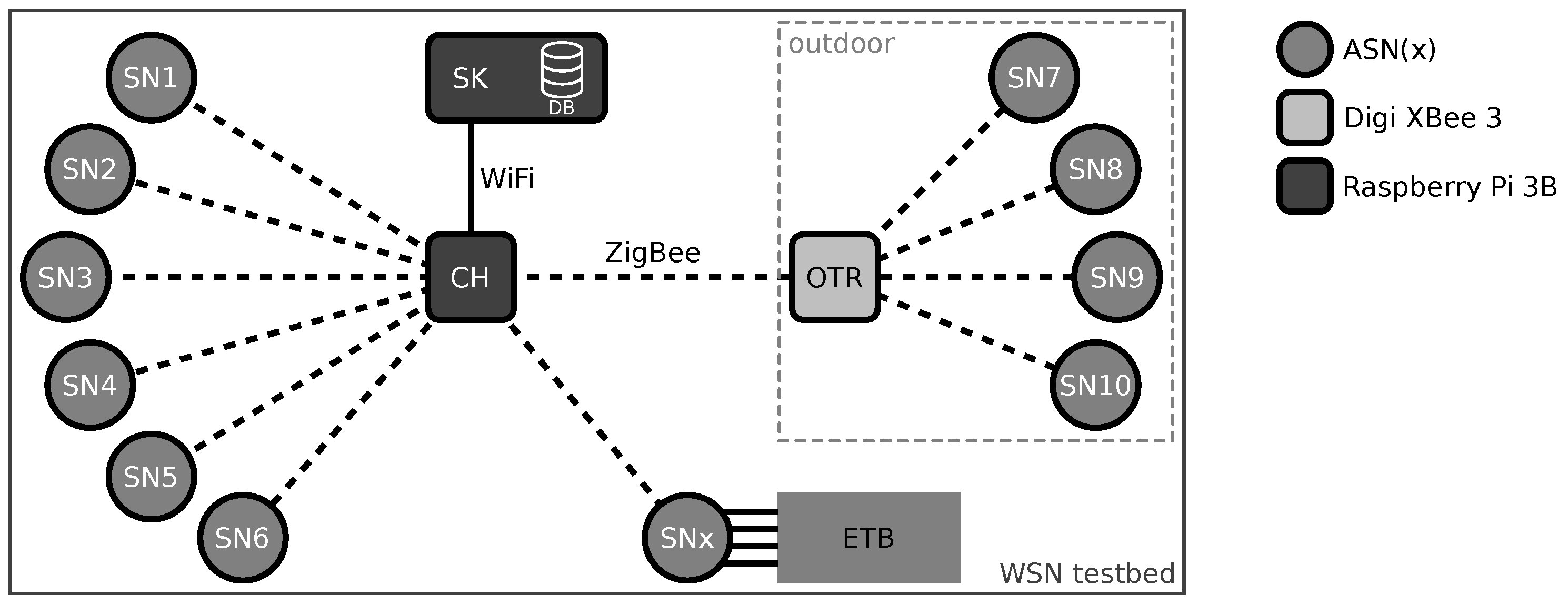
5. Evaluation Experiment Setup
- an indoor deployment consisting of six SNs,
- an outdoor deployment consisting of four SNs, and
- a lab experiment setup analyzing one dedicated SN controlled by our embedded testbench (ETB).
5.1. Indoor Deployment
5.2. Outdoor Deployment
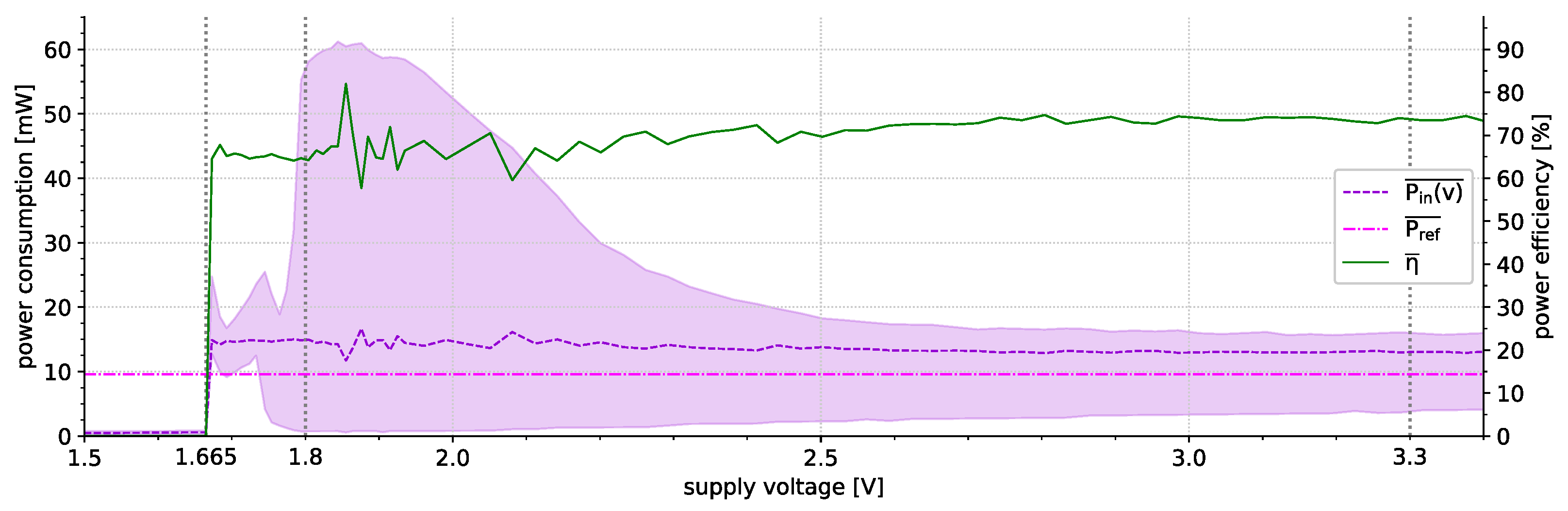
5.3. Embedded Testbench (ETB)-Based Lab Experiments
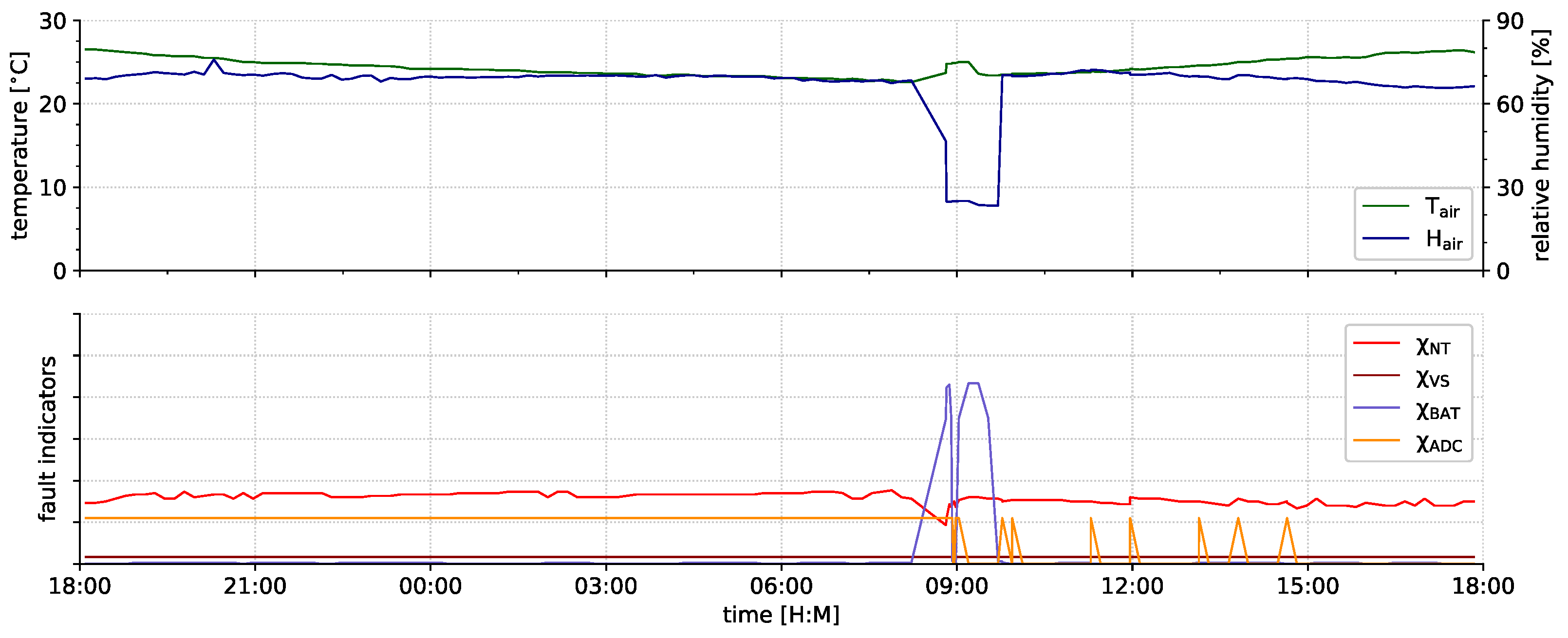
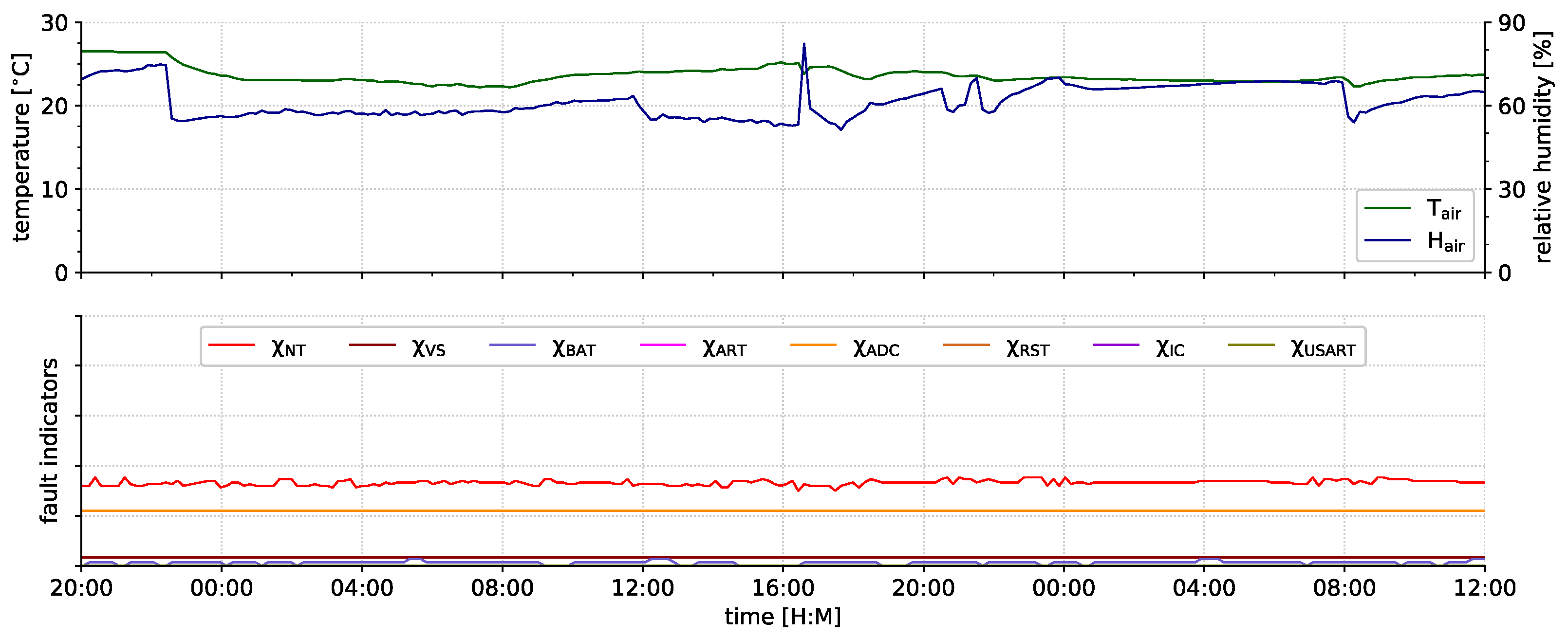
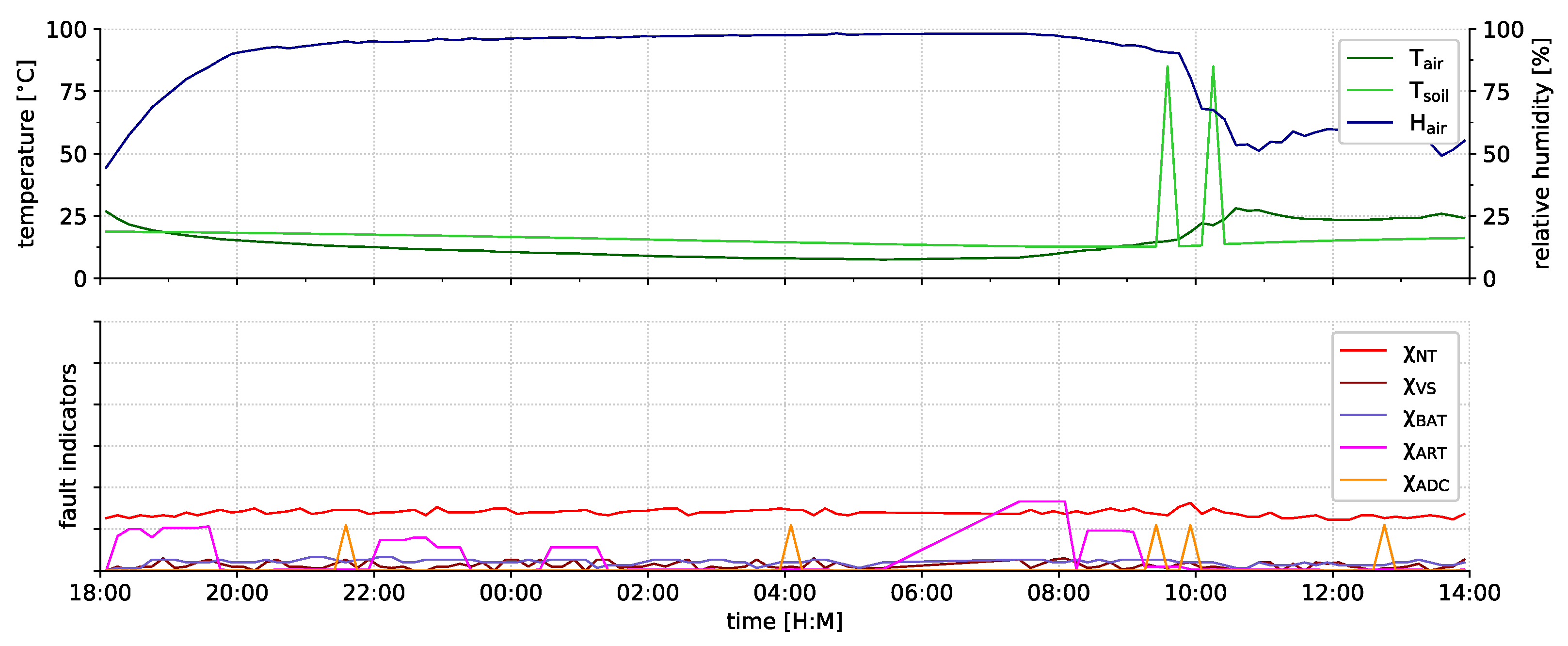
6. Results
- reliability and
- energy efficiency.
- the fault indicators can indicate an impaired node operation.
- the fault indicators do not cause false alarms in case of rare but proper events.
- some types of faults were not detected by our current fault indicators.
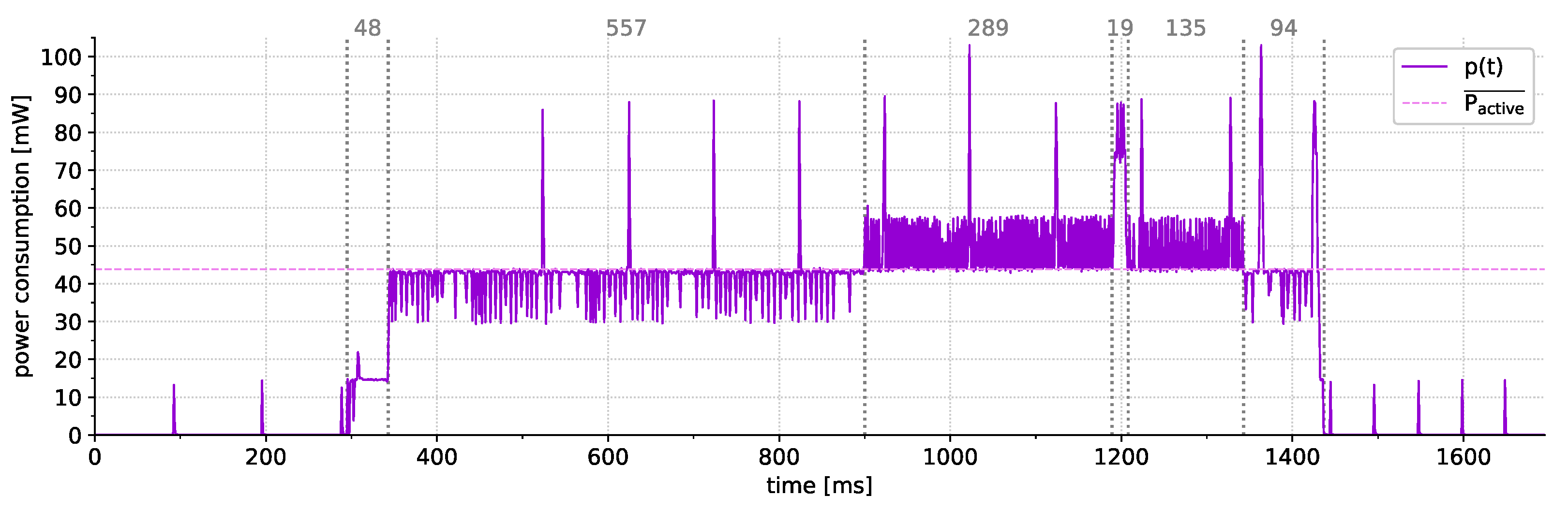
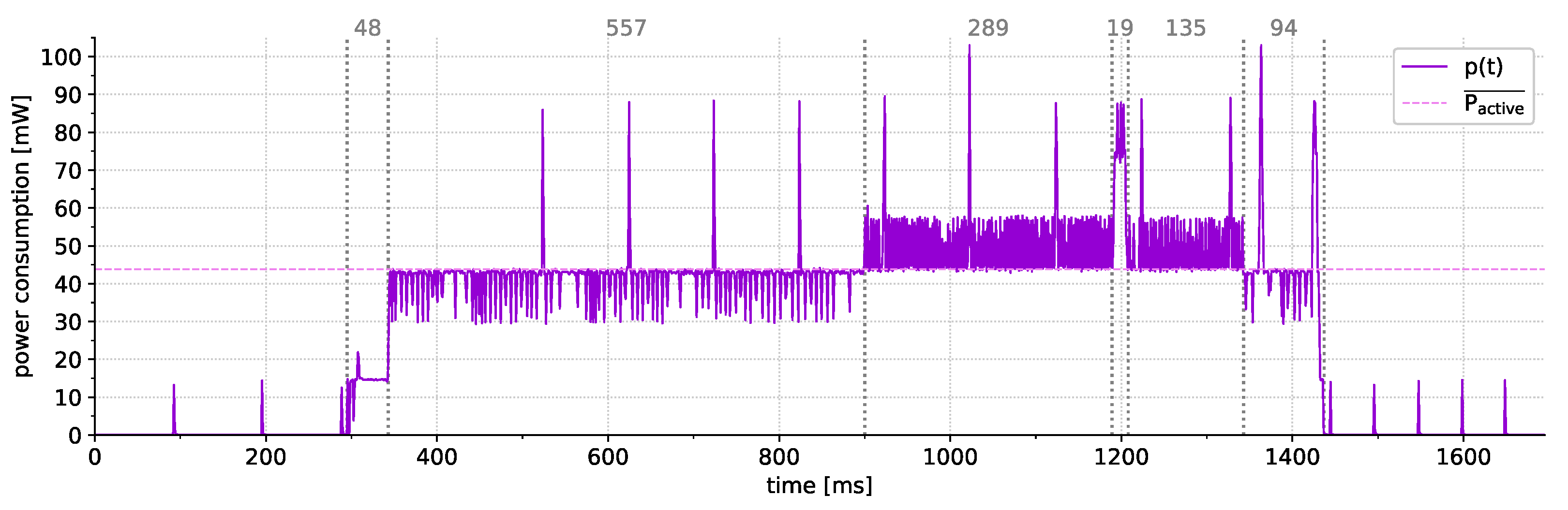
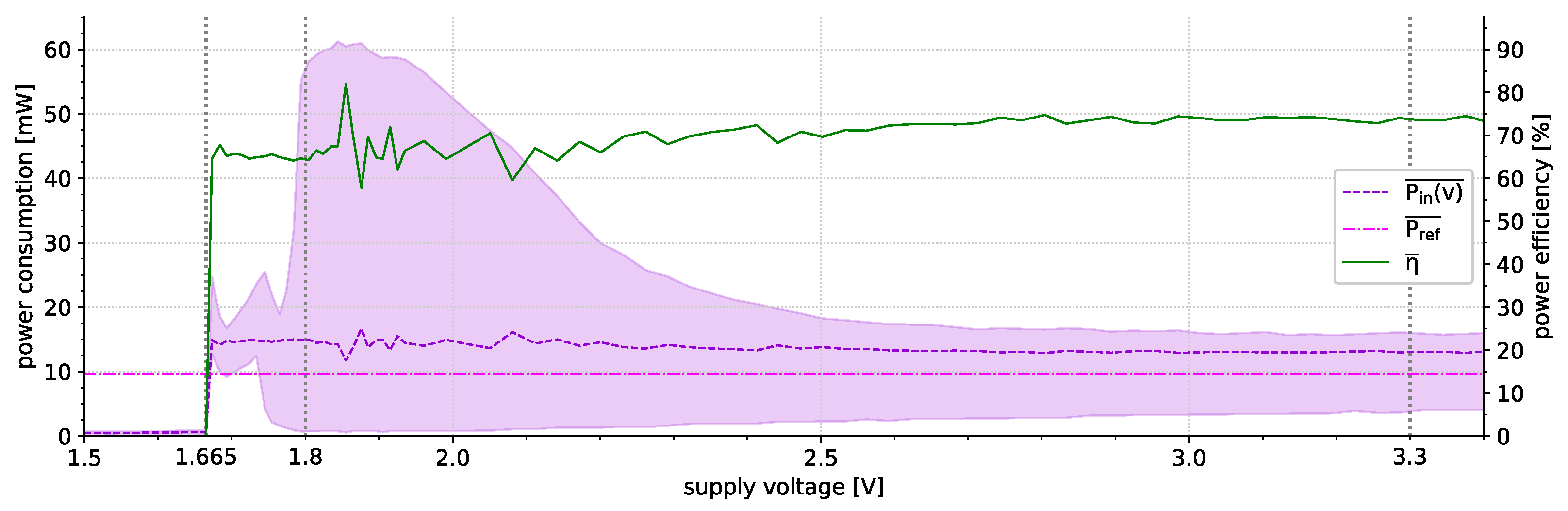
6.1. Power Consumption
- 13.4 mA/44.22 mW (MCU idling; XBee enabled; diagnostics enabled),
- 12.2 mA/40.26 mW (MCU idling; XBee enabled; diagnostics disabled),
- 4.68 mA/15.44 mW (MCU idling; XBee disabled; diagnostics disabled).
- 36.7 A/121.11 W (MCU power-down; XBee disabled; diagnostics disabled)
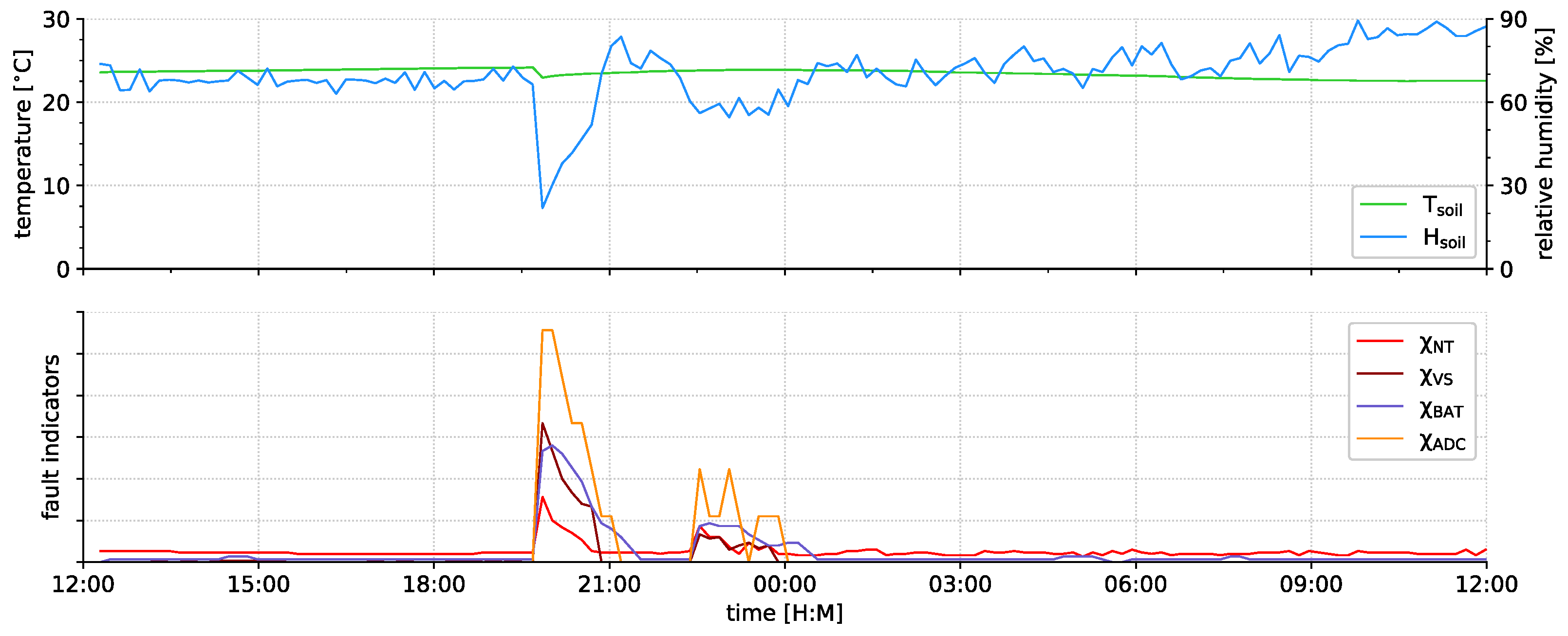
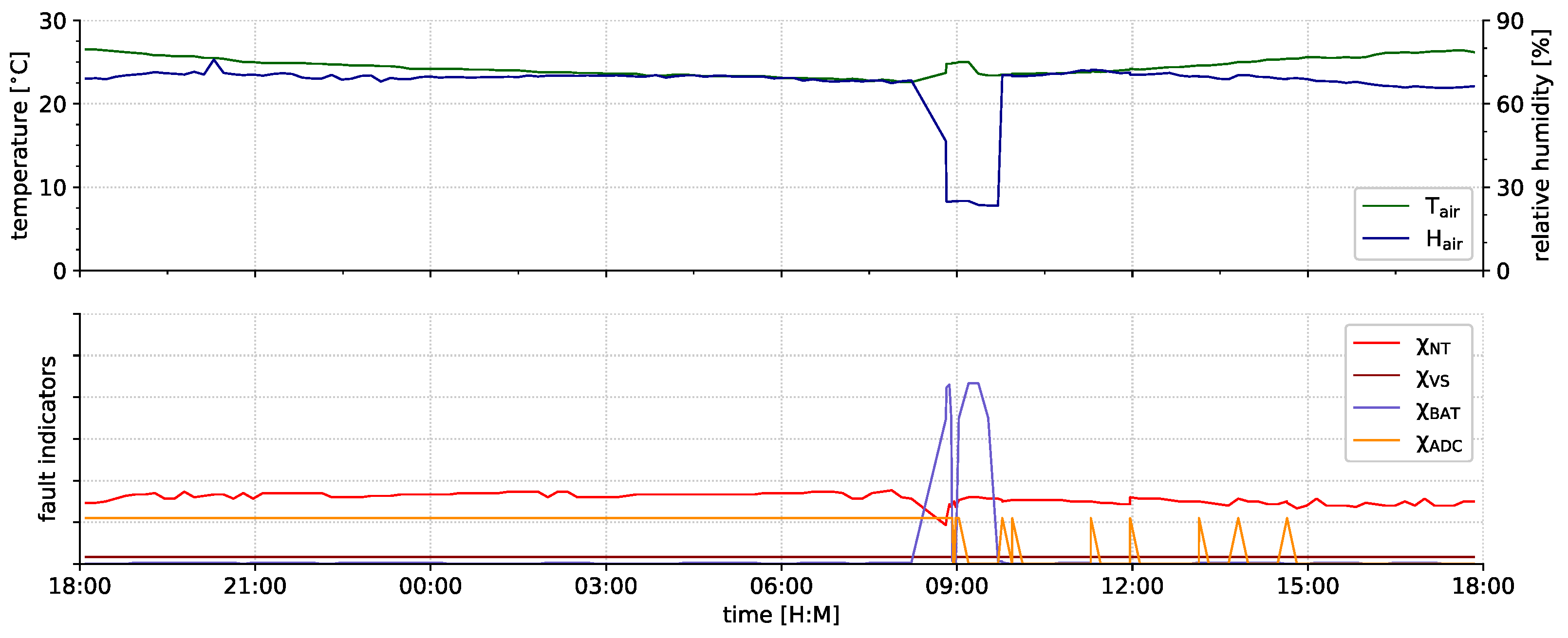
6.2. Indicator Evaluation
- successfully detected faults (see Section 6.2.1),
- proper events that can be distinguished from faults (see Section 6.2.2), and
- faults that have not been indicated by our current fault indicators (see Section 6.2.3).
6.2.1. Fault Indication
6.2.2. Event Indication
6.2.3. Undetected Faults
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ADC | analog-to-digital converter |
| ALU | arithmetic logic unit |
| AIS | artificial immune system |
| ASN(x) | AVR-based Sensor Node with Xbee radio |
| AVR | Alf and Vegard’s RISC |
| BLE | Bluetooth low energy |
| CH | cluster head |
| CMOS | complementary metal oxide semiconductor |
| CPS | cyber-physical system |
| CPU | central processing unit |
| DFS | dynamic frequency scaling |
| DSP | digital signal processor |
| DUT | device under test |
| DVS | dynamic voltage scaling |
| EEPROM | electrically erasable programmable read-only memory |
| ETB | embedded testbench |
| FPGA | field-programmable gate array |
| GPIO | general purpose input/output |
| HCI | hot carrier injection |
| I2C | inter-integrated circuit |
| IEEE | Institute of Electrical and Electronics Engineers |
| ISM | industrial, scientific and medical |
| ISP | in-system programmer |
| JTAG | Joint Test Action Group |
| LDO | low-dropout regulator |
| LED | light-emitting diode |
| LoRaWAN | long-range wide-area network |
| LPWAN | low-power wide-area network |
| MCU | microcontroller unit |
| MCUSR | MCU status register |
| MIPS | million instructions per second |
| MOSFET | metal-oxide-semiconductor field-effect transistor |
| NB-IoT | narrowband Internet of Things |
| NBTI | negative bias temperature instability |
| NTC | negative temperature coefficient |
| OS | operating system |
| OTR | outdoor relay node |
| OWI | one-wire interface |
| PCB | printed circuit board |
| RAM | random-access memory |
| RF | radio frequency |
| RISC | reduced instruction set computer |
| RSSI | received signal strength indicator |
| RTC | real-time clock |
| SDM | sequential dependency model |
| SK | sink node |
| SN | sensor node |
| SNR | signal-to-noise ratio |
| SoC | system-on-a-chip |
| SPI | serial peripheral interface |
| SQL | structured query language |
| SRAM | static random-access memory |
| SVM | support-vector machine |
| TDDB | time dependent dielectric breakdown |
| THT | through-hole technology |
| TWI | two-wire interface |
| USART | universal synchronous/asynchronous receiver-transmitter |
| ULP | ultra low power |
| USB | universal serial bus |
| WDT | watchdog timer |
| WSN | wireless sensor network |
References
- Peng, N.; Zhang, W.; Ling, H.; Zhang, Y.; Zheng, L. Fault-Tolerant Anomaly Detection Method in Wireless Sensor Networks. Information 2018, 9, 236. [Google Scholar] [CrossRef] [Green Version]
- Titouna, C.; Aliouat, M.; Gueroui, M. FDS: Fault Detection Scheme for Wireless Sensor Networks. Wirel. Pers. Commun. 2016, 86, 549–562. [Google Scholar] [CrossRef]
- Widhalm, D.; Goeschka, K.M.; Kastner, W. SoK: A Taxonomy for Anomaly Detection in Wireless Sensor Networks Focused on Node-Level Techniques. In Proceedings of the 15th International Conference on Availability, Reliability and Security, ARES’20, New York, NY, USA, 25–28 August 2020. [Google Scholar] [CrossRef]
- Widhalm, D.; Goeschka, K.M.; Kastner, W. Node-level indicators of soft faults in wireless sensor networks. In Proceedings of the 2021 40th International Symposium on Reliable Distributed Systems (SRDS), Virtual Event, 20–23 September 2021; pp. 13–22. [Google Scholar] [CrossRef]
- Avizienis, A.; Laprie, J.; Randell, B.; Landwehr, C. Basic concepts and taxonomy of dependable and secure computing. IEEE Trans. Dependable Secur. Comput. 2004, 1, 11–33. [Google Scholar] [CrossRef] [Green Version]
- Widhalm, D.; Goeschka, K.M.; Kastner, W. Is Arduino a suitable platform for sensor nodes? In Proceedings of the IECON 2021 The 47th Annual Conference of the IEEE Industrial Electronics Society, Virtual Event, 13–16 October 2021. In Press. [Google Scholar]
- Widhalm, D.; Goeschka, K.M.; Kastner, W. Undervolting on wireless sensor nodes: A critical perspective. In Proceedings of the 2022 23rd International Conference on Distributed Computing and Networking (ICDCN), New Delhi, India, 4–7 January 2022. In Press. [Google Scholar] [CrossRef]
- Kulau, U.; Szafranski, D.; Wolf, L. Effective but Lightweight Online Selftest for Energy-Constrained WSNs. In Proceedings of the 2018 IEEE 43rd Conference on Local Computer Networks Workshops (LCN Workshops), Chicago, IL, USA, 1–4 October 2018; pp. 23–29. [Google Scholar]
- Dehwah, A.H.; Mousa, M.; Claudel, C.G. Lessons Learned on Solar Powered Wireless Sensor Network Deployments in Urban, Desert Environments. Ad Hoc Netw. 2015, 28, 52–67. [Google Scholar] [CrossRef]
- Ni, K.; Ramanathan, N.; Chehade, M.N.H.; Balzano, L.; Nair, S.; Zahedi, S.; Kohler, E.; Pottie, G.; Hansen, M.; Srivastava, M. Sensor Network Data Fault Types. ACM Trans. Sens. Netw. 2009, 5, 1–25. [Google Scholar] [CrossRef] [Green Version]
- Bhuiyan, M.Z.A.; Wang, G.; Wu, J.; Cao, J.; Liu, X.; Wang, T. Dependable Structural Health Monitoring Using Wireless Sensor Networks. IEEE Trans. Dependable Secur. Comput. 2017, 14, 363–376. [Google Scholar] [CrossRef]
- Marathe, S.; Nambi, A.; Swaminathan, M.; Sutaria, R. CurrentSense: A Novel Approach for Fault and Drift Detection in Environmental IoT Sensors. In Proceedings of the International Conference on Internet-of-Things Design and Implementatio, IoTDI’21n, Charlottesvle, VA, USA, 18–21 May 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 93–105. [Google Scholar] [CrossRef]
- Xu, Y.; Koren, I.; Krishna, C.M. AdaFT: A Framework for Adaptive Fault Tolerance for Cyber-Physical Systems. ACM Trans. Embed. Comput. Syst. 2017, 16, 1–25. [Google Scholar] [CrossRef]
- Tomiyama, T.; Moyen, F. Resilient architecture for cyber-physical production systems. CIRP Ann. 2018, 67, 161–164. [Google Scholar] [CrossRef]
- Moridi, E.; Haghparast, M.; Hosseinzadeh, M.; Jassbi, S.J. Fault management frameworks in wireless sensor networks: A survey. Comput. Commun. 2020, 155, 205–226. [Google Scholar] [CrossRef]
- Raposo, D.; Rodrigues, A.; Sinche, S.; Silva, J.S.; Boavida, F. Industrial IoT Monitoring: Technologies and Architecture Proposal. Sensors 2018, 18, 3568. [Google Scholar] [CrossRef] [Green Version]
- Gerostathopoulos, I.; Skoda, D.; Plasil, F.; Bures, T.; Knauss, A. Architectural Homeostasis in Self-Adaptive Software-Intensive Cyber-Physical Systems. In Software Architecture; Tekinerdogan, B., Zdun, U., Babar, A., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 113–128. [Google Scholar]
- Hamdan, D.; Aktouf, O.; Parissis, I.; Hijazi, A.; Sarkis, M.; El Hassan, B. SMART Service for Fault Diagnosis in Wireless Sensor Networks. In Proceedings of the 2012 Sixth International Conference on Next Generation Mobile Applications, Services and Technologies, Paris, France, 12–14 September 2012; pp. 211–216. [Google Scholar]
- Johnson, B.W. Fault-Tolerant Microprocessor-Based Systems. IEEE Micro 1984, 4, 6–21. [Google Scholar] [CrossRef]
- Cinque, M.; Cotroneo, D.; Di Martino, C.; Russo, S.; Testa, A. AVR-INJECT: A tool for injecting faults in Wireless Sensor Nodes. In Proceedings of the 2009 IEEE International Symposium on Parallel Distributed Processing, Rome, Italy, 23–29 May 2009; pp. 1–8. [Google Scholar] [CrossRef]
- Sharma, A.B.; Golubchik, L.; Govindan, R. Sensor Faults: Detection Methods and Prevalence in Real-World Datasets. ACM Trans. Sens. Netw. 2010, 6, 1–39. [Google Scholar] [CrossRef]
- Boano, C.; Wennerström, H.; Zuniga, M.; Brown, J.; Keppitiyagama, C.; Oppermann, F.; Roedig, U.; Norden, L.A.; Voigt, T.; Römer, K. Hot Packets: A Systematic Evaluation of the Effect of Temperature on Low Power Wireless Transceivers. In Proceedings of the Extreme Conference on Communication, Thorsmork, Iceland, 24–30 August 2013; Association of Computing Machinery: New York, NY, USA, 2013; pp. 7–12. [Google Scholar]
- Wennerström, H.; Hermans, F.; Rensfelt, O.; Rohner, C.; Nordén, L. A long-term study of correlations between meteorological conditions and 802.15.4 link performance. In Proceedings of the 2013 IEEE International Conference on Sensing, Communications and Networking (SECON), New Orleans, LA, USA, 24–27 June 2013; pp. 221–229. [Google Scholar]
- Marzat, J.; Piet-Lahanier, H.; Bertrand, S. Cooperative fault detection and isolation in a surveillance sensor network: A case study. IFAC-PapersOnLine 2018, 51, 790–797. [Google Scholar] [CrossRef]
- Xie, G.; Zeng, G.; An, J.; Li, R.; Li, K. Resource-Cost-Aware Fault-Tolerant Design Methodology for End-to-End Functional Safety Computation on Automotive Cyber-Physical Systems. ACM Trans. Cyber-Phys. Syst. 2018, 3, 1–27. [Google Scholar] [CrossRef]
- Muhammed, T.; Shaikh, R.A. An analysis of fault detection strategies in wireless sensor networks. J. Netw. Comput. Appl. 2017, 78, 267–287. [Google Scholar] [CrossRef]
- Ayadi, A.; Ghorbel, O.; Obeid, A.M.; Abid, M. Outlier detection approaches for wireless sensor networks: A survey. Comput. Netw. 2017, 129, 319–333. [Google Scholar] [CrossRef]
- Chander, B.; Kumaravelan, G. Outlier detection strategies for WSNs: A survey. J. King Saud Univ. Comput. Inf. Sci. 2021. [Google Scholar] [CrossRef]
- Li, W.; Galluccio, L.; Bassi, F.; Kieffer, M. Distributed Faulty Node Detection in Delay Tolerant Networks: Design and Analysis. IEEE Trans. Mob. Comput. 2018, 17, 831–844. [Google Scholar] [CrossRef] [Green Version]
- Senapati, B.R.; Khilar, P.M.; Swain, R.R. Composite fault diagnosis methodology for urban vehicular ad hoc network. Veh. Commun. 2021, 29, 100337. [Google Scholar] [CrossRef]
- Swain, R.R.; Dash, T.; Khilar, P.M. A complete diagnosis of faulty sensor modules in a wireless sensor network. Ad Hoc Netw. 2019, 93, 101924. [Google Scholar] [CrossRef]
- Peng, Y.; Song, J.; Peng, X. A self detection technique in fault management in WSN. In Proceedings of the 2011 IEEE International Instrumentation and Measurement Technology Conference, Hangzhou, China, 10–12 May 2011; pp. 1–4. [Google Scholar]
- Alduais, N.A.M.; Abdullah, J.; Jamil, A.; Audah, L.; Alias, R. Sensor node data validation techniques for realtime IoT/WSN application. In Proceedings of the 2017 14th International Multi-Conference on Systems, Signals Devices (SSD), Marrakech, Morocco, 28–31 March 2017; pp. 760–765. [Google Scholar] [CrossRef]
- Sun, Q.Y.; Sun, Y.M.; Liu, X.J.; Xie, Y.X.; Chen, X.G. Study on fault diagnosis algorithm in WSN nodes based on RPCA model and SVDD for multi-class classification. Clust. Comput. 2018, 22, 6043–6057. [Google Scholar] [CrossRef]
- Zhao, Y.; He, X.; Zhou, D. Distributed fault source detection and topology accommodation design of wireless sensor networks. In Proceedings of the IECON 2017 43rd Annual Conference of the IEEE Industrial Electronics Society, Beijing, China, 29 October–1 November 2017; pp. 5529–5534. [Google Scholar]
- Gao, Y.; Xiao, F.; Liu, J.; Wang, R. Distributed Soft Fault Detection for Interval Type-2 Fuzzy-Model-Based Stochastic Systems With Wireless Sensor Networks. IEEE Trans. Ind. Inform. 2019, 15, 334–347. [Google Scholar] [CrossRef]
- Mali, B.; Laskar, S.H. Incipient fault detection of sensors used in wastewater treatment plants based on deep dropout neural network. SN Appl. Sci. 2020, 2, 2121. [Google Scholar] [CrossRef]
- Arunthavanathan, R.; Khan, F.; Ahmed, S.; Imtiaz, S.; Rusli, R. Fault detection and diagnosis in process system using artificial intelligence-based cognitive technique. Comput. Chem. Eng. 2020, 134, 106697. [Google Scholar] [CrossRef]
- Krivulya, G.; Skarga-Bandurova, I.; Tatarchenko, Z.; Seredina, O.; Shcherbakova, M.; Shcherbakov, E. An Intelligent Functional Diagnostics of Wireless Sensor Network. In Proceedings of the 2019 7th International Conference on Future Internet of Things and Cloud Workshops (FiCloudW), Istanbul, Turkey, 26–28 August 2019; pp. 135–139. [Google Scholar]
- Theissler, A. Detecting known and unknown faults in automotive systems using ensemble-based anomaly detection. Knowl.-Based Syst. 2017, 123, 163–173. [Google Scholar] [CrossRef]
- Joshi, V.; Desai, O.; Kowli, A. High accuracy sensor fault detection for energy management applications. In Proceedings of the 2017 IEEE International Conference on Signal Processing, Informatics, Communication and Energy Systems (SPICES), Kollam, India, 8–10 August 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Saeed, U.; Jan, S.U.; Lee, Y.D.; Koo, I. Fault diagnosis based on extremely randomized trees in wireless sensor networks. Reliab. Eng. Syst. Saf. 2021, 205, 107284. [Google Scholar] [CrossRef]
- Chessa, S.; Santi, P. Comparison-based system-level fault diagnosis in ad hoc networks. In Proceedings of the 20th IEEE Symposium on Reliable Distributed Systems, New Orleans, LA, USA, 31 October 2001; pp. 257–266. [Google Scholar] [CrossRef]
- Alshammari, K.; Ahmed, A.E.S. An efficient approach for detecting nodes failures in wireless sensor network based on clustering. In Proceedings of the 2017 International Symposium on Networks, Computers and Communications (ISNCC), Marrakech, Morocco, 16–18 May 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Ding, M.; Chen, D.; Xing, K.; Cheng, X. Localized fault-tolerant event boundary detection in sensor networks. In Proceedings of the IEEE 24th Annual Joint Conference of the IEEE Computer and Communications Societies, Miami, FL, USA, 13–17 March 2005; Volume 2, pp. 902–913. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Zhang, X.; Tseng, Y.C.; Lin, C.K. Parallel and local diagnostic algorithm for wireless sensor networks. In Proceedings of the 2017 19th Asia-Pacific Network Operations and Management Symposium (APNOMS), Seoul, Korea, 27–29 September 2017; pp. 334–337. [Google Scholar] [CrossRef]
- Bosman, H.H.; Iacca, G.; Tejada, A.; Wörtche, H.J.; Liotta, A. Spatial anomaly detection in sensor networks using neighborhood information. Inf. Fusion 2017, 33, 41–56. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Jiang, Y.; Song, X.; Hung, W.N.N.; Gu, M.; Sun, J. Sequential dependency and reliability analysis of embedded systems. In Proceedings of the 2013 18th Asia and South Pacific Design Automation Conference (ASP-DAC), Yokohama, Japan, 22–25 January 2013; pp. 423–428. [Google Scholar]
- Ji, Y. Application of fault detection using distributed sensors in smart cities. Phys. Commun. 2021, 46, 101182. [Google Scholar] [CrossRef]
- Mohapatra, S.; Khilar, P.M. Artificial immune system based fault diagnosis in large wireless sensor network topology. In Proceedings of the TENCON 2017—2017 IEEE Region 10 Conference, Penang, Malaysia, 5–8 November 2017; pp. 2687–2692. [Google Scholar]
- Chanak, P.; Banerjee, I. Fuzzy rule-based faulty node classification and management scheme for large scale wireless sensor networks. Expert Syst. Appl. 2016, 45, 307–321. [Google Scholar] [CrossRef]
- Elsayed, W.; Elhoseny, M.; Riad, A.M.; Hassanien, A.E. Autonomic Self-healing Approach to Eliminate Hardware Faults in Wireless Sensor Networks. In Proceedings of the International Conference on Advanced Intelligent Systems and Informatics 2017 (AISI2017), Cairo, Egypt, 9–11 September 2017; Springer International Publishing: Cham, Switzerland, 2017; pp. 151–160. [Google Scholar] [CrossRef]
- Das, S.; Kar, P.; Jana, D.K. SDH: Self Detection and Healing mechanism for dumb nodes in Wireless Sensor Network. In Proceedings of the 2016 IEEE Region 10 Conference (TENCON), Singapore, 22–25 November 2016; pp. 2792–2795. [Google Scholar]
- Raposo, D.; Rodrigues, A.; Sinche, S.; Silva, J.S.; Boavida, F. Security and Fault Detection in In-node components of IIoT Constrained Devices. In Proceedings of the 2019 IEEE 44th Conference on Local Computer Networks (LCN), Osnabrueck, Germany, 14–17 October 2019; pp. 282–290. [Google Scholar]
- Ioannou, C.; Vassiliou, V.; Sergiou, C. RMT: A Wireless Sensor Network Monitoring Tool. In Proceedings of the 13th ACM Symposium on Performance Evaluation of Wireless Ad Hoc, Sensor, & Ubiquitous Networks, PE-WASUN’16, Valletta, Malta, 13–17 November 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 45–49. [Google Scholar] [CrossRef]
- Liu, X.; Zhou, H.; Xiong, S.; Hou, K.M.; De Vaulx, C.; Shi, H. Development of a Resource-Efficient and Fault-Tolerant Wireless Sensor Network System. In Proceedings of the 2015 2nd International Symposium on Dependable Computing and Internet of Things (DCIT), Wuhan, China, 16–18 November 2015; pp. 122–127. [Google Scholar] [CrossRef]
- Karray, F.; Jmal, M.W.; Garcia-Ortiz, A.; Abid, M.; Obeid, A.M. A comprehensive survey on wireless sensor node hardware platforms. Comput. Netw. 2018, 144, 89–110. [Google Scholar] [CrossRef]
- Kim, H.S.; Andersen, M.P.; Chen, K.; Kumar, S.; Zhao, W.J.; Ma, K.; Culler, D.E. System Architecture Directions for Post-SoC/32-Bit Networked Sensors. In Proceedings of the 16th ACM Conference on Embedded Networked Sensor Systems, SenSys’18, Shenzhen, China, 4–7 November 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 264–277. [Google Scholar] [CrossRef]
- Gajjar, S.; Choksi, N.; Sarkar, M.; Dasgupta, K. Comparative analysis of wireless sensor network motes. In Proceedings of the 2014 International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 20–21 February 2014. [Google Scholar] [CrossRef]
- Ramasamy, V. Mobile Wireless Sensor Networks: An Overview. In Wireless Sensor Networks—Insights and Innovations; InTechOpen: London, UK, 2017. [Google Scholar] [CrossRef] [Green Version]
- Kumar, P.; Reddy, S.R.N. Wireless sensor networks: A review of motes, wireless technologies, routing algorithms and static deployment strategies for agriculture applications. CSI Trans. ICT 2020, 8, 331–345. [Google Scholar] [CrossRef]
- Fattah, S.; Gani, A.; Ahmedy, I.; Idris, M.Y.I.; Targio Hashem, I.A. A Survey on Underwater Wireless Sensor Networks: Requirements, Taxonomy, Recent Advances, and Open Research Challenges. Sensors 2020, 20, 5393. [Google Scholar] [CrossRef]
- Narayanan, R.P.; Sarath, T.V.; Vineeth, V. Survey on Motes Used in Wireless Sensor Networks: Performance & Parametric Analysis. Wirel. Sens. Netw. 2016, 8, 67–76. [Google Scholar] [CrossRef] [Green Version]
- Kulau, U.; Büsching, F.; Wolf, L. IdealVolting: Reliable Undervolting on Wireless Sensor Nodes. ACM Trans. Sens. Netw. 2016, 12, 1–38. [Google Scholar] [CrossRef]
- Puspitasari, W.; Perdana R, H.Y. Real-Time Monitoring and Automated Control of Greenhouse Using Wireless Sensor Network: Design and Implementation. In Proceedings of the 2018 International Seminar on Research of Information Technology and Intelligent Systems (ISRITI), Yogyakarta, Indonesia, 21–22 November 2018; pp. 362–366. [Google Scholar] [CrossRef]
- Godase, M.; Bhanarkar, M.K. WSN Node for Air Pollution Monitoring. In Proceedings of the 2021 6th International Conference for Convergence in Technology (I2CT), Maharashtra, India, 2–4 April 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Panda, G.; Saha, T. Building of Low Cost Reliable Wireless Sensor Network for Smart Indoor Agriculture Products. In Proceedings of the 2018 2nd International Conference on Electronics, Materials Engineering Nano-Technology (IEMENTech), Kolkata, India, 4–5 May 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Fitriawan, H.; Susanto, M.; Arifin, A.S.; Mausa, D.; Trisanto, A. ZigBee based wireless sensor networks and performance analysis in various environments. In Proceedings of the 2017 15th International Conference on Quality in Research (QiR): International Symposium on Electrical and Computer Engineering, Nusa Dua, Bali, Indonesia, 24–27 July 2017; pp. 272–275. [Google Scholar] [CrossRef]
- Georgitzikis, V.; Akribopoulos, O.; Chatzigiannakis, I. Controlling Physical Objects via the Internet using the Arduino Platform over 802.15.4 Networks. IEEE Lat. Am. Trans. 2012, 10, 1686–1689. [Google Scholar] [CrossRef]
- Kumbhar, H. Wireless sensor network using Xbee on Arduino Platform: An experimental study. In Proceedings of the 2016 International Conference on Computing Communication Control and automation (ICCUBEA), Pune, India, 12–13 August 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Ferdoush, S.; Li, X. Wireless Sensor Network System Design Using Raspberry Pi and Arduino for Environmental Monitoring Applications. Procedia Comput. Sci. 2014, 34, 103–110. [Google Scholar] [CrossRef] [Green Version]
- Zeni, M.; Ondula, E.; Mbitiru, R.; Nyambura, A.; Samuel, L.; Fleming, K.; Weldemariam, K. Low-Power Low-Cost Wireless Sensors for Real-Time Plant Stress Detection. In Proceedings of the 2015 Annual Symposium on Computing for Development, DEV’15, London, UK, 1–2 December 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 51–59. [Google Scholar] [CrossRef]
- TelosB Mote Platform. Document Part Number: 6020-0094-01 Rev B. Available online: http://www.willow.co.uk/TelosB_Datasheet.pdf (accessed on 11 November 2021).
- BTnode Project ETH Zurich. BTnodes—A Distributed Environment for Prototyping Ad Hoc Networks. 2007. Available online: http://www.btnode.ethz.ch/ (accessed on 28 July 2021).
- Crossbow Technology, MPR-MIB Users Manual. 2006. Revision B, PN: 7430-0021-07. Available online: http://cpn.unl.edu/?q=system/files/devices/moteManual.pdf (accessed on 11 November 2021).
- Burns, A.; Greene, B.R.; McGrath, M.J.; O’Shea, T.J.; Kuris, B.; Ayer, S.M.; Stroiescu, F.; Cionca, V. SHIMMER—A Wireless Sensor Platform for Noninvasive Biomedical Research. IEEE Sens. J. 2010, 10, 1527–1534. [Google Scholar] [CrossRef]
- Vilajosana, X.; Tuset, P.; Watteyne, T.; Pister, K. OpenMote: Open-Source Prototyping Platform for the Industrial IoT. In Ad Hoc Networks; Mitton, N., Kantarci, M.E., Gallais, A., Papavassiliou, S., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 211–222. [Google Scholar]
- Libelium Comunicaciones Distribuidas. Waspmote v15 Datasheet. 2019. v8.2. Available online: https://usermanual.wiki/Document/waspmotetechnicalguide.1793491487/view (accessed on 11 November 2021).
- Lignan, A. Zolertia RE-Mote Platform. 2016. Available online: https://github.com/Zolertia/Resources/wiki/RE-Mote (accessed on 28 July 2021).
- WiSense Technologies. WiSense WSN1120L Datasheet. 2019. Available online: http://wisense.in/datasheets/WSN1120L-datasheet.pdf (accessed on 11 November 2021).
- Industrial Shields. Open Mote B User Guide. 2019. SKU: IS.OMB-001, Rev. 0: 22-08-2019. Available online: https://openmote.com/wp-content/uploads/2021/06/content.pdf (accessed on 11 November 2021).
- Madabhushi, N. KMote—Design and Implementation of a Low Cost, Low Power Hardware Platform for Wireless Sensor Networks. Master’s Thesis, Indian Institute of Technology, Kanpur, India, 2007. [Google Scholar]
- Hoskins, A.; McCann, J. Beasties: Simple wireless sensor nodes. In Proceedings of the 2008 33rd IEEE Conference on Local Computer Networks (LCN), Montreal, QC, Canada, 14–17 October 2008; pp. 707–714. [Google Scholar] [CrossRef]
- Büsching, F.; Kulau, U.; Wolf, L. Architecture and evaluation of INGA an inexpensive node for general applications. In Proceedings of the 2012 IEEE SENSORS, Taipei, Taiwan, 28–31 October 2012; pp. 1–4. [Google Scholar] [CrossRef] [Green Version]
- Andersen, M.P.; Fierro, G.; Culler, D.E. System Design Trade-offs in a Next-Generation Embedded Wireless Platform. In Technical Report UCB/EECS-2014-162; EECS Department, University of California Berkeley: Berkeley, CA, USA, 2014. [Google Scholar]
- Raju, K.S.; Pratap, N.V.P.R. A reliable hardware platform for wireless sensor networks. In Proceedings of the 2015 International Symposium on Advanced Computing and Communication (ISACC), Silchar, India, 14–15 September 2015; pp. 310–314. [Google Scholar] [CrossRef]
- Berenguer, D. panStamp Wiki. 2018. Available online: https://github.com/panStamp/panstamp/wiki (accessed on 28 July 2021).
- Karray, F.; Garcia-Ortiz, A.; Jmal, M.W.; Obeid, A.M.; Abid, M. EARNPIPE: A Testbed for Smart Water Pipeline Monitoring Using Wireless Sensor Network. Procedia Comput. Sci. 2016, 96, 285–294. [Google Scholar] [CrossRef] [Green Version]
- Sallouha, H.; Van den Bergh, B.; Wang, Q.; Pollin, S. ULoRa: Ultra Low-Power, Low-Cost and Open Platform for the LoRa Networks. In Proceedings of the 4th ACM Workshop on Hot Topics in Wireless, HotWireless’17, Snowbird, UT, USA, 16 October 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 43–47. [Google Scholar] [CrossRef]
- Rusu, A.; Dobra, P. The implementation of an ARM-based low-power wireless process control system. In Proceedings of the 2017 21st International Conference on System Theory, Control and Computing (ICSTCC), Sinaia, Romania, 19–21 October 2017; pp. 666–670. [Google Scholar] [CrossRef]
- Andersen, M.P.; Kim, H.S.; Culler, D.E. Hamilton: A Cost-Effective, Low Power Networked Sensor for Indoor Environment Monitoring. In Proceedings of the 4th ACM International Conference on Systems for Energy-Efficient Built Environments, BuildSys’17, Delft, The Netherlands, 8–9 November 2017; Association for Computing Machinery: New York, NY, USA, 2017. [Google Scholar] [CrossRef]
- Pervan, B.; Guberovic, E.; Turcinovic, F. Hazelnut—An Energy Efficient Base IoT Module for Wide Variety of Sensing Applications. In Proceedings of the 6th Conference on the Engineering of Computer Based Systems, ECBS’19, Bucharest, Romania, 2–3 September 2019; Association for Computing Machinery: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Babusiak, B.; Smondrk, M.; Borik, S. Design of Ultra-Low-Energy Temperature and Humidity Sensor Based on nRF24 Wireless Technology. In Proceedings of the 2019 42nd International Conference on Telecommunications and Signal Processing (TSP), Budapest, Hungary, 1–3 July 2019; pp. 397–401. [Google Scholar] [CrossRef]
- Misra, S.; Roy, S.K.; Roy, A.; Obaidat, M.S.; Jha, A. MEGAN: Multipurpose Energy-Efficient, Adaptable, and Low-Cost Wireless Sensor Node for the Internet of Things. IEEE Syst. J. 2020, 14, 144–151. [Google Scholar] [CrossRef]
- Zhang, Z.; Shu, L.; Zhu, C.; Mukherjee, M. A Short Review on Sleep Scheduling Mechanism in Wireless Sensor Networks. In Quality, Reliability, Security and Robustness in Heterogeneous Systems; Wang, L., Qiu, T., Zhao, W., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 66–70. [Google Scholar]
- Tozlu, S.; Senel, M. Battery lifetime performance of Wi-Fi enabled sensors. In Proceedings of the 2012 IEEE Consumer Communications and Networking Conference (CCNC), Las Vegas, NV, USA, 14–17 January 2012; pp. 429–433. [Google Scholar] [CrossRef]
- Pughat, A.; Sharma, V. Optimal power and performance trade-offs for dynamic voltage scaling in power management based wireless sensor node. Perspect. Sci. 2016, 8, 536–539. [Google Scholar] [CrossRef] [Green Version]
- Microchip. AN2447: Measure VCC/Battery Voltage Without Using I/O Pin on tinyAVR and megaAVR. Application note. 2019. Available online: http://ww1.microchip.com/downloads/en/AppNotes/00002447A.pdf (accessed on 11 November 2021).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor Node | Year | MCU/SoC | Arch. [bit] | FCPU [MHz] | Flash [kB] | RAM [kB] | EEPROM [kB] | Radio Transceiver | Communication Standard | Vcore [V] | Vbat [V] | Active Mode [mW] | Power-Saving [W] | Voltage Regulation | Energy-Efficiency | Self-Diagnostic | Open Source | Available | Price [$] | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Commercial | UC Berkeley TelosB [73] | 2005 | MSP430F1611 | 16 | 8 | 1072 a | 10 | 16 | CC2420 | IEEE 802.15.4 (Zigbee) | 3.0 | 1.8–3.6 | 6.6 | 20.1 |  |  | |  | | 99.00 |
| ETH Zürich Btnode [74] | 2005 | ATmega128L | 8 | 8 | 128 | 64 b | 4 | ZV4002 + CC1000 | IEEE 802.15.1 v1.2 + 433/868 MHz | 3.3 | 0.5–4.4 | 39.6 | 9900 | | | | | | 215.00 | |
| UC Berkeley IRIS [75] | 2007 | ATmega1281 | 8 | 7.37 | 640 c | 8 | 4 | AT RF230 | IEEE 802.15.4 (Zigbee) | 3.0 | 2.7–3.6 | 26.4 | 26.4 | | | | | | 115.00 | |
| SHIMMER [76] | 2010 | MSP430F1611 | 16 | 8 | 48 | 10 | 16 | CC2420 + RN-41 | IEEE 802.15.4 + 802.15.1 v2 | 3.3 | 1.8–3.6 | 5.9 | 16.8 | | | | | | 269.00 | |
| OpenMote CC2538 [77] | 2015 | CC2538SF53 g | 32 | 32 | 512 | 32 | – | CC2538 g | IEEE 802.15.4 (6TiSCH) | 3.3 | 2.0–3.6 | 42.9 | × | | | | | | × | |
| Libelium Waspmote v15 [78] | 2016 | ATmega1281 | 8 | 14.75 | 128 | 8 | 4 | 15 modules available (e.g., Zigbee, LoRaWAN) | 3.0 | 3.3–4.2 | 56.1 | 99.0 | | | | | | 174.00 | ||
| Zolertia RE-Mote [79] | 2016 | CC2538SF53 g | 32 | 32 | 512 | 32 | – | CC2538 g + CC1200 | IEEE 802.15.4 (Zigbee) | 3.3 | 3.3–16 | 66.0 | 4.3 | | | | | | 112.00 | |
| WiSense WSN1120L [80] | 2019 | MSP430G2955 | 16 | 16 | 56 | 4 | 128 | CC1120 | sub-1 GHz narrowband | 3.0 | 1.8–3.6 | 56.1 | 56.1 | | | | | | 48.00 | |
| OpenMote B [81] | 2019 | CC2538SF53 g | 32 | 32 | 512 | 32 | – | CC2538 j + AT86RF215 | IEEE 802.15.4/802.15.4g | 3.3 | 2.0–3.6 | 42.9 | 4.3 | | | | | | 125.00 | |
| Academia | Kmote [82] | 2007 | MSP430F1611 | 16 | 8 | 8240 d | 10 | 16 | CC2420 | IEEE 802.15.4 (Zigbee) | 3.3 | 2.3–6.0 | 4.9 | 22.1 | | | | | | 37.85 |
| Beasties [83] | 2008 | ATmega8L | 8 | 4 | 8 | 33 e | 0.5 | Radiometrix NiM2 | 433 MHz (proprietary) | 5.0 | 7.0–20 | 77.5 | 40000 | | | | | | 139.00 | |
| INGA [84] | 2012 | ATmega1284P | 8 | 4 | 128 | 16 | 4 | AT86RF231 | IEEE 802.15.4 | 3.3 | × | 61.7 | × | | | | | | 120.00 | |
| Storm [85] | 2014 | ATSAM4LC8C | 32 | 48 | 1536 f | 64 | – | AT86RF233 | IEEE 802.15.4 | 3.3 | 1.8–3.6 | 4.5 | 7.6 | | | | | | 50.00 | |
| Raju and Pratap [86] | 2015 | MSP430F5438 | 16 | 25 | 256 | 16 | – | CC2520 | IEEE 802.15.4 (Zigbee) | 3.3 | 1.8–3.8 | × | × | | | | | | × | |
| Zeni et al. [72] | 2015 | ATmega328P | 8 | 1 | 32 | 2 | 1 | nRF24L01+ | 2.4 GHz (proprietary) | 3.0 | 1.9–3.6 | 5.8 | 15 | | | | | | 12.00 | |
| panStamp NRG3 [87] | 2016 | CC430F5137 | 16 | 20 | 32 | 4 | – | CC1101 | 433/868 MHz (proprietary) | 3.3 | 2.0–3.6 | 46.2 | 8.3 | | | | | | × | |
| EARNPIPE h [88] | 2016 | AT91SAM3X8E | 32 | 84 | 512 | 100 | – | × | IEEE 802.15.1 i | 3.3 | 7.0–12 | × | × | | | | | | × | |
| uLoRa [89] | 2017 | STM32L051K8T6 | 32 | 32 | 64 | 8 | 2 | DRF1272F | 868 MHz (incl. LoRa) | 3.3 | × | 34.7 | 1.2 | × | | | | | 12.00 | |
| Rusu and Dobra [90] | 2017 | STM32L443RC | 32 | 80 | 256 | 64 | – | AT86RF212B | IEEE 802.15.4 (ISA100) | 3.3 | × | × | × | × | | | | | × | |
| Hamilton [58,91] | 2017 | ATSAMR21 g | 32 | 48 | 256 | 32 | – | AT86RF233 g | IEEE 802.15.4 | 3.0 | × | 3.2 | 19.5 | | | | | | 25.00 | |
| Hazelnut [92] | 2019 | ATtiny85 j | 8 | 1 | 8 | 0.5 | 0.5 | ESP8266 j | IEEE 802.11 b/g/n | 3.3 | × | 231 | 650 | | | | | | × | |
| Raposo et al. [54] | 2019 | MSP430F5229 | 16 | 25 | 128 | 8 | – | Linear DC9003A-C | IEEE 802.15.4 (WirelessHART) | 3.3 | × | × | × | | | | | | × | |
| Babusiak et al. [93] | 2019 | ATmega328P | 8 | 1 | 32 | 2 | 1 | nRF24L01+ | 2.4 GHz (proprietary) | 3.0 | 1.5–3.6 | 10.5 | 22.2 | | | | | | 11.00 | |
| MEGAN [94] | 2020 | ATmega324PA | 8 | 8 | 32 | 2 | 1 | Digi Xbee S2 | IEEE 802.15.4 (Zigbee) | 3.3 | × | 26.2 | 33.3 | | | | | | 20.00 | |
| ASN(x) | 2021 | ATmega1284P | 8 | 4 | 128 | 16 | 4 | Digi Xbee 3 | IEEE 802.15.4 (Zigbee) | 3.3 | 1.8–5.5 | 15.4 | 121.1 | | | | | | 50.00 | |
| supported partly supported not supported – not available × no information available | ||||||||||||||||||||
| Indicator | Category | Section | |
|---|---|---|---|
| node temperature monitor | artificial generic | Section 4.5.1 | |
| supply voltage monitor | inherent component-specific | Section 4.5.2 | |
| battery voltage monitor | artificial generic | Section 4.5.3 | |
| active runtime monitor | inherent component-specific | Section 4.5.4 | |
| reset monitor | inherent component-specific | Section 4.5.5 | |
| software incident counter | inherent common | Section 4.5.6 | |
| ADC self-check | artificial generic | Section 4.5.7 | |
| USART self-check | artificial component-specific | Section 4.5.8 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Widhalm, D.; Goeschka, K.M.; Kastner, W. An Open-Source Wireless Sensor Node Platform with Active Node-Level Reliability for Monitoring Applications. Sensors 2021, 21, 7613. https://doi.org/10.3390/s21227613
Widhalm D, Goeschka KM, Kastner W. An Open-Source Wireless Sensor Node Platform with Active Node-Level Reliability for Monitoring Applications. Sensors. 2021; 21(22):7613. https://doi.org/10.3390/s21227613
Chicago/Turabian StyleWidhalm, Dominik, Karl M. Goeschka, and Wolfgang Kastner. 2021. "An Open-Source Wireless Sensor Node Platform with Active Node-Level Reliability for Monitoring Applications" Sensors 21, no. 22: 7613. https://doi.org/10.3390/s21227613
APA StyleWidhalm, D., Goeschka, K. M., & Kastner, W. (2021). An Open-Source Wireless Sensor Node Platform with Active Node-Level Reliability for Monitoring Applications. Sensors, 21(22), 7613. https://doi.org/10.3390/s21227613