Path Planning for Multi-Arm Manipulators Using Deep Reinforcement Learning: Soft Actor–Critic with Hindsight Experience Replay


Abstract
:1. Introduction
1.1. Motivation
1.2. Background and Related Work
1.3. Proposed Solution
2. Problem Setup and Preliminaries
2.1. Sampling-Based Path Planning for Robot Manipulator and Configuration Space
2.2. Collision Detection in Workspace Using the Oriented Bounding Box (OBB)
2.3. Reinforcement Learning
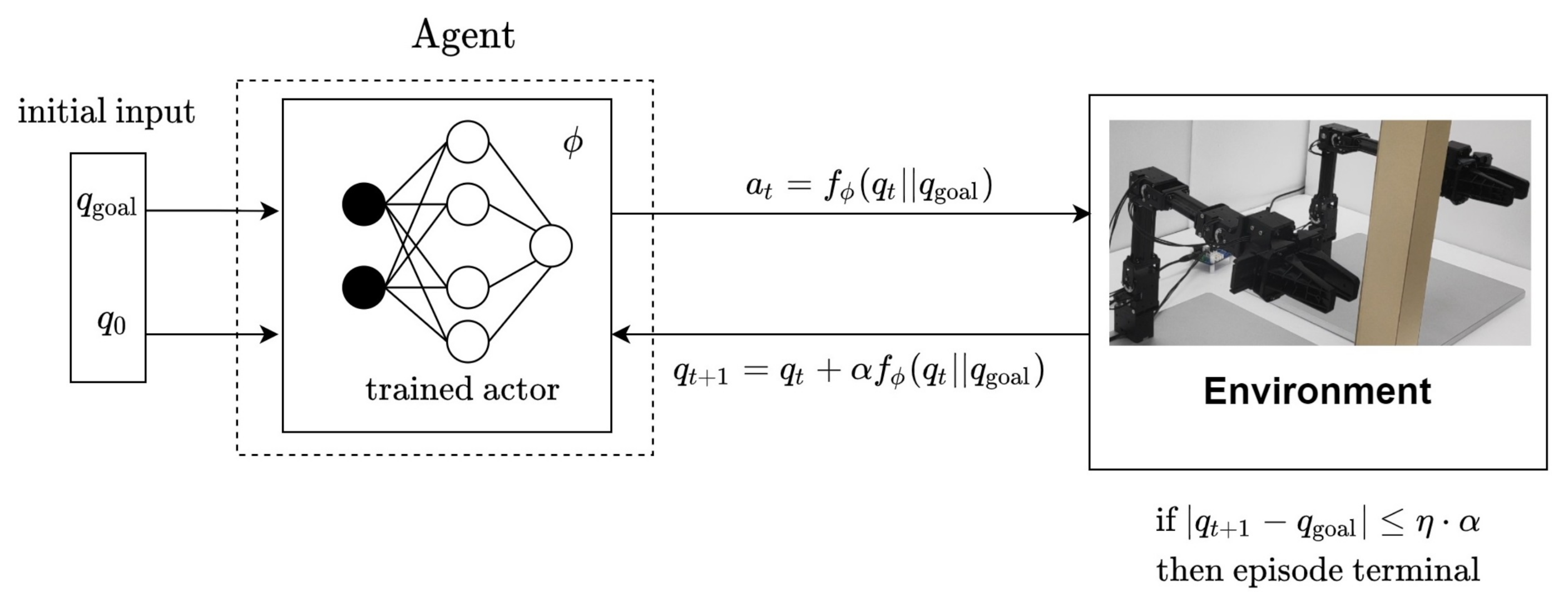
3. Method
3.1. Path Planning for the Multi-Arm Manipulator and Augmented Configuration Space
3.2. Multi-Arm Manipulator Markov Decision Process (MAMMDP)
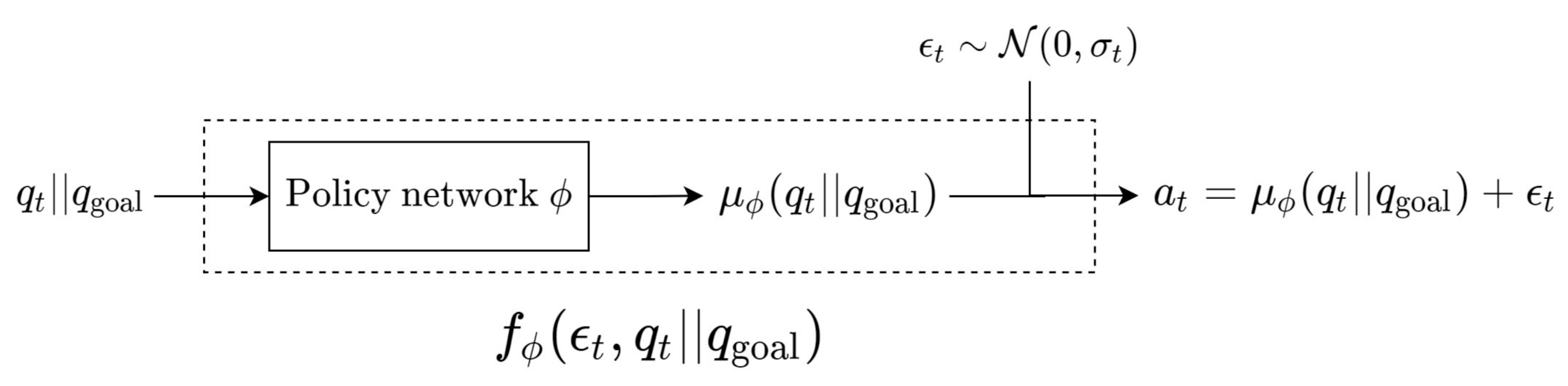
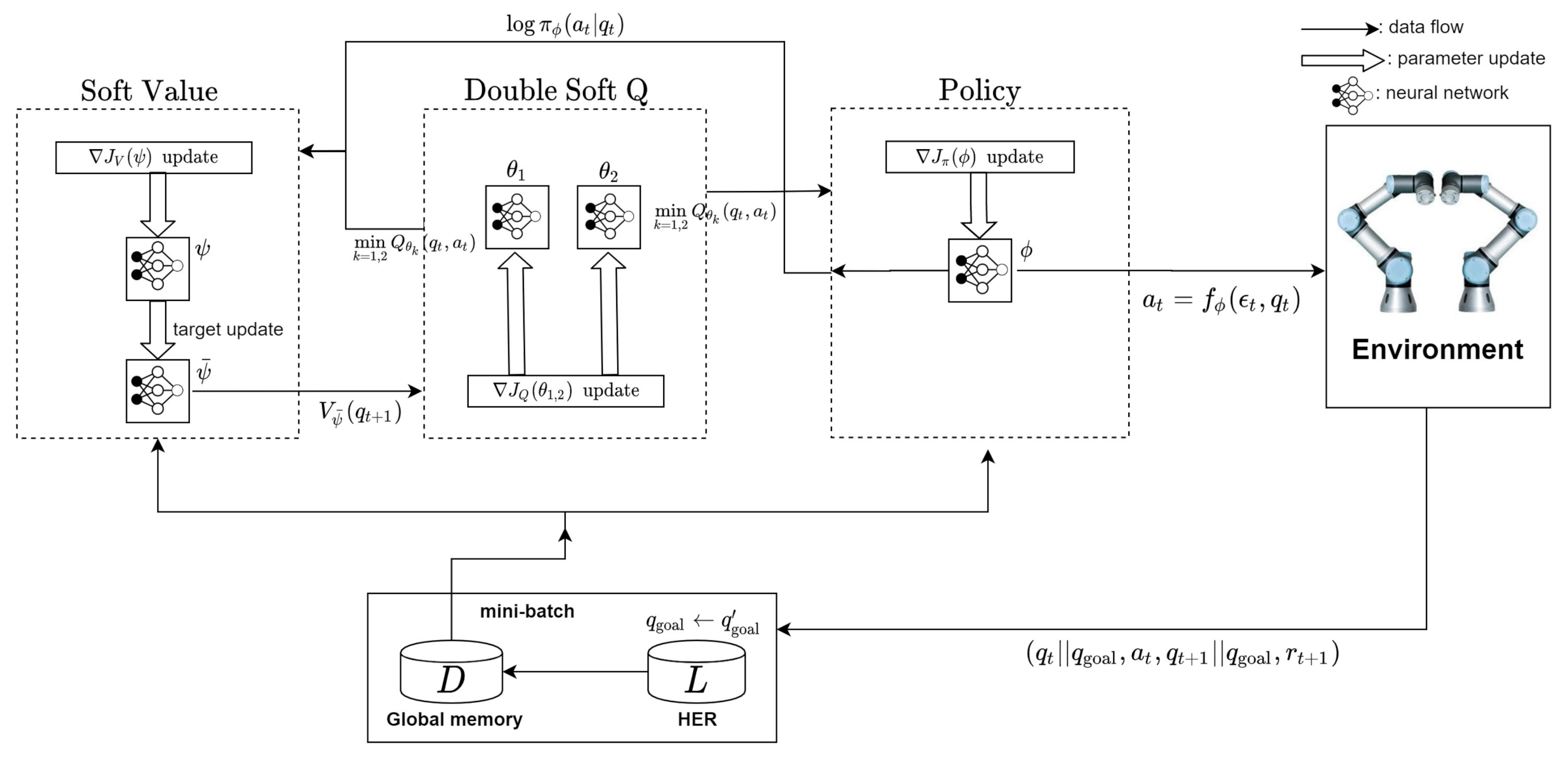
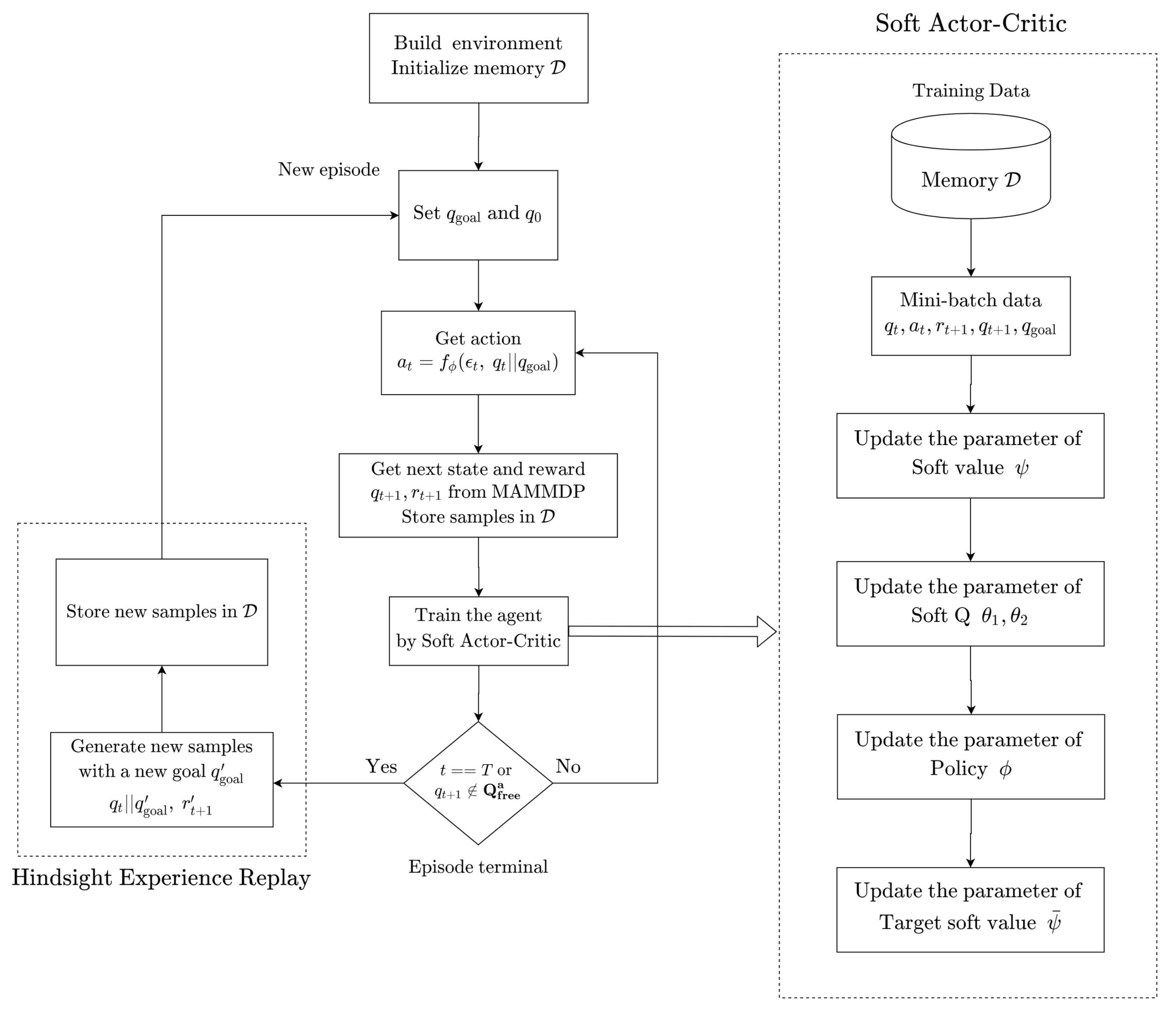
3.3. Soft Actor-Critic (SAC)
3.4. Hindsight Experience Replay (HER)
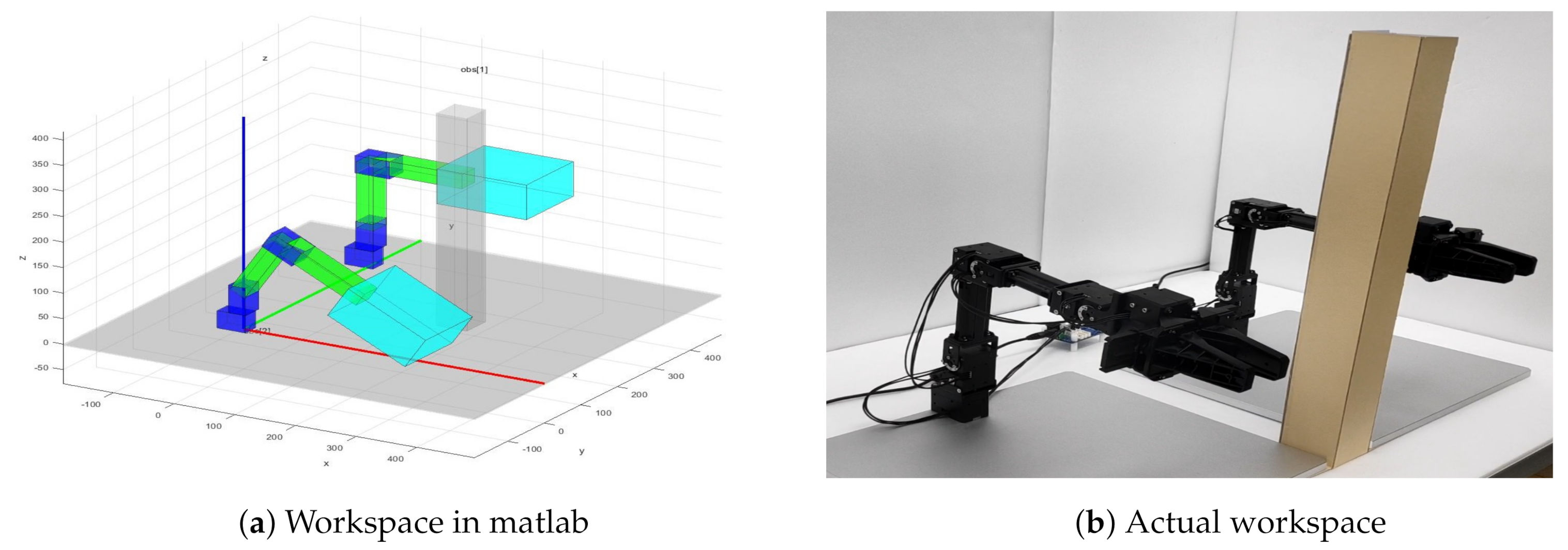
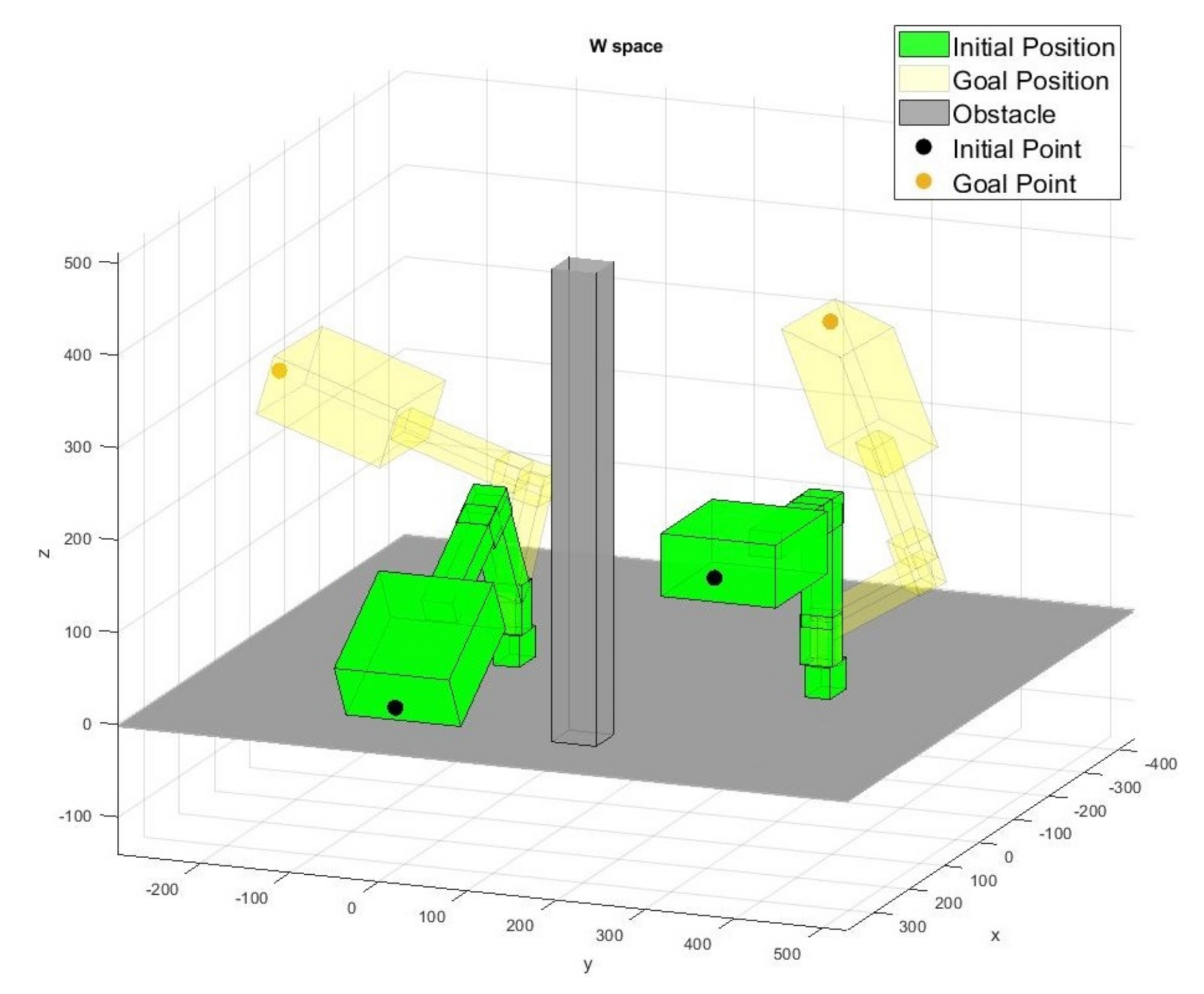
4. Results and Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| MAMMDP | Multi-Arm Manipulator Markov Decision Process |
| SAC | Soft Actor-Critic |
| HER | Hindsight Experience Replay |
| AI | Artificial Intelligence |
| FMMs | Fast Marching Methods |
| PRM | Probabilistic Road Map |
| RRT | Rapid exploring Random Trees |
| DNN | Deep Neural Network |
| TD3 | Twin Delayed Deep Deterministic Policy Gradient |
| MDP | Markov Decision Process |
| DOF | Degree of Freedom |
| OBB | Oriented Bounding Boxes |
| DQN | Deep Q-Network |
| DPG | Deterministic Policy Gradient |
| DDPG | Deep Deterministic Policy Gradient |
| A3C | Asynchronous Advantage Actor-Critic |
| TRPO | Trust Region Policy Optimization |
| MPO | Maximum a Posteriori Policy Optimisation |
| D4PG | Distributed Distributional Deep Deterministic Policy Gradient |
| KL | Kullback-Leibler |
Appendix A
| Algorithm 1: Proposed SAC-based path planning algorithm for multi-arm manipulator. |
|
References
- Spong, M.; Hutchinson, S.; Vidyasagar, M. Robot Modeling and Control; Wiley: New York, NY, USA, 2006. [Google Scholar]
- Albu-Schäffer, A.; Hirzinger, G. A globally stable state feedback controller for flexible joint robots. Adv. Robot. 2001, 15, 799–814. [Google Scholar] [CrossRef] [Green Version]
- Basile, F.; Caccavale, F.; Chiacchio, P.; Coppola, J.; Curatella, C. Task-oriented motion planning for multi-arm robotic systems. Robot. -Comput.-Integr. Manuf. 2012, 28, 569–582. [Google Scholar] [CrossRef]
- Shome, R.; Bekris, K.E. Anytime Multi-arm Task and Motion Planning for Pick-and-Place of Individual Objects via Handoffs. In Proceedings of the 2019 International Symposium on Multi-Robot and Multi-Agent Systems (MRS), New Brunswick, NJ, USA, 22–23 August 2019; pp. 37–43. [Google Scholar]
- Lynch, K.M.; Park, F.C. Modern Robotics: Mechanics, Planning, and Control; Cambridge University Press: Cambridge, England, 2017. [Google Scholar]
- Choset, H.M.; Hutchinson, S.; Lynch, K.M.; Kantor, G.; Burgard, W.; Kavraki, L.E.; Thrun, S.; Arkin, R.C. Principles of Robot Motion: Theory, Algorithms, and Implementation; MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Karaman, S.; Frazzoli, E. Sampling-based algorithms for optimal motion planning. Int. J. Robot. Res. 2011, 30, 846–894. [Google Scholar] [CrossRef]
- Janson, L.; Schmerling, E.; Clark, A.; Pavone, M. Fast marching tree: A fast marching sampling-based method for optimal motion planning in many dimensions. Int. J. Robot. Res. 2015, 34, 883–921. [Google Scholar] [CrossRef] [PubMed]
- Gharbi, M.; Cortés, J.; Simeon, T. A sampling-based path planner for dual-arm manipulation. In Proceedings of the 2008 IEEE/ASME International Conference on Advanced Intelligent Mechatronics, Xi’an, China, 2–5 July 2008; pp. 383–388. [Google Scholar]
- Kuffner, J.J.; LaValle, S.M. RRT-connect: An efficient approach to single-query path planning. In Proceedings of the IEEE International Conference on Robotics and Automation, San Francisco, CA, USA, 24–28 April 2000; Volume 2, pp. 995–1001. [Google Scholar]
- LaValle, S.M.; Kuffner, J.J. Rapidly-exploring random trees: Progress and prospects. Algorithmic Comput. Robot. New Dir. 2001, 5, 293–308. [Google Scholar]
- Preda, N.; Manurung, A.; Lambercy, O.; Gassert, R.; Bonfè, M. Motion planning for a multi-arm surgical robot using both sampling-based algorithms and motion primitives. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 1422–1427. [Google Scholar]
- Kurosu, J.; Yorozu, A.; Takahashi, M. Simultaneous Dual-Arm Motion Planning for Minimizing Operation Time. Appl. Sci. 2017, 7, 1210. [Google Scholar] [CrossRef] [Green Version]
- Kavraki, L.E.; Latombe, J.C.; Motwani, R.; Raghavan, P. Randomized Query Processing in Robot Path Planning. J. Comput. Syst. Sci. 1995, 57, 50–60. [Google Scholar] [CrossRef] [Green Version]
- Hsu, D.; Latombe, J.C.; Kurniawati, H. On the Probabilistic Foundations of Probabilistic Roadmap Planning. Int. J. Robot. Res. 2006, 25, 627–643. [Google Scholar] [CrossRef]
- De Santis, A.; Albu-Schaffer, A.; Ott, C.; Siciliano, B.; Hirzinger, G. The skeleton algorithm for self-collision avoidance of a humanoid manipulator. In Proceedings of the IEEE/ASME international conference on advanced intelligent mechatronics, Zurich, Switzerland, 4–7 September 2007; pp. 1–6. [Google Scholar]
- Dietrich, A.; Wimböck, T.; Täubig, H.; Albu-Schäffer, A.; Hirzinger, G. Extensions to reactive self-collision avoidance for torque and position controlled humanoids. In Proceedings of the IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 3455–3462. [Google Scholar]
- Sugiura, H.; Gienger, M.; Janssen, H.; Goerick, C. Real-Time Self Collision Avoidance for Humanoids by means of Nullspace Criteria and Task Intervals. In Proceedings of the 6th IEEE-RAS International Conference on Humanoid Robots, Genova, Italy, 4–6 December 2006; pp. 575–580. [Google Scholar]
- Martínez, C.; Jiménez, F. Implementation of a Potential Field-Based Decision-Making Algorithm on Autonomous Vehicles for Driving in Complex Environments. Sensors 2019, 19, 3318. [Google Scholar] [CrossRef] [Green Version]
- Sichkar, V.N. Reinforcement Learning Algorithms in Global Path Planning for Mobile Robot. In Proceedings of the International Conference on Industrial Engineering, Applications and Manufacturing (ICIEAM), Sochi, Russia, 25–29 March 2019; pp. 1–5. [Google Scholar]
- Wang, C.; Zhang, Q.; Tian, Q.; Li, S.; Wang, X.; Lane, D.; Petillot, Y.; Wang, S. Learning Mobile Manipulation through Deep Reinforcement Learning. Sensors 2020, 20, 939. [Google Scholar] [CrossRef] [Green Version]
- Guo, S.; Zhang, X.; Zheng, Y.; Du, Y. An Autonomous Path Planning Model for Unmanned Ships Based on Deep Reinforcement Learning. Sensors 2020, 20, 426. [Google Scholar] [CrossRef] [Green Version]
- Bae, H.; Kim, G.; Kim, J.; Qian, D.; Lee, S. Multi-Robot Path Planning Method Using Reinforcement Learning. Appl. Sci. 2019, 9, 3057. [Google Scholar] [CrossRef] [Green Version]
- Gu, S.; Holly, E.; Lillicrap, T.; Levine, S. Deep Reinforcement Learning for Robotic Manipulation with Asynchronous Off-Policy Updates. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3389–3396. [Google Scholar]
- Liu, C.; Gao, J.; Bi, Y.; Shi, X.; Tian, D. A Multitasking-Oriented Robot Arm Motion Planning Scheme Based on Deep Reinforcement Learning and Twin Synchro-Control. Sensors 2020, 20, 3515. [Google Scholar] [CrossRef] [PubMed]
- Umay, I.; Fidan, B.; Melek, W. An Integrated Task and Motion Planning Technique for Multi-Robot-Systems. In Proceedings of the IEEE International Symposium on Robotic and Sensors Environments (ROSE), Ottawa, ON, Canada, 17–18 June 2019; pp. 1–7. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 15 July 2018; pp. 1861–1870. [Google Scholar]
- Andrychowicz, M.; Wolski, F.; Ray, A.; Schneider, J.; Fong, R.; Welinder, P.; McGrew, B.; Tobin, J.; Pieter Abbeel, O.; Zaremba, W. Hindsight Experience Replay. In Proceedings of the 31st Conference on Neural Information Processing System, Long Beach, CA, USA, 4–9 December 2017; pp. 5048–5058. [Google Scholar]
- Chen, J.; Zhou, Y.; Gong, J.; Deng, Y. An Improved Probabilistic Roadmap Algorithm with Potential Field Function for Path Planning of Quadrotor. In Proceedings of the Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 3248–3253. [Google Scholar]
- Kim, M.; Han, D.K.; Park, J.H.; Kim, J.S. Motion Planning of Robot Manipulators for a Smoother Path Using a Twin Delayed Deep Deterministic Policy Gradient with Hindsight Experience Replay. Appl. Sci. 2020, 10, 575. [Google Scholar] [CrossRef] [Green Version]
- Latombe, J.C. Robot Motion Planning; Kluwer Academic Publishers: Norwell, MA, USA, 1991. [Google Scholar]
- Lozano-Perez. Spatial Planning: A Configuration Space Approach. IEEE Trans. Comput. 1983, C-32, 108–120. [Google Scholar] [CrossRef] [Green Version]
- Laumond, J.P.P. Robot Motion Planning and Control. In Lecture Notes in Control and Information Sciences; Springer: Berlin, Germany, 1998. [Google Scholar]
- Bergen, G.V.D.; Bergen, G.J. Collision Detection in Interactive 3D Environments, 1st ed.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2003. [Google Scholar] [CrossRef]
- Ericson, C. Real-Time Collision Detection; CRC Press, Inc.: Boca Raton, FL, USA, 2004. [Google Scholar] [CrossRef]
- Fares, C.; Hamam, Y. Collision Detection for Rigid Bodies: A State of the Art Review. GraphiCon 2005. Available online: https://https://www.graphicon.org/html/2005/proceedings/papers/Fares.pdf (accessed on 19 August 2019).
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming, 1st ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1994. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018; ISBN 978-0-262-03924-6. [Google Scholar]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy Gradient Methods for Reinforcement Learning with Function Approximation. In Proceedings of the 12th International Conference on Neural Information Processing Systems, Denver, CO, USA, 30 November–2 December 1999; NIPS’99. pp. 1057–1063. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic Policy Gradient Algorithms. In Proceedings of the 31st International Conference on International Conference on Machine Learning, Beijing, China, 22–24 June 2014; pp. I–387–I–395. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. ICLR (Poster). arXiv 2016, arXiv:1509.02971. [Google Scholar]
- Abdolmaleki, A.; Springenberg, J.T.; Tassa, Y.; Munos, R.; Heess, N.; Riedmiller, M. Maximum a Posteriori Policy Optimisation. arXiv 2018, arXiv:1806.06920. [Google Scholar]
- Barth-Maron, G.; Hoffman, M.W.; Budden, D.; Dabney, W.; Horgan, D.; Dhruva, T.; Muldal, A.; Heess, N.; Lillicrap, T. Distributed Distributional Deterministic Policy Gradients. arXiv 2018, arXiv:1804.08617. [Google Scholar]
- Degris, T.; White, M.; Sutton, R. Off-Policy Actor-Critic. arXiv 2012, arXiv:1205.4839. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Fujimoto, S.; Hoof, H.; Meger, D. Addressing Function Approximation Error in Actor-Critic Methods. arXiv 2018, arXiv:1802.09477. [Google Scholar]
- Haarnoja, T.; Tang, H.; Abbeel, P.; Levine, S. Reinforcement Learning with Deep Energy-Based Policies. arXiv 2017, arXiv:1702.08165. [Google Scholar]
- Hasselt, H.V. Double Q-learning. Adv. Neural Inf. Process. Syst. 2010, 2613–2621. Available online: http://papers.nips.cc/paper/3964-double-q-learning (accessed on 19 August 2019).
- Green, P.J.; Silverman, B.W. Nonparametric Regression and Generalized Linear Models: a Roughness Penalty Approach; CRC Press: Boca Raton, FL, USA, 1993. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Value | Notation |
|---|---|---|
| The number of joints for each manipulator | 3 | n |
| The number of manipulators | 2 | m |
| Dimension of | 6 | |
| Joint maximum | (140, −45, 150, 140, −45, 150) | |
| Joint minimum | (−140, −180, 45, −140, −180, 45) |
| Name | Value | Notation |
|---|---|---|
| Policy network size | 12∗800∗500∗400∗400∗300∗6 | |
| Soft Q network size | 18∗800∗500∗400∗400∗300∗1 | |
| Soft value network size | 12∗800∗500∗400∗400∗300∗1 | |
| Learning rate | 0.0001 | |
| Replay memory size | ||
| Episode maximum step | 100 | T |
| Soft value target copy rate | 0.005 | |
| Mini batch size | 512 | m |
| Environment noise deviation | 0.002 | |
| Action step size | 0.3813 | |
| Goal boundary | 0.2 | |
| Dicount factor | 0.98 | |
| Entropy temperature parameter | 0.2 |
| Method | Average Path Cost | Cost Percentage | Roughness |
|---|---|---|---|
| PRM | 3.4162 | 100% | 0.4153 |
| TD3 | 3.3402 | 97.8% | 0.0437 |
| SAC | 3.0862 | 90.3% | 0.0206 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prianto, E.; Kim, M.; Park, J.-H.; Bae, J.-H.; Kim, J.-S. Path Planning for Multi-Arm Manipulators Using Deep Reinforcement Learning: Soft Actor–Critic with Hindsight Experience Replay. Sensors 2020, 20, 5911. https://doi.org/10.3390/s20205911
Prianto E, Kim M, Park J-H, Bae J-H, Kim J-S. Path Planning for Multi-Arm Manipulators Using Deep Reinforcement Learning: Soft Actor–Critic with Hindsight Experience Replay. Sensors. 2020; 20(20):5911. https://doi.org/10.3390/s20205911
Chicago/Turabian StylePrianto, Evan, MyeongSeop Kim, Jae-Han Park, Ji-Hun Bae, and Jung-Su Kim. 2020. "Path Planning for Multi-Arm Manipulators Using Deep Reinforcement Learning: Soft Actor–Critic with Hindsight Experience Replay" Sensors 20, no. 20: 5911. https://doi.org/10.3390/s20205911
APA StylePrianto, E., Kim, M., Park, J.-H., Bae, J.-H., & Kim, J.-S. (2020). Path Planning for Multi-Arm Manipulators Using Deep Reinforcement Learning: Soft Actor–Critic with Hindsight Experience Replay. Sensors, 20(20), 5911. https://doi.org/10.3390/s20205911