Towards Network Lifetime Enhancement of Resource Constrained IoT Devices in Heterogeneous Wireless Sensor Networks

 ,
,  ,
, 

Abstract
1. Introduction
- We propose an efficient CH declaration scheme to reduce the energy consumption of nodes and to prolong the network lifetime. The propose scheme provides a mechanism through which a node declares itself as a CH based on the available resources such as residual energy, computational capability, and available storage. Once the CH is declared, it remains CH until the resources fall short than a certain threshold level.
- For the un-associated nodes, we employ the multi-criteria decision-making technique known as Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS) to select an optimal CH.
- We also provide mechanisms of CH-acquaintanceship and CH-friendship to reduce the energy consumption, optimize the workload, minimize the packet drop rate, and extend the lifetime of CH. In acquaintanceship mechanism, the CHs in the network may collaborate with each other for mutual benefits. Whereas, in CH-friendship, the low resources CH may request high resources CH to perform operation on behalf of low resources CH to avoid early failure and data loss.
- Simulations are performed in Castalia (OMNET++) to reveal the performance of the proposed scheme with relevant and state of art scheme in terms of CH lifetime, re-clustering frequency, packets loss, control overhead and average energy consumption of the network.
2. Background and Related Work
2.1. Clustering Overview
- The whole network is partitioned into clusters.
- After cluster formation process, the selected CHs gather and aggregate the data received from member nodes and transmit it towards the sink node. Usually, the CHs consume more energy as compared to the other nodes and ran out of power due to high load. Therefore, to balance the energy consumption, the role of CH is switched among different sensor nodes, meaning that a CH may not be CH for longer time in the network and other high resources sensor nodes can take over the role of CH. However, in order to elect an optimal CH, the following strategies may be adopted and are discussed as follows:
- Deterministic CH election: In deterministic schemes, CHs are super-nodes having high resources such as energy, storage, and computational capability etc.
- Random CH election: In these schemes a CH is elected based on randomly generated value.
- Adaptive CH election: Instead of electing CH randomly, adaptive CH election schemes provide a mechanism to elect CH based on several parameters such as residual energy, computational capability, storage, distance, etc. The combination of the multiple parameters is utilized to elect an optimal CH among several potential candidates.
- After CHs election, each CH broadcasts its information of becoming a CH to other nodes in its communication range. The receiving nodes may receive information from several CHs in its vicinity and decide which CH to join based on several metrics such as distance from CH, computational capability, residual energy and storage capability of CH, etc. After joining a particular CH, the node forwards its sensed data towards that CH.
- When resources of a current CH falls below a certain threshold, re-clustering is performed to avoid the data loss. However, frequent re-clustering degrades the performance of network due to control overhead.
2.2. Related Work
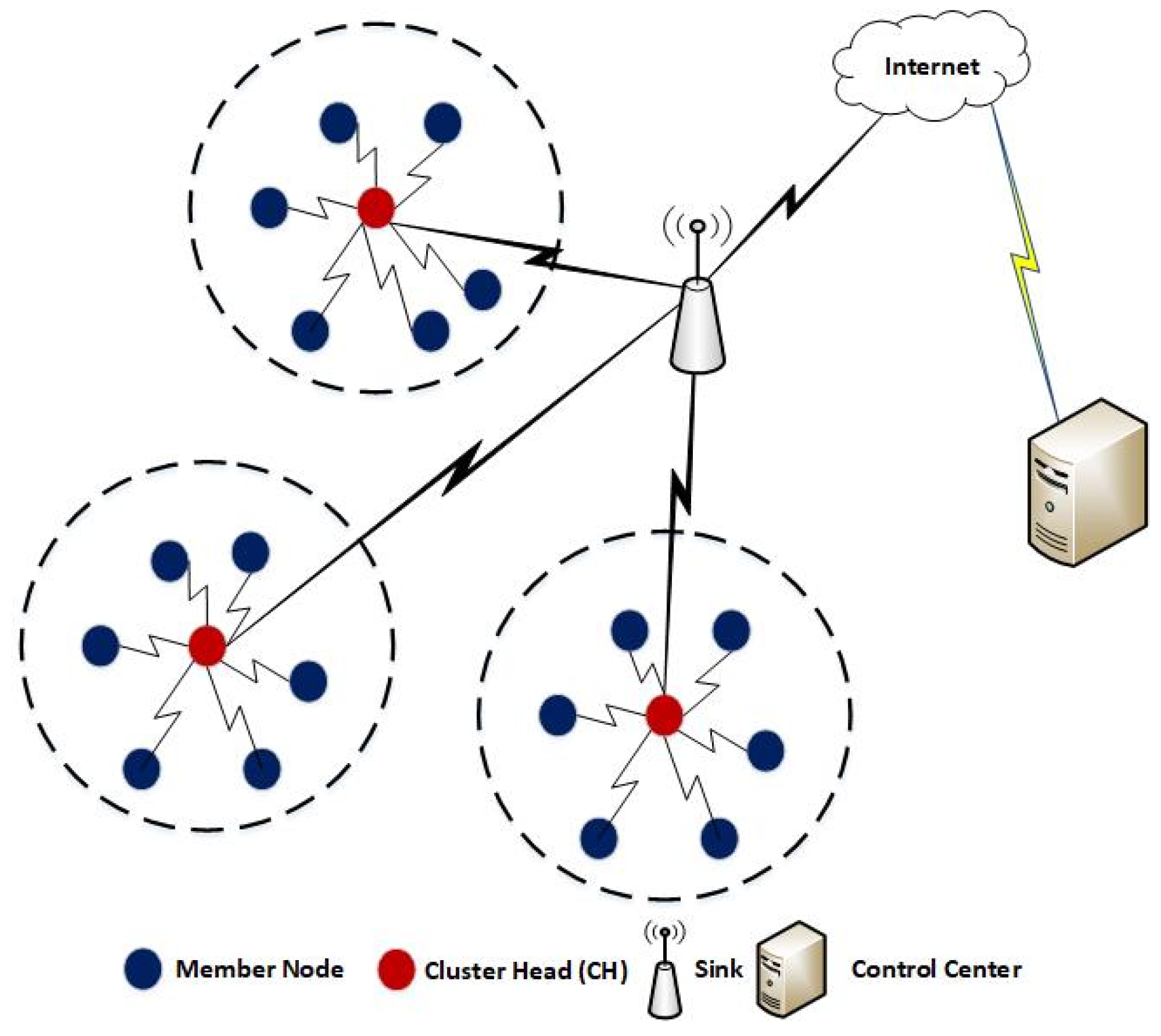
3. Problem Scenario
4. Proposed Scheme
4.1. Cluster Head (CH) Declaration Phase
| Algorithm 1 CH Declaration Algorithm |
|
4.2. New Node-Association
- Decision Matrix DevelopmentConsider a child node having “m” CHs in its range. The child node organizes the CHs attributes in a decision matrix (X) as defined in Equation (4).where is the value of nth resource criteria of mth CH, m represents the total number of CHs, and n is the total number of the resource criteria such as residual energy, computation capability, traffic load, distance from CH to the sink node, and distance from the child node itself to the CH.
- Resource Criteria NormalizationThe values of all these criteria do not lie in the same range (e.g., the value of residual energy is not equal to available storage), therefore, the resource criteria must have to be normalized to a common range in order to fairly select the CH. The normalized form of the decision matrix is obtained by employing Equation (5) and is defined as follows:The normalized decision matrix, is obtained using Equation (6).
- Weights Assignment
- Ideal Positive Solutions () and Ideal Negative Solutions ()Ideal Positive Solution (): The resource criteria where high attribute values such as residual energy, computational capability, and storage capacity are desired are named as . The residual energy of the node is very important, as the overall lifetime of the node depends on its residual energy. Therefore, the highest value of energy is taken as . Similarly, the high storage capacity is also an important criterion, since providing the large storage to a CH prevents congestion and packet drop on a CH. Likewise, the high computational capability reduces the processing delays. All these aforementioned criteria optimize the packet drop rate and enhance the performance of the network. is computed using Equation (8) and is defined as follows:Ideal Negative Solution : The resource criteria where the low attribute values such as traffic load on CH, distance from CH to the sink node, and distance from a child node to the CH are desired considered as . For instance, if there is a high traffic load on CH, the CH cannot accommodate more data packets from its child nodes due to storage limitations. Similarly, If the distance between the sink node and CH is high, the CH consumes high amount of energy in data transmission towards the sink node. Likewise, if the distance between the child node and a CH is high, the child node has to consume high mount of energy to transmit data. The high values of the aforementioned resource criteria(s) are not beneficial; therefore, these criteria are considered as . is computed using Equation (9) and is defined as follows.
- Difference of each CH from and
- Ranking Index for final decisionEquations (10) and (11) compute the difference of each CH node from and respectively. By doing so, the child node obtains a deviated value of all CHs from and . Since the CHs are heterogeneous in terms available resource, it is highly likely that the deviated value of each CH varies from each other. Based on these deviated values, the child node computes the rank index () of each CH node by employing Equation (12). The computed from Equation (12) guarantees that the CH with the best available resources is assigned a highest rank as compare to the other potential CHs. Once the child node has the list of CHs with their ranked value, the child node selects the CH which have highest rank. of each CH node is computed using Equation (12) and is defined as follows.where, is the ranking index of ith CH candidate node.
| Algorithm 2 New Node(s) Association Algorithm |
|
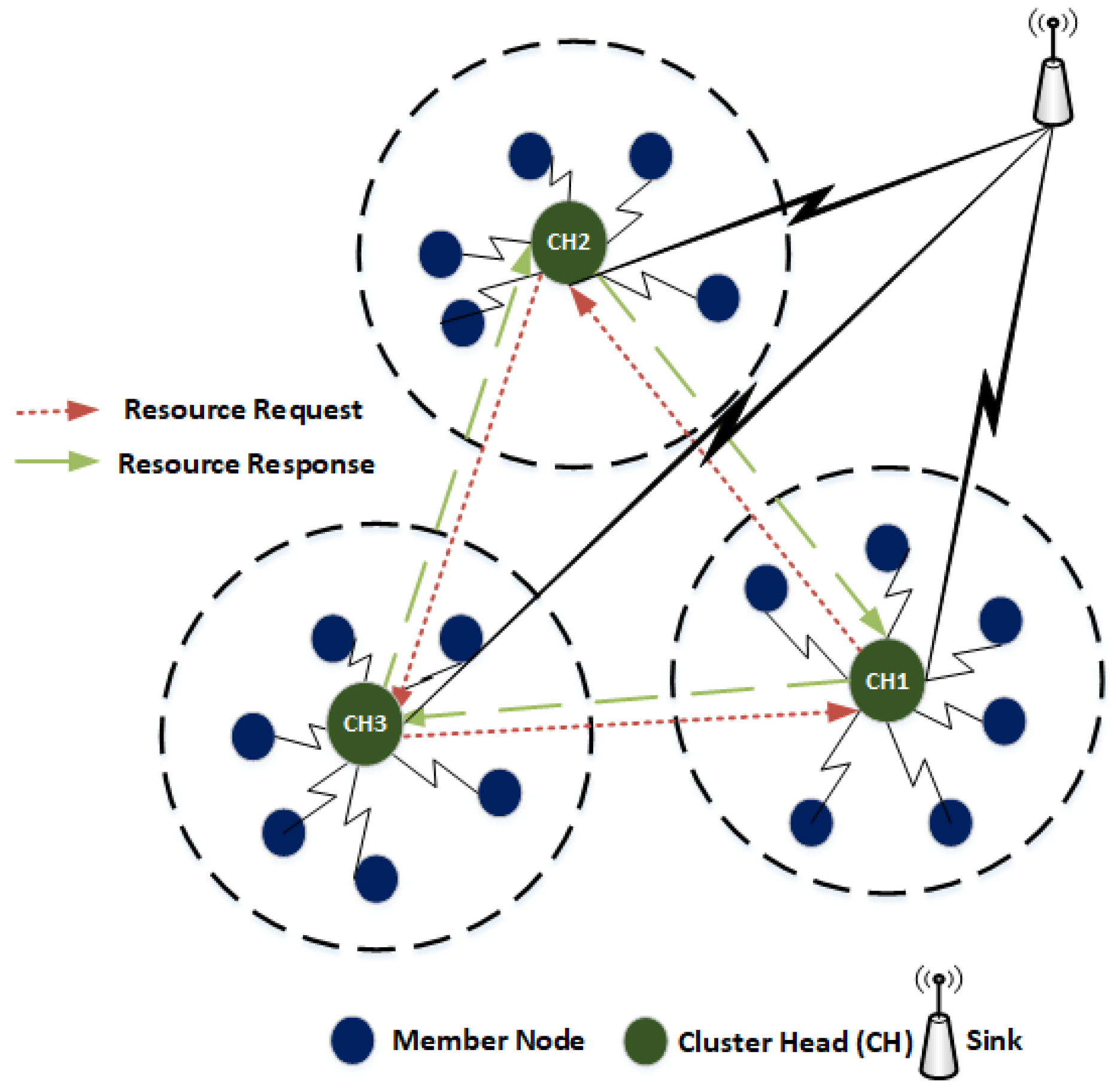
4.3. CH-Acquaintanceship
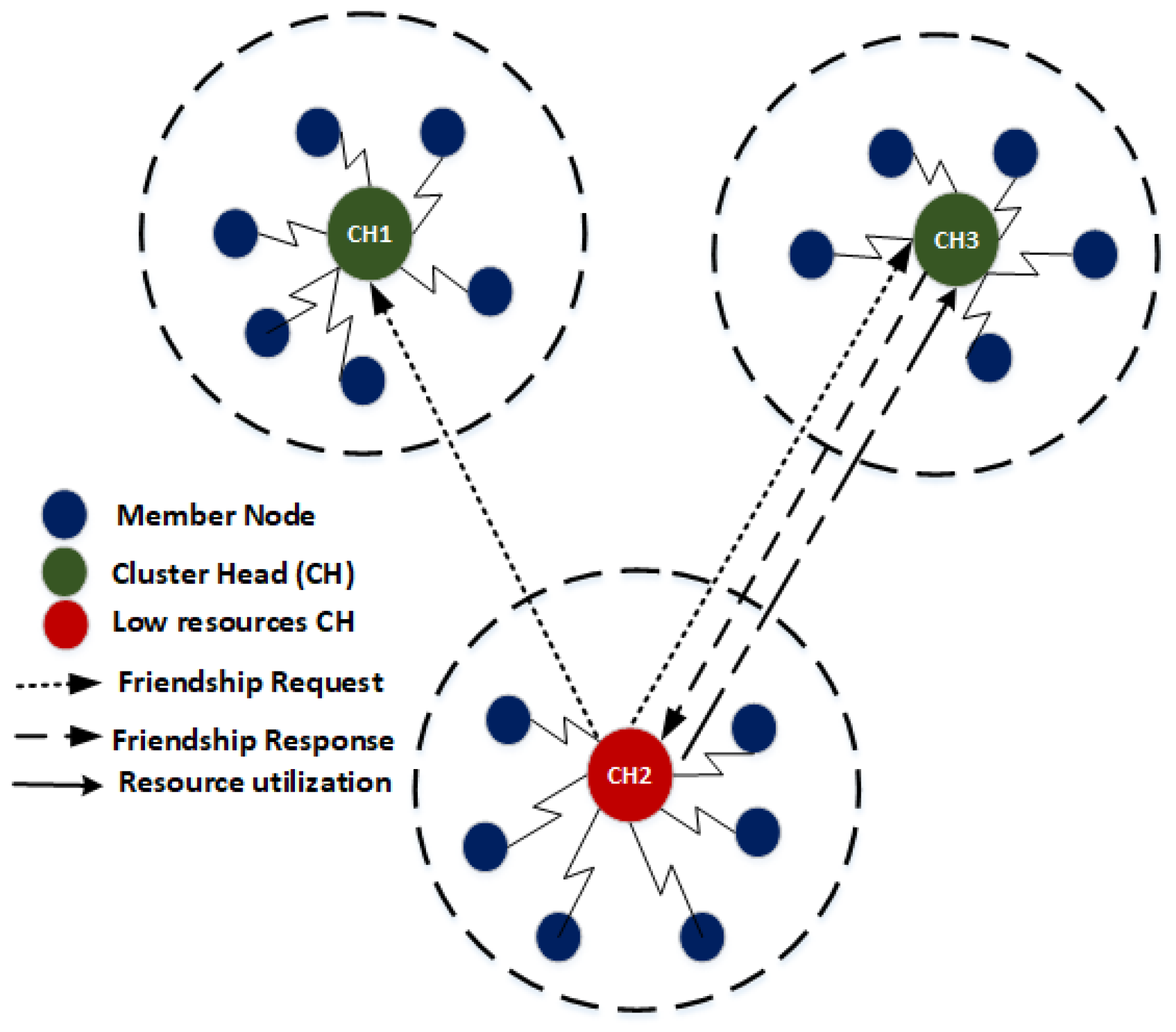
4.4. CH-Friendship
5. Performance Evaluations
5.1. Performance Evaluation Metrics
- CH Lifetime: The CH lifetime is defined as the amount of time a node can act as a CH. In other words, it is the time of CH until re-clustering.
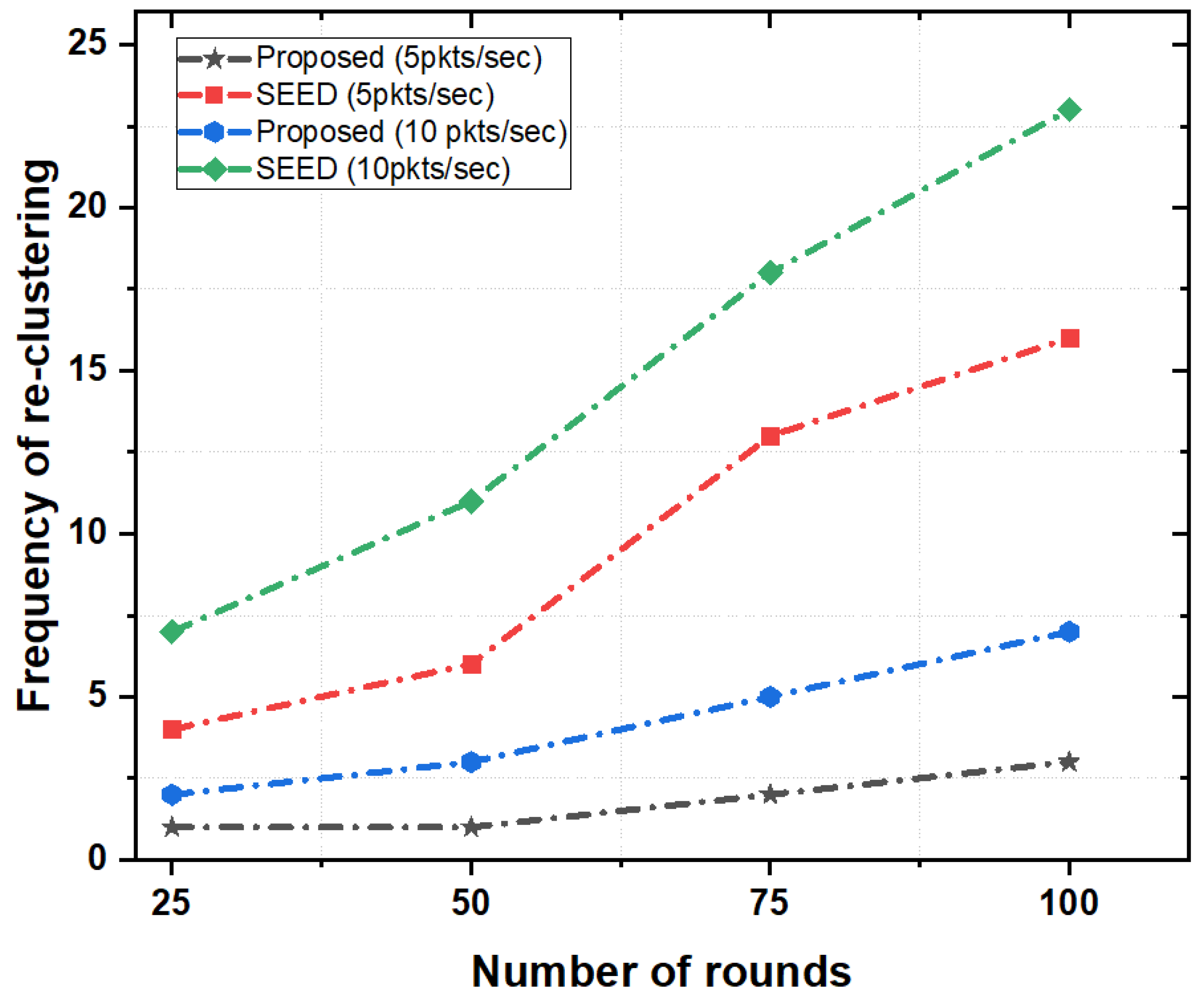
- Re-clustering Frequency: Re-clustering is the process of electing new CH to avoid CH communication failure. Re-clustering mechanism is executed when the available resources of CH go down than a certain threshold (e.g., the energy of CH). Re-clustering frequency is defined as the frequency of re-electing the CHs during the entire network lifetime.
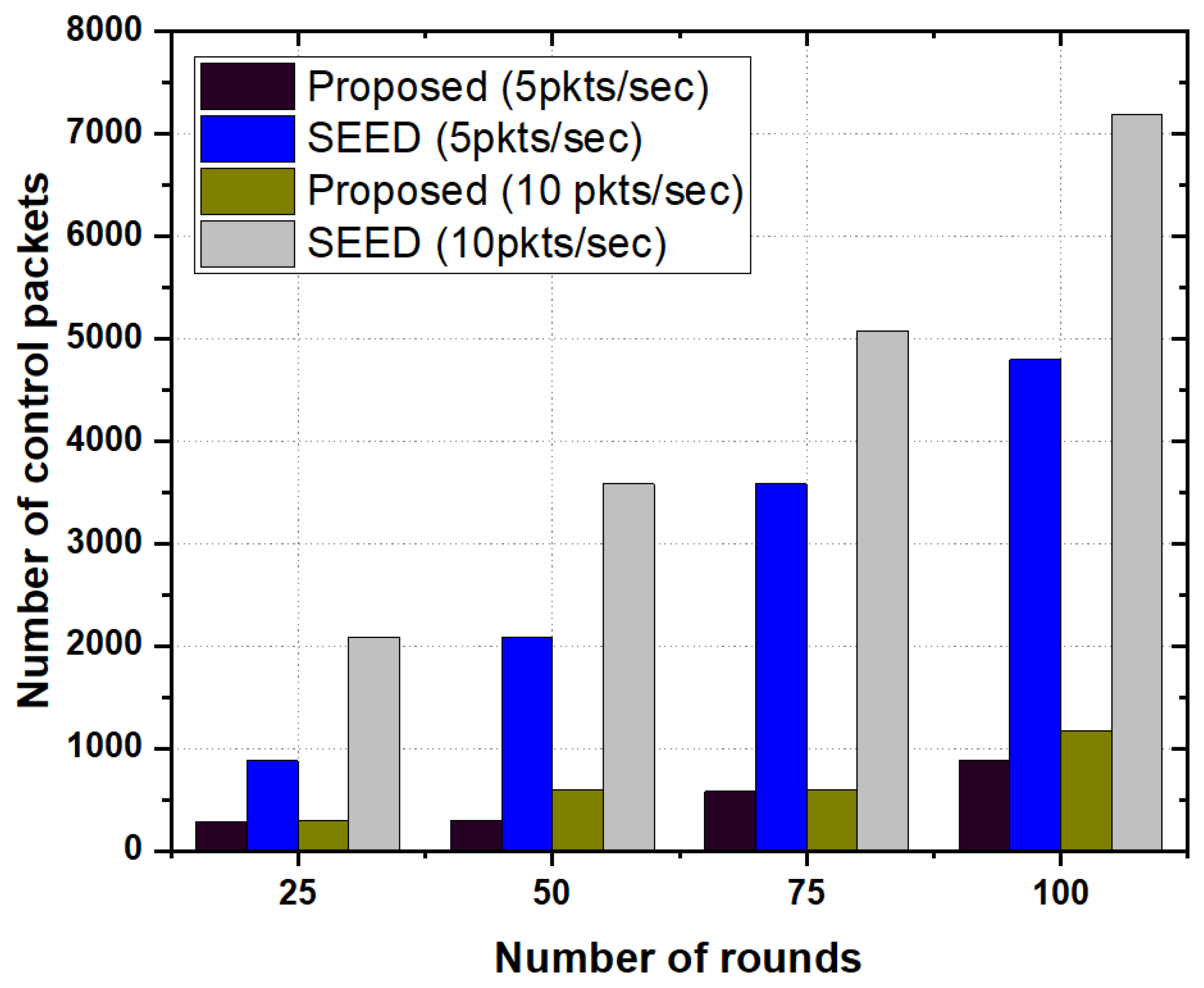
- Number of Control Packets: The control packets considered as overheads and are defined as the packets used for route establishment from a source to a destination e.g., CH announcement, Join CH and TDMA etc.
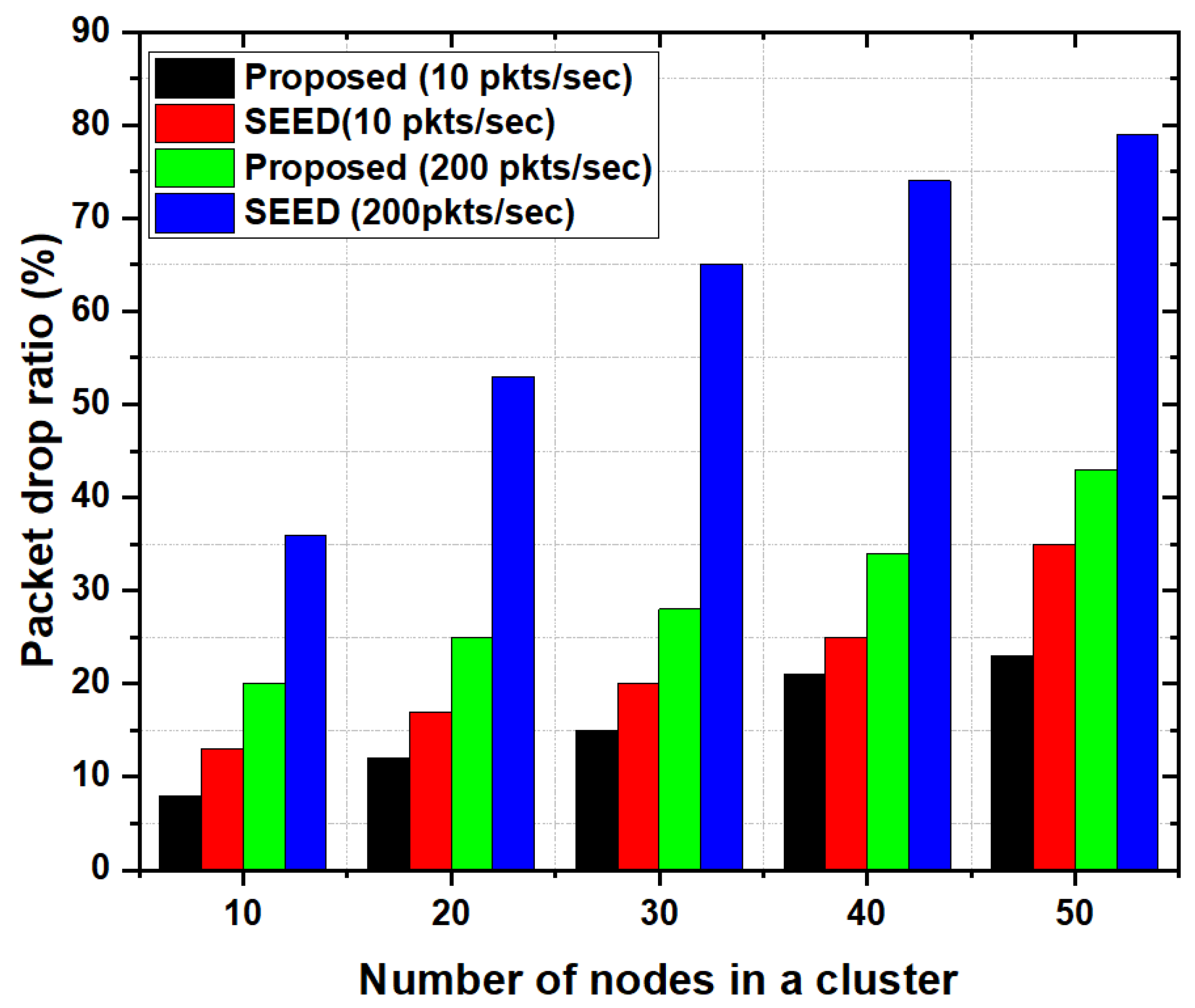
- Packet Drop Ratio: Packet drop ratio is defined as the ratio of the number of packets lost (not received at receiving node e.g., CH or Sink node) to the total number of sent packets.
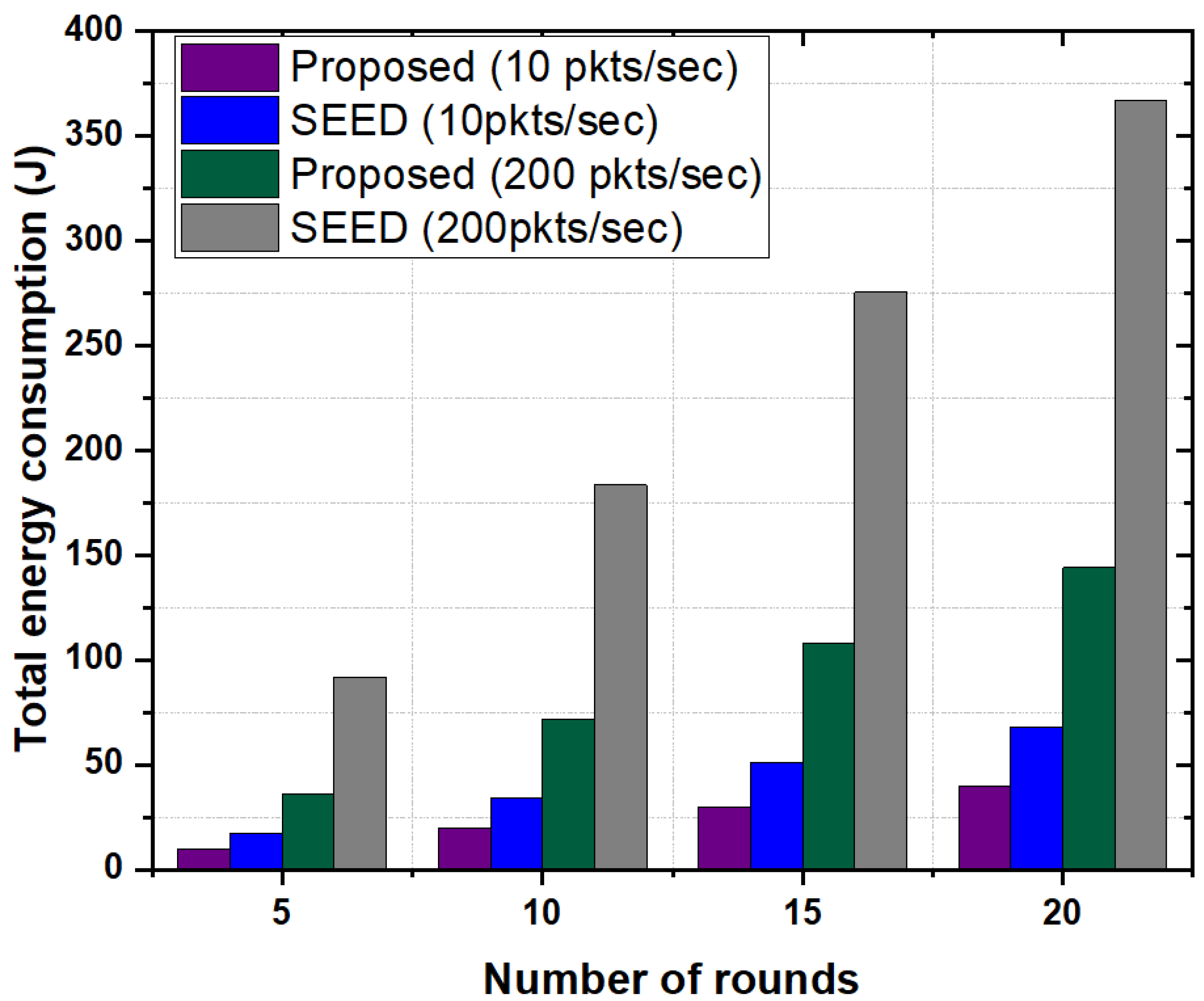
- Total Energy Consumption: The energy consumption of a node mainly depends on two main factors (e.g., packet processing and transmissions or receptions) [37]. The cumulative energy consumption of a node is presented in Equation (13) and is defined as follows.where is the energy consumed in processing, and and represents the energy consumed for receiving and transmitting a data packet, respectively.The total energy consumption of the network is directly proportional to the number of packets transmitted in the network and is defined as follows.where “n” represents the total number of packets.
5.2. Simulation Environment
5.3. Results and Discussions
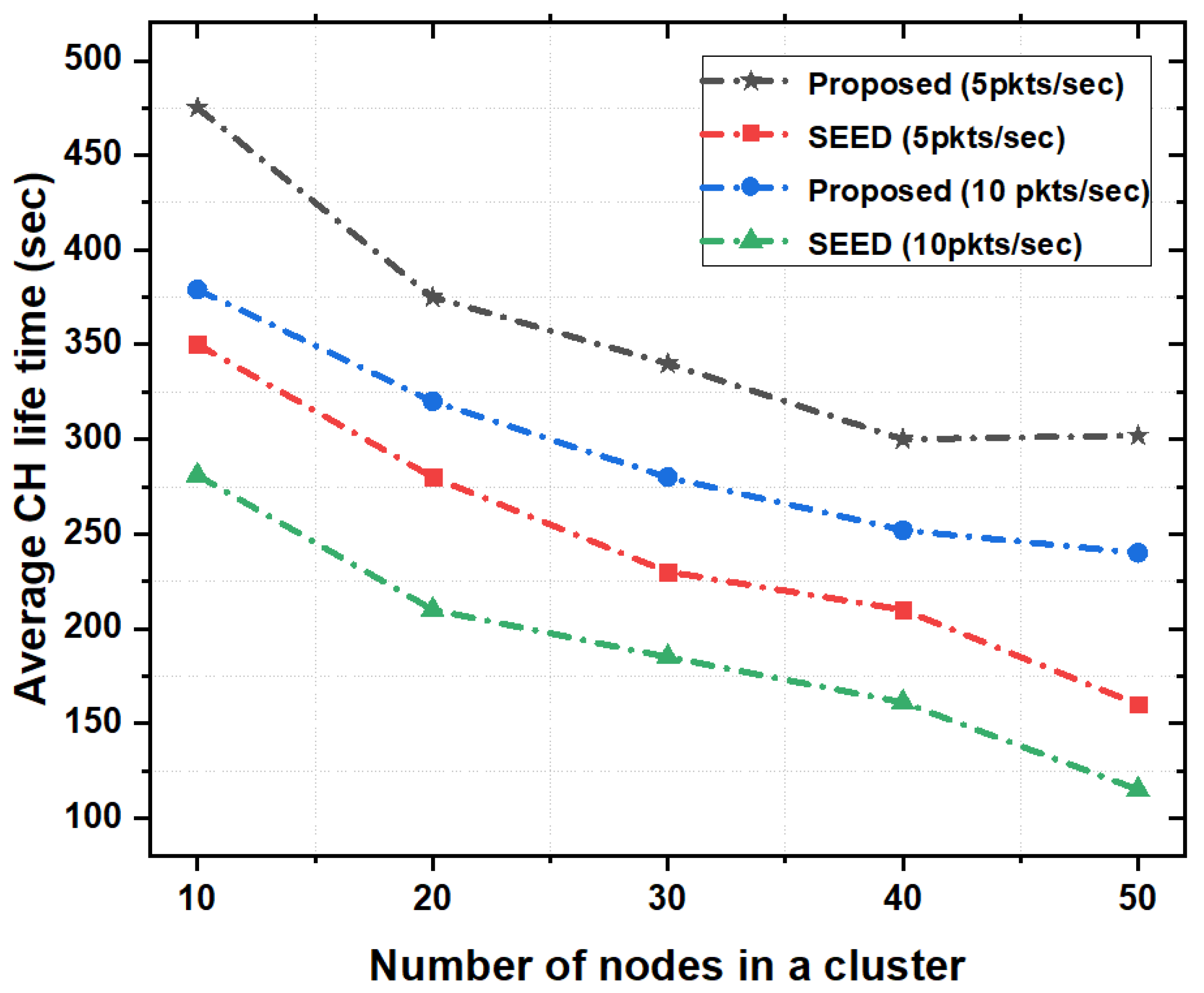
5.3.1. CH Lifetime
5.3.2. Re-Clustering Frequency
5.3.3. Number of Control Packets
5.3.4. Packet Drop Ratio
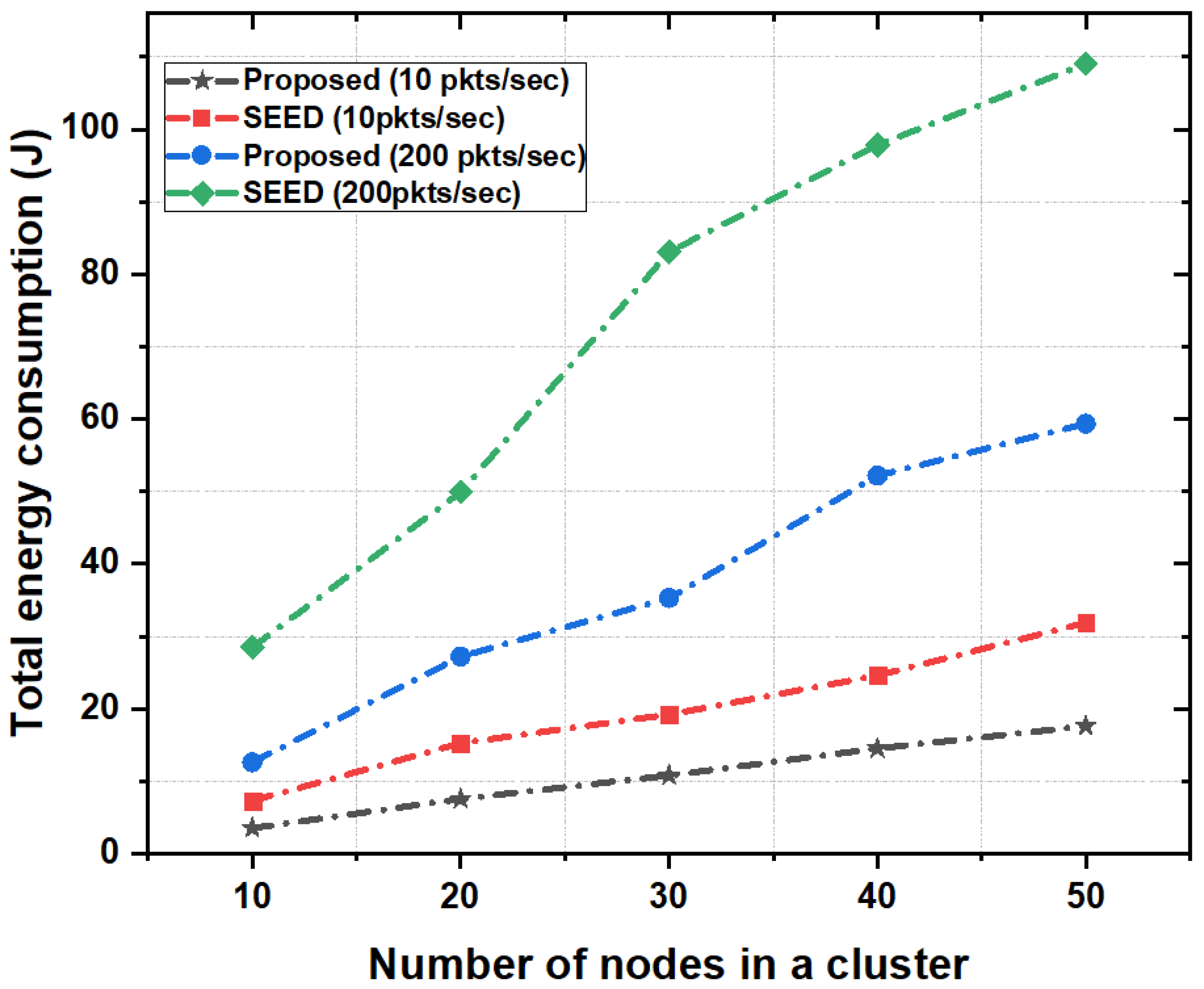
5.3.5. Total Energy Consumption
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Srbinovska, M.; Gavrovski, C.; Dimcev, V.; Krkoleva, A.; Borozan, V. Environmental parameters monitoring in precision agriculture using wireless sensor networks. J. Clean. Prod. 2015, 88, 297–307. [Google Scholar] [CrossRef]
- Boulmaiz, A.; Messadeg, D.; Doghmane, N.; Taleb-Ahmed, A. Robust acoustic bird recognition for habitat monitoring with wireless sensor networks. Int. J. Speech Technol. 2016, 19, 631–645. [Google Scholar] [CrossRef]
- Ghosh, K.; Neogy, S.; Das, P.K.; Mehta, M. Intrusion detection at international borders and large military barracks with multi-sink wireless sensor networks: An energy efficient solution. Wirel. Pers. Commun. 2018, 98, 1083–1101. [Google Scholar] [CrossRef]
- Amale, O.; Patil, R. IOT Based Rainfall Monitoring System Using WSN Enabled Architecture. In Proceedings of the 2019 3rd International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 27–29 March 2019; pp. 789–791. [Google Scholar] [CrossRef]
- Ullah, R.; Faheem, Y.; Kim, B. Energy and Congestion-Aware Routing Metric for Smart Grid AMI Networks in Smart City. IEEE Access 2017, 5, 13799–13810. [Google Scholar] [CrossRef]
- Hao, Z. Design of WSN traffic forecasting system with delayed self-sensing. Int. J. Comput. Appl. 2020, 42, 30–35. [Google Scholar] [CrossRef]
- Molina-Pico, A.; Cuesta-Frau, D.; Araujo, A.; Alejandre, J.; Rozas, A. Forest monitoring and wildland early fire detection by a hierarchical wireless sensor network. J. Sens. 2016, 2016, 1–8. [Google Scholar] [CrossRef]
- Kumar, A.; Zhao, M.; Wong, K.J.; Guan, Y.L.; Chong, P.H.J. A comprehensive study of IoT and WSN MAC protocols: Research issues, challenges and opportunities. IEEE Access 2018, 6, 76228–76262. [Google Scholar] [CrossRef]
- Pantazis, N.A.; Nikolidakis, S.A.; Vergados, D.D. Energy-efficient routing protocols in wireless sensor networks: A survey. IEEE Commun. Surv. Tutor. 2013, 15, 551–591. [Google Scholar] [CrossRef]
- Afsar, M.M.; Tayarani-N, M.H. Clustering in sensor networks: A literature survey. J. Netw. Comput. Appl. 2014, 46, 198–226. [Google Scholar] [CrossRef]
- Xu, L.; Collier, R.; O’Hare, G.M. A Survey of Clustering Techniques in WSNs and Consideration of the Challenges of Applying Such to 5G IoT Scenarios. IEEE Internet Things J. 2017, 4, 1229–1249. [Google Scholar] [CrossRef]
- Younis, O.; Krunz, M.; Ramasubramanian, S. Node clustering in wireless sensor networks: Recent developments and deployment challenges. IEEE Netw. 2006, 20, 20–25. [Google Scholar] [CrossRef]
- Gupta, V.; Pandey, R. An improved energy aware distributed unequal clustering protocol for heterogeneous wireless sensor networks. Eng. Sci. Technol. Int. J. 2016, 19, 1050–1058. [Google Scholar] [CrossRef]
- Jan, B.; Farman, H.; Javed, H.; Montrucchio, B.; Khan, M.; Ali, S. Energy efficient hierarchical clustering approaches in wireless sensor networks: A survey. Wirel. Commun. Mob. Comput. 2017, 2017, 1–14. [Google Scholar] [CrossRef]
- Rostami, A.S.; Badkoobe, M.; Mohanna, F.; Hosseinabadi, A.A.R.; Sangaiah, A.K. Survey on clustering in heterogeneous and homogeneous wireless sensor networks. J. Supercomput. 2018, 74, 277–323. [Google Scholar] [CrossRef]
- Heinzelman, W.R.; Chandrakasan, A.; Balakrishnan, H. Energy-efficient communication protocol for wireless microsensor networks. In Proceedings of the 33rd Annual Hawaii International Conference on System Sciences, Maui, HI, USA, 7 January 2000; Volume 2, p. 10. [Google Scholar]
- Behera, T.M.; Mohapatra, S.K.; Samal, U.C.; Khan, M.S.; Daneshmand, M.; Gandomi, A.H. Residual energy-based cluster-head selection in WSNs for IoT application. IEEE Internet Things J. 2019, 6, 5132–5139. [Google Scholar] [CrossRef]
- Afsar, M.M.; Younis, M. An energy- and proximity-based unequal clustering algorithm for Wireless Sensor Networks. In Proceedings of the 39th Annual IEEE Conference on Local Computer Networks, Edmonton, AB, Canada, 8–11 September 2014; pp. 262–269. [Google Scholar] [CrossRef]
- Ahmed, G.; Zou, J.; Fareed, M.M.S.; Zeeshan, M. Sleep-awake energy efficient distributed clustering algorithm for wireless sensor networks. Comput. Electr. Eng. 2016, 56, 385–398. [Google Scholar] [CrossRef]
- Hosen, A.S.; Cho, G.H. An energy centric cluster-based routing protocol for wireless sensor networks. Sensors 2018, 18, 1520. [Google Scholar] [CrossRef]
- Panag, T.S.; Dhillon, J.S. Dual head static clustering algorithm for wireless sensor networks. AEU-Int. J. Electron. Commun. 2018, 88, 148–156. [Google Scholar] [CrossRef]
- Yu, J.; Qi, Y.; Wang, G. An energy-driven unequal clustering protocol for heterogeneous wireless sensor networks. J. Control Theory Appl. 2011, 9, 133–139. [Google Scholar] [CrossRef]
- Smaragdakis, G.; Matta, I.; Bestavros, A. SEP: A stable election protocol for clustered heterogeneous wireless sensor networks. Available online: https://www.cs.bu.edu/techreports/pdf/2004-022-sep.pdf (accessed on 26 July 2020).
- Mehmood, A.; Khan, S.; Shams, B.; Lloret, J. Energy-efficient multi-level and distance-aware clustering mechanism for WSNs. Int. J. Commun. Syst. 2015, 28, 972–989. [Google Scholar] [CrossRef]
- Amgoth, T.; Jana, P.K.; Thampi, S. Energy-Aware Routing Algorithm for Wireless Sensor Networks. Comput. Electr. Eng. 2015, 41, 357–367. [Google Scholar] [CrossRef]
- Gu, X.; Yu, J.; Yu, D.; Wang, G.; Lv, Y. ECDC: An energy and coverage-aware distributed clustering protocol for wireless sensor networks. Comput. Electr. Eng. 2014, 40, 384–398. [Google Scholar] [CrossRef]
- Sabet, M.; Naji, H.R. A decentralized energy efficient hierarchical cluster-based routing algorithm for wireless sensor networks. AEU-Int. J. Electron. Commun. 2015, 69, 790–799. [Google Scholar] [CrossRef]
- Dahnil, D.P.; Singh, Y.P.; Ho, C.K. Topology-controlled adaptive clustering for uniformity and increased lifetime in wireless sensor networks. IET Wirel. Sens. Syst. 2012, 2, 318–327. [Google Scholar] [CrossRef]
- Wang, S.S.; Chen, Z.P. LCM: A link-aware clustering mechanism for energy-efficient routing in wireless sensor networks. IEEE Sens. J. 2013, 13, 728–736. [Google Scholar] [CrossRef]
- Mahajan, S.; Malhotra, J.; Sharma, S. An energy balanced QoS based cluster head selection strategy for WSN. Egypt. Inform. J. 2014, 15, 189–199. [Google Scholar] [CrossRef]
- Farman, H.; Jan, B.; Javed, H.; Ahmad, N.; Iqbal, J.; Arshad, M.; Ali, S. Multi-criteria based zone head selection in Internet of Things based wireless sensor networks. Future Gener. Comput. Syst. 2018, 87, 364–371. [Google Scholar] [CrossRef]
- Boulanouar, I.; Rachedi, A.; Lohier, S.; Roussel, G. Energy-aware object tracking algorithm using heterogeneous wireless sensor networks. In Proceedings of the 2011 IFIP Wireless Days (WD), Niagara Falls, ON, Canada, 10–12 October 2011; pp. 1–6. [Google Scholar]
- Liu, X.; Yang, T.; Yan, B. Internet of Things for wildlife monitoring. In Proceedings of the 2015 IEEE/CIC International Conference on Communications in China-Workshops (CIC/ICCC), Shenzhen, China, 2–4 November 2015; pp. 62–66. [Google Scholar]
- Olson, D. Comparison of weights in TOPSIS models. Math. Comput. Model. 2004, 40, 721–727. [Google Scholar] [CrossRef]
- Jain, B.; Brar, G.; Malhotra, J.; Rani, S. A novel approach for smart cities in convergence to wireless sensor networks. Sustain. Cities Soc. 2017, 35, 440–448. [Google Scholar] [CrossRef]
- Wahid, A.; Shah, M.A.; Qureshi, F.F.; Maryam, H.; Iqbal, R.; Chang, V. Big data analytics for mitigating broadcast storm in Vehicular Content Centric networks. Future Gener. Comput. Syst. 2018, 86, 1301–1320. [Google Scholar] [CrossRef]
- Ullah, R.; Rehman, M.A.U.; Kim, B.S. Hierarchical Name-Based Mechanism for Push-Data Broadcast Control in Information-Centric Multihop Wireless Networks. Sensors 2019, 19, 3034. [Google Scholar] [CrossRef] [PubMed]
- Boulis, A. Castalia: Revealing Pitfalls in Designing Distributed Algorithms in WSN. In Proceedings of the 5th International Conference on Embedded Networked Sensor Systems, Sydney, Australia, 6–9 November 2007; pp. 407–408. [Google Scholar] [CrossRef]
- Yuste-Delgado, A.J.; Cuevas-Martinez, J.C.; Triviño-Cabrera, A. A Distributed Clustering Algorithm Guided by the Base Station to Extend the Lifetime of Wireless Sensor Networks. Sensors 2020, 20, 2312. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Simulator | Castalia v-3.2 |
| Area | 100 × 100 |
| Total number of sensor nodes | 100 |
| Node distribution | Random |
| Initial Energy of nodes | 6 J–10 J |
| MAC | Tunable Mac (T-Mac) |
| Packet rate | 5 pkts/s, 10 pkts/s, 200 pkts/s |
| Packet Size | 4000 bits |
| Energy Consumption | 0.5 J/bit |
| Buffer size | Max bits |
| Propagation Model | Log-Normal Shadowing Model |
| Simulation time | 2000 s |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
din, M.S.u.; Rehman, M.A.U.; Ullah, R.; Park, C.-W.; Kim, B.S. Towards Network Lifetime Enhancement of Resource Constrained IoT Devices in Heterogeneous Wireless Sensor Networks. Sensors 2020, 20, 4156. https://doi.org/10.3390/s20154156
din MSu, Rehman MAU, Ullah R, Park C-W, Kim BS. Towards Network Lifetime Enhancement of Resource Constrained IoT Devices in Heterogeneous Wireless Sensor Networks. Sensors. 2020; 20(15):4156. https://doi.org/10.3390/s20154156
Chicago/Turabian Styledin, Muhammad Salah ud, Muhammad Atif Ur Rehman, Rehmat Ullah, Chan-Won Park, and Byung Seo Kim. 2020. "Towards Network Lifetime Enhancement of Resource Constrained IoT Devices in Heterogeneous Wireless Sensor Networks" Sensors 20, no. 15: 4156. https://doi.org/10.3390/s20154156
APA Styledin, M. S. u., Rehman, M. A. U., Ullah, R., Park, C.-W., & Kim, B. S. (2020). Towards Network Lifetime Enhancement of Resource Constrained IoT Devices in Heterogeneous Wireless Sensor Networks. Sensors, 20(15), 4156. https://doi.org/10.3390/s20154156