1. Introduction
The weather radar is one of the important sensors for atmospheric active remote sensing. It transmits a pulse signal into the atmosphere and then receives a part of the signal backscattered by the conglomerate of scatterers (e.g., aerosols, hydrometeors, such as raindrops, snow, etc.) [
1]. The received scattering signal, known as weather radar echo, can help forecasters identify and classify weather systems. Beyond this, forecasters can predict the future movement and evolution of weather systems based on radar echo extrapolation, which is the prediction of the appearance, intensity, and distribution of future echoes according to historical echo observations. Thus, radar echo extrapolation has become one of the most fundamental means for short-term weather forecasting and precipitation nowcasting [
2,
3]. Its significant application value, as well as the difficulty and complexity of the problem, have attracted numerous studies over recent decades.
The earliest research on radar echo extrapolation can be traced back to 1970s [
4]. To date, there three categories of traditional extrapolation methods have been developed: centroid tracking, cross-correlation, and optical flow. Centroid tracking methods [
5,
6,
7,
8,
9] identify the thunderstorm echo cells and track their movement. However, they are limited to the extrapolation of severe convective systems. In comparison, cross-correlation methods [
10,
11,
12,
13] take sub-regions of the echo as the extrapolation target and predict their movements. Although cross-correlation methods can deal with stratiform precipitation systems that are gently varied, the prediction of severe convective systems which are fast-moving and evolving rapidly is difficult due to increasing incorrect calculations of motion vectors. Optical flow methods [
14,
15] calculate the flow field of the echo and extrapolate the radar echo by solving the optical flow constraint equation with additional constraints, such as the Horn–Schunck global smoothing constraint [
16] and the Lucas–Kanade local constraint [
17]. Optical flow methods assume that there are only motion changes in continuous echoes, regardless of the changes in echo intensity in the time sequence, which is not coincident with the reality that echoes change with both position and intensity through time. Overall, these three methods only trace back a few steps for previous echoes and their capability of modeling non-linear motion patterns is weak. Thus, they have inherent limitations, such as short timeliness and low precision.
In recent years, some researchers have applied deep learning [
18], which can effectively learn representations of data with multiple levels of abstraction and has achieved significant progress in computer vision, to deal with radar echo extrapolation. Compared to conventional radar echo extrapolation methods, deep learning based methods possess greater modeling capacity as they can fit sophisticated designed neural networks by learning from large-scale historical radar echo datasets. Generally, there are two main types of deep learning models, the convolutional neural network (CNN) [
19,
20,
21] and the recurrent neural network (RNN) [
22,
23,
24], while the CNN specializes in extracting spatial features from a single frame, the RNN is more suitable for capturing temporal correlation from sequential data. For the extrapolation methods based on CNN, Klein et al. (2015) [
25] proposed a dynamic convolutional layer applying a dynamically varied convolution kernel on the last input echo frame to extrapolate, where the kernel is generated based on input, but it is limited to extrapolating only one echo frame at a time. Shi et al. (2018) [
26] combined a recurrent dynamic sub-network and a probability prediction layer to form their model, where the recurrent dynamic sub-network is a CNN incorporated with a recurrent structure. For the RNN models, Shi et al. (2015) [
27] first defined the radar echo extrapolation problem as a spatiotemporal sequence prediction problem, then proposed the Convolutional Long Short-Term Memory (ConvLSTM), in which the dot products in the fully connected LSTM [
28] are substituted by the convolution operations, to better capture spatiotemporal correlations from radar echo sequences. In addition, they built an encoding-forecasting structure with ConvLSTM as a basic building block for sequence-to-sequence multistep prediction. Wang et al. (2017) [
29] extended the ConvLSTM with an additional spatiotemporal memory integrated with its origin memory cell and conveyed across the network vertically; they showed that this would be conducive to learn spatial and temporal representations simultaneously. Shi et al. (2017) [
30] considered that the local weather systems sometimes have motion patterns, such as rotation and scaling, and the location-invariant kernel used by the convolution operation may not be sufficient to model them. Thus a structure generating network was used to dynamically generate a local connection structure between hidden states for state-to-state transition. To improve the image quality of the extrapolated echoes, Tran and Song (2019) [
31] employed some of the visual image quality assessment metrics including the structural similarity index measure (SSIM) and multi-scale SSIM to train their model.
Although the above deep learning based extrapolation methods have exhibited a remarkable improvement in extrapolation performance compared with traditional methods as they can forecast more complicated temporal motion patterns and some spatial deformations caused by the motion, there are still two limitations which should be considered. For the first, in reality, the variations of weather systems are more than only advection motion, weather systems will simultaneously experience an evolutionary process from formation to dissipation, which also affects the extrapolation accuracy but has been rarely investigated by the existing methods. And for the second, the extrapolated echo of existing deep learning methods tends to be increasingly blurry as the extrapolation goes deeper, which may due to the widely used mean square error (MSE) or mean absolute error (MAE) loss functions [
32,
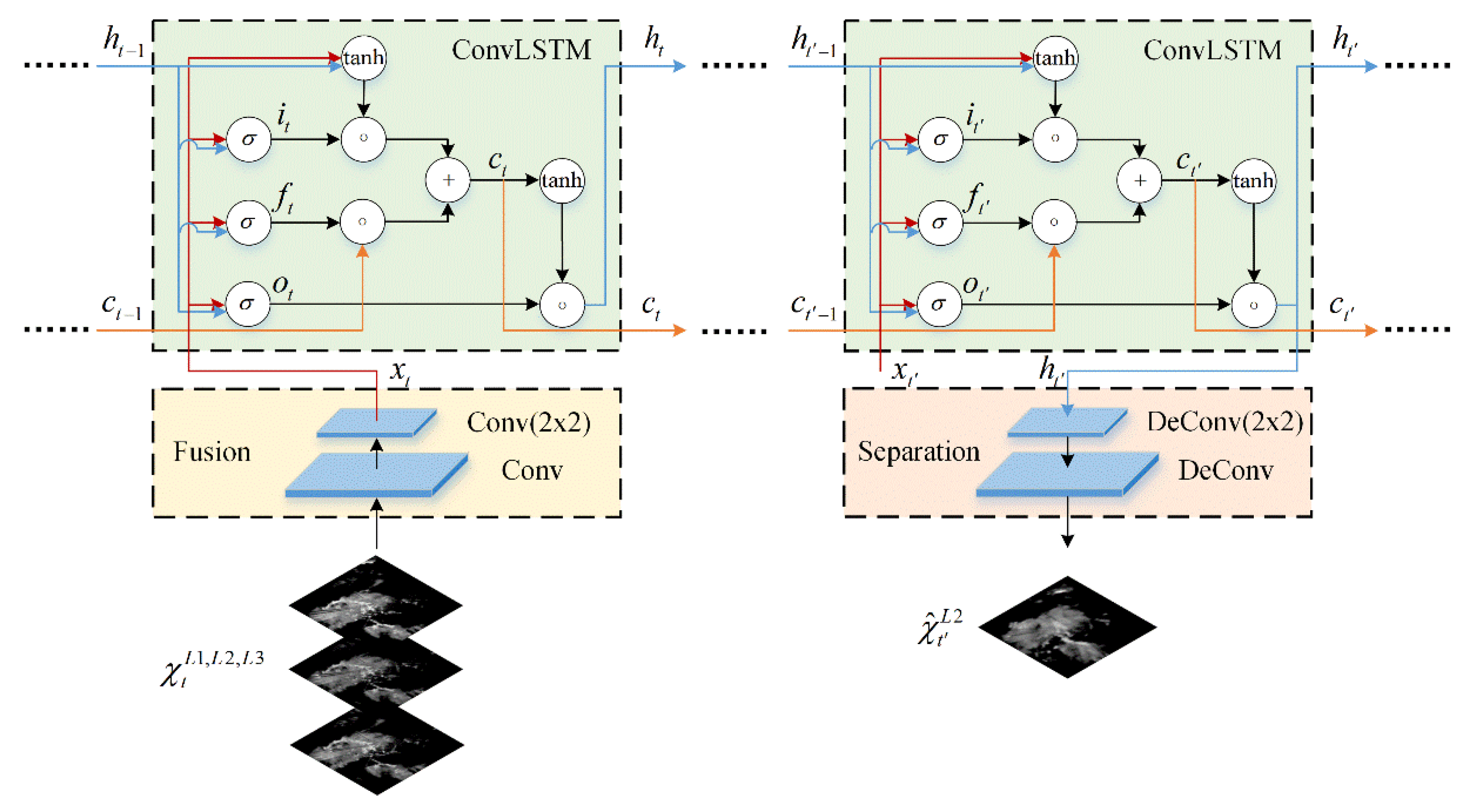
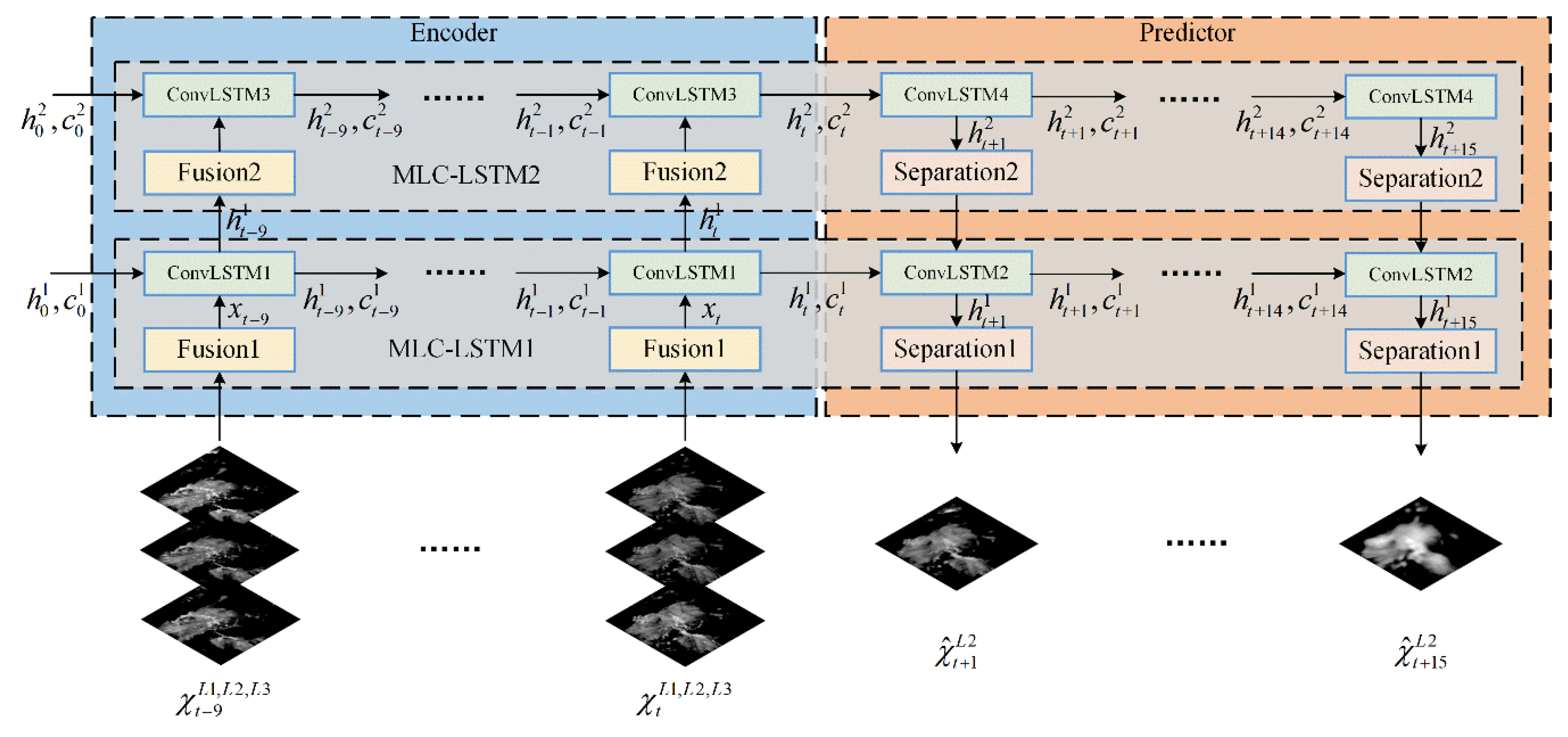
33] as they lead to averaging all potential predictions and lose echo details. In our work, these two limitations are considered, and a deep learning model is constructed to predict the echo evolution and extrapolate echo more accurately. First, motivated by the physical characteristics of weather systems’ evolutionary process, a variant of the RNN unit called Multi-level Correlation LSTM (MLC-LSTM) is proposed to exploit the spatiotemporal correlation between multi-level radar echoes and model the echo’s spatiotemporal evolution. To be specific, there are usually abundant vertical, horizontal, and diagonal atmospheric motions existing in weather systems [
34], which drive the evolution and development of weather systems (which can be viewed as 3D entities) and cause them to have a strong spatiotemporal correlation between different height levels. Thus, it makes sense that the MLC-LSTM can take multi-level echoes as input and exploit their spatiotemporal correlation for extrapolation that will fit the physical conditions more adequately and contribute to performing prediction of evolution more effectively. Second, to address the problem of blurry echo prediction, the recent success of generative adversarial network (GAN) [
35,
36,
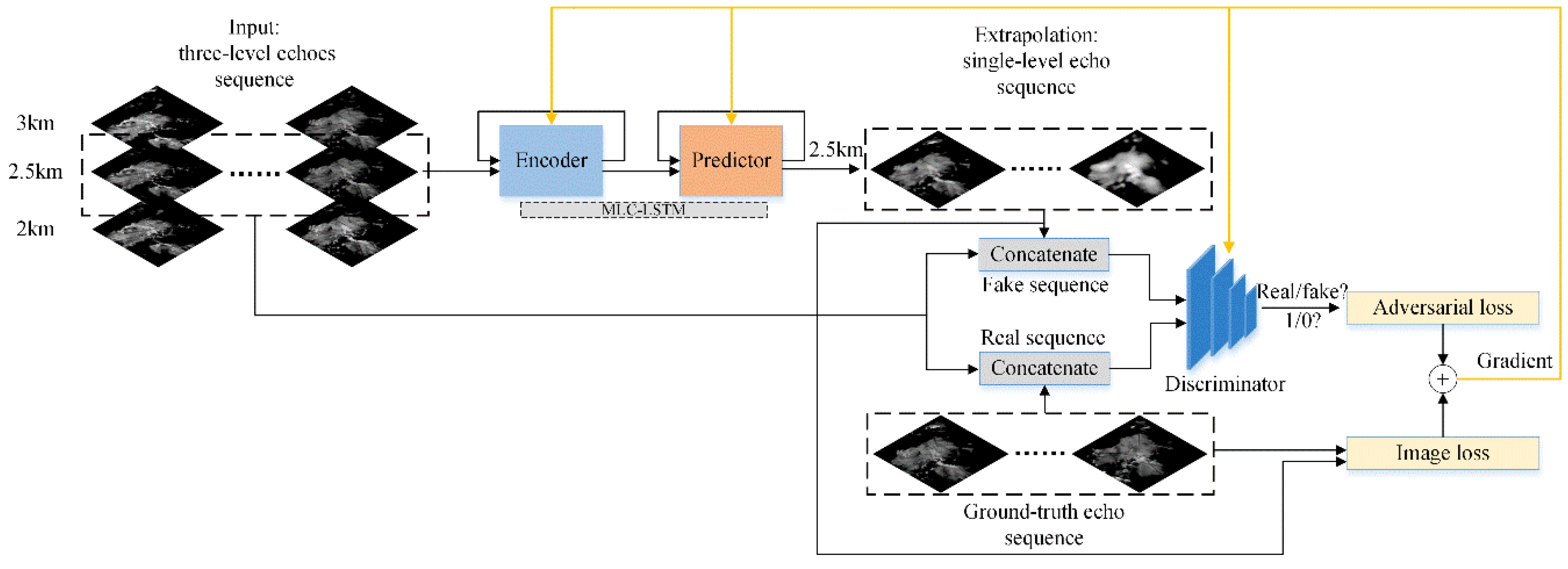
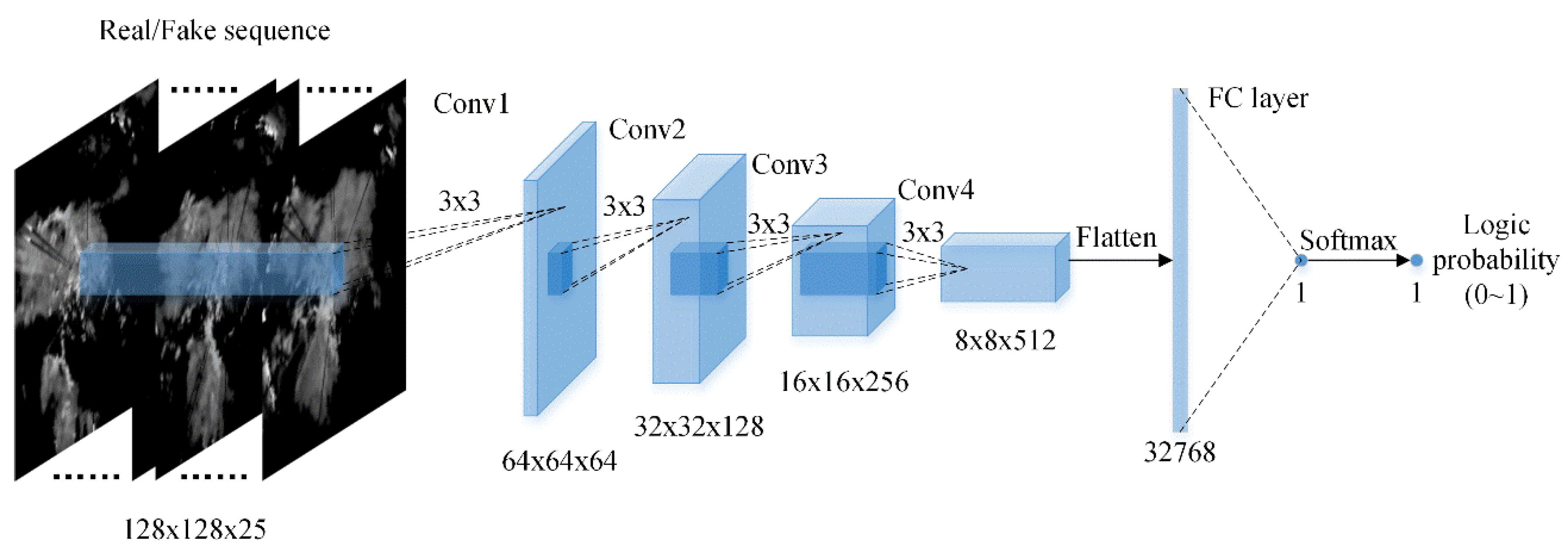
37] has inspired us to integrate adversarial training into our approach, which is training a generator and a discriminator in an alternative way to lead the generated data distribution to match the real data distribution. Thus, the generated data could be sharp and realistic. We first construct an encoder–predictor architecture based on the MLC-LSTM for end-to-end radar echo extrapolation to act as the generator, then design a CNN structure as the discriminator. They are trained with both the image loss and the adversarial loss to lead the extrapolation echo results to be more fine-grained and realistic.
For model training and testing, we have built a real-life multi-level radar echoes dataset. Through the extrapolation experiments conducted on this dataset, the effectiveness of the different components of our model has been verified first, then compared with other state-of-the-art extrapolation methods. The results show that our model can extrapolate radar echo more effectively and accurately and that it has important application value in weather forecasting practice.
The rest of the paper is organized as follows; the proposed model is described in detail in
Section 2. The dataset, experiments settings, evaluation metrics, effectiveness analysis of model components, qualitative and quantitative evaluation results are presented in
Section 3. The work of this paper is summarized, and an outlook of future work is given in
Section 4.
3. Experiments and Results
In this section, we have conducted several experiments to verify the effectiveness of our model. In
Section 3.1, the construct steps and details of the real-life multi-level radar echoes dataset are introduced. In
Section 3.2, the settings of the experiments, including the hyperparameters, adversarial training strategy, and evaluation metrics, are given. In
Section 3.3, the effectiveness of different components of our model has been validated. In
Section 3.4, experimental results are compared with the state-of-the-art methods and analyzed. In
Section 3.5, the performance of the model is evaluated. All the experiments in this paper are implemented using Python, MATLAB, and Tensorflow [
40] and conducted on 4 RTX 2080Ti GPUs and 1 Intel Xeon Gold 5118 CPU.
3.1. Dataset
Since our model aims at exploiting the spatiotemporal correlation between multi-level radar echoes for extrapolation, we have constructed a real-life multi-level radar echoes dataset. The type of the radar sensor we chose is the CINRAD/SA Doppler Weather Radar [
41], which works in the VCP21 detection mode and has a 6-min interval of volume scanning and 9 detection elevations (from 0.5° to 19.5°). The raw radar echo dataset we used was provided by the National Meteorological Information Center, China, which contained data detected and collected by Hangzhou, Nanjing, Xiamen, Changsha, and Fuzhou stations from 2016 to 2017. Considering that rainy days usually have a more effective precipitation echo for model training and validation, a total of 307 rainy days’ data were selected based on the historical daily precipitation observations to construct the final dataset
For data pre-processing, we first interpolated the raw radar echo data into cartesian coordinate to obtain a multi-level constant altitude plan position indicator (CAPPI) images [
42]. Since the valid detection radius of the radar was about 240 km on the 2 to 3 km altitudes, the central 480 × 480 (480 × 480 km
2) region of echo images was cropped and remained. Then, they were resized to 128 × 128 size with bilinear interpolation to be more suitable for model training and test. In addition, the reflectivity factor values of echo images were clipped to be between 0 and 75 dBZ and then normalized into gray-level pixel value which was between 0 and 1. The clutter has also been suppressed.
In our work, 10 historical three-level echo images were input, and the subsequent 15 future echo images on the middle-level were output as extrapolation results. Thus, a sliding window with length 25 and stride 3 was applied on each rainy day’s data to divide them into echo image sequences. A total of 12,144 sequences were obtained and randomly split into a training set of 8508 sequences, a validation set of 1200 sequences, and a test set of 2436 sequences. In the experiments, the training set was used for training the deep learning model, the validation set was used for judging when to adopt early-stopping and adjusting the model hyper-parameters, such as learning rate, kernel size, and dropout rate. All the comparison and evaluation experiments were conducted on the test set.
3.2. Experiments Settings
During the training of the MLC-LSTM, we set the weight of image loss
and adversarial loss
to 1 and 0.02, respectively, to make sure that the two sub-loss were both located on the same scale of magnitude. All the neural network weights were initialized with a Xavier initializer [
43], and all the biases were initialized to 0. Both of the generator and the discriminator were optimized by the Adam optimizer [
44] with momentum
,
, and initial learning rate 0.0001. The adversarial training was launched starting from the discriminator and then the generator. The updating ratio for the generator and discriminator was set as 2:1, which means that the generator was updated 2 steps per updating step of the discriminator as we found that the discriminator usually converges faster than the generator and that the updating ratio can contribute to stabilizing the adversarial training. Since it was hard to decide when to stop training by visualizing the fluctuant training loss, we performed the training for 20000 to 50000 iterations and chose the stopping point when the model performed best on the validation set. The batch size of the training was set to 4.
For quantitative evaluation metrics, we adopted the probability of detection (POD), false alarm rate (FAR), critical success index (CSI) [
45], and Heidke skill score (HSS) [
46], structural similarity index measure (SSIM) [
47], and peak signal to noise ratio (PSNR) [
48] in this paper. The SSIM and PSNR are two image-level similarity metrics used widely in the computer vision field, and a higher value denotes a higher similarity. The POD, FAR, CSI, and HSS are commonly used metrics for evaluating the quality of precipitation nowcasting, where the POD represents the ratio of successful predictions to the total number of events, the FAR represents the proportion of incorrect predictions to all predictions, and the CSI and HSS are more comprehensive metrics as they take into consideration both the successful and incorrect predictions. A larger score of the POD, CSI, HSS, and a lower score of the FAR means that the nowcasting quality is better.
To calculate these metrics, we first mapped the pixel values of ground-truth echo and extrapolation echo back to reflectivity factors, then converted the reflectivity factor to rainfall rate using the Z-R relationship as
where
denotes the reflectivity factor of radar echo,
is the rainfall rate and
,
are two constants set to 58.53 and 1.56, respectively, according to usual experience.
After that, the ground-truth echo and extrapolation echo were transformed into two
matrices at a threshold of 0.5 mm/h rainfall rate (the threshold indicating raining or not raining) and the hits
(ground-truth = 1, extrapolation = 1), misses
(ground-truth = 1, extrapolation = 0), false alarms
(ground-truth = 0, extrapolation = 1), and correct rejections
(ground-truth = 0, extrapolation = 0) were counted. Then, the POD, FAR, CSI, and HSS can be calculated by
where the POD, FAR, CSI, and HSS are ranges between 0 and 1.
3.3. Effectiveness Validation
In this section, we conduct experiments to verify the effectiveness of the different components of our model, including the effectiveness of the model architecture, dropout, and adversarial training strategy, see
Section 3.3.1,
Section 3.3.2 and
Section 3.3.3 for detailed results.
3.3.1. The Effectiveness of Model Architecture
In this paper, we stacked two MLC-LSTMs to form our model architecture. To prove it can balance the memory consumption and the modeling capability, we compared it with two model variants, MLC-LSTM with only one layer and MLC-LSTM with three layers stacked. For the one-layer model variant, it removed the second MLC-LSTM. For the three layers model variant, the additional third MLC-LSTM doubled the number of channels to 256 and had the same 3 × 3 size kernel.
The echo at Hangzhou, China, 8 August 2016, 23:07 UTC was chosen as a sample for extrapolation. The extrapolation results predicted by the three models are shown in
Figure 5. In the ground-truth, the echo located in the southeast was continuously moving to the southwest. Meanwhile, the main part of the echo was gradually separating and dissipating. It can be seen that our model predicted this process accurately, although, in the later stage, the shape of the extrapolated echoes was not fully consistent with the ground-truth. The echo motion and dissipation have been well modeled. Compared with our model, the other two model variants did not predict the echo motion as accurately. For the dissipation process, the MLS-LSTM with only one layer had little ability to predict it. The extrapolated echoes seem not changed. The MLC-LSTM with three layers stacked predicted the dissipation roughly and excessively. It only shrank the whole echo cell and cut the echo contents, not considering that the echo shape had dispersed and changed, which was also not in line with the ground-truth. These differences, we think, may be related to the modeling capability, the two model variants cannot do well as they have a limited and excess modeling capability, respectively, while our model possesses a moderate modeling capability and thus, extrapolates the echo appropriately.
The evaluation results of three models on POD, FAR, CSI, HSS, SSIM, and PSNR metrics are given in
Table 2. Our model achieved almost the best scores, except for the POD, which was obtained by the one-layer model variant. This can be explained reasonably, as shown in
Figure 5, the MLC-LSTM with a single layer was poor at predicting the dissipation and tends to predict the echo with more incorrect contents. Thus, its POD was higher than the others and FAR was also the highest. In addition, a performance evaluation of our model was also performed, which will be described in
Section 3.5. Totally, our model did not consume much memory and simultaneously kept a decent modeling capability.
3.3.2. The Effectiveness of Dropout
To verify the effectiveness of dropout we used in this paper, we compared our model with the MLC-LSTM without using the dropout and MLC-LSTM with 0.5 rate dropout. For the same echo sample as
Section 3.3.1, the extrapolation results obtained by the three models are shown in
Figure 6.
From
Figure 6, we can see both of the three models capture the echo motion and predict a satisfactory echo in the first half extrapolation stage (from t + 1 to t + 10), but during the second half (from t + 10 to t + 15), the MLC-LSTM without dropout and MLC-LSTM with 0.5 rate dropout did not predict the dissipation process as good as our model. For the MLC-LSTM without dropout, its predicted echo has a thicker main body than others. This is probably because it has a weak generalization ability so that it makes a maximization hypothesis and tends to predict more potential but incorrect echo contents. For the MLC-LSTM with 0.5 dropout rate, its extrapolation of the echo is more dispersive in distribution and even vanished. This might be because it adopts a relative larger dropout rate, and there are fewer neural connects activated, which diminishes the modeling capability. Overall, our model MLC-LSTM with a 0.3 dropout rate, ensures both the generalization ability and the modeling capability, thus performs better against other models.
The quantitative evaluation results, as shown in
Table 3, indicate that our model also does almost the best on both six metrics quantitatively, which corroborates its effectiveness, too. In addition, the MLC-LSTM without dropout achieves the highest FAR among the three models, which is consistent with the fact that it is inclined to predict more incorrect echo contents.
3.3.3. The Effectiveness of Adversarial Training Strategy
In this section, we aim to verify the validity of our adversarial training strategy. Considering the loss function, in our work, a combination of the image loss, including the MSE and MAE, with the adversarial loss is chosen to avoid the blurry prediction problem and predict realistic echo. Here for comparison, we have also tried another four training loss schemes: training with the MAE and adversarial loss (MAE + adv), MSE and adversarial loss (MSE + adv), adversarial loss only (adv), and image loss only (MSE + MAE). The extrapolation results of the model trained with different loss schemes are shown in
Figure 7.
As illustrated in
Figure 7, training the MLC-LSTM with MSE + MAE generated a quite blurry prediction of the echo, since it is only guided by optimizing the averaging difference it is hard for the model to generate complicated real echo distribution. The MLC-LSTM trained with the adversarial loss only also has an inferior performance. The generated echoes were less realistic and contained some checkboard artifacts. This may be due to the adversarial loss not being sufficient to constrain the generated data distribution matching the ground-truth since there are many plausible distributions. For the MLC-LSTM trained with the MAE + adv, it predicted the echo with an approximately correct shape and contour but did not contain much texture detail. In contrast, the MLC-LSTM trained with MSE + adv was good at rendering texture details but failed to maintain the echo shape. This difference might be caused by the fact that the MAE and MSE are sensitive to the shape and texture, respectively. Our model trained with the MAE, MSE, and adversarial loss, takes both the echo shape and texture into consideration and generated more realistic extrapolation results.
The quantitative evaluation results of five training loss schemes are given in
Table 4. Training with only the adversarial loss obtained the worst performance on six metrics. Training with MSE + MAE achieved the best score of FAR but did not perform well on POD, as it predicted fewer and blurry echo contents. Our training loss scheme obtained a comprehensive best performance, with the highest score of CSI, HSS, and SSIM and the second score of POD, FAR, and PSNR.
Another experiment was carried out to verify the effectiveness of training the generator and discriminator with different updating rates. In this paper, we adopted an updating ratio of 2:1 for the generator and discriminator. To analyze how the updating ratio would affect the model performance, we changed it to 1:2, 1:1, and 3:1, respectively. The extrapolation results and quantitative evaluation results of the model trained with different updating ratios are reported in
Figure 8 and
Table 5.
It can be seen from
Figure 8 that the higher the updating rate of the generator to the discriminator (from 1G:2D to 3G:1D), the fewer echo contents were predicted. The MLC-LSTM trained with updating ratios of 1:2 and 1:1 generated more echo contents than the ground-truth while the 3:1 updating ratio produced less than the ground-truth, and our 2:1 updating ratio was just enough. From the evaluation results shown in
Table 5, it also indicates that the POD had a negative correlation with the updating ratio and the FAR had a positive correlation, which was consistent with the predicted echo contents decreasing as the updating ratio increased. The 2:1 updating ratio used in this paper was the most suitable for our model.
Moreover, in our model, the number of parameters of the generator and discriminator were 2,601,601 and 1,590,273, respectively, which was closest to the ratio of 2:1. Therefore, we conclude that a proper updating ratio of the generator and discriminator should be aligned with the ratio of the number of their parameters.
3.4. Comparison Experiments
In this section, we conducted comparison experiments to evaluate the effectiveness of our whole model using the best setting described above. The model was compared with two typical traditional extrapolation methods, TREC [
10] and Optical flow [
17], and two state-of-the-art deep learning methods, ConvLSTM [
27] and TrajGRU [
30]. In addition, to make a fair comparison and demonstrate the effectiveness of exploiting the spatiotemporal correlation between three-level radar echoes sufficiently, we also compared the model with the ConvLSTM which takes three-level echoes as input and the MLC-LSTM which only receives one-level echo as input. They are denote as ConvLSTM (three-level input) and MLC-LSTM (one-level input).
The extrapolation samples are shown in
Figure 9, including an echo advection motion process at Nanjing, China, 6 September 2016, 10:20 UTC, an echo formation process at Nanjing, China, 6 September 2016, 13:54 UTC, and an echo dissipation process at Hangzhou, China, 8 August 2016, 23:07 UTC. For the two traditional extrapolation methods TREC and Optical flow, the extrapolated echo the shape was hard to maintain, and each patch of the echo dispersed sharply as time went by. The echo formation and dissipation were also barely predicted. This happens as their modeling ability is limited only extrapolating the echo using the motion vectors field, which basically cannot predict the echo evolution. Even for calculating a relative effective motion vector field, additional constraints and complex parameter settings are usually required. Thus, the TREC and Optical flow find it difficult to provide accurate predictions for actual nowcasting practice. For the deep learning models, they were generally superior to the traditional models in both extrapolations of the echo motion, formation, and dissipation, but it can be noticed that after the first few steps of extrapolation (usually 5 to 8 steps), the ConvLSTM and TrajGRU encountered the problem of blurry echo prediction. The extrapolated echo became homogenized, and the echo details were missing. Only in the prediction by the MLC-LSTM was this problem avoided, which can be attributed to the adopted adversarial training. Considering the exploitation of the spatiotemporal correlation, when the ConvLSTM also took the three-level echoes as input, the prediction results remained almost the same as the original ConvLSTM, and the extrapolation performance was not promoted much. When the MLC-LSTM only receives one-level input, the ability to predict the echo evolution reduced. For example, in
Figure 9b, its extrapolated echo shape was not consistent with the ground-truth. The MLC-LSTM with three-level echoes input predicts the echo much closer to the ground-truth. Therefore, it demonstrates that our model can exploit the spatiotemporal correlation between three-level radar echoes more effectively and use it to assist in predicting the echo evolution.
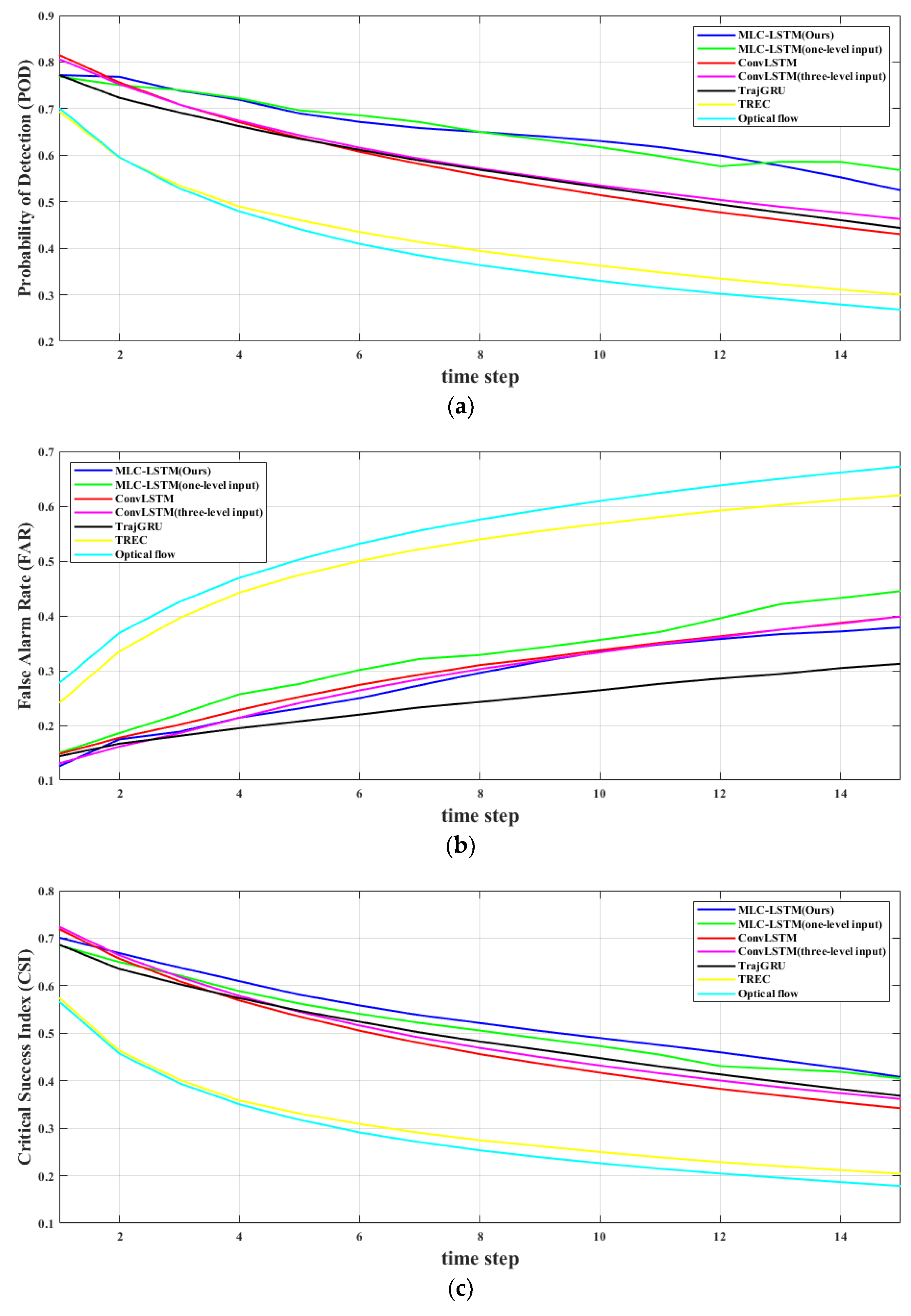
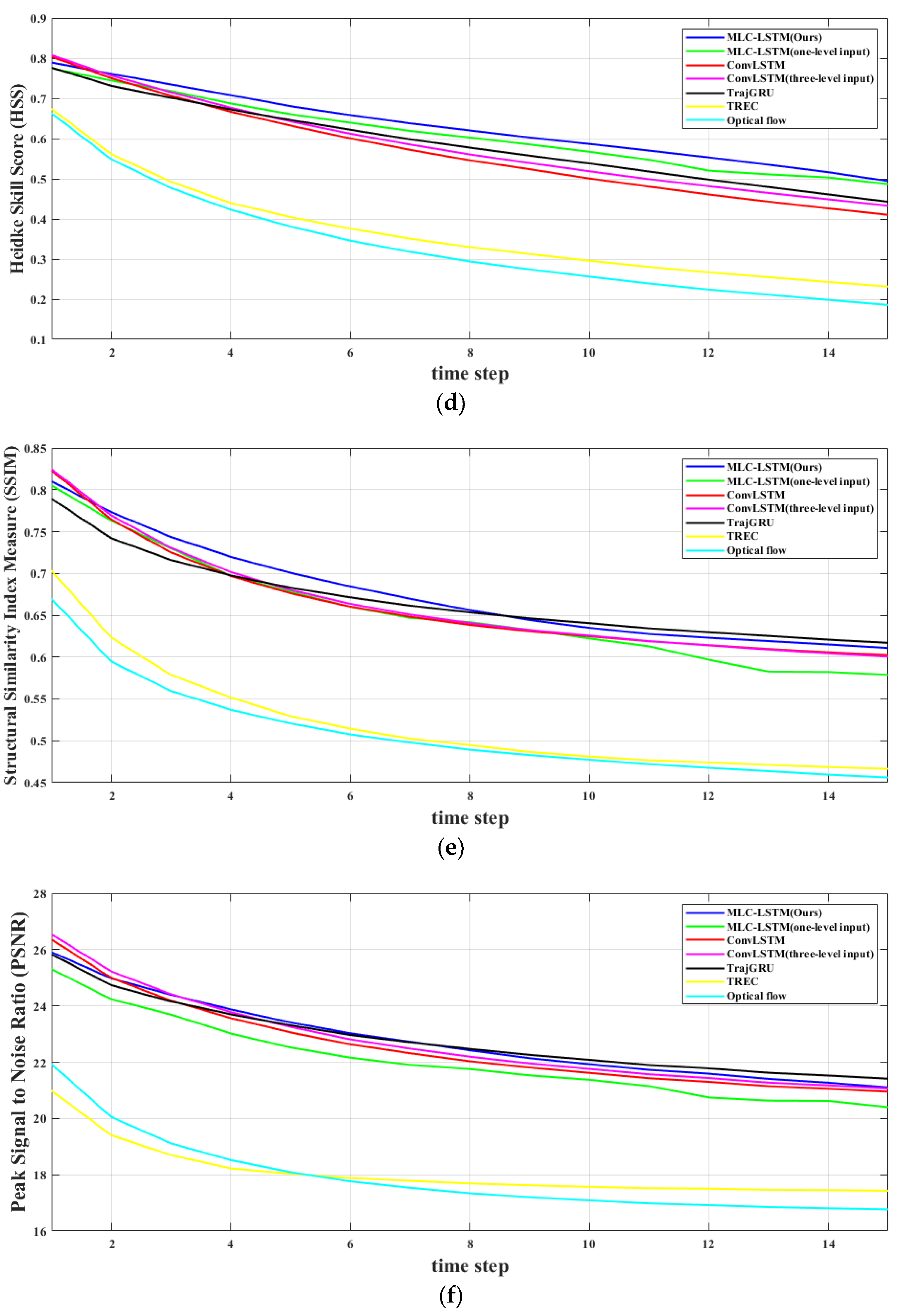
The quantitative evaluation results on extrapolating echo for 0.5, 1, and 1.5 h, and frame-wise comparison results of all models are illustrated in
Table 6 and
Figure 10, respectively. The two traditional methods, TREC and Optical flow, achieved the lowest performance on all metrics. The ConvLSTM and TrajGRU perform well on FAR. This might simply be because they tend to predict less and more concentrated echo contents. For POD, CSI, and HSS, all the deep learning models perform approximately the same for short-term forecasting (0.5 h). However, when the extrapolation carried forward deeper, our model MLC-LSTM outperformed the ConvLSTM and TrajGRU, which is aligned with the ConvLSTM and TrajGRU suffering from the blurry prediction problem while the MLC-LSTM maintains a relative realistic prediction. It can also be noticed that when deep learning models take the three-level echoes as input, the evaluation scores on CSI and HSS improved and FAR reduced. Overall, our model is comprehensively the best one, both in echo motion and evolution prediction, visual realistic reliability, and quantitative evaluation.
3.5. Performance Analysis
In this section, we have evaluated the performance on time-consuming and memory-consuming for MLC-LSTM, ConvLSTM, TrajGRU, TREC, and Optical flow. The results are shown in
Table 7. The TREC and Optical flow consume the least memory, but they need about 1 to 2 s to extrapolate one sample. The deep learning models usually request larger memory and take a while for model training, but once the training is finished, the converged model can be near-instantaneous. For our model, training the MLC-LSTM per iteration in our hardware conditions takes about 0.56 s, and the full training procedure usually lasts 3 to 6 h, but for the test, it only needs 0.0927s to extrapolate one sample, which can satisfy the real-time application requirement. For memory consumption, although it occupies 6985.04 MB video memory during the training phase, it is less than 8 GB. Therefore, our model can be trained and deployed conveniently conduct on any GPU which memory is equal to or greater than 8 GB.
4. Conclusions
In this paper, we have studied the weather radar extrapolation for short-term weather forecasting and precipitation nowcasting, which is the prediction of the appearance, intensity, and distribution of future echoes according to historical echo observations. Although the recent applications of deep learning for extrapolation have made remarkable progress compared with the traditional extrapolation methods, there still exist two major problems. The first one is that the echo evolution has been little investigated which also influences the accuracy of extrapolation. The second is that current deep learning models generate blurry predictions as the extrapolation goes deeper. To address the two issues, first, we proposed the MLC-LSTM for exploiting the spatiotemporal correlation between multi-level radar echoes and modeling echo evolution. Then we adopted adversarial training to make the extrapolated echo realistic and sharp.
To train and test our model, a real-life multi-level radar echoes dataset was built. Through the extrapolation experiments, it demonstrated that our model can effectively predict the echo motion and evolution while the blurry prediction problem is avoided, the extrapolated echo is visually realistic and fine-grained. For quantitative evaluation, our model also achieved a comprehensive optimal score on metrics that are commonly used for precipitation nowcasting. In terms of hardware performance, our model can be easily and cost-effectively employed on most common hardware setups. Its running speed also meets the requirement of the application. Therefore, our model has promising potential for actual short-term weather forecasting practice.
In addition to the advantages of our model, there is still room for improvement. First, even though the echo motion and evolution have been modeled appropriately, the extrapolated echo shape did not match the ground-truth perfectly, and sometimes the echo intensity fluctuated, and the consistency of intensity was not guaranteed. For this, we consider that introducing some kind of morphometric loss and the technique for maintaining intensity consistency are useful. Second, in reality, short-term weather forecasting practice requires the quality of extrapolation to remain reliable, even when the validation time is greater than 2 h (more than 20 echo frames). Therefore, a well-designed long-term extrapolation model would be necessary, which can ensure both the long-term extrapolation accuracy and model performance. The above two problems will be studied in our future work.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}