Abstract
This paper investigates point-to-point multimodal digital semantic communications in a task-oriented setup, where messages are classified at the receiver. We employ a pre-trained transformer model to extract semantic information and propose three methods for generating semantic codewords. First, we propose semantic quantization that uses quantized embeddings of source realizations as a codebook. We investigate the fixed-length coding, considering the source semantic structure and end-to-end semantic distortion. We propose a neural network-based codeword assignment mechanism incorporating codeword transition probabilities to minimize the expected semantic distortion. Second, we present semantic compression that clusters embeddings, exploiting the inherent semantic redundancies to reduce the codebook size, i.e., further compression. Third, we introduce a semantic vector-quantized autoencoder (VQ-AE) that learns a codebook through training. In all cases, we follow this semantic source code with a standard channel code to transmit over the wireless channel. In addition to classification accuracy, we assess pre-communication overhead via a novel metric we term system time efficiency. Extensive experiments demonstrate that our proposed semantic source-coding approaches provide comparable accuracy and better system time efficiency compared to their learning-based counterparts.
1. Introduction
6G is envisioned as AI-native, seamlessly integrating human–machine and machine-to-machine communications to support emerging applications such as digital twins, fully autonomous vehicles, and smart environments, all of which are expected to generate and exchange unprecedented data volumes [1,2]. Conventional communication systems treat information exchange as the precise reconstruction of digital sequences at endpoints, without regard to their semantic content [3] and thus rely exclusively on syntactic error metrics such as bit error rate (BER) and symbol error rate (SER). While this semantic-agnostic framework simplifies design and enables modular optimization, it overlooks the meaning of transmitted data, which can be leveraged for improving efficiency. As 6G applications impose ever-more stringent demands for reliability and latency, there is a growing need to incorporate semantic awareness into communication systems to optimize resource utilization and better serve these requirements.
Semantic communication [4] moves in this direction by shifting the focus from transmitting complete sequences to conveying intended meanings. Paying attention to what messages mean enables the transmission of relevant information. Such efforts can potentially enable more efficient use of spectrum resources in future generations of connectivity.
Efforts towards semantics go back as early as shortly after the seminal work in [3], but have achieved limited adoption in communications design [5,6,7,8]. More recently, a decade ago, reference [9] has introduced the concept of semantic distortion as an error metric, addressing the transmission of words over noisy channels by optimizing codeword assignments to minimize semantic distortion (loss). The same reference points to the importance of context availability at the receiver, which can further improve resource efficiency. Reference [10] builds upon this latter concept and analyzes a system that consists of a transmitter-receiver pair and an external agent that can provide helpful or deceiving context to the receiver. It is important to note that these studies, while fundamental to the concept, were limited to small systems owing to the computational complexity.
Following the machine learning revolution and its entry into the wireless physical layer design [11], efforts in semantic communications were rejuvenated. These efforts adopted deep learning (DL) architectures, structured around four core components: (i) semantic encoder, (ii) channel encoder, (iii) channel decoder, and (iv) semantic decoder [4]. A semantic encoder can extract semantic information from source, generating low-dimensional embeddings using DL models, such as text or vision transformers [12], transmitted over the channel. At the receiver, the semantic decoder processes the reconstructed embeddings to perform tasks from reconstruction to classification, or translation [13,14]. This architecture adopts an autoencoder-based design with end-to-end training with task-specific loss functions [15,16,17,18].
This approach, though a clear paradigm shift, is not without its challenges. Notably, the training overhead can be significant, due to large model size, which requires substantial data [19]. In addition, solutions are often case-specific, which necessitates retraining often in dynamic environments. This creates a training overhead in system design that needs to be addressed. In our preliminary conference papers [20,21], we have demonstrated that utilizing pre-trained embedding models can overcome this limitation.
In this paper, building on these initial ideas, we provide a comprehensive framework for harnessing the power of pre-trained models to digitally communicate semantics extracted from text and images. As an example of this framework, we focus on a task-oriented scenario where the receiver is tasked with classification of said text and images. We concatenate these resulting source codewords by a standard channel coder, this is performed to demonstrate that a backward-compatible, modular, i.e., source-channel separation-based approach [3], is sufficient to obtain significant gains. Our contributions are as follows:
- We propose three semantic codebook generation methods: (i) semantic quantization, which forms a fixed codebook from source realizations; (ii) semantic compression, which builds on quantization by exploiting semantic redundancy; and (iii) semantic vector-quantized autoencoder (VQ-AE), which trains a codebook.
- For semantic quantization and compression, we design a neural network-based source code that minimizes end-to-end semantic distortion.
- We introduce a novel performance metric called system time efficiency to account for pre-communication overhead in machine-learning aided wireless communication systems. It quantifies task completion given a time budget by jointly accounting for training and transmission phases, enabling fair comparison and penalizing models with excessive training overhead. Simulations on multiple datasets demonstrate that semantic quantization and compression improve time efficiency over wireless channels, while reducing training cost and enhancing resilience under data scarcity compared to the learning-based semantic VQ-AE.
The rest of the paper is organized as follows. Preliminaries are provided in Section 2, followed by the system model in Section 3. Proposed approaches are presented in Section 4 with numerical results pointing to significant savings against baselines in Section 5. Section 6 concludes the paper.
Notation: Lowercase letters, x, denote scalars, italic uppercase letters, X, denote random variables (RVs), bold lowercase letters, , denote vectors, and bold uppercase letters, , denote matrices. For matrix , denotes the row vector, denotes the element at row column, and denotes the transpose. and are the Euclidean and Frobenius norm, respectively. denotes identity matrix of rank t. denotes binary matrix of dimensions . denotes the modulo operation with respect to t. is the ceiling. denotes the . is the Hamming distance. denotes logarithm with base 2. and denotes the real and complex sets. denotes uniform RV in range . denotes complex Gaussian RV with mean and variance .
2. Preliminaries
In this section, we provide preliminaries of methods we adopt from large language models and unsupervised learning, as these may be less familiar to communications researchers.
Representing text semantics as learned real-valued vectors, i.e., neural embeddings, goes back to word embeddings, which capture relationships between words by placing semantically similar words close together in an embedding space [22]. More recently, BERT, one of the first large language models (LLMs), uses the attention mechanism to generate context-aware token embeddings [23], and Sentence-BERT (SBERT) extends this notion to the sentence level by mapping semantically similar sentences to nearby vectors and dissimilar ones to distant vectors [24]. Our preliminary work in references [20,21] utilizes SBERT for semantic text communications.
In this work, our adopted pre-trained model is a recently developed multimodal one. OpenAI CLIP employs transformer-based encoders for both images and text. It uses contrastive learning to jointly train these encoders by predicting the correct (image, text) pairings in a batch. The training objective involves a symmetric loss that equally weights cross-entropies of text-to-image and image-to-text predictions. This ensures consistent embedding properties across both modalities, enabling the unified representation of text and images [25].
Pre-trained embeddings effectively capture semantic information and have demonstrated strong performance across various downstream tasks [26,27]. They serve as compact feature representations, allowing new tasks to be addressed by optimizing only the task-specific block, without retraining the entire model. In this work, we use these embeddings to encapsulate message semantics and optimize a classification block for CLIP embeddings.
In unsupervised learning, affinity propagation (AP) is a clustering algorithm that selects centroids from the actual data points, termed “exemplars”. The main objective is to assign each sample to an exemplar by optimizing the defined similarity metric. For minimizing the Euclidean distance, the similarity between points and is expressed as follows [28].
The algorithm employs message-passing by exchanging “responsibility” and “availability” messages between data points. The “responsibility” message, , is sent from each sample i to candidate exemplar k, indicating the suitability of k as an exemplar for i. Correspondingly, the “availability” message, , is sent from the candidate exemplar k to sample i, reflecting the level of suitability for i to select k as its exemplar. The equations for these messages are as follows [28].
where for , the update reduces to . A key advantage of AP is that it does not require the number of clusters to be specified beforehand. Instead, it determines the appropriate number dynamically based on the similarities and message-passing. The number of clusters can be adjusted by changing the preference; setting it to the median of the input similarities typically yields a moderate number of clusters [28].
3. System Model
We consider a point-to-point task-oriented communication scenario. The message s at the source may be text, image, or a combination of both. The receiver is tasked to predict a class label, denoted by . The goal thus is to transmit the essential semantic information needed for accurate classification. Inspired by the use of pre-trained neural models in inverse problems without additional training [29,30], we adopt the OpenAI CLIP transformer as a semantic encoder. This enables us to extract the semantic information of the message as embeddings, denoted by , without any further training. The (digitized) CLIP embedding thus becomes the message to be sent to the receiver for classification.
We use semantic distortion [9], denoted as , to quantify the loss in meaning. For a message s with embedding , the semantic distortion is
where is the receiver’s estimate.
Consider a dataset, denoted as , consisting of embeddings of randomly selected messages. This dataset serves as the initial codebook with n codewords of length m each, where n represents the number of embeddings and m is the embedding dimension. We will investigate several approaches to utilize for semantic quantization, semantic compression, and semantic VQ AE proposed in Section 4.1, Section 4.2 and Section 4.3.
For a channel input , the channel output is as follows.
where denotes the additive noise, and represents the fading coefficient.
We employ a neural network (NN) with fully connected layers for the classification block at the receiver. This block takes the reconstructed CLIP embeddings as input for classification.
4. Proposed Methods
In this section, we propose three semantic representations, each using the OpenAI CLIP to generate embeddings from messages and incorporating the available dataset .
4.1. Semantic Quantization
We propose first using as a shared codebook by arguing that the semantic structure of the source can be inferred from its realizations. This approach encodes messages with actual content (source samples), enabling the interpretability of codeword meanings and their alignment with human understanding, as discussed in Section 5.2. Through semantic quantization, we assign message embeddings to codebook indices that minimize the semantic distortion. In particular, we obtain the codebook index for message embedding by the semantic index assignment operation, denoted by , as follows.
The (source) codeword is then mapped using a standard channel code, that is we have a backward compatible design with existing digital communications systems: a (semantic) source coder followed by a channel coder. At the receiver, the index is reconstructed as and the associated embedding is passed to the classifier to obtain the prediction . We illustrate this process in Figure 1.
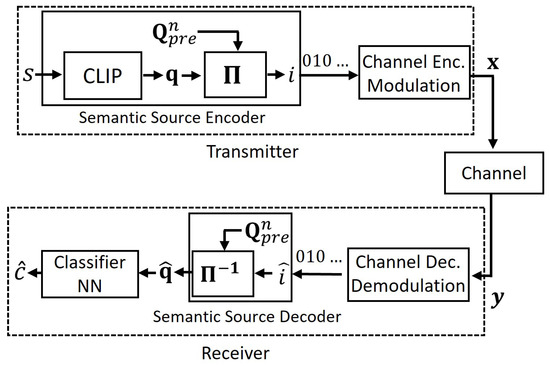
Figure 1.
The proposed semantic quantization method.
We explore the fixed-length coding scheme inspired by an early approach that incorporates channel effects into the semantic distortion objective and exploits semantic relationships among source symbols to improve noise robustness [9]. In particular, we investigate the distortion in Equation (4) by incorporating the codeword transition probabilities over the noisy channel. Denote the codewords as , where row contains the codeword assigned to index j, with a fixed length of . The expected semantic distortion is as follows [9]:
In Equation (7), the distortion and index probability terms are fixed. We focus on minimizing the objective by choosing the codewords, which determine the channel transition probabilities . This makes the problem similar to minimizing a linear function over a probability simplex; it is easy to conclude that we need codewords such that higher transition probabilities correspond to lower semantic distortion. To achieve this goal, we design the codewords by linking transition probabilities to Hamming distances, where smaller Hamming distances indicate higher transition probabilities. This serves as a model-based insight guiding our design. Therefore, the objective is to assign codewords such that the Hamming distance reflects the Euclidean distance between their embeddings, ensuring that closer indices have codewords with smaller Hamming distances.
Building on this model-based intuition, we propose the NN-based codeword assignment mechanism to minimize the expected distortion in Equation (7). Specifically, we consider an NN, which takes as input and aligns codeword Hamming distances with a output activation, as follows.
where is the learnable parameter vector, and represents the NN soft outputs, which are binarized afterward to form the codewords. To align these assignments with the semantic relationships between indices, we design the loss function as a convex combination of multiple components. In particular, we optimize the following loss function through mini-batches of size .
where is the batch soft output, and are the positive and negative sample indices of sample j as in Algorithm 1, is the margin, is the pairwise distance matrix in Algorithm 2. We design codewords by adjusting soft output distances so that outputs with close Euclidean distances are binarized to codewords with small Hamming distances. We use triplet loss to align soft outputs with positions of embeddings in associated with indices. Specifically, we generate triplets such that positive and negative samples correspond to closer and farther embeddings in a batch, as outlined in Algorithm 1. Instead of generating fixed triplets, we repeatedly generate new ones for each batch, helping the model to align better by adapting to dynamic pairs. As the triplet loss can lead to duplicate assignments, we introduce regularization terms to the loss function to penalize the model for producing outputs that cluster too densely. We provide the training procedure in Algorithm 2.
| Algorithm 1 Triplet Generation for Triplet Loss in Each Batch |
 |
| Algorithm 2 Training Codeword Assignment Model |
 |
After training, we pass through the model, as in Equation (8), to obtain the soft outputs. We then binarize them based on their sign, resulting in . Although we have designed the loss to encourage distinct assignments, this does not directly ensure unique decodability. To address this, we map to distinct codewords of the same length by minimizing the Hamming distance, formulating the problem as follows.
The problem in Equation (11) is a linear sum assignment problem, which involves minimizing the total assignment cost over one-to-one mappings between agents and tasks [31]. We define the cost by the pairwise Hamming distances between the and unique codewords to be assigned . In particular, we construct a cost matrix as given in Algorithm 3. However, when n is not a power of 2, we add dummy rows with a cost greater than the maximum of non-dummy rows. This ensures the use of all distinct codewords of length . Utilizing this cost matrix, we solve the problem using a modified Jonker-Volgenant algorithm [32], an efficient variant of the Hungarian algorithm that improves time complexity. We summarize the complete process in Algorithm 3.
4.2. Semantic Compression
In Section 4.1, increasing n improves resolution in for quantization, but leads to a larger codebook. Semantics contain inherent redundancies, where the meaning is the same despite variations in sentence structures, or even words [33]. To reduce the codebook size while maintaining resolution, we propose semantic compression, which clusters similar embeddings in , exploiting these semantic redundancies.
In particular, we use the affinity propagation (AP) algorithm for clustering explained in Section 2 which identifies the optimal number of clusters. We assign message embeddings to the resulting clusters by minimizing semantic distortion, as follows.
where contains centroids with . The codeword corresponding to the assigned cluster label, l, is transmitted using the same transmission scheme in Section 4.1. At the receiver, the reconstructed cluster label, , is used to retrieve the associated embedding , which is then fed into the classifier to obtain the prediction , as illustrated in Figure 2.
| Algorithm 3 Codeword Assignment for Codebook Indices |
 |
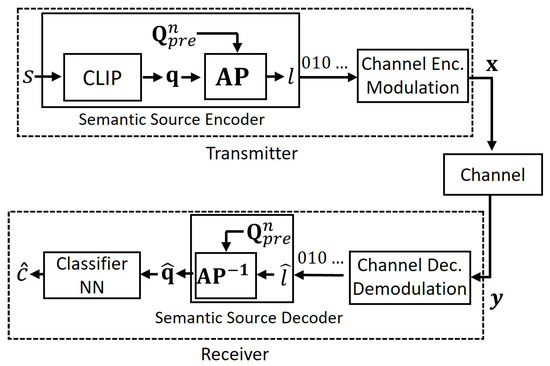
Figure 2.
The proposed semantic compression method.
We employ Algorithms 1–3 for a fixed-length coding of cluster labels similar to the Section 4.1. However, instead of utilizing to design codewords of length , here we use clustered version to design codewords of length .
4.3. Semantic Vector-Quantized Autoencoder
In this section, we focus on learning-based semantic communication by using as training data instead of directly employing it as a codebook. Drawing inspiration from the vector-quantized variational autoencoder (VQ VAE) [34], we propose the semantic vector-quantized autoencoder (VQ AE) to generate learned discrete representations for message embeddings. The VQ AE consists of an encoder, a decoder, and a codebook , which contains d latent space points for quantizing the encoder’s output vectors. In particular, the encoder maps the message embedding to a latent vector, denoted as , expressed as follows.
where denotes the learnable parameter vector of the encoder. In the latent space, the vector is then quantized by assigning it to one of the elements in the codebook , as follows.
Equation (14) assigns the codebook element for , denoted as , where p is the index of the selected element. We then pass through the decoder to reconstruct the embedding, , as
where is the learnable parameter vector of the decoder. In this architecture, the encoder and decoder constitute an autoencoder, both employing a neural network with fully connected (FC) layers and a parameter . In the encoder, the initial FC layer maps embeddings to -dimensional space, then iteratively scales down dimensions by until reaching . Here, j and are chosen such that j represents the largest number where , and represents the smallest number where . The final FC layer maps directly to , i.e., to the latent space. Conversely, the decoder mirrors the encoder’s architecture, progressively increasing dimensions to reconstruct the embeddings from the codebook elements. The parameter determines the model’s depth, with smaller values yielding more layers. We illustrate this structure in Figure 3, employing as the activation function. We optimize the encoder, decoder, and codebook using the VQ-VAE training algorithm, employing the following loss function [34].
where represents the commitment parameter, and denotes the stop gradient operator, preventing parameter updates by ensuring zero partial derivatives. The first term is the reconstruction loss for accurate embedding reconstruction at the decoder. The codebook is learned through the second term, minimizing the distance between and . The final term, i.e., commitment loss, penalizes the encoder for deviating from the codebook elements [34].
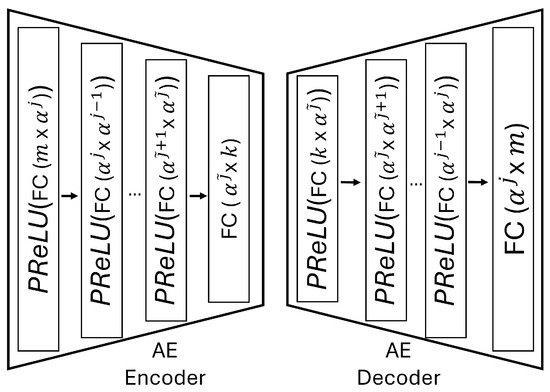
Figure 3.
Structure of the AE encoder–AE decoder in semantic VQ AE.
In Section 4.1 and Section 4.2, we have designed an NN-based codeword assignment mechanism. Here, we utilize adversarial training [35]. This approach provides latent space points that are resilient to channel effects. Specifically, we simulate channel conditions by perturbing selected index p to and passing the perturbed latent vector, , through the decoder. Unlike in previous sections, we note that the channel effects here directly modify the discrete representations in the latent space. We provide the details of the perturbation in Algorithm 4 and the training algorithm of the semantic VQ AE in Algorithm 5.
| Algorithm 4 Index Perturbation for Adversarial Training |
 |
After training the model on the loss in Equation (16), the learned codebook and encoder–decoder components are shared between the transmitter and receiver. We then assign message embeddings to the learned codebook elements by using Equations (13) and (14). The resulting index p is converted to binary and transmitted using the same transmission scheme in Section 4.1 and Section 4.2. At the receiver, reconstructed index retrieves which is used to reconstruct through Equation (15) and then obtain the prediction . We illustrate this process in Figure 4.
| Algorithm 5 Training Semantic VQ AE Model |
 |
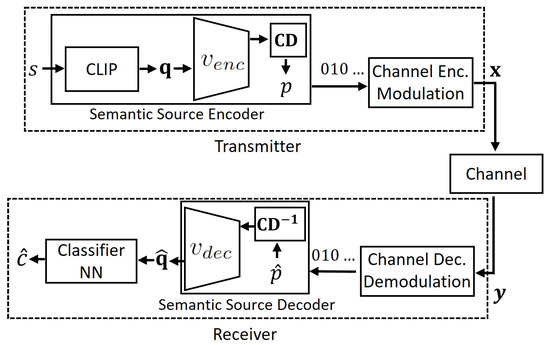
Figure 4.
The proposed semantic VQ AE method.
4.4. Performance Metrics
The task in this paper is classification. Naturally, classification accuracy is the performance metric against which to measure the proposed methods. In addition, we introduce a novel performance metric that enables comparing pure deep learning-based approaches and the approaches we propose utilizing pre-trained models. System time efficiency, denoted by , quantifies the number of correct task executions in a specified time frame, including the training phase, hence providing a measure for the pre-communication overhead of various machine learning methods. Specifically, for a method that achieves u correct classifications per second following a training phase of seconds, we define for a time budget as follows.
In Equation (17), the higher the better the efficiency. This metric addresses a gap often overlooked in recent works, where the computational cost of training is not explicitly included in comparisons with conventional systems.
5. Results
In this section, we present the numerical results for source compression and transmission over wireless channels.
5.1. Datasets and Simulation Settings
We evaluate the proposed methods using four classification datasets: (i) AG’s News [36], which contains news articles from 4 categories; (ii) DBPedia 14 [36], consisting of text samples from 14 ontology classes; (iii) CIFAR 10 [37], including RGB images of 10 object categories; and (iv) STL 10 [38], with RGB images from 10 object categories. We present details of these datasets in Table 1. For consistency, we test on 2000 balanced samples with respect to class labels for each dataset. We employ the clip-ViT-B-32 as the CLIP model to obtain message embeddings.

Table 1.
Summary of AG’s News, DBPedia 14, CIFAR 10, and STL 10.
The classifier NN involves three layers with 128, 32, and hidden units, where corresponds to the number of classes in the dataset. We train the NN on the receiver’s dataset, which consists of message embeddings, , and their corresponding labels, .
In the semantic compression method, we use the negative Euclidean distance, defined in Equation (1), as the similarity metric to minimize semantic distortion in Equation (4). To determine the optimal number of clusters, we use the median of sample similarities as the preference, as discussed in Section 2. The codeword neural network (NN) has a simple structure consisting of three fully connected layers with 256, 64, and units ( for semantic compression). We use activation in the hidden layers and at the output. For semantic VQ AE, we set d to match the number of clusters determined by the AP algorithm, as given in Table 3. This ensures a fair comparison among methods. We determine the optimal values through grid search and , primarily considering model performance, while also accounting for model size and computational complexity. We set the commitment parameter in Equation (16) to . To optimize both classification accuracy and expedite the training process, we increase the learning rate and adjust the number of epochs for proper optimization in fewer steps.
Table 2 lists all the parameters used in simulations. We construct by selecting n samples from the shuffled training data. The remaining training samples constitute the receiver dataset, denoted as and . For the classification block training, we split and into training and validation sets with ratios of 0.85 and 0.15, respectively. We use the model with the minimum validation loss achieved across the training epochs. We simulate the multimodal scenario by combining 2500 samples each from the AG’s News and STL 10 datasets, forming with . We assume the receiver uses separate classifiers for images and text, trained with the same parameters as those used for the original datasets, as given in Table 2. Training procedures of the codeword NN and semantic VQ AE have the same parameters in the AG’s News dataset, except for and for semantic VQ AE. We simulate the multimodal case using 2000 test samples from each dataset, resulting in 4000 in total, which are also balanced with respect to class labels.
Table 2.
Simulation settings.
We implement conventional source-coding baselines to investigate the efficacy of the proposed semantic methods. We employ Huffman coding for text compression and JPEG2000 for image compression. We adopt block coding for Huffman, where compression symbols consist group of three characters. We derive empirical probabilities for these blocks from the provided text. Regarding the JPEG2000 algorithm, we use the Python Pillow package (version 9.3.0), adhering to its default parameters, except for configuring the quality layers parameter, set to 20. As these algorithms ensure exact reconstruction, we assess their accuracy using the original embeddings of messages, without any form of quantization or compression.
For wireless channel simulations, for the AWGN channel and for Rayleigh fading channels with . We employ an average power constraint of 1 for all transmission methods. Consequently, the channel signal-to-noise ratio (SNR) becomes dB. We adjust the noise variance, , to emulate average channel SNR values. We employ transmit power control (channel inversion) to mitigate the effects of fading.
Table 3.
Number of bits required to compress test messages and their classification accuracies for fixed-length coding (mean ± 1 SD, 10 runs).
Table 3.
Number of bits required to compress test messages and their classification accuracies for fixed-length coding (mean ± 1 SD, 10 runs).
| Dataset | Method | Number of Bits | Acc. (%) |
|---|---|---|---|
| AG’s News | Conventional | 1,480,599 | |
| Sem. Quan. | 26,000 | ||
| Sem. Comp. 501 * | 18,000 | ||
| Sem. VQ AE 501 + | 18,000 | ||
| DBPedia 14 | Conventional | 2,160,054 | |
| Sem. Quan. | 24,000 | ||
| Sem. Comp. 252 * | 16,000 | ||
| Sem. VQ AE 252 + | 16,000 | ||
| CIFAR 10 | Conventional | 4,073,328 | |
| Sem. Quan. | 24,000 | ||
| Sem. Comp. 147 * | 16,000 | ||
| Sem. VQ AE 147 + | 16,000 | ||
| STL 10 | Conventional | 22188432 | |
| Sem. Quan. | 22,000 | ||
| Sem. Comp. 88 * | 14,000 | ||
| Sem. VQ AE 88 + | 14,000 | ||
| Multi Modal | Conventional | 23,659,964 | |
| Sem. Quan. | 52,000 | ||
| Sem. Comp. 208 * | 32,000 | ||
| Sem. VQ AE 208 + | 32,000 |
* The number of clusters determined by the AP algorithm. + The size of , i.e., the value of d in semantic VQ AE.
We conduct simulations on a computer equipped with an Intel Core i9-13950HX CPU at 1.6 GHz and an NVIDIA GeForce RTX 4070 GPU, which is employed to accelerate neural model training. To ensure reliable results, we measure the simulation times while the computer is idle and all background applications are disabled. For each method, we repeat the simulations 10 times and present the mean scores with standard deviations (SD) to quantify the uncertainty. In each run, we use a different seed to initialize the neural network parameters and shuffle the data, resulting in distinct across runs.
5.2. Source Compression
We start by examining the structure of pre-trained embeddings in . To visualize, we project the embeddings into using uniform manifold approximation and projection (UMAP) [39]. As we have described in Section 3, consists of random samples without any prior knowledge. However, just for this visualization, we use the class information of embeddings to illustrate their structure. Figure 5 indicates that embeddings from the same class tend to cluster together. This supports the intuition that class-related semantics can be preserved, even after clustering.
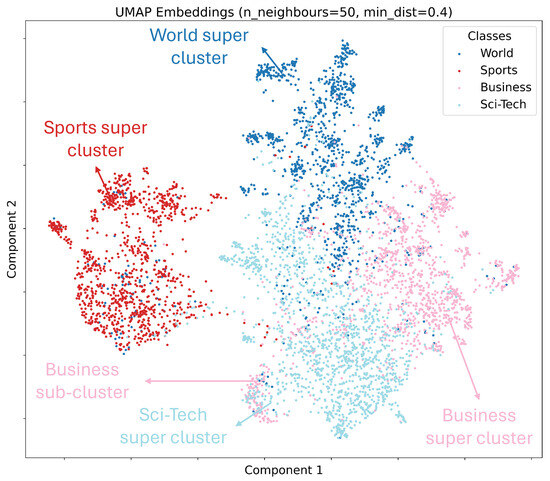
Figure 5.
UMAP projection of AG’s News embeddings into .
Table 3 presents the source compression results, including the number of bits required to compress test samples and their associated classification accuracies. We observe that the proposed semantic methods improve resource efficiency compared to conventional baselines. Regarding classification accuracies, semantic quantization attains the highest score, likely due to its larger codebook, which offers finer semantic resolution at the cost of higher bit usage. By contrast, semantic compression maintains comparable accuracy while using fewer bits, effectively preserving resolution by removing redundancy. These findings confirm that exploiting semantic redundancy reduces data size without a major accuracy loss. Furthermore, as detailed in Section 5.1, we ensure a fair comparison between semantic compression and semantic VQ AE in terms of resource utilization by having the same codebook size. Under these equal conditions, we observe that semantic compression achieves higher classification accuracies than semantic VQ AE. This suggests that, given the same resource constraints, semantic compression better preserves class-related semantics while utilizing the same amount of resources. These observations are consistent across all datasets, including the custom multimodal dataset. This highlights the feasibility of constructing a unified multimodal codebook consisting of codewords for both image and text messages. Overall, the results demonstrate that semantic quantization and compression methods can generalize across diverse contexts and modalities without requiring separate training for each to obtain learned discrete representations.
The number of clusters determined by the AP algorithm in Table 3 is significantly large. We attribute this to the high dimensionality of the embeddings () and the existence of small sub-clusters in broader super-clusters. For example, Figure 5 demonstrates a small group from the “Business” class embedded in the “Sci-Tech” class, leading to an additional cluster.
In Table 4, we select a random sample from the AG’s News test set denoted as s, and retrieve the messages corresponding to the assigned index and cluster label denoted as and , respectively. A comparison of these messages reveals a strong alignment with human understanding, reinforcing the interpretability discussed in Section 4.1 and Section 4.2. This alignment suggests that the semantics required for the classification task are effectively conveyed while enhancing efficiency, which is the aim of this work.
Table 4.
Example of assigned messages using AG’s News dataset.
We examine how the value of n impacts performance. While a larger n demands more computational resources, n needs to be sufficiently large to ensure an adequate number of samples per class for effective codebook construction. Figure 6 provides the accuracy of methods as n varies from 50 to 10,000 for the DBPedia 14 and CIFAR 10 datasets. For , the accuracy plateaus for all methods, indicating diminishing returns. The proposed semantic quantization and compression methods achieve rapid convergence in accuracy. They perform well even with smaller datasets and demonstrate robustness to varying data sizes. By contrast, semantic VQ AE struggles to achieve high accuracy and converges more slowly. This highlights the data-greedy nature of learning-based approaches, which are sensitive to data size during optimization.
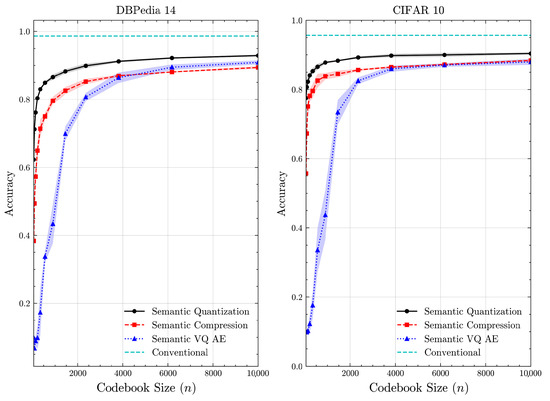
Figure 6.
Classification accuracy vs. n for DBPedia 14 and CIFAR 10 datasets (mean ± 1 SD, 10 runs).
5.3. Wireless Channel Simulations
In this section, we evaluate the proposed methods over wireless channels, assuming the exact channel state for transmit power control, i.e., . We employ Reed–Solomon coding with rate RS(31, 25) and quadrature phase shift keying (QPSK) modulation. We use the accuracy of the conventional approach at infinite SNR as the upper bound, representing lossless transmission. We examine the convergence of the semantic methods to this limit.
We begin by examining the impact of incorporating codeword transition probabilities. To this end, we establish baselines for semantic quantization and compression. In these baselines, the resulting i and l values are directly encoded into binary format and transmitted with RS(31, 25). For the semantic VQ AE, we train the baseline in a noiseless setup, i.e., without any perturbations to p. In this comparison, we have the same number of channel uses for all schemes, as the codeword lengths and the channel coding rates are the same. Thus, any observed improvement in accuracy is attributed to integrating transition probabilities in the system design.
Figure 7 and Figure 8 illustrate the accuracies of designed codewords over wireless channels for semantic quantization and noisy training in the semantic VQ AE. Figure 9 and Figure 10 further present these accuracies with the full accuracy range , as requested by the anonymous reviewer. For the semantic quantization, we observe a significant accuracy improvement in the low SNR region compared to the baseline. This is achieved without adding redundancy and decreasing the rate, making the result promising. The accuracy is the same for high SNR regions, as the proposed codeword assignment mechanism does not interfere with the discrete message representations. For the semantic VQ AE, we observe increased accuracy in low SNR regions, highlighting the benefits of adversarial training. However, a performance gap emerges between noisy and noiseless training in the high SNR region. Unlike semantic quantization, noisy training in semantic VQ AE impacts the discrete representations assigned to codewords. Thus, we interpret this gap as the channel simulation during training acting as a regularizer. Given the small training dataset, the limited number of samples can lead to overfitting. Hence, introducing a regularizer improves performance and ensures more robust discrete representations.
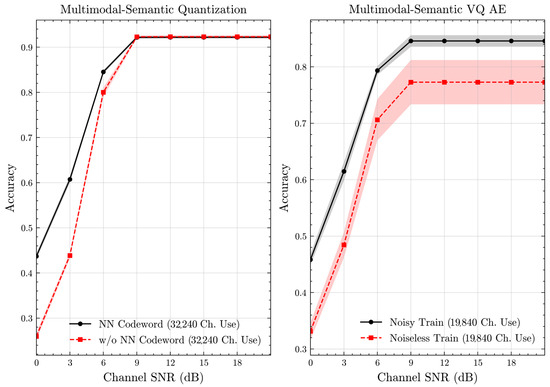
Figure 7.
Classification accuracies for the multimodal dataset over AWGN channel (mean ± 1 SD, 10 runs).
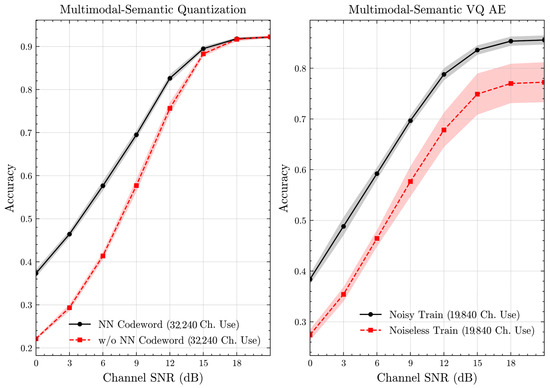
Figure 8.
Classification accuracies for the multimodal dataset over Rayleigh channel (mean ± 1 SD, 10 runs).
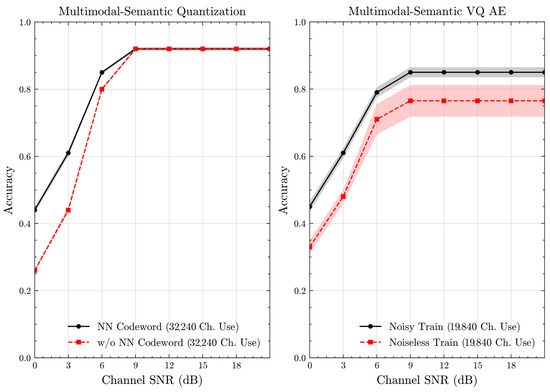
Figure 9.
Classification accuracies with full accuracy range for the multimodal dataset over AWGN channel (mean ± 1 SD, 10 runs).
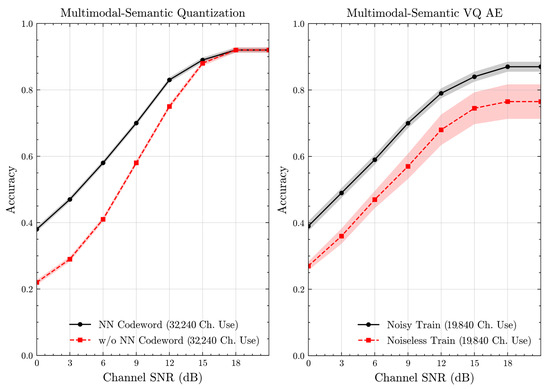
Figure 10.
Classification accuracies with full accuracy range for the multimodal dataset over Rayleigh channel (mean ± 1 SD, 10 runs).
We present the accuracy, time efficiency scores, and corresponding channel uses of the methods for each dataset in Figure 11, Figure 12, Figure 13 and Figure 14 and Figure 19, Figure 20, Figure 21 and Figure 22. Figure 15, Figure 16, Figure 17 and Figure 18 further present these accuracies with the full accuracy range , as requested by the anonymous reviewer. The performance over wireless channels is consistent with the source compression results in Table 3, as expected. Notably, we highlight the small n value, representing the scarce data scenario. For larger n values, the methods are expected to converge more closely to the upper limit. Additionally, the variations in convergence across datasets are linked to the semantic structure of the data in the semantic space, which is illustrated for AG’s News in Figure 5.
We allocate time budgets based on modalities, message lengths, and training sizes. For example, CIFAR 10 receives more time than STL 10 due to its larger n. Results demonstrate that semantic compression consistently achieves the highest time efficiency, while semantic quantization and semantic VQ AE exhibit inferior performance. We observe that the pre-communication phase of semantic VQ AE, i.e., , is significantly longer than that of quantization. However, the smaller codebook of VQ AE helps mitigate this during communication, enabling larger u values compared to quantization.
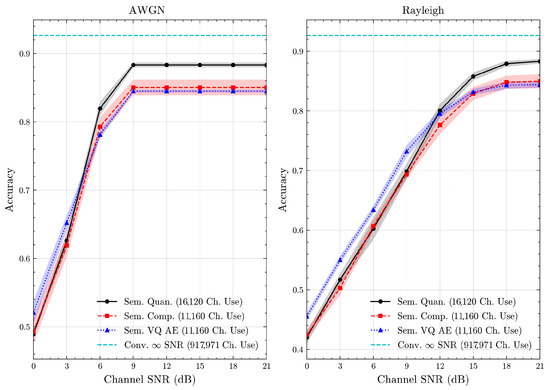
Figure 11.
AG’s News dataset classification accuracies over AWGN and Rayleigh channels (mean ± 1 SD, 10 runs).
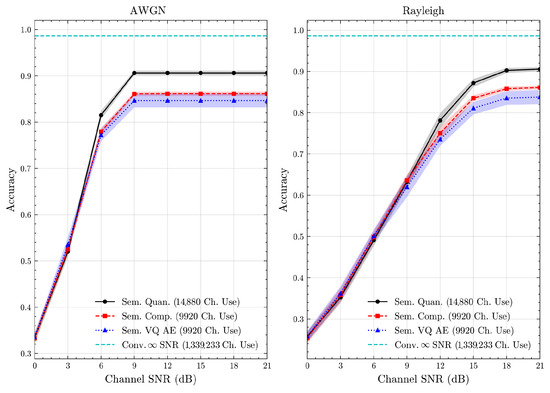
Figure 12.
DBPedia 14 dataset classification accuracies over AWGN and Rayleigh channels (mean ± 1 SD, 10 runs).
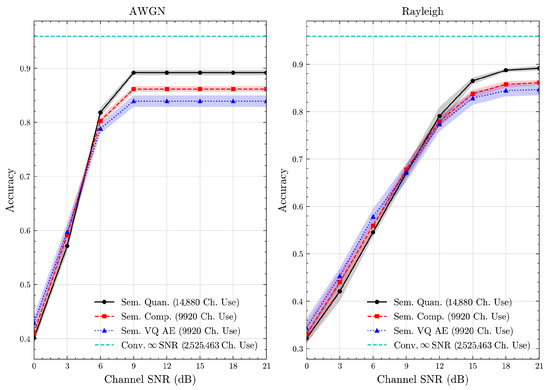
Figure 13.
CIFAR 10 dataset classification accuracies over AWGN and Rayleigh channels (mean ± 1 SD, 10 runs).
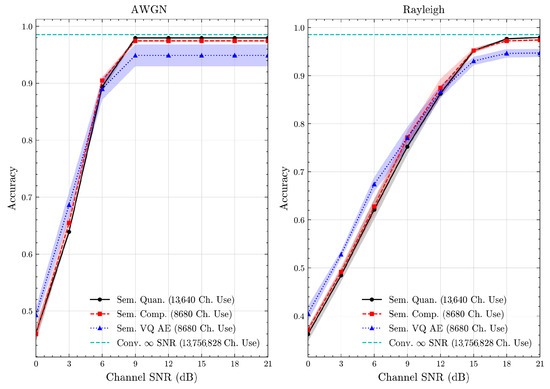
Figure 14.
STL 10 dataset classification accuracies over AWGN and Rayleigh channels (mean ± 1 SD, 10 runs).
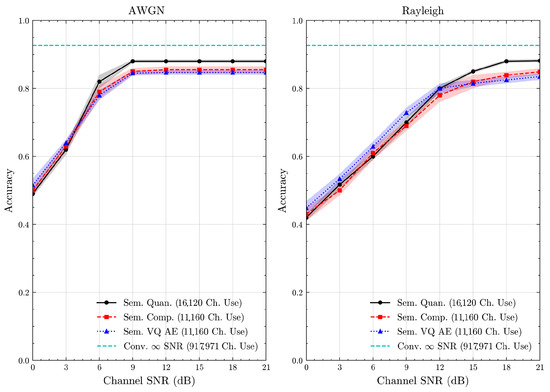
Figure 15.
AG’s News dataset classification accuracies with full accuracy range over AWGN and Rayleigh channels (mean ± 1 SD, 10 runs).
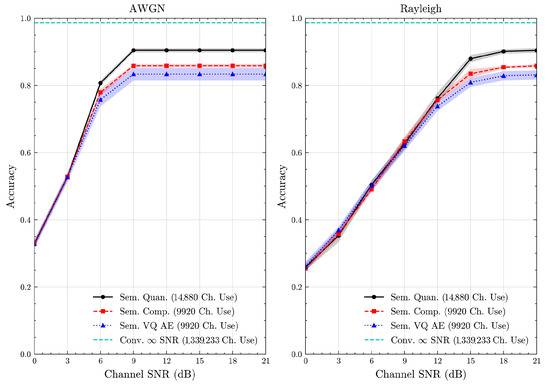
Figure 16.
DBPedia 14 dataset classification accuracies with full accuracy range over AWGN and Rayleigh channels (mean ± 1 SD, 10 runs).
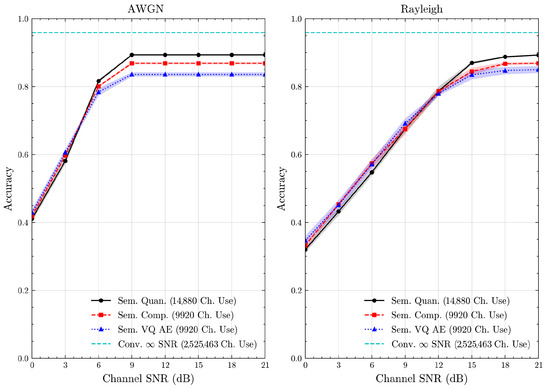
Figure 17.
CIFAR 10 dataset classification accuracies with full accuracy range over AWGN and Rayleigh channels (mean ± 1 SD, 10 runs).
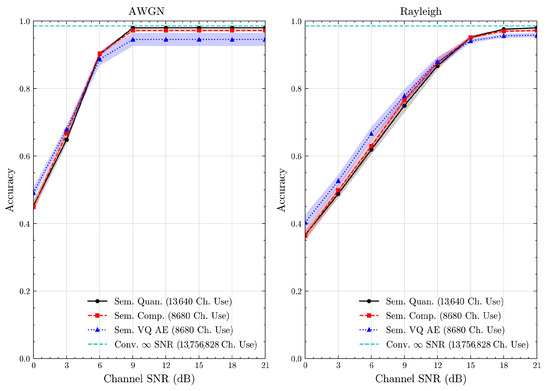
Figure 18.
STL 10 dataset classification accuracies with full accuracy range over AWGN and Rayleigh channels (mean ± 1 SD, 10 runs).
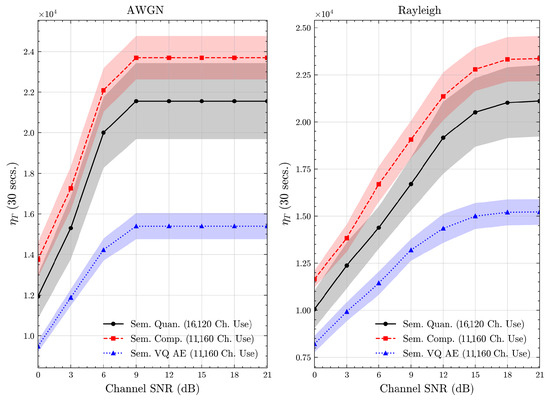
Figure 19.
AG’s News dataset system time efficiency scores over AWGN and Rayleigh channels (mean ± 1 SD, 10 runs).
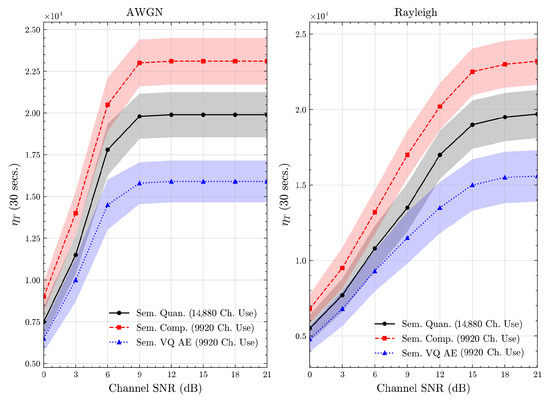
Figure 20.
DBPedia 14 dataset system time efficiency scores over AWGN and Rayleigh channels (mean ± 1 SD, 10 runs).
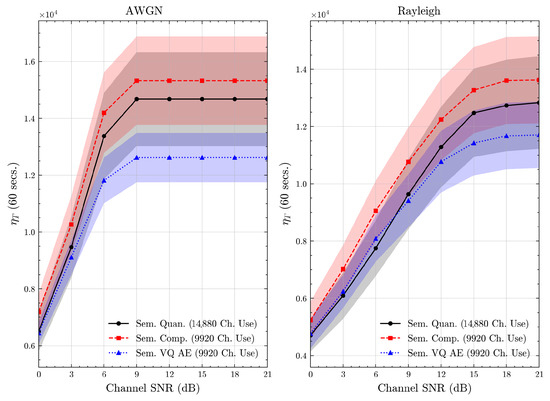
Figure 21.
CIFAR 10 dataset system time efficiency scores over AWGN and Rayleigh channels (mean ± 1 SD, 10 runs).
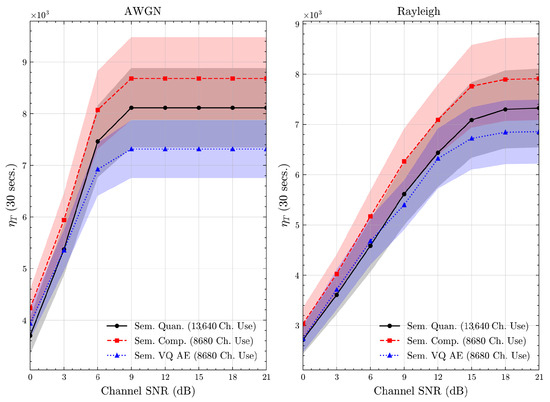
Figure 22.
STL 10 dataset system time efficiency scores over AWGN and Rayleigh channels (mean ± 1 SD, 10 runs).
We compare the time efficiency of quantization and compression, focusing on the impact of clustering. Compression involves a clustering step that reduces codebook size. This results in an overhead for clustering but leads to a smaller model and faster training for the codeword NN. During communication, quantization’s larger codebook increases computational demands, i.e., the calculation of Equation (4), while compression benefits from a smaller codebook. According to Equation (17), although compression has a similar , its larger u enables it to achieve better efficiency scores than quantization.
We observe that integrating model-based insights with pre-trained models simplifies the objective, e.g., aligning codeword Hamming distances with Euclidean distances in the embedding space. In contrast, purely end-to-end approaches, such as semantic VQ-AE, optimize without any structural guidance, making the process more challenging. This highlights the need to combine model-based reasoning with learning-based methods for effective ML-aided communication. Overall, leveraging semantic redundancies reduces computational load and improves the efficiency of wireless resource utilization. We validate performance via 5 different datasets. Proposed semantic methods are compatible with any pre-trained embedding model that shares semantic relation properties, with semantic quantization and compression methods being particularly adaptable due to their lower computational demands. Proposed methods also allow for the change of the classification block with one suited for other tasks using reconstructed embeddings, without requiring changes to their design.
6. Conclusions
In this paper, we have considered classification-oriented multimodal semantic communications. We have used a pre-trained transformer model to extract semantic information, and proposed three different methods for generating their codebooks to minimize semantic distortion. The semantic quantization and compression methods have directly used the available dataset as a codebook, whereas the learning-based method has been trained on the same dataset. We have observed that the proposed methods provide excellent classification accuracy performance, and that pre-training-based methods provide effective compression, resulting in much better system time efficiency with comparable accuracy to their end-to-end learning counterparts. Our study points to the inherent power of utilizing pre-trained models at the edge and demonstrates that with an effective “fine tuning” of codewords, we can have efficient semantic communications.
Future work along these lines include communicating multimodal semantics in multi-node task-oriented networks with personalized tasks.
Author Contributions
Conceptualization, E.K. and A.Y.; methodology, E.K. and A.Y.; software, E.K.; validation, E.K. and A.Y.; writing—original draft preparation, E.K. and A.Y.; writing—review and editing, E.K. and A.Y.; project management, A.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Acknowledgments
We thank the anonymous reviewer for requesting plots with full accuracy range.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Jameel, F.; Chang, Z.; Huang, J.; Ristaniemi, T. Internet of Autonomous Vehicles: Architecture, Features, and Socio-Technological Challenges. IEEE Wirel. Commun. 2019, 26, 21–29. [Google Scholar] [CrossRef]
- Atzori, L.; Iera, A.; Morabito, G. The Internet of Things: A Survey. Comput. Netw. 2010, 54, 2787–2805. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Gündüz, D.; Qin, Z.; Aguerri, I.E.; Dhillon, H.S.; Yang, Z.; Yener, A.; Wong, K.K.; Chae, C.B. Beyond Transmitting Bits: Context, Semantics, and Task-Oriented Communications. IEEE J. Sel. Areas Commun. 2023, 41, 5–41. [Google Scholar] [CrossRef]
- Shannon, C.E.; Weaver, W. The Mathematical Theory of Communication; University of Illinois Press: Champaign, IL, USA, 1949. [Google Scholar]
- Carnap, R.; Bar-Hillel, Y. An Outline of a Theory of Semantic Communication; RLE Technical 522 Reports; Research Laboratory of Electronics, Massachusetts Institute of Technology: Cambridge, MA, USA, 1952; Volume 247. [Google Scholar]
- Melamed, I.D. Measuring Semantic Entropy. In Proceedings of the Tagging Text with Lexical Semantics: Why, What, and How? Washington, DC, USA, 4–5 April 1997. [Google Scholar]
- Juba, B.; Sudan, M. Universal semantic communication I. In Proceedings of the Fortieth Annual ACM Symposium on Theory of Computing, New York, NY, USA, 17–20 May 2008; STOC ’08. pp. 123–132. [Google Scholar] [CrossRef]
- Guler, B.; Yener, A. Semantic index assignment. In Proceedings of the IEEE International Conference on Pervasive Computing and Communication Workshops (PerCom), Budapest, Hungary, 24–28 March 2014; pp. 431–436. [Google Scholar]
- Güler, B.; Yener, A.; Swami, A. The Semantic Communication Game. IEEE Trans. Cogn. Commun. Netw. 2018, 4, 787–802. [Google Scholar] [CrossRef]
- O’Shea, T.; Hoydis, J. An Introduction to Deep Learning for the Physical Layer. IEEE Trans. Cogn. Commun. Netw. 2017, 3, 563–575. [Google Scholar] [CrossRef]
- Ma, S.; Qiao, W.; Wu, Y.; Li, H.; Shi, G.; Gao, D.; Shi, Y.; Li, S.; Al-Dhahir, N. Task-oriented Explainable Semantic Communications. IEEE Trans. Wirel. Commun. 2023, 22, 9248–9262. [Google Scholar] [CrossRef]
- Sheng, Y.; Li, F.; Liang, L.; Jin, S. A Multi-Task Semantic Communication System for Natural Language Processing. In Proceedings of the 2022 IEEE 96th Vehicular Technology Conference (VTC2022-Fall), London, UK, 26–29 September 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Farsad, N.; Rao, M.; Goldsmith, A. Deep Learning for Joint Source-Channel Coding of Text. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2326–2330. [Google Scholar] [CrossRef]
- Jankowski, M.; Gündüz, D.; Mikolajczyk, K. Wireless Image Retrieval at the Edge. IEEE J. Sel. Areas Commun. 2021, 39, 89–100. [Google Scholar] [CrossRef]
- Weng, Z.; Qin, Z. Semantic Communication Systems for Speech Transmission. IEEE J. Sel. Areas Commun. 2021, 39, 2434–2444. [Google Scholar] [CrossRef]
- Xie, H.; Qin, Z.; Tao, X.; Letaief, K.B. Task-Oriented Multi-User Semantic Communications. IEEE J. Sel. Areas Commun. 2022, 40, 2584–2597. [Google Scholar] [CrossRef]
- Sagduyu, Y.E.; Erpek, T.; Ulukus, S.; Yener, A. Is Semantic Communication Secure? A Tale of Multi-Domain Adversarial Attacks. IEEE Commun. Mag. 2023, 61, 50–55. [Google Scholar] [CrossRef]
- Kaplan, J.; McCandlish, S.; Henighan, T.; Brown, T.B.; Chess, B.; Child, R.; Gray, S.; Radford, A.; Wu, J.; Amodei, D. Scaling Laws for Neural Language Models. arXiv 2020. [Google Scholar] [CrossRef]
- Kutay, E.; Yener, A. Semantic Text Compression for Classification. In Proceedings of the 2023 IEEE International Conference on Communications Workshops (ICC Workshops), Rome, Italy, 28 May–1 June 2023; pp. 1368–1373. [Google Scholar] [CrossRef]
- Kutay, E.; Yener, A. Classification-Oriented Semantic Wireless Communications. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 9096–9100. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the 1st International Conference on Learning Representations, ICLR 2013, Scottsdale, AZ, USA, 2–4 May 2013. Workshop Track Proceedings. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in NLP, Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models from Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; Volume 139, pp. 8748–8763. [Google Scholar]
- Arora, S.; May, A.; Zhang, J.; Ré, C. Contextual Embeddings: When Are They Worth It? In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Jurafsky, D., Chai, J., Schluter, N., Tetreault, J., Eds.; pp. 2650–2663. [Google Scholar] [CrossRef]
- Grollmisch, S.; Cano, E.; Kehling, C.; Taenzer, M. Analyzing the Potential of Pre-Trained Embeddings for Audio Classification Tasks. In Proceedings of the 2020 28th European Signal Processing Conference (EUSIPCO), Amsterdam, The Netherlands, 18–22 January 2021; pp. 790–794. [Google Scholar] [CrossRef]
- Frey, B.J.; Dueck, D. Clustering by Passing Messages Between Data Points. Science 2007, 315, 972–976. [Google Scholar] [CrossRef] [PubMed]
- Daras, G.; Dean, J.; Jalal, A.; Dimakis, A. Intermediate Layer Optimization for Inverse Problems using Deep Generative Models. In Proceedings of the 38th International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; Volume 139, pp. 2421–2432. [Google Scholar]
- Bora, A.; Jalal, A.; Price, E.; Dimakis, A.G. Compressed Sensing using Generative Models. In Proceedings of the 34th International Conference on Machine Learning, PMLR, Sydney, NSW, Australia, 6–11 August 2017; Volume 70, pp. 537–546. [Google Scholar]
- Burkard, R.E.; Derigs, U. The Linear Sum Assignment Problem. In Assignment and Matching Problems: Solution Methods with FORTRAN-Programs; Springer: Berlin/Heidelberg, Germany, 1980; pp. 1–15. [Google Scholar] [CrossRef]
- Crouse, D.F. On implementing 2D rectangular assignment algorithms. IEEE Trans. Aerosp. Electron. Syst. 2016, 52, 1679–1696. [Google Scholar] [CrossRef]
- Liu, X.; Chen, Q.; Wu, X.; Hua, Y.; Chen, J.; Li, D.; Tang, B.; Wang, X. Gated Semantic Difference Based Sentence Semantic Equivalence Identification. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2770–2780. [Google Scholar] [CrossRef]
- van den Oord, A.; Vinyals, O.; Kavukcuoglu, K. Neural Discrete Representation Learning. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Hu, Q.; Zhang, G.; Qin, Z.; Cai, Y.; Yu, G.; Li, G.Y. Robust Semantic Communications with Masked VQ-VAE Enabled Codebook. IEEE Trans. Wirel. Commun. 2023, 22, 8707–8722. [Google Scholar] [CrossRef]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level Convolutional Networks for Text Classification. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Cortes, C., Lawrence, N., Lee, D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2015; Volume 28. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Technical Report 0; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Coates, A.; Ng, A.; Lee, H. An Analysis of Single-Layer Networks in Unsupervised Feature Learning. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, PMLR, Ft. Lauderdale, FL, USA, 11–13 April 2011; Volume 15, pp. 215–223. [Google Scholar]
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. arXiv 2018. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).