1. Introduction
Quantum Error Correction (QEC) is an indispensable pillar in the advancement of quantum computing. In the quantum realm, where information resides in fragile quantum states, even trivial interactions with the external environment can introduce errors, thereby threatening computational integrity [
1]. Quantum systems are uniquely susceptible to two main types of errors: bit-flip and phase-flip, while classical systems often contend with bit-flip errors, the quantum realm introduces the added challenge of phase-flip errors. Classical error correction schemes [
2] are ineffective for quantum information due to multiple reasons [
3], necessitating QEC. Surface codes [
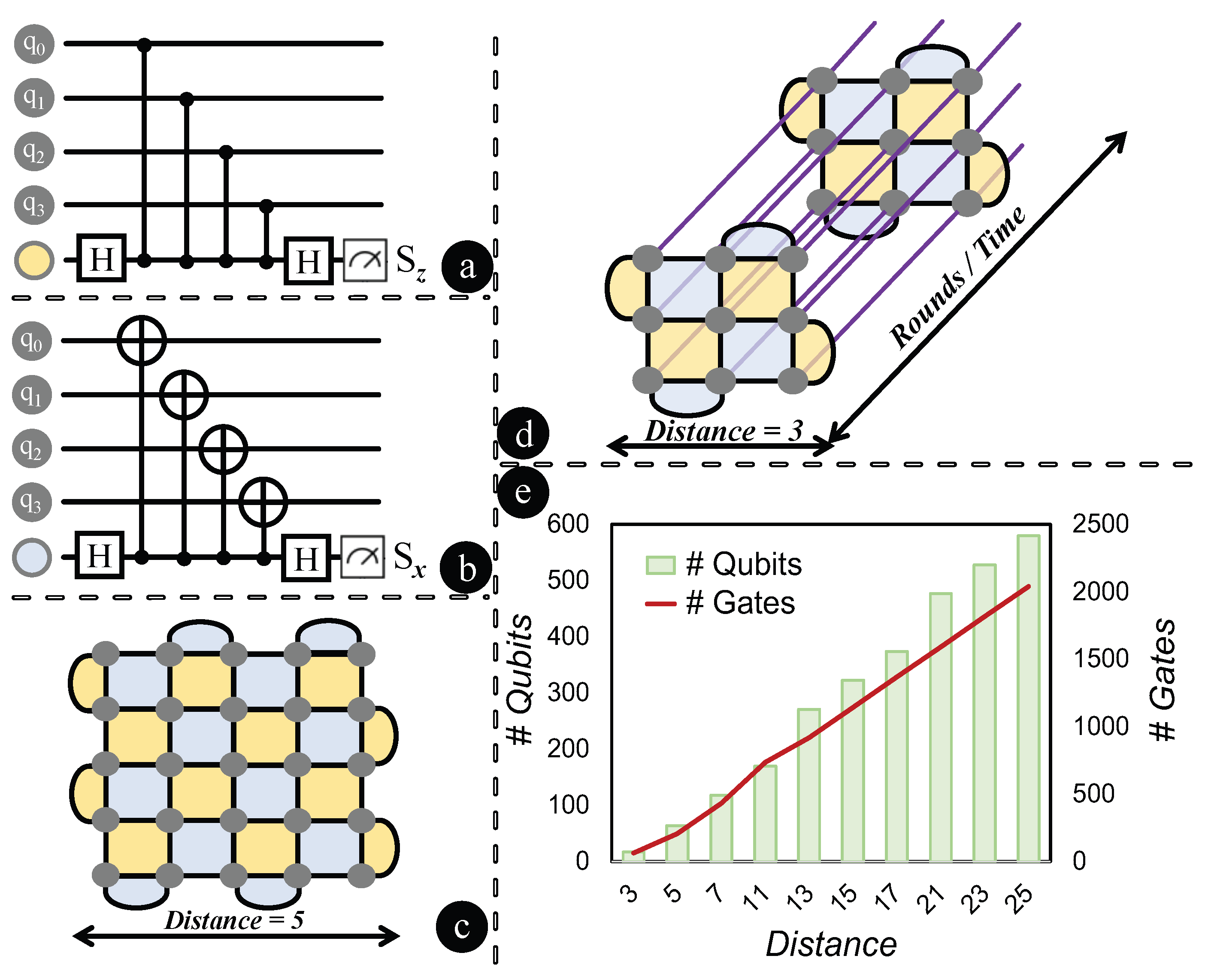
4] address both bit and phase errors by using a two-dimensional qubit layout. Such an approach makes them a frontrunner for near-term fault-tolerant quantum computing. Within this category, there are ‘rotated’ and ‘unrotated’ variants. Rotated surface codes offer a higher resistance to errors and are somewhat less complex to implement than the unrotated versions [
5]. The need for QEC becomes increasingly crucial as we aim for larger, more reliable quantum systems. It is the key to ensure that the quantum computations are both accurate and consistent.
Motivation: Quantum computing advancements prompt a critical inquiry: Does the expansion of error-correcting codes consistently reduce logical errors in practical applications? Consider, for example, a distance 25 rotated surface code requiring roughly 580 qubits and 2040 gates, which approaches fault tolerance. However, the necessity for such a large-scale setup is questionable. Theoretically, larger codes are expected to lower logical errors, but QECC entails significant trade-offs, such as the need for more qubits and longer computation times [
6], potentially heightening decoherence risks [
7]. Although increasing the code distance and the number of rounds adds more gates and physical operations, thereby increasing the potential for physical error events, the essence of quantum error correction is to suppress logical errors. Provided the physical error rate remains below the code threshold, increasing the code distance exponentially decreases the logical error rate. Thus, larger distances are not simply overhead costs, but critical enablers of achieving robust, fault-tolerant computation. However, this comes with resource trade-offs that must be carefully balanced in practice. The effectiveness of QECCs also depends on the specific environmental noise they address. Thus, selecting the optimal QECC is not merely about reducing errors but also about customizing the code to match the physical error characteristics of the quantum computer in question.
Furthermore, quantum computers undergo routine calibration, leading to fluctuations in physical error rates. This may require frequent adjustments to surface code parameters to meet the target error rate or save expensive resources. Over six weeks, we collected error readings from ‘ibm_osaka’ quantum computer. From this dataset, showcased in
Table 1, are three random instances to identify the precise surface code parameters needed to decrease the logical error rate to
. Although the physical error values showed minimal variation, significant differences were observed in the required overhead for surface code parameters. For example, while ‘instance 1’ necessitated a code distance of 21, ‘instance 3’ demanded a code distance of 25. Thus, to avoid employing an additional 100 qubits for ‘instance 1’, it becomes crucial to determine the optimal code distance and the number of rounds needed. Since quantum computers are scarce and expensive, the users would be interested in optimizing the QEC parameters for obtaining desired computation results without paying for unnecessary resources. In practice, rapid and unpredictable noise drift—especially on superconducting platforms—means that optimal QEC parameters can become suboptimal within hours. This temporal instability underscores the need for automated tools like MITS that can quickly regenerate QEC parameters post-calibration, avoiding resource wastage and preserving target logical error rates without lengthy trial and error.
Identifying optimal parameters through simulations for surface codes is significantly time-consuming and complex. This is shown in
Table 1 assuming a user conducts only 40 trial and error for rounds. For a single set of physical errors starting at the smallest distance,
d requires around
h for just one round. Considering the need to run about 40 rounds for each distance to ensure accuracy, and assuming a user needs to determine parameters for 3 different error models, the total time escalates dramatically. Specifically, for one set of physical errors, the cumulative simulation time reaches 160 h (∼6.6 days). The task of optimizing QEC parameters is especially challenging due to the need for rapid adjustments following regular calibrations. Our main challenge is quickly finding the optimal mix of code distance and rounds to meet a target logical error rate, considering the quantum system’s current physical errors.
Contribution: To the best of our knowledge, MITS is the first tool specifically tailored to account for the physical noise characteristics of quantum systems, to swiftly recommend a customized combination of distance and rounds for rotated surface codes. The aim is to achieve a target logical error rate while maintaining an optimal balance between qubit, gate, and time usage. The contributions to building MITS are as follows: ❶
Utilization of Quantum Simulation: We employ STIM [
8], a leading simulator for quantum stabilizer circuits.
As indicated by a recent study [
9],
STIM effectively mirrors the performance of QECCs on real quantum machines. Given the qubit limitations in quantum computers, making execution of full QECCs infeasible, STIM proves invaluable for our purposes. ❷
Development of MITS from STIM’s Framework: While STIM operates conventionally—using parameters like distance, rounds, and physical error to yield logical error rates—MITS adopts an inverse approach. We have tailored a dataset from STIM, aiming to infer the optimal distance and round configurations. This reverse engineering substantially expedites the process, cutting down simulation time. ❸
Model Selection using Heuristics and Machine Learning: Recognizing that one-size-fits-all models are rarely effective, we explored multiple heuristics and machine learning models. This iterative approach allowed us to evaluate and select the best-fit model for our predictive needs, thereby ensuring that MITS’s recommendations are reliable. ❹
Flexibility of the Framework: MITS is designed to be universally applicable, not exclusively tailored to STIM. It can be trained using any QECC simulator-generated or real hardware dataset.
Paper Structure: Section 2 overviews surface codes.
Section 3 discusses constructing MITS by reverse engineering STIM, creating datasets, and exploring various heuristics and machine learning models.
Section 4 compares and evaluates the selected model, demonstrating its effectiveness. The paper concludes in
Section 5.
3. MITS: An Inverted Approach
If a user knows the noise level of their quantum machine (typically available for hardware) and has a target error rate in mind, they can input this information into MITS. In return, MITS will recommend the optimal ‘distance’ and ‘rounds’ for a rotated surface code. It will save hours the users would otherwise spend on simulations to refine distance and round using trial and error. We prepared a detailed dataset using STIM simulations and then employed various machine learning models and heuristics to predict the distance and rounds. This section first explains the dataset creation followed by testing and selection of the best model.
Figure 3 illustrates the systematic progression of MITS, detailing both its development stages and operational workflow.
3.1. Modeling Noise for Experimental Setup
Depolarizing Error: A single-qubit depolarizing error randomly applies one of the Pauli errors (X, Y, or Z) to a qubit, with probabilities determined by coherence time and the duration of quantum gate exposure. In our model, depolarizing errors are applied to all data qubits both before each round of the original surface code and after every Clifford gate. Gate Error: Gate errors arise from sources such as miscalibration and environmental noise. To model these, we apply Pauli-X and Pauli-Z errors to all data qubits following each surface code round. For single-qubit Clifford operations, an error is introduced based on a fixed probability. For two-qubit Clifford operations, a randomly selected pair of Pauli errors is applied. Readout and Reset Error: Readout errors are modeled as probabilistic Pauli flips occurring just before measurement (pre-measurement), while reset errors are modeled as probabilistic flips immediately following the reset operation (post-reset) on qubits initialized to the 0 state. These errors are introduced after measurement, reset, and measure-reset sequences.
3.2. Dataset Compilation from STIM
STIM was used in batch mode to simulate logical error rates for rotated surface codes under varying noise conditions and code parameters. Each simulation specified distance, number of rounds, and four independent physical noise parameters (depolarizing, gate, reset, and readout). We used STIM’s default noise injection methods, and decoding was performed using PyMatching’s MWPM decoder. Logical error rates were extracted from the final measurement outcomes using STIM’s built-in observable tracking mechanism.
Utilizing STIM [
8], a stabilizer simulator, we estimated logical error rates based on physical error attributes, distance, and rounds of rotated surface codes. In total, we conducted 8640 experiments, culminating in a database built over weeks. Our exploration focused on four types of physical error rates: depolarizing, gate, reset, and readout errors.
We determined the error range for each type by examining the minimum and maximum errors across all available IBM quantum computers. This range is representative of most quantum computers and is subject to minimal variation due to calibration. MITS is not specific to IBM quantum computers, while we used IBM’s reported range of error values as an example to illustrate how physical error rates fluctuate over time, the dataset used for training MITS was entirely generated using STIM simulations. Since STIM allows the user to specify physical error rates, MITS can be applied to any quantum computing platform, including superconducting qubits, ion traps, and neutral atoms, as long as appropriate noise characteristics are available. The noise models used in this study were obtained directly from STIM, as provided by Google. We did not manually select or modify specific noise parameters. Instead, we used STIM’s built-in noise models as they are widely used in quantum error correction research.
A summary of the error parameter ranges used for depolarizing, gate, readout, and reset noise models in our STIM simulations is provided in
Table 2. Each STIM experiment simulated a complete surface code circuit including initialization, syndrome extraction rounds, and final measurement. For a given distance d and rounds r, the circuit included r rounds of alternating X- and Z-stabilizer measurements using Clifford operations. The noise parameters ranged as follows: Depolarizing error: 5.5
to 9.0
; Gate error: 1.8
to 2.6
; Readout error: 1.5
to 2.7
; and Reset error: 1.5
to 2.7
. These values were chosen to match the spread reported by IBM quantum devices over multiple calibrations. For decoding, Minimum Weight Perfect Matching (MWPM) was used. Circuits were simulated with full noise injection as defined by STIM’s built-in noise models, without manual customization.
The experiments systematically spanned distances of 3 to 19 and rounds between 1 to 60. Notably, when the logical error rate reached or fell below
in our tests, STIM deems it fault-tolerant. Consequently, any subsequent trials with the current set of error attributes were terminated, preventing redundant additions to the dataset due to the known inverse relationship between error rates and code distance. Drawing from actual quantum computer error levels and carefully curated to exclude redundant values, this dataset stands as the most comprehensive resource tailored for this specific purpose. Across all experiments, we employed the Minimum Weight Perfect Matching (MWPM) decoder [
11]. For computational efficiency, the simulations utilized 4 parallel workers, enabling faster execution across multiple CPU cores. Post-data collection, we segregated the data, randomly reserving
as a test set. Both datasets were pivotal for developing the predictive models that underpin MITS.
3.3. Exploration for Predictive Models
We started with heuristics, as they provide intuitive approaches, before delving into the complexities of machine learning to find the ideal model. We follow a two-step predictive method across all of our models: firstly predicting the code distance using the physical error rate and target logical error rate, and secondly predicting the rounds based on the deduced distance and target logical error rate. This approach is adopted for several reasons. The distance directly influences the logical error rate and serves as a foundational parameter of a surface code. By predicting the distance based on physical error rates and the desired logical error rate, we streamline the process, allowing for a more focused prediction. With the distance determined, the complexity of predicting rounds is reduced. If we aimed to predict both distance and rounds simultaneously, the inherent complexity would rise, potentially compromising the accuracy of our models. It is worth noting that when distance predictions are decimal, we round them up for better round predictions in the subsequent model, while MITS currently employs Minimum Weight Perfect Matching (MWPM) decoding using PyMatching, the framework is not inherently restricted to MWPM. The methodology can be extended to support alternative decoding algorithms, including machine learning-based and tensor-network decoders, by retraining the model with datasets generated using those decoders. The Pearson correlation coefficient measures the correlation between actual and predicted variables; a value near 0 indicates little to no correlation, while a value near 1 suggests a strong positive correlation.
Figure 4 showcases a comparison of all models evaluated during our exploration, using the Pearson coefficient as the metric.
Heuristic Methods: We examined heuristics from two perspectives: assigning weights to physical error attributes based on their system impact, with gate errors receiving the highest due to their extensive effect, followed by depolarizing, readout, and reset errors. Weighted models (‘_w’) use these aggregated weights as a singular feature, whereas non-weighted models (‘_n_w’) treat each error attribute independently without specific weights. ❶ Search by Range: This model uses a distance-based heuristic to find the nearest points in a training dataset. It calculates the Euclidean distance between prediction data and training entries and then retrieves the associated code distance and rounds. ❷ Linear Interpolation: This model performs linear interpolation on a training dataset to estimate distance and round values for a prediction dataset. Linear interpolation is a method of estimating values between two known data points using the formula: . The function sorts the training data based on proximity to each reference value from the prediction set and then uses the two nearest points for interpolation. ❸ Polynomial Interpolation: Using a training dataset, this model fits a 2nd degree polynomial to the three closest points for each prediction value. If the polynomial fit encounters an error, the function gracefully falls back to linear interpolation using the two nearest points. ❹ Multivariate Interpolation: This function employs multivariate interpolation to estimate distance and round values for a prediction dataset based on a training dataset. For each entry in the prediction set, the function uses the ‘’ method to interpolate values based on the given input attributes. The training data serves as the input points and values for this interpolation.
Machine Leaning Models: Our objective was to ascertain whether the machine learning algorithms could offer improved predictive accuracy over the heuristic approaches. ❶ Linear Regression: Using two sequential models, the first predicts a feature distance with hyperparameter tuning via grid search. The predictions then serve as input features for the second model, which predicts the optimal round. ❷ Support Vector Regression: In a two-stage process, the first SVR model predicts a distance using hyperparameter tuning. Its predictions are then used as inputs for the second model, which predicts another target feature. Both stages use five-fold cross-validation for robustness. ❸ Random Forest Regression: The first model predicts a distance based on several features and undergoes hyperparameter tuning. Its rounded predictions, combined with another feature, are inputs for the second model predicting rounds. A variant incorporating principal component analysis was also explored. ❹ XGBoost Regression: In this two-stage process, the first model predicts a distance and undergoes hyperparameter tuning. Its rounded predictions are then used by the second model to predict rounds, with both stages using five-fold cross-validation. ❺ Neural Network: A two-stage deep learning approach is employed. The first neural network predicts distance, and its predictions serve as input for the second model predicting rounds. Both models have three-layer architectures and use the Mean Squared Error loss with the Adam optimizer.
4. Comparison and Evaluation
After assessing various heuristics and machine learning models, multivariate interpolation stood out as the top heuristic. Both XGBoost and Random Forest showed similar high performance, as depicted in
Figure 4. We chose one model for distance prediction and another for round prediction, capitalizing on their strengths, while other models could be viable for prediction, the exceptional performance of our chosen models negated the need to explore additional options. This section delves into the details of XGBoost and Random Forest’s roles in distance and round predictions.
Predictive models, in their essence, do not always yield whole number outcomes. For distance, we round up the raw prediction to the subsequent odd number, while theoretically, surface codes can accommodate even distances, in practical scenarios, odd distances have proven to be more resilient and efficient. This is primarily because odd distances offer a better balance of error correction capability, ensuring the system’s robustness. For rounds, we adjust the raw predictions to the nearest whole number. Regardless of the raw value for distance or rounds, we consistently elevate it to the next odd or whole number. This strategy is imperative to consistently achieve the desired logical error rate. Reducing the distance could jeopardize meeting this target rate. Both raw and adjusted predictions are vital in our analysis. In our approach to finalize the MITS, we employed a two-tiered modeling strategy. Initially, we utilized the XGBoost’s
for predicting distance. Key parameters for this model included a
learning_rate of
,
max_depth of 6,
min_child_weight of 5,
gamma of
, and
n_estimators set to 200. Following this, the predicted distance values were fed into a Random Forest Regressor to predict rounds. The Random Forest model was configured with a
max_depth of 20,
min_samples_split of 10, and
n_estimators set to 10. The training times for the models were approximately 30 min and 7 min, respectively. The shorter duration for the latter is due to its use of a smaller dataset containing only distance and target logical error rate attributes, compared to the former which utilized the full dataset.
Table 3 displays the Pearson correlation coefficients of these models with respect to raw and rounded values. Hyperparameter tuning with
was utilized to prevent overfitting.
Validation on the training dataset yielded correlation coefficients of and for models predicting d and r, closely matching Pearson coefficients from the test dataset predictions. This similarity confirms the absence of overfitting.The ‘optimal’ values referenced in
Figure 5 were determined by exhaustively simulating various combinations of code distances and rounds in STIM until the desired target logical error rate was achieved using the smallest possible distance and fewest rounds. These values thus represent a manually determined baseline through simulation-based trial and error against which MITS predictions are compared. The scatter plots in
Figure 5a,c compare the predicted distance values, both in their raw form and when rounded, to the optimal distance values. It is evident from the plots that all distance values are rounded up to the nearest odd number, with a minimum value set at three. In
Figure 5b,d, scatter plots are depicted comparing rounds in their raw form and when rounded. Given that raw rounds are simply rounded up to the nearest integer, there is minimal discernible difference between the two plots. The intricacies and variations among the original, predicted, and rounded values for both distance and rounds can be more comprehensively understood through the box plots.
Figure 5e,f provide a clear visual representation of these values. Upon examination of the data, it is evident that the original and predicted values for distance are closely aligned. However, a noticeable divergence emerges when the predicted values are rounded up to the nearest odd integer. Conversely, for the rounds, there is no discernible difference between the original, predicted, and rounded values. The Pearson correlation coefficients in
Table 3 demonstrate that, despite rounding both the distances and rounds, the predicted results remain closely aligned with the actual values.
Next, we evaluate the logical error rates. To begin with a recap, it is essential to note that for surface codes to yield optimal results, there is a necessity to increase the rounds in tandem with the distance.
Figure 6a illustrates a scatter plot comparing the predicted distance and rounds. The evident trend of increasing rounds with the rise in distance underscores our assertion. In
Figure 6b, we present a heatmap illustrating the comparison between predicted d values and their optimal counterparts. This visualization aids in determining the frequency with which certain values are predicted as d. Particularly, we focus on instances where predictions fall below the optimal values, as these cases signify potential failures to achieve the target logical error rate. We performed another experiment to validate the logical error rate obtained from STIM by using the
d and
r values predicted by MITS and comparing them against the target logical error rate. In
Figure 6c, the relationship between the derived error and the target error is illustrated. Notably, the derived error rate is predominantly lower than the target rate, with a few exceptions exhibiting minimal discrepancies. We quantify the discrepancy between the Derived Logical Error Rate (DLER) and the Target Logical Error Rate (TLER) by subtracting them.
Figure 6d presents a histogram illustrating the frequency distribution of this difference. From the histogram, it is evident that the predominant distribution is centered at 0, affirming that MITS consistently achieves the target logical error rate. A significant portion of the distribution also leans towards the positive side, indicating that MITS often surpasses the target by reducing the logical error rate even further—a favorable outcome. There is a minor distribution on the negative spectrum, the magnitude of these differences is so minuscule that they can be considered negligible.
Figure 6e depicts the exponential increase in STIM’s simulation time for surface codes as distance
d and rounds
r grow. Adjusting for rounds and variable physical error rates requires more time. Given the daily error calibrations of quantum computers, users may frequently need to adjust parameters to maintain efficiency. This task can prove particularly challenging when dealing with multiple variations in physical errors and target outcomes, significantly increasing the time required to identify optimal parameters. MITS significantly reduces trial-and-error-based simulation time from hours to
milliseconds on a pre-trained model, swiftly predicting the required distance and rounds to achieve a specified target logical error rate.
5. Conclusions
This paper presented MITS, a new methodology to optimize surface code implementations by predicting ideal distance and rounds given target logical error rates and known physical noise levels of the hardware. By devising an inverse modeling approach and training on a comprehensive simulation dataset of over 8500 experiments, MITS can rapidly recommend surface code parameters that balance qubit usage with error rate goals. Our comparative assessment validated the efficacy of the XGBoost and Random Forest models underpinning MITS’s predictions, which achieved Pearson correlation coefficients of and for distance and rounds, respectively. We further confirmed that the predicted combination of distance and rounds from MITS consistently attained the target logical error rates, with deviations centered around 0. MITS can cut hours from surface code calibration, assisting in the realization of practical error-corrected quantum processors. MITS is designed as a general framework rather than a tool restricted to a specific hardware platform, decoder, or noise model. However, MITS’s generality is contingent on retraining. Using a different decoder (e.g., tensor networks) or targeting a different hardware backend (e.g., ion traps) would require generating a new dataset reflective of that context. This retraining step may involve days of simulation effort depending on the noise model and parameter space, which we acknowledge as a practical limitation for rapid deployment across very heterogeneous systems, while our current study focuses on IBM-like error rates and MWPM decoding, the methodology itself is fully adaptable. By retraining the model with new datasets, MITS can be extended to different noise models, quantum architectures, and decoding techniques. This flexibility makes it a valuable tool for optimizing surface codes in a wide range of quantum computing environments.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}