A Survey of Information Entropy Metrics for Complex Networks



Abstract
1. Introduction
2. Preliminaries
2.1. Complex Networks
2.2. Notation
2.3. Traditional Centrality Metrics
2.3.1. Degree
2.3.2. Strength
2.3.3. Betweenness
2.3.4. Closeness
2.3.5. Eigenvector
2.3.6. Clustering Coefficient
2.4. Information Functional
2.5. Shannon’s Entropy
- Because Shannon’s information entropy is a measure of uncertainty, the entropy H increases as the probabilities become equal. In fact, H attains its maximum possible value when all of the are exactly equal. In this case, where all , .
- For equiprobable outcomes, the value of the entropy H increases with n.
- When there is only one possible outcome, the system is perfectly predictable and, thus, .
- The mathematical formulation that is presented in Equation (10) is that of a continuous function of . Additionally, thus, small changes in result in small changes in H.
- Equation (10) is a symmetric function, i.e., exchanging the values of two probabilities does not change the resulting value of the entropy H.
2.6. Other Definitions
2.6.1. Paths, Geodesics, Walks and Trails
2.6.2. Distance in Graph G
2.6.3. Graph Diameter
3. Materials and Methods
- Is Shannon’s entropy used as a network or node metric?
- When Shannon’s entropy is used with the objective of ranking nodes by importance (also known as a centrality metric), is the entropy of the node calculated directly or obtained as the difference between the entropy of the graph before and after node removal?
- What is the definition of the probability distribution ?
- To which type of complex network is the metric applicable? Undirected or directed graph? Weighted or unweighted? Should the graph be strongly connected? Are self-loops allowed? And so on.
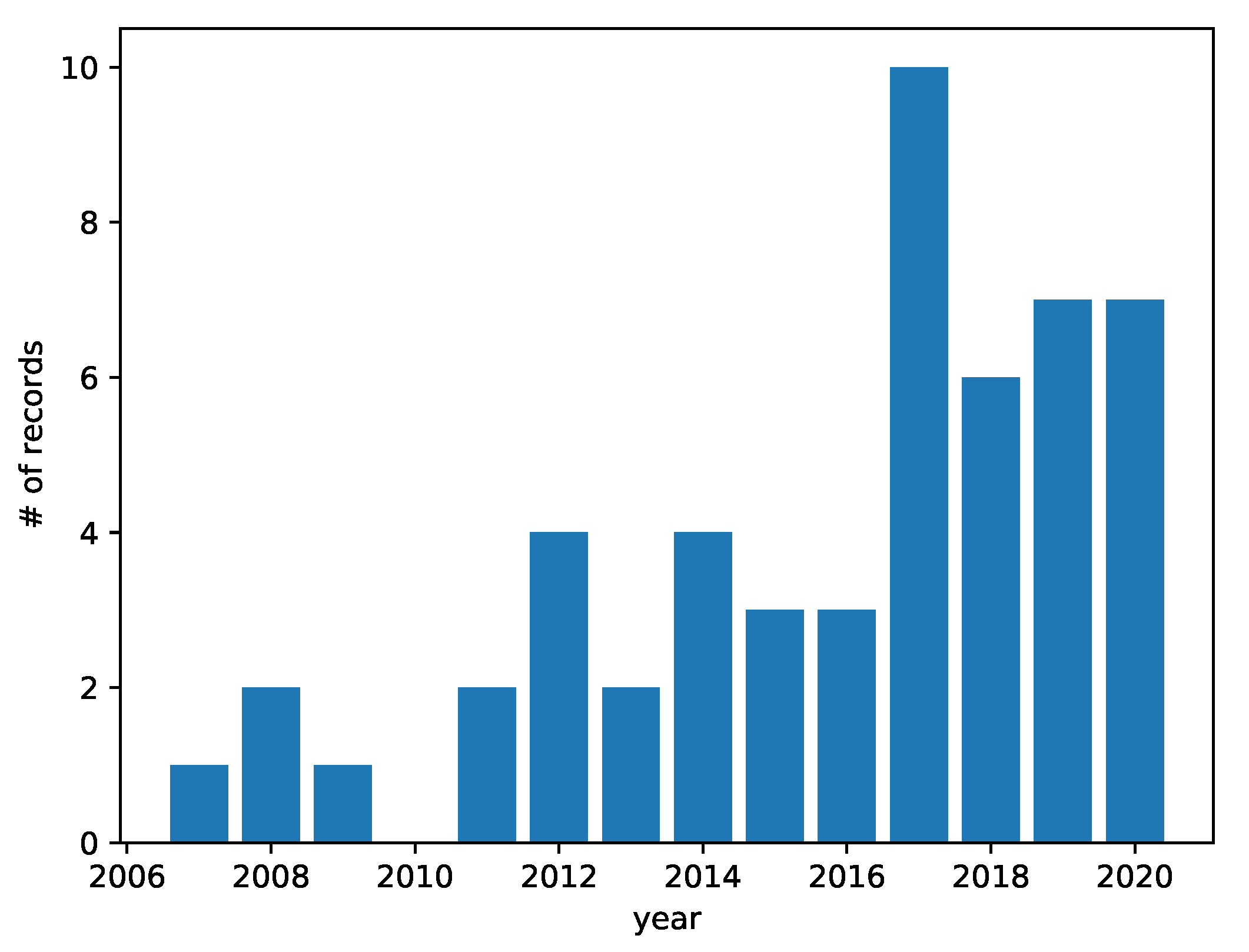
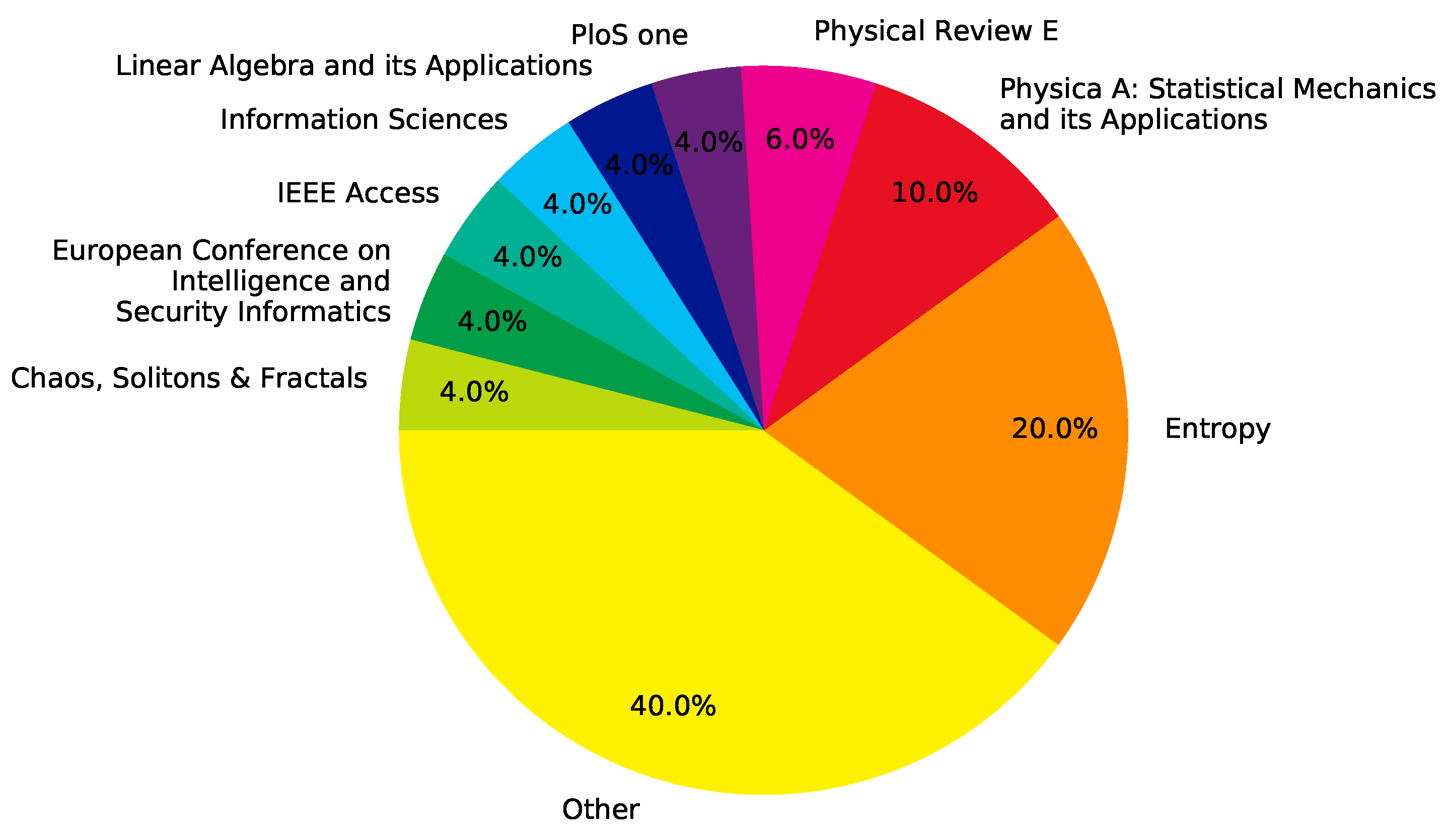
4. Results
4.1. Shannon’s Entropy as a Networks vs. Node Metric
4.1.1. Graph Entropy
4.1.2. Node Entropy
4.2. Centrality of Nodes: Direct vs. Indirect Entropy Metrics
- “Key players are those elements in the network that are considered to be important, in regard to some criteria.” [16]
- “... in any centrality application one should take into account the characteristics of the flow of traffic through the network.” [17]
- “Choosing the right centrality for a specific problem is usually a hard task and [a] common approach is comparing different centralities for the same network and building hypothesis about the discovered central nodes.” [21]
- “Different measures of centrality capture different aspects of what it means for a node to be ‘central’ to the network.” [29]
- “A centrality is optimal for one application, yet is often sub-optimal for a different application.” [32]
- “Centrality is an important concept in network theory, yet there is no unique definition.” [37]
- “Centrality is a measure of the importance of a node in a complex network with respect to a specific criterion, where several centrality criteria have been proposed.” [40]
- “... a specific centrality is ideal for one application, yet regularly imperfect for an alternate application.” [44]
- “The significance [the authors mean importance] of a node can have different meanings depending on its application.” [45]
- “What most important’ means is not universally defined, therefore numerous notions of centrality have been proposed.” [46]
- “[centrality measures] ... are intended to capture the role played by each node within the network by optimizing an opportunely defined objective function.” [49]
- “The meaning of ‘important’ depends on the nature of the problem analyzed.” [54]
- “... all of these methods [centrality metrics] have some limitations and specific application scenarios that are related to the way they consider the problem. A valid method for ranking nodes in a complex network remains an open issue.” [57]
- “In general, each network has a specific node importance ranking, and different identification methods consider different structural properties of the network, which would give different ranking lists.” [58]
- “Various centrality metrics establish different aspects for the meaning of an actor to be central to the network.” [63]
4.3. Probability Distributions
- degree or strength (18 records),
- betweenness (eight records),
- paths (five records),
- walks (six records),
- closeness (four records),
- distance (three records),
- eigenvector (two records), and
- other definitions (nine records).
4.3.1. Based on Node Degree
Based on the Degree of Node i
Based on the Strength of Node i
Based on the Degree and/or Strength of the Neighbors of Node i
Based on the Degree and/or Strength of Nodes in a Subgraph of Node i
4.3.2. Based on Betweenness
4.3.3. Based on Paths
4.3.4. Based on Walks
4.3.5. Based on Closeness
4.3.6. Based on Distance
4.3.7. Based on Eigenvector
4.3.8. Other Definitions
4.4. Metric Applicability
5. Discussion
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| Greek Letters | |
| Tunable parameter called confidence strength used in [60] | |
| Neighbors of node i | |
| Betweenness centrality of node i | |
| Largest eigenvalue of | |
| Total number of geodesic paths between nodes i and j | |
| Number of geodesic paths between nodes i and j that pass through v | |
| Roman Letters | |
| Adjacency matrix of elements used to describe graph G | |
| Closeness centrality of node i | |
| Distance between nodes i and j | |
| E | Set of edges in graph G |
| f | Abstract information function of G |
| G | Graph |
| Subgraph where node i is the central node | |
| H | Information or Shannon’s entropy |
| Improved k-shells of node i | |
| Degree of node i | |
| In-degree of node i | |
| Out-degree of node i | |
| Maximum degree in graph G | |
| Minimum degree in graph G | |
| q degree power of node i | |
| Sum of the degree of the neighbors of i, i.e., | |
| Sum of the degree of the neighbors of i’s neighbors, i.e., | |
| Degree of node j in the subgraph that has node i as central node | |
| N | Number of nodes in G, |
| Probability of an outcome | |
| Strength of node i | |
| In-strength of node i | |
| Out-strength of node i | |
| V | Set of edges in graph G, , |
| Weight matrix of elements used to describe G | |
| Eigenvector centrality of node i |
References
- Shannon, C.E. A mathematical theory of communication. Bell. Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Boccaletti, S.; Latora, V.; Moreno, Y.; Chavez, M.; Hwang, D.U. Complex networks: Structure and dynamics. Phys. Rep. 2006, 424, 175–308. [Google Scholar] [CrossRef]
- Freeman, L.C. A set of measures of centrality based on betweenness. Sociometry 1977, 35–41. [Google Scholar] [CrossRef]
- Freeman, L.C. Centrality in social networks conceptual clarification. Soc. Netw. 1978, 1, 215–239. [Google Scholar] [CrossRef]
- Bonacich, P. Factoring and weighting approaches to status scores and clique identification. J. Math. Sociol. 1972, 2, 113–120. [Google Scholar] [CrossRef]
- Bonacich, P. Some unique properties of eigenvector centrality. Soc. Netw. 2007, 29, 555–564. [Google Scholar] [CrossRef]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ‘small-world’ networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef] [PubMed]
- Saramäki, J.; Kivelä, M.; Onnela, J.P.; Kaski, K.; Kertesz, J. Generalizations of the clustering coefficient to weighted complex networks. Phys. Rev. E 2007, 75, 027105. [Google Scholar] [CrossRef]
- Fagiolo, G. Clustering in complex directed networks. Phys. Rev. E 2007, 76, 026107. [Google Scholar] [CrossRef]
- Dehmer, M. Information processing in complex networks: Graph entropy and information functionals. Appl. Math. Comput. 2008, 201, 82–94. [Google Scholar] [CrossRef]
- Zenil, H.; Kiani, N.; Tegnér, J. A review of graph and network complexity from an algorithmic information perspective. Entropy 2018, 20, 551. [Google Scholar] [CrossRef] [PubMed]
- Borgatti, S.P. Centrality and network flow. Soc. Netw. 2005, 27, 55–71. [Google Scholar] [CrossRef]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G.; Prisma Group. Preferred reporting items for systematic reviews and meta-analyses: The PRISMA statement. PLoS Med. 2009, 6, e1000097. [Google Scholar] [CrossRef] [PubMed]
- Tutzauer, F. Entropy as a measure of centrality in networks characterized by path-transfer flow. Soc. Netw. 2007, 29, 249–265. [Google Scholar] [CrossRef]
- Hussain, D.A.; Ortiz-Arroyo, D. Locating key actors in social networks using bayes’ posterior probability framework. In Proceedings of the European Conference on Intelligence and Security Informatics, Esbjerg, Denmark, 3–5 December 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 27–38. [Google Scholar] [CrossRef]
- Ortiz-Arroyo, D.; Hussain, D.A. An information theory approach to identify sets of key players. In Proceedings of the European Conference on Intelligence and Security Informatics, Esbjerg, Denmark, 3–5 December 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 15–26. [Google Scholar] [CrossRef]
- Tutzauer, F.; Elbirt, B. Entropy-Based Centralization and its Sampling Distribution in Directed Communication Networks. Commun. Monogr. 2009, 76, 351–375. [Google Scholar] [CrossRef]
- Dehmer, M.; Mowshowitz, A. A history of graph entropy measures. Inf. Sci. 2011, 181, 57–78. [Google Scholar] [CrossRef]
- Delvenne, J.C.; Libert, A.S. Centrality measures and thermodynamic formalism for complex networks. Phys. Rev. E 2011, 83, 046117. [Google Scholar] [CrossRef]
- Sun, R.; Mu, A.l.; Li, L.; Zhong, M. Evaluation of node importance based on topological potential in weighted complex networks. In Proceedings of the Fourth International Conference on Machine Vision (ICMV 2011): Machine Vision, Image Processing, and Pattern Analysis, Singapore, 13 February 2012; Volume 8349, p. 83492K. [Google Scholar] [CrossRef]
- Serin, E.; Balcisoy, S. Entropy based sensitivity analysis and visualization of social networks. In Proceedings of the 2012 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Istanbul, Turkey, 26–29 August 2012; pp. 1099–1104. [Google Scholar] [CrossRef]
- Dehmer, M.; Sivakumar, L. Recent developments in quantitative graph theory: Information inequalities for networks. PLoS ONE 2012, 7, e31395. [Google Scholar] [CrossRef]
- Fewell, J.H.; Armbruster, D.; Ingraham, J.; Petersen, A.; Waters, J.S. Basketball teams as strategic networks. PLoS ONE 2012, 7, e47445. [Google Scholar] [CrossRef]
- Chellappan, V.; Sivalingam, K.M. Application of entropy of centrality measures to routing in tactical wireless networks. In Proceedings of the 2013 19th IEEE Workshop on Local & Metropolitan Area Networks (LANMAN), Bussels, Belgium, 10–12 April 2013; pp. 1–6. [Google Scholar] [CrossRef]
- Chellappan, V.; Sivalingam, K.M.; Krithivasan, K. An entropy maximization problem in shortest path routing networks. In Proceedings of the 2014 IEEE 20th International Workshop on Local Metropolitan Area Networks(LANMAN), Reno, NV, USA, 21–23 May 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Estrada, E.; José, A.; Hatano, N. Walk entropies in graphs. Linear Algebra Its Appl. 2014, 443, 235–244. [Google Scholar] [CrossRef]
- Benzi, M. A note on walk entropies in graphs. Linear Algebra Its Appl. 2014, 445, 395–399. [Google Scholar] [CrossRef]
- Chen, Z.; Dehmer, M.; Shi, Y. A note on distance-based graph entropies. Entropy 2014, 16, 5416–5427. [Google Scholar] [CrossRef]
- Nikolaev, A.G.; Razib, R.; Kucheriya, A. On efficient use of entropy centrality for social network analysis and community detection. Soc. Netw. 2015, 40, 154–162. [Google Scholar] [CrossRef]
- Caravelli, F. Ranking nodes according to their path-complexity. Chaos Solitons Fractals 2015, 73, 90–97. [Google Scholar] [CrossRef]
- Lu, G.; Li, B.; Wang, L. Some new properties for degree-based graph entropies. Entropy 2015, 17, 8217–8227. [Google Scholar] [CrossRef]
- Nie, T.; Guo, Z.; Zhao, K.; Lu, Z.M. Using mapping entropy to identify node centrality in complex networks. Phys. Stat. Mech. Its Appl. 2016, 453, 290–297. [Google Scholar] [CrossRef]
- Gialampoukidis, I.; Kalpakis, G.; Tsikrika, T.; Vrochidis, S.; Kompatsiaris, I. Key player identification in terrorism-related social media networks using centrality measures. In Proceedings of the 2016 European Intelligence and Security Informatics Conference (EISIC), Uppsala, Sweden, 17–19 August 2016; pp. 112–115. [Google Scholar] [CrossRef]
- Chellappan, V.; Sivalingam, K.M.; Krithivasan, K. A centrality entropy maximization problem in shortest path routing networks. Comput. Networks 2016, 104, 1–15. [Google Scholar] [CrossRef]
- Singh, P.; Chakraborty, A.; Manoj, B. Link influence entropy. Phys. Stat. Mech. Its Appl. 2017, 465, 701–713. [Google Scholar] [CrossRef]
- Weber, C.M.; Hasenauer, R.P.; Mayande, N.V. Quantifying nescience: A decision aid for practicing managers. In Proceedings of the 2017 Portland International Conference on Management of Engineering and technology (PICMET), Portland, OR, USA, 9–13 July 2017; pp. 1–14. [Google Scholar] [CrossRef]
- Bekiros, S.; Nguyen, D.K.; Junior, L.S.; Uddin, G.S. Information diffusion, cluster formation and entropy-based network dynamics in equity and commodity markets. Eur. J. Oper. Res. 2017, 256, 945–961. [Google Scholar] [CrossRef]
- Wang, Q.; Zeng, G.; Tu, X. Information technology project portfolio implementation process optimization based on complex network theory and entropy. Entropy 2017, 19, 287. [Google Scholar] [CrossRef]
- Ai, X. Node importance ranking of complex networks with entropy variation. Entropy 2017, 19, 303. [Google Scholar] [CrossRef]
- Jimenez-Martinez, J.; Negre, C.F. Eigenvector centrality for geometric and topological characterization of porous media. Phys. Rev. E 2017, 96, 013310. [Google Scholar] [CrossRef] [PubMed]
- Cai, M.; Cui, Y.; Stanley, H.E. Analysis and evaluation of the entropy indices of a static network structure. Sci. Rep. 2017, 7, 1–10. [Google Scholar] [CrossRef]
- Wiedermann, M.; Donges, J.F.; Kurths, J.; Donner, R.V. Mapping and discrimination of networks in the complexity-entropy plane. Phys. Rev. E 2017, 96, 042304. [Google Scholar] [CrossRef] [PubMed]
- Zareie, A.; Sheikhahmadi, A.; Fatemi, A. Influential nodes ranking in complex networks: An entropy-based approach. Chaos Solitons Fractals 2017, 104, 485–494. [Google Scholar] [CrossRef]
- Qiao, T.; Shan, W.; Zhou, C. How to identify the most powerful node in complex networks? A novel entropy centrality approach. Entropy 2017, 19, 614. [Google Scholar] [CrossRef]
- Tulu, M.M.; Hou, R.; Younas, T. Identifying influential nodes based on community structure to speed up the dissemination of information in complex network. IEEE Access 2018, 6, 7390–7401. [Google Scholar] [CrossRef]
- Oggier, F.; Phetsouvanh, S.; Datta, A. Entropic Centrality for Non-Atomic Flow Networks. In Proceedings of the 2018 International Symposium on Information Theory and Its Applications (ISITA), Singapore, 28–31 October 2018; pp. 50–54. [Google Scholar] [CrossRef]
- Stella, M.; De Domenico, M. Distance entropy cartography characterises centrality in complex networks. Entropy 2018, 20, 268. [Google Scholar] [CrossRef]
- Qiao, T.; Shan, W.; Yu, G.; Liu, C. A novel entropy-based centrality approach for identifying vital nodes in weighted networks. Entropy 2018, 20, 261. [Google Scholar] [CrossRef]
- Barucca, P.; Caldarelli, G.; Squartini, T. Tackling information asymmetry in networks: A new entropy-based ranking index. J. Stat. Phys. 2018, 173, 1028–1044. [Google Scholar] [CrossRef]
- Zhang, Z.; Ma, W.; Zhang, Z.; Xiong, C. A transportation network stability analysis method based on betweenness centrality entropy maximization. In Proceedings of the 2018 Chinese Control And Decision Conference (CCDC), Shenyang, China, 9–11 June 2018; pp. 2741–2745. [Google Scholar] [CrossRef]
- Xu, M.; Wu, J.; Liu, M.; Xiao, Y.; Wang, H.; Hu, D. Discovery of Critical Nodes in Road Networks Through Mining From Vehicle Trajectories. IEEE Trans. Intell. Transp. Syst. 2019, 20, 583–593. [Google Scholar] [CrossRef]
- Zareie, A.; Sheikhahmadi, A.; Jalili, M. Influential node ranking in social networks based on neighborhood diversity. Future Gener. Comput. Syst. 2019, 94, 120–129. [Google Scholar] [CrossRef]
- Zarghami, S.A.; Gunawan, I.; Schultmann, F. Entropy of centrality values for topological vulnerability analysis of water distribution networks. Built Environ. Proj. Asset Manag. 2019. [Google Scholar] [CrossRef]
- Oggier, F.; Phetsouvanh, S.; Datta, A. A split-and-transfer flow based entropic centrality. PeerJ Comput. Sci. 2019, 5, e220. [Google Scholar] [CrossRef]
- Zhao, J.; Lei, X. Predicting Essential Proteins Based on Second-Order Neighborhood Information and Information Entropy. IEEE Access 2019, 7, 136012–136022. [Google Scholar] [CrossRef]
- Wang, L.; Dai, W.; Luo, G.; Zhao, Y. A Novel Approach to Support Failure Mode, Effects, and Criticality Analysis Based on Complex Networks. Entropy 2019, 21, 1230. [Google Scholar] [CrossRef]
- Li, Y.; Cai, W.; Li, Y.; Du, X. Key node ranking in complex networks: A novel entropy and mutual information-based approach. Entropy 2020, 22, 52. [Google Scholar] [CrossRef] [PubMed]
- Wen, T.; Deng, Y. Identification of influencers in complex networks by local information dimensionality. Inf. Sci. 2020, 512, 549–562. [Google Scholar] [CrossRef]
- Guo, C.; Yang, L.; Chen, X.; Chen, D.; Gao, H.; Ma, J. Influential Nodes Identification in Complex Networks via Information Entropy. Entropy 2020, 22, 242. [Google Scholar] [CrossRef]
- Ni, C.; Yang, J.; Kong, D. Sequential seeding strategy for social influence diffusion with improved entropy-based centrality. Phys. Stat. Mech. Its Appl. 2020, 545, 123659. [Google Scholar] [CrossRef]
- Bashiri, H.; Rahmani, H.; Bashiri, V.; Módos, D.; Bender, A. EMDIP: An Entropy Measure to Discover Important Proteins in PPI networks. Comput. Biol. Med. 2020, 120, 103740. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Li, W.; Guo, Y.; Peng, X.; Li, Y. Identifying influential spreaders in complex networks based on improved k-shell method. Phys. Stat. Mech. Its Appl. 2020, 554, 124229. [Google Scholar] [CrossRef]
- Saxena, C.; Doja, M.; Ahmad, T. Entropy based flow transfer for influence dissemination in networks. Phys. Stat. Mech. Its Appl. 2020, 555, 124630. [Google Scholar] [CrossRef]
- Cioabă, S.M. Sums of powers of the degrees of a graph. Discret. Math. 2006, 306, 1959–1964. [Google Scholar] [CrossRef]
- Brandes, U. A faster algorithm for betweenness centrality. J. Math. Sociol. 2001, 25, 163–177. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Refs. | Authors | Year | Record Type | Journal/Booktitle |
|---|---|---|---|---|
| [14] | Tutzauer, Frank | 2007 | article | Social networks |
| [15] | Hussain, DM Akbar and Ortiz-Arroyo, Daniel | 2008 | proceeding | European Conference on Intelligence and Security Informatics |
| [16] | Ortiz-Arroyo, Daniel and Hussain, DM Akbar | 2008 | proceeding | European Conference on Intelligence and Security Informatics |
| [17] | Tutzauer, Frank and Elbirt, Benjamin | 2009 | article | Communication Monographs |
| [18] | Dehmer, Matthias and Mowshowitz, Abbe | 2011 | article | Information Sciences |
| [19] | Delvenne, Jean-Charles and Libert, Anne-Sophie | 2011 | article | Physical Review E |
| [20] | Sun, Rui and Mu, A-li and Li, Lin and Zhong, Mi | 2012 | proceeding | Fourth International Conference on Machine Vision (ICMV 2011): Machine Vision, Image Processing, and Pattern Analysis |
| [21] | Serin, Ekrem and Balcisoy, Selim | 2012 | proceeding | 2012 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining |
| [22] | Dehmer, Matthias and Sivakumar, Lavanya | 2012 | article | PloS one |
| [23] | Fewell, Jennifer H and Armbruster, Dieter and Ingraham, John and Petersen, Alexander and Waters, James S | 2012 | article | PloS one |
| [24] | Chellappan, Vanniarajan and Sivalingam, Krishna M | 2013 | proceeding | 2013 19th IEEE Workshop on Local & Metropolitan Area Networks (LANMAN) |
| [25] | V. Chellappan and K. M. Sivalingam and K. Krithivasan | 2014 | proceeding | 2014 IEEE 20th International Workshop on Local Metropolitan Area Networks (LANMAN) |
| [26] | Estrada, Ernesto and José, A and Hatano, Naomichi | 2014 | article | Linear Algebra and its Applications |
| [27] | Benzi, Michele | 2014 | article | Linear Algebra and its Applications |
| [28] | Chen, Zengqiang and Dehmer, Matthias and Shi, Yongtang | 2014 | article | Entropy |
| [29] | Nikolaev, Alexander G and Razib, Raihan and Kucheriya, Ashwin | 2015 | article | Social Networks |
| [30] | Caravelli, Francesco | 2015 | article | Chaos, Solitons & Fractals |
| [31] | Lu, Guoxiang and Li, Bingqing and Wang, Lijia | 2015 | article | Entropy |
| [32] | Nie, Tingyuan and Guo, Zheng and Zhao, Kun and Lu, Zhe-Ming | 2016 | article | Physica A: Statistical Mechanics and its Applications |
| [33] | Gialampoukidis, Ilias and Kalpakis, George and Tsikrika, Theodora and Vrochidis, Stefanos and Kompatsiaris, Ioannis | 2016 | proceeding | 2016 European Intelligence and Security Informatics Conference (EISIC) |
| [34] | Chellappan, Vanniyarajan and Sivalingam, Krishna M and Krithivasan, Kamala | 2016 | article | Computer Networks |
| [35] | Singh, Priti and Chakraborty, Abhishek and Manoj, BS | 2017 | article | Physica A: Statistical Mechanics and its Applications |
| [36] | Weber, Charles M and Hasenauer, Rainer P and Mayande, Nitin V | 2017 | proceeding | 2017 Portland international conference on management of engineering and technology (PICMET) |
| [37] | Bekiros, Stelios and Nguyen, Duc Khuong and Junior, Leonidas Sandoval and Uddin, Gazi Salah | 2017 | article | European Journal of Operational Research |
| [38] | Wang, Qin and Zeng, Guangping and Tu, Xuyan | 2017 | article | Entropy |
| [39] | Ai, Xinbo | 2017 | article | Entropy |
| [40] | Jimenez-Martinez, Joaquin and Negre, Christian FA | 2017 | article | Physical Review E |
| [41] | Cai, Meng and Cui, Ying and Stanley, H Eugene | 2017 | article | Scientific reports |
| [42] | Wiedermann, Marc and Donges, Jonathan F and Kurths, Jürgen and Donner, Reik V | 2017 | article | Physical Review E |
| [43] | Zareie, Ahmad and Sheikhahmadi, Amir and Fatemi, Adel | 2017 | article | Chaos, Solitons & Fractals |
| [44] | Qiao, Tong and Shan, Wei and Zhou, Chang | 2017 | article | Entropy |
| [45] | Tulu, Muluneh Mekonnen and Hou, Ronghui and Younas, Talha | 2018 | article | IEEE Access |
| [46] | Oggier, Frédérique and Phetsouvanh, Silivanxay and Datta, Anwitaman | 2018 | proceeding | 2018 International Symposium on Information Theory and Its Applications (ISITA) |
| [47] | Stella, Massimo and De Domenico, Manlio | 2018 | article | Entropy |
| [48] | Qiao, Tong and Shan, Wei and Yu, Ganjun and Liu, Chen | 2018 | article | Entropy |
| [49] | Barucca, Paolo and Caldarelli, Guido and Squartini, Tiziano | 2018 | article | Journal of Statistical Physics |
| [50] | Zhang, Zundong and Ma, Weixin and Zhang, Zhaoran and Xiong, Changzhe | 2018 | proceeding | 2018 Chinese Control And Decision Conference (CCDC) |
| [51] | M. Xu and J. Wu and M. Liu and Y. Xiao and H. Wang and D. Hu | 2019 | article | IEEE Transactions on Intelligent Transportation Systems |
| [52] | Ahmad Zareie and Amir Sheikhahmadi and Mahdi Jalili | 2019 | article | Future Generation Computer Systems |
| [53] | Zarghami, Seyed Ashkan and Gunawan, Indra and Schultmann, Frank | 2019 | article | Built Environment Project and Asset Management |
| [54] | Oggier, Frédérique and Phetsouvanh, Silivanxay and Datta, Anwitaman | 2019 | article | PeerJ Computer Science |
| [55] | J. Zhao and X. Lei | 2019 | article | IEEE Access |
| [56] | Wang, Lixiang and Dai, Wei and Luo, Guixiu and Zhao, Yu | 2019 | article | Entropy |
| [57] | Li, Yichuan and Cai, Weihong and Li, Yao and Du, Xin | 2020 | article | Entropy |
| [58] | Tao Wen and Yong Deng | 2020 | article | Information Sciences |
| [59] | Guo, Chungu and Yang, Liangwei and Chen, Xiao and Chen, Duanbing and Gao, Hui and Ma, Jing | 2020 | article | Entropy |
| [60] | Ni, Chengzhang and Yang, Jun and Kong, Demei | 2020 | article | Physica A: Statistical Mechanics and its Applications |
| [61] | Hamid Bashiri and Hossein Rahmani and Vahid Bashiri and Dezső Módos and Andreas Bender | 2020 | article | Computers in Biology and Medicine |
| [62] | Min Wang and Wanchun Li and Yuning Guo and Xiaoyan Peng and Yingxiang Li | 2020 | article | Physica A: Statistical Mechanics and its Applications |
| [63] | Chandni Saxena and M.N. Doja and Tanvir Ahmad | 2020 | article | Physica A: Statistical Mechanics and its Applications |
| Refs. | Entropy Formulation | Notes |
|---|---|---|
| [16] | Note that, . Thus, Ortiz’ formulation is equivalent to that of [39,41,56]. | |
| [21] | ||
| [31] | is the q degree power of node i. | |
| [39,41,56] | Identical to [31] with . Note that [41] uses the natural logarithm. | |
| [41] | is the distribution function of the degree. | |
| [41] | where is the distribution probability of node degree and . | |
| [41] | where , , W is the maximum flow matrix and is the matrix when row l and column l are removed from W. | |
| [42] | ||
| [45] | where for , and for & . | |
| [49] | is the Configuration Model representation. |
| Refs. | Entropy Formulation | Notes |
|---|---|---|
| [38] | is the number of projects in community j. | |
| [56,60] | Note that in this case the summation over produces the same result as conducted over . |
| Refs. | Entropy Formulation | Notes |
|---|---|---|
| [32] | Note that this is not strictly based on Shannon’s entropy. | |
| [43,59] | is the total degree of the neighbors of node i. | |
| [43] | is the total degree of the neighbors of node i’s neighbors. | |
| [57] | x represents either the “in” or “out” component of the degree. | |
| [57] | x represents either the “in” or “out” component of the strength. | |
| [60] | “confidence influence entropy” | |
| [62] | ||
| [63] |
| Refs. | Entropy Formulation | Notes |
|---|---|---|
| [44,48] | is the subgraph that has node i as central node. | |
| [48] | is the subgraph that has node i as central node. |
| Refs. | Entropy Formulation | Notes |
|---|---|---|
| [21] | ||
| [24,25,34] | where is the shortest path betweenness centrality of a link for every pair of source-sink nodes. | |
| [33] | Not strictly following Shannon’s formulation. | |
| [39,53] | ||
| [50] | While similar to the formulation in [24,25,34], the chosen logarithm base is different. |
| Refs. | Entropy Formulation | Notes |
|---|---|---|
| [14,17] | where is the probability of a path starting in node i and ending on node j which is a function of the transfer and the stopping probabilities. | |
| [16] | is the fraction of paths in graph G that start on node . | |
| [46] | where P is a path in the set of paths between s and j, . is the split and transfer probability, is the flow incoming to node v and is the number of edges to which the flow can be split into. | |
| [54] | where is the probability of choosing an outgoing edge and . is a weight associated with the edge such that , i.e., the flow that reached node u. |
| Refs. | Entropy Formulation | Notes |
|---|---|---|
| [19] | t is the path length, is the dominant eigenvalue of , u is the left eigenvector and v is the right one. | |
| [23] | N/A | Formulation is not provided by the authors. |
| [26,27] | is the adjacency matrix, is the inverse temperature and is the partition function for the graph. | |
| [29] | are the elements of the Markov chain transition probability and t is the number of transitions. | |
| [30] | with , the Markov operator. |
| Refs. | Entropy Formulation | Notes |
|---|---|---|
| [21] | ||
| [22,53] | ||
| [38] | where and . The range of is and is divided into ten intervals with . |
| Refs. | Entropy Formulation | Notes |
|---|---|---|
| [28] | is the number of vertices with distance l to a given vertex. | |
| [35] | where is the distance of the path between i and j. | |
| [35] | ||
| [47] | and . |
| Refs. | Entropy Formulation | Notes |
|---|---|---|
| [40] | is the probability of a node with eigenvector centrality value . | |
| [53] |
| Refs. | Entropy Formulation | Notes |
|---|---|---|
| [15] | Based on Bayes posterior probability but it is unclear how is obtained. | |
| [20] | is the topological potential which is a function of the strength , the shortest path between all pairs of nodes and an optimized impact factor . | |
| [36] | i is a process step, is the event that the fault is produced in step i and is the probability of this fault occurring in . | |
| [38] | where and . The range of is and is divided into ten intervals with . | |
| [51] | is the total number of origin-destination pairs, is the probability that the flow on node i is from origin-destination pair s. | |
| [52] | is the improved k-shell index. | |
| [55] | is an dimensional vector representing the protein associated complex information (. The probability of a protein complex where is the number of proteins contained in the protein complex and is the number of proteins in the standard protein complex C. | |
| [55] | is an dimensional vector representing the protein associated subcellular localization information (. The probability of a protein complex where is the number of proteins contained in the protein complex and is the number of proteins in the standard protein complex C. | |
| [58] | Note that this is the information of a box of size l around node i, not the entropy. | |
| [61] | where i is a node or protein, N is the number of annotations in the annotation list and where the value of is 1 or 0 depending on i being annotated by annotation . |
| Refs. | Undirected | Directed | Unweighted | Weighted | Other Requirements |
|---|---|---|---|---|---|
| [14] | X | X | X | X | |
| [15] | X | X | acyclic | ||
| [16] | X | X | acyclic | ||
| [17] | X | X | X | X | |
| [18] | X | X | |||
| [19] | X | X | strongly connected, aperiodic | ||
| [20] | X | X | connected | ||
| [21] | X | X | |||
| [22] | X | X | |||
| [23] | X | X | |||
| [24] | X | X | no self-loops | ||
| [25] | X | X | |||
| [26] | X | X | |||
| [27] | X | X | |||
| [28] | X | X | no self-loops | ||
| [29] | X | X | X | ||
| [30] | X | X | |||
| [31] | X | X | |||
| [32] | X | X | |||
| [33] | X | X | |||
| [34] | X | X | |||
| [35] | X | X | |||
| [36] | X | X | |||
| [37] | X | X | |||
| [38] | X | X | |||
| [39] | X | X | |||
| [40] | X | X | |||
| [41] | X | X | |||
| [42] | X | X | no self-loops | ||
| [43] | X | X | |||
| [44] | X | X | |||
| [45] | X | X | |||
| [46] | X | X | |||
| [47] | X | X | connected | ||
| [48] | X | X | |||
| [49] | X | X | X | X | |
| [50] | X | X | |||
| [51] | X | X | |||
| [52] | X | X | |||
| [53] | X | X | X | ||
| [54] | X | X | |||
| [55] | X | X | |||
| [56] | X | X | |||
| [57] | X | X | |||
| [58] | not specified | ||||
| [59] | X | X | |||
| [60] | X | X | |||
| [61] | X | X | |||
| [62] | X | X | |||
| [63] | X | X |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Omar, Y.M.; Plapper, P. A Survey of Information Entropy Metrics for Complex Networks. Entropy 2020, 22, 1417. https://doi.org/10.3390/e22121417
Omar YM, Plapper P. A Survey of Information Entropy Metrics for Complex Networks. Entropy. 2020; 22(12):1417. https://doi.org/10.3390/e22121417
Chicago/Turabian StyleOmar, Yamila M., and Peter Plapper. 2020. "A Survey of Information Entropy Metrics for Complex Networks" Entropy 22, no. 12: 1417. https://doi.org/10.3390/e22121417
APA StyleOmar, Y. M., & Plapper, P. (2020). A Survey of Information Entropy Metrics for Complex Networks. Entropy, 22(12), 1417. https://doi.org/10.3390/e22121417