
Water Saturation Prediction in the Middle Bakken Formation Using Machine Learning

 , ,
, , 
 ,
,
Abstract
1. Introduction
2. Geological Settings
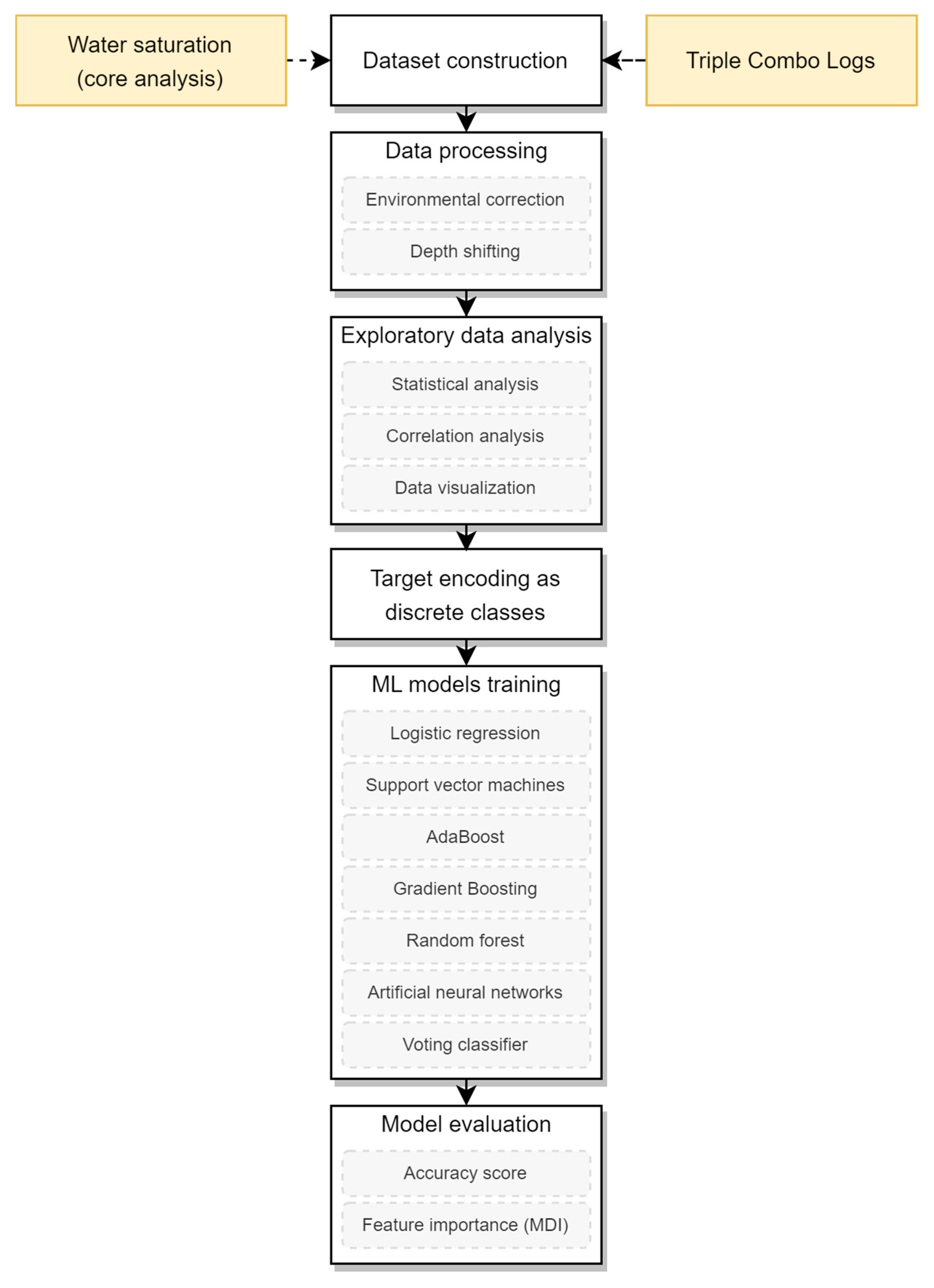
3. Materials and Methods
3.1. Petrophysical Data Processing
3.2. Machine Learning Model Description
3.2.1. Logistic Regression
3.2.2. Support Vector Classifier
3.2.3. Random Forest Classifier
3.2.4. AdaBoost
3.2.5. Gradient Boosting Classifier
3.2.6. Artificial Neural Networks
3.2.7. Voting Classifier
- Hard voting: the final prediction is based on the majority vote of the estimators.
- Soft voting: the final prediction is the average of the class probabilities predicted by each model.
3.3. Data Scaling
- Improved model performance by reducing the effect of variables’ differences in scale.
- Faster model convergence, especially for neural networks with gradient descent optimization.
- Better interpretability by making it easier to compare the different coefficients head-to-head rather than being scaled.
4. Results and Discussion
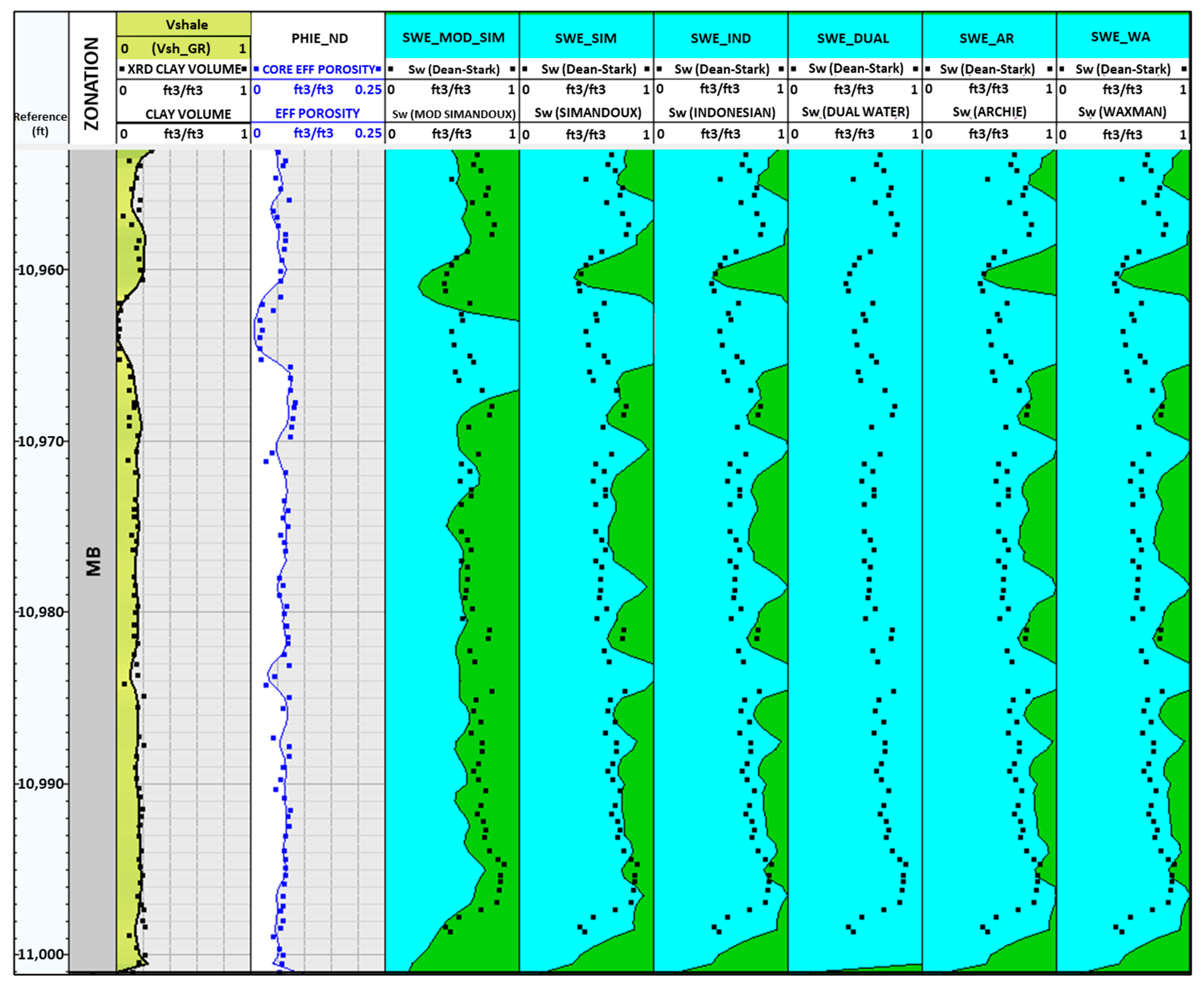
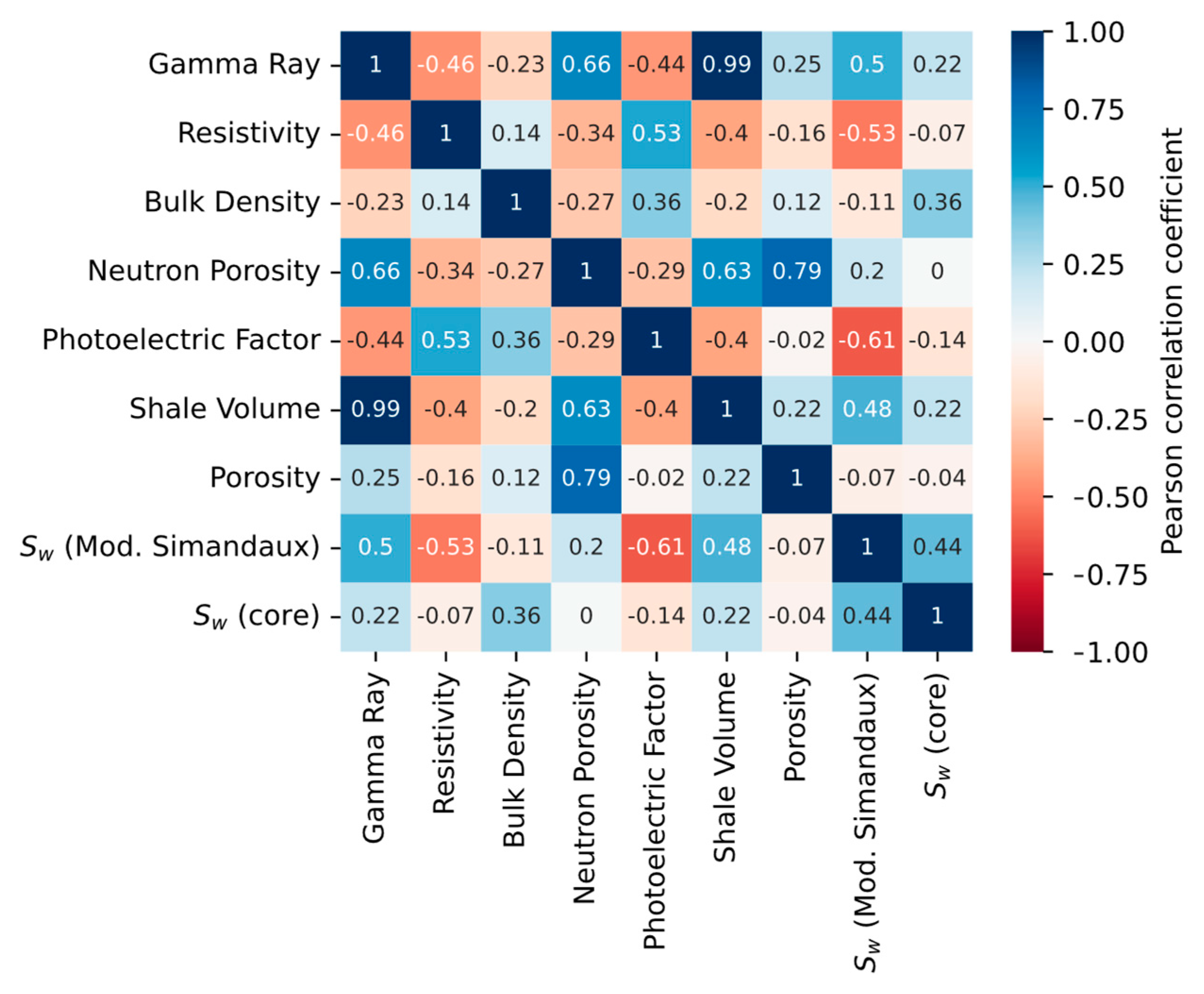
- Investigate the potential linear relationship between well logs, Sw calculated using the modified Simandoux method, and Dean–Stark Sw.
- Assess the performance of the Sw prediction models and compare their accuracy with that of conventional methods.
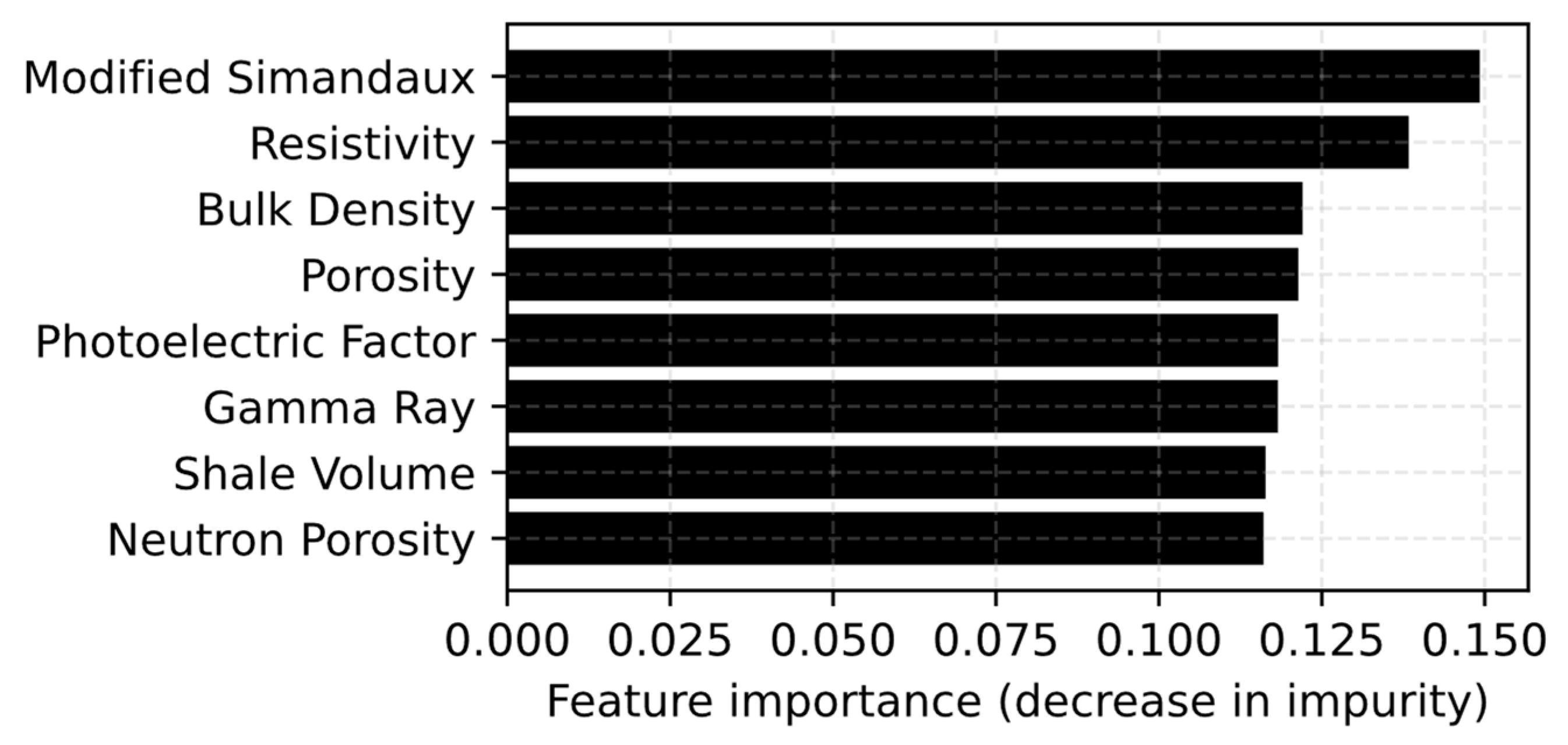
- Determine the well logs that have the highest feature importance among the applied ML models.
4.1. Petrophysical Analysis
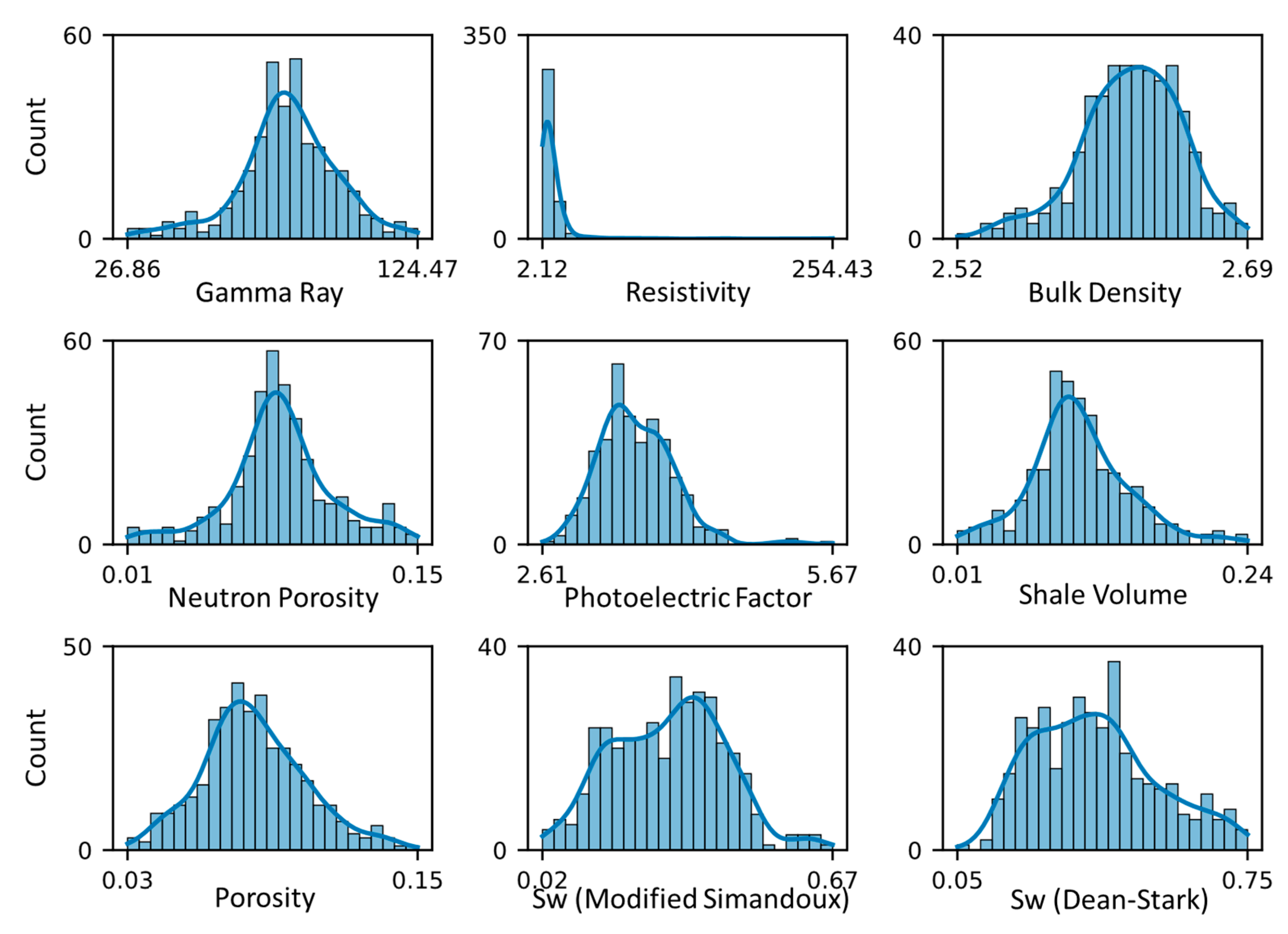
4.2. Exploratory Data Analysis
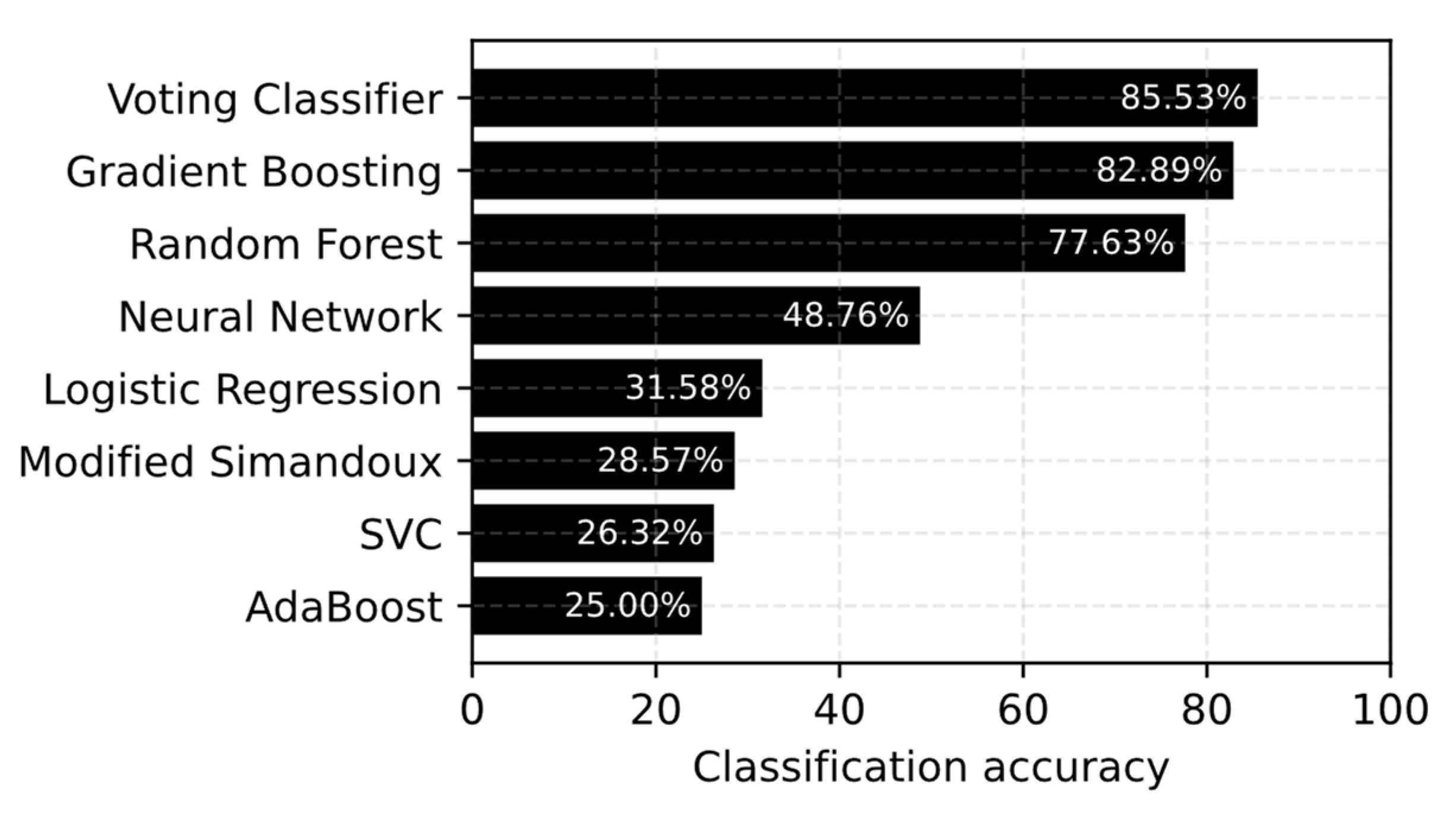
4.3. Machine Learning Model Performance
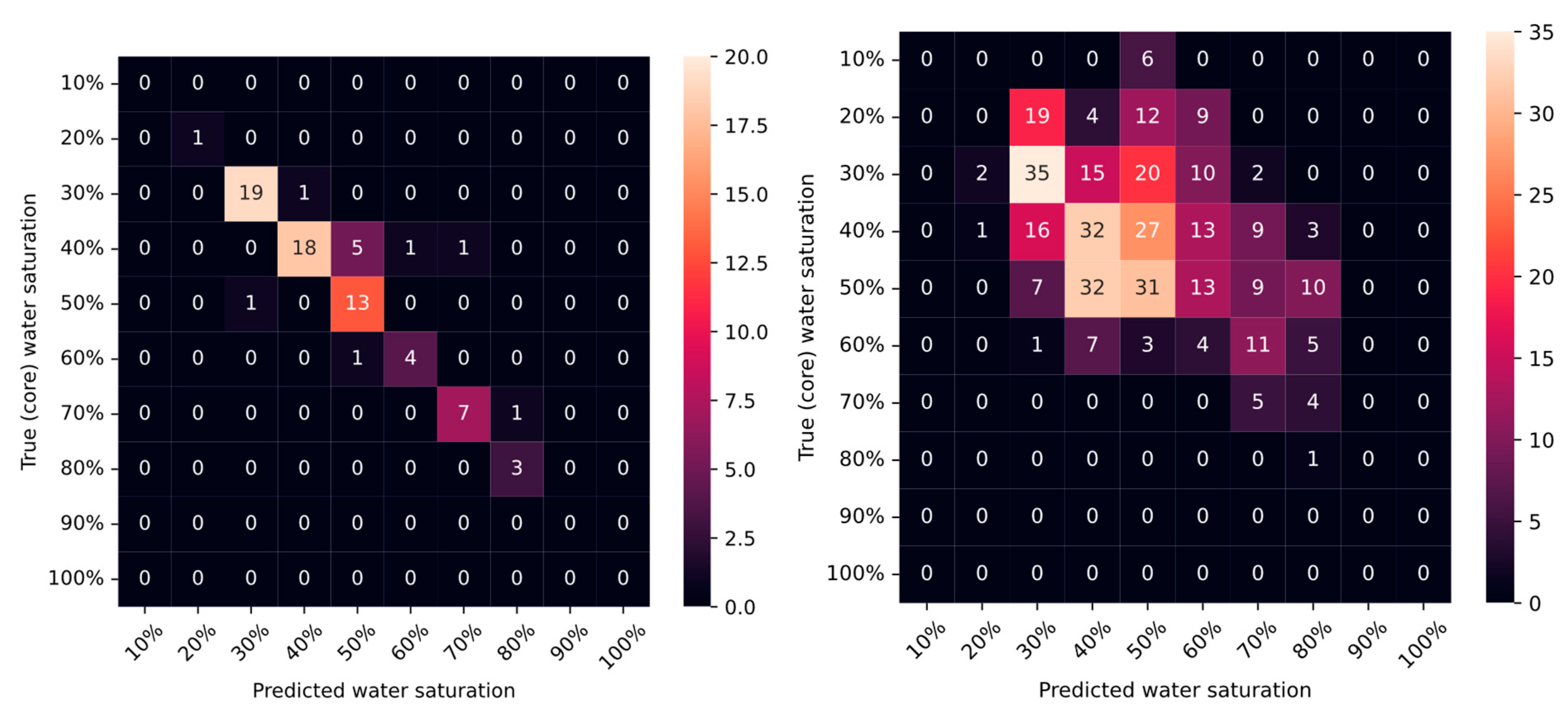
4.4. Model Evaluation
- High heterogeneity of the MBM, including the presence of extremely thin laminations and significant variation in the volume of cement minerals.
- The low resolution of logging tools cannot accurately represent the high variation of physical properties (bulk density, neutron porosity, photoelectric factor, and resistivity) of such formations, which are used as inputs for Sw prediction.
- The uncertainty associated with laboratory measurement of Sw in tight cores using the Dean–Stark method, which undermines the accuracy of Sw prediction using ML regression algorithms, even when models show a high correlation coefficient.
5. Conclusions
- The voting classifier model, based on gradient boosting and random forest, displays the highest accuracy of Sw in the MBM.
- The Sw calculated using the modified Simandoux method tends to be overestimated in the MBM. However, using it as input to train and test the classification ML models improved result accuracy.
- Petrophysical data processing, which consists of depth shifting, environmental correction, and log normalization, is crucial for accurate prediction of Sw.
- The voting classifier model, based on gradient boosting and random forest, can accurately match the Dean–Stark Sw within a specific range. Therefore, it can be a viable alternative to expensive laboratory tests.
- We propose applying classification ML models to predict other rock properties, such as permeability and shale volume. This suggestion stems from the recognition that these properties share similar limitations as water saturation.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sorenson, J.; Hawthorne, S.; Jin, L.; Bosshart, N.; Torres, J.; Azzolina, N.; Smith, S.; Jacobson, L.; Doll, T.; Gorecki, C.; et al. Bakken CO2 Storage and Enhanced Recovery Program—Phase II Final Report; U.S. Department of Energy: Pittsburgh, PA, USA, 2018. [Google Scholar]
- Shawaf, A.; Rasouli, V.; Dehdouh, A. The Impact of Formation Anisotropy and Stresses on Fractural Geometry—A Case Study in Jafurah’s Tuwaiq Mountain Formation (TMF), Saudi Arabia. Processes 2023, 11, 1545. [Google Scholar] [CrossRef]
- Kurtoglu, B.; Sorensen, J.A.; Braunberger, J. Geologic Characterization of a Bakken Reservoir for Potential CO2 EOR. In Proceedings of the SPE/AAPG/SEG Unconventional Resources Technology Conference, Denver, CO, USA, 12–14 August 2013. [Google Scholar]
- Malki, M.L.; Rasouli, V.; Saberi, M.; Mellal, I.; Ozotta, O.; Sennaoui, B.; Chellal, H. Effect of Mineralogy, Pore Geometry, and Fluid Type on the Elastic Properties of the Bakken Formation. In Proceedings of the 56th U.S. Rock Mechanics/Geomechanics Symposium, Santa Fe, NM, USA, 26–29 June 2022. [Google Scholar] [CrossRef]
- Malki, M.L.; Rasouli, V.; Saberi, M.R.; Sennaoui, B.; Ozotta, O.; Chellal, H. Effect of CO2 on Mineralogy, Fluid, and Elastic Properties in Middle Bakken Formation using Rock Physics Modeling. In Proceedings of the 56th U.S. Rock Mechanics/Geomechanics Symposium, Santa Fe, NM, USA, 26–29 June 2022. [Google Scholar] [CrossRef]
- Malki, M.L.; Rasouli, V.; Mehena, M.; Mellal, I.; Saberi, M.R.; Sennaoui, B.; Chellal, H. The Impact of Thermal Maturity on the Organic-Rich Shales Properties: A Case Study in Bakken. In Proceedings of the SPE/AAPG/SEG Unconventional Resources Technology Conference, Denver, CO, USA, 13–15 June 2023. [Google Scholar] [CrossRef]
- Laalam, A.; Boualam, A.; Ouadi, H.; Djezzar, S.; Tomomewo, O.; Mellal, I.; Bakelli, O.; Merzoug, A.; Chemmakh, A.; Latreche, A.; et al. Application of Machine Learning for Mineralogy Prediction from Well Logs in the Bakken Petroleum System. In Proceedings of the SPE Annual Technical Conference and Exhibition, Houston, TX, USA, 3–5 October 2022. [Google Scholar] [CrossRef]
- Ouadi, H.; Mellal, I.; Chemmakh, A.; Djezzar, S.; Boualam, A.; Merzoug, A.; Laalam, A.; Mouedden, N.; Khetib, Y.; Rasouli, V.; et al. New Approach for Stress-Dependent Permeability and Porosity Response in the Bakken Formation. In Proceedings of the SPE Annual Technical Conference and Exhibition, Houston, TX, USA, 3–5 October 2022. [Google Scholar] [CrossRef]
- Boualam, A. Impact of Stress on the Characterization of the Flow Units in the Complex Three Forks Reservoir, Williston Basin. Ph.D. Thesis, University of North Dakota, Grand Forks, ND, USA, 2019. Available online: https://commons.und.edu/theses (accessed on 30 April 2023).
- Amiri, M.; Ghiasi-Freez, J.; Golkar, B.; Hatampourd, A. Improving Water Saturation Estimation in a Tight Shaly Sandstone Reservoir Using Artificial Neural Network Optimized by Imperialist Competitive Algorithm—A Case Study. J. Pet. Sci. Eng. 2015, 127, 347–358. [Google Scholar] [CrossRef]
- Miah, M.I.; Zendehboudi, S.; Ahmed, S. Log Data-Driven Model and Feature Ranking for Water Saturation Prediction Using Machine Learning Approach. J. Pet. Sci. Eng. 2020, 194, 107291. [Google Scholar] [CrossRef]
- Hadavimoghaddam, F.; Ostadhassan, M.; Sadri, M.A.; Bondarenko, T.; Chebyshev, I.; Semnani, A. Prediction of Water Saturation from Well Log Data by Machine Learning Algorithms: Boosting and Super Learner. J. Mar. Sci. Eng. 2021, 9, 666. [Google Scholar] [CrossRef]
- Ibrahim, F.; Elkatatny, S.; Al Ramadan, M. Prediction of Water Saturation in Tight Gas Sandstone Formation Using Artificial Intelligence. ACS Omega 2022, 7, 215–222. [Google Scholar] [CrossRef] [PubMed]
- Merzoug, A.; Ellafi, A. Optimization of Child Well Hydraulic Fracturing Design: A Bakken Case Study. In Proceedings of the SPE Oklahoma City Oil and Gas Symposium, Oklahoma City, OK, USA, 17–19 April 2023. [Google Scholar] [CrossRef]
- Sorensen, J.; Jacobson, L.; Pekot, L.; Torres, J.; Jin, L.; Hamling, J.; Doll, T.; Zandy, A.; Smith, S.; Wilson, J.; et al. Bakken CO2 Storage and Enhanced Recovery Program—Phase I Final Report; Energy & Environmental Research Center: Grand Forks, ND, USA, 2014. [Google Scholar]
- Hester, T.; Schmoker, J. Selected Physical Properties of the Bakken Formation, North Dakota and Montana Part of the Williston Basin; U.S. Geological Survey: Montana, ND, USA, 1985. [Google Scholar]
- Merzoug, A.; Chellal, H.A.K.; Brinkerhoff, R.; Rasouli, V.; Olaoye, O. Parent-Child Well Interaction in Multi-Stage Hydraulic Fracturing: A Bakken Case Study. In Proceedings of the 56th U.S. Rock Mechanics/Geomechanics Symposium, Santa Fe, NM, USA, 26–29 June 2022. [Google Scholar] [CrossRef]
- Mellal, I.; Malki, M.; Latrach, A.; Ameur-Zaimech, O.; Bakelli, O. Multiscale Formation Evaluation and Rock Types Identification in The Middle Bakken Formation. In Proceedings of the SPWLA 64th Annual Logging Symposium, Lake Conroe, TX, USA, 10–14 June 2023. [Google Scholar] [CrossRef]
- Laalam, A.; Ouadi, H.; Merzoug, A.; Chemmakh, A.; Boualam, A.; Djezzar, S.; Mellal, I.; Djoudi, M. Statistical Analysis of the Petrophysical Properties of the Bakken Petroleum System. In Proceedings of the SPE/AAPG/SEG Unconventional Resources Technology Conference, Houston, TX, USA, 20–22 June 2022; pp. 1–21. [Google Scholar] [CrossRef]
- Chellal, H.; Merzoug, A.; Rasouli, V.; Brinkerhoff, R. Effect of Rock Elastic Anisotropy on Hydraulic Fracture Containment in the Bakken Formation. In Proceedings of the 56th U.S. Rock Mechanics/Geomechanics Symposium, Santa Fe, NM, USA, 26–29 June 2022. [Google Scholar]
- Mellal, I.; Rasouli, V.; Dehdouh, A.; Letrache, A.; Abdelhamid, C.; Malki, M.L.; Bakelli, O. Formation Evaluation Challenges of Tight and Shale Reservoirs. A Case Study of the Bakken Petroleum System. In Proceedings of the 57th U.S. Rock Mechanics/Geomechanics Symposium, Atlanta, GA, USA, 25–28 June 2023. [Google Scholar] [CrossRef]
- Shawaf, A.; Rasouli, V.; Dehdouh, A. Applications of Differential Effective Medium (DEM)-Driven Correlations to Estimate Elastic Properties of Jafurah Tuwaiq Mountain Formation (TMF). Processes 2023, 11, 1643. [Google Scholar] [CrossRef]
- Sorensen, A.; Kurz, B.A.; Hawthorne, S.B.; Jin, L.; Smith, S.A.; Azenkeng, A. Laboratory Characterization and Modeling to Examine CO2 Storage and Enhanced Oil Recovery in an Unconventional Tight Oil Formation. In Energy Procedia; Elsevier: Amsterdam, The Netherlands, 2017; pp. 5460–5478. [Google Scholar] [CrossRef]
- Kazak, E.S.; Kazak, A.V. A Novel Laboratory Method for Reliable Water Content Determination of Shale Reservoir Rocks. J. Pet. Sci. Eng. 2019, 183, 106301. [Google Scholar] [CrossRef]
- Rymarczyk, T.; Kozłowski, E.; Kłosowski, G.; Niderla, K. Logistic Regression for Machine Learning in Process Tomography. Sensors 2019, 19, 3400. [Google Scholar] [CrossRef] [PubMed]
- Pisner, A.; Schnyer, D.M. Support Vector Machine. In Machine Learning: Methods and Applications to Brain Disorders; Elsevier: Amsterdam, The Netherlands, 2019; pp. 101–121. [Google Scholar] [CrossRef]
- Laoufi, H.; Megherbi, Z.; Zeraibi, N.; Merzoug, A.; Ladmia, A. Selection of Sand Control Completion Techniques Using Machine Learning. In Proceedings of the International Geomechanics Symposium, Abu Dhabi, United Arab Emirates, 7–10 November 2022. [Google Scholar] [CrossRef]
- Abdulkareem, N.M.; Abdulazeez, A.M. Machine Learning Classification Based on Radom Forest Algorithm: A Review. Int. J. Sci. Bus. 2021, 5, 128–142. [Google Scholar] [CrossRef]
- Chellal, H.A.K.; Egenhoff, S.; Latrach, A.; Bakelli, O. Machine Learning Based Predictive Models for UCS and Young’s Modulus of the Dakota Sand Using Schmidt Hammer Rebound. In Proceedings of the 57th U.S. Rock Mechanics/Geomechanics Symposium, Atlanta, GA, USA, 25–28 June 2023. [Google Scholar] [CrossRef]
- Schapire, R.E. The Boosting Approach to Machine Learning: An Overview. In Nonlinear Estimation and Classification; Springer Science & Business Media: New York, NY, USA, 2003. [Google Scholar]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobot. 2013, 7, 21. [Google Scholar] [CrossRef] [PubMed]
- Ouadi, H.; Mishani, S.; Rasouli, V. Applications of Underbalanced Fishbone Drilling for Improved Recovery and Reduced Carbon Footprint in Unconventional Plays. Pet. Petrochem. Eng. J. 2023, 7, 1–15. [Google Scholar] [CrossRef]
- Ouadi, H.; Laalam, A.; Hassan, A.; Chemmakh, A.; Rasouli, V.; Mahmoud, M. Design and Performance Analysis of Dry Gas Fishbone Wells for Lower Carbon Footprint. Fuels 2023, 4, 92–110. [Google Scholar] [CrossRef]
- Latrach, A. Application of Deep Learning for Predictive Maintenance of Oilfield Equipment. Master’s Thesis, Université M’hamed Bougara Boumerdès, Boumerdas, Algeria, 2020. [Google Scholar] [CrossRef]
- Emon, M.U.; Keya, M.S.; Meghla, T.I.; Rahman, M.M.; Al Mamun, M.S.; Kaiser, M.S. Performance Analysis of Machine Learning Approaches in Stroke Prediction. In Proceedings of the 2020 4th International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 5–7 November 2020. [Google Scholar]
- Ahsan, M.; Mahmud, M.A.P.; Saha, P.K.; Gupta, K.D.; Siddique, Z. Effect of Data Scaling Methods on Machine Learning Algorithms and Model Performance. Technologies 2021, 9, 52. [Google Scholar] [CrossRef]
- Khan, R.; Tariq, Z.; Abdulraheem, A. Machine Learning Derived Correlation to Determine Water Saturation in Complex Lithologies. In Proceedings of the SPE Kingdom of Saudi Arabia Annual Technical Symposium and Exhibition, Dammam, Saudi Arabia, 23–26 April 2018; Available online: http://onepetro.org/SPESATS/proceedings-pdf/18SATS/All-18SATS/SPE-192307-MS/1246152/spe-192307-ms.pdf/1 (accessed on 20 May 2023).
- Hamada, G.; Elsakka, A.; Chaw, N. Artificial Neural Network (ANN) Prediction of Porosity and Water Saturation of Shaly Sandstone Reservoirs. Adv. Appl. Sci. Res. 2018, 9, 26–31. Available online: www.pelagiaresearchlibrary.com (accessed on 22 May 2023).
- Ghalanlo, H.; Amirpour, M.; Ahmadi, S. Estimation of water by using radial based function artificial neural network in carbonate reservoir: A case study in Sarvak formation. Petroleum 2016, 2, 166–170. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GR | R | RHO | NPOR | PE | Vsh | Por | SwSimandoux | Swcore | |
|---|---|---|---|---|---|---|---|---|---|
| mean | 80.79 | 11.02 | 2.62 | 0.0865 | 3.59 | 0.1101 | 0.0818 | 0.3016 | 0.3836 |
| std | 16.56 | 18.84 | 0.03 | 0.0263 | 0.39 | 0.0393 | 0.0221 | 0.1248 | 0.1466 |
| min | 26.86 | 2.11 | 2.51 | 0.0108 | 2.61 | 0.0133 | 0.0278 | 0.0200 | 0.0540 |
| 25% | 73.25 | 4.59 | 2.60 | 0.750 | 3.33 | 0.0890 | 0.0675 | 0.2022 | 0.2593 |
| 50% | 80.89 | 6.44 | 2.62 | 0.0851 | 3.55 | 0.1063 | 0.0800 | 0.3151 | 0.3695 |
| 75% | 90.88 | 11.0 | 2.64 | 0.0993 | 3.83 | 0.1315 | 0.0958 | 0.3883 | 0.4690 |
| max | 124.47 | 254.43 | 2.69 | 0.1550 | 5.66 | 0.2435 | 0.1518 | 0.6682 | 0.7490 |
| Loss | Learning Rate | Num. of Estimators | Criterion | Max Depth | Minimum Sample Split | |
|---|---|---|---|---|---|---|
| Gradient boosting classifier | log_loss | 0.1 | 100 | friedman_mse | 3 | 2 |
| Random forest classifier | N/A | N/A | 100 | Gini | None | 2 |
| Author | Samples and Wells Number | ML Model | Formation | Results |
|---|---|---|---|---|
| Ibrahim et al. [36] | 782 samples, 2 wells | ANN, ANFIS | Tight gas sandstone | = 0.93 |
| Hadavimoghaddam et al. [12] | 11 wells | XGBoost | Sandstone | = 0.999 |
| Miah et al. [10] | 182 samples | ANN and SVM | N/A (Bengal Basin) | = 0.999 |
| Khan et al. [37] | 150 samples | ANN and ANFIS | N/A (South Asian field) | = 0.94 |
| Hamada et al. [38] | 269 samples | ANN | Shaly sandstone | MSE = 0.012 |
| Gholanlo et al. [39] | 564 samples, 1 well | ANN | Carbonate | = 0.87 |
| Boualam et al. [9] | 2509 samples | SVM and ANN | Tight carbonate | = 0.78 |
| This study | 378 samples, 29 wells | Voting classifier | Ultra tight and multimineral formation | Accuracy = 85.53% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mellal, I.; Latrach, A.; Rasouli, V.; Bakelli, O.; Dehdouh, A.; Ouadi, H. Water Saturation Prediction in the Middle Bakken Formation Using Machine Learning. Eng 2023, 4, 1951-1964. https://doi.org/10.3390/eng4030110
Mellal I, Latrach A, Rasouli V, Bakelli O, Dehdouh A, Ouadi H. Water Saturation Prediction in the Middle Bakken Formation Using Machine Learning. Eng. 2023; 4(3):1951-1964. https://doi.org/10.3390/eng4030110
Chicago/Turabian StyleMellal, Ilyas, Abdeljalil Latrach, Vamegh Rasouli, Omar Bakelli, Abdesselem Dehdouh, and Habib Ouadi. 2023. "Water Saturation Prediction in the Middle Bakken Formation Using Machine Learning" Eng 4, no. 3: 1951-1964. https://doi.org/10.3390/eng4030110
APA StyleMellal, I., Latrach, A., Rasouli, V., Bakelli, O., Dehdouh, A., & Ouadi, H. (2023). Water Saturation Prediction in the Middle Bakken Formation Using Machine Learning. Eng, 4(3), 1951-1964. https://doi.org/10.3390/eng4030110