1. Introduction
Decision-making procedures in construction projects are complex because a large number of factors and/or variables (e.g., risk events and work packages) are involved that have interrelationships and often-conflicting objectives [
1,
2]. Large projects with long durations entail a wide range of activities in different areas, as well as opposing stakeholder interests, making them particularly complex. Human actions and subjective reasoning complicate the interacting aspects that must be taken into consideration while making project management decisions [
3]. In construction projects, decisions are often made based on analysis of complex systems and imprecise or unstructured data [
3]. The influence of uncertainties on project objectives, which can be either positive or negative, may be managed through modeling complicated construction risk and uncertainty management systems comprising risk identification, quantitative and quantitative risk analysis, and planning risk responses [
4,
5].
In construction, common types of uncertainty include random uncertainty and subjective uncertainty [
6]. Random uncertainty has been widely investigated, necessitating enormous amounts of project data to accurately estimate it. However, numerical project data frequently falls short of the amount or quality requirements for successful modeling, or the data may not be fully representative of new project environments. Subjective uncertainty exists in many decision-making processes in construction projects, which stems from the use of approximate reasoning and expert knowledge, which are expressed linguistically [
3]. Helton [
6] characterized uncertainty’s twofold nature by dividing it into “objective uncertainty” and “subjective uncertainty.” The variability that arises from an environment’s stochastic characteristics is referred to as objective uncertainty, and its concepts are based on probability theory. Subjective uncertainty, on the other hand, results from the use of approximate reasoning and linguistically articulated expert knowledge. Subjective uncertainty is classified by Fayek and Lourenzutti [
7] as vagueness, ambiguity, and subjectivity. Vagueness arises from the absence of clear distinctions between important concepts. Ambiguity occurs when an object lacks specific distinctions that define it, from conflicting distinctions, or from both. Subjectivity arises as a consequence of the impact of personal beliefs or emotions rather than objective facts [
8].
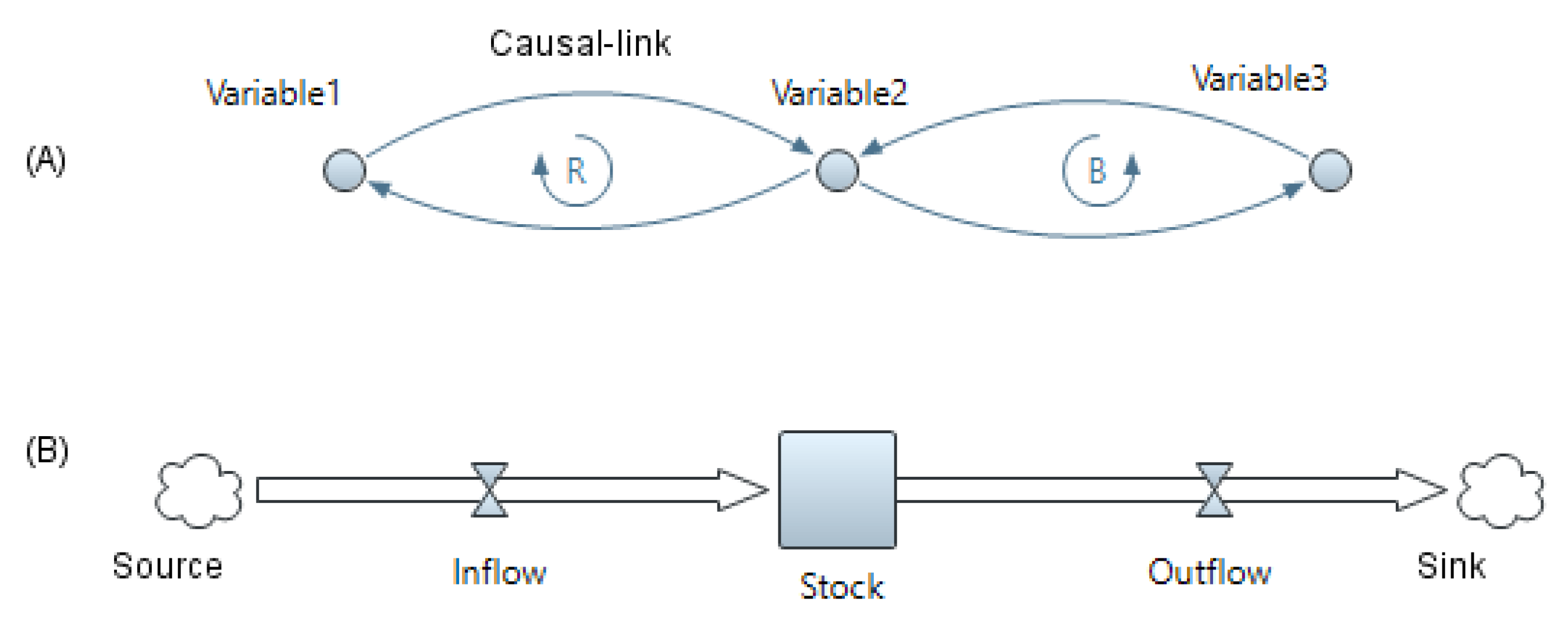
Fuzzy system dynamics (FSD), a hybridization of system dynamics (SD) and fuzzy logic, is capable of capturing the dynamism and interactivity of real-world system components while addressing the limitations of SD, such as the lack of ability to deal with subjective uncertainties. FSD is concerned with system feedback loops and is capable of modeling systems in which the system variables change continuously through time [
3]. FSD can also keep track of the changes in the dynamics of variables (e.g., risk events, work packages) in construction projects. FSD is a suitable simulation approach when the primary areas of interest for the modeler are analyzing the changes in variables in the system over time, detecting the impacts of factors influencing the system’s variables, and capturing vagueness, ambiguity, and subjectivity in linguistic terms [
3,
9]. Causal loop diagrams (CLDs) are employed in FSD models to map soft (subjective) and hard (objective) causal relationships and causal structures among model variables. When the mathematical form of a causal relationship is known, it is said to be “hard” (e.g., relationship between risk severity and risk impact). Soft causal relationships, on the other hand, are those in which the mathematical form of the causal relationship is unknown (e.g., relationship between the probability of occurrence of a risk event and a secondary risk event) [
10,
11]. Soft causal relationships are expressed in linguistic terms. Regular or fuzzy arithmetic can be applied for hard relationships depending on the objectivity or subjectivity of variables. However, the literature reveals a lack of structured and systematic methods for constructing and analyzing complex soft relationships among the elements of a system in order to develop CLDs [
4].
To develop a quantitative FSD simulation model, the crisp value of all causal relationships (i.e., soft and hard) needs to be calculated. To determine the crisp value of soft causal relationships in practice, it is necessary to determine the membership functions (MBFs) of linguistic terms resulted from a heterogenous expert’s opinions [
11]. The opinions of experts about forming MBFs of linguistic terms may differ based on their attitude, knowledge, and experience [
12]. Two main categories of MBF estimation are expert-driven approaches, in which MBF elicitation is considered a method of acquiring less or more sophisticated knowledge through interaction with a domain expert, and data-driven approaches, in which the elicitation of MBFs is based on organizing data into a structure [
13]. The analytical hierarchy process (AHP) [
14] is an expert-driven technique that enables experts to do pairwise assessments of alternatives in order to establish their MBF. There are some limitations to and eventual biases in the aforementioned techniques for eliciting MBFs [
15]. The expert-driven method may become broad in nature and may not even be necessarily reflective of the experimental data used to generate these fuzzy sets [
16]. This limitation is especially evident when such fuzzy sets are included in the resulting fuzzy model, which may occur as a result of the absence of experimental support for some MBFs [
13]. For example, in a construction risk management system, AHP as an expert-driven method is not applicable in forming the MBFs of linguistic terms related to construction risks since employing AHP means all risks and opportunities must be considered as alternatives for pairwise comparison, which can be impossible or very time-consuming [
17,
18]; for example, for a project with 100 risk events, almost 4900 pairwise comparison among risk events must be performed by each expert to form only probability MBF, and the result is not necessarily linear. On the other hand, because of the difficulty of obtaining qualified numerical data on risk management for construction industry projects, data-driven methods are not applicable in the majority of cases [
3,
17]. Additionally, using data-driven methods may result in semantically meaningless fuzzy sets [
17], which implies that fuzzy clustering could result in some “crowded” fuzzy sets with ambiguous meaning that need to be tuned by an optimization method, such as simulated annealing algorithm, genetic algorithm, or tabu search [
15,
16]. These limitations make data-driven methods inefficient and time consuming. As a result, their further modifications, when optimizing the fuzzy model that comprises the fuzzy sets, may significantly impair the interpretability of the fuzzy sets and the entire model [
15]. Aggregation methods used in previously published FSD approaches do not account for risk management experts’ levels of expertise. In most instances, a moderator or project manager assigns importance weights to experts directly [
10]. The principle of justifiable granularity (PJG) is a well-known paradigm and fundamental concept of granular computing, offering robust guidance for structuring information granules based on existing experimental data. PJG can be employed to optimize interval type-2 fuzzy sets and form type-1 MBFs [
13].
The current construction literature lacks a structured method for constructing and investigating soft causal relationships in FSD modeling of construction risk analysis. To form the soft causal relationships in an FSD model, MBFs of linguistic terms pertaining to these relationships must be determined. However, both expert-driven and data-driven methods have limitations to forming MBFs of linguistic terms of soft causal relationships by experts, which are necessary to assess them. To address these research gaps, the objective of this paper is to propose an adaptive hybrid model for calculating crisp values of causality degrees of soft causal relationships in FSD modeling of construction risk management. The proposed model consists of fuzzy analytical hierarchy process (FAHP), weighted principle of justifiable granularity (WPJG), and fuzzy aggregation operators. FAHP enables the proposed model to calculate the level of risk expertise (importance weight) of different experts based on several factors and consider these importance weights in both processes of forming MBFs for linguistic terms and integrating experts’ assessments of soft causal relationships. Moreover, WPJG [
15] is applied to increase the accuracy of constructing MBFs of soft causal relationships by determining the optimum value of upper and lower bounds before converting them into type-1 MBFs. Furthermore, fuzzy aggregation operators are employed to aggregate the assessments of several heterogeneous experts’ opinions using constructed fuzzy MBFs and the importance weight of each expert. The resulting crisp value of soft causal relationships then can be employed to form CLDs and run the FSD simulation model.
The rest of this paper is organized as follows. First, the advantages and disadvantages of available methods of modeling complex systems in analyzing construction risks are reviewed and compared in
Section 2.1. Second,
Section 2.2,
Section 2.3 and
Section 2.4 review and discuss the benefits, literature, and capabilities of techniques used in the proposed model, including FAHP, WPJG, and fuzzy aggregation operators, respectively. In
Section 3, the proposed adaptive hybrid model is presented for calculating the causality degree of soft causal relationships in FSD modeling of construction risk management systems.
Section 4 reports how the proposed model is implemented in a wind farm project to show how the adaptive hybrid model can be implemented in practice. Finally,
Section 5 discusses the contributions, and results of this research are presented, along with potential future extensions.
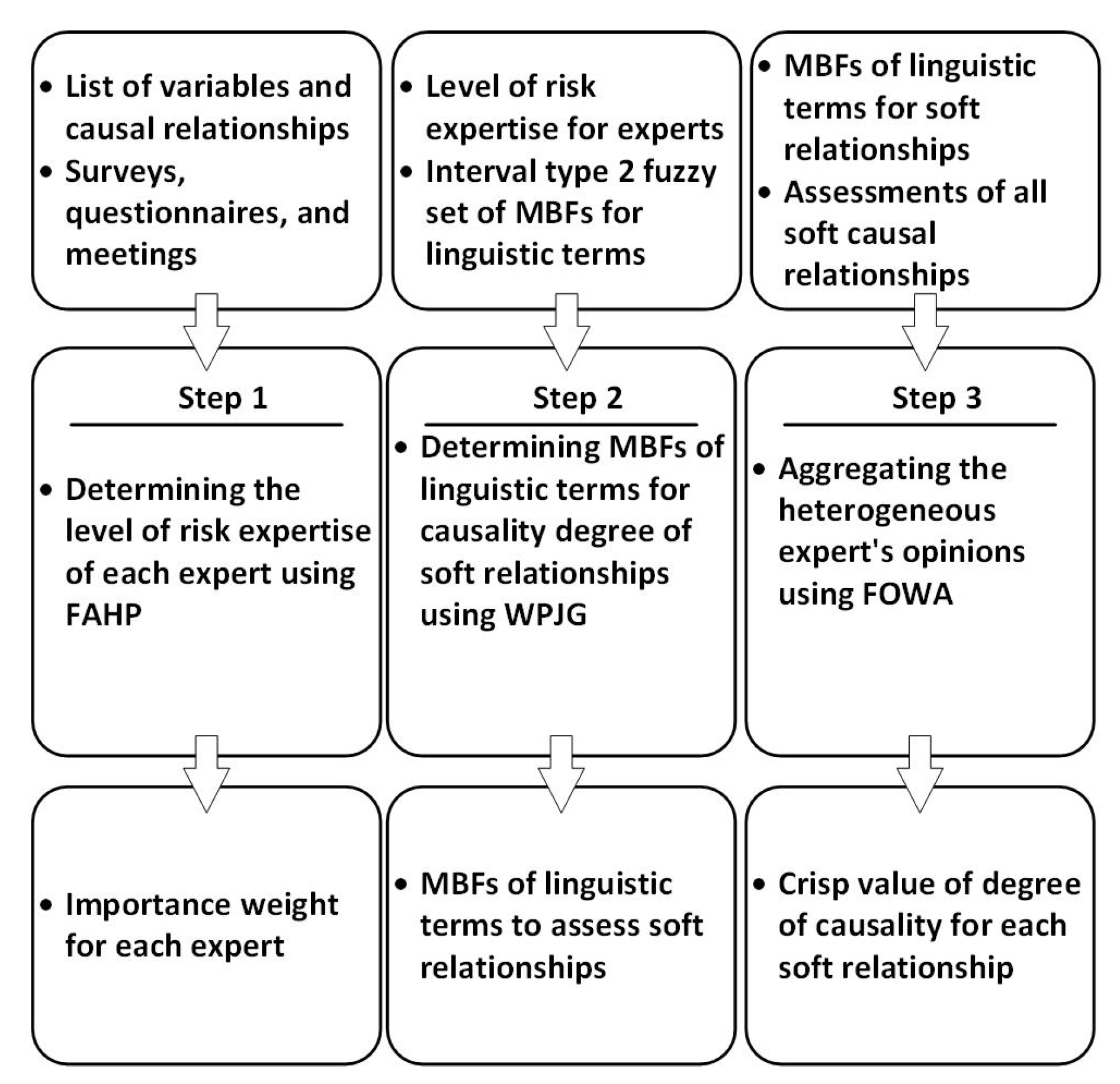
3. Methodology: Developing Adaptive Hybrid Model to Form CLDs in FSD Modeling
Development of an FSD model, as discussed in
Section 2.1, is divided into two general phases: (1) creating a qualitative model and (2) developing a quantitative model. Qualitative modeling allows for identification of system variables and causal relationships, as well as the development of stocks and flows. In the quantitative modeling phase, the values of variables should be established using crisp numbers and probability distributions. Moreover, all causal relationships and interdependencies among the model variables should be formulated in order to run the model and identify the effect of variables [
27]. So, while mathematical equations are always used to define hard relationships, soft causal relationships can be determined in three steps, as illustrated in
Figure 2.
The 3-step process for determining soft causal relationships begins with evaluating experts’ risk expertise to enhance knowledge elicitation and avoid making faulty judgments using FAHP. The output of the first step, which is determining the importance weight for each expert, can be utilized in the second step where MBFs of linguistic terms (e.g., “Low” or “High”) for assessing causal relationships are built, optimized, and aggregated in order to use the knowledge and skills of all project decision makers and experts. In step 2, interval type-2 fuzzy sets are initially formed that contain all possible viewpoints of the experts. Then, constructed interval type-2 fuzzy sets are optimized and integrated using WPJG, resulting in MBFs of linguistic terms for the assessment of soft causal relationships. In the third step, all qualified experts are required to assess degree of causality for soft causal relationships based on optimized and aggregated MBFs in the second step. Then, the FOWA aggregation operator is used to aggregate the assessments of all experts. The output of the first step, importance weight for each expert, is utilized as one of inputs of third step, since FOWA is a weighted aggregation operator. Next, the aggregated fuzzy degree of causality between variables can be established and defuzzified to obtain the crisp degree of causality. The details of each step are described as follows.
3.1. Step 1—Determining the Importance Weight of Each Expert Using FAHP
When aggregating expert judgments of the degrees of soft causal relationships among variables in the model, the importance weights of the experts must be accounted for. For example, Monzer et al. [
52] recommended assessing experts’ level of risk expertise based on seven criteria comprising experience, knowledge, professional performance, risk management practice, project specifics, reputation, and personal qualities and skills. These criteria are employed in this paper to calculate level of risk expertise (importance weight) for each expert. Each of the seven criteria has quantitative or qualitative subcriteria, and for each of the qualitative attributes assessed using a preset rating scale (1–5), detailed information can be found in Monzer et al. [
52]. The importance weights of the experts, (
Wk), are derived using FAHP weight-assigning approach after analyzing the experts’ level of expertise based on the mentioned attributes. Unlike standard AHP, which utilizes crisp numbers, the FAHP approach allows experts to do pairwise comparisons using fuzzy linguistic evaluations [
54]. As a result, the FAHP approach is used to calculate the relative weights of qualifying attributes and criteria based on expert pairwise assessments. For further information about FAHP equations and concepts, refer to Monzer et al. [
52]. The importance weight of each expert can be employed in both steps 2 and 3 in order to (1) form MBFs of linguistic terms for degree of causality and (2) aggregate several assessments of degree of causality.
3.2. Step 2—Forming MBFs of Soft Causal Relationships Using WPJG
Linguistic terms (e.g., “Very Low” or “Very High”) for illustrating the causality degree of soft causal relationships are defined in order to enable experts to assess them. Defined linguistic terms for causality degree of soft relationships among variables are fuzzy numbers. These fuzzy numbers can be represented by triangular or trapezoidal fuzzy numbers, since the most popular forms for fuzzy numbers with open intervals of real numbers are triangular and trapezoidal [
7,
12]. Trapezoidal fuzzy numbers are a subset of triangular fuzzy numbers. The degree of causality between variables is denoted in this model by five linguistic terms: ”Very Low,” “Low,” ”Medium,” “High,” and ”Very High.” Various MBFs for causal relationships are established and aggregated in order to benefit from the collective knowledge and expertise of all project decision makers and experts. A type-1 fuzzy set projects a single crisp number for the membership degree of each linguistic term, whereas interval type-2 fuzzy sets project an interval for the membership degree of each linguistic term [
55,
56,
57]. Consequently, interval type-2 fuzzy sets are more appropriate because they give more information than type-1 fuzzy sets and are more accurate. In addition, an interval type-2 fuzzy set encompasses all possible viewpoints. Consequently, the intervals’ lower and upper bounds are initially defined in this step by the lowest and highest heights of the MBFs constructed for linguistic terms (e.g., ”Low,” “Medium,” “High”) to assess degree of causality using the information from various risk experts.
After forming interval type-2 fuzzy sets of linguistic terms, the WPJG is applied in order to optimize these intervals and construct information granules. Coverage and specificity are two essential requirements invoked by the WPJG. The two criteria are at odds, which means that increasing coverage decreases specificity, and vice versa. Therefore, constructing information granules is a result of tradeoff between them, and there is an optimization problem with a multiplicative form of the objective function, shown by Equation (1), where
D is an information granule based on the available experimental evidence resulting in a form of a collection of one-dimensional numeric data, and
D = {
x1,
x2, …,
xN}, where
xk ∈
R. Coverage is expressed as the cardinality (count) of the data
X included in the interval [
m,
b], assuming
m is the numeric representative of a data set, such as a median. In addition, specificity can be related directly with the length of the interval and define any decreasing function of the length that is |
m −
b| or |
m −
a|, where
a and
b are the optimized values of the lower and upper bounds of the interval, respectively.
Equation (1) can be implemented separately for the lower and upper bounds of the interval as follows:
By maximizing
V(
b), we achieve an optimal value of
b, which is to say,
The optimal upper bound bopt can be obtained by maximizing the value of V(b), namely V(bopt) = maxb>med(D)V(b). The lower bound of the information granule is constructed in the same way: aopt, that is, V(aopt) = maxa<med(D)V(a).
The importance weights of each expert calculated in the last step using FAHP can be integrated with PJG, resulting in WPJG. To form WPJG, Equations (2) and (3) can be extended to deal with situations where data are associated with relative weights [
17]. In this case, given the data form (
xi,
wi), where
wi represent weights in the range of an [0,1] interval,
w = [
w1,
w2, …,
wN], the upper and lower bounds can be determined by maximizing the performance index
V as follows:
where
med(
D,
w) is a weighted median as follows:
After implementing WPJG and optimizing the upper and lower bounds of interval fuzzy sets, MBFs are type-reduced to standard MBFs for the purpose of performing crisp output computation. In this research, the procedure described in Reference [
12] is used to transform an interval type-2 MBF to a type-1 MBF.
3.3. Step 3—Aggregating the Heterogeneous Expert’s Opinions Using Aggregation Operators
In step 3, MBFs of linguistic terms determined in the previous step are utilized to assess degree of causality for soft causal relationships. Assessments of several experts are aggregated using FOWA. The FOWA aggregation operator is a weighted aggregation operator for combining the linguistic opinions of diverse experts [
48,
49], as a simple extension of the ordered weighted average (OWA) operator used in uncertain scenarios where the available data input and knowledge source may be evaluated using fuzzy numbers [
51,
52]. FOWA supports parameterization of a family of aggregation operators, including the fuzzy maximum, fuzzy minimum, and fuzzy average criteria. Additionally, FOWA shares many of the same characteristics as OWA [
48]. Letting 𝑓
: Θ𝑛 → Θ, where
Θ is the set of all fuzzy numbers, the formula for applying FOWA is:
where
is the weighting vector, and
∈
Θ, which means
are fuzzy number representing experts’ opinions. In addition,
, and
, and
is the largest
jth of the
[
17]. Here, the weighting vector 𝑤𝑗 is calculated in Step 1 using FAHP. The aggregated fuzzy number of causality degree among variables can then be determined and is defuzzified to calculate crisp degree of causality. Consequently, crisp values of causality degree are employed to form CLDs and run the FSD model to assess construction risks.
4. Case Study: The Proposed Adaptive Hybrid Model
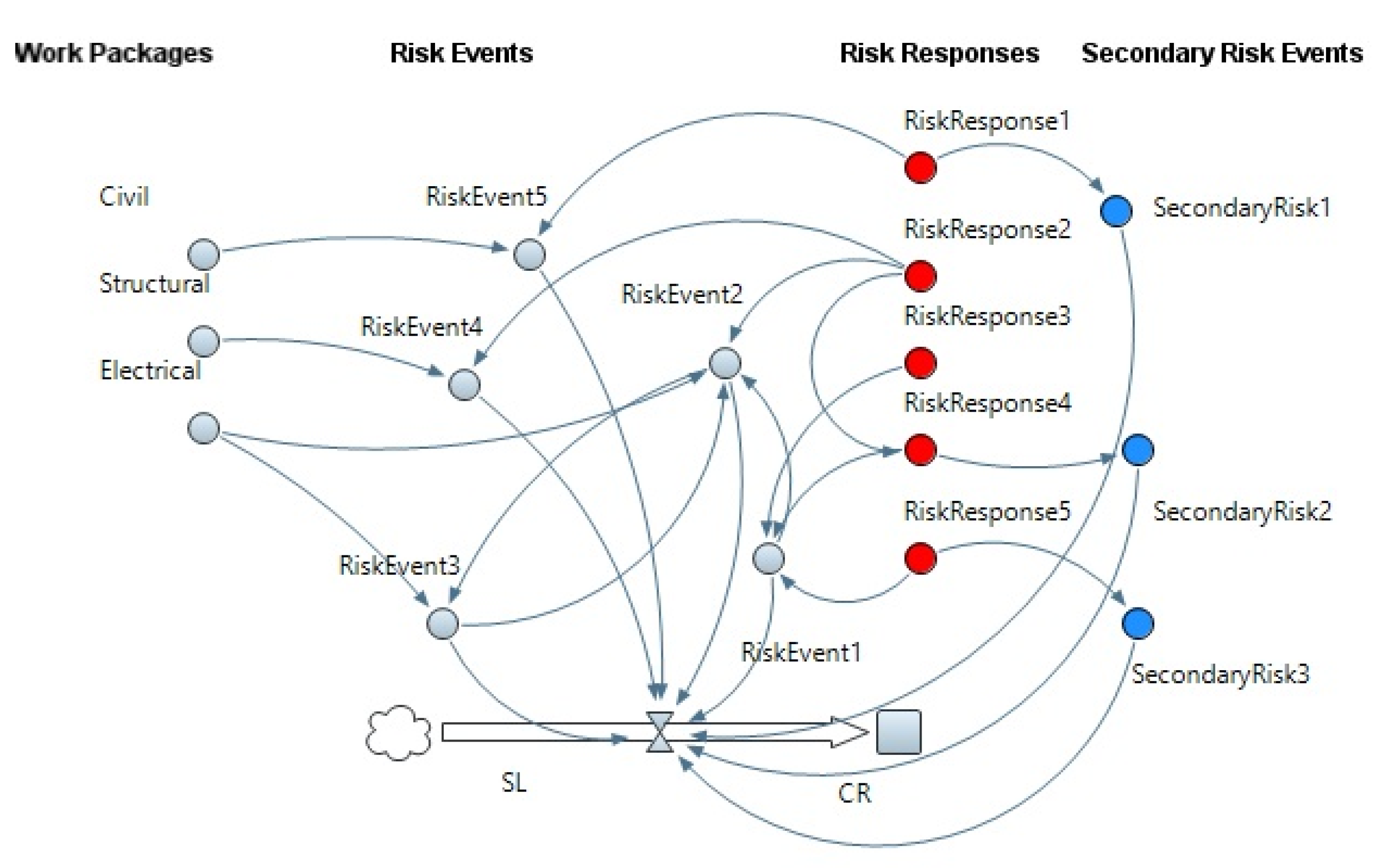
The main purpose of the case study was to illustrate how to implement the proposed model for analyzing risks of a construction project. The proposed model was employed as part of forming an FSD simulation model for analyzing construction risks of a real wind farm power generation construction project, since authors had access to some project information. However, the model can be implemented in any kind of construction project. Implementation of the proposed model is illustrated to (1) form MBFs of causality degree for soft causal relationships and (2) determine the crisp value of causality degree for soft causal relationships. To maintain confidentiality of project information, some actual information and value of used relationships and variables were substituted in the case study for some hypothetical data. Names and values of some variables comprising risks, risk responses, secondary risks, and assessments of causality degree for soft causal relationships are substituted. However, actual data and information were utilized to calculate experts’ level of risk expertise. Moreover, the type of objective and subjective variables and the types of hard and soft relationships between them are real and were extracted from a risk analysis model of a real wind farm project in North America. The real wind farm project had eight construction work packages, which are categorized as civil, structural, and electrical.
FSD modeling begins with qualitative modeling, followed by quantitative modeling, to formulate all identified variables and relationships. The process of developing a qualitative model starts with the identification of system variables (e.g., risk events) and all hard and soft relationships and interactions between variables. Additionally, it incorporates the feedback structure for various variables (e.g., response actions that are available to address identified risks). The initial model boundaries, as well as the degree of aggregation, may then be determined in order to achieve the objective of realistic representation. Although the model boundary indicates the extent of the modeling exercise, the aggregation level indicates the breakdown of activities into subsystems. Using CLDs, stock and flow maps, and other tools, the interdependencies, causal structures, feedback structures, stocks, and flows are all visualized and represented graphically. Next, the layout of the qualitative model is developed, as depicted in
Figure 3.
To formulate soft causal relationships in the quantitative modeling phase, the proposed model in this study is implemented in the following three steps.
4.1. Step 1: Determining Risk Expertise
In the first step in formulating soft causal relationships, the experts’ level of risk expertise (importance weights) is calculated. The criteria for choosing experts were their engagement in the project, their overall years of experience, their years of risk management experience, and the number of similar projects in which they had participated. A diverse group was established from four real experts who were actively involved in the project. Each expert was a part of the project team and had worked on more than five comparable-scale projects. They had an average of 23 years of total construction experience and an average of 12 years of risk management experience [
10].
In Step 1 of determining soft causal relationships, the risk expertise levels (importance weights) of the experts were determined using a combination of numerical and linguistics attributes, as detailed in
Table 1. Next, the evaluation data were normalized to the range [0,1]. Then, the weights assigned to the criterion and subcriteria were used to compute the experts’ level of risk expertise. The FAHP weight assignment technique was then used to compute the importance weights (
Wk) of the four experts,
W1,
W2,
W3, and
W4. Calculated weights, such as each expert’s importance weight (risk expertise), must be normalized before being used as the expert’s importance weight. The experts’ importance weights are relative weights that, when added, equal 1. This guarantees that the opinions of experts with a higher weight of importance have a greater effect on the experts’ collective evaluation. The four experts’ importance weights were 0.25, 0.27, 0.22, and 0.26.
4.2. Step 2: Constructing MBFs of Soft Causal Relationships
In the second step, MBFs of linguistic terms for assessing causality degree of soft relationships are formed by expert opinions using WPJG. The following phase establishes linguistic terms, their scales, and associated fuzzy sets in order to analyze the degree of causality for project components with soft causal relationships. So, Step 2 begins with gathering opinions of several experts about the scales of linguistic terms of causality degree (e.g., “Very Low,” “Low,” “Medium,” “High,” and “Very High”). For example, based on the opinion of Expert 1, the linguistic term “Very Low” for causality degree ranges from 0 to 18 percent with the membership value of 1 in 0 percent. Then, interval type-2 fuzzy sets of each linguistic term are constructed for degree of causality in soft causal relationships. Interval type-2 fuzzy sets capture more uncertainty than their type-1 counterparts [
55,
57,
58,
59]. Thus, the opinions of all experts are employed to form interval type-2 fuzzy set. Since there were four experts in the project whose opinions were critical to risk modeling, interval type-2 fuzzy sets were employed to account for all MBFs these experts proposed. The interval type-2 fuzzy set was constructed by calculating the lowest and highest bounds of the proposed MBFs.
Then, the tradeoff between specificity and coverage of each interval is conducted using the WPJG and considering it as a multiplicative optimization problem [
17,
44,
46]. The parametric WPJG can mitigate the influence of irrelevant and biased opinions. Equations (5) and (6) are employed to determine the optimized upper and lower bounds of each interval by maximizing the performance index.
For crisp output calculation, type-2 fuzzy sets are subsequently converted to standard MBFs. The process of converting an interval type-2 fuzzy set to a type-1 fuzzy set, proposed by Fateminia et al. [
13] and Pedrycz [
17], is applied in this study. The objective of the type reducing process is to determine the line that best fits these interval fuzzy values. Initially, mean and domain values are used to represent the interval fuzzy values statistically. The interval sets are represented by their corresponding mean points in the
x–
y space, which are (0,1), (10,0.75), (15,0.6), and (20,0.05). The mean values of all interval type-2 fuzzy sets may not be linear. Therefore, to get the best-fit linear equation, a linear equation between (0,1) and the mean point of each interval set is required to be solved for an
x-axis intercept value. Statistically, the modeled linguistic term should fall inside the range
[
13,
17]. Here,
is the mean of the interval type-2 fuzzy set’s left endpoints, and
is the mean of the set’s right endpoints. If the endpoint uncertainties are removed, the preceding interval type-2 fuzzy set degrades to a type-1 fuzzy set with
a =
b =
=
. The mean of these points is at
= 22 with standard deviation
s = 3.06. Consequently, the optimized MBFs for various linguistic terms are similarly calculated as illustrated in
Table 2. The optimized fuzzy numbers in
Table 2 can be employed to assess risks and opportunities in the next step.
4.3. Step 3: Aggregating Assessments
In the third step of the model, several experts assess the causality degree of soft causal relationships based on linguistic terms constructed in Step 2 (
Table 2). Then, FOWA is employed to aggregate the assessments of the four experts, resulting in creation of a single fuzzy number that reflects the group’s opinion. Experts offer their evaluations of causality degree for soft causal relationships using linguistic terms that are represented by fuzzy numbers that are optimized and formed in step 2. The importance weights of the experts, calculated in Step 1 using FAHP, are utilized by FOWA as the weight vector for the experts’ assessments in order to reflect their level of expertise. The aggregated fuzzy number of causality degrees across variables are then calculated. Finally, aggregated fuzzy number of causality degree is defuzzified to obtain the crisp value for degree of causality for the soft causal relationship.
4.4. Results and Discussion
The proposed hybrid model results in calculated the crisp value of causality degree for soft causal relationship among each pair of variables (e.g., variables 1 and 2) while considering the level of risk expertise for each assessor. Crisp values of causality degree for soft causal relationships are employed to formulate the value of the second variable (affected by first variable through a soft causal relationship) in different time steps of the FSD simulation. As a result, the FSD simulation model comprising of soft causal relationships can be quantified and run in simulation software (e.g., Anylogic) to evaluate construction risks.
The crisp value of causality degree for soft causal relationships among project components in this study are: 0.37 between risk event 2 and work package-electrical; 0.56 between risk event 2 and risk event 3; 0.6 between risk response 1 and secondary risk 1; and 0.40 between risk event 1 and risk response 5. The crisp value of causality degree can be utilized to formulate the soft causal relationships between interrelated variables in FSD modeling. The suggested adaptive hybrid model can provide industry professionals with a systematic and structured approach to modeling complex construction risk systems through FSD simulation comprising soft causal relationships. The model can be a potential alternative for traditional techniques (e.g., modified horizontal approach) for determining the MBFs of linguistic terms for degree of causality. Traditionally, modelers used to utilize the modified horizontal approach coupled with curve fitting, which is an expert-driven and direct method, to develop MBFs of linguistic terms. The modified horizontal approach is very straightforward to apply and enables condensing of many questions into a single one. However, it is highly reliant on expert judgments and is, thus, susceptible to mistakes owing to experts’ subjectivity and inconsistency in responding to questions.
The interval type-2 fuzzy sets used in the proposed adaptive hybrid model capture more uncertainties compared to standard fuzzy sets, offer better knowledge representation, and accounts for the opinions of a larger number of experts compared to standard fuzzy sets. Moreover, WPJG optimizes these interval type-2 fuzzy sets by maximizing the performance indexes of two criteria—coverage and specificity—, thereby mitigating the impact of irrelevant and biased expert opinions. The suggested model is an alternative to existing techniques for eliciting MBFs, such as fuzzy clustering and AHP, which are ineffective for eliciting MBFs for risk analysis linguistic terms. Additionally, the proposed model meets the requirements for (1) aggregating expert opinions on the MBFs of identified linguistic terms, (2) aggregating expert evaluations of soft causal relationships, and (3) removing irrelevant and biased opinions.
5. Conclusions and Future Research
Decision-making in construction projects is a complex process involving a large number of risks and uncertainty that requires efficient modeling and computing techniques to mitigate the impacts of risk and uncertainty on project objectives and to manage project contingency reserve. In this paper, an adaptive hybrid model was proposed for improving the efficiency of constructing CLDs in FSD modeling of complex construction risk analysis systems. The model integrates FAHP, WPJG, and FOWA to (1) form and optimize the MBFs of linguistic terms and (2) aggregate assessments of causality degree for each soft causal relationship made based on the constructed MBFs. FAHP is employed to determine the level of risk expertise (importance weight) of various experts based on several criteria. WPJG is applied to determine the optimal value of the upper and lower bounds of interval type-2 MBFs of soft causal relationships, and FOWA is utilized to aggregate the opinions of heterogenous experts.
This study contributes to the modeling and analysis of risks in construction projects by proposing a systematic and organized technique via an adaptive hybrid model for calculating the crisp value of causality degree for soft causal relationships among the elements of construction projects. The proposed model can address the following issues with prior techniques: (1) considering the level of risk expertise (importance weights) of several experts in both developing the MBFs of linguistic terms and assessing the degree of causality based on constructed developed MBFs, (2) mitigating the influence of irrelevant and biased opinions on the development of MBFs for linguistic terms of causality degree, and (3) aggregating several expert’s assessments of causality degree of soft causal relationships.
The results of the proposed adaptive hybrid model for FSD modeling of construction risks are: (1) optimized MBFs of linguistic terms for causality degree of soft causal relationships and (2) the crisp value of causality degree of soft causal relationships. The first result can be employed in assessing degree of causality of soft causal relationships among project variables by experts, and the second can be utilized in formulating the value of impacted variable based on the value of caused variable in each time step of the FSD simulation. The study results will enable risk analysts to: (1) calculate the crisp value of soft causal relationships when quantitative project data falls short of the quantity or quality required for effective modeling and (2) benefit from the opinions of several experts while modeling the dynamic behavior of complex construction projects using FSD. The developed adaptive hybrid model was implemented on a hypothetical case study that was extracted from a real wind farm project.
When determining the degree of causality, the experts’ importance weights were assumed to remain constant for a particular project, independent of the work package being evaluated. However, some experts are more informed than others or have more relevant backgrounds for a certain work package. Therefore, the weights assigned to experts must vary according to the work package being evaluated. Thus, future research should focus on the creation of a weighting technique that accounts for the level of expertise of the experts assigned to the work package under evaluation. Additionally, the proposed model can be implemented in several FSD models of construction risk analysis to compare the results with conventional methods (e.g., modified horizontal approach coupled with curve fitting).







{kind=link}
{kind=link}
{kind=link}