


Probabilistic Machine Learning Methods for Fractional Brownian Motion Time Series Forecasting


Abstract
1. Introduction
- Methods that assume parameters of a specific probability distribution that the forecast variable follows, such as the Gaussian, Gamma, or Weibull distribution. These methods are characterized by a finite set of parameters that are estimated from the data. Examples of parametric methods include Natural Gradient Boosting for Probabilistic Prediction (NGBoost) [17], XGBoostLSS and LightGBMLSS, which model all moments of a parametric distribution: mean, location, scale, and shape (LSS) [18,19], Catboost with Uncertainty (CBU), Probabilistic Gradient Boosting Machines (PGBM) [20], and Instance-Based Uncertainty Estimation for Gradient-Boosted Regression Trees (IBUG) [21].
- Methods that estimate the distribution directly from the data without relying on any predefined shape, often focusing on predicting quantiles. These methods provide increased flexibility when modeling complex distributions, making them especially valuable when the true distribution is unknown or significantly deviates from standard parametric forms. Quantile regression is a popular nonparametric technique [22,23]. The newest approach is Nonparametric Probabilistic Regression with Coarse Learners (PRESTO) [24].
- We demonstrate that the self-similar properties of the fBm time series can be reliably reproduced in the continuations of the series predicted by machine learning methods.
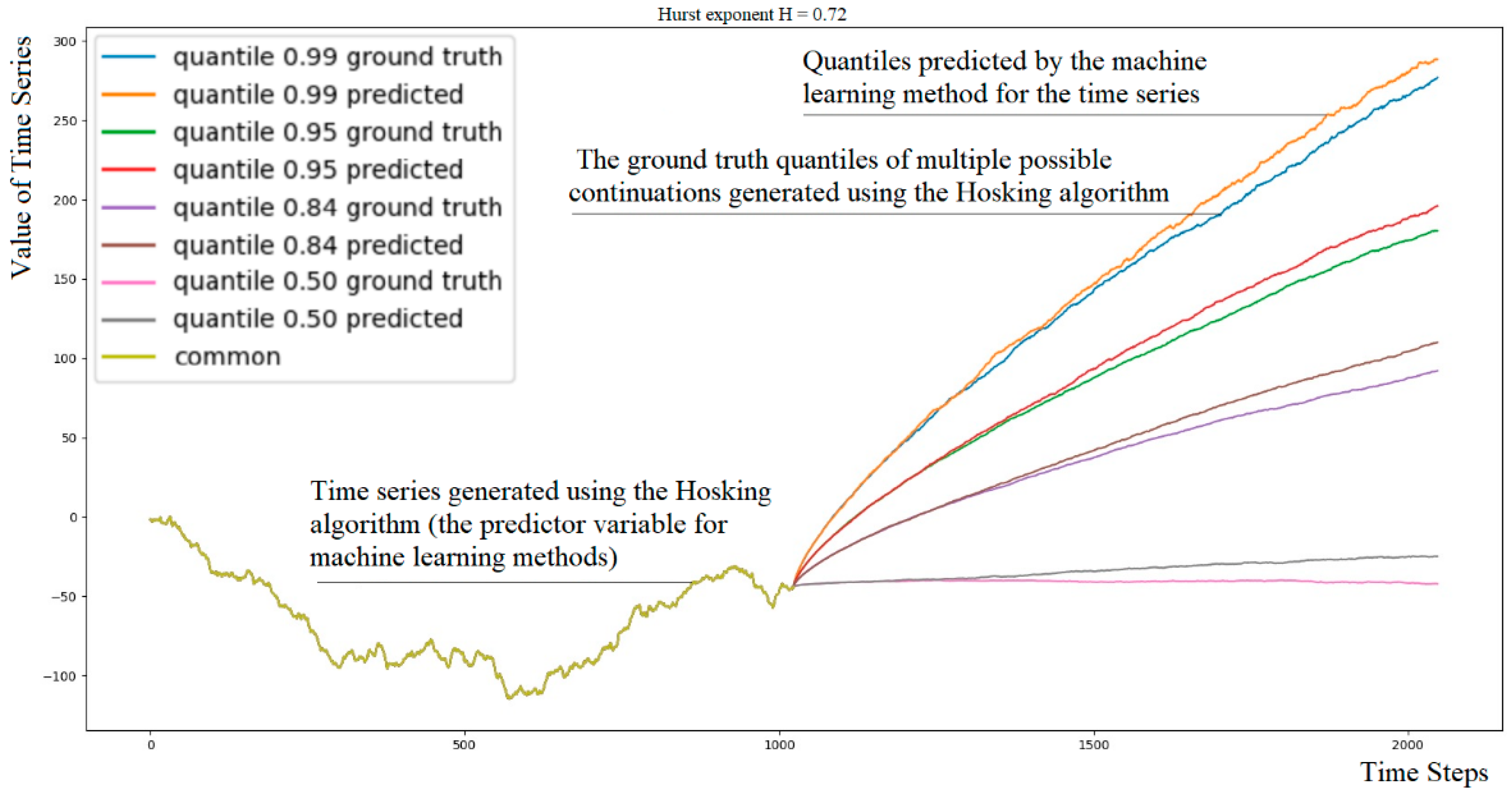
- We propose an approach for evaluating probabilistic methods in forecasting the fBm time series. Our method involves efficiently computing multiple continuations of a single fBm time series using the Hosking algorithm, resulting in a dataset with ground truth quantiles of possible continuations. Using a one-period-ahead model, iterated forward for the desired number of periods, we can predict quantiles of continuations of fBm time series over hundreds or thousands of time steps and compare them with the ground truth quantiles (Figure 1).
- We conducted an experimental comparison of various probabilistic forecasting methods using this approach, providing insights into their performance and potential applications in the analysis and modeling of fractal time series.
2. Materials and Methods
2.1. Problem Setting
2.2. Method of Creating the Evaluating Dataset
- We use the Hosking method to generate values of the first N time steps of the predictor variable, which is a time series X(t) given by expression (5);
- Starting from the state of the internal variables of the Hosking algorithm after generating step N, we continue generating values for the next K time steps, obtaining a continuation Xc(t), defined by (6);
- We repeat step 2 M times, obtaining M different continuations from the original common starting point:
- 4.
- For each time step k, k = 1, 2, …, K, we determine the quantiles of the values of M continuations, obtaining the desired quantile matrix;
- 5.
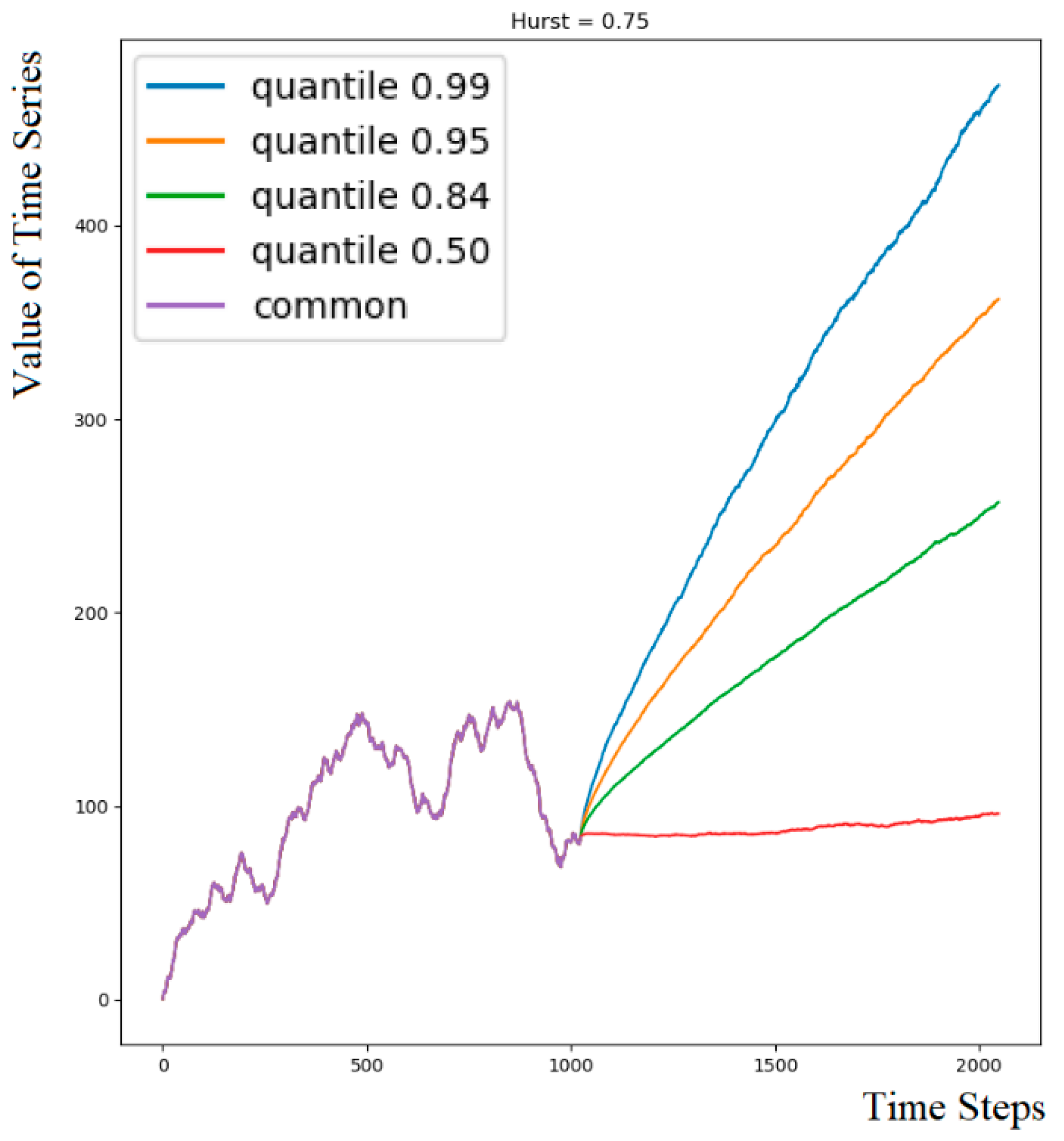
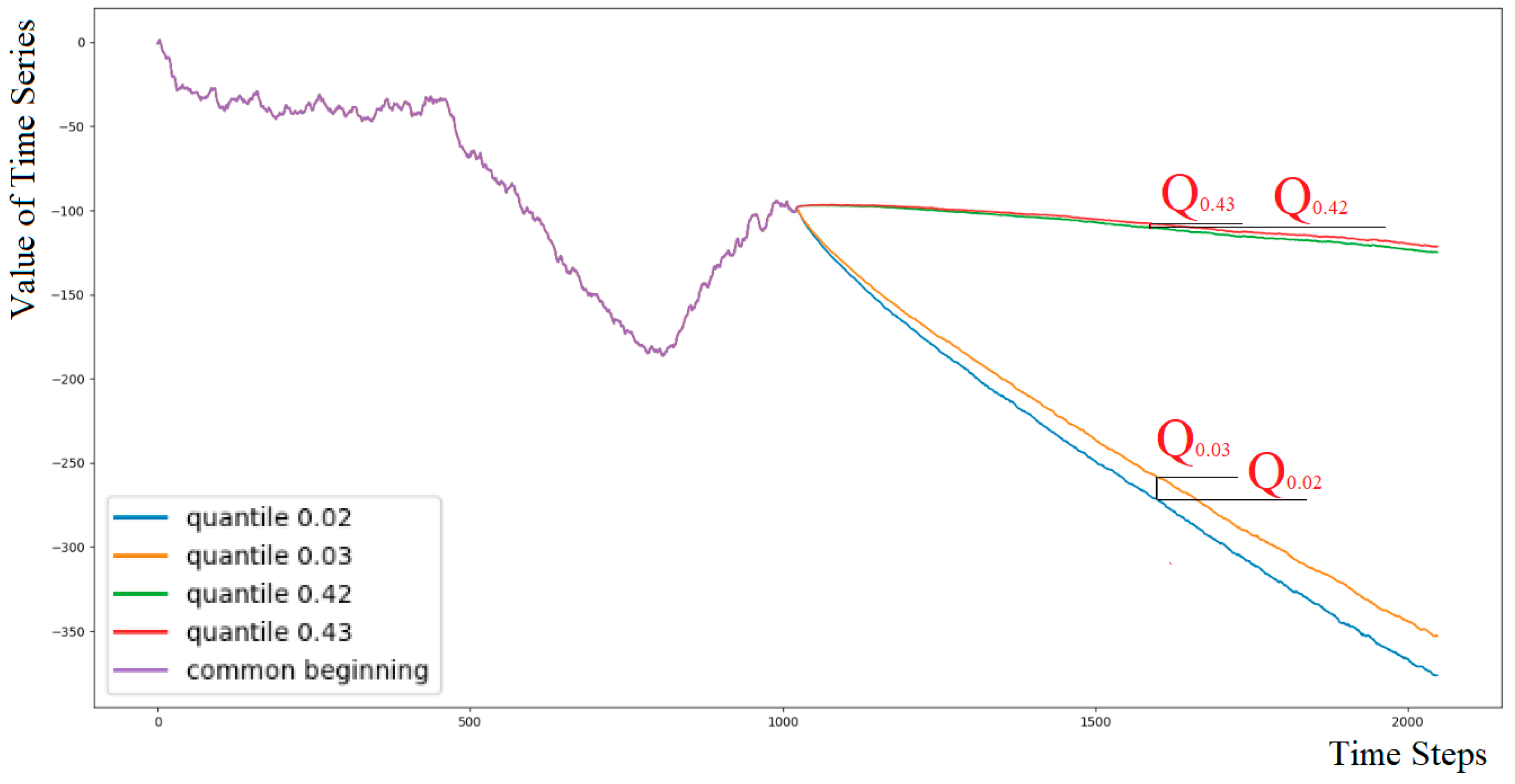
- The dataset stores the target Hurst exponent, for example, X(t), the predictor variable X(t) of length N, and matrix Qα = {Q(αi,tj)} of size 101× K, which contains, for each time step tj = 1, 2, …, K, quantiles αi, i = 1, 2, …, 101 of the distribution of M continuations {Xcm(t)}. The 0th and 1.0 quantiles represent the minimum and maximum values among the M variants at each time step tj.
2.3. Predicting Quantiles of Time Series for Multiple Future Time Steps
- Train the machine learning model to output the distribution of the next time series value given the previous ones. The result can be in the form of parameters of a certain distribution, quantiles, or any other form that we can sample values from.
- Given a test example with a time series length of N X(t), the model predicts the distribution F represented by (7) of the next N + 1 value X(N + 1). Sample one value from the distribution F to obtain one possible next value of the continuation, Xc(1).
- Concatenate X(t) with Xc(t) and iteratively predict the next time step distribution, sampling one value for Xc(t + 1) for the next K time steps, obtaining a continuation Xc(t), defined by Equation (6).
- Repeat the second and third steps many times, obtaining many different continuations from the original single test example.
- Determine the quantiles of the values of the continuations, obtaining the desired quantiles for each time step.
2.4. Assessment of Accuracy and Reliability of Continuations
- Calculating the Hurst exponent (H) using the Whittle estimator demonstrated the best accuracy for time series with lengths of 512 and above, which we plan to evaluate, as shown in a comparative study [32]. This allows us to assess whether the fractal properties of the original time series X(t) are preserved in the generated continuations Xc(t).
- Determining if the increments are normally distributed using the Anderson–Darling test. This test is a statistical method used to check whether a given sample of data follows a specific distribution (in our case, normal distribution). If the increments are normally distributed, it indicates that the generated continuations Xc(t) maintain the same distribution law as the original time series X(t).
- Comparing the standard deviations of increments (S) between the original time series X(t) and the generated continuations Xc(t). By ensuring that the standard deviations of increments are preserved, we can confirm that the scale of the generated continuations Xc(t) is consistent with the original time series X(t).
2.5. Machine Learning Methods for Probabilistic Forecasting
3. Results
3.1. Dataset
3.1.1. Training Dataset
3.1.2. Evaluating Dataset
- Number of files—99, each for the value of H from 0.01 to 0.99 with a step of 0.01;
- Number of records in each file—50;
- The length of the original time series N—1024;
- The length of the continuations of the original series, for which quantiles are provided K—1024;
- The number of continuations of the time series to calculate quantiles M—10,001;
- The number of quantiles for each time step is 101 (the 0th and 1.0th quantiles are equal to the maximum and minimum values among M examples);
- Time series increments are normalized (divided by STD of increments); the standard deviations of increments for all examples are one;
- Original time series are presented as cumulative sums of increments. Quantiles are calculated on their cumulative continuations.
3.2. Experiment Setting
- Feeding the entire time series of length 1024 from the dataset to the machine learning model and extending it by 1024 steps, allowing for the evaluation of the Hurst exponent of the continuations and the model’s ability to reliably extend the series for a large number of time steps. Since the dataset was prepared using Hosking’s algorithm, and the series is included entirely starting from the zero value and the first increment obtained by the algorithm, the models receive complete data in this case. The series depends only on itself and does not depend on past increments unknown to the model.
- Feeding only the last 512 values out of the 1024 available in the dataset to the machine learning model. In this case, the true values depend on some unknown past that the model is not aware of. We extend the series by only 64 steps, which significantly reduces the computation time and allows for obtaining performance estimates of the models when they are not constrained by strict time frames.
3.3. Investigating the Properties of Continuations
3.3.1. Calculating the Hurst Exponent of Continuations
3.3.2. Determining If the Increments Are Normally Distributed
3.3.3. Checking the Standard Deviation of the Increments
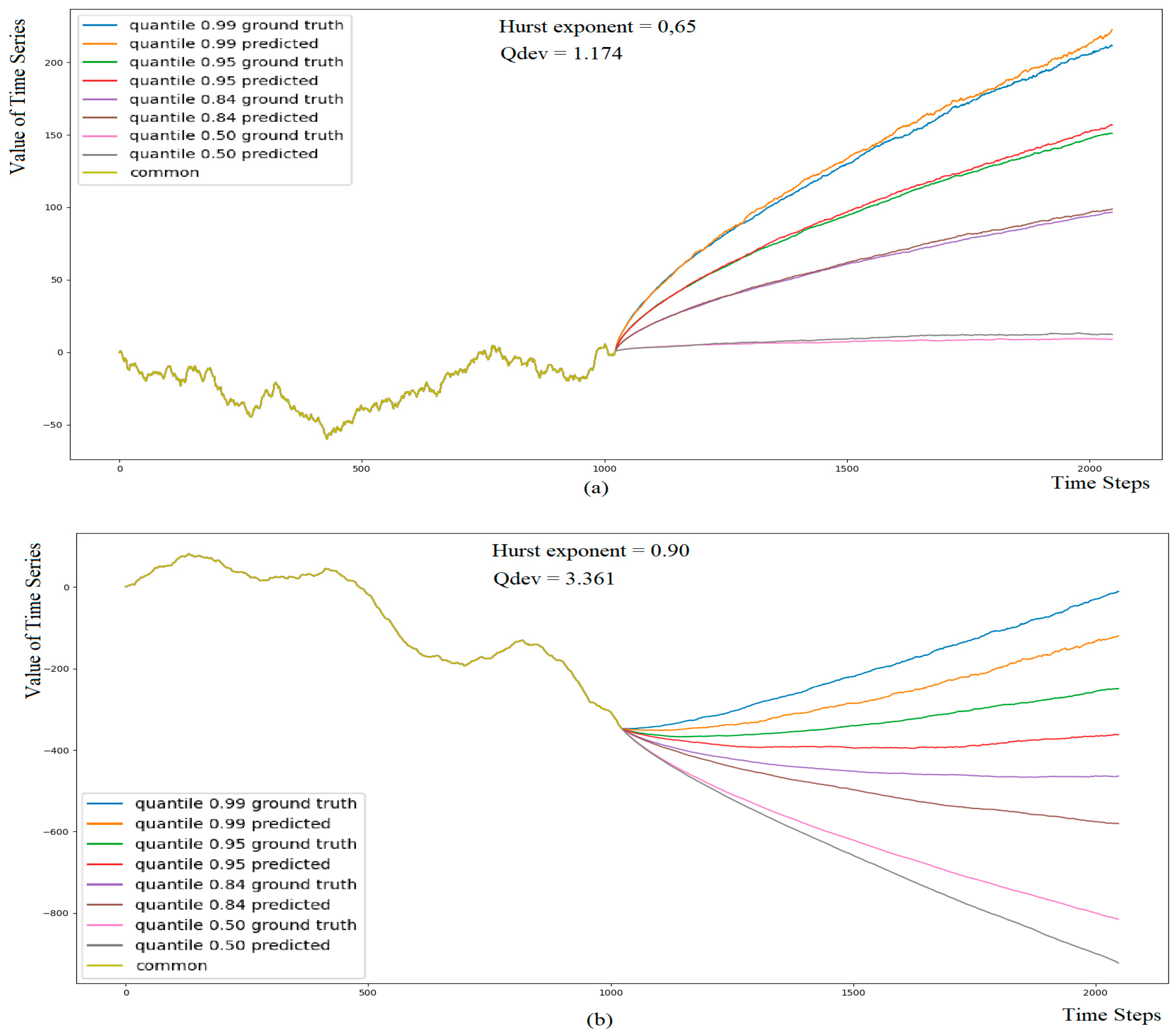
3.4. Investigating Forecasting Accuracy When Extending a Time Series of Length 1024 by 1024 Time Steps
3.5. Investigating Forecasting Accuracy When Extending a Time Series of Length 512 by 64 Time Steps
3.6. Comparing Forecasting Accuracy Given Time Series of Length 1024 and 512
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Feder, J. Fractals; Springer: New York, NY, USA, 2013. [Google Scholar]
- Radivilova, T.; Kirichenko, L.; Ageyev, D.; Tawalbeh, M.; Bulakh, V.; Zinchenko, P. Intrusion Detection Based on Machine Learning Using Fractal Properties of Traffic Realizations. In Proceedings of the 2019 IEEE International Conference on Advanced Trends in Information Theory (ATIT), Kyiv, Ukraine, 18–20 December 2019. [Google Scholar] [CrossRef]
- Brambila, F. (Ed.) Fractal Analysis—Applications in Physics, Engineering and Technology; InTech: London, UK, 2017. [Google Scholar] [CrossRef]
- Kirichenko, L.; Saif, A.; Radivilova, T. Generalized Approach to Analysis of Multifractal Properties from Short Time Series. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 183–198. [Google Scholar] [CrossRef]
- Burnecki, K.; Sikora, G.; Weron, A.; Tamkun, M.M.; Krapf, D. Identifying Diffusive Motions in Single-Particle Trajectories on the Plasma Membrane via Fractional Time-Series Models. Phys. Rev. E 2019, 99, 012101. [Google Scholar] [CrossRef] [PubMed]
- Peters, E.E. Fractal Market Analysis: Applying Chaos Theory to Investment and Economics; Wiley: New York, NY, USA, 2009. [Google Scholar]
- Kirichenko, L.; Pavlenko, K.; Khatsko, D. Wavelet-Based Estimation of Hurst Exponent Using Neural Network. In Proceedings of the 2022 IEEE 17th International Conference on Computer Sciences and Information Technologies (CSIT), Lviv, Ukraine, 10–12 November 2022. [Google Scholar] [CrossRef]
- Sidhu, G.S.; Ibrahim Ali Metwaly, A.; Tiwari, A.; Bhattacharyya, R. Short Term Trading Models Using Hurst Exponent and Machine Learning. SSRN Electron. J. 2021. [Google Scholar] [CrossRef]
- Pilgrim, I.; Taylor, R.P. Fractal Analysis of Time-Series Data Sets: Methods and Challenges. In Fractal Analysis; InTech Open: London, UK, 2018. [Google Scholar] [CrossRef]
- Kirichenko, L.; Radivilova, T.; Zinkevich, I. Forecasting Weakly Correlated Time Series in Tasks of Electronic Commerce. In Proceedings of the 2017 12th International Scientific and Technical Conference on Computer Sciences and Information Technologies (CSIT), Lviv, Ukraine, 5–8 September 2017. [Google Scholar] [CrossRef]
- Huang, C.; Wang, J.; Chen, X.; Cao, J. Bifurcations in a Fractional-Order BAM Neural Network with Four Different Delays. Neural Netw. 2021, 141, 344–354. [Google Scholar] [CrossRef] [PubMed]
- Ou, W.; Xu, C.; Cui, Q.; Liu, Z.; Pang, Y.; Farman, M.; Ahmad, S.; Zeb, A. Mathematical Study on Bifurcation Dynamics and Control Mechanism of Tri-Neuron Bidirectional Associative Memory Neural Networks Including Delay. Math. Methods Appl. Sci. 2023. [Google Scholar] [CrossRef]
- Hou, H.; Zhang, H. Stability and Hopf Bifurcation of Fractional Complex–Valued BAM Neural Networks with Multiple Time Delays. Appl. Math. Comput. 2023, 450, 127986. [Google Scholar] [CrossRef]
- Garcin, M. Forecasting with Fractional Brownian Motion: A Financial Perspective. Quant. Financ. 2022, 2, 1495–1512. [Google Scholar] [CrossRef]
- Song, W.; Li, M.; Li, Y.; Cattani, C.; Chi, C.-H. Fractional Brownian Motion: Difference Iterative Forecasting Models. Chaos Solitons Fractals 2019, 123, 347–355. [Google Scholar] [CrossRef]
- Wang, J.; Liu, Y.; Wu, H.; Lu, S.; Zhou, M. Ensemble FARIMA Prediction with Stable Infinite Variance Innovations for Supermarket Energy Consumption. Fractal Fract. 2022, 6, 276. [Google Scholar] [CrossRef]
- Duan, T.; Avati, A.; Ding, D.Y.; Thai, K.K.; Basu, S.; Ng, A.Y.; Schuler, A. NGBoost: Natural Gradient Boosting for Probabilistic Prediction. arXiv 2020, arXiv:1910.03225. [Google Scholar] [CrossRef]
- März, A. XGBoostLSS—An Extension of XGBoost to Probabilistic Forecasting. arXiv 2019, arXiv:1907.03178. [Google Scholar] [CrossRef]
- März, A.; Kneib, T. Distributional Gradient Boosting Machines. arXiv 2022, arXiv:2204.00778. [Google Scholar] [CrossRef]
- Sprangers, O.; Schelter, S.; de Rijke, M. Probabilistic Gradient Boosting Machines for Large-Scale Probabilistic Regression. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 1510–1520. [Google Scholar] [CrossRef]
- Brophy, J.; Lowd, D. Instance-Based Uncertainty Estimation for Gradient-Boosted Regression Trees. arXiv 2022, arXiv:2205.11412. [Google Scholar] [CrossRef]
- Meinshausen, N. Quantile Regression Forests. J. Mach. Learn. Res. 2006, 7, 983–999. [Google Scholar]
- Koenker, R.; Hallock, K.F. Quantile Regression. J. Econ. Perspect. 2001, 15, 143–156. [Google Scholar] [CrossRef]
- Lucena, B. Nonparametric Probabilistic Regression with Coarse Learners. arXiv 2022, arXiv:2210.16247. [Google Scholar] [CrossRef]
- Banna, O.; Mishura, Y.; Ralchenko, K.; Shklyar, S. Fractional Brownian Motion; John Wiley & Sons: Hoboken, NJ, USA, 2019. [Google Scholar] [CrossRef]
- Anderson, T.W.; Darling, D.A. A Test of Goodness of Fit. J. Am. Stat. Assoc. 1954, 49, 765–769. [Google Scholar] [CrossRef]
- Sato, K. Self-Similar Processes with Independent Increments. Probab. Theory Relat. Fields 1991, 89, 285–300. [Google Scholar] [CrossRef]
- Rao, P. Self-Similar Processes, Fractional Brownian Motion and Statistical Inference. Lect. Notes-Monogr. Ser. 2004, 45, 98–125. [Google Scholar] [CrossRef]
- Mandelbrot, B.B.; Van Ness, J.W. Fractional Brownian Motions, Fractional Noises and Applications. SIAM Rev. 1968, 10, 422–437. [Google Scholar] [CrossRef]
- Feder, J. Random Walks and Fractals. In Fractals. Physics of Solids and Liquids; Springer: Boston, MA, USA, 1988; pp. 163–183. [Google Scholar] [CrossRef]
- Tyralis, H.; Papacharalampous, G. A Review of Probabilistic Forecasting and Prediction with Machine Learning. arXiv 2022, arXiv:2209.08307. [Google Scholar] [CrossRef]
- Shang, H.L. A Comparison of Hurst Exponent Estimators in Long-Range Dependent Curve Time Series. J. Time Ser. Econom. 2020, 12, 20190009. [Google Scholar] [CrossRef]
- Abdar, M.; Pourpanah, F.; Hussain, S.; Rezazadegan, D.; Liu, L.; Ghavamzadeh, M.; Fieguth, P.; Cao, X.; Khosravi, A.; Acharya, U.R.; et al. A Review of Uncertainty Quantification in Deep Learning: Techniques, Applications and Challenges. Inf. Fusion 2021, 76, 243–297. [Google Scholar] [CrossRef]
- Papacharalampous, G.; Tyralis, H. A Review of Machine Learning Concepts and Methods for Addressing Challenges in Probabilistic Hydrological Post-Processing and Forecasting. Front. Water 2022, 4, 961954. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Output | Implementation |
|---|---|---|
| Natural gradient boosting NGBoost [17] | Estimates of the mean and standard deviation of the normal distribution | Python package ngboost |
| Catboost with Uncertainty (CBU) | Estimates of the mean and standard deviation of the normal distribution | Python package catboost |
| Mean, location, scale, and shape (LSS) XGBoostLSS and LightGBMLSS [18,19] | Estimates of the mean and standard deviation of the normal distribution | Alexander März’s (StatMixedML) repository on github |
| Nonparametric Probabilistic Regression (PRESTO) [24] | Distribution without predefined shape | Our implementation of the author’s idea using CatBoost, LightGBM, and Scikit-learn’s Logistic Regression |
| Training a separate model for each quantile | Quantiles predictions | Python packages catboost, lightgbm |
| Quantile regression (QuantReg) [23] | Quantiles predictions | Python package statsmodels |
| Random Forest Quantile Regression [22] | Quantiles predictions | Python package sklearn_quantile |
| Method | H = 0.3 | H = 0.35 | H = 0.45 | H = 0.53 | H = 0.6 | H = 0.65 | H = 0.72 | H = 0.85 | H = 0.9 | H = 0.93 |
|---|---|---|---|---|---|---|---|---|---|---|
| CBU 500 iter. | 0.299 | 0.349 | 0.451 | 0.529 | 0.6 | 0.649 | 0.718 | 0.848 | 0.895 | 0.935 |
| CBU 1000 iter. | 0.299 | 0.351 | 0.449 | 0.529 | 0.599 | 0.649 | 0.719 | 0.848 | 0.897 | 0.935 |
| LightGBMLSS Gaussian | 0.298 | 0.349 | 0.453 | 0.528 | 0.598 | 0.648 | 0.711 | 0.843 | 0.895 | 0.926 |
| LightGBMLSS Gaussian_AutoGrad | 0.297 | 0.349 | 0.451 | 0.531 | 0.602 | 0.654 | 0.713 | 0.849 | 0.895 | 0.83 * |
| XGBoostLSS Gaussian | 0.301 | 0.356 | 0.447 | 0.534 | 0.597 | 0.651 | 0.719 | 0.844 | 0.9 | 0.922 |
| PRESTO with CatBoost | 0.298 | 0.349 | 0.449 | 0.529 | 0.598 | 0.648 | 0.718 | 0.846 | 0.894 | 0.925 |
| PRESTO with LightGBM | 0.302 | 0.352 | 0.452 | 0.527 | 0.595 | 0.644 | 0.713 | 0.841 | 0.889 | 0.922 |
| PRESTO with Logistic Regression | 0.299 | 0.35 | 0.448 | 0.529 | 0.599 | 0.649 | 0.719 | 0.848 | 0.897 | 0.928 |
| CatBoost for each quantile | 0.306 | 0.357 | 0.454 | 0.525 | 0.593 | 0.643 | 0.713 | 0.84 | 0.886 | 0.914 |
| LightGBM for each quantile | 0.306 | 0.357 | 0.454 | 0.525 | 0.593 | 0.644 | 0.713 | 0.839 | 0.886 | 0.916 |
| Method | H = 0.3 | H = 0.35 | H = 0.45 | H = 0.53 | H = 0.6 | H = 0.65 | H = 0.72 | H = 0.85 | H = 0.9 | H = 0.93 |
|---|---|---|---|---|---|---|---|---|---|---|
| CBU 500 iter. | 0.956 | 0.974 | 0.996 | 0.998 | 0.986 | 0.965 | 0.921 * | 0.75 * | 0.573 * | 0.418 * |
| CBU 1000 iter. | 0.955 | 0.973 | 0.995 | 0.997 | 0.985 | 0.965 | 0.919 * | 0.753 * | 0.578 * | 0.414 * |
| LightGBMLSS Gaussian | 0.996 | 0.997 | 1.003 | 0.998 | 1.002 | 0.996 | 0.997 | 0.975 | 0.892 | 0.778 |
| LightGBMLSS Gaussian_AutoGrad | 0.995 | 0.996 | 0.996 | 1.001 | 1.002 | 0.996 | 0.998 | 0.981 | 0.902 | 0.274 * |
| XGBoostLSS Gaussian | 0.996 | 0.998 | 0.998 | 0.998 | 0.998 | 0.997 | 0.995 | 0.976 | 0.899 | 0.776 |
| PRESTO with CatBoost | 1 | 1.001 | 1.001 | 1.001 | 1.002 | 1 | 0.999 | 0.986 | 0.897 | 0.786 |
| PRESTO with LightGBM | 1.001 | 1.002 | 1.002 | 1.002 | 1.002 | 1.001 | 0.999 | 0.978 | 0.903 | 0.795 |
| PRESTO with Logistic Regression | 1.001 | 1.001 | 1.002 | 1.002 | 1.002 | 1.001 | 1 | 0.977 | 0.906 | 0.789 |
| CatBoost for each quantile | 1.004 | 1.004 | 1.004 | 1.004 | 1.005 | 1.003 | 1.002 | 0.983 | 0.905 | 0.809 |
| LightGBM for each quantile | 1.004 | 1.004 | 1.004 | 1.004 | 1.004 | 1.003 | 1.002 | 0.983 | 0.907 | 0.814 |
| Method | H = 0.3 | H = 0.35 | H = 0.45 | H = 0.53 | H = 0.6 | H = 0.65 | H = 0.72 | H = 0.85 | H = 0.9 | H = 0.93 |
|---|---|---|---|---|---|---|---|---|---|---|
| CBU 500 iter. | 1.854 | 1.331 | 0.741 | 0.544 | 1.339 | 1.614 | 2.805 | 6.659 * | 10.597 * | 14.594 * |
| CBU 1000 iter. | 1.803 | 1.271 | 0.71 | 0.963 | 1.127 | 1.604 | 3.02 | 6.289 * | 10.706 * | 14.917 * |
| LightGBMLSS Gaussian | 1.405 | 1.175 | 0.914 | 1.256 | 1.077 | 2.134 | 3.142 | 2.74 | 4.477 | 6.573 |
| LightGBMLSS Gaussian_AutoGrad | 1.44 | 1.24 | 1.113 | 0.594 | 1.223 | 2.514 | 1.971 | 3.741 | 4.594 | 36.382 |
| XGBoostLSS Gaussian | 1.493 | 1.174 | 0.955 | 0.861 | 1.236 | 1.676 | 1.975 | 11.028 * | 4.49 | 6.806 |
| PRESTO with CatBoost | 1.606 | 1.557 | 1.307 | 1.668 | 2.035 | 1.669 | 2.355 | 3.976 | 4.609 | 6.925 |
| PRESTO with LightGBM | 1.62 | 1.408 | 0.975 | 1.058 | 1.512 | 1.579 | 1.99 | 3.703 | 5.651 | 8.709 |
| PRESTO with Logistic Regression | 1.319 | 1.024 | 0.647 | 0.729 | 1.85 | 1.174 | 1.41 | 1.856 | 3.361 | 5.863 |
| CatBoost for each quantile | 2.338 | 1.978 | 1.26 | 1.334 | 1.602 | 2.747 | 2.964 | 7.037 * | 5.984 | 9.793 |
| LightGBM for each quantile | 2.101 | 1.846 | 1.059 | 0.923 | 1.536 | 3.014 | 3.767 | 4.742 | 5.961 | 9.713 |
| Method | H = 0.3 | H = 0.35 | H = 0.45 | H = 0.53 | H = 0.6 | H = 0.65 | H = 0.72 | H = 0.85 | H = 0.9 | H = 0.93 |
|---|---|---|---|---|---|---|---|---|---|---|
| NGBoost | 2.576 | 1.756 | 1.02 | 0.8 | 1.386 | 1.782 | 2.168 | 4.163 | 4.19 | 7.863 |
| CBU | 2.178 | 1.966 | 1.984 | 1.642 | 2.146 | 2.177 | 2.036 | 6.938 | 10.688 | 13.962 |
| XGBoostLSS Gaussian | 1.123 | 0.838 | 0.781 | 0.831 | 1.207 | 1.176 | 1.025 | 2.115 | 2.751 | 6.001 |
| LightGBMLSS Gaussian | 1.111 | 1.066 | 0.589 | 0.599 | 1.388 | 1.042 | 1.068 | 4.607 | 3.203 | 32.828 |
| PRESTO with CatBoost | 1.499 | 1.174 | 1.565 | 1.49 | 1.794 | 1.219 | 1.576 | 1.977 | 3.556 | 6.048 |
| PRESTO with LightGBM | 0.995 | 0.804 | 0.727 | 0.767 | 0.774 | 1.034 | 1.077 | 1.895 | 3.022 | 5.783 |
| PRESTO with Logistic Regression | 0.94 | 0.747 | 0.505 | 0.502 | 0.669 | 0.905 | 1.077 | 1.626 | 2.747 | 5.839 |
| LightGBM for each quantile | 1.165 | 1.022 | 0.618 | 0.798 | 1.045 | 1.013 | 1.262 | 1.931 | 2.971 | 5.592 |
| CatBoost for each quantile | 1.318 | 1.178 | 0.764 | 0.795 | 1.02 | 1.296 | 1.831 | 2.789 | 4.256 | 8.73 |
| QR statsmodels | 1.096 | 0.74 | 0.689 | 0.611 | 0.769 | 0.878 | 1.135 | 1.467 | 2.961 | 5.53 |
| Random Forest QR | 1.629 | 1.502 | 1.55 | 1.639 | 1.307 | 1.579 | 1.666 | 5.672 | 4.13 | 6.45 |
| Features | H = 0.3 | H = 0.35 | H = 0.45 | H = 0.53 | H = 0.6 | H = 0.65 | H = 0.72 | H = 0.85 | H = 0.9 | H = 0.93 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1/32 of 1024 | 0.659 | 0.648 | 0.505 | 0.656 | 0.66 | 0.56 | 0.544 | 0.86 | 2.394 | 5.204 |
| 1/16 of 512 | 0.986 | 0.702 | 0.527 | 0.537 | 0.678 | 0.858 | 1.031 | 1.601 | 2.915 | 5.521 |
| 1/32 of 512 | 1.036 | 0.722 | 0.551 | 0.466 | 0.633 | 0.949 | 1.021 | 1.79 | 3.019 | 5.348 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kirichenko, L.; Lavrynenko, R. Probabilistic Machine Learning Methods for Fractional Brownian Motion Time Series Forecasting. Fractal Fract. 2023, 7, 517. https://doi.org/10.3390/fractalfract7070517
Kirichenko L, Lavrynenko R. Probabilistic Machine Learning Methods for Fractional Brownian Motion Time Series Forecasting. Fractal and Fractional. 2023; 7(7):517. https://doi.org/10.3390/fractalfract7070517
Chicago/Turabian StyleKirichenko, Lyudmyla, and Roman Lavrynenko. 2023. "Probabilistic Machine Learning Methods for Fractional Brownian Motion Time Series Forecasting" Fractal and Fractional 7, no. 7: 517. https://doi.org/10.3390/fractalfract7070517
APA StyleKirichenko, L., & Lavrynenko, R. (2023). Probabilistic Machine Learning Methods for Fractional Brownian Motion Time Series Forecasting. Fractal and Fractional, 7(7), 517. https://doi.org/10.3390/fractalfract7070517