Edge Machine Learning: Enabling Smart Internet of Things Applications



Abstract
1. Introduction
- (a)
- How could machine learning algorithms be applied to IoT smart data?
- (b)
- Is it feasible to run machine learning algorithms on IoT?
- (c)
- What measures could be taken to enhance the execution of these algorithms on IoT devices?
- (d)
- What would be the next step forward in applying machine learning to IoT smart data?
2. Related Work
3. Machine Learning Methods
3.1. Multi-Layer Perceptron
3.1.1. Random Forest
3.2. Support Vector Machine
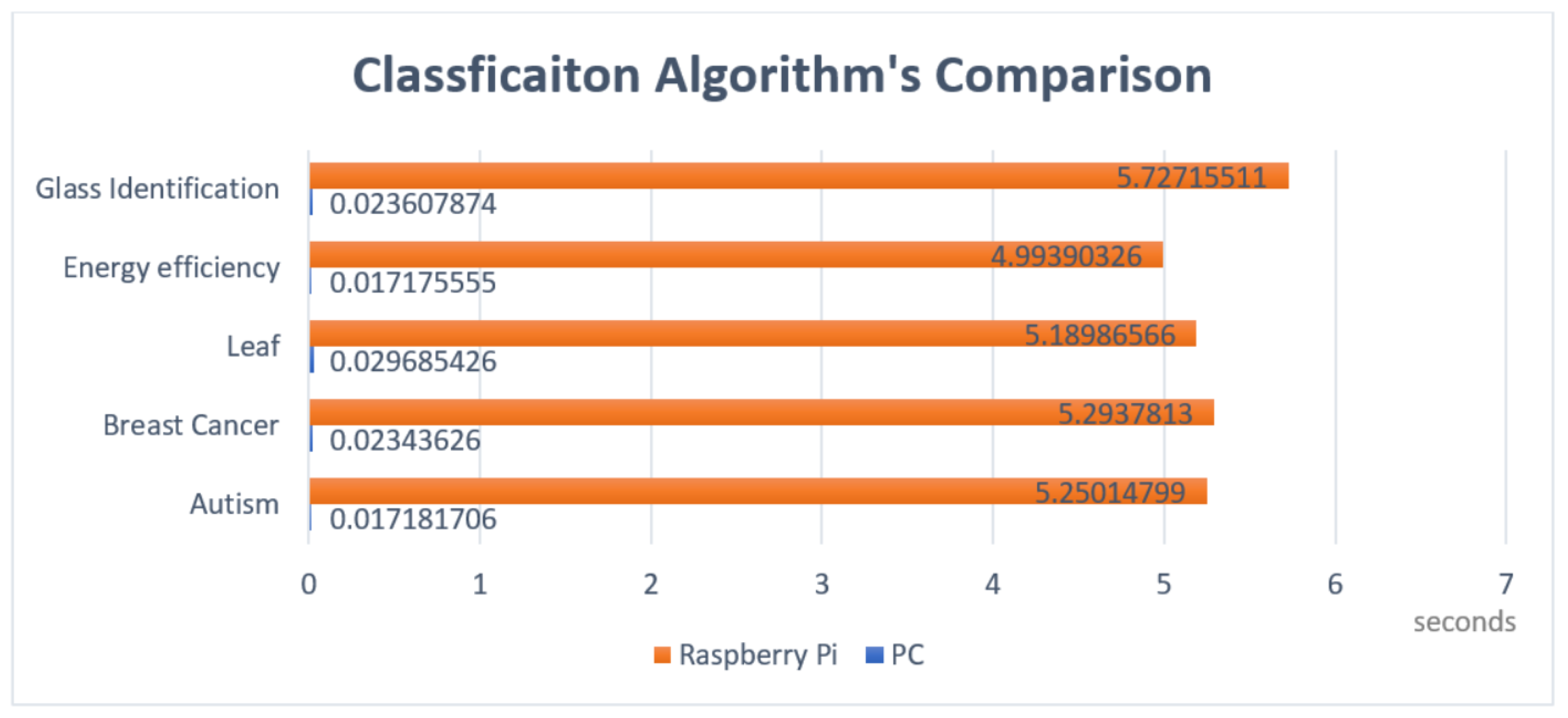
4. Experimental Study
4.1. Data Sets
4.1.1. Regression Data Sets
4.1.2. Classification Data Sets
4.2. Machine Learning Algorithms
4.3. Test Computer, IoT Device and Software
4.4. Measurement Tools
4.4.1. Accuracy
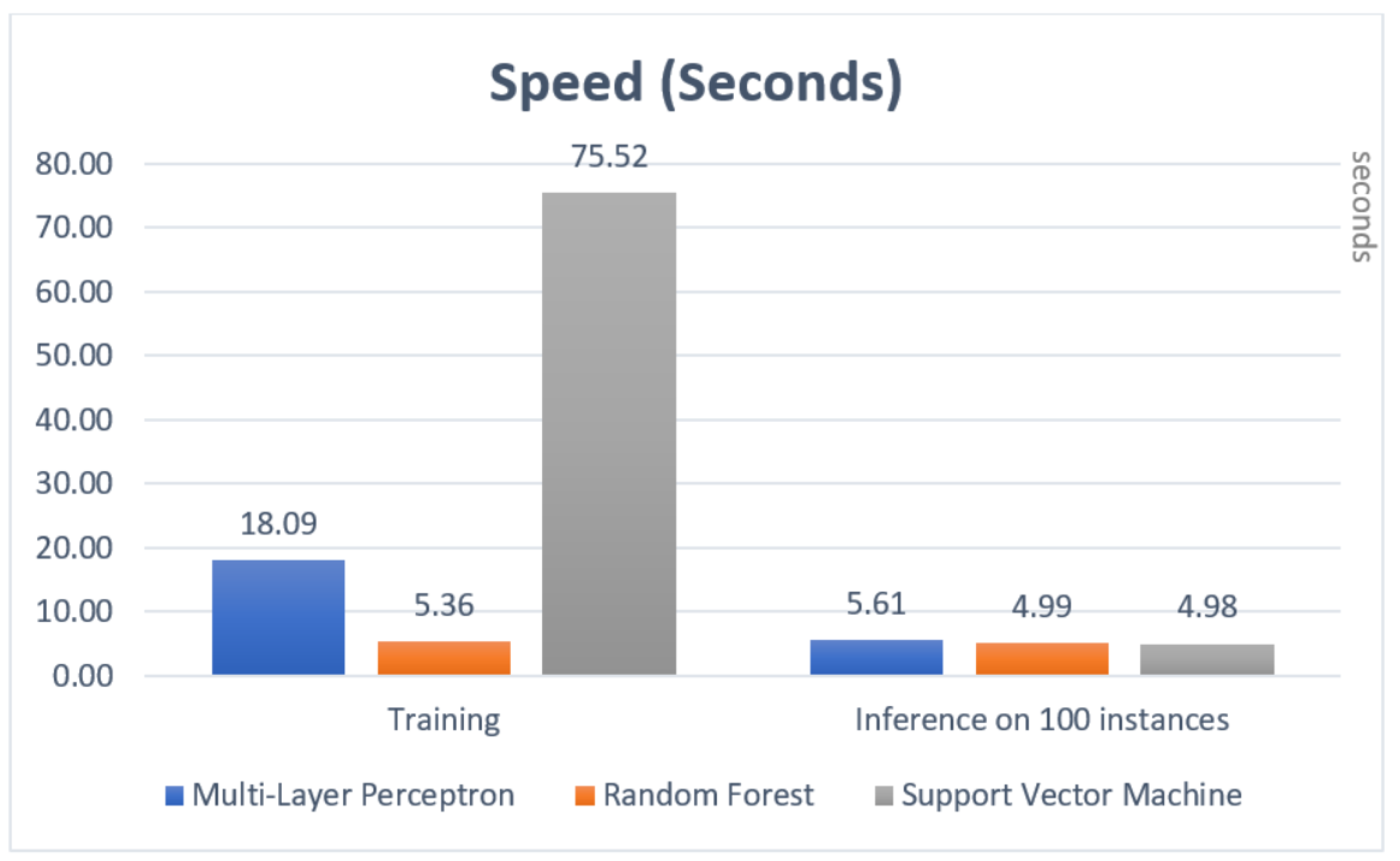
4.4.2. Speed
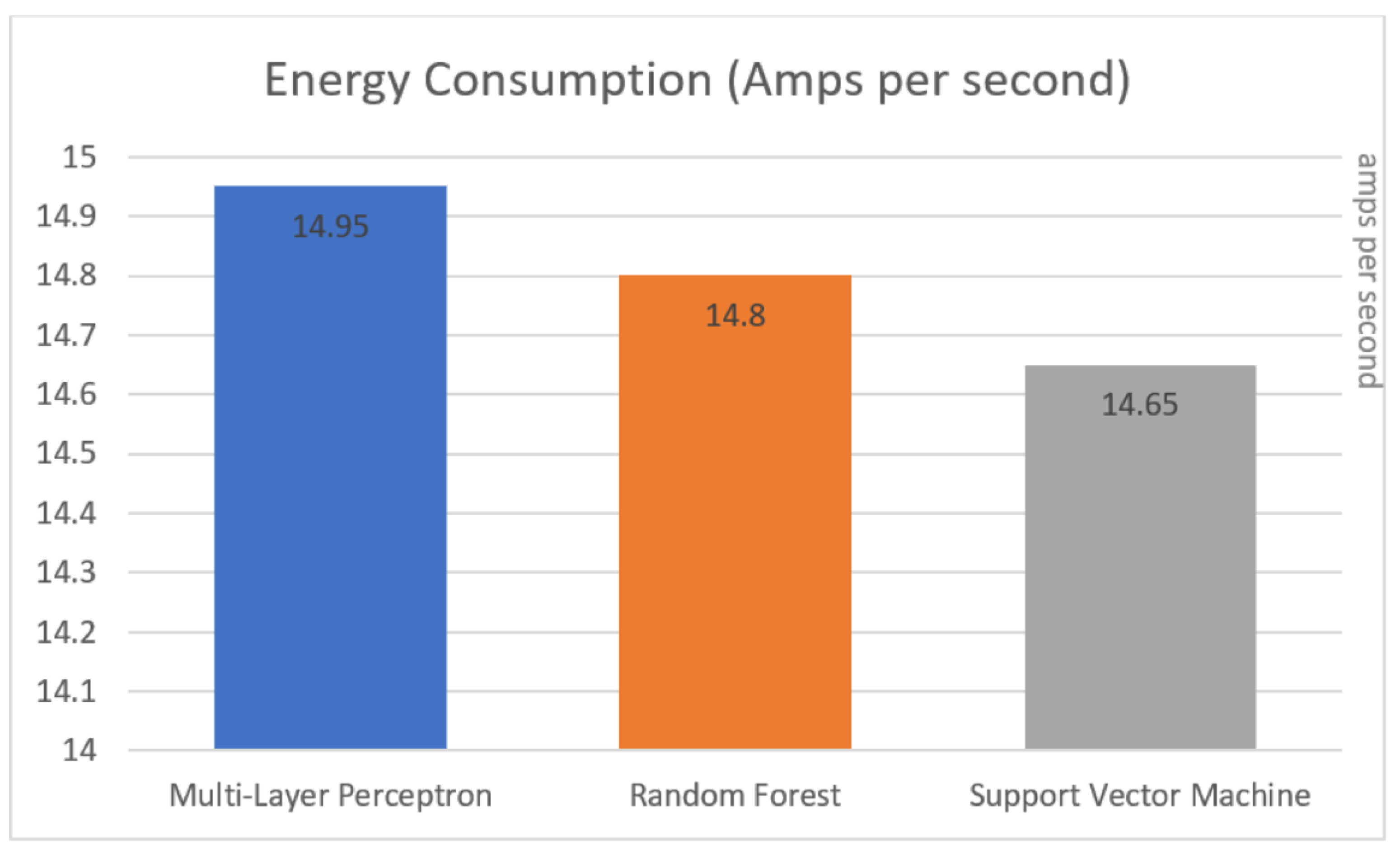
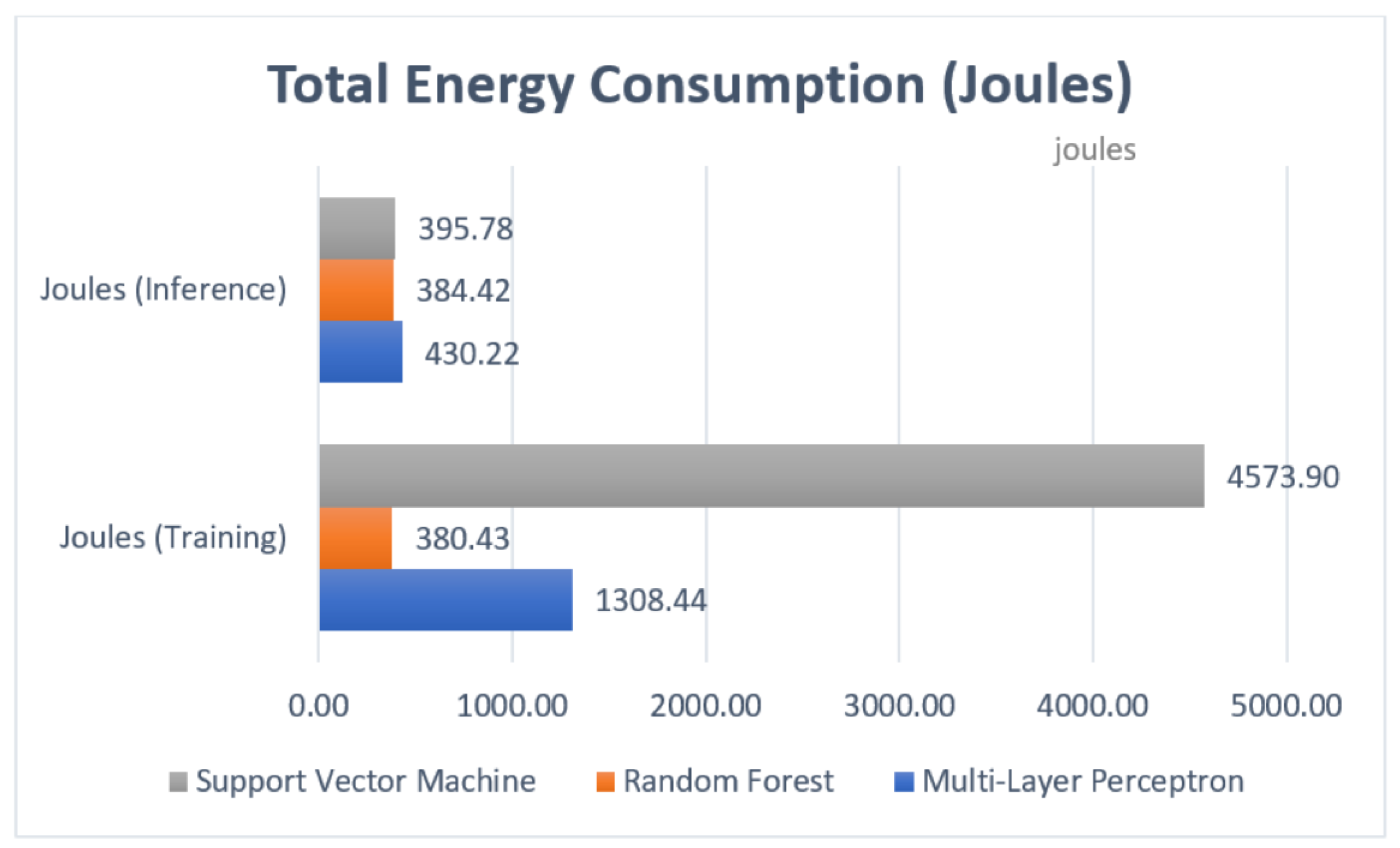
4.4.3. Power Consumption
4.5. Implementation
4.5.1. Models
- For Multi-Layer Perceptron ‘MLPClassifier’ is used for classification and ‘MLPRegressor’ for regression;
- For Support Vector Machine ‘svm’ and ‘SVR’ are used;
- and, finally, for Random Forest, ‘RandomForestClassifier’ and ‘RandomForestRegressor’ are used.
4.5.2. Pre-Processing and Tuning
5. Experimental Results
5.1. Testing
5.2. Evaluation
6. Discussion
7. Conclusions
Author Contributions
Conflicts of Interest
References
- Green, H. The Internet of Things in the Cognitive Era: Realizing the Future and Full Potential of Connected Devices; Technical Report; IBM Watson IoT: New York, NY, USA, 2015. [Google Scholar]
- Gubbi, J.; Buyya, R.; Marusic, S.; Palaniswami, M. Internet of Things (IoT): A vision, architectural elements, and future directions. Future Gener. Comput. Syst. 2013, 29, 1645–1660. [Google Scholar] [CrossRef]
- Evans, D. The Internet of Things: How the Next Evolution of the Internet is Changing Everything. CISCO White Paper 2011, 1, 1–11. [Google Scholar]
- Manyika, J.; Chui, M.; Bisson, P.; Woetzel, J.; Dobbs, R.; Bughin, J.A.D. Unlocking the Potential of the Internet of Things; Technical Report; McKinsey Global Institute: New York, NY, USA, 2015. [Google Scholar]
- Lee, I.; Lee, K. The Internet of Things (IoT): Applications, investments, and challenges for enterprises. Bus. Horiz. 2015, 58, 431–440. [Google Scholar] [CrossRef]
- Yoo, Y.; Henfridsson, O.; Lyytinen, K. The New Organizing Logic of Digital Innovation: An Agenda for Information Systems Research. Inf. Syst. Res. 2010, 21, 724–735. [Google Scholar] [CrossRef]
- Wortmann, F.; Fluchter, K. Internet of Things: Technology and Value Added. Bus. Inf. Syst. Eng. 2015, 57, 221–224. [Google Scholar] [CrossRef]
- Fleisch, E.; Weinberger, M.; Wortmann, F. Business Models for the Internet of Things-Bosch IoT Lab White Paper; Universität St. Gallen: St. Gallen, Switzerland, 2014. [Google Scholar]
- Kargupta, H.; Park, B.H.; Pittie, S.; Liu, L.; Kushraj, D.; Sarkar, K. MobiMine: Monitoring the stock market from a PDA. ACM SIGKDD Explor. Newsl. 2002, 3, 37–46. [Google Scholar] [CrossRef]
- Kargupta, H.; Bhargava, R.; Liu, K.; Powers, M.; Blair, P.; Bushra, S.; Dull, J.; Sarkar, K.; Klein, M.; Vasa, M.; et al. VEDAS: A mobile and distributed data stream mining system for real-time vehicle monitoring. In Proceedings of the 2004 SIAM International Conference on Data Mining, Lake Buena Vista, FL, USA, 22–24 April 2004; pp. 300–311. [Google Scholar]
- Gaber, M.M.; Philip, S.Y. A holistic approach for resource-aware adaptive data stream mining. New Gener. Comput. 2006, 25, 95–115. [Google Scholar] [CrossRef]
- Gaber, M.M. Data stream mining using granularity-based approach. In Foundations of Computational, Intelligence Volume 6; Springer: Berlin/Heidelberg, Germany, 2009; pp. 47–66. [Google Scholar]
- Gaber, M.M.; Krishnaswamy, S.; Zaslavsky, A. On-board mining of data streams in sensor networks. In Advanced Methods for Knowledge Discovery From Complex Data; Springer: Goldaming, UK, 2005; pp. 307–335. [Google Scholar]
- Gaber, M.M.; Gomes, J.B.; Stahl, F. Pocket Data Mining. In Big Data on Small Devices; Series: Studies in Big Data; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Anwar, S.; Hwang, K.; Sung, W. Structured pruning of deep convolutional neural networks. ACM J. Emerg. Technol. Comput. Syst. (JETC) 2017, 13, 32. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv, 2017; arXiv:1704.04861. [Google Scholar]
- Fernández-Delgado, M.; Cernadas, E.; Barro, S.; Amorim, D. Do we need hundreds of classifiers to solve real world classification problems? J. Mach. Learn. Res. 2014, 15, 3133–3181. [Google Scholar]
- Chavan, G.; Momin, B. An integrated approach for weather forecasting over Internet of Things: A brief review. In Proceedings of the 2017 International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), Palladam, India, 10–11 February 2017; pp. 83–88. [Google Scholar] [CrossRef]
- Han, S.; Mao, H.; Dally, W.J. Deep Compression: Compressing Deep Neural Network with Pruning, Trained Quantization and Huffman Coding. arXiv, 2015; arXiv:1510.00149. [Google Scholar]
- Ata, R. Artificial neural networks applications in wind energy systems: A review. Renew. Sustain. Energy Rev. 2015, 49, 534–562. [Google Scholar] [CrossRef]
- Raschka, S. Python Machine Learning: Effective Algorithms for Practical Machine Learning and Deep Learning, 2nd ed.; Packt Publishing Limited: Birmingham, UK, 2017. [Google Scholar]
- Tu, J.V. Advantages and disadvantages of using artificial neural networks versus logistic regression for predicting medical outcomes. J. Clin. Epidemiol. 1996, 49, 1225–1231. [Google Scholar] [CrossRef]
- Tang, J.; Sun, D.; Liu, S.; Gaudiot, J.L. Enabling Deep Learning on IoT Devices. Computer 2017, 50, 92–96. [Google Scholar] [CrossRef]
- Ng, A. Neural Networks and Deep Learning-Coursera. 2017. Available online: https://www.coursera.org/learn/neural-networks-deep-learning/ (accessed on 27 August 2018).
- Mestre, D.; Fonseca, J.M.; Mora, A. Monitoring of in-vitro plant cultures using digital image processing and random forests. In Proceedings of the 8th International Conference of Pattern Recognition Systems (ICPRS 2017), Madrid, Spain, 11–13 July 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Dogru, N.; Subasi, A. Traffic accident detection using random forest classifier. In Proceedings of the 2018 15th Learning and Technology Conference (L T), Jeddah, Saudi Arabia, 25–26 February 2018; pp. 40–45. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.A. Data Mining: Practical Machine Learning Tools and Techniques, 3rd ed.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2011. [Google Scholar]
- Tian, Y.; Qi, Z.; Ju, X.; Shi, Y.; Liu, X. Nonparallel Support Vector Machines for Pattern Classification. IEEE Trans. Cybern. 2014, 44, 1067–1079. [Google Scholar] [CrossRef] [PubMed]
- Kruczkowski, M.; Szynkiewicz, E.N. Support Vector Machine for Malware Analysis and Classification. In Proceedings of the 2014 IEEE/WIC/ACM International Joint Conferences on Web Intelligence (WI) and Intelligent Agent Technologies (IAT), Warsaw, Poland, 11–14 August 2014; Volume 2, pp. 415–420. [Google Scholar] [CrossRef]
- Amin, S.; Singhal, A.; Rai, J.K. Identification and classification of neuro-degenerative diseases using statistical features and support vector machine classifier. In Proceedings of the 2017 8th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Delhi, India, 3–5 July 2017; pp. 1–8. [Google Scholar] [CrossRef]
- Asuncion, A.; Newman, D. UCI Machine Learning Repository. Available online: https://archive.ics.uci.edu/ml/index.php (accessed on 27 August 2018).
- Scikit-Learn. Documentation of Scikit-Learn 0.19.1. Available online: https://github.com/amueller/scipy-2017-sklearn (accessed on 27 August 2018).
- Van Rossum, G. Python Tutorial; Technical Report CS-R9526; Centrum voor Wiskunde en Informatica (CWI): Amsterdam, The Netherlands, 1995. [Google Scholar]
- Rahm, E.; Do, H.H. Data cleaning: Problems and current approaches. IEEE Data Eng. Bull.108 2000, 24, 3–13. [Google Scholar]
- Bermingham, M.L.; Pong-Wong, R.; Spiliopoulou, A.; Hayward, C.; Rudan, I.; Campbell, H.; Wright, A.F.; Wilson, J.F.; Agakov, F.; Navarro, P.; et al. Application of high-dimensional feature selection: Evaluation for genomic prediction in man. Sci. Rep. 2015, 5, 10312. [Google Scholar] [CrossRef] [PubMed]
- Guyon, I.; Elisseeff, A. An Introduction to Variable and Feature Selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Choudhury, M.D.; Lin, Y.R.; Sundaram, H.; Candan, K.S.; Xie, L.; Kelliher, A. How Does the Data Sampling Strategy Impact the Discovery of Information Diffusion in Social Media? In Proceedings of the Fourth International AAAI Conference on Weblogs and Social Media (ICWSM), Washington, DC, USA, 23–26 May 2010. [Google Scholar]
- Kong, W.; Dong, Z.Y.; Luo, F.; Meng, K.; Zhang, W.; Wang, F.; Zhao, X. Effect of automatic hyperparameter tuning for residential load forecasting via deep learning. In Proceedings of the 2017 Australasian Universities Power Engineering Conference (AUPEC), Melbourne, Australia, 19–22 November 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Rossum, G. Python Reference Manual. Available online: https://docs.python.org/2.0/ref/ref.html (accessed on 27 August 2018).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set Name | Category | No. of Instances | No. of Attributes |
|---|---|---|---|
| Air quality | Regression | 9358 | 15 |
| Concrete compressive strength | Regression | 1030 | 9 |
| Energy efficiency | Regression | 768 | 8 |
| Indidual household electric power consumption | Regression | 2,075,259 | 9 |
| Yacht hydrodynamics | Regression | 308 | 7 |
| Autism screening adult | Classification | 704 | 21 |
| Breast cancer | Classification | 286 | 9 |
| Energy efficiency | Classification | 768 | 8 |
| Glass identification | Classification | 214 | 10 |
| Leaf | Classification | 340 | 16 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yazici, M.T.; Basurra, S.; Gaber, M.M. Edge Machine Learning: Enabling Smart Internet of Things Applications. Big Data Cogn. Comput. 2018, 2, 26. https://doi.org/10.3390/bdcc2030026
Yazici MT, Basurra S, Gaber MM. Edge Machine Learning: Enabling Smart Internet of Things Applications. Big Data and Cognitive Computing. 2018; 2(3):26. https://doi.org/10.3390/bdcc2030026
Chicago/Turabian StyleYazici, Mahmut Taha, Shadi Basurra, and Mohamed Medhat Gaber. 2018. "Edge Machine Learning: Enabling Smart Internet of Things Applications" Big Data and Cognitive Computing 2, no. 3: 26. https://doi.org/10.3390/bdcc2030026
APA StyleYazici, M. T., Basurra, S., & Gaber, M. M. (2018). Edge Machine Learning: Enabling Smart Internet of Things Applications. Big Data and Cognitive Computing, 2(3), 26. https://doi.org/10.3390/bdcc2030026