Topological Signature of 19th Century Novelists: Persistent Homology in Text Mining


Abstract
1. Introduction
2. Background
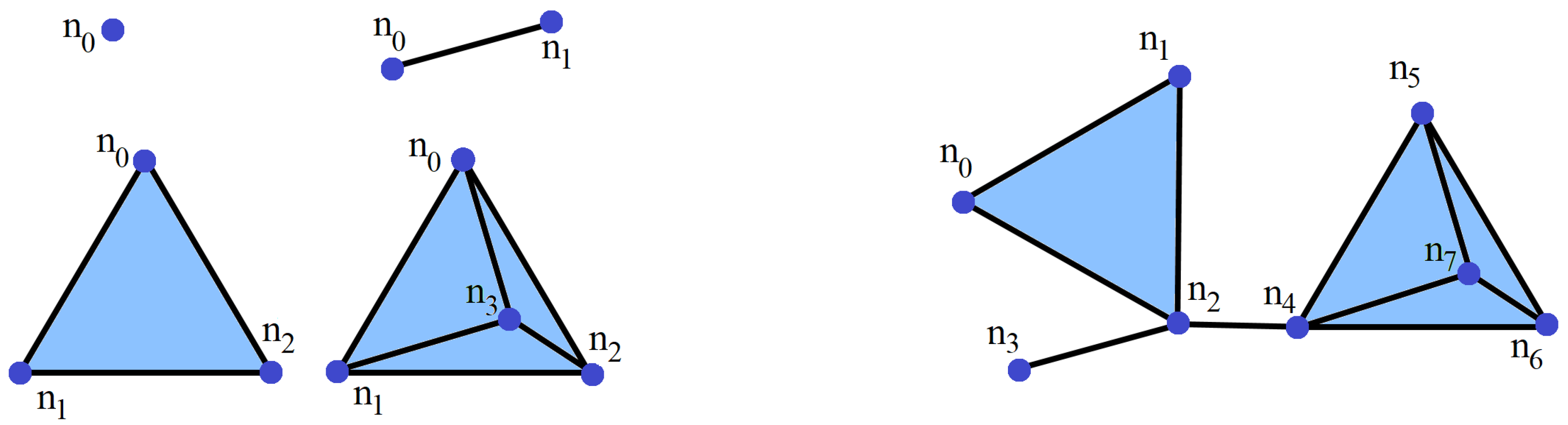
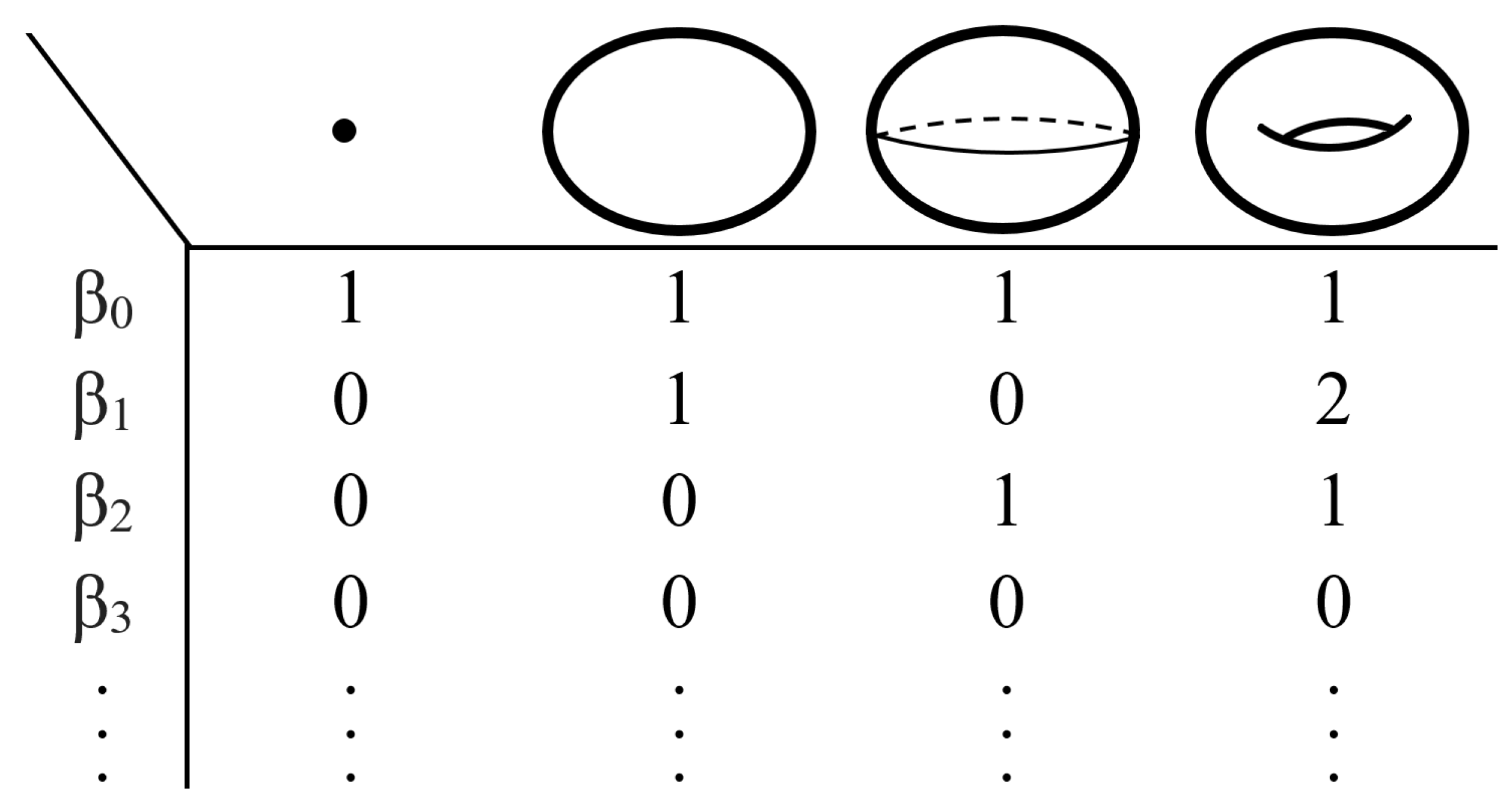
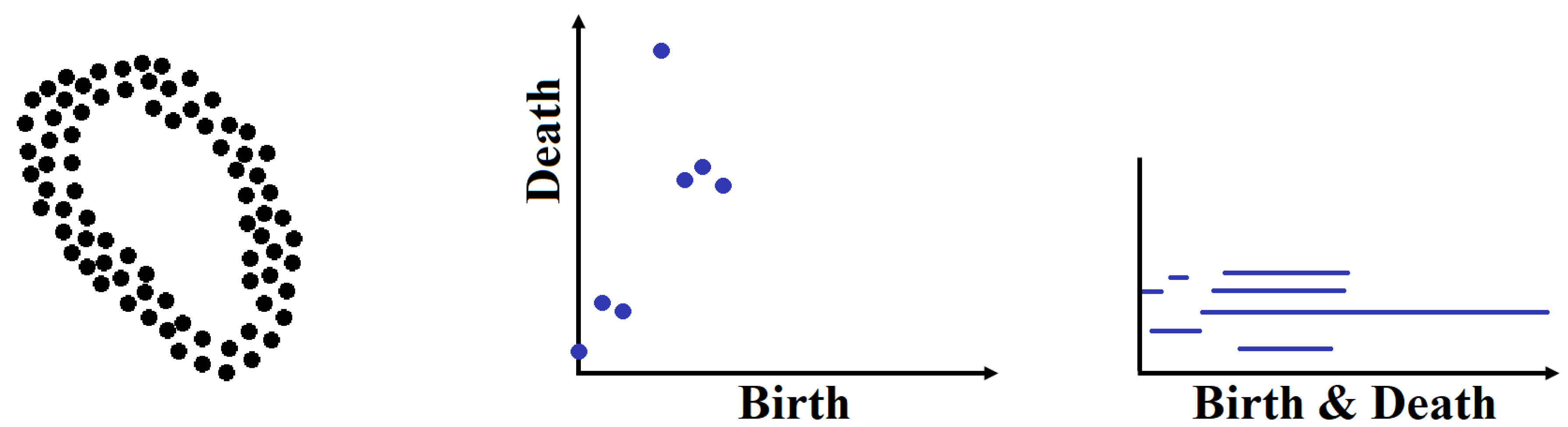
2.1. Fundamental Definitions
2.2. Related Work
3. Methodology
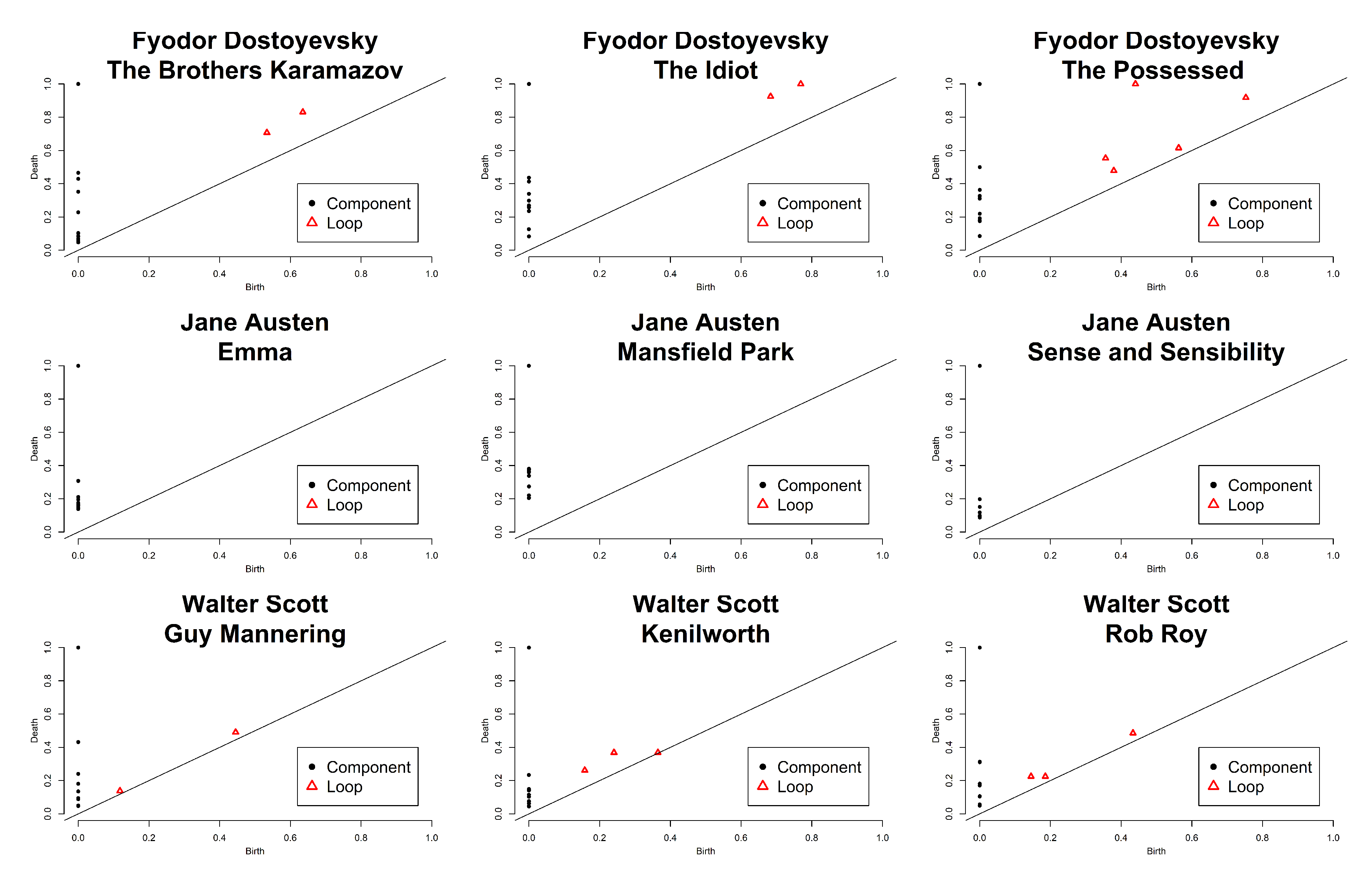
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| TDA | Topological Data Analysis |
| NER | Named Entity Recognizer |
| SIFTS | Similarity Filtration with Time Skeleton |
| k-NN | k-Nearest Neighbors |
References
- Zomorodian, A. Computational topology. In Algorithms and Theory of Computation Handbook; Chapman & Hall/CRC: London, UK, 2010; pp. 3.3–3.4. [Google Scholar]
- Edelsbrunner, H.; Letscher, D.; Zomorodian, A. Topological persistence and simplification. In Proceedings of the 41st Annual Symposium on Foundations of Computer Science, Redondo Beach, CA, USA, 12–14 November 2000; pp. 454–463. [Google Scholar]
- Carlsson, G. Topology and data. Bull. Am. Math. Soc. 2009, 46, 255–308. [Google Scholar] [CrossRef]
- Edelsbrunner, H.; Harer, J. Persistent homology-a survey. Contemp. Math. 2008, 453, 257–282. [Google Scholar]
- Chen, L.M.; Su, Z.; Jiang, B. Mathematical Problems in Data Science; Springer: Berlin, Germany, 2015. [Google Scholar]
- Zomorodian, A.; Carlsson, G. Computing persistent homology. Discret. Comput. Geometry 2005, 33, 249–274. [Google Scholar] [CrossRef]
- Collins, A.; Zomorodian, A.; Carlsson, G.; Guibas, L.J. A barcode shape descriptor for curve point cloud data. Comput. Graph. 2004, 28, 881–894. [Google Scholar] [CrossRef]
- Carlsson, G.; Zomorodian, A.; Collins, A.; Guibas, L.J. Persistence barcodes for shapes. Int. J. Shape Model. 2005, 11, 149–187. [Google Scholar] [CrossRef]
- Ghrist, R. Barcodes: The persistent topology of data. Bull. Am. Math. Soc. 2008, 45, 61–75. [Google Scholar] [CrossRef]
- Munch, E. A user’s guide to topological data analysis. J. Learn. Anal. 2017, 4, 47–61. [Google Scholar] [CrossRef]
- Wagner, H.; Dłotko, P.; Mrozek, M. Computational topology in text mining. In Computational Topology in Image Context; Springer: Berlin, Germany, 2012; pp. 68–78. [Google Scholar]
- Zhu, X. Persistent Homology: An Introduction and a New Text Representation for Natural Language Processing. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Beijing, China, 3–9 August 2013; pp. 1953–1959. [Google Scholar]
- Doshi, P.; Zadrozny, W. Movie Genre Detection Using Topological Data Analysis. In Proceedings of the International Conference on Statistical Language and Speech Processing (SLSP), Mons, Belgium, 15–16 October 2018; pp. 117–128. [Google Scholar]
- Guan, H.; Tang, W.; Krim, H.; Keiser, J.; Rindos, A.; Sazdanovic, R. A topological collapse for document summarization. In Proceedings of the 2016 IEEE 17th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Edinburgh, UK, 3–6 July 2016; pp. 1–5. [Google Scholar]
- Wilkerson, A.C.; Moore, T.J.; Swami, A.; Krim, H. Simplifying the homology of networks via strong collapses. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 5258–5262. [Google Scholar]
- Almgren, K.; Kim, M.; Lee, J. Mining Social Media Data Using Topological Data Analysis. In Proceedings of the 2017 IEEE International Conference on Information Reuse and Integration (IRI), San Diego, CA, USA, 4–6 August 2017; pp. 144–153. [Google Scholar]
- Singh, G.; Mémoli, F.; Carlsson, G.E. Topological methods for the analysis of high dimensional data sets and 3d object recognition. In Proceedings of the Fourth IEEE/Eurographics Symposium on Point-Based Graphics (SPBG), Prague, Czech Republic, 2–3 September 2007; pp. 91–100. [Google Scholar]
- Almgren, K.; Kim, M.; Lee, J. Extracting knowledge from the geometric shape of social network data using topological data analysis. Entropy 2017, 19, 360. [Google Scholar] [CrossRef]
- Chiang, I.J. Discover the semantic topology in high-dimensional data. Expert Syst. Appl. 2007, 33, 256–262. [Google Scholar] [CrossRef]
- Torres-Tramón, P.; Hromic, H.; Heravi, B.R. Topic Detection in Twitter Using Topology Data Analysis. In Proceedings of the International Conference on Web Engineering, Rotterdam, The Netherlands, 23–26 June 2015; pp. 186–197. [Google Scholar]
- Zadrozny, W.; Garbayo, L. A Sheaf Model of Contradictions and Disagreements. Preliminary Report and Discussion. arXiv, 2018; arXiv:1801.09036. [Google Scholar]
- Pereira, C.M.; de Mello, R.F. Persistent homology for time series and spatial data clustering. Expert Syst. Appl. 2015, 42, 6026–6038. [Google Scholar] [CrossRef]
- Khasawneh, F.A.; Munch, E. Stability determination in turning using persistent homology and time series analysis. In Proceedings of the ASME 2014 International Mechanical Engineering Congress and Exposition, Montreal, QC, Canada, 14–20 November 2014. [Google Scholar]
- Perea, J.A.; Harer, J. Sliding windows and persistence: An application of topological methods to signal analysis. Found. Comput. Math. 2015, 15, 799–838. [Google Scholar] [CrossRef]
- Maletić, S.; Zhao, Y.; Rajković, M. Persistent topological features of dynamical systems. Chaos Interdiscip. J. Nonlinear Sci. 2016, 26, 053105. [Google Scholar] [CrossRef] [PubMed]
- Stolz, B.J.; Harrington, H.A.; Porter, M.A. Persistent homology of time-dependent functional networks constructed from coupled time series. Chaos Interdiscip. J. Nonlinear Sci. 2017, 27, 047410. [Google Scholar] [CrossRef] [PubMed]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.J.; McClosky, D. The Stanford CoreNLP Natural Language Processing Toolkit. In Proceedings of the Association for Computational Linguistics (ACL) System Demonstrations, Baltimore, MD, USA, 22–27 June 2014; pp. 55–60. [Google Scholar]
- Fasy, B.T.; Kim, J.; Lecci, F.; Maria, C. Introduction to the R package TDA. arXiv, 2014; arXiv:1411.1830. [Google Scholar]
- Edelsbrunner, H.; Harer, J. Computational Topology: An Introduction; American Mathematical Society: Providence, RI, USA, 2010. [Google Scholar]
- Benatallah, B.; Venugopal, S.; Ryu, S.H.; Motahari-Nezhad, H.R.; Wang, W. A systematic review and comparative analysis of cross-document coreference resolution methods and tools. Computing 2017, 99, 313–349. [Google Scholar]
Sample Availability: All books used in this study were retrieved from project Gutenberg and are in US public domain. All the codes for this study are available through this link: https://github.com/shervin821/Novels_TDA.git. |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Charles Dickens | Émile Zola | Fyodor Dostoyevsky | Jane Austen | Mark Twain | Walter Scott | |
|---|---|---|---|---|---|---|
| (17) | (18) | (8) | (6) | (8) | (18) | |
| C. Dickens | - | 87.0 | 72.2 | 100.0 | 74.6 | 73.9 |
| É. Zola | 87.0 | - | 65.0 | 64.2 | 68.8 | 83.3 |
| F. Dostoyevsky | 72.2 | 65.0 | - | 90.2 | 73.3 | 55.8 |
| J. Austen | 100.0 | 64.2 | 90.2 | - | 82.9 | 94.7 |
| M. Twain | 74.6 | 68.8 | 73.3 | 82.9 | - | 68.5 |
| W. Scott | 73.9 | 83.3 | 55.8 | 94.7 | 68.5 | - |
| Average | 81.5 | 73.7 | 71.3 | 86.4 | 73.6 | 75.2 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gholizadeh, S.; Seyeditabari, A.; Zadrozny, W. Topological Signature of 19th Century Novelists: Persistent Homology in Text Mining. Big Data Cogn. Comput. 2018, 2, 33. https://doi.org/10.3390/bdcc2040033
Gholizadeh S, Seyeditabari A, Zadrozny W. Topological Signature of 19th Century Novelists: Persistent Homology in Text Mining. Big Data and Cognitive Computing. 2018; 2(4):33. https://doi.org/10.3390/bdcc2040033
Chicago/Turabian StyleGholizadeh, Shafie, Armin Seyeditabari, and Wlodek Zadrozny. 2018. "Topological Signature of 19th Century Novelists: Persistent Homology in Text Mining" Big Data and Cognitive Computing 2, no. 4: 33. https://doi.org/10.3390/bdcc2040033
APA StyleGholizadeh, S., Seyeditabari, A., & Zadrozny, W. (2018). Topological Signature of 19th Century Novelists: Persistent Homology in Text Mining. Big Data and Cognitive Computing, 2(4), 33. https://doi.org/10.3390/bdcc2040033