Mechanisms Underlying Directional Motion Processing and Form-Motion Integration Assessed with Visual Perceptual Learning

 ,
,  ,
,  , ,
, , 
Abstract
1. Introduction
2. Method
2.1. Participants
2.2. Stimuli
2.3. Apparatus
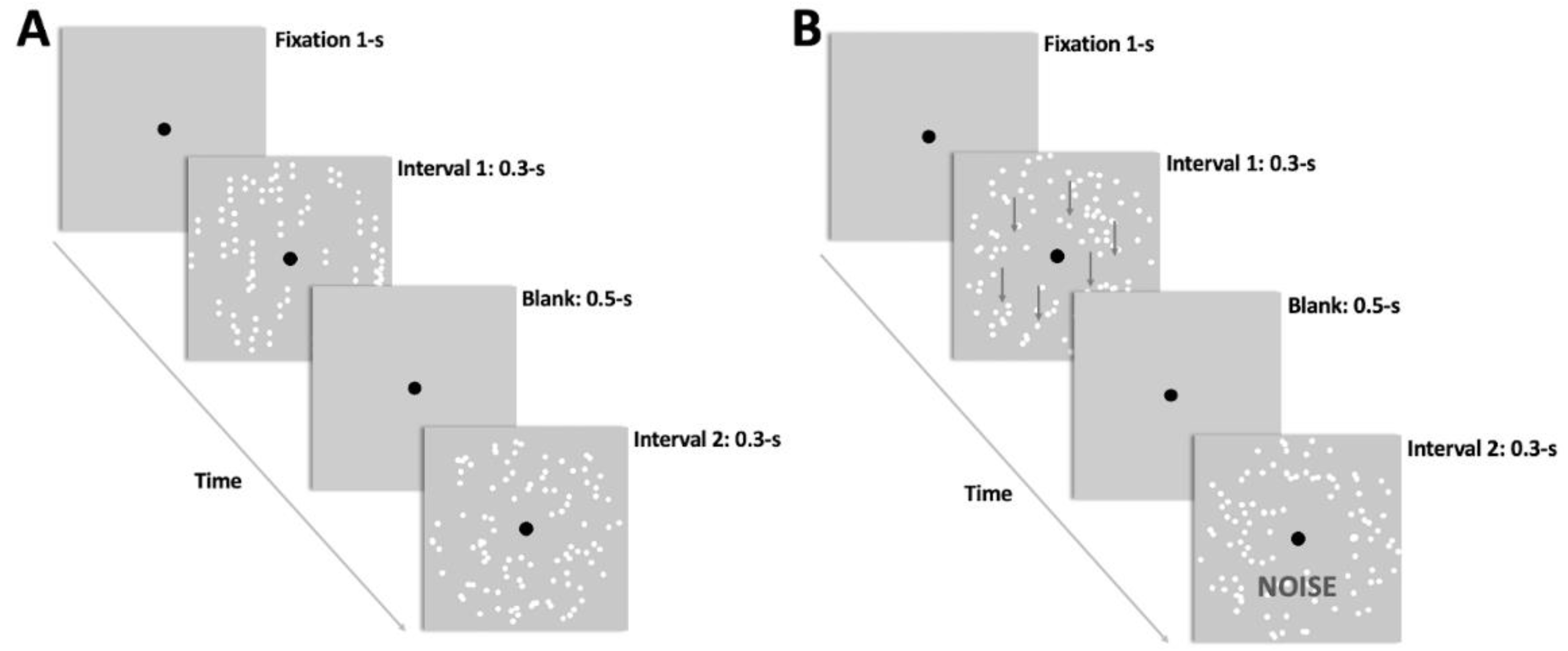
2.4. Experimental Procedure
2.4.1. Familiarization Procedure
2.4.2. Pre- and Post-Test Assessments
2.4.3. Training Procedure
2.4.4. Data Analysis
3. Results
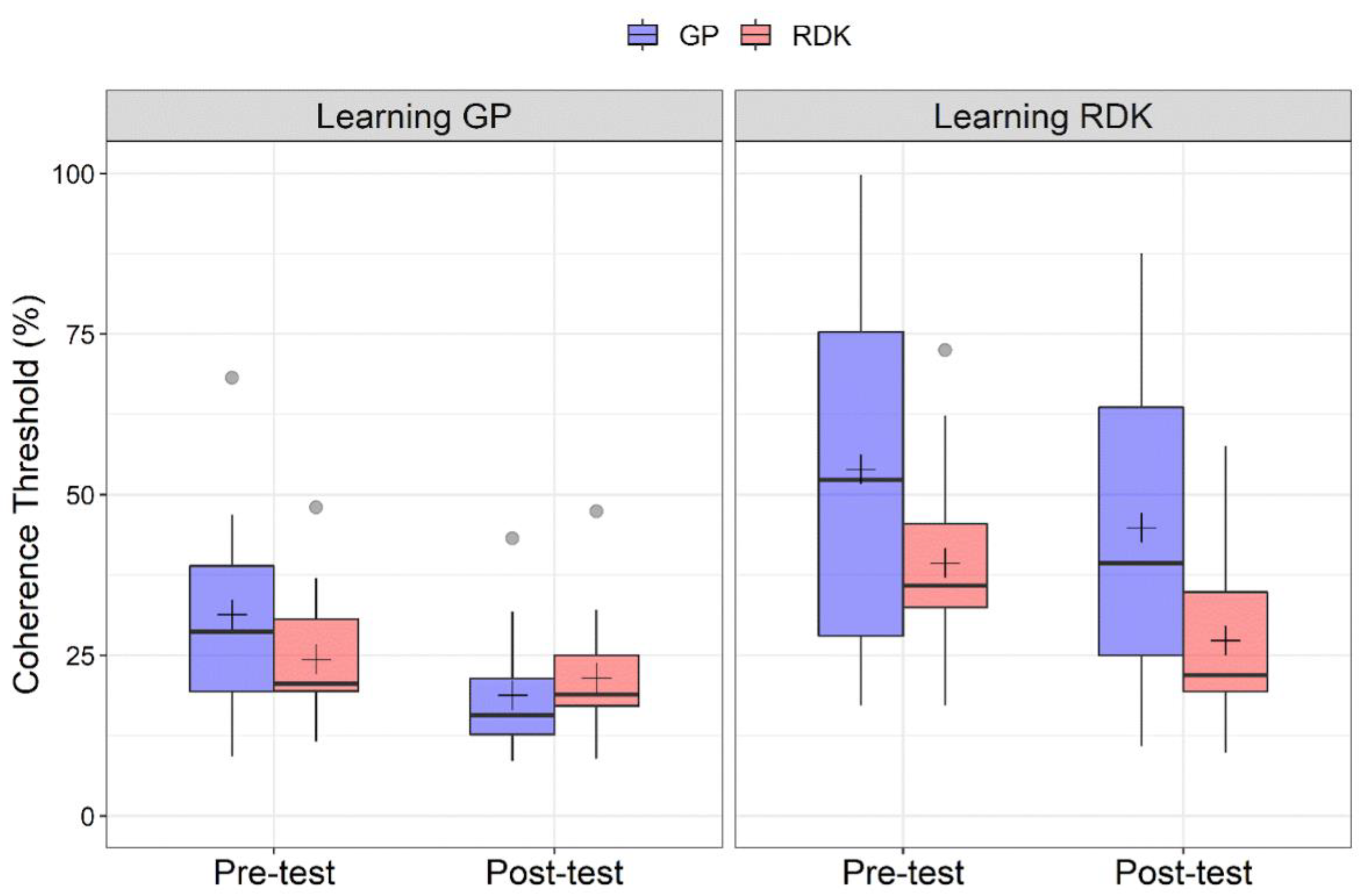
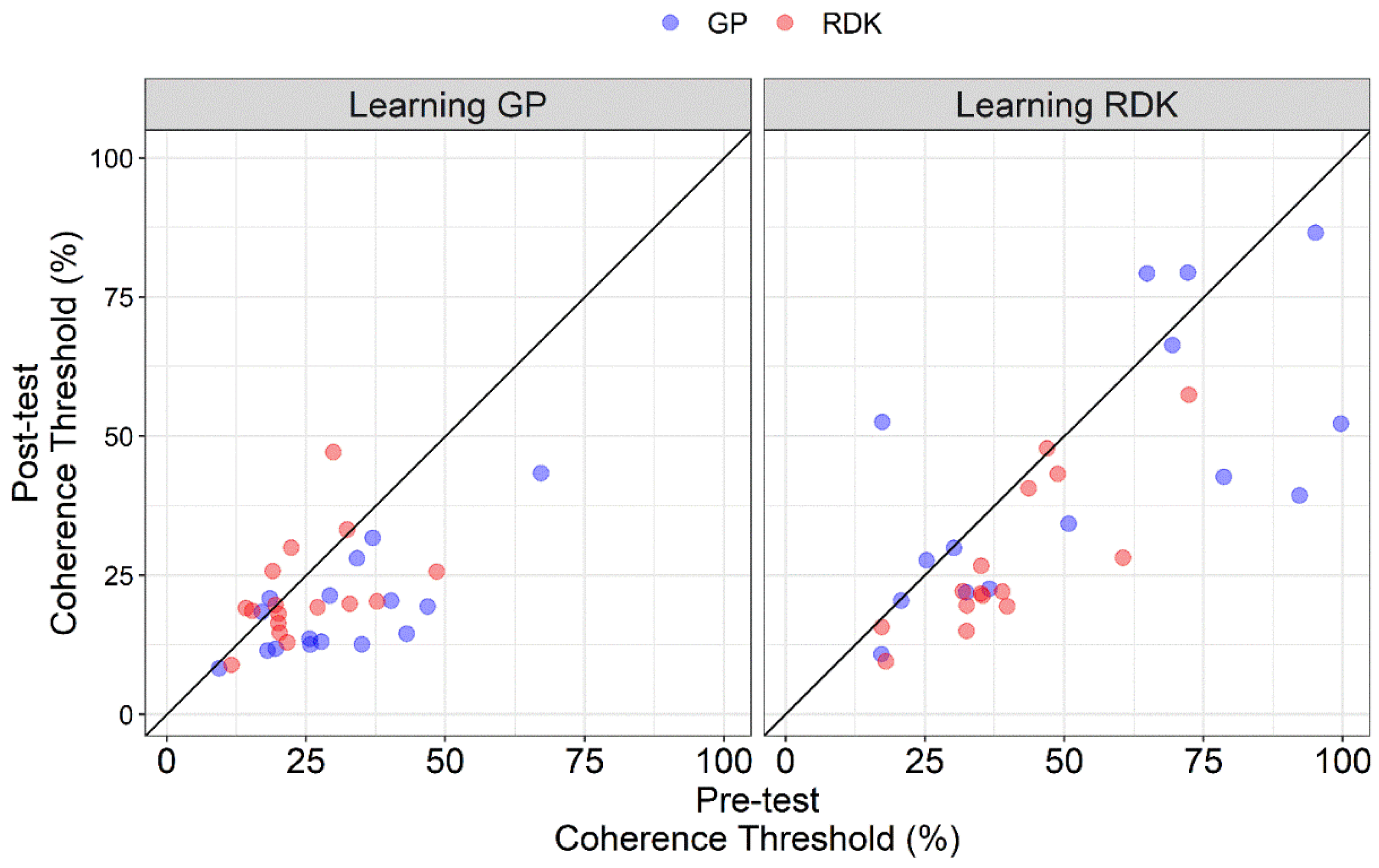
3.1. Analysis of Pre- and Post-Tests
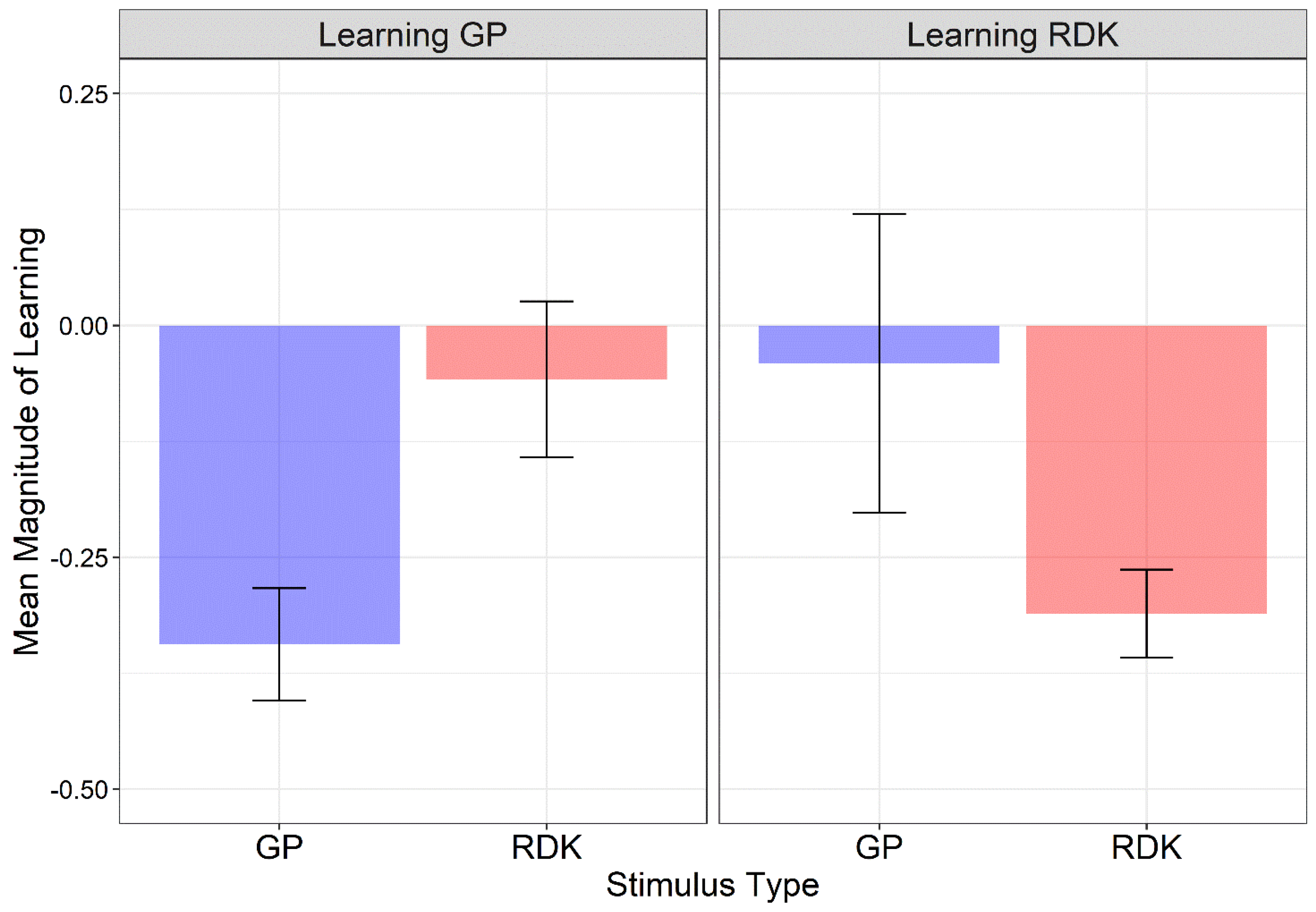
3.2. Magnitude of Learning
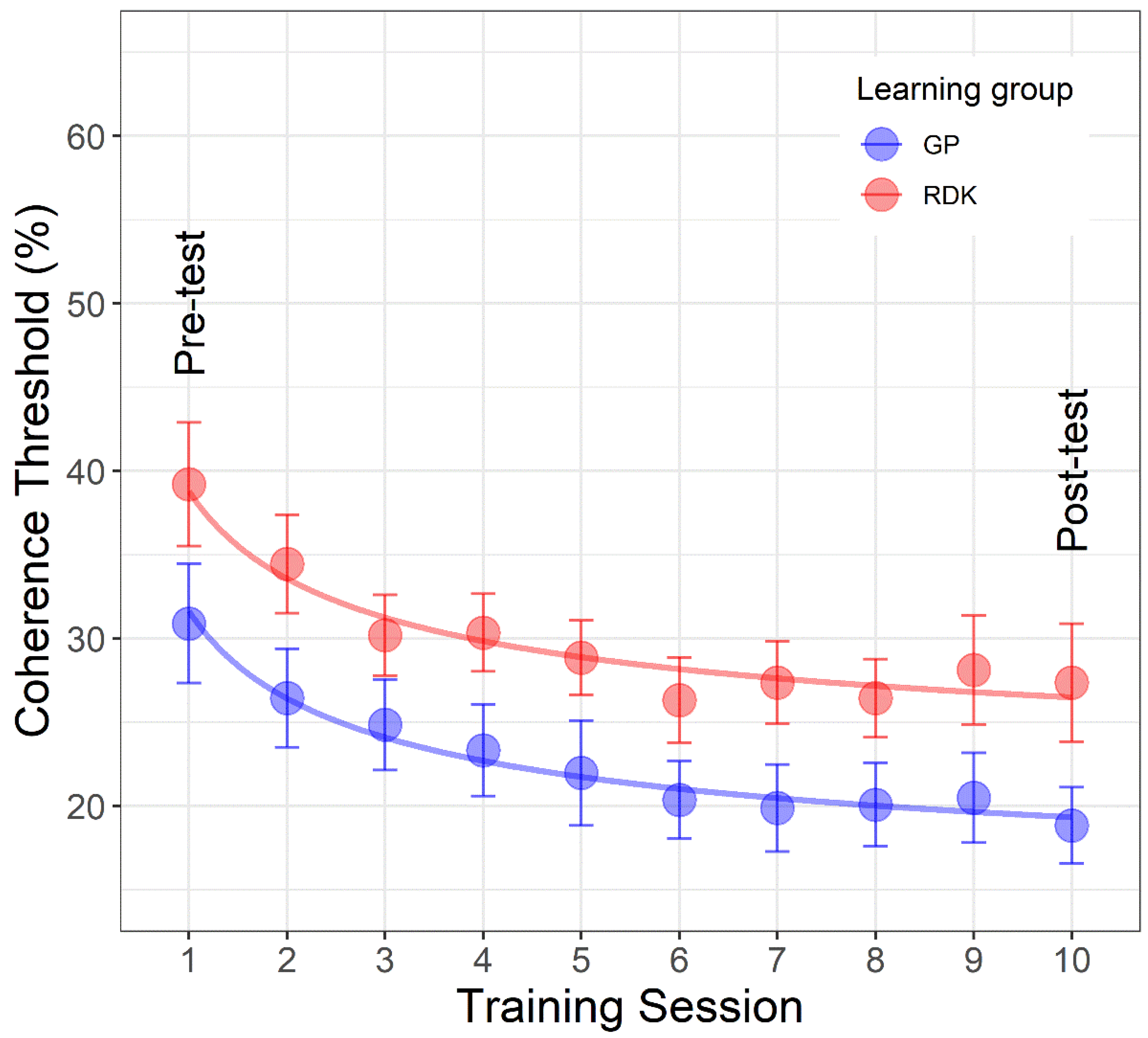
3.3. Learning Curves
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Modified 1-Up/3-Down Staircase
- gave 6 good answers in a row (2 sets of 3 correct answers);
- then gave 2 wrong answers;
- then gave 2 good answers;
- then gave 1 wrong answer;
- then gave 3 good answers.
References
- Ungerleider, L.G. Two Cortical Visual Systems. Analysis of Visual Behavior; MIT Press: Cambridge, MA, USA, 1982. [Google Scholar]
- Burr, D.C.; Ross, J. Direct Evidence That “Speedlines” Influence Motion Mechanisms. J. Neurosci. 2002, 22, 8661–8664. [Google Scholar] [CrossRef] [PubMed]
- Geisler, W.S. Motion Streaks Provide a Spatial Code for Motion Direction. Nature 1999, 400, 65–69. [Google Scholar] [CrossRef] [PubMed]
- Kourtzi, Z.; Krekelberg, B.; van Wezel, R.J.A. Linking Form and Motion in the Primate Brain. Trends Cogn. Sci. 2008, 12, 230–236. [Google Scholar] [CrossRef]
- Pavan, A.; Marotti, R.B.; Mather, G. Motion-Form Interactions beyond the Motion Integration Level: Evidence for Interactions between Orientation and Optic Flow Signals. J. Vis. 2013, 13, 16. [Google Scholar] [CrossRef] [PubMed]
- Mather, G.; Pavan, A.; Bellacosa, R.M.; Casco, C. Psychophysical Evidence for Interactions between Visual Motion and Form Processing at the Level of Motion Integrating Receptive Fields. Neuropsychologia 2012, 50, 153–159. [Google Scholar] [CrossRef] [PubMed]
- Mather, G.; Pavan, A.; Bellacosa Marotti, R.; Campana, G.; Casco, C. Interactions between Motion and Form Processing in the Human Visual System. Front. Comput. Neurosci. 2013, 7, 65. [Google Scholar] [CrossRef] [PubMed]
- Pavan, A.; Bimson, L.M.; Gall, M.G.; Ghin, F.; Mather, G. The Interaction between Orientation and Motion Signals in Moving Oriented Glass Patterns. Vis. Neurosci. 2017, 34, E010. [Google Scholar] [CrossRef] [PubMed]
- Donato, R.; Pavan, A.; Campana, G. Investigating the Interaction Between Form and Motion Processing: A Review of Basic Research and Clinical Evidence. Front. Psychol. 2020, 11, 566848. [Google Scholar] [CrossRef]
- Glass, L. Moiré Effect from Random Dots. Nature 1969, 223, 578–580. [Google Scholar] [CrossRef]
- Morgan, M.J.; Ward, R. Conditions for Motion Flow in Dynamic Visual Noise. Vis. Res. 1980, 20, 431–435. [Google Scholar] [CrossRef]
- Day, A.M.; Palomares, M. How Temporal Frequency Affects Global Form Coherence in Glass Patterns. Vis. Res. 2014, 95, 18–22. [Google Scholar] [CrossRef]
- Donato, R.; Pavan, A.; Nucci, M.; Campana, G. The Neural Mechanisms Underlying Directional and Apparent Circular Motion Assessed with Repetitive Transcranial Magnetic Stimulation (rTMS). Neuropsychologia 2020, 149, 107656. [Google Scholar] [CrossRef]
- Pavan, A.; Ghin, F.; Donato, R.; Campana, G.; Mather, G. The Neural Basis of Form and Form-Motion Integration from Static and Dynamic Translational Glass Patterns: A rTMS Investigation. Neuroimage 2017, 157, 555–560. [Google Scholar] [CrossRef]
- Pavan, A.; Contillo, A.; Ghin, F.; Donato, R.; Foxwell, M.J.; Atkins, D.W.; Mather, G.; Campana, G. Spatial and Temporal Selectivity of Translational Glass Patterns Assessed with the Tilt After-Effect. Iperception 2021, 12, 20416695211017924. [Google Scholar] [CrossRef]
- Maloney, R.K.; Mitchison, G.J.; Barlow, H.B. Limit to the Detection of Glass Patterns in the Presence of Noise. J. Opt. Soc. Am. A 1987, 4, 2336–2341. [Google Scholar] [CrossRef]
- Ross, J. The Perceived Direction and Speed of Global Motion in Glass Pattern Sequences. Vis. Res. 2004, 44, 441–448. [Google Scholar] [CrossRef]
- Apthorp, D.; Alais, D. Tilt Aftereffects and Tilt Illusions Induced by Fast Translational Motion: Evidence for Motion Streaks. J. Vis. 2009, 9, 27. [Google Scholar] [CrossRef][Green Version]
- Edwards, M.; Crane, M.F. Motion Streaks Improve Motion Detection. Vis. Res. 2007, 47, 828–833. [Google Scholar] [CrossRef]
- Apthorp, D.; Samuel Schwarzkopf, D.; Kaul, C.; Bahrami, B.; Alais, D.; Rees, G. Direct Evidence for Encoding of Motion Streaks in Human Visual Cortex. Proc. R. Soc. B Biol. Sci. 2013, 280, 20122339. [Google Scholar] [CrossRef]
- Krekelberg, B.; Vatakis, A.; Kourtzi, Z. Implied Motion from Form in the Human Visual Cortex. J. Neurophysiol. 2005, 94, 4373–4386. [Google Scholar] [CrossRef]
- Krekelberg, B.; Dannenberg, S.; Hoffmann, K.P.; Bremmer, F.; Ross, J. Neural Correlates of Implied Motion. Nature 2003, 424, 674–677. [Google Scholar] [CrossRef] [PubMed]
- Nankoo, J.F.; Madan, C.R.; Spetch, M.L.; Wylie, D.R. Perception of Dynamic Glass Patterns. Vis. Res. 2012, 72, 55–62. [Google Scholar] [CrossRef] [PubMed]
- Dosher, B.; Lu, Z.L. Visual Perceptual Learning and Models. Annu. Rev. Vis. Sci. 2017, 3, 343–363. [Google Scholar] [CrossRef] [PubMed]
- Kumano, H.; Uka, T. Neuronal Mechanisms of Visual Perceptual Learning. Behav. Brain Res. 2013, 249, 75–80. [Google Scholar] [CrossRef]
- Awada, A.; Bakhtiari, S.; Pack, C.C. Visual Perceptual Learning Generalizes to Untrained Effectors. J. Vis. 2021, 21, 10. [Google Scholar] [CrossRef]
- Sasaki, Y.; Nanez, J.E.; Watanabe, T. Advances in Visual Perceptual Learning and Plasticity. Nat. Rev. Neurosci. 2010, 11, 53–60. [Google Scholar] [CrossRef]
- Wu, D.; Zhang, P.; Li, C.; Liu, N.; Jia, W.; Chen, G.; Ren, W.; Sun, Y.; Xiao, W. Perceptual Learning at Higher Trained Cutoff Spatial Frequencies Induces Larger Visual Improvements. Front. Psychol. 2020, 11, 265. [Google Scholar] [CrossRef]
- Barollo, M.; Contemori, G.; Battaglini, L.; Pavan, A.; Casco, C. Perceptual Learning Improves Contrast Sensitivity, Visual Acuity, and Foveal Crowding in Amblyopia. Restor. Neurol. Neurosci. 2017, 35, 483–496. [Google Scholar] [CrossRef]
- Gibson, E.J. Principles of Perceptual Learning and Development. Leonardo 1973, 6, 190. [Google Scholar] [CrossRef]
- Battaglini, L.; Oletto, C.M.; Contemori, G.; Barollo, M.; Ciavarelli, A.; Casco, C. Perceptual Learning Improves Visual Functions in Patients with Albinistic Bilateral Amblyopia: A Pilot Study. Restor. Neurol. Neurosci. 2021, 39, 45–59. [Google Scholar] [CrossRef]
- Casco, C.; Campana, G.; Grieco, A.; Fuggetta, G. Perceptual Learning Modulates Electrophysiological and Psychophysical Response to Visual Texture Segmentation in Humans. Neurosci. Lett. 2004, 371, 18–23. [Google Scholar] [CrossRef]
- Lengyel, G.; Fiser, J. The Relationship between Initial Threshold, Learning, and Generalization in Perceptual Learning. J. Vis. 2019, 19, 28. [Google Scholar] [CrossRef]
- Moret, B.; Camilleri, R.; Pavan, A.; lo Giudice, G.; Veronese, A.; Rizzo, R.; Campana, G. Differential Effects of High-Frequency Transcranial Random Noise Stimulation (hf-tRNS) on Contrast Sensitivity and Visual Acuity When Combined with a Short Perceptual Training in Adults with Amblyopia. Neuropsychologia 2018, 114, 125–133. [Google Scholar] [CrossRef]
- Wu, D.; Xu, P.; Zhou, Y.; Liu, N.; Sun, K.; Xiao, W. The Effect of Initial Performance on Motion Perception Improvements Is Modulated by Training Method. Atten. Percept. Psychophys. 2022, 84, 179–187. [Google Scholar] [CrossRef]
- Campana, G.; Camilleri, R.; Pavan, A.; Veronese, A.; Giudice, G. lo Improving Visual Functions in Adult Amblyopia with Combined Perceptual Training and Transcranial Random Noise Stimulation (tRNS): A Pilot Study. Front. Psychol. 2014, 5, 1402. [Google Scholar] [CrossRef]
- Maniglia, M.; Pavan, A.; Cuturi, L.F.; Campana, G.; Sato, G.; Casco, C. Reducing Crowding by Weakening Inhibitory Lateral Interactions in the Periphery with Perceptual Learning. PLoS ONE 2011, 6, e25568. [Google Scholar] [CrossRef]
- Camilleri, R.; Pavan, A.; Campana, G. The Application of Online Transcranial Random Noise Stimulation and Perceptual Learning in the Improvement of Visual Functions in Mild Myopia. Neuropsychologia 2016, 89, 225–231. [Google Scholar] [CrossRef]
- Ahissar, M.; Hochstein, S. Task Difficulty and the Specificity of Perceptual Learning. Nature 1997, 387, 401–406. [Google Scholar] [CrossRef]
- Censor, N.; Sagi, D. Global Resistance to Local Perceptual Adaptation in Texture Discrimination. Vis. Res. 2009, 49, 2550–2556. [Google Scholar] [CrossRef]
- Fahle, M. Specificity of Learning Curvature, Orientation, and Vernier Discriminations. Vis. Res. 1997, 37, 1885–1895. [Google Scholar] [CrossRef]
- Jeter, P.E.; Dosher, B.A.; Petrov, A.; Lu, Z.L. Task Precision at Transfer Determines Specificity of Perceptual Learning. J. Vis. 2009, 9, 1. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z. Perceptual Learning in Motion Discrimination That Generalizes across Motion Directions. Proc. Natl. Acad. Sci. USA 1999, 96, 14085–14087. [Google Scholar] [CrossRef] [PubMed]
- Xiao, L.Q.; Zhang, J.Y.; Wang, R.; Klein, S.A.; Levi, D.M.; Yu, C. Complete Transfer of Perceptual Learning across Retinal Locations Enabled by Double Training. Curr. Biol. 2008, 18, 1922–1926. [Google Scholar] [CrossRef] [PubMed]
- Ball, K.; Sekuler, R. Direction-Specific Improvement in Motion Discrimination. Vis. Res. 1987, 27, 953–965. [Google Scholar] [CrossRef]
- Ball, K.; Sekuler, R. A Specific and Enduring Improvement in Visual Motion Discrimination. Science 1982, 218, 697–698. [Google Scholar] [CrossRef]
- Dosher, B.A.; Lu, Z.L. Perceptual Learning Reflects External Noise Filtering and Internal Noise Reduction through Channel Reweighting. Proc. Natl. Acad. Sci. USA 1998, 95, 13988–13993. [Google Scholar] [CrossRef]
- Fendick, M.; Westheimer, G. Effects of Practice and the Separation of Test Targets on Foveal and Peripheral Stereoacuity. Vis. Res. 1983, 23, 145–150. [Google Scholar] [CrossRef]
- Furmanski, C.S.; Engel, S.A. Perceptual Learning in Object Recognition: Object Specificity and Size Invariance. Vis. Res. 2000, 40, 473–484. [Google Scholar] [CrossRef]
- Ramachandran, V.S.; Braddick, O. Orientation Specific Learning in Stereopsis. Perception 1973, 2, 371–376. [Google Scholar] [CrossRef]
- Shiu, L.P.; Pashler, H. Improvement in Line Orientation Discrimination Is Retinally Local but Dependent on Cognitive Set. Percept. Psychophys. 1992, 52, 582–588. [Google Scholar] [CrossRef]
- Vogels, R.; Orban, G.A. The Effect of Practice on the Oblique Effect in Line Orientation Judgments. Vis. Res. 1985, 25, 1679–1687. [Google Scholar] [CrossRef]
- World Medical Association. World Medical Association Declaration of Helsinki. Bull. World Health Organ. 2013, 79, 373. [Google Scholar]
- Scase, M.O.; Braddick, O.J.; Raymond, J.E. What Is Noise for the Motion System? Vis. Res. 1996, 36, 2579–2586. [Google Scholar] [CrossRef]
- Li, Q.; Joo, S.J.; Yeatman, J.D.; Reinecke, K. Controlling for Participants’ Viewing Distance in Large-Scale, Psychophysical Online Experiments Using a Virtual Chinrest. Sci. Rep. 2020, 10, 904. [Google Scholar] [CrossRef]
- de Leeuw, J.R. JsPsych: A JavaScript Library for Creating Behavioral Experiments in a Web Browser. Behav. Res. Methods 2015, 47, 1–12. [Google Scholar] [CrossRef]
- Lange, K.; Kühn, S.; Filevich, E. “Just Another Tool for Online Studies” (JATOS): An Easy Solution for Setup and Management of Web Servers Supporting Online Studies. PLoS ONE 2015, 10, e0130834. [Google Scholar] [CrossRef]
- Levitt, H. Transformed Up-Down Methods in Psychoacoustics. J. Acoust. Soc. Am. 1971, 49, 467–477. [Google Scholar] [CrossRef]
- Breslow, N.E.; Clayton, D.G. Approximate Inference in Generalized Linear Mixed Models. J. Am. Stat. Assoc. 1993, 88, 9–25. [Google Scholar] [CrossRef]
- Stroup, W.W. Generalized Linear Mixed Models Modern Concepts, Methods and Applications; CRC Press: Boca Raton, FL, USA, 2012; ISBN 97814. Available online: https://www.Routledge.Com/Generalized-Linear-Mixed-Models-Modern-Concepts-Methods-and-Applications/Stroup/p/Book/9781439815120 (accessed on 18 April 2022).
- Jiang, J.; Nguyen, T. Linear and Generalized Linear Mixed Models and Their Applications; Springer: New York, NY, USA, 2007. [Google Scholar]
- Bates, D.M.; Kliegl, R.; Vasishth, S.; Baayen, H. Parsimonious Mixed Models Douglas Bates. arXiv 2015, arXiv:1506.04967. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021; Available online: http://www.R-project.org (accessed on 18 April 2022).
- RStudio Team. RStudio: Integrated Development for R; RStudio, Inc.: Boston, MA, USA, 2021. [Google Scholar]
- Zuur, A.F.; Ieno, E.N.; Elphick, C.S. A Protocol for Data Exploration to Avoid Common Statistical Problems. Methods Ecol. Evol. 2010, 1, 3–14. [Google Scholar] [CrossRef]
- Delignette-Muller, M.L.; Dutang, C. Fitdistrplus: An R Package for Fitting Distributions. J. Stat. Softw. 2015, 64, 1–34. [Google Scholar] [CrossRef]
- Lo, S.; Andrews, S. To Transform or Not to Transform: Using Generalized Linear Mixed Models to Analyse Reaction Time Data. Front. Psychol. 2015, 6, 1171. [Google Scholar] [CrossRef] [PubMed]
- Leys, C.; Ley, C.; Klein, O.; Bernard, P.; Licata, L. Detecting Outliers: Do Not Use Standard Deviation around the Mean, Use Absolute Deviation around the Median. J. Exp. Soc. Psychol. 2013, 49, 764–766. [Google Scholar] [CrossRef]
- Nguyen, K.N.; Watanabe, T.; Andersen, G.J. Role of Endogenous and Exogenous Attention in Task-Relevant Visual Perceptual Learning. PLoS ONE 2020, 15, e0237912. [Google Scholar] [CrossRef]
- Higgins, J.J.; Blair, R.C.; Tashtoush, S. The aligned rank transform procedure. Conf. Appl. Stat. Agric. 1990, 185–195, 185–195. [Google Scholar] [CrossRef]
- Wobbrock, J.O.; Findlater, L.; Gergle, D.; Higgins, J.J. The Aligned Rank Transform for Nonparametric Factorial Analyses Using Only ANOVA Procedures. In Proceedings of the Conference on Human Factors in Computing Systems, Vancouver, BC, Canada, 7–12 May 2011. [Google Scholar]
- Salter, K.C.; Fawcett, R.F. The Art Test of Interaction: A Robust and Powerful Rank Test of Interaction in Factorial Models. Commun. Stat. Simul. Comput. 1993, 22, 137–153. [Google Scholar] [CrossRef]
- Elkin, L.A.; Kay, M.; Higgins, J.J.; Wobbrock, J.O. An Aligned Rank Transform Procedure for Multifactor Contrast Tests. In Proceedings of the UIST 2021—Proceedings of the 34th Annual ACM Symposium on User Interface Software and Technology, Virtual Event, USA, 10–14 October 2021. [Google Scholar]
- Pavan, A.; Hobaek, M.; Blurton, S.P.; Contillo, A.; Ghin, F.; Greenlee, M.W. Visual Short-Term Memory for Coherent Motion in Video Game Players: Evidence from a Memory-Masking Paradigm. Sci. Rep. 2019, 9, 6027. [Google Scholar] [CrossRef]
- Donato, R.; Pavan, A.; Almeida, J.; Nucci, M.; Campana, G. Temporal Characteristics of Global Form Perception in Translational and Circular Glass Patterns. Vis. Res. 2021, 187, 102–109. [Google Scholar] [CrossRef]
- Bejjanki, V.R.; Zhang, R.; Li, R.; Pouget, A.; Green, C.S.; Lu, Z.L.; Bavelier, D. Action Video Game Play Facilitates the Development of Better Perceptual Templates. Proc. Natl. Acad. Sci. USA 2014, 111, 16961–16966. [Google Scholar] [CrossRef]
- Garcia, A.; Kuai, S.G.; Kourtzi, Z. Differences in the Time Course of Learning for Hard Compared to Easy Training. Front. Psychol. 2013, 4, 110. [Google Scholar] [CrossRef]
- Swettenham, J.B.; Anderson, S.J.; Thai, N.J. MEG Responses to the Perception of Global Structure within Glass Patterns. PLoS ONE 2010, 5, e13865. [Google Scholar] [CrossRef]
- Zeki, S.; Watson, J.D.G.; Frackowiak, R.S.J. Going beyond the Information given: The Relation of Illusory Visual Motion to Brain Activity. Proc. R. Soc. B Biol. Sci. 1993, 252, 215–222. [Google Scholar] [CrossRef]
- Maunsell, J.H.R.; van Essen, D.C. Functional Properties of Neurons in Middle Temporal Visual Area of the Macaque Monkey. I. Selectivity for Stimulus Direction, Speed, and Orientation. J. Neurophysiol. 1983, 49, 1127–1147. [Google Scholar] [CrossRef]
- Albright, T.D. Direction and Orientation Selectivity of Neurons in Visual Area MT of the Macaque. J. Neurophysiol. 1984, 52, 1106–1130. [Google Scholar] [CrossRef]
- Tootell, R.B.H.; Reppas, J.B.; Kwong, K.K.; Malach, R.; Born, R.T.; Brady, T.J.; Rosen, B.R.; Belliveau, J.W. Functional Analysis of Human MT and Related Visual Cortical Areas Using Magnetic Resonance Imaging. J. Neurosci. 1995, 15, 3215–3230. [Google Scholar] [CrossRef] [PubMed]
- Watson, J.D.G.; Shipp, S.; Zeki, S.; Watson, J.D.G.; Myers, R.; Frackowiak, R.S.J.; Hajnal, J.V.; Woods, R.P.; Mazziotta, J.C. Area v5 of the Human Brain: Evidence from a Combined Study Using Positron Emission Tomography and Magnetic Resonance Imaging. Cereb. Cortex 1993, 3, 79–94. [Google Scholar] [CrossRef]
- Britten, K.H.; Shadlen, M.N.; Newsome, W.T.; Movshon, J.A. The Analysis of Visual Motion: A Comparison of Neuronal and Psychophysical Performance. J. Neurosci. 1992, 12, 4745–4765. [Google Scholar] [CrossRef]
- Zeki, S.M. Functional Organization of a Visual Area in the Posterior Bank of the Superior Temporal Sulcus of the Rhesus Monkey. J. Physiol. 1974, 236, 549–573. [Google Scholar] [CrossRef]
- Zeki, S.; Watson, J.D.G.; Lueck, C.J.; Friston, K.J.; Kennard, C.; Frackowiak, R.S.J. A Direct Demonstration of Functional Specialization in Human Visual Cortex. J. Neurosci. 1991, 11, 641–649. [Google Scholar] [CrossRef]
- Assad, J.A.; Maunsell, J.H.R. Neuronal Correlates of Inferred Motion in Primate Posterior Parietal Cortex. Nature 1995, 373, 518–521. [Google Scholar] [CrossRef]
- Williams, Z.M.; Elfar, J.C.; Eskandar, E.N.; Toth, L.J.; Assad, J.A. Parietal Activity and the Perceived Direction of Ambiguous Apparent Motion. Nat. Neurosci. 2003, 6, 616–623. [Google Scholar] [CrossRef] [PubMed]
- Zihl, J.; von Cramon, D.; Mai, N. Selective Disturbance of Movement Vision after Bilateral Brain Damage. Brain 1983, 106, 313–340. [Google Scholar] [CrossRef] [PubMed]
- Beckers, G.; Homberg, V. Cerebral Visual Motion Blindness: Transitory Akinetopsia Induced by Transcranial Magnetic Stimulation of Human Area V5. Proc. R. Soc. B Biol. Sci. 1992, 249, 173–178. [Google Scholar] [CrossRef]
- Sterzer, P.; Haynes, J.D.; Rees, G. Primary Visual Cortex Activation on the Path of Apparent Motion Is Mediated by Feedback from hMT+/V5. Neuroimage 2006, 32, 1308–1316. [Google Scholar] [CrossRef]
- Johansson, G. Visual Perception of Biological Motion and a Model for Its Analysis. Percept. Psychophys. 1973, 14, 201–211. [Google Scholar] [CrossRef]
- Or, C.C.F.; Khuu, S.K.; Hayes, A. Moving Glass Patterns: Asymmetric Interaction between Motion and Form. Perception 2010, 39, 447–463. [Google Scholar] [CrossRef]
- Rubin, N.; Nakayama, K.; Shapley, R. Abrupt Learning and Retinal Size Specificity in Illusory-Contour Perception. Curr. Biol. 1997, 7, 461–467. [Google Scholar] [CrossRef][Green Version]
- Liu, Z.; Weinshall, D. Mechanisms of Generalization in Perceptual Learning. Vis. Res. 2000, 40, 812. [Google Scholar] [CrossRef]
- Ahissar, M.; Hochstein, S. The Reverse Hierarchy Theory of Visual Perceptual Learning. Trends Cogn. Sci. 2004, 8, 457–464. [Google Scholar] [CrossRef]
- Fahle, M.; Henke-Fahle, S. Interobserver Variance in Perceptual Performance and Learning. Investig. Ophthalmol. Vis. Sci. 1996, 37, 869–877. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predictors | Estimate | SE | t-Value | Pr (>|t|) |
|---|---|---|---|---|
| (Intercept) | 28.01 | 2.953 | 9.485 | <0.0001 |
| Learning Group | 19.746 | 6.341 | 3.114 | 0.0018 |
| Time (pre/post) | −10.697 | 2.677 | −3.996 | <0.0001 |
| Stimulus (GP/RDK) | −5.430 | 3.645 | −1.490 | 0.1362 |
| Group * Time | 2.475 | 4.478 | 0.552 | 0.580 |
| Group * Stimulus | −5.399 | 5.742 | −0.940 | 0.347 |
| Time * Stimulus | 7.819 | 2.350 | 3.328 | 0.0008 |
| Group * Time * Stimulus | −12.220 | 4.238 | −2.883 | 0.0039 |
| Name | Variance | SD |
|---|---|---|
| Time (Pre-test) | 244.1305 | 15.6247 |
| Time (Post-test) | 155.3663 | 12.4646 |
| Stimulus (RDK) | 152.6115 | 12.3536 |
| Residual | 0.0487 | 0.2208 |
| Group | Time | Stimulus | p-Value |
|---|---|---|---|
| Learning GP Learning RDK | Pre-test | GP | 0.0277 |
| Learning GP | Pre-test Post-test | GP | 0.0013 |
| Learning GP Learning RDK | Post-test | GP | 0.0003 |
| Learning RDK | Post-test | GP RDK | 0.0031 |
| Learning RDK | Pre-test Post-test | RDK | 0.0015 |
| Function Name | Equation | Number of Parameters |
|---|---|---|
| Fully Saturated | 6 | |
| Restricted 1 | 5 | |
| Restricted 2 | 5 | |
| Restricted 3 | 5 | |
| Restricted 4 | 4 | |
| Restricted 5 | 4 | |
| Restricted 6 | 4 | |
| Maximally Restricted | 3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Donato, R.; Pavan, A.; Cavallin, G.; Ballan, L.; Betteto, L.; Nucci, M.; Campana, G. Mechanisms Underlying Directional Motion Processing and Form-Motion Integration Assessed with Visual Perceptual Learning. Vision 2022, 6, 29. https://doi.org/10.3390/vision6020029
Donato R, Pavan A, Cavallin G, Ballan L, Betteto L, Nucci M, Campana G. Mechanisms Underlying Directional Motion Processing and Form-Motion Integration Assessed with Visual Perceptual Learning. Vision. 2022; 6(2):29. https://doi.org/10.3390/vision6020029
Chicago/Turabian StyleDonato, Rita, Andrea Pavan, Giovanni Cavallin, Lamberto Ballan, Luca Betteto, Massimo Nucci, and Gianluca Campana. 2022. "Mechanisms Underlying Directional Motion Processing and Form-Motion Integration Assessed with Visual Perceptual Learning" Vision 6, no. 2: 29. https://doi.org/10.3390/vision6020029
APA StyleDonato, R., Pavan, A., Cavallin, G., Ballan, L., Betteto, L., Nucci, M., & Campana, G. (2022). Mechanisms Underlying Directional Motion Processing and Form-Motion Integration Assessed with Visual Perceptual Learning. Vision, 6(2), 29. https://doi.org/10.3390/vision6020029