
Decision Fusion at Pixel Level of Multi-Band Data for Land Cover Classification—A Review



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. Hyperspectral Data
1.2. Multispectral Data
1.3. SAR and Optical Data
2. A Two-Step Decision Fusion of Hyperspectral and Multispectral Images for Urban Classification [18]
- At the observation level: This involves the combination of a high-resolution panchromatic (PAN) image with a lower-resolution multispectral image to generate a high-resolution multispectral image. A comprehensive overview of these types of methods can be found in reference [81].
2.1. Fuzzy Rules
- (1)
- A conjunctive T-norm Min operator:
- (2)
- A disjunctive T-norm Max operator:
- (3)
- A compromise operator [89]:
- -
- When the dissension between and is low (i.e., ), the operator action is conjunctive.
- -
- When the dissention between and is high (i.e., ), the operator action is disjunctive.
- -
- When the dissention is partial (i.e., ), the operator acts in a compromise way.
- (4)
- (5)
- An accuracy-dependent (AD) operator [72] takes into account local and global confidence measurements:
2.2. Bayesian Combination
2.3. Margin-Based Rule (Margin-Max)
2.4. Dempster–Shafer Evidence Theory-Based Rule
- -
- -
- Simple classes: ∀pixel , and , , where is the mass affected in class by source , and P is a pointwise membership probability of the considered class.
- -
- Compound classes: The compound class masses are here generated as follows: ∀pixel and .
2.5. Global Regularization
3. Decision Fusion of Hyperspectral Data Based on Markov and Conditional Random Fields [24]
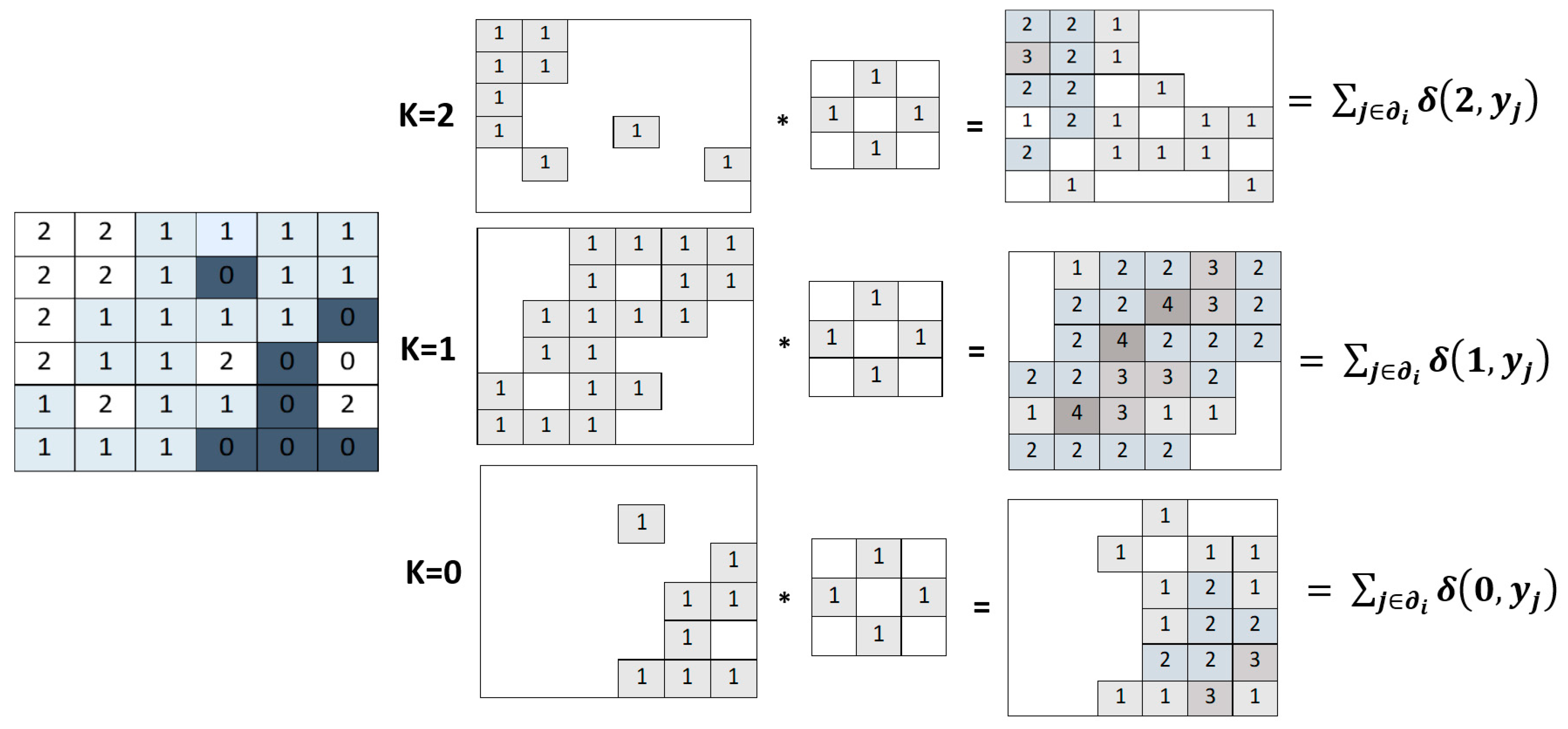
3.1. MRF Regularization
3.2. CRF Regularization
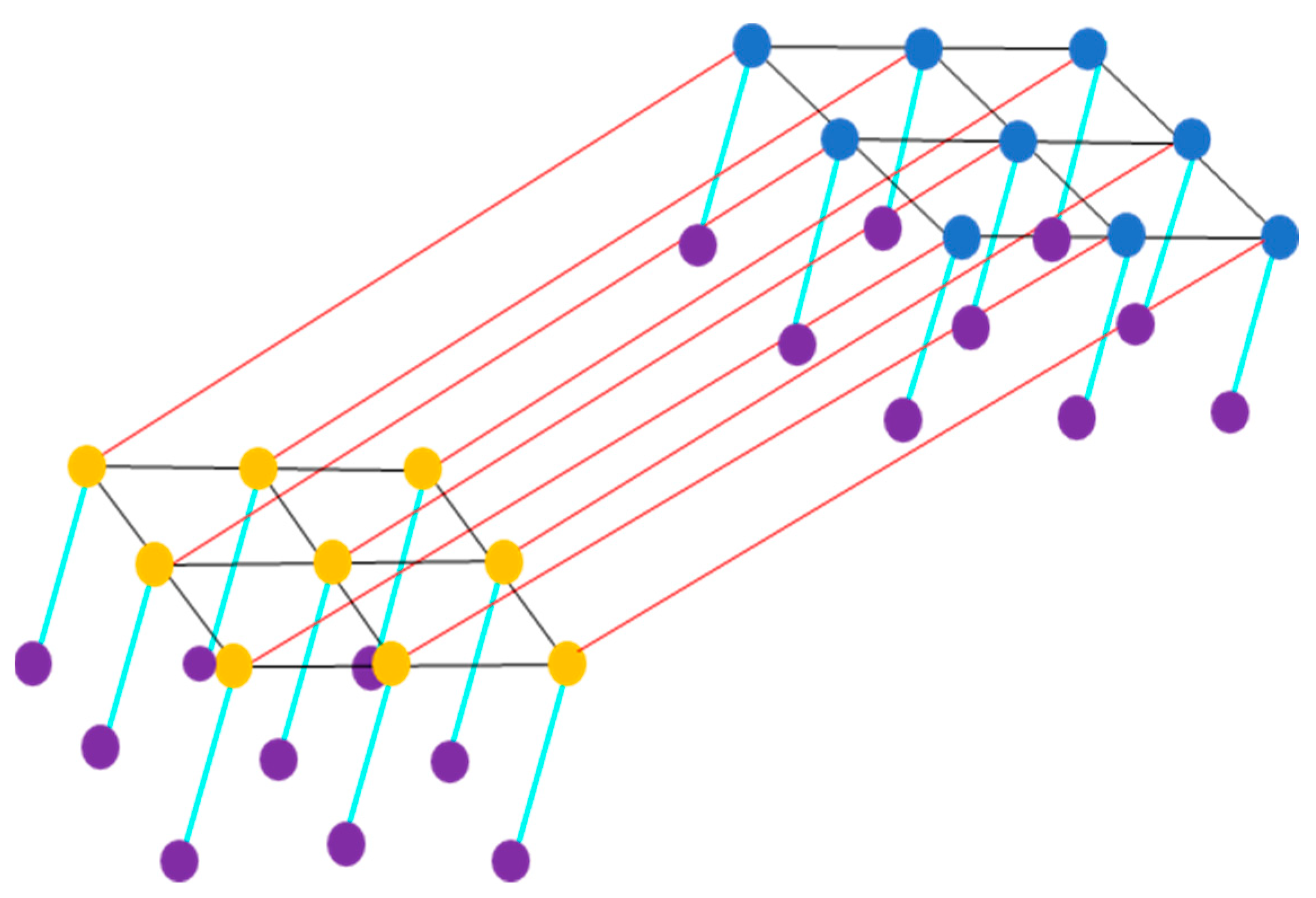
3.3. The Decision Sources
3.4. MRF Incorporating Cross-Links for Fusion (MRFL)
3.5. CRF with Cross-Links for Fusion (CRFL)
4. Integrating MODIS and Landsat Data for Land Cover Classification by Multilevel Decision Rule
4.1. Comprehensive Fusion Strategy
4.2. Fuzzy Classification and Operation
4.3. Uncertainty and Decision
5. Decision Fusion of Optical and SAR Images [77]
5.1. Fusion with Partially Overlapping Sets of Classes
5.2. Fast Formulation of ICM
6. SAR Image Fusion Classification Based on the Decision-Level Combination of Multi-Band Information [71]
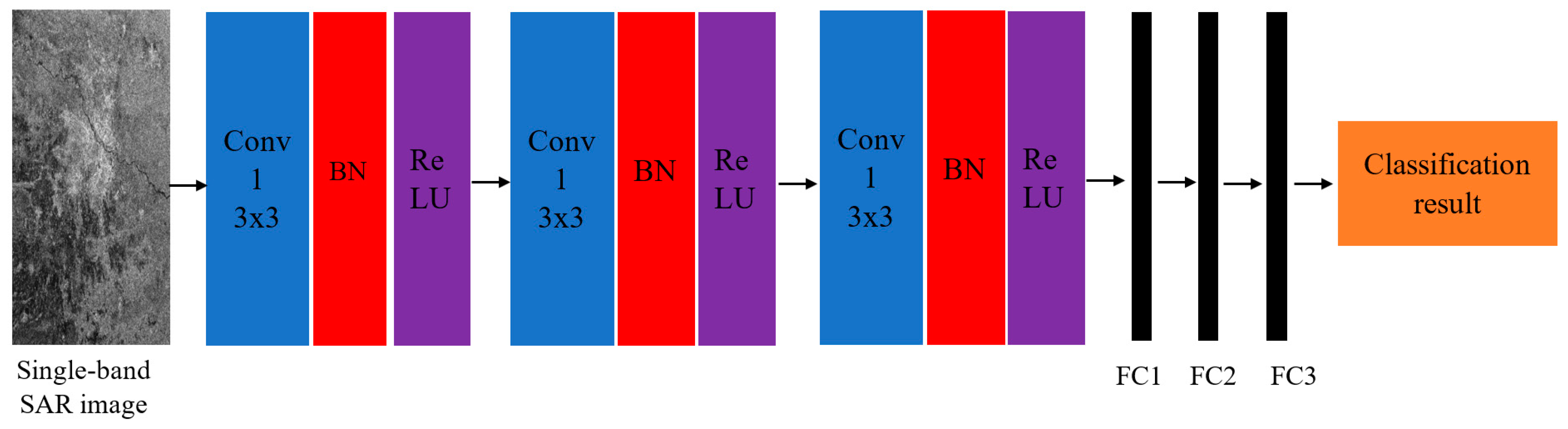
6.1. Single-Band SAR Image Classification Based on CNN
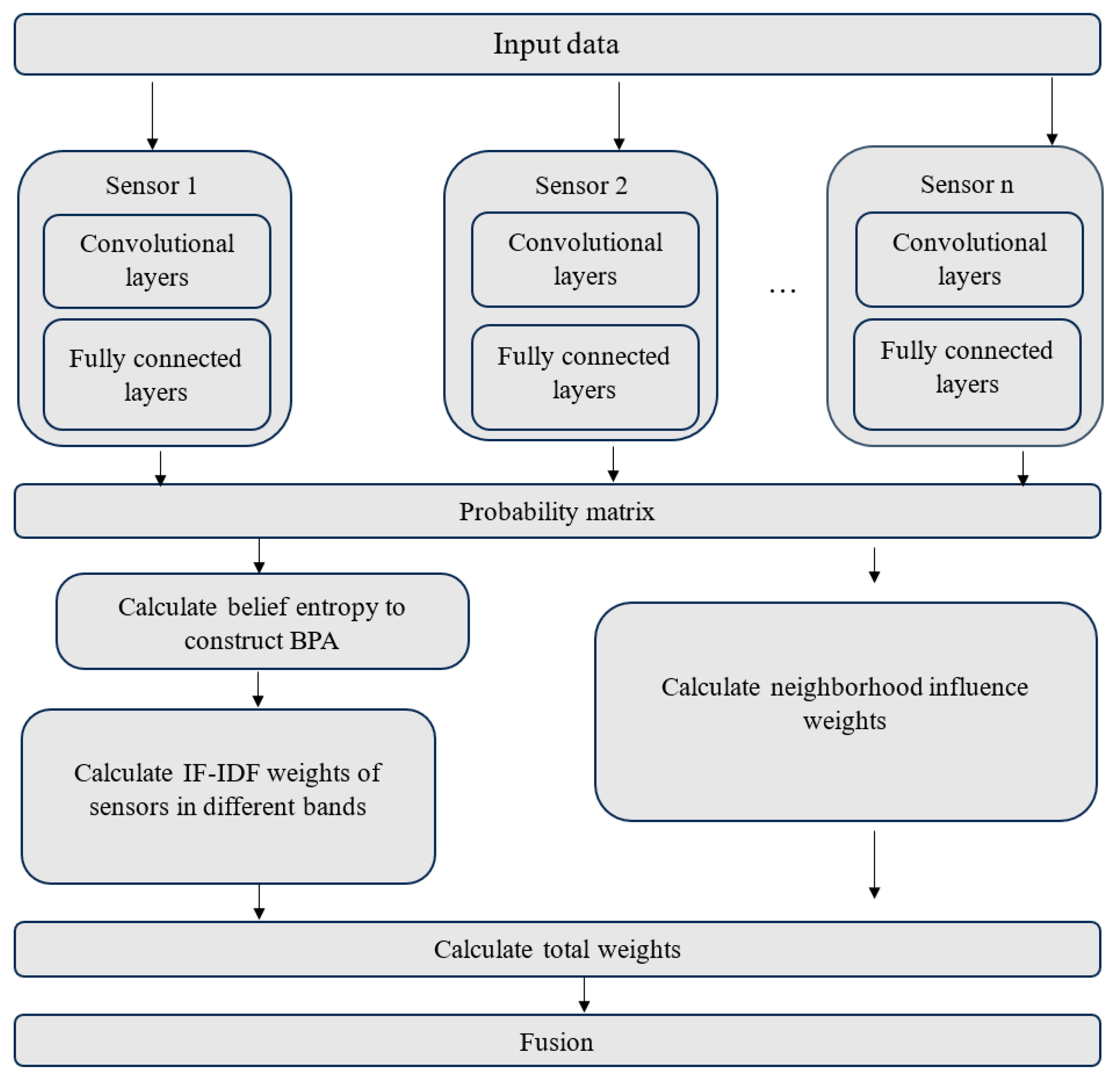
6.2. Method for SAR Image Classification through Decision-Level Fusion of Multi-Band Information
7. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jimenez, L.O.; Morales-Morell, A.; Creus, A. Classification of Hyperdimensional Data Based on Feature and Decision Fusion Approaches Using Projection Pursuit, Majority Voting, and Neural Networks. IEEE Trans. Geosci. Remote Sens. 1999, 37, 1360–1366. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Kanellopoulos, I. Classification of Multisource and Hyperspectral Data Based on Decision Fusion. IEEE Trans. Geosci. Remote Sens. 1999, 37, 1367–1377. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Palmason, J.A.; Sveinsson, J.R.; Chanussot, J. Decision Level Fusion in Classification of Hyperspectral Data from Urban Areas. In Proceedings of the 2004 IEEE International Geoscience and Remote Sensing Symposium, Anchorage, AK, USA, 20–24 September 2004. [Google Scholar] [CrossRef]
- Prasad, S.; Bruce, L. Hemanth Kalluri A Robust Multi-Classifier Decision Fusion Framework for Hyperspectral, Multi-Temporal Classification. In Proceedings of the IGARSS 2008-2008 IEEE International Geoscience and Remote Sensing Symposium, Boston, MA, USA, 7–11 July 2008. [Google Scholar] [CrossRef]
- Prasad, S.; Bruce, L.M. Decision Fusion with Confidence-Based Weight Assignment for Hyperspectral Target Recognition. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1448–1456. [Google Scholar] [CrossRef]
- Du, Q. Decision Fusion for Classifying Hyperspectral Imagery with High Spatial Resolution. SPIE Newsroom 2009, 1–3. [Google Scholar] [CrossRef]
- Yang, H.; Du, Q.; Ma, B. Decision Fusion on Supervised and Unsupervised Classifiers for Hyperspectral Imagery. IEEE Geosci. Remote Sens. Lett. 2010, 7, 875–879. [Google Scholar] [CrossRef]
- Kalluri, H.R.; Prasad, S.; Bruce, L.M. Decision-Level Fusion of Spectral Reflectance and Derivative Information for Robust Hyperspectral Land Cover Classification. IEEE Trans. Geosci. Remote Sens. 2010, 48, 4047–4058. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L. A Multilevel Decision Fusion Approach for Urban Mapping Using Very High-Resolution Multi/Hyperspectral Imagery. Int. J. Remote Sens. 2011, 33, 3354–3372. [Google Scholar] [CrossRef]
- Thoonen, G.; Mahmood, Z.; Peeters, M.; Scheunders, P. Multisource Classification of Color and Hyperspectral Images Using Color Attribute Profiles and Composite Decision Fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 510–521. [Google Scholar] [CrossRef]
- Song, B.; Li, J.; Li, P.; Plaza, A. Decision Fusion Based on Extended Multi-Attribute Profiles for Hyperspectral Image Classification. In Proceedings of the 2013 5th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS), Gainesville, FL, USA, 26–28 June 2013. [Google Scholar] [CrossRef]
- Li, W.; Prasad, S.; Fowler, J.E. Decision Fusion in Kernel-Induced Spaces for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 3399–3411. [Google Scholar] [CrossRef]
- Bigdeli, B.; Samadzadegan, F.; Reinartz, P. A Decision Fusion Method Based on Multiple Support Vector Machine System for Fusion of Hyperspectral and LIDAR Data. Int. J. Image Data Fusion 2014, 5, 196–209. [Google Scholar] [CrossRef]
- Ye, Z.; Prasad, S.; Li, W.; Fowler, J.H.; He, M. Classification Based on 3-D DWT and Decision Fusion for Hyperspectral Image Analysis. IEEE Geosci. Remote Sens. Lett. 2014, 11, 173–177. [Google Scholar] [CrossRef]
- Li, W.; Chen, C.; Su, H.; Du, Q. Local Binary Patterns and Extreme Learning Machine for Hyperspectral Imagery Classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3681–3693. [Google Scholar] [CrossRef]
- Shokrollahi, M.; Ebadi, H. Improving the Accuracy of Land Cover Classification Using Fusion of Polarimetric SAR and Hyperspectral Images. J. Indian Soc. Remote Sens. 2016, 44, 1017–1024. [Google Scholar] [CrossRef]
- Li, S.; Lu, T.; Fang, L.; Jiang, Z.-P. Jon Atli Benediktsson Probabilistic Fusion of Pixel-Level and Superpixel-Level Hyperspectral Image Classification. IEEE Geosci. Remote Sens. 2016, 54, 7416–7430. [Google Scholar] [CrossRef]
- Ouerghemmi, W.; Le Bris, A.; Chehata, N.; Mallet, C. A two-step decision fusion strategy: Application to hyperspectral and multispectral images for urban classification. ISPRS J. Photogramm. 2017, XLII-1/W1, 167–174. [Google Scholar] [CrossRef]
- Ye, Z.; Bai, L. Yongjian Nian Decision Fusion for Hyperspectral Image Classification Based on Multiple Features and Locality-Preserving Analysis. Eur. J. Remote Sens. 2017, 50, 166–178. [Google Scholar] [CrossRef]
- Kumar, B. Onkar Dikshit Hyperspectral Image Classification Based on Morphological Profiles and Decision Fusion. Int. J. Remote Sens. 2017, 38, 5830–5854. [Google Scholar] [CrossRef]
- Bo, C.; Lu, H. Ben Zhong Tang Hyperspectral Image Classification via JCR and SVM Models with Decision Fusion. IEEE Geosci. Remote Sens. Lett. 2016, 13, 177–181. [Google Scholar] [CrossRef]
- Ye, Z.; Bai, L. Lian Huat Tan Hyperspectral Image Classification Based on Gabor Features and Decision Fusion. In Proceedings of the 2017 2nd International Conference on Image, Vision and Computing (ICIVC), Chengdu, China, 2–4 June 2017. [Google Scholar] [CrossRef]
- Zhong, Y.; Cao, Q.; Zhao, J.; Ma, A.; Zhao, B.; Zhang, L. Optimal Decision Fusion for Urban Land-Use/Land-Cover Classification Based on Adaptive Differential Evolution Using Hyperspectral and LiDAR Data. Remote Sens. 2017, 9, 868. [Google Scholar] [CrossRef]
- Andrejchenko, V.; Liao, W.; Philips, W.; Scheunders, P. Decision Fusion Framework for Hyperspectral Image Classification Based on Markov and Conditional Random Fields. Remote Sens. 2019, 11, 624. [Google Scholar] [CrossRef]
- Hu, Y.; Zhang, J.; Ma, Y.; An, J.; Ren, G.; Li, X. Hyperspectral Coastal Wetland Classification Based on a Multiobject Convolutional Neural Network Model and Decision Fusion. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1110–1114. [Google Scholar] [CrossRef]
- Jia, S.; Zhan, Z.; Zhang, R.; Xu, M.; Ceccarelli, M.; Zhou, J.; Jiang, Z.-P. Multiple Feature-Based Superpixel-Level Decision Fusion for Hyperspectral and LiDAR Data Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1437–1452. [Google Scholar] [CrossRef]
- Wang, Q.; Gu, Y.; Tuia, D. Discriminative Multiple Kernel Learning for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3912–3927. [Google Scholar] [CrossRef]
- Jeon, B.; Landgrebe, D.A. Decision Fusion Approach for Multitemporal Classification. IEEE Trans. Geosci. Remote Sens. 1999, 37, 1227–1233. [Google Scholar] [CrossRef]
- Petrakos, M.; Atli Benediktsson, J.; Kanellopoulos, I. The Effect of Classifier Agreement on the Accuracy of the Combined Classifier in Decision Level Fusion. IEEE Trans. Geosci. Remote Sens. 2001, 39, 2539–2546. [Google Scholar] [CrossRef]
- Moshiri, B.; Besharati, F. Remote Sensing Images Classifications Based on Decision Fusion. 2002. Available online: https://www.researchgate.net/profile/Behzad-Moshiri/publication/255662297_Remote_sensing_images_classifications_based_on_decision_fusion/links/54e5fe030cf2cd2e028b59d2/Remote-sensing-images-classifications-based-on-decision-fusion.pdf (accessed on 1 August 2023).
- Zhao, S.; Chen, X.; Wang, S.; Li, J.; Yang, W. A New Method of Remote Sensing Image Decision-Level Fusion Based on Support Vector Machine. In Proceedings of the International Conference on Recent Advances in Space Technologies, Istanbul, Turkey, 20–22 November 2003. [Google Scholar] [CrossRef]
- Mitrakis, N.E.; Topaloglou, C.A.; Alexandridis, T.K.; Theocharis, J.B.; Zalidis, G.C. Decision Fusion of GA Self-Organizing Neuro-Fuzzy Multilayered Classifiers for Land Cover Classification Using Textural and Spectral Features. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2137–2152. [Google Scholar] [CrossRef]
- Farah, I.R.; Boulila, W.; Ettabaa, K.S.; Ahmed, M.B. Multiapproach System Based on Fusion of Multispectral Images for Land-Cover Classification. IEEE Trans. Geosci. Remote Sens. 2008, 46, 4153–4161. [Google Scholar] [CrossRef]
- García, M.; Riaño, D.; Chuvieco, E.; Salas, J.; Danson, F.M. Multispectral and LiDAR Data Fusion for Fuel Type Mapping Using Support Vector Machine and Decision Rules. Remote Sens. Environ. 2011, 115, 1369–1379. [Google Scholar] [CrossRef]
- Li, Q.; Tao, J.; Hu, Q.; Liu, P. Decision Fusion of Very High Resolution Images for Urban Land-Cover Mapping Based on Bayesian Network. J. Appl. Remote Sens. 2013, 7, 073551. [Google Scholar] [CrossRef]
- Song, B.; Li, P. A Novel Decision Fusion Method Based on Weights of Evidence Model. Int. J. Image Data Fusion 2014, 5, 123–137. [Google Scholar] [CrossRef]
- Shingare, P.; Hemane, P.M.; Dandekar, D.S. Fusion Classification of Multispectral and Panchromatic Image Using Improved Decision Tree Algorithm. In Proceedings of the 2014 International Conference on Signal Propagation and Computer Technology, Ajmer, India, 12–13 July 2014. [Google Scholar] [CrossRef]
- Mahmoudi, F.; Samadzadegan, F.; Reinartz, P. Object Recognition Based on the Context Aware Decision-Level Fusion in Multiviews Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 12–22. [Google Scholar] [CrossRef]
- Wang, J.; Li, C.; Gong, P. Adaptively Weighted Decision Fusion in 30 M Land-Cover Mapping with Landsat and MODIS Data. Int. J. Remote Sens. 2015, 36, 3659–3674. [Google Scholar] [CrossRef]
- Löw, F.; Conrad, C.; Michel, U. Decision Fusion and Non-Parametric Classifiers for Land Use Mapping Using Multi-Temporal RapidEye Data. ISPRS J. Photogramm. 2015, 108, 191–204. [Google Scholar] [CrossRef]
- Guan, X.; Liu, G.; Huang, C.; Liu, Q.; Jin, Y.; Li, Y. An Object-Based Linear Weight Assignment Fusion Scheme to Improve Classification Accuracy Using Landsat and MODIS Data at the Decision Level. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6989–7002. [Google Scholar] [CrossRef]
- Wang, G.; Li, A.; He, G.; Liu, J.; Zhang, Z.; Wang, M. Classification of High Spatial Resolution Remote Sensing Images Based on Decision Fusion. J. Adv. Inf. Technol. 2017, 8, 42–46. [Google Scholar] [CrossRef]
- Zhang, C.; Pan, X.; Li, H.; Gardiner, A.; Sargent, I.; Hare, J.; Atkinson, P.M. A Hybrid MLP-CNN Classifier for Very Fine Resolution Remotely Sensed Image Classification. ISPRS J. Photogramm. 2018, 140, 133–144. [Google Scholar] [CrossRef]
- Zhang, C.; Sargent, I.; Pan, X.; Gardiner, A.; Hare, J.; Atkinson, P.M. VPRS-Based Regional Decision Fusion of CNN and MRF Classifications for Very Fine Resolution Remotely Sensed Images. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4507–4521. [Google Scholar] [CrossRef]
- Zhao, B.; Tang, P.; Yan, J. Land-Cover Classification from Multiple Classifiers Using Decision Fusion Based on the Probabilistic Graphical Model. Int. J. Remote Sens. 2019, 40, 4560–4576. [Google Scholar] [CrossRef]
- Chen, S.; Useya, J.; Mugiyo, H. Decision-Level Fusion of Sentinel-1 SAR and Landsat 8 OLI Texture Features for Crop Discrimination and Classification: Case of Masvingo, Zimbabwe. Heliyon 2020, 6, e05358. [Google Scholar] [CrossRef]
- Bui, D.H.; Mucsi, L. From Land Cover Map to Land Use Map: A Combined Pixel-Based and Object-Based Approach Using Multi-Temporal Landsat Data, a Random Forest Classifier, and Decision Rules. Remote Sens. 2021, 13, 1700. [Google Scholar] [CrossRef]
- Guan, X.; Huang, C.; Zhang, R. Integrating MODIS and Landsat Data for Land Cover Classification by Multilevel Decision Rule. Land 2021, 10, 208. [Google Scholar] [CrossRef]
- Jin, Y.; Guan, X.; Ge, Y.; Jia, Y.; Li, W. Improved Spatiotemporal Information Fusion Approach Based on Bayesian Decision Theory for Land Cover Classification. Remote Sens. 2022, 14, 6003. [Google Scholar] [CrossRef]
- Ge, C.; Ding, H.; Molina, I.; He, Y.; Peng, D. Object-Oriented Change Detection Method Based on Spectral–Spatial–Saliency Change Information and Fuzzy Integral Decision Fusion for HR Remote Sensing Images. Remote Sens. 2022, 14, 3297. [Google Scholar] [CrossRef]
- Stankevich, S.A.; Levashenko, V.; Zaitseva, E. Fuzzy Decision Tree Model Adaptation to Multi- and Hyperspectral Imagery Supervised Classification. In Proceedings of the International Conference on Digital Technologies, Zilina, Slovakia, 29–31 May 2013. [Google Scholar] [CrossRef]
- Bui, D.H.; Mucsi, L. Comparison of Layer-Stacking and Dempster-Shafer Theory-Based Methods Using Sentinel-1 and Sentinel-2 Data Fusion in Urban Land Cover Mapping. Geo-Spat. Inf. Sci. 2022, 25, 425–438. [Google Scholar] [CrossRef]
- Cloude, S.R.; Pottier, E. A Review of Target Decomposition Theorems in Radar Polarimetry. IEEE Trans. Geosci. Remote Sens. 1996, 34, 498–518. [Google Scholar] [CrossRef]
- Freeman, A.; Durden, S.L. A Three-Component Scattering Model for Polarimetric SAR Data. IEEE Trans. Geosci. Remote Sens. 1998, 36, 963–973. [Google Scholar] [CrossRef]
- Yamaguchi, Y.; Moriyama, T.; Ishido, M.; Yamada, H. Four-Component Scattering Model for Polarimetric SAR Image Decomposition. IEEE Trans. Geosci. Remote Sens. 2005, 43, 1699–1706. [Google Scholar] [CrossRef]
- Cameron, W.L.; Rais, H. Conservative Polarimetric Scatterers and Their Role in Incorrect Extensions of the Cameron Decomposition. IEEE Trans. Geosci. Remote Sens. 2006, 44, 3506–3516. [Google Scholar] [CrossRef]
- Krogager, E. New Decomposition of the Radar Target Scattering Matrix. Electron. Lett. 1990, 26, 1525. [Google Scholar] [CrossRef]
- Vanzyl, J.J. Application of Cloude’s Target Decomposition Theorem to Polarimetric Imaging Radar Data. Radar Polarim. 1993, 1748, 184–191. [Google Scholar] [CrossRef]
- Touzi, R. Target Scattering Decomposition in Terms of Roll-Invariant Target Parameters. IEEE Trans. Geosci. Remote Sens. 2007, 45, 73–84. [Google Scholar] [CrossRef]
- Yang, M.-S.; Moon, W.M. Decision Level Fusion of Multi-Frequency Polarimetric SAR and Optical Data with Dempster-Shafer Evidence Theory. In Proceedings of the IGARSS 2003—2003 IEEE International Geoscience and Remote Sensing Symposium, Toulouse, France, 21–25 July 2004. [Google Scholar] [CrossRef]
- Ban, Y.; Hu, H.; Rangel, I. Fusion of RADARSAT Fine-Beam SAR and QuickBird Data for Land-Cover Mapping and Change Detection. Proc. SPIE 2007, 6752, 871–881. [Google Scholar] [CrossRef]
- Waske, B.; van der Linden, S. Classifying Multilevel Imagery from SAR and Optical Sensors by Decision Fusion. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1457–1466. [Google Scholar] [CrossRef]
- Cui, M.; Prasad, S.; Mahrooghy, M.; Aanstoos, J.V.; Lee, M.A.; Bruce, L.M. Decision Fusion of Textural Features Derived from Polarimetric Data for Levee Assessment. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 970–976. [Google Scholar] [CrossRef]
- Gokhan Kasapoglu, N. Torbjørn Eltoft Decision Fusion of Classifiers for Multifrequency PolSAR and Optical Data Classification. In Proceedings of the 2013 6th International Conference on Recent Advances in Space Technologies (RAST), Istanbul, Turkey, 12–14 June 2013. [Google Scholar] [CrossRef]
- Abdikan, S.; Bilgin, G.; Sanli, F.B.; Uslu, E.; Ustuner, M. Enhancing Land Use Classification with Fusing Dual-Polarized TerraSAR-X and Multispectral RapidEye Data. J. Appl. Remote Sens. 2015, 9, 096054. [Google Scholar] [CrossRef]
- Mazher, A.; Li, P. A Decision Fusion Method for Land Cover Classification Using Multi-Sensor Data. In Proceedings of the Fourth International Workshop on Earth Observation and Remote Sensing Applications, Guangzhou, China, 4–6 July 2016. [Google Scholar] [CrossRef]
- Shao, Z.; Fu, H.; Fu, P.; Yin, L. Mapping Urban Impervious Surface by Fusing Optical and SAR Data at the Decision Level. Remote Sens. 2016, 8, 945. [Google Scholar] [CrossRef]
- Khosravi, I.; Safari, A.; Homayouni, S.; McNairn, H. Enhanced Decision Tree Ensembles for Land-Cover Mapping from Fully Polarimetric SAR Data. Int. J. Remote Sens. 2017, 38, 7138–7160. [Google Scholar] [CrossRef]
- Fernandez-Beltran, R.; Haut, J.M.; Paoletti, M.E.; Plaza, J.; Plaza, A.; Pla, F. Remote Sensing Image Fusion Using Hierarchical Multimodal Probabilistic Latent Semantic Analysis. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4982–4993. [Google Scholar] [CrossRef]
- Chen, Y.; He, X.; Xu, J.; Guo, L.; Lu, Y.; Zhang, R. Decision Tree-Based Classification in Coastal Area Integrating Polarimetric SAR and Optical Data. Data Technol. Appl. 2021, 56, 342–357. [Google Scholar] [CrossRef]
- Zhu, J.; Pan, J.; Jiang, W.; Yue, X.; Yin, P. SAR Image Fusion Classification Based on the Decision-Level Combination of Multi-Band Information. Remote Sens. 2022, 14, 2243. [Google Scholar] [CrossRef]
- Fauvel, M.; Chanussot, J.; Benediktsson, J.A. Decision Fusion for the Classification of Urban Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2828–2838. [Google Scholar] [CrossRef]
- Cervone, G.; Haack, B. Supervised Machine Learning of Fused RADAR and Optical Data for Land Cover Classification. J. Appl. Remote Sens. 2012, 6, 063597. [Google Scholar] [CrossRef]
- Seresht, M.K.; Ghassemian, H. Remote Sensing Panchromatic Images Classification Using Moment Features and Decision Fusion. In Proceedings of the Iranian Conference on Electrical Engineering (ICEE), Shiraz, Iran, 10–12 May 2016. [Google Scholar] [CrossRef]
- Wendl, C.; Le Bris, A.; Chehata, N.; Puissant, A.; Postadjian, T. Decision Fusion of Spot6 and Multitemporal Sentinel2 Images for Urban Area Detection. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018. [Google Scholar] [CrossRef]
- Xu, L.; Chen, Y.; Pan, J.; Gao, A. Multi-Structure Joint Decision-Making Approach for Land Use Classification of High-Resolution Remote Sensing Images Based on CNNs. IEEE Access 2020, 8, 42848–42863. [Google Scholar] [CrossRef]
- Maggiolo, L.; Solarna, D.; Moser, G.; Serpico, S.B. Optical-Sar Decision Fusion with Markov Random Fields for High-Resolution Large-Scale Land Cover Mapping. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 5508–5511. [Google Scholar] [CrossRef]
- Thomas, N.; Hendrix, C.; Congalton, R.G. A Comparison of Urban Mapping Methods Using High-Resolution Digital Imagery. Photogramm. Eng. Remote Sens. 2003, 69, 963–972. [Google Scholar] [CrossRef]
- Carleer, A.P.; Debeir, O.; Wolff, E. Assessment of Very High Spatial Resolution Satellite Image Segmentations. Photogramm. Eng. Remote Sens. 2005, 71, 1285–1294. [Google Scholar] [CrossRef]
- Yu, Q.; Gong, P.; Clinton, N.; Biging, G.; Kelly, M.; Schirokauer, D. Object-Based Detailed Vegetation Classification with Airborne High Spatial Resolution Remote Sensing Imagery. Photogramm. Eng. Remote Sens. 2006, 72, 799–811. [Google Scholar] [CrossRef]
- Loncan, L.; de Almeida, L.B.; Bioucas-Dias, J.M.; Briottet, X.; Chanussot, J.; Dobigeon, N.; Fabre, S.; Liao, W.; Licciardi, G.A.; Simoes, M.; et al. Hyperspectral Pansharpening: A Review. IEEE Geosci. Remote Sens. 2015, 3, 27–46. [Google Scholar] [CrossRef]
- Fauvel, M.; Benediktsson, J.A.; Chanussot, J.; Sveinsson, J.R. Spectral and Spatial Classification of Hyperspectral Data Using SVMs and Morphological Profiles. IEEE Trans. Geosci. Remote Sens. 2008, 46, 3804–3814. [Google Scholar] [CrossRef]
- Wegner, J.D.; Hansch, R.; Thiele, A.; Soergel, U. Building Detection from One Orthophoto and High-Resolution InSAR Data Using Conditional Random Fields. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 4, 83–91. [Google Scholar] [CrossRef]
- Ban, Y.; Jacob, A. Object-Based Fusion of Multitemporal Multiangle ENVISAT ASAR and HJ-1B Multispectral Data for Urban Land-Cover Mapping. IEEE Trans. Geosci. Remote Sens. 2013, 51, 1998–2006. [Google Scholar] [CrossRef]
- Mohammad-Djafari, A. A Bayesian Approach for Data and Image Fusion. Nucleation Atmos. Aerosols 2003, 659, 386–408. [Google Scholar] [CrossRef]
- Vapnik, V.N. An Overview of Statistical Learning Theory. IEEE Trans. Neural Netw. Learn. Syst. 1999, 10, 988–999. [Google Scholar] [CrossRef]
- Dubois, D.; Prade, H. Possibility Theory and Data Fusion in Poorly Informed Environments. Control Eng. Pract. 1994, 2, 811–823. [Google Scholar] [CrossRef]
- Pal, N.R.; Bezdek, J.C. Measuring Fuzzy Uncertainty. IEEE Trans. Fuzzy Syst. 1994, 2, 107–118. [Google Scholar] [CrossRef]
- Dubois, D.; Prade, H. Combination of Fuzzy Information in the Framework of Possibility Theory. In Data Fusion in Robotics and Machine Intelligence; Abidi, M.A., Gonzalez, R.C., Eds.; Academic Press: New York, NY, USA, 1992; pp. 481–505. [Google Scholar]
- Boykov, Y.; Kolmogorov, V. An Experimental Comparison of Min-Cut/Max- Flow Algorithms for Energy Minimization in Vision. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 1124–1137. [Google Scholar] [CrossRef]
- Hervieu, A.; Le Bris, A.; Mallet, C. Fusion of hyperspectral and VHR multispectral image classifications in urban α–AREAS. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, III-3, 457–464. [Google Scholar] [CrossRef]
- Rother, C.; Kolmogorov, V.; Blake, A. “GrabCut”. ACM Trans. Graph. 2004, 23, 309. [Google Scholar] [CrossRef]
- Hughes, G. On the Mean Accuracy of Statistical Pattern Recognizers. IEEE Trans. Inf. Theor. 2006, 14, 55–63. [Google Scholar] [CrossRef]
- Licciardi, G.; Pacifici, F.; Tuia, D.; Prasad, S.; West, T.; Giacco, F.; Thiel, C.; Inglada, J.; Christophe, E.; Chanussot, J.; et al. Decision fusion for the classification of hyperspectral data: Outcome of the 2008 GRSS data fusion contest. IEEE Trans. Geosci. Remote Sens. 2009, 47, 3857–3865. [Google Scholar] [CrossRef]
- Bioucas-Dias, J.; Figueiredo, M. Alternating direction algorithms for constrained sparse regression: Application to hyperspectral unmixing. In Proceedings of the 2ndWorkshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS), Reykjavik, Iceland, 14–16 June 2010. [Google Scholar] [CrossRef]
- Dopido, I.; Li, J.; Gamba, P.; Plaza, A. A new hybrid strategy combining semisupervised classification and unmixing of hyperspectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 3619–3629. [Google Scholar] [CrossRef]
- Lu, T.; Li, S.; Fang, L.; Jia, X.; Benediktsson, J.A. From subpixel to superpixel: A novel fusion framework for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4398–4411. [Google Scholar] [CrossRef]
- Tuia, D.; Volpi, M.; Moser, G. Decision fusion with multiple spatial supports by conditional random fields. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3277–3289. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Scheunders, P.; Tuia, D.; Moser, G. Contributions of machine learning to remote sensing data analysis. In Comprehensive Remote Sensing; Liang, S., Ed.; Elsevier: Amsterdam, The Netherlands, 2017; Volume 2, Chapter 10. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer: New York, NY, USA, 2009. [Google Scholar]
- Namin, S.T.; Najafi, M.; Salzmann, M.; Petersson, L. A multi-modal graphical model for scene analysis. In Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2015; pp. 1006–1013. [Google Scholar] [CrossRef]
- Boykov, Y.; Veksler, O.; Zabih, R. Fast approximation energy minimization via graph cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1222–1239. [Google Scholar] [CrossRef]
- Kohli, P.; Ladicky, L.; Torr, P. Robust higher order potentials for enforcing label consistency. Int. J. Comp. Vis. 2009, 82, 302–324. [Google Scholar] [CrossRef]
- Kohli, P.; Ladicky, L.; Torr, P. Graph Cuts for Minimizing Robust Higher Order Potentials; Technical Report; Oxford Brookes University: Oxford, UK, 2008. [Google Scholar]
- Albert, L.; Rottensteiner, F.; Heipke, C. A higher order conditional random field model for simultaneous classification of land cover and land use. Int. J. Photogramm. Remote Sens. 2017, 130, 63–80. [Google Scholar] [CrossRef]
- Cihlar, J. Land cover mapping of large areas from satellites: Status and research priorities. Int. J. Remote Sens. 2000, 21, 1093–1114. [Google Scholar] [CrossRef]
- Pohl, C.; Van Genderen, J.L. Review article multisensor image fusion in remote sensing: Concepts, methods and applications. Int. J. Remote Sens. 1998, 19, 823–854. [Google Scholar] [CrossRef]
- Lee, D.H.; Park, D. An efficient algorithm for fuzzy weighted average. Fuzzy Sets Syst. 1997, 87, 39–45. [Google Scholar] [CrossRef]
- Elfes, A. Multi-source spatial data fusion using Bayesian reasoning. In Data Fusion in Robotics and Machine Intelligence; Academic Press: Cambridge, MA, USA, 1992; pp. 137–163. [Google Scholar]
- Basir, O.; Yuan, X. Engine fault diagnosis based on multi-sensor information fusion using dempster–Shafer evidence theory. Inf. Fusion 2007, 8, 379–386. [Google Scholar] [CrossRef]
- Hilker, T.; Wulder, M.A.; Coops, N.C.; Linke, J.; McDermid, G.; Masek, J.G.; Gao, F.; White, J.C. A new data fusion model for high spatial-and temporal-resolution mapping of forest disturbance based on Landsat and Modis. Remote Sens. Environ. 2009, 113, 1613–1627. [Google Scholar] [CrossRef]
- Szmidt, E.; Kacprzyk, J. Entropy for intuitionistic fuzzy sets. Fuzzy Sets Syst. 2001, 118, 467–477. [Google Scholar] [CrossRef]
- Bloch, I. Information combination operators for data fusion: A comparative review with classification. IEEE Trans. Syst. ManCybern. Part A Syst. Hum. 1996, 26, 52–67. [Google Scholar] [CrossRef]
- Guan, X.; Huang, C.; Liu, G.; Meng, X.; Liu, Q. Mapping Rice Cropping Systems in Vietnam Using an NDVI-Based Time-Series Similarity Measurement Based on DTW Distance. Remote Sens. 2016, 8, 19. [Google Scholar] [CrossRef]
- Lhermitte, S.; Verbesselt, J.; Verstraeten, W.W.; Coppin, P. A comparison of time series similarity measures for classification and change detection of ecosystem dynamics. Remote Sens. Environ. 2011, 115, 3129–3152. [Google Scholar] [CrossRef]
- Geerken, R.; Zaitchik, B.; Evans, J. Classifying rangeland vegetation type and coverage from ndvi time series using Fourier filtered cycle similarity. Int. J. Remote Sens. 2005, 26, 5535–5554. [Google Scholar] [CrossRef]
- Hollmann, R.; Merchant, C.J.; Saunders, R.; Downy, C.; Buchwitz, M.; Cazenave, A.; Chuvieco, E.; Defourny, P.; de Leeuw, G.; Forsberg, R.; et al. The ESA Climate Change Initiative: Satellite Data Records for Essential Climate Variables. Bull Am. Meteorol. Soc. 2013, 94, 1541–1552. [Google Scholar] [CrossRef]
- Lehmann, E.A.; Caccetta, P.; Lowell, K.; Mitchell, A.; Zhou, Z.-S.; Held, A.; Milne, T.; Tapley, I. SAR and Optical Remote Sensing: Assessment of Complementarity and Interoperability in the Context of a Large-Scale Operational Forest Monitoring System. Remote Sens. Environ. 2015, 156, 335–348. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Swain, P.H. Consensus Theoretic Classification Methods. IEEE Trans. Syst. Man Cybern. Syst. 1992, 22, 688–704. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Sveinsson, J.R.; Swain, P.H. Hybrid Consensus Theoretic Classification. IEEE Trans. Geosci. Remote Sens. 1997, 35, 833–843. [Google Scholar] [CrossRef]
- Kato, Z.; Zerubia, J. Markov Random Fields in Image Segmentation. Found. Trends Mach. Learn 2012, 5, 1–155. [Google Scholar] [CrossRef]
- Szeliski, R.; Zabih, R.; Scharstein, D.; Veksler, O.; Kolmogorov, V.; Agarwala, A.; Tappen, M.; Rother, C. A Comparative Study of Energy Minimization Methods for Markov Random Fields with Smoothness-Based Priors. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1068–1080. [Google Scholar] [CrossRef]
- Singha, S.; Johansson, M.; Hughes, N.; Hvidegaard, S.M.; Skourup, H. Arctic Sea Ice Characterization Using Spaceborne Fully Polarimetric L-, C-, and X-Band SAR with Validation by Airborne Measurements. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3715–3734. [Google Scholar] [CrossRef]
- Del Frate, F.; Latini, D.; Scappiti, V. On neural networks algorithms for oil spill detection when applied to C-and X-band SAR. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), FortWorth, TX, USA, 23–28 July 2017; pp. 5249–5251. [Google Scholar] [CrossRef]
- Huang, Z.; Dumitru, C.O.; Pan, Z.; Lei, B.; Datcu, M. Classification of Large-Scale High-Resolution SAR Images with Deep Transfer Learning. IEEE Geosci. Remote Sens. Lett. 2020, 18, 107–111. [Google Scholar] [CrossRef]
- Mohammadimanesh, F.; Salehi, B.; Mahdianpari, M.; Gill, E.; Molinier, M. A new fully convolutional neural network for semantic segmentation of polarimetric SAR imagery in complex land cover ecosystem. ISPRS J. Photogramm. Remote Sens. 2019, 151, 223–236. [Google Scholar] [CrossRef]
- Yue, Z.; Gao, F.; Xiong, Q.; Wang, J.; Huang, T.; Yang, E.; Zhou, H. A Novel Semi-Supervised Convolutional Neural Network Method for Synthetic Aperture Radar Image Recognition. Cogn. Comput. 2019, 13, 795–806. [Google Scholar] [CrossRef]
- Hong, D.; Yokoya, N.; Xia, G.S.; Chanussot, J.; Zhu, X.X. X-ModalNet: A semi-supervised deep cross-modal network for classification of remote sensing data. ISPRS J. Photogramm. Remote Sens. 2020, 167, 12–23. [Google Scholar] [CrossRef]
- Rostami, M.; Kolouri, S.; Eaton, E.; Kim, K. Deep Transfer Learning for Few-Shot SAR Image Classification. Remote Sens. 2019, 11, 1374. [Google Scholar] [CrossRef]
- Deng, J.; Deng, Y.; Cheong, K.H. Combining conflicting evidence based on Pearson correlation coefficient and weighted graph. Int. J. Intell. Syst. 2021, 36, 7443–7460. [Google Scholar] [CrossRef]
- Zhao, J.; Deng, Y. Complex Network Modeling of Evidence Theory. IEEE Trans. Fuzzy Syst. 2020, 29, 3470–3480. [Google Scholar] [CrossRef]
- Li, R.; Chen, Z.; Li, H.; Tang, Y. A new distance-based total uncertainty measure in Dempster-Shafer evidence theory. Appl. Intell. 2021, 52, 1209–1237. [Google Scholar] [CrossRef]
- Deng, Y. Deng entropy. Chaos Solitons Fractals 2016, 91, 549–553. [Google Scholar] [CrossRef]
- Christian, H.; Agus, M.P.; Suhartono, D. Single Document Automatic Text Summarization using Term Frequency-Inverse Document Frequency (TF-IDF). ComTech Comput. Math. Eng. Appl. 2016, 7, 285–294. [Google Scholar] [CrossRef]
- Havrlant, L.; Kreinovich, V. A simple probabilistic explanation of term frequency-inverse document frequency (TF-IDF) heuristic (and variations motivated by this explanation). Int. J. Gen. Syst. 2017, 46, 27–36. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Papadopoulos, S.; Koukiou, G.; Anastassopoulos, V. Decision Fusion at Pixel Level of Multi-Band Data for Land Cover Classification—A Review. J. Imaging 2024, 10, 15. https://doi.org/10.3390/jimaging10010015
Papadopoulos S, Koukiou G, Anastassopoulos V. Decision Fusion at Pixel Level of Multi-Band Data for Land Cover Classification—A Review. Journal of Imaging. 2024; 10(1):15. https://doi.org/10.3390/jimaging10010015
Chicago/Turabian StylePapadopoulos, Spiros, Georgia Koukiou, and Vassilis Anastassopoulos. 2024. "Decision Fusion at Pixel Level of Multi-Band Data for Land Cover Classification—A Review" Journal of Imaging 10, no. 1: 15. https://doi.org/10.3390/jimaging10010015
APA StylePapadopoulos, S., Koukiou, G., & Anastassopoulos, V. (2024). Decision Fusion at Pixel Level of Multi-Band Data for Land Cover Classification—A Review. Journal of Imaging, 10(1), 15. https://doi.org/10.3390/jimaging10010015