
A Systematic Review of Recent Deep Learning Approaches for 3D Human Pose Estimation


Abstract
:1. Introduction
2. Previous Surveys
3. Survey Methodology
3.1. Research Questions
- RQ1: What are the primary pipelines and taxonomies utilized in HPE?
- RQ2: What are the known approaches and associated challenges in different scenarios?
- RQ3: Which framework outperforms others in each case, and which techniques are required to mitigate these challenges?
- RQ4: What are the most widely used public databases and evaluation metrics in the field of 3D human posture estimation?
- RQ5: What are the current limitations and areas for future improvement in this field?
3.2. Search Strategy
3.3. Inclusion/Exclusion Criteria
- Searched and extracted conference proceedings and journal papers containing terms such as “3D human pose(s) estimation”, “3D multi-person pose(s) estimation”, “deep learning”, “monocular image(s)/video(s)”, or “single-view” in the title, abstract, or keywords.
- Included only online papers written in English and open access full texts.
- Considered only peer-reviewed articles, which were cross-verified in the Scopus database.
- Excluded direct duplicates and literature review papers to avoid redundancy.
- Prioritized the papers based on relevance and excluded those with weaker or less pertinent contributions.
- Included papers that provided novel methodologies, significant improvements, or substantial contributions to the field of 3D human pose estimation.
- Excluded papers that did not provide sufficient experimental results or lack rigorous methodological details.
- Included a select number of papers on multi-view pose estimation for comparative analysis, despite the main focus being on monocular pose estimation.
- For papers published prior to 2021, we focused on those that presented original ideas or marked significant improvements in the field.
3.4. Data Extraction, Analysis, and Synthesis
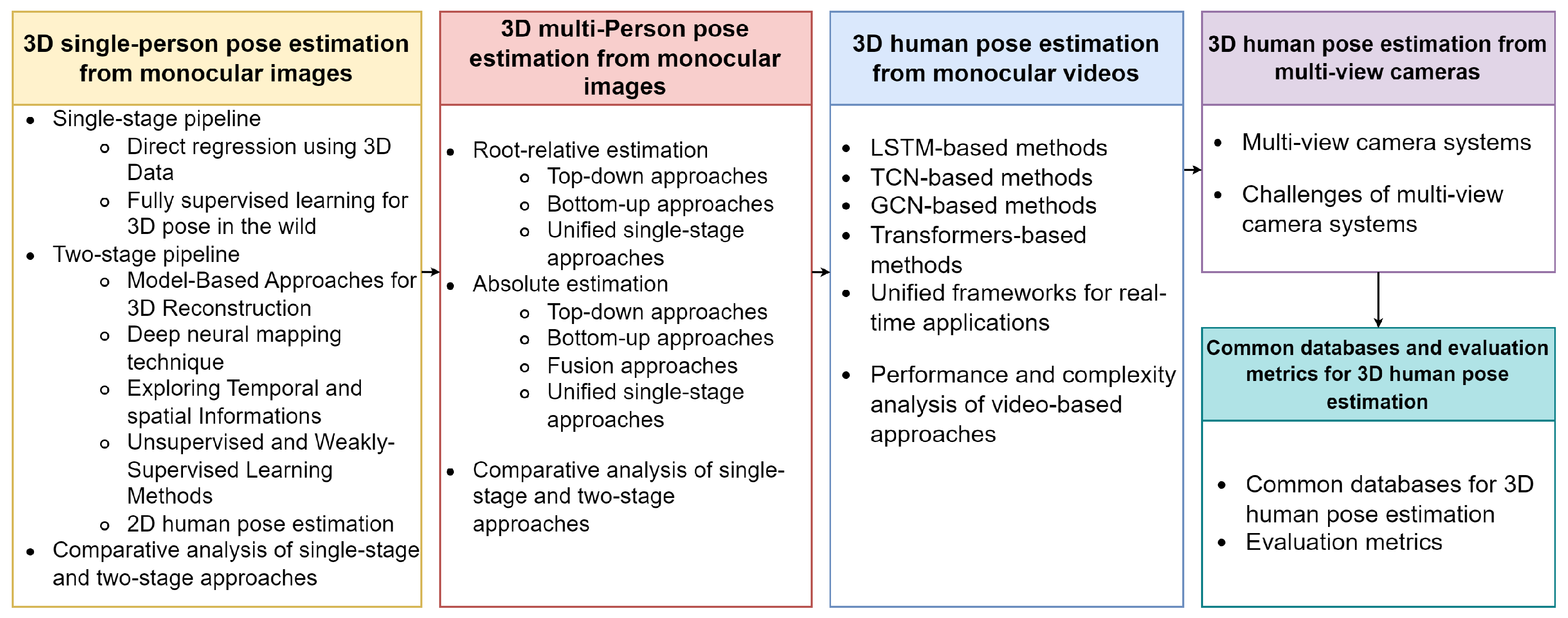
4. Taxonomy of the Survey
- 3D single-person pose estimation from monocular images: In this section, we focus on approaches that aim at estimating the pose of a single person from monocular images. We further classify this into single-stage and two-stage pipelines, with the latter involving an intermediate 2D human pose estimation step.
- 3D multi-person pose estimation from monocular images: This section broadens our review to methods designed to estimate the poses of multiple individuals from monocular images. We differentiate these based on whether they perform relative estimation or absolute pose estimation, with further subdivisions within absolute estimation into top-down, bottom-up, fusion, and unified single-stage approaches.
- 3D human pose estimation from monocular videos: Transitioning from static images to video data, we review methods that are designed to estimate poses irrespective of the number of individuals. We categorize these methods based on the type of deep learning model they use, such as long short-term memory (LSTM), temporal convolutional networks (TCNs), graph convolutional networks (GCNs), transformers, or unified frameworks for real-time applications. A performance and complexity analysis of these methods is also included.
- 3D human pose estimation from multi-view cameras: Lastly, we delve into methods that employ multi-view camera systems for human pose estimation, emphasizing how these methods exploit the additional depth information obtainable from multiple camera angles.
5. Three-Dimensional Single-Person Pose Estimation from Monocular Images
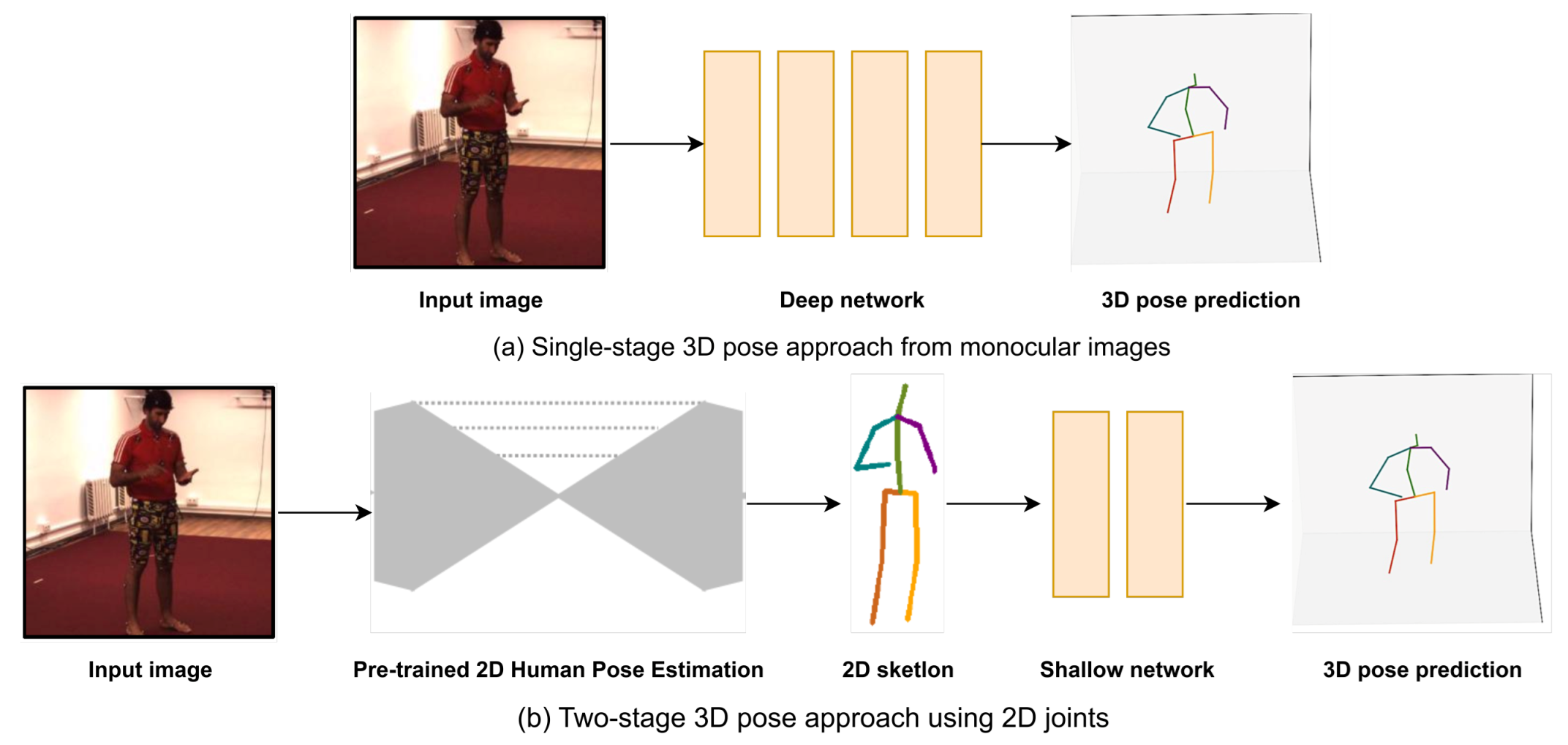
5.1. Single-Stage Pipeline
5.1.1. Direct Regression Using Only 3D Data
5.1.2. Fully Supervised Learning for 3D Pose in the Wild
Integrated Feature Sharing Models
Combined 2D and 3D Data Learning Models
5.2. Two-Stage Pipeline
5.2.1. Model-Based Approaches for 3D Reconstruction
5.2.2. Deep Neural Mapping Techniques
5.2.3. Exploring Temporal and Spatial Information
5.2.4. Unsupervised and Weakly Supervised Learning Methods
5.2.5. Two-Dimensional Human Pose Estimation
5.3. Comparative Analysis of Single-Stage and Two-Stage Approaches
6. Three-Dimensional Multi-Person Pose Estimation from Monocular Images
6.1. Root-Relative Human Pose Estimation
6.2. Absolute Human Pose Estimation
6.2.1. Top-Down Approaches
6.2.2. Bottom-Up Approaches
6.2.3. Fusion Approaches
6.2.4. Unified Single-Stage Approaches
6.3. Analytical Comparison of Multi-Person Pose Estimation Methods
7. Three-Dimensional Human Pose Estimation from Monocular Videos
7.1. Methods Based on LSTM
7.2. Methods Based on TCNs
7.3. Methods Based on GCNs
7.4. Methods Based on Transformers
7.5. Unified Frameworks for Real-Time Applications
7.6. Performance and Complexity Analysis of Video-Based Approaches
8. Three-Dimensional Human Pose Estimation from Multi-View Cameras
Challenges of Multi-View Camera Systems
9. Common Databases and Evaluation Metrics for 3D Human Pose Estimation
10. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gupta, A.; Martinez, J.; Little, J.J.; Woodham, R.J. 3D pose from motion for cross-view action recognition via non-linear circulant temporal encoding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2601–2608. [Google Scholar]
- Zimmermann, C.; Welschehold, T.; Dornhege, C.; Burgard, W.; Brox, T. 3D human pose estimation in rgbd images for robotic task learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1986–1992. [Google Scholar]
- Bridgeman, L.; Volino, M.; Guillemaut, J.Y.; Hilton, A. Multi-person 3D pose estimation and tracking in sports. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Kumarapu, L.; Mukherjee, P. Animepose: Multi-person 3D pose estimation and animation. Pattern Recognit. Lett. 2021, 147, 16–24. [Google Scholar] [CrossRef]
- Potter, T.E.; Willmert, K.D. Three-dimensional human display model. In Proceedings of the 2nd Annual Conference on Computer Graphics and Interactive Techniques, Bowling Green, OH, USA, 25–27 June 1975; pp. 102–110. [Google Scholar]
- Badler, N.I.; O’Rourke, J. A Human Body Modelling System for Motion Studies. 1977. Available online: https://repository.upenn.edu/entities/publication/4dddaab2-cf2c-4ab1-8c92-6cc9e1f5c563 (accessed on 30 November 2023).
- O’rourke, J.; Badler, N.I. Model-based image analysis of human motion using constraint propagation. IEEE Trans. Pattern Anal. Mach. Intell. 1980, 6, 522–536. [Google Scholar] [CrossRef]
- Hogg, D. Model-based vision: A program to see a walking person. Image Vis. Comput. 1983, 1, 5–20. [Google Scholar] [CrossRef]
- Lee, H.J.; Chen, Z. Determination of 3D human body postures from a single view. Comput. Vis. Graph. Image Process. 1985, 30, 148–168. [Google Scholar] [CrossRef]
- Ramakrishna, V.; Kanade, T.; Sheikh, Y. Reconstructing 3D Human Pose from 2D Image Landmarks. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 573–586. [Google Scholar]
- Sminchisescu, C. 3D human motion analysis in monocular video: Techniques and challenges. In Human Motion; Springer: Berlin/Heidelberg, Germany, 2008; pp. 185–211. [Google Scholar]
- Alimoussa, M.; Porebski, A.; Vandenbroucke, N.; El Fkihi, S.; Oulad Haj Thami, R. Compact Hybrid Multi-Color Space Descriptor Using Clustering-Based Feature Selection for Texture Classification. J. Imaging 2022, 8, 217. [Google Scholar] [CrossRef] [PubMed]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3. 6m: Large scale datasets and predictive methods for 3D human sensing in natural environments. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1325–1339. [Google Scholar] [CrossRef]
- Ionescu, C.; Li, F.; Sminchisescu, C. Latent structured models for human pose estimation. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2220–2227. [Google Scholar]
- Mori, G.; Malik, J. Recovering 3D human body configurations using shape contexts. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1052–1062. [Google Scholar] [CrossRef]
- Ionescu, C.; Carreira, J.; Sminchisescu, C. Iterated second-order label sensitive pooling for 3D human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1661–1668. [Google Scholar]
- Onishi, K.; Takiguchi, T.; Ariki, Y. 3D human posture estimation using the HOG features from monocular image. In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- Burenius, M.; Sullivan, J.; Carlsson, S. 3D pictorial structures for multiple view articulated pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3618–3625. [Google Scholar]
- Kostrikov, I.; Gall, J. Depth Sweep Regression Forests for Estimating 3D Human Pose from Images. In Proceedings of the The British Machine Vision Conference, BMVC, Nottingham, UK, 1–14 September 2014; Volume 1, p. 5. [Google Scholar]
- El Kaid, A.; Baïna, K.; Baïna, J. Reduce false positive alerts for elderly person fall video-detection algorithm by convolutional neural network model. Procedia Comput. Sci. 2019, 148, 2–11. [Google Scholar] [CrossRef]
- El Kaid, A.; Baïna, K.; Baina, J.; Barra, V. Real-world case study of a deep learning enhanced Elderly Person Fall Video-Detection System. In Proceedings of the VISAPP 2023, Lisbon, Portugal, 19–21 February 2023. [Google Scholar]
- Black, K.M.; Law, H.; Aldoukhi, A.; Deng, J.; Ghani, K.R. Deep learning computer vision algorithm for detecting kidney stone composition. BJU Int. 2020, 125, 920–924. [Google Scholar] [CrossRef]
- da Costa, A.Z.; Figueroa, H.E.; Fracarolli, J.A. Computer vision based detection of external defects on tomatoes using deep learning. Biosyst. Eng. 2020, 190, 131–144. [Google Scholar] [CrossRef]
- Moeslund, T.B.; Granum, E. A survey of computer vision-based human motion capture. Comput. Vis. Image Underst. 2001, 81, 231–268. [Google Scholar] [CrossRef]
- Sarafianos, N.; Boteanu, B.; Ionescu, B.; Kakadiaris, I.A. 3D human pose estimation: A review of the literature and analysis of covariates. Comput. Vis. Image Underst. 2016, 152, 1–20. [Google Scholar] [CrossRef]
- Liu, Z.; Zhu, J.; Bu, J.; Chen, C. A survey of human pose estimation: The body parts parsing based methods. J. Vis. Commun. Image Represent. 2015, 32, 10–19. [Google Scholar] [CrossRef]
- Gong, W.; Zhang, X.; Gonzàlez, J.; Sobral, A.; Bouwmans, T.; Tu, C.; Zahzah, E.H. Human pose estimation from monocular images: A comprehensive survey. Sensors 2016, 16, 1966. [Google Scholar] [CrossRef] [PubMed]
- Dang, Q.; Yin, J.; Wang, B.; Zheng, W. Deep learning based 2d human pose estimation: A survey. Tsinghua Sci. Technol. 2019, 24, 663–676. [Google Scholar] [CrossRef]
- Li, Y.; Sun, Z. Vision-based human pose estimation for pervasive computing. In Proceedings of the 2009 Workshop on Ambient Media Computing, Beijing, China, 19–24 October 2009; pp. 49–56. [Google Scholar]
- Zhang, H.B.; Zhang, Y.X.; Zhong, B.; Lei, Q.; Yang, L.; Du, J.X.; Chen, D.S. A comprehensive survey of vision-based human action recognition methods. Sensors 2019, 19, 1005. [Google Scholar] [CrossRef] [PubMed]
- Perez-Sala, X.; Escalera, S.; Angulo, C.; Gonzalez, J. A survey on model based approaches for 2D and 3D visual human pose recovery. Sensors 2014, 14, 4189–4210. [Google Scholar] [CrossRef]
- Poppe, R. Vision-based human motion analysis: An overview. Comput. Vis. Image Underst. 2007, 108, 4–18. [Google Scholar] [CrossRef]
- Moeslund, T.B.; Hilton, A.; Krüger, V. A survey of advances in vision-based human motion capture and analysis. Comput. Vis. Image Underst. 2006, 104, 90–126. [Google Scholar] [CrossRef]
- Holte, M.B.; Tran, C.; Trivedi, M.M.; Moeslund, T.B. Human pose estimation and activity recognition from multi-view videos: Comparative explorations of recent developments. IEEE J. Sel. Top. Signal Process. 2012, 6, 538–552. [Google Scholar] [CrossRef]
- Zhang, H.B.; Lei, Q.; Zhong, B.N.; Du, J.X.; Peng, J. A survey on human pose estimation. Intell. Autom. Soft Comput. 2016, 22, 483–489. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Munea, T.L.; Jembre, Y.Z.; Weldegebriel, H.T.; Chen, L.; Huang, C.; Yang, C. The progress of human pose estimation: A survey and taxonomy of models applied in 2D human pose estimation. IEEE Access 2020, 8, 133330–133348. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, F.; Ge, S.S. A comprehensive survey on 2D multi-person pose estimation methods. Eng. Appl. Artif. Intell. 2021, 102, 104260. [Google Scholar] [CrossRef]
- de Souza Reis, E.; Seewald, L.A.; Antunes, R.S.; Rodrigues, V.F.; da Rosa Righi, R.; da Costa, C.A.; da Silveira, L.G., Jr.; Eskofier, B.; Maier, A.; Horz, T.; et al. Monocular multi-person pose estimation: A survey. Pattern Recognit. 2021, 118, 108046. [Google Scholar] [CrossRef]
- Wang, J.; Tan, S.; Zhen, X.; Xu, S.; Zheng, F.; He, Z.; Shao, L. Deep 3D human pose estimation: A review. Comput. Vis. Image Underst. 2021, 210, 103225. [Google Scholar] [CrossRef]
- Shapii, A.; Pichak, S.; Mahayuddin, Z.R. 3D Reconstruction technique from 2D sequential human body images in sports: A review. Technol. Rep. Kansai Univ. 2020, 62, 4973–4988. [Google Scholar]
- Zheng, C.; Wu, W.; Yang, T.; Zhu, S.; Chen, C.; Liu, R.; Shen, J.; Kehtarnavaz, N.; Shah, M. Deep learning-based human pose estimation: A survey. arXiv 2020, arXiv:2012.13392. [Google Scholar] [CrossRef]
- Desmarais, Y.; Mottet, D.; Slangen, P.; Montesinos, P. A review of 3D human pose estimation algorithms for markerless motion capture. Comput. Vis. Image Underst. 2021, 212, 103275. [Google Scholar] [CrossRef]
- Josyula, R.; Ostadabbas, S. A review on human pose estimation. arXiv 2021, arXiv:2110.06877. [Google Scholar]
- PRISMA PC. Transparent Reporting of Systematic Reviews and Meta-Analyses; University of Oxford Ottawa: Ottawa, ON, Canada, 2015. [Google Scholar]
- Zhao, L.; Peng, X.; Tian, Y.; Kapadia, M.; Metaxas, D.N. Semantic graph convolutional networks for 3D human pose regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3425–3435. [Google Scholar]
- Wei, W.L.; Lin, J.C.; Liu, T.L.; Liao, H.Y.M. Capturing humans in motion: Temporal-attentive 3D human pose and shape estimation from monocular video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13211–13220. [Google Scholar]
- Liu, J.; Akhtar, N.; Mian, A. Deep reconstruction of 3D human poses from video. IEEE Trans. Artif. Intell. 2022, 4, 497–510. [Google Scholar] [CrossRef]
- Choi, J.; Shim, D.; Kim, H.J. DiffuPose: Monocular 3D Human Pose Estimation via Denoising Diffusion Probabilistic Model. arXiv 2022, arXiv:2212.02796. [Google Scholar]
- Mitra, R.; Gundavarapu, N.B.; Sharma, A.; Jain, A. Multiview-consistent semi-supervised learning for 3D human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6907–6916. [Google Scholar]
- Cheng, Y.; Wang, B.; Yang, B.; Tan, R.T. Monocular 3D multi-person pose estimation by integrating top-down and bottom-up networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7649–7659. [Google Scholar]
- Cheng, Y.; Wang, B.; Tan, R.T. Dual networks based 3D multi-person pose estimation from monocular video. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1636–1651. [Google Scholar] [CrossRef]
- Wandt, B.; Rosenhahn, B. Repnet: Weakly supervised training of an adversarial reprojection network for 3D human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7782–7791. [Google Scholar]
- Rochette, G.; Russell, C.; Bowden, R. Weakly-supervised 3D pose estimation from a single image using multi-view consistency. arXiv 2019, arXiv:1909.06119. [Google Scholar]
- Iqbal, U.; Molchanov, P.; Kautz, J. Weakly-supervised 3D human pose learning via multi-view images in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5243–5252. [Google Scholar]
- Wandt, B.; Rudolph, M.; Zell, P.; Rhodin, H.; Rosenhahn, B. Canonpose: Self-supervised monocular 3D human pose estimation in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13294–13304. [Google Scholar]
- Cong, P.; Xu, Y.; Ren, Y.; Zhang, J.; Xu, L.; Wang, J.; Yu, J.; Ma, Y. Weakly Supervised 3D Multi-person Pose Estimation for Large-scale Scenes based on Monocular Camera and Single LiDAR. arXiv 2022, arXiv:2211.16951. [Google Scholar] [CrossRef]
- Yang, C.Y.; Luo, J.; Xia, L.; Sun, Y.; Qiao, N.; Zhang, K.; Jiang, Z.; Hwang, J.N.; Kuo, C.H. CameraPose: Weakly-Supervised Monocular 3D Human Pose Estimation by Leveraging In-the-wild 2D Annotations. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 2924–2933. [Google Scholar]
- Drover, D.; MV, R.; Chen, C.H.; Agrawal, A.; Tyagi, A.; Phuoc Huynh, C. Can 3D pose be learned from 2D projections alone? In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Chen, C.H.; Tyagi, A.; Agrawal, A.; Drover, D.; Stojanov, S.; Rehg, J.M. Unsupervised 3D pose estimation with geometric self-supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5714–5724. [Google Scholar]
- Tripathi, S.; Ranade, S.; Tyagi, A.; Agrawal, A. PoseNet3D: Unsupervised 3D Human Shape and Pose Estimation. arXiv 2020, arXiv:2003.03473. [Google Scholar]
- Yu, Z.; Ni, B.; Xu, J.; Wang, J.; Zhao, C.; Zhang, W. Towards alleviating the modeling ambiguity of unsupervised monocular 3D human pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 8651–8660. [Google Scholar]
- Wandt, B.; Little, J.J.; Rhodin, H. ElePose: Unsupervised 3D Human Pose Estimation by Predicting Camera Elevation and Learning Normalizing Flows on 2D Poses. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6635–6645. [Google Scholar]
- Kocabas, M.; Karagoz, S.; Akbas, E. Self-supervised learning of 3D human pose using multi-view geometry. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1077–1086. [Google Scholar]
- Xu, D.; Xiao, J.; Zhao, Z.; Shao, J.; Xie, D.; Zhuang, Y. Self-supervised spatiotemporal learning via video clip order prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10334–10343. [Google Scholar]
- Jakab, T.; Gupta, A.; Bilen, H.; Vedaldi, A. Self-supervised learning of interpretable keypoints from unlabelled videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8787–8797. [Google Scholar]
- Nath Kundu, J.; Seth, S.; Jampani, V.; Rakesh, M.; Venkatesh Babu, R.; Chakraborty, A. Self-Supervised 3D Human Pose Estimation via Part Guided Novel Image Synthesis. arXiv 2020, arXiv:2004.04400. [Google Scholar]
- Wang, J.; Jiao, J.; Liu, Y.H. Self-supervised video representation learning by pace prediction. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XVII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 504–521. [Google Scholar]
- Gong, K.; Li, B.; Zhang, J.; Wang, T.; Huang, J.; Mi, M.B.; Feng, J.; Wang, X. PoseTriplet: Co-evolving 3D human pose estimation, imitation, and hallucination under self-supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11017–11027. [Google Scholar]
- Shan, W.; Liu, Z.; Zhang, X.; Wang, S.; Ma, S.; Gao, W. P-stmo: Pre-trained spatial temporal many-to-one model for 3D human pose estimation. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part V. Springer: Berlin/Heidelberg, Germany, 2022; pp. 461–478. [Google Scholar]
- Honari, S.; Constantin, V.; Rhodin, H.; Salzmann, M.; Fua, P. Temporal Representation Learning on Monocular Videos for 3D Human Pose Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 6415–6427. [Google Scholar] [CrossRef]
- Kundu, J.N.; Seth, S.; YM, P.; Jampani, V.; Chakraborty, A.; Babu, R.V. Uncertainty-aware adaptation for self-supervised 3D human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20448–20459. [Google Scholar]
- Bo, L.; Sminchisescu, C.; Kanaujia, A.; Metaxas, D. Fast algorithms for large scale conditional 3D prediction. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Sminchisescu, C.; Kanaujia, A.; Li, Z.; Metaxas, D. Discriminative density propagation for 3D human motion estimation. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 390–397. [Google Scholar]
- Shotton, J.; Fitzgibbon, A.; Cook, M.; Sharp, T.; Finocchio, M.; Moore, R.; Kipman, A.; Blake, A. Real-time human pose recognition in parts from single depth images. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1297–1304. [Google Scholar]
- Agarwal, A.; Triggs, B. Recovering 3D human pose from monocular images. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 28, 44–58. [Google Scholar] [CrossRef]
- Agarwal, A.; Triggs, B. 3D human pose from silhouettes by relevance vector regression. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2004, CVPR 2004, Washington, DC, USA, 27 June–2 July 2004; Volume 2, p. II. [Google Scholar]
- Bo, L.; Sminchisescu, C. Twin gaussian processes for structured prediction. Int. J. Comput. Vis. 2010, 87, 28. [Google Scholar] [CrossRef]
- Li, S.; Chan, A.B. 3D human pose estimation from monocular images with deep convolutional neural network. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 332–347. [Google Scholar]
- Zhou, X.; Sun, X.; Zhang, W.; Liang, S.; Wei, Y. Deep kinematic pose regression. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 186–201. [Google Scholar]
- Tekin, B.; Katircioglu, I.; Salzmann, M.; Lepetit, V.; Fua, P. Structured prediction of 3D human pose with deep neural networks. arXiv 2016, arXiv:1605.05180. [Google Scholar]
- Tekin, B.; Rozantsev, A.; Lepetit, V.; Fua, P. Direct prediction of 3D body poses from motion compensated sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 991–1000. [Google Scholar]
- Sigal, L.; Balan, A.O.; Black, M.J. Humaneva: Synchronized video and motion capture dataset and baseline algorithm for evaluation of articulated human motion. Int. J. Comput. Vis. 2010, 87, 4. [Google Scholar] [CrossRef]
- Tripathi, S.; Müller, L.; Huang, C.H.P.; Taheri, O.; Black, M.J.; Tzionas, D. 3D human pose estimation via intuitive physics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 4713–4725. [Google Scholar]
- Shimada, S.; Golyanik, V.; Xu, W.; Pérez, P.; Theobalt, C. Neural monocular 3D human motion capture with physical awareness. ACM Trans. Graph. (ToG) 2021, 40, 1–15. [Google Scholar] [CrossRef]
- Huang, C.H.P.; Yi, H.; Höschle, M.; Safroshkin, M.; Alexiadis, T.; Polikovsky, S.; Scharstein, D.; Black, M.J. Capturing and inferring dense full-body human-scene contact. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13274–13285. [Google Scholar]
- Shi, M.; Aberman, K.; Aristidou, A.; Komura, T.; Lischinski, D.; Cohen-Or, D.; Chen, B. Motionet: 3D human motion reconstruction from monocular video with skeleton consistency. ACM Trans. Graph. (TOG) 2020, 40, 1–15. [Google Scholar] [CrossRef]
- Luvizon, D.C.; Tabia, H.; Picard, D. Ssp-net: Scalable sequential pyramid networks for real-time 3D human pose regression. Pattern Recognit. 2023, 142, 109714. [Google Scholar] [CrossRef]
- Luvizon, D.C.; Picard, D.; Tabia, H. Multi-task deep learning for real-time 3D human pose estimation and action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2752–2764. [Google Scholar] [CrossRef]
- Zhang, J.; Cai, Y.; Yan, S.; Feng, J. Direct multi-view multi-person 3D pose estimation. Adv. Neural Inf. Process. Syst. 2021, 34, 13153–13164. [Google Scholar]
- Sun, Y.; Liu, W.; Bao, Q.; Fu, Y.; Mei, T.; Black, M.J. Putting people in their place: Monocular regression of 3D people in depth. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13243–13252. [Google Scholar]
- Wang, Z.; Nie, X.; Qu, X.; Chen, Y.; Liu, S. Distribution-aware single-stage models for multi-person 3D pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13096–13105. [Google Scholar]
- Pavlakos, G.; Zhou, X.; Derpanis, K.G.; Daniilidis, K. Coarse-to-fine volumetric prediction for single-image 3D human pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7025–7034. [Google Scholar]
- Mehta, D.; Sridhar, S.; Sotnychenko, O.; Rhodin, H.; Shafiei, M.; Seidel, H.P.; Xu, W.; Casas, D.; Theobalt, C. Vnect: Real-time 3D human pose estimation with a single rgb camera. ACM Trans. Graph. (TOG) 2017, 36, 1–14. [Google Scholar] [CrossRef]
- Tome, D.; Russell, C.; Agapito, L. Lifting from the deep: Convolutional 3D pose estimation from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2500–2509. [Google Scholar]
- Ghezelghieh, M.F.; Kasturi, R.; Sarkar, S. Learning camera viewpoint using CNN to improve 3D body pose estimation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 685–693. [Google Scholar]
- Zhang, Y.; You, S.; Gevers, T. Orthographic Projection Linear Regression for Single Image 3D Human Pose Estimation. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 8109–8116. [Google Scholar]
- Joo, H.; Neverova, N.; Vedaldi, A. Exemplar fine-tuning for 3D human model fitting towards in-the-wild 3D human pose estimation. In Proceedings of the 2021 International Conference on 3D Vision (3DV), London, UK, 1–3 December 2021; pp. 42–52. [Google Scholar]
- Luvizon, D.C.; Picard, D.; Tabia, H. 2d/3D pose estimation and action recognition using multitask deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5137–5146. [Google Scholar]
- Li, S.; Zhang, W.; Chan, A.B. Maximum-margin structured learning with deep networks for 3D human pose estimation. In Proceedings of the IEEE international conference on computer vision, Santiago, Chile, 7–13 December 2015; pp. 2848–2856. [Google Scholar]
- Zhou, X.; Huang, Q.; Sun, X.; Xue, X.; Wei, Y. Towards 3D human pose estimation in the wild: A weakly-supervised approach. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 398–407. [Google Scholar]
- Roy, S.K.; Citraro, L.; Honari, S.; Fua, P. On Triangulation as a Form of Self-Supervision for 3D Human Pose Estimation. In Proceedings of the 2022 International Conference on 3D Vision (3DV), Prague, Czech Republic, 12–16 September 2022; pp. 1–10. [Google Scholar]
- Du, Y.; Wong, Y.; Liu, Y.; Han, F.; Gui, Y.; Wang, Z.; Kankanhalli, M.; Geng, W. Marker-less 3D human motion capture with monocular image sequence and height-maps. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 20–36. [Google Scholar]
- Zhou, X.; Zhu, M.; Leonardos, S.; Daniilidis, K. Sparse representation for 3D shape estimation: A convex relaxation approach. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1648–1661. [Google Scholar] [CrossRef]
- Zhou, X.; Zhu, M.; Leonardos, S.; Derpanis, K.G.; Daniilidis, K. Sparseness meets deepness: 3D human pose estimation from monocular video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4966–4975. [Google Scholar]
- Chen, C.H.; Ramanan, D. 3D human pose estimation= 2d pose estimation+ matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7035–7043. [Google Scholar]
- Yasin, H.; Iqbal, U.; Kruger, B.; Weber, A.; Gall, J. A dual-source approach for 3D pose estimation from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4948–4956. [Google Scholar]
- Rogez, G.; Schmid, C. Mocap-guided data augmentation for 3D pose estimation in the wild. Adv. Neural Inf. Process. Syst. 2016, 29, 3108–3116. [Google Scholar]
- Jiang, H. 3D human pose reconstruction using millions of exemplars. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 1674–1677. [Google Scholar]
- Simo-Serra, E.; Quattoni, A.; Torras, C.; Moreno-Noguer, F. A joint model for 2d and 3D pose estimation from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3634–3641. [Google Scholar]
- Loper, M.; Mahmood, N.; Romero, J.; Pons-Moll, G.; Black, M.J. SMPL: A skinned multi-person linear model. ACM Trans. Graph. (TOG) 2015, 34, 1–16. [Google Scholar] [CrossRef]
- Bogo, F.; Kanazawa, A.; Lassner, C.; Gehler, P.; Romero, J.; Black, M.J. Keep it SMPL: Automatic estimation of 3D human pose and shape from a single image. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 561–578. [Google Scholar]
- Pishchulin, L.; Insafutdinov, E.; Tang, S.; Andres, B.; Andriluka, M.; Gehler, P.V.; Schiele, B. Deepcut: Joint subset partition and labeling for multi person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4929–4937. [Google Scholar]
- Moreno-Noguer, F. 3D human pose estimation from a single image via distance matrix regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2823–2832. [Google Scholar]
- Martinez, J.; Hossain, R.; Romero, J.; Little, J.J. A simple yet effective baseline for 3D human pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 2640–2649. [Google Scholar]
- Mehta, D.; Rhodin, H.; Casas, D.; Fua, P.; Sotnychenko, O.; Xu, W.; Theobalt, C. Monocular 3D human pose estimation in the wild using improved cnn supervision. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 506–516. [Google Scholar]
- Wu, Y.; Ma, S.; Zhang, D.; Huang, W.; Chen, Y. An improved mixture density network for 3D human pose estimation with ordinal ranking. Sensors 2022, 22, 4987. [Google Scholar] [CrossRef] [PubMed]
- Zeng, A.; Sun, X.; Yang, L.; Zhao, N.; Liu, M.; Xu, Q. Learning skeletal graph neural networks for hard 3D pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11436–11445. [Google Scholar]
- Zou, Z.; Tang, W. Modulated graph convolutional network for 3D human pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11477–11487. [Google Scholar]
- Xu, Y.; Wang, W.; Liu, T.; Liu, X.; Xie, J.; Zhu, S.C. Monocular 3D pose estimation via pose grammar and data augmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6327–6344. [Google Scholar] [CrossRef] [PubMed]
- Ci, H.; Ma, X.; Wang, C.; Wang, Y. Locally connected network for monocular 3D human pose estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1429–1442. [Google Scholar] [CrossRef] [PubMed]
- Gu, R.; Wang, G.; Hwang, J.N. Exploring severe occlusion: Multi-person 3D pose estimation with gated convolution. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 8243–8250. [Google Scholar]
- Zhao, W.; Tian, Y.; Ye, Q.; Jiao, J.; Wang, W. Graformer: Graph convolution transformer for 3D pose estimation. arXiv 2021, arXiv:2109.08364. [Google Scholar]
- Li, W.; Liu, H.; Tang, H.; Wang, P.; Van Gool, L. Mhformer: Multi-hypothesis transformer for 3D human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13147–13156. [Google Scholar]
- Luvizon, D.C.; Picard, D.; Tabia, H. Consensus-based optimization for 3D human pose estimation in camera coordinates. Int. J. Comput. Vis. 2022, 130, 869–882. [Google Scholar] [CrossRef]
- Toshev, A.; Szegedy, C. Deeppose: Human pose estimation via deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1653–1660. [Google Scholar]
- Carreira, J.; Agrawal, P.; Fragkiadaki, K.; Malik, J. Human pose estimation with iterative error feedback. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4733–4742. [Google Scholar]
- Tompson, J.J.; Jain, A.; LeCun, Y.; Bregler, C. Joint training of a convolutional network and a graphical model for human pose estimation. Adv. Neural Inf. Process. Syst. 2014, 27, 1799–1807. [Google Scholar]
- Lifshitz, I.; Fetaya, E.; Ullman, S. Human pose estimation using deep consensus voting. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 246–260. [Google Scholar]
- Wei, S.E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional pose machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4724–4732. [Google Scholar]
- Bulat, A.; Tzimiropoulos, G. Human pose estimation via convolutional part heatmap regression. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 717–732. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 483–499. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Groos, D.; Ramampiaro, H.; Ihlen, E.A. EfficientPose: Scalable single-person pose estimation. Appl. Intell. 2021, 51, 2518–2533. [Google Scholar] [CrossRef]
- Zanfir, A.; Marinoiu, E.; Sminchisescu, C. Monocular 3D pose and shape estimation of multiple people in natural scenes-the importance of multiple scene constraints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2148–2157. [Google Scholar]
- Benzine, A.; Chabot, F.; Luvison, B.; Pham, Q.C.; Achard, C. Pandanet: Anchor-based single-shot multi-person 3D pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6856–6865. [Google Scholar]
- Mehta, D.; Sotnychenko, O.; Mueller, F.; Xu, W.; Sridhar, S.; Pons-Moll, G.; Theobalt, C. Single-shot multi-person 3D pose estimation from monocular rgb. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 120–130. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Rogez, G.; Weinzaepfel, P.; Schmid, C. Lcr-net: Localization-classification-regression for human pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3433–3441. [Google Scholar]
- Rogez, G.; Weinzaepfel, P.; Schmid, C. Lcr-net++: Multi-person 2d and 3D pose detection in natural images. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 45, 1146–1161. [Google Scholar] [CrossRef]
- Moon, G.; Chang, J.Y.; Lee, K.M. Camera distance-aware top-down approach for 3D multi-person pose estimation from a single rgb image. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 10133–10142. [Google Scholar]
- Sun, X.; Xiao, B.; Wei, F.; Liang, S.; Wei, Y. Integral human pose regression. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 529–545. [Google Scholar]
- Lin, J.; Lee, G.H. Hdnet: Human depth estimation for multi-person camera-space localization. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 633–648. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Li, J.; Wang, C.; Liu, W.; Qian, C.; Lu, C. Hmor: Hierarchical multi-person ordinal relations for monocular multi-person 3D pose estimation. arXiv 2020, arXiv:2008.00206. [Google Scholar]
- Cheng, Y.; Wang, B.; Yang, B.; Tan, R.T. Graph and temporal convolutional networks for 3D multi-person pose estimation in monocular videos. arXiv 2020, arXiv:2012.11806. [Google Scholar] [CrossRef]
- Reddy, N.D.; Guigues, L.; Pishchulin, L.; Eledath, J.; Narasimhan, S.G. Tessetrack: End-to-end learnable multi-person articulated 3D pose tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15190–15200. [Google Scholar]
- Fabbri, M.; Lanzi, F.; Calderara, S.; Alletto, S.; Cucchiara, R. Compressed volumetric heatmaps for multi-person 3D pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7204–7213. [Google Scholar]
- Zhen, J.; Fang, Q.; Sun, J.; Liu, W.; Jiang, W.; Bao, H.; Zhou, X. Smap: Single-shot multi-person absolute 3D pose estimation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–28 August 2020; pp. 550–566. [Google Scholar]
- Zhang, J.; Wang, J.; Shi, Y.; Gao, F.; Xu, L.; Yu, J. Mutual Adaptive Reasoning for Monocular 3D Multi-Person Pose Estimation. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 1788–1796. [Google Scholar]
- Benzine, A.; Luvison, B.; Pham, Q.C.; Achard, C. Single-shot 3D multi-person pose estimation in complex images. Pattern Recognit. 2021, 112, 107534. [Google Scholar] [CrossRef]
- Mehta, D.; Sotnychenko, O.; Mueller, F.; Xu, W.; Elgharib, M.; Fua, P.; Seidel, H.P.; Rhodin, H.; Pons-Moll, G.; Theobalt, C. XNect: Real-time multi-person 3D motion capture with a single RGB camera. ACM Trans. Graph. (TOG) 2020, 39, 82:1–82:17. [Google Scholar] [CrossRef]
- Jin, L.; Xu, C.; Wang, X.; Xiao, Y.; Guo, Y.; Nie, X.; Zhao, J. Single-stage is enough: Multi-person absolute 3D pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13086–13095. [Google Scholar]
- Zhan, Y.; Li, F.; Weng, R.; Choi, W. Ray3D: Ray-based 3D human pose estimation for monocular absolute 3D localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13116–13125. [Google Scholar]
- Liu, J.; Guang, Y.; Rojas, J. GAST-Net: Graph Attention Spatio-temporal Convolutional Networks for 3D Human Pose Estimation in Video. arXiv 2020, arXiv:2003.14179. [Google Scholar]
- Pavllo, D.; Feichtenhofer, C.; Grangier, D.; Auli, M. 3D human pose estimation in video with temporal convolutions and semi-supervised training. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7753–7762. [Google Scholar]
- Lee, K.; Lee, I.; Lee, S. Propagating lstm: 3D pose estimation based on joint interdependency. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 119–135. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Zhang, H.; Shen, C.; Li, Y.; Cao, Y.; Liu, Y.; Yan, Y. Exploiting temporal consistency for real-time video depth estimation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1725–1734. [Google Scholar]
- Shan, W.; Lu, H.; Wang, S.; Zhang, X.; Gao, W. Improving Robustness and Accuracy via Relative Information Encoding in 3D Human Pose Estimation. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, China, 20–24 October 2021; pp. 3446–3454. [Google Scholar]
- Lea, C.; Flynn, M.D.; Vidal, R.; Reiter, A.; Hager, G.D. Temporal convolutional networks for action segmentation and detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 156–165. [Google Scholar]
- Chen, T.; Fang, C.; Shen, X.; Zhu, Y.; Chen, Z.; Luo, J. Anatomy-aware 3D human pose estimation with bone-based pose decomposition. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 198–209. [Google Scholar] [CrossRef]
- Ghafoor, M.; Mahmood, A. Quantification of occlusion handling capability of 3D human pose estimation framework. IEEE Trans. Multimed. 2022, 25, 3311–3318. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, X. Simplified-attention Enhanced Graph Convolutional Network for 3D human pose estimation. Neurocomputing 2022, 501, 231–243. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, Y.; Tu, Z. Uncertainty-Aware 3D Human Pose Estimation from Monocular Video. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 5102–5113. [Google Scholar]
- Li, W.; Liu, H.; Ding, R.; Liu, M.; Wang, P.; Yang, W. Exploiting temporal contexts with strided transformer for 3D human pose estimation. IEEE Trans. Multimed. 2022, 25, 1282–1293. [Google Scholar] [CrossRef]
- Zhang, J.; Tu, Z.; Yang, J.; Chen, Y.; Yuan, J. Mixste: Seq2seq mixed spatio-temporal encoder for 3D human pose estimation in video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13232–13242. [Google Scholar]
- Zheng, C.; Zhu, S.; Mendieta, M.; Yang, T.; Chen, C.; Ding, Z. 3D human pose estimation with spatial and temporal transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11656–11665. [Google Scholar]
- Nguyen, H.C.; Nguyen, T.H.; Scherer, R.; Le, V.H. Unified end-to-end YOLOv5-HR-TCM framework for automatic 2D/3D human pose estimation for real-time applications. Sensors 2022, 22, 5419. [Google Scholar] [CrossRef]
- El Kaid, A.; Brazey, D.; Barra, V.; Baïna, K. Top-Down System for Multi-Person 3D Absolute Pose Estimation from Monocular Videos. Sensors 2022, 22, 4109. [Google Scholar] [CrossRef] [PubMed]
- Dong, J.; Fang, Q.; Jiang, W.; Yang, Y.; Huang, Q.; Bao, H.; Zhou, X. Fast and robust multi-person 3D pose estimation and tracking from multiple views. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6981–6992. [Google Scholar] [CrossRef] [PubMed]
- Elmi, A.; Mazzini, D.; Tortella, P. Light3DPose: Real-time Multi-Person 3D Pose Estimation from Multiple Views. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 2755–2762. [Google Scholar]
- Hu, W.; Zhang, C.; Zhan, F.; Zhang, L.; Wong, T.T. Conditional directed graph convolution for 3D human pose estimation. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, China, 20–24 October 2021; pp. 602–611. [Google Scholar]
- Liu, R.; Shen, J.; Wang, H.; Chen, C.; Cheung, S.c.; Asari, V. Attention mechanism exploits temporal contexts: Real-time 3D human pose reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5064–5073. [Google Scholar]
- Zhou, X.; Huang, Q.; Sun, X.; Xue, X.; Wei, Y. Weakly-supervised transfer for 3D human pose estimation in the wild. In Proceedings of the IEEE International Conference on Computer Vision, ICCV, Venice, Italy, 22–29 October 2017; Volume 3, p. 7. [Google Scholar]
- Rhodin, H.; Spörri, J.; Katircioglu, I.; Constantin, V.; Meyer, F.; Müller, E.; Salzmann, M.; Fua, P. Learning monocular 3D human pose estimation from multi-view images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8437–8446. [Google Scholar]
- Zhou, X.; Karpur, A.; Gan, C.; Luo, L.; Huang, Q. Unsupervised domain adaptation for 3D keypoint estimation via view consistency. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 137–153. [Google Scholar]
- Kadkhodamohammadi, A.; Padoy, N. A generalizable approach for multi-view 3D human pose regression. Mach. Vis. Appl. 2021, 32, 6. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, Z.; Han, Y.; Meng, H.; Yang, M.; Rajasegarar, S. Deep learning-based real-time 3D human pose estimation. Eng. Appl. Artif. Intell. 2023, 119, 105813. [Google Scholar] [CrossRef]
- Ma, H.; Chen, L.; Kong, D.; Wang, Z.; Liu, X.; Tang, H.; Yan, X.; Xie, Y.; Lin, S.Y.; Xie, X. Transfusion: Cross-view fusion with transformer for 3D human pose estimation. arXiv 2021, arXiv:2110.09554. [Google Scholar]
- Gholami, M.; Rezaei, A.; Rhodin, H.; Ward, R.; Wang, Z.J. Self-supervised 3D human pose estimation from video. Neurocomputing 2022, 488, 97–106. [Google Scholar] [CrossRef]
- Véges, M.; Lőrincz, A. Temporal Smoothing for 3D Human Pose Estimation and Localization for Occluded People. In Proceedings of the International Conference on Neural Information Processing, Bangkok, Thailand, 18–22 November 2020; pp. 557–568. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Learning Paradigm | Description | References |
|---|---|---|
| Supervised Learning | Refers to the use of labeled training data where each input sample (e.g., an image or a video frame) is paired with its corresponding ground truth 3D pose annotation. Using this labeled data, a supervised learning algorithm, often a deep neural network, is trained to learn the correlation between the input data and the corresponding 3D poses. The training process involves tweaking the model’s parameters to minimize the difference between the predicted 3D poses and the ground truth 3D poses. This is accomplished by defining an appropriate loss function, such as mean squared error (MSE) or L1 loss. | [46,47,48,49] |
| Semi-Supervised Learning | Refers to an algorithm that conducts supervised learning when only a subset of the input data is labeled. The algorithm utilizes both labeled and unlabeled data for training the model. The model is initially trained on the labeled data, whereas the unlabeled data are employed to regulate the learning process or enhance generalization. | [50,51,52] |
| Weakly Supervised Learning | These methods do not use exact 3D pose annotations; rather, they utilize less precise data like 2D joint locations or multi-view images. The model could be trained using these 2D joint annotations when direct 3D pose labels are not available. Consequently, the model learns to estimate the 3D human pose from these 2D joint locations without any direct supervision related to the 3D poses themselves. | [53,54,55,56,57,58] |
| Unsupervised learning | These algorithms learn from input variables without having any associated output variables. In the context of 3D human pose estimation, it does not utilize any 3D data or additional views. The objective of unsupervised learning is to deduce the 3D pose structure directly from unlabeled 2D data, without the necessity for explicit 3D pose annotations. Some methods employ strategies like structure-from-motion or multi-view geometry, using multiple 2D views to infer relative 3D poses. Alternatively, some methods use models such as autoencoders or generative adversarial networks (GANs) to learn a latent representation of 3D poses. | [59,60,61,62,63] |
| Self-Supervised Learning | This is a specific type of unsupervised learning that makes use of the inherent structure or information within the data to generate its own labels. The model produces its own training labels using the available 2D annotations or certain substitute tasks. Additionally, some self-supervised methods may employ the concept of temporal consistency. | [64,65,66,67,68,69,70,71,72] |
| Acronym | Meaning | Explanation |
|---|---|---|
| 2D | Two-dimensional | Refers to something having width and height but no depth. In the context of pose estimation, 2D refers to poses estimated within a two-dimensional space, such as an image. |
| 3D | Three-dimensional | Refers to something having width, height, and depth. In the context of pose estimation, 3D refers to poses estimated within a three-dimensional space, providing a more realistic representation of human poses. |
| PCA | Principal component analysis | A statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables called principal components. |
| CNN | Convolutional neural network | A type of artificial neural network used in image recognition and processing that is specifically designed to process pixel data. |
| LSTM | Long short-term memory | These models utilize long short-term memory units to capture temporal information across video frames. |
| TCN | Temporal convolutional network | These networks are designed for sequence modeling and use dilated convolutions and causal connections to capture long-range dependencies in time-series data. |
| GCN | Graph convolutional network | These models operate directly on graphs and can take into account the structure of the graph and the attributes of its nodes and edges. They are employed for their ability to model non-Euclidean data structures like human skeletons. |
| Transformers | Transformer-based methods | These deep learning architectures utilize self-attention mechanisms to handle sequential data, including text or images. Transformers can discern long-range dependencies and spatial relationships among features and are capable of modeling global dependencies among all elements in a sequence. |
| SMPL | Skinned multi-person linear model | A method for estimating human body shape and pose from images. |
| MDNs | Mixture density networks | A type of neural network that can model a conditional probability distribution over a multi-modal output space. |
| IKNet-body | Inverse kinematics network | A type of network used to calculate the angles of joints in a mechanism (like a robotic arm or a human skeleton) to achieve a desired pose. |
| IEF | Iterative error feedback | A method used in machine learning to iteratively correct the errors made by a model. |
| P2P-MeshNet | Point-to-pose mesh fitting network | Incorporates a collaborative approach between a deep learning network, an inverse kinematics network (IKNet-body), and an iterative error feedback network (IEF), enabling improved accuracy in estimating 3D poses. |
| HOGs | Histogram of oriented gradients | A feature descriptor used in computer vision and image processing for the purpose of object detection. |
| LCN | Locally connected network | A type of neural network where each neuron is connected to its neighboring neurons, but not necessarily to all other neurons in the network. |
| Method | 3D-PCK | 3D-PCK | |
|---|---|---|---|
| Top-down approaches | GnTCN [146] | 87.50 | 45.7 |
| HDNet [143] | 83.70 | 35.2 | |
| HMOR [145] | 82.00 | 43.8 | |
| 3DMPPE-POSENET [141] | 81.80 | 31.5 | |
| Bottom-up approaches | Single shot [151] | 72.7 | 20.9 |
| SMAP [149] | 80.50 | 38.7 | |
| Mutual Adaptive Reasoning [150] | 81.5 | 39.5 | |
| Fusion approaches | TDBU_Net [51] | 89.60 | 48.0 |
| Dual networks [52] | 89.6 | 48.1 |
| Category | Performance | Complexity | Key Features | Best Used For |
|---|---|---|---|---|
| LSTM-based methods | Good with short-term patterns, struggle with long-term patterns | Low complexity | Work well with data that follow a sequence | Tasks with short-term sequential data |
| TCN-based methods | Great with long-term patterns | Low complexity | Use special connections to capture long-term patterns | Tasks needing to capture long-term patterns |
| GCN-based methods | Very accurate with network-like structures | High complexity | Capture relationships between different points, good for spatial relationships | Tasks where estimation involves a network-like structure |
| Transformers | Promising results with long-term patterns and hidden points | High complexity | Use attention mechanism, good for understanding spatial relationships | Tasks needing to understand long-term patterns and spatial relationships |
| Unified frameworks | High accuracy; performance depends on the mix of methods | High complexity | Combine advantages of different methods, needs careful setup | Complex tasks where combining different methods could improve results |
| Method | Temporal Network Type | Frames Needed | Average MPJPE (mm) |
|---|---|---|---|
| Mixtse [167] | Transformer | 243 | 21.6 |
| U-CondDGConv [173] | GCN | 243 | 22.7 |
| GAST-Net [155] | GCN+TCN | 243 | 25.1 |
| StridedTransformer [166] | Transformer | 243 | 28.5 |
| P-STMO [70] | Transformer | 243 | 29.3 |
| Modulated GCN [119] | GCN | 50 | 30.06 |
| MHFormer [124] | Transformer | 243 | 30.5 |
| PoseFormer [168] | Transformer | 81 | 31.3 |
| Anatomy3D [162] | TCN | 243 | 32.3 |
| SemGCN [46] | GCN | 50 | 33.53 |
| Attention-based framework [174] | TCN | 243 | 34.7 |
| VideoPose3D [156] | TCN | 243 | 37.2 |
| Propagating LSTM [157] | LSTM | 3 | 38.4 |
| Dataset | Description | Evaluation Metrics | |
|---|---|---|---|
| Single Person | HumanEva-I [83] 2010 | Seven calibrated video sequences using multiple RGB and gray-scale cameras, synchronized with 3D body poses obtained using marker-based motion capture system. The database contains 4 subjects performing 6 common actions. | 3D error metric |
| Human3.6M [13] 2013 | The most popular and biggest benchmark for 3D human pose estimation. 3.6 million indoor video frames and corresponding poses of 11 professional actors captured by MoCap system from 4 camera viewpoints. Subjects 9 and 11 are used for testing, as in prior studies. | MPJPE Procrustes aligned MPJPE MRPE | |
| MPI-INF-3DHP [116] 2017 | It consists of more than 1.3 million frame captured with markerless motion capture using 14 RGB cameras, consisting of both constrained indoor and complex outdoor scenes. It has 8 subjects performing 8 activity sets. | MPJPE 3D_PCK AUC | |
| Multiple Person | MuCo-3DHP [137] 2018 | Training dataset which merges randomly sampled 3D poses from single-person 3D human pose dataset MPI-INF-3DHP to form realistic multi-person scenes. | MPJPE 3D-PCK AUC 3DPCK |
| MuPoTS-3D [137] 2018 | A dataset used for testing real-world shots of a 3D human pose dataset containing 20 videos (8000 frames) captured in both indoor and outdoor scenes, with challenging occlusions and person–person interactions. | 3D-PCK AUC 3DPCK | |
| Muco-Temp [182] 2020 | A dataset generated in the same way as MuCo-3DHP. It consists of videos instead of frames Usually used for temporal networks training. | 3D-PCK AUC 3DPCK MPJPE MRPE |
| Evaluation Metric | Name | Description | |
|---|---|---|---|
| Person-centric (relative pose) | 3D error metric | 3D error metric | Measures the average squared distance between the predicted pose coordinates and the actual ones. |
| MPJPE | Mean per-joint position error | Is the mean Euclidean error averaged over all joints and all poses, calculated after aligning the human root of the estimated and ground truth 3D poses.
| |
| 3DPCK | 3D Percentage of correct keypoints | Measures the percentage of correctly estimated keypoints within a certain distance threshold. In studies, an estimated joint is considered correct if it is within a 150 mm distance from the corresponding ground truth joint. | |
| AUC | Area under 3D-PCK curve | This performance metric is calculated by plotting the PCK values against different distance thresholds and integrating the area under the curve. A higher value of this metric indicates better performance of the algorithm. | |
| Camera-centric (absolute pose) | MRPE | Mean root position error | The average error in
the absolute root joint (the hip) localization.
|
| AP | Average precision of the root | Allows the 3D human root location prediction error to be measured, which considers the prediction as correct when the Euclidean distance between the estimated and the ground truth coordinates is smaller than 25 cm. | |
| 3DPCK | 3D percentage of correct absolute keypoints | 3DPCK without root alignment to evaluate the absolute poses. In studies, the threshold distance used for an absolute joint to be estimated as correct is 250 mm. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
El Kaid, A.; Baïna, K. A Systematic Review of Recent Deep Learning Approaches for 3D Human Pose Estimation. J. Imaging 2023, 9, 275. https://doi.org/10.3390/jimaging9120275
El Kaid A, Baïna K. A Systematic Review of Recent Deep Learning Approaches for 3D Human Pose Estimation. Journal of Imaging. 2023; 9(12):275. https://doi.org/10.3390/jimaging9120275
Chicago/Turabian StyleEl Kaid, Amal, and Karim Baïna. 2023. "A Systematic Review of Recent Deep Learning Approaches for 3D Human Pose Estimation" Journal of Imaging 9, no. 12: 275. https://doi.org/10.3390/jimaging9120275
APA StyleEl Kaid, A., & Baïna, K. (2023). A Systematic Review of Recent Deep Learning Approaches for 3D Human Pose Estimation. Journal of Imaging, 9(12), 275. https://doi.org/10.3390/jimaging9120275