
Combining Synthetic Images and Deep Active Learning: Data-Efficient Training of an Industrial Object Detection Model


Abstract
1. Introduction
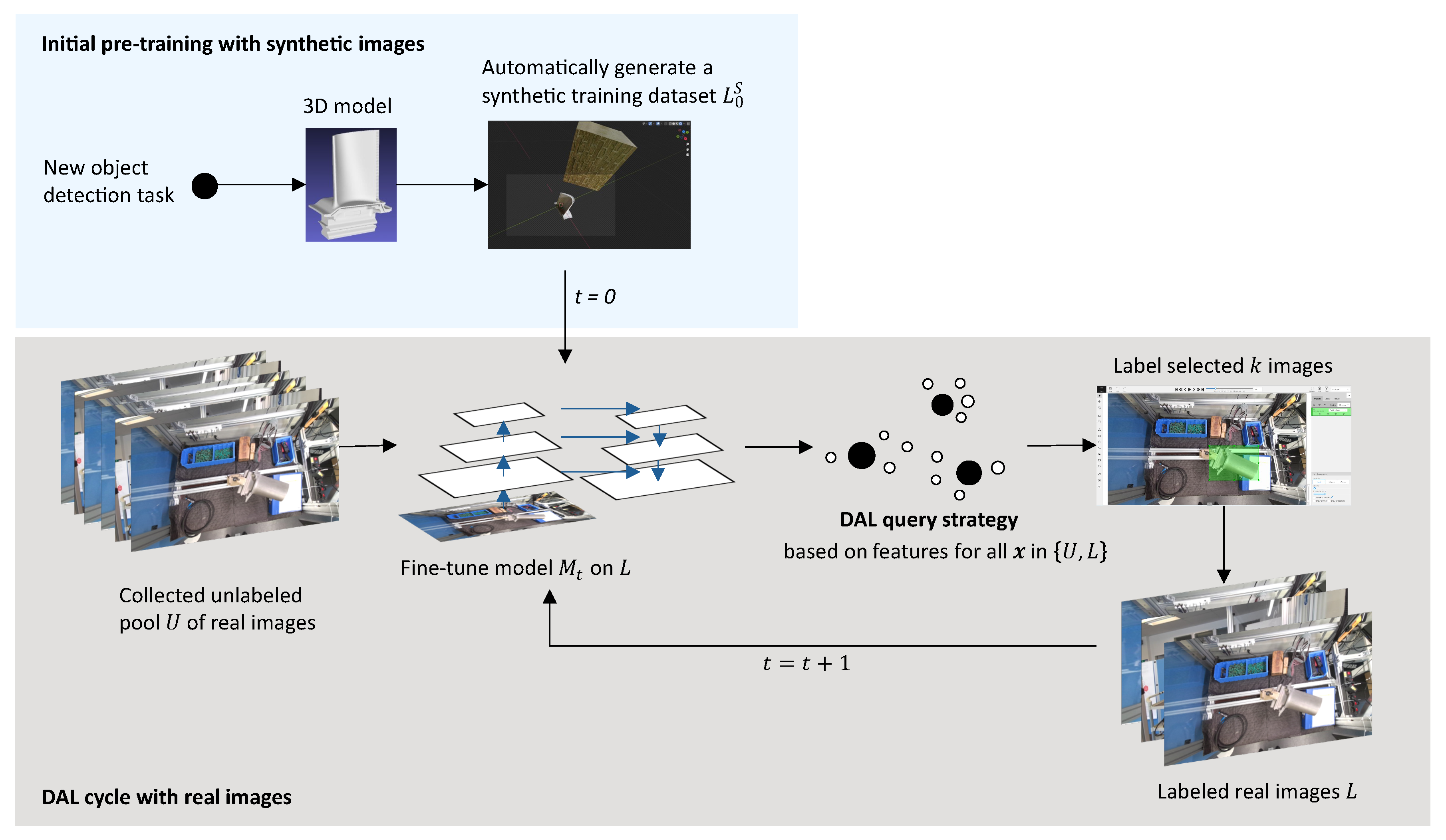
- A workflow is presented to efficiently train industrial object detection models by automatically generating synthetic training images based on 3D models and then using deep active learning to iteratively improve the model with reduced annotation cost.
- Different deep active learning query strategies are investigated on a collected industrial dataset for a real-world object detection use case.
- Multiple deep active learning cycles are compared to a single cycle with an equivalent amount of manually labeled training images.
2. Related Works
2.1. Using Synthetic Images to Train Computer Vision Models
2.2. Deep Active Learning
2.3. Deep Active Learning for Object Detection
2.4. Combining Deep Active Learning with Synthetic Images
3. Materials and Methods
3.1. Generating a Synthetic Training Dataset
3.2. Real Dataset of Our Industrial Object Detection Use Case
3.3. Object Detection Model Training Details
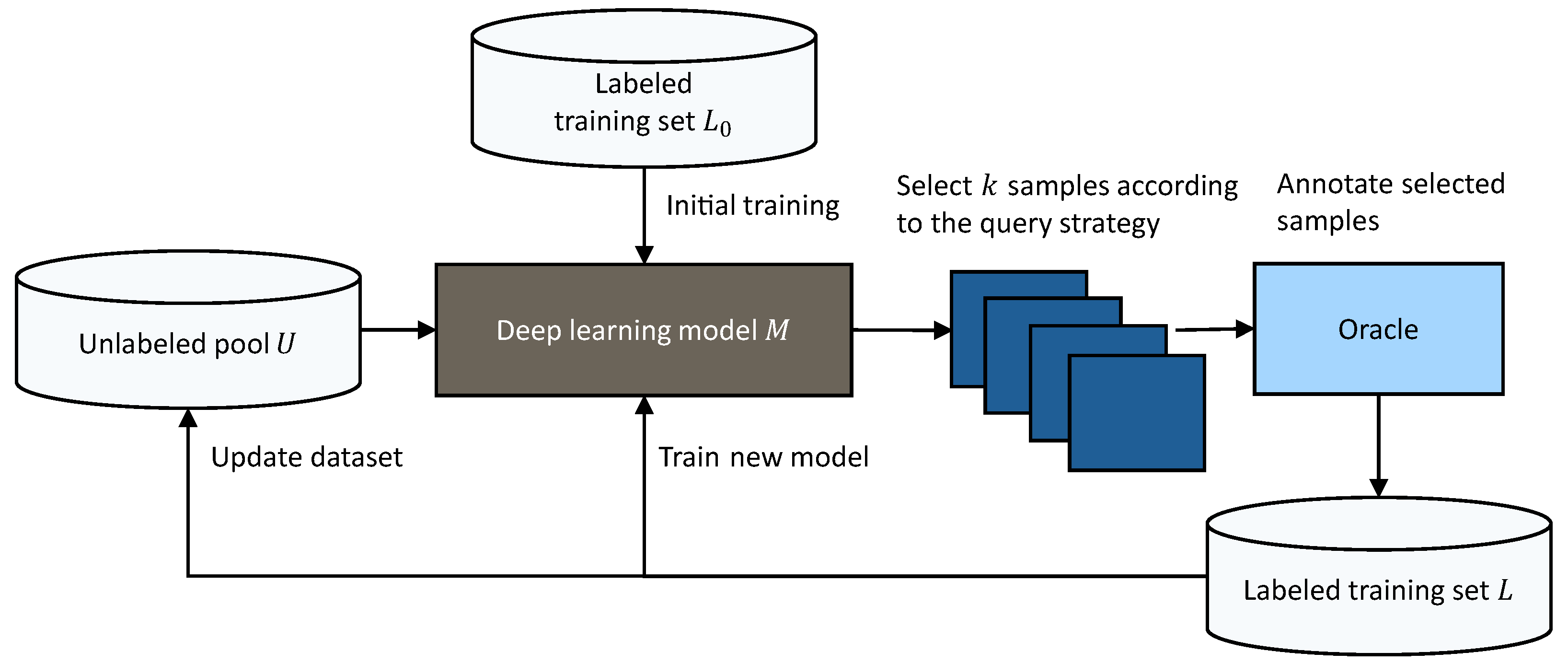
3.4. Deep Active Learning Pipeline
3.4.1. Uncertainty-Based Query Strategy
| Algorithm 1 Maximum margin sampling |
| Input: Unlabeled pool of images U, empty labeled training set L, query batch size k, pre-trained model Output: Fine-tuned model M 1: 2: loop 3: Obtain informativeness score for every image 4: if an image x has no detections then 5: Set 6: end if 7: Select and label top k images with the highest scores, add them to L 8: Fine-tune object detection model on labeled training set L 9: 10: end loop |
3.4.2. Hybrid Query Strategy
| Algorithm 2 DBAL |
| Input: Unlabeled pool of images U, empty labeled training set L, query batch size k, pre-filter factor , pre-trained model Output: Fine-tuned model M 1: 2: loop 3: Obtain informativeness score for every image 4: if an image x has no detections then 5: Set 6: end if 7: Pre-filter to top informative images 8: Cluster images to k clusters with weighted KMeans++ 9: Select and label k images closest to the cluster centers, add them to L 10: Fine-tune the object detection model on labeled training set L 11: 12: end loop |
4. Results
4.1. Combining Synthetic Images and Deep Active Learning for One DAL Cycle
4.2. Multiple Deep Active Learning Cycles
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AL | active learning |
| AP | average precision |
| DAL | deep active learning |
| DBAL | diverse mini-batch active learning |
| MLOps | machine learning operations |
| OD | object detection |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Strategy | Number of Real Training Images | AP@[0.5:0.95] Random Seed 1 | AP@[0.5:0.95] Random Seed 2 | AP@[0.5:0.95] Random Seed 3 | (Average) AP@[0.5:0.95] |
|---|---|---|---|---|---|
| R Random * | 10 | 0.479 | 0.507 | 0.507 | 0.498 |
| 25 | 0.578 | 0.582 | 0.601 | 0.587 | |
| 50 | 0.686 | 0.665 | 0.645 | 0.665 | |
| 100 | 0.733 | 0.732 | 0.720 | 0.728 | |
| 150 | 0.754 | 0.761 | 0.751 | 0.755 | |
| 200 | 0.765 | 0.771 | 0.763 | 0.766 | |
| S+R Random * | 0 | 0.555 | |||
| 10 | 0.636 | 0.655 | 0.660 | 0.650 | |
| 25 | 0.671 | 0.692 | 0.698 | 0.687 | |
| 50 | 0.724 | 0.718 | 0.720 | 0.721 | |
| 100 | 0.757 | 0.765 | 0.757 | 0.760 | |
| 150 | 0.778 | 0.782 | 0.778 | 0.779 | |
| 200 | 0.782 | 0.788 | 0.790 | 0.787 | |
| S+R Max. Margin | 0 | 0.555 | |||
| 10 | 0.668 | ||||
| 25 | 0.712 | ||||
| 50 | 0.725 | ||||
| 100 | 0.753 | ||||
| 150 | 0.773 | ||||
| 200 | 0.776 | ||||
| S+R DBAL | 0 | 0.555 | |||
| 10 | 0.666 | ||||
| 25 | 0.718 | ||||
| 50 | 0.735 | ||||
| 100 | 0.763 | ||||
| 150 | 0.782 | ||||
| 200 | 0.791 | ||||
| S+R DBAL (8 cycles) | 0 | 0.555 | |||
| 25 | 0.718 | ||||
| 50 | 0.747 | ||||
| 75 | 0.768 | ||||
| 100 | 0.778 | ||||
| 125 | 0.791 | ||||
| 150 | 0.796 | ||||
| 175 | 0.798 | ||||
| 200 | 0.800 |
References
- Gupta, C.; Farahat, A. Deep Learning for Industrial AI: Challenges, New Methods and Best Practices. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, New York, NY, USA, 6–10 July 2020. [Google Scholar] [CrossRef]
- Torralba, A.; Efros, A.A. Unbiased look at dataset bias. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2011), Colorado Springs, CO, USA, 20–25 June 2011; IEEE: New York, NY, USA, 2011. [Google Scholar] [CrossRef]
- Coyner, A.S.; Chen, J.S.; Chang, K.; Singh, P.; Ostmo, S.; Chan, R.V.P.; Chiang, M.F.; Kalpathy-Cramer, J.; Campbell, J.P. Synthetic Medical Images for Robust, Privacy-Preserving Training of Artificial Intelligence: Application to Retinopathy of Prematurity Diagnosis. Ophthalmol. Sci. 2022, 2, 100126. [Google Scholar] [CrossRef] [PubMed]
- Northcutt, C.; Athalye, A.; Mueller, J. Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1 (NeurIPS Datasets and Benchmarks 2021), Virtual, 6–14 December 2021; Vanschoren, J., Yeung, S., Eds.; Curran: Red Hook, NY, USA, 2021; Volume 1. [Google Scholar]
- Tobin, J.; Fong, R.; Ray, A.; Schneider, J.; Zaremba, W.; Abbeel, P. Domain randomization for transferring deep neural networks from simulation to the real world. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; IEEE: New York, NY, USA, 2017. [Google Scholar] [CrossRef]
- Lambrecht, J.; Kästner, L. Towards the Usage of Synthetic Data for Marker-Less Pose Estimation of Articulated Robots in RGB Images. In Proceedings of the 2019 19th International Conference on Advanced Robotics (ICAR), Belo Horizonte, Brazil, 2–6 December 2019; IEEE: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Nowruzi, F.E.; Kapoor, P.; Kolhatkar, D.; Hassanat, F.A.; Laganiere, R.; Rebut, J. How much real data do we actually need: Analyzing object detection performance using synthetic and real data. arXiv 2019, arXiv:1907.07061. [Google Scholar] [CrossRef]
- Movshovitz-Attias, Y.; Kanade, T.; Sheikh, Y. How Useful Is Photo-Realistic Rendering for Visual Learning? In Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; pp. 202–217. [Google Scholar] [CrossRef]
- de Melo, C.M.; Rothrock, B.; Gurram, P.; Ulutan, O.; Manjunath, B. Vision-Based Gesture Recognition in Human-Robot Teams Using Synthetic Data. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Virtual, 24 October 2020–24 January 2021; pp. 10278–10284. [Google Scholar] [CrossRef]
- Yang, X.; Fan, X.; Wang, J.; Lee, K. Image Translation Based Synthetic Data Generation for Industrial Object Detection and Pose Estimation. IEEE Robot. Autom. Lett. 2022, 7, 7201–7208. [Google Scholar] [CrossRef]
- Eversberg, L.; Lambrecht, J. Generating Images with Physics-Based Rendering for an Industrial Object Detection Task: Realism versus Domain Randomization. Sensors 2021, 21, 7901. [Google Scholar] [CrossRef] [PubMed]
- Schraml, D. Physically based synthetic image generation for machine learning: A review of pertinent literature. In Proceedings of the Photonics and Education in Measurement Science 2019, Jena, Germany, 17–19 September 2019; SPIE: Bellingham, WA USA, 2019; Volume 11144. [Google Scholar] [CrossRef]
- Georgakis, G.; Mousavian, A.; Berg, A.; Kosecka, J. Synthesizing Training Data for Object Detection in Indoor Scenes. In Proceedings of the Robotics: Science and Systems XIII. Robotics: Science and Systems Foundation, Cambridge, MA, USA, 12–16 July 2017. [Google Scholar] [CrossRef]
- Dwibedi, D.; Misra, I.; Hebert, M. Cut, Paste and Learn: Surprisingly Easy Synthesis for Instance Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: New York, NY, USA, 2017. [Google Scholar] [CrossRef]
- Gorschlüter, F.; Rojtberg, P.; Pöllabauer, T. A Survey of 6D Object Detection Based on 3D Models for Industrial Applications. J. Imaging 2022, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Tremblay, J.; Prakash, A.; Acuna, D.; Brophy, M.; Jampani, V.; Anil, C.; To, T.; Cameracci, E.; Boochoon, S.; Birchfield, S. Training Deep Networks with Synthetic Data: Bridging the Reality Gap by Domain Randomization. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; IEEE: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Prakash, A.; Boochoon, S.; Brophy, M.; Acuna, D.; Cameracci, E.; State, G.; Shapira, O.; Birchfield, S. Structured Domain Randomization: Bridging the Reality Gap by Context-Aware Synthetic Data. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, Canada, 20–24 May 2019; IEEE: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Hodan, T.; Vineet, V.; Gal, R.; Shalev, E.; Hanzelka, J.; Connell, T.; Urbina, P.; Sinha, S.N.; Guenter, B. Photorealistic Image Synthesis for Object Instance Detection. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; IEEE: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Jabbar, A.; Farrawell, L.; Fountain, J.; Chalup, S.K. Training Deep Neural Networks for Detecting Drinking Glasses Using Synthetic Images. In Neural Information Processing; Springer International Publishing: Cham, Switzerland, 2017; pp. 354–363. [Google Scholar] [CrossRef]
- Pharr, M.; Jakob, W.; Humphreys, G. Physically Based Rendering: From Theory to Implementation, 3rd ed.; Morgan Kaufmann: Burlington, MA, USA, 2016. [Google Scholar]
- Shrivastava, A.; Pfister, T.; Tuzel, O.; Susskind, J.; Wang, W.; Webb, R. Learning From Simulated and Unsupervised Images Through Adversarial Training. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2242–2251. [Google Scholar] [CrossRef]
- Sankaranarayanan, S.; Balaji, Y.; Jain, A.; Lim, S.N.; Chellappa, R. Learning From Synthetic Data: Addressing Domain Shift for Semantic Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3752–3761. [Google Scholar] [CrossRef]
- Peng, X.; Saenko, K. Synthetic to Real Adaptation with Generative Correlation Alignment Networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; IEEE: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Rojtberg, P.; Pollabauer, T.; Kuijper, A. Style-transfer GANs for bridging the domain gap in synthetic pose estimator training. In Proceedings of the 2020 IEEE International Conference on Artificial Intelligence and Virtual Reality (AIVR), Virtual, 14–18 December 2020; IEEE: New York, NY, USA, 2020. [Google Scholar] [CrossRef]
- Su, Y.; Rambach, J.; Pagani, A.; Stricker, D. SynPo-Net—Accurate and Fast CNN-Based 6DoF Object Pose Estimation Using Synthetic Training. Sensors 2021, 21, 300. [Google Scholar] [CrossRef] [PubMed]
- Settles, B. Active Learning Literature Survey; Computer Sciences Technical Report 1648; University of Wisconsin: Madison, WI, USA, 2009. [Google Scholar]
- Ren, P.; Xiao, Y.; Chang, X.; Huang, P.Y.; Li, Z.; Gupta, B.B.; Chen, X.; Wang, X. A Survey of Deep Active Learning. ACM Comput. Surv. 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Zhan, X.; Wang, Q.; hao Huang, K.; Xiong, H.; Dou, D.; Chan, A.B. A Comparative Survey of Deep Active Learning. arXiv 2022, arXiv:2203.13450. [Google Scholar] [CrossRef]
- Wang, D.; Shang, Y. A new active labeling method for deep learning. In Proceedings of the 2014 International Joint Conference on Neural Networks (IJCNN), Beijing, China, 6–11 July 2014; IEEE: New York, NY, USA, 2014. [Google Scholar] [CrossRef]
- Sener, O.; Savarese, S. Active Learning for Convolutional Neural Networks: A Core-Set Approach. In Proceedings of the 2018 International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Ash, J.T.; Zhang, C.; Krishnamurthy, A.; Langford, J.; Agarwal, A. Deep Batch Active Learning by Diverse, Uncertain Gradient Lower Bounds. In Proceedings of the 2020 International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Yin, C.; Qian, B.; Cao, S.; Li, X.; Wei, J.; Zheng, Q.; Davidson, I. Deep Similarity-Based Batch Mode Active Learning with Exploration-Exploitation. In Proceedings of the 2017 IEEE International Conference on Data Mining (ICDM), New Orleans, LA, USA, 18–21 November 2017; IEEE: New York, NY, USA, 2017. [Google Scholar] [CrossRef]
- Zhdanov, F. Diverse mini-batch Active Learning. arXiv 2019, arXiv:1901.05954. [Google Scholar] [CrossRef]
- Li, Y.; Fan, B.; Zhang, W.; Ding, W.; Yin, J. Deep active learning for object detection. Inf. Sci. 2021, 579, 418–433. [Google Scholar] [CrossRef]
- Brust, C.A.; Käding, C.; Denzler, J. Active Learning for Deep Object Detection. In Proceedings of the 14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP), Prague, Czech Republic, 25–27 February 2019; SciTePress: Setúbal, Portugal, 2019; pp. 181–190. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Everingham, M.; Gool, L.V.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2009, 88, 303–338. [Google Scholar] [CrossRef]
- Haussmann, E.; Fenzi, M.; Chitta, K.; Ivanecky, J.; Xu, H.; Roy, D.; Mittel, A.; Koumchatzky, N.; Farabet, C.; Alvarez, J.M. Scalable Active Learning for Object Detection. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; IEEE: New York, NY, USA, 2020. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Peng, H.; Lin, S.; King, D.; Su, Y.H.; Bly, R.A.; Moe, K.S.; Hannaford, B. Reducing Annotating Load: Active Learning with Synthetic Images in Surgical Instrument Segmentation. arXiv 2021, arXiv:2108.03534. [Google Scholar] [CrossRef]
- Houlsby, N.; Huszár, F.; Ghahramani, Z.; Lengyel, M. Bayesian Active Learning for Classification and Preference Learning. arXiv 2011, arXiv:1112.5745. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar] [CrossRef]
- Niemeijer, J.; Mittal, S.; Brox, T. Synthetic Dataset Acquisition for a Specific Target Domain. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Paris, France, 2–6 October 2023; pp. 4055–4064. [Google Scholar]
- Wang, Y.; Ilic, V.; Li, J.; Kisačanin, B.; Pavlovic, V. ALWOD: Active Learning for Weakly-Supervised Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 6459–6469. [Google Scholar]
- Denninger, M.; Sundermeyer, M.; Winkelbauer, D.; Olefir, D.; Hodan, T.; Zidan, Y.; Elbadrawy, M.; Knauer, M.; Katam, H.; Lodhi, A. BlenderProc: Reducing the Reality Gap with Photorealistic Rendering. In Proceedings of the Robotics: Science and Systems (RSS), Virtual, 12–16 July 2020. [Google Scholar]
- Dirr, J.; Gebauer, D.; Yao, J.; Daub, R. Automatic Image Generation Pipeline for Instance Segmentation of Deformable Linear Objects. Sensors 2023, 23, 3013. [Google Scholar] [CrossRef] [PubMed]
- Druskinis, V.; Araya-Martinez, J.M.; Lambrecht, J.; Bøgh, S.; de Figueiredo, R.P. A Hybrid Approach for Accurate 6D Pose Estimation of Textureless Objects From Monocular Images. In Proceedings of the 2023 IEEE 28th International Conference on Emerging Technologies and Factory Automation (ETFA), Sinaia, Romania, 12–15 September 2023; pp. 1–8. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014; Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Eversberg, L.; Lambrecht, J. Evaluating digital work instructions with augmented reality versus paper-based documents for manual, object-specific repair tasks in a case study with experienced workers. Int. J. Adv. Manuf. Technol. 2023, 127, 1859–1871. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28, pp. 91–99. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and Flexible Image Augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- Padilla, R.; Passos, W.L.; Dias, T.L.B.; Netto, S.L.; da Silva, E.A.B. A Comparative Analysis of Object Detection Metrics with a Companion Open-Source Toolkit. Electronics 2021, 10, 279. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. k-means++: The Advantages of Careful Seeding. In Proceedings of the Eighteenth annual ACM-SIAM symposium on Discrete algorithms, New Orleans, LA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Kreuzberger, D.; Kühl, N.; Hirschl, S. Machine Learning Operations (MLOps): Overview, Definition, and Architecture. IEEE Access 2023, 11, 31866–31879. [Google Scholar] [CrossRef]
- Moreno-Torres, J.G.; Raeder, T.; Alaiz-Rodríguez, R.; Chawla, N.V.; Herrera, F. A unifying view on dataset shift in classification. Pattern Recognit. 2012, 45, 521–530. [Google Scholar] [CrossRef]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eversberg, L.; Lambrecht, J. Combining Synthetic Images and Deep Active Learning: Data-Efficient Training of an Industrial Object Detection Model. J. Imaging 2024, 10, 16. https://doi.org/10.3390/jimaging10010016
Eversberg L, Lambrecht J. Combining Synthetic Images and Deep Active Learning: Data-Efficient Training of an Industrial Object Detection Model. Journal of Imaging. 2024; 10(1):16. https://doi.org/10.3390/jimaging10010016
Chicago/Turabian StyleEversberg, Leon, and Jens Lambrecht. 2024. "Combining Synthetic Images and Deep Active Learning: Data-Efficient Training of an Industrial Object Detection Model" Journal of Imaging 10, no. 1: 16. https://doi.org/10.3390/jimaging10010016
APA StyleEversberg, L., & Lambrecht, J. (2024). Combining Synthetic Images and Deep Active Learning: Data-Efficient Training of an Industrial Object Detection Model. Journal of Imaging, 10(1), 16. https://doi.org/10.3390/jimaging10010016