1. Introduction
China firmly ranks first in the global apple production and consumption field. Data show that in 2022, the planting area of apples in China was about 1.9557 million hectares, with a total output of 47.5718 million tons, accounting for about 57.36% of the world’s total apple production [
1]. Given the short maturity cycle of apples and their distinct seasonal characteristics during harvesting, if the optimal harvesting time is missed, the fruit will quickly rot. Therefore, the efficiency of apple harvesting has a significant impact on subsequent stages such as fruit storage, transportation, processing, and market sales. At present, apple picking still mainly relies on manpower [
2,
3,
4,
5,
6,
7], which not only has high labor and time requirements but also poses significant safety risks when picking apples from high places. With the rapid advancements in machine vision, robotics technology [
8,
9,
10], and artificial intelligence technology, apple-picking robots are gradually becoming a new development direction for reducing labor costs by replacing traditional manual picking. Therefore, exploring and optimizing the key technologies of apple-picking robots in depth to achieve efficient and automated picking operations is of great significance for ensuring timely apple picking and for promoting the intelligent development of agricultural production. Among these, precise intelligent perception of fruit information on apple trees is one of the core technologies of harvesting robots. In order to improve harvesting efficiency, it is necessary to first achieve rapid and accurate detection of fruit targets [
11,
12,
13,
14,
15,
16,
17].
The perception and acquisition system of fruit position information is one of the most important components of apple-picking robots, and it is the front-end information perception part of the picking robot. Therefore, in order to improve the fruit-picking efficiency of apple-picking robots, it is necessary to achieve the rapid recognition and precise positioning of fruit targets on apple trees [
17,
18]. The first step of the apple-picking robot in the picking operation is to perceive and obtain position information for the apple fruit on the fruit tree; based on the digital image of the fruit target obtained by the vision system carried by the picking robot, the apple area is effectively extracted, and its coordinate position is determined according to the characteristics of the fruit target. Furthermore, based on the control system of the picking robot, the operation of picking apple fruits is carried out using the picking robotic arm and end effector. Therefore, obtaining fruit position information based on visual systems is the forefront and primary task of apple-picking robots, which directly affects the success rate and efficiency of robot picking operations. Fruit recognition algorithms [
15,
16] are the core of the target fruit position information acquisition task.
However, currently, although many deep-learning-based apple-recognition models have high fruit object-detection accuracy, the complexity and large size of the models, due to the inclusion of a large number of parameters, result in relatively high operating costs for the designed recognition models on hardware computing devices [
17,
18]. Therefore, it is still urgent to conduct in-depth research on how to improve and design more lightweight fruit recognition algorithms while ensuring the accuracy of apple target recognition in order to meet the intelligent fruit recognition needs of harvesting robots in practical landing applications. YOLOv5 has lower training and inference costs, making it particularly suitable for resource-constrained agricultural applications such as mobile robots. YOLOv11 performs better in multi-task support and complex scene detection but may sacrifice some efficiency in single-object-detection tasks due to its architectural complexity. On the other hand, the training platform requirements for the YOLOv11 model are also higher than those for YOLOv5. Based on our specific requirements for apple object-detection tasks, we comprehensively considered the design of an apple detection model based on the YOLOv5 network.
The advantages of YOLOv5 in apple object-detection tasks stem from its balance of speed, accuracy, and model size, flexible network optimization, targeted data augmentation strategies, and mature deployment ecology. These characteristics make it the preferred model in scenarios such as agricultural robots and orchard automation management. Considering that this task is aimed at object detection in unstructured environments, selecting a network with high deployment and training requirements for the model may increase the difficulty of practical application and model maintenance in the later stage.
The YOLOv5s detection model has the advantages of fast detection speed and high accuracy, and it is widely used in the field of fruit detection; for example, a citrus detection model based on an improved YOLOv5s algorithm has been proposed [
19]. Our paper proposes a lightweight apple tree fruit object-detection method based on an improved YOLOv5s model [
20,
21,
22] using artificial intelligence algorithms to address issues such as the large size of the apple-recognition model and the need for further improvements in the model detection speed and accuracy. The original YOLOv5s network is improved and designed by replacing the embedded Depthwise Separable Convolution (DWConv) module in its Backbone network, which reduces the size of the model while ensuring detection accuracy, making it more suitable for deployment in hardware devices of picking-robot [
23,
24,
25] vision systems to achieve the real-time detection of fruit objects.
2. Acquisition and Preprocessing of Experimental Data
2.1. Apple Image Acquisition Method
According to differences in the fruit tree planting layout, apple orchards are divided into two categories: traditional and modern standardized (or standardized). The traditional apple orchard has significant characteristics, with staggered branches between fruit trees and narrow and closed space between rows, which restrict the smooth operation of mechanical work in the orchard.
For modern standardized apple orchards, the dwarf-rootstock dense-planting cultivation mode dominates. This mode, with its low crown, convenient management, low labor demand, superior ventilation and light transmission performance, uniform fruit coloring, superior quality, and ease of intelligent agricultural machinery operation, has become an effective way to achieve orchard standardization, scale, and intelligent management. This model is widely used in advanced countries for apple production worldwide and is also a core development direction in the modernization process of China’s apple industry.
Statistical data show that as of 2018, the total area of apple orchards in China for dwarf-rootstock-intensive cultivation is about 500 thousand hectares, with Shaanxi Province being the main province promoting this cultivation model and making particularly outstanding contributions. Specifically, Baishui County in Weinan City, Shaanxi Province, serves as a model for dwarf apple cultivation nationwide and widely adopts the spindle-shaped cultivation mode. Compared with other cultivation modes such as the “V” shape, “Y” shape, and “wall” shape, the spindle-shaped mode is favored for its abundant fruiting branches and strong fruit-bearing capacity, becoming the mainstream choice in the construction of modern standard orchards in China. The spindle-shaped apple trees are shown in
Figure 1.
The spindle-shaped apple tree in the Qian County Agricultural Science and Technology Experimental Demonstration Base in Shaanxi Province and the Baishui Apple Experimental Station of Northwest A&F University was taken as the research object. We used the Canon PowerShot G16 camera (Canon, Tokyo, Japan) to capture images during different time periods (morning, noon, afternoon) on sunny and cloudy days. The shooting distance (distance between the camera and the apple tree) during image acquisition varied from 0.5 to 1.5 m, and images were captured from multiple angles, including with varying degrees of obstruction of fruits by leaves or branches, overlapping between fruits, and under different lighting conditions (forward, side, and backlight) (
Figure 2). A total of 801 apple tree images were collected. The image resolution was 4000 pixels by 3000 pixels, and images were saved in JPEG format. The images were then processed on a Lenovo Legion Y7000P computer (Lenovo Group, Beijing, China) equipped with an Intel Core i7-9750H CPU (with a clock speed of 2.6 GHz, Intel Corporation, Santa Clara, CA, USA) and 16 GB of memory and combined with an NVIDIA RTX 2060 graphics processor (NVIDIA Corporation, Santa Clara, CA, USA) and the Windows 10 operating system.
2.2. Preprocessing of Experimental Image Data
The first step in building a deep-learning-based object-detection model to recognize apples is the preparation and processing of the image dataset. Preprocessing of the dataset was based on the following strategy for the 801 collected apple images:
- (1)
To evaluate the model performance, 156 images were randomly selected from the overall dataset as independent test sets. The remaining 645 images were used as the training set for the training and learning of the detection model. The specific composition details of the training and testing sets are shown in
Table 1.
- (2)
Due to the large size of the original image data, direct processing may lead to excessive consumption of computing resources and low training efficiency. Therefore, the images in the training set were subjected to size-compression processing. Uniformly compressing the length and width of each image to one-fifth of its original size not only reduces the storage space occupied by the data but also speeds up subsequent model training.
- (3)
Based on the LabelImg image-annotation tool software (Version 1.8.1), the smallest bounding rectangle box surrounding each apple target was drawn on the compressed image. After completing the image annotation, the generated annotation file containing the size and coordinate information of the bounding rectangle of the fruit target was saved in XML format for reading and use during model training.
3. Improvement Design of Network Architecture
3.1. YOLOv5s Network Architecture
Machine learning, as the cornerstone of artificial intelligence, is committed to exploring the ability of computers to simulate human learning mechanisms, aiming to acquire new knowledge or skills by simulating human learning behavior and to reconstruct existing knowledge systems based on this, continuously enhancing system performance. This field extensively integrates interdisciplinary achievements. According to different learning mechanisms, machine learning can be divided into four categories: supervised learning, semi-supervised learning, unsupervised learning, and reinforcement learning. From a methodological perspective, machine learning can be further divided into traditional machine learning, deep learning, and other branches.
Deep learning simulates the mechanisms of the human brain to efficiently parse complex data such as images [
26,
27], sounds, and texts. It relies on data-driven strategies to optimize system performance, mining inherent patterns through analyzing observed datasets and predicting future or unknown data based on them, while traditional machine learning relies more on experience accumulation to improve system efficiency. In contrast, deep learning has demonstrated stronger capabilities in information processing and structured data mining. In recent years, with the leaps in artificial intelligence technology, deep learning technology has deeply penetrated the field of object detection and become one of the key technologies driving its development. YOLOv5, as an outstanding representative in the field of deep learning, is an efficient object-detection algorithm. Its application further demonstrates the enormous potential of deep learning in complex scene recognition and localization tasks.
The YOLOv5 network [
28] has excellent detection accuracy and high recognition speed, with a maximum detection rate of 140 frames per second, which significantly improves detection efficiency. In addition, the network model exhibits obvious lightweight characteristics, with a significant reduction of about 90% in the weight file size compared to the YOLOv4 model. This advantage greatly promotes its potential application in embedded systems, making it widely used in the field of object detection. This study uses YOLOv5 as the basic architecture to improve and optimize the network in order to design a fruit recognition network with better performance for apple-picking robots.
The YOLOv5 network series [
29,
30,
31,
32,
33,
34,
35] has designed four different architecture configurations, namely YOLOv5s, v5m [
36], v5l, and v5x. The core difference between these configurations lies in the differentiated configuration of the number of feature-extraction modules and convolution kernels used at specific levels in the network architecture. Specifically, as the network architecture model gradually increases from s to x, it not only enhances the complexity of the network but also accompanies a significant increase in the number and volume of model parameters. This design strategy provides flexible selection space for performance requirements in different application scenarios. The specific parameter indicators of different models are shown in
Table 2.
Due to the focus of this study being on the recognition task of specific target objects (i.e., fruits on apple trees) and the high requirements for the real-time response ability and lightweight level of the model recognition, based on a comprehensive consideration of the model’s recognition accuracy, processing efficiency, and model size, the YOLOv5s network (as shown in
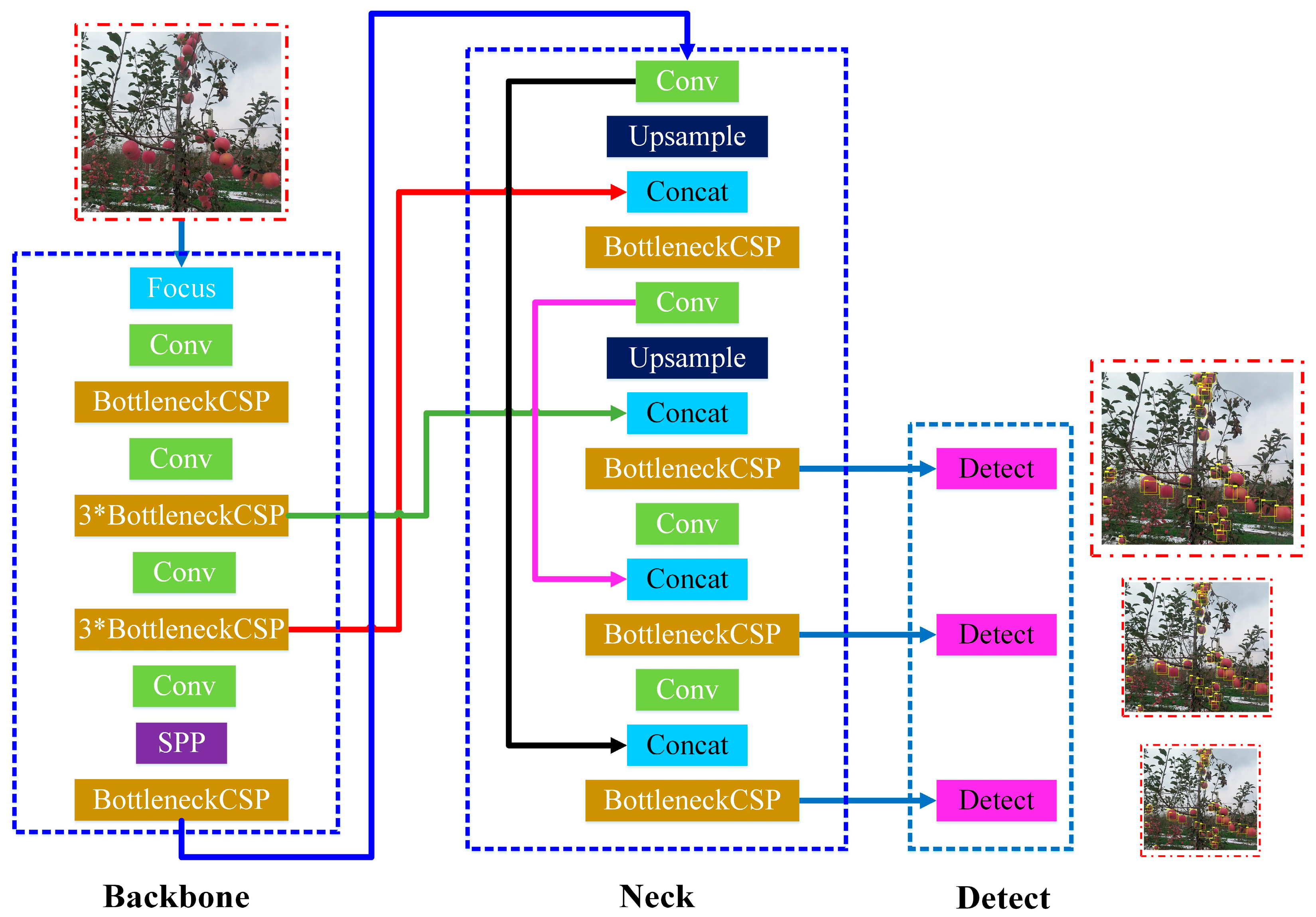
Figure 3) was chosen as the benchmark architecture, and targeted improvement design was carried out accordingly, with the aim of establishing an efficient and lightweight apple target recognition network.
The YOLOv5s architecture consists of three core network structures: the Backbone, Neck, and Detect networks. Among them, the Backbone network plays the role of a feature extractor, utilizing the powerful feature-extraction capability of convolutional neural networks (CNNs) to extract and generate rich image-feature representations from multiple fine-grained levels of the input image. Specifically, the third level of the Backbone network adopts the BottleneckCSP module, which is designed to further enhance the network’s ability to capture and learn deep and complex features of images. The core structure of the BottleneckCSP module is the Bottleneck module, which is a lightweight convolutional neural network structure. The module also includes a residual connection structure (shortcut), which is used to directly add input features to output features to alleviate the gradient-vanishing problem and to accelerate the training convergence. The schematic diagram of the Bottleneck module structure is shown in
Figure 4.
The BottleneckCSP module is an improvement and extension of the Bottleneck module, which extends its functionality by introducing a CSP structure to optimize the network performance and efficiency. Compared with traditional Bottleneck modules, BottleneckCSP modules can improve the learning ability and generalization performance of the model while reducing computational and parameter complexity. The schematic diagram of the BottleneckCSP module structure is shown in
Figure 5.
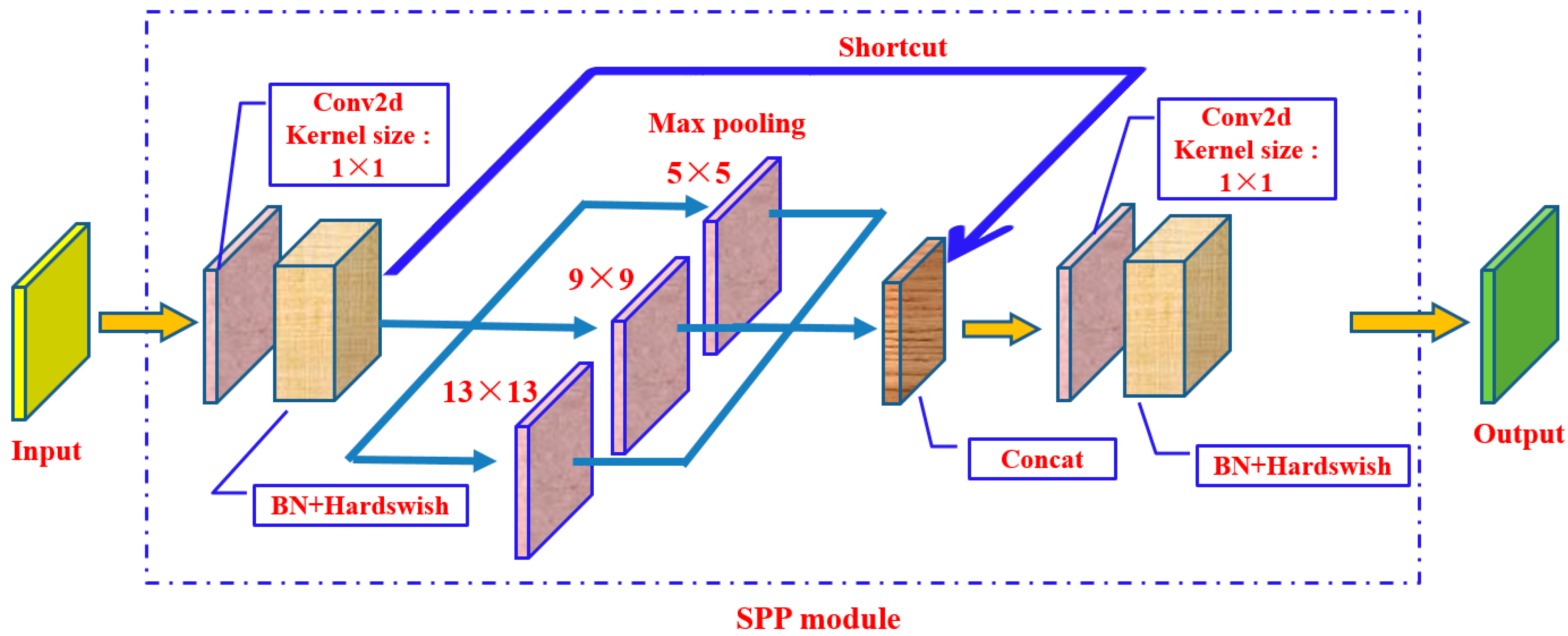
In addition, the Spatial Pyramid Pooling (SPP) module has been introduced at the ninth level, which can map feature maps of any size to fixed dimensional feature vectors, effectively expanding the global view of the network and enhancing the model’s ability to integrate global information from images. The schematic diagram of the SPP module structure is shown below (
Figure 6):
The Neck network is a key component for implementing feature fusion, and its architecture is based on a feature-fusion strategy that combines top–down and bottom–up information flows to achieve deep integration and optimization of cross-scale image features. This process not only promotes the effective transfer of low-level detail features to high-level semantic features but also significantly enhances the detection sensitivity and adaptability of the model to target objects of different sizes, thereby improving the recognition accuracy and robustness of the model when facing different size and scale changes in the same target object. Finally, as the terminal of the overall architecture, the Detect network undertakes the tasks of inference and detection. This network incorporates an anchor box mechanism based on the multi-level feature map output by the Neck network. Through this mechanism, the network can generate a comprehensive vector that encompasses target category prediction probability, detection confidence evaluation, and target bounding-box coordinate information, which would allow accurate recognition and localization of target objects to be achieved.
3.2. Improvement of the Backbone Network
In convolutional neural networks, standard convolution modules (Conv) typically act synchronously on both spatial and channel dimensions to extract features. In contrast, the Depthwise Separable Convolution (DWConv) module adopts another feature-extraction strategy, which decomposes the complete convolution process into two consecutive steps: (1) channel-wise convolution and (2) point-wise convolution. This two-step feature-extraction strategy reduces the computational complexity and parameter count while maintaining good feature-extraction capabilities. The specific operation process of the Depthwise Separable Convolution module is shown in
Figure 7. Compared with standard convolution, the Depthwise Separable Convolution module significantly reduces the computational and parameter complexity of the model, making it more suitable for lightweight object-detection models.
In order to improve the lightweight design of the original YOLOv5s model while ensuring detection accuracy, this study introduces Depthwise Separable Convolution modules to replace the four Conv layers embedded in the original YOLOv5s architecture Backbone network. The purpose is to reduce the parameter count and model size of the improved network model without compromising the detection accuracy. The improved YOLOv5s network architecture is shown in
Figure 8.
4. Training and Evaluation of Models
4.1. Experimental Platform and Model Training
Based on the Lenovo Legion Y7000P computer equipped with an Intel Core i7-9750H CPU (with a clock speed of 2.6 GHz) and 16 GB of memory, combined with the NVIDIA RTX 2060 graphics processor, the Pytorch deep learning framework (version 1.6.0) was built on the Windows 10 operating system. In addition, the Python programming language (version 3.7.6) was used to call and integrate key library files required for the model to support the training and testing experiments of the apple object-detection model.
During the model training phase, based on the improved YOLOv5s network architecture, the improved network was trained using an end-to-end joint training strategy through stochastic gradient descent (SGD). The relevant parameter settings for the model training were as follows: four samples per batch (Batch Size) were processed, then Batch Normalization (BN layer) was used for regularization processing during each weight update, and the momentum factor was set to 0.937, the weight decay rate to 0.0005, and the initial learning rate to 0.01. The entire training process lasted for 300 epochs. After training, the obtained recognition model weight file was saved. In order to improve the accuracy of the detection results, non-maximum suppression techniques were applied to eliminate redundant prediction boxes. Finally, the model output the apple target prediction category with the highest confidence level and returned the coordinate information of the prediction box.
In the training of the model, image-enhancement parameters were set for the images in the training set, with the image HSV Hue augmentation parameter set to 0.015, the HSV Saturation augmentation parameter set to 0.7, the HSV Value augmentation parameter set to 0.4, the image scale-transformation parameter set to 0.5, and the image flip left–right parameter set to 0.5.
4.2. Model Training Results
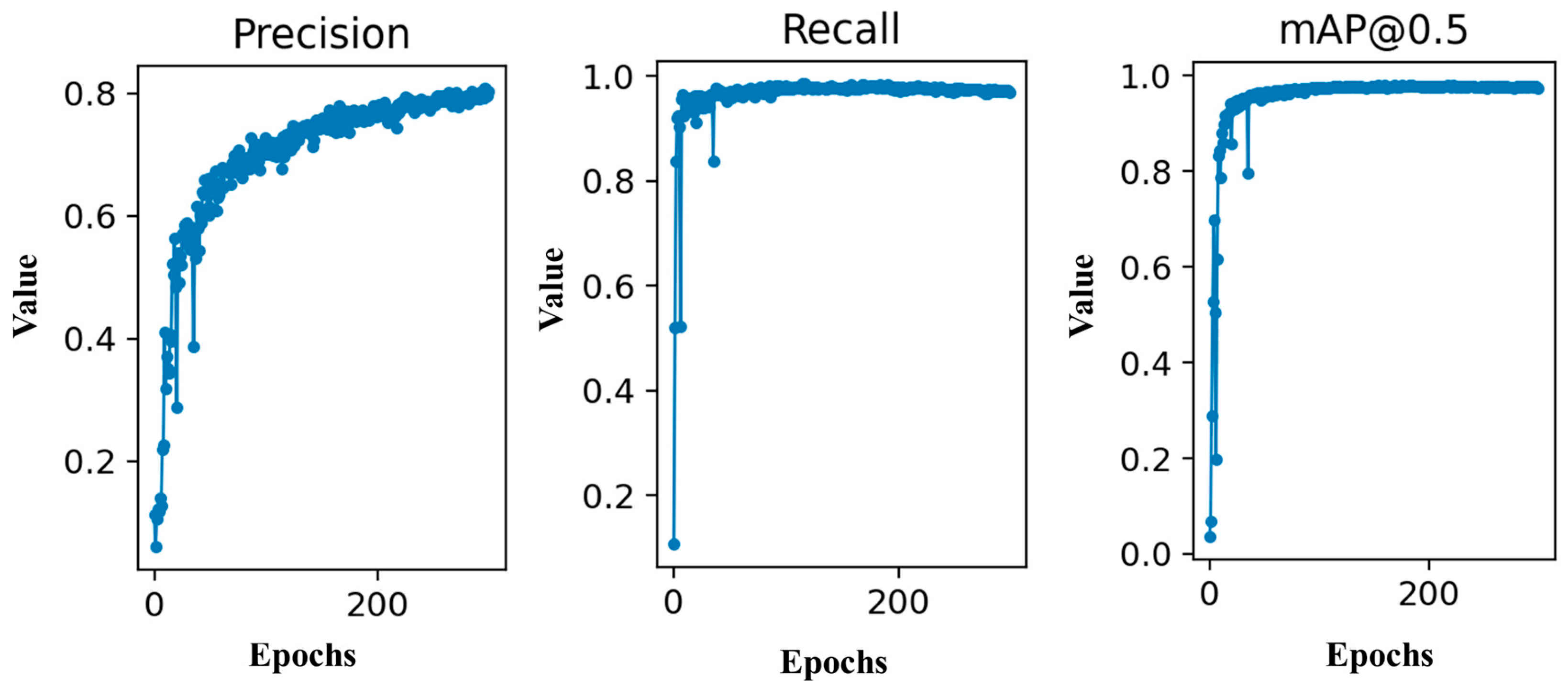
The changes in Precision, Recall, and mAP scores of the model during the network training process are shown in
Figure 9. It can be observed that the Precision of the model continuously improved throughout the entire 300 rounds of training, indicating that the recognition accuracy of the model for apple targets gradually increased. Recall showed a fast upward speed in the early stages of training and had reached a high level by the time it completed 300 rounds of training. As Precision and Recall increased, the mAP score eventually reached a stable state of over 90%.
4.3. Evaluation Indicators for Model Recognition Performance
The evaluation metrics such as fruit detection accuracy (Precision) (1), fruit recall (Recall) (2), mAP (3), and F1 score (4) were used in the study to evaluate the performance of the trained apple object-detection model. The calculation formulas are as follows:
In the formula, TP represents the number of correctly identified apple targets, FP represents the number of incorrectly identified background apple targets, FN represents the number of unrecognized apple targets, Precision represents precision, and Recall represents recall.
5. Results and Discussion
5.1. Apple Target Recognition Results and Analysis
To verify the performance of the established apple-recognition model, the apple-recognition results of the model were analyzed using the test set images. The test-set images contained a total of 2511 apple targets. Based on the improved YOLOv5s model, fruit detection was performed on 156 images. The specific recognition results are shown in
Table 3. It can be seen that the recognition accuracy of the model was 91.2%, the recall rate was 94%, the overall average detection accuracy mAP value was 92.3%, and the F1 score was 92.6%, which meets the accuracy requirements for apple target recognition by the robot.
In this article, we provide an example of apple target-detection results using the improved model design under different weather and lighting conditions, as shown in
Figure 10. Among them, the identified fruit targets are marked with yellow boxes. Based on
Figure 10, it can be determined that the recognition model established in this study exhibits high environmental adaptability and robustness. Its effective recognition ability for apple targets is not limited to uniformly illuminated apple tree images collected under cloudy conditions, as it can also effectively detect fruit targets under strong lighting conditions in sunny environments. On the other hand, the model can accurately recognize fruit targets on apple trees when dealing with images under various complex lighting conditions, such as forward, side, and reverse lighting.
5.2. Comparison of the Recognition Performance of the Improved YOLOv5s and the Original Model
In order to further evaluate the performance of the improved apple-recognition algorithm, this study conducted a comparative test experiment on the recognition effect of the improved network and the original YOLOv5s network on the test-set images. The evaluation criteria include multiple key indicators, such as the mean average recognition accuracy (mAP), the average recognition speed of a single frame image, and the model volume, to comprehensively measure the performance of the model.
Table 4 provides a detailed list of experimental performance indicator parameters for each model under the aforementioned evaluation dimensions.
From
Table 4, it can be seen that the improved YOLOv5s recognition model proposed in this paper has the highest mAP value, which is 0.8% higher than that of the original YOLOv5s network. Regarding the discussion on real-time detection [
37,
38] of object-detection models, real-time detection usually requires a detection speed of ≥24 FPS, corresponding to a single-frame processing time of ≤41.7 ms. Therefore, the detection chromaticity of the model proposed in this paper (0.033 s/frame, i.e., 30 FPS) has reached the general real-time standard and is suitable for most agricultural robot scenes. The average recognition speed of the model on the test-set images in this article can meet the requirements for the real-time detection of apple targets during intelligent agricultural equipment operation. Compared with the original YOLOv5s model (0.043 s/frame, 23 f/s), the recognition speed has increased by nearly 23.3%. From
Table 4, it can also be seen that the recognition model proposed in this paper occupies only 11.1 MB of storage space (volume), which is 79.3% of the original YOLOv5s model. On the other hand, the parameter count of the model proposed in this article (5.69 × 10
6) is significantly reduced compared with the parameter count of the original model (7.25 × 10
6). This indicates that the proposed model effectively achieves lightweight improvement while ensuring detection accuracy (slightly improved compared with the original YOLOv5s).
On the other hand, although the YOLO series has launched updated versions of object-detection models, such as YOLOv8, which may improve the detection accuracy of target objects, YOLOv5 has more advantages in situations where network computing hardware resources are limited. The lightweight design and efficient network structure of the YOLOv5 model allow for flexible adjustment of the network structure, significantly reducing the number of model parameters and the computation involved. On the other hand, YOLOv5 supports model compression and sparsity, which reduces memory usage and computing requirements, making it particularly suitable for edge-device deployment. In addition, YOLOv5 supports cross-platform deployment, including for CPU, GPU, and edge devices. The advantages of YOLOv5 come from its efficient network architecture, flexible lightweight improvement space, ability to adapt to multiple types of hardware, and the combination of data augmentation and model compression technology. These characteristics enable it to give consideration to both performance and efficiency in resource-constrained environments (such as detection in agricultural unstructured scenes and in edge computing) and to become the preferred network architecture in agricultural practical applications. Smaller model sizes and relatively low hardware conditions for network operation are crucial for ensuring the practicality of agricultural harvesting robots. The lightweight YOLOv5 model design and optimized network architecture proposed in this article enables it to run at a faster speed even with lower hardware versions of graphics processing units (GPUs), and its detection accuracy of fruit targets can meet practical job requirements. This is particularly important for agricultural equipment application scenarios where the cost has to be limited or where high-performance computing devices cannot be deployed.
In summary, the model proposed in this article effectively reduces the size of the model while ensuring the accuracy of model detection, making it more suitable for deployment in hardware devices of robot-vision harvesting systems to achieve real-time detection of apple targets.
5.3. Comparative Analysis of Our Detection Model and Other Models for Apple Fruits
In order to comprehensively evaluate the performance of our proposed model, a comparative analysis was conducted between the model proposed in this paper and other studies using deep learning algorithms for apple object detection.
Table 5 presents a detailed comparison of the recognition performance between our improved YOLOv5s model and several AI-based object-detection models on an apple-detection task. The evaluation metrics include the mean average precision (mAP), detection speed, and model size.
Table 5.
Comparison of recognition performance between the improved YOLOv5s model and other models.
Table 5.
Comparison of recognition performance between the improved YOLOv5s model and other models.
| Apple-Detection Model | mAP (%) | Detection Speed (s) | Model Size (MB) | Reference |
|---|
| Faster R-CNN (VGG16) | 87.9 | 0.241 | 512 | [39] |
| Our model | 92.3 | 0.033 | 11.1 | - |
| Original YOLOv5s | 91.5 | 0.043 | 14.0 | - |
| Improved YOLOv5m | 80.7 | 0.025 | 37 | [40] |
| Improved FCOS | 85.6 | - | 32 | [41] |
| Improved YOLOv5 | 86.75 | 0.015 | 12.7 | [42] |
| Lad-YXNet | 94.88 | 0.01 | 16.6 | [17] |
| Rep-Vision-GCN | 92.7 | - | 15.8 | [43] |
Compared with the original YOLOv5s model, the improved YOLOv5s model has an improved mAP value and a faster detection speed. Moreover, the size of the detection model is more lightweight, and its overall performance has been improved.
Compared with the model proposed in [
39], our model has a higher average detection accuracy and significantly faster detection time, making it more suitable for real-time detection tasks. Moreover, the volume of the model proposed by [
39] is 512 MB, while the volume of our proposed model is only 11.1 MB. Compared with the detection model proposed in [
40], our proposed model has higher detection accuracy but relatively slower detection time. However, the detection speed of our proposed model can still meet the requirements of real-time detection. On the other hand, the volume of our model is smaller than that of the model proposed in [
40], so it has better application value under limited hardware conditions. Compared with the apple-detection model proposed in [
41], we have an advantage in detection accuracy, and our model is also lighter in size. In addition, the detection speed of the model proposed by [
42] (0.015 s/frame) is higher than that of our model, but the size of that model (12.7 MB) is slightly larger than that of our proposed model. In comparison with the model proposed in [
17], its detection accuracy (94.88%) is higher than that of our model, and its detection speed is faster (0.01 s/frame), but its model size (16.6 MB) is larger than ours. Although the detection accuracy of our proposed model is slightly lower compared with the model proposed in [
17], it can still meet the actual detection task requirements, and the detection speed can reach real-time detection levels. Therefore, our proposed model still has good application value in terms of comprehensive performance, indicating a good balance between accuracy, detection speed, and model size in our improved YOLOv5s model. Compared with the model proposed in [
43], although the mAP of our proposed detection model is slightly lower, our model is more lightweight in size.
The basic hardware deployment conditions for YOLOv5 are that it can be deployed under a GPU (high-performance scenario) with deployed hardware such as the NVIDIA Jetson series (such as Jetson AGX Xavier, Jetson Nano) and a desktop GPU (such as RTX 3080). It can also be deployed in a lower-performance environment, such as in CPU deployment (low-cost edge computing), using hardware platforms such as Intel Xeon and ARM architecture chips (such as Raspberry pie 4B and Ruixin micro RK3588). Therefore, YOLOv5 has flexible application value and is suitable for various configurations of agricultural robot platforms.
6. Conclusions
A lightweight apple target intelligent recognition method was proposed to address the issues of large sizes of models and the need for further improvements in model detection speed and accuracy in deep-learning-based apple-recognition models. We improved the original YOLOv5s network architecture by replacing the embedded Depthwise Separable Convolution module in its Backbone network, achieving a reduction in model size while ensuring the model’s detection accuracy. The experimental results show that the proposed improved model had an average recognition accuracy of 92.3% on the test set, an average detection time of 0.033 s for a single-frame image, and a model volume of only 11.1 MB. Thus, compared with the original YOLOv5s model, the average recognition accuracy has been increased by 0.8%, the single-frame image recognition speed has increased by 23.3%, and the model volume has been compressed by 20.7%.
The improved recognition model shows certain potential in terms of model size and computational efficiency, and it may be more suitable for deployment on embedded hardware platforms for robot-vision harvesting systems. This model exhibits a fast inference speed in experimental environments, which has certain adaptability advantages for dealing with dynamic and changing work scenarios in unstructured orchard environments. Preliminary test data show that the model can maintain relatively stable recognition accuracy under specific lighting conditions and occlusion levels, which may provide necessary visual-inspection technology support for the intelligent harvesting of apples by robotic arms in the future.
Apple object detection based on deep learning, as a cutting-edge application in the field of computer vision, utilizes deep learning models to automatically extract features from massive image data to accurately identify and locate apples. This process is not only a deep mining of image information but also a precise capturing and understanding of complex features such as object shape, texture, and even spatial position. Deep learning models demonstrate the powerful ability of artificial intelligence in solving specific problems by continuously learning and iterating to optimize their recognition algorithms.
The detection algorithm proposed in the study can be extended to the intelligent measurement of apple biological and physical characteristics, including the following: (1) Size measurement: Through deep learning algorithms, it is possible to accurately measure the size information of apples such as diameter and circumference, which is of great significance for evaluating the maturity and grading sales of apples. (2) Shape analysis: Deep learning algorithms can recognize the shape features of apples, such as circles, ellipses, etc., which have reference value for understanding the variety characteristics and growth environment of apples. (3) Color analysis: The color of apples is also an important component of their biological and physical characteristics. Deep learning algorithms can analyze information such as the color distribution and brightness of apples, providing a basis for quality assessment, pest and disease monitoring, and more.
On the other hand, it can also be expanded for the following: (1) Real-time monitoring: The apple object-detection system based on deep learning can monitor the growth of apples in the orchard in real time, including changes in their quantity, size, color, etc., providing timely management suggestions for fruit farmers. (2) Precise management: Through the analysis results of deep learning algorithms, fruit farmers can more accurately formulate management strategies such as fertilization, irrigation, pruning, etc., improving the production efficiency and fruit quality of the orchard. (3) Disease and pest warning: Deep learning algorithms can also be used to monitor the occurrence of apple diseases and pests. Once abnormalities are detected, immediate warnings can be issued to help farmers take timely measures and reduce losses.
This study focuses on improving the real-time detection robustness of apple targets in complex orchard environments. The current work optimizes the lightweight network structure design to achieve a balance between detection accuracy, inference speed, and model size in specific scenarios. Tasks such as size and morphological feature analysis require the introduction of additional sensor calibration (such as for depth cameras). Although the current model does not integrate a size/color quantification module, its output target-localization box and confidence data can provide a basic data interface for tasks such as fruit size and morphology analysis in subsequent mechanized harvesting. For example, based on the coordinate information for the detection box, combined with binocular vision or LiDAR point cloud data, the three-dimensional shape and size of the fruit can be further calculated.
7. Positive Effects in Horticulture
The research on apple object detection based on deep learning has important practical value and scientific significance in the field of horticulture, and its positive effects are mainly reflected in the following aspects:
- (1)
Improving the intelligence and efficiency of orchard management
Automated fruit monitoring: Orchard images are collected through drones or fixed cameras, and deep learning models such as YOLO can detect the position, quantity, and maturity of apples in real time, reducing manual inspection costs. Accurate yield prediction: Combining target detection and counting algorithms to accurately estimate orchard yield and to optimize supply chain management and market planning. Growth status analysis: detecting fruit size, color, and distribution patterns, providing data support for irrigation, fertilization, and pruning and improving resource utilization efficiency.
- (2)
Optimizing harvesting operations
Intelligent picking robot: A robotic arm based on object detection can locate and pick mature apples, solving the problem of labor shortages and reducing harvesting losses. Maturity grading: Mature fruits can be identified through color and texture features, which allows for staged harvesting and improves the commercialization rate and storage life of fruits.
- (3)
Disease, pest, and defect detection
Early disease identification: Disease spots (such as black spot disease, brown rot disease) or pest traces on the surface of apples can be detected, providing timely warnings and allowing precise prevention and control to be implemented, which also reduces pesticide abuse. Quality sorting: In the post-harvest processing stage, abnormal, damaged, or moldy fruits are automatically removed to ensure product consistency and to reduce manual sorting errors.
- (4)
Supporting genetic breeding and phenotype research
Phenotypic data collection: Large-scale detection of apple morphological characteristics (such as shape, size, color) can accelerate the process of breeding excellent varieties. Environmental response analysis: The differences in fruit performance under different cultivation conditions can be studied, providing a basis for the cultivation of stress-resistant varieties.
- (5)
Promoting precision agriculture and sustainable development
Resource optimization: Detection results can be combined to guide precise fertilization and irrigation, reducing water and fertilizer waste, and lowering the environmental burden. Reduce losses: By intervening against pests and diseases in a timely manner and optimizing harvesting, economic losses in orchard production can be reduced and economic benefits can be improved.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}