

Parallel Bootstrap-Based On-Policy Deep Reinforcement Learning for Continuous Fluid Flow Control Applications

Abstract
1. Introduction
2. Parallel Bootstrap-Based on-Policy Deep Reinforcement Learning
2.1. On-Policy DRL Algorithms

- on-policy algorithms usually require that the samples they use for training are generated with the current policy. In other words, after having collected a batch of transitions using the current policy, these data are used to update the agent and cannot be re-used for future updates;

- off-policy algorithms are able to train on samples that were not collected with their current policy. They usually use a replay buffer to store transitions, and randomly sample mini-batches from it to perform updates. Hence, samples collected with a given policy can be re-used multiple times during the training procedure.

2.2. Proximal Policy Optimization (PPO)
2.3. Bootstrapping
| Algorithm 1 Traditional advantage vector assembly | |
| 1: | given: the reward vector |
| 2: | given: the value vector |
| 3: | given: the termination mask |
| 4: | for do |
| 5: | if is terminal else |
| 6: | end for |
| 7: | for do |
| 8: | |
| 9: | end for |
| 10: | |
2.4. Parallel Bootstrap-Based Learning
3. Continuous Flow Control Application
3.1. Control of Instabilities in a Falling Fluid Film
3.2. Default PPO Parameters
4. Results
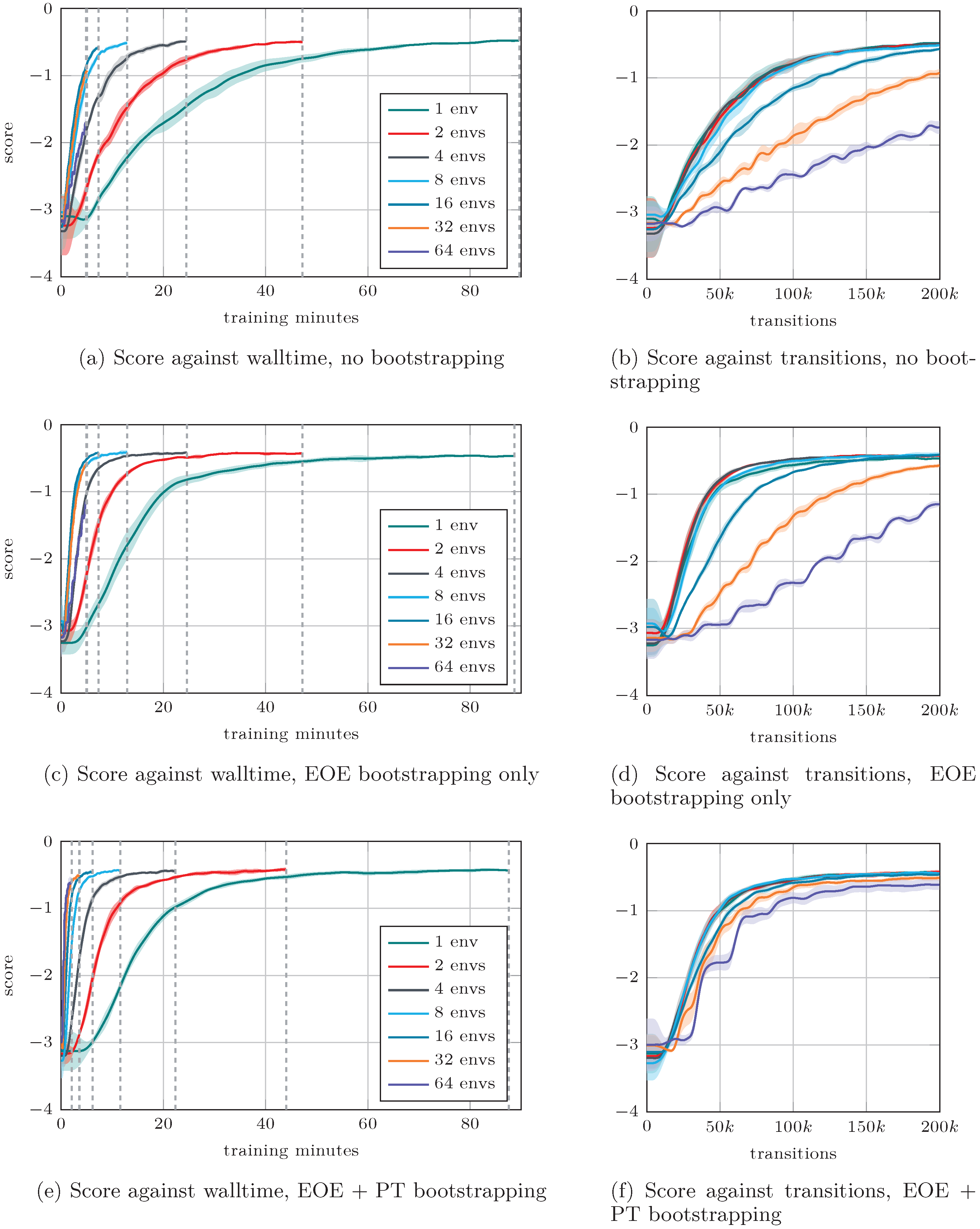
4.1. End-of-Episode Bootstrapping
4.2. Bootstrap-Based Parallelism

- For ,the performance remains stable in each of the three configurations. This is expected, as the use of parallel environments only modifies the pace at which the updates occur, but the constitution of the update buffers is the same as it would have been for . Yet, the use of EOE bootstrapping leads to a faster convergence than the regular case, as was already observed in previous section. Moreover, as PT bootstrapping does not occur when full episodes are used, Figure 7d,f present similar results for ;

- For , a rapid decrease in convergence speed and final score is observed for the regular approach, with , resulting in very poor performance (Figure 7b). This illustrates the reasons that motivated the present contribution, i.e., that the standard parallel paradigm results in impractical constraints, which prevents massive environment parallelism. Introducing EOE bootstrapping (Figure 7d) improves the situation by (i) generally speeding up the convergence, and (ii) improving the final performance of the agents, although the final score obtained for remains sub-optimal, while that of is poor. Additionally, the “flat steps” phenomenon described in [18] clearly appears for and 64, with the length of the steps being roughly equal to the number of transitions unrolled between two updates of the agent. When adding PT bootstrapping (Figure 7f), a clear improvement in the convergence speed is observed even for large values, and the gap in final performance significantly reduces. The flat steps phenomenon is still observed in the early stages of learning for and 64, although with significantly reduced intensity.

- Similarly to [18], we observe decent speedups for , with , against . This difference is attributed to the additional buffering overhead required in the regular approach, as more transitions are unrolled and stored between each update compared to PT bootstrapping. For higher numbers of parallel environments, we measure against , and against . Again, the excessive memory and buffering requirements of the regular case are the most probable cause of this discrepancy, as is evidenced by the fact that . In the present case, we underline that speedups could probably be improved by replacing the computation of a random initial state at each reset step of the environment by the loading of pre-computed initial states from files.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
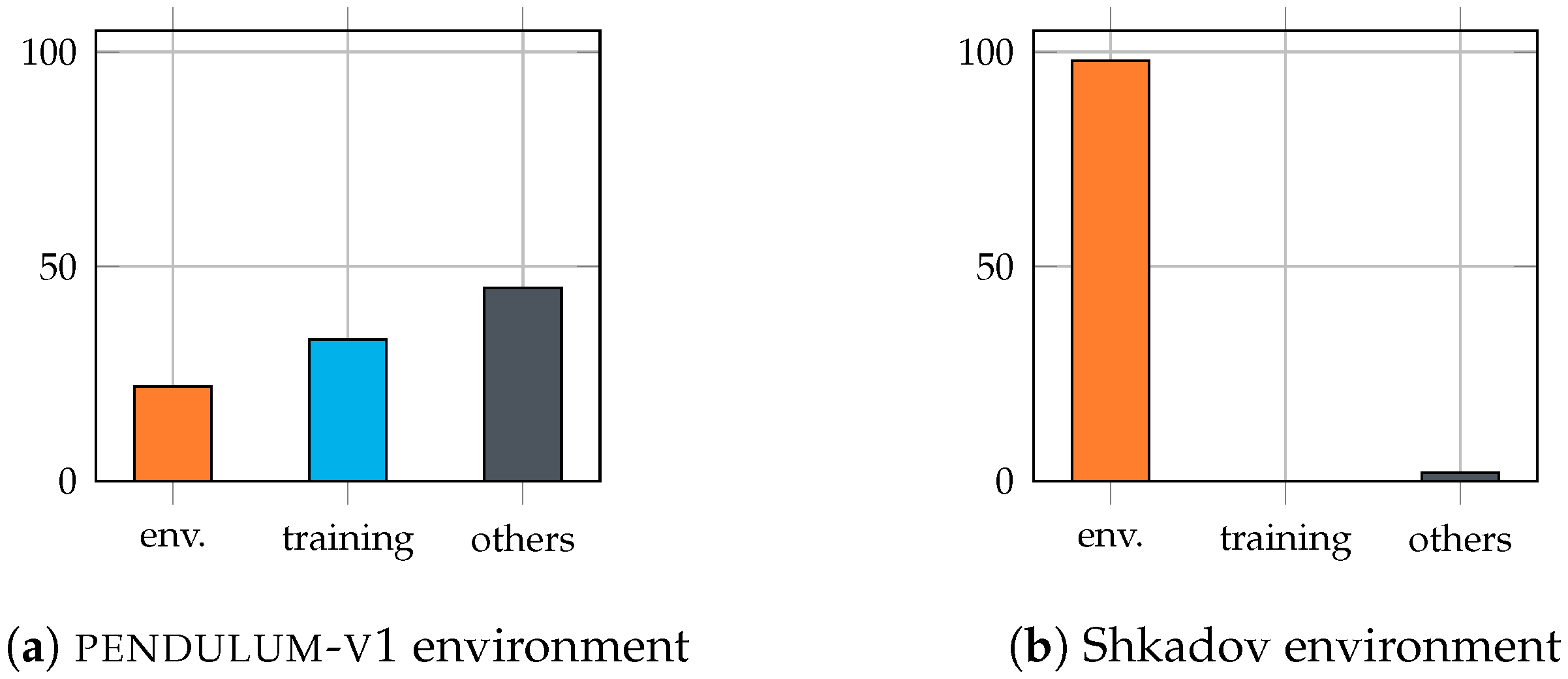
Appendix A. End-of-Episode Bootstrapping on gym Environments

Appendix B. Convergence of the Numerical Discretization

Appendix C. Solved Shkadov Environment

References
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef] [PubMed]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef]
- Nassif, A.B.; Shahin, I.; Attili, I.; Azzeh, M.; Shaalan, K. Speech recognition using deep neural networks: A systematic review. IEEE Access 2019, 7, 19143–19165. [Google Scholar] [CrossRef]
- Gui, J.; Sun, Z.; Wen, Y.; Tao, D.; Ye, J. A review on generative adversarial networks: Algorithms, theory, and applications. arXiv 2020, arXiv:2001.06937. [Google Scholar] [CrossRef]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical text-conditional image generation with CLIP latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Pinto, L.; Andrychowicz, M.; Welinder, P.; Zaremba, W.; Abbeel, P. Asymmetric actor critic for image-based robot learning. arXiv 2017, arXiv:1710.06542. [Google Scholar]
- Bahdanau, D.; Brakel, P.; Xu, K.; Goyal, A.; Lowe, R.; Pineau, J.; Courville, A.; Bengio, Y. An actor-critic algorithm for sequence prediction. arXiv 2016, arXiv:1607.07086. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of Go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef]
- Kendall, A.; Hawke, J.; Janz, D.; Mazur, P.; Reda, D.; Allen, J.M.; Lam, V.D.; Bewley, A.; Shah, A. Learning to drive in a day. arXiv 2018, arXiv:1807.00412. [Google Scholar]
- Bewley, A.; Rigley, J.; Liu, Y.; Hawke, J.; Shen, R.; Lam, V.D.; Kendall, A. Learning to drive from simulation without real world labels. arXiv 2018, arXiv:1812.03823. [Google Scholar]
- Knight, W. Google Just Gave Control over Data Center Cooling to an AI; MIT Technology Review; MIT Technology: Cambridge, MA, USA, 2018. [Google Scholar]
- Rabault, J.; Kuchta, M.; Jensen, A.; Réglade, U.; Cerardi, N. Artificial neural networks trained through deep reinforcement learning discover control strategies for active flow control. J. Fluid Mech. 2019, 865, 281–302. [Google Scholar] [CrossRef]
- Novati, G.; Verma, S.; Alexeev, D.; Rossinelli, D.; van Rees, W.M.; Koumoutsakos, P. Synchronisation through learning for two self-propelled swimmers. Bioinspir. Biomim. 2017, 12, 036001. [Google Scholar] [CrossRef] [PubMed]
- Beintema, G.; Corbetta, A.; Biferale, L.; Toschi, F. Controlling Rayleigh–Bénard convection via reinforcement learning. J. Turbul. 2020, 21, 585–605. [Google Scholar] [CrossRef]
- Garnier, P.; Viquerat, J.; Rabault, J.; Larcher, A.; Kuhnle, A.; Hachem, E. A review on deep reinforcement learning for fluid mechanics. Comput. Fluids 2021, 225, 104973. [Google Scholar] [CrossRef]
- Viquerat, J.; Meliga, P.; Hachem, E. A review on deep reinforcement learning for fluid mechanics: An update. Phys. Fluids 2022, 34, 111301. [Google Scholar] [CrossRef]
- Rabault, J.; Kuhnle, A. Accelerating deep reinforcement learning strategies of flow control through a multi-environment approach. Phys. Fluids 2019, 31, 094105. [Google Scholar] [CrossRef]
- Metelli, A.; Papini, M.; Faccio, F.; Restelli, M. Policy optimization via importance sampling. arXiv 2018, arXiv:1809.06098. [Google Scholar]
- Tomczak, M.B.; Kim, D.; Vrancx, P.; Kim, K.E. Policy optimization through approximate importance sampling. arXiv 2019, arXiv:1910.03857. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Pardo, F.; Tavakoli, A.; Levdik, V.; Kormushev, P. Time limits in reinforcement learning. arXiv 2017, arXiv:1712.00378. [Google Scholar]
- Belus, V.; Rabault, J.; Viquerat, J.; Che, Z.; Hachem, E.; Reglade, U. Exploiting locality and translational invariance to design effective deep reinforcement learning control of the 1-dimensional unstable falling liquid film. AIP Adv. 2019, 9, 125014. [Google Scholar] [CrossRef]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.P.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. arXiv 2016, arXiv:1602.01783. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Fujimoto, S.; van Hoof, H.; Meger, D. Addressing function approximation error in actor-critic methods. arXiv 2018, arXiv:1802.09477. [Google Scholar]
- Schulman, J.; Moritz, P.; Levine, S.; Jordan, M.; Abbeel, P. High-dimensional continuous control using generalized advantage estimation. arXiv 2015, arXiv:1506.02438. [Google Scholar]
- Shkadov, V.Y. Wave flow regimes of a thin layer of viscous fluid subject to gravity. Fluid Dyn. 1967, 2, 29–34. [Google Scholar] [CrossRef]
- Lavalle, G. Integral Modeling of Liquid Films Sheared by a Gas Flow. Ph.D. Thesis, ISAE—Institut Supérieur de l’Aéronautique et de l’Espace, Toulouse, France, 2014. [Google Scholar]
- Chang, H.C.; Demekhin, E.A.; Saprikin, S.S. Noise-driven wave transitions on a vertically falling film. J. Fluid Mech. 2002, 462, 255–283. [Google Scholar] [CrossRef]
- Chang, H.C.; Demekhin, E.A. Complex Wave Dynamics on Thin Films; Elsevier: Amsterdam, The Netherlands, 2002. [Google Scholar]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Todorov, E.; Erez, T.; Tassa, Y. MuJoCo: A physics engine for model-based control. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 5026–5033. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| – | agent type | PPO-clip |
| discount factor | 0.99 | |
| actor learning rate | 5 × 10−4 | |
| critic learning rate | 2 × 10−3 | |
| – | optimizer | adam |
| – | weights initialization | orthogonal |
| – | activation (hidden layers) | relu |
| – | activation (actor final layer) | tanh, sigmoid |
| – | activation (critic final layer) | linear |
| PPO clip value | 0.2 | |
| entropy bonus | 0.01 | |
| g | gradient clipping value | 0.1 |
| – | actor network | |
| – | critic network | |
| – | observation normalization | yes |
| – | observation clipping | no |
| – | advantage type | GAE |
| bias-variance trade-off | 0.99 | |
| – | advantage normalization | yes |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Viquerat, J.; Hachem, E. Parallel Bootstrap-Based On-Policy Deep Reinforcement Learning for Continuous Fluid Flow Control Applications. Fluids 2023, 8, 208. https://doi.org/10.3390/fluids8070208
Viquerat J, Hachem E. Parallel Bootstrap-Based On-Policy Deep Reinforcement Learning for Continuous Fluid Flow Control Applications. Fluids. 2023; 8(7):208. https://doi.org/10.3390/fluids8070208
Chicago/Turabian StyleViquerat, Jonathan, and Elie Hachem. 2023. "Parallel Bootstrap-Based On-Policy Deep Reinforcement Learning for Continuous Fluid Flow Control Applications" Fluids 8, no. 7: 208. https://doi.org/10.3390/fluids8070208
APA StyleViquerat, J., & Hachem, E. (2023). Parallel Bootstrap-Based On-Policy Deep Reinforcement Learning for Continuous Fluid Flow Control Applications. Fluids, 8(7), 208. https://doi.org/10.3390/fluids8070208