1. Introduction
The cornerstone of modern machine learning techniques, the perceptron, was introduced by Rosenblatt in 1957 [
1]. Back then, the envisaged applications included “concept formation, language translation, collation of military intelligence, and solution of problems through inductive logic”. Indeed, the vision of Rosenblatt has been materialised with the modern machine learning applications, which include clustering (i.e., divide and organise a population into a priorly unknown number of classes), automatic translation (e.g., Google Translate, Babel Fish), classification (i.e., label entities according to their characteristics), heuristic algorithms boosted by neural networks (e.g., AlphaGo), etc. The rather long period (more than half of a century) it took to accomplish these achievements is partly attributed to a misunderstanding after the publication of the book of Minsky and Papert [
2], who proved that a single-layer perceptron is not capable of reproducing the XOR (exclusive or) function. The misunderstanding was that larger networks would also suffer this limitation. As a result, between 1969 and the mid 80s the interest in artificial intelligence was reduced. Then, the publication of Rumelhart et al. [
3] came, which popularized backpropagation and paved the way for the achievements of modern machine learning.
Regarding hydrology, in the last 10 years the interest in machine learning applications has been growing linearly and the interest in deep learning (a subset of machine learning) exponentially [
4]. A review of the early and modern machine learning methods utilised in water resources can be found in [
5]. However, the scientific research in statistical hydrology is more reluctant to adopt machine learning techniques, most probably because of the lack of a rigorous mathematical formulation of the provided solutions. As a consequence, there is only a limited number of publications on relevant thematics, such as the stochastic synthesis of time series (e.g., [
6]), the model residual analysis (e.g., [
7,
8]), and the uncertainty estimation (e.g., [
9,
10]).
In this study, we focus on the use of machine learning for estimating the uncertainty of hydrological models. We attempt to provide a theoretical foundation and demonstrate the potential benefits of machine learning. More specifically, we combine the idea of using the k-nearest neighbours (KNN) algorithm [
11] in estimating the uncertainty of hydrological models [
9] with the concept behind Bluecat, a direct and simple pure statistical method [
12].
A careful inspection of the way KNN functions in this type of applications revealed that it is algorithmically almost equivalent to Bluecat. Then, taking advantage of the machine learning flexibility, more complicated sampling schemes were examined with KNN. Though this was straightforward with KNN, it would require significant changes in the code of Bluecat. KNN and Bluecat were applied in two real-world case studies giving similar results. Furthermore, conclusions regarding the more complicated sampling schemes with KNN were obtained. Finally, a simple technique is suggested to allow KNN to provide uncertainty estimations for simulation values that are outside the range of the data available for the KNN inference. The results indicate that KNN is a simple and reliable method for estimating the uncertainty of hydrological modelling.
Uncertainty estimation is typically performed with repeated runs of the hydrological model in Monte Carlo simulations (e.g., [
13]), or with stochastic weather generators to generate various scenarios (e.g., [
14,
15]). However, these approaches are not appealing to practitioners. On the contrary, data-driven approaches are much simpler to implement and employ. For this reason, in this study, we have prepared and made publicly available a tool to facilitate practitioners to take advantage of the suggested method. This tool is very light, does not require any library or application to run (e.g., R or MATLAB) and was developed with minimal resources (a couple of days of coding). This wouldn’t be possible and worthwhile if the suggested method was not simple, reliable and theoretically founded.
3. Results
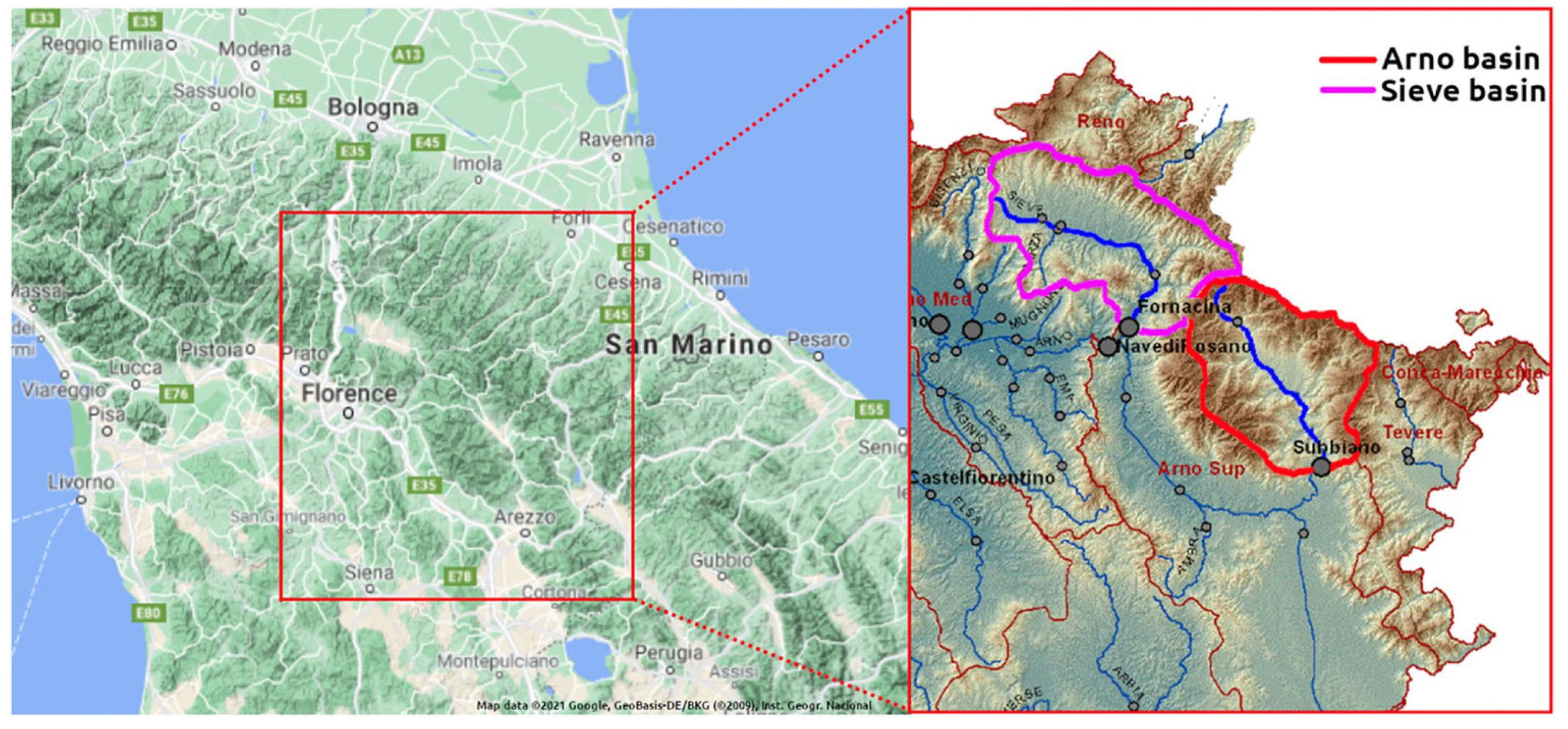
This section provides the results of KNN and Bluecat applied in the two case studies (Arno River at Subbiano and Sieve River at Fornacina). The results are displayed employing (i) plots of the simulation values during the validation period, including the upper and lower bounds of the 80% confidence interval, and the median value; (ii) the scatter plots of the confidence interval, the median, and the observed values against the values simulated by the hydrological model (HyMod in these case studies); and (iii) the combined probability-probability plots of the median and the hydrological model values.
Regarding the plots of the simulation values, the criteria of the quantitative evaluation are the proximity of the median values to the corresponding observed values, and the successful envelopment of most of the observations by the confidence interval (approximately 10% should be above the upper limit and 10% below the lower limit).
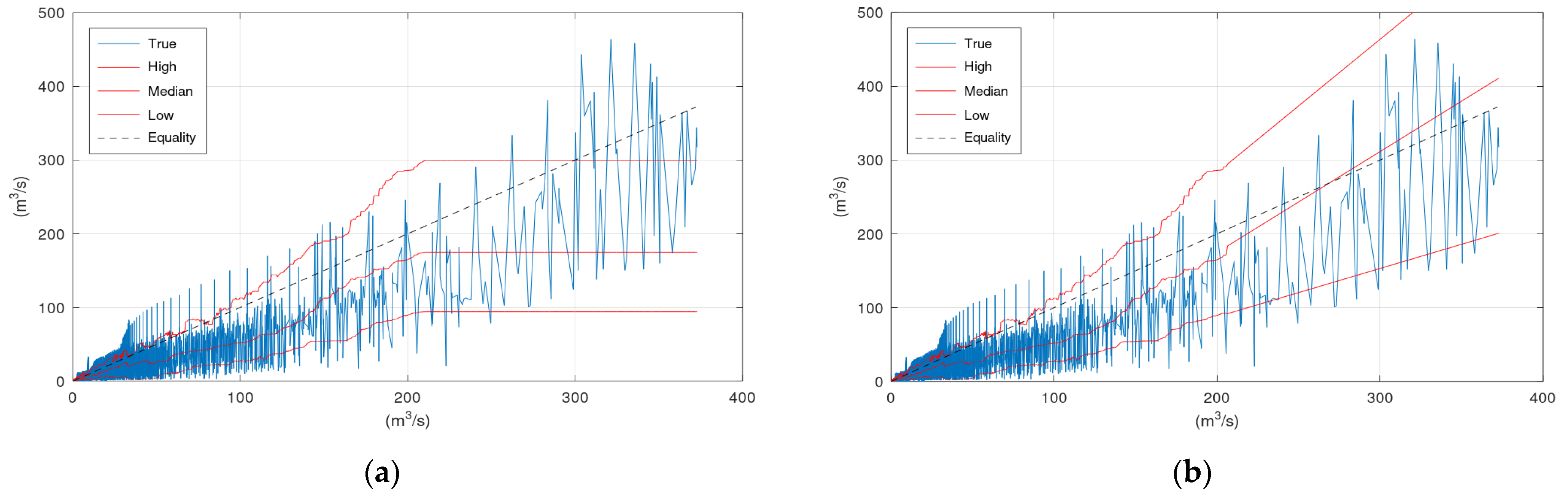
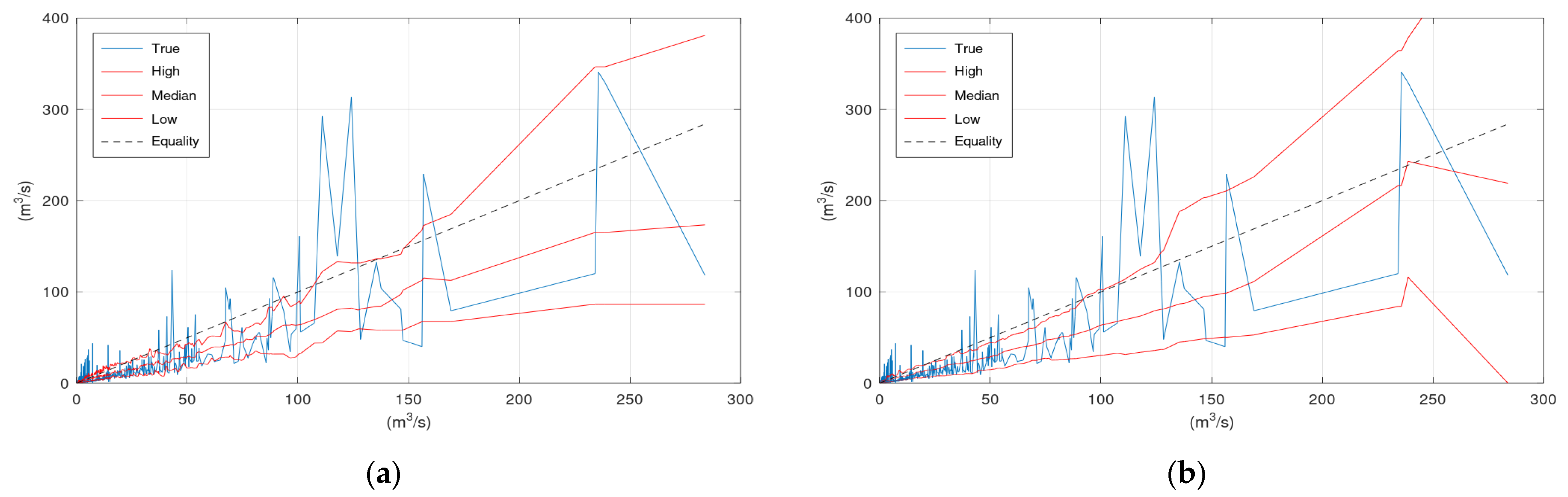
The scatter plots include in the x-axis the sorted simulation values of the hydraulic model. The line labelled “True” is obtained when the y-axis refers to the corresponding observed values, the line labelled “Median” when the y-axis refers to the corresponding median values, the line labelled “High” when the y-axis refers to the corresponding upper bound of the 80% confidence interval, and the line labelled “Low” when the y-axis refers to the corresponding lower bound of the 80% confidence interval. A deviation of the Equality line from the “True” line indicates errors or bias in the hydrological model. The smoother the “True” line, the lower the model errors. The spikes of the “True” line should be evenly placed above and below the Equality line, otherwise the model introduces bias. Regarding the KNN and Bluecat outputs, the “Median” should lay close to the “True” line (for the same reason the Equality line should be close to the “True” line). The percentage of the “True” line outside the “High” and “Low” lines should be equal to the selected confidence level. Ideally, this percentage should not be influenced by the magnitude of the simulation value.
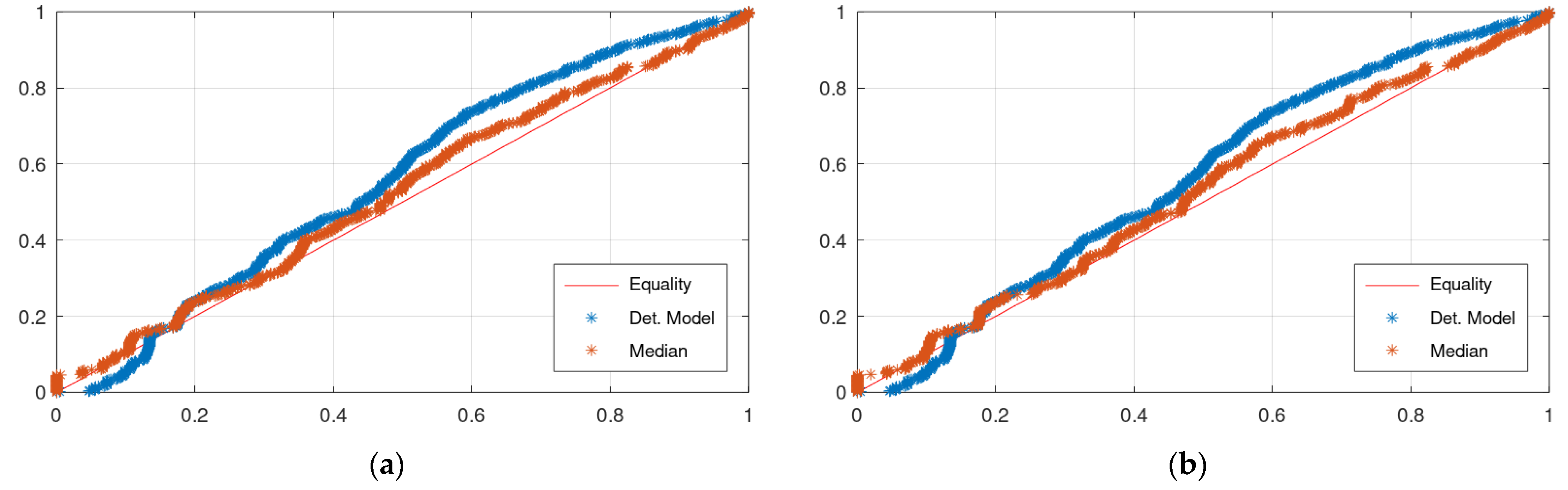
The combined probability-probability (CPP) plot is the plot of the values of the empirical distribution function of the median from KNN or Bluecat, or the hydrological model simulations (y-axis) against the corresponding values of the empirical distribution function of the observations (x-axis). Ideally, the CPP plot should be on the Equality line.
The scatter plots are superior in assessing the performance of a model at extreme values, where there are usually very few simulated and observed values. At this range, even if there is a significant deviation between these two, the difference between the corresponding values of the empirical distributions could be negligible because of the limited number of values at this range compared to the number of values in the whole assessed period. Thus, this small difference (e.g., 0.97 against 0.99) will pass unnoticed in the CPP plot. On the other hand, CPP plots are better for assessing the performance of a model at the range where the majority of simulations/observations occur.
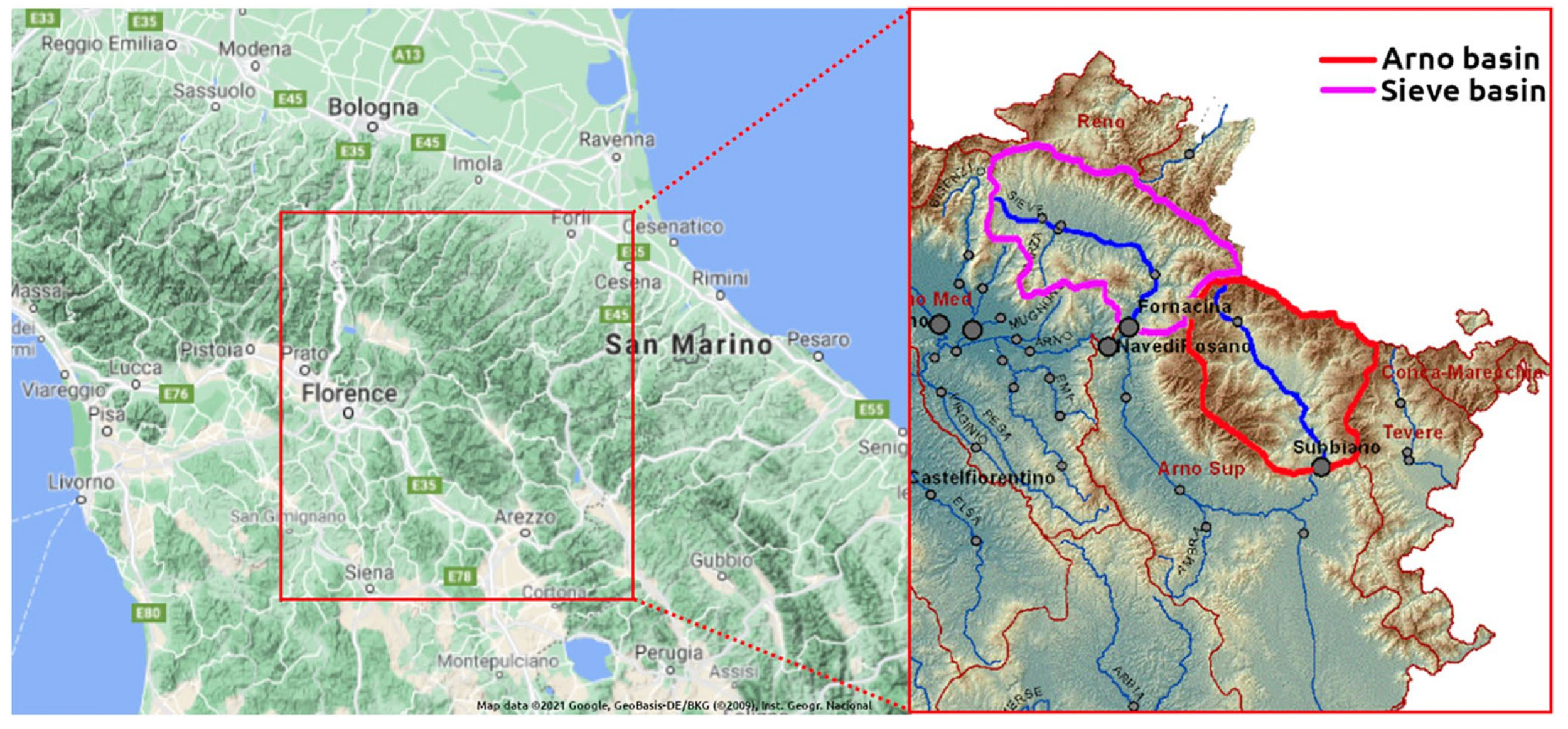
3.1. Case Study—Arno
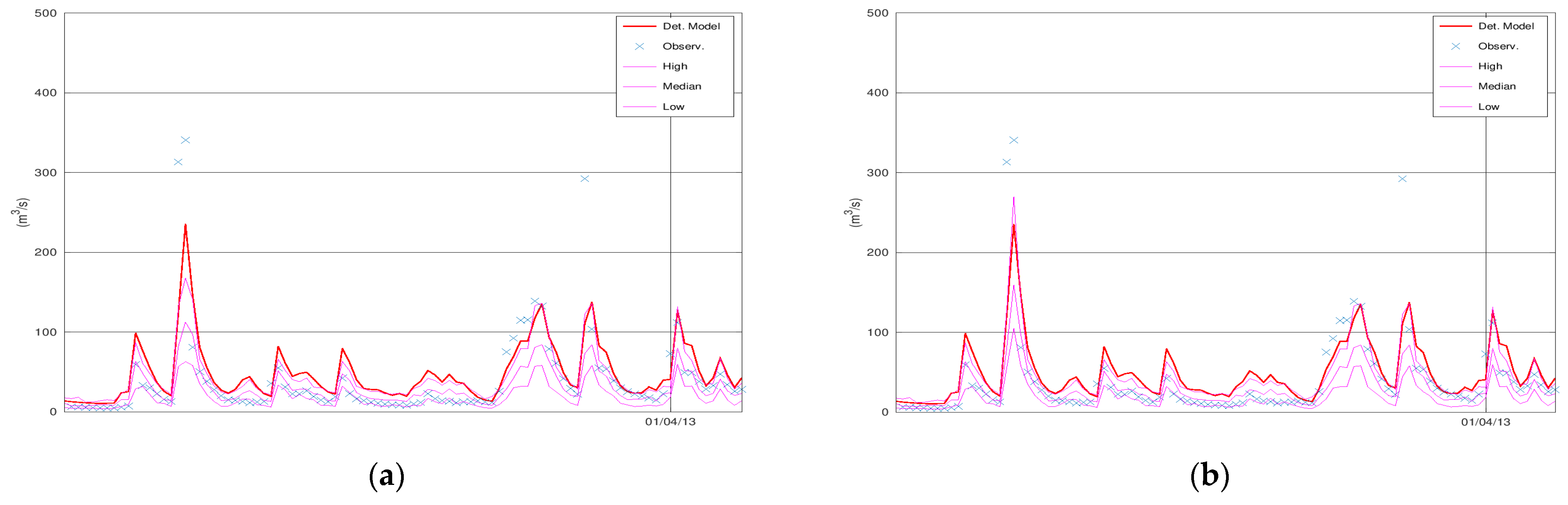
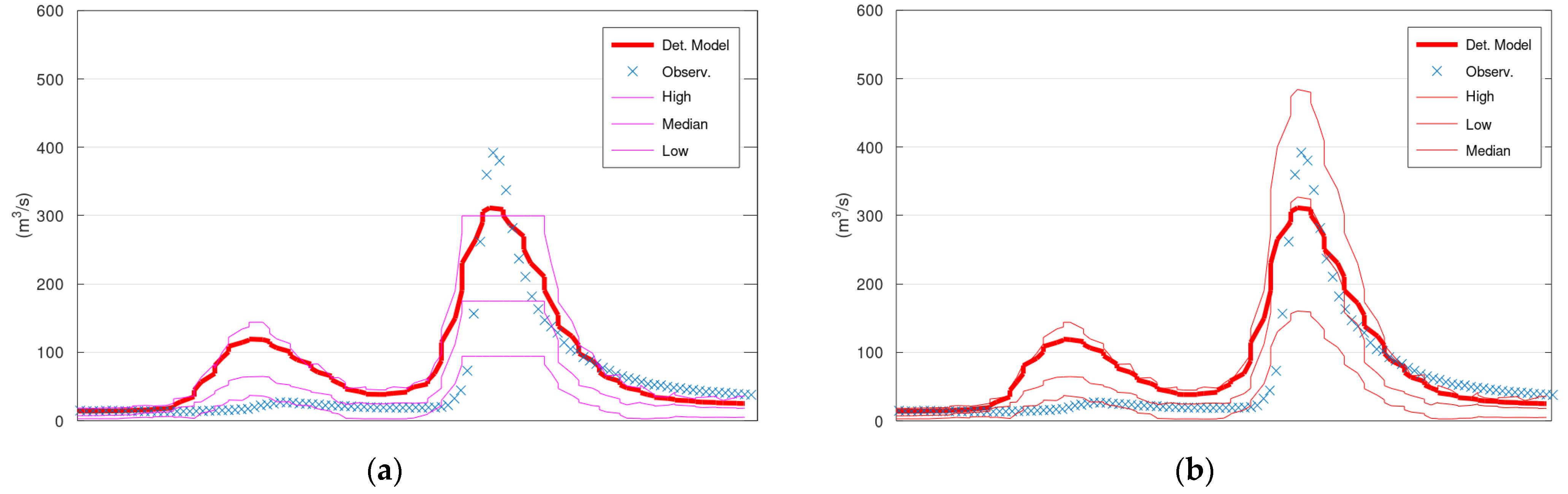
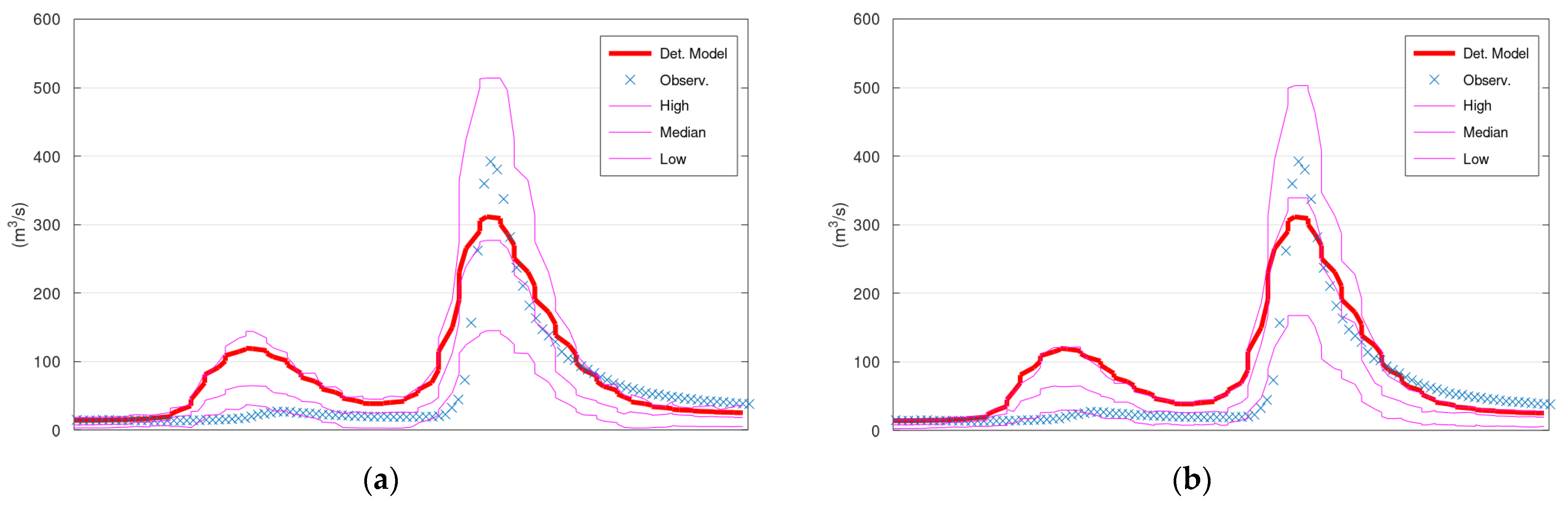
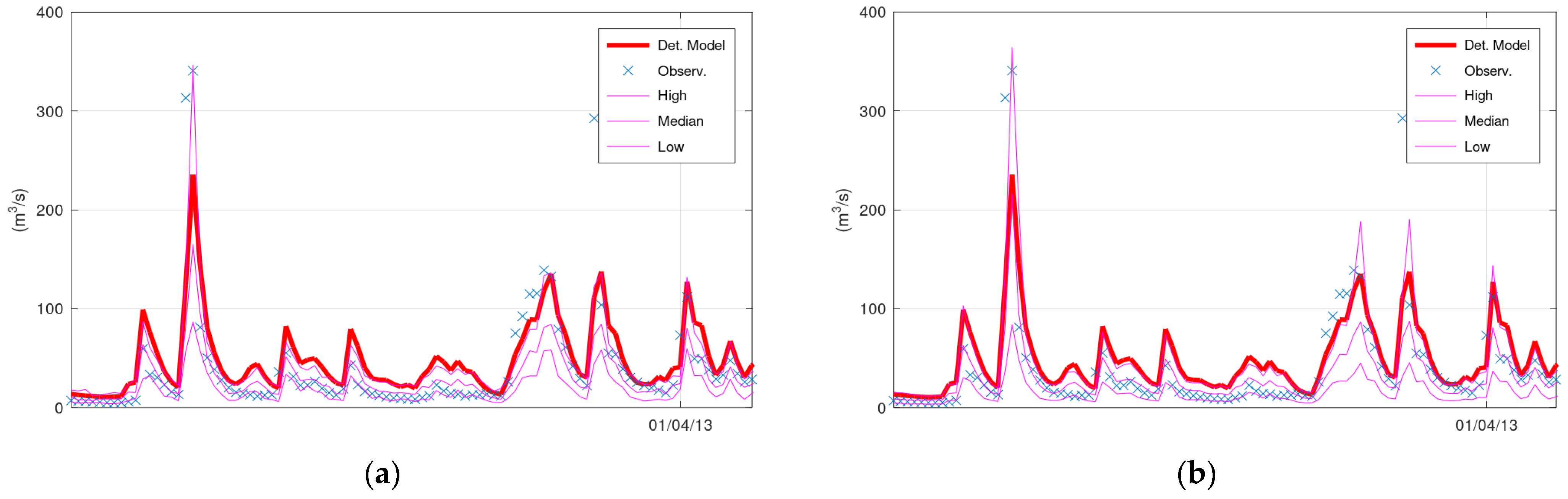
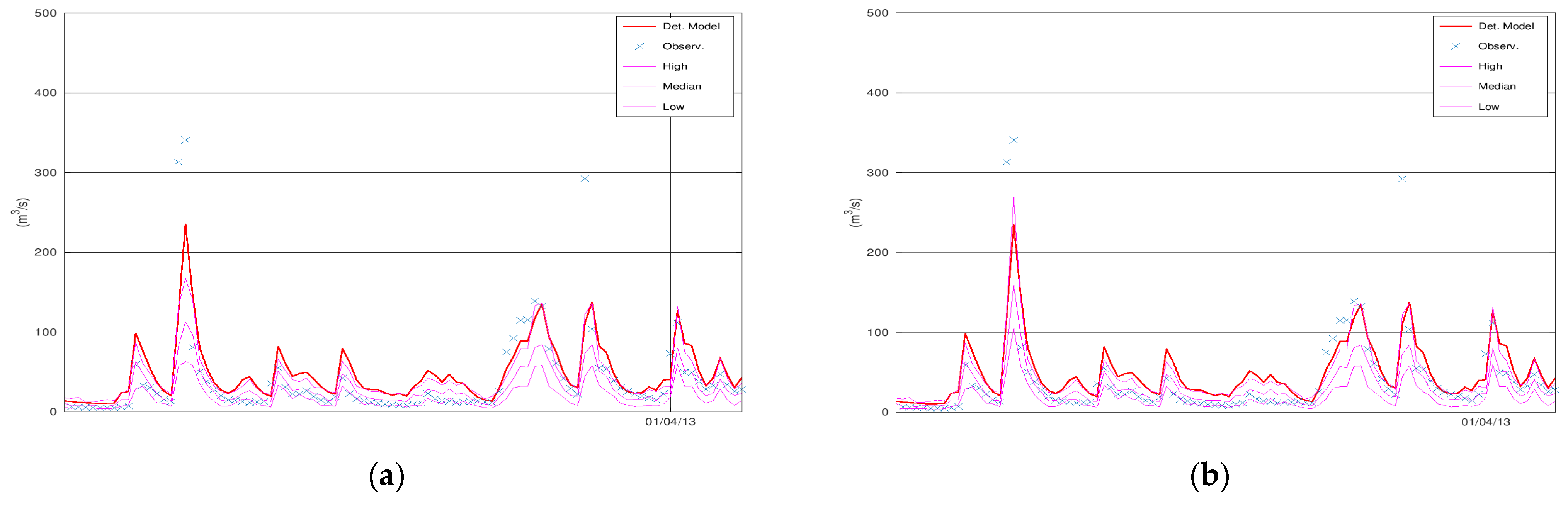
Figure 2 displays the simulated discharge of 100 days (out of the 731 in total) of the validation period (from 1 January 2013 until 11 April 2013), the corresponding confidence interval (“High” and “Low” lines), and the median values of KNN and Bluecat. The left panel displays the results of KNN with 40 neighbours, whereas the right panel displays the results of Bluecat. There are minor differences between these two figures regarding the confidence interval bounds at the two peaks before 1 April 2013.
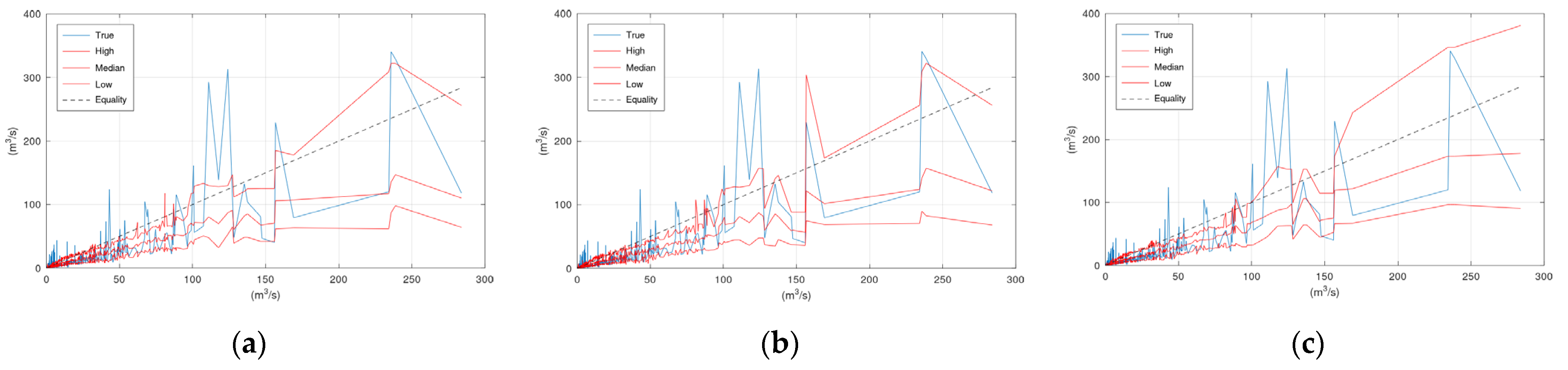
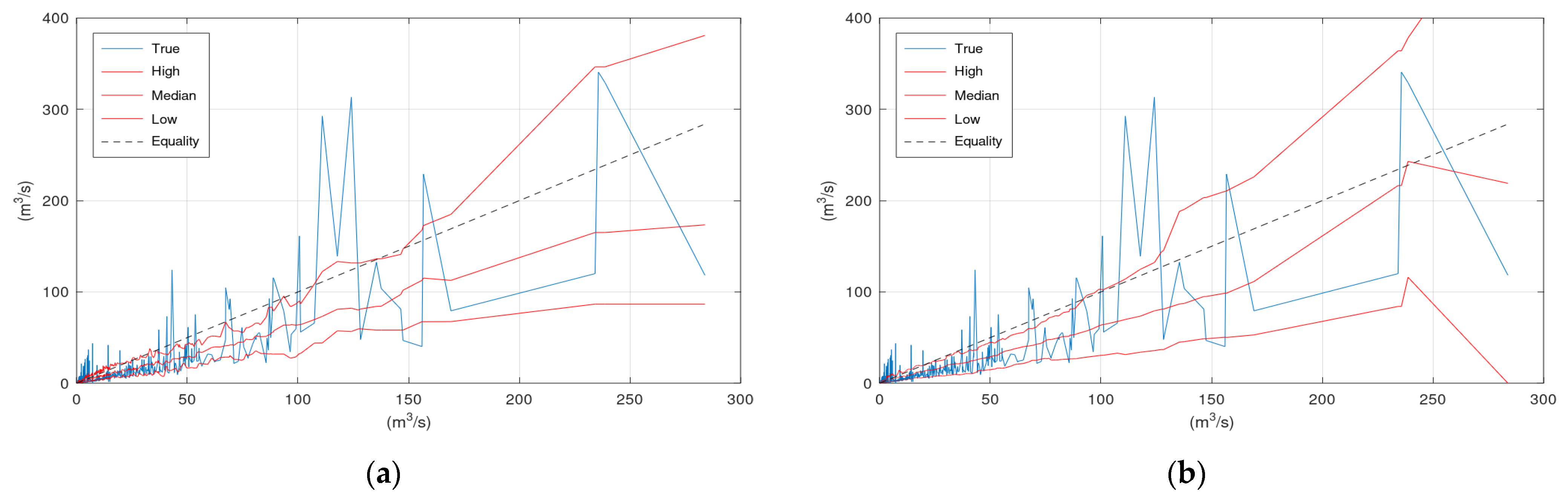
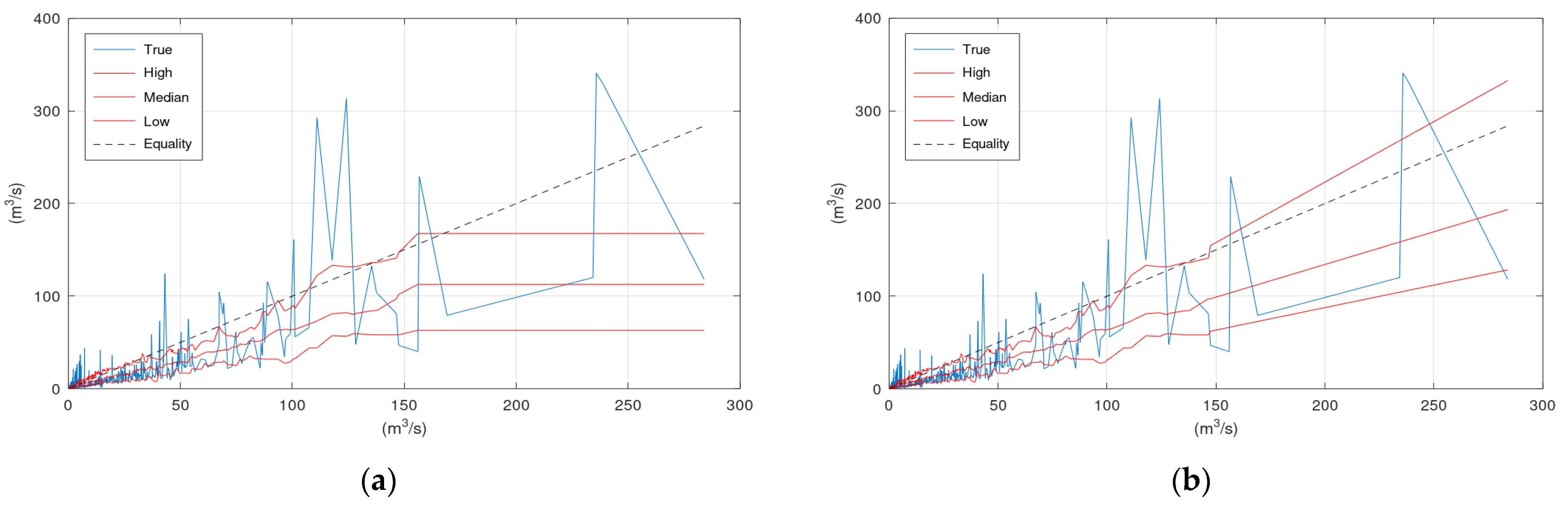
Figure 3 displays the scatter plots of the application of KNN and Bluecat to the validation period of the Arno River case study. Significant differences between the plots of the two models appear in the region of very high flows. These differences are related to the limited number of observations and simulations at this range of values.
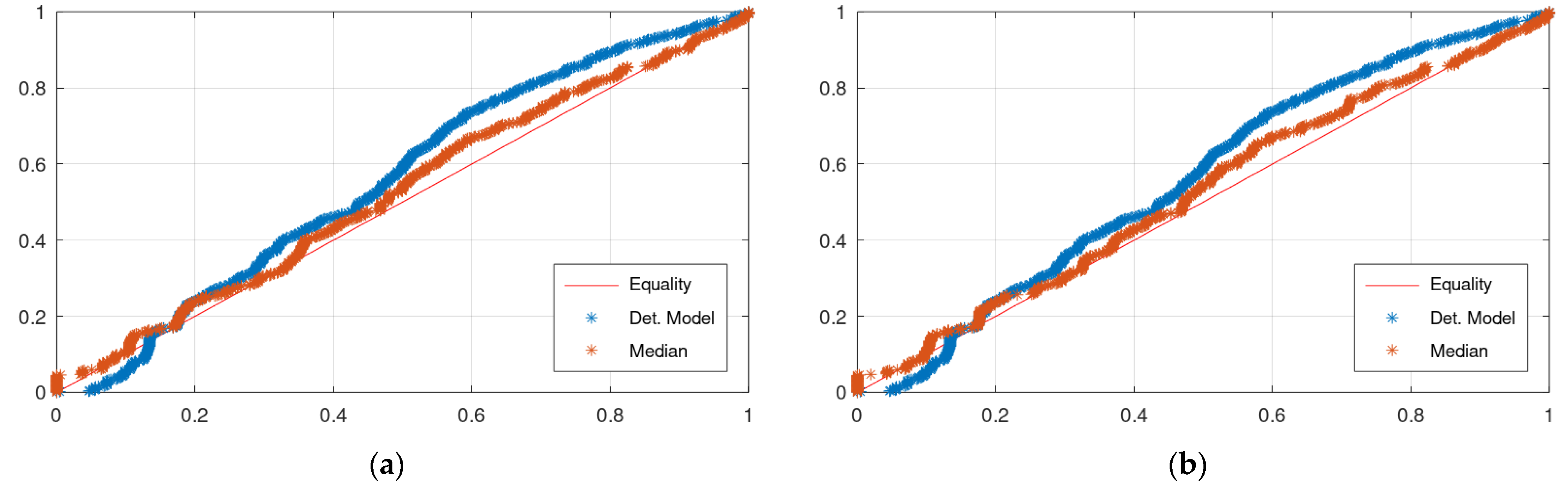
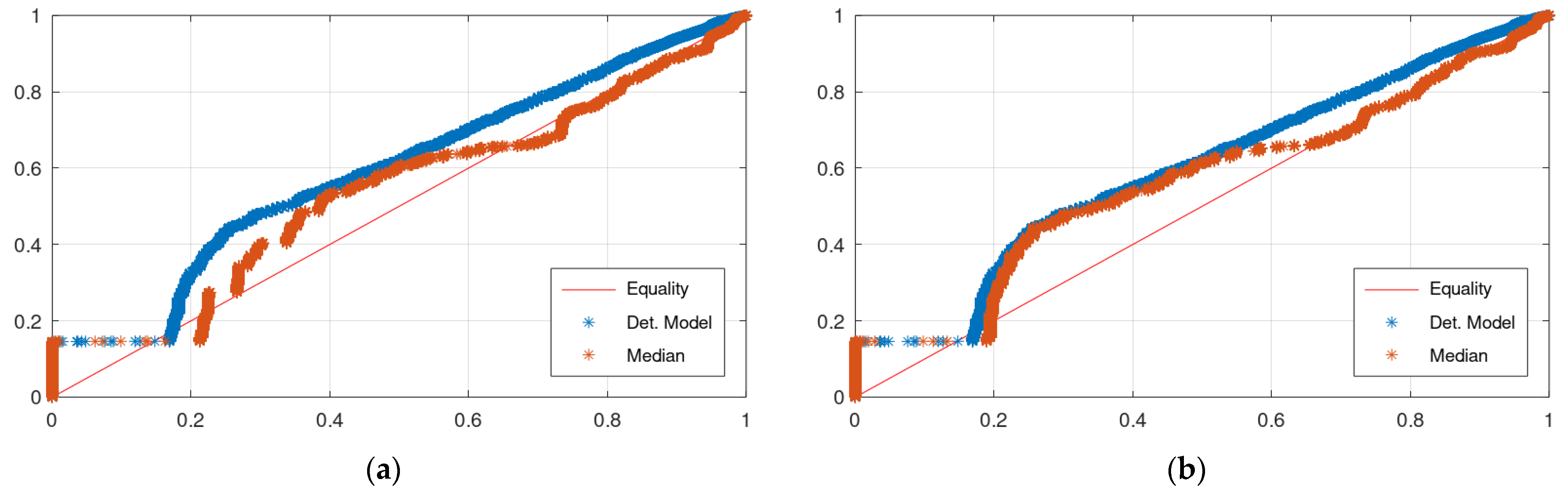
Figure 4 displays the CPP of the application of KNN and Bluecat to the validation period of the Arno River case study. The differences between the plots of the two models are insignificant.
3.2. Case Study—Sieve
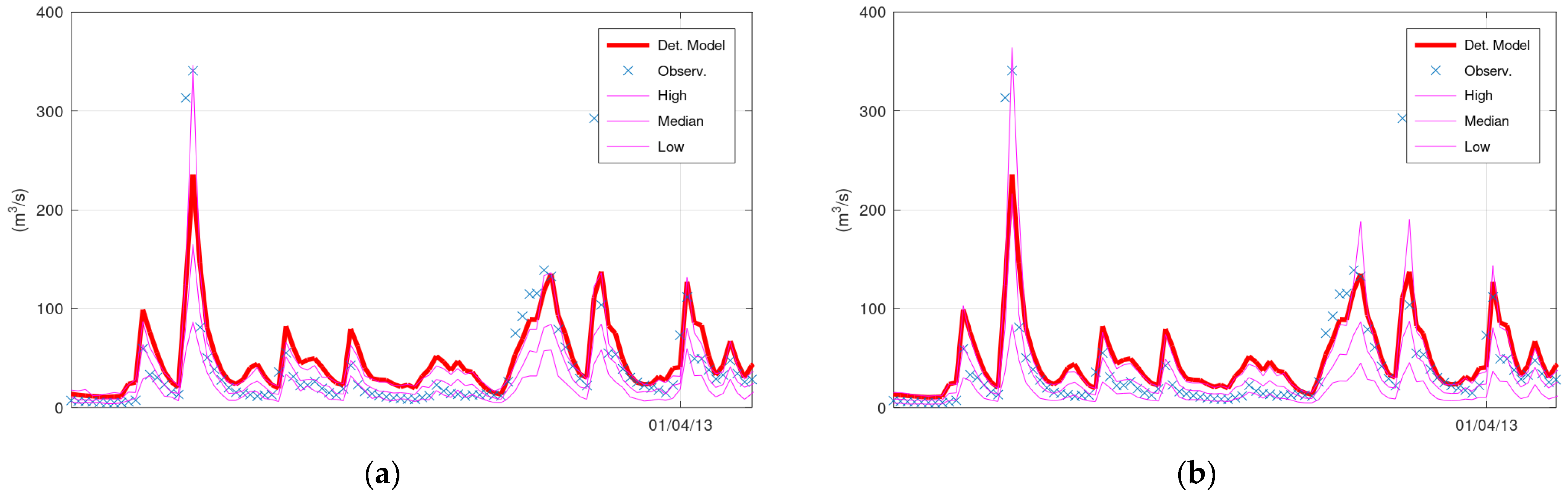
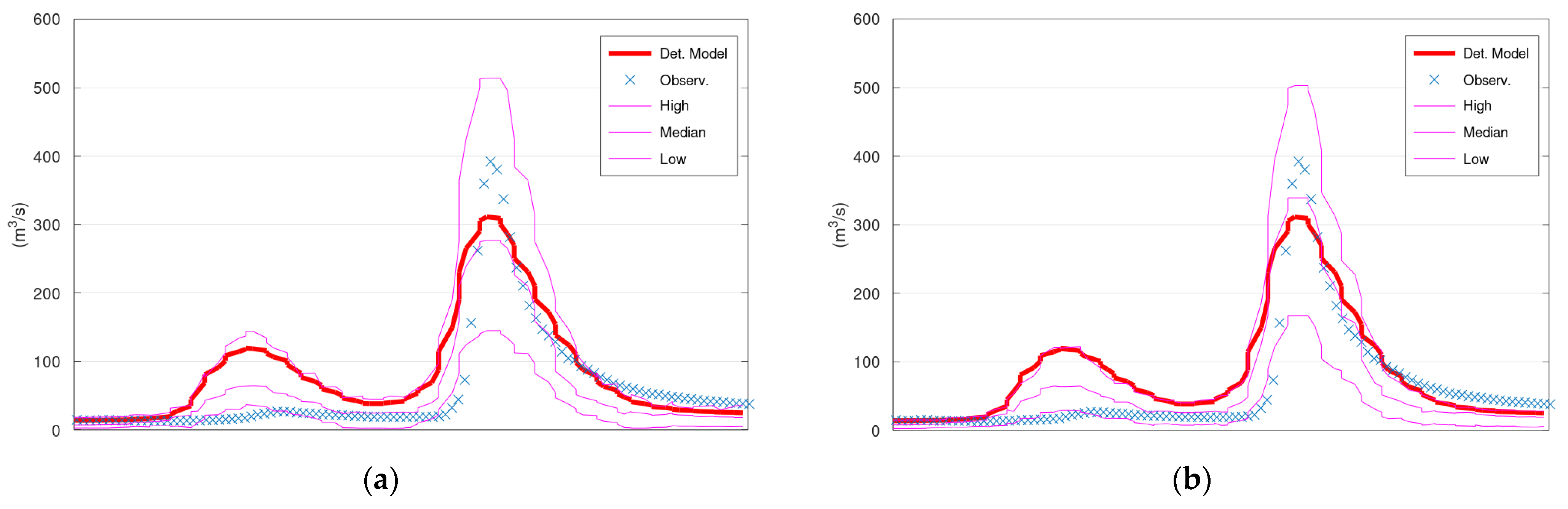
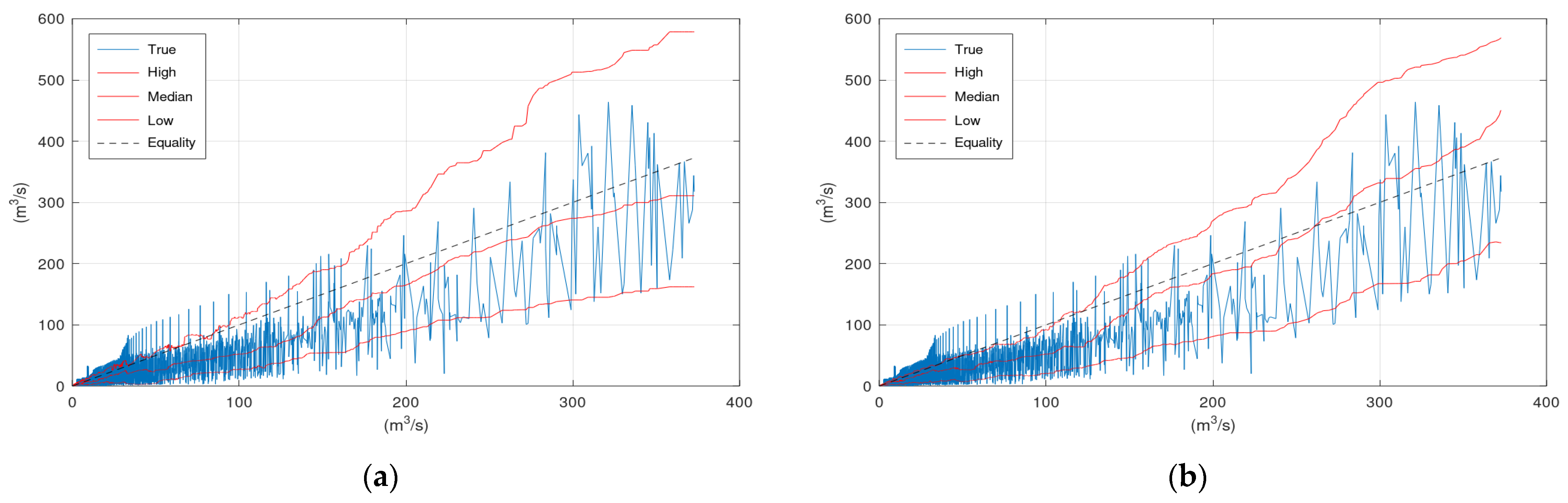
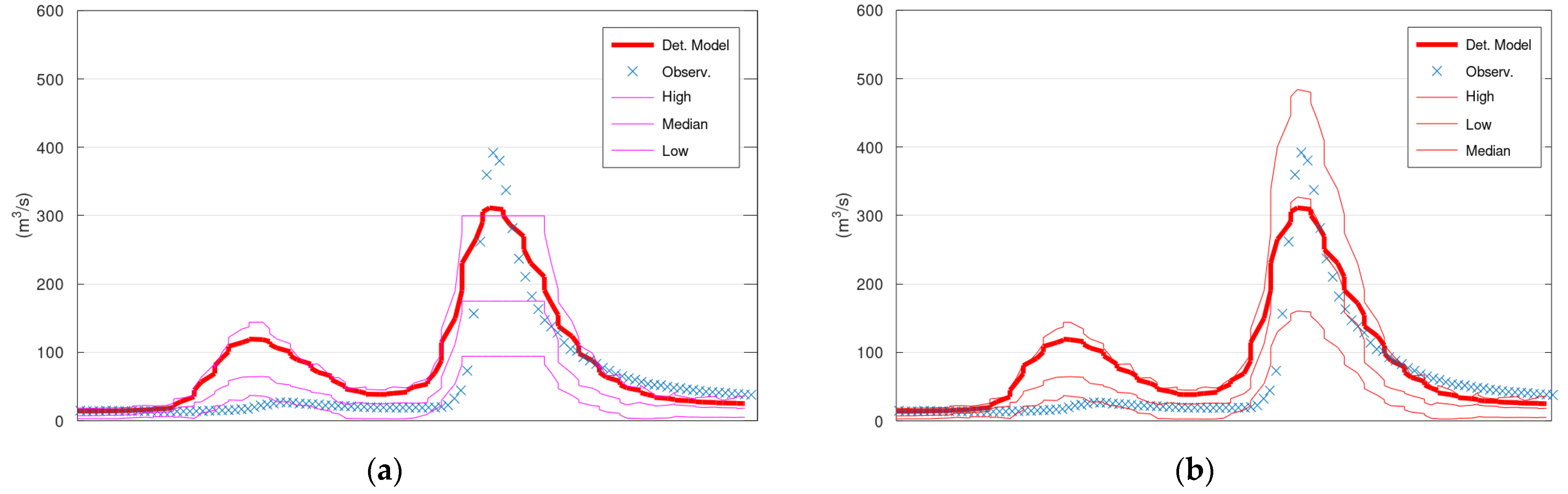
Figure 5 displays the simulated discharge of 150 h (out of the 13,896 in total) of the validation period (starting from 5 January 1996), the corresponding confidence interval (“High” and “Low” lines) and the median values of KNN and Bluecat. The left panel displays the results of KNN with 200 neighbours, whereas the right panel displays the results of Bluecat. The median values of Bluecat appear closer to the observed values around the peak of this figure.
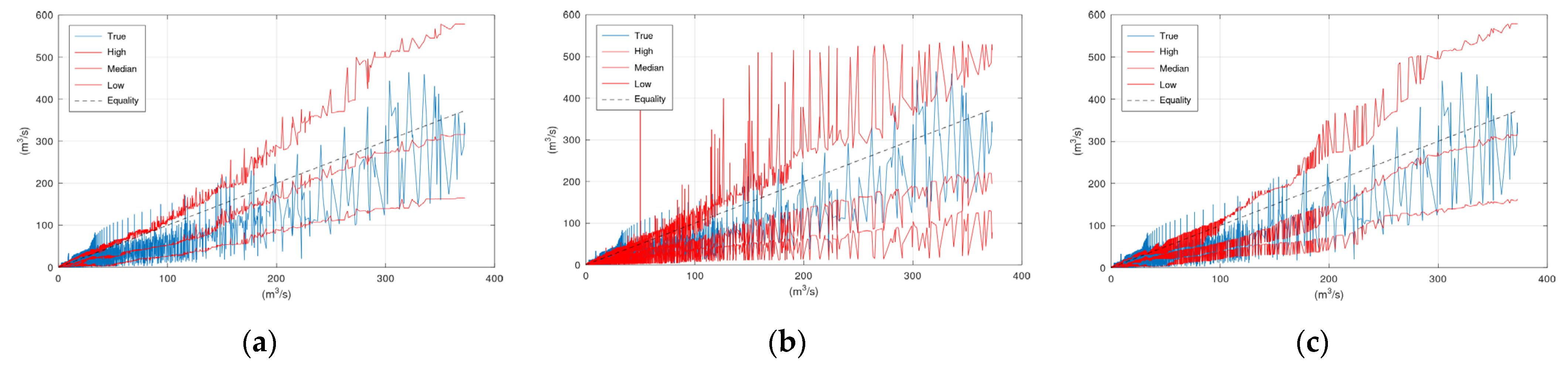
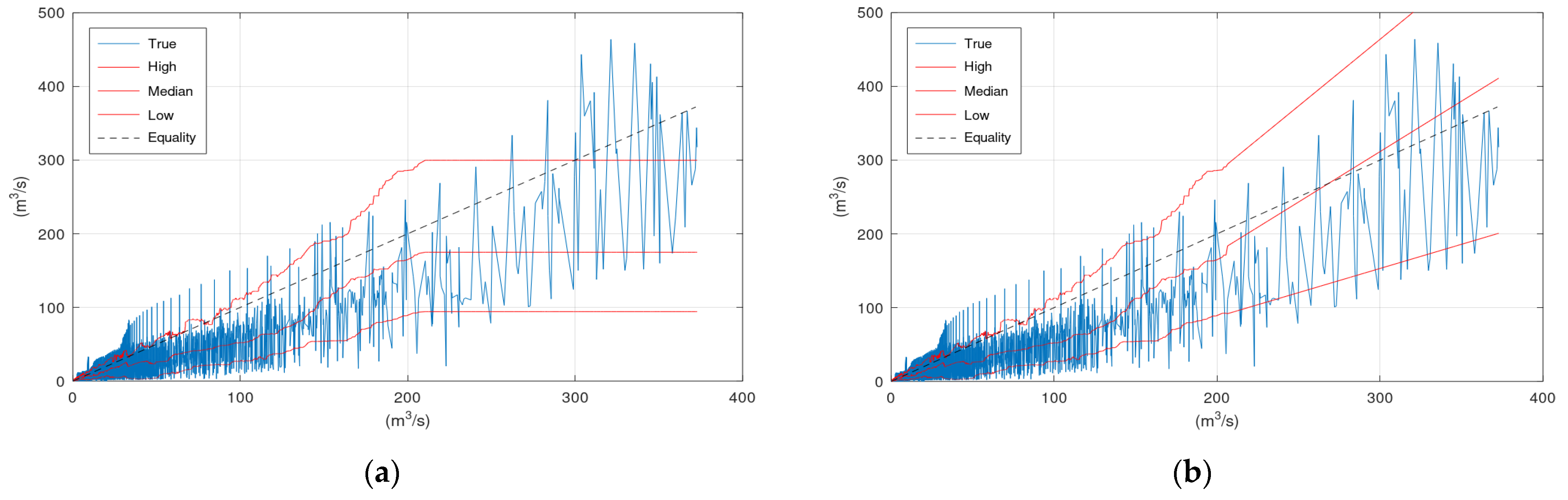
Figure 6 displays the scatter plots of the application of KNN and Bluecat to the validation period of the Sieve River case study. The “High” lines of KNN and Bluecat are very similar with minor differences at discharges around 200 m
3/s. The “Low” line of Bluecat tends to be higher at high flows. The “Median” line of Bluecat seems to deviate from the “True” line at high flows.
Figure 7 displays the CPP of the application of KNN and Bluecat to the validation period of the Sieve River case study. The CPP of KNN appears slightly closer to the Equality line.
4. Discussion
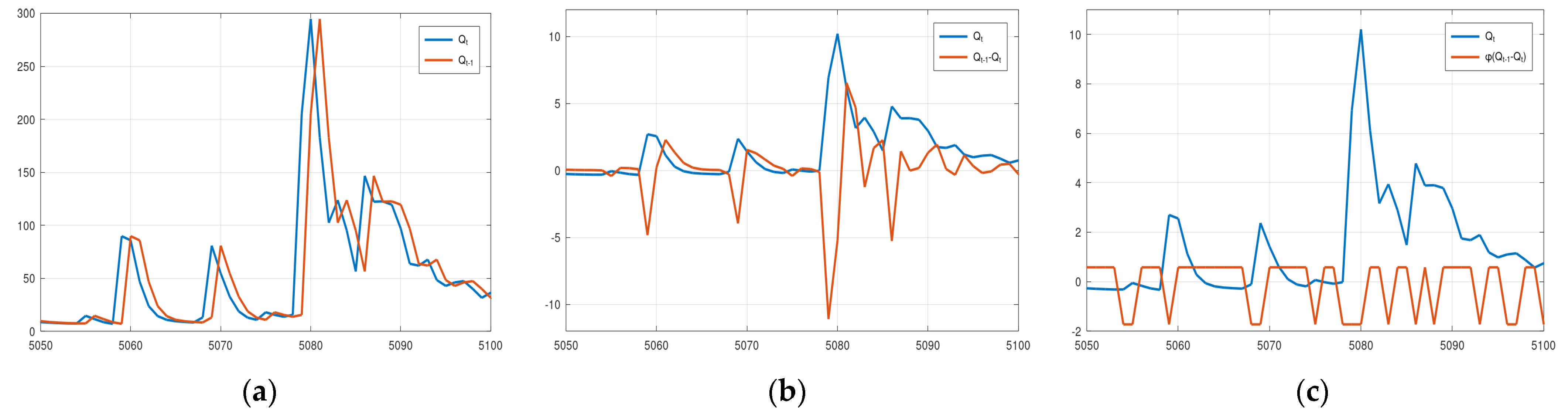
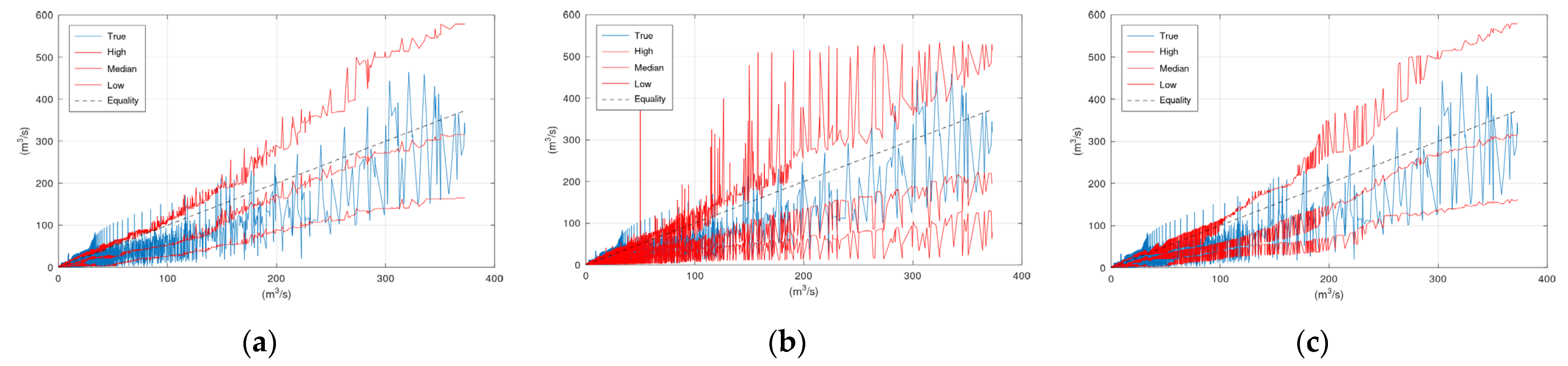
Regarding the three 2D options for sampling the model status, the basic idea for increasing the dimension of the sampling space was that this could discriminate between the rising and falling limbs of the hydrograph. A hydrological model may exhibit different magnitudes of errors when switching from one condition (rising) to another (recession), which could be captured by the 2D sampling. Option 1 includes the assessed discharge and the discharge of the previous step, Option 2 includes the assessed discharge and the change, and Option 3 includes the discharge and a binary value, 0 for rising and 1 for recession. An assessment of the properties of the Euclidean metric reveals that Option 1 may not be always appropriate for distinguishing between the rising and falling limbs. For example, suppose the assessed hydrological model with status vector (
Qt,
Qt−1), where
Qt = 99 and
Qt−1 = 100. In this case, the vector (100, 99) is closer to the assessed status vector than the vector (100, 102). Yet the former corresponds to a rising part of the hydrograph, whereas the latter and the status vector correspond to a recession. The distinction between rising and falling limbs of the hydrograph is guaranteed with Option 2 and Option 3. However, these options may overemphasise this distinction. For example,
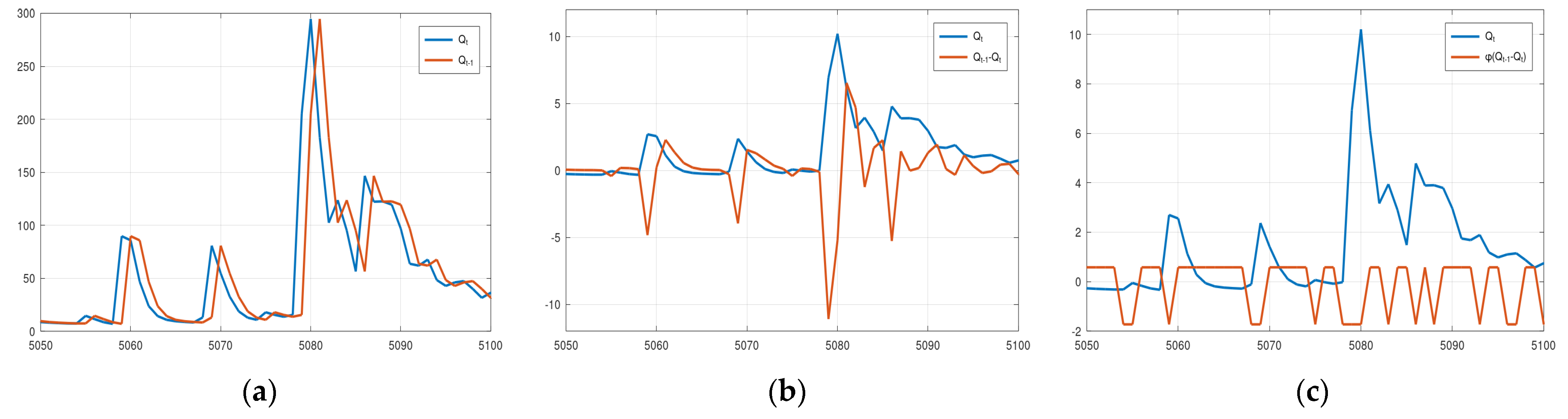
Figure 8 displays the plots of the elements (a.k.a. features) of status vector
x for the three 2D options (normalised values in Options 2 and 3) for the Arno River case study. It is evident that in Option 2 two status vectors corresponding to successive simulated discharges may have very large Euclidean distance because the difference
Qt−1 −
Qt fluctuates strongly when passing from the rising to the falling limb (
Figure 8b before and after 5080). This is probably the reason the boundaries of the confidence interval and the median value in
Figure A2b exhibit the intense fluctuations. This effect is mitigated in Option 3. However, according to
Figure A1 and
Figure A2 neither option appears to offer any advantage over the simplest 1D option. It should be noted that this may be happening just because the error of the hydrological model used in this study and for these specific two case studies is similar in the rising and falling parts of the hydrograph. If this is the case, then the uncertainty depends only on the model output and not on its state. Therefore, the model output alone can be used in a data-driven method to obtain estimations of its uncertainty.
The results of KNN and Blueacat displayed in
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6 and
Figure 7 indicate only insignificant differences between the two methods.
Figure 3 and
Figure 6 indicate that the “Median” line is closer to the “True” line than the Equality line, which means that the former is less biassed compared to the simulation values (
Table 1). Furthermore, the upper bound of the 80% confidence interval has encapsulated the more extreme events in both case studies indicating that this would be a more reliable signal than the hydrological model simulation to be used in an early warning system. Finally,
Figure 4 and
Figure 7 indicate that the CPP line of the median values is closer to the Equality line, which means that the median value would be useful in applications of water resources management.
Regarding the insignificant differences between the two methods, a closer inspection of the theory behind them reveals algorithmic similarities. Applying Bayesian inference to Equation (4) gives,
where
mQ, is the number of simulation values within the range (
Q − Δ
Q1,
Q + Δ
Q2) of which the corresponding observations are less than
q,
nq is the number of observations that are less than
q,
n is the total number of observations, and 2
m + 1 is the predetermined total number of simulation values within the range (
Q − Δ
Q1,
Q + Δ
Q2).
To obtain the number mQ, the observations that correspond to the 2m + 1 simulations within the range (Q − ΔQ1, Q + ΔQ2) need to be identified. These observations are more or less the output of KNN(k, x) in Equation (1) with only one difference, Equation (1) does not take extra care to ensure an equal number of values above and below Q. Furthermore, the right side of Equation (5) is the empirical distribution of the 2m + 1 observations. It is exactly the inverse of this empirical distribution that is used as f in Equation (1) to obtain the 90th and 10th percentiles, and the median value.
The previously mentioned difference between KNN and Bluecat regarding the selection of neighbours may result in a biased estimation of the conditional distribution
Fq|Q(
q|
Q) at high and low
Q by KNN because of an unbalanced number of values below and above
Q. That is, the higher the assessed value
Q the less the number of simulated values in the calibration period higher than
Q. As a result, for very high
Q values, KNN will return mostly observations corresponding to neighbours of
Q lower than
Q. This bias is the reason that the upper bound of the 80% confidence interval in
Figure 2a coincides with the hydrological model simulation at the two peaks before 1 April 2013. It is also the reason for the differences between
Figure 3a,b.
In both case studies, the maximum simulated discharge during the validation period was significantly lower than the maximum simulated discharge during the calibration. This allowed a sufficient number of neighbours above any
Q value, even for the maximum
Q value of the validation. However, it is not guaranteed this will be the case in every hydrological application. Recently, Koutsoyiannis and Montanari suggested a technique to address this issue [
23]. In this study, we suggest a simpler approach, which is inspired by the scatter plots in
Figure 3 and
Figure 6.
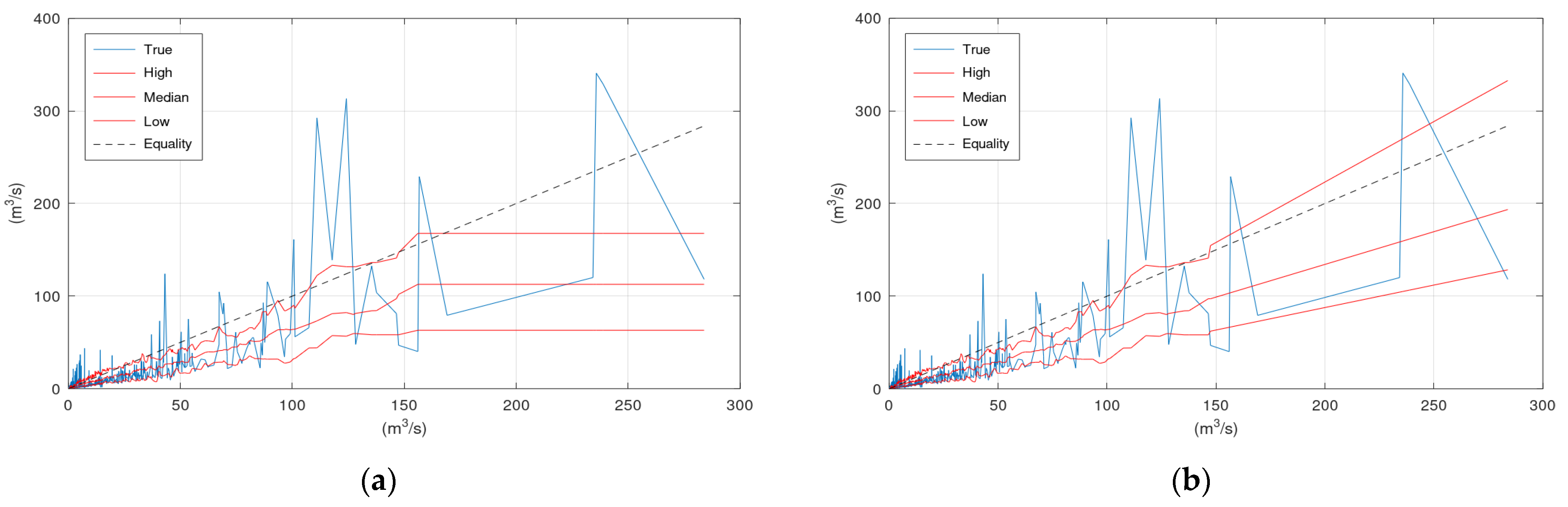
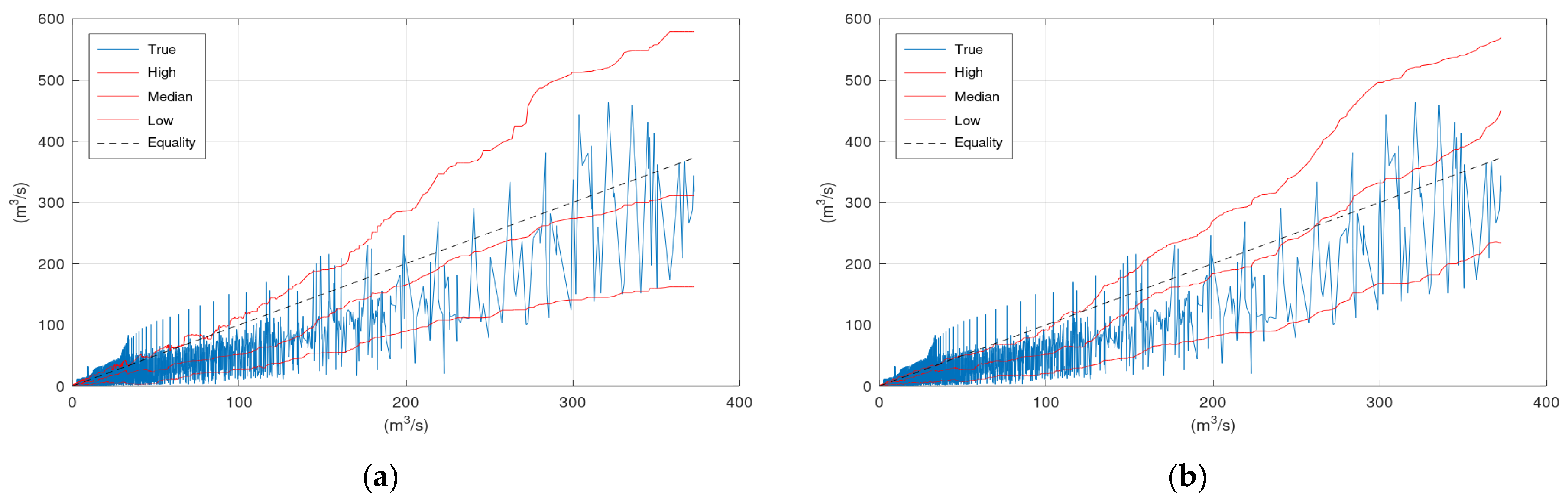
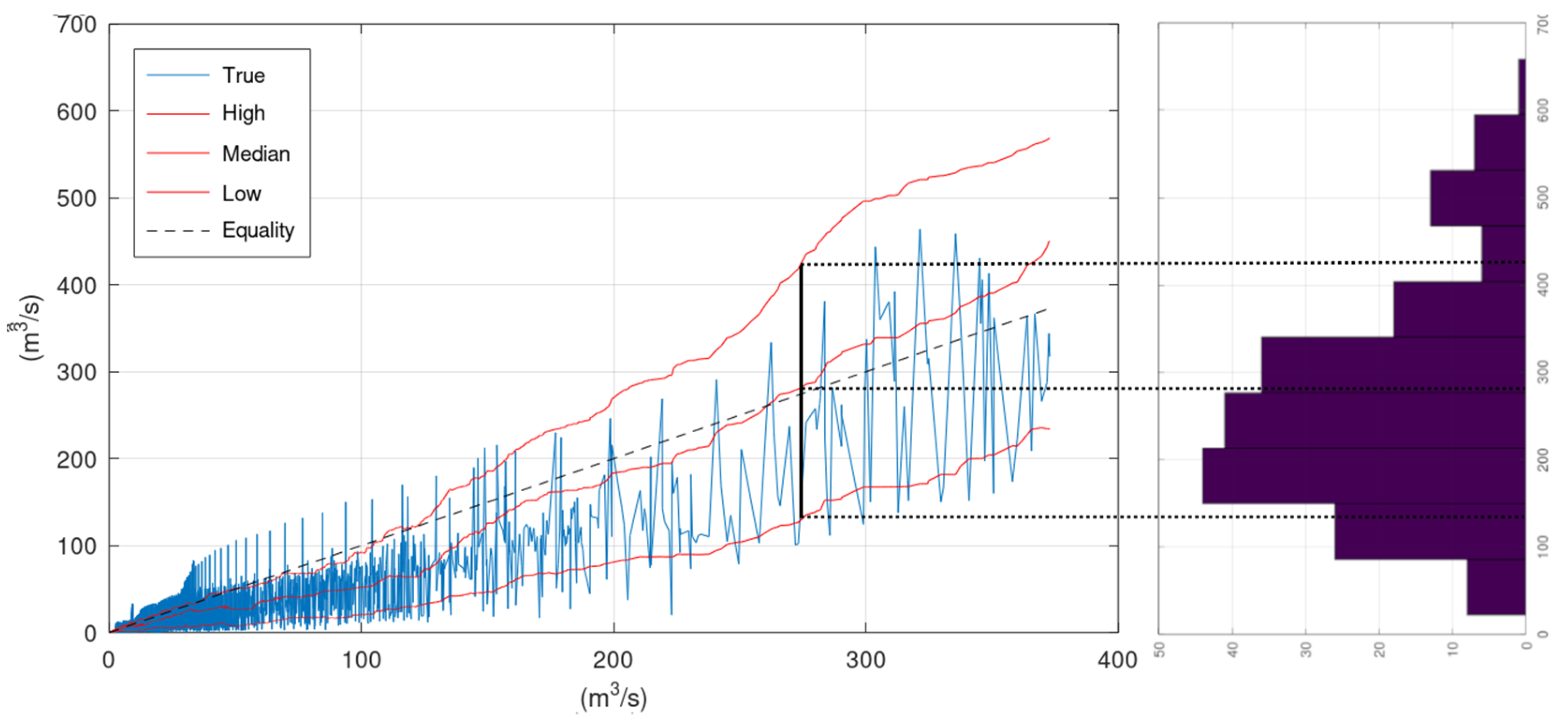
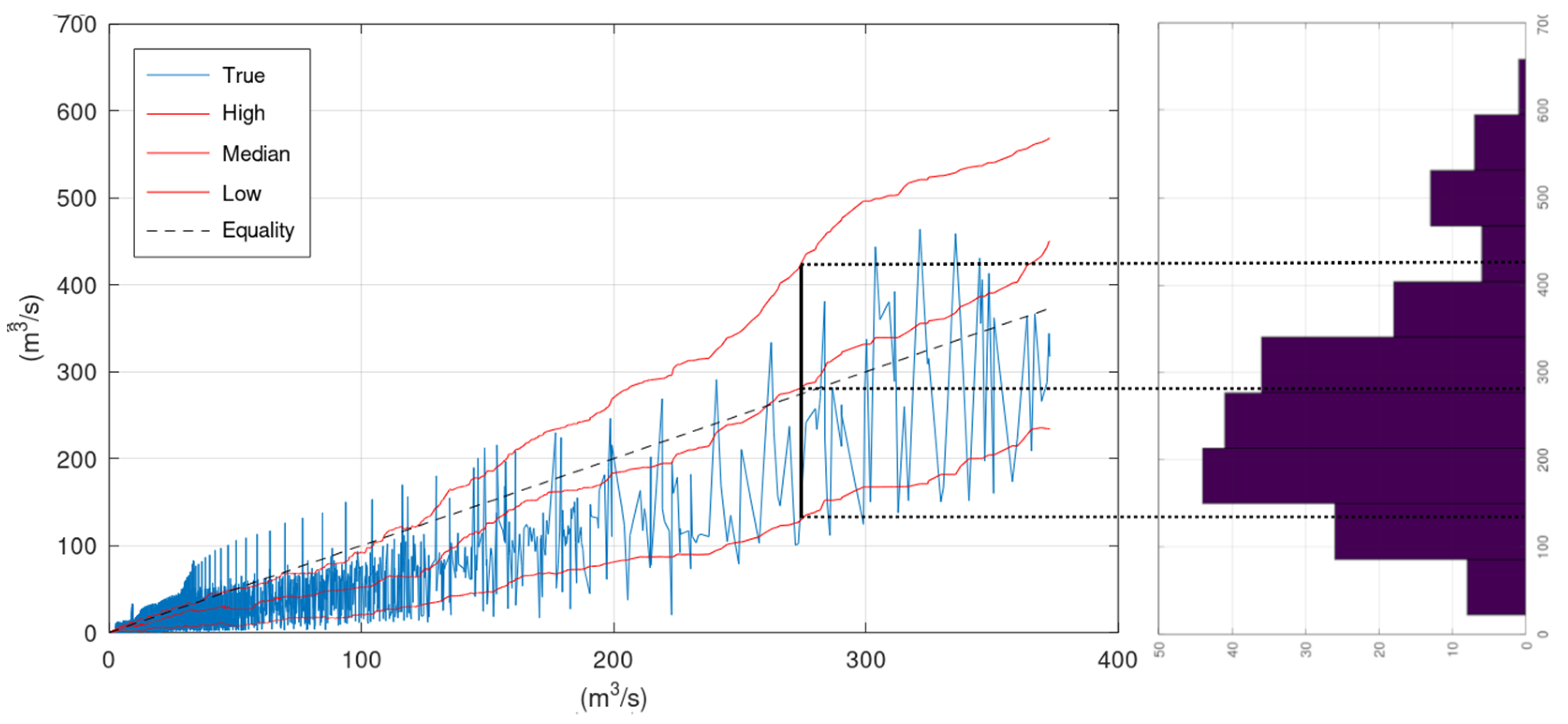
On the right side of
Figure 9 lies the histogram of the observations that correspond to the simulated by the hydrological model values that are closer to the assessed simulation value of 275 m
3/s. A rough representation of this histogram can be obtained by the values of the upper and lower confidence interval bounds and the median value that correspond to 275 m
3/s (see vertical black and dotted lines in
Figure 9). Therefore, the lines “High”, “Median”, and “Low” provide a rough representation of the histograms (or the graphical representation of the probability density function of
Fq|Q(
q|
Q)) of all assessed
Q values.
KNN and Bluecat can draw these three lines up to the
Q value of the validation period that is covered by a sufficient number of greater discharges simulated by the hydrological model during the calibration period. The simplest approach to extend these three lines beyond this specific
Q value, and, consequently, to obtain an estimation of the conditional distribution
Fq|Q(
q|
Q) for
Q values beyond the available information, is to extrapolate them with linear regression. The application of this simple approach for the two case studies is demonstrated in
Appendix B.
5. Conclusions
In this study, we have employed a statistical data-driven method (Bluecat) and a machine learning method (k-nearest neighbours) to assess the uncertainty of a hydrological model simulation. The two methods were applied in two real-world case studies. The lessons from these applications were the following.
The machine learning method is more flexible than the statistical method, which allows using more complex sampling schemes at higher dimensions (e.g., model simulation values from multiple time steps). This may improve the reliability of the estimated uncertainty in some cases. However, the application in the two case studies did not prove any advantage over the simplest approach (1D sampling, only the discharge). This finding cannot be generalized since it depends on the performance of the selected hydrological model in each specific case study. Nevertheless, it appears that the simplest approach captures successfully most (if not all) of the characteristics of the uncertainty.
Machine learning is usually considered a black-box approach with some abstract/intuitive understanding of its functionality. However, in some applications, a close inspection can reveal similarities, or even equivalency, with rigorous mathematical approaches. The identification of the deviations of the algorithm underneath a machine learning method from the rigorous approach allows detecting the conditions under which the machine learning model may exhibit poor performance, and thus, increase its credibility.
A very simple approach based on linear regression was employed to estimate the statistical structure of the assessed hydrological model uncertainty at conditions never met in the available data. This approach was tested in the two case studies and was found to perform satisfactorily.
The data-driven analysis of the uncertainty of the hydrological model (based on machine learning or statistical theory) in the two case studies can offer not only an estimation of the confidence we can have in the model results, but also operational benefits. For example, the median values had significantly less bias than the values simulated by the hydrological model. More specifically, the hydrological model overestimated the mean discharge by 50% whereas the median values by only 4%. Therefore, the median values can be more useful in applications of water resources management. Similarly, appropriate confidence levels, corresponding to an acceptable risk, could be selected to obtain probabilistic estimations of extreme values providing more reliable early warning systems. The latter requires research on the main weakness of the data-driven methods, i.e., the estimation of the uncertainty at conditions never met in the available data. A more thorough assessment of the simple approach (linear regression) employed here should be performed and more elaborated approaches (e.g., multi-layer perceptrons) need to be considered, which may prove more advantageous.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}