
Understanding Quality of Pinot Noir Wine: Can Modelling and Machine Learning Pave the Way?

 ,
,
Abstract
1. Introduction
1.1. Perception of Quality in Pinot Noir Wines
1.2. Modelling Human Responses to Sensory Stimuli
1.3. Chemical and Physiochemical Correlates of Perceived Quality
1.4. Computational Modelling of Perceived Quality
1.5. Industry Relevance
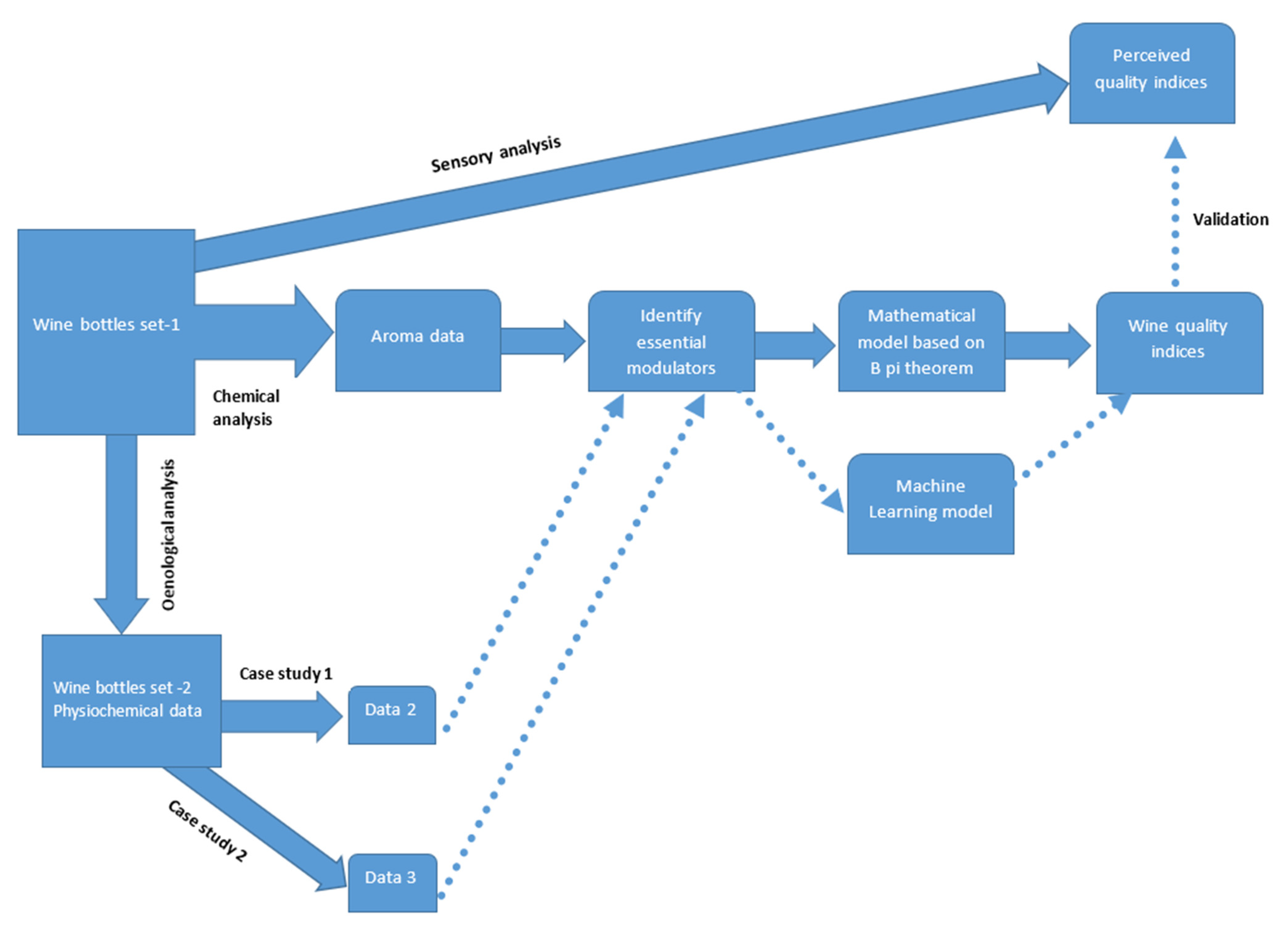
2. Methods
2.1. Sensory Methods
2.1.1. Participants
2.1.2. Wines
2.1.3. Experimental Design
2.1.4. Procedure
2.2. Mathematical Methods
2.2.1. Identifying Essential Modulators
2.2.2. Buckingham’s Pi Theorem for Predicting Wine Quality Indices
- Selecting important variables through DA before conducting further analysis saves time. It shows a clear direction in selecting relevant variables that ultimately improve the accuracy of the model in predicting wine quality.
2.3. Machine Learning Analysis
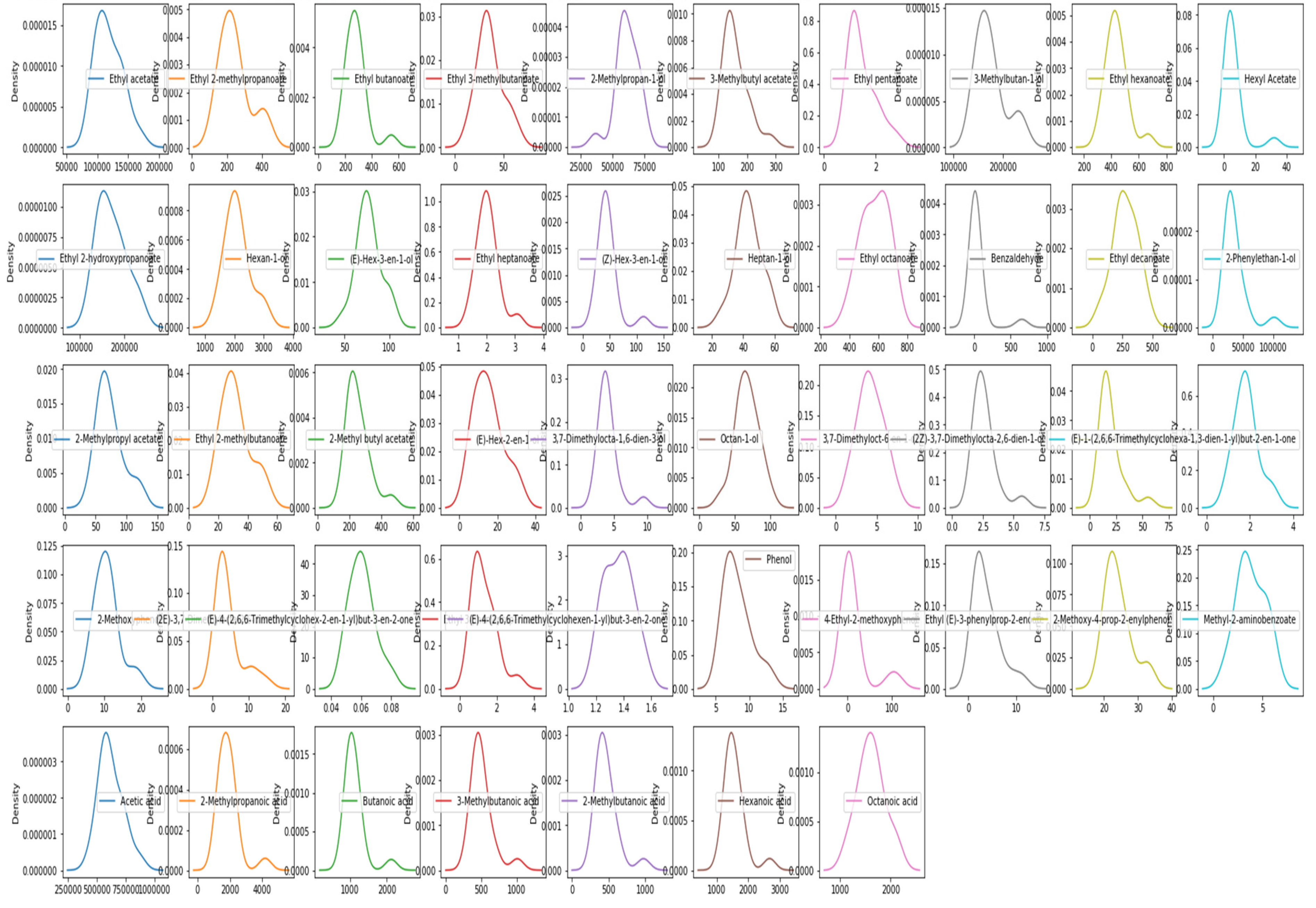
2.4. Data Analysis
3. Results
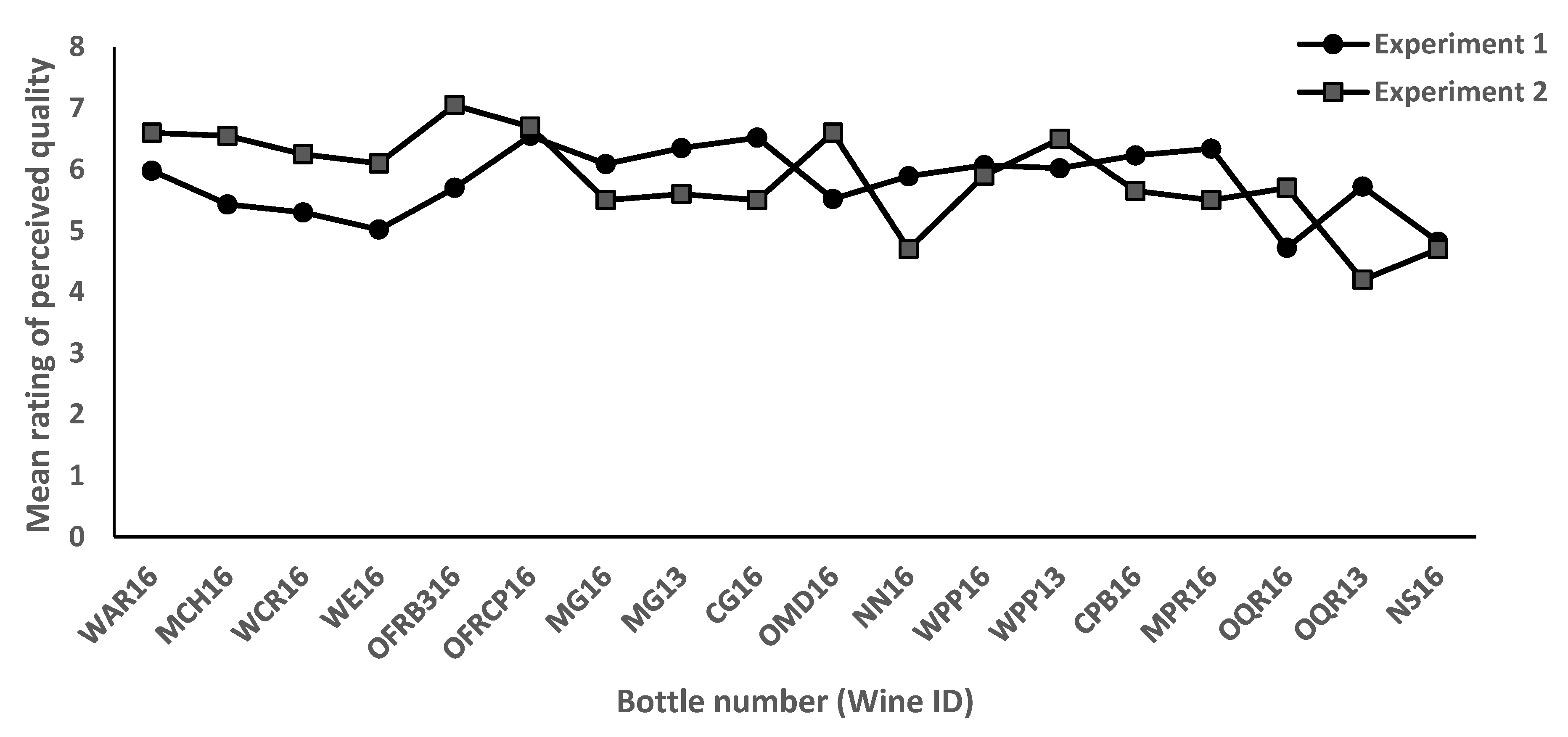
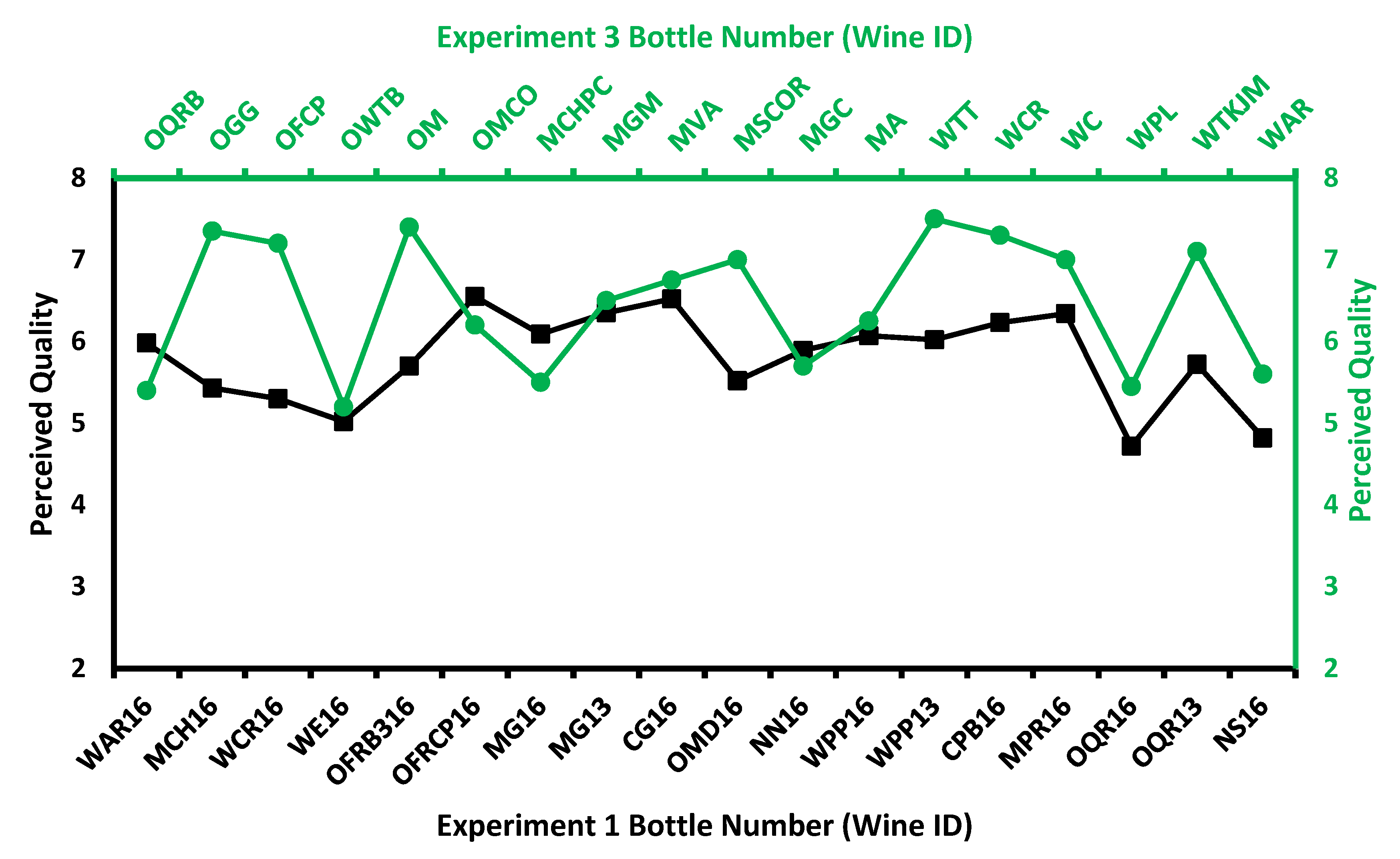
3.1. Sensory Results
- Visual influence (i.e., the glass-colour manipulation) was not a major driver of judgments of perceived quality, despite anecdotal evidence suggesting that it would be.
- Perceived quality differed significantly across the 18 wines, but wine region was not a significant factor (the within-region variability was too great to find the between-region significant variation with such a small # of wines in the sample set).
- The perception of the quality in the wines was highly and positively associated with perceived varietal typicality, a concept that refers to whether a Pinot noir wine exemplifies a taster’s concept of what a Pinot noir wine should be like. (i.e., is the wine true to grape type?)
- The perception of quality was closely and positively associated with perceived complexity, and to a lesser degree, with the perceived familiarity of a wine, these two concepts have been shown in food science research to be important influencers of consumer preferences and behaviour.
- Key, specific drivers of Pinot noir quality were wine attributes of attractive fruit aromatics, expressiveness, overall structure, harmony and balance.
- The 18 wines differed significantly on most of the in-mouth attributes assessed, including the perceived overall quality.
- Again, quality and varietal typicality appeared virtually synonymous concepts for the tasters.
- The major sensory dimension separating the wines was a tactile aspect, with wines judged as soft, gentle, smooth, silky, velvety and supple; as opposed to wines judged to be sour, bitter, coarse, rough, astringent and with harsh tannins (PCA output).
- A second important dimension was related to wine overall body, with attributes of weight, heaviness, density, fullness, roundness and volume opposing the descriptor ‘thin/watery’.
- Perceived overall quality was positively associated with the tactile attributes relating to the soft/smooth aspects, and negatively correlated with bitterness, astringency and harsh tannins.
- Overall, mouthfeel attributes important to quality were multi-dimensional, involving tactile (e.g., harsh/soft), body/weight and oiliness/viscosity dimensions.
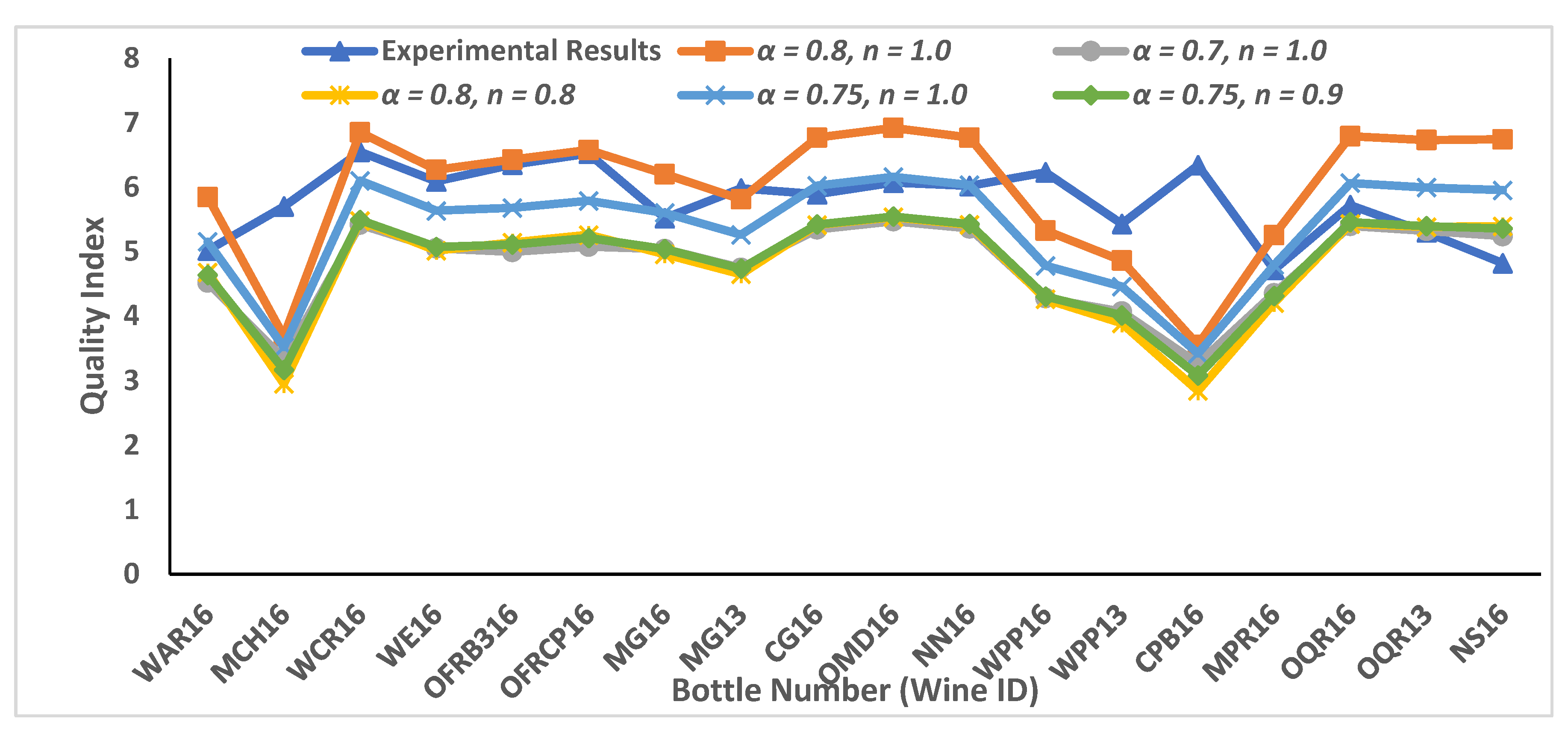
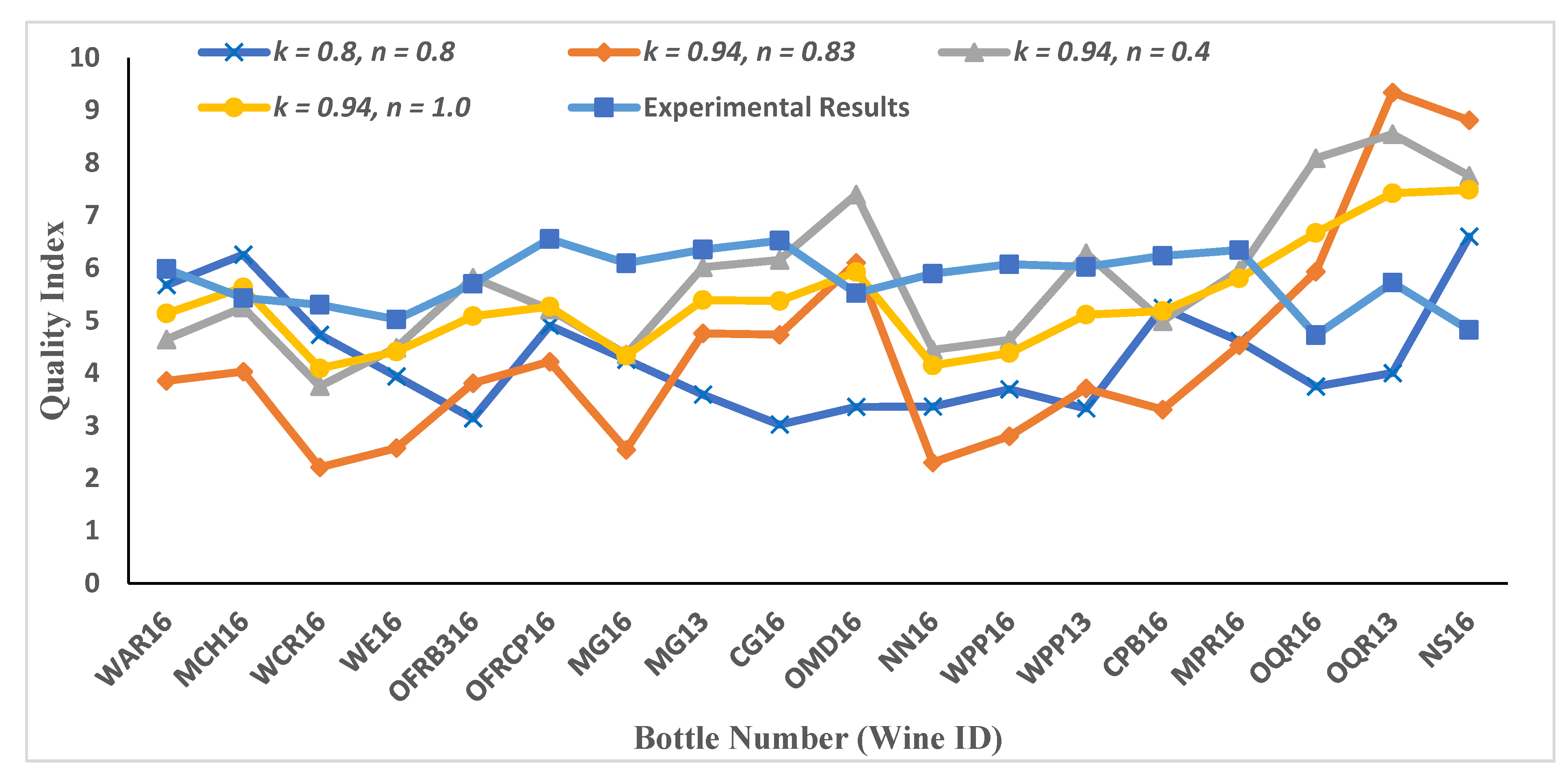
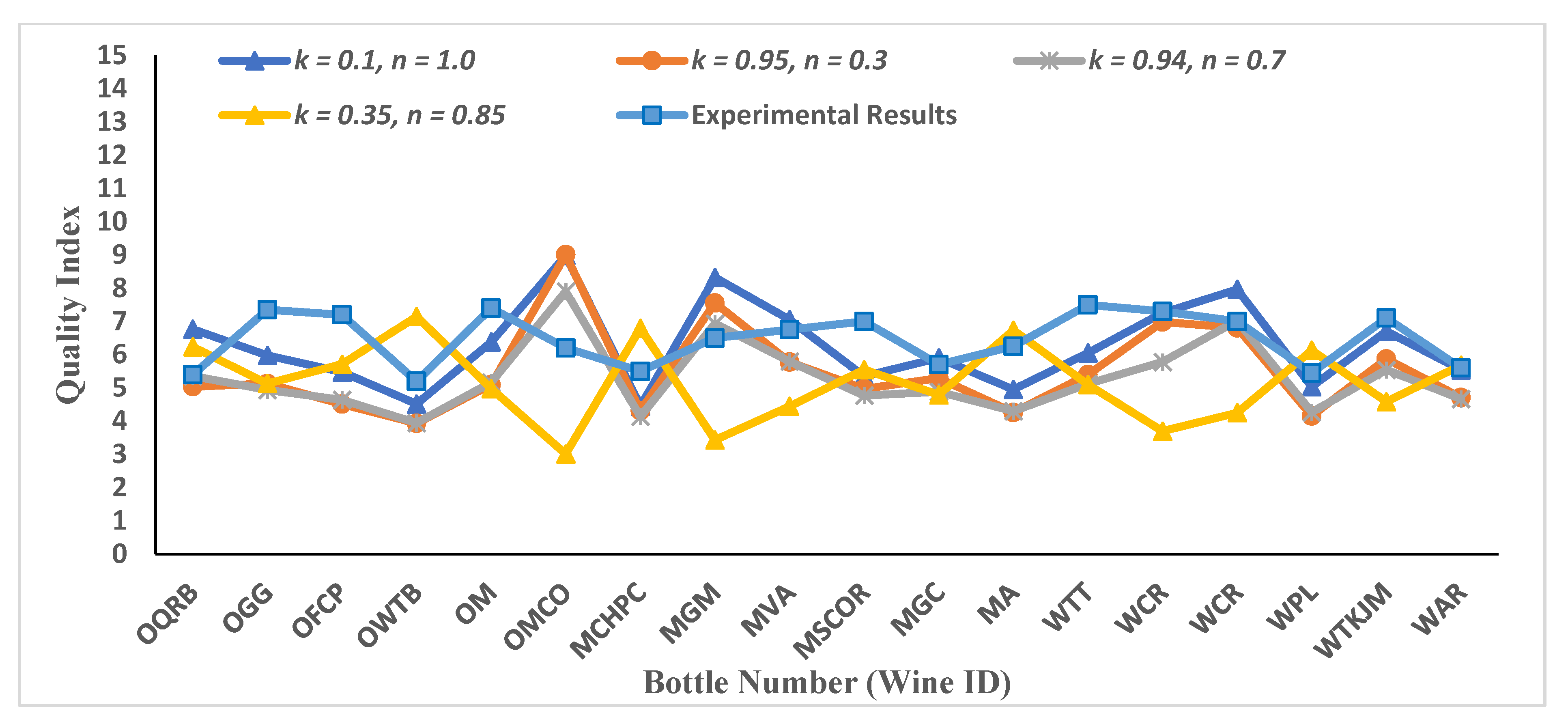
3.2. Mathematical Results for Quality Indices (Selection of Optimal Essential Modulators and Evaluating Pi-Terms)
3.3. Mathematical Results for Case Study 1 and Case Study 2
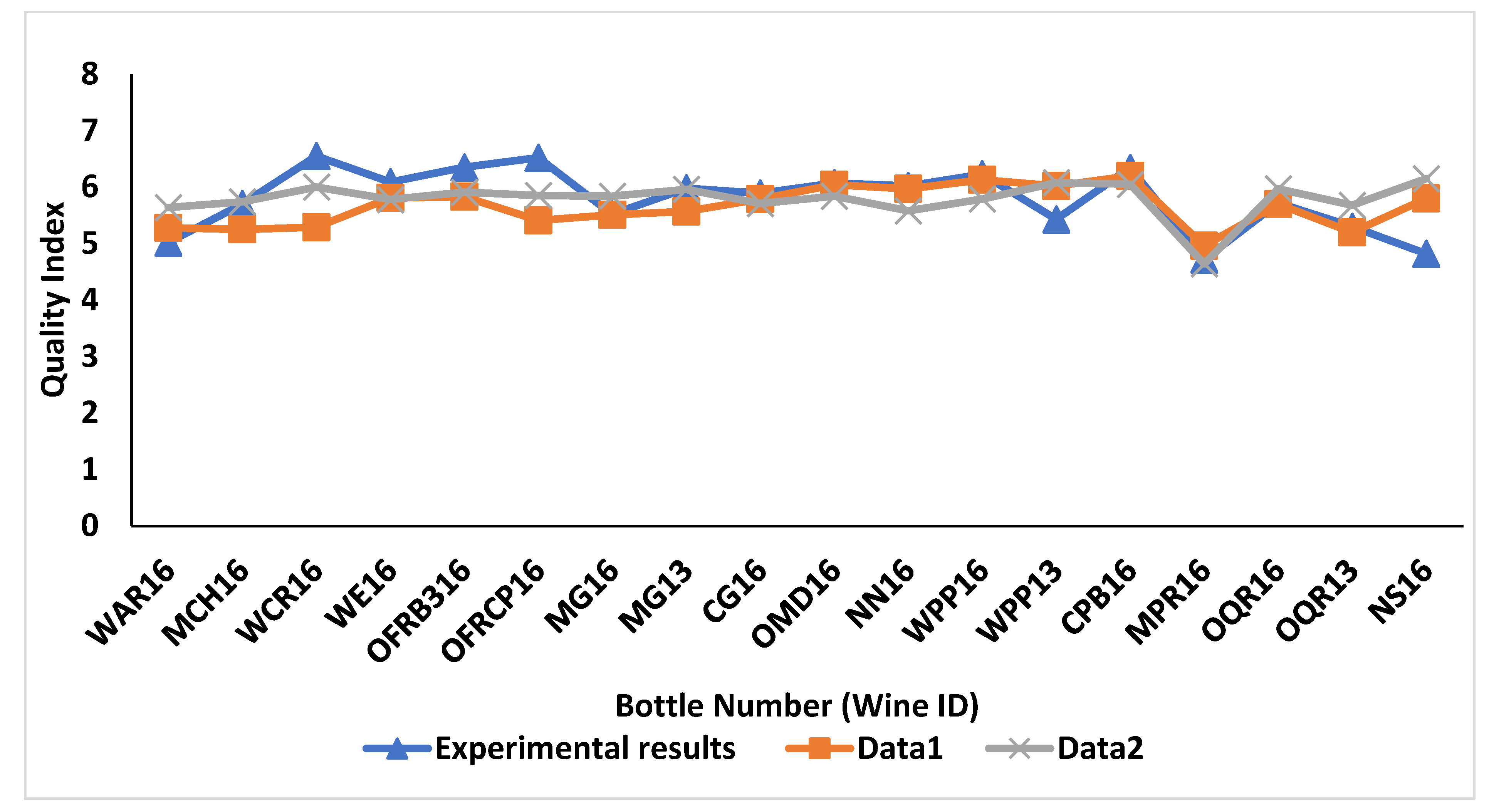
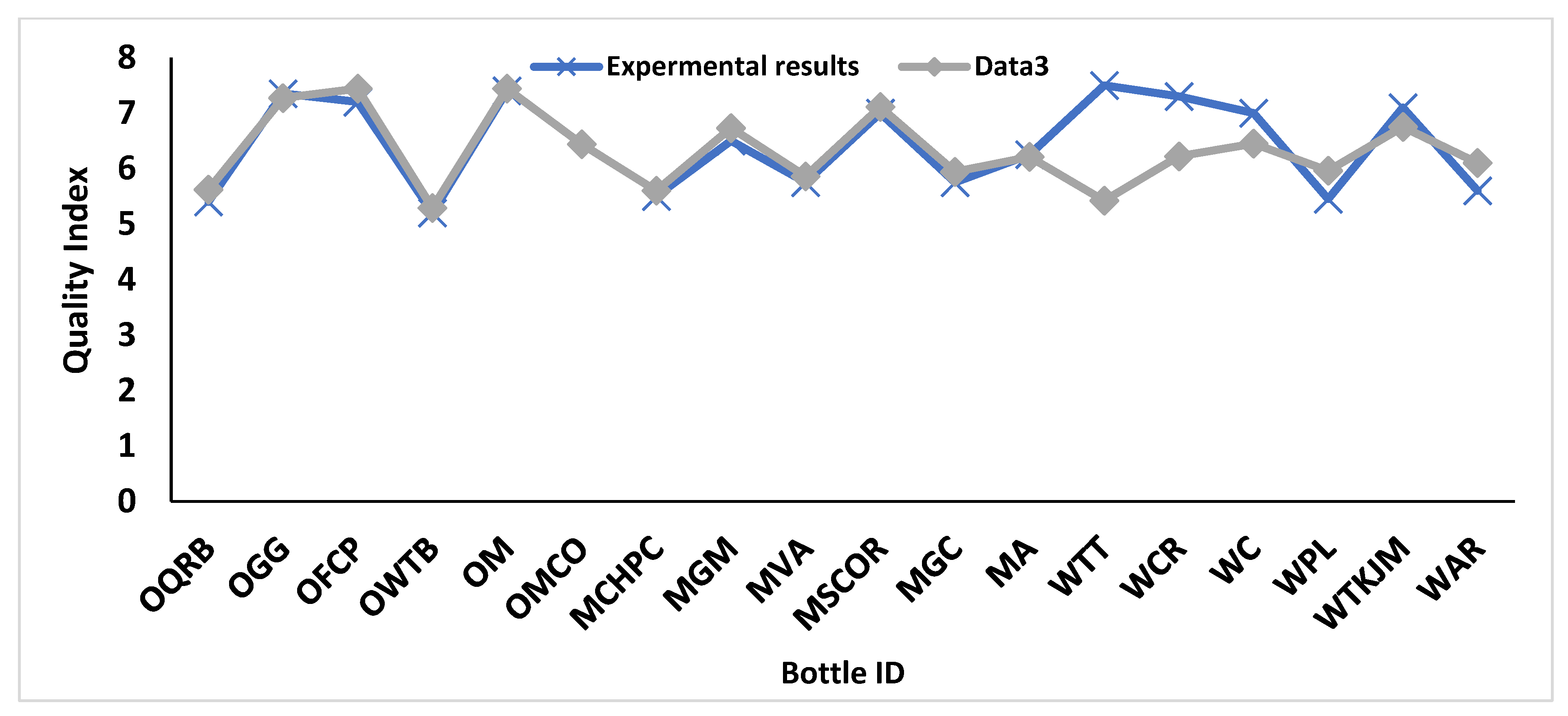
3.4. Validation/Significance of ML Models
3.5. Limitations
4. Summary of Findings and Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Parr, W.V. Demystifying wine tasting: Cognitive psychology’s contribution. Food Res. Int. 2019, 124, 230–233. [Google Scholar] [CrossRef] [PubMed]
- Urdapilleta, I.; Parr, W.; Dacremont, C.; Green, J. Semantic and perceptive organisation of Sauvignon blanc wine characteristics: Influence of expertise. Food Qual. Prefer. 2011, 22, 119–128. [Google Scholar] [CrossRef]
- Valentin, D.; Parr, W.V.; Peyron, D.; Grose, C.; Ballester, J. Colour as a driver of Pinot noir wine quality judgments: An investigation involving French and New Zealand wine professionals. Food Qual. Prefer. 2015, 48, 251–261. [Google Scholar] [CrossRef]
- Burlingame, G.A.; Doty, R.L. Chapter 49. In Handbook of Olfaction and Gustation, 3rd ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2015; pp. 1079–1088. Available online: https://onlinelibrary.wiley.com/doi/full/10.1002/9781118971758.ch49 (accessed on 3 June 2022).
- Bell, G.A.; Parr, W.V. Olfaction and Taste in the Food and Beverage Industries. In Handbook of Olfaction and Gustation, 3rd ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2015; pp. 1049–1066. [Google Scholar]
- Parr, W.V.; Grose, C.; Hedderley, D.; Maraboli, M.M.; Masters, O.; Araujo, L.D.; Valentin, D. Perception of quality and complexity in wine and their links to varietal typicality: An investigation involving Pinot noir wine and professional tasters. Food Res. Int. 2020, 137, 109423. [Google Scholar] [CrossRef] [PubMed]
- Araujo, L.D.; Parr, W.V.; Grose, C.; Hedderley, D.; Masters, O.; Kilmartin, P.A.; Valentin, D. In-mouth attributes driving perceived quality of Pinot noir wines: Sensory and chemical characterisation. Food Res. Int. 2021, 149, 110665. [Google Scholar] [CrossRef]
- Charters, S.; Pettigrew, S. The dimensions of wine quality. Food Qual. Prefer. 2007, 18, 997–1007. [Google Scholar] [CrossRef]
- Hopfer, H.; Heymann, H. Judging wine quality: Do we need experts, consumers or trained panelists? Food Qual. Prefer. 2014, 32, 221–233. [Google Scholar] [CrossRef]
- Parr, W.V.; Mouret, M.; Blackmore, S.; Pelquest-Hunt, T.; Urdapilleta, I. Representation of complexity in wine: Influence of expertise. Food Qual. Prefer. 2011, 22, 647–660. [Google Scholar] [CrossRef]
- Parker, M.; Smith, P.; Birse, M.; Francis, I.; Kwiatkowski, M.; Lattey, K.; Liebich, B.; Herderich, M. The effect of pre- and post-ferment additions of grape derived tannin on Shiraz wine sensory properties and phenolic composition. Aust. J. Grape Wine Res. 2007, 13, 30–37. [Google Scholar] [CrossRef]
- NZ Pinot Noir Gets Regional | JancisRobinson.com [Internet]. Available online: https://www.jancisrobinson.com/articles/nz-pinot-noir-gets-regional (accessed on 3 June 2022).
- Longo, R.; Carew, A.; Sawyer, S.; Kemp, B.; Kerslake, F. A review on the aroma composition of Vitis vinifera L. Pinot noir wines: Origins and influencing factors. Crit. Rev. Food Sci. Nutr. 2021, 61, 1589–1604. [Google Scholar] [CrossRef]
- Tomasino, E.; Harrison, R.; Breitmeyer, J.; Sedcole, R.; Sherlock, R.; Frost, A. Aroma composition of 2-year-old New Zealand Pinot Noir wine and its relationship to sensory characteristics using canonical correlation analysis and addition/omission tests. Aust. J. Grape Wine Res. 2015, 21, 376–388. [Google Scholar] [CrossRef]
- Panel Tasting: 44 Top Rated South Island Pinot Noirs [Internet]. Available online: https://app.gourmettravellerwine.com/editions/june-july-21/article/beautiful-south.html (accessed on 3 June 2022).
- Pinot Noir 2010—Conclusions on Pinot Noir in New Zealand, and Reviews: 120 Reviews [Internet]. Available online: http://www.geoffkellywinereviews.co.nz/index.php?ArticleID=169 (accessed on 3 June 2022).
- Mercurio, M.D.; Dambergs, R.G.; Cozzolino, D.; Herderich, M.J.; Smith, P.A. Relationship between Red Wine Grades and Phenolics. 1. Tannin and Total Phenolics Concentrations. J. Agric. Food Chem. 2010, 58, 12313–12319. [Google Scholar] [CrossRef] [PubMed]
- Casassa, L.F.; Sari, S.E.; Bolcato, E.A.; Diaz-Sambueza, M.A.; Catania, A.A.; Fanzone, M.; Raco, F.; Barda, N. Chemical and Sensory Effects of Cold Soak, Whole Cluster Fermentation, and Stem Additions in Pinot noir Wines. Am. J. Enol. Vitic. 2019, 70, 19–33. [Google Scholar] [CrossRef]
- Parr, W.V.; Green, J.A.; White, K.G.; Sherlock, R.R. The distinctive flavour of New Zealand Sauvignon blanc: Sensory characterisation by wine professionals. Food Qual. Prefer. 2007, 18, 849–861. [Google Scholar] [CrossRef]
- Wei, Y.J.; Yang, L.L.; Liang, Y.P.; Li, J.M. Application of Electronic Nose for Detection of Wine-Aging Methods. Adv. Mater. Res. 2014, 875–877, 2206–2213. [Google Scholar] [CrossRef]
- Gardner, D.M.; Zoecklein, B.W.; Mallikarjunan, K. Electronic Nose Analysis of Cabernet Sauvignon (Vitis vinifera L.) Grape and Wine Volatile Differences during Cold Soak and Postfermentation. Am. J. Enol. Vitic. 2011, 62, 81–90. [Google Scholar] [CrossRef]
- Royet, J.-P.; Plailly, J.; Saive, A.-L.; Veyrac, A.; Delon-Martin, C. The impact of expertise in olfaction. Front. Psychol. 2013, 4, 928. [Google Scholar] [CrossRef]
- Moreno, I.M.; Gutiérrez, A.J.; Rubio, C.; González, A.G.; González-Weller, D.; Bencharki, N.; Hardisson, A.; Revert, C. Classification of Spanish Red Wines Using Artificial Neural Networks with Enological Parameters and Mineral Content. Am. J. Enol. Vitic. 2018, 69, 167–175. [Google Scholar] [CrossRef]
- Saenz-Navajas, M.-P.; Ferrero-Del-Teso, S.; Romero, M.; Pascual, D.; Diaz, D.; Ferreira, V.; Fernández-Zurbano, P. Modelling wine astringency from its chemical composition using machine learning algorithms. OENO One 2019, 53, 499–509. [Google Scholar] [CrossRef]
- Fuentes, S.; Torrico, D.D.; Tongson, E.; Viejo, C.G. Machine Learning Modeling of Wine Sensory Profiles and Color of Vertical Vintages of Pinot Noir Based on Chemical Fingerprinting, Weather and Management Data. Sensors 2020, 20, 3618. [Google Scholar] [CrossRef]
- Kasimati, A.; Espejo-Garcia, B.; Vali, E.; Malounas, I.; Fountas, S. Investigating a Selection of Methods for the Prediction of Total Soluble Solids among Wine Grape Quality Characteristics Using Normalized Difference Vegetation Index Data from Proximal and Remote Sensing. Front. Plant Sci. 2021, 12, 683078. [Google Scholar] [CrossRef] [PubMed]
- Bhardwaj, P.; Tiwari, P.; Olejar, K.; Parr, W.; Kulasiri, D. A machine learning application in wine quality prediction. Mach. Learn. Appl. 2022, 8, 100261. [Google Scholar] [CrossRef]
- de Orduña, R.M. Climate change associated effects on grape and wine quality and production. Food Res. Int. 2010, 43, 1844–1855. [Google Scholar] [CrossRef]
- Oczkowski, E. The Effect of Weather on Wine Quality and Prices: An Australian Spatial Analysis. J. Wine Econ. 2016, 11, 48–65. Available online: https://www.cambridge.org/core/journals/journal-of-wine-economics/article/effect-of-weather-on-wine-quality-and-prices-an-australian-spatial-analysis/2F38F443E52890E88E792773A33CA664 (accessed on 3 June 2022). [CrossRef]
- González-Barreiro, C.; Rial-Otero, R.; Cancho-Grande, B.; Simal-Gándara, J. Wine Aroma Compounds in Grapes: A Critical Review. Crit. Rev. Food Sci. Nutr. 2015, 55, 202–218. [Google Scholar] [CrossRef]
- Auvray, M.; Spence, C. The multisensory perception of flavor. Conscious. Cogn. 2008, 17, 1016–1031. [Google Scholar] [CrossRef]
- Markoski, M.M.; Garavaglia, J.; Oliveira, A.; Olivaes, J.; Marcadenti, A. Molecular Properties of Red Wine Compounds and Cardiometabolic Benefits. Nutr. Metab. Insights 2016, 9, 51–57. [Google Scholar] [CrossRef]
- Mateo, J.; Jiménez, M. Monoterpenes in grape juice and wines. J. Chromatogr. A 2000, 881, 557–567. [Google Scholar] [CrossRef]
- Parr, W.V.; Heatherbell, D.; White, K.G. Demystifying Wine Expertise: Olfactory Threshold, Perceptual Skill and Semantic Memory in Expert and Novice Wine Judges. Chem. Senses 2002, 27, 747–755. Available online: https://academic.oup.com/chemse/article/27/8/747/387724 (accessed on 3 June 2022). [CrossRef]
- Schlich, P.; Maraboli, M.M.; Urbano, C.; Parr, W. Perceived complexity in Sauvignon Blanc wines: Influence of domain-specific expertise. Aust. J. Grape Wine Res. 2015, 21, 168–178. [Google Scholar] [CrossRef]
- Extreme Wine: Searching the World for the Best, the Worst, the Outrageously Cheap, the Insanely Overpriced, and the Undiscovered—9781442219236. Available online: https://rowman.com/ISBN/9781442219236/Extreme-Wine-Searching-the-World-for-the-Best-the-Worst-the-Outrageously-Cheap-the-Insanely-Overpriced-and-the-Undiscovered (accessed on 3 June 2022).
- Boss, P.K.; Pearce, A.D.; Zhao, Y.; Nicholson, E.L.; Dennis, E.G.; Jeffery, D.W. Potential Grape-Derived Contributions to Volatile Ester Concentrations in Wine. Molecules 2015, 20, 7845–7873. [Google Scholar] [CrossRef] [PubMed]
- Guillaumie, S.; Ilg, A.; Rety, S.; Brette, M.; Trossat-Magnin, C.; Decroocq, S.; Léon, C.; Keime, C.; Ye, T.; Baltenweck-Guyot, R.; et al. Genetic Analysis of the Biosynthesis of 2-Methoxy-3-Isobutylpyrazine, a Major Grape-Derived Aroma Compound Impacting Wine Quality. Plant Physiol. 2013, 162, 604–615. [Google Scholar] [CrossRef] [PubMed]
- Amargianitaki, M.; Spyros, A. NMR-based metabolomics in wine quality control and authentication. Chem. Biol. Technol. Agric. 2017, 4, 1–12. [Google Scholar] [CrossRef]
- Tian, R.-R.; Pan, Q.-H.; Zhan, J.-C.; Li, J.-M.; Wan, S.-B.; Zhang, Q.-H.; Huang, W.-D. Comparison of Phenolic Acids and Flavan-3-ols During Wine Fermentation of Grapes with Different Harvest Times. Molecules 2009, 14, 827–838. [Google Scholar] [CrossRef] [PubMed]
- Dimensional Analysis Beyond the Pi Theorem (Paperback)—Walmart.com. Available online: https://www.walmart.com/ip/Dimensional-Analysis-Beyond-the-Pi-Theorem-Paperback-9783319833590/324487875 (accessed on 3 June 2022).
- García-Barrachina, L.; Gámez, A.J. Dimensional Analysis of Superplastic Processes with the Buckingham Π Theorem. Metals 2020, 10, 1575. [Google Scholar] [CrossRef]
- Constantine, P.G.; del Rosario, Z.; Iaccarino, G. Data-driven dimensional analysis: Algorithms for unique and relevant dimensionless groups. arXiv 2017. [Google Scholar] [CrossRef]
- Vignaux, V.; Scott, J. Simplifying Regression Models Using Dimensional Analysis. Aust. N. Z. J. Stat. 1999, 41, 31–41. [Google Scholar] [CrossRef]
- Jean, E.; Katherine, Z. Physical Requirement Guidelines for Sensory Evaluation Laboratories: A Manual; American Society for Testing and Materials: Philadelphia, PA, USA, 1986; 54p. [Google Scholar]
- Julia Harding MW—Wine Critic | Your Personal Wine Professional | Tastingbook. Available online: https://tastingbook.com/pro/Julia_Harding?language=en (accessed on 3 June 2022).
- Parr, W.V.; White, K.G.; Heatherbell, D.A. The nose knows: Influence of colour on perception of wine aroma. J. Wine Res. 2003, 14, 79–101. [Google Scholar] [CrossRef]
- Mouret, M.; Monaco, G.L.; Urdapilleta, I.; Parr, W.V. Social representations of wine and culture: A comparison between France and New Zealand. Food Qual. Prefer. 2013, 30, 102–107. [Google Scholar] [CrossRef]
- Buckingham, E. On Physically Similar Systems; Illustrations of the Use of Dimensional Equations. Phys. Rev. Ser. I 1914, 4, 345–376. [Google Scholar] [CrossRef]
- Collier, J. What We Can Discover from Dimensional Analysis of the Information Concept. Proceedings 2017, 1, 68. [Google Scholar] [CrossRef]
- Sonin, A.A. A generalization of the Π-theorem and dimensional analysis. Proc. Natl. Acad. Sci. USA 2004, 101, 8525–8526. [Google Scholar] [CrossRef] [PubMed]
- Zohuri, B. Dimensional Analysis Beyond the Pi Theorem; Springer: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- Bajer, D.; Zonc, B.; Dudjak, M.; Martinovic, G. Performance Analysis of SMOTE-based Oversampling Techniques When Dealing with Data Imbalance. In International Conference on Systems, Signals, and Image Processing; IEEE Computer Society: Newyork, NY, USA, 2019; pp. 265–271. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. Available online: https://www.jair.org/index.php/jair/article/view/10302 (accessed on 3 June 2022). [CrossRef]
- Shrivastava, S.; Jeyanthi, P.M.; Singh, S. Failure prediction of Indian Banks using SMOTE, Lasso regression, bagging and boosting. Cogent Econ. Financ. 2020, 8, 1729569. [Google Scholar] [CrossRef]
- Davies, E.R.; Turk, M. (Eds.) Advanced Methods and Deep Learning in Computer Vision; Elsevier: Amsterdam, The Netherlands, 2022. [Google Scholar]
- Oostwal, E.; Straat, M.; Biehl, M. Hidden unit specialization in layered neural networks: ReLU vs. sigmoidal activation. Phys. A Stat. Mech. Its Appl. 2021, 564, 125517. [Google Scholar] [CrossRef]
- Tahmassebi, A.; Gandomi, A.H.; Fong, S.; Meyer-Baese, A.; Foo, S.Y. Multi-stage optimization of a deep model: A case study on ground motion modeling. PLoS ONE 2018, 13, e0203829. [Google Scholar] [CrossRef]
- Kingma, D.P.; Lei Ba, J. Adam: A method for stochastic optimization. arXiv 2017. [Google Scholar] [CrossRef]
- Kolmogorov, A.N. The local structure of turbulence in incompressible viscous fluid for very large Reynolds numbers. Proc. R. Soc. A Math. Phys. Eng. Sci. 1890, 434, 9–13. [Google Scholar]
- Taylor, G.I. The formation of a blast wave by a very intense explosion I. Theoretical discussion. Proc. R. Soc. London. Ser. A Math. Phys. Sci. 1950, 201, 159–174. [Google Scholar] [CrossRef]
- Hu, P.; Chang, C.-K. Research on optimize application of Buckingham Pi theorem to wind tunnel test and its aerodynamic simulation verification. J. Phys. Conf. Ser. 2020, 1507, 082047. [Google Scholar] [CrossRef]
- Lawal, A.I.; Olajuyi, S.I.; Kwon, S.; Onifade, M. A comparative application of the Buckingham π (pi) theorem, white-box ANN, gene expression programming, and multilinear regression approaches for blast-induced ground vibration prediction. Arab. J. Geosci. 2021, 14, 1–15. [Google Scholar] [CrossRef]
- Singh, J.; Singh, R.; Singh, H. Surface roughness prediction using Buckingham’s Pi-theorem for SS-316L hip implant prepared as rapid investment casting. Mater. Today Proc. 2018, 5, 18080–18088. [Google Scholar] [CrossRef]
- Arabi, M.; Faezipour, M.; Layeghi, M.; Enayati, A.; Zahed, R. Prediction of bending strength and stiffness strength of particleboard based on structural parameters by Buckingham’s p-theorem. J. Indian Acad. Wood Sci. 2011, 7, 65–70. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Wine Identity | NZ Region | Vintage | Price Point | Vine Yield | Production Philosophy | Closure | RRP NZD |
|---|---|---|---|---|---|---|---|
| WAR16 | Wairarapa | 2016 | Premium | Low | BioGro cert | SC | 82 |
| WPP16 | Wairarapa | 2016 | Commercial | Mod | conventional | SC | 26 |
| WPP13 | Wairarapa | 2013 | Commercial | Mod | conventional | SC | 26 |
| WE16 | Wairarapa | 2016 | Premium | Low | Organic in transition | SC | 52 |
| WCR16 | Wairarapa | 2016 | Premium | Low | conventional | SC | 140 |
| MCH16 | Marlb | 2016 | Premium | Low | BioGro cert | Cork | 44 |
| MPR16 | Marlb | 2016 | Commercial | High | conventional | SC | 15 |
| MG16 | Marlb | 2016 | Premium | Low | BioGro cert | SC | 63 |
| MG13 | Marlb | 2013 | Premium | Low | BioGro cert | SC | 63 |
| OMD16 | Central Otago | 2016 | Commercial | High | conventional | SC | 28 |
| OFRCP16 | Central Otago | 2016 | Premium | Low | Demeter cert | SC | 76 |
| OFRB316 | Central Otago | 2016 | Premium | Low | Demeter cert | SC | 102 |
| OQR16 | Central Otago | 2016 | Premium | Low | BioGro and Demeter cert | SC | 79 |
| OQR13 | Central Otago | 2013 | Premium | Low | BioGro and Demeter cert | SC | 79 |
| NN16 | Nelson | 2016 | Premium | Low | BioGro cert | SC | 67 |
| NS16 | Nelson | 2016 | Commercial | High | conventional | SC | 13 |
| CPB16 | Nth Canterbury | 2016 | Commercial | Mod | conventional | SC | 22 |
| CG16 | Nth Canterbury | 2016 | Premium | Low | organic in transition | SC | 43 |
| Descriptors Experiment 1 | Anchors | Descriptors Experiment 2 | Anchors |
|---|---|---|---|
| Attractive fruit aromatics | Low–Intense | Overall quality | Poor–Good |
| Attractive floral aromatics | Low–Intense | Softness/gentleness/suppleness | Low–Intense |
| Earthy/mushroom notes | Low–Intense | Smoothness/silky/velvety | Low–Intense |
| Reductive notes | Low–Intense | Weight/heaviness/density | Low–Intense |
| Bitterness | Low–Intense | Volume/fullness/roundness | Low–Intense |
| Astringency | Low–Intense | Viscosity/mouth-coating/oiliness | Low–Intense |
| Sweetness | Low–Intense | Bitterness | Low–Intense |
| Harshness of tannins | Low–Intense | Dry/puckering | Low–Intense |
| Green/herbaceous notes | Low–Intense | Dusty | Low–Intense |
| Overall quality | Poor–Good | Coarse/grainy/rough | Low–Intense |
| Balanced acidity | Poor–Good | Harsh tannins/aggressive | Low–Intense |
| Elegance/precision | Poor–Good | Astringency | Low–Intense |
| Softness/silkiness | Poor–Good | Thin/watery | Low–Intense |
| Freshness | Poor–Good | Burning sensation/hot | Low–Intense |
| Expressiveness | Poor–Good | Sourness/acidity | Low–Intense |
| Fruit ripeness | Poor–Good | Overall body | Poor–Good |
| Oak influence | Poor–Good | Pinot noir varietal typicality | Poor–Good |
| Concentration in mouth | Poor–Good | ||
| Overall structure | Poor–Good | ||
| Pinot noir varietal typicality | Poor–Good |
| Essential Modulators | Chemical Compounds |
|---|---|
| Fruity (π1) | Ethyl octanoate |
| Ethyl butanoate | |
| Ethyl hexanoate | |
| Herbal (π2) | Hexan-1-ol |
| (E)-Hex-3-en-1-ol | |
| Heptan-1-ol | |
| Floral (π3) | (E)-1-(2,6,6-Trimethylcyclohexa-1,3-dien-1-yl) but-2-en-1-one (Beta) |
| 2-Phenylethan-1-ol | |
| 3,7-Dimethylocta-1,6-dien-3-ol (linalool) | |
| Oak and Woody (π4) | 4-Ethyl-2-methoxyphenol (eugenol) |
| Benzaldehyde | |
| 2-Methoxyphenol (guaiacol) | |
| Others (π5) | Phenol |
| 4-Ethyl-2-methoxyphenol (eugenol) |
| List of Chemical Compounds | |
|---|---|
| Ethyl acetate | (E)-Hex-3-en-1-ol |
| 3-Methylbutyl acetate | Ethyl heptanoate |
| Ethyl pentanoate | (E)-Hex-2-en-1-ol |
| Ethyl 2-hydroxypropanoate | Octan-1-ol |
| (Z)-Hex-3-en-1-ol | (E)-1-(2,6,6-Trimethylcyclohexa-1,3-dien-1-yl) but-2-en-1-one |
| Ethyl octanoate | 2-Methoxyphenol |
| Benzaldehyde | (E)-4-(2,6,6-Trimethylcyclohexen-1-yl) but-3-en-2-one |
| Ethyl decanoate | 2-Methylpropanoic acid |
| (2E)-3,7-Dimethylocta-2,6-dien-1-ol | Butanoic acid |
| (E)-4-(2,6,6-Trimethylcyclohex-2-en-1-yl) but-3-en-2-one | Ethyl 2-methylpropanoate |
| Acetic acid | Hexyl Acetate |
| 2-Methylbutanoic acid | Heptan-1-ol |
| Ethyl butanoate | 2-Methyl butyl acetate |
| Ethyl 3-methylbutanoate | 3,7-Dimethylocta-1,6-dien-3-ol |
| 3-Methylbutan-1-ol | 3,7-Dimethyloct-6-en-1-ol |
| 2-Phenylethan-1-ol | methyl-2-aminobenzoate |
| 2-Methylpropyl acetate | 2-Methoxy-4-prop-2-enylphenol |
| Ethyl 2-methylbutanoate | Methyl-2-aminobenzoate |
| (2Z)-3,7-Dimethylocta-2,6-dien-1-ol | 3-Methylbutanoic acid |
| 2-Phenethyl acetate | Hexanoic acid |
| Phenol | Octanoic acid |
| 4-Ethyl-2-methoxyphenol | 2-Methylpropan-1-ol |
| Ethyl (E)-3-phenylprop-2-enoate | Ethyl hexanoate |
| Hexan-1-ol | |
| Parameters | Data1 | Data2 | Data3 |
|---|---|---|---|
| Input dimension | 14 | 6 | 6 |
| Layers | 5 | 5 | 5 |
| Node (layer1)/Activation | 64/RELU | 64/RELU | 128/RELU |
| Node (layer2)/Activation | 64/ELU | 64/RELU | 128/ELU |
| Node (layer3)/Activation | 32/ELU | 64/RELU | 64/ELU |
| Node (layer4)/Activation | 16/ELU | 8/RELU | 64/ELU |
| Node (layer 5) | 1 | 1 | 1 |
| Optimiser | RMSprop | Adam | Adam |
| Epoch with early stopping | 2000 | 2000 | 2000 |
| Loss metric | MAE | MAE | MAE |
| Wine ID Set A | Perceived Wine Quality | Wine Quality Proxy Indices (Mathematical Model) | ||||
|---|---|---|---|---|---|---|
| α = 0.8 n = 1.0 | α = 0.7 n = 1.0 | α = 0.8 n = 0.8 | α = 0.75 n = 1.0 | α = 0.75 n = 0.9 | ||
| WAR16 | 5.02 | 5.848 | 4.521 | 4.678 | 5.154 | 4.639 |
| MCH16 | 5.7 | 3.688 | 3.333 | 2.950 | 3.520 | 3.168 |
| WCR16 | 6.55 | 6.849 | 5.418 | 5.479 | 6.101 | 5.491 |
| WE16 | 6.09 | 6.271 | 5.051 | 5.017 | 5.636 | 5.072 |
| OFRB316 | 6.35 | 6.428 | 4.997 | 5.142 | 5.678 | 5.110 |
| OFRCP16 | 6.52 | 6.576 | 5.077 | 5.261 | 5.790 | 5.211 |
| MG16 | 5.52 | 6.203 | 5.039 | 4.962 | 5.601 | 5.041 |
| MG13 | 5.98 | 5.813 | 4.748 | 4.651 | 5.263 | 4.736 |
| CG16 | 5.89 | 6.768 | 5.346 | 5.415 | 6.025 | 5.423 |
| OMD16 | 6.07 | 6.920 | 5.471 | 5.536 | 6.163 | 5.546 |
| NN16 | 6.02 | 6.768 | 5.360 | 5.415 | 6.032 | 5.429 |
| WPP16 | 6.23 | 5.327 | 4.278 | 4.262 | 4.782 | 4.304 |
| WPP13 | 5.43 | 4.863 | 4.071 | 3.890 | 4.459 | 4.013 |
| CPB16 | 6.34 | 3.554 | 3.267 | 2.843 | 3.421 | 3.079 |
| MPR16 | 4.72 | 5.257 | 4.353 | 4.205 | 4.792 | 4.313 |
| OQR16 | 5.72 | 6.790 | 5.398 | 5.432 | 6.065 | 5.458 |
| OQR13 | 5.3 | 6.730 | 5.322 | 5.384 | 5.995 | 5.396 |
| NS16 | 4.82 | 6.742 | 5.242 | 5.394 | 5.954 | 5.359 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tiwari, P.; Bhardwaj, P.; Somin, S.; Parr, W.V.; Harrison, R.; Kulasiri, D. Understanding Quality of Pinot Noir Wine: Can Modelling and Machine Learning Pave the Way? Foods 2022, 11, 3072. https://doi.org/10.3390/foods11193072
Tiwari P, Bhardwaj P, Somin S, Parr WV, Harrison R, Kulasiri D. Understanding Quality of Pinot Noir Wine: Can Modelling and Machine Learning Pave the Way? Foods. 2022; 11(19):3072. https://doi.org/10.3390/foods11193072
Chicago/Turabian StyleTiwari, Parul, Piyush Bhardwaj, Sarawoot Somin, Wendy V. Parr, Roland Harrison, and Don Kulasiri. 2022. "Understanding Quality of Pinot Noir Wine: Can Modelling and Machine Learning Pave the Way?" Foods 11, no. 19: 3072. https://doi.org/10.3390/foods11193072
APA StyleTiwari, P., Bhardwaj, P., Somin, S., Parr, W. V., Harrison, R., & Kulasiri, D. (2022). Understanding Quality of Pinot Noir Wine: Can Modelling and Machine Learning Pave the Way? Foods, 11(19), 3072. https://doi.org/10.3390/foods11193072