SCDeep: Single-Channel Depth Encoding for 3D-Range Geometry Compression Utilizing Deep-Learning Techniques

 , , and
, , and
Abstract
:1. Introduction
2. Principle
2.1. Phase-Shifting-Range Scanning Techniques
2.2. Image-Based Range Geometry Compression
2.3. Single-Channel Depth Encoding
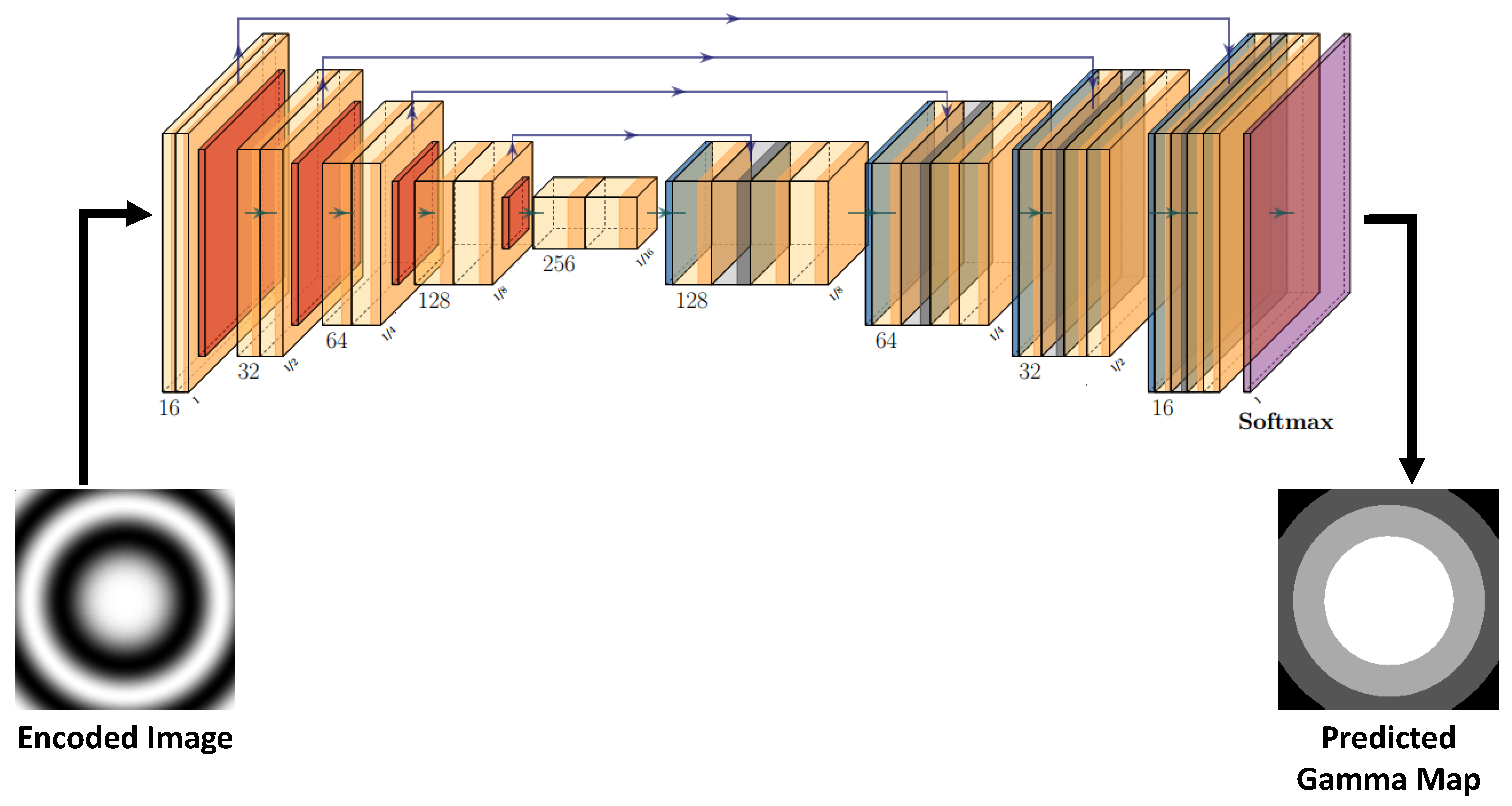
2.4. Single-Channel Depth Decoding with Semantic Segmentation
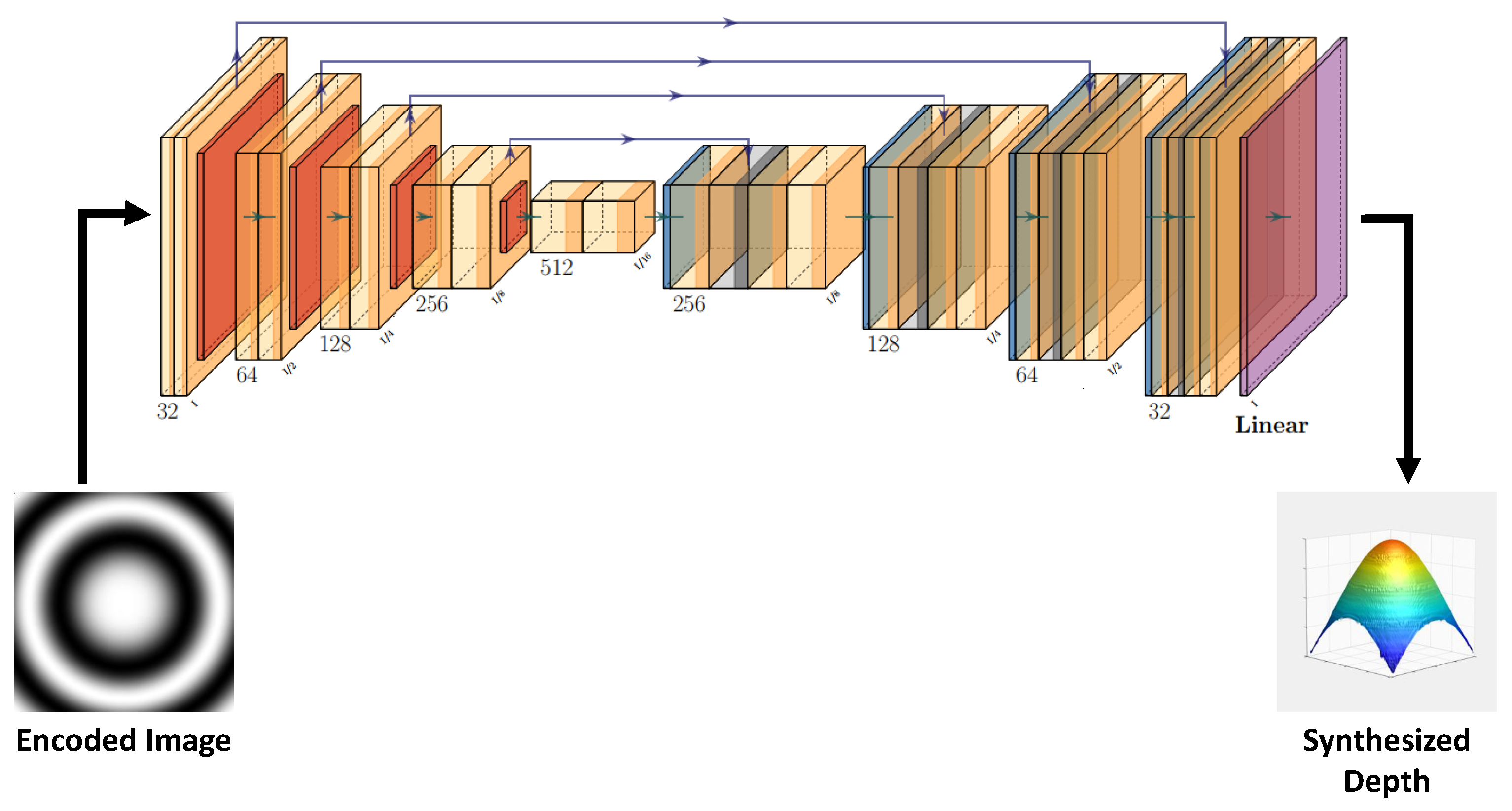
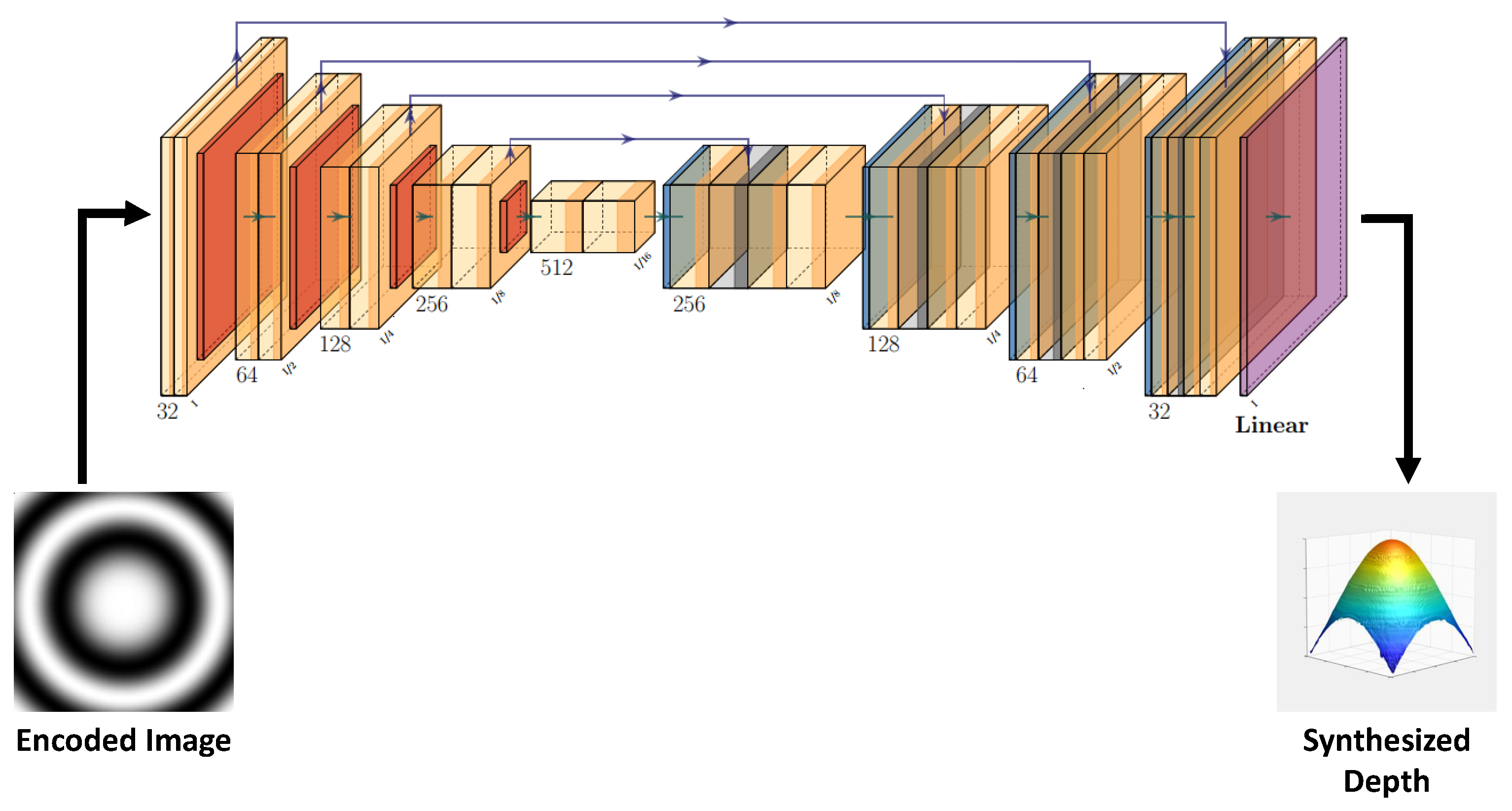
2.5. Single-Channel Depth Decoding with End-to-End Synthesis of Depth
3. Experimental Results
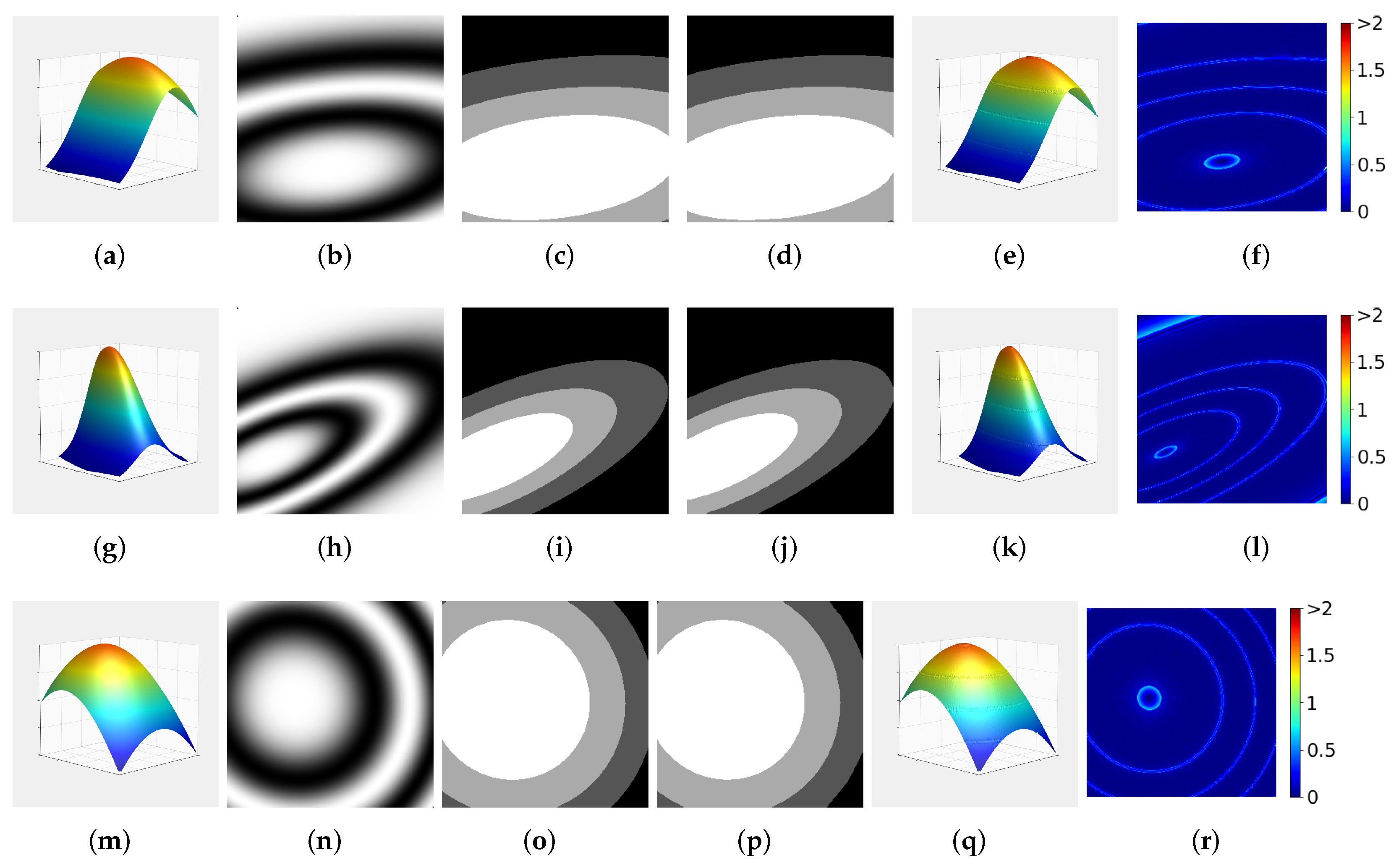
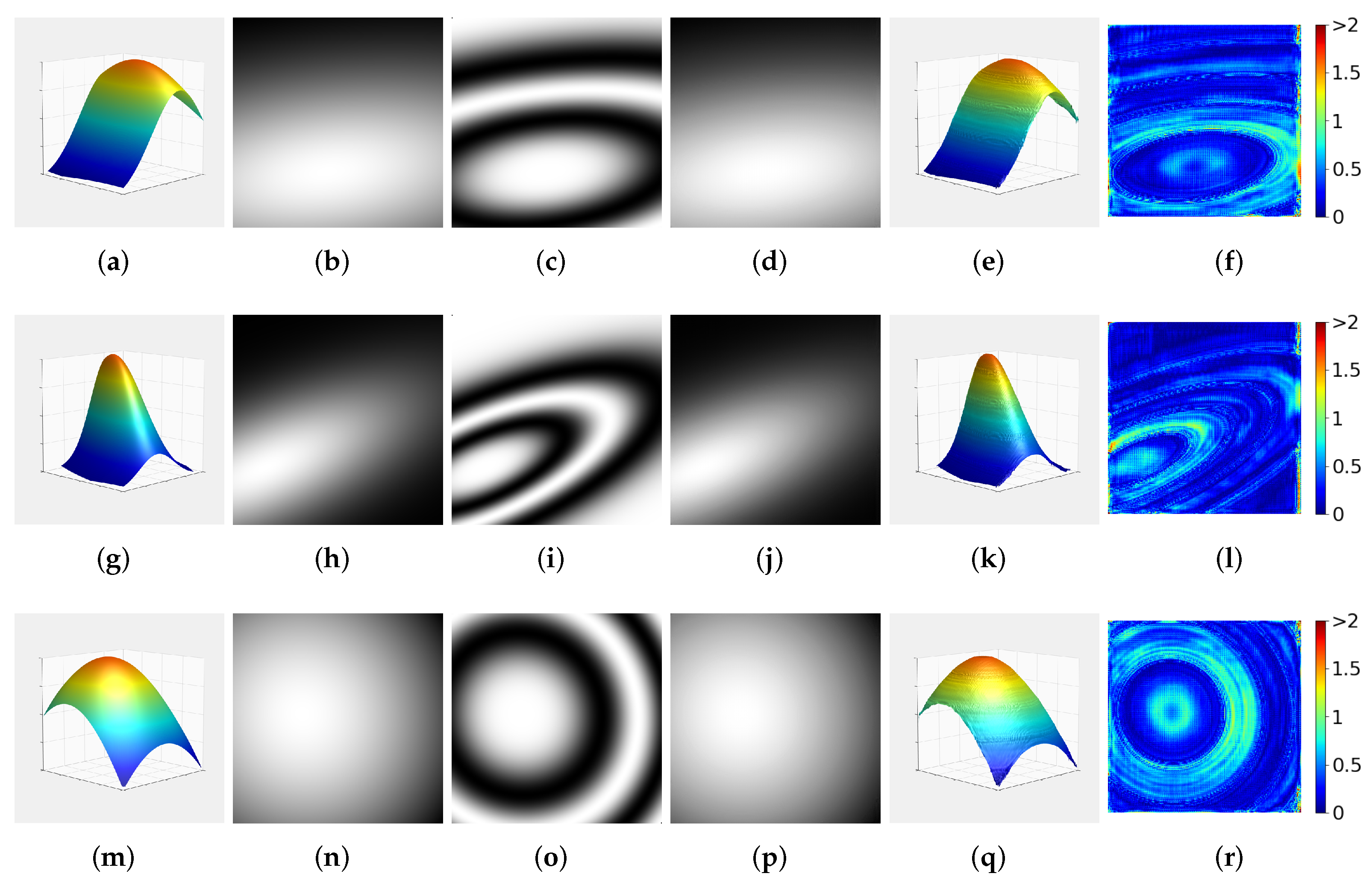
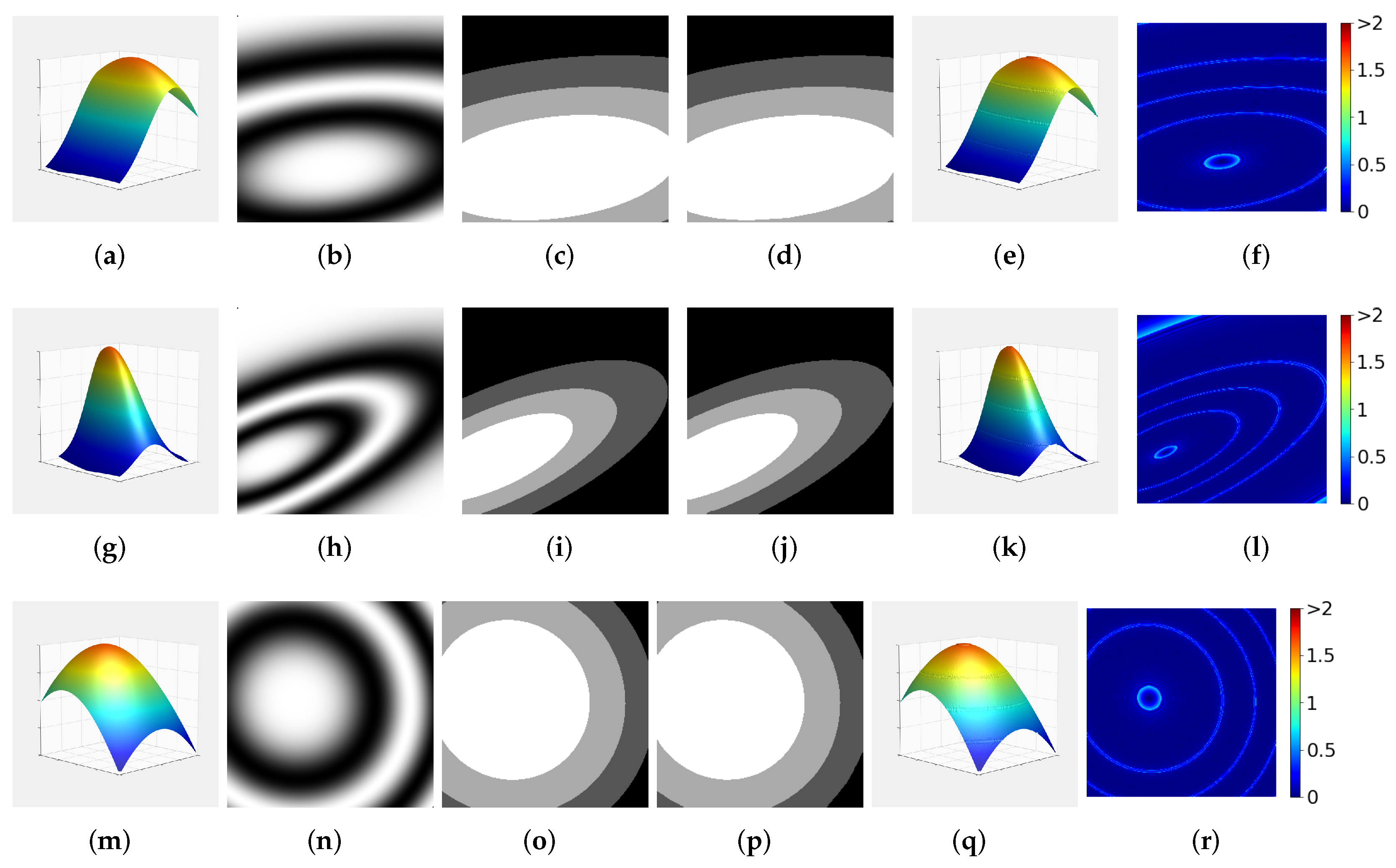
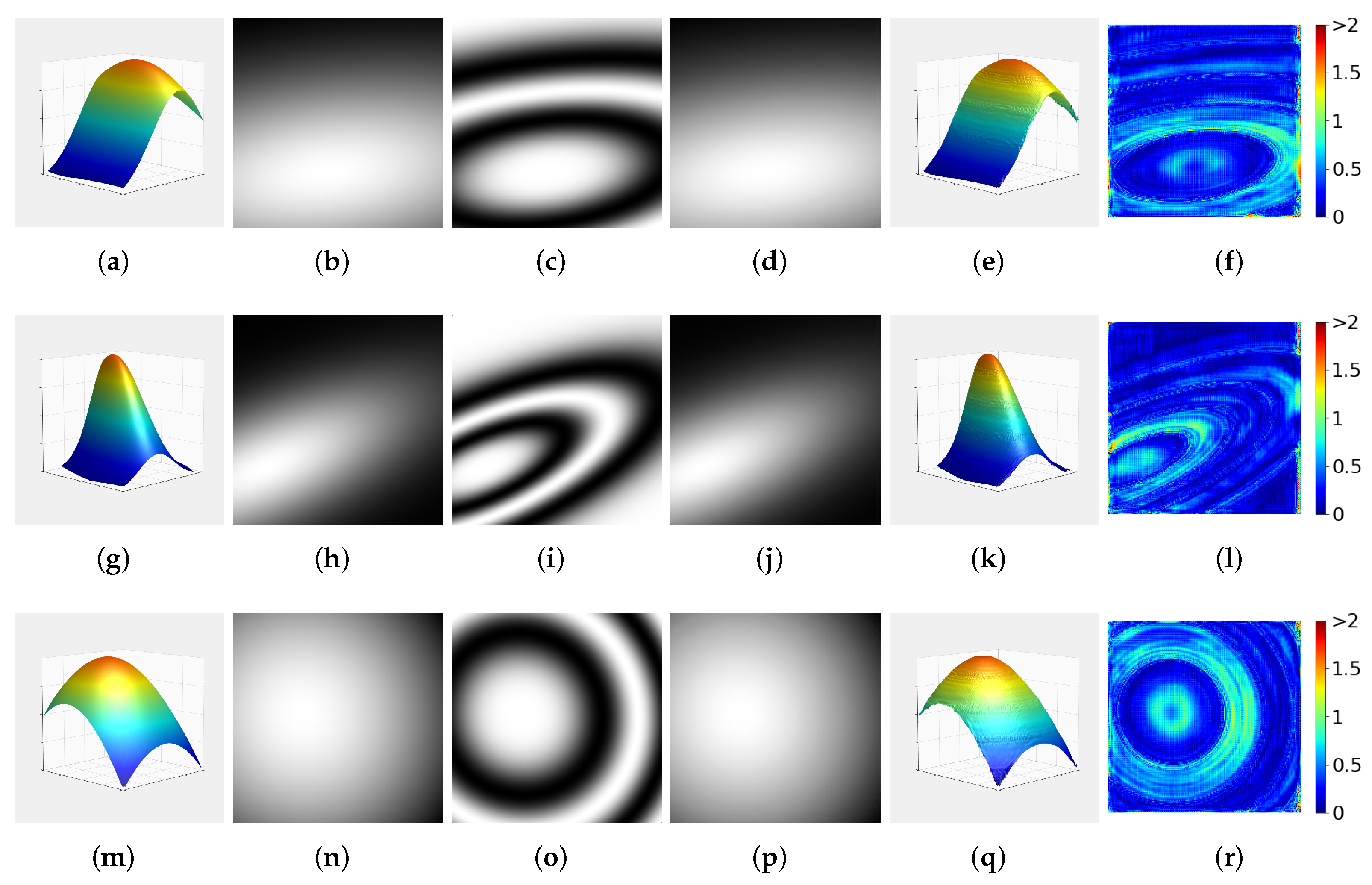
3.1. Random Gaussian Surfaces
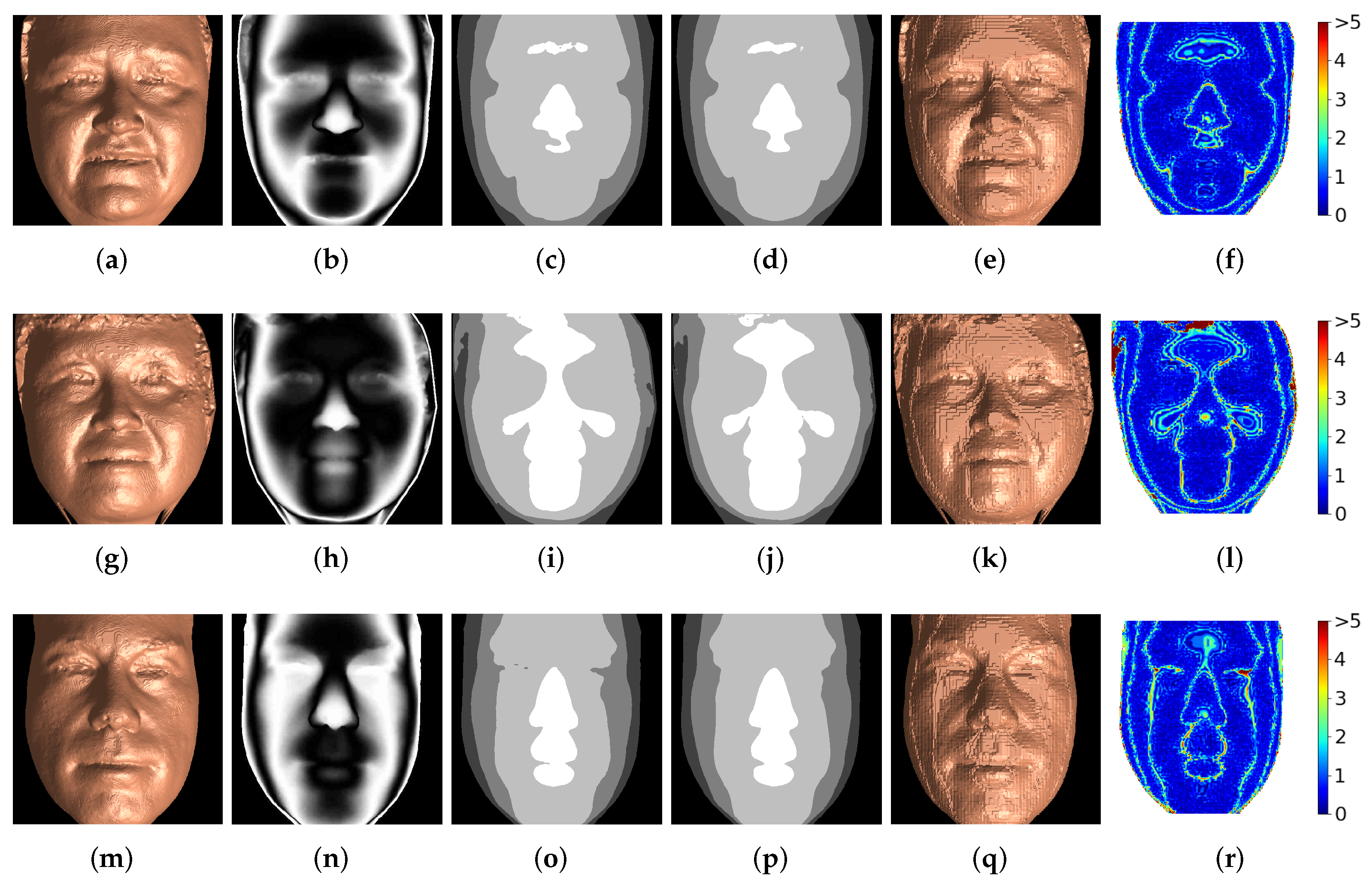
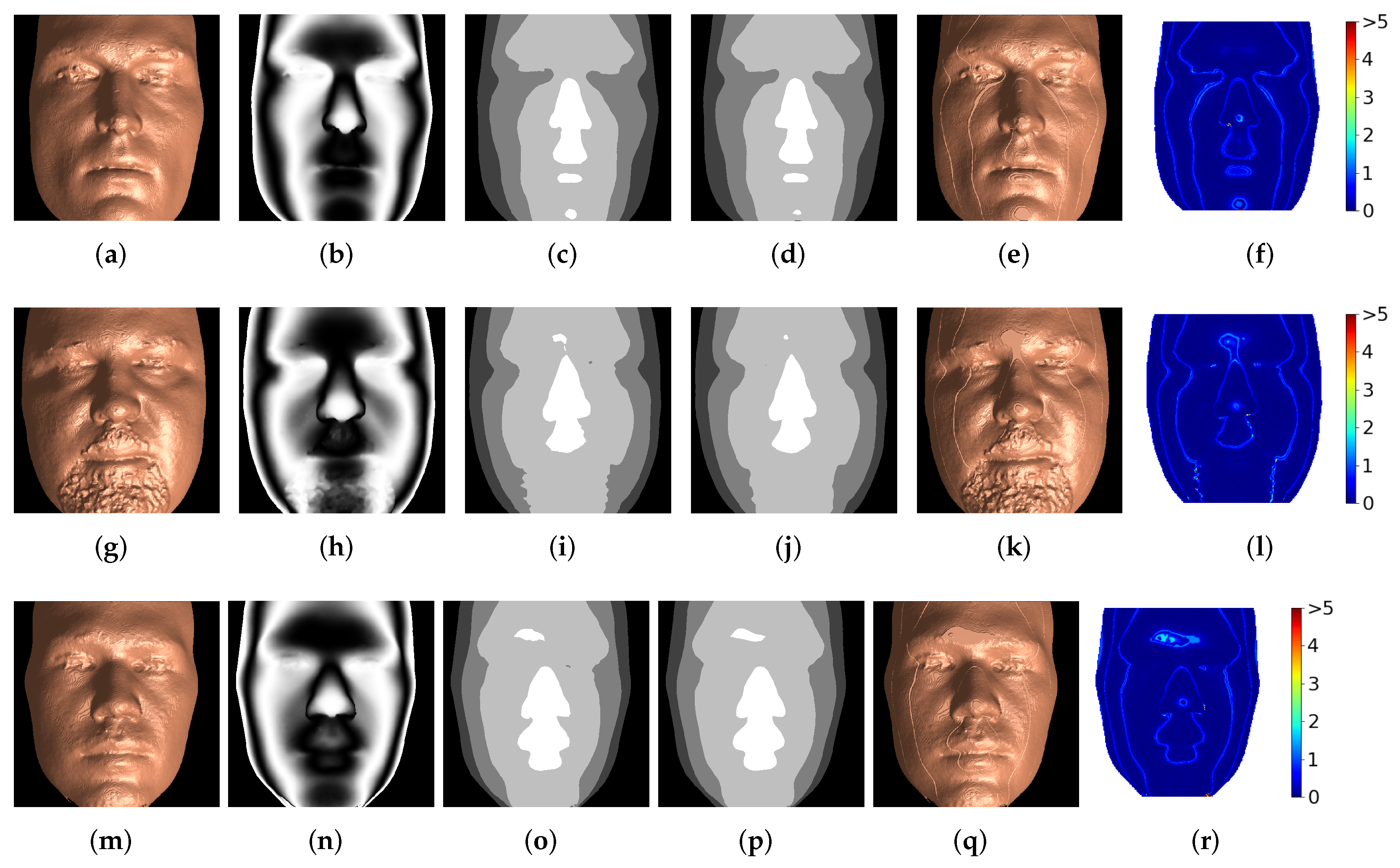
3.2. Texas 3D Face Recognition Database
4. Discussion
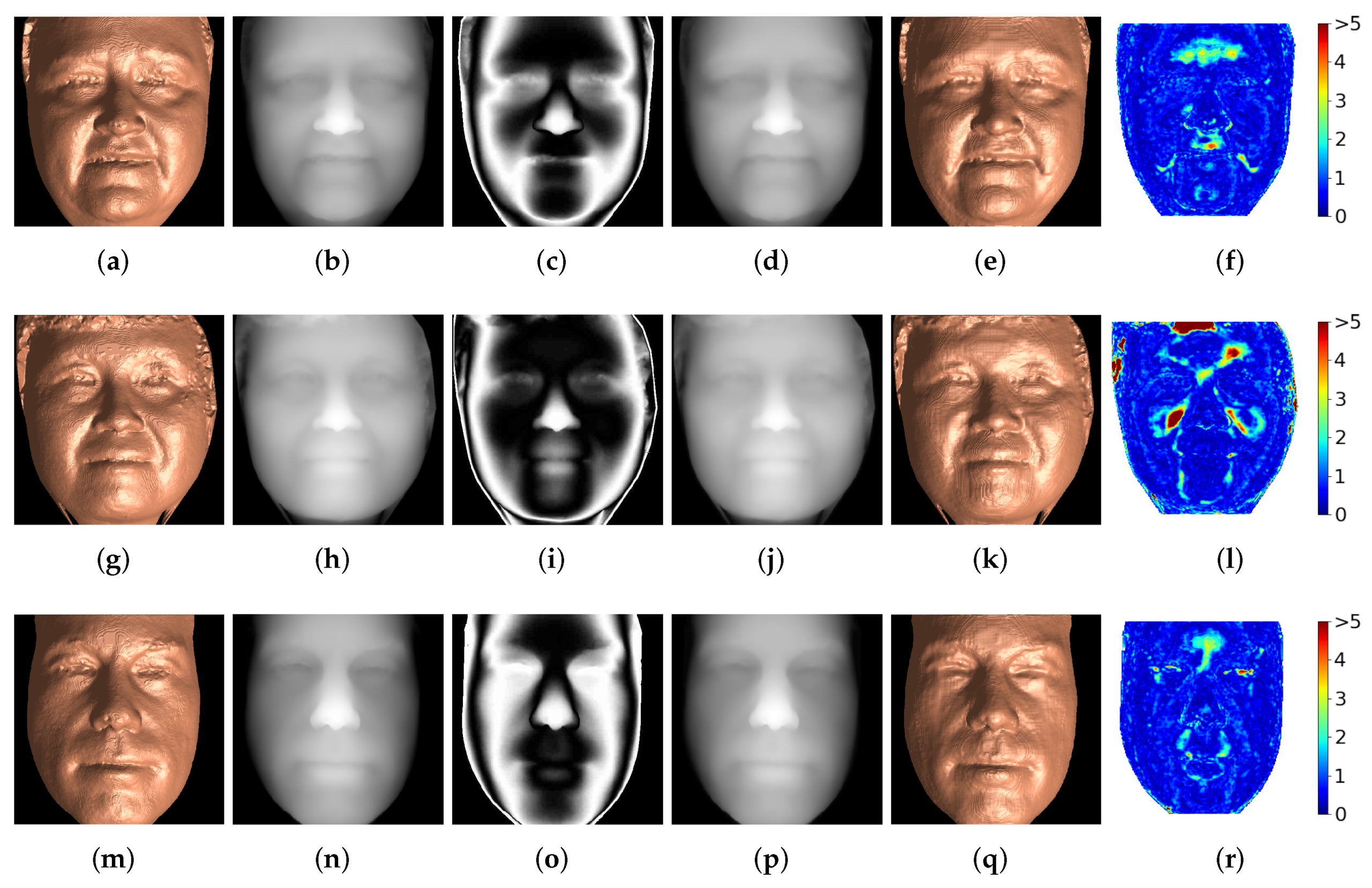
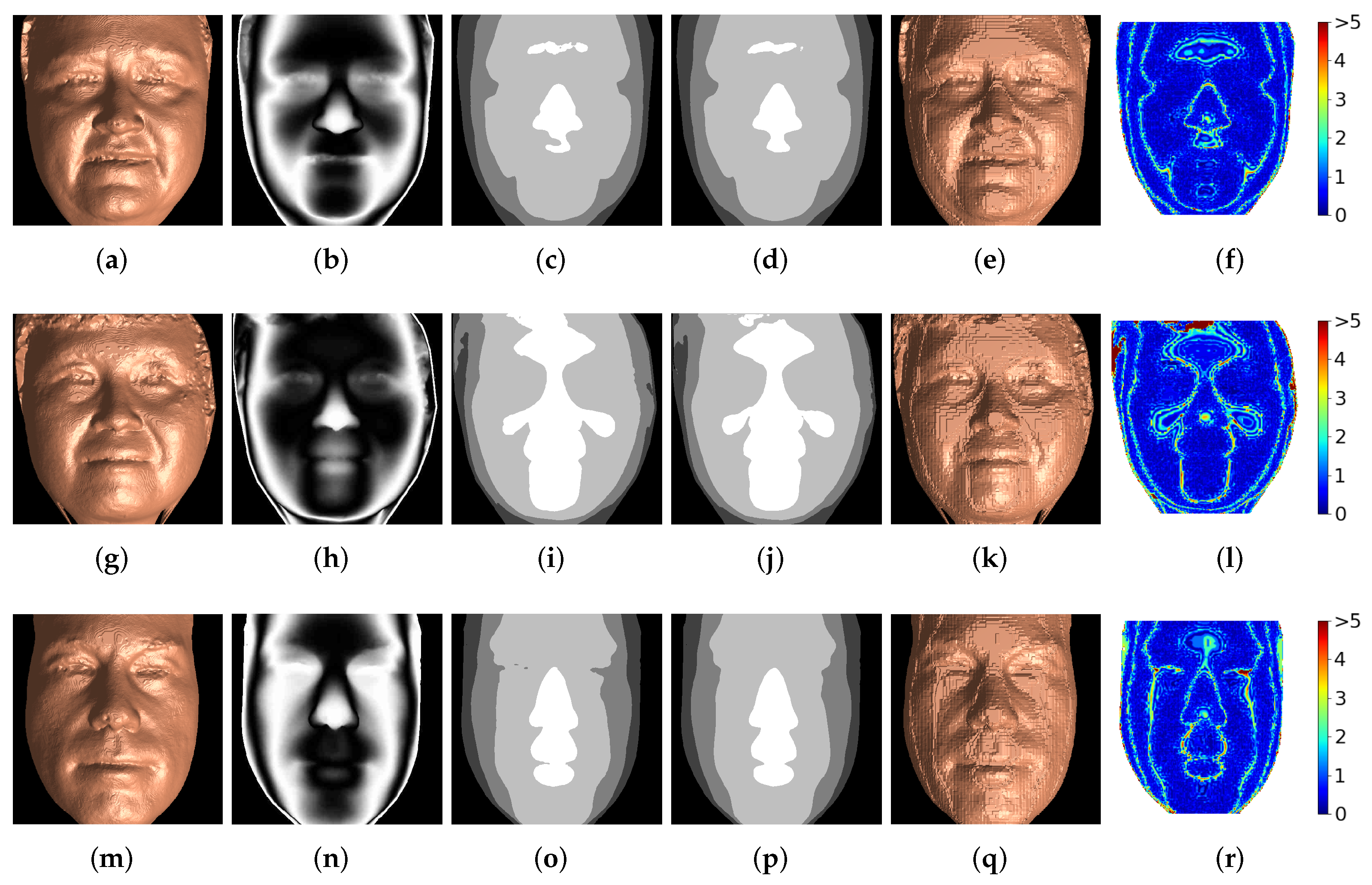
- Generalizability.Section 3 illustrates the performance of both the segmentation and synthesis approaches to the recovery of depth information from a single-channel encoding. However, it is also important to evaluate the generalizability of the proposed methods to 3D-range scans from alternate datasets. This is demonstrated in Figure 10. Figure 10a is a 3D rendering of depth data from the University of York’s 3D Face Dataset [27]. In this case, the data is a 3D scan of a human face that has been cropped and reshaped to pixels in order to match the dimensions expected by the trained segmentation and synthesis models. Figure 10b is the corresponding 2D depth map, normalized between zero and 255 mm after removing unconnected components and being passed through a Gaussian filter () in order to ensure floating-point precision. Figure 10c is the sinusoidally encoded depth map, generated according to Equation (9) and stored in the PNG image format. Figure 10d is a 3D rendering of the segmentation method’s output, trained using the Texas 3D Face Recognition Database [24,25,26], when the sinusoidal encoding in (c) is used as input. Figure 10e is a 3D rendering of the synthesis model’s output, trained using the Texas 3D Face Recognition Database [24,25,26], when the sinusoidal encoding in (c) is used as input. It can be seen that the depth recovered by both segmentation and synthesis are reasonably faithful to the original 3D-range data, especially when artifacts near the surface edges are ignored. This shows that the segmentation and synthesis models are reasonably generalizable to similar data from alternate datasets; however, it was necessary to carefully crop this alternate input in order to match the approximate structure and alignment of the data used to train the models. It is important to note that, while these models may perform adequately for one particular type of data, they do not necessarily have the ability to generalize and perform well on any given encoding of 3D-range data. For instance, all results presented thus far have shown that depth data can be recovered from the segmentation and synthesis models trained with encodings of a particular class of depth data: Gaussian random surfaces were recovered from their encodings with models trained on encodings of Gaussian random surfaces, and 3D faces were recovered from their encodings with models trained on encodings of 3D faces. If the Gaussian-trained models were tasked with recovering depth from encodings of 3D faces, for example, they may have trouble as deformations in the encodings caused by facial structures (i.e., eyes, noses, mouths) were not seen within the training data. Figure 10f,g show the models’ limited ability to generalize outside of its training set. In these examples, an encoding of the face data in Figure 10a was decoded using the segmentation and synthesis models trained on random Gaussian surfaces. It is clear that both approaches fail to reconstruct the proper shape of the face. This is expected, as each Gaussian-trained model (segmentation and synthesis) was never provided information on how to reconstruct facial encodings (i.e., they only know how to aid in recovering the depth of Gaussian surface encodings). Further, this indicates that each model is not simply learning how to perform an operation analogous to phase unwrapping, but that the models are learning and relying on the underlying structure of the 3D shape represented within the encodings. One naturally imagines a sophisticated model that can successfully recover depth of facial encodings, random Gaussian encodings, and surfaces in between. Achieving this level of broad generalizability is challenging; however, useful avenues of future work to help ensure that trained models are more generalizable include: (1) training with more robust datasets that contain various subject categories with both single continuous and multiple disjoint surfaces; (2) data augmentation; and (3) automated dataset generation via virtual environments [20].
- Encoding Frequency. Throughout this manuscript, depth information was successfully recovered—with a high degree of accuracy—from within 8-bit grayscale images. However, the performance of the proposed segmentation and synthesis methods was only evaluated for a relatively low depth range and number of encoding periods (). It is important to note that, as the number of encoding periods increases, the complexity of the problem that must be solved by the segmentation approach also increases. This is because the number of regions that must be correctly segmented and labeled in order to generate the gamma map, , increases proportionally to the number of encoding periods. This proportional increase in segmentation complexity will result in a higher rate of error and a subsequent loss in subjective visual fidelity, particularly at segmentation boundaries. Liang et al. proposed a method that mitigates this problem of increased semantic segmentation complexity associated with a higher number of encoding periods for phase unwrapping in DFP systems [28]. This was performed through the use of two deep-learning networks in series. The first network generates a segmented and labeled image associated with the features of the captured fringes; the second network uses this semantic segmentation as input and outputs correctly unwrapped phase images. Similar techniques could potentially be applied to phase unwrapping for the 3D-range geometry compression of either multiple disjoint or single continuous surfaces, although the authors of this manuscript leave it as an avenue for future work.
- Error Correction. The numerical performance of the segmentation and synthesis approaches discussed in this manuscript are nearly identical when a lossless image format such as PNG is used to store the encoded output. However, the segmentation approach has reconstruction error that, in general, manifests as rigid, ring-like artifacts that occur at boundaries between the labeled regions segmented by the model. The synthesis approach has an error that occurs with less structure, and is more evenly distributed throughout the 3D scene. One method of potentially reducing the impact of the segmentation errors on subjective visual fidelity is to perform error correction using the output of both the segmentation and synthesis models. For example, an edge-detection algorithm could be applied to the gamma map generated by the segmentation approach; this would correspond to regions of assumed error, since most of the segmentation error is associated with these boundaries. Next, the depth information decoded using the segmentation approach could have its regions of assumed error replaced with the corresponding pixels from the synthesized depth information. Finley and Bell experimentally demonstrated a conceptually similar method of error correction using heavily filtered data to replace regions of assumed error [14]. Additionally, deep-learning techniques have been recently applied to the classification and correction of errors in 3D representations [29] and are an exciting future avenue for potential error-correction frameworks.
- Potential Applications. This manuscript illustrated two novel methods for the recovery of floating-point depth information from only a single 8-bit image channel. Both of these methods utilize deep-learning techniques in order to decode the depth information and are able to achieve above 99% RMS reconstruction accuracy even when the depth encoding is stored in the JPG-20 image format. This allows for very large compression ratios to be achieved when compared to the original floating-point depth information. However, since these two methods of 3D-range geometry compression are enabled through the use of deep-learning networks, they are constrained to use cases where a large quantity of similarly structured depth data is available for training. Additionally, since the priority of these compression methods is small file sizes instead of high fidelity, they are potentially suitable for applications where some small degree of measurement error or reduction in visual fidelity can be tolerated. Some example applications that typically meet these requirements are real-time 3D telepresence and 3D facial recognition. However, the ethical ramifications of potential misrepresentation due to decoding errors must also be considered when applying deep-learning techniques to applications such as facial recognition. Given the potential uncertainty and abstract nature of the results produced by deep-learning models, it is often challenging to determine—from the output data alone—how representative of the original data the output may be.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, S. High-speed 3D shape measurement with structured light methods: A review. Opt. Lasers Eng. 2018, 106, 119–131. [Google Scholar] [CrossRef]
- Maglo, A.; Lavoué, G.; Dupont, F.; Hudelot, C. 3D Mesh Compression: Survey, Comparisons, and Emerging Trends. ACM Comput. Surv. 2015, 47, 1–41. [Google Scholar] [CrossRef]
- Orts-Escolano, S.; Rhemann, C.; Fanello, S.; Chang, W.; Kowdle, A.; Degtyarev, Y.; Kim, D.; Davidson, P.L.; Khamis, S.; Dou, M.; et al. Holoportation: Virtual 3d teleportation in real-time. In Proceedings of the 29th Annual Symposium on User Interface Software and Technology, Tokyo, Japan, 16–19 October 2016; pp. 741–754. [Google Scholar]
- Guo, K.; Lincoln, P.; Davidson, P.; Busch, J.; Yu, X.; Whalen, M.; Harvey, G.; Orts-Escolano, S.; Pandey, R.; Dourgarian, J.; et al. The relightables: Volumetric performance capture of humans with realistic relighting. ACM Trans. Graph. TOG 2019, 38, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Gu, X.; Gortler, S.J.; Hoppe, H. Geometry images. In Proceedings of the 29th Annual Conference on Computer Graphics and Interactive Techniques, San Antonio, TX, USA, 23–26 July 2002; pp. 355–361. [Google Scholar]
- Gu, X.; Zhang, S.; Huang, P.; Zhang, L.; Yau, S.T.; Martin, R. Holoimages. In Proceedings of the 2006 ACM Symposium on Solid and Physical Modeling, Cardiff, UK, 6–8 June 2006; pp. 129–138. [Google Scholar]
- Karpinsky, N.; Zhang, S. Composite phase-shifting algorithm for three-dimensional shape compression. Opt. Eng. 2010, 49, 063604. [Google Scholar] [CrossRef]
- Zhang, S. Three-dimensional range data compression using computer graphics rendering pipeline. Appl. Opt. 2012, 51, 4058–4064. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ou, P.; Zhang, S. Natural method for three-dimensional range data compression. Appl. Opt. 2013, 52, 1857–1863. [Google Scholar] [CrossRef] [PubMed]
- Bell, T.; Zhang, S. Multiwavelength depth encoding method for 3D range geometry compression. Appl. Opt. 2015, 54, 10684–10691. [Google Scholar] [CrossRef] [PubMed]
- Hou, Z.; Su, X.; Zhang, Q. Virtual structured-light coding for three-dimensional shape data compression. Opt. Lasers Eng. 2012, 50, 844–849. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, L.; Yang, S.; Ji, F. Two-channel high-accuracy Holoimage technique for three-dimensional data compression. Opt. Lasers Eng. 2016, 85, 48–52. [Google Scholar] [CrossRef]
- Bell, T.; Vlahov, B.; Allebach, J.P.; Zhang, S. Three-dimensional range geometry compression via phase encoding. Appl. Opt. 2017, 56, 9285–9292. [Google Scholar] [CrossRef] [PubMed]
- Finley, M.G.; Bell, T. Two-channel depth encoding for 3D range geometry compression. Appl. Opt. 2019, 58, 6882–6890. [Google Scholar] [CrossRef] [PubMed]
- Finley, M.G.; Bell, T. Two-channel 3D range geometry compression with primitive depth modification. Opt. Lasers Eng. 2022, 150, 106832. [Google Scholar] [CrossRef]
- Li, B.; Karpinsky, N.; Zhang, S. Novel calibration method for structured-light system with an out-of-focus projector. Appl. Opt. 2014, 53, 3415–3426. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S. Absolute phase retrieval methods for digital fringe projection profilometry: A review. Opt. Lasers Eng. 2018, 107, 28–37. [Google Scholar] [CrossRef]
- Yin, W.; Chen, Q.; Feng, S.; Tao, T.; Huang, L.; Trusiak, M.; Asundi, A.; Zuo, C. Temporal phase unwrapping using deep learning. Sci. Rep. 2019, 9, 20175. [Google Scholar] [CrossRef] [PubMed]
- Qian, J.; Feng, S.; Tao, T.; Hu, Y.; Li, Y.; Chen, Q.; Zuo, C. Deep-learning-enabled geometric constraints and phase unwrapping for single-shot absolute 3D shape measurement. Apl Photonics 2020, 5, 046105. [Google Scholar] [CrossRef]
- Zheng, Y.; Wang, S.; Li, Q.; Li, B. Fringe projection profilometry by conducting deep learning from its digital twin. Opt. Express 2020, 28, 36568–36583. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16); USENIX Association: Savannah, GA, USA, 2016; pp. 265–283. [Google Scholar]
- Gupta, S.; Markey, M.K.; Bovik, A.C. Anthropometric 3D face recognition. Int. J. Comput. Vis. 2010, 90, 331–349. [Google Scholar] [CrossRef]
- Gupta, S.; Castleman, K.R.; Markey, M.K.; Bovik, A.C. Texas 3D face recognition database. In Proceedings of the 2010 IEEE Southwest Symposium on Image Analysis & Interpretation (SSIAI), Austin, TX, USA, 23–25 May 2010; pp. 97–100. [Google Scholar]
- Gupta, S.; Castleman, K.R.; Markey, M.K.; Bovik, A.C. Texas 3D Face Recognition Database. 2020. Available online: http://live.ece.utexas.edu/research/texas3dfr/index.htm (accessed on 27 June 2020).
- Heseltine, T.; Pears, N.; Austin, J. Three-dimensional face recognition using combinations of surface feature map subspace components. Image Vis. Comput. 2008, 26, 382–396. [Google Scholar] [CrossRef]
- Liang, J.; Zhang, J.; Shao, J.; Song, B.; Yao, B.; Liang, R. Deep convolutional neural network phase unwrapping for fringe projection 3d imaging. Sensors 2020, 20, 3691. [Google Scholar] [CrossRef] [PubMed]
- Tanner, M.; Săftescu, S.; Bewley, A.; Newman, P. Meshed up: Learnt error correction in 3D reconstructions. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 3201–3206. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PNG | Original File Size (KB) | Mean File Size (KB) | Mean Compression Ratio | Mean RMSE (mm) | Mean RMS Reconstruction Accuracy |
|---|---|---|---|---|---|
| Segmentation | 256 | 12.55 | 20:1 | 0.294 | 99.70% |
| Synthesis | 0.539 | 99.46% |
| (a) | |||||
| PNG | Original File Size (KB) | Mean File Size (KB) | Mean Compression Ratio | Mean RMSE (mm) | Mean RMS Reconstruction Accuracy |
| Segmentation | 1024 | 65.46 | 15:1 | 1.182 | 99.53% |
| Synthesis | 0.996 | 99.60% | |||
| (b) | |||||
| JPG 20 | Original File Size (KB) | Mean File Size (KB) | Mean Compression Ratio | Mean RMSE (mm) | Mean RMS Reconstruction Accuracy |
| Segmentation | 1024 | 9.65 | 106:1 | 2.066 | 99.18% |
| Synthesis | 1.031 | 99.59% | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Finley, M.G.; Schwartz, B.S.; Nishimura, J.Y.; Kubicek, B.; Bell, T. SCDeep: Single-Channel Depth Encoding for 3D-Range Geometry Compression Utilizing Deep-Learning Techniques. Photonics 2022, 9, 449. https://doi.org/10.3390/photonics9070449
Finley MG, Schwartz BS, Nishimura JY, Kubicek B, Bell T. SCDeep: Single-Channel Depth Encoding for 3D-Range Geometry Compression Utilizing Deep-Learning Techniques. Photonics. 2022; 9(7):449. https://doi.org/10.3390/photonics9070449
Chicago/Turabian StyleFinley, Matthew G., Broderick S. Schwartz, Jacob Y. Nishimura, Bernice Kubicek, and Tyler Bell. 2022. "SCDeep: Single-Channel Depth Encoding for 3D-Range Geometry Compression Utilizing Deep-Learning Techniques" Photonics 9, no. 7: 449. https://doi.org/10.3390/photonics9070449
APA StyleFinley, M. G., Schwartz, B. S., Nishimura, J. Y., Kubicek, B., & Bell, T. (2022). SCDeep: Single-Channel Depth Encoding for 3D-Range Geometry Compression Utilizing Deep-Learning Techniques. Photonics, 9(7), 449. https://doi.org/10.3390/photonics9070449