Self-Supervised Monocular Depth Estimation Based on Channel Attention


Abstract
:1. Introduction
- (1)
- A new network architecture is proposed, which combines two channel attention modules in the depth prediction network to capture more contextual information of the scene and emphasize detailed features.
- (2)
- The spm is based on frequency channel attention to enhance the perception of the scene structure and obtain more feature information. The dem is based on the channel attention mechanism to efficiently fuse features at different scales and emphasize important details to obtain clearer depth estimates.
- (3)
- The superior performance of the proposed method is validated on the KITTI benchmark and the Make 3D dataset.
2. Related Work
2.1. Supervised Depth Estimation
2.2. Self-Supervised Monocular Depth Estimation
2.3. Self-Attention Mechanism
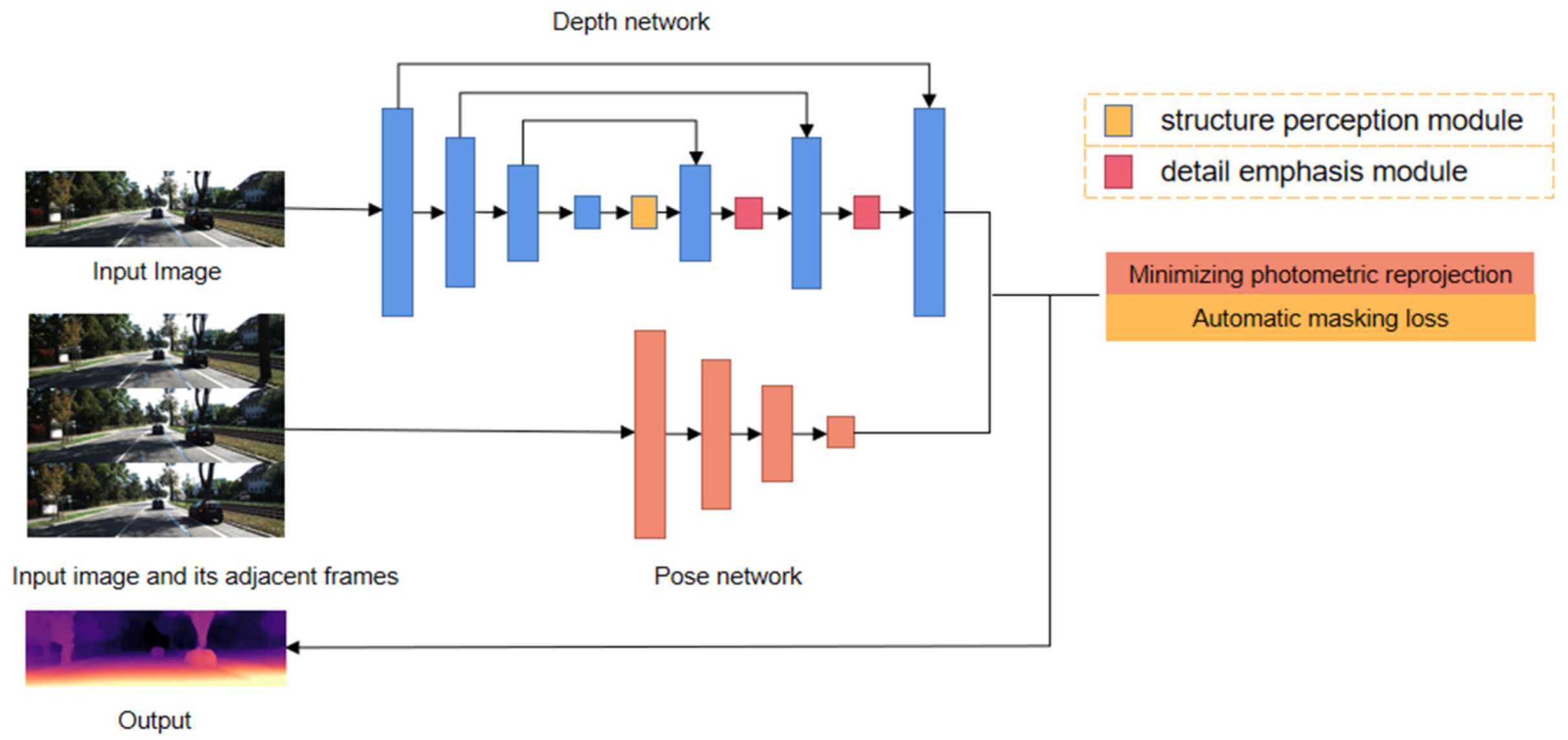
3. Self-Supervised Depth Estimation and Network Models
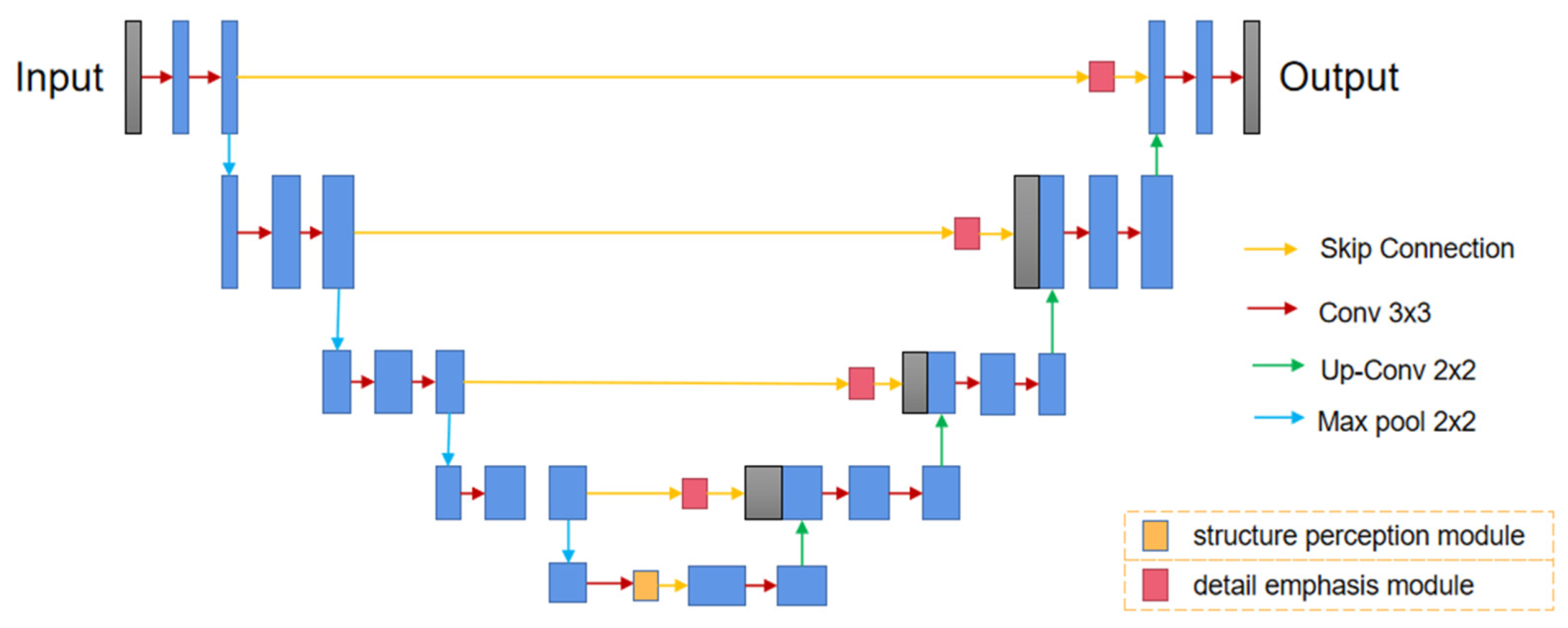
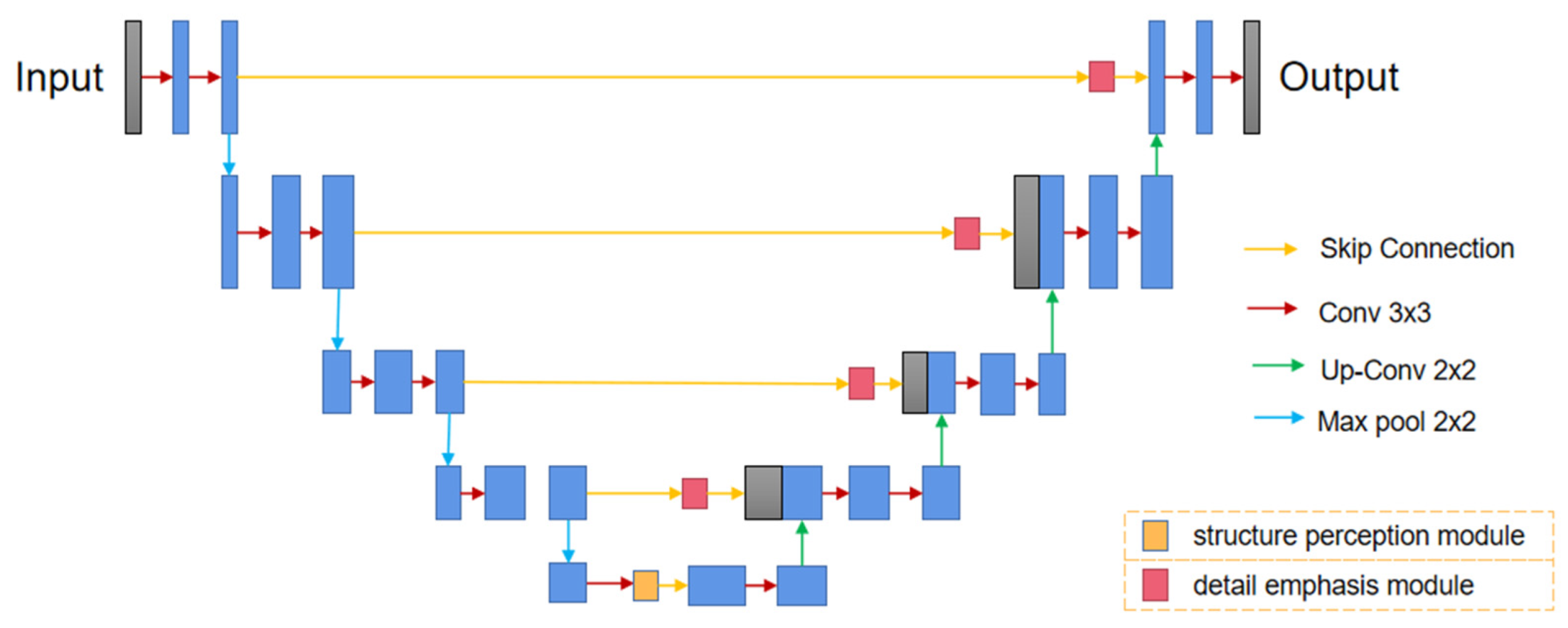
3.1. Network Model
3.1.1. Attention U-Net Architecture
3.1.2. Depth Network
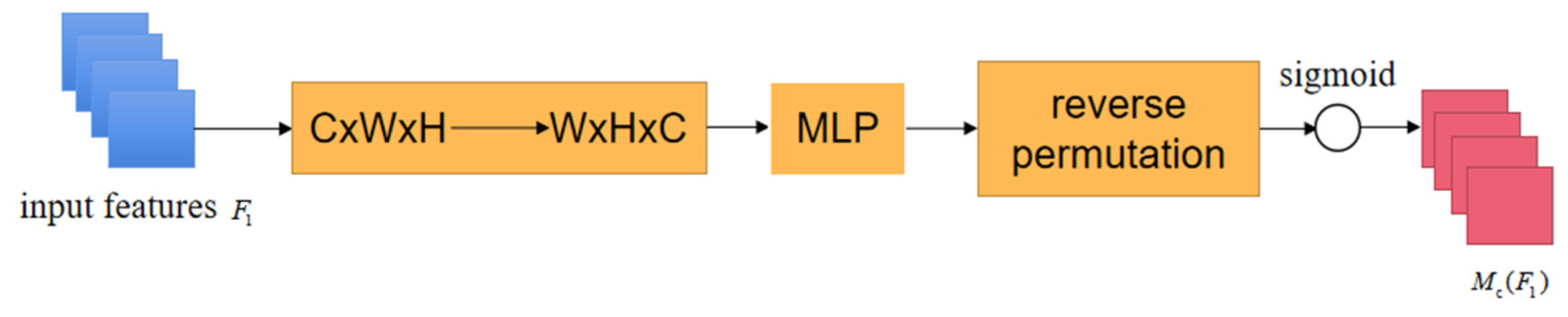
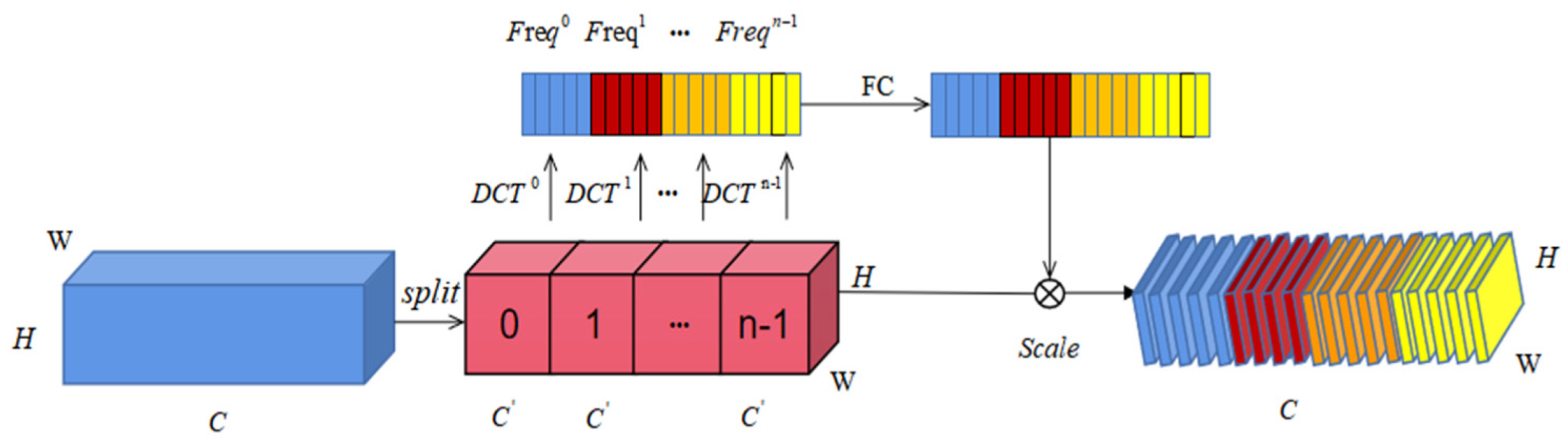
3.2. Structure Perception Module
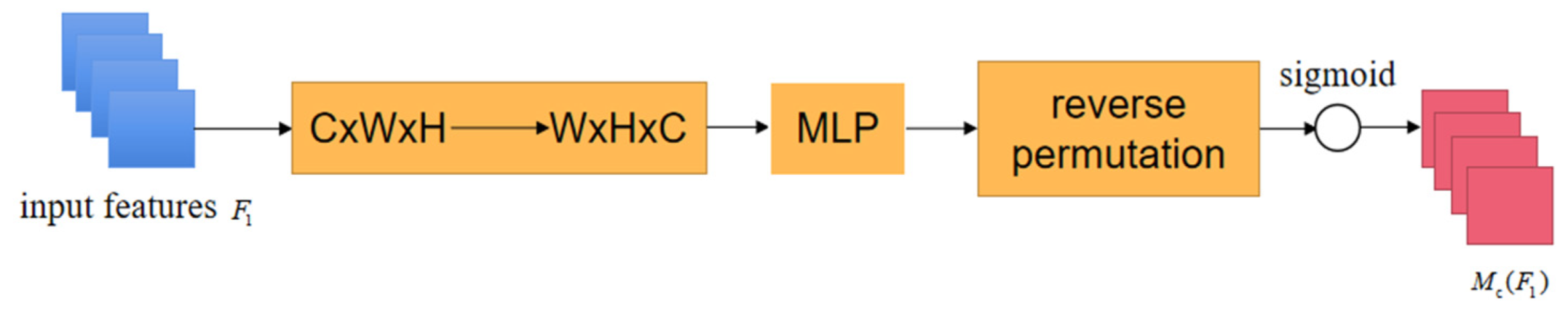
3.3. Detail Emphasis Module
3.4. Loss Function
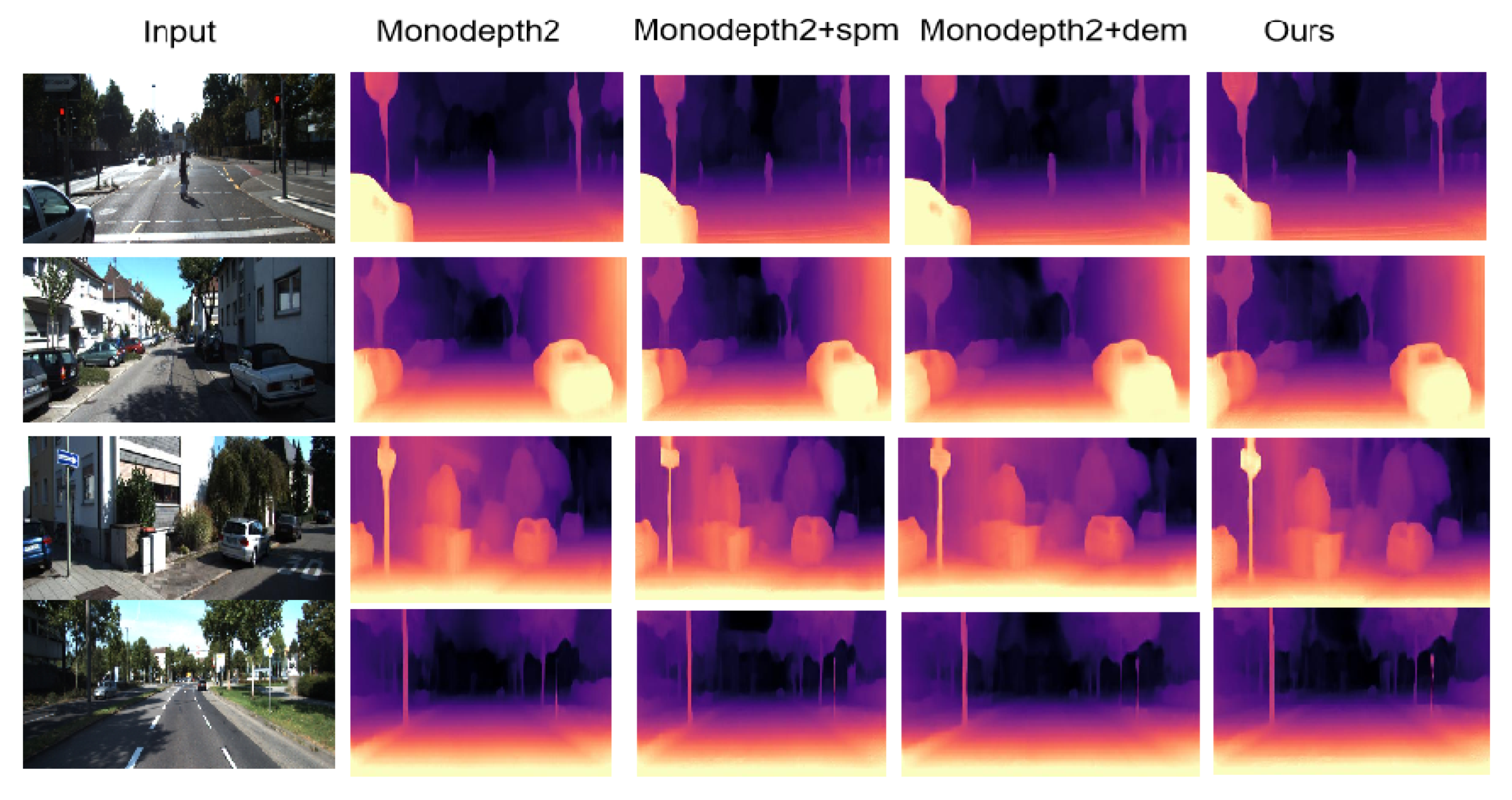
4. Experiments and Analysis
4.1. Implementation Details
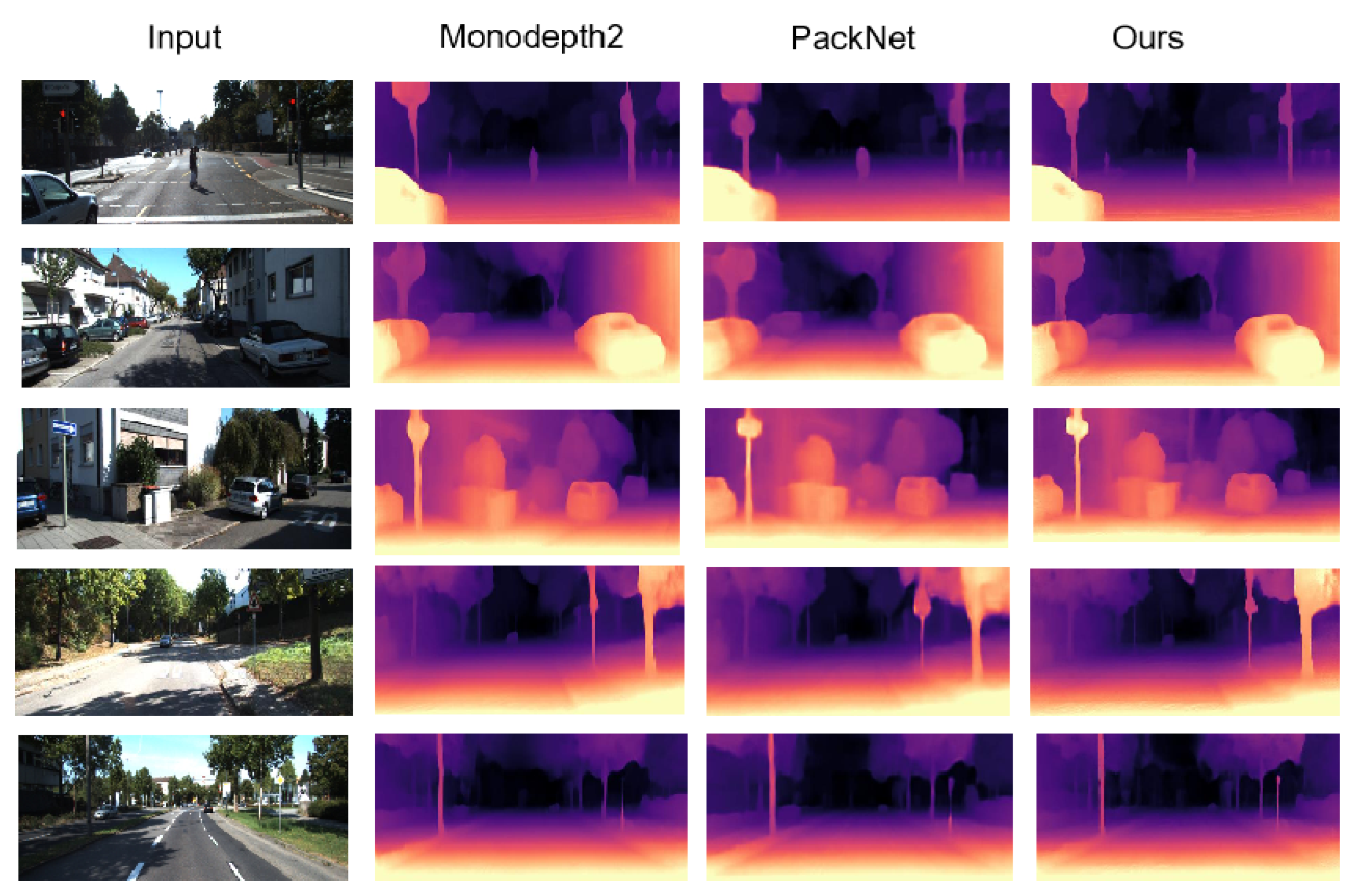
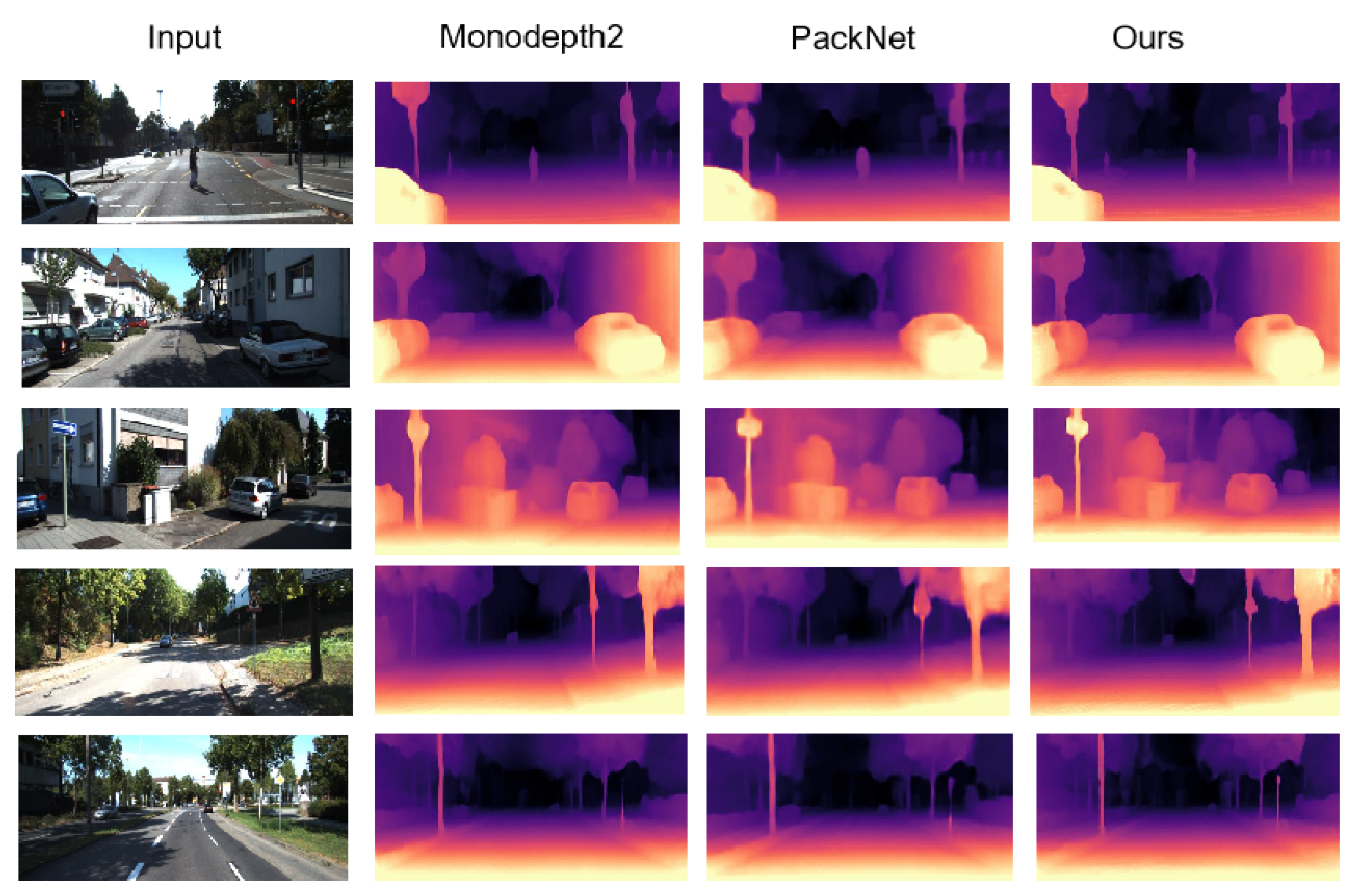
4.2. KITTI Results
4.3. Make 3D Results
4.4. Ablation Study
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- DeSouza, G.N.; Kak, A.C. Vision for mobile robot navigation: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 237–267. [Google Scholar] [CrossRef] [Green Version]
- Menze, M.; Geiger, A. Object scene flow for autonomous vehicles. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3061–3070. [Google Scholar]
- Newcombe, R.A.; Lovegrove, S.J.; Davison, A.J. Dtam: Dense tracking and mapping in real-time. In Proceedings of the 2011 International Conference on Computer Vision, Washington, DC, USA, 6–13 November 2011; pp. 2320–2327. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. arXiv 2014, arXiv:1406.2283. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting depth, surface normal and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar]
- Laina, I.; Rupprecht, C.; Belagiannis, V.; Tombari, F.; Navab, N. Deeper depth prediction with fully convolutional residual networks. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 239–248. [Google Scholar]
- Cao, Y.; Wu, Z.; Shen, C. Estimating depth from monocular images as classifification using deep fully convolutional residual networks. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 3174–3182. [Google Scholar] [CrossRef] [Green Version]
- Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; Tao, D. Deep ordinal regression network for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2002–2011. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised learning of depth and ego-motion from video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1851–1858. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 270–2792. [Google Scholar]
- Tao, B.; Liu, Y.; Huang, L.; Chen, G.; Chen, B. 3D reconstruction based on photoelastic fringes. Concurr. Comput. Pract. Exp. 2022, 34, e6481. [Google Scholar] [CrossRef]
- Tao, B.; Wang, Y.; Qian, X.; Tong, X.; He, F.; Yao, W.; Chen, B.; Chen, B. Photoelastic Stress Field Recovery Using Deep Convolutional Neural Network. Front. Bioeng. Biotechnol. 2022, 10, 818112. [Google Scholar] [CrossRef] [PubMed]
- Hao, Z.; Wang, Z.; Bai, D.; Tao, B.; Tong, X.; Chen, B. Intelligent detection of steel defects based on improved split attention networks. Front. Bioeng. Biotechnol. 2022, 9, 810876. [Google Scholar] [CrossRef]
- Jiang, D.; Li, G.; Sun, Y.; Hu, J.; Yun, J.; Liu, Y. Manipulator grabbing position detection with information fusion of color image and depth image using deep learning. J. Ambient Intell. Humaniz. Comput. 2021, 12, 10809–10822. [Google Scholar] [CrossRef]
- Tao, B.; Huang, L.; Zhao, H.; Li, G.; Tong, X. A time sequence images matching method based on the siamese network. Sensors 2021, 21, 5900. [Google Scholar] [CrossRef]
- Jiang, D.; Li, G.; Tan, C.; Huang, L.; Sun, Y.; Kong, J. Semantic segmentation for multiscale target based on object recognition using the improved Faster-RCNN model. Future Gener. Comput. Syst. 2021, 123, 94–104. [Google Scholar] [CrossRef]
- Wang, H.M.; Lin, H.Y.; Chang, C.C. Object Detection and Depth Estimation Approach Based on Deep Convolutional Neural Networks. Sensors 2021, 21, 4755. [Google Scholar] [CrossRef]
- Ming, Y.; Meng, X.; Fan, C.; Yu, H. Deep learning for monocular depth estimation: A review. Neurocomputing 2021, 438, 14–33. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhang, F.; Zhu, X.; Ye, M. Fast Human Pose Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards Balanced Learning for Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Lyu, H.; Fu, H.; Hu, X.; Liu, L. Esnet: Edge-based segmentation network for real-time semantic segmentation in traffic scenes. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1855–1859. [Google Scholar]
- Sun, Y.; Huang, P.; Cao, Y.; Jiang, G.; Yuan, Z.; Dongxu, B.; Liu, X. Multi-objective optimization design of ladle refractory lining based on genetic algorithm. Front. Bioeng. Biotechnol. 2022, 10, 900655. [Google Scholar] [CrossRef]
- Liu, Y.; Jiang, D.; Tao, B.; Qi, J.; Jiang, G.; Yun, J.; Huang, L.; Tong, X.; Chen, B.; Li, G. Grasping Posture of Humanoid Manipulator Based on Target Shape Analysis and Force Closure. Alex. Eng. J. 2022, 61, 3959–3969. [Google Scholar] [CrossRef]
- Bai, D.; Sun, Y.; Tao, B.; Tong, X.; Xu, M.; Jiang, G.; Chen, B.; Cao, Y.; Sun, N.; Li, Z. Improved single shot multibox detector target detection method based on deep feature fusion. Concurr. Comput. Pract. Exp. 2022, 34, e6614. [Google Scholar] [CrossRef]
- Liu, Y.; Xu, M.; Jiang, G.; Tong, X.; Yun, J.; Liu, Y.; Chen, B.; Cao, Y.; Sun, N.; Li, Z. Target localization in local dense mapping using RGBD SLAM and object detection. Concurr. Comput. Pract. Exp. 2022, 34, e6655. [Google Scholar] [CrossRef]
- Liu, Y.; Li, C.; Jiang, D.; Chen, B.; Sun, N.; Cao, Y.; Tao, B.; Li, G. Wrist angle prediction under different loads based on GAELM neural network and sEMG. Concurr. Comput. Pract. Exp. 2022, 34, e6574. [Google Scholar] [CrossRef]
- Yang, Z.; Jiang, D.; Sun, Y.; Tao, B.; Tong, X.; Jiang, G.; Xu, M.; Yun, J.; Liu, Y.; Chen, B.; et al. Dynamic Gesture recognition using surface EMG signals based on multi-stream residual network. Front. Bioeng. Biotechnol. 2021, 9, 779353. [Google Scholar] [CrossRef]
- Tosi, F.; Aleotti, F.; Poggi, M.; Mattoccia, S. Learning monocular depth estimation infusing traditional stereo knowledge. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9799–9809. [Google Scholar]
- Wong, A.; Soatto, S. Bilateral cyclic constraint and adaptive regularization for unsupervised monocular depth prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5644–5653. [Google Scholar]
- Mancini, M.; Costante, G.; Valigi, P.; Ciarfuglia, T.A. Fast robust monocular depth estimation for obstacle detection with fully convolutional networks. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 4296–4303. [Google Scholar]
- Mahjourian, R.; Wicke, M.; Angelova, A. Unsupervised learning of depth and ego-motion from monocular video using 3d geometric constraints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5667–5675. [Google Scholar]
- Guizilini, V.; Ambrus, R.; Pillai, S.; Raventos, A.; Gaidon, A. 3d packing for self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2485–2494. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Firman, M.; Brostow, G.J. Digging into self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3828–3838. [Google Scholar]
- Wang, C.; Buenaposada, J.M.; Zhu, R.; Lucey, S. Learning depth from monocular videos using direct methods. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2022–2030. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 7354–7363. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 10–15 June 2019; pp. 3146–3154. [Google Scholar]
- Johnston, A.; Carneiro, G. Self-supervised monocular trained depthestimation using self-attention and discrete disparity volume. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4756–4765. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. Fcanet: Frequency channel attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 783–792. [Google Scholar]
- Liu, Y.; Shao, Z.; Hoffmann, N. Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions. arXiv 2021, arXiv:2112.05561. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zou, Y.; Luo, Z.; Huang, J.B. DF-Net: Unsupervised joint learning of depth and flow using cross-task consistency. In Proceedings of the European Conference on Computer Vision (ECCV) 2018, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Ranjan, A.; Jampani, V.; Balles, L.; Kim, K.; Sun, D.; Wulff, J.; Black, M.J. Competitive collaboration: Joint unsupervised learning of depth, camera motion, optical flow and motion segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2019, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Luo, C.; Yang, Z.; Wang, P.; Wang, Y.; Xu, W.; Nevatia, R.; Yuille, A. Every pixel counts++: Joint learning of geometry and motion with 3d holistic understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2624–2641. [Google Scholar] [CrossRef] [Green Version]
- Casser, V.; Pirk, S.; Mahjourian, R.; Angelova, A. Depth prediction without the sensors: Leveraging structure for unsupervised learning from monocular videos. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8001–8008. [Google Scholar]
- Klingner, M.; Termöhlen, J.A.; Mikolajczyk, J.; Fingscheidt, T. Self-supervised monocular depth estimation: Solving the dynamic object problem by semantic guidance. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 582–600. [Google Scholar]
- Lyu, X.; Liu, L.; Wang, M.; Kong, X.; Liu, L.; Liu, Y.; Chen, X.; Yuan, Y. Hr-depth: High resolution self-supervised monocular depth estimation. arXiv 2020, arXiv:2012.07356. [Google Scholar]
- Saxena, A.; Sun, M.; Ng, A.Y. Make3d:Learning 3d scene structure from a single still image. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 824–840. [Google Scholar] [CrossRef] [PubMed] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | k | s | c | Activation |
|---|---|---|---|---|
| convl | 7 | 2 | 64 | ReLU |
| maxpool | 3 | 2 | 64 | - |
| econv1 | 3 | 1 | 64 | ReLU |
| econv2 | 3 | 2 | 128 | ReLU |
| econv3 | 3 | 2 | 256 | ReLU |
| econv4 | 3 | 2 | 512 | ReLU |
| spm | 3 | - | 512 | - |
| Layers | k | s | c | Activation |
|---|---|---|---|---|
| upconv6 | 3 | 1 | 512 | ELU |
| dem | 3 | 1 | 512 | ReLU |
| iconv6 | 3 | 1 | 512 | ELU |
| upconv5 | 3 | 1 | 256 | ELU |
| dem | 3 | 1 | 256 | ReLU |
| iconv5 | 3 | 1 | 256 | ELU |
| disp5 | 3 | 1 | 1 | Sigmoid |
| upconv4 | 3 | 1 | 128 | ELU |
| dem | 3 | 1 | 128 | ReLU |
| iconv4 | 3 | 1 | 128 | ELU |
| disp4 | 3 | 1 | 1 | Sigmoid |
| upconv3 | 3 | 1 | 64 | ELU |
| dem | 3 | 1 | 64 | ReLU |
| iconv3 | 3 | 1 | 64 | ELU |
| disp3 | 3 | 1 | 1 | Sigmoid |
| upconv2 | 3 | 1 | 32 | ELU |
| dem | 3 | 1 | 32 | ReLU |
| iconv2 | 3 | 1 | 32 | ELU |
| disp2 | 3 | 1 | 1 | Sigmoid |
| upconv1 | 3 | 1 | 16 | ELU |
| dem | 3 | 1 | 16 | ReLU |
| iconv1 | 3 | 1 | 16 | ELU |
| disp1 | 3 | 1 | 1 | Sigmoid |
| Method | Train | Abs Rel | Sq Rel | RMSE | RMSE Log | δ < 1.25 | δ < 1.252 | δ < 1.253 |
|---|---|---|---|---|---|---|---|---|
| DDVO [36] | M | 0.151 | 1.257 | 5.583 | 0.228 | 0.810 | 0.936 | 0.974 |
| DF-Net [45] | M | 0.150 | 1.124 | 5.507 | 0.223 | 0.806 | 0.933 | 0.973 |
| Ranjan [46] | M | 0.148 | 1.149 | 5.464 | 0.226 | 0.815 | 0.935 | 0.973 |
| EPC++ [47] | M | 0.141 | 1.029 | 5.350 | 0.216 | 0.816 | 0.941 | 0.976 |
| Struct2depth [48] | M | 0.141 | 1.026 | 5.291 | 0.215 | 0.816 | 0.945 | 0.979 |
| Monodepth [11] | M | 0.124 | 1.388 | 6.125 | 0.217 | 0.818 | 0.929 | 0.966 |
| SGDdepth [49] | M | 0.117 | 0.907 | 4.844 | 0.196 | 0.875 | 0.954 | 0.979 |
| Monodepth2 [35] | M | 0.115 | 0.903 | 4.863 | 0.193 | 0.877 | 0.959 | 0.981 |
| PackNet-SfM [34] | M | 0.111 | 0.785 | 4.601 | 0.189 | 0.878 | 0.960 | 0.982 |
| HR-Depth [50] | M | 0.109 | 0.792 | 4.632 | 0.185 | 0.884 | 0.962 | 0.983 |
| Johnston [39] | M | 0.106 | 0.861 | 4.699 | 0.185 | 0.889 | 0.962 | 0.982 |
| Ours | M | 0.107 | 0.765 | 4.532 | 0.184 | 0.893 | 0.963 | 0.983 |
| Method | Train | Abs Rel | Sq Rel | RMSE | RMSE Log |
|---|---|---|---|---|---|
| Monodepth [11] | S | 0.544 | 10.94 | 11.760 | 0.193 |
| Zhou [10] | M | 0.383 | 5.321 | 10.470 | 0.478 |
| DDVO [36] | M | 0.387 | 4.720 | 8.090 | 0.204 |
| Monodepth2 [35] | M | 0.322 | 3.589 | 7.417 | 0.163 |
| Ours | M | 0.314 | 3.112 | 7.048 | 0.159 |
| Method | Backbone | Abs Rel | Sq Rel | RMSE | RMSE Log | δ < 1.25 | δ < 1.252 | δ < 1.253 |
|---|---|---|---|---|---|---|---|---|
| Baseline (monodepth2) | R18 | 0.115 | 0.903 | 4.863 | 0.193 | 0.877 | 0.959 | 0.981 |
| Baseline + spm | R18 | 0.111 | 0.833 | 4.768 | 0.191 | 0.881 | 0.961 | 0.982 |
| Baseline + dem | R18 | 0.110 | 0.812 | 4.733 | 0.190 | 0.882 | 0.961 | 0.982 |
| Ours | R18 | 0.110 | 0.810 | 4.678 | 0.190 | 0.882 | 0.962 | 0.983 |
| Method | Backbone | Abs Rel | Sq Rel | RMSE | RMSE Log | δ < 1.25 | δ < 1.252 | δ < 1.253 |
|---|---|---|---|---|---|---|---|---|
| Baseline (monodepth2) | R50 | 0.110 | 0.831 | 4.642 | 0.187 | 0.883 | 0.962 | 0.982 |
| Baseline + spm | R50 | 0.109 | 0.768 | 4.554 | 0.183 | 0.885 | 0.963 | 0.983 |
| Baseline + dem | R50 | 0.109 | 0.772 | 4.593 | 0.185 | 0.886 | 0.962 | 0.982 |
| Ours | R50 | 0.107 | 0.765 | 4.532 | 0.184 | 0.893 | 0.963 | 0.983 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tao, B.; Chen, X.; Tong, X.; Jiang, D.; Chen, B. Self-Supervised Monocular Depth Estimation Based on Channel Attention. Photonics 2022, 9, 434. https://doi.org/10.3390/photonics9060434
Tao B, Chen X, Tong X, Jiang D, Chen B. Self-Supervised Monocular Depth Estimation Based on Channel Attention. Photonics. 2022; 9(6):434. https://doi.org/10.3390/photonics9060434
Chicago/Turabian StyleTao, Bo, Xinbo Chen, Xiliang Tong, Du Jiang, and Baojia Chen. 2022. "Self-Supervised Monocular Depth Estimation Based on Channel Attention" Photonics 9, no. 6: 434. https://doi.org/10.3390/photonics9060434
APA StyleTao, B., Chen, X., Tong, X., Jiang, D., & Chen, B. (2022). Self-Supervised Monocular Depth Estimation Based on Channel Attention. Photonics, 9(6), 434. https://doi.org/10.3390/photonics9060434