Quantifying the Effect of Machine Translation in a High-Quality Human Translation Production Process


Abstract
1. Introduction
2. Related Research
3. Method
3.1. Data Collection
3.2. Survey
- When making use of machine translation suggestions, do you think you work slower/at the same speed/somewhat faster/much faster than without using machine translation?
- Has participating in the study, during which you were partially prevented from using machine translation, changed this perception?
- Time constraints aside, do you prefer to translate with or without machine translation? Why?
- Is there a difference in that regard depending on document type?
- What is your assessment of the quality of the machine translation output you are provided with in DGT, as related to your professional translation needs: very poor, poor, ok, good, excellent?
- From a professional perspective, what are the main problems in the machine translation suggestions you are provided with?
4. Results
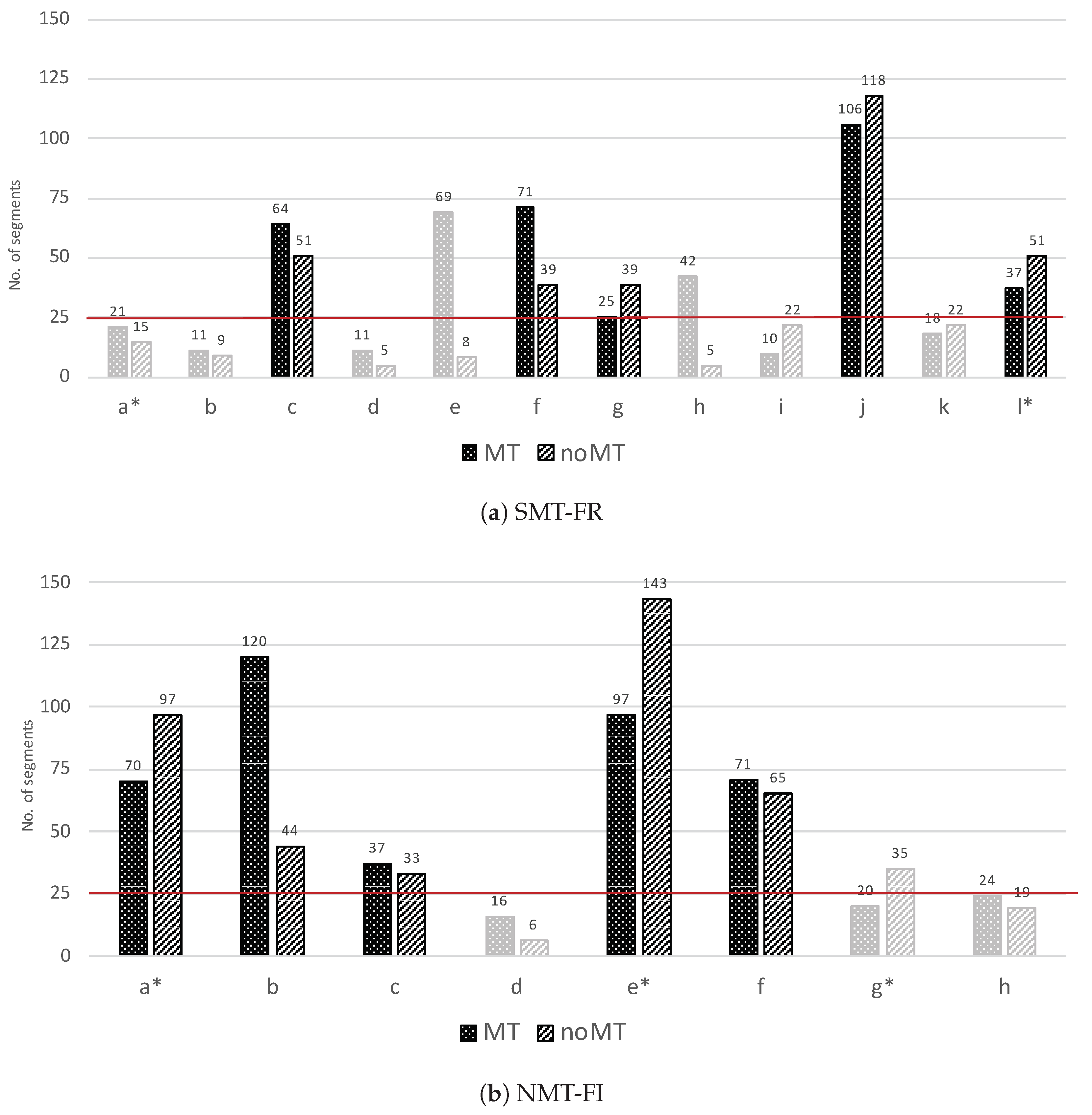
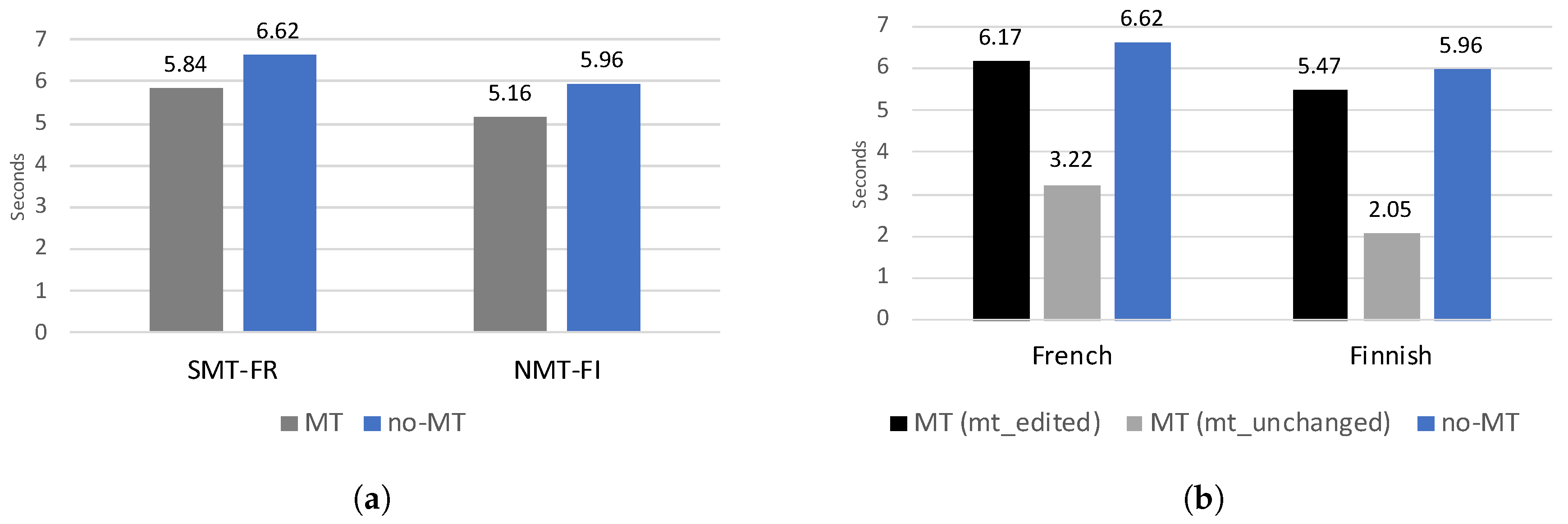
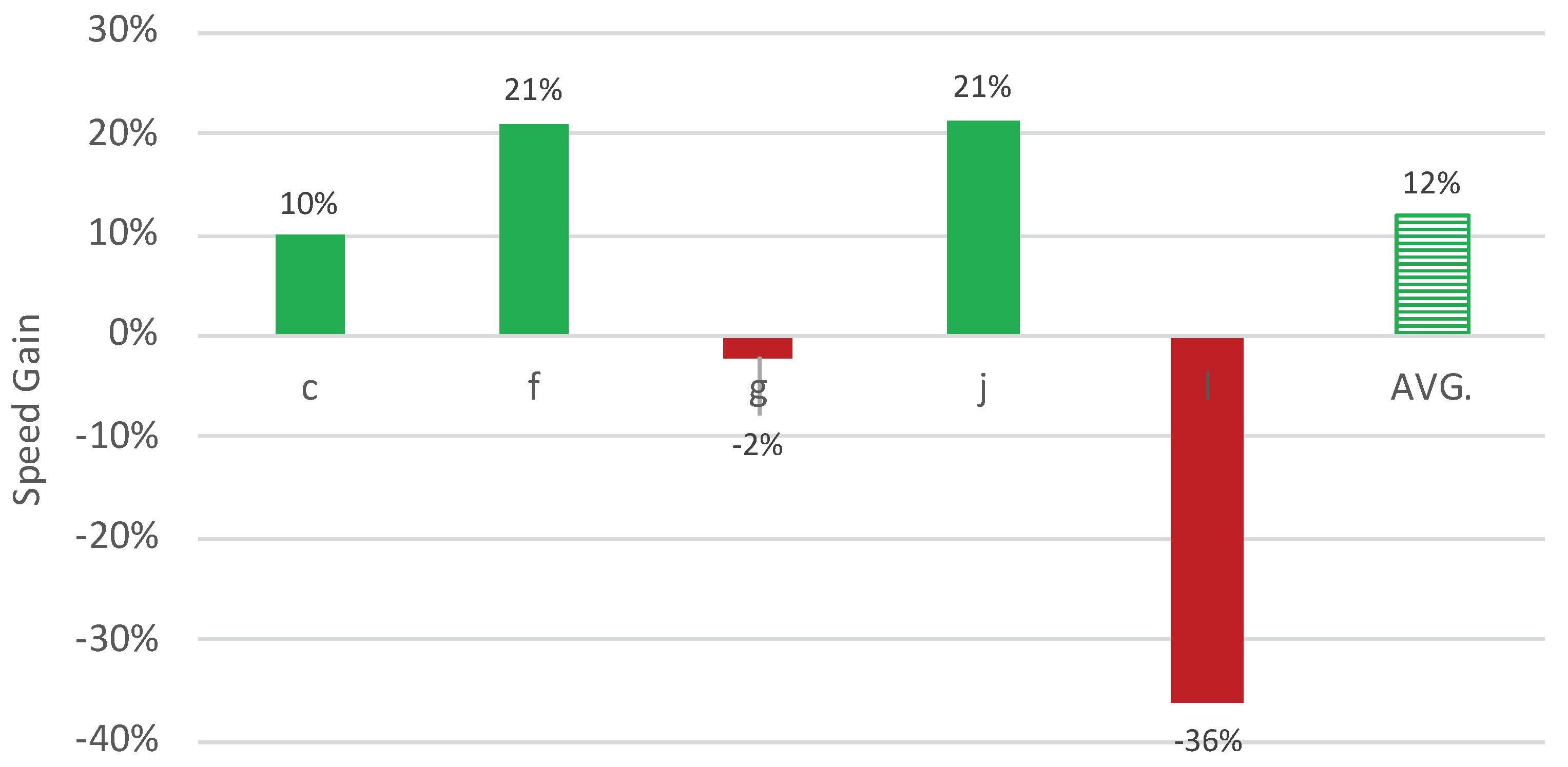
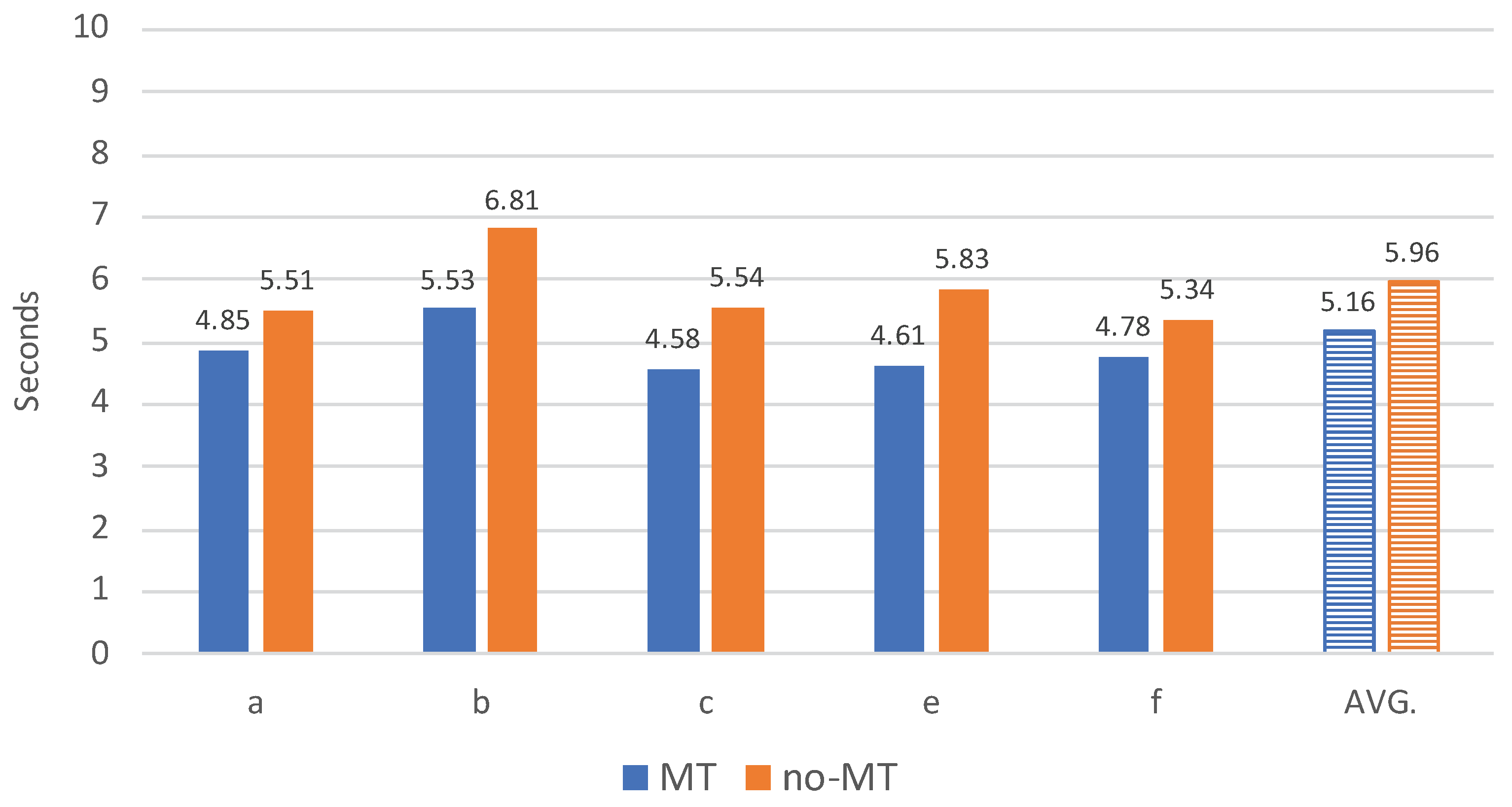
4.1. Processing Speed
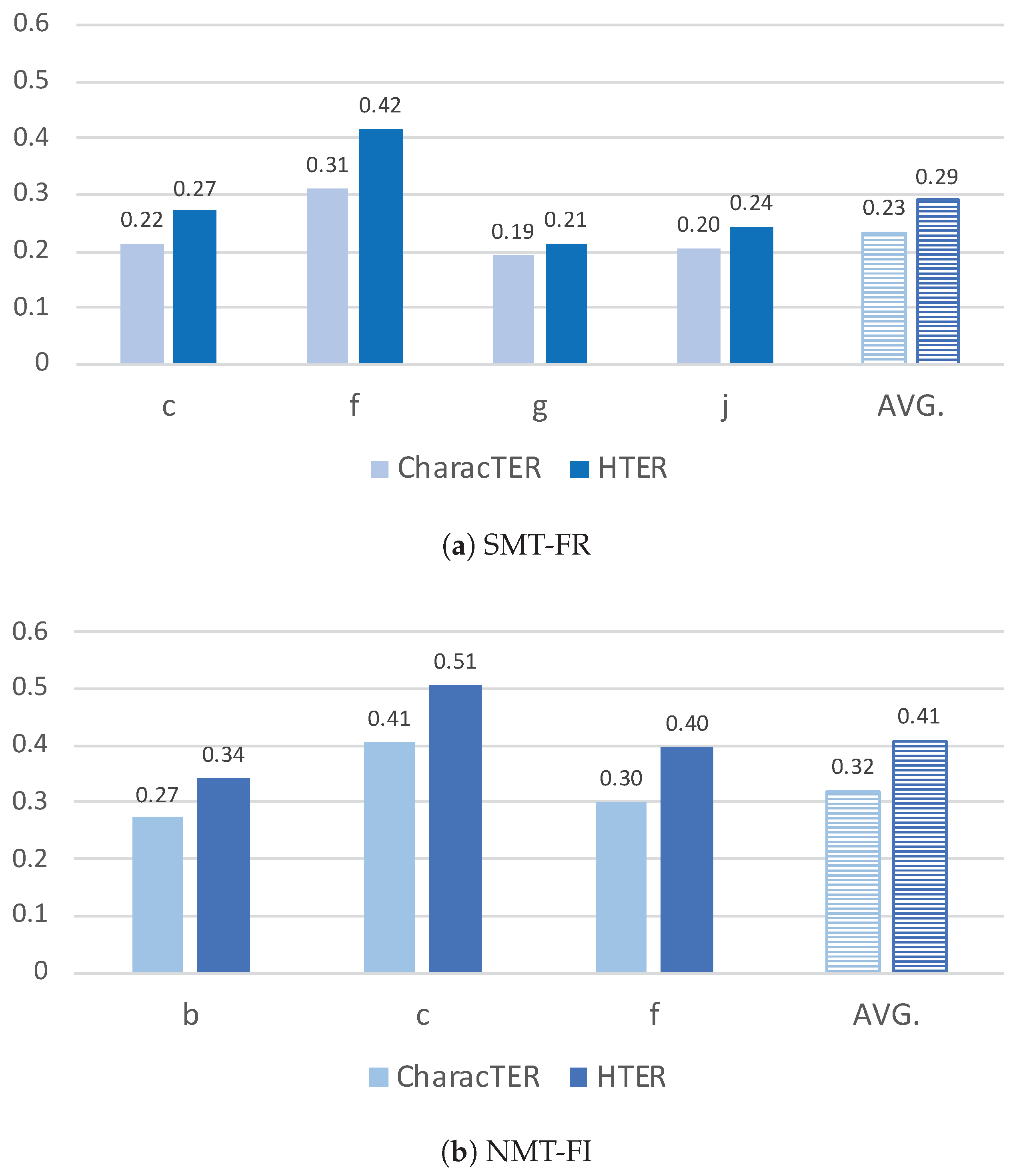
4.2. Amount of Editing
4.3. Survey
- One participant notes that the use of machine translation only has a very marginal effect on the overall speed: “Other factors have a much greater impact, such as the clarity of the text, its technical complexity, its links with previous texts, its degree of idiomaticity, and how much research is necessary to understand it and choose the right terminology. In other words, MT might save me some of the time necessary to type the text, but typing is a very small fraction of the work involved in the translation of a text.”
- One participant relates speed to both translation memory match rate and the quality of the original documents: “With a low (retrieval) match rate, I work somewhat faster with MT than without if the original is in English and well written. With higher match rates, I work at the same speed. With badly written originals, I might even work much slower (as I use full segment insertion, I have to delete text then retype my translation).”
- “I prefer to translate with machine translation because I have the impression that I have a base, a foundation on which I can build. It’s a reassuring feeling.”
- “Not having to start from scratch is reassuring.”
- “I also like the feeling that I’m not working alone—even if it is just a silly machine that is there to help me.”
- “With MT, because I am lazy, and when I see that the segments are already filled, it gives me the impression that the work is already partly done.”
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AVG | average |
| DGT | Directorate-General for Translation of the European Commission |
| FI | Finnish |
| FR | French |
| HTER | human-targeted translation edit rate |
| MT | machine translation |
| NMT | neural machine translation |
| NMT-FI | English–Finnish neural MT engine |
| PBSMT | phrase-based statistical machine translation |
| PET | post-editing time |
| RBMT | rule-based machine translation |
| SMT-FR | English–French phrase-based statistical MT engine |
| TMX | Translation Memory eXchange |
References
- Pigott, I.M. The importance of feedback from translators in the development of high-quality machine translation. In Practical Experience of Machine Translation; Lawson, V., Ed.; North-Holland Publishing Company: Amsterdam, The Netherlands; New York, NY, USA; Oxford, UK, 1982; pp. 61–74. [Google Scholar]
- Wagner, E. Post-editing SYSTRAN, a challenge for Commission Translators. In Terminologie et Traduction; Commission des Communautés Européennes: Luxembourg, 1985; pp. 1–7. [Google Scholar]
- Koehn, P.; Hoang, H.; Birch, A.; Callison-Burch, C.; Federico, M.; Bertoldi, N.; Cowan, B.; Shen, W.; Moran, C.; Zens, R.; et al. Moses: Open Source Toolkit for Statistical Machine Translation. In Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics, Companion Volume Proceedings of the Demo and Poster Sessions, Prague, Czech Republic, 23–30 June 2007; pp. 177–180. [Google Scholar]
- Drugan, J.; Strandvik, I.; Vuorinen, E. Translation quality, quality management and agency: Principles and practice in the European Union institutions. In Translation Quality Assessment; Moorkens, J., Castilho, S., Gaspari, F., Doherty, S., Eds.; Springer: Cham, Switzerland, 2018; pp. 39–68. [Google Scholar]
- Krings, H.P. Repairing texts. In Empirical Investigations of Machine Translation Post-Editing Processes; Kent State University Press: Kent, Ohio, 2001. [Google Scholar]
- Snover, M.; Dorr, B.; Schwartz, R.; Micciulla, L.; Makhoul, J. A study of translation edit rate with targeted human annotation. In Proceedings of the Association for Machine Translation in the Americas, Cambridge, MA, USA, 8–12 August 2006; pp. 223–231. [Google Scholar]
- Lacruz, I.; Denkowski, M.; Lavie, A. Cognitive Demand and Cognitive Effort in Post-Editing. In Proceedings of the eleventh conference of the Association for Machine Translation in the Americas, Workshop on Post-editing Technology and Practice, Vancouver, BC, Canada, 22–26 October 2014; pp. 73–84. [Google Scholar]
- Daems, J.; Vandepitte, S.; Hartsuiker, R.; Macken, L. Identifying the machine translation error types with the greatest impact on post-editing effort. Front. Psychol. 2017, 8, 15. [Google Scholar] [CrossRef] [PubMed]
- Daems, J.; Macken, L. Interactive adaptive SMT versus interactive adaptive NMT: A user experience evaluation. Mach. Transl. 2019, 33, 117–134. [Google Scholar] [CrossRef]
- Herbig, N.; Pal, S.; Vela, M.; Krüger, A.; van Genabith, J. Multi-modal indicators for estimating perceived cognitive load in post-editing of machine translation. Mach. Transl. 2019, 33, 91–115. [Google Scholar] [CrossRef]
- Lesznyák, Á. Hungarian translators’ perceptions of Neural Machine Translation in the European Commission. In Proceedings of Machine Translation Summit XVII Volume 2: Translator, Project and User Tracks; European Association for Machine Translation: Dublin, Ireland, 2019; pp. 16–22. [Google Scholar]
- Aziz, W.; Castilho, S.; Specia, L. PET: A Tool for Post-editing and Assessing Machine Translation. In Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC’12), Istanbul, Turkey, 23–25 May 2012; European Language Resources Association (ELRA): Istanbul, Turkey, 2012; pp. 3982–3987. [Google Scholar]
- Carl, M. Translog-II: A Program for Recording User Activity Data for Empirical Reading and Writing Research. In Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC’12), Istanbul, Turkey, 23–25 May 2012; European Language Resources Association (ELRA): Istanbul, Turkey, 2012; pp. 4108–4112. [Google Scholar]
- Alabau, V.; Bonk, R.; Buck, C.; Carl, M.; Casacuberta, F.; García-Martínez, M.; González, J.; Koehn, P.; Leiva, L.; Mesa-Lao, B.; et al. CASMACAT: An open source workbench for advanced computer aided translation. Prague Bull. Math. Linguist. 2013, 100, 101–112. [Google Scholar] [CrossRef]
- O’Brien, S. Pauses as indicators of cognitive effort in post-editing machine translation output. Across Lang. Cult. 2006, 7, 1–21. [Google Scholar] [CrossRef]
- Lacruz, I.; Shreve, G.M.; Angelone, E. Average pause ratio as an indicator of cognitive effort in post-editing: A case study. In Proceedings of the tenth conference of the Association for Machine Translation in the Americas, Workshop on Post-Editing Technology and Practice, San Diego, CA, USA, 28 October–1 November 2012; pp. 21–30. [Google Scholar]
- Doherty, S.; O’Brien, S.; Carl, M. Eye tracking as an MT evaluation technique. Mach. Transl. 2010, 24, 1–13. [Google Scholar] [CrossRef]
- Carl, M.; Dragsted, B.; Elming, J.; Hardt, D.; Jakobsen, A.L. The process of post-editing: A pilot study. Cph. Stud. Lang. 2011, 41, 131–142. [Google Scholar]
- Daems, J.; Vandepitte, S.; Hartsuiker, R.; Macken, L. Translation methods and experience: A comparative analysis of human translation and post-editing with students and professional translators. Meta J. Des Traducteurs/Meta Transl. J. 2017, 62, 245–270. [Google Scholar] [CrossRef]
- Läubli, S.; Fishel, M.; Massey, G.; Ehrensberger-Dow, M.; Volk, M. Assessing post-editing efficiency in a realistic translation environment. In Proceedings of the MT Summit XIV Workshop on Post-Editing Technology and Practice, Nice, France, 2 September 2013; pp. 83–91. [Google Scholar]
- Federico, M.; Cattelan, A.; Trombetti, M. Measuring user productivity in machine translation enhanced computer assisted translation. In Proceedings of the Tenth Conference of the Association for Machine Translation in the Americas (AMTA), San Diego, CA, USA, 28 October–1 November 2012; AMTA: Madison, WI, USA, 2012; pp. 44–56. [Google Scholar]
- Parra Escartín, C.; Arcedillo, M. Machine translation evaluation made fuzzier: A study on post-editing productivity and evaluation metrics in commercial settings. In Proceedings of the MT Summit XV, Miami, FL, USA, 30 October–3 November 2015; pp. 131–144. [Google Scholar]
- Cadwell, P.; O’Brien, S.; Teixeira, C.S. Resistance and accommodation: Factors for the (non-)adoption of machine translation among professional translators. Perspectives 2018, 26, 301–321. [Google Scholar] [CrossRef]
- Rossi, C.; Chevrot, J.P. Uses and perceptions of Machine Translation at the European Commission. J. Spec. Transl. (JoSTrans) 2019, 31, 177–200. [Google Scholar]
- Wang, W.; Peter, J.T.; Rosendahl, H.; Ney, H. Character: Translation edit rate on character level. In Proceedings of the First Conference on Machine Translation: Volume 2, Shared Task Papers, Berlin, Germany, 11–12 August 2016; pp. 505–510. [Google Scholar]
- Schober, P.; Boer, C.; Schwarte, L.A. Correlation coefficients: Appropriate use and interpretation. Anesth. Analg. 2018, 126, 1763–1768. [Google Scholar] [CrossRef] [PubMed]
- Plitt, M.; Masselot, F. A productivity test of statistical machine translation post-editing in a typical localisation context. Prague Bull. Math. Linguist. 2010, 93, 7–16. [Google Scholar] [CrossRef]
- O’Brien, S. Towards predicting post-editing productivity. Mach. Transl. 2011, 25, 197. [Google Scholar] [CrossRef]
- Gaspari, F.; Toral, A.; Naskar, S.K.; Groves, D.; Way, A. Perception vs reality: Measuring machine translation post-editing productivity. In Proceedings of the Third Workshop on Post-Editing Technology and Practice, Vancouver, BC, Canada, 22–26 October 2014. [Google Scholar]
- Moorkens, J.; O’brien, S.; Da Silva, I.A.; de Lima Fonseca, N.B.; Alves, F. Correlations of perceived post-editing effort with measurements of actual effort. Mach. Transl. 2015, 29, 267–284. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
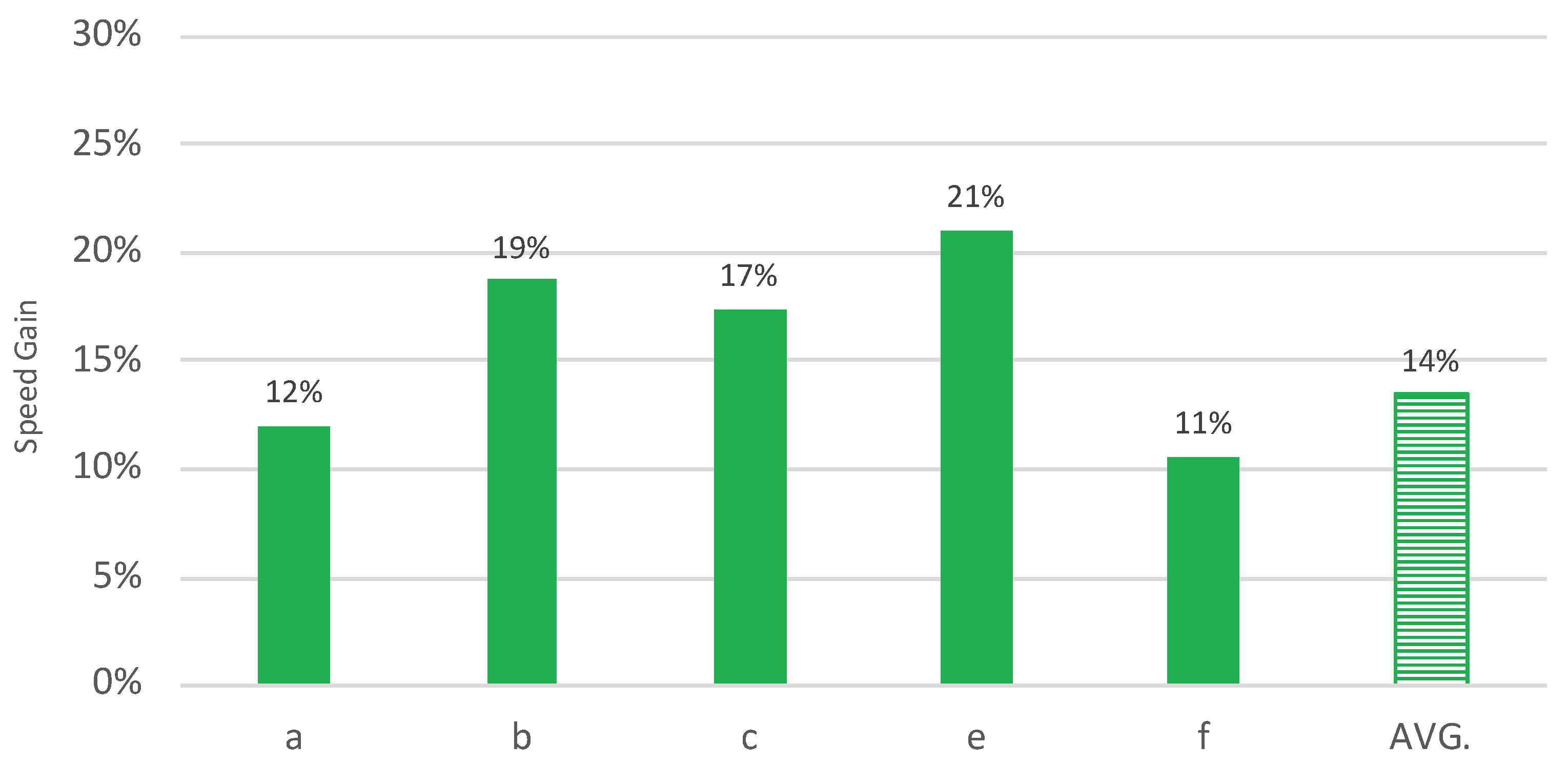{kind=link}
{kind=link}
| Segment Type | French | Finnish | ||||
|---|---|---|---|---|---|---|
| #s | #w | #w (AVG) | #s | #w | #w (AVG) | |
| autoprop_edited | 25 | 359 | 14.36 | 430 | 722 | 1.68 |
| autoprop_unchanged | 1927 | 6513 | 3.38 | 1320 | 4620 | 3.50 |
| copy_source | 527 | 1264 | 2.40 | 1970 | 4866 | 2.47 |
| copy_source_edited | 354 | 6553 | 18.51 | 412 | 3869 | 9.39 |
| perfect | 1225 | N/A | N/A | 3322 | N/A | N/A |
| tm_edited | 1908 | 46,002 | 24.11 | 1449 | 30,067 | 20.75 |
| tm_unchanged | 2921 | 29,853 | 10.22 | 2555 | 21,258 | 8.32 |
| from_scratch | 1183 | 31,196 | 26.37 | 1165 | 25,921 | 22.25 |
| mt_edited | 1259 | 33,489 | 26.60 | 1271 | 31,406 | 24.71 |
| mt_unchanged | 107 | 984 | 9.20 | 75 | 792 | 10.57 |
| Total | 11,436 | 156,213 | 15.29 | 13,969 | 123,521 | 11.44 |
| Filter Type | French | Finnish | ||||
|---|---|---|---|---|---|---|
| #s | #w | #w (AVG) | #s | #w | #w (AVG) | |
| Total | 2549 | 58,721 | 23.03 | 2511 | 50,299 | 20.03 |
| Non-valid segment ID | 4 | 108 | 27 | 9 | 242 | 26.88 |
| Non-sequential editing | 1400 | 34,300 | 24.5 | 1202 | 25,884 | 21.53 |
| Non-valid time stamp | 133 | 2787 | 20.95 | 188 | 3153 | 16.77 |
| Processing speed threshold | 147 | 3291 | 22.38 | 223 | 5235 | 23.48 |
| Retained no. of segments | 869 | 18,343 | 21.10 | 897 | 16,027 | 17.87 |
| PET/HTER | PET/CharacTER | |
|---|---|---|
| SMT-FR | ||
| Pearson (r) | 0.157 | 0.151 |
| Spearman () | 0.327 | 0.328 |
| NMT-FI | ||
| Pearson (r) | 0.305 | 0.306 |
| Spearman () | 0.401 | 0.396 |
| Slower | Same Speed | Somewhat Faster | Much Faster | |
|---|---|---|---|---|
| SMT-FR | 0 | 2 | 7 | 2 |
| NMT-FI | 0 | 1 | 7 | 1 |
| Very Poor | Poor | OK | Good | Excellent | |
|---|---|---|---|---|---|
| SMT-FR | 0 | 1 | 4 | 6 | 0 |
| NMT-FI | 0 | 1 | 3 | 5 | 0 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Macken, L.; Prou, D.; Tezcan, A. Quantifying the Effect of Machine Translation in a High-Quality Human Translation Production Process. Informatics 2020, 7, 12. https://doi.org/10.3390/informatics7020012
Macken L, Prou D, Tezcan A. Quantifying the Effect of Machine Translation in a High-Quality Human Translation Production Process. Informatics. 2020; 7(2):12. https://doi.org/10.3390/informatics7020012
Chicago/Turabian StyleMacken, Lieve, Daniel Prou, and Arda Tezcan. 2020. "Quantifying the Effect of Machine Translation in a High-Quality Human Translation Production Process" Informatics 7, no. 2: 12. https://doi.org/10.3390/informatics7020012
APA StyleMacken, L., Prou, D., & Tezcan, A. (2020). Quantifying the Effect of Machine Translation in a High-Quality Human Translation Production Process. Informatics, 7(2), 12. https://doi.org/10.3390/informatics7020012