
Sparse STATIS-Dual via Elastic Net

 ,
,  ,
,  and
and 
Abstract
1. Introduction
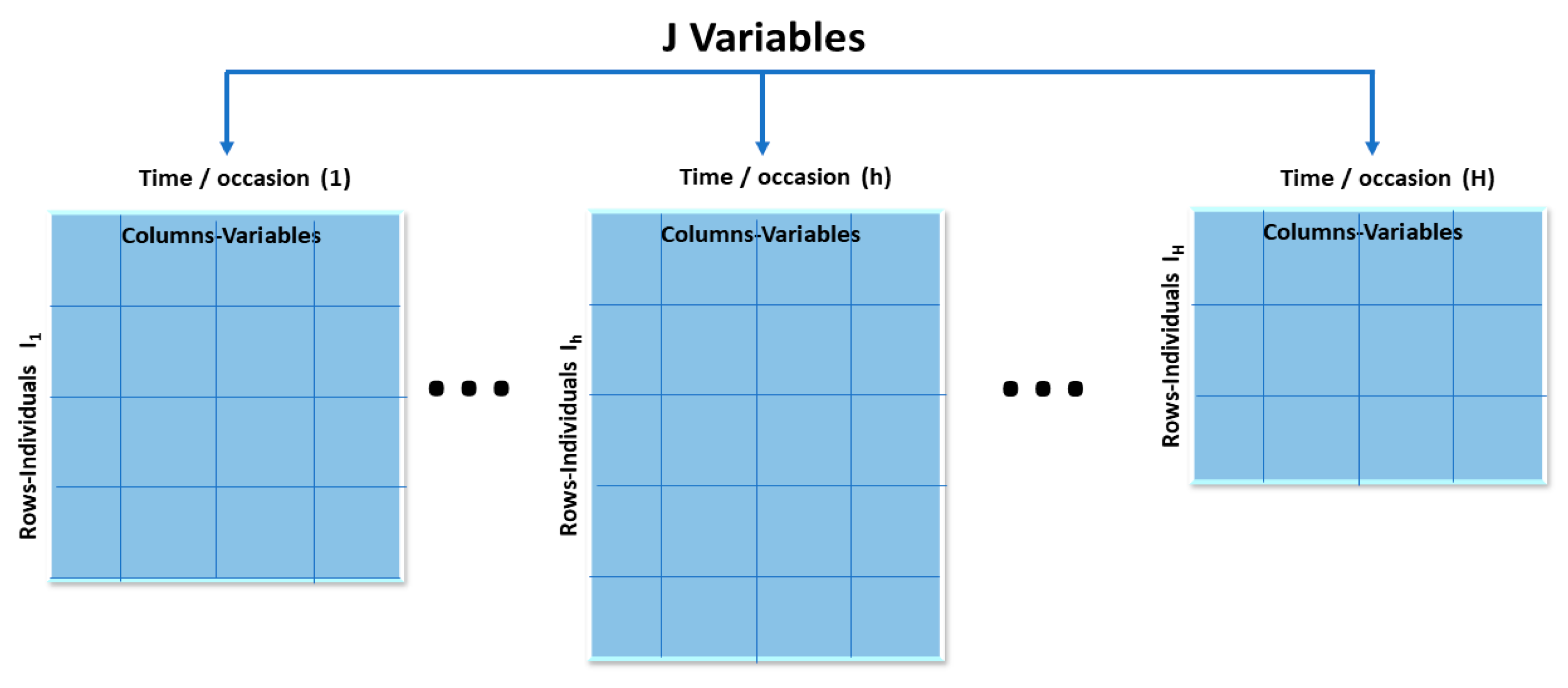
2. Materials and Methods
2.1. STATIS-Dual Method
2.2. STATIS-Dual Steps
3. Sparse STATIS-Dual
| Algorithm 1. Sparse STATIS-Dual. |
| Step 1. Consider an array of data nxp. Step 2. A tolerance value is set (1 × 10−5). Step 3. The data are transformed (center or standardize). Step 4. Matrices of cross products are obtained.Step 5. The cosine matrix between studies is obtained. Step 6. A PCA is performed on . Step 7. The compromise matrix is obtained. Step 8. The decomposition in SVD of the compromise matrix is carried out. Step 9. We take as the charges of the first m components . Step 10. is calculated by: Step 14. The columns , are normalized. Step 15. The restricted loads are obtained to project the variables in the compromise. Step 16. The STATIS-dual Sparse obtained through the previous steps is plotted. |
4. Illustrative Example
5. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indicator Code | Description |
|---|---|
| INSTITUTIONS (IN) | |
| IN1 | Political and operational stability |
| IN2 | Government effectiveness |
| IN3 | Regulatory quality |
| IN4 | Rule of law |
| IN5 | Cost of redundancy dismissal, salary weeks |
| IN6 | Ease of starting a business |
| IN7 | Ease of resolving insolvency |
| HUMAN CAPITAL & RESEARCH (HC) | |
| HC1 | Expenditure on education, % GDP |
| HC2 | Government funding/pupil, secondary, % GDP/cap |
| HC3 | School life expectancy, years |
| HC4 | PISA scales in reading, maths, & science |
| HC5 | Pupil-teacher ratio, secondary |
| HC6 | Tertiary enrolment, % gross |
| HC7 | Graduates in science & engineering, % |
| HC8 | Tertiary inbound mobility, % |
| HC9 | Researchers, FTE/mn pop |
| HC10 | Gross expenditure on R&D, % GDP |
| HC11 | Global R&D companies, avg. exp. top 3, mn $US |
| HC12 | QS university ranking, average score top 3 |
| INFRASTRUCTURE (IF) | |
| IF1 | ICT access |
| IF2 | ICT use |
| IF3 | Government’s online service |
| IF4 | E-participation |
| IF5 | Electricity output, kWh/mn pop |
| IF6 | Logistics performance |
| IF7 | Gross capital formation, % GDP |
| IF8 | GDP/unit of energy use |
| IF9 | Environmental performance |
| IF10 | ISO 14001 environmental certificates/bn PPP$ GDP |
| MARKET SOPHISTICATION (MS) | |
| MS1 | Ease of getting credit |
| MS2 | Domestic credit to private sector, % GDP |
| MS3 | Microfinance gross loans, % GDP |
| MS4 | Ease of protecting minority investors |
| MS5 | Market capitalization, % GDP |
| MS6 | Venture capital deals/bn PPP$ GDP |
| MS7 | Applied tariff rate, weighted avg., % |
| MS8 | Intensity of local competition† |
| MS9 | Domestic market scale, bn PPP$ |
| BUSINESS SOPHISTICATION (BS) | |
| BS1 | Knowledge-intensive employment, % |
| BS2 | Firms offering formal training, % |
| BS3 | GERD performed by business, % GDP |
| BS4 | GERD financed by business, % |
| BS5 | Females employed w/advanced degrees, % |
| BS6 | University/industry research collaboration |
| BS7 | State of cluster development |
| BS8 | GERD financed by abroad, % GDP |
| BS9 | JV-strategic alliance deals/bn PPP$ GDP |
| BS10 | Patent families 2+ offices/bn PPP$ GDP |
| BS11 | Intellectual property payments, % total trade |
| BS12 | High-tech imports, % total trade |
| BS13 | ICT services imports, % total trade |
| BS14 | FDI net inflows, % GDP |
| BS15 | Research talent, % in business enterprise |
| KNOWLEDGE & TECHNOLOGY OUTPUTS (KT) | |
| KT1 | Patents by origin/bn PPP$ GDP |
| KT2 | PCT patents by origin/bn PPP$ GDP |
| KT3 | Utility models by origin/bn PPP$ GDP |
| KT4 | Scientific & technical articles/bn PPP$ GDP |
| KT5 | Citable documents H-index |
| KT6 | Growth rate of PPP$ GDP/worker, % |
| KT7 | New businesses/th pop. 15−64 |
| KT8 | Computer software spending, % GDP |
| KT9 | ISO 9001 quality certificates/bn PPP$ GDP |
| KT10 | High- and medium-high-tech manufacturing |
| KT11 | Intellectual property receipts, % total trade |
| KT12 | High-tech net exports, % total trade |
| KT13 | ICT services exports, % total trade |
| KT14 | FDI net outflows, % GDP |
| CREATIVE OUTPUTS (CP) | |
| CP1 | Trademarks by origin/bn PPP$ GDP |
| CP2 | Generic top-level domains (TLDs)/th pop. 15−69 |
| CP3 | Country-code TLDs/th pop. 15−69 |
| CP4 | Wikipedia edits/mn pop. 15−69 |
| CP5 | Mobile app creation/bn PPP$ GDP |
| CP6 | Cultural & creative services exports, % total trade |
| CP7 | National feature films/mn pop. 15−69 |
| CP8 | Entertainment & Media market/th pop. 15−69 |
| CP9 | Printing and other media, % manufacturing |
| CP10 | Creative goods exports, % total trade |
| CP11 | Global brand value, top 5000, % GDP |
| CP12 | Industrial designs by origin/bn PPP$ GDP |
| CP13 | ICTs & organizational model creation |
References
- Cuadras, C.M. Nuevos Métodos de Análisis Multivariante; CMC Edicions: Barcelona, Spain, 1996. [Google Scholar]
- Gabriel, K.R. The biplot graphic display of matrices with application to principal component analysis. Biometrika 1971, 58, 453–467. [Google Scholar] [CrossRef]
- Gabriel, K.R.; Odoroff, C.L. Biplots in biomedical research. Stat. Med. 1990, 9, 469–485. [Google Scholar] [CrossRef] [PubMed]
- Tucker, L.R. Some mathematical notes on three-mode factor analysis. Psychometrika 1966, 31, 279–311. [Google Scholar] [CrossRef]
- Geladi, P. Analysis of multi-way (multi-mode) data. Chemom. Intell. Lab. Syst. 1989, 7, 11–30. [Google Scholar] [CrossRef]
- Carroll, J.D.; Arabie, P. Multidimensional Scaling. Annu. Rev. Psychol. 1980, 31, 607–649. [Google Scholar] [CrossRef]
- Kiers, H.A.L. Comparison of“anglo-saxon” and “french” three-mode methods. Stat. Anal. Données 1988, 13, 14–32. [Google Scholar]
- Kiers, H.A.L. Hierarchical relations among three-way methods. Psychometrika 1991, 56, 449–470. [Google Scholar] [CrossRef]
- Kroonenberg, P.M. Three-mode component models: A review of the literature. Stat. Appl. 1992, 4, 619–633. [Google Scholar]
- Escoufier, Y. L’analyse conjointe de plusieurs matrices de données. In Biométrie et Temps; Jolivet, M., Ed.; Société Française de Biométrie: Paris, France, 1980; pp. 59–76. [Google Scholar]
- L’Hermier des Plantes, H. Structuration des Tableaux à Trois Indices de la Statistique; Université de Montpellier II: Montpellier, France, 1976. [Google Scholar]
- Lavit, C. Analyse Conjointe de Tableaux Quantitatifs; Masson: Paris, France, 1988; ISBN 2225814783. [Google Scholar]
- Lavit, C.; Escoufier, Y.; Sabatier, R.; Traissac, P. The ACT (STATIS method). Comput. Stat. Data Anal. 1994, 18, 97–119. [Google Scholar] [CrossRef]
- González-García, N. Análisis Sparse de Tensores Multidimensionales; Universidad de Salamanca: Salamanca, Spain, 2019. [Google Scholar]
- Abdi, H.; Williams, L.J.; Valentin, D.; Bennani-Dosse, M. STATIS and DISTATIS: Optimum multitable principal component analysis and three way metric multidimensional scaling. WIREs Comput. Stat. 2012, 4, 124–167. [Google Scholar] [CrossRef]
- Llobell, F.; Cariou, V.; Vigneau, E.; Labenne, A.; Qannari, E.M. Analysis and clustering of multiblock datasets by means of the STATIS and CLUSTATIS methods. Application to sensometrics. Food Qual. Prefer. 2020, 79, 103520. [Google Scholar] [CrossRef]
- Llobell, F.; Vigneau, E.; Qannari, E.M. Clustering datasets by means of CLUSTATIS with identification of atypical datasets. Application to sensometrics. Food Qual. Prefer. 2019, 75, 97–104. [Google Scholar] [CrossRef]
- Fournier, M.; Motelay-Massei, A.; Massei, N.; Aubert, M.; Bakalowicz, M.; Dupont, J.P. Investigation of transport processes inside karst aquifer by means of STATIS. Ground Water 2009, 47, 391–400. [Google Scholar] [CrossRef] [PubMed]
- Chaya, C.; Perez-Hugalde, C.; Judez, L.; Wee, C.S.; Guinard, J.-X. Use of the STATIS method to analyze time-intensity profiling data. Food Qual. Prefer. 2003, 15, 3–12. [Google Scholar] [CrossRef]
- Stanimirova, I.; Walczak, B.; Massart, D.L.; Simeonov, V.; Saby, C.A.; Di Crescenzo, E. STATIS, a three-way method for data analysis. Application to environmental data. Chemom. Intell. Lab. Syst. 2004, 73, 219–233. [Google Scholar] [CrossRef]
- Coquet, R.; Troxler, L.; Wipff, G. The STATIS method: Characterization of conformational states of flexible molecules from molecular dynamics simulations in solution. J. Mol. Graph. 1996, 14, 206–212. [Google Scholar] [CrossRef]
- Rodríguez-Martínez, C.C. Contribuciones a los Métodos STATIS Basados en Técnicas de Aprendizaje no Supervisado; Universidad de Salamanca. Ph.D. Thesis, Universidad de Salamanca, Salamanca, Spain, 2020. [Google Scholar]
- Zou, H.; Hastie, T.; Tibshirani, R. Sparse Principal Component Analysis. J. Comput. Graph. Stat. 2006, 15, 265–286. [Google Scholar] [CrossRef]
- Cubilla-Montilla, M.; Nieto-Librero, A.B.; Galindo-Villardón, P.; Torres-Cubilla, C.A. Sparse HJ Biplot: A New Methodology via Elastic Net. Mathematics 2021, 9, 1298. [Google Scholar] [CrossRef]
- Rodríguez-Martínez, C.C.; Cubilla-Montilla, M. SparseSTATISdual: R package for penalized STATIS-dual análisis. Available online: https://github.com/CCRM07/SparseSTATISdual (accessed on 15 June 2021).
- Global Innovation Index. Available online: https://www.globalinnovationindex.org/analysis-indicator (accessed on 10 April 2021).
- Escoufier, Y. Objectifs et procédures de l’analyse conjointe de plusieurs tableaux de donnés. Stat. Anal. Données 1985, 10, 1–10. [Google Scholar]
- Abdi, H.; Valentin, D. DISTATIS How to analyze multiple distance matrices. In Encyclopedia of Measurement and Statistics; SAGE Publications, Inc.: Thousand Oaks, CA, USA, 2007; Volume 3. [Google Scholar]
- Hotelling, H. Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 1933, 24, 417. [Google Scholar] [CrossRef]
- Jolliffe, I.T. Principal Component Analysis, 2nd ed.; Springer: New York, NY, USA, 2002. [Google Scholar]
- Pearson, K. On lines and planes of closest fit to systems of points in space. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1901, 2, 559–572. [Google Scholar] [CrossRef]
- Ambapour, S. Statis: Une méthode d’analyse conjointe de plusieurs tableaux de données, Document de travail (DT 01/2001), Bureau d’Application des Methodes Statistiques et Informatiques. 2001, pp. 1–20. Available online: https://www.yumpu.com/fr/document/read/37543574/statis-une-macthode-danalyse-conjointe-de-plusieurs-cnsee (accessed on 15 June 2021).
- L’Hermier des Plantes, H.; Thiébaut, B. Étude de la pluviosité au moyen de la méthode STATIS. Rev. Stat. Appl. 1977, 25, 57–81. [Google Scholar]
- Kroonenberg, P.M. Applied Multiway Data Analysis; Wiley Series in Probabity and Statistics; John Wiley & Sons, Inc.: New York, NY, USA, 2008; ISBN 978-0-470-16497-6. [Google Scholar]
- Niang, N.; Fogliatto, F.; Saporta, G. Contrôle multivarié de procédés par lots à l’aide de Statis. In Proceedings of the 41èmes Journée de Statistique, Nice, France, 25–29 May 2009. [Google Scholar]
- Lekve, K. Species richness and environmental conditions of fish along the Norwegian Skagerrak coast. ICES J. Mar. Sci. 2002, 59, 757–769. [Google Scholar] [CrossRef]
- Lobry, J.; Lepage, M.; Rochard, E. From seasonal patterns to a reference situation in an estuarine environment: Example of the small fish and shrimp fauna of the Gironde estuary (SW France). Estuar. Coast. Shelf Sci. 2006, 70, 239–250. [Google Scholar] [CrossRef]
- da Silva, J.L.; Ramos, L.P. On the rate of convergence of uniform approximations for sequences of distribution functions. J. Korean Stat. Soc. 2014, 43, 47–65. [Google Scholar] [CrossRef]
- Ferraro, S.; Ardoino, I.; Bassani, N.; Santagostino, M.; Rossi, L.; Biganzoli, E.; Bongo, A.S.; Panteghini, M. Multi-marker network in ST-elevation myocardial infarction patients undergoing primary percutaneous coronary intervention: When and what to measure. Clin. Chim. Acta 2013, 417, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Caballero-Juliá, D.; Galindo-Villardón, P.; García, M.-C. JK-Meta-Biplot y STATIS Dual como herramientas de análisis de tablas textuales múltiples. RISTI Rev. Ibérica Sist. Tecnol. Inf. 2017, 25, 18–33. [Google Scholar] [CrossRef][Green Version]
- Marcondes Filho, D.; de Oliveira, L.P.L.; Fogliatto, F.S. Erratum to: Multivariate quality control of batch processes using STATIS. Int. J. Adv. Manuf. Technol. 2017, 88, 2355. [Google Scholar] [CrossRef]
- Enachescu, C.; Postelnicu, T. Patterns in journal citation data revealed by exploratory multivariate analysis. Scientometrics 2003, 56, 43–59. [Google Scholar] [CrossRef]
- Ramos-Barberán, M.; Hinojosa-Ramos, M.V.; Ascencio-Moreno, J.; Vera, F.; Ruiz-Barzola, O.; Galindo-Villardón, P. Batch process control and monitoring: A Dual STATIS and Parallel Coordinates (DS-PC) approach. Prod. Manuf. Res. 2018, 6, 470–493. [Google Scholar] [CrossRef]
- Robert, P.; Escoufier, Y. A Unifying Tool for Linear Multivariate Statistical Methods: The RV-Coefficient. Appl. Stat. 1976, 25, 257. [Google Scholar] [CrossRef]
- Lebart, L.; Morineau, A.; Piron, M. Statistique Exploratoire Multidimensionnelle; Dunod: Paris, France, 1995. [Google Scholar]
- Oliveira, M.M.; Mexia, J. ANOVA-like analysis of matched series of studies with a common structure. J. Stat. Plan. Inference 2007, 137, 1862–1870. [Google Scholar] [CrossRef]
- Vicente-Galindo, P.; Galindo-Villardón, P. El método Statis como alternativa para detectar” response shift” en estudios de calidad de vida relacionada con la salud. Revista de Matemática: Teoría y Aplicaciones 2009, 16, 1–15. [Google Scholar] [CrossRef][Green Version]
- Eckart, C.; Young, G. The approximation of one matrix by another of lower rank. Psychometrika 1936, 1, 211–218. [Google Scholar] [CrossRef]
- Castillo Elizondo, W.; González Varela, J. STATIS DUAL: Software y Análisis de datos reales. Revista de Matemática: Teoría y Aplicaciones 1998, 5, 149–162. [Google Scholar]
- Giordani, P.; Rocci, R. Constrained CANDECOMP/PARAFAC via the Lasso. Psychomotrika 2013, 78, 669–685. [Google Scholar] [CrossRef] [PubMed]
- Giordani, P.; Rocci, R. Candecomp/Parafac with ridge regularization. Chemom. Intell. Lab. Syst. 2013, 129, 3–9. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Hoerl, A.E.; Kennard, R.W. Ridge Regression: Biased Estimation for Nonorthogonal Problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression Shrinkage and Selection Via the Lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Gower, J.C. Procrustes Analysis. In International Encyclopedia of the Social & Behavioral Sciences, 2nd ed.; Elsevier: Amsterdam, The Netherlands, 2015; ISBN 9780080970875. [Google Scholar]
- Erichson, N.B.; Zheng, P.; Manohar, K.; Brunton, S.L.; Kutz, J.N.; Aravkin, A.Y. Sparse Principal Component Analysis via Variable Projection. SIAM J. Appl. Math. 2020, 80, 977–1002. [Google Scholar] [CrossRef]
- R Development Core Team R Software. R: A Language and Environment Statistical Computing; R Foundation for Statical Computing: Vienna, Austria; Available online: https://www.R-project.org/ (accessed on 15 June 2021).
- Grané, A.; Sow-Barry, A.A. Visualizing Profiles of Large Datasets of Weighted and Mixed Data. Mathematics 2021, 9, 891. [Google Scholar] [CrossRef]
- Laria, J.C.; Aguilera-Morillo, M.C.; Álvarez, E.; Lillo, R.E.; López-Taruella, S.; del Monte-Millán, M.; Picornell, A.C.; Martín, M.; Romo, J. Iterative Variable Selection for High-Dimensional Data: Prediction of Pathological Response in Triple-Negative Breast Cancer. Mathematics 2021, 9, 222. [Google Scholar] [CrossRef]






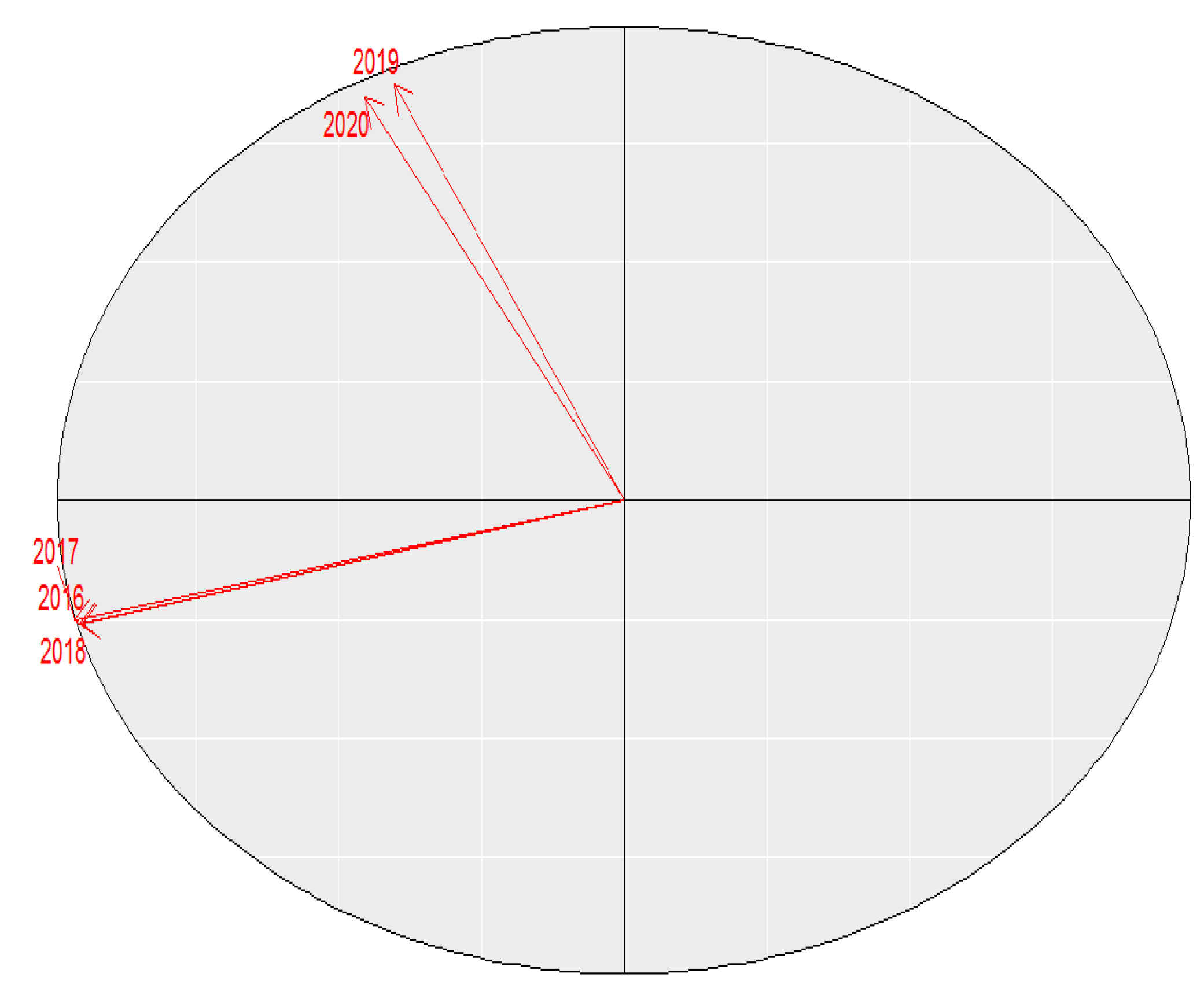
| Axis | Weights |
|---|---|
| 2016 | 0.3956 |
| 2017 | 0.3994 |
| 2018 | 0.3941 |
| 2019 | 0.1672 |
| 2020 | 0.1881 |
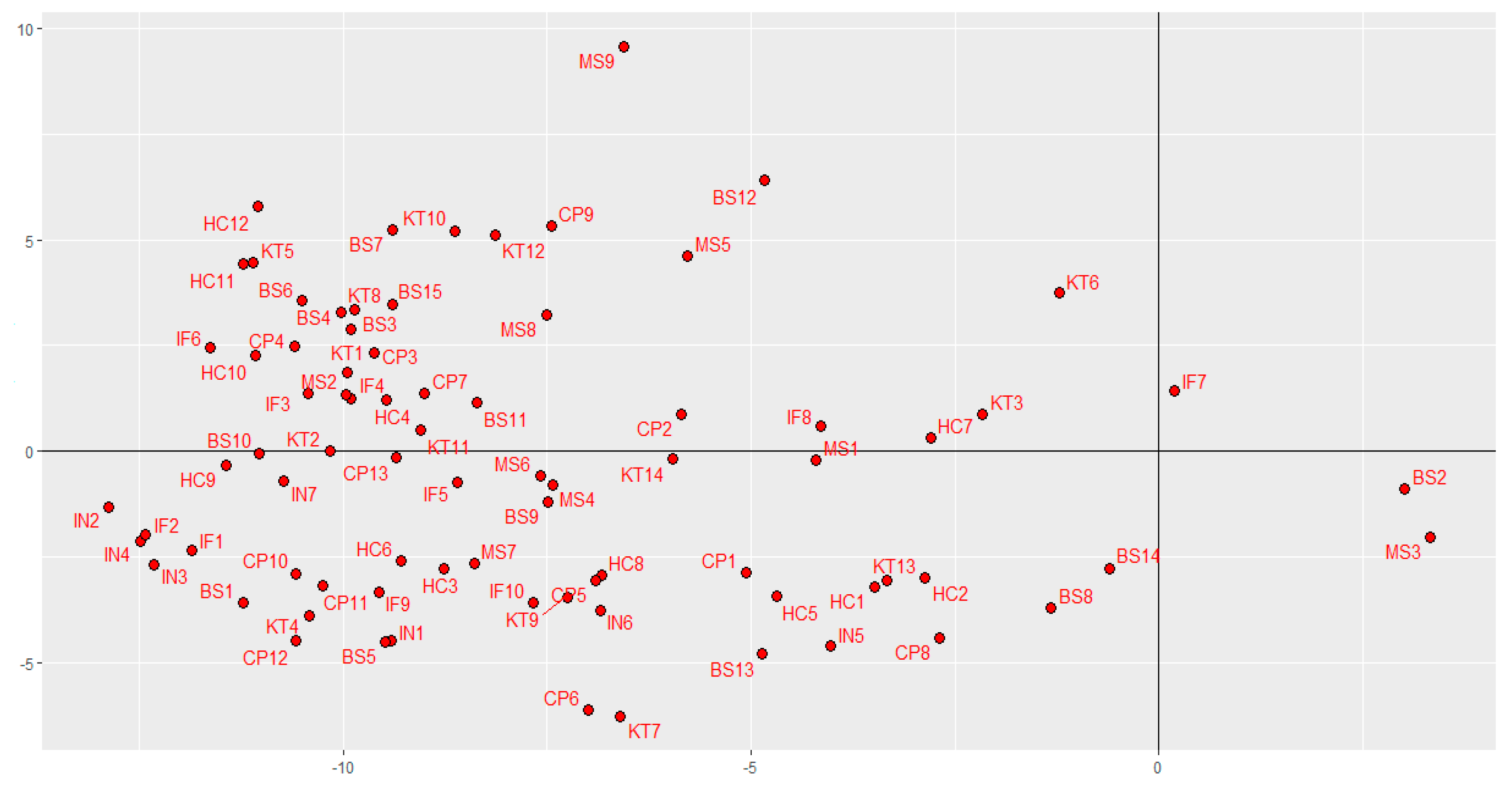
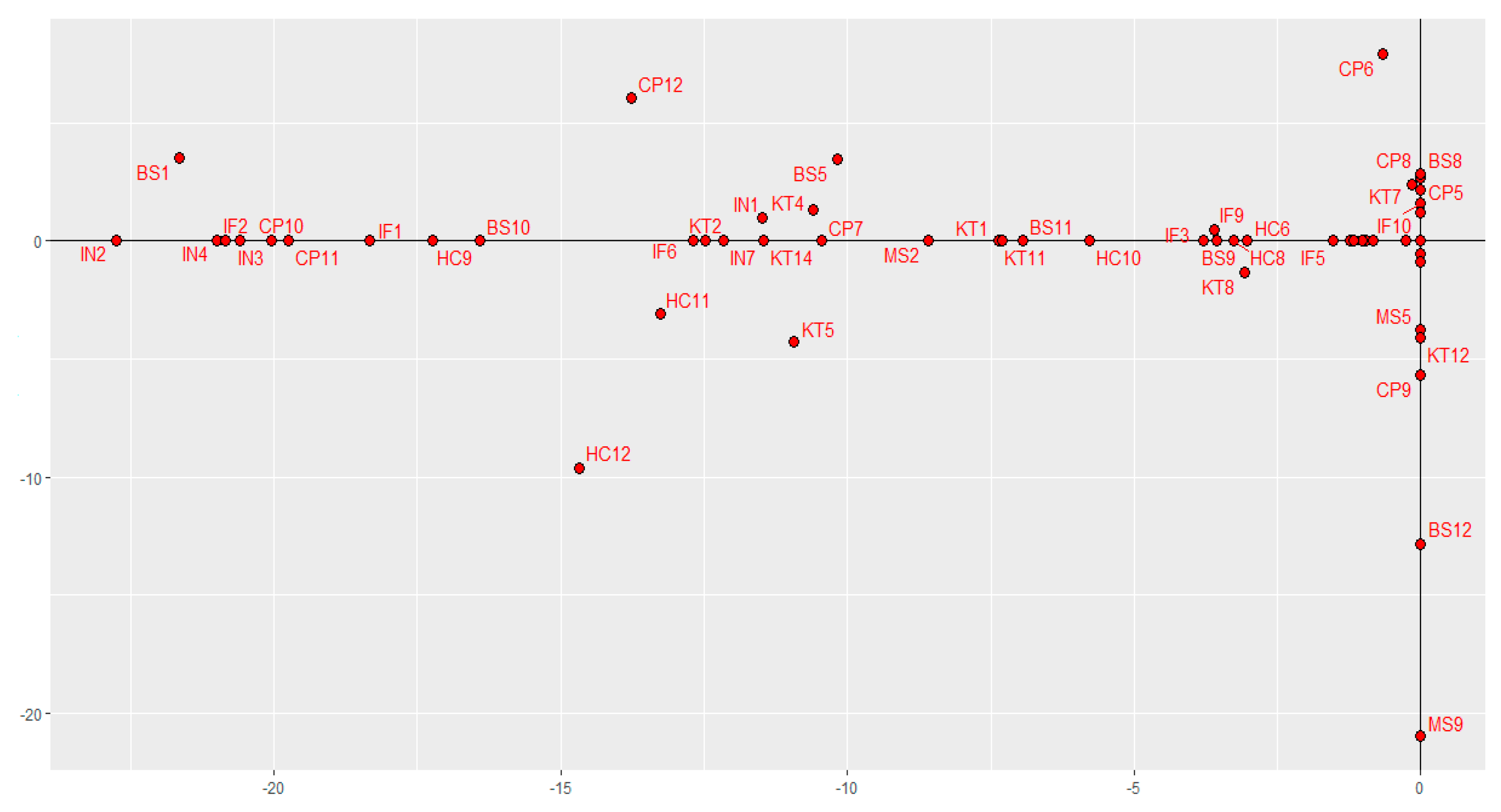
| Indicators | STATIS-Dual | Sparse STATIS-Dual | ||||
|---|---|---|---|---|---|---|
| Axis 1 | Axis 2 | Axis 3 | Axis 1 | Axis 2 | Axis 3 | |
| IN1 | −9.407 | −4.458 | 0.171 | −11.496 | 0.958 | 0 |
| IN2 | −12.876 | −1.326 | −0.389 | −22.754 | 0 | 0 |
| IN3 | −12.318 | −2.665 | −0.639 | −20.605 | 0 | 0 |
| IN4 | −12.484 | −2.132 | −1.767 | −20.992 | 0 | 0 |
| IN5 | −4.026 | −4.586 | −1.891 | 0 | 0 | 0 |
| IN6 | −6.850 | −3.741 | 0.712 | −0.969 | 0 | 0 |
| IN7 | −10.728 | −0.710 | 1.185 | −12.158 | 0 | 0 |
| HC1 | −3.481 | −3.195 | −0.607 | 0 | 0 | 0 |
| HC2 | −2.865 | −2.996 | −1.373 | 0 | 0 | 0 |
| HC3 | −8.772 | −2.766 | 4.567 | 0 | 0 | 9.612 |
| HC4 | −9.469 | 1.214 | −1.286 | −0.266 | 0 | 0 |
| HC5 | −4.693 | −3.414 | 4.649 | 0 | 0 | 3.718 |
| HC6 | −9.290 | −2.582 | 6.100 | −3.022 | 0 | 14.754 |
| HC7 | −2.803 | 0.316 | 3.349 | 0 | 0 | 5.670 |
| HC8 | −6.828 | −2.935 | −4.465 | −3.267 | 0 | −0.486 |
| HC9 | −11.442 | −0.319 | −2.178 | −17.242 | 0 | 0 |
| HC10 | −11.081 | 2.269 | −1.695 | −5.776 | 0 | 0 |
| HC11 | −11.225 | 4.429 | −1.061 | −13.263 | −3.114 | 0 |
| HC12 | −11.041 | 5.776 | 0.397 | −14.666 | −9.619 | 0 |
| IF1 | −11.859 | −2.339 | 2.262 | −18.329 | 0 | 0.239 |
| IF2 | −12.420 | −1.966 | 1.659 | −20.854 | 0 | 0 |
| IF3 | −10.434 | 1.375 | 3.590 | −3.783 | 0 | 1.138 |
| IF4 | −9.901 | 1.247 | 4.421 | 0 | 0 | 3.205 |
| IF5 | −8.606 | −0.725 | −1.401 | −1.525 | 0 | 0 |
| IF6 | −11.629 | 2.461 | −0.939 | −12.690 | 0 | 0 |
| IF7 | 0.191 | 1.429 | 1.250 | 0 | 0 | 0 |
| IF8 | −4.145 | 0.592 | −0.230 | 0 | 0 | 0 |
| IF9 | −9.568 | −3.322 | 3.980 | −3.609 | 0.462 | 4.520 |
| IF10 | −7.677 | −3.558 | 6.018 | 0 | 1.566 | 8.599 |
| MS1 | −4.201 | −0.216 | 3.565 | 0 | 0 | 0 |
| MS2 | −9.960 | 1.334 | −0.915 | −8.587 | 0 | 0 |
| MS3 | 3.327 | −2.018 | 1.068 | 0 | 0 | 0 |
| MS4 | −7.436 | −0.783 | 2.959 | 0 | 0 | 0.237 |
| MS5 | −5.774 | 4.606 | −4.881 | 0 | −3.755 | −5.575 |
| MS6 | −7.587 | −0.569 | −6.428 | −1.185 | 0 | −6.019 |
| MS7 | −8.395 | −2.652 | 2.479 | −0.832 | 0 | 0 |
| MS8 | −7.511 | 3.223 | 0.710 | 0 | 0 | 0 |
| MS9 | −6.558 | 9.565 | 3.786 | 0 | −20.989 | 0 |
| BS1 | −11.226 | −3.558 | 0.899 | −21.651 | 3.505 | 0 |
| BS2 | 3.009 | −0.892 | 6.874 | 0 | 0 | 1.667 |
| BS3 | −9.907 | 2.885 | −2.446 | −1.032 | 0 | −2.004 |
| BS4 | −10.032 | 3.291 | 0.352 | 0 | 0 | 0 |
| BS5 | −9.483 | −4.497 | 3.686 | −10.185 | 3.437 | 2.683 |
| BS6 | −10.513 | 3.552 | −2.799 | −1.244 | 0 | 0 |
| BS7 | −9.400 | 5.219 | −2.592 | 0 | −0.551 | 0 |
| BS8 | −1.327 | −3.702 | −1.609 | 0 | 2.673 | 0 |
| BS9 | −7.488 | −1.205 | −5.744 | −3.558 | 0 | −4.372 |
| BS10 | −11.026 | −0.062 | −3.100 | −16.404 | 0 | −0.797 |
| BS11 | −8.365 | 1.145 | −0.748 | −6.938 | 0 | 0 |
| BS12 | −4.837 | 6.407 | 3.225 | 0 | −12.855 | 0 |
| BS13 | −4.864 | −4.774 | −4.248 | 0 | 0 | 0 |
| BS14 | −0.612 | −2.777 | −3.615 | 0 | 0 | −5.485 |
| BS15 | −9.403 | 3.468 | −2.028 | 0 | 0 | −0.856 |
| KT1 | −9.955 | 1.870 | 0.468 | −7.369 | 0 | 0 |
| KT2 | −10.164 | 0.004 | −2.983 | −12.489 | 0 | −1.787 |
| KT3 | −2.164 | 0.883 | 5.046 | 0 | 0 | 0 |
| KT4 | −10.422 | −3.882 | 0.282 | −10.594 | 1.2813 | 0 |
| KT5 | −11.100 | 4.453 | 0.386 | −10.928 | −4.2657 | 0 |
| KT6 | −1.226 | 3.740 | −0.109 | 0 | 0 | 0 |
| KT7 | −6.606 | −6.269 | −0.608 | −0.164 | 2.363 | 0 |
| KT8 | −9.858 | 3.351 | −0.238 | −3.083 | −1.333 | 0 |
| KT9 | −7.257 | −3.439 | 6.139 | 0 | 1.189 | 9.004 |
| KT10 | −8.638 | 5.197 | 1.039 | 0 | −0.883 | 0 |
| KT11 | −9.057 | 0.498 | −3.782 | −7.295 | 0 | −3.882 |
| KT12 | −8.141 | 5.118 | 3.562 | 0 | −4.118 | −0.215 |
| KT13 | −3.332 | −3.059 | −2.231 | 0 | 0 | 0 |
| KT14 | −5.959 | −0.173 | −2.480 | −11.464 | 0 | −0.857 |
| CP1 | −5.059 | −2.849 | 4.737 | 0 | 0 | 0 |
| CP2 | −5.852 | 0.891 | 3.246 | 0 | 0 | 0 |
| CP3 | −9.621 | 2.315 | −0.623 | 0 | 0 | 0 |
| CP4 | −10.598 | 2.492 | −0.640 | 0 | 0 | 0 |
| CP5 | −6.902 | −3.051 | −0.116 | 0 | 2.161 | 0 |
| CP6 | −6.999 | −6.115 | −1.789 | −0.657 | 7.923 | 0 |
| CP7 | −9.002 | 1.380 | −5.604 | −10.456 | 0 | −1.136 |
| CP8 | −2.694 | −4.406 | −1.410 | 0 | 2.859 | 0 |
| CP9 | −7.449 | 5.332 | 5.023 | 0 | −5.683 | 0 |
| CP10 | −10.576 | −2.898 | −3.105 | −20.054 | 0 | 0 |
| CP11 | −10.249 | −3.175 | −0.456 | −19.742 | 0 | 0 |
| CP12 | −10.576 | −4.470 | 0.979 | −13.762 | 6.030 | 0 |
| CP13 | −9.352 | −0.128 | −1.566 | −1.162 | 0 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodríguez-Martínez, C.C.; Cubilla-Montilla, M.; Vicente-Galindo, P.; Galindo-Villardón, P. Sparse STATIS-Dual via Elastic Net. Mathematics 2021, 9, 2094. https://doi.org/10.3390/math9172094
Rodríguez-Martínez CC, Cubilla-Montilla M, Vicente-Galindo P, Galindo-Villardón P. Sparse STATIS-Dual via Elastic Net. Mathematics. 2021; 9(17):2094. https://doi.org/10.3390/math9172094
Chicago/Turabian StyleRodríguez-Martínez, Carmen C., Mitzi Cubilla-Montilla, Purificación Vicente-Galindo, and Purificación Galindo-Villardón. 2021. "Sparse STATIS-Dual via Elastic Net" Mathematics 9, no. 17: 2094. https://doi.org/10.3390/math9172094
APA StyleRodríguez-Martínez, C. C., Cubilla-Montilla, M., Vicente-Galindo, P., & Galindo-Villardón, P. (2021). Sparse STATIS-Dual via Elastic Net. Mathematics, 9(17), 2094. https://doi.org/10.3390/math9172094