1. Introduction
Recommendation systems play a crucial role in various online platforms, especially in helping users find the content of interest from massive amounts of information. Traditional recommendation methods such as CF [
1] typically rely on long-term user–item interaction data. However, these methods often perform poorly when user information is insufficient or unavailable. To address this issue, session-based recommendation (SBR) [
2] has been proposed, which aims to predict items of interest to users based solely on anonymous behavior sequences within the current session.
Early SBR methods can be broadly categorized into similarity-based models [
1] and sequence-based models [
3]. Similarity-based models rely on co-occurrence information of items within the current session but neglect sequential behavior patterns. Sequence-based models infer user preferences by predicting possible behavioral paths between items, yet their computational cost becomes prohibitive when the number of items is large. With the development of deep learning, recurrent neural networks (RNNs) have been successfully applied to session-based recommendation tasks, such as GRU4REC [
4] and NARM [
5]. These methods leverage pairwise item-transition relationships to model user preferences and have achieved significant progress. However, RNN models are limited in their ability to capture complex item-transition patterns.
Recently, graph neural networks (GNNs) [
6] have been introduced into session-based recommendation. For example, SR-GNN [
7] utilizes graph structures to capture long-range dependencies between items; GC-SAN [
8] combines GNNs with self-attention mechanisms; FGNN [
9] models the information flow between items through a multi-weight graph attention layer. Wang et al. proposed GCE-GNN [
10], which expanded the scope of user preference modeling by integrating item-transition information from both the current and historical sessions, achieving significant performance improvements. MAE-GNN [
11], on the other hand, employs multi-head attention mechanisms to capture user preferences from multiple dimensions. Despite the strong performance of GNN-based methods in SBR tasks, they still face certain limitations. For example, existing models may introduce irrelevant session information when modeling global user preferences, or suffer from imbalanced positive and negative samples during training. Moreover, the fusion of information from local and global graph embeddings still has room for improvement.
On the other hand, self-supervised learning (SSL), particularly contrastive learning (CL) [
12], has gradually become a research hotspot in recommendation systems. Zhou et al. [
13] applied SSL to recommendation systems and improved representation learning through mutual information maximization. Xia et al. [
14] leveraged dual-view learning to model intra- and inter-session information, enhancing model performance. However, in SBR tasks, selecting the appropriate contrastive learning perspective remains a challenging problem due to the limited information available in each session.
To address these issues, we propose a novel Multi-View Graph Contrastive Learning Neural Network (MVGCL-GNN). Unlike traditional methods, MVGCL-GNN comprehensively models multi-view information by constructing a global category graph, a global item graph, and a session graph. The global category graph captures category-level correlations, the global item graph aggregates item-transition patterns across sessions, and the session graph models item dependencies within the current session. By introducing graph-based contrastive learning, MVGCL-GNN reduces noise interference and improves embedding quality when learning global and local item representations. Furthermore, MVGCL-GNN adopts an attention-based embedding fusion mechanism to enhance interactions between global- and session-level information, providing richer feature representations for user preference modeling.
The main contributions of this work are summarized as follows:
We significantly improve model performance in complex session scenarios by performing contrastive learning on the information from global and session graphs.
We introduce a unified modeling of category and item graphs, enabling multi-dimensional representations of user preferences.
Extensive experiments on multiple real-world datasets demonstrate that MVGCL-GNN outperforms state-of-the-art methods on various evaluation metrics.
4. Proposed Method
4.1. Methodological Rationale
The design of MVGCL-GNN is guided by the need to comprehensively model various forms of dependencies in session-based recommendation. Traditional RNN-based models such as GRU4Rec and NARM primarily capture local sequential signals within sessions, while early GNN-based approaches like SR-GNN focus on item transitions without considering global patterns or semantic context.
To overcome these limitations, we propose a multi-view framework that integrates three complementary perspectives: session-level short-term transitions, global item co-occurrence, and category-level semantic relationships. This setup allows the model to learn both fine-grained and high-level patterns that affect user behavior. We further introduce contrastive learning to enhance embedding robustness, especially under data sparsity or noise.
We also considered simpler architectures that use only the session graph or a single global graph (global item graph or global category graph). However, these designs performed worse in our ablation studies, indicating that they lack the flexibility and depth needed to fully capture user behavior. For this reason, our final model combines multiple views and learning strategies to achieve a better balance between accuracy and robustness.
4.2. Model Overview
We propose a novel model for session-based recommendation called MVGCL-GNN. The model aims to capture user preferences in the current session by modeling item transitions at both the session level and the global level, thereby providing more accurate recommendations.
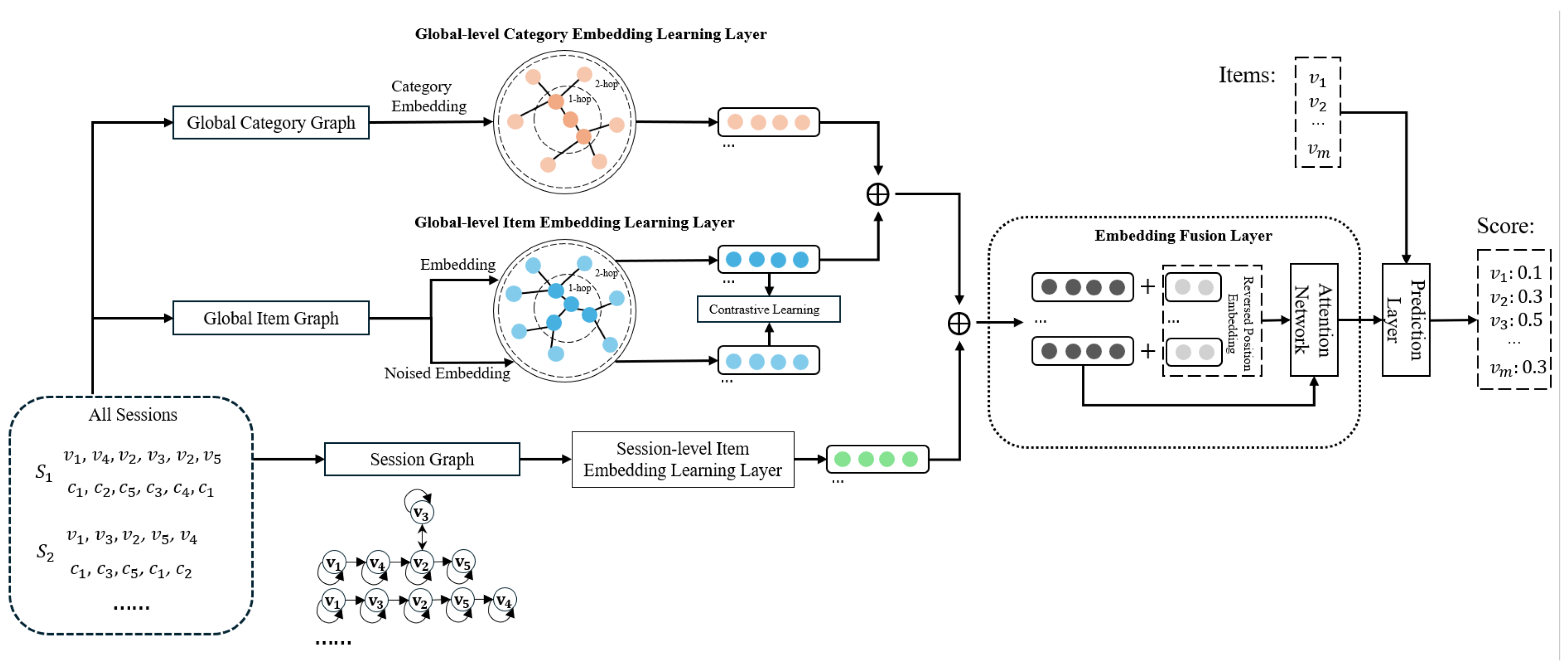
Figure 3 illustrates the architecture of the proposed model, which consists of five main components:
(1) Global-level Item Embedding Learning Layer: This component learns global-level item embeddings across all sessions based on the global item graph structure. It utilizes Graph Convolutional Networks (GCNs) combined with a contrastive learning mechanism to enhance the embeddings.
(2) Session-level Item Embedding Learning Layer: Using Graph Attention Networks (GATs) on the session graph, this component learns session-level item embeddings for the current session.
(3) Global-level Category Embedding Learning Layer: A global category graph is constructed to model the relationships between item categories. Graph Convolutional Networks are applied to recursively aggregate the embeddings of each node from its neighbors, thereby learning category-level item embeddings. Additionally, a contrastive learning module is introduced, where noised embeddings are generated and compared against true embeddings to enhance the robustness of category embeddings and mitigate the impact of noise.
(4) Embedding Fusion Layer: This layer fuses global category embeddings, global item embeddings, and session-level item embeddings. A novel attention mechanism is employed to process the fused features to capture user preferences in the current session.
(5) Prediction Layer: This component outputs the predicted scores for candidate items to be recommended.
Next, we will elaborate on each component in detail.
4.2.1. Global-Level Item Embedding Learning Layer
Following prior works, we adopted a global item embedding learning module based on Graph Convolutional Networks (GCNs). This module is designed to extract item transition information from the global item graph, providing rich contextual support for the recommendation task. Items in the global item graph may appear in multiple sessions, and the transition information across these sessions is highly valuable for the current recommendation task. To fully utilize this information, we combine session-aware attention mechanisms with message propagation and aggregation operations to extract item embeddings from the global item graph.
We perform a weighted aggregation of the features of the neighboring nodes to generate the neighborhood feature representation of
v as follows:
where
is the attention weight representing the importance of different neighbors, and
is the unified embedding representation of node
. To highlight the relevance to the preferences in the current session, we compute the attention weight
using a session-aware attention mechanism as follows:
where LeakyReLU is the activation function,
is the weight of the edge
in the graph,
and
are trainable parameters, ⊙ denotes element-wise multiplication, and ‖ denotes vector concatenation. The session feature representation
is computed by averaging the representations of all items in the session:
This process dynamically adjusts the importance of neighboring nodes, assigning higher influence to nodes more relevant to the current session preferences. To ensure interpretability of the weights, we normalize the attention weights of the neighborhood nodes using the softmax function:
After completing the weighted aggregation of neighborhood features, the item representation is formed by combining its own features
and the neighborhood features
:
where
is a trainable weight matrix, and ReLU is the activation function used to introduce non-linearity.
To capture high-order neighborhood information, we extend the message propagation and aggregation process to a multi-layer architecture. By stacking multiple propagation layers, the model can integrate contextual information from farther neighbors. The representation of item
v at the
k-th layer is generated as
where
is the representation of item
v generated from the
-th layer,
is the neighborhood representation of
v, and
is the aggregation weight for the
k-th layer. At the initial step (
), the item representation
is the raw embedding.
Through layer-by-layer aggregation, the model captures high-order structural information of the items, enabling the embedding representation to incorporate not only its own features but also the transition information of the items in the global item graph.
4.2.2. Session-Level Item Embedding Learning Layer
To better capture the dynamic relationships of items in the session graph, we employ a Graph Attention Network (GAT) to learn the embeddings of items within the session graph. In the session graph, item nodes are connected by edges, representing pairwise transition relationships between items in the same session. Through the attention mechanism, the model can dynamically assign importance weights to neighboring nodes, enabling more precise item embeddings.
Specifically, for a given node
in the session graph, the importance weight of its neighbor
is computed using element-wise multiplication and a non-linear transformation:
where
represents the importance weight of neighbor
to node
,
denotes the relationship between
and
,
is the weight vector, and ⊙ denotes element-wise multiplication.
For different relationships, we trained four distinct weight vectors:
,
,
, and
, corresponding to incoming edges, outgoing edges, bidirectional edges, and self-loops, respectively. To ensure the comparability of weights between nodes, the computed attention weights are normalized using the softmax function:
where
is the normalized attention weight. Due to the asymmetry of neighborhoods,
, reflecting the asymmetric nature of the attention weights.
After obtaining the attention weights, the final feature representation of node
is generated through the weighted aggregation of its neighbors’ features:
This process dynamically adjusts the importance of neighboring nodes via the attention mechanism, effectively reducing noise and improving the model’s ability to capture item transition relationships. Additionally, it integrates the information of each node with its neighbors, yielding a local item embedding representation for every node.
4.2.3. Global-Level Category Embedding Learning Layer
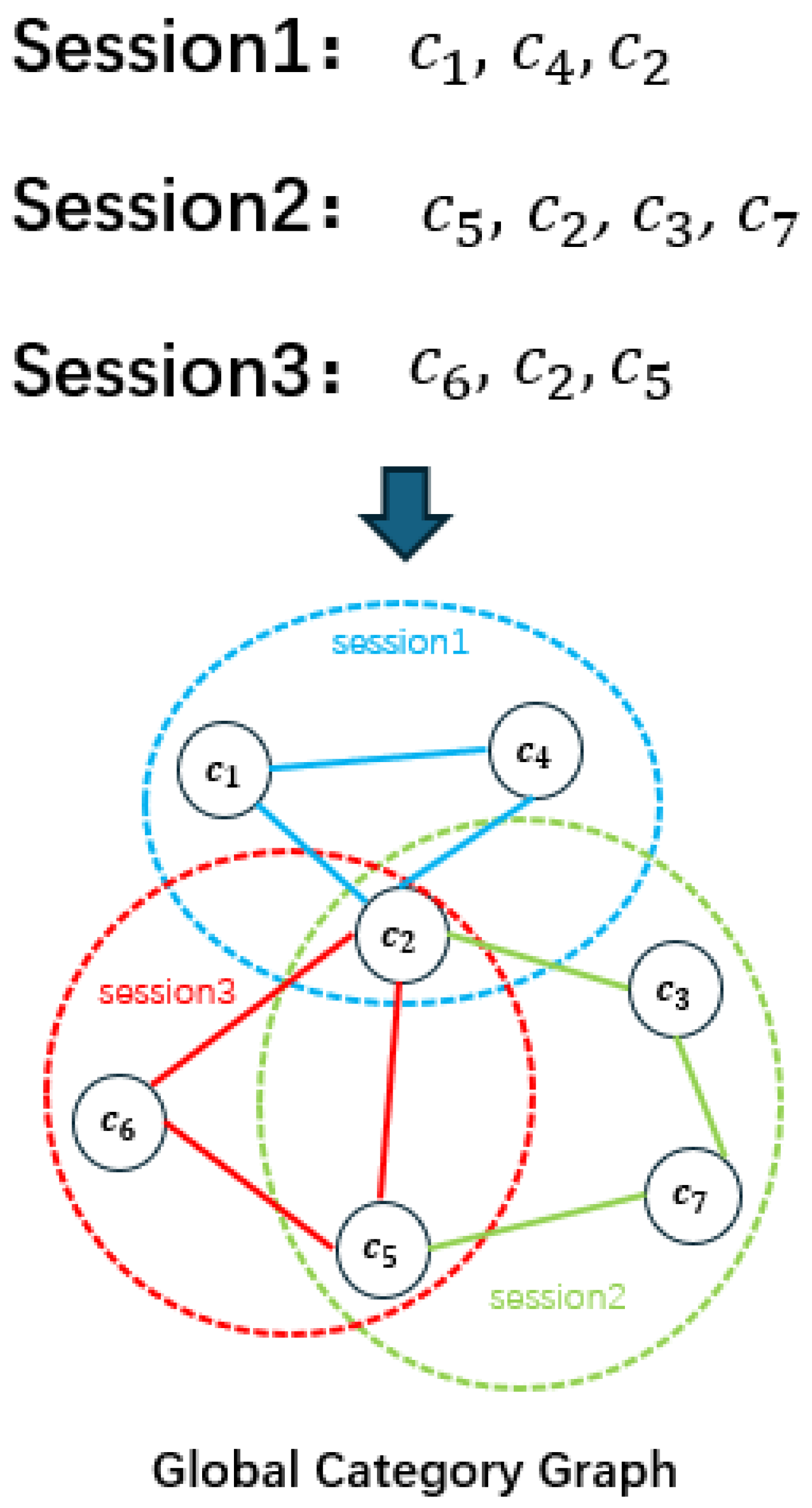
To model global transition relationships between categories and enhance the semantic representation for recommendation, we design a global category embedding learning module based on Graph Convolutional Networks (GCNs). This module aims to extract transition information between categories from the global category graph, providing rich contextual support for the recommendation task. The global category graph is constructed by integrating the category transition information across all sessions, similar to the construction of the global item graph.
For any category
c, its neighborhood
includes all directly connected category nodes. The neighborhood feature representation of category
c is generated through weighted aggregation of the features of neighboring nodes:
where
is the attention weight representing the importance of different neighbors, and
is the unified embedding representation of category
. To emphasize the relevance of categories to the semantic preferences in the current session, we compute the attention weight
using a session-aware attention mechanism as follows:
where
represents the weight of the edge between
and
,
and
are trainable parameters, ⊙ denotes element-wise multiplication, and ‖ denotes vector concatenation. The session feature
is calculated as the average feature of all categories in the session:
To adjust the importance of neighboring nodes and better match the preferences of the current session, the attention weights of neighboring nodes are normalized using the softmax function:
After completing the weighted aggregation of neighborhood features, the category representation is formed by combining its own features
and the neighborhood features
. To capture deeper connections between categories, we extend the aggregator to a multi-layer architecture. By stacking multiple aggregation layers, the model integrates information from farther neighbors, enabling it to capture higher-order connectivity and enhance the representation of global category embeddings. The representation of category
c at the
k-th layer is defined as
where
is the aggregation weight for the
k-th layer, ReLU is the activation function used to introduce non-linear features, and
is generated from the
-th layer.
Through layer-by-layer aggregation, the model captures high-order structural information of categories, enabling the embeddings to integrate not only their own features but also the transition information between categories in the global category graph. This process enriches the semantic representation of the model.
4.2.4. Contrastive Learning Module
To enhance the robustness and generalization of global item embeddings, we introduce a simple graph contrastive learning module inspired by SimGCL [
24]. Specifically, we constructed two different views of item embeddings: one from the original global item graph and one from a perturbed version with random noise added to the normalized embeddings.
Let
denote the item-level embeddings obtained from the original global item graph, and
denote the embeddings from the perturbed view. Following SimGCL, the perturbed view is computed as
where
is a hyperparameter controlling the noise intensity, and
represents
normalization. This additive perturbation allows the model to contrast each item with its noisy counterpart without relying on complex graph augmentations.
We compute the InfoNCE-based contrastive loss at the item level to maximize the agreement between the two views:
where
are
-normalized item embeddings from two views,
denotes the dot-product similarity, and
is a temperature hyperparameter.
This loss encourages each item embedding from the original view to be close to its noisy version while remaining distinguishable from other items, thus improving the stability of the item representation under structural perturbations. The hyperparameter is selected by validation and follows the SimGCL design guidelines.
4.2.5. Embedding Fusion Layer
After obtaining the global embeddings and session embeddings, it is necessary to fuse these pieces of information for the recommendation task. In this work, we adopt an attention-based fusion mechanism to combine the embeddings from three perspectives: the session-level item embedding, the global item embedding, and the global category embedding. This design is motivated by recent advances in multi-view learning [
29], where attention has been shown to be an effective and lightweight approach to capture the relative importance of multiple input representations in a data-adaptive way.
Compared with alternatives like cross-attention [
30] or gating networks [
31], our soft attention mechanism provides a balance between representation flexibility and computational efficiency. Although cross-attention introduces a quadratic complexity and is more suitable for sequence-to-sequence alignment, our design focuses on weighting three fixed-length views. In addition, gating mechanisms typically require manually predefined interactions and are sensitive to feature scale, which may limit robustness in noisy sessions. In contrast, soft attention can learn adaptive weights for each view component in an end-to-end fashion with minimal parameter overhead.
First, we apply dropout to the global item embeddings and global category embeddings, and then perform a sum-pooling operation by combining them with the session embeddings. The formula is as follows:
where
represents the fused item embedding that integrates multi-level information,
and
are the global item embeddings and global category embeddings, respectively, and
is the session embedding. Through this fusion operation, information from different levels is effectively integrated, providing a comprehensive foundation for generating session representations in the subsequent steps.
Considering that items clicked later in the session and noise filtering are usually more valuable for recommendations, we introduce a position-based attention mechanism. First, the sequential session data are input to the graph neural network, from which we obtain the representations of the items in the session, denoted as
Next, we generate an inverse position embedding matrix for all items:
where
represents the inverse position vector of item
i. Then, we concatenate the item embeddings with the position embeddings and perform a non-linear transformation to generate the fused position embeddings:
where
,
are learnable parameters, and ‖ denotes concatenation. The inverse position information can more accurately reflect the contribution of items to the target recommendation, as items closer to the target item generally have a greater impact on the prediction result.
The average of the session embeddings is obtained by the following formula:
To further optimize the fused item embeddings, we use a soft attention mechanism to learn the corresponding weights. The attention score for each item is calculated as
where
, and
are learnable parameters. To address the vanishing gradient problem, the activation function is chosen to be ReLU.
Finally, the session embedding is generated by the following formula:
where
S is the final representation of the current session, which integrates global item embeddings, global category embeddings, and session embeddings, while also incorporating position and sequential information. Through this mechanism, the model is able to comprehensively consider the global transition patterns between items, category associations, and session context relationships, leading to more accurate recommendation results.
4.2.6. Prediction Layer
After generating the session representation
S, the Prediction Layer is responsible for calculating the recommendation probability of each item based on the candidate item’s initial embedding and the session representation. Specifically, by performing a dot-product operation between the session representation and each item’s embedding, and combining it with the softmax function, the recommendation probability is obtained:
where
represents the probability that item
will be selected in the current session,
is the embedding representation of item
, and
S is the session representation.
The model’s optimization objective uses the cross-entropy loss function, which is defined as
where
y is the one-hot encoded vector of the target item,
indicates whether item
is the next clicked item, and
m is the total number of candidate items.
To further enhance the model’s robustness, the Prediction Layer incorporates a self-supervised contrastive learning (SSL) loss as an auxiliary optimization objective for the recommendation task. The overall loss function is defined as
where
is a hyperparameter that balances the recommendation loss and the contrastive learning loss. Through this joint optimization objective, the model can learn from both supervised signals and self-supervised signals, thereby improving the accuracy and robustness of the recommendation results.
5. Experiments
To systematically validate the effectiveness of the MVGCL-GNN framework, we designed a comprehensive experimental protocol addressing five critical research questions:
RQ1: Does MVGCL-GNN achieve superior recommendation accuracy compared to state-of-the-art session-based recommendation (SBR) baselines?
RQ2: How do the global graph with global-level encoder and the category graph with category-aware encoder contribute to performance improvement? How does MVGCL-GNN perform with varying neighborhood propagation depths (k)?
RQ3: What quantitative impact do positional vector embeddings have on the model’s representational capability?
RQ4: How does MVGCL-GNN perform under different aggregation operations?
RQ5: To what extent do regularization hyperparameters (particularly dropout rates) influence the accuracy of MVGCL-GNN?
5.1. Experimental Setup
5.1.1. Dataset
This study uses two publicly available e-commerce datasets for experiments, namely Tmall and Nowplaying. The Tmall dataset is sourced from the IJCAI-15 competition and contains shopping log data from anonymous users on the Tmall platform, where each item is associated with category labels. The Nowplaying dataset describes users’ music listening behaviors and comes from [
32]. This dataset also includes category information for songs. Both datasets have been widely used in research on session-based recommendation (SBR) systems.
To ensure fairness in the experiments, the same preprocessing steps [
7,
8] were applied to both datasets. Specifically, sessions with a length of 1 were filtered out, as well as items that appeared fewer than 5 times. Category information was also considered, and items without category labels were filtered out. Then, data from the previous week were used as the test set, with the remaining data used for training. Additionally, for each session data
and the corresponding category sequence
, training and test sequence pairs with labels were generated through sequence splitting. For example,
Table 2 shows the statistics of each dataset after preprocessing.
5.1.2. Baselines
To evaluate the effectiveness of our proposed MVGCL-GNN model, we compared it with the following classic models and state-of-the-art deep learning recommendation algorithms:
5.1.3. Evaluation Metrics
To evaluate the performance of the model, we referred to previous studies [
7,
9,
10,
20] and adopted two widely used Top-K recommendation evaluation metrics: P@K (Precision) and MRR@K (Mean Reciprocal Rank).
5.1.4. Parameter Settings
To ensure a fair comparison across all models, we adopted the same hyperparameter settings as previous studies [
7,
10,
14,
20]. Specifically, the dimension of the latent vectors was fixed to 100, and the mini-batch size was set to 100 for all models. For the CSRM model, the memory size was also set to 100, consistent with the batch size. For the FGNN model, the number of GNN layers was set to 3, with 8 heads for the multi-head attention mechanism. All model parameters were initialized using a Gaussian distribution with a mean of 0 and a standard deviation of 0.1. In terms of optimization, we used the Adam optimizer with an initial learning rate of 0.001, which decays by a factor of 0.1 every 3 epochs. To prevent overfitting, an L2 regularization term was applied with a penalty coefficient of
. Additionally, the dropout rate was searched over the range
and the best value was selected based on performance on a validation set, which is a random 10% subset of the training set. For graph construction, the number of neighbors was set to 12, meaning that each item had a maximum of 12 neighbors. The maximum distance (
) between adjacent items was set to 3, controlling the range of information propagation in the graph.
5.2. Comparison with Baselines (RQ1)
To validate the overall performance of MVGCL-GNN, we compared it with several representative baseline models.
Table 3 shows the experimental results in terms of metrics such as P@10 and M@20, with the best results highlighted in bold. It can be observed that MVGCL-GNN achieved significant improvements in most metrics across all datasets, demonstrating its effectiveness and superiority.
As shown in
Table 3, MVGCL-GNN outperformed other methods on the Tmall and Nowplaying datasets, particularly in P@10 and M@20, where it significantly led. This result indicates that MVGCL-GNN is effective in capturing the complex dependencies between user behaviors and items.
Traditional methods typically perform poorly. POP and Item-KNN are early traditional recommendation methods, while FPMC makes recommendations based on Markov chains. Their performance is lower than that of MVGCL-GNN, mainly because they do not leverage advanced deep learning networks and cannot effectively model complex user interest patterns. In contrast, MVGCL-GNN introduces category graphs and noise addition to the global graph, and optimizes the global graph representation using simple graph contrastive learning (SimGCL), significantly improving recommendation performance.
Compared with traditional methods, recent deep learning approaches exhibit stronger performance in capturing complex user behaviors. Although GRU4Rec performs worse than Item-KNN on the Diginetica and Nowplaying datasets, it still demonstrates the effectiveness of RNNs in sequence modeling. However, GRU4Rec only focuses on the relationships between items in the sequence, neglecting changes in user preferences, which is why it performs worse than NARM and STAMP. NARM is an RNN-based sequential model that considers unidirectional transitions between items, while STAMP uses an attention mechanism and multi-layer perceptron (MLP) networks to capture both global and current user preferences. Despite STAMP’s enhancement through self-attention mechanisms, it still fails to comprehensively model complex inter-session dependencies.
Next, the CSRM method surpassed NARM and STAMP on the Diginetica and Tmall datasets, indicating that considering item transition information from other sessions can significantly improve recommendation performance. However, compared to MVGCL-GNN, CSRM still fails to fully capture global context information. The advantage of MVGCL-GNN lies in the addition of global category graphs and the optimization of global graph embeddings through simple graph contrastive learning (SimGCL). In this way, MVGCL-GNN can better model complex relationships between items and changes in user preferences, further improving recommendation accuracy. Compared to other GNN methods such as SR-GNN and GCE-GNN, MVGCL-GNN significantly enhances the representational power and information richness of the global graph, thus achieving superior performance on the Tmall and Nowplaying datasets.
5.3. The Impact of Different Graph Embeddings (RQ2)
In this section, we present the experiments conducted on two datasets to evaluate the effectiveness of the global item graph, global category graph, and session graph embeddings in the MVGCL-GNN model. We designed four contrast models to analyze the impact of removing specific graph embeddings:
MVGCL-GNN w/o session: MVGCL-GNN without the session graph embedding, relying only on global item graph and global category graph embeddings.
MVGCL-GNN w/o item_g: MVGCL-GNN without the global item graph embedding, using only session graph and global category graph embeddings.
MVGCL-GNN w/o category_g: MVGCL-GNN without the global category graph embedding, using only session graph and global item graph embeddings.
MVGCL-GNN: The full model, which includes all graph embeddings: session graph, global item graph, and global category graph.
Table 4 shows the comparison between these contrast models. The results indicate that including both session and global graph embeddings significantly improves the model’s performance. Specifically, removing the session graph leads to a significant performance drop, suggesting that session-level graph embeddings are crucial for capturing fine-grained item transitions within sessions.
Additionally, removing the global item graph reduces the model’s ability to capture global item co-occurrence relationships, which negatively affects recommendation accuracy. However, the performance drop due to removing the global category graph is relatively smaller. It is worth noting that when the global category graph is included, the model’s performance significantly improves. Incorporating category information helps the model better understand item attribute relationships, thereby providing more contextual information during the recommendation process, which enhances both accuracy and stability.
From the results on the Tmall and Nowplaying datasets, it is evident that MVGCL-GNN outperforms all other contrast models in terms of both P@20 and MRR@20, highlighting the importance of considering category information for improving model performance in recommendation systems. Removing the category graph embedding results in a decline in recommendation accuracy, further proving the critical role of category information in global graph embeddings.
5.4. Impact of Position Vector (RQ3)
In the MVGCL-GNN model, the position vector is used to help the model understand the contribution of each item in a session. Although earlier models, such as SASRec, introduced forward position vectors to improve recommendation performance, we believe that the forward position vector may have limited effectiveness for session-based recommendation (SBR) tasks. To investigate this, we designed several contrast models:
Table 5 presents the performance of the three models across different datasets. Our experiments show that MVGCL-GNN, which incorporates reversed position embedding, outperforms the other two variants.
MVGCL-GNN-NP performs poorly on both datasets. This is likely due to the failure of the forward position vector to effectively capture the item distance within sessions, leading to poorer recommendations, especially in sessions with varying lengths.
MVGCL-GNN-SA performs better than MVGCL-GNN-NP, highlighting the importance of self-attention, which can better weigh the relevance of items. However, despite the improvement, it still does not surpass MVGCL-GNN, as it lacks a nuanced understanding of item position, which is crucial for better session modeling.
When comparing all three models, the reversed position embedding in MVGCL-GNN proves to be more effective. The combination of the reversed position vector and the attention mechanism allows the model to more accurately capture the importance of each item in a session, particularly in sessions with varying lengths. This combination improves the model’s performance, as the attention mechanism helps filter out irrelevant information.
5.5. Impact of Dropout (RQ4)
To prevent the model from overfitting, we adopted dropout as a regularization strategy [
34]. This technique has been proven effective in various neural network architectures [
35,
36], including graph neural networks. The core idea of dropout is to randomly drop a portion of neurons with probability during training, while using all neurons during testing.
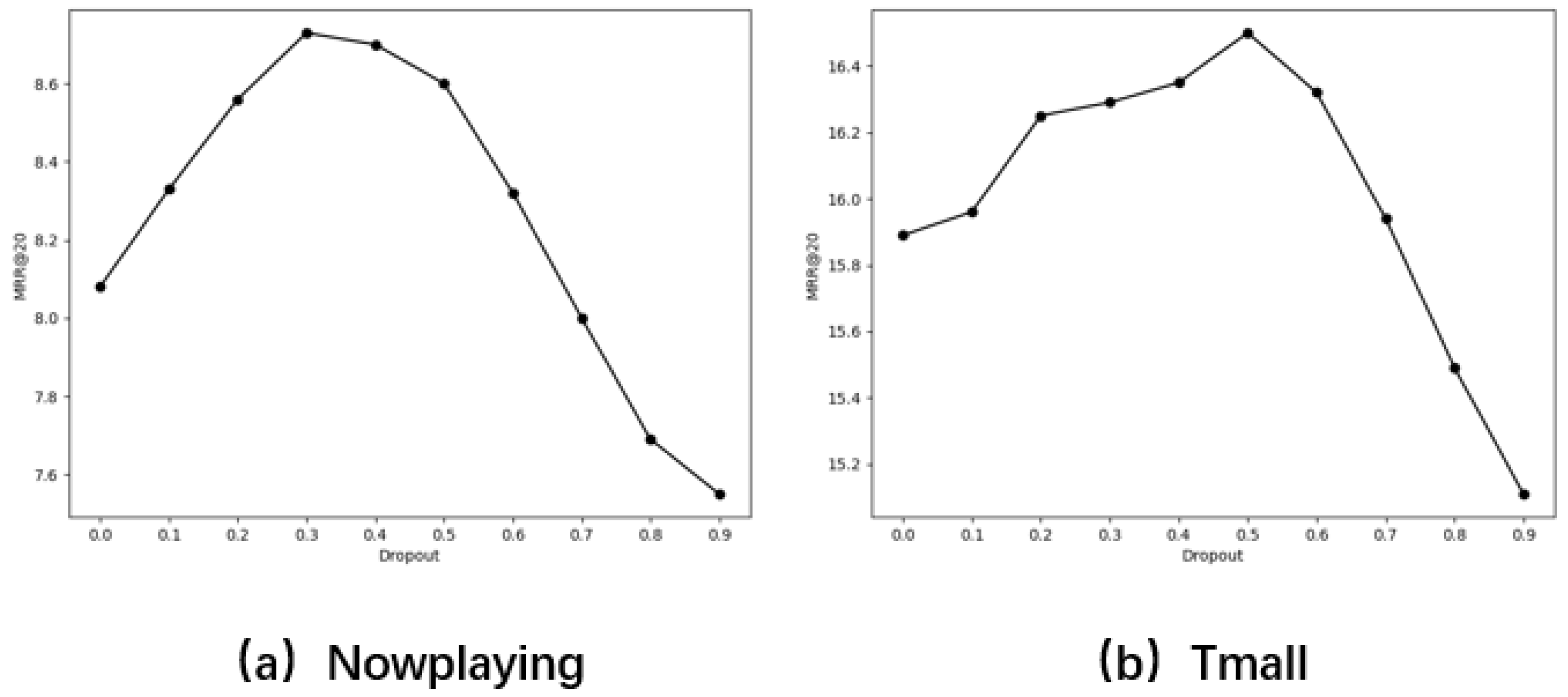
Figure 4 shows the impact of dropout in Equation (
18) on the Nowplaying and Tmall datasets. From the figure, it can be observed that when the dropout rate is low, the model performs poorly, indicating that the data are prone to overfitting. As the dropout rate increases, the model’s performance gradually improves, reaching its optimal value at approximately 0.3 for the Nowplaying dataset and 0.5 for the Tmall dataset. However, when the dropout rate continues to increase, the model’s performance starts to decline, possibly due to the reduced number of available neurons, which limits its learning capacity and negatively affects recommendation quality.
5.6. Model Complexity and Efficiency Analysis (RQ5)
Although MVGCL-GNN incorporates multiple graph encoders and a contrastive learning module, its computational complexity remains manageable due to the modular design and shared parameterization across graph layers.
Specifically, each graph encoder (session, global item, and global category) adopts lightweight GNN architectures with a limited number of layers (typically 2 or 3), which ensures linear time complexity with respect to the number of nodes and edges in each graph. Since the graphs are preconstructed and relatively sparse (as each node retains only top-k neighbors), message passing within the graphs is efficient and parallelizable.
In addition, the contrastive learning module is implemented via SimGCL, which avoids costly graph augmentations and only requires a single forward–backward pass with noise injection. This design significantly reduces training overhead compared to other contrastive GNNs such as GraphCL or GCC.
From a memory perspective, all graph modules operate independently with separate adjacency matrices, allowing efficient memory allocation during training. Batch-wise processing and shared embedding layers further contribute to memory reuse and optimization.
While our model is more complex than single-view GNN methods such as SR-GNN or GCE-GNN, its additional components introduce only a linear increase in parameters and computation. The overall architecture remains scalable to large-scale datasets, as demonstrated in our experiments on the Tmall and Nowplaying datasets, which contain 40,728 and 60,417 unique items, respectively.
We acknowledge the importance of empirical runtime comparisons. We are currently unable to provide direct measurements of training and inference times due to device limitations. Nonetheless, the proposed theoretical analysis and architectural design work together to show that MVGCL-GNN is computationally efficient and can be extended to session-based recommendation tasks in the real world. In future work, we plan to provide a more detailed runtime and memory profiling under different configurations and compare the training efficiency across models.
6. Conclusions and Future Work
In this paper, we propose MVGCL-GNN, a novel session-based recommendation model that integrates multi-view graph construction and simple graph contrastive learning. Specifically, our model builds three types of graph structures—session graph, global item graph, and global category graph—to capture the complex dependencies between items at different semantic levels. We further incorporate a soft attention-based fusion module with position-aware embeddings to generate effective session representations.
To enhance model robustness and alleviate the influence of noise, we adopt a SimGCL-based contrastive learning strategy, which efficiently improves the quality of item embeddings without requiring complex data augmentation. Extensive experiments conducted on two real-world datasets, Tmall and Nowplaying, demonstrate that our model consistently outperforms several state-of-the-art baselines across multiple metrics. The ablation study confirms the individual contributions of each component, including the session graph, global-level graphs, positional embeddings, and the contrastive learning module.
While MVGCL-GNN demonstrates strong performance on e-commerce and music datasets (Tmall and Nowplaying), we acknowledge that the model’s generalizability to other domains such as news, social media, or cold-start scenarios remains unexplored in this study. Nevertheless, the modular architecture of MVGCL-GNN—particularly the separate modeling of global item transitions, category semantics, and session-level behaviors—makes it highly adaptable to other session-based recommendation tasks. In future work, we plan to evaluate MVGCL-GNN on diverse datasets and investigate its robustness under sparse or cold-start conditions, further extending its applicability in real-world recommendation systems. Another limitation of the model is that the constructed graph structures—session graph, global item graph, and global category graph—are all static and do not evolve with time or user behavior. However, in real-world scenarios, user preferences and item relationships are often dynamic and context-dependent. As part of our future work, we plan to explore dynamic graph modeling techniques that can incrementally update graph structures based on recent user interactions. This would enable MVGCL-GNN to better capture evolving session patterns and improve recommendation accuracy in real-time or streaming environments.




{kind=link}
{kind=link}
{kind=link}
{kind=link}