1. Introduction
High-resolution remote sensing imagery has become an important source of geoinformation, playing a vital role in various applications, including environmental monitoring, urban planning, crop identification, building extraction, and the detection of small objects, among others [
1,
2,
3,
4].
These images enable a detailed analysis of spatial and temporal patterns, which are essential for informed decision-making in precision agriculture, natural resource management, and disaster monitoring [
3]. For example, precise vegetation detection enables crop health assessment and irrigation planning. At the same time, urban analysis facilitates the identification of key infrastructure and monitoring changes in population density [
5,
6]. However, the acquisition of high-resolution (HR) images faces significant challenges due to the limitations of remote sensing hardware. These systems are susceptible to platform vibrations, optical diffraction, and noise interference, resulting in blurred images with a loss of information [
4].
To mitigate these limitations, an alternative solution is to apply super-resolution (SR) techniques to enhance the spatial quality of the imagery. This approach is more viable than upgrading satellite and optical sensors, which is often infeasible due to the high cost and complexity of implementing new acquisition systems. Consequently, super-resolution provides a cost-effective alternative for achieving the desired image quality without requiring modifications to the sensing hardware.
Super-resolution techniques have gained popularity as an effective alternative for reconstructing HR images from low-resolution (LR) ones, which enhances image quality without requiring new sensors. A point worth mentioning is that the input LR images are assumed to be free from substantial noise that could interfere with the SR process.
Super-resolution techniques are classified into three main approaches: interpolation-based, reconstruction-based, and deep learning-based methods [
7]. Among the deep learning-based methods, Convolutional Neural Networks (CNNs) have proven to be powerful tools for super-resolution, outperforming traditional methods due to their ability to learn complex patterns in the mapping between HR and LR images in a supervised manner, achieving better results in terms of visual fidelity and recovering high-frequency information more effectively [
8].
Some classic models, such as SRCNN [
9], VDSR [
10], and EDSR [
11], have established themselves as foundational in super-resolution, demonstrating the capability of these methods to reconstruct fine details. Subsequently, SRResNet, proposed by Leding et al. [
12], introduced deep residual architectures, showcasing their ability to recover fine details with greater visual fidelity. Although these networks are effective on natural images, applying these methods to remote sensing images still presents challenges, such as the presence of noise, integrating information across channels, and reconstructing contours and textures.
In addition to CNN-based methods, the literature also includes Generative Adversarial Network (GAN)-based models, which aim to improve perceptual quality through adversarial training. For example, PCA-SRGAN [
13] introduces a principal component projection mechanism into the discriminator, enabling the generator to progressively reconstruct image features from coarse structure to fine texture by leveraging orthogonal projections of facial data, thus enhancing contour clarity and texture realism. Similarly, NVS-GAN [
14] incorporates architectural components such as identity skip connections, bilinear sampling, and depthwise separable convolutions and is optimized using a combination of loss functions (MAE, SSIM, and Huber loss), resulting in efficient models with reduced computational cost.
However, despite their potential, GAN-based models often struggle to produce geometrically accurate textures and may generate visually plausible but spatially incorrect features [
13]. This limitation is particularly problematic in remote sensing tasks, where preserving authentic spatial information is essential for downstream applications, such as land cover classification, change detection, or urban analysis.
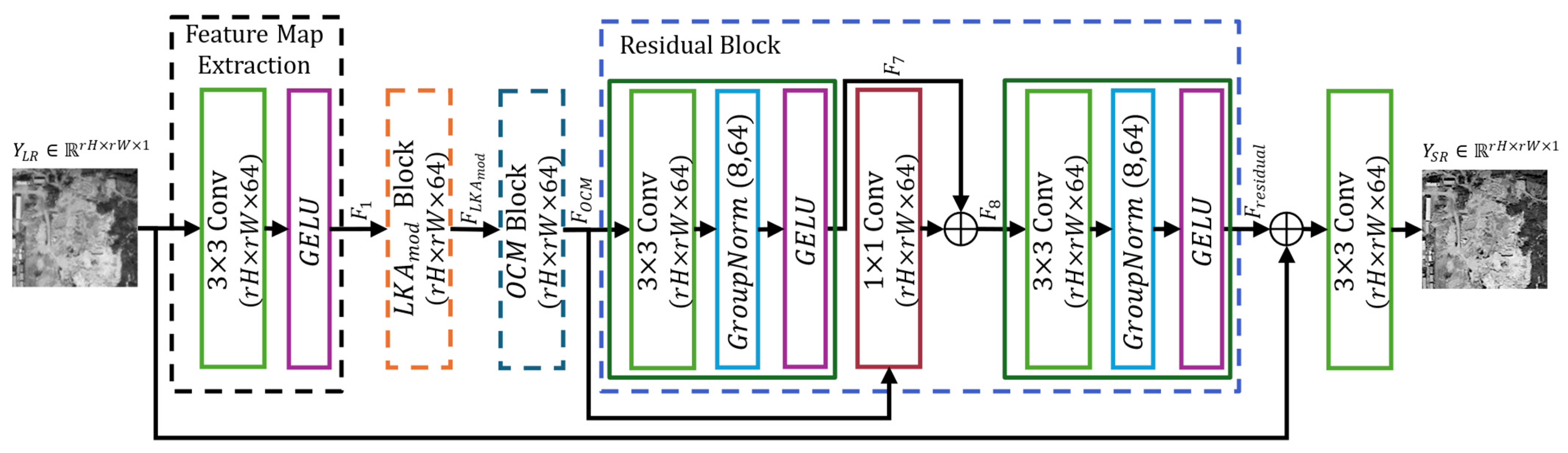
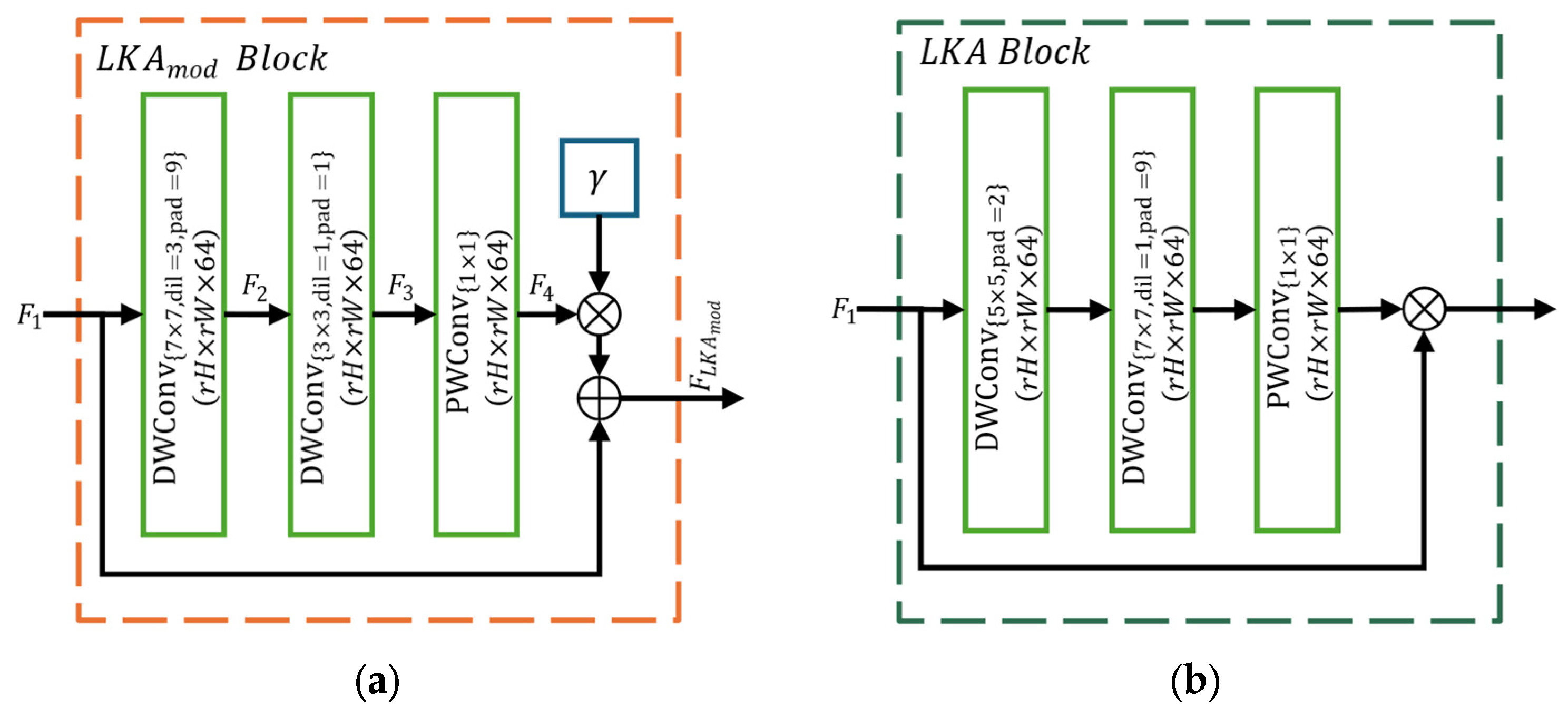
In this study, we propose an SR model based on residual neural networks, incorporating optimized attention modules to enhance the reconstruction of remote sensing images. Our method integrates a modified Large Kernel Attention (LKA) module to capture long-range spatial dependencies through dilated and grouped convolutions and an Optimized Convolutional Module (OCM) module to refine local contours and textures, thereby reducing information loss in high-frequency details. Additionally, the model utilizes a residual architecture with group normalization and skip connections, which enhances gradient propagation and ensures greater training stability.
The remainder of this document is structured as follows:
Section 2 reviews related works, providing context and background on previous research.
Section 3 describes the materials and methods employed in this study, beginning with an overview of the proposed approach and then including details about the network architecture. The results are subsequently presented in
Section 4, with subsections dedicated to ablation tests and the performance of the proposed method using the Remote Sensing Super-Resolution Dataset (RRSSRD) [
15]. Finally,
Section 5 discusses the findings, followed by the conclusions in
Section 6.
4. Experimental Results and Discussion
This section presents the results of the experiments conducted to evaluate the effectiveness of the proposed OARN model. Various tests were performed using the RRSSRD dataset, with performance assessed through metrics such as PSNR, SSIM, and EPI, enabling the evaluation of both perceptual quality and structural fidelity of the generated images.
The analysis is organized into six subsections.
Section 4.1 examines the effectiveness of attention modules using visual activation maps at various training epochs.
Section 4.2 presents an ablation study to identify the contributions of the model’s key components.
Section 4.3 investigates the impact of different optimizers and loss functions through a sensitivity analysis.
Section 4.4 provides a comparative evaluation against state-of-the-art methods.
Section 4.5 discusses qualitative visual results, and
Section 4.6 summarizes the overall performance trends observed across all experimental settings.
4.1. Attention Module Effectiveness
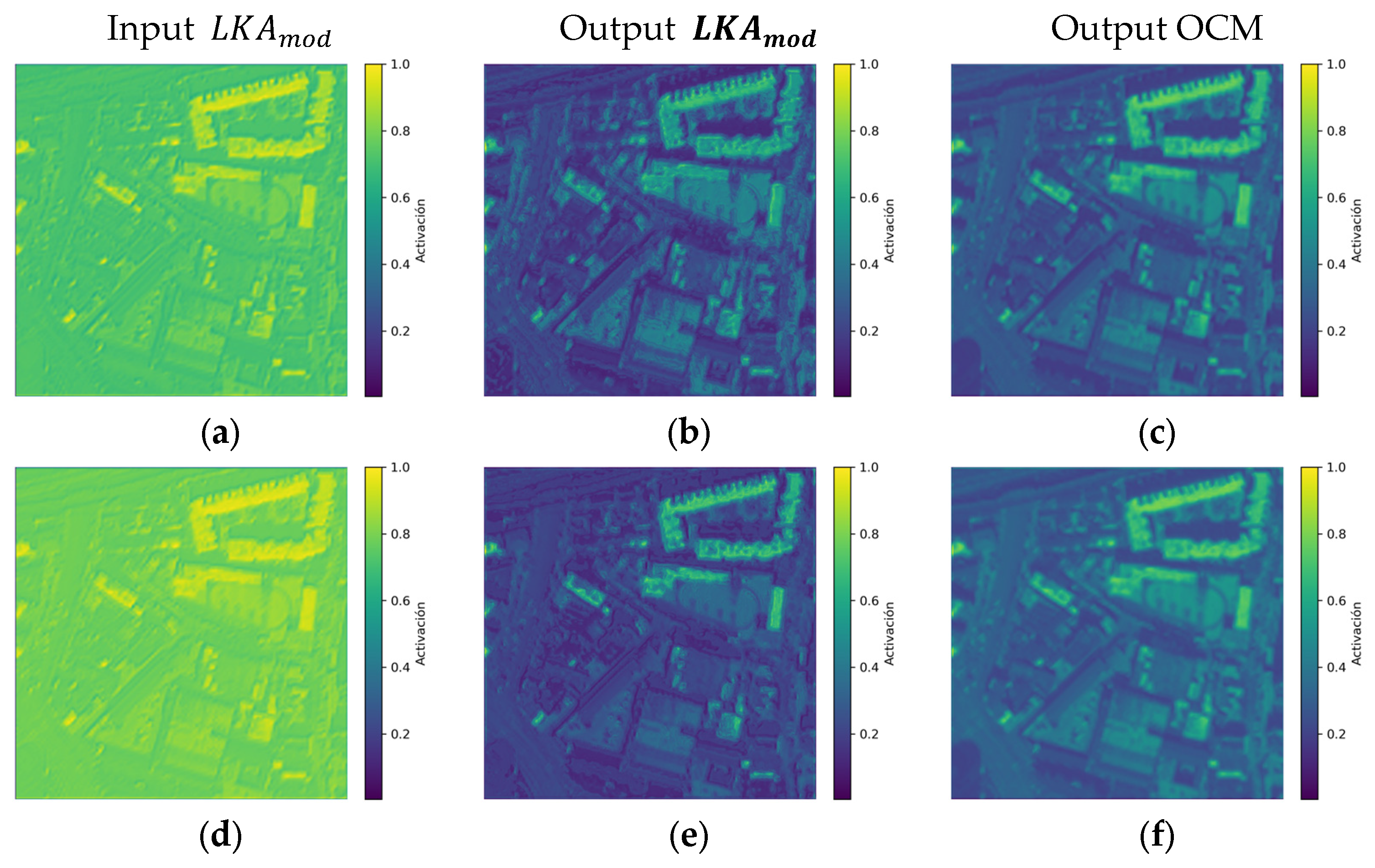
To visually verify that the attention modules integrated into the proposed architecture are effectively learning relevant features, we applied LayerCAM [
42] to multiple intermediate layers across different training epochs. In particular, we compare activations at epochs 5 and 60 for the OARN (AdamW + L1) model.
Figure 4 clearly illustrates how the activations of the attention modules evolve as the OARN (AdamW + L1) model is trained. At epoch 5, the output of the
module (
Figure 4b) exhibits diffuse and less defined activations, indicating that the model is still in an early learning stage, without focused attention on relevant regions.
In contrast, at epoch 60, the output of the
LKAmod (
Figure 4e) displays much more concentrated attention, where the activation maps clearly highlight the contours of buildings, roads, and other important geometric structures, demonstrating that the module progressively learns to identify relevant spatial patterns. Likewise, in the output of the OCM module (
Figure 4f), the attention is focused on structurally and semantically valuable regions, such as street intersections and building edges, indicating that this module has improved its ability to direct attention to important elements in the image.
During the visual analysis conducted with LayerCAM on the activation maps generated at various stages of training, specific limitations in the performance of the proposed attention modules were identified. One of the main observations was that the model has difficulty distinguishing edges and relevant structures in images predominantly composed of green areas and mountainous regions. In such scenes, urban elements like rooftops, building contours, or roads are often partially obscured or softened by vegetation, making precise spatial detection more challenging. This issue particularly affects the LKAmod module during early training stages.
At epoch 5, it was observed that in several cases, the module failed to correctly distinguish contours or relevant structures when the buildings were surrounded by dense vegetation or when they consisted of large constructions with irregular or oval geometric shapes. The model’s learning improves significantly by epoch 60, and exhibits more concentrated and effective attention over structurally significant regions. However, the OCM module was occasionally unable to adequately recover the information previously detected by , which limits the final refinement of features. Out of the 160 images analyzed, 47 cases at epoch 5 were identified where and OCM jointly failed to recover the relevant regions of the image. At epoch 60, despite the LKA correctly identifying spatial patterns in most images, approximately 23 images were found in which the OCM module failed to reinforce or reconstruct the captured information effectively.
These limitations suggest that, although the proposed attention modules significantly improve the model’s performance in urban or structurally well-defined environments, their behavior may still be compromised in scenarios dominated by natural or homogeneous surroundings.
4.2. Ablation Test
To evaluate the impact of the different modules within the proposed model, an ablation study was conducted using the four test sets defined in
Section 3.3.1, focusing on a
scaling factor, as it represents a more constrained scenario in terms of information recovery. Different model variants were trained and compared by removing or replacing key components such as LKA, OCM, DCANet [
27], and the residual blocks, as well as testing alternative attention mechanisms like CBAM [
23] and SE [
22]. To ensure a fair evaluation, all variants were trained under the same configuration, using the L2 loss function defined in Equation (17) and the Stochastic Gradient Descent (SGD) optimizer (SGD + L2), both of which are widely adopted as a baseline setup in super-resolution tasks. The SGD optimizer was implemented with a learning rate of 0.0001, a momentum of 0.9 and a weight decay of
. Moreover, the batch size was set to 64, and the number of training epochs was set to 60.
Table 2 shows the configuration of the tested models. The first columns (
and
) indicate whether spatial attention mechanisms are present or absent before the OCM block. The OCM+ column specifies the attention mechanism integrated within the OCM block, replacing the
module indicated in Equation (9). The final column indicates whether residual blocks were retained within the OCM block.
Table 3 summarizes the average performance of all variants across the four test sets, using PSNR, SSIM, and EPI metrics, which reflects the robustness of the models when different acquisition sensors are employed. The results show that the OARN (SGD + L2) model achieves the best overall performance. The model incorporating the modified LKA module (
achieved superior performance across evaluation metrics, as evidenced by the comparison between OARN (SGD + L2) and variant Modification 3. Specifically, OARN (SGD + L2) outperformed Modification 3 by 0.01 in EPI, indicating improved edge preservation. Similarly, the variants in which the OCM and Residual modules were excluded (Modifications 2 and 4) obtained comparable but consistently lower results than the proposed method. Furthermore, the variants in which the
module is replaced (Modification 5–Modification 8) demonstrated reduced performance, with at least a 0.17 dB decrease in PSNR compared to the proposed approach.
Across all test sets, the proposed OARN (SGD + L2) model consistently outperformed its variants. The removal or replacement of attention modules resulted in the degradation of either structural quality or edge preservation, especially when spatial attention was removed. These results confirm the effectiveness of the proposed architecture, including the , OCM, and residual blocks.
To assess the statistical significance of the performance differences between the modifications and the base model OARN (SGD + L2), a paired t-test was conducted with a 95% confidence level, corresponding to a significance threshold of Bonferroni-corrected . The test was performed across the four test sets, comprising a total of 160 image samples, resulting in 159 degrees of freedom. The results indicate that the performance gains of OARN (SGD + L2) are statistically significant and unlikely to have occurred by chance, with p-values below for PSNR, for EPI and for SSIM, except for Modification 8, where the p-value for SSIM was 0.08. This result suggests that Modification 8 does not significantly alter the global structure compared to OARN (SGD + L2). Nonetheless, OARN (SGD + L2) outperforms Modification 8 in the PSNR and EPI metrics.
4.3. Optimizer and Loss Function Selection
To evaluate the impact of the optimizer on the performance of the proposed OARN model, a sensitivity analysis was conducted using a scale factor of ×4. In this test, the SGD, Adam, AdamW, and Root Mean Square Propagation (RMSProp) optimizers were compared along with two widely used loss functions: L1 and L2.
The L2 loss function, defined in Equation (17), penalizes larger errors more heavily, often leading to smoother reconstructions but potentially over-smoothing high-frequency details. On the other hand, the L1 loss function, given in Equation (16), is often used in image reconstruction tasks.
The four optimizers were implemented using a learning rate of 0.0001. The SGD optimizer uses a momentum of 0.9 and a weight decay of , the AdamW optimizer utilizes a weight decay of and the RMSprop optimizer employs . The remaining parameters were set to the default values provided by PyTorch’s optim module. The number of training epochs was set to 60, and a batch size of 64 was employed.
The results are presented in
Table 4, which displays the average values obtained across the four test sets described in
Table 1. The results indicate that the AdamW + L1 combination was the most robust, achieving the highest average performance. Compared to the worst-performing configuration, RMSProp + L1, the AdamW + L1 setup achieved an improvement of
dB in PSNR and
dB in EPI, demonstrating better training capability and superior preservation of high-frequency details, as reflected in the EPI metric.
On the other hand, the Adam configurations also showed competitive results. For instance, Adam + L1 achieved an improvement of dB in PSNR compared to SGD + L2 and dB when compared to Adam + L2, suggesting a more accurate reconstruction of fine details. Nonetheless, the Adam + L1 configuration presents a slight decrement compared to its counterpart using AdamW.
To compare the impact of different optimizers and loss functions on model performance, statistical validation was conducted using a paired t-test with a 95% confidence level (Bonferroni-corrected ) on the 160 image samples of the test sets. The baseline configuration selected for comparison was the model trained with AdamW and L1 loss, due to its strong overall results. The results show that AdamW + L1 yields statistically significant improvements over the alternative settings, with observed p-values as low as for PSNR, for SSIM, and for EPI. An exception was found in the configuration using AdamW + L2, which yielded a p-value of 0.09 for EPI, suggesting no significant difference in that metric.
The training and validation curves for the four optimizers and the L1 and L2 loss functions are displayed in
Figure 5a,b, allowing the observation of convergence stability and PSNR behavior on both training and validation sets throughout the epochs.
As observed in
Figure 5a, the L1 loss combined with AdamW exhibits the highest PSNR values in both training and validation. On the other hand, RMSProp shows slower convergence with lower PSNR values and considerable instability, particularly in the validation curve. The Adam optimizer demonstrates performance similar to AdamW but with a lower PSNR in validation tests, while SGD displays slower convergence. Moreover, RMSProp exhibits poor stability in the validation data, indicating a reduced learning capacity. A point worth mentioning is that the combination of L2 loss with AdamW results in high and stable PSNR values during training. However, compared to the L1 loss function in Equation (16), the L2 loss in Equation (17) is generally slightly more computationally expensive. While this difference is often minimal in most scenarios, it becomes relevant when processing millions of samples or when models are deployed in resource-constrained embedded systems. In such contexts, L1 loss is preferable due to its lower computational overhead, making it a more suitable choice for remote sensing applications. Consequently, the model configured with AdamW and L1 loss was selected as the most appropriate baseline for comparing the proposed method against other state-of-the-art models.
4.4. Comparison with State-of-the-Art Methods
To evaluate the performance of the proposed OARN model, a direct comparison was conducted against several state-of-the-art super-resolution methods, including classical interpolation techniques (Bicubic), early CNN-based models (SRCNN [
9] and VDSR [
10]), and deeper residual architectures (EDSR [
11], SRResNet [
12], and SwinIR [
24]). The evaluation was carried out on four independent test sets using three scale factors (
,
, and
), and the results are summarized in
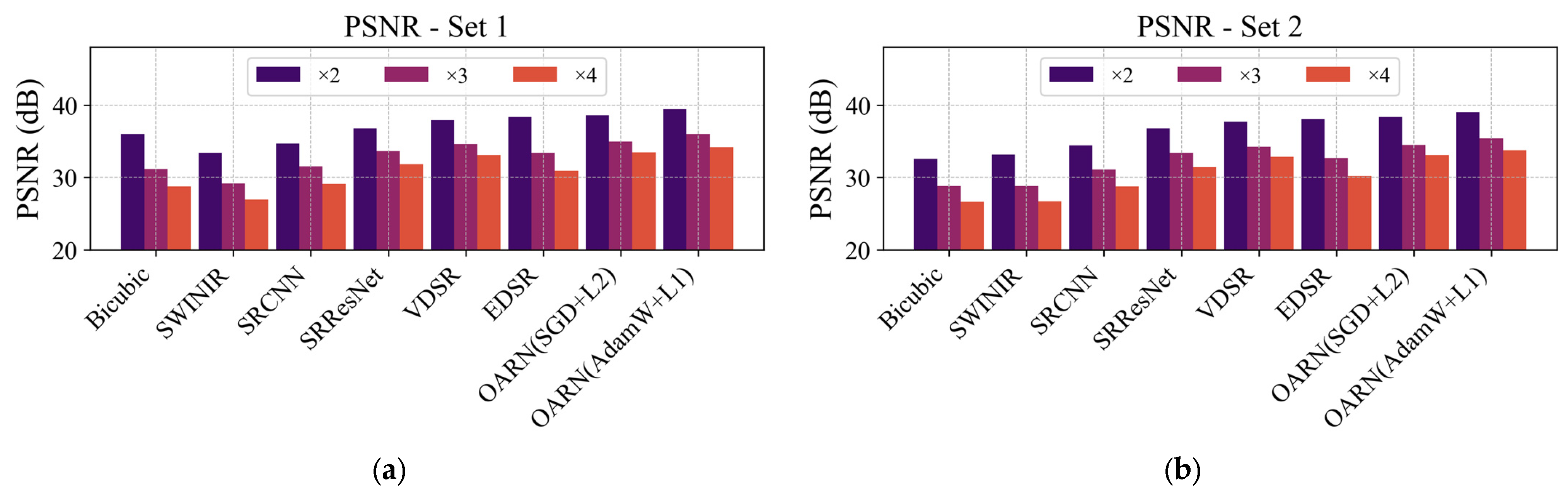
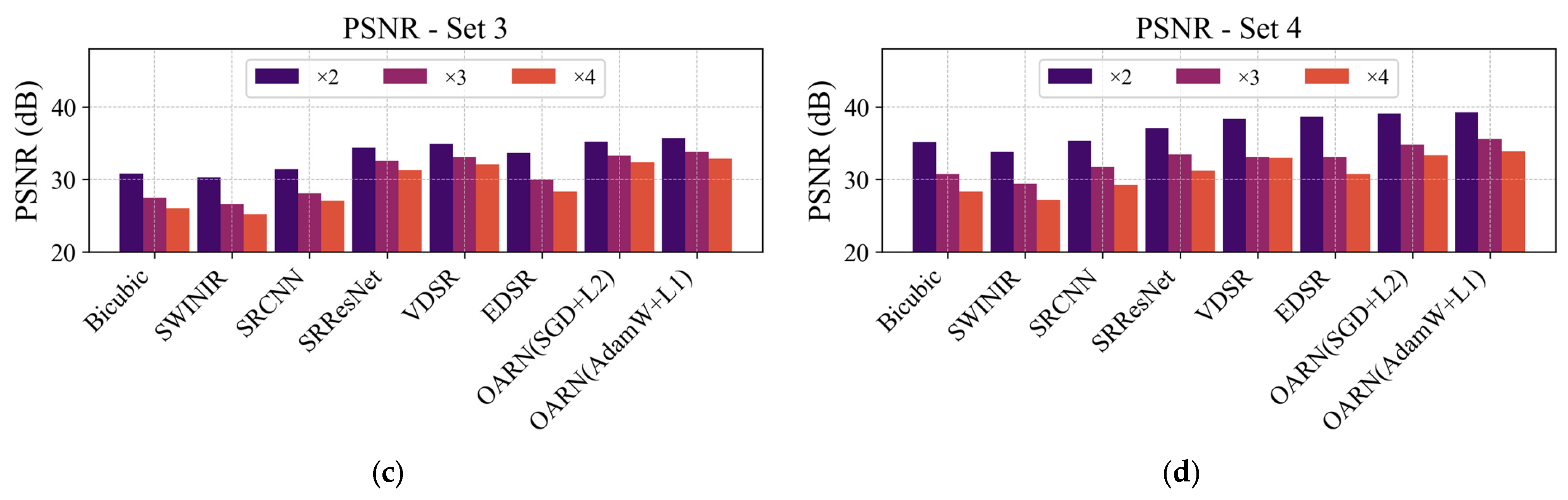
Figure 6.
Figure 6 shows that the OARN model consistently outperforms comparative methods in terms of PSNR across all test sets and scale factors. The OARN (AdamW + L1) configuration achieved the highest average PSNR in all scenarios, reaching up to
dB at scale
(
Figure 5a),
dB at
, and
dB at
, even surpassing deeper models such as EDSR, whose maximum was 38.37 dB at
.
Compared to VDSR, OARN (AdamW + L1) showed an average improvement of over dB across all test sets at scale , demonstrating superior capability in recovering fine structures under conditions of spatial information loss. Similarly, concerning SRResNet, OARN achieved gains ranging from to dB, highlighting its efficiency without requiring an excessively deep network.
In contrast, SwinIR demonstrated lower performance than convolution-based models, such as VDSR and EDSR, across all sets and scales, as Swin Transformer blocks require longer training to effectively capture high-frequency textures.
Test set 1, composed of HR images acquired with the WorldView-2 satellite, showed that the OARN model achieved the highest PSNR values among all methods, particularly for the ×2 and ×3 scaling factors, demonstrating the model’s ability to leverage spatial information effectively. In test sets 2 and 4, which include images from Microsoft Virtual Earth, improvements were also observed despite variations in lighting and environmental conditions. In contrast, test set 3, which is based on images from the GaoFen-2 satellite with a resolution of 0.8 m per pixel, exhibited lower PSNR values, indicating that the OARN model struggled to recover details when the spatial resolution was more limited. Although this ground sampling distance is relatively close to that of WorldView-2 and Microsoft Virtual Earth datasets (0.5 m), the difference in native spatial resolution significantly impacts the quality of fine detail reconstruction, which contributes to the lower quantitative results observed in this case. Nevertheless, the proposed model still achieved PSNR values above 30 dB, demonstrating acceptable reconstruction quality under these more challenging conditions.
These results validate the robustness of the proposed approach, showing that OARN achieves a competitive balance between reconstruction quality and computational efficiency, outperforming state-of-the-art methods across multiple test scenarios.
4.5. Qualitative Analysis
The quantitative analysis shown in
Figure 6 demonstrates that the proposed model, OARN (AdamW + L1), achieves the highest PSNR values across all test sets and scale factors. To complement these results, a comparative qualitative analysis was conducted using reconstructed images from test sets 3, 1, and 2, evaluated at a
scale factor. These scenes are presented in
Figure 7,
Figure 8 and
Figure 9, respectively, and were selected due to their high complexity and rich textures. They include elements such as buildings, trees, and roads, which introduce numerous edges and fine structural details. Such characteristics pose greater challenges for SR models, making them ideal for visually assessing the model’s ability to preserve details and accurately reconstruct complex patterns. To visually assess the differences in reconstruction quality, error maps were generated for each of the compared methods. These maps were obtained by computing the inverse absolute difference between the original HR image and its corresponding reconstruction in the cropped region. The error was normalized between 0 and 1 and subsequently inverted to highlight more accurate regions in lighter tones. The visualization corresponds to the average absolute error across the three RGB channels, multiplied by 255 for display in greyscale.
In
Figure 7, corresponding to test set 3, it can be observed that the OARN (AdamW + L1) model presents a more uniform and clearer error map compared to the other methods. Although EDSR achieves a more detailed reconstruction of edges, its PSNR is lower by 5.92 dB, which is attributed to the presence of artifacts and inconsistencies in more complex regions.
Although EDSR generates visually sharp images and achieves high EPI values, its low PSNR score suggests notable discrepancies in pixel-wise intensity values. In other words, while the reconstructed images appear visually coherent in terms of color and structure, the pixels’ intensities deviate more significantly from the ground truth. This behavior could be attributed to the model overfitting on global structures, potentially at the expense of accurately capturing fine-grained local details. Furthermore, OARN (AdamW + L1) achieves the lowest MSE (46.71) and MAE (5.45) scores, indicating a closer match to the ground truth at the pixel level. In contrast, SwinIR exhibits the worst performance, with the lowest PSNR (22.76) and the highest MSE (355.15) and MAE (18.84), indicating significant distortions in pixel intensity. Similarly, although EDSR obtains a lower LPIPS value than OARN (0.279 vs. 0.308), suggesting better perceptual similarity from a human perspective, its MSE (182.67) and MAE (10.78) scores indicate lower fidelity to the original image in terms of pixel-level accuracy.
In
Figure 8, OARN (AdamW + L1) preserves cylindrical structures and geometric details, while methods such as VDSR and SRResNet display irregular edges and darker error maps in high-frequency regions. Although SRResNet achieves competitive metrics, it tends to alter colors and lose texture in complex areas, as reflected in its higher MSE (51.96) and MAE (5.75) compared to OARN’s lower MSE (32.95) and MAE (4.57). In terms of perceptual quality, OARN also achieves a lower LPIPS score (0.146) than SRResNet (0.283), indicating a better perceptual similarity to the ground truth. On the other hand, EDSR achieved a slightly higher EPI score (0.474) compared to OARN (0.441), suggesting marginally better edge preservation. Nevertheless, OARN (AdamW + L1) produced a more consistent error map and a cleaner reconstruction, demonstrating a balance between structural fidelity and computational efficiency with a significantly lighter architecture. In contrast, SwinIR recorded the highest errors in all three metrics (MSE = 237.56, MAE = 15.41, and LPIPS = 0.369), revealing substantial perceptual and numerical distortions.
Finally, in
Figure 9, corresponding to an urban scene with buildings and complex infrastructure, OARN (AdamW + L1) exhibits sharper and more continuous recovery of building and road contours. In contrast, SRCNN and VDSR produce irregular lines and less-defined edges, as evidenced by both the reconstructions and the error maps. Although EDSR slightly outperforms OARN (AdamW + L1) in EPI (0.390 vs. 0.388), as in the previous case, this marginal difference is offset by a cleaner and more consistent visual output produced by the proposed model. Furthermore, OARN (AdamW + L1) achieves a higher PSNR, reinforcing its ability to maintain an appropriate balance between visual accuracy and structural preservation, particularly in images acquired from the Microsoft Virtual Earth dataset. Additionally, it obtains the lowest MSE (43.17) and MAE (5.24), as well as a relatively low LPIPS value (0.191), indicating high pixel-wise and perceptual similarity to the ground truth. In contrast, SwinIR presents the highest MSE (315.40), MAE (17.75), and LPIPS (0.387), confirming significant perceptual and structural degradation.
As shown in
Figure 7,
Figure 8 and
Figure 9, EDSR generates images with well-defined edges and continuous structures; however, it introduces slight inconsistencies in intensity values, particularly in textured areas, which affects the PSNR. These results suggest that EDSR tends to overfit to high-level structural patterns, potentially compromising pixel-wise accuracy. While the model may produce perceptually coherent reconstructions, it does so at the cost of precise alignment with ground truth at the pixel level. In contrast, OARN achieves a balanced performance in both PSNR and EPI, producing homogeneous error maps and reconstructions that are closer to the actual pixel values.
4.6. Training Time and Computational Efficiency Analysis
The results discussed in the previous sections demonstrate that OARN (AdamW + L1) not only achieves the highest PSNR and EPI values across multiple test sets and scales but also preserves both structural and perceptual quality, even in scenes acquired from different sensors with varying characteristics. These improvements are evident considering the model’s computational efficiency.
Table 5 presents a comparative analysis of the computational efficiency of the proposed OARN (AdamW + L1) model against other state-of-the-art super-resolution methods. The evaluation includes the number of parameters, floating-point operations (GFlops), total training time, and average inference time per image. RAM consumption was measured using the torchinfo library [
43], with an input size of 120 × 120 pixels to generate a SR output of 480 × 480 pixels, which represents a ×4 scale.
The OARN (AdamW + L1) method features a reduced number of parameters (169,345) and exhibits a low computational cost across all scale factors, with 9.73 GFlops at scale , 4.33 GFlops at scale , and 2.43 GFlops at scale , making it highly efficient for multiscale scenarios. Despite its compact design, the approach achieves competitive performance due to its optimized architecture.
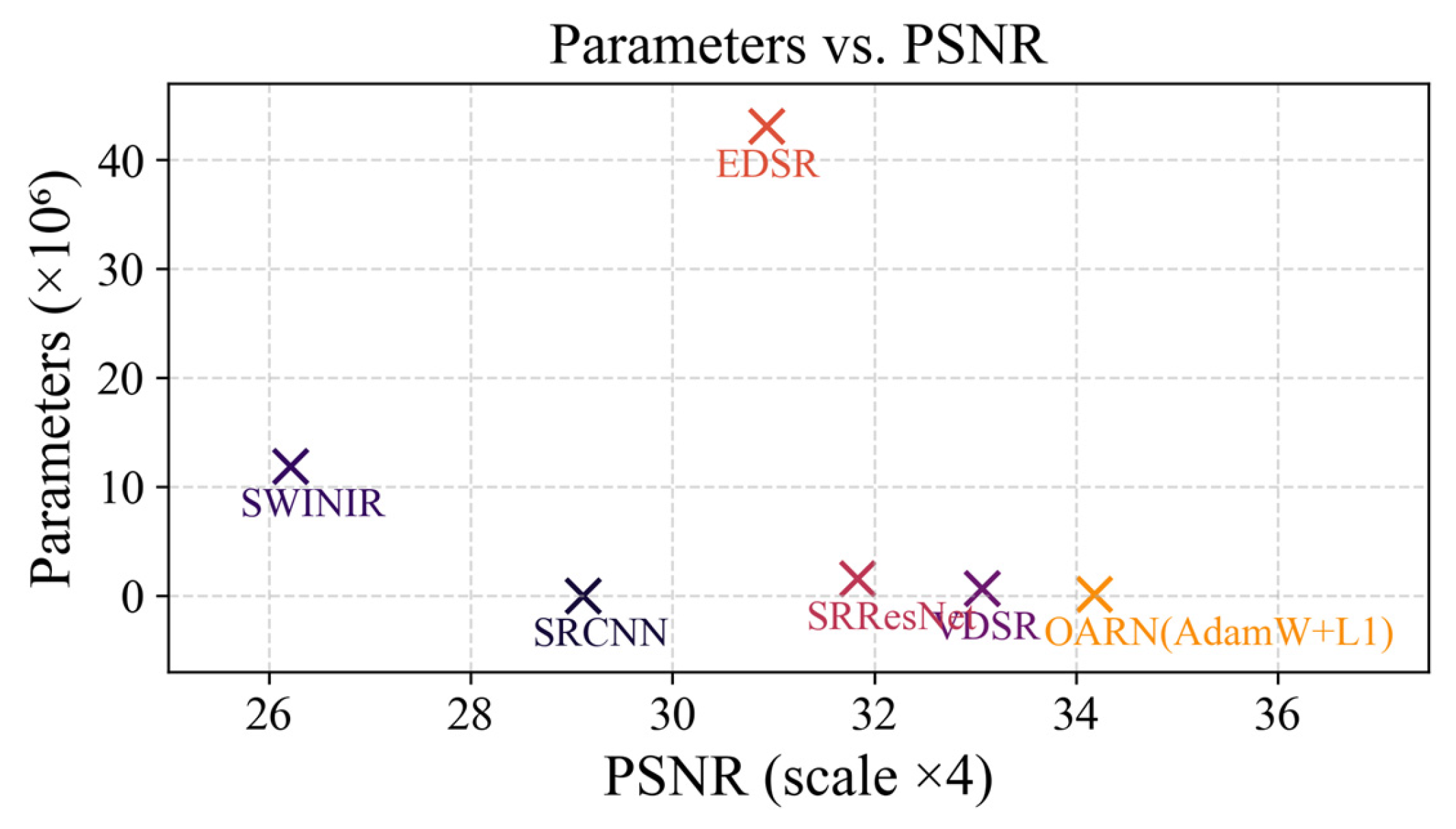
Although the proposed method has a higher number of parameters compared to SRCNN, which exhibits low computational complexity with only 8129 parameters and significantly lower reconstruction quality, the scatter plot in
Figure 10 shows that OARN (AdamW + L1) achieves a higher PSNR while using considerably fewer parameters than deeper models such as EDSR. Therefore, although the proposed method involves greater complexity than some simpler models, it achieves a more efficient balance between quality and computational cost, making it a better overall alternative.
In comparison, EDSR exhibits a computational load of 722.508 GFlops at scale. This indicates that OARN (AdamW + L1) reduces operations by approximately 99%, requiring around 297 times fewer operations to reconstruct at the same scale.
Even against intermediate models such as SRResNet, which reaches 32.002 GFlops at scale, OARN (AdamW + L1) achieves a reduction of in computational cost, offering better efficiency while consuming fewer computational resources.
Moreover, the SwinIR model exhibits high computational complexity, with 11.9 million parameters and a GFLOPs count that exceeds OARN’s across all three scales, being 73 times higher at ×4 scale.
Regarding inference time, the proposed OARN (AdamW + L1) method achieved an inference time of s, representing improvement compared to EDSR, which takes s per image.
OARN (AdamW + L1) demonstrates a significant improvement over SRResNet, which requires s, resulting in approximately 94% reduction in time. Even compared to VDSR, the proposed model is faster. Although the SRCNN model achieves an inference time of s, it exhibits significantly lower reconstruction quality. Therefore, OARN offers a better balance between reconstruction quality and inference efficiency.
SwinIR, in contrast, requires 0.0938 s per image, making it the slowest among all evaluated models and highlighting its limited practicality in real-time applications. In terms of estimated RAM usage, SwinIR consumes the highest amount at 7133.76 MB, followed by EDSR with 2710.47 MB and SRResNet with 926.12 MB.
OARN (AdamW + L1) achieves one of the lowest RAM usages with only 104.07 MB, which demonstrates that it performs better in memory-constrained environments without compromising accuracy. In comparison, VDSR uses 142.91 MB, while SRCNN has the lowest footprint at 9.82 MB, albeit with significantly poorer reconstruction quality.
As shown in
Figure 10, the OARN (AdamW + L1) model achieves the highest PSNR value (34.18 dB) at the ×4 scale reconstruction with only 169,345 parameters. In contrast, EDSR requires over 43 million parameters while obtaining a lower PSNR (30.93 dB). This demonstrates that greater model complexity does not necessarily guarantee better reconstruction quality. Similarly, SRResNet and VDSR achieve PSNR values of 31.83 dB and 33.07 dB with 1.54 million and 0.66 million parameters, respectively, showing significantly lower performance compared to OARN (AdamW + L1). SwinIR, despite its complex transformer-based design with over 11 million parameters, achieves a PSNR of only 26.49 dB, further validating that architectural size does not imply better quality.
This indicates that the proposed model strikes a balance between efficiency and quality, achieving the highest PSNR with a considerably more compact architecture than other state-of-the-art methods, thereby validating its effectiveness in terms of both accuracy and resource utilization.
5. Discussion
The experimental results demonstrate that the OARN model is highly effective for the task of SR in satellite imagery. The proposed architecture, which integrates the block and the OCM module, achieves significant improvements in reconstructing structural and textural details, outperforming both traditional and state-of-the-art methods in terms of PSNR, SSIM, and EPI. These enhancements are achieved without resorting to very deep networks or incurring excessive computational costs.
One of the main advantages of OARN lies in its efficient design. With only 169,345 parameters and a computational cost of 2.43 GFLOPs at scale
, the model remains lightweight while achieving superior performance. In contrast, EDSR requires over 43 million parameters and 722.508 GFLOPs to perform at a lower quality level, indicating that higher complexity does not necessarily translate into better results. The trade-off between quality and the computational burden is clearly favorable for OARN, as shown in
Figure 10, where it achieves the highest PSNR with a considerably smaller model.
The block enables the capture of long-range spatial dependencies, while the OCM module refines local features such as edges and textures, thereby enhancing image fidelity. In addition, the optimized residual blocks promote gradient flow and training stability while facilitating the learning of residual differences between LR and HR images.
Another major contribution of this study is the model’s robustness across multisensory-acquired datasets. OARN was evaluated on four independent test sets, including imagery from WorldView-2, GaoFen-2, and Microsoft Virtual Earth, each with distinct spatial resolutions and spectral properties. The model consistently delivered competitive results across all sets, particularly in structurally complex scenes. For instance, in test set 3 (GaoFen-2), where spatial degradation poses a challenge, OARN maintained high PSNR and EPI values. Meanwhile, in test set 1 (WorldView-2), it demonstrated its ability to fully exploit fine spatial information.
Moreover, the proposed method operates solely on the intensity channel, which makes its extension to multispectral or hyperspectral images a promising direction for future work. Since the chroma channels ( and ) are processed using a conventional bicubic upsampling strategy, the core architecture remains independent of color-specific operations and could be adapted to handle other spectral bands similarly. However, the current implementation relies exclusively on RGB input data, which limits the exploitation of additional spectral information available in richer imaging modalities. While this simplifies the model design and training, it also restricts its applicability in domains where non-visible bands (e.g., infrared) carry essential information.
Nonetheless, some limitations remain. While the
and OCM modules significantly improve spatial attention and texture preservation, their performance depends on the careful tuning of hyperparameters and kernel configurations. The ablation study revealed that removing or replacing these components with alternatives, such as SE or CBAM, can result in performance drops of up to 3.69 dB in PSNR and 0.019 in EPI. These results highlight the importance of these modules but also suggest room for further optimization. In addition, as discussed in
Section 4.1, the model showed decreased effectiveness in more homogeneous or natural environments, where structural information is less prominent. This behavior suggests that the proposed attention modules may have limited capacity to generalize across diverse landscape types. Future work may explore the integration of hybrid attention mechanisms that simultaneously leverage spatial and spectral features, further enhancing the model’s generalization capability and resilience in real-world remote sensing scenarios.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}