


Auxcoformer: Auxiliary and Contrastive Transformer for Robust Crack Detection in Adverse Weather Conditions


Abstract
1. Introduction
- We propose a unified approach that combines a primary crack detection network with an auxiliary weather restoration network to leverage a robust representation of restored crack features. This integration performs efficient and robust crack detection using the synergy between restoration and detection tasks.
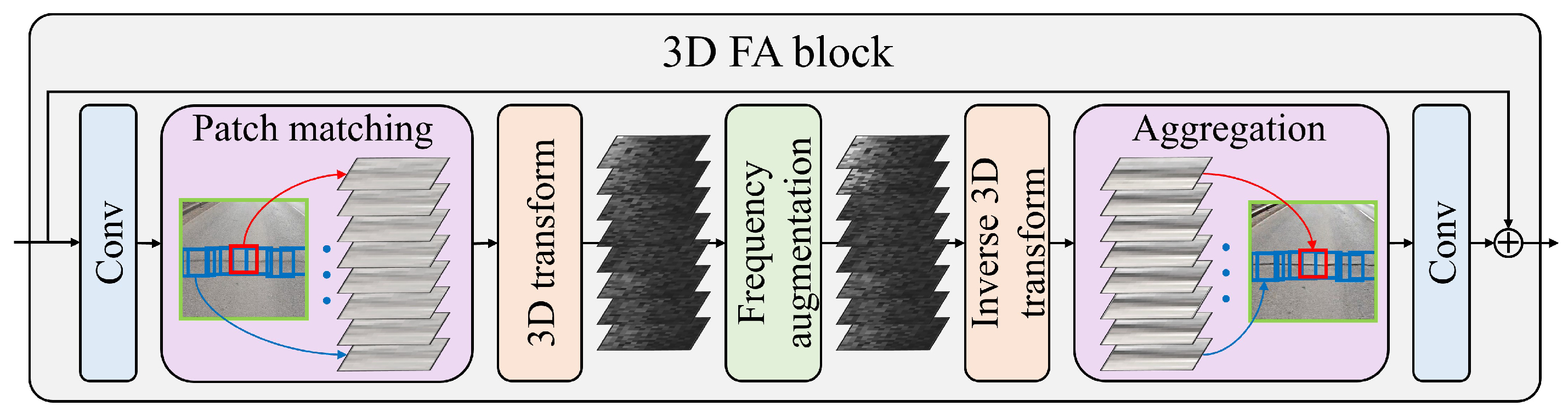
- We propose a 3D frequency augmentation (FA) block to optimize crack detection. This block uses non-local matching of adjacent and similar patches to perform a 3D discrete cosine transform (DCT) and selectively amplify crack-related frequency components while minimizing noise.
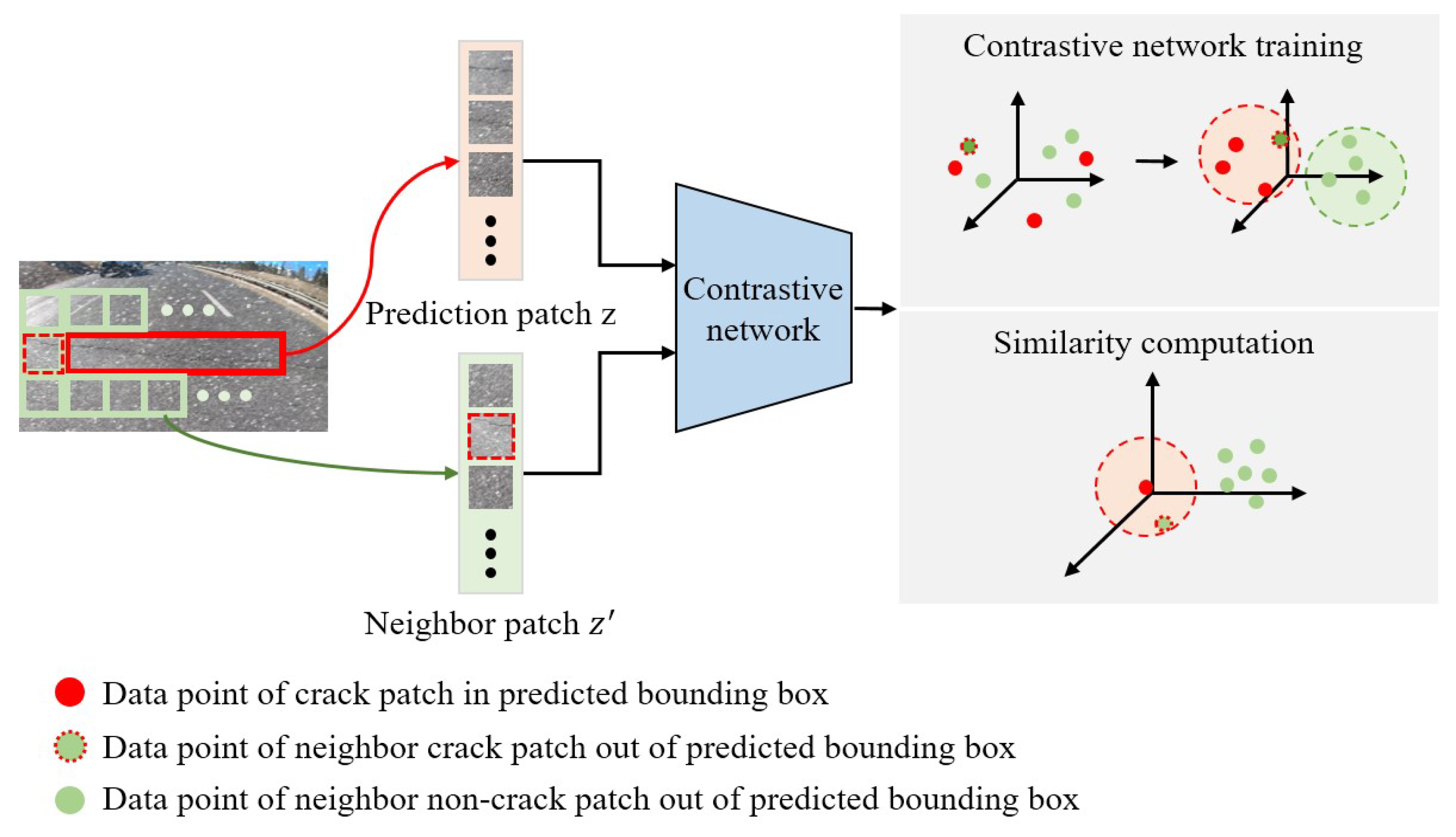
- We propose a contrastive patch loss function designed for precisely localizing cracks. This loss function evaluates the similarity between patches inside and adjacent to the bounding boxes to capture the inherent connectivity of cracks and improve detection accuracy.
2. Related Work
2.1. Crack Detection
2.2. Adverse Weather Restoration
2.3. Auxiliary Learning
2.4. Contrastive Learning
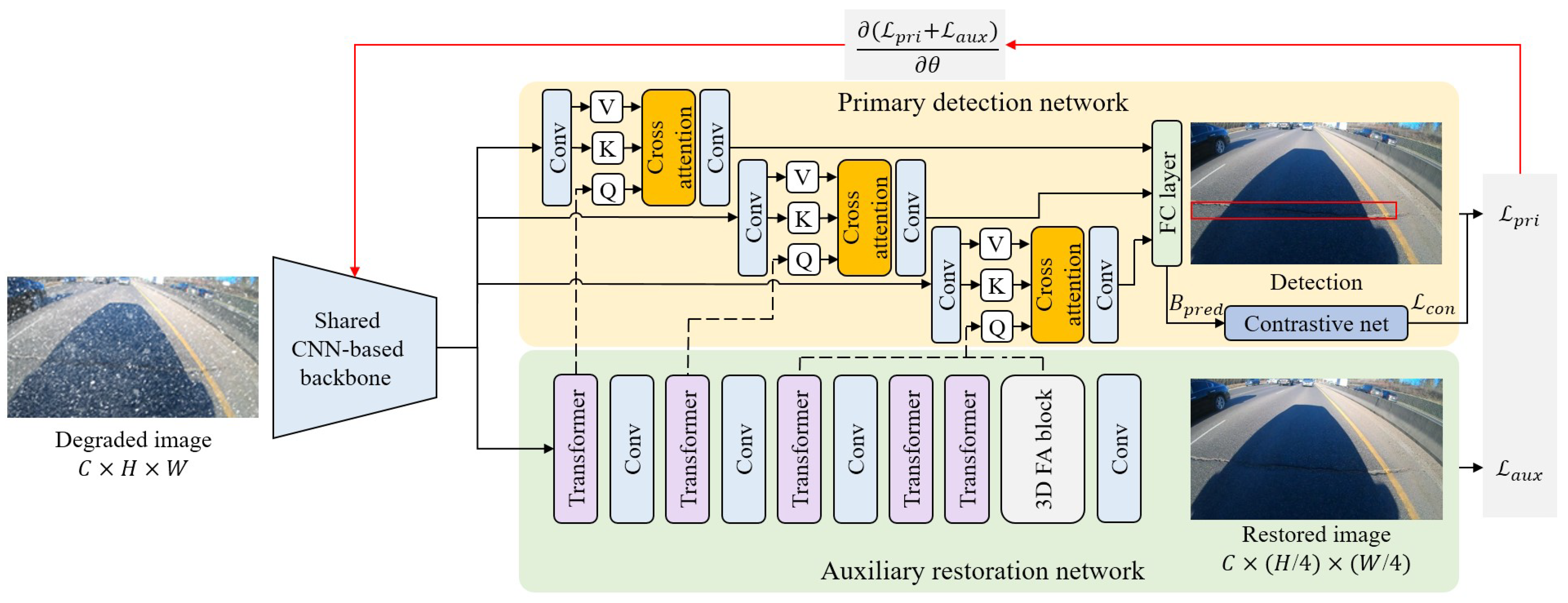
3. Method
3.1. Overview
3.2. Auxiliary Restoration Network for Crack Detection
3.3. Primary Detection Network
3.4. Contrastive Patch Loss

4. Experiment
4.1. Datasets
4.2. Implementation Details
4.3. Experimental Results and Analysis
4.4. Ablation Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1833–1844. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 7–12. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Nie, M.; Wang, K. Pavement distress detection based on transfer learning. In Proceedings of the 2018 5th International Conference on Systems and Informatics (ICSAI), Nanjing, China, 10–12 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 435–439. [Google Scholar]
- Hascoet, T.; Zhang, Y.; Persch, A.; Takashima, R.; Takiguchi, T.; Ariki, Y. Fasterrcnn monitoring of road damages: Competition and deployment. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 5545–5552. [Google Scholar]
- Vishwakarma, R.; Vennelakanti, R. Cnn model & tuning for global road damage detection. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 5609–5615. [Google Scholar]
- Pei, Z.; Lin, R.; Zhang, X.; Shen, H.; Tang, J.; Yang, Y. CFM: A consistency filtering mechanism for road damage detection. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 5584–5591. [Google Scholar]
- Xiang, X.; Wang, Z.; Qiao, Y. An improved YOLOv5 crack detection method combined with transformer. IEEE Sensors J. 2022, 22, 14328–14335. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 20–22 June 2023; pp. 7464–7475. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 6569–6578. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Yu, G.; Zhou, X. An Improved YOLOv5 Crack Detection Method Combined with a Bottleneck Transformer. Mathematics 2023, 11, 2377. [Google Scholar] [CrossRef]
- Mandal, V.; Uong, L.; Adu-Gyamfi, Y. Automated road crack detection using deep convolutional neural networks. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 5212–5215. [Google Scholar]
- Shao, C.; Zhang, L.; Pan, W. PTZ camera-based image processing for automatic crack size measurement in expressways. IEEE Sensors J. 2021, 21, 23352–23361. [Google Scholar] [CrossRef]
- Zhang, R.; Shi, Y.; Yu, X. Pavement crack detection based on deep learning. In Proceedings of the 2021 33rd Chinese Control and Decision Conference (CCDC), Kunming, China, 22–24 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 7367–7372. [Google Scholar]
- Zhang, X.; Xia, X.; Li, N.; Lin, M.; Song, J.; Ding, N. Exploring the tricks for road damage detection with a one-stage detector. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 5616–5621. [Google Scholar]
- Liu, Y.; Zhang, X.; Zhang, B.; Chen, Z. Deep network for road damage detection. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 5572–5576. [Google Scholar]
- Mandal, V.; Mussah, A.R.; Adu-Gyamfi, Y. Deep learning frameworks for pavement distress classification: A comparative analysis. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 5577–5583. [Google Scholar]
- Guo, G.; Zhang, Z. Road damage detection algorithm for improved YOLOv5. Sci. Rep. 2022, 12, 15523. [Google Scholar] [CrossRef]
- Hu, G.X.; Hu, B.L.; Yang, Z.; Huang, L.; Li, P. Pavement crack detection method based on deep learning models. Wirel. Commun. Mob. Comput. 2021, 2021, 5573590. [Google Scholar] [CrossRef]
- Hong, Y.; Yoo, S.B. OASIS-Net: Morphological Attention Ensemble Learning for Surface Defect Detection. Mathematics 2022, 10, 4114. [Google Scholar] [CrossRef]
- YOLOv8 by MMYOLO. Available online: https://github.com/open-mmlab/mmyolo/ (accessed on 13 May 2023).
- Wang, J.; Chen, Y.; Dong, Z.; Gao, M. Improved YOLOv5 network for real-time multi-scale traffic sign detection. Neural Comput. Appl. 2023, 35, 7853–7865. [Google Scholar] [CrossRef]
- Yu, J.; Oh, H.; Fichera, S.; Paoletti, P.; Luo, S. Multi-source Domain Adaptation for Unsupervised Road Defect Segmentation. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation, London, UK, 29 May–2 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 5638–5644. [Google Scholar]
- Hong, Y.; Lee, S.; Yoo, S.B. AugMoCrack: Augmented morphological attention network for weakly supervised crack detection. Electron. Lett. 2022, 58, 651–653. [Google Scholar] [CrossRef]
- Zong, Z.; Song, G.; Liu, Y. Detrs with collaborative hybrid assignments training. arXiv 2022, arXiv:2211.12860. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 19–21 June 2021; 2021; pp. 10012–10022. [Google Scholar]
- Kim, M.H.; Yoo, S.B. Memory-Efficient Discrete Cosine Transform Domain Weight Modulation Transformer for Arbitrary-Scale Super-Resolution. Mathematics 2023, 11, 3954. [Google Scholar] [CrossRef]
- Hong, Y.; Kim, M.J.; Lee, I.; Yoo, S.B. Fluxformer: Flow-Guided Duplex Attention Transformer via Spatio-Temporal Clustering for Action Recognition. IEEE Robot. Autom. Lett. 2023, 8, 6411–6418. [Google Scholar] [CrossRef]
- Li, F.; Zhang, H.; Xu, H.; Liu, S.; Zhang, L.; Ni, L.M.; Shum, H.Y. Mask dino: Towards a unified transformer-based framework for object detection and segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 20–22 June 2023; pp. 3041–3050. [Google Scholar]
- Kalwar, S.; Patel, D.; Aanegola, A.; Konda, K.R.; Garg, S.; Krishna, K.M. GDIP: Gated Differentiable Image Processing for Object Detection in Adverse Conditions. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 7083–7089. [Google Scholar]
- Xia, Y.; Monica, J.; Chao, W.L.; Hariharan, B.; Weinberger, K.Q.; Campbell, M. Image-to-Image Translation for Autonomous Driving from Coarsely-Aligned Image Pairs. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 7756–7762. [Google Scholar]
- Feng, X.; Pei, W.; Jia, Z.; Chen, F.; Zhang, D.; Lu, G. Deep-masking generative network: A unified framework for background restoration from superimposed images. IEEE Trans. Image Process. 2021, 30, 4867–4882. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Liu, X.; Hu, P.; Wu, Z.; Lv, J.; Peng, X. All-in-one image restoration for unknown corruption. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 17452–17462. [Google Scholar]
- Yun, J.S.; Yoo, S.B. Single image super-resolution with arbitrary magnification based on high-frequency attention network. Mathematics 2022, 10, 275. [Google Scholar] [CrossRef]
- Yun, J.S.; Yoo, S.B. Kernel-attentive weight modulation memory network for optical blur kernel-aware image super-resolution. Opt. Lett. 2023, 48, 2740–2743. [Google Scholar] [CrossRef] [PubMed]
- Yun, J.S.; Kim, M.H.; Kim, H.I.; Yoo, S.B. Kernel adaptive memory network for blind video super-resolution. Expert Syst. Appl. 2024, 238, 122252. [Google Scholar] [CrossRef]
- Li, R.; Tan, R.T.; Cheong, L.F. All in one bad weather removal using architectural search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3175–3185. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 5728–5739. [Google Scholar]
- Özdenizci, O.; Legenstein, R. Restoring vision in adverse weather conditions with patch-based denoising diffusion models. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10346–10357. [Google Scholar] [CrossRef]
- Valanarasu, J.M.J.; Yasarla, R.; Patel, V.M. Transweather: Transformer-based restoration of images degraded by adverse weather conditions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 2353–2363. [Google Scholar]
- Lee, Y.; Jeon, J.; Ko, Y.; Jeon, B.; Jeon, M. Task-driven deep image enhancement network for autonomous driving in bad weather. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 13746–13753. [Google Scholar]
- Wang, J.; Chen, Y.; Ji, X.; Dong, Z.; Gao, M.; Lai, C.S. Vehicle-mounted adaptive traffic sign detector for small-sized signs in multiple working conditions. IEEE Trans. Intell. Transp. Syst. 2023, 25, 710–724. [Google Scholar] [CrossRef]
- Zhai, X.; Oliver, A.; Kolesnikov, A.; Beyer, L. S4l: Self-supervised semi-supervised learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 1476–1485. [Google Scholar]
- Heo, Y.; Kang, S. A Simple Framework for Scene Graph Reasoning with Semantic Understanding of Complex Sentence Structure. Mathematics 2023, 11, 3751. [Google Scholar] [CrossRef]
- Wen, H.; Zhang, J.; Wang, Y.; Lv, F.; Bao, W.; Lin, Q.; Yang, K. Entire space multi-task modeling via post-click behavior decomposition for conversion rate prediction. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, China, 25–30 July 2020; pp. 2377–2386. [Google Scholar]
- Du, Y.; Czarnecki, W.M.; Jayakumar, S.M.; Farajtabar, M.; Pascanu, R.; Lakshminarayanan, B. Adapting auxiliary losses using gradient similarity. arXiv 2018, arXiv:1812.02224. [Google Scholar]
- Shi, B.; Hoffman, J.; Saenko, K.; Darrell, T.; Xu, H. Auxiliary task reweighting for minimum-data learning. Adv. Neural Inf. Process. Syst. 2020, 33, 7148–7160. [Google Scholar]
- Lin, X.; Baweja, H.; Kantor, G.; Held, D. Adaptive auxiliary task weighting for reinforcement learning. Adv. Neural Inf. Process. Syst. 2019, 32, 4772–4783. [Google Scholar]
- Dery, L.M.; Dauphin, Y.; Grangier, D. Auxiliary task update decomposition: The good, the bad and the neutral. arXiv 2021, arXiv:2108.11346. [Google Scholar]
- Navon, A.; Achituve, I.; Maron, H.; Chechik, G.; Fetaya, E. Auxiliary Learning by Implicit Differentiation. arXiv 2020, arXiv:2007.02693. [Google Scholar]
- Chen, H.; Wang, X.; Guan, C.; Liu, Y.; Zhu, W. Auxiliary learning with joint task and data scheduling. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 3634–3647. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, PMLR, Vienna, Austria, 12–18 July 2020; pp. 1597–1607. [Google Scholar]
- Xiong, H.; Yan, Z.; Zhao, H.; Huang, Z.; Xue, Y. Triplet Contrastive Learning for Aspect Level Sentiment Classification. Mathematics 2022, 10, 4099. [Google Scholar] [CrossRef]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Tian, Y.; Sun, C.; Poole, B.; Krishnan, D.; Schmid, C.; Isola, P. What makes for good views for contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 6827–6839. [Google Scholar]
- Liu, X.; Zhang, F.; Hou, Z.; Mian, L.; Wang, Z.; Zhang, J.; Tang, J. Self-supervised learning: Generative or contrastive. IEEE Trans. Knowl. Data Eng. 2021, 35, 857–876. [Google Scholar] [CrossRef]
- Zhou, X.; Li, S.; Pan, Z.; Zhou, G.; Hu, Y. Multi-Aspect SAR Target Recognition Based on Non-Local and Contrastive Learning. Mathematics 2023, 11, 2690. [Google Scholar] [CrossRef]
- Xie, E.; Ding, J.; Wang, W.; Zhan, X.; Xu, H.; Sun, P.; Li, Z.; Luo, P. Detco: Unsupervised contrastive learning for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 19–21 June 2021; pp. 8392–8401. [Google Scholar]
- Park, T.; Efros, A.A.; Zhang, R.; Zhu, J.Y. Contrastive learning for unpaired image-to-image translation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 319–345. [Google Scholar]
- Qian, R.; Meng, T.; Gong, B.; Yang, M.H.; Wang, H.; Belongie, S.; Cui, Y. Spatiotemporal contrastive video representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognitionn, Nashville, TN, USA, 19–21 June 2021; pp. 6964–6974. [Google Scholar]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschoinot, A.; Krishnan, D. Supervised contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Johnson, J.; Alahi, A.; Li, F.-F. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34. [Google Scholar]
- Mei, Q.; Gül, M. A cost effective solution for pavement crack inspection using cameras and deep neural networks. Constr. Build. Mater. 2020, 256, 119397. [Google Scholar] [CrossRef]
- Liu, Y.; Yao, J.; Lu, X.; Xie, R.; Li, L. DeepCrack: A deep hierarchical feature learning architecture for crack segmentation. Neurocomputing 2019, 338, 139–153. [Google Scholar] [CrossRef]
- Özgenel, Ç.F.; Sorguç, A.G. Performance comparison of pretrained convolutional neural networks on crack detection in buildings. In Proceedings of the International Symposium on Automation and Robotics in Construction (ISARC 2018), Berlin, Germany, 20–25 July 2018; IAARC Publications: Edinburgh, UK, 2018; Volume 35, pp. 1–8. [Google Scholar]
- Liu, Y.F.; Jaw, D.W.; Huang, S.C.; Hwang, J.N. DesnowNet: Context-aware deep network for snow removal. IEEE Trans. Image Process. 2018, 27, 3064–3073. [Google Scholar] [CrossRef]
- Yang, W.; Tan, R.T.; Feng, J.; Liu, J.; Guo, Z.; Yan, S. Deep joint rain detection and removal from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1357–1366. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Deng, J. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Detection | Metric (AP50/AP50:95) | ||
|---|---|---|---|---|
| Snow | Rain | Mean | ||
| EDMCrack600 [69] | Co-DETR [29] | 38.7/23.2 | 53.6/33.8 | 46.2/28.5 |
| MaskDINO [33] | 38.5/25.1 | 49.0/32.6 | 43.8/28.9 | |
| MGDIP [34] | 40.0/19.9 | 45.2/20.5 | 42.6/20.2 | |
| AugMoCrack [28] | 37.4/19.5 | 36.2/19.9 | 36.8/19.7 | |
| YOLOv8l [25] | 37.3/19.9 | 40.6/22.3 | 39.0/21.1 | |
| YOLOv8x [25] | 39.6/23.6 | 44.4/24.2 | 42.0/23.9 | |
| Ours | 62.4/43.6 | 68.0/48.6 | 65.2/46.1 | |
| DeepCrack [70] | Co-DETR [29] | 70.5/46.0 | 74.4/51.0 | 72.5/48.5 |
| MaskDINO [33] | 67.7/41.1 | 70.9/48.1 | 69.3/44.6 | |
| MGDIP [34] | 73.2/38.5 | 71.0/40.6 | 72.1/39.6 | |
| AugMoCrack [28] | 65.0/39.3 | 66.6/39.4 | 65.8/39.4 | |
| YOLOv8l [25] | 54.1/36.3 | 61.8/39.8 | 58.0/38.1 | |
| YOLOv8x [25] | 77.1/53.7 | 70.0/53.1 | 73.6/53.4 | |
| Ours | 88.5/63.1 | 90.9/65.7 | 89.7/64.4 | |
| CC [71] | Co-DETR [29] | 64.3/35.6 | 64.7/35.7 | 64.5/35.7 |
| MaskDINO [33] | 66.7/35.3 | 68.8/36.7 | 67.8/36.0 | |
| MGDIP [34] | 79.5/46.2 | 76.9/39.6 | 78.2/42.9 | |
| AugMoCrack [28] | 78.8/52.4 | 75.1/46.3 | 77.0/49.4 | |
| YOLOv8l [25] | 76.0/48.1 | 70.0/42.0 | 73.0/45.1 | |
| YOLOv8x [25] | 76.9/47.9 | 75.4/44.5 | 76.2/46.2 | |
| Ours | 94.4/71.3 | 92.6/69.6 | 93.5/70.5 | |
| Dataset | Restoration | Detection | Metric (AP50/AP50:95) | ||
|---|---|---|---|---|---|
| Snow | Rain | Mean | |||
| EDMCrack600 [69] | Restormer [42] | Co-DETR [29] | 51.6/32.3 | 58.1/36.3 | 54.9/34.3 |
| MaskDINO [33] | 49.8/30.2 | 57.9/36.1 | 53.9/33.2 | ||
| MGDIP [34] | 50.3/30.6 | 59.6/35.0 | 55.0/32.8 | ||
| YOLOv8x [25] | 48.6/32.2 | 57.8/39.0 | 53.2/35.6 | ||
| WeatherDiff [43] | Co-DETR [29] | 44.9/27.3 | 52.9/31.6 | 48.9/29.5 | |
| MaskDINO [33] | 44.0/26.5 | 50.8/30.2 | 47.4/28.4 | ||
| MGDIP [34] | 52.4/25.1 | 52.6/24.4 | 52.5/24.8 | ||
| YOLOv8x [25] | 50.5/32.8 | 45.4/24.6 | 48.0/28.7 | ||
| Ours | 62.4/43.6 | 68.0/48.6 | 65.2/46.1 | ||
| DeepCrack [70] | Restormer [42] | Co-DETR [29] | 79.8/52.0 | 89.8/63.9 | 84.8/58.0 |
| MaskDINO [33] | 76.2/50.9 | 87.1/62.4 | 81.7/56.7 | ||
| MGDIP [34] | 80.1/49.3 | 88.0/58.1 | 84.1/53.7 | ||
| YOLOv8x [25] | 74.4/50.7 | 82.8/56.2 | 78.6/53.5 | ||
| WeatherDiff [43] | Co-DETR [29] | 57.4/34.3 | 73.6/42.0 | 65.5/38.2 | |
| MaskDINO [33] | 58.5/36.7 | 76.3/42.2 | 67.4/39.5 | ||
| MGDIP [34] | 65.7/40.3 | 77.3/45.5 | 71.5/42.9 | ||
| YOLOv8x [25] | 73.6/47.4 | 83.3/53.9 | 78.5/50.7 | ||
| Ours | 88.5/63.1 | 90.9/65.7 | 89.7/64.4 | ||
| CC [71] | Restormer [42] | Co-DETR [29] | 66.8/36.0 | 68.7/34.8 | 67.8/35.4 |
| MaskDINO [33] | 64.0/34.8 | 69.5/34.7 | 66.8/34.8 | ||
| MGDIP [34] | 79.2/42.6 | 74.4/40.6 | 76.8/41.6 | ||
| YOLOv8x [25] | 83.0/51.7 | 80.5/49.8 | 81.8/50.8 | ||
| WeatherDiff [43] | Co-DETR [29] | 63.4/30.5 | 63.2/27.4 | 63.3/29.0 | |
| MaskDINO [33] | 62.6/29.7 | 60.8/27.0 | 61.7/28.4 | ||
| MGDIP [34] | 80.7/45.6 | 83.1/49.8 | 81.9/47.7 | ||
| YOLOv8x [25] | 87.4/60.4 | 87.1/61.5 | 87.3/61.0 | ||
| Ours | 94.4/71.3 | 92.6/69.6 | 93.5/70.5 | ||
| Task | Model | FLOPs (G) | Param (M) | Time (ms) |
|---|---|---|---|---|
| Detection | Co-DETR [29] | 612.7 | 235.5 | 380.0 |
| MaskDINO [33] | 1326.5 | 223.1 | 163.9 | |
| MGDIP [34] | 210.7 | 68.4 | 131.5 | |
| AugMoCrack [28] | 203.8 | 86.2 | 14.8 | |
| YOLOv8l [25] | 165.2 | 43.7 | 10.7 | |
| YOLOv8x [25] | 257.8 | 68.2 | 17.0 | |
| Restoration | Restormer [42] | 881.2 | 26.1 | 159.8 |
| WeatherDiff [43] | 1,016,482.5 | 29.7 | 97,749.9 | |
| Ours | 238.5 | 69.5 | 21.6 | |
| Auxiliary Restoration Network | 3D FA Block | Cross-Attention | Auxiliary Loss | Contrastive Patch Loss | Mean AP50/AP50:95 |
|---|---|---|---|---|---|
| ✓ | ✓ | ✓ | ✓ | ✓ | 65.2/46.1 |
| ✓ | 48.3/29.6 | ||||
| ✓ | ✓ | ✓ | ✓ | 58.7/40.0 | |
| ✓ | ✓ | ✓ | ✓ | 56.2/38.4 | |
| ✓ | ✓ | ✓ | ✓ | 50.2/36.7 | |
| ✓ | ✓ | ✓ | ✓ | 61.1/42.7 |
| Snow | Rain | Mean | |||
|---|---|---|---|---|---|
| 1.0 | 1.0 | 1.0 | 53.8/38.5 | 63.3/43.1 | 58.6/40.8 |
| 0.5 | 1.0 | 0.5 | 60.1/41.1 | 67.4/47.8 | 63.8/44.5 |
| 0.1 | 1.0 | 0.1 | 62.4/43.6 | 68.0/48.6 | 65.2/46.1 |
| 0.1 | 1.0 | 0.0 | 47.9/35.1 | 52.5/38.3 | 50.2/36.7 |
| 0.0 | 1.0 | 0.1 | 58.8/41.7 | 63.3/43.6 | 61.1/42.7 |
| 0.0 | 1.0 | 0.0 | 44.2/27.5 | 51.2/32.0 | 47.7/29.8 |
| Metric (AP50/AP50:95) | |||
|---|---|---|---|
| Snow | Rain | Mean | |
| 10 | 48.5/25.9 | 54.6/30.6 | 51.6/28.3 |
| 50 | 62.4/43.6 | 68.0/48.6 | 65.2/46.1 |
| 100 | 51.6/27.9 | 55.7/31.4 | 53.7/29.7 |
| 10,000 | 55.1/38.2 | 62.3/41.7 | 58.7/40.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoon, J.H.; Jung, J.W.; Yoo, S.B. Auxcoformer: Auxiliary and Contrastive Transformer for Robust Crack Detection in Adverse Weather Conditions. Mathematics 2024, 12, 690. https://doi.org/10.3390/math12050690
Yoon JH, Jung JW, Yoo SB. Auxcoformer: Auxiliary and Contrastive Transformer for Robust Crack Detection in Adverse Weather Conditions. Mathematics. 2024; 12(5):690. https://doi.org/10.3390/math12050690
Chicago/Turabian StyleYoon, Jae Hyun, Jong Won Jung, and Seok Bong Yoo. 2024. "Auxcoformer: Auxiliary and Contrastive Transformer for Robust Crack Detection in Adverse Weather Conditions" Mathematics 12, no. 5: 690. https://doi.org/10.3390/math12050690
APA StyleYoon, J. H., Jung, J. W., & Yoo, S. B. (2024). Auxcoformer: Auxiliary and Contrastive Transformer for Robust Crack Detection in Adverse Weather Conditions. Mathematics, 12(5), 690. https://doi.org/10.3390/math12050690