


Image Steganography and Style Transformation Based on Generative Adversarial Network
Abstract
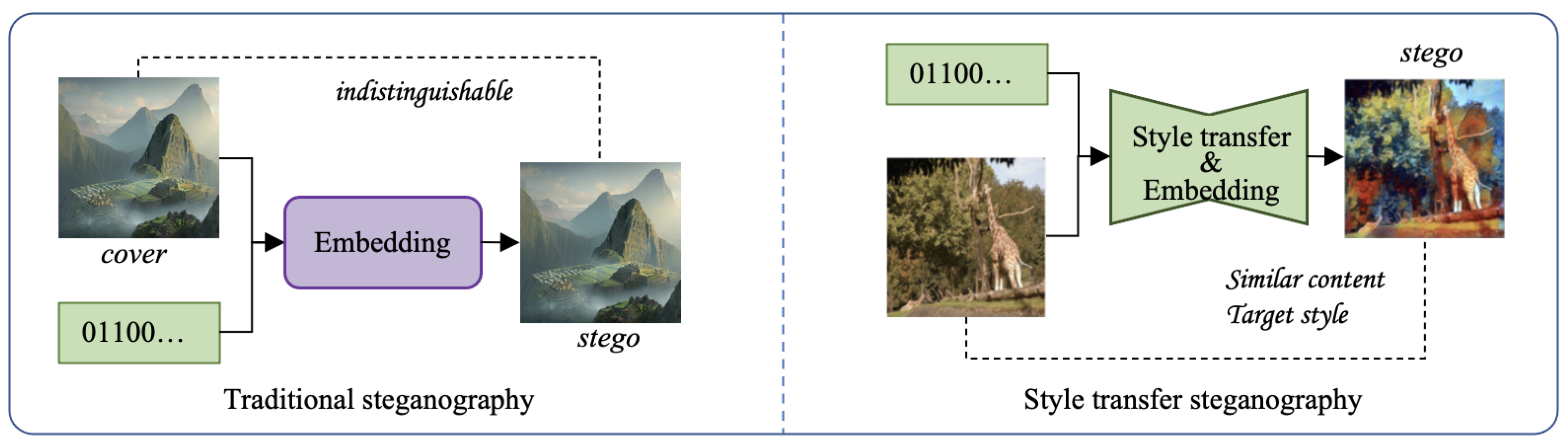
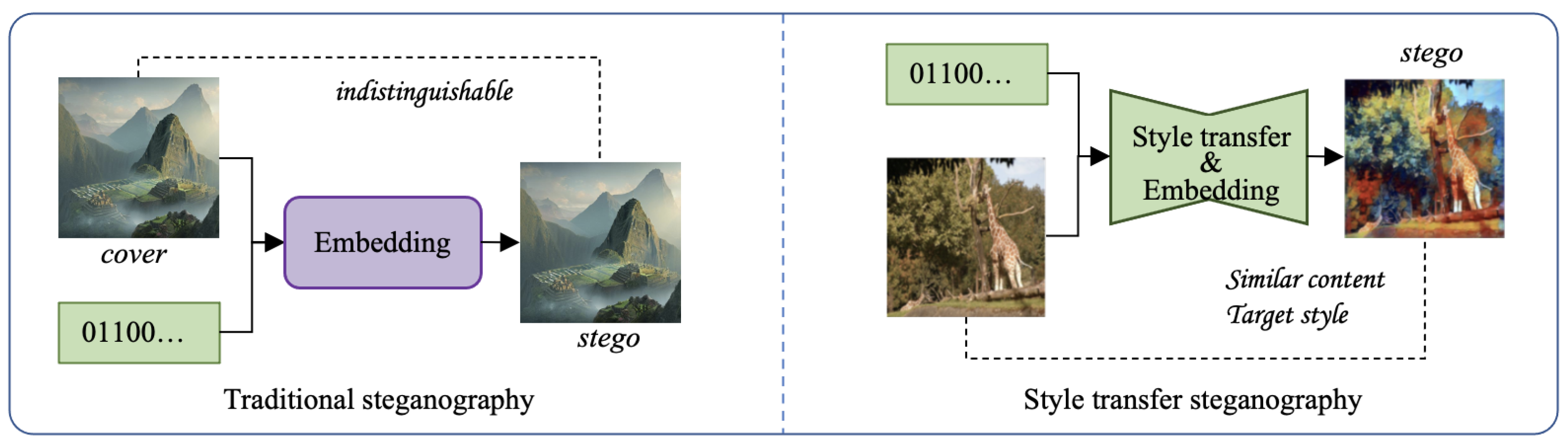
1. Introduction
- We designed a framework for image steganography during the process of image style transfer. The proposed method is more secure compared to traditional steganography since the steganalysis without the corresponding cover–stego pairs is difficult.
- We validated the effectiveness of the proposed method by experiments. The results showed that the proposed approach can successfully embed 1 bpcpp, and the generated stego cannot be distinguished from the clean style-transferred images generated by a model without steganography. The accuracy of the recovered information was 99%. Though it was not 100%, this can be solved by coding secret information using error-correction codes before hiding them in the image.
2. Related Works
2.1. Image Steganography
2.1.1. Cost-Based Steganography
2.1.2. Model-Based Steganography
2.1.3. Coverless Steganography
2.2. Image Style Transfer
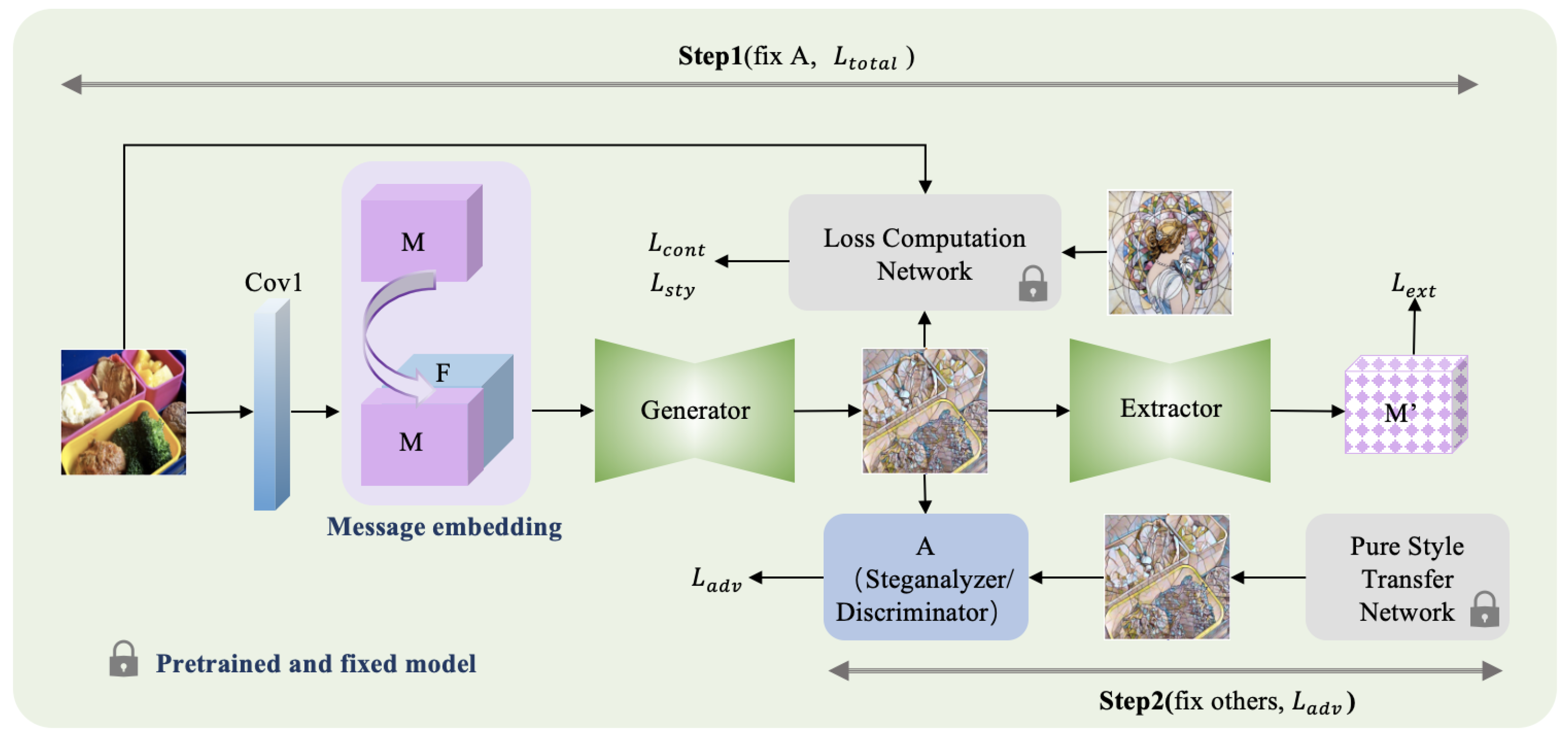
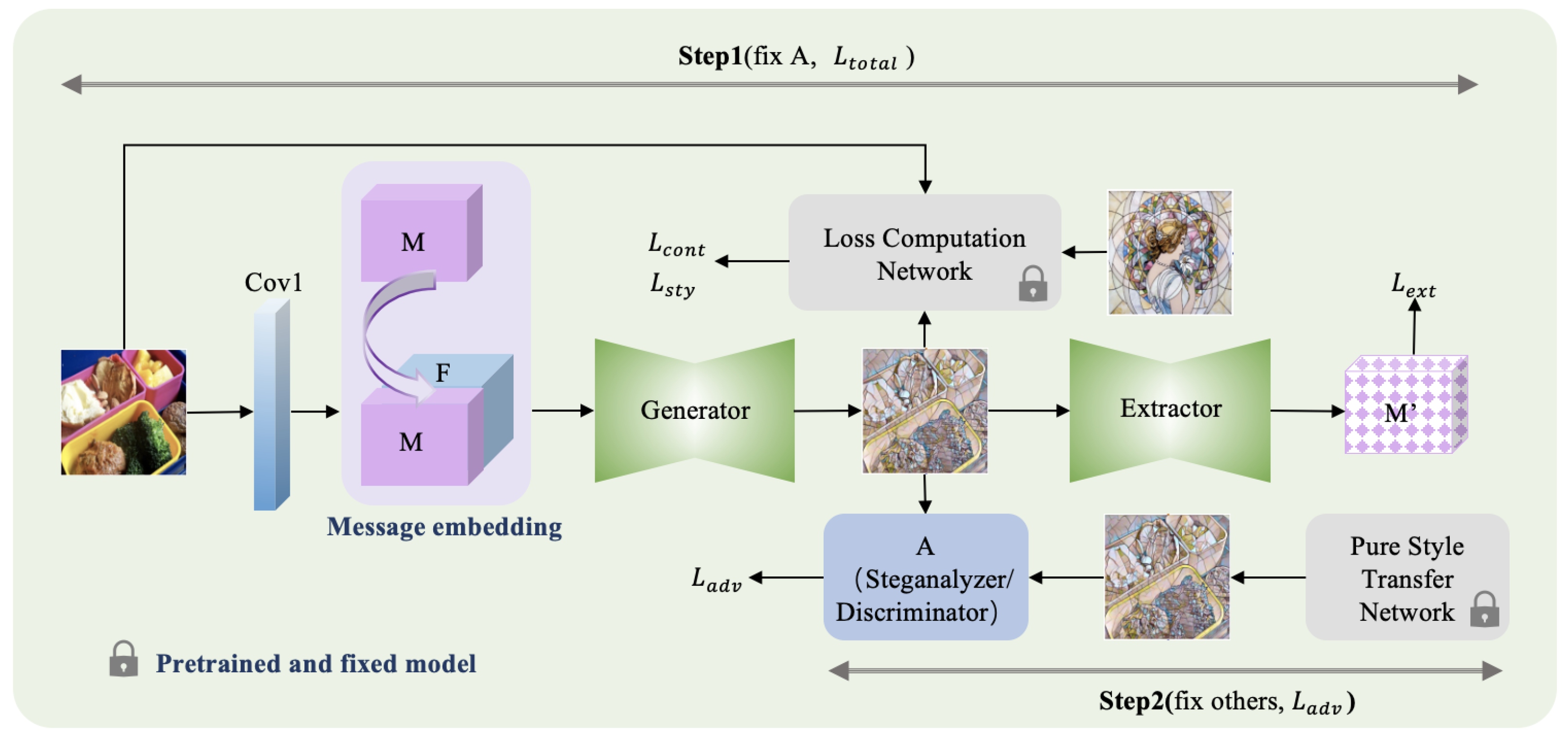
3. Proposed Methods
3.1. Style Transfer Loss Computing
3.1.1. Content Reconstruction Loss
3.1.2. Style Reconstruction Loss
3.2. Extractor
3.3. Adversary
3.4. Training
4. Experiments
4.1. Message Extraction Accuracy Analysis
4.2. Security in Resisting Steganalysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Filler, T.; Judas, J.; Fridrich, J. Minimizing Additive Distortion in Steganography using Syndrome-Trellis Codes. IEEE Trans. Inf. Forensics Secur. 2011, 6, 920–935. [Google Scholar] [CrossRef]
- Yao, Q.; Zhang, W.; Chen, K.; Yu, N. LDGM Codes Based Near-optimal Coding for Adaptive Steganography. IEEE Trans. Commun. 2023, 2023, 1. [Google Scholar] [CrossRef]
- Pevný, T.; Filler, T.; Bas, P. Using high-dimensional image modelsto perform highly undetectable steganography. In Proceedings of the International Workshop on Information Hiding, Calgary, AB, Canada, 28–30 June 2010; pp. 161–177. [Google Scholar]
- Sedighi, V.; Cogranne, R.; Fridrich, J. Content-Adaptive Steganography by Minimizing Statistical Detectability. IEEE Trans. Inf. Forensics Secur. 2015, 11, 221–234. [Google Scholar] [CrossRef]
- Holub, V.; Fridrich, J. Designing Steganographic Distortion Using Directional Filters. In Proceedings of the IEEE Workshop on Information Forensic and Security (WIFS), Tenerife, Spain, 2–5 December 2012; pp. 234–239. [Google Scholar]
- Holub, V.; Fridrich, J.; Denemark, T. Universal Distortion Function for Steganography in an Arbitrary Domain. EURASIP J. Inf. Secur. 2014, 2014, 1–13. [Google Scholar] [CrossRef]
- Li, B.; Wang, M.; Huang, J.; Li, X. A new cost function for spatial image steganography. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 4206–4210. [Google Scholar]
- Li, B.; Wang, M.; Li, X.; Tan, S.; Huang, J. A strategy of clustering modification directions in spatial image steganography. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1905–1917. [Google Scholar]
- Denemark, T.; Fridrich, J. Improving steganographic security by synchronizing the selection channel. In Proceedings of the 3rd ACM Information Hiding and Multimedia Security Workshop, Portland, OR, USA, 17–19 June 2015; pp. 5–14. [Google Scholar]
- Li, W.; Zhang, W.; Chen, K.; Zhou, W.; Yu, N. Defining joint distortion for JPEG steganography. In Proceedings of the 6th ACM Workshop on Information Hiding and Multimedia Security, Innsbruck, Austria, 20–22 June 2018; pp. 5–16. [Google Scholar]
- Kodovský, J.; Fridrich, J.; Holub, V. Ensemble classifiers for steganalysis of digital media. IEEE Trans. Inf. Forensics Secur. 2012, 7, 432–444. [Google Scholar] [CrossRef]
- Holub, V.; Fridrich, J. Low-complexity features for JPEG steganalysis using undecimated DCT. IEEE Trans. Inf. Forensics Secur. 2015, 10, 219–228. [Google Scholar] [CrossRef]
- Li, B.; Li, Z.; Zhou, S.; Tan, S.; Zhang, X. New steganalytic features for spatial image steganography based on derivative filters and threshold LBP operator. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1242–1257. [Google Scholar] [CrossRef]
- Fridrich, J.; Kodovsky, J. Rich models for steganalysis of digital images. IEEE Trans. Inf. Forensics Secur. 2012, 7, 868–882. [Google Scholar] [CrossRef]
- Qian, Y.; Dong, J.; Wang, W.; Tan, T. Deep learning for steganalysis via Convolutional Neural Networks. Proc. SPIE 2015, 9409, 94090J. [Google Scholar]
- Xu, G.; Wu, H.Z.; Shi, Y.Q. Structural design of Convolutional Neural Networks for steganalysis. IEEE Signal Process. Lett. 2016, 23, 708–712. [Google Scholar] [CrossRef]
- Ye, J.; Ni, J.; Yi, Y. Deep learning hierarchical representations for image steganalysis. IEEE Trans. Inf. Forensics Secur. 2017, 12, 2545–2557. [Google Scholar] [CrossRef]
- Boroumand, M.; Chen, M.; Fridrich, J. Deep residual network for steganalysis of digital images. IEEE Trans. Inf. Forensics Secur. 2018, 14, 1181–1193. [Google Scholar] [CrossRef]
- Butora, J.; Yousfi, Y.; Fridrich, J. How to Pretrain for Steganalysis. In Proceedings of the 9th Information Hiding and Multimedia Security Workshop, Brussels, Belgium, 22–25 June 2021. [Google Scholar]
- Zhang, J.; Chen, K.; Li, W.; Zhang, W.; Yu, N. Steganography with Generated Images: Leveraging Volatility to Enhance Security. IEEE Trans. Dependable Secur. Comput. 2023, 2023, 1–12. [Google Scholar] [CrossRef]
- Chen, K.; Zhou, H.; Wang, Y.; Li, M.; Zhang, W.; Yu, N. Cover Reproducible Steganography via Deep Generative Models. IEEE Trans. Dependable Secur. Comput. 2022, 20, 3787–3798. [Google Scholar] [CrossRef]
- Zhu, J.; Kaplan, R.; Johnson, J.; Li, F.F. Hidden: Hiding data with deep networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 657–672. [Google Scholar]
- Tan, J.; Liao, X.; Liu, J.; Cao, Y.; Jiang, H. Channel Attention Image Steganography with Generative Adversarial Networks. IEEE Trans. Netw. Sci. Eng. 2022, 9, 888–903. [Google Scholar] [CrossRef]
- Tang, W.; Li, B.; Mauro, B.; Li, J.; Huang, J. An automatic cost learning framework for image steganography using deep reinforcement learning. IEEE Trans. Inf. Forensics Secur. 2020, 16, 952–967. [Google Scholar] [CrossRef]
- Guan, Z.; Jing, J.; Deng, X.; Xu, M.; Jiang, L.; Zhang, Z.; Li, Y. DeepMIH: Deep invertible network for multiple image hiding. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 372–390. [Google Scholar] [CrossRef]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical Text-Conditional Image Generation with Clip Latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Bui, T.; Agarwal, S.; Yu, N.; Collomosse, J. RoSteALS: Robust Steganography using Autoencoder Latent Space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 933–942. [Google Scholar]
- Yu, J.; Zhang, X.; Xu, Y.; Zhang, J. CRoSS: Diffusion Model Makes Controllable, Robust and Secure Image Steganography. arXiv 2023, arXiv:2305.16936. [Google Scholar]
- Zhong, N.; Qian, Z.; Wang, Z.; Zhang, X. Steganography in stylized images. J. Electron. Imaging 2019, 28, 033005. [Google Scholar] [CrossRef]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. A neural algorithm of artistic style. arXiv 2015, arXiv:1508.06576. [Google Scholar] [CrossRef]
- Johnson, J.; Alahi, A.; Li, F. Perceptual losses for real-time style transfer and super-resolution. In European Conference on Computer Vision; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 694–711. [Google Scholar]
- Huang, X.; Belongie, S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1501–1510. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Message-Embedding Network | Message-Embedding Network | ||
|---|---|---|---|
| Network Layer | Output Size | Network Layer | Output Size |
| input | input | ||
| padding() | conv, step 1 | ||
| conv, step 1 | conv, step | ||
| secret message | conv, step 1 | ||
| message concat | residual block, 128 filters | ||
| conv, step 2 | residual block, 128 filters | ||
| conv, step 2 | residual block, 128 filters | ||
| residual block, 128 filters | residual block, 128 filters | ||
| residual block, 128 filters | residual block, 128 filters | ||
| residual block, 128 filters | conv, step 2 | ||
| residual block, 128 filters | conv, step 2 | ||
| residual block, 128 filters | conv, step 2 | ||
| conv, step | conv, step 1 | ||
| conv, step | |||
| conv, step 1 | |||
| Nettest | Net1 | Net2 | Net3 | Net4 | Net5 | |
|---|---|---|---|---|---|---|
| Nettrain | ||||||
| 0.99 | 0.39 | 0.31 | 0.28 | 0.32 | ||
| 0.37 | 0.99 | 0.28 | 0.23 | 0.38 | ||
| 0.31 | 0.19 | 0.99 | 0.33 | 0.41 | ||
| 0.40 | 0.29 | 0.31 | 0.99 | 0.34 | ||
| 0.29 | 0.32 | 0.37 | 0.19 | 0.98 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, L.; Zhang, X.; Chen, K.; Feng, G.; Wu, D.; Zhang, W. Image Steganography and Style Transformation Based on Generative Adversarial Network. Mathematics 2024, 12, 615. https://doi.org/10.3390/math12040615
Li L, Zhang X, Chen K, Feng G, Wu D, Zhang W. Image Steganography and Style Transformation Based on Generative Adversarial Network. Mathematics. 2024; 12(4):615. https://doi.org/10.3390/math12040615
Chicago/Turabian StyleLi, Li, Xinpeng Zhang, Kejiang Chen, Guorui Feng, Deyang Wu, and Weiming Zhang. 2024. "Image Steganography and Style Transformation Based on Generative Adversarial Network" Mathematics 12, no. 4: 615. https://doi.org/10.3390/math12040615
APA StyleLi, L., Zhang, X., Chen, K., Feng, G., Wu, D., & Zhang, W. (2024). Image Steganography and Style Transformation Based on Generative Adversarial Network. Mathematics, 12(4), 615. https://doi.org/10.3390/math12040615