1. Introduction
As each day passes, the volume of data in our world increases exponentially, necessitating the development of new statistical distributions to better characterize the features of many phenomena and experiments. While a great deal of lifetime data appear to be continuous, they are originally discrete. This discrepancy ensures the need for more appropriate methods to generate discrete distributions that more accurately represent the data in the experiment. Discrete distributions are frequently employed in statistical modeling for several reasons.
Discrete distributions are used to model data that can only take on a finite or countably infinite number of values, such as counts, proportions, and binary outcomes, for example, the number of customers in a store, the number of heads in a coin flip, or the number of defective items in a production line. Discrete distributions are often easy to understand and interpret as they model data that take on a limited number of values. The probability mass function (pmf) or probability generating function (pgf) of a discrete distribution is a simple function that provides the probability of each possible outcome. Also, many discrete distributions have closed-form expressions for their pmf or pgf, which makes it easy to work with them mathematically. This allows for efficient computation of probabilities and moments without the need for integration. Furthermore, discrete distributions can be used to model a wide variety of real-world phenomena, such as the distribution of species in an ecosystem, the distribution of genetic variations in a population, or the distribution of traffic on a road network.
Recently, many discrete distributions have been considered, particularly in medicine, engineering, reliability, survival analysis, and more. For more descriptions and applications of discrete distributions, refer to [
1,
2,
3,
4,
5,
6,
7,
8,
9]. Hence, many authors have conducted much work to originate and develop discrete models from different aspects.
The characterization of continuous random variables can be performed either by their probability density function, cumulative distribution function, moments, moment-generating function, hazard rate functions, or others. Different discretization methods appeared in the literature to create an appropriate discrete distribution based on the underlying continuous model.
By deriving discrete analogs or counterparts of well-known continuous distributions, statisticians can better tailor their models to the specific nature of the data. Usually, creating a discrete analog from a continuous distribution is based on the principle of preserving one or more characteristic properties of the continuous one. Consequently, different ways to discretize a continuous distribution appear in the literature depending on the property the researcher intends to preserve; for example, Lai [
10] used the survival and the hazard rate preservation methods to create discrete distributions from different continuous ones. Haj Ahmad and Almetwally [
11] used the survival, hazard rate, and probability distribution function preservation methods to discretize the generalized Pareto distribution.
The benefit of using the survival discretization method is that it can maintain the statistical properties of the original distribution, including median and percentiles, in addition to the overall shape of the distribution. A drawback of this method is that it can be computationally intensive and may require numerical methods for complex distributions.
For the hazard preservation method, the main benefit is that it preserves the hazard function of the continuous distribution. This is important in applications like reliability analysis where the failure rate is a key parameter. On the other hand, mathematical complexity can be viewed using this method, especially for continuous distributions with nonlinear hazard functions. This complexity can increase computational time and resource requirements. Another drawback of the hazard preservation method is that it only preserves the hazard function, but other characteristics of the distribution (like mean, variance, or skewness) may not be as accurately retained. For more details about other discretization methods and their properties, one may refer to [
12,
13] who provided a review of several discretization methods.
From the previous research work, it is evident that the results look appealing and motivational to continue creating new discrete distributions to model new data.
In the present study, we obtain a discrete analog of the continuous new generalized Rayleigh distribution (NGRD) using the survival discretization method that depends on the survival function. See for example [
6,
7], in which the survival discretization approach was used to obtain the discrete normal and discrete Rayleigh distributions, respectively. Using the same approach, more discrete distributions have been introduced and studied; see for example [
14,
15,
16,
17,
18,
19,
20,
21,
22,
23].
Still, there is an enduring need to create and develop more discrete models and to generate new ones because of modeling and fitting real data, which appear and spread constantly in human life. The efficiency in discretization methods refers to the ability of a method to produce accurate and useful discretized versions of continuous data with minimal loss of information. Also, discrete distributions derived from continuous ones can inherit their flexibility and adaptability. This allows statisticians to model a wider range of data characteristics, such as skewness or kurtosis, which might be difficult with standard discrete distributions. In statistical methodology, continuous distributions may have characteristics that are missing in the discrete space; hence, creating discrete analogs can fill these gaps, providing new tools for data analysis.
The suggested discrete model with three parameters offers an immense degree of fitness to skewed, symmetric, monotone, and inverse J-shape types of data. Therefore, some statistical functions and properties are achieved, in addition to observing the submodels and limiting behavior of the proposed discrete distribution. Examining statistical inference is crucial; therefore, point and interval estimation for the unknown parameters using the maximum likelihood estimator and the Bayesian method is performed.
Simulation analysis via numerical techniques such as Monte Carlo simulation is employed to evaluate the estimators using the maximum likelihood and the Bayesian estimation methods to compare the performance of these two methods. The efficiency is assessed using the relative bias, the mean squared error, and the coverage probability of the confidence intervals. Two real datasets are analyzed to emphasize the empirical validation of the new model, where several goodness-of-fit measures are employed. The first example is related to the industrial field, where several strikes that occurred in coal mining in the UK were recorded over four weeks. Modeling and predicting the number of strikes will save human lives and money. The second example is related to the number of fires that occurred in Greece’s forests in the year 1998 during the summer months. The main purposes of this study are, first, to introduce new discrete analogs of the continuous NGRD and evaluate some of its important statistical functions, second, to perform the inferential statistics related to the new distributions’ parameters and compare the results, and, third, to assess the efficiency of the new discrete distribution by modeling real data examples and comparing the goodness-of-fit measures with other discrete distributions that were studied earlier in the literature.
The originality of this work emanates from the basis of exploring the creation of a new discrete analog from less commonly used continuous distributions and investigating their properties, potential applications, and how they compare to existing distributions. Also, it focuses on specific application areas, such as the industrial, engineering, and reliability fields. To our knowledge, no previous work has studied the discrete new generalized Rayleigh distribution and employed it to model real-life data examples from different scientific fields.
The authors’ contributions to this study can be summarized as follows:
Development of a New Discrete Model: Creation of a discrete analog of the continuous new generalized Rayleigh distribution (NGRD) using the survival discretization method.
Statistical Functions and Properties: Achievement of various statistical functions and properties of the proposed discrete distribution, including observing its submodels and limiting behavior.
Statistical Inference Examination: Conducting point and interval estimation for the unknown parameters using both the maximum likelihood estimator (MLE) and the Bayesian method.
Simulation Analysis for Estimator Evaluation: Implementation of numerical techniques such as Monte Carlo simulation to evaluate the estimators derived from MLE and Bayesian estimation methods through relative bias, mean squared error, and coverage probability of confidence intervals
Empirical Validation via Real Data Analysis: Analyzing two real datasets to validate the new model empirically, including modeling industrial and environmental phenomena.
Comparison with other Distributions: Comparing the goodness of fit of the new model with other discrete distributions previously studied in the literature.
The remaining parts of this work are organized as follows:
Section 2 describes the new generalized Rayleigh distribution. The discretization methods are presented in
Section 3, along with some statistical functions. In
Section 4, the maximum likelihood and the Bayesian inference are presented. In
Section 5, simulation analysis and the tabulated results are carried out. Some real data examples are provided in
Section 6. Finally, conclusions are remarked on in
Section 7.
2. Model Description
The Rayleigh distribution (RD) is a continuous distribution that has much practical importance; hence, many of its statistical characteristics, inference, and reliability analysis have been studied by several authors, and numerous extended forms of the Rayleigh distribution have been proposed. For example, Ref. [
24] applied the inverse Rayleigh to the failure times data. Ref. [
25] introduced the transmuted Rayleigh and used it to model the amount of nicotine in the blood. In [
26], the authors studied the beta-generalized Rayleigh distribution and its application. Ref. [
27] obtained the transmuted inverse Rayleigh distribution to lifetime data. Ref. [
28] obtained a new modified Rayleigh distribution named the Kumaraswamy generalized Rayleigh distribution with application to real data. For more information, refer to [
29,
30,
31]. In this work, we are interested in studying a new form of the Rayleigh distribution called a new generalized Rayleigh distribution (NGR), which was first introduced by Shen et al. [
32]. It has three parameters and it was shown that the NGR is suitable for modeling large data values rather than small data values. However, as a continuous distribution, it is restricted from describing discrete data forms. Discretizing the NGR distribution is our goal; therefore, it yields a subsequent distribution that accommodates the countable data while retaining the influential tail modeling characteristics of the NGR. In this study, we carry out a discrete version of the NGR and use it to model real data.
The probability density function (
pdf) and the survival function (
S) of the continuous NGR are provided respectively as:
and
in which the parameters
.
The hazard rate function is
To identify submodels or special distributions that arise from this general form, we can consider different values or limits of parameters , , and . Here are some special cases:
Standard Rayleigh Distribution: When and , the term simplifies to the CDF of the standard Rayleigh distribution. This is observed if the parameter also approaches infinity, which simplifies the formula to , the CDF of the standard Rayleigh distribution.
Exponential Distribution: If approaches infinity, the term = can approach an exponential-like behavior for small values of x, depending on how is defined.
Modified Rayleigh Distribution: For specific fixed values of and , you can obtain various forms of modified Rayleigh distributions, where the behavior is measured by the degree of skewness and kurtosis determined by these parameters.
Weibull-like Distribution: By interchanging between and , especially when is not equal to 1, the distribution can possess Weibull-like properties.
By discretizing the continuous range of x, discrete versions of this distribution can be derived, which may be useful for certain types of count data or integer-valued measurements.
Since our goal in this work is to define a new discrete NGR distribution, we generate a discrete analog based on the survival discretization method, which is denoted by DNGR. The pmf and cumulative distribution function (CDF) are obtained. Furthermore, the moments, stress–strength function, the mean residual, and mean past lifetimes, order statistics, and L-moments are obtained. All these statistical functions are used for studying the features of the DNGR.
3. The Discrete New Generalized Rayleigh Distribution
Roy and Gupta [
3,
4] defined the probability mass function (
pmf) for a discrete distribution using the survival function and it was expressed as follows:
where
is the survival function provided by Equation (
2); hence, the
pmf of the discrete analog of NGR distribution, namely DNGR, is written as
where
.
The CDF of the DNGR distribution can be written as
The quantile function with given values of parameters as
, and
of the DNGR distribution is provided by
The hazard rate function (
HRF) of the DNGR distribution is provided by
We also observe that the reversed hazard rate function for the DNGR of this distribution is provided by
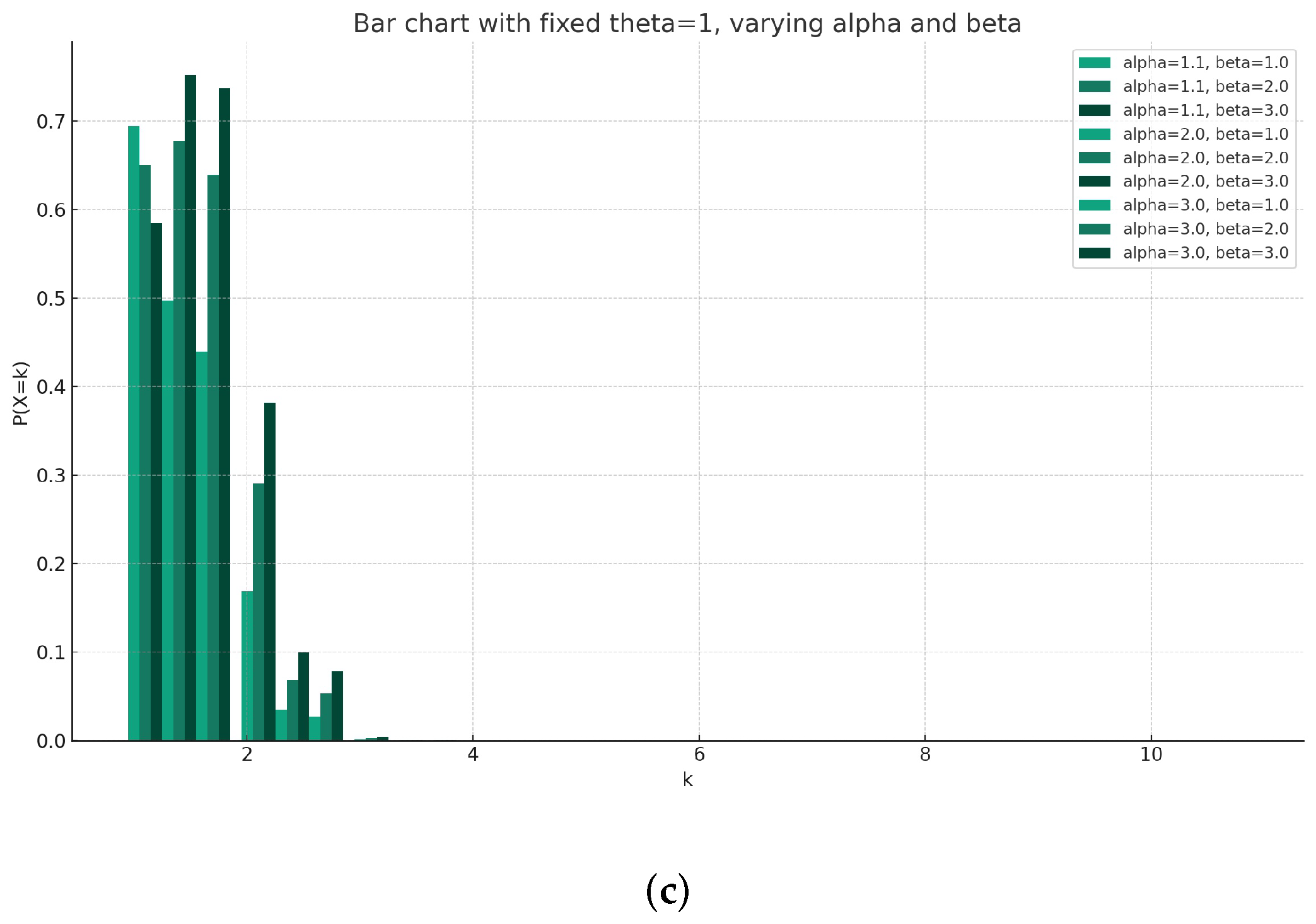
In
Figure 1, the bar charts represent each parameter
that has a specific role in the behavior of the
pmf, and their effects are observable when we fix one and vary the others. An explanation of the effect of each parameter based on the plots is as follows:
- 1.
Effect of when and are changeable:
When is fixed, the variations in and create different trends in the probability values. Higher values of tend to stretch the curve horizontally, meaning, for a given , as increases, the decrease in probability values with increasing k is less steep. Higher values of tend to amplify the curve vertically, making the probability have fewer values for higher k values. The reaction between and at a fixed demonstrates that affects the spread of the distribution, while affects the sharpness of the probability decrease.
- 2.
Effect of when and are changeable:
With fixed, the changes in and show distinct patterns. An increase in generally results in higher probability values across all k. This is because a higher relative to (k; ,) increases the numerator and decreases the denominator of the function , resulting in a larger overall value. The effect of at a fixed is similar to its effect when is fixed; it controls the sharpness of the decrease in probability values. Higher values cause a quicker decline in probability as k increases.
- 3.
Fixing and varying and , we can see that
As increases, for a fixed , the overall probability values increase, similar to when is fixed. The role of here is nuanced; for lower values of k, the impact of changing is minimal, but, as k increases, higher values preserve higher probabilities, indicating a wider spread in the distribution. From the above explanations, it is clear that primarily scales the probability values, determines the rate at which the probability values decline as k increases (sharpness of the distribution), and controls the spread or dispersion of the distribution across k values. The combination of these three parameters can thus shape the function’s distribution in various ways, and each has a distinctive role in the form of the probability curve.
In
Figure 2, the plots represent the
HRF of the DNGR distribution for various combinations of parameters
. Each subplot corresponds to a different set of these parameters. The values of
k range from 1 to 10. The curves are increasing for different values of the parameters; we can realize the effect of increasing the parameter
while keeping other parameters fixed by going steeply to the left. For the effect of
, assuming other parameters are fixed, it can be figured by increasing in a slower mode when
k takes small values. Finally, the effect of increasing the values of
while fixing the remaining parameters is going to the left more steeply.
The limiting behavior of DNGR for different choices in parameter values at the boundary points includes
, ,
, ,
,
and .
From the above limiting behavior of the DNGR, some submodels and special cases can be derived, such as
Discrete standard Rayleigh Distribution: When and , and approaches infinity, the pmf simplifies to , which represents the pmf of the discrete Rayleigh distribution created from applying the survival discretization method.
Discrete Exponential-like Distribution: For large values of and specific values of , the DNGR distribution might possess characteristics similar to an exponential distribution for smaller values of k, where the exponential decay behavior is more evident, since the term = has a decaying form and can be considered as exponential-like function.
Discrete Uniform Distribution: If the parameters , , and are chosen such that the pmf becomes constant for all k within a certain range, the DNGR distribution could approximate a discrete uniform distribution.
Geometric-like Distribution: By adjusting and , you might be able to create a distribution that behaves like the geometric distribution, especially if the probability of larger k values decays like the geometric series.
These possible submodels and special cases demonstrate the versatility and adaptability of the DNGR distribution. The ability to derive such a variety of distributions from a single distribution highlights the potential utility of the DNGR distribution in modeling a wide range of discrete data scenarios. Each submodel or special case would be suited to different types of data and could provide unique insights depending on the context of the analysis.
3.1. Moments
Assume a non-negative random variable
. The
moment, say
, can be expressed as follows
and then
It is impossible to write an exact form of the
moment; hence, R programming with version (4.3.0) is helpful, and the moment is evaluated numerically. Equation (
11) is convergent for
, and
.
Table 1 explores some functions like the minimum, mean, variance, maximum, skewness (SK), and kurtosis (Kt) for different values of
, and
. In addition, the DNGR distribution is appropriate for modeling both over- and under-dispersed data since, in this model, the variance can be smaller than the mean, which is the case with some standard classical discrete distributions, in addition to the positive and negative skewness values, which show that this distribution can be skewed to the right or left. Also, a very small skew value that tends to zero indicates a symmetry possible curve for the
pmf. A higher kurtosis means more of the variation is due to infrequent extreme deviations as opposed to frequent modestly sized deviations. By varying
,
, and
, one can realize the distribution changes. For instance, with
= 0.8 and
= 0.5,
changing from 0.84 to 2.73 drastically increases the kurtosis, indicating a heavier tail.
3.2. Stress–Strength Analysis
The stress–strength (reliability) analysis is an important tool in mechanical design. The idea relies on the probability of failure that is obtained from the probability of
exceeding
. Assume that both
and
are in the positive domain. The expected reliability (
) can be calculated by
in which
and
, and then
can be expressed as follows
where
and
.
We cannot obtain a closed form for the above equation; consequently, simulation analysis is utilized to obtain a numerical solution. In
Section 6, numerical analysis is performed to obtain the value of the stress–strength function under two real data applications.
3.3. The Mean Residual and the Mean Past Lifetimes
In reliability and survival analysis, many lifetime measures have been discussed in the literature. They were defined to study the aging behavior of the experimental units. One of these measures is the mean residual lifetime (
MRL), which is a helpful tool in determining burn-in and maintenance policies. For discrete distributions, the
MRL is defined as follows:
where
If the random variable
k follows the DNGR distribution with parameters
, and
, which is denoted by
, then the
MRL is expressed as
The mean past lifetime (
MPL) is another important measure in reliability analysis. The
MPL measures the time elapsed after the failure of
units given that the system has failed sometime earlier to
i. In the discrete case, the
MPL is defined as follows
where
; see [
33].
3.4. Order Statistics
Let
be a random sample with the DNGR distribution and
denote the corresponding order statistics. Then, the
CDF of
order statistics at the value k can be written as follows
By using the negative binomial theorem, then
Consequently, the
pmf of the
order statistic under the DNGR can be derived and expressed as follows
So, the
moments of
can be written as follows
6. Real Data Examples
This section presents the analysis of two applications using different real datasets. The main goals of this section are
Examine the usefulness and applicability of the proposed model to real phenomena;
Show the applicability of the inferential results to a real practical situation;
Evaluate whether the proposed model is a better choice than the other seven models.
Data I: The first dataset includes the number of strikes that occurred in the UK coal mining industry over four consecutive week periods between 1948 and 1959. It was derived from Kendall [
34]. An empirical model was used to analyze this example by Ridout and Besbeas [
35] and is presented in
Table 4.
Data II: The number of fires that occurred in Greece between 1 July and 31 August, 1998. We only take into account fires in forest districts. These data have a sample size of 124. The minimum value is 0, the first quartile is 2, the median value is 4, the mean value is 5.065, the third quartile’s maximum value is 8, and the variance value is 18.256. The data are as follows: 2, 4, 4, 3, 3, 1, 2, 4, 3, 1, 1, 0, 5, 5, 0, 3, 1, 1, 0, 1, 0, 2, 0, 1, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 4, 2, 2, 1, 2, 1, 2, 0, 2, 2, 1, 0, 3, 2, 1, 2, 2, 7, 3, 5, 2, 5, 4, 5, 6, 5, 4, 3, 8, 4, 3, 8, 4, 4, 3, 10, 5, 4, 5, 12, 3, 8, 12, 10, 11, 6, 1, 8, 9, 12, 9, 4, 8, 12, 11, 8, 6, 4, 7, 9, 15, 12, 15, 15, 12, 9, 16, 7, 11, 9, 11, 6, 5, 20, 9, 8, 8, 5, 7, 10, 6, 6, 5, 5, 15, 6, 8, 5, 6. These data were discussed by [
36].
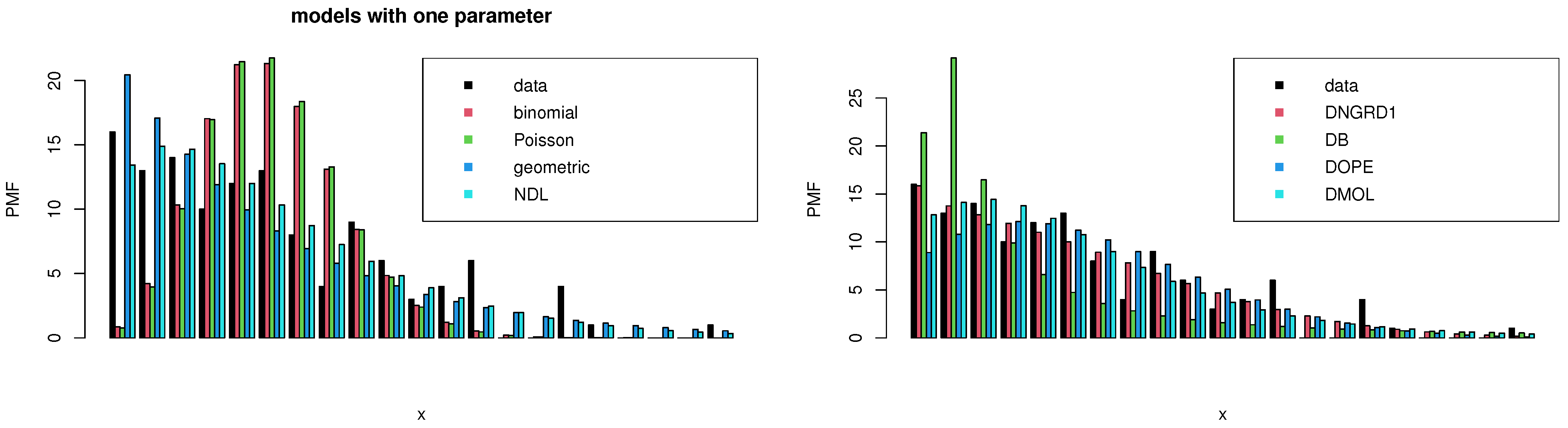
Based on the first and second datasets, the DNGRD probability model is contrasted and compared with the other seven competing models to show the reliability and superiority of the proposed model, including Poisson, binomial, geometric, discrete Burr (DB) by [
37], discrete Marshall–Olkin Lomax (DMOL) by [
38], new discrete Lindley (NDL) by [
39], and discrete odd perks exponential (DOPE) by [
40] distributions. To specify the best model, several criteria are used, namely: Akaike
, where
p is the length of the model parameter and
is log-likelihood value, consistent Akaike
, Bayesian
, and Hannan–Quinn
information criteria. Along with these, the
statistic and its
p-value are taken into account. If a probability model distribution has the highest
p-value and the lowest values for all other metrics, it is obvious that it will provide the best fit for a particular collection of data. The maximum likelihood estimates (with their standard errors (St.Es)), as well as the fitted model selection criteria, are shown in
Table 5 and
Table 6 using the R programming language and the ’bbmle’ package in R program with version number (4.3.0), that was recommended.
To compare the performance and efficiency of the DNGR distribution with other distributions listed in
Table 5, using measures of goodness of fit and
p-values, we can proceed as follows:
1-DNGR versus DOPE:
DNGR shows a better fit with a lower , , , and . The chi-squared value is lower for DNGR, indicating a better fit. DNGR has a higher p-value, suggesting a better fit to the data than DOPE.
2-DNGR versus Binomial/Poisson:
DNGR has a higher p-value than both binomial and Poisson distributions, indicating a more suitable model for the data. The information criteria (AIC, CAIC, HQIC) for DNGR are lower compared to binomial and Poisson, suggesting a better fit than binomial and Poisson.
3-DNGR versus DMOL:
DNGR and DMOL have comparable p-values, but DNGR shows better performance in terms of information criteria.
4-DNGR versus DB:
DNGR has a higher p-value than DB, indicating that DNGR shows slightly better performance in terms of information criteria.
5-DNGR versus Geometric/NDL:
DNGR outperforms both geometric and NDL distributions in terms of p-value, indicating a significantly better fit. DNGR has lower information criteria values, further suggesting its superiority in model fitting. Overall, DNGR appears to offer a more efficient and suitable fit for Data I compared to the other listed distributions.
Figure 3,
Figure 4 and
Figure 5 confirm these results for Data I (the black point refer to data; the pink point refer to DNGR distribution). Additionally, it is evident from Data II in
Table 6 that the DNGR distribution is the best distribution among all the examined models in terms of the P-value, whereas
Figure 6,
Figure 7 and
Figure 8 confirm these results for Data II.
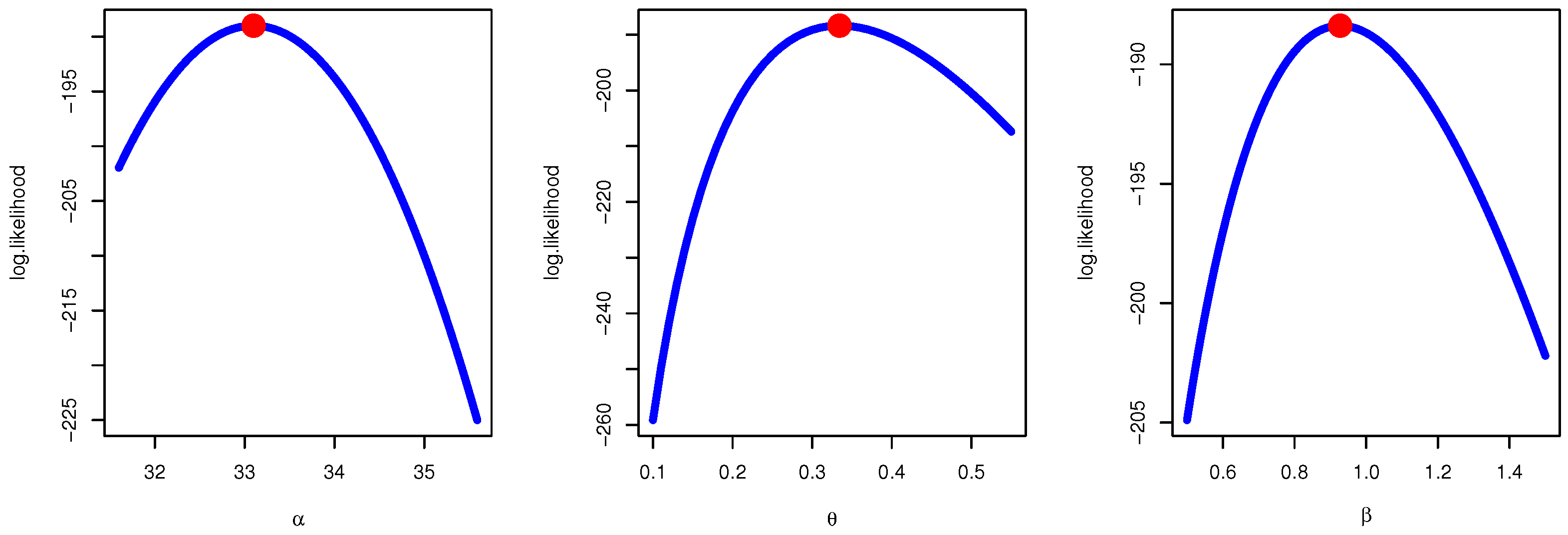
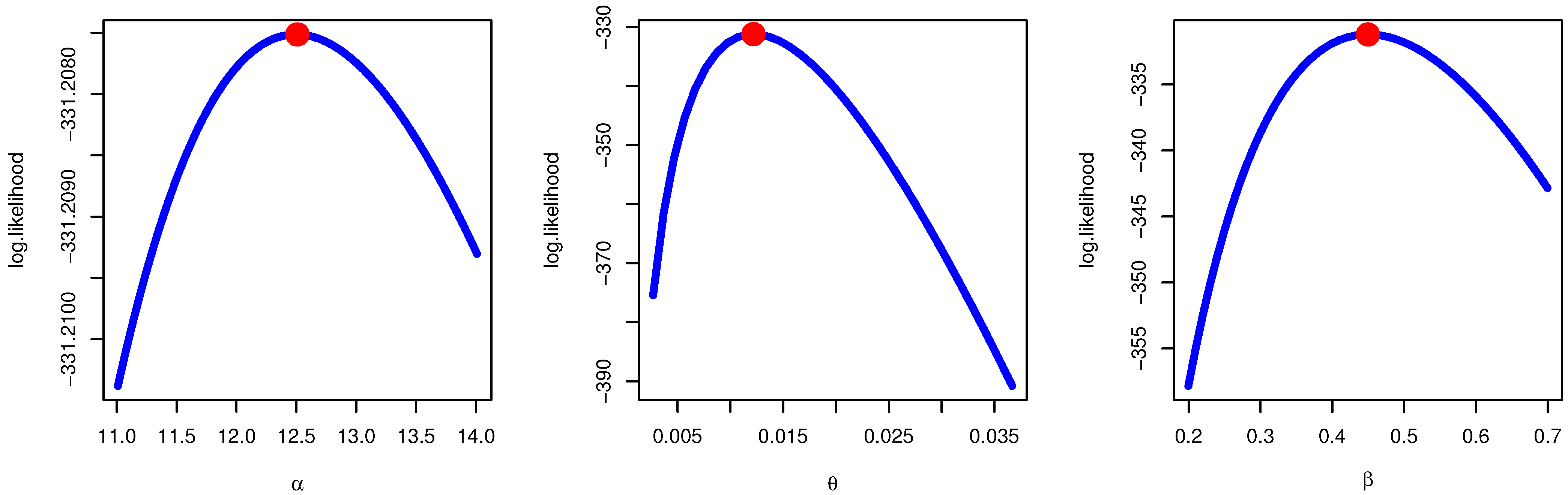
Figure 3 confirms the results of MLE fitting and demonstrates the existence, uniqueness, and maximum point of likelihood value of the likelihood estimates for Data I.
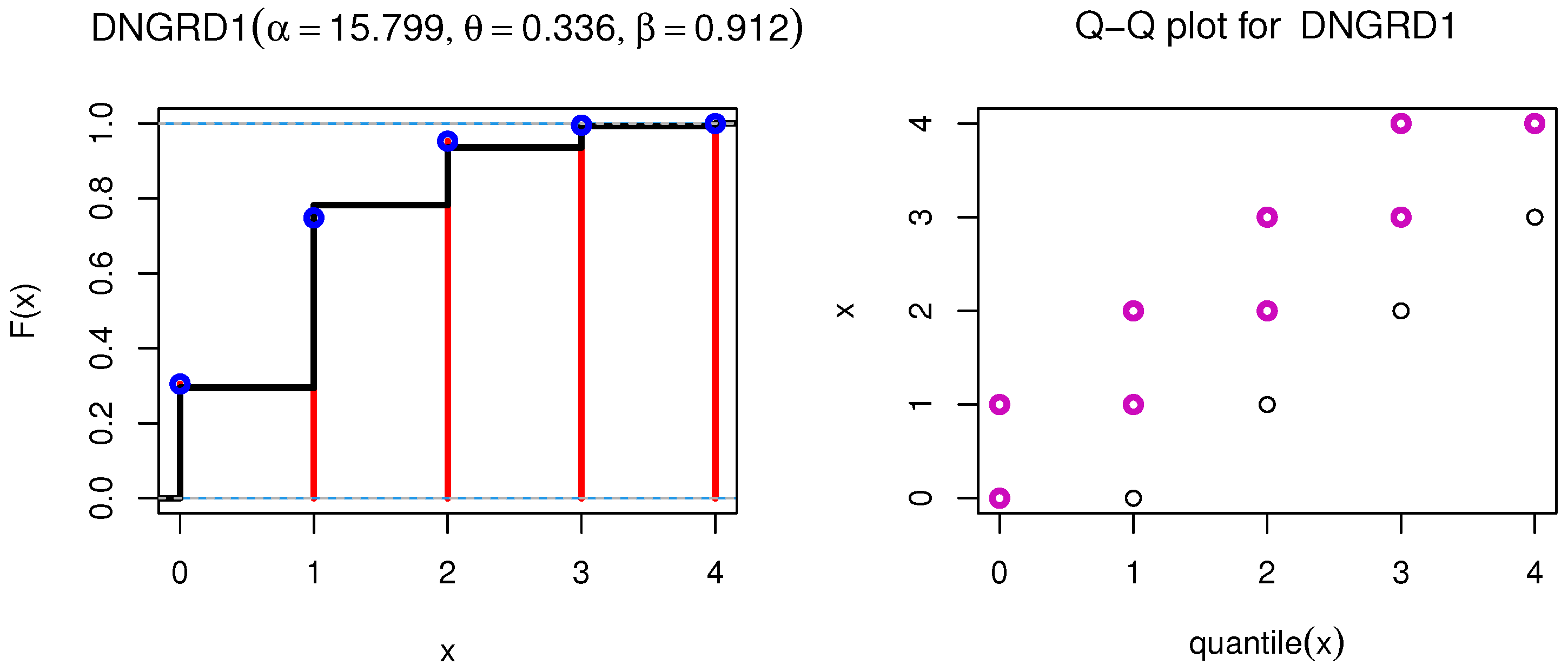
Figure 4 regarding associated empirical CDF and estimated CDF plot illustrates the connection between observed cumulative probability and observation through a visual plot and also Q–Q plot for Data I.
Figure 5 highlights estimated frequency by using PMF for each comparative model for Data I.
Table 7 indicates survival and hazard rate functions for DNGR distribution with different values of Data I, noting that the survival value decreased when the values of Data I increased, while the hazard rate value increased when the values
x of Data I increased.
Figure 6 confirms the results of MLE fitting and demonstrates the existence, uniqueness, and maximum point of likelihood value of the likelihood estimates for Data II.
Figure 7 regarding associated empirical CDF and estimated CDF plot illustrates the connection between observed cumulative probability and observation through a visual plot and Q–Q plot for Data II.
Figure 8 highlights estimated frequency by using PMF for each comparative model for Data II.
Table 8 indicates survival and hazard rate functions for DNGR distribution with different values of Data II, noting that the survival values decreased when the values of Data II increased, while the hazard rate value increased when the values
x of Data II increased.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}