

Identifying Hidden Factors Associated with Household Emergency Fund Holdings: A Machine Learning Application

Abstract
1. Introduction
2. Background
2.1. Household Emergency Funds
2.2. An Introduction to Machine Learning
2.3. Methodological Background: Machine Learning (ML) Algorithms and Their Applications in Financial and Consumer Research
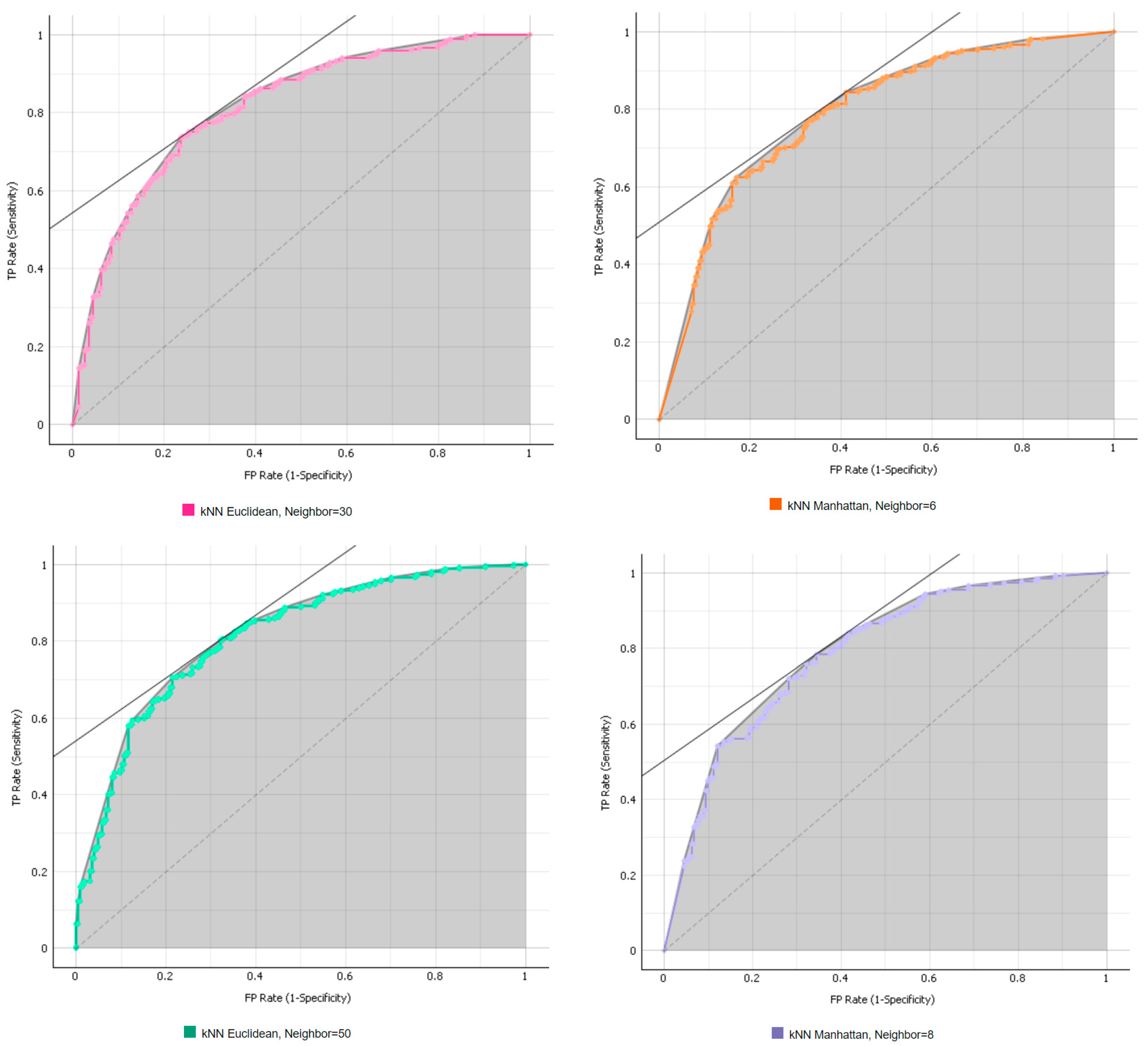
2.3.1. k-Nearest Neighbor (kNN)
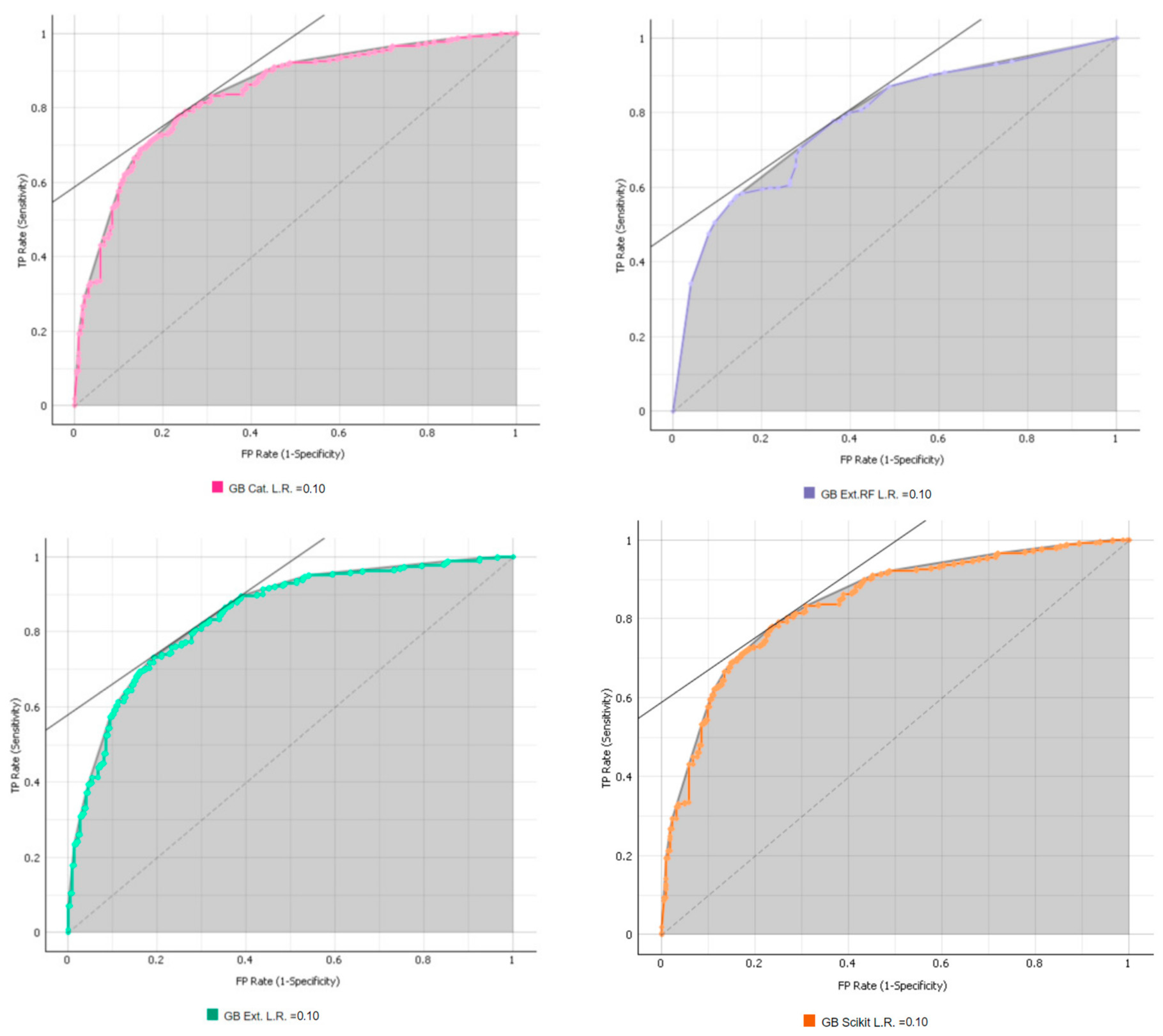
2.3.2. Gradient Boosting
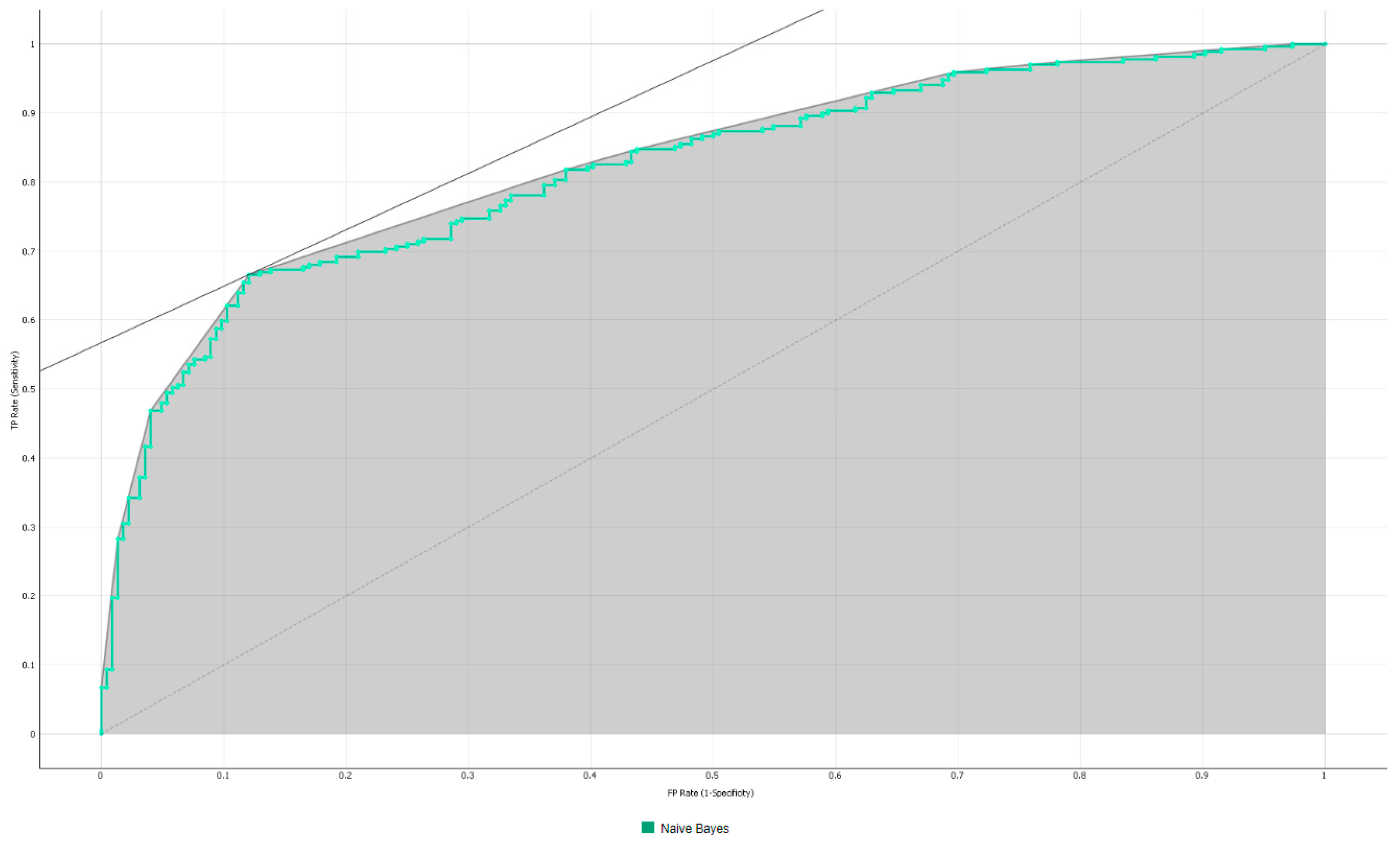
2.3.3. Naïve Bayes
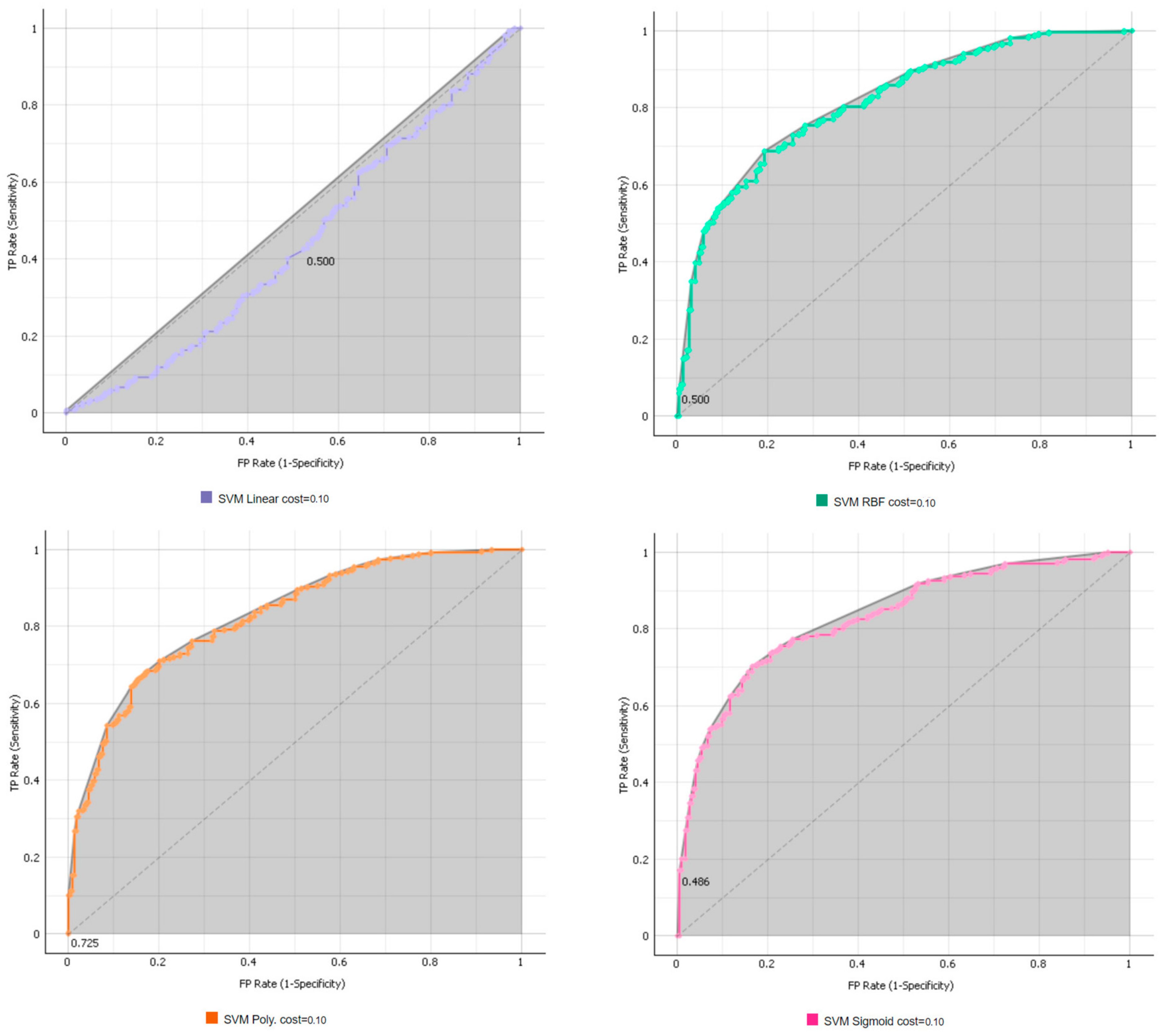
2.3.4. Support Vector Machine (SVM)
2.3.5. Stochastic Gradient Descent (SGD)
2.3.6. Neural Networks (NN)
2.3.7. Comparison Analysis
3. Empirical Model Flow
3.1. Research Purpose and Analysis Structure
3.2. Analytic ML and the Conventional Analysis Process
3.3. The Accuracy Estimation Method
3.4. The Factor Ranking Method
4. Data and Measurement
4.1. Data
4.2. Measurement
5. Results
5.1. Identify the Best Parameters among the Various ML Algorithms
5.2. Results for Step 2: Find the Best ML Prediction Method among the Various ML Algorithms
5.3. Results for Step 3: Check Whether the Accuracy of the ML Algorithms Is Higher Than the Accuracy Offered by a Logistic Regression
5.4. Results for Step 4: Determine Which Factors Are Associated with Holding an Emergency Fund
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Variable | Frequency | Percentage | Mean | SD |
|---|---|---|---|---|---|
| Outcome | Em. Fund (=Have) | 538 | 54.51% | ||
| Financial Factors | Auto loan (=Have) | 355 | 35.97% | ||
| Student loan (=Have) | 307 | 31.10% | |||
| Farm loan (=Have) | 156 | 15.81% | |||
| Equity loan (=Have) | 181 | 18.34% | |||
| Mortgage loan (=Have) | 320 | 32.42% | |||
| Own house | 487 | 49.34% | |||
| Saving acct. | 650 | 65.86% | |||
| Checking acct. | 807 | 81.76% | |||
| Term L.I. | 418 | 42.35% | |||
| Whole L.I. | 289 | 29.28% | |||
| FA have | 330 | 33.43% | |||
| FA do not know | 143 | 14.19% | |||
| FA no | 514 | 52.08% | |||
| Payday loan | 274 | 27.76% | |||
| Health insurance | 776 | 78.62% | |||
| FP Dist. 5 miles | 216 | 21.88% | |||
| FP Dist. 10 miles | 229 | 22.29% | |||
| FP Dist. 20 miles | 140 | 14.18% | |||
| FP Dist. 50 miles | 67 | 6.79% | |||
| FP Dist. Over 50 | 44 | 4.46% | |||
| FP Dist. na | 300 | 30.40% | |||
| Financial Education | Fin course in H.S. (=Have) | 363 | 36.78% | ||
| Fin course in Col. (=Have) | 296 | 29.99% | |||
| Obj. Fin Knw. | 1.56 | 1.00 | |||
| Psych. Factors | Fin R.T. | 22.70 | 4.71 | ||
| Fin Satisfaction | 22.54 | 7.31 | |||
| Fin Stress | 66.95 | 27.71 | |||
| Fin Self-efficacy | 15.59 | 5.22 | |||
| L.O.C. | 18.57 | 6.27 | |||
| S.W.L.S. | 21.56 | 8.73 | |||
| Self-esteem | 28.38 | 5.05 | |||
| Job insecurity | 19.69 | 4.55 | |||
| Demo. Factors | WS Full-time | 396 | 40.12% | ||
| WS Part-time | 93 | 9.42% | |||
| WS Self-empl. | 80 | 8.11% | |||
| WS Homemaker | 59 | 5.98% | |||
| WS Full stud. | 78 | 7.90% | |||
| WS Not working | 281 | 28.47% | |||
| Agri. Farm | 113 | 11.45% | |||
| Agri. Ranch | 21 | 2.13% | |||
| Agri. R.Busi | 66 | 6.69% | |||
| Agri. No | 787 | 79.74% | |||
| Ed High | 279 | 28.27% | |||
| Ed AA | 269 | 27.25% | |||
| Ed BA | 269 | 27.25% | |||
| Ed Grad. | 170 | 17.22% | |||
| Single | 503 | 50.96% | |||
| Female | 501 | 50.76% | |||
| Age | 38.86 | 15.29 | |||
| Urban | 419 | 42.45% | |||
| Suburban | 396 | 40.12% | |||
| Rural | 172 | 17.43% | |||
| Ethn. White | 357 | 36.17% | |||
| Ethn. Hispanic | 135 | 13.68% | |||
| Ethn. Black | 250 | 25.33% | |||
| Ethn. Asian | 149 | 15.10% | |||
| Ethn. Pacific | 38 | 3.85% | |||
| Ethn. Others | 58 | 5.88% | |||
| Inc. < 15 k | 175 | 17.73% | |||
| Inc. 15 k to 25 k | 118 | 11.96% | |||
| Inc. 25 k to 35 k | 138 | 13.98% | |||
| Inc. 35 k to 50 k | 127 | 12.87% | |||
| Inc. 50 k to 75 k | 148 | 14.99% | |||
| Inc. 75 k to 100 k | 98 | 9.93% | |||
| Inc. 100 k to 150 k | 110 | 11.14% | |||
| Inc. > 150 k | 73 | 7.40% | |||
| No. of Child | 0.74 | 1.08 | |||
| Hth. Excellent | 280 | 28.37% | |||
| Hth. Good | 468 | 47.42% | |||
| Hth. Fair | 190 | 19.25% | |||
| Hth. Poor | 49 | 4.96% | |||
| Region | - | - | |||
| C-19 Factors | Fin Situation | 2.33 | 1.08 | ||
| H.Situation | 2.00 | 1.05 | |||
| WB.Situation | 2.29 | 1.07 | |||
| Work. Situation | 2.27 | 1.09 | |||
| 3 months expect | 2.06 | 0.90 | |||
| 6 months expect | 1.91 | 0.89 | |||
| 1 year expect | 1.72 | 0.88 | |||
| Stim. Apr. | 164 | 16.62% | |||
| Stim. May. | 101 | 10.23% | |||
| Stim. Jun. | 78 | 7.90% | |||
| Stim. Jul. | 61 | 6.18% | |||
| Stim. Aft. Jul. | 159 | 16.11% | |||
| Stim. Dk | 133 | 13.48% | |||
| Stim. Na | 39 | 3.95% | |||
| Stim. No get | 129 | 13.07% | |||
| Stim. Not elig. | 123 | 12.46% |
Appendix B
| Training | Test | |||
|---|---|---|---|---|
| Number of | Euclidean | Manhattan | Euclidean | Manhattan |
| Neighbors | AUC | AUC | AUC | AUC |
| 1 | 1.000 | 1.000 | 0.686 | 0.835 |
| 2 | 1.000 | 1.000 | 0.742 | 0.834 |
| 3 | 1.000 | 1.000 | 0.754 | 0.840 |
| 4 | 1.000 | 1.000 | 0.775 | 0.840 |
| 5 | 1.000 | 1.000 | 0.779 | 0.840 |
| 6 | 1.000 | 1.000 | 0.785 | 0.844 |
| 7 | 1.000 | 1.000 | 0.786 | 0.838 |
| 8 | 1.000 | 1.000 | 0.786 | 0.842 |
| 9 | 1.000 | 1.000 | 0.786 | 0.838 |
| 10 | 1.000 | 1.000 | 0.794 | 0.836 |
| 20 | 1.000 | 1.000 | 0.809 | 0.828 |
| 30 | 1.000 | 1.000 | 0.810 | 0.825 |
| 40 | 1.000 | 1.000 | 0.807 | 0.818 |
| 50 | 1.000 | 1.000 | 0.811 | 0.809 |
| 60 | 1.000 | 1.000 | 0.802 | 0.806 |
| 70 | 1.000 | 1.000 | 0.803 | 0.799 |
| 80 | 1.000 | 1.000 | 0.801 | 0.776 |
| 90 | 1.000 | 1.000 | 0.799 | 0.708 |
| 100 | 1.000 | 1.000 | 0.795 | 0.834 |
| Training | Test | |||||||
|---|---|---|---|---|---|---|---|---|
| Cat. | Ext. | Ext. RF | Scikit | Cat. | Ext. | Ext. RF | Scikit | |
| L.R. | AUC | AUC | AUC | AUC | AUC | AUC | AUC | AUC |
| 0.10 | 0.988 | 1.000 | 1.000 | 0.968 | 0.849 | 0.842 | 0.842 | 0.836 |
| 0.15 | 1.000 | 1.000 | 1.000 | 0.981 | 0.835 | 0.840 | 0.840 | 0.838 |
| 0.20 | 0.998 | 1.000 | 1.000 | 0.985 | 0.827 | 0.840 | 0.840 | 0.842 |
| 0.25 | 1.000 | 1.000 | 1.000 | 0.991 | 0.838 | 0.834 | 0.834 | 0.833 |
| 0.30 | 0.999 | 1.000 | 1.000 | 0.994 | 0.833 | 0.838 | 0.838 | 0.829 |
| Training | Test |
|---|---|
| AUC | AUC |
| 0.871 | 0.818 |
| Training | Test | |||||||
|---|---|---|---|---|---|---|---|---|
| Linear | Poly. | RBF | Sigmoid | Linear | Poly. | RBF | Sigmoid | |
| c | AUC | AUC | AUC | AUC | AUC | AUC | AUC | AUC |
| 0.10 | 0.584 | 0.944 | 0.901 | 0.836 | 0.442 | 0.822 | 0.812 | 0.826 |
| 1.00 | 0.754 | 0.982 | 0.969 | 0.774 | 0.719 | 0.778 | 0.825 | 0.773 |
| 5.00 | 0.754 | 0.977 | 0.997 | 0.769 | 0.720 | 0.762 | 0.784 | 0.747 |
| 10.00 | 0.754 | 0.977 | 0.996 | 0.765 | 0.720 | 0.762 | 0.803 | 0.738 |
| 50.00 | 0.754 | 0.977 | 0.996 | 0.759 | 0.720 | 0.762 | 0.803 | 0.733 |
| 100.00 | 0.754 | 0.977 | 0.996 | 0.754 | 0.280 | 0.762 | 0.803 | 0.729 |
| Training | Test | |||||
|---|---|---|---|---|---|---|
| Elastic | Lasso | Ridge | Elastic | Lasso | Ridge | |
| L.R. | AUC | AUC | AUC | AUC | AUC | AUC |
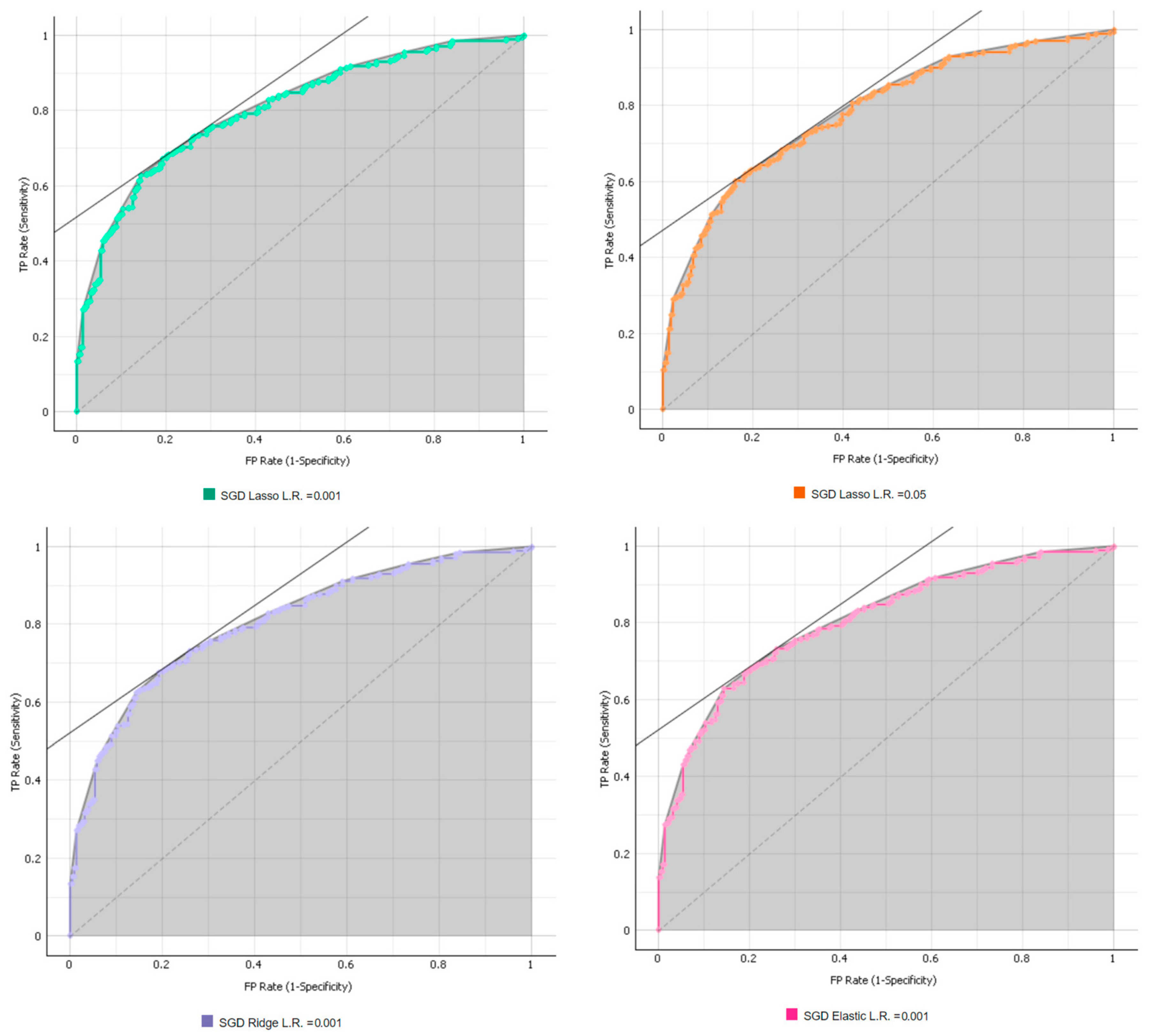
| 0.001 | 0.919 | 0.919 | 0.919 | 0.801 | 0.802 | 0.802 |
| 0.005 | 0.924 | 0.924 | 0.924 | 0.790 | 0.786 | 0.785 |
| 0.010 | 0.923 | 0.922 | 0.922 | 0.778 | 0.780 | 0.787 |
| 0.050 | 0.896 | 0.896 | 0.895 | 0.713 | 0.759 | 0.770 |
| 0.100 | 0.870 | 0.890 | 0.877 | 0.759 | 0.774 | 0.659 |
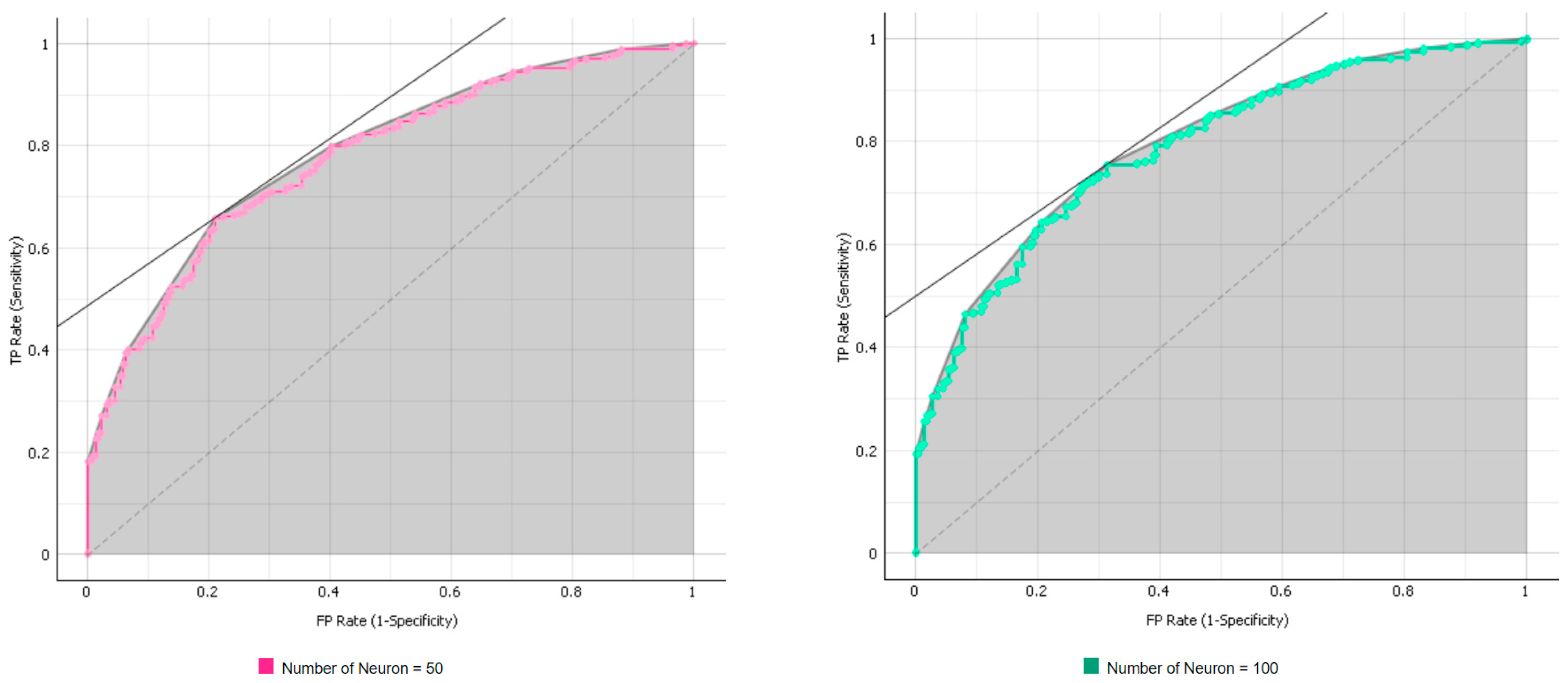
| Number of Neuron | Training | Test |
|---|---|---|
| AUC | AUC | |
| 1 | 0.843 | 0.720 |
| 5 | 0.958 | 0.791 |
| 10 | 0.994 | 0.781 |
| 15 | 1.000 | 0.790 |
| 20 | 1.000 | 0.779 |
| 25 | 1.000 | 0.779 |
| 30 | 1.000 | 0.799 |
| 35 | 1.000 | 0.786 |
| 40 | 1.000 | 0.783 |
| 45 | 1.000 | 0.776 |
| 50 | 1.000 | 0.776 |
| 55 | 1.000 | 0.793 |
| 60 | 1.000 | 0.781 |
| 65 | 1.000 | 0.787 |
| 70 | 1.000 | 0.780 |
| 75 | 1.000 | 0.768 |
| 80 | 1.000 | 0.785 |
| 85 | 1.000 | 0.783 |
| 90 | 1.000 | 0.780 |
| 95 | 1.000 | 0.790 |
| 100 | 1.000 | 0.787 |

References
- Bronfenbrenner, U. Toward an experimental ecology of human development. Am. Psychol. 1977, 32, 513–531. [Google Scholar] [CrossRef]
- Salignac, F.; Hamilton, M.; Noone, J.; Marjolin, A.; Muir, K. Conceptualizing financial wellbeing: An ecological life-course approach. J. Happiness Stud. 2020, 21, 1581–1602. [Google Scholar] [CrossRef]
- Despard, M.R.; Friedline, T.; Martin-West, S. Why do households lack emergency savings? The role of financial capability. J. Fam. Econ. Issues 2020, 41, 542–557. [Google Scholar] [CrossRef]
- Gjertson, L. Emergency Saving and Household Hardship. J. Fam. Econ. Issues 2016, 37, 1–17. [Google Scholar] [CrossRef]
- Wang, W.; Cui, Z.; Chen, R.; Wang, Y.; Zhao, X. Regression Analysis of Clustered Panel Count Data with Additive Mean Models. Statistical Papers. Advanced Online Publication. 2023. Available online: https://link.springer.com/article/10.1007/s00362-023-01511-3#citeas (accessed on 1 November 2023).
- Heo, W. The Demand for Life Insurance: Dynamic Ecological Systemic Theory Using Machine Learning Techniques; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Luo, C.; Shen, L.; Xu, A. Modelling and estimation of system reliability under dynamic operating environments and lifetime ordering constraints. Reliab. Eng. Syst. Saf. 2022, 218 Pt A, 108136. [Google Scholar] [CrossRef]
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]
- Carmona, P.; Climent, F.; Momparler, A. Predicting failure in the U.S. banking sector: An extreme gradient boosting approach. Int. Rev. Econ. Financ. 2019, 61, 304–323. [Google Scholar] [CrossRef]
- Guelman, L. Gradient boosting trees for auto insurance loss cost modeling and prediction. Experts Syst. Appl. 2012, 39, 3659–3667. [Google Scholar] [CrossRef]
- Heo, W.; Lee, J.M.; Park, N.; Grable, J.E. Using artificial neural network techniques to improve the description and prediction of household financial ratios. J. Behav. Exp. Financ. 2020, 25, 100273. [Google Scholar] [CrossRef]
- Jadhav, S.; He, H.; Jenkins, K. Information gain directed genetic algorithm wrapper feature selection for credit rating. Appl. Soft Comput. 2018, 69, 541–553. [Google Scholar] [CrossRef]
- Kalai, R.; Ramesh, R.; Sundararajan, K. Machine Learning Models for Predictive Analytics in Personal Finance. In Modeling, Simulation and Optimization; Das, B., Patgiri, R., Bandyopadhyay, S., Balas, V.E., Eds.; Smart Innovation, Systems and Technologies; Springer: Singapore, 2022; Volume 292. [Google Scholar]
- Viaene, S.; Derrig, R.A.; Dedene, G. A case study of applying boosting Naïve Bayes to claim fraud diagnosis. IEEE Trans. Knowl. Data Eng. 2004, 16, 612–620. [Google Scholar] [CrossRef]
- Zhang, Y.; Haghni, A. A gradient boosting method to improve travel time predictions. Transp. Res. Part C-Emerg. Technol. 2015, 58 Pt B, 308–324. [Google Scholar] [CrossRef]
- Zhou, L.; Pan, S.; Wang, J.; Vasilakos, A.V. Machine learning on big data: Opportunities and challenges. Neurocomputing 2017, 237, 350–361. [Google Scholar] [CrossRef]
- Harness, N.; Diosdado, L. Household financial ratios. In De Gruyter Handbook of Personal Finance; Grable, J.E., Chatterjee, S., Eds.; De Gruyter: Berlin, Germany, 2022; pp. 171–188. [Google Scholar]
- Johnson, D.P.; Widdows, R. Emergency fund levels of households. In Proceedings of the 31st Annual Conference of the American Council on Consumer Interests, Fort Worth, TX, USA, 27–30 March 1985; pp. 235–241. [Google Scholar]
- Lytton, R.H.; Garman, E.T.; Porter, N. How to use financial ratios when advising clients. J. Financ. Couns. Plan. 1991, 2, 3–23. [Google Scholar]
- Prather, C.G.; Hanna, S. Ratio analysis of personal financial statements: Household norms. In Proceedings of the Association for Financial Counseling and Planning Education; Edmondsson, M.E., Perch, K.L., Eds.; AFCPE: Westerville, OH, USA, 1987; pp. 80–88. [Google Scholar]
- Greninger, S.A.; Hampton, V.L.; Kim, K.A.; Achacoso, J.A. Ratios and benchmarks for measuring the financial well-being of families and individuals. Financ. Serv. Rev. 1996, 5, 57–70. [Google Scholar] [CrossRef]
- Bi, L.; Montalto, C.P. Emergency funds and alternative forms of saving. Financ. Serv. Rev. 2004, 13, 93–109. [Google Scholar]
- Hanna, S.; Fan, J.X.; Change, Y.R. Optimal life cycle savings. J. Financ. Couns. Plan. 1995, 6, 1–16. [Google Scholar]
- Cagetti, M. Wealth accumulation over the life cycle and precautionary saving? Rev. Econ. Stat. 2003, 80, 410–419. [Google Scholar] [CrossRef]
- Kudyba, S.; Kwatinetz, M. Introduction to the big data era. In Big Data, Mining, and Analytics; Kudyba, S., Ed.; CRC Press and Taylor and Francis: Boca Raton, FL, USA, 2014; pp. 1–15. [Google Scholar]
- Thompson, W. Data mining methods and the rise of big data. In Big Data, Mining, and Analytics; Kudyba, S., Ed.; CRC Press and Taylor and Francis: Boca Raton, FL, USA, 2014; pp. 71–101. [Google Scholar]
- Sarker, I.H. Machine learning: Algorithms, real-World applications and research directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar] [CrossRef]
- Abiodun, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Mohamed, N.A.; Arshard, H. State-of-the-art in artificial neural network applications: A survey. Heliyon 2018, 4, e00938. [Google Scholar] [CrossRef]
- Demsar, J.; Curk, T.; Erjavec, A.; Gorup, C.; Hočevar, T.; Milutinovič, M.; Možina, M.; Polajnar, M.; Toplak, M.; Starič, A.; et al. Orange: Data mining toolbox in Python. J. Mach. Learn. Res. 2013, 14, 2349–2353. [Google Scholar]
- Pisner, D.A.; Schnyer, D.M. Chapter 6—Support vector machine. In Machine Learning; Mechelli, A., Vieira, S., Eds.; Academic Press: Cambridge, MA, USA, 2020; pp. 101–121. [Google Scholar]
- Rudin, C.; Daubechies, I.; Schapire, R. Fin The dynamics of AdaBoost: Cyclic behavior and convergence of margins. J. Mach. Learn. Res. 2004, 5, 1557–1595. [Google Scholar]
- Suthaharan, S. Support Vector Machine. In Machine Learning Models and Algorithms for Big Data Classification: Thinking with Examples for Effective Learning; Suthaharan, S., Ed.; Springer: New York, NY, USA, 2016; pp. 207–235. [Google Scholar]
- Meng, Y.; Li, X.; Zheng, X.; Wu, F.; Sun, X.; Zhang, T.; Li, J. Fast Nearest Neighbor Machine Translation. arXiv 2021, arXiv:2105.14528. [Google Scholar]
- Wu, X.; Kumar, V.; Quinlan, J.R.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Philip, S.Y.; et al. Top 10 algorithms in data mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef]
- Triguero, I.; Garcia-Gil, D.; Maillo, J.; Luengo, J.; Garcia, S.; Herrera, F. Transforming big data into smart data: An insight on the use of the k-nearest neighbor algorithms to obtain quality data. WIREs Data Min. Knowl. Discov. 2018, 9, e1289. [Google Scholar] [CrossRef]
- Fix, E.; Hodges, J.L. Discriminatory analysis. Nonparametric discrimination: Consistency properties. Int. Stat. Rev. Rev. Int. De Stat. 1989, 57, 238–247. [Google Scholar] [CrossRef]
- Singh, A.; Yadav, A.; Rana, A. K-means with three different distance metrics. Int. J. Comput. Appl. 2013, 67, 13–17. [Google Scholar] [CrossRef]
- Östermark, R. A fuzzy vector valued KNN-algorithm for automatic outlier detection. Appl. Soft Comput. 2009, 9, 1263–1272. [Google Scholar] [CrossRef]
- Maede, N. A comparison of the accuracy of short-term foreign exchange forecasting methods. Int. J. Forecast. 2002, 18, 67–83. [Google Scholar] [CrossRef]
- Phongmekin, A.; Jarumaneeroj, P. Classification Models for Stock’s Performance Prediction: A Case Study of Finance Sector in the Stock Exchange of Thailand. In Proceedings of the 2018 International Conference on Engineering, Applied Sciences, and Technology (ICEAST), Phuket, Thailand, 4–7 July 2018; pp. 1–4. [Google Scholar]
- Breiman, L. Arcing the Edge; Technical Report 486; Statistics Department, University of California at Berkeley: Berkeley, CA, USA, 1997. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A Gradient Boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Sagi, O.; Rokach, L. Ensemble learning: Survey. WIREs Data Min. Knowl. Discov. 2017, 8, e1249. [Google Scholar] [CrossRef]
- Chang, Y.; Chang, K.; Wu, G. Application of eXtreme gradient boosting trees in the construction of credit risk assessment models for financial institutions. Appl. Soft Comput. 2018, 73, 914–920. [Google Scholar] [CrossRef]
- Liu, J.; Wu, C.; Li, Y. Improving financial distress prediction using financial network-based information and GA-based Gradient Boosting model. Comput. Econ. 2017, 53, 851–872. [Google Scholar] [CrossRef]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient Boosting with Categorical Features Support. arXiv 2018, arXiv:1810.11363v1. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22Nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Hand, D.J.; Yu, K. Idiot’s Bayes—Not so stupid after all? Int. Stat. Rev. 2001, 69, 385–398. [Google Scholar]
- Lowd, D.; Domingos, P. Naïve Bayes models for probability estimation. In Proceedings of the ICML ‘05: Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; pp. 529–536. [Google Scholar]
- Zhang, H. Exploring conditions for the optimality of Naïve Bayes. Int. J. Pattern Recognit. Artif. Intell. 2005, 19, 183–198. [Google Scholar] [CrossRef]
- Yang, F. An implementation of Naïve Bayes classifier. In Proceedings of the 2018 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 12–14 December 2018; pp. 301–306. [Google Scholar]
- Deng, Q. Detection of fraudulent financial statements based on Naïve Bayes classifier. In Proceedings of the 2010 5th International Conference on Computer Science and Education, Hefei, China, 24–27 August 2010; pp. 1032–1035. [Google Scholar]
- Shihavuddin, A.S.M.; Ambia, M.N.; Arefin, M.M.N.; Hossain, M.; Anwar, A. Prediction of stock price analyzing the online financial news using Naïve Bayes classifier and local economic trends. In Proceedings of the 2010 3rd International Conference on Advanced Computer Theory and Engineering (ICACTE), Chengdu, China, 20–22 August 2010; pp. V4-22–V4-26. [Google Scholar]
- Noble, W.S. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef]
- Yu, L.; Yao, X.; Wang, S.; Lai, K.K. Credit risk evaluation using a weighted least squares SVM classifier with design of experiment for parameter selection. Expert Syst. Appl. 2011, 38, 15392–15399. [Google Scholar] [CrossRef]
- Chen, F.; Li, F. Combination of feature selection approaches with SVM in credit scoring. Expert Syst. Appl. 2010, 37, 4902–4909. [Google Scholar] [CrossRef]
- Chen, W.; Du, Y. Using neural networks and data mining techniques for the financial distress prediction model. Expert Syst. Appl. 2009, 36, 4075–4086. [Google Scholar] [CrossRef]
- Baesens, B.; Van Gestel, T.; Viaene, S.; Stepanova, M.; Suykens, J.; Vanthienen, J. Benchmarking state-of-the-art classification algorithms for credit scoring. J. Oper. Res. Soc. 2003, 54, 627–635. [Google Scholar] [CrossRef]
- Yang, Y. Adaptive credit scoring with kernel learning methods. Eur. J. Oper. Res. 2007, 183, 1521–1536. [Google Scholar] [CrossRef]
- Kim, K.; Ahn, H. A corporate credit rating model using multi-class support vector machines with an ordinal pairwise partitioning approach. Comput. Oper. Res. 2012, 39, 1800–1811. [Google Scholar] [CrossRef]
- Chaudhuri, A.; De, K. Fuzzy support vector machine for bankruptcy prediction. Appl. Soft Comput. 2011, 11, 2472–2486. [Google Scholar] [CrossRef]
- Chen, L.; Hsiao, H. Feature selection to diagnose a business crisis by using a real Ga-based support vector machine: An empirical study. Expert Syst. Appl. 2008, 35, 1145–1155. [Google Scholar] [CrossRef]
- Hsieh, T.; Hsiao, H.; Yeh, W. Mining financial distress trend data using penalty guided support vector machines based on hybrid of particle swarm optimization and artificial bee colony algorithms. Neurocomputing 2012, 82, 196–206. [Google Scholar] [CrossRef]
- Amari, S. A theory of adaptive pattern classifiers. IEEE Trans. Electron. Comput. 1967, EC-16, 299–307. [Google Scholar] [CrossRef]
- Amari, S. Backpropagation and stochastic gradient descent method. Neurocomputing 1993, 5, 185–196. [Google Scholar] [CrossRef]
- Ketkar, N. Stochastic Gradient Descent. In Deep Learning with Python; Apress: Berkeley, CA, USA, 2017. [Google Scholar]
- Song, S.; Chaudhuri, K.; Sarwate, A.D. Stochastic gradient descent with differentially private updates. In Proceedings of the 2013 IEEE Global Conference on Signal and Information Processing, Austin, TX, USA, 3–5 December 2013; pp. 245–248. [Google Scholar]
- Newton, D.; Pasupathy, R.; Yousefian, F. Recent trends in stochastic gradient decent for machine learning and big data. In Proceedings of the 2018 Winter Simulation Conference (WSC), Gothenburg, Sweden, 9–12 December 2018; pp. 366–380. [Google Scholar]
- Deepa, N.; Prabadevi, B.; Maddikunta, P.K.; Gadekallu, T.R.; Baker, T.; Khan, M.A.; Tariq, U. An AI-based intelligent system for healthcare analysis using Ridge-Adaline Stochastic Gradient Descent Classifier. J. Supercomput. 2020, 77, 1998–2017. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Matías, J.M.; Vaamonde, A.; Taboada, J.; González-Manteiga, W. Support vector machines and gradient boosting for graphical estimation of a slate deposit. Stoch. Environ. Res. Risk Assess. 2004, 18, 309–323. [Google Scholar] [CrossRef]
- Moisen, G.G.; Freeman, E.A.; Blackard, J.A.; Frescino, T.S.; Zimmermann, N.E.; Edward, T.C., Jr. Predicting tree species presence and basal area in Utah: A comparison of stochastic gradient boosting, generalized additive models, and tree-based methods. Ecol. Model. 2006, 199, 176–187. [Google Scholar] [CrossRef]
- Baum, E.B. Neural nets for economics. In The Economy as an Evolving Complex System, Proceedings of the Evolutionary Paths of the Global Economy Workshop, Sante Fe, NM, USA, 8–18 September 1987; Anderson, P., Arrow, K., Pindes, D., Eds.; Addison-Wesley: Reading, MA, USA, 1988; pp. 33–48. [Google Scholar]
- Kirkos, E.; Spathis, C.; Manolopoulos, Y. Data mining techniques for the detection of fraudulent financial statement. Expert Syst. Appl. 2007, 32, 995–1003. [Google Scholar] [CrossRef]
- Cerullo, M.J.; Cerullo, V. Using neural networks to predict financial reporting fraud: Part 1. Comput. Fraud. Secur. 1999, 5, 14–17. [Google Scholar]
- Dorronsoro, J.R.; Ginel Fin Sgnchez, C.; Cruz, C.S. Neural fraud detection in credit card operations. IEEE Trans. Neural Netw. 1997, 8, 827–834. [Google Scholar] [CrossRef]
- Chauhan, N.; Ravi, V.; Chandra, D.K. Differential evolution trained wavelet neural networks: Application to bankruptcy prediction in banks. Expert Syst. Appl. 2009, 36, 7659–7665. [Google Scholar] [CrossRef]
- Iturriaga, F.J.L.; Sanz, I.P. Bankruptcy visualization and prediction using neural networks: A study of U.S. commercial banks. Expert Syst. Appl. 2015, 42, 2857–2869. [Google Scholar] [CrossRef]
- Menard, S. Applied Logistic Regression Analysis, 2nd ed.; Sage Publications: Thousand Oaks, CA, USA, 2002. [Google Scholar]
- Arcuri, A.; Fraser, G. Parameter tuning or default values? An empirical investigation in search-based software engineering. Empir. Softw. Eng. 2013, 18, 594–623. [Google Scholar] [CrossRef]
- Joseph, V.R. Optimal ratio for data splitting. Stat. Anal. Data Min. 2022, 15, 531–538. [Google Scholar] [CrossRef]
- Afendras, G.; Markatou, M. Optimality of training/test size and resampling effectiveness in cross-validation. J. Stat. Plan. Inference 2019, 199, 286–301. [Google Scholar] [CrossRef]
- Picard, R.R.; Berk, K.N. Data Splitting. Am. Stat. 1990, 44, 140–147. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Kira, K.; Rendell, L.A. A practical approach to feature selection. In Machine Learning: Proceedings of International Conference (ICML’92); Sleeman, D., Edwards, P., Eds.; Morgan Kaufmann: Burlington, MA, USA, 1992; pp. 249–256. [Google Scholar]
- Kononenko, I. Estimating attributes: Analysis and extensions of Relief. In Machine Learning: ECML-94; De Raedt, L., Bergadano, F., Eds.; Springer: Berlin/Heidelberg, Germany, 1994; pp. 171–182. [Google Scholar]
- Robnik-Šikonja, M.; Kononenko, I. Theoretical and empirical analysis of ReliefF and RReliefF. Mach. Learn. 2003, 53, 23–69. [Google Scholar] [CrossRef]
- Heo, W.; Cho, S.; Lee, P. APR Financial Stress Scale: Development and Validation of a Multidimensional Measurement. J. Financ. Ther. 2020, 11, 2. [Google Scholar] [CrossRef]
- Xiao, J.J.; Ahn, S.Y.; Serido, J.; Shim, S. Earlier financial literacy and later financial behavior of college students. Int. J. Consum. Stud. 2014, 38, 593–601. [Google Scholar] [CrossRef]
- Lusardi, A. Financial literacy and the need for financial education: Evidence and implications. Swiss J. Econ. Stat. 2019, 155, 1. [Google Scholar] [CrossRef]
- Grable, J.E.; Lytton, R.H. Financial risk tolerance revisited: The development of a risk assessment instrument. Financ. Serv. Rev. 1999, 8, 163–191. [Google Scholar] [CrossRef]
- Loibl, C.; Hira, T.K. Self-directed financial learning and financial satisfaction. J. Financ. Couns. Plan. 2005, 16, 11–22. [Google Scholar]
- Lown, J.M. Development and validation of a financial self-efficacy scale. J. Financ. Couns. Plan. 2011, 22, 54–63. [Google Scholar]
- Perry, V.G.; Morris, M.D. Who is in control? The role of self-perception, knowledge, and income in explaining consumer financial Behavior. J. Consum. Aff. 2005, 39, 299–313. [Google Scholar] [CrossRef]
- Diener, E.; Emmons, R.A.; Larsen, R.J.; Griffin, S. The satisfaction with life scale. J. Personal. Assess. 1985, 49, 71–75. [Google Scholar] [CrossRef] [PubMed]
- Rosenberg, M. Society and the Adolescent Self-Image; Princeton University Press: Princeton, NJ, USA, 1965. [Google Scholar]
- Hellgren, J.; Sverke, M.; Isaksson, K. A two-dimensional approach to job insecurity: Consequences for employee attitudes and well-being. Eur. J. Work. Organ. Psychol. 1999, 8, 179–195. [Google Scholar] [CrossRef]

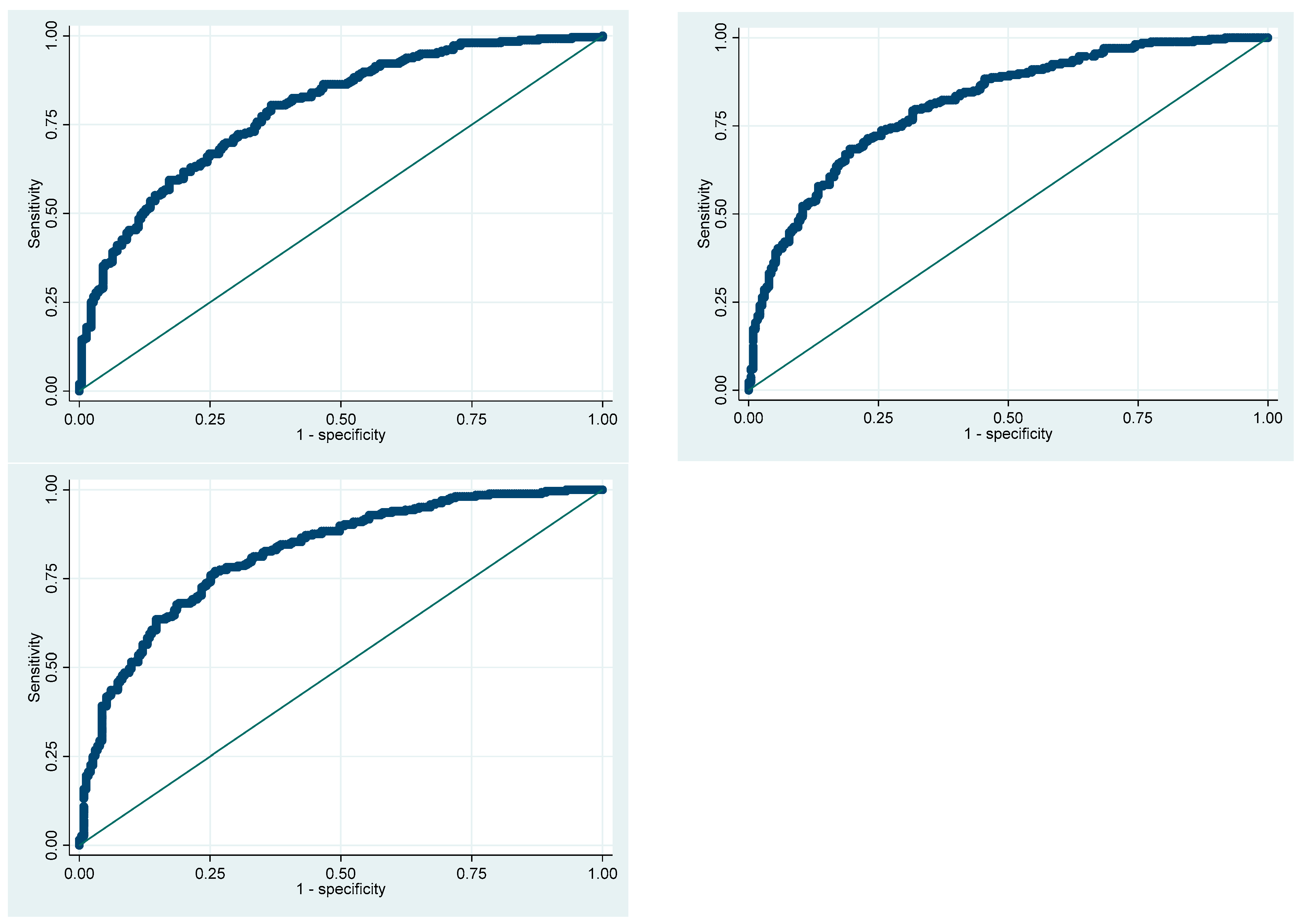
| ML | Selected Algorithm | Selected Parameter | Training | Test |
|---|---|---|---|---|
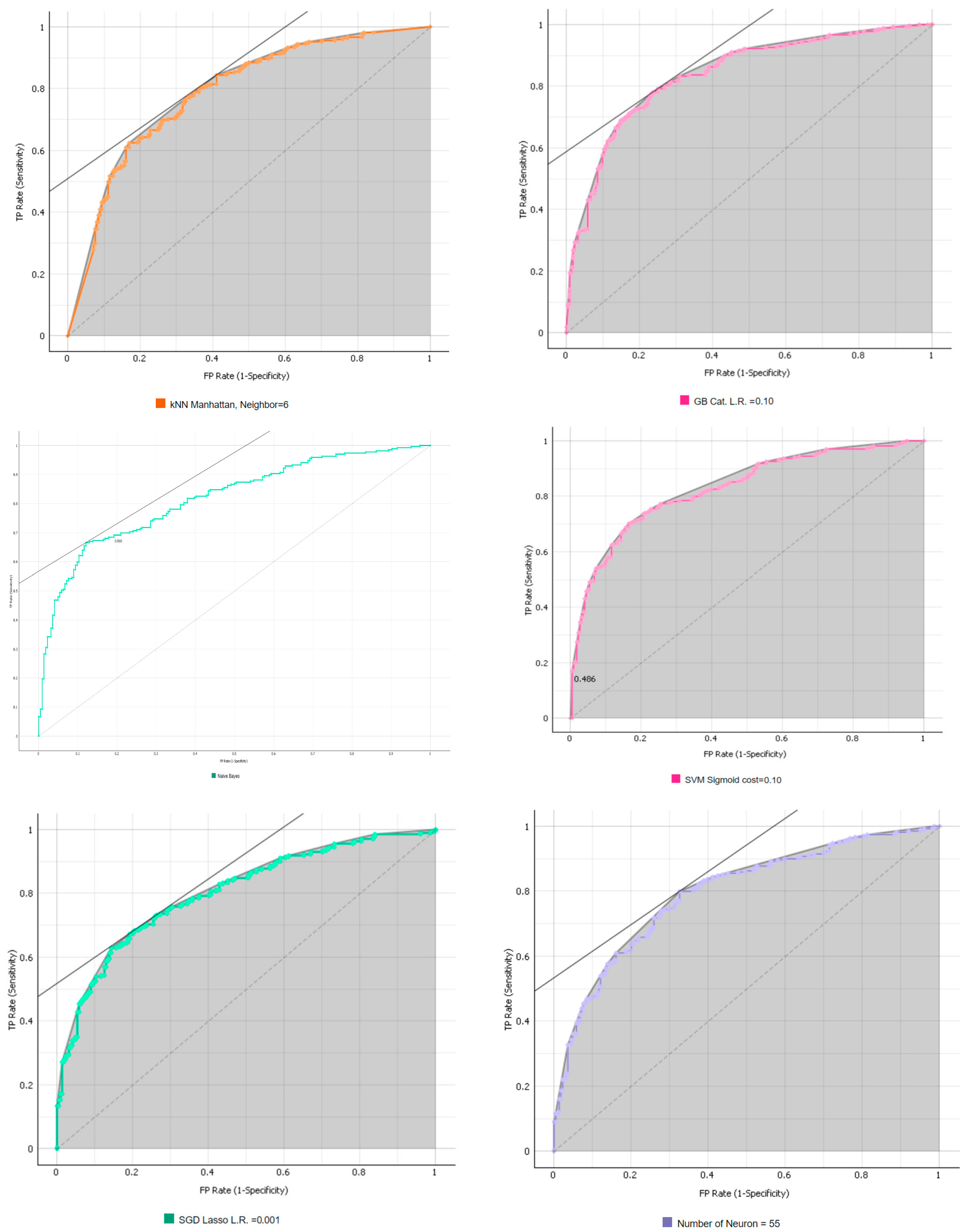
| kNN | Neighbor = 6 | 1.000 | 0.844 | |
| Gradient Boosting | Categorical | L.R. = 0.10 | 0.988 | 0.849 |
| Naïve Bayes | 0.871 | 0.818 | ||
| SVM | Sigmoid | cost = 0.10 | 0.836 | 0.826 |
| SGD | Lasso/Ridge | L.R. = 0.001 | 0.919 | 0.802 |
| NN | Neuron = 30 | 1.000 | 0.793 |
| Variables | Logistic Regression with All Variables | Logistic Regression with Forward Stepwise | Logistic Regression with Backward Stepwise | |||
|---|---|---|---|---|---|---|
| Coefficient | SE | Coefficient | SE | Coefficient | SE | |
| Auto loan | 0.40 | 0.46 | ||||
| Student loan | −0.61 | 0.47 | ||||
| Farm loan | −0.04 | 0.80 | ||||
| Equity loan | 0.22 | 0.66 | ||||
| Mortgage loan | −1.48 | 0.51 | −0.69 * | 0.31 | ||
| Own house | 0.50 | 0.51 | ||||
| Saving acct. | −1.86 | 0.51 | −1.40 *** | 0.29 | −1.28 *** | 0.30 |
| Checking acct. | −0.33 | 0.57 | ||||
| Term L.I. | −0.08 | 0.41 | ||||
| Whole L.I. | −1.02 | 0.51 | −0.90 ** | 0.33 | −0.81 * | 0.34 |
| FA do not know | −1.27 | 0.64 | ||||
| FA no | −1.82 | 0.53 | −1.12 *** | 0.28 | −1.14 *** | 0.28 |
| Payday loan | −0.66 | 0.56 | ||||
| Health insurance | 0.61 | 0.52 | ||||
| FP Dist. 10 miles | 0.49 | 0.56 | ||||
| FP Dist. 20 miles | 1.06 | 0.61 | ||||
| FP Dist. 50 miles | 1.08 | 0.91 | ||||
| FP Dist. Over 50 | 1.40 | 1.19 | ||||
| FP Dist. na | −0.21 | 0.57 | −0.70 * | 0.29 | −0.80 ** | 0.30 |
| Fin course in H.S. | −0.81 | 0.45 | −1.01 ** | 0.29 | −0.95 ** | 0.30 |
| Fin course in Col. | −0.47 | 0.53 | ||||
| Obj. Fin Knw. | −0.08 | 0.21 | ||||
| Fin R.T. | 0.04 | 0.05 | ||||
| Fin Satisfaction | 0.09 | 0.04 | 0.07 ** | 0.02 | 0.06 * | 0.03 |
| Fin Stress | 0.02 | 0.01 | ||||
| Fin Self-efficacy | −0.19 | 0.06 | −0.08 * | 0.03 | ||
| L.O.C. | −0.05 | 0.05 | ||||
| S.W.L.S. | 0.08 | 0.03 | 0.08 *** | 0.02 | 0.08 *** | 0.02 |
| Self-esteem | 0.01 | 0.05 | ||||
| Job insecurity | 0.05 | 0.04 | ||||
| WS Part-time | 0.20 | 0.71 | ||||
| WS Self-empl. | 1.31 | 0.70 | ||||
| WS Homemaker | −1.36 | 1.00 | ||||
| WS Full stud. | 0.28 | 0.82 | ||||
| WS Not working | 0.11 | 0.58 | ||||
| Agri. Work | 0.92 | 1.67 | ||||
| Agri. R.Busi. | −0.77 | 1.02 | ||||
| Agri. No. | −0.03 | 0.90 | ||||
| Ed AA | 0.44 | 0.50 | ||||
| Ed BA | 0.93 | 0.55 | ||||
| Ed Grad. | 0.66 | 0.74 | ||||
| Single | 0.22 | 0.45 | ||||
| Female | 0.12 | 0.41 | ||||
| Age | 0.02 | 0.02 | ||||
| Suburban | 0.42 | 0.44 | ||||
| Rural | 0.95 | 0.59 | ||||
| Ethn. Hispanic | 0.16 | 0.59 | ||||
| Ethn. Black | −0.22 | 0.52 | ||||
| Ethn. Asian | 0.42 | 0.55 | ||||
| Ethn. Pacific | −0.13 | 1.07 | ||||
| Ethn. Others | −0.98 | 0.87 | ||||
| Inc. 15 k to 25 k | −0.71 | 0.68 | ||||
| Inc. 25 k to 35 k | −1.12 | 0.70 | ||||
| Inc. 35 k to 50 k | −1.09 | 0.73 | ||||
| Inc. 50 k to 75 k | −0.27 | 0.72 | ||||
| Inc. 75 k to 100 k | −0.95 | 0.86 | ||||
| Inc. 100 k to 150 k | −1.27 | 0.85 | ||||
| Inc. > 150 k | 1.26 | 1.27 | ||||
| No. of Child | −0.66 | 0.20 | −0.26 * | 0.12 | −0.27 * | 0.12 |
| Hth. Good | −0.24 | 0.49 | ||||
| Hth. Fair | −1.17 | 0.68 | ||||
| Hth. Poor | 0.36 | 1.23 | ||||
| Fin Situation | −0.48 | 0.23 | −0.32 * | 0.13 | ||
| H.Situation | −0.10 | 0.26 | ||||
| WB.Situation | 0.03 | 0.28 | ||||
| Work. Situation | 0.32 | 0.26 | ||||
| 3 months expect | −0.31 | 0.29 | ||||
| 6 months expect | 0.14 | 0.27 | ||||
| 1 year expect | 0.31 | 0.25 | ||||
| Stim. May | 0.58 | 0.77 | ||||
| Stim. Jun. | −1.24 | 0.91 | ||||
| Stim. Jul. | 0.94 | 0.99 | ||||
| Stim. Aft. Jul. | −0.74 | 0.66 | ||||
| Stim. Dk | −0.72 | 0.72 | ||||
| Stim. Na | −0.62 | 1.06 | ||||
| Stim. No get | −1.10 | 0.74 | ||||
| Stim. No elig. | −0.44 | 0.81 | ||||
| Constant | 8.47 | 3.90 | 3.93 *** | 1.06 | 5.28 *** | 1.25 |
| R2 | 0.54 | 0.41 | 0.41 | |||
| F | 352.60 | 264.57 *** | 268.99 *** | |||
| ML | AUC from Test | Logistic Regression | AUC from Test |
|---|---|---|---|
| kNN | 0.844 | With all variables | 0.703 |
| Gradient Boosting | 0.849 | Forward stepwise | 0.741 |
| Naïve Bayes | 0.818 | Backward stepwise | 0.754 |
| SVM | 0.826 | ||
| SGD | 0.802 | ||
| NN | 0.793 |
| kNN | RF | GB | RF | Naïve Bayes | RF | SVM | RF | SGD | RF | NN | RF | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy Rank = 2 | Accuracy Rank = 1 | Accuracy Rank = 4 | Accuracy Rank = 3 | Accuracy Rank = 5 | Accuracy Rank = 6 | |||||||
| 1 | Region | 0.090 | Education level | 0.110 | Fin Self-efficacy | 0.075 | Fin Course in Col. | 0.176 | Ever FA | 0.128 | Fin Course in Col. | 0.136 |
| 2 | Equity loan | 0.080 | Fin Course in Col. | 0.104 | Farm loan | 0.070 | Education level | 0.158 | Fin Course in Col. | 0.108 | Farm loan | 0.134 |
| 3 | Farm loan | 0.076 | Whole L.I. | 0.102 | Ever FA | 0.069 | Whole L.I. | 0.158 | Fin Course in H.S. | 0.080 | Ever FA | 0.117 |
| 4 | Fin Course in Col. | 0.072 | Region | 0.089 | Checking acct. | 0.062 | Farm loan | 0.144 | Single | 0.078 | Equity loan | 0.102 |
| 5 | Fin Course in H.S. | 0.070 | Ever FA | 0.079 | Fin Satisfaction | 0.057 | S.W.L.S. | 0.115 | Fin Satisfaction | 0.074 | Whole L.I. | 0.088 |
| 6 | Single | 0.064 | Farm loan | 0.062 | Region | 0.054 | Fin Satisfaction | 0.112 | Own house | 0.072 | Student loan | 0.086 |
| 7 | Ever FA. | 0.061 | Fin Satisfaction | 0.061 | Saving acct. | 0.046 | Ever FA | 0.109 | Gender | 0.070 | Payday loan | 0.082 |
| 8 | Education level | 0.060 | Gender | 0.056 | S.W.L.S. | 0.044 | Fin Stress | 0.101 | Farm loan | 0.068 | Education level | 0.080 |
| 9 | S.W.L.S. | 0.054 | Single | 0.054 | Payday loan | 0.042 | Fin Course in H.S. | 0.092 | Fin Self-efficacy | 0.061 | Fin Satisfaction | 0.072 |
| 10 | Payday loan | 0.048 | Fin Self-efficacy | 0.053 | Income level | 0.040 | Payday loan | 0.088 | S.W.L.S. | 0.058 | Term L.I. | 0.064 |
| 11 | Term L.I. | 0.040 | Income level | 0.051 | Age | 0.035 | Single | 0.088 | Fin Stress | 0.057 | S.W.L.S. | 0.055 |
| 12 | Fin Satisfaction | 0.036 | Mortgage loan | 0.048 | 1 year expect | 0.033 | Agri. Work. Type | 0.087 | Dist. To. FP | 0.046 | Agri. Work. Type | 0.051 |
| 13 | Mortgage loan | 0.034 | Fin Stress | 0.044 | Fin Stress | 0.028 | Fin Self-efficacy | 0.081 | Obj. Fin Knw. | 0.045 | Auto loan | 0.048 |
| 14 | Health status | 0.032 | Own house | 0.042 | Education level | 0.028 | Term L.I. | 0.076 | Mortgage loan | 0.044 | Fin Self-efficacy | 0.047 |
| 15 | Fin Situation | 0.031 | Saving acct. | 0.040 | Stimulus | 0.027 | Checking acct. | 0.070 | Student loan | 0.040 | Fin Stress | 0.046 |
| 16 | Gender | 0.028 | Dist. To. FP | 0.039 | Fin Course in H.S. | 0.026 | Own house | 0.070 | Term L.I. | 0.040 | Saving acct. | 0.044 |
| 17 | Auto loan | 0.028 | Obj. Fin Knw. | 0.035 | WB.Situation | 0.023 | Fin Situation | 0.067 | Payday loan | 0.034 | Single | 0.038 |
| 18 | Income level | 0.025 | Equity loan | 0.034 | Equity loan | 0.022 | Health status | 0.066 | Agri. Work. Type | 0.033 | Ethnic | 0.032 |
| 19 | Fin Self-efficacy | 0.023 | 6 months expect | 0.032 | Dist. To. FP | 0.021 | Work status | 0.065 | Region | 0.033 | WB.Situation | 0.032 |
| 20 | H.Situation | 0.023 | S.W.L.S. | 0.031 | Work status | 0.019 | Equity loan | 0.064 | Job insecurity | 0.032 | Fin Course in H.S. | 0.032 |
| 21 | Student loan | 0.022 | Job insecurity | 0.031 | Agri. Work. Type | 0.019 | H.Situation | 0.059 | Equity loan | 0.032 | Income | 0.031 |
| 22 | 1 year expect | 0.021 | Term L.I. | 0.030 | L.O.C. | 0.019 | WB.Situation | 0.059 | Saving acct. | 0.032 | Checking acct. | 0.030 |
| 23 | Urban type | 0.020 | Agri. Work. Type | 0.028 | Auto loan | 0.016 | 3 months expect | 0.055 | L.O.C. | 0.031 | Self-esteem | 0.028 |
| 24 | Agri. Work. Type | 0.019 | Fin Course in H.S. | 0.024 | 6 months expect | 0.016 | L.O.C. | 0.047 | Education level | 0.030 | Work. Situation | 0.026 |
| 25 | Self-esteem | 0.017 | Ethnic | 0.024 | Health status | 0.015 | Obj. Fin Knw. | 0.043 | Age | 0.030 | Region | 0.026 |
| 26 | Fin Stress | 0.014 | Health status | 0.022 | Term L.I. | 0.014 | Work. Situation | 0.041 | WB.Situation | 0.029 | Fin Situation | 0.023 |
| 27 | Saving acct. | 0.014 | Payday loan | 0.022 | Fin R.T. | 0.012 | Stimulus | 0.040 | Income level | 0.026 | L.O.C. | 0.023 |
| 28 | Job insecurity | 0.013 | Auto loan | 0.022 | Obj. Fin Knw. | 0.011 | Income level | 0.040 | Self-esteem | 0.025 | Job insecurity | 0.021 |
| 29 | 6 months expect | 0.013 | H.Situation | 0.020 | Single | 0.010 | Health insurance | 0.040 | Work status | 0.024 | Gender | 0.020 |
| 30 | Obj. Fin Knw. | 0.012 | L.O.C. | 0.018 | Urban | 0.010 | 6 months expect | 0.039 | Health status | 0.023 | Mortgage loan | 0.016 |
| 31 | Work status | 0.010 | Age | 0.016 | H.Situation | 0.010 | Job insecurity | 0.037 | Urban type | 0.021 | Work status | 0.013 |
| 32 | Age | 0.009 | 1 year expect | 0.014 | Self-esteem | 0.007 | Age | 0.034 | Health insurance | 0.016 | Age | 0.010 |
| 33 | Ethnic | 0.008 | Self-esteem | 0.012 | Fin Situation | 0.007 | Mortgage loan | 0.034 | 1 year expect | 0.015 | Health status | 0.009 |
| 34 | Own house | 0.006 | No. of Child | 0.005 | Own house | 0.006 | Self-esteem | 0.032 | H.Situation | 0.014 | Fin R.T. | 0.008 |
| 35 | Health insurance | 0.006 | Fin R.T. | 0.005 | Job insecurity | 0.003 | Region | 0.031 | Fin Situation | 0.011 | H.Situation | 0.008 |
| 36 | L.O.C. | 0.005 | Checking acct. | 0.004 | Work. Situation | 0.003 | Student loan | 0.030 | Checking acct. | 0.010 | 3 months expect | 0.007 |
| 37 | Stimulus | 0.005 | Fin Situation | 0.003 | Student loan | 0.000 | Saving acct. | 0.028 | Fin R.T. | 0.009 | Dist. To. FP | 0.007 |
| 38 | No. of Child | 0.003 | Work. Situation | 0.000 | No. of Child | −0.001 | Auto loan | 0.026 | Auto loan | 0.008 | 1 year expect | 0.001 |
| 39 | Whole L.I. | 0.000 | WB.Situation | −0.004 | Ethnic | −0.009 | Dist. To. FP | 0.010 | Work. Situation | 0.008 | No. of Child | 0.000 |
| 40 | Fin R.T. | −0.002 | 3 months expect | −0.005 | 3 months expect | −0.010 | No. of Child | 0.009 | Stimulus | 0.005 | Own house | 0.000 |
| 41 | WB. Situation | −0.003 | Health insurance | −0.006 | Gender | −0.012 | 1 year expect | 0.007 | 6 months expect | 0.004 | Obj. Fin Knw. | −0.002 |
| 42 | Checking acct. | −0.012 | Student loan | −0.010 | Health insurance | −0.014 | Gender | 0.004 | Whole L.I. | 0.004 | Urban type | −0.004 |
| 43 | 3 months expect | −0.025 | Work status | −0.021 | Mortgage loan | −0.018 | Ethnic | −0.002 | No. of Child | −0.004 | Stimulus | −0.005 |
| 44 | Work. Situation | −0.029 | Urban type | −0.021 | Whole L.I. | −0.024 | Fin R.T. | −0.004 | Ethnic | −0.013 | Health insurance | −0.014 |
| 45 | Dist. To FP. | −0.034 | Stimulus | −0.030 | Fin Course in Col. | −0.024 | Urban type | −0.019 | 3 months expect | −0.020 | 6 months expect | −0.017 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Heo, W.; Kim, E.; Kwak, E.J.; Grable, J.E. Identifying Hidden Factors Associated with Household Emergency Fund Holdings: A Machine Learning Application. Mathematics 2024, 12, 182. https://doi.org/10.3390/math12020182
Heo W, Kim E, Kwak EJ, Grable JE. Identifying Hidden Factors Associated with Household Emergency Fund Holdings: A Machine Learning Application. Mathematics. 2024; 12(2):182. https://doi.org/10.3390/math12020182
Chicago/Turabian StyleHeo, Wookjae, Eunchan Kim, Eun Jin Kwak, and John E. Grable. 2024. "Identifying Hidden Factors Associated with Household Emergency Fund Holdings: A Machine Learning Application" Mathematics 12, no. 2: 182. https://doi.org/10.3390/math12020182
APA StyleHeo, W., Kim, E., Kwak, E. J., & Grable, J. E. (2024). Identifying Hidden Factors Associated with Household Emergency Fund Holdings: A Machine Learning Application. Mathematics, 12(2), 182. https://doi.org/10.3390/math12020182