1. Introduction
Approximating functions is motivated by reducing the computational complexity and achieving the analytical tractability of mathematical models. This also includes the problems of finding low-complexity and low-dimensional mathematical models for continuous or discrete-time observations, such as time-series data, and empirically determined features, such as histograms. This paper is concerned with the latter problem, i.e., how to effectively model the probability distributions of observation data. In particular, it is proposed to define polynomial probability distributions rather than to assume polynomial approximations of probability distributions. This is a major departure from the reasoning found in the existing literature.
Polynomial distributions provide superior flexibility over other canonical distributions, albeit at a cost of a larger number of parameters, and the support interval is constrained to a finite range of values. The main advantages of polynomial distributions are that they can yield parameterized closed-form expressions and enable the modeling of complex multi-modal and time-evolving probability distributions. These distributions are encountered, for example, when describing causal interactions and state transitions in dynamic systems. This may lead to the development of novel probabilistic mathematical frameworks. The disadvantage is that, in the case of a general polynomial function, it may be difficult to ensure that the polynomial is non-negative over the whole intended interval of support. The non-negativity can be guaranteed, for example, by assuming squared polynomials.
The Weierstrass theorem [
1] is the fundamental result in the approximation theory of functions. It states that every continuous function can be uniformly approximated with an arbitrary precision over any finite interval by a polynomial of a sufficient order. The uniform approximation can be expressed as a sequence of algebraic polynomials uniformly converging over a given interval to the function of interest. The approximation accuracy can be evaluated by different metrics including
-norms, minimax norm, and others. The best approximating function from a set or a sequence of functions and its properties can be determined by the Jackson theorem. The Stone–Weierstrass theorem generalizes the function approximation to cases of multivariate functions and functions in multiple dimensions [
2].
Runge’s phenomenon arises when the approximating polynomials contain a set of predefined points, which can prevent uniform convergence from being possible [
3]. The equidistant approximating points can be optimized using the Lebesgue constant as a measure of the approximation accuracy [
4,
5].
Polynomials can be used to approximate known probability distributions as well as distributions estimated as histograms [
6,
7]. Reference [
8] is one of the earlier works that assume the approximation of probability distributions by a polynomial. The fitting of multivariate polynomials to multivariate cumulative distributions and their partial derivatives is studied in [
9], whereas multivariate polynomial interpolation is studied in [
10]. The conditions for the coefficients of a polynomial to be a sum of two squared polynomials are determined in [
11].
The problem of fitting a polynomial into a finite number of data samples has been investigated in the classic reference [
12]. The polynomial curve fitting methods are often available in various software packages [
13]. Modeling times series data by piecewise polynomials is considered in [
14,
15]. The least-squares polynomial approximation of random data samples with standard and induced densities is compared in [
16]. A new method for polynomial interpolation of data points within a plane is proposed in [
17]. Interestingly, the recent survey [
18] on approximating probability distributions does not mention polynomial approximation as one of the available methods.
The polynomial expansion of chaos for the reliability analysis of systems is proposed in [
19]. A polynomial kernel for feature learning from data is considered in [
20]. The Stone–Weierstrass theorem is assumed in [
21] to design a neural network that can approximate an arbitrary measurable function. The method for function approximation by a polynomial using a neural network is investigated in [
22].
Polynomials can be sparse, i.e., only some of their coefficients—including the coefficient determining the order—are non-zero. The polynomials with special properties are named; for example, there are Lagrange, Legendre, Diskson, Chebyshev, and Bernstein polynomials [
23,
24]. Special polynomials, such as Hermite and Lagrangian polynomials, can form the basis for function decomposition. There is a close link between approximating periodic continuous functions and trigonometric polynomials in the Fourier analysis [
25]. A procedure for orthogonal polynomial decomposition of multivariate distributions was devised in [
26] in order to compute the output of a multidimensional system with the stochastic input.
Reference [
23] is a comprehensive textbook on the theory of polynomials covering fundamental theorems, special polynomials, polynomial algebra, finding and approximating polynomial roots, finding polynomial factors, solving polynomial equations, and defining polynomial inequalities and properties of polynomial approximations. The other textbook [
24] includes additional topics, such as critical points of polynomials, the compositions of polynomial functions, theorems and conjectures about polynomials, and defining extremal properties of polynomials. Although the textbook [
27] focuses on solving differential equations by polynomial approximations, it also provides a necessary background on polynomials including their definitions and properties. Differential equations are solved by Jacobi polynomial approximation in [
28].
The properties of minima and maxima of polynomials were studied in [
29]. An algorithm for finding the global minimum of a general multivariate polynomial was developed in [
30]. The number of local minima of a multivariate polynomial is bounded in [
31]. Sturm series are assumed in [
32] to find the maxima of a polynomial.
In this paper, polynomial distributions are introduced in
Section 2 including transformations of the polynomial distributions, fitting a histogram with a polynomial distribution, constructing a piecewise polynomial distribution, and defining the basic properties of a random polynomial function. In
Section 3, selected properties of the polynomial distributions are derived. The estimation problems involving polynomial distributions and determining the polynomial order are considered in
Section 4. Numerical examples are presented in
Section 5 including constructing a piecewise polynomial, generating polynomially distributed random samples, estimating parameters of polynomial distributions by the method of moments and by fitting the observations, and approximating distributions by Lagrange interpolation.
Section 5 ends with a summary of key findings. The paper is concluded in
Section 6. In addition, the key expressions for polynomial functions in Form I, II, and III are summarized in
Appendix A,
Appendix B and
Appendix C, respectively.
The following notations are used in the paper: X denotes a random variable whereas x denotes a specific value of this random variable; is matrix transpose; is matrix inverse; the operators, and , denote expectation and variance, respectively; denotes factorial, is used to find a value satisfying the indicated equality, and denotes the dot-product of two vectors.
2. Defining Polynomial Distributions
Given a continuous and finite interval,
,
, the probability density function (PDF),
, of a random variable,
X, with the support,
, must satisfy the following two conditions,
Assume that the PDF,
, can be linearly expanded as
into the
n-dimensional basis of generally non-linear functions,
. These functions can also be parameterized as
. Provided that the functions,
, are themselves PDFs, i.e., they satisfy the conditions (
1), then the PDF (
2) is referred to as mixture distribution, and
.
In this paper, the functions,
, are assumed, so that, the expression (
2) represents an ordinary univariate polynomial of degree,
n. The coefficients,
, can be a function of another common variable, e.g.,
,
; this multivariate polynomial is referred to as algebraic function. The multivariate polynomial having the same degree of a non-zero term is referred to as being homogeneous (formerly a quantic polynomial).
The following three representations of real-valued polynomial functions are considered in this paper.
Form I is a canonical polynomial function. Form II indicates that every
n-degree polynomial has exactly
n, generally complex-valued, roots
[
33]. The number of real-valued roots can be determined by Sturm’s theorem. Form III is a rational polynomial function. The basic properties of the polynomial Forms I, II, and III are summarized in
Appendix A,
Appendix B and
Appendix C, respectively, including roots, indefinite and definite integrals, derivatives, general statistical moments, and characteristic or moment-generating functions. Note that every polynomial function,
, of any order,
n, diverges when its argument,
x, becomes unbounded. In addition, Forms I and II are equivalent as shown in
Appendix B, and, for complex-conjugate roots,
. Form I defined by (
3a) can also be computed recursively as
A Form I or II polynomial,
, of degree
n and all of its derivatives,
,
, is continuous and strictly bounded over a finite interval,
. However, the polynomial forms in Definition 1 represent a PDF,
if and only if, they satisfy both conditions (
1). This can be achieved by using linear and non-linear transformations, which are defined in the following lemma.
Lemma 1. A polynomial, , can become a PDF by using either of the following transformations.
- (a)
There exist finite real constants, A and B, such that the linearly transformed polynomial, , satisfies PDF conditions (1). - (b)
There exists a real positive constant, , such that the polynomial, , or, , satisfies PDF conditions (1) where denotes absolute value, and changes the negative values of its argument to zero. - (c)
There exists a low-degree polynomial, , such that the polynomial, , satisfies PDF conditions (1); for instance, [cf. (a)], or, , .
Proof. - (a)
Let, , so that, . Then, , and, .
- (b)
For any, x, the functions, , and, . Then, , or, , respectively.
- (c)
The linear transformation, , was considered in (a). The transformation, , and, .
□
The polynomial PDFs defined in Lemma 1 can be further constrained by the required number of local minima, maxima, and roots within the interval of support, . There can also be additional constraints on smoothness expressed in terms of the minimum required polynomial order.
By Bolzano’s theorem, a continuous function having opposite sign values in an interval also has a root between these values. Consequently, a polynomial,
, of order
n have at least one maximum or minimum between every two adjacent roots, and there can be a maximum or minimum located at the roots themselves [
29]. Moreover, provided that the polynomial is considered over a finite interval, the boundary points of the support interval should be treated as additional roots, i.e., the boundary points can create local maximum or minimum as well as allow additional extrema to exist before the first nearest root. In the case of Form II polynomials, the condition of the first derivative to be zero can be equivalently expressed as
However, this approach still requires finding the roots of (
5) for every sub-interval,
,
, where
and
. It may be much easier to find the local extrema by considering the recursion,
provided that the roots of the polynomial,
, are known, and,
, denotes the constant of integration. These roots can be known by design, i.e., the locations of minima and maxima are selected a priori in a given interval of support. More importantly, in the case of a polynomial PDF, the local maxima represent the modes of such a distribution.
The Form I polynomial PDF can be generalized as
where
is a mathematical expression (i.e., not a transformation). For instance, it is possible to assume polynomials with fractional rather than integer powers of the independent variable [
34].
For
,
,
, the PDF (
7) becomes the truncated exponential Fourier series, i.e.,
The corresponding
k-th general moments are then computed as
where
is the Fourier transform of a rectangular window located over the interval,
.
For
, PDF (
7) becomes,
which can be readily integrated, although general statistical moments can only be expressed as special functions.
Consider now the general case of PDF (
7), for
. Thus, given
and
, and positive integers
and
, the task is to find the coefficients
,
and
of the PDF decomposition,
Multiplying both sides of (
11) by
and integrating, we obtain,
Assuming a substitution,
, Equation (
12) can be rewritten as
Provided that,
, and
is an odd-integer, and
is an even-integer, then, for
and
, respectively,
and, therefore,
The offset,
, must be computed from some other constraint, for example, as the minimum value to guarantee a non-negativity of
. Note that the function,
, in (
11) must be chosen, so the integrals (
15) converge.
2.1. Probability Density Transformations
In general, if
is an invertible transformation of a random variable,
X, having the PDF,
, the PDF,
, of random output variable,
, is, [
35]
where
. Assuming
is a Form I polynomial PDF,
, the transformed PDF is also a Form I polynomial, i.e.,
in the variable,
.
Assuming a linear transformation,
, the PDF (
17) is also a polynomial PDF of the same order, i.e.,
However, the linear transformation changes the support, of , to , if , and , if .
Another example of a non-linear transformation with memory that preserves polynomial form of the resulting distribution is an integrator. In particular, let,
, i.e.,
, such that,
, for
. Then, substituting into (
16), the transformed PDF can be written as
where
and
are arbitrary real constants. Provided that
is a polynomial of order,
k,
is a polynomial of order,
(cf.
Appendix A) and, thus,
. The family of PDFs with a form similar to (
19) are considered in [
36], which could be investigated also for our case of the polynomial distributions.
Consider now a general case of a polynomial nonlinear transformation,
, and denote as
,
, all the roots of,
. Then, the PDF (
16) is rewritten as
i.e., it is a sum of ratios of polynomials, i.e.,
is a polynomial of a certain order,
m.
Linear and non-linear transformations of a random variable can be used to change the interval of support of its probability distribution. The following Lemma 2 assumes linear transformations to convert the interval of support, , into and vice versa. Lemma 3 proposes two transformations on how to convert the interval of support, , to semi-finite or infinite intervals of support, respectively.
Lemma 2. The interval of support, , of a PDF, , is changed to the interval, , by a linear transformation, , which transforms the PDF, , to the PDF, . Furthermore, the linear transformation, , transforms the PDF, , with support, , into the PDF, , with the interval of support, .
Proof. The linear transformation,
, transforms any PDF,
, into the PDF,
, [
35]. □
Lemma 3. The PDF, , defined over the finite interval of support, , can be transformed into the PDF, , with semi-infinite support, , using the non-linear transformation, . Similarly, the non-linear transformation, , can be assumed to extend the support to all real numbers, for a PDF, , defined over the support interval, . The transformed PDF becomes .
Proof. The functions,
, and,
, are increasing, i.e., invertible in the interval,
. Then, in (
20),
, the inverse transforms,
, and,
, and their derivatives,
, and,
, respectively. □
Furthermore, there are scenarios when deterministic values,
, are transformed by a polynomial function,
, having the random coefficients,
. The output value of such a transformation,
is a random variable. Provided that
are independent and distributed as
, and conditioned on
x, the random variable
Y is a sum of independent random variables, so its PDF is given by a multi-fold convolution,
since,
, are distributed as
. Furthermore, the conditional mean and variance of
Y, respectively, are,
Provided that have equal means, then for any n and , , if , and , if . Note also that, if have equal variances, then the variance of Y is minimized for , and, it is equal to, .
The bounds for the number of real roots of random but sparse polynomials were provided in [
37]. A numerical method for efficiently finding the zeros of complex-valued polynomials of very large orders was developed in [
38]. Another method for a rapid root finding of polynomials is presented in [
39].
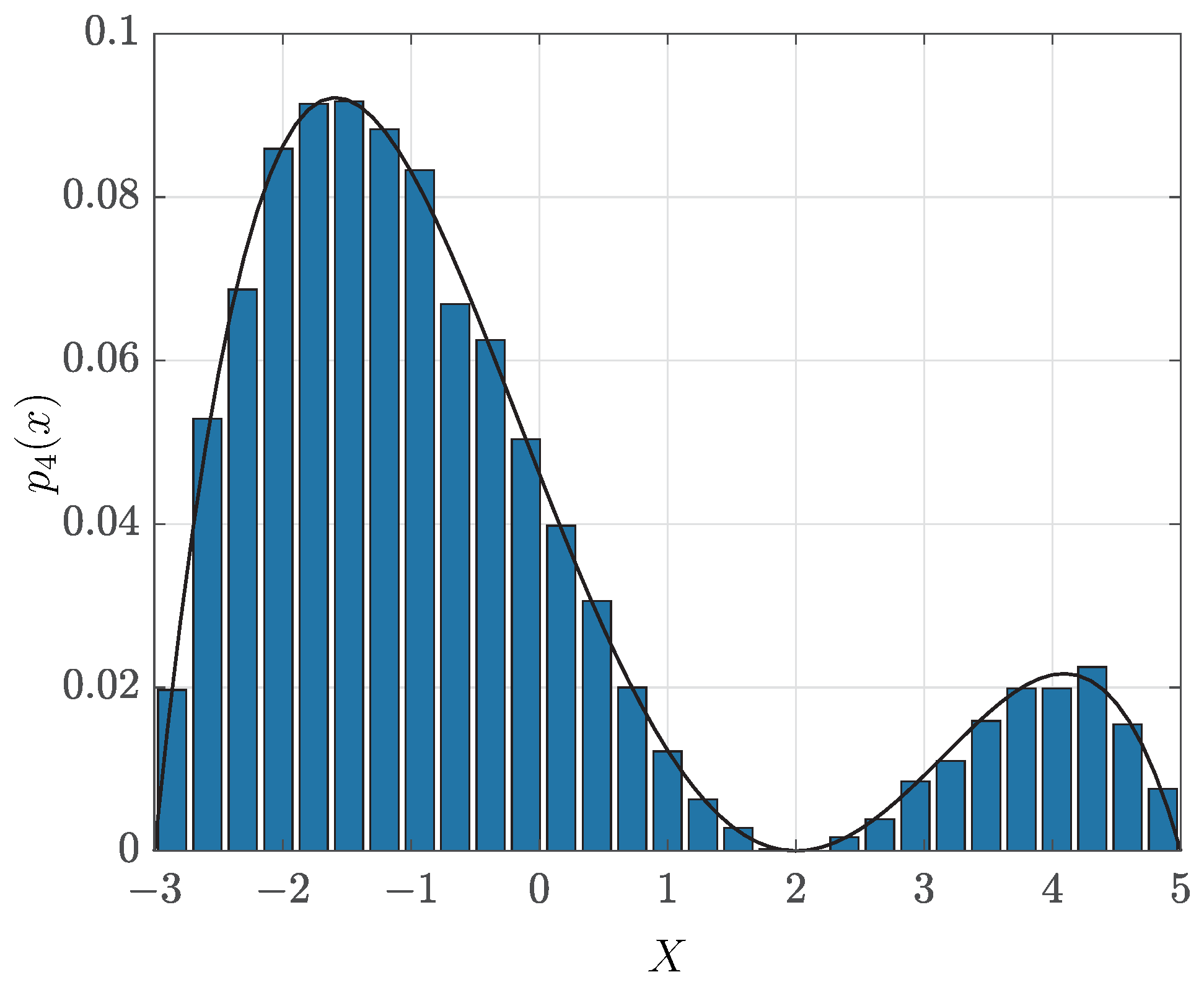
2.2. Polynomial PDF Fit of a Histogram
Approximating a continuous function by a polynomial over a finite interval is formalized by the well-known Weierstrass theorem [
1]. Runge’s phenomenon occurs when the approximating function must contain predefined points [
3]. The polynomial approximation represents the problems of existence as well as the uniqueness of such a polynomial, and also the problem of how to find it. These problems are crucially dependent on the choice of metric for the goodness of approximation.
Hence, consider the problem of approximating a PDF having the finite support by a polynomial PDF. For instance, the empirical histogram can be fitted by a polynomial function, or a known PDF can be approximated by a polynomial in order to achieve mathematical tractability. However, in neither of these cases, the resulting polynomial is guaranteed to satisfy conditions (
1), since the polynomial coefficients are normally chosen to obtain the best fit.
The polynomial PDF can be obtained by assuming a polynomial function, which is non-negative over a given interval for any values of its coefficients. One example of such a polynomial is,
, which has degree,
. The true PDF,
, can be then approximated as
The latter strategy by first transforming with a square root is numerically more stable. Other invertible transformations of can also be assumed, provided that they yield the non-negative polynomial, , since scaling to have a unit area usually does not affect the approximation error significantly.
For instance, the data points,
,
,
, can be interpolated by Lagrange polynomials [
5],
Then, the true PDF,
, is approximated as
which is a polynomial of order,
. In order to normalize the approximation (
26), let,
and,
Then, the area is calculated as
The Lagrange polynomials satisfy,
, so they are subject to Runge’s phenomenon [
3]. In particular, the approximation error can be estimated as [
3],
where
. Provided that
, for
, and,
,
converges uniformly to
, i.e.,
, as
. The PDF,
, is often only known as a sequence of sample points,
, so the derivatives,
, cannot be determined. However, the approximation can be improved by using Chebyshev or extended Chebyshev points instead of equally spaced points [
4].
The most common method for fitting a polynomial to a histogram is a linear regression [
40]. Denote the vectors,
,
, and,
,
, and the matrix,
. The constrained least squares (LS) problem is then formulated as
where the weights,
, assuming the support interval,
. The first derivative of the corresponding Lagrangian is set equal to zero, and the estimated coefficients,
, of the fitting polynomial,
, are computed as [
41],
In order to approximate a known continuous distribution,
, over a finite interval,
, representing the full or truncated support of that distribution, the constrained least-squares (
32) can be again used assuming the distribution samples,
,
.
If
is the best polynomial fit of a histogram, or of a sampled known PDF, then it must be evaluated whether it is non-negative over the whole support of interest,
, for example, due to Runge’s phenomenon as discussed in
Section 2.2. This can be readily and reliably tested by numerically computing the integral,
, or,
. If
contains negative values within the interval,
, then
, and
, respectively. It is also possible to assume a logarithm instead of the square root in the definition of the integral,
.
In this case, the polynomial fitted to a histogram contains negative values, a constant, , can be added to the observed data points, i.e., , where , and the scaling ensures that, . Correspondingly, the fitted polynomial is also shifted and scaled as , so .
Furthermore, the roots of a polynomial, , can be constrained in order to guarantee that it is non-negative over a finite interval, . This is formulated in the following theorem.
Theorem 1. A Form II real-valued polynomial, , of order n with and the roots, , is non-negative over the interval, , provided that all its roots satisfy at least one of the following conditions:
- (a)
a root has even multiplicity;
- (b)
a root has a complex conjugate pair;
- (c)
a (real-valued) root is smaller than l;
- (d)
a real-valued root has odd multiplicity and is larger than u; the number of such roots must be even.
Proof. Form II polynomial is a product of linear functions, . Cases (a), (b), and (c) are trivial. Case (d) is a combinatorial problem. The roots with odd multiplicity cannot be smaller than u. Even if these roots are all larger than u, then their number must be even in order for their negative parts to cancel out for all values smaller than u. □
Corollary 1. A Form II real-valued polynomial, , of order n with and the roots, , has negative values in the interval, , provided that there is an odd-number of real-valued roots with odd multiplicities that are greater than l, or, there is an even number of real-valued roots with odd multiplicities, and at least one root is located between l and u.
Theorem 1 can also be used for Form I polynomials, provided that they are converted to Form II as indicated in
Appendix B. Even though the roots cannot be obtained analytically for polynomials of order
(Abel-–Ruffini’s theorem), it may be sometimes possible to consider a product,
, of polynomials of orders,
, for
.
2.3. Piecewise Polynomial PDF
In some applications, a piecewise polynomial curve fitting can be assumed. In particular, the following construction is proposed to fit a set of points, , , , and , representing local extrema of a histogram, or of a known PDF. The construction yields a piecewise polynomial PDF, , of the same order n, over the interval, , with and , such that, exactly, . The data points, , are referred to as control points of the piecewise polynomial . It should be noted that univariate piecewise polynomial functions are generally referred to as splines, and their control points as knots.
The following construction defines a piecewise polynomial PDF by sample points representing an alternating sequence of local maxima and minima. The points between the subsequent extrema are then interpolated by increasing or decreasing polynomial segments with a defined continuity order between these segments. As long as the minima are non-negative, all segments are non-negative. However, the resulting curve must be normalized, so that it has a unit area, i.e., it is a PDF.
Definition 2. Let be piecewise continuous, and composed of M non-overlapping polynomial segments, , i.e.,The segments, , are increasing, i.e., , over their support intervals, . The points, , define the local minima and maxima, such that, if is a local minimum, then is a local maximum and vice versa. The weights, , if is a local minimum, and , if is a local maximum. The constant, , is chosen, so that, , integrates to unity over its interval of support, . In addition, a continuity (smoothness) of order C requires that the first C derivatives,which needs to be true at all points of the local minima and maxima, i.e., In order to construct the desired segment polynomials,
, consider two increasing polynomials,
, and,
, such that, for some
, the derivatives,
or, in matrix notation,
For
, Equation (
37) can be rewritten as
so the coefficients
and
are in the null space of
.
Provided that
denotes the coefficients of
, it is required that,
Note that the matrices, , are computed assuming the control points, .
Given the first vector of coefficients,
, the other coefficient vectors,
,
, can be computed iteratively using the underdetermined sets of Equation (
39). The numerical feasibility of this problem requires that the order,
.
The vector,
, must be selected, so that
, and,
, and
is
C-continuous for
. Let sample
at
K equidistant points between
and
. The coefficients
are then the solution of the quadratic program,
where
, and
is the equidistant sampling step. The last condition in (
40) enforces
to be approximately increasing between the points
and
. The other coefficients,
,
, are computed similarly to the program (
40), but with an additional constraint due to (
39). The extended quadratic program to compute these coefficients is defined as
where
, and
.
More importantly, quadratic programs (
40) and (
41) require that the constraints are sufficiently underdetermined, i.e.,
, otherwise, the solution may be difficult to find, or even may not exist. Moreover, the solution is less numerically stable for a linear program than for a quadratic program and, therefore, the quadratic programs should be considered.
3. Derived Characteristics of a Polynomial Distribution
The cumulative distribution function (CDF) can be readily obtained for Form I polynomial PDF as shown in
Appendix A, i.e.,
Note also that, for symmetric support interval, when , , so the normalization of PDF to unity is only affected by even-index coefficients, .
In the case of a Form II polynomial PDF, it is best to convert it to Form I first as shown in
Appendix B.
The median (
), and more generally, the quantile,
, of a polynomial distribution is defined as
Denoting, , the quantile is the unique root of the polynomial, .
The expressions for general moments and characteristic or moment-generating functions are derived in
Appendix A,
Appendix B and
Appendix C, respectively.
The Kullback–Leibler (KL) divergence or relative entropy between two polynomial distributions,
, and,
, is defined as
The inner integral, , can be expressed in terms of the hypergeometric, , functions with the help of, for example, Mathematica software.
Differential entropy of a polynomial distribution,
, is defined as
Finally, the sum,
, of two independent random variables,
X, and,
Y, having the polynomial distributions,
, and,
, respectively, with the same interval of support,
, also has the polynomial distribution,
, given by the convolution,
4. Estimation Problems Involving Polynomial Distributions
The parameter estimation of the polynomial distributions is subject to the following equality and inequality constraints, respectively,
where the column vectors,
, and,
,
. The equality constraint guarantees that the estimated polynomial integrates to unity. The second constraint requires that the estimated polynomial is non-negative at
K equidistant points within the interval of support,
. The value of
K must be determined empirically.
Consider the problem of estimating the coefficients,
, of a polynomial PDF,
. For
M independent measurements,
, the likelihood function is,
where the column vector,
,
. The Karush–-Kuhn-–Tucker (KKT) function representing the constrained maximum (log-) likelihood (ML) estimation is [
42],
where
, and,
, for
. The first vector-derivative of
by
[
41] must be equal to zero, i.e.,
Expression (
50) together with constraint (
47) represent the set of
non-linear equations with the same number of unknowns, which must be solved numerically.
The cosine theorem can be assumed instead of logarithm in maximizing (
49) and (
50), since,
where
is the angle between the vectors
and
. The unconstrained maximization of (
51) can be performed using the geometric-arithmetic mean inequality [
43]. Specifically, the likelihood (
51) is maximized when the coefficient vector,
, is aligned with all the observations,
. It can be approximated by assuming that the distances between the normalized vectors,
, and,
, are constant, for
. Then, the estimate is the centroid of observations, i.e.,
.
The estimator complexity can be greatly reduced if constraint (
47) is ignored. In this case, the estimated coefficients,
, may not satisfy the PDF conditions (
1). Assuming that the estimate,
, is not too far from the true vector,
, the first estimate can be improved by the subsequent estimator,
The estimator (
52) minimizes the distance between the first estimate,
, and the subsequent estimate,
, under constraint (
47). More importantly, the corresponding set of equations to solve (
52) is now linear.
In the sequel, we drop the inequality constraints in (
47) since closed-form expressions can be obtained with the equality constraint. For
, or, equivalently, only two out of
M measurements are considered at a time, the ML estimator can be constrained as in (
31), i.e.,
where
,
, and
is a
square matrix. The first derivative of the corresponding Lagrangian must be equal to zero, i.e., [
41]
Consequently, the ML estimate is,
and its likelihood is equal to,
. Finally, the observation pairs,
,
,
…, are independent, so the final ML estimate is,
The Cramer–Rao bound has been defined to lower-bound the covariance matrix of the estimation error,
, of any unbiased estimator, i.e.,
where
is the Fisher information matrix. In order to calculate the elements of this matrix, it is better to assume Form II of the polynomial distribution,
, and the problem of estimating the parameters,
, i.e.,
The last integral in (
58) can be computed by converting the Form II polynomial into Form I.
The coefficients,
, can also be estimated by the method of moments [
7,
44]. In particular, the
k-th general moment of a polynomial distribution,
, is, (cf.
Appendix A)
Observing a vector of the first
K general moments,
,
, and pre-computing the matrix,
,
, and ignoring non-negativity constraint in (
47), the estimation can be again defined as the constrained or unconstrained least-square regression, i.e.,
which can be efficiently solved as in (
32).
Other Estimation Problems
In addition to estimating the coefficients,
, of the polynomial distribution,
, an important task is to also decide the polynomial order,
n. The usual strategy is to estimate a sequence of PDFs,
, with increasing orders,
, and then choose the one minimizing the Akaike information criterion (AIC),
which penalizes the model complexity,
, while maximizing the likelihood
L defined in (
48).
However, the AIC cannot be used with non-parametric and other likelihood-free estimation methods. In the case of the polynomial distributions, the empirical moments can be readily computed from the observed random samples as well as estimated using the inferred distribution parameters. In particular, denote
, the vector of the first
K empirical moments. Let,
be the vector of the first
K moments computed assuming the estimated coefficients of the polynomial distribution,
. Similarly to the AIC definition (
61), we propose that the goodness of fit (GoF) of a polynomial distribution to observed data can be estimated as
Thus, the squared Euclidean distance between the two-moment vectors is penalized by the number of model coefficients, i.e., . In our numerical examples, we observed that n should be chosen as the smallest polynomial order causing a sudden significant drop in the value of .
Furthermore, Bayesian estimation methods for estimating the coefficients, , require adopting a prior, . Since the coefficients are likely to be mutually correlated, defining the prior distribution may be challenging, unless a Gaussian prior can be assumed. On the other hand, consider a general probabilistic model with observations X and a parameter, , which is described by the likelihood, , and the prior, . If the likelihood and the prior are both polynomially distributed, then the corresponding posterior, , is also polynomially distributed.
Finally, polynomial distributions can also be considered in variational Bayesian inference to approximate the posterior, , and lower-bound the evidence, . The parameters of the polynomial distribution can also be inferred without computing the likelihood by assuming the approximate Bayesian computations.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







