In this section, we present the experimental part. We first introduce the evaluation metrics, a comparison of methods and datasets, and parameter settings. Then, we give the experimental results and analysis. Finally, we study model parameter selection and parameter sensitivity. The hardware environment of the experiment is Intel (R) Core (TM) i7-4790 CPU (processor base frequency is 3.60 GHz, total cores are 8), 32G memory, and the Windows 10 operating system. We use Python to write codes and implement them based on the PyTorch deep learning framework.
5.1. Evaluation Metrics
The experiments evaluate the network alignment effects using four metrics, including
Accuracy [
6],
MAP [
15],
Hit-precision [
6], and
Precision@
K [
15], to verify the performance of the proposed method and baselines.
Accuracy is a straightforward metric. The larger the value of
Accuracy, the better the performance of network alignment methods. After obtaining the alignment matrix
S, we use the heuristic greedy matching algorithm as a post-processing step for each algorithm. The heuristic algorithm iterates over the alignment matrix
to find the largest score
and record the node pair
, then deletes any scores involving node
or nodes from the matrix (replace them with zero values). The following formula calculates
Accuracy:
where
denotes the correctly identified node pairs,
denotes the truly aligned node pairs.
Accuracy is a metric of direct alignment that requires one-to-one node alignment, where to select the node with the highest similarity is the sole pair of aligned nodes. Without loss of generality, we use three metrics to evaluate the performance of network alignment from ranking and prediction.
For ranking metrics, we employ MAP (Mean Average Precision) and Hit-Precision.
Hit-Precision is defined as
We construct a candidate list for the node in the source network, select the Top-K potential nodes most similar to the node from the target network, and add them to the candidate list. is the index value of the node in the candidate list that correctly matches the node . MAP and Hit-Precision focus on the ranking value of correctly matched nodes in the candidate list.
For prediction, we employ a general metric
Precision@
K. We calculate the similarity of the node
in the source network and each node in the target network, rank them in descending order, and take
Top-K nodes as the potential matching nodes of the node
. We compare the
Id of the candidate matching node with the
Id of the true matching node in sequence, and if there is a hit, the nodes match successfully. The following formula calculates
Precision@
K:
where
is the indicating function,
,
, For a node
in the source network, proposition
represents if the true alignment node exists in the potential matching nodes.
5.2. Baselines and Datasets
For the examination, we selected five state-of-the-art unsupervised embedding-based network alignment methods for comparison with the URNA. We divide the baselines into two categories: network alignment methods based on traditional representation learning and graph neural networks. In the first type, REGAL [
19] uses the low-rank matrix factorization method, xNetMF, to learn node embeddings, and NAWAL [
17] uses the DeepWalk [
34] to learn node embeddings. DeepWalk adopts random walk to sample node sequences, and the node embeddings in the same sequence are closer to each other, preserving the homogeneity of nodes. In the second type, GAlign [
15] uses GCN [
24] to learn embeddings for each node, and uses a data augmentation and refinement mechanism to adapt the method to coincidence conflicts and noise. WAlign [
18] learns embeddings of the nodes using a lightweight graph neural network (LGCN) [
18] with a flat structure and then uses the Wasserstein distance discriminator to discover candidate node pairs to update the node embeddings. Grad-Align [
16] learns node embeddings using a Graph Isomorphism Network (GIN) [
27]. GIN can collect higher-order node features. Grad-Align uses the generated embedding similarity and Tversky similarity [
28] to align node pairs progressively.
We used four public datasets with attribute information: douban [
6], allmv/imdb [
15], flickr/myspace [
6], and flickr/lastfm [
6]. Each dataset contains two real-world networks, and we present the basic statistics for these datasets in
Table 1. Dataset douban comes from a social network with two sub-networks: an offline activity network and an online follower network. Each node is a user. Offline activity networks connect users based on their co-occurrence in offline activities. Each edge of the online following network presents who follows who in Douban. The node attribute is the location information of the user. Dataset allmv/imdb comes from two Internet movie databases, AllMovie and Internet Movie Database (IMDB). Each node is a movie, and the edge means that at least one actor is the same in both films. Datasets flickr/myspace and flickr/lastfm come from three different online social platforms, Flickr, MySpace, and Last. FM, where each node is a user and node attributes are part of the user’s profile information.
5.4. Experimental Results and Analysis
To evaluate the performance of FSNA, we first evaluate the computational efficiency and alignment performance of FSNA and baselines on the datasets douban, allmv/imdb, flickr/myspace, and flickr/lastfm by three metrics, namely
Accuracy,
MAP, and
Hit-precision, and the experimental results are shown in
Table 2.
According to the experimental results shown in
Table 2, REGAL, which uses matrix factorization to learn node embeddings, is more computationally time efficient than the baselines based on graph neural networks, but has lower alignment performance. In terms of time complexity, GAlign < WAlign < Grad-Align for the baselines based on graph neural networks. WAlign uses adversarial training to map the embedding space of the two networks to the same vector space. While this End-to-End training approach can update embeddings in real-time and enhance alignment precision, it also adds the computational burden of the model. Grad-Align uses an iterative mechanism to select node pairs with high similarity by node embeddings and gradually align nodes in combination with Tversky similarity; however, this strategy consumes a significant amount of memory space and significantly lengthens the computation time of the algorithm. Our method has a significant computational speed advantage on the four datasets and performs best on all data sets except for the douban dataset, where the computational time efficiency is slightly lower than that of REGAL. Compared to GAlign, running time is reduced by 77.59% on the dual dataset, 81.61% on the allmv/imdb dataset, 95.69% on the flickr/myspace dataset, and 96.85% on the flickr/lastfm dataset. The experimental results validate the efficiency of URNA. The advantage of URNA becomes more apparent as network size rises, and it can use for network alignment tasks on large-scale networks.
On four datasets, the alignment performance of different algorithms varies significantly in terms of Accuracy, MAP, and Hit-precision. Among them, DeepWalk-based NAWAL performs the worst and is nearly comparable to random alignment, which is logically reasonable given that it cannot capture the similarity of nodes between the two networks. REGAL requires information on the degrees of neighbors of different orders as structural features to express nodes. We cannot obtain the experimental results because the allmv/imdb dataset contains some isolated nodes. It can be seen that baselines using the graph neural network have a better and more stable network alignment performance. On all four datasets, URNA achieved optimal results. Experimental results validate the usefulness of URNA in network alignment tasks.
Next, we evaluate the soft alignment performance of all algorithms using the metric
Precision@
K, and the experimental results are shown in
Table 3,
Table 4,
Table 5 and
Table 6. Experimental results show that URNA exhibits excellent performance overall. For the soft alignment, the GNN-based GAlign, WAlign, and Grad-Align algorithms also show stable and better performance in different
K values. GAlign outperforms the other baselines on the datasets douban and allmv/imdb, which have the most attribute information, and WAlign outperforms the other baselines on the datasets flickr/myspace and flickr/lastfm, which have little attribute information, demonstrating that using training methods based on generative adversarial methods can exploit uncertain information in the network to improve network alignment correctness. On the four datasets, URNA outperforms the other baselines.
Precision@1 outperforms the best-performing Grad-Align on the douban dataset by 23.45%, the best-performing WAlign on the allmv/imdb dataset by 4.78%, the best-performing WAlign in the baselines on the flickr/myspace dataset by 56.25%, and the best-performing WAlign in the baselines on the flickr/lastfm dataset by 49.44%. In conclusion, the URNA outperforms other baselines in datasets of various sizes in terms of running time and alignment accuracy.
5.5. Hyper-Parameter Sensitivity Analysis
We analyze the sensitivity of the hyper-parameters affecting our method on four datasets to investigate the effect of different hyper-parameters on the experimental results. The network compression ratio r, the embedding dimension d, and the number of convolutional layers k are compared. The hyper-parameters are r = 0.8, d = 200, and k = 2 if not indicated otherwise. The variation of hyper-parameters reflects the relevance of the elements that affect our strategy. The metric Precision@5 is used to compare network alignment effects.
First, we investigated the hyper-parameter r. During the experiment, we kept the other parameters constant, and increased the r value from 0.1 to 0.9, increasing it by 0.1 each time, and the experimental results are shown in
Figure 2 and
Figure 3.
Figure 2 indicates the trend of our method’s running time in the four data sets with the change of the r value.
Figure 3 represents the trend of our method’s metric
Precision@5 in the four data sets with the change of r value. As can be observed in
Figure 2, the computational time efficiency of the model increases significantly with increasing r values in the four datasets. The dataset flickr/lastfm shows the most significant improvement in the computational efficiency of the model when compared to the other three datasets. When the r value hits 0.8, the model’s running time on the four datasets lowers by 75.11%, 74.52%, 90.69%, and 94.04%, respectively, when compared to the un-coarsened network.
For
Precision@5, the fluctuation amplitude of the four broken lines in
Figure 3 is small, indicating that the value of r has little influence on the performance index within the above value range, indicating that our method has low sensitivity to parameter r. Even when the d value reaches 0.8, it still maintains good performance. Compared to the un-coarsened network, the
Precision@5 in the dataset douban increases by 0.60%, in the dataset allmv/imdb, the
Precision@5 drops by 6.42%, and the same level is maintained in the
Precision@5 in the dataset flickr/myspace, and in the dataset flickr/lastfm, the
Precision@5 increases by 25.00 percent. In general, as the value of r increases, the alignment performance of our approach does not change significantly. As a result, by greatly compressing the network size, we can guarantee the alignment accuracy of the network and reduce the training time and memory requirements of the GNN model to achieve more outstanding performance on large-scale datasets.
Next, we study how the embedding dimension
d affects the performance of URNA. In the experiments, we set the values of
d to 5, 10, 25, 50, 100, 150, and 200 in order, while keeping the other parameters fixed.
Figure 4 shows the experimental results, which depict the trend in the variation of the metric
Precision@5 for different values of
d on the four datasets. We can see from
Figure 4 that the metric values change differently for the four datasets as the value of
d increases. Overall, the metric
Precision@5 increases steadily with an increasing value of
d. On the dataset Douban, the metric reaches its optimal value for
d = 150, and on the datasets allmv/imdb and flickr/myspace, the metric reaches its optimal value for
d = 200. On the other hand, on the dataset flickr/lastfm, the metric value is optimal when the value of
d = 50, which may be related to the large size of the dataset. On the other hand, on the flickr/myspace and flickr/lastfm datasets, the model effects fluctuate with increasing values of
d, which may be related to the fact that the datasets have too few attributes.
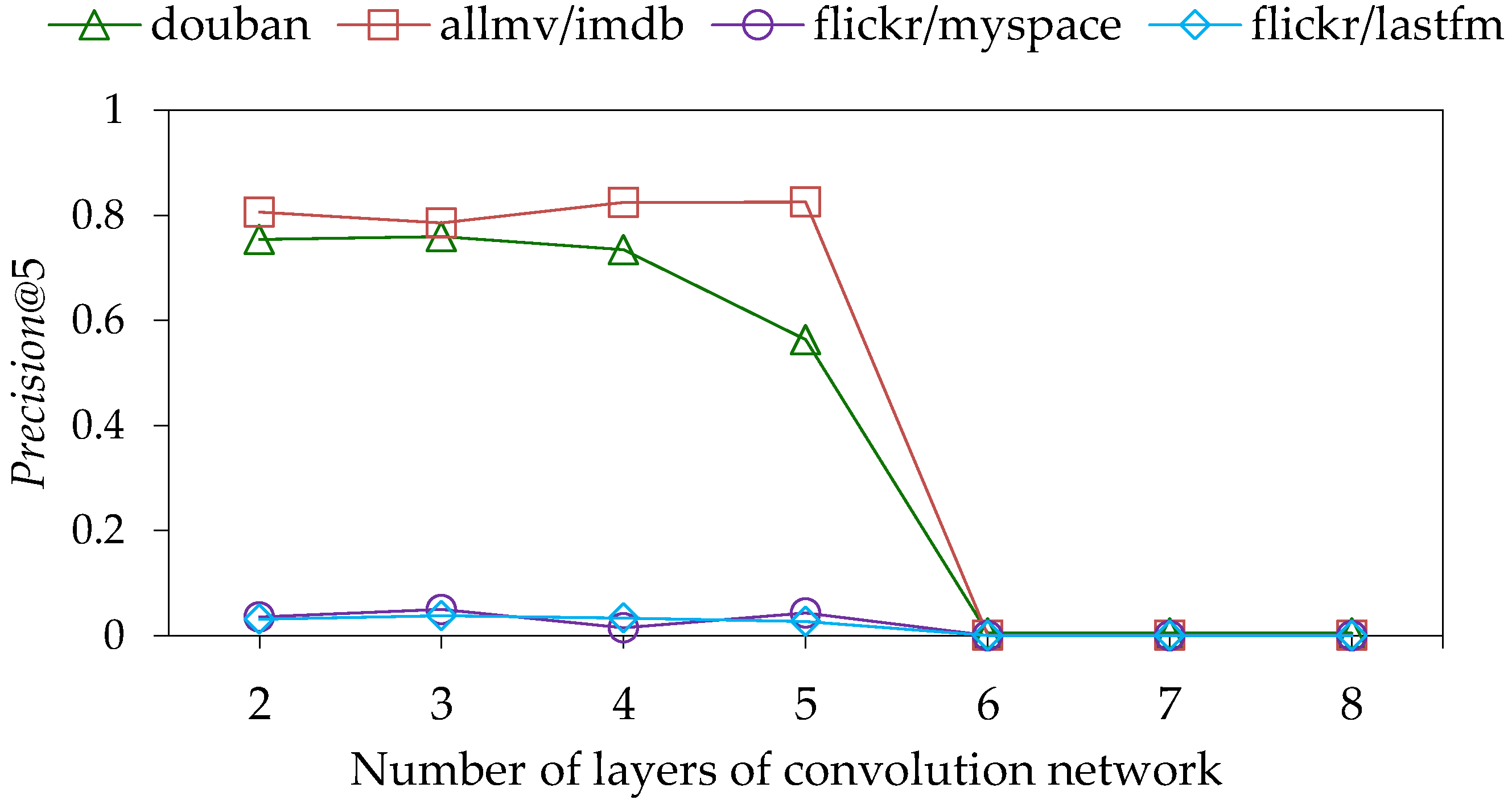
Finally, we study how the number of convolutional layers
k affects the performance of URNA. In the experiments, we kept the other parameters fixed and increased the value of
k from 2 to 8, increasing it by 1 each time. The experimental results are shown in
Figure 5. We can observe that the metric
Precision@5 achieves better results for a smaller number of
k values on the four datasets. For values of
k above 5, the effect of the model decreases precipitously. This is because we stack multiple convolutional layers by cascade. Although the deeper convolution layer aggregates the higher-order features of the nodes, it also leads to the over-smoothing of the node embedding [
29]. More similar node embeddings lead to the matching confusion problem during network alignment. In addition, we do not distinguish the importance of different alignment matrices, resulting in a significant worsening of the alignment effect. The difference is that the metric
Precision@5 reaches optimal at
k = 3 for the datasets douban, flickr/myspace, and flickr/lastfm, and at
k =5 for the dataset allmv/imdb, which may be related to the excessive number of edges in the dataset allmv/imdb relative to the number of nodes.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}