
A Novel Neighborhood Granular Meanshift Clustering Algorithm
 , and
, and
Abstract
1. Introduction
2. Granulation
2.1. Neighborhood Granulation
2.2. Granular Vector Operations
3. Granular Meanshift Based on Neighborhood Systems
3.1. Granular Vector Metric
3.2. Neighborhood Granular Meanshift Clustering Theory
3.3. Neighborhood Granular Meanshift Clustering Algorithm Implementation
| Algorithm 1 Granular meanshift clustering algorithm |
Input: The data set is , where the sample set is the set of attributes is ; the neighborhood parameter , the maximum number of iterations N; the bandwidth parameter h, granular vectors distance threshold . Output: Cluster division .
|
4. Experimental Analysis
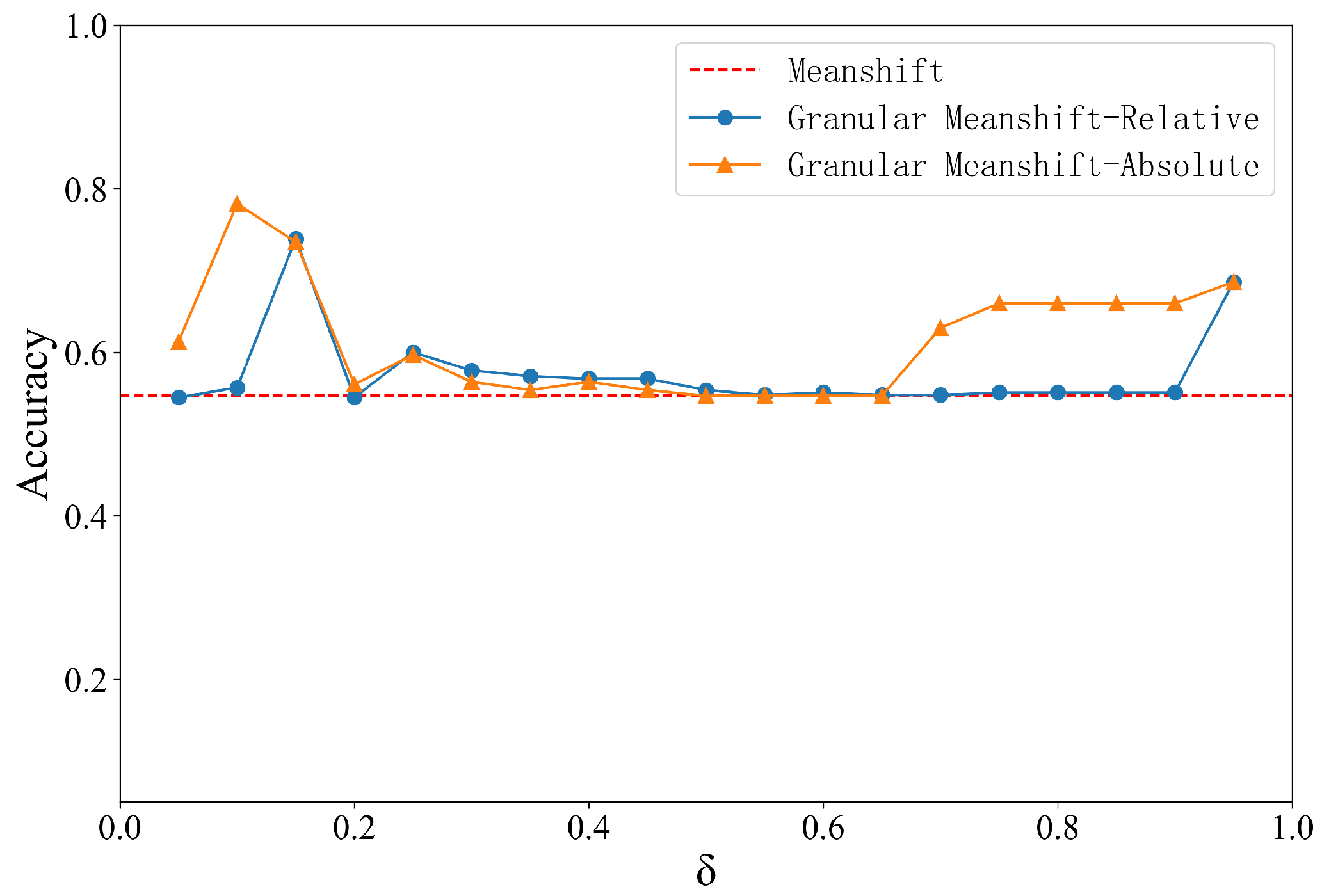
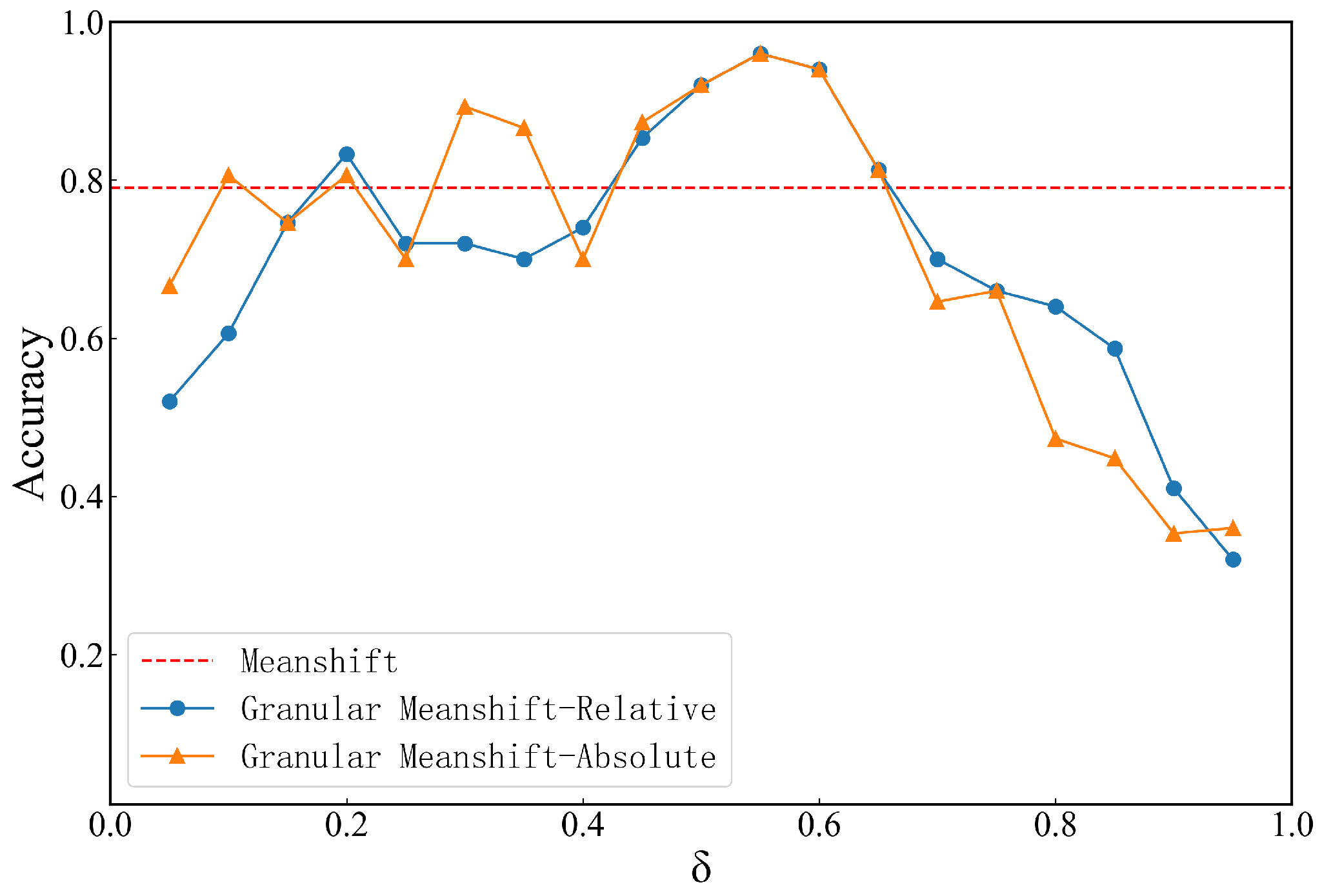
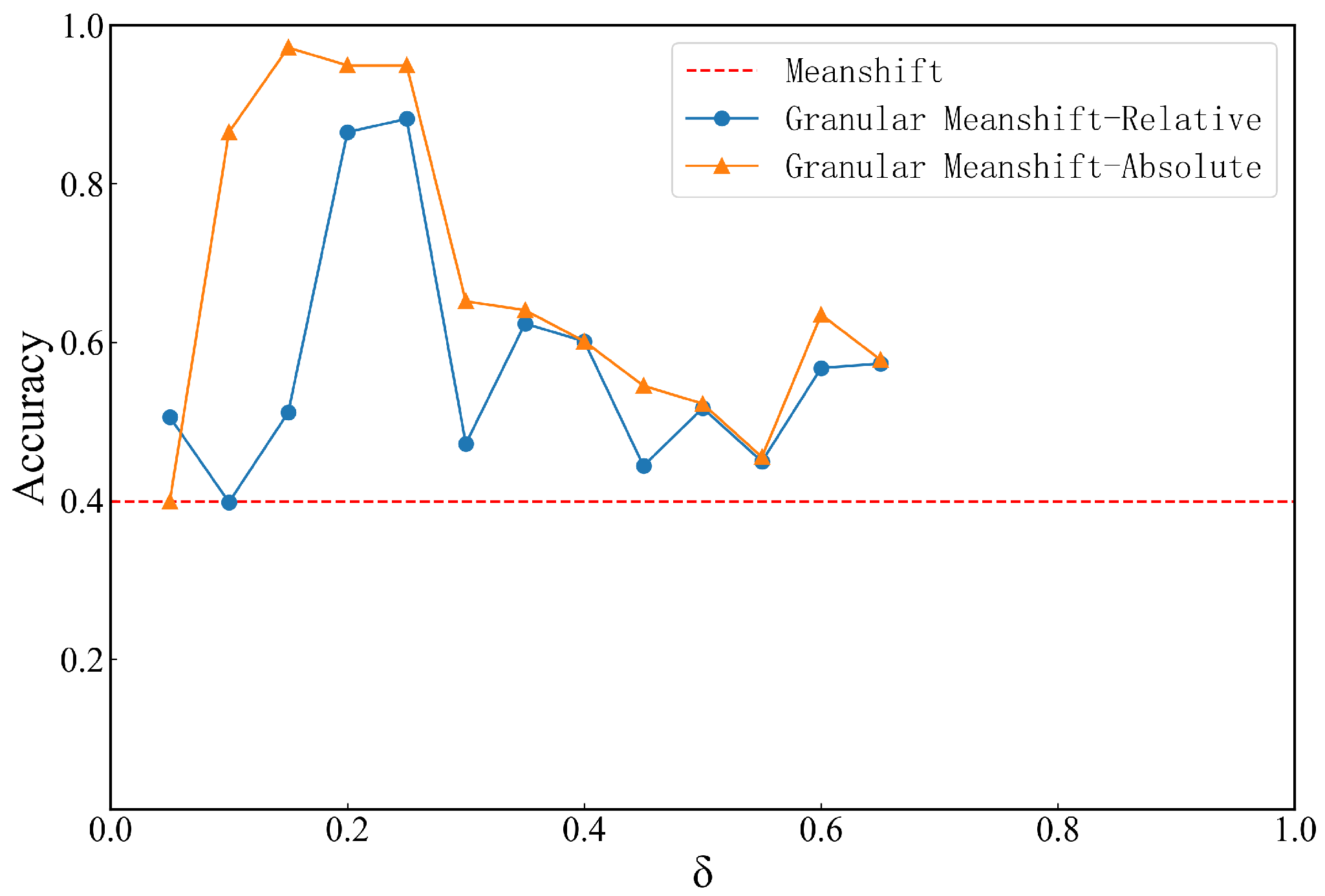
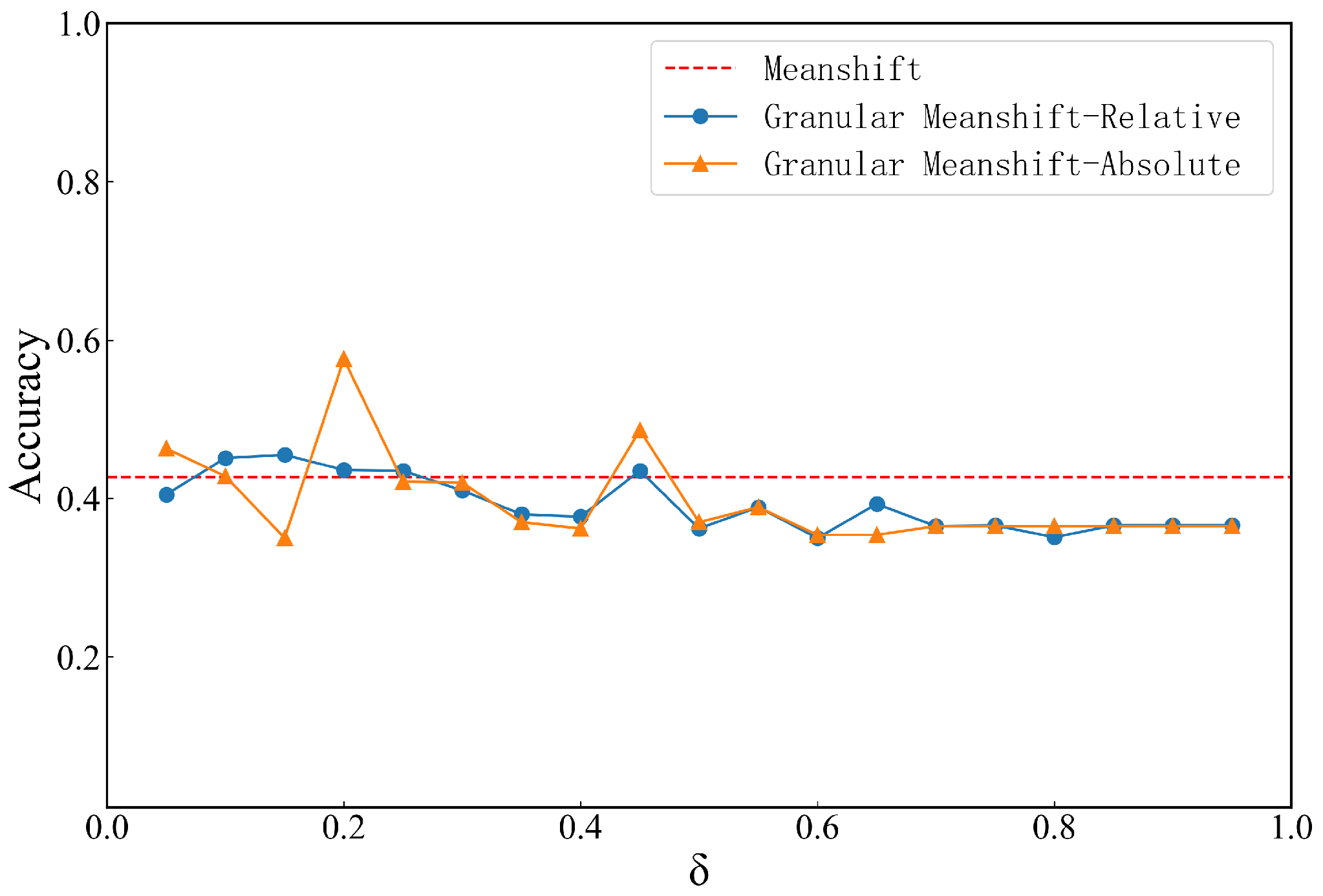
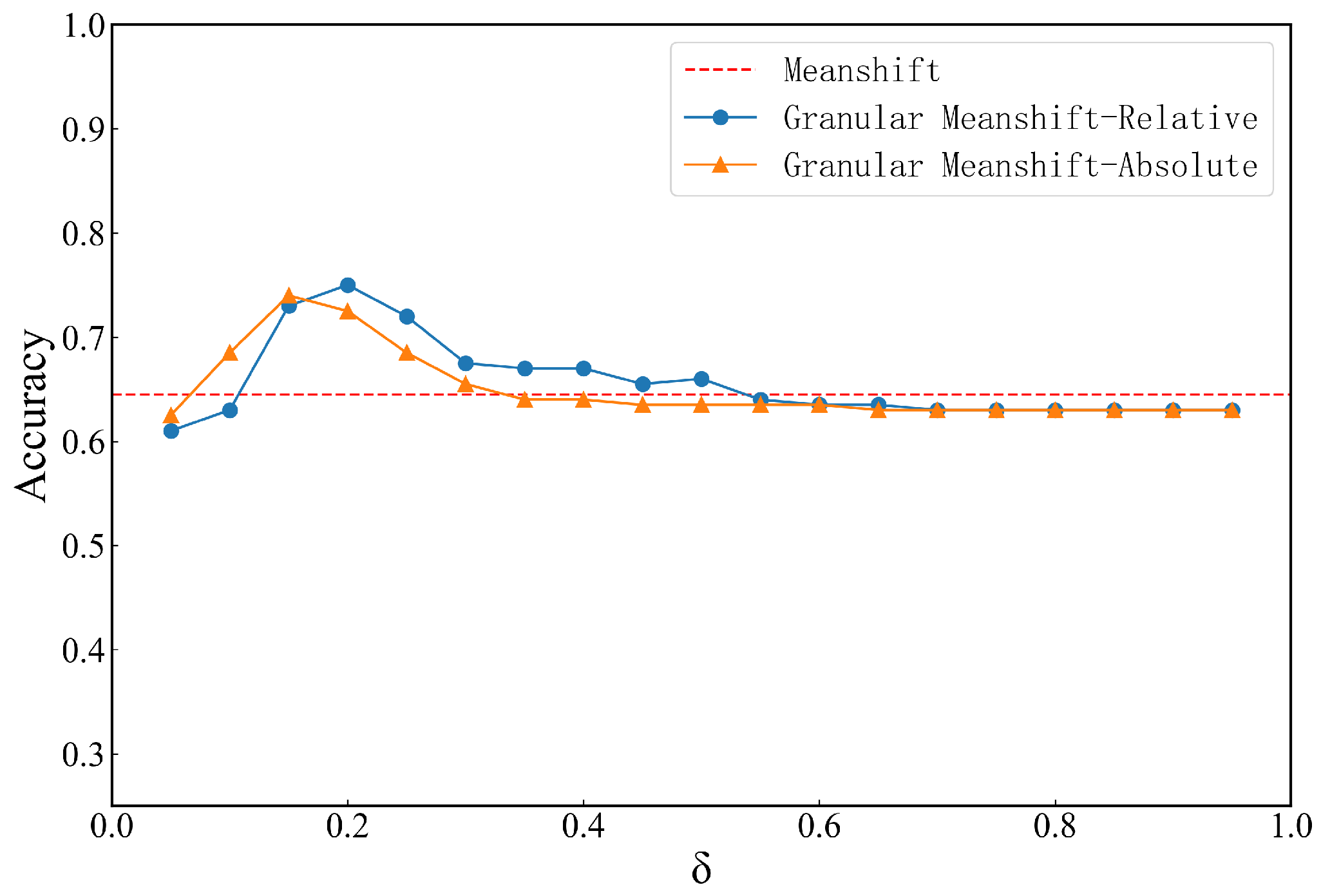
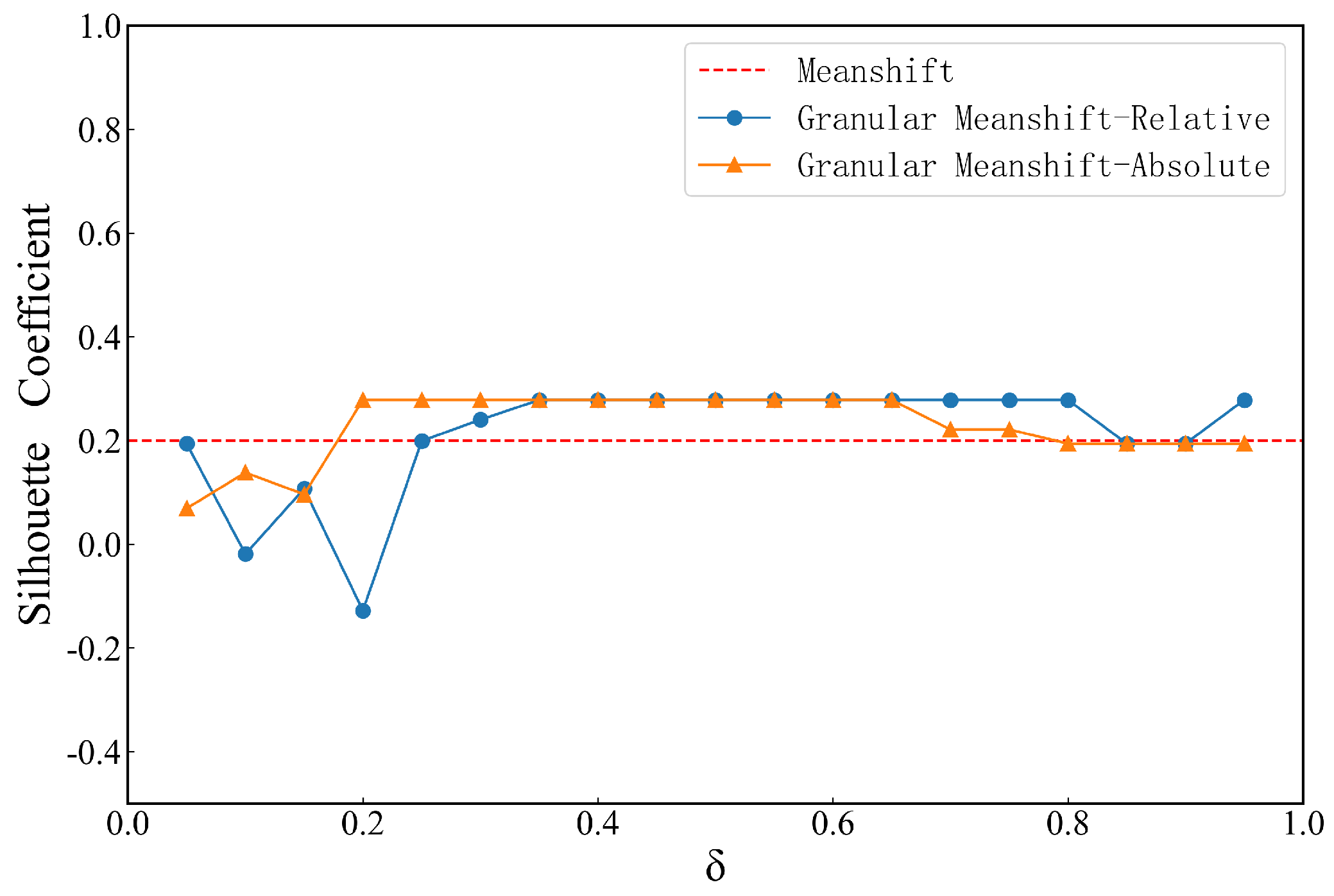
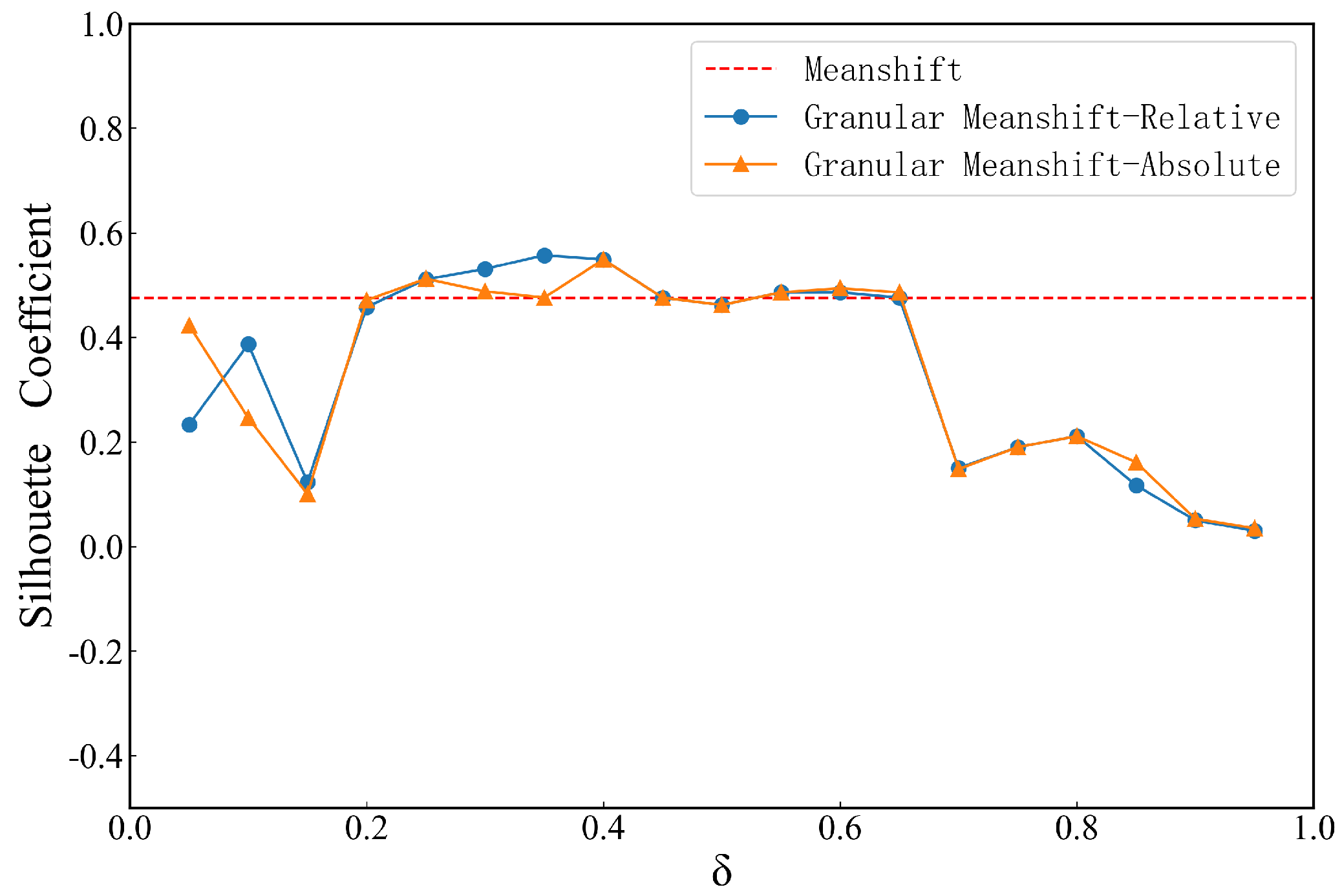
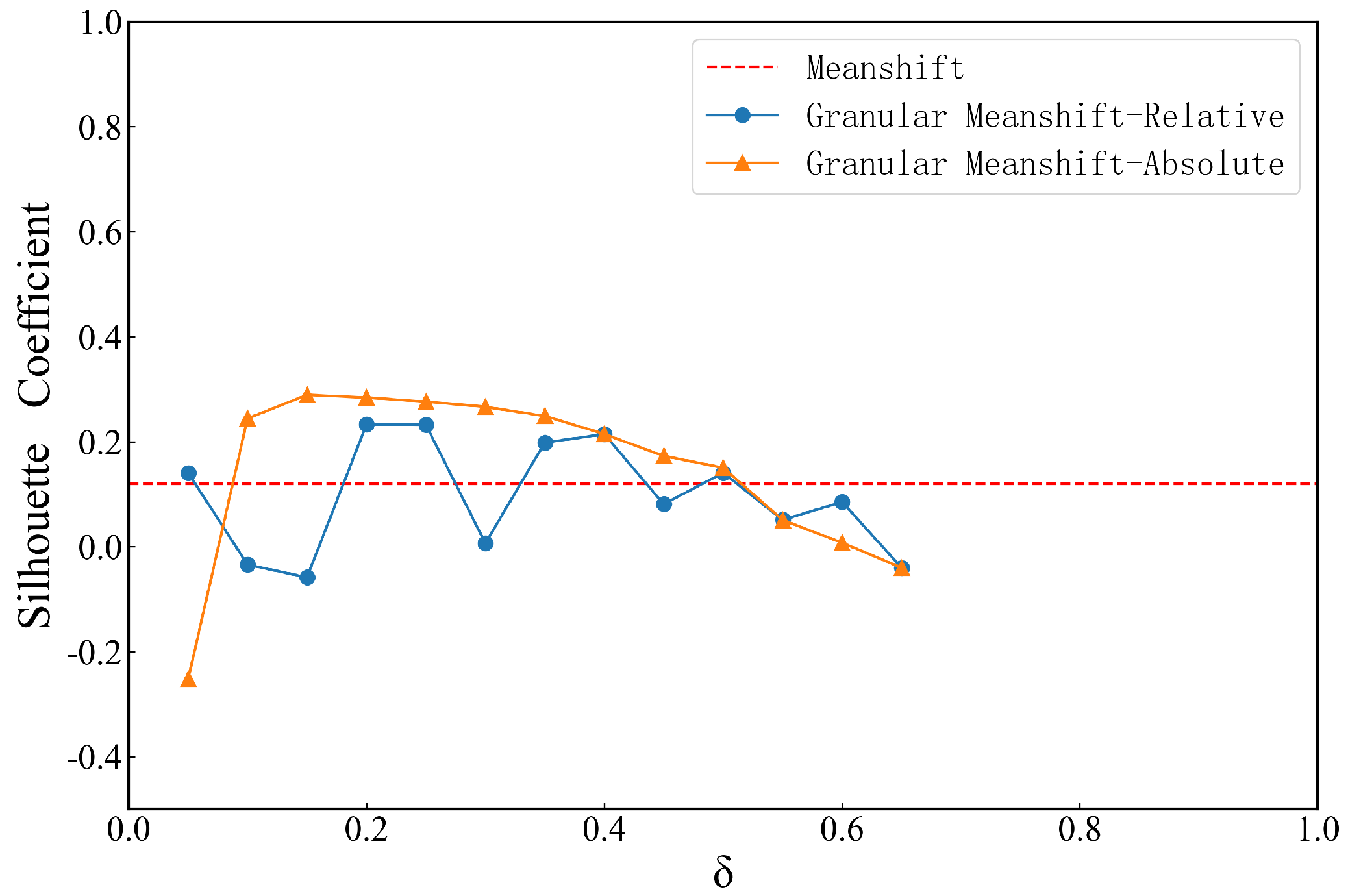
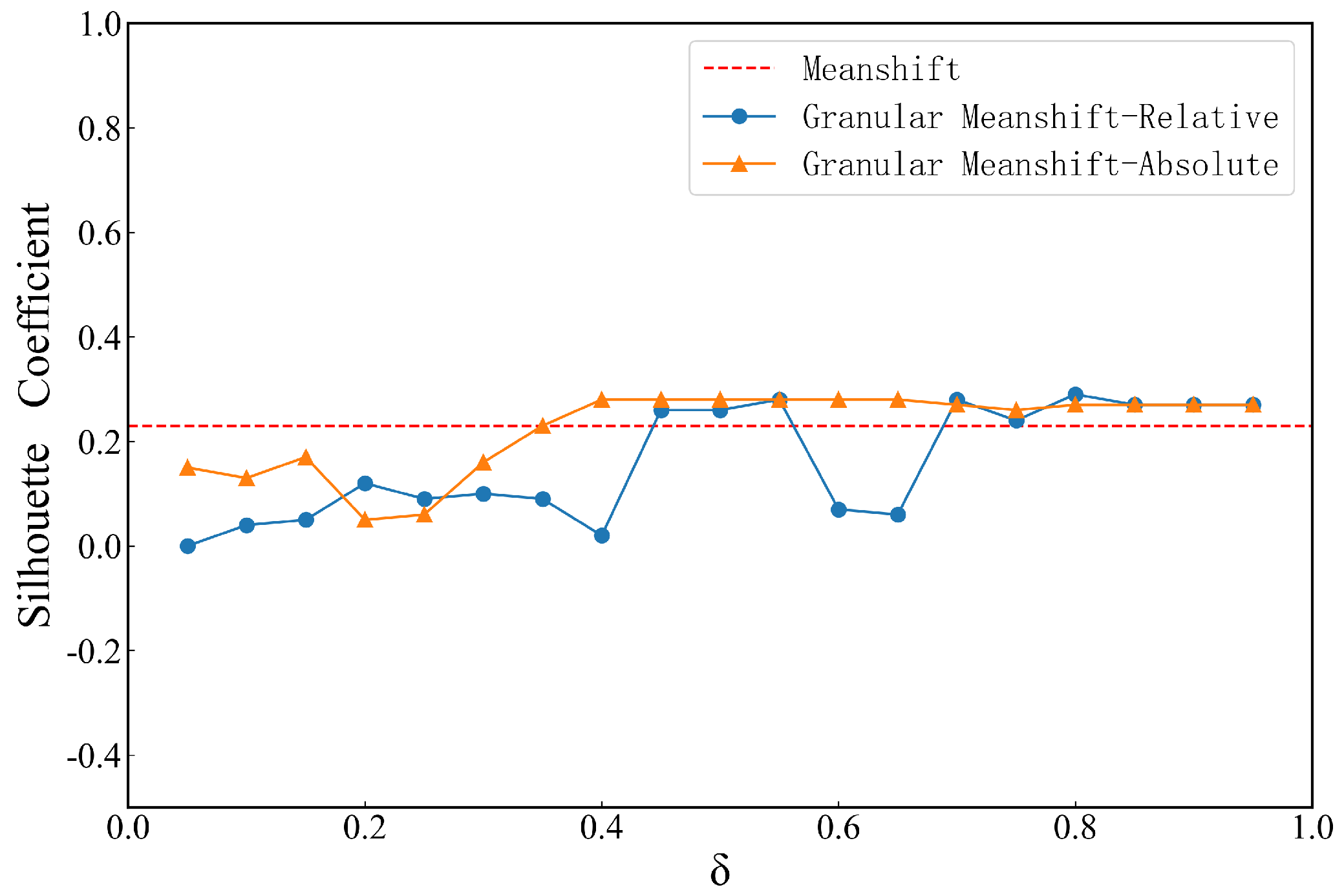
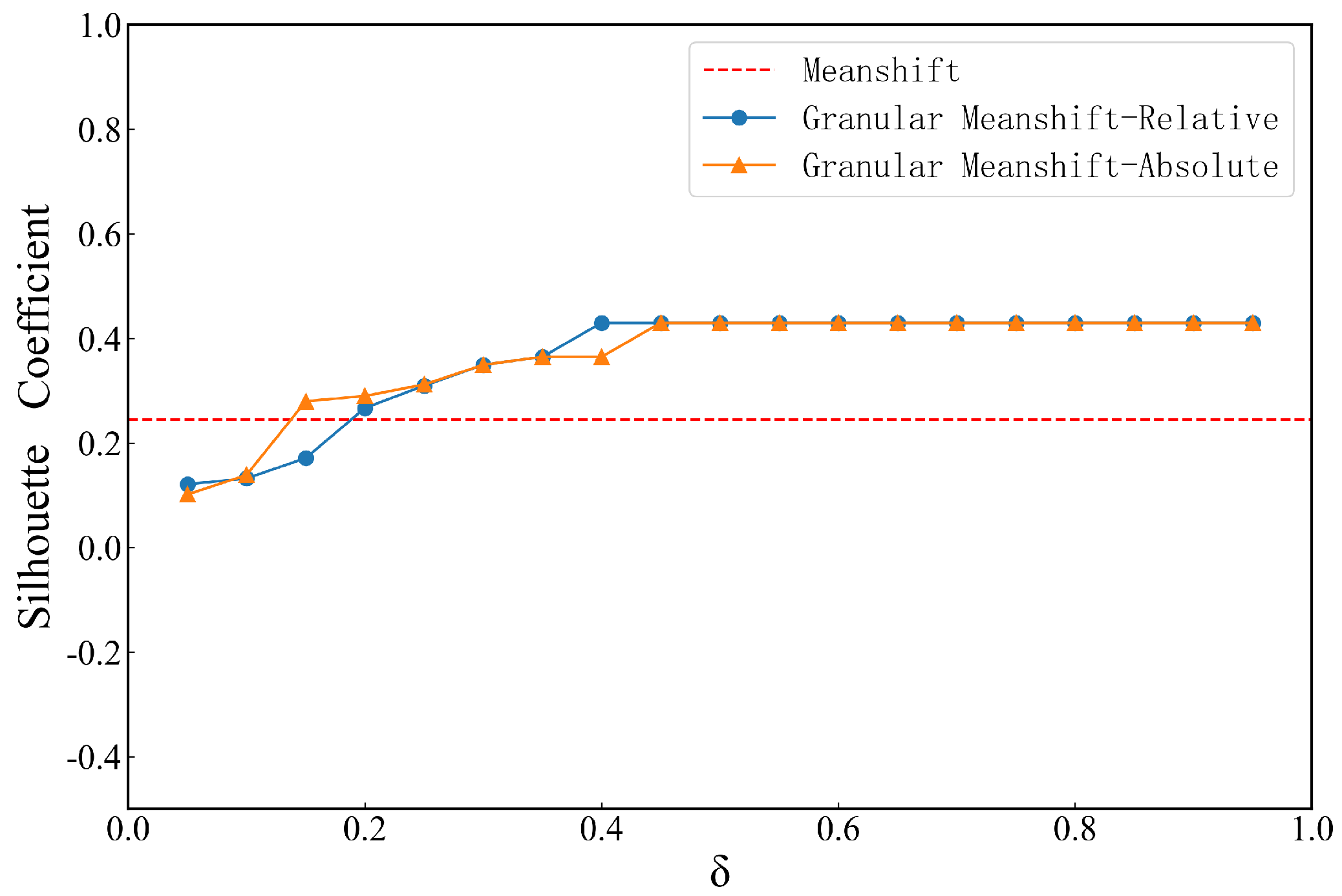
4.1. Effect of Neighborhood Granular Parameters
4.2. Comparison Experiment with Traditional Clustering Algorithms
4.3. Discussions
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Pawlak, Z. Rough sets. Int. J. Inf. Comput. Sci. 1982, 11, 341–356. [Google Scholar] [CrossRef]
- Yao, Y.Y. Relational interpretations of neighborhood operators and rough set approximation operators. Inform. Sci. 1998, 111, 239–259. [Google Scholar] [CrossRef]
- Lin, T.Y. Data Mining: Granular Computing Approach. Lect. Notes Comput. Sci. 1999, 1574, 24–33. [Google Scholar]
- Yager, R.R.; Filev, D. Operations for granular computing: Mixing words with numbers. In Proceedings of the 1998 IEEE International Conference on Fuzzy Systems, Anchorage, AK, USA, 4–9 May 1998; pp. 123–128. [Google Scholar]
- Lin, T.Y.; Zadeh, L.A. Special issue on granular computing and data mining. Int. Intell. Syst. 2004, 19, 565–566. [Google Scholar] [CrossRef]
- Lin, C.F.; Wang, S.D. Fuzzy support vector machines. IEEE Trans. Neural Netw. 2002, 3, 464–471. [Google Scholar]
- Wang, G.Y.; Zhang, Q.H.; Ma, X.; Yang, Q.S. Granular computing models for knowledge uncertainty. J. Softw. 2011, 22, 676–694. [Google Scholar] [CrossRef]
- Hu, Q.; Yu, D.; Liu, J.; Wu, C. Neighborhood rough set based heterogeneous feature subset selection. Inform. Sci. 2008, 178, 3577–3594. [Google Scholar] [CrossRef]
- Miao, D.Q.; Fan, S.D. The calculation of knowledge granulation and its application. Syst. Eng.-Theory Pract. 2002, 22, 48–56. [Google Scholar]
- Hu, Q.H.; Yu, D.R.; Xie, Z.X. Neighborhood classifiers. Expert Syst. Appl. 2008, 34, 866–876. [Google Scholar] [CrossRef]
- Qian, Y.H.; Liang, J.Y.; Dang, C.Y. Incomplete multigranulation rough set. IEEE Trans. Syst. Man Cybern-Part A 2010, 40, 420–431. [Google Scholar] [CrossRef]
- Miao, D.Q.; Xu, F.F.; Yao, Y.Y.; Wei, L. Set-theoretic formulation of granular computing. Chin. J. Comput. 2012, 35, 351–363. [Google Scholar] [CrossRef]
- Qian, J.; Miao, D.Q.; Zhang, Z.H.; Yue, X. Parallel attribute reduction algorithms using MapReduce. Inform. Sci. 2014, 279, 671–690. [Google Scholar] [CrossRef]
- Chen, Y.M.; Miao, D.Q.; Wang, R. A rough set approach to feature selection based on ant colony optimization. Pattern Recognit. Lett. 2010, 31, 226–233. [Google Scholar] [CrossRef]
- Chen, Y.M.; Zhu, Q.; Xu, H. Finding rough set reducts with fish swarm algorithm. Knowl. Based Syst. 2015, 81, 22–29. [Google Scholar] [CrossRef]
- Chen, Y.M.; Qin, N.; Li, W.; Xu, F. Granule structures, distances and measures in neighborhood systems. Knowl.-Based Syst. 2019, 165, 268–281. [Google Scholar] [CrossRef]
- Lei, T.; Jia, X.; Zhang, Y.; Liu, S.; Meng, H.; Nandi, A.K. Superpixel-Based Fast Fuzzy C-Means Clustering for Color Image Segmentation. IEEE Trans. Fuzzy Syst. 2019, 27, 1753–1766. [Google Scholar] [CrossRef]
- Zhou, J.; Pedrycz, W.; Wan, J.; Gao, C.; Lai, Z.-H.; Yue, X. Low-Rank Linear Embedding for Robust Clustering. IEEE Trans. Knowl. Data Eng. 2022. [Google Scholar] [CrossRef]
- Zhou, J.; Lai, Z.; Miao, D.; Gao, C.; Yue, X. Multigranulation rough-fuzzy clustering based on shadowed sets. Inf. Sci. 2020, 507, 553–573. [Google Scholar] [CrossRef]
- Fujita, H.; Gaeta, A.; Loia, V.; Orciuoli, F. Hypotheses analysis and assessment in counter-terrorism activities: A method based on OWA and fuzzy probabilistic rough sets. IEEE Trans. Fuzzy Syst. 2019, 28, 831–845. [Google Scholar] [CrossRef]
- Yue, X.D.; Zhou, J.; Yao, Y.Y.; Miao, D.Q. Shadowed neighborhoods based on fuzzy rough transformation for three-way classification. IEEE Trans. Fuzzy Syst. 2020, 28, 978–991. [Google Scholar] [CrossRef]
- Li, W.; Ma, X.; Chen, Y.; Dai, B.; Chen, R.; Tang, C.; Luo, Y.; Zhang, K. Random fuzzy granular decision tree. Math. Probl. Eng. 2021, 1–17. [Google Scholar] [CrossRef]
- Kaburlasos, V.G.; Lytridis, C.; Vrochidou, E.; Bazinas, C.; Papakostas, G.A.; Lekova, A.; Bouattane, O.; Youssfi, M.; Hashimoto, T. Granule-Based-Classifier (GbC): A Lattice Computing Scheme Applied on Tree Data Structures. Mathematics 2021, 9, 2889. [Google Scholar] [CrossRef]
- Chen, Y.M.; Zhu, S.Z.; Li, W.; Qin, N. Fuzzy granular convolutional classifiers. Fuzzy Sets Syst. 2021, 426, 145–162. [Google Scholar] [CrossRef]
- He, L.J.; Chen, Y.M.; Wu, K.S. Fuzzy granular deep convolutional network with residual structures. Knowl.-Based Syst. 2022, 258, 109941. [Google Scholar] [CrossRef]
- He, L.J.; Chen, Y.M.; Zhong, C.M.; Wu, K.S. Granular Elastic Network Regression with Stochastic Gradient Descent. Mathematics 2022, 10, 2628. [Google Scholar] [CrossRef]
- Perez, G.A.; Villarraso, J.C. Identification through DNA Methylation and Artificial Intelligence Techniques. Mathematics 2021, 9, 2482. [Google Scholar] [CrossRef]
- Fukunaga, K.; Hostetler, L. The estimation of the gradient of a density function, with applications in pattern recognition. IEEE Trans. Inform. Theory 1975, 21, 32–40. [Google Scholar] [CrossRef]
- Chen, Y.Z. Mean shift, mode seeking, and clustering. IEEE Trans. Pattern Anal. Mach. Intell. 1995, 8, 790–799. [Google Scholar]
- Comaniciu, D.; Meer, P. Mean shift: A robust approach toward feature space analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef]
- Wu, X.R.L.I.F.C.; Hu, Z.Y. Convergence of a mean shift algorithm. J. Softw. 2005, 16, 365–374. [Google Scholar]
- Lai, J.; Wang, C. Kernel and graph: Two approaches for nonlinear competitive learning clusterin. Front. Electr. Electron. Eng. 2012, 7, 134–146. [Google Scholar] [CrossRef]
- Chen, C.; Lin, K.Y.; Wang, C.D.; Liu, J.B.; Huang, D. CCMS: A nonlinear clustering method based on crowd movement and selection. Neurocomputing 2017, 269, 120–131. [Google Scholar] [CrossRef]
- Qin, Y.; Yu, Z.L.; Wang, C.D.; Gu, Z.; Li, Y. A novel clustering method based on hybrid k-nearest-neighbor graph. Pattern Recognit. 2018, 74, 1–14. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Samples | Features | Categories |
|---|---|---|---|
| CMC | 1473 | 9 | 3 |
| Iris | 150 | 4 | 3 |
| Heart Disease | 303 | 13 | 2 |
| Wine | 178 | 13 | 3 |
| Pim | 768 | 8 | 2 |
| Dataset | Granular Meanshift Relative | Granular Meanshift Absolute | Meanshift | Kmeans | Gaussian Mixture | Birch | Agglomerative Clustering |
|---|---|---|---|---|---|---|---|
| CMC | 0.576 | 0.455 | 0.4270 | 0.4372 | 0.4270 | 0.4276 | 0.4297 |
| Iris | 0.9667 | 0.96 | 0.7933 | 0.9666 | 0.9666 | 0.8666 | 0.8866 |
| Heart Disease | 0.782 | 0.739 | 0.547 | 0.719 | 0.719 | 0.544 | 0.679 |
| Pim | 0.74 | 0.75 | 0.645 | 0.625 | 0.675 | 0.645 | 0.64 |
| Wine | 0.97191 | 0.882 | 0.3988 | 0.9494 | 0.9606 | 0.6067 | 0.9775 |
| Dataset | Granular Meanshift Relative | Granular Meanshift Absolute | Meanshift | Kmeans | Gaussian Mixture | Birch | Agglomerative Clustering |
|---|---|---|---|---|---|---|---|
| CMC | 0.2889 | 0.2857 | 0.2316 | 0.2345 | 0.2959 | 0.2776 | 0.2963 |
| Iris | 0.5494 | 0.5578 | 0.4764 | 0.4507 | 0.4507 | 0.5061 | 0.5043 |
| Heart Disease | 0.278 | 0.278 | 0.2 | 0.251 | 0.251 | 0.215 | 0.213 |
| Pim | 0.4297 | 0.4297 | 0.2455 | 0.2268 | 0.1778 | 0.1765 | 0.1956 |
| Wine | 0.2891 | 0.2332 | 0.1194 | 0.3008 | 0.2993 | 0.281 | 0.2948 |
| Dataset | Granular Meanshift Relative | Granular Meanshift Absolute | Meanshift | Kmeans | Gaussian Mixture | Birch | Agglomerative Clustering |
|---|---|---|---|---|---|---|---|
| CMC | 0.5685 | 0.5685 | 0.5171 | 0.3635 | 0.4356 | 0.4780 | 0.4303 |
| Iris | 0.9364 | 0.9232 | 0.7476 | 0.9355 | 0.9355 | 0.7946 | 0.8158 |
| Heart Disease | 0.7069 | 0.7069 | 0.7069 | 0.6191 | 0.6191 | 0.6127 | 0.6065 |
| Pim | 0.7257 | 0.7257 | 0.6800 | 0.5202 | 0.6086 | 0.5602 | 0.5526 |
| Wine | 0.9448 | 0.7937 | 0.5605 | 0.9026 | 0.9215 | 0.6799 | 0.9542 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Q.; He, L.; Diao, Y.; Zhang, K.; Zhao, G.; Chen, Y. A Novel Neighborhood Granular Meanshift Clustering Algorithm. Mathematics 2023, 11, 207. https://doi.org/10.3390/math11010207
Chen Q, He L, Diao Y, Zhang K, Zhao G, Chen Y. A Novel Neighborhood Granular Meanshift Clustering Algorithm. Mathematics. 2023; 11(1):207. https://doi.org/10.3390/math11010207
Chicago/Turabian StyleChen, Qiangqiang, Linjie He, Yanan Diao, Kunbin Zhang, Guoru Zhao, and Yumin Chen. 2023. "A Novel Neighborhood Granular Meanshift Clustering Algorithm" Mathematics 11, no. 1: 207. https://doi.org/10.3390/math11010207
APA StyleChen, Q., He, L., Diao, Y., Zhang, K., Zhao, G., & Chen, Y. (2023). A Novel Neighborhood Granular Meanshift Clustering Algorithm. Mathematics, 11(1), 207. https://doi.org/10.3390/math11010207