Abstract
In this paper, an extension of the power half-normal (PHN) distribution is introduced. This new model is built on the application of slash methodology for positive random variables. The result is a distribution with greater kurtosis than the PHN; i.e., its right tail is heavier than the PHN distribution. Its probability density, survival and hazard rate function are studied, and moments, skewness and kurtosis coefficientes are obtained, along with relevant properties of interest in reliability. It is also proven that the new model can be expressed as the scale mixture of a PHN and a uniform distribution. Moreover, the new model holds the PHN distribution as a limit case when the new parameter tends to infinity. The parameters in the model are estimated by the method of moments and maximum likelihood. A simulation study is given to illustrate the good behavior of maximum likelihood estimators. Two real applications to survival and fatigue fracture data are included, in which our proposal outperforms other models.
Keywords:
half-normal distribution; power distribution; slash distribution; lifetime models; kurtosis; maximum likelihood MSC:
62E15; 62E20
1. Introduction
The half-normal (HN) distribution is suitable to fit positive data. For this reason, it is of interest in reliability and survival analysis as a lifetime model. The HN model also exhibits a large number of theoretical properties; for instance, it can be obtained as a particular case of the folded normal, the truncated normal, or the central chi distribution with one degree of freedom; details can be seen in Johnson et al. [1]. Recall that a random variable (rv) Z follows an HN distribution with scale parameter , if its probability density function (pdf) is given by
where and denotes the pdf of a distribution.
Properties of the HN distribution and first applications can be seen in the papers by Rogers and Tukey [2] and Mosteller and Tukey [3]. Pewsey [4,5] introduced the general location-scale HN distribution and studied asymptotic inference based on maximum likelihood (ML) estimators. Later, Wiper et al. [6] obtained Bayesian results in the general HN and half-t distributions. Cooray and Ananda [7] proposed the generalized half-normal (GHN) distribution as a lifetime model useful for items subjects to static fatigue. Ahmadi and Yousefzadeh [8] obtained results in the GHN for type I interval censoring data. Olmos et al. [9,10] used the slash methodology to extend the HN and GHN distributions. They proposed models with more kurtosis than their precedents.
On the other hand, Gómez and Bolfarine [11] introduced the two-parameter PHN distribution. This is a model useful to fit positive data with a shape parameter, which provides flexibility to the pdf, survival, and hazard rate function with respect to the HN distribution. They also showed that the PHN model is a competitor of the GHN model, and therefore, it can be used as a static fatigue lifetime model. Due to its good properties, the PHN will be the starting point to introduce our proposal. Our aim is to get the slashed version of the PHN model.
Next, we recall the main features of the PHN model (see [11]). It is said that an rv X follows a PHN distribution, , if its pdf is given by
where and are scale and shape parameters, respectively, and denotes the cumulative distribution function (cdf) of a .
Lemma 1
(Properties of PHN distribution, [11]). Let . Then
- 1.
- The cdf of X is
- 2.
- The rth-moment iswith
- 3.
- In particular
- (a)
- .
- (b)
- .
- (c)
- Skewness coefficient, defined as , is
- (d)
- Kurtosis coefficient, defined as , is
It can be seen in [11] that and are decreasing functions of . The aim of this paper is to propose an extension of the PHN model whose kurtosis coefficient exhibits a greater range of values than the kurtosis coefficient in the PHN model, and therefore, it may be used to accommodate outlying observations.
In this sense, it is well known that the slash models have heavier tails than other classical distributions, such as the normal one. Relevant papers, which illustrate the main properties of slash models, are Segovia et al. [12], Wang et al. [13] and Iriarte et al. [14].
The outline of this paper is as follows. In Section 2, the stochastic representation of the slash power half-normal (SPHN) model is given, its pdf, cdf, properties, relationships and approximations to other models, expression as a mixture, moments, asymmetry and kurtosis coefficients, and stochastic ordering properties are studied. In Section 3, given a random sample of the SPHN model, inference for the unknown parameters is carried out by using moment and maximum likelihood methods. In Section 4, a simulation study is carried out. An algorithm to generate random values in the SPHN model is proposed, and the consistency of ML estimators is analyzed there. In Section 5, two real applications dealing with survival and fatigue fracture data are given. In this section, our model is compared to other competing models, such as PHN, GHN, Slash Power Maxwell (see [12]), LogNormal and slash generalized half-normal (SGHN) (see [10]). It is proven that our proposal outperforms the competitors. Finally, a brief discussion, some conclusions and future tasks are given in Section 6.
2. The Slashed Power Half-Normal Distribution
In this section, the new model is introduced, and its theoretical properties are studied. First, the stochastic representation of the SPHN model is given; that is, a continuous, non-negative rv T follows a SPHN distribution, , if T is obtained as
where and are independent, , , and .
In (6), is a scale parameter, whereas and are shape parameters. It will be seen in Section 2.3 that q increases the range of possible values for the kurtosis coefficient in the SPHN model with respect to the PHN distribution. In the next proposition, the pdf of (6) is obtained.
Proposition 1.
Let . Then, the pdf of T is given by
where , , , and
Proof.
Making the change of variable , we have
Finally, by considering the change of variable , (7) is obtained. □
Figure 1 shows the pdf of the SPHN model for fixed values of , , and several values of parameter . This plot suggests that the right tail in this model becomes heavier as q becomes smaller.
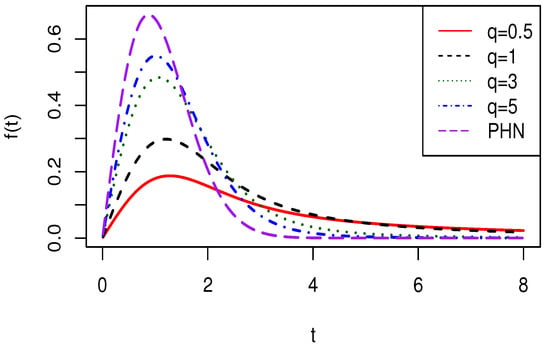
Figure 1.
Plots of the SPHN() model.
Moreover, Table 1 compares the right tail in the PHN and SPHN distributions for several values of q, . Note that for a fixed t value, the closer to zero q is, the greater is obtained. These appreciations agree with the fact that q is mainly related to the kurtosis in this new model, as it will be seen in Section 2.3.

Table 1.
Right tail comparison for different SPHN and PHN distributions.
Remark 1.
For completeness, plots of the pdf of the SPHN model for and (), and increasing values of q are given in Appendix A.1 and Appendix A.2, respectively. In this way, we have displayed all the possibilities as for the shape of SHPN pdfs.
2.1. Properties
Next the cdf, survival and hazard rate function are obtained. Relationships with these features in the PHN model are included.
Proposition 2.
Proof.
Corollary 1.
Let . Then, the survival function, , and the hazard function, , of T are given by
with , , , and given in (8).
From Corollary 1, the next relationship between the survival function of and the model follows.
Corollary 2.
Let . Then, the survival function, , can be expressed as
with the survival function of .
Plots of the cdf, survival and hazard function of are given in Figure 2 for and fixed and several values of q, ( corresponds to the ). On the other hand, plots for the cdf, survival and hazard rate function of SPHN model, taken , for (), and , by considering increasing values of q are given in Appendix A.1 and Appendix A.2, respectively.
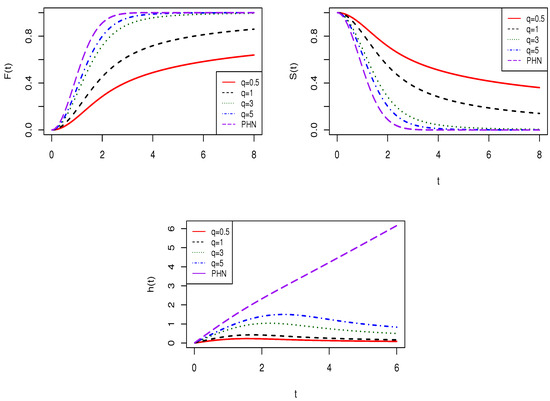
Figure 2.
Plots of the cdf, survival function and hazard function for the SPHN .
These plots suggest that:
- (1)
- For increasing values of q, the approaches the distribution (proven in Proposition 5).
- (2)
- For and fixed, these models are stochastically ordered with respect to q (proven in Section 2.4).
Proposition 3.
Let . Then
- 1.
- For , the mode of T is at zero.
- 2.
- For , the mode of T can be obtained as the solution for ofwhere , , , was introduced in (8), and denotes the pdf of a model.
Proof.
1. It follows from the fact that for , the pdf of T is a strictly decreasing function of t.
2. For , let us consider , i.e.,
Equivalently,
Thus,
which is equivalent to (10). □
Remark 2.
(10) must be solved numerically.
Next, it is proven that the SPHN model can be expressed as a scale mixture of distributions.
Proposition 4.
Let and . Then, .
Proof.
Note that the marginal pdf of T can be obtained as
Making the change of variable , the proposed result is obtained. □
By applying the method proposed in Barranco-Chamorro et al. [15], the convergence in law of the model, as , to a distribution is next established. To highlight the fact that we are taking the limit for , the subindex q is used to refer to .
Proposition 5.
Let . If , then converges in distribution to .
Proof.
It is given in Appendix B. □
Note that the result given in Proposition 5 states that for large values of q, the model can be approached by a distribution.
2.2. Relationships among Distributions
In the following, we will see special cases that are associated with the SPHN distribution.
- According to Proposition 5, if then , where . That is, the SPHN model contains the PHN model as a limit case.
- If , then with , where Y follows a slash half-normal (SHN) distribution introduced in Olmos et al. [9].
- If and , then , where M follows an distribution.
These relationships among distributions are summarized in Figure 3.
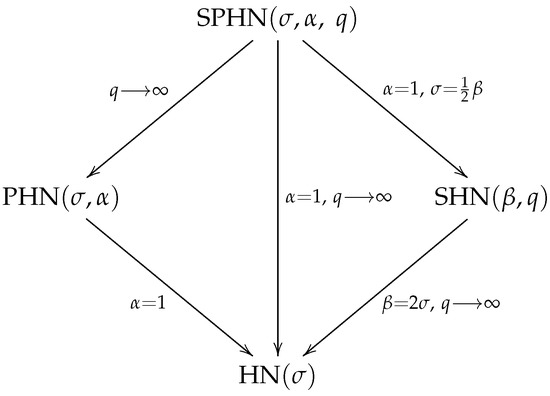
Figure 3.
Relationships among distributions in the SPHN family.
2.3. Moments
The next proposition gives us the expresion of noncentral moments in the SPHN distribution. The expected value, variance, skewness and kurtosis coefficients follow in a straightforward way.
Proposition 6.
Let . Then, for and , the rth-non-central moment of T exists and is given by
where
Proof.
By using the stochastic representation for the SPHN distribution given in (6), we have that
On the one hand, we have that exists for and On the other hand, is the rth-moment of a model given in (2).
So, (11) is obtained. □
Remark 3.
Note that from Proposition 6, given , for , is infinity.
Corollary 3.
Let and . Then
Corollary 4.
Let . Then
where
For illustrative purposes, the expected value, variance and mode for different values of parameters in the SHPN model are given in Table 2. We observe that the expected value, variance and mode decrease as q increases for the the values of the parameters under consideration.
Table 2.
Values of mean, variance and mode.
Corollary 5.
Let . Then, the skewness, , and kurtosis, , coefficients are, for ,
and for ,
where .
Remark 4.
The skewness and kurtosis coefficients were obtained by using
Figure 4 and Figure 5 provides plots for the skewness and kurtosis coefficients in the SPHN distribution. Both coefficients depend on and q parameters. and do not depend on , since is a scale parameter.
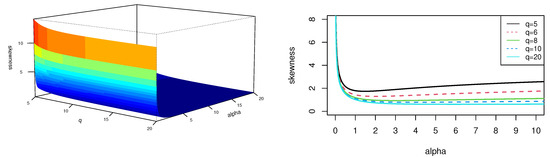
Figure 4.
Plots of the skewness coefficient in the SPHN model.
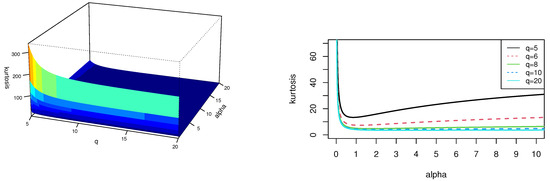
Figure 5.
Plots of the kurtosis coefficient in the SPHN model.
2.4. Stochastic Ordering
Proposition 7.
Let , , and with (σ, fixed). Then, X is stochastically smaller than , , and is stochastically smaller than , . So, as summary, we can write
Proof.
From Corollary 2, and the fact that , defined in (8), is a decreasing function of q, we can write the following relationship among the survival functions of X, and
It can be seen in [16] that this is the definition of stochastic order, and therefore, (15) follows. □
Corollary 6.
Let , , and with (σ, fixed). Then
In addition, some relationships can be given for the order statistics of these distributions.
Proposition 8.
Let be a random sample of , and let us denote by the j- order statistic in this sample, . Similarly, let us consider a random sample of , with , and denotes the j- order statistic for the sample of . Then, the j- order statistics are also stochastically ordered, explicitly,
Proof.
It can be seen in [16] that this result is a consequence of (15). □
3. Inference
In this section, the estimation of parameters is carried out by applying moment and maximum likelihood (ML) methods. A simulation study is carried out in Section 4 to asses the performance of ML estimates when the sample size increases.
3.1. Moment Estimators
Let be a random sample of . From and (11), we can write
By using (11) again, and replacing the second and third population moments by the corresponding second and third sampling moments, the following equations are obtained
3.2. ML Estimators
In this subsection, the ML equations are introduced for the parameters on the SPHN model. Let be a random sample from . Then, the log-likelihood function can be expressed as
where and .
The ML estimates are obtained by maximizing the equation given in (21). Taking the first derivative of the log-likelihood function with respect to each parameter, the following estimating equations are obtained, where we denote by
where , and .
Equations (22)–(24) must be solved by using numerical procedures, such as the optim function in R software. Other maximization techniques could be applied, which directly maximize the log-likelihood function: for instance, the method proposed in McDonald [18].
Under regularity conditions, the asymptotic distribution of the MLEs is a trivariate normal with mean vector and variance–covariance matrix that is the inverse of the Fisher information matrix, . Usually, is estimated by the observed information matrix given by
whose elements are
with and .
From the asymptotic normality of MLEs, approximate confidence intervals can be proposed for . So, an Asymptotic Confidence Interval (ACI) at confidence level , , for , , q is
the standard error of , , is the squared root of the diagonal element of , and denotes the quantile of order in the distribution.
4. Simulation Study
In this section, a simulation study is conducted aiming to investigate ML estimation performance for parameters , and q in the SPHN model. Specifically, 1000 random samples of sizes 50, 100 and 200 were generated under the SPHN model by using the algorithm given below. A summary of the results obtained in this study are depicted in Table 3. The empirical means correspond to the means of the estimated parameters over the 1000 simulated samples. The SE given in Table 3 is the average of the standard errors obtained in every simulation, , which were calculated as the square root of the corresponding diagonal element in the inverse of the observed information matrix. Moreover, Asymptotic Confidence Intervals (ACIs) at confidence level , , have been built based on the asymptotic normality of MLEs. Specifically,
Table 3.
Empirical means and SE for the ML estimates of , and q.
The level confidence is . To asses the performance of these summaries, the empirical covarage probability (CP) of (25) has been included in Table 3. That is the proportion of ACIs that contain the true value of the parameter.
In Table 3, RMSE denotes the square root of the empirical mean squared error: for instance, for , it is calculated as
and so on.
Next, the algorithm used to generate samples from is introduced. The Algorithm 1 is based on (6) and the inversion of the cdf given in (1).
| Algorithm 1: for generate samples from . |
|
As conclusions of this simulation study, we highlight that as the sample size increases, estimates become closer to the true parameter values. These results suggest that the estimated standard errors and RMSE become smaller as sample size increases: that is, the proposed estimators are consistent. As for the ACI, the results are satisfactory. We highlight that their empirical CP approaches to the nominal 0.95 confidence level as n increases.
Following reviewers’ recommendations, similar plots to the ones proposed in [19] have been carried out to illustrate the results in Table 3. So, the empirical coverage probabilities obtained for the asymptotic confidence intervals at 95% for , and q for the sample sizes have been plotted in Figure 6. The columns correspond to the cases , and in Table 3 and the panels by rows to . It can be appreciated there that, in all cases, the empirical coverage probability approaches the confidence level 0.95 as the sample size increases. This plot also suggests that the approximate confidence intervals for q and perform better than those for .
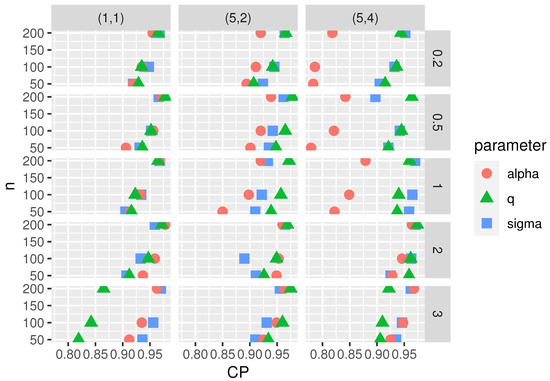
Figure 6.
Empirical CP for the ACI () in the SPHN model , , with . In all panels, results for (red point), q (green triangle), and (blue square).
5. Applications
In this section, two real data sets with high kurtosis levels are considered. In these data sets, the PHN, GHN, Slash Power Maxwell (SPM) introduced in Segovia et al. [12], SGHN introduced in Olmos et al. [10] and SPHN distributions are considered. Details about these models can be seen in Appendix C.
The parameters are estimated by ML. The Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC), histograms and Q-Q plots are considered to compare these models.
5.1. Application 1
Let us consider the data set of kevlar 49/epoxy, which corresponds to fatigue fracture to constant pressure at the 90% stress level until the fail happened. This data set has been previously analyzed by Andrews and Herzberg [20], Barlow et al. [21] and Olmos et al. [9,10] among others. The data set consists of 101 observations with the presence of outliers. Explicitly, in Table 4:
Table 4.
Data set of kevlar 49/epoxy.
In Table 5, the descriptive analysis is provided. We can see that this data set exhibits a high sample kurtosis coefficient of , so it is interesting to see what can our model do here.
Table 5.
Descriptive analysis for fatigue fracture data.
For the SPHN model, the moment estimates are , and . These estimates are used as starting values to get the ML estimates by using numerical methods.
Table 6 shows the estimated parameters for each model under consideration. If we apply the AIC and BIC criteria, then the SPHN distribution must be preferred over the GHN, PHN, SPM and SGHN distributions, since its AIC and BIC are the smallest ones.
Table 6.
Estimated values, standard errors (SE) in parentheses and criteria.
Figure 7 shows the histograms for the fatigue fracture data set, along with the fitted distributions by using ML estimates in SPHN, GHN and SGHN models. The QQ-plot is also included to asses the good fit provided by the SPHN model to this data set.
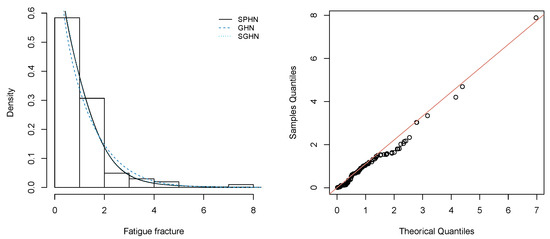
Figure 7.
Left panel: Histograms of the fatigue fracture data fitted with the GHN, SGHN and SPHN distributions. Right panel: QQ plot for the SPHN distribution.
5.2. Application 2
Here, the data set previously analyzed by Gómez and Bolfarine [11] is considered. This data set corresponds to 72 survival times of guinea pigs injected with different doses of tubercle bacilli, which are in Table 7.
Table 7.
Data set of survival times of guinea pigs.
The moment estimates for the parameters in the SPHN model are: , and . Again, these estimates are used as initial values to get the ML estimates by using numerical methods.
In Table 8, the descriptive analysis is given. We have that the sample kurtosis coefficient is , so it is also interesting to see if the SPHN distribution can provide a good fit to this data set.
Table 8.
Descriptive analysis for the survival times of guinea pigs.
Table 9 shows the estimated parameters for each distribution. If we apply the statistical information criteria then, in all cases, both criteria choose the SPHN model over the GHN, PHN, SPM and SGHN distributions.
Table 9.
Estimated values, SE and information criteria.
Figure 8 shows the histograms for the guinea pigs survival time data along with the fitted distributions: SPHN, LogNormal, and SGHN, whose parameters were estimated by ML. The QQ-plot is also included for the proposed SPHN model, which provides the best fit to this data set.
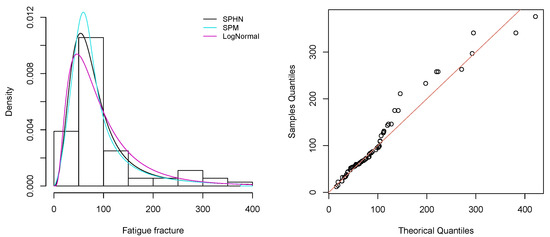
Figure 8.
Left panel: Histograms of the survival times of guinea pigs data fitted by the LogNormal, SGHN and SPHN distributions. Right panel: QQ-plot of the SPHN distribution.
6. Conclusions
This paper introduces the SPHN distribution, which is built from the PHN distribution by using the slash methodology proposed in (6). In this way, a model with higher kurtosis than the PHN is obtained. The SPHN is a three-parameter model whose right tail is heavier for smaller values of the kurtosis parameter q. Relevant results of interest in reliability are discussed, such as cdf, survival, hazard rate function and stochastic orderings. The convergence in distribution to the PHN model is studied when the parameter of kurtosis q increases, along with the relationships with the PHN, SHN and HN models. All these relationships are summarized in Figure 3 and enhance the interest of our model. It is shown that the SPHN can be expressed of a scale mixture of a PHN and a uniform distribution. This property allows us to propose an algorithm to generate random values of the SPHN model. The unknown parameters in the model are estimated via ML. A simulation study is given where the good properties of ML estimators can be seen. As applications, two real data sets are considered with moderate and high kurtosis. These are Applications 2 and 1, respectively. Several common models are considered as competitors of SPHN. By applying information criteria (AIC and BIC), it is shown that our proposal provides the best fit to these data sets. Due to this fact, it is of interest to spread out the use and applications of this model.
Author Contributions
Conceptualization, L.B. and Y.M.G.; methodology, Y.M.G. and H.W.G.; software, L.B.; validation, H.W.G., I.B.-C. and O.V.; formal analysis, L.B., I.B.-C. and Y.M.G.; investigation, L.B., Y.M.G., H.W.G. and O.V.; resources, O.V. and H.W.G.; writing—original draft preparation, L.B., Y.M.G. and I.B.-C.; writing—review and editing, O.V. and I.B.-C.; supervision, Y.M.G. All authors have read and agreed to the published version of the manuscript.
Funding
The research of Leonardo Barrios was supported by Proyecto ATA1899 of the Universidad de Atacama, the research of Yolanda M. Gómez was supported by proyecto DIUDA programa de inserción # 22367 of the Universidad de Atacama and the research of Héctor W. Gómez was funded by SEMILLERO UA-2022.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data sets used in the applications are explicitly presented in the text of the manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
In this appendix, plots for the pdf, cdf, survival and hazard rate function are given to illustrate the behavior of these functions in the cases.
Appendix A.1. SPHN for 0 < α < 1
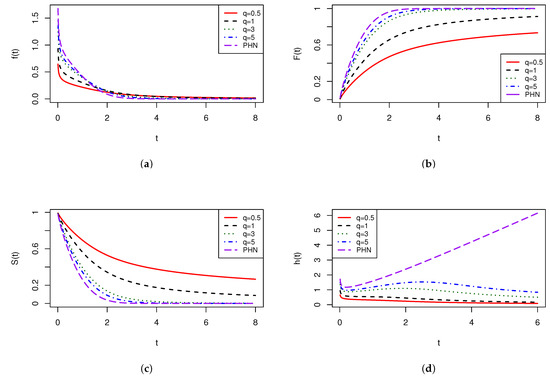
Figure A1.
SPHN for different values of q. In all panels, (red), (black), (green), (blue), and (purple). (a) pdf of SPHN . (b) cdf of SPHN . (c) Survival function of SPHN . (d) hazard rate function of SPHN .
Appendix A.2. SPHN for α = 1, Which Corresponds to the SHN Model
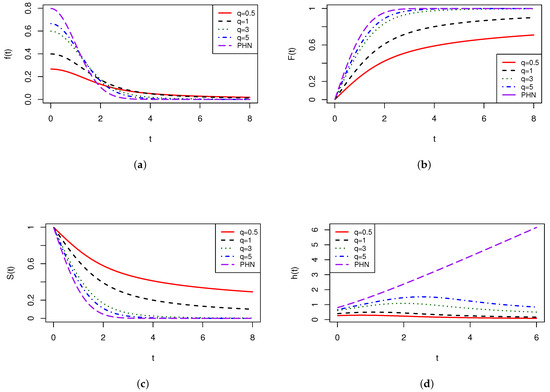
Figure A2.
SPHN for different values of q. In all panels, (red), (black), (green), (blue), and (purple). (a) pdf of SPHN . (b) cdf of SPHN . (c) Survival function of SPHN . (d) hazard rate function of SPHN .
Appendix B
In this appendix, the proof of Proposition 5 is given.
Proof of Proposition 5.
From (6), we can write , with , , and .
Recall that if , then , and therefore
By using Chebyshev’s inequality, we have that
and since the right-hand side of (A1) tends to zero as
where denotes convergence in probability [22]. On the other hand, for , we have that
Therefore,
By applying Slutsky’s theorem (Corollary 2.3.2 in [23]) to , it follows that
i.e., converges in distribution to distribution as . □
Appendix C
In this appendix, details are given about the models under consideration in Section 5. These models are:
- Log-Normal, , whose pdf is
- Generalized Half Normal, . Cooray and Ananda (2008) [7]) proposed this model as an alternative to gamma, Weibull, log-normal and Birnbaum–Saunders distribution for modeling lifetime data. The pdf isis a scale parameter and is a shape parameter.
- introduced in Section 1.
- Slash Power Maxwell, , by Segovia et al. (2020) [12], whose pdf iswhere denotes the gamma function and is the cdf of a gamma distribution.
- Slash Generalized Half Normal, , proposed by Olmos et al. (2014) [10], whose pdf iswhere , , , and denotes the cdf of a gamma distribution.
References
- Johnson, N.L.; Kotz, S.; Balakrishnan, N. Continuous Univariate Distributions, 2nd ed.; Wiley: New York, NY, USA, 1994; Volume 1. [Google Scholar]
- Rogers, W.H.; Tukey, J.W. Understanding some long-tailed symmetrical distributions. Stat. Neerl. 1972, 26, 211–226. [Google Scholar] [CrossRef]
- Mosteller, F.; Tukey, J.W. Data Analysis and Regression; A Second Course in Statistics; Addison-Wesley: Reading, MA, USA, 1977. [Google Scholar]
- Pewsey, A. Large-sample inference for the general half-normal distribution. Commun. Stat. Theory Methods 2002, 31, 1045–1054. [Google Scholar] [CrossRef]
- Pewsey, A. Improved likelihood based inference for the general half-normal distribution. Commun. Stat. Theory Methods 2004, 33, 197–204. [Google Scholar] [CrossRef]
- Wiper, M.P.; Girón, F.J.; Pewsey, A. Objective Bayesian inference for the half-normal and half-t distributions. Commun. Stat. Theory Methods 2008, 37, 3165–3185. [Google Scholar] [CrossRef]
- Cooray, K.; Ananda, M.M.A. A Generalization of the Half-Normal Distribution with Applications to Lifetime Data. Commun. Stat. Theory Methods 2008, 37, 1323–1337. [Google Scholar] [CrossRef]
- Ahmadi, K.; Yousefzadeh, F. Estimation for the parameters of generalized half-normal distribution based on progressive type-I interval censoring. Commun. Stat. Simul. Comput. 2015, 44, 2671–2695. [Google Scholar] [CrossRef]
- Olmos, N.M.; Varela, H.; Gómez, H.W.; Bolfarine, H. An extension of the half-normal distribution. Stat. Pap. 2012, 53, 875–886. [Google Scholar] [CrossRef]
- Olmos, N.M.; Varela, H.; Bolfarine, H.; Gómez, H.W. An extension of the generalized half-normal distribution. Stat. Pap. 2014, 55, 967–981. [Google Scholar] [CrossRef]
- Gómez, Y.M.; Bolfarine, H. Likelihood-based inference for the power half-normal distribution. J. Stat. Theory Appl. 2015, 14, 383–398. [Google Scholar] [CrossRef] [Green Version]
- Segovia, F.A.; Gómez, Y.M.; Venegas, O.; Gómez, H.W. A power Maxwell distribution with heavy tails and applications. Mathematics 2020, 8, 1116. [Google Scholar] [CrossRef]
- Wang, J.; Genton, M. The multivariate skew-slash distribution. J. Stat. Plan. Inference 2006, 136, 209–220. [Google Scholar] [CrossRef]
- Iriarte, Y.A.; Gómez, H.W.; Varela, H.; Bolfarine, H. Slashed Rayleigh distribution. Rev. Colomb. Estadístic. 2015, 38, 31–44. [Google Scholar] [CrossRef]
- Barranco-Chamorro, I.; Iriarte, Y.A.; Gómez, Y.M.; Astorga, J.M.; Gómez, H.W. A Generalized Rayleigh Family of Distributions based on the Modified Slash Model. Symmetry 2021, 13, 1226. [Google Scholar] [CrossRef]
- David, H.A.; Nagaraja, H.N. Order Statistics, 3rd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2003. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing. Available online: http://www.R-project.org (accessed on 10 January 2022).
- MacDonald, I.L. Does Newton-Raphson really fail? Stat. Methods Med. Res. 2014, 23, 308–311. [Google Scholar] [CrossRef] [PubMed]
- Nassar, M.; Alam, F.M.A. Analysis of Modified Kies Exponential Distribution with Constant Stress Partially Accelerated Life Tests under Type-II Censoring. Mathematics 2022, 10, 819. [Google Scholar] [CrossRef]
- Andrews, D.F.; Herzberg, A.M. Data: A Collection of Problems from Many Fields for the Student and Research Worker; Springer: New York, NY, USA, 1985. [Google Scholar]
- Barlow, R.E.; Toland, R.H.; Freeman, T. A Bayesian Analysis of Stress-Rupture Life of Kevlar 49/epoxy Spherical Pressure Vessels. In Proceedings of the 5th Canadian Conference in Applied Statistics, Montreal, QC, Canada, 1–4 July 2011; Marcel Dekker: New York, NY, USA, 1984. [Google Scholar]
- Rohatgi, V.K.; Saleh, A.K.M.E. An Introduction to Probability Theory and Mathematical Statistics, 3rd ed.; John Wiley: New York, NY, USA, 2001. [Google Scholar]
- Lehmann, E. Elements of Large-Sample Theory; Springer: New York, NY, USA, 1999. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).