1. Introduction
In equity markets, mean reversion assumes that stocks that recently produced higher-than-average returns will tend to generate lower-than-average returns, and vice versa. The overreaction hypothesis states that the mean reversion occurs when stock prices overreact to information [
1]. In recent decades, there have been controversial findings on the existence of the mean reversion. Fama and French [
2] found the evidence of negative autocorrelations in stock returns, Balvers et al. [
3] provided the empirical support for the mean reversion across national stock markets, and Gropp [
4] showed that it is possible to earn excess returns by exploiting the mean reversion property. However, Kim et al. [
5] reported that evidence of mean reversion in U.S. stock returns was weak, and Booth et al. [
6] suggested that mean reversion assumption is not needed because the small-firm effect alone can explain the anomaly.
In contrast to mean reversion, the momentum effect documented in Jegadeesh and Titman [
7] states that stocks that have performed well in the past tend to generate better returns at 3 to 12-month horizons than stocks that have performed poorly in the past. Jegadeesh and Titman [
8] demonstrated the existence of the momentum effect on the U.S. stock markets from 1965 to 1998, and Fama and French [
9] found strong momentum returns in international stock markets. The momentum effect is attributable to investors’ delayed overreactions [
8] or underreactions to new information [
10].
Online portfolio selection (OLPS) is a procedure of selling stocks with low expected returns and purchasing stocks with high expected returns. OLPS aims to maximize cumulative return by periodically adjusting the weights of stocks in an portfolio using the historical prices of the stocks. There are two representative types of OLPS strategies. The follow-the-leader methods [
11,
12,
13] pursue the best strategy so far, whereas the follow-the-loser methods [
14,
15,
16,
17] exploit the mean reversion property. Refer to [
18] for a comprehensive survey of he OLPS.
There are three types of mean reversion strategy that outperform other OLPS strategies on traditional benchmark datasets: a passive aggressive mean reversion (PAMR) strategy [
15], an online moving average reversion (OLMAR) strategy [
16], and a transaction cost optimization (TCO) strategy [
17]. The PAMR uses the daily prices of a stock to determine if the stock is mean-revertible, whereas OLMAR utilizes the moving average of daily prices. The TCO can use either the daily prices or the moving average of daily prices to exploit the mean reversion property.
Investors pay transaction costs when they trade securities. Explicit transaction costs include taxes and commissions, and implicit transaction costs include price-impact costs and bid–ask spreads. Based on institutional trading data, Keim and Madhavan [
19] found that explicit and implicit transaction costs were at least 0.13% and 0.11%, respectively. They also reported that the total transaction costs incurred by the transaction initiators were at least 0.26% on the New York Stock Exchange (NYSE) and NYSE American. As transaction costs depend on the trading volume, it is desirable to avoid unnecessary transactions.
The genetic algorithm (GA) is a metaheuristic inspired by biological evolution. To simulate natural selection, the GA evolves a population of candidate solutions through selection, crossover, mutation, and replacement operations. The behavior of GA is determined by the exploration and exploitation relationship [
20]. Here, exploration is the process of visiting entirely new regions of a search space, and exploitation is the process of visiting the neighborhood of previously visited regions [
21]. The GA has many successful real-world applications, including bioinformatics [
22,
23], operational research [
24,
25], medical image processing [
26,
27], and financial engineering [
28,
29,
30].
The GA has been used extensively to solve the Markowitz mean-variance portfolio optimization problem [
31], which maximizes expected return while minimizing risk. For example, Chang et al. [
32] used GA to find the cardinality constrained efficient frontier, Skolpadungket et al. [
33] compared various multi-objective GAs for solving portfolio optimization with multiple constraints, Chen et al. [
34] proposed a non-dominated sorting and local search based multi-objective evolutionary framework to solve cardinality constrained portfolio optimization, and Kalayci et al. [
35] used a hybrid metaheuristic that embeds GAs to find the cardinality-constrained efficient frontier.
A GA hybridized with a local search heuristic is called a hybrid GA (HGA). Using an HGA, we propose a mean reversion strategy for an OLPS. The HGA uses historical price information to evolve a population of portfolio vectors representing proportions of portfolio assets, and our strategy selects the most prominent mean-revertible vector on every trading day. We tested our strategy using 10 datasets from S&P 500, and compared the results with those obtained using state-of-the-art mean reversion strategies from other researches [
15,
16,
17]. We believe that this is the first application of GA to OLPS.
The rest of this paper is organized as follows: In
Section 2, we present some preliminaries on OLPS. In
Section 3, we provide the details of the genetic mean reversion strategy. In
Section 4, we present the experimental setup and results. Finally, in
Section 5, we draw some concluding remarks and discuss future research directions.
2. Preliminaries
Let m be the number of securities in a portfolio, and n be the number of total trading days. On the day, the closing prices of the securities are represented by , where is the closing price of the security. The daily returns of the securities are represented by a price relative vector, , where . Before the start of the trading day, we decide a portfolio vector, , where denotes the weight of the security and . After the trading day, the daily return is calculated as , and the cumulative return for the n trading days is calculated as .
The objective of OLPS is to maximize the cumulative return for investors. We assume that all securities can be divided into fractional shares that can be traded at their closing prices on every trading day. These notation and assumptions are common in OLPS studies [
11,
13,
15,
16,
17,
36].
A buy-and-hold strategy (
) is a passive strategy in which an investor buys stocks according to the portfolio vector
on the first day and holds them for the entire period. The uniform BAH is denoted by
, where
. A constant rebalanced portfolio (
) is a strategy that reallocates the wealth of the investor according to the portfolio vector
on every trading day. In hindsight, the best portfolio vector
for CRP can be determined as follows:
Universal portfolios (UPs) [
11] asymptotically achieve the performance of
by dividing its initial wealth among all possible CRPs. Good approximation algorithms can efficiently implement a UP [
37,
38]. In this study,
and a UP were used as benchmark measures of performance.
Passive aggressive mean reversion (PAMR) [
15] exploits the single-period mean reversion because it generates the next portfolio vector using
, the daily returns of stocks in the portfolio. The PAMR utilizes the passive aggressive online learning algorithm [
39] to generate the next portfolio vector that is mean-revertible and close to the current portfolio vector; that is,
To benefit from the single-period reversion (
), this strategy seeks a portfolio vector whose latest return is confined to
. We set
to 0.5 as in Li et al. [
15].
Another state-of-the-art mean reversion strategy is online moving average reversion (OLMAR) [
16], which is a multi-period mean reversion strategy. Unlike PAMR, the OLMAR uses a simple moving average (SMA) to generate the next portfolio vector. The SMA is the arithmetic average of the closing prices. Here,
denotes the SMA on the
day; that is,
where
is the window length. The OLMAR produces the next portfolio vector that is mean-revertible and close to the current portfolio vector; that is,
where
is the reversion threshold, and
is the predicted relative price; that is,
where ⊘ represents the Hadamard (element-wise) division. As in Li et al. [
16], we set
to 10 and
w to 5.
The other state-of-the-art mean reversion strategy is the transaction cost optimization (TCO) [
17], which aims to perform well even in the presence of non-zero transaction costs. The TCO does not allow trivial trades to reduce transaction costs. Let
be the closing price adjusted portfolio vector on the the
day, and
be the proportions to be reallocated after the
day. The TCO then uses the predicted relative price to calculate
; that is,
where
, ⊙ denotes the Hadamard (element-wise) product, and
is a smoothing parameter. The positive elements of
have above-average expected returns, and thus their weights will be increased on the
day day, and vice versa; that is,
for all
, where
is a trade-off parameter. Only changes larger than
are used to determine the next portfolio vector. We set
to 10 and
to
, where
is the transaction cost rate. (Li et al. [
17] stated that they set
to
. However, their implementation set
to
, which produces better results than
and coincides with the results of their study.) As the elements of
may not summed to 1,
needs to be normalized; that is,
The TCO calculates the predictive relative prices using either the single-period or the multi-period mean reversion property. The TCO-1 uses the daily returns, whereas TCO-2 utilizes the moving average of closing prices; that is,
3. Methods
We used a steady-state hybrid genetic algorithm (HGA), whose pseudocode is given in Algorithm 1. Each individual is represented by a real-valued chromosome, which is a portfolio vector
. The chromosome is a point in the
m-dimensional simplex
, specifying the proportions of a portfolio with
m assets. We set the population size to 100 and generated the initial population by sampling 100 chromosomes uniformly from
. The population of candidate portfolio vectors evolved through a hybrid genetic framework.
| Algorithm 1 The outline of our HGA. |
- 1:
Create an initial population P - 2:
for to n do ▷n is the last trading day - 3:
FitnessUpdate(P, , ) - 4:
)) - 5:
- 6:
Mutation() - 7:
LocalSearch() - 8:
Replace(P, )
|
3.1. Fitness Update
Financial returns are assumed to be log-normal [
40], and the objective of the portfolio optimization is often set to maximize the expected log return [
18,
41]. Therefore, we used the expected relative log return as the fitness of a chromosome. The benchmark of the relative log return is a uniform portfolio vector
, which has the average return of all assets in the portfolio.
The uniform portfolio vector also provides a baseline indicating whether each chromosome is mean-revertible on the day. Let be a chromosome and be the relative price vector on the day. If the return of is less than that of , i.e., , is mean-revertible on the day because its recent performance is below the benchmark; otherwise, it is trend following on the day.
To effectively exploit the mean reversion property, we maintain two versions of fitness for a chromosome: the mean-revertible fitness and trend-following fitness. Each fitness is the expected relative log return parameterized by the mean and standard deviation, which are initialized to 0. The mean-revertible fitness is used to select a promising individual for a crossover, and the trend-following fitness is used to find an undesirable individual that needs to be replaced.
When
is revealed,
incrementally updates the parameters of the fitness, mean-revertible chromosomes update their own mean-revertible fitness, and trend-following chromosomes update their own trend-following fitness. The pseudocode of the fitness-updating procedure is given in Algorithm 2. Here,
and
are the mean and standard deviation of the mean-revertible chromosome
, and
and
are those of the trend-following chromosome
.
| Algorithm 2 FitnessUpdate . |
- 1:
for eachdo - 2:
rtn ▷ relative log return - 3:
if then ▷ for mean-revertible chromosomes - 4:
Update incrementally using rtn - 5:
else ▷ for trend-following chromosomes - 6:
Update incrementally using rtn
|
3.2. Selection
For the genetic algorithm, the selection is the source of exploitation [
42], which is the ability of the algorithm to move toward the direction of desired improvement [
43]. After each
trading day, we select two prominent mean-revertible chromosomes as parents for later breeding. Only chromosomes that produced below-average returns on the
tth day were considered. The fitness of the chromosome is its expected relative log return when it is mean-revertible. To obtain the mean-revertible fitness of a chromosome
, we sample a relative log return from
, using the Box-Muller transform [
44]. The pseudocode of the selection function is given in Algorithm 3.
| Algorithm 3 Select ). |
- 1:
▷ stores the best fitness - 2:
for each do - 3:
if then ▷ test whether is mean-revertible - 4:
Sample - 5:
if then - 6:
▷ stores the fittest chromosome - 7:
ifthen - 8:
Randomly sample ▷ all chromosomes are trend following - 9:
return
|
3.3. Crossover and Mutation
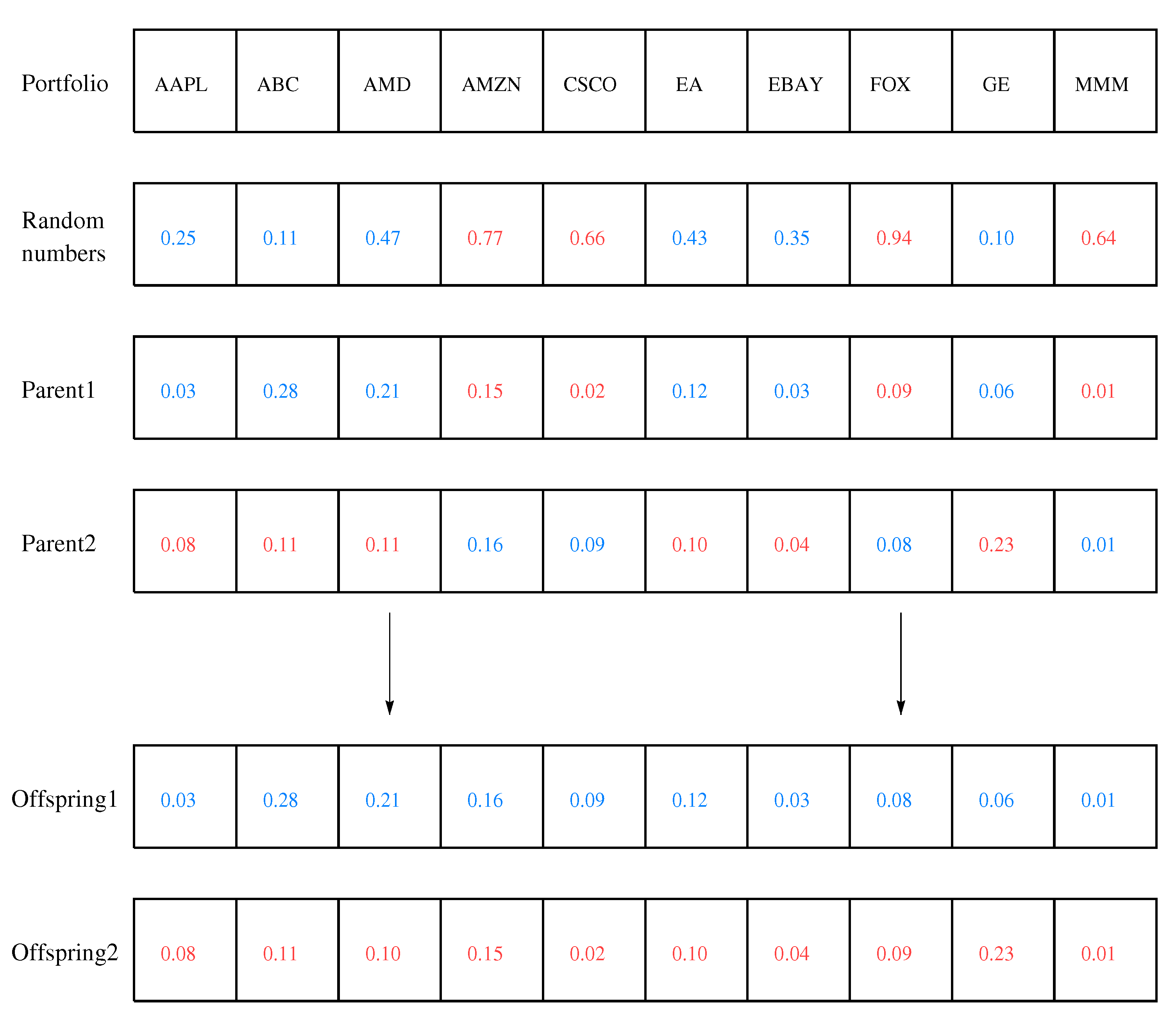
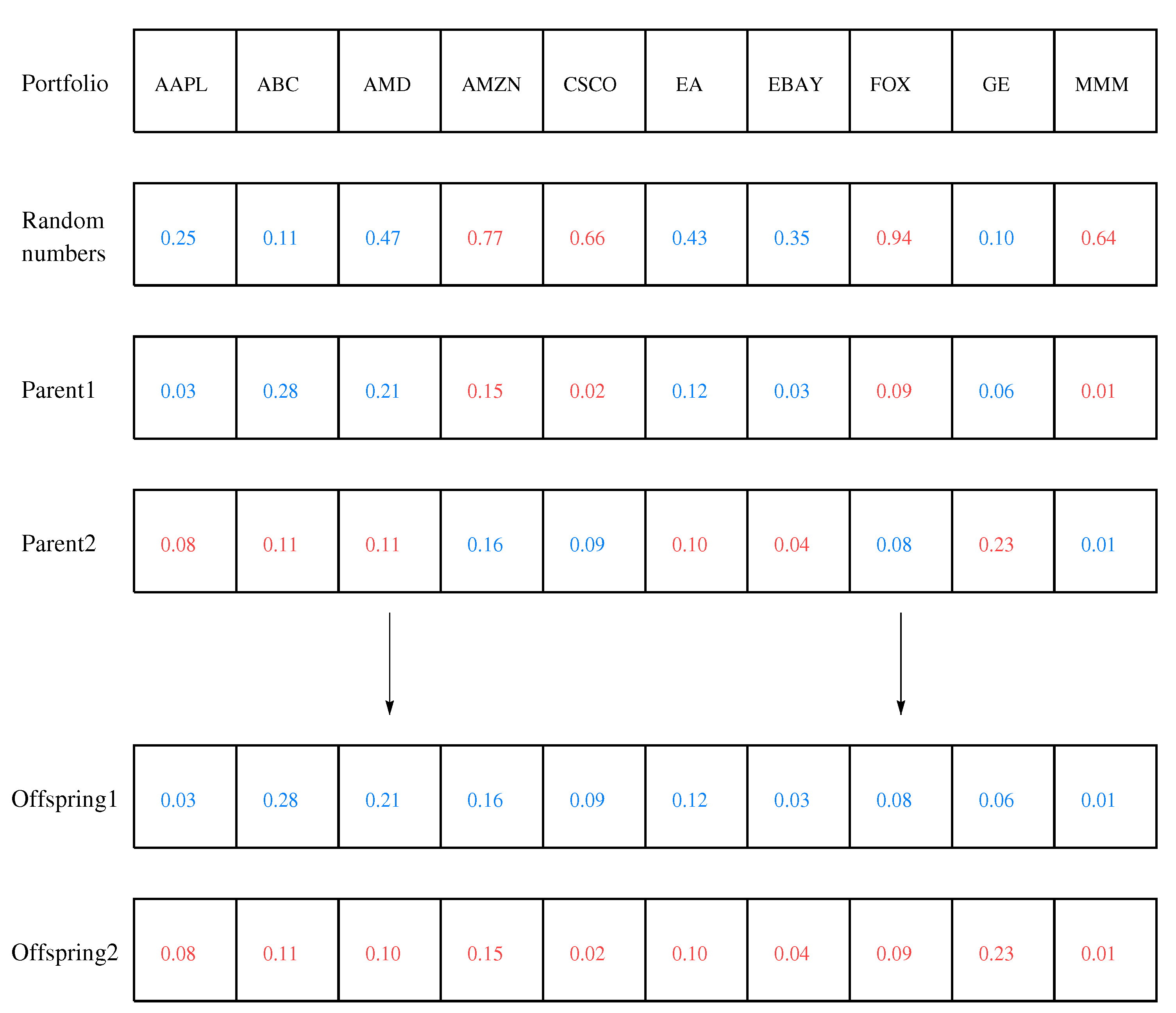
A crossover combines two parents to create new offspring. We used a uniform crossover in which each gene was inherited from either parent with equal probability.
Figure 1 shows an example of a uniform crossover, which results in two offspring. The crossover is exploitative because it recombines the material of promising parents; however, it is also explorative because it generates new offspring [
42].
After a crossover, each offspring undergoes a mutation. The mutation rate was set to
, and the mutated gene was multiplied by
or
. The multiplicand was randomly selected with the same probability. We set
to 0.05 and
to 0.5. A mutation can also be seen as both explorative and exploitative because it introduces new offspring in an unbiased manner while conserving most of the original chromosome [
42].
3.4. Local Search Heuristic
The GA can explore a wide range of search spaces using explorative operators when the hyperparameters are appropriately set. However, it is weak in fine-tuning capability near the local or global optima, which can be alleviated by HGA [
45]. Thus, we incorporated a local search heuristic into the GA to improve the fine-tuning capability.
We first generated two additional chromosomes by taking the inverse of each gene in the two offspring. We then manipulated each gene of the two offspring and the two new chromosomes. On the day, each gene in the four chromosomes is multiplied by if the return of the stock is below average; otherwise, it is multiplied by . We set to 0.5.
This heuristic makes the chromosomes perform worse on the
day, which strengthens the mean reversion property on the next day. Each chromosome
is normalized such that it belongs to the simplex—that is,
—and the best mean-revertible chromosome is chosen for replacement. The pseudocode of the local search heuristic is given in Algorithm 4.
| Algorithm 4 LocalSearch (). |
- 1:
▷ stores the average return - 2:
for to m do - 3:
▷ denotes the gene - 4:
- 5:
- 6:
for to m do - 7:
if then - 8:
for each do - 9:
- 10:
else - 11:
for each do - 12:
- 13:
for eachdo - 14:
▷ normalization - 15:
▷ select the best mean-revertible chromosome - 16:
return
|
3.5. Replacement
The mean reversion property expects the current best strategy to fail. Therefore, we replace the best trend-following chromosome with the best mean-revertible chromosome. On the
day, we choose an individual only from the chromosomes that produce above-average returns. The fitness of a chromosome is its expected relative log return when it is trend following. To obtain the trend-following fitness of a chromosome
, we sample a relative log return from
. The pseudocode of the replacement procedure is given in Algorithm 5.
| Algorithm 5 Replace ). |
- 1:
▷ stores the best fitness - 2:
for eachdo - 3:
if then ▷ test whether is trend following or not - 4:
Sample - 5:
if then - 6:
▷ stores the best trend-following chromosome - 7:
ifthen - 8:
Randomly sample ▷ all chromosomes are mean-revertible - 9:
|
3.6. Genetic Mean Reversion Strategy
Our strategy starts with a uniform portfolio vector—that is,
. After the
day, a new portfolio vector is generated by combining the previous portfolio vector with the most promising mean-revertible vector in the population
P; that is,
where
is a user-defined parameter that prevents excessive trading. We set
to
, where
is the transaction cost rate and
. As
is proportional to the actual transaction cost of changing the portfolio vector from
to
,
is set adaptively to reduce the transaction costs. We set
to 1 when there is no transaction cost.
Our hybrid genetic framework maintains profitable individuals with the mean reversion property and tries to achieve higher returns than the benchmarks by selecting the most mean-revertible portfolio vector according to the market conditions. The results of our strategy are compared with those of previous state-of-the-art mean reversion strategies [
15,
16,
17].
4. Results
4.1. Data
We used the historical daily prices of the companies in the S&P 500 from 2000 to 2017. This dataset contains 389 stocks with price information for the entire period. The dataset was used in our preliminary study [
46], and generated in the following way: the stocks were sorted in alphabetical order based on their ticker symbols, and 10 portfolios were generated sequentially in that order. To the best of our knowledge, this is the largest dataset used in an OLPS study. Our dataset is summarized in
Table 1. (The dataset in .mat and .csv formats is available at the following address:
https://github.com/uramoon/mr_dataset (Accessed on: 13 February 2022). A detailed description of the dataset is provided in the README file.)
Appendix A presents the experimental results on the single portfolio of all 389 stocks.
We also tested our strategy using traditional datasets, which have been widely used by many researchers [
12,
14,
15,
36,
47]. However, some of these datasets do not provide the criteria for stock selection [
15] and have abnormal patterns that can be easily exploited using mean reversion strategies. Therefore, although we mainly used our own datasets, we also provide the details of traditional datasets and the experimental results using them in
Appendix B.
4.2. Experimental Setup
The genetic mean reversion (GMR) strategy was written in C#, and the results of the GMR were averaged over 100 independent runs for all experiments. The averaged results can be implemented in the real market by splitting the initial wealth evenly among the 100 runs and prohibiting the transfer of money between runs [
38]. When there are transaction costs, the average performance can be improved by offsetting trades among the runs [
37].
For the other strategies, we used the implementations of Li et al. [
16,
17,
48]. Here,
and UP were used as benchmark measures of performance. We also compared our strategy with the state-of-the-art mean reversion strategies: PAMR, OLMAR, TCO-1, and TCO-2 [
15,
16,
17].
Even if there is no commission, traders incur an implicit cost in the difference between the actual transaction price and the benchmark price [
49]. To incorporate all expenses that can be incurred in actual trading, we used the proportional commission model [
36] in which an investor pays at a rate of
for each buy and each sell such that the daily return on the
day is
). Here,
is the closing price adjusted portfolio vector (i.e.,
), and
is set to 0%, 0.25%, and 0.5%, which are reasonable transaction cost rates for OLPS [
17,
50]. The transaction on the
tth day is profitable only when the excess profit from the transaction (
) outweighs the transaction costs (
).
Cumulative wealth at the end of the trading period is our main performance criterion. The cumulative wealth measures the wealth of a trading strategy with an initial wealth of 1. We also calculated the average daily turnover ratio () for each strategy, which denotes the mean ratio of assets that have been replaced on every trading day. As the transaction costs depend on the turnover ratio, it is desirable to avoid unnecessary transactions.
We also compare the results of GMR with those of
in terms of annualized percentage yield (APY), annualized standard deviation (ASD), Sharpe ratio (SR), the maximum drawdown (MDD), alpha (
),
t-statistics, and
p-value. The APY is annual compound return, and the ASD is the standard deviation of daily returns multiplied by the squared root of the number of annual trading days. The SR measures the risk-adjusted performance of a trading strategy compared to a risk-free asset, i.e.,
, where
is the risk-free return (U.S. Treasury bill rate). The MDD is the maximum observed loss from a peak to a valley, which measures the downside risk over a certain period.
is the intercept from the market model regression [
51] that measures the excess daily return of GMR against
. The
t-statistic is the test statistic for the null hypothesis that the
is zero [
52], and the
p-value is computed from the
t-statistic. A low
p-value indicates that we can reject the null hypothesis.
4.3. Cumulative Wealth without Transaction Costs
We first conducted experiments to test the GMR strategy in the absence of the transaction costs. As transaction costs were not considered, it would be extremely difficult to achieve a similar performance in the real market.
Table 2 lists the cumulative wealth achieved using various strategies. The results of
show that there is a strong upward trend in all datasets; the simple
increased its wealth by over 6-fold on every dataset. The other benchmark UP improved the performance of
overall with a small turnover ratio, but achieved less than half the wealth of
on the SP500(6).
Although previous mean reversion strategies largely outperformed the benchmarks on many datasets, they showed a poor performance on the SP500(0), SP500(1), and SP500(6), all of which failed to beat on these three datasets, except for TCO-1, which performed better than on SP500(1). Although the OLMAR produced the best average performance by achieving tremendous wealth on SP500(3), it lost 82% of its wealth on SP500(0). In general, the multi-period mean reversion strategies (OLMAR and TCO-2) worked better than their single-period counterparts (PAMR and TCO-1) in terms of the average wealth and turnover ratio.
We also tested whether the results from GMR are significantly better than those from
.
Table 3 presents further details on the performance of both strategies. Although the GMR had higher risks (ASDs and MDDs) than
, it exhibited higher returns (APYs) and risk-adjusted returns (SRs) on all datasets. The
p-values indicate that the excess returns (
) of GMR against
are statistically significant on the eight datasets.
Our method produced the best results on the four datasets SP500(0), SP500(1), SP500(6), and SP500(8), and outperformed the benchmarks on all datasets. To work well on unseen datasets, it is desirable to produce stable results on many different datasets. It is also worth noting that it showed the best results on the three datasets where the previous strategies failed to outperform the benchmarks. Although the average performance of GMR was below the previous strategies, its win ratio was the highest among the mean reversion strategies.
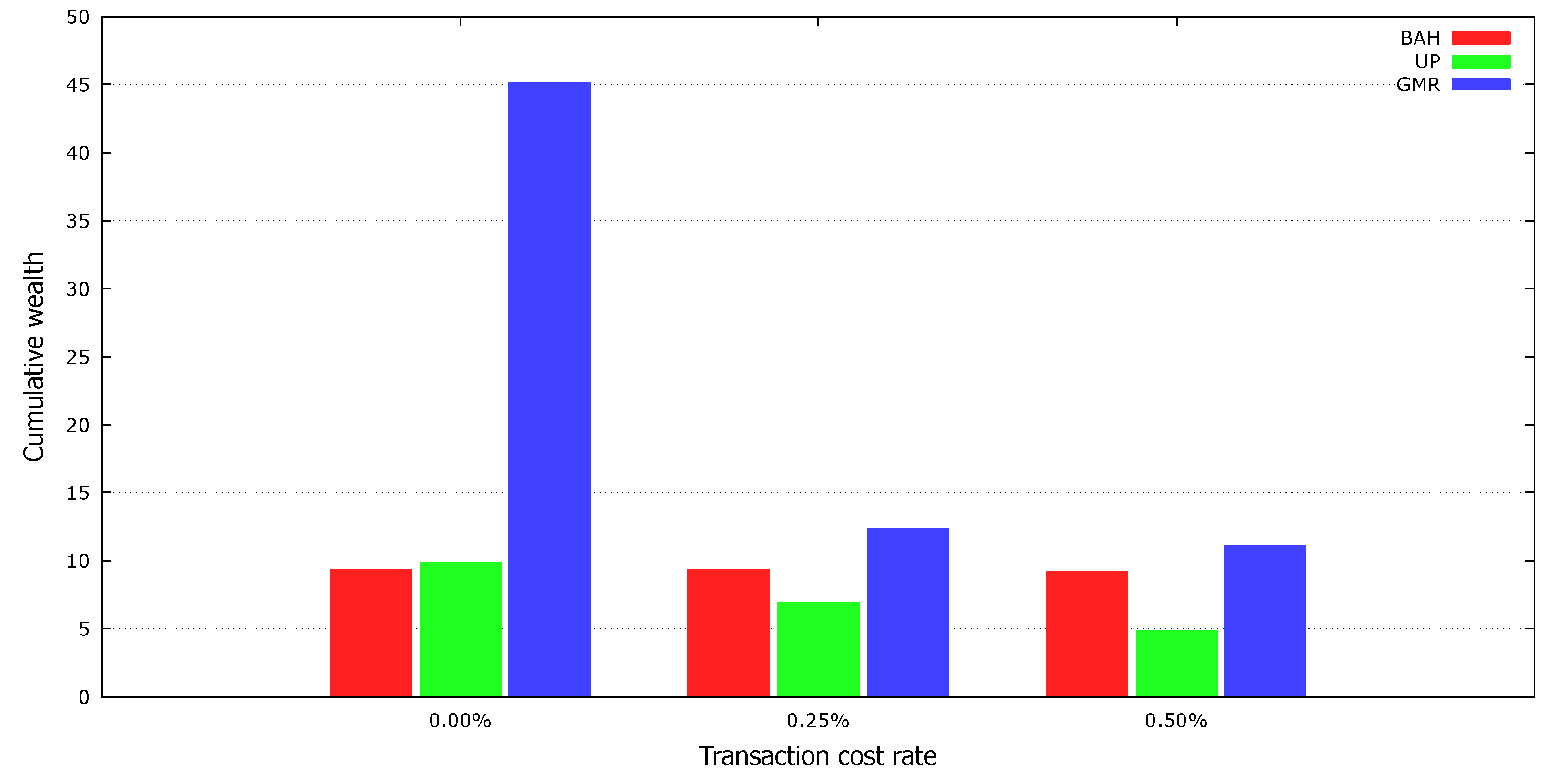
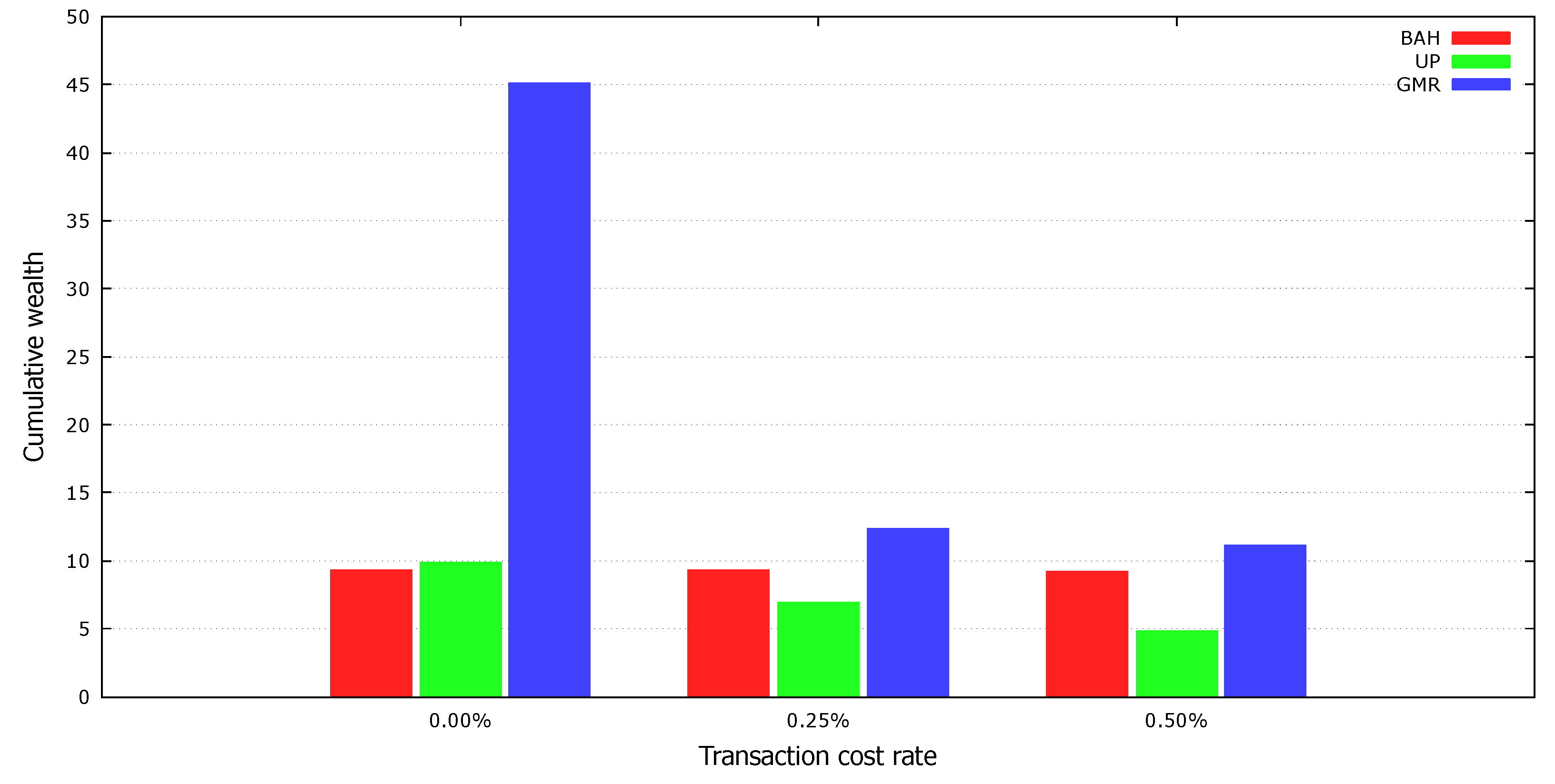
4.4. Cumulative Wealth with Transaction Costs
We tested the proposed strategy in the presence of transaction costs. The experimental results with reasonable transaction costs suggest how well each strategy will be applied in the real market.
Table 4 shows the cumulative wealth achieved by various strategies when the transaction cost rate is 0.25%. The performance of
barely changed because it pays the transaction costs only on the first day. However, the performance of UP was no better than
on most datasets; the transaction costs of 0.25% outweighed the benefits of the asset reallocation.
Previous mean reversion strategies also did not perform well with transaction costs of 0.25%. The PAMR and OLMAR spent all their money on transaction costs because they did not consider the transaction costs when changing the portfolio vectors. The TCOs reduced their trading volumes by less than half, but failed to outperform the benchmarks on most datasets; TCO-2 performed the best on two datasets, but failed to outperform the benchmarks on the other eight datasets, and TCO-1 performed worse than the benchmarks on all datasets.
Similar to the previous mean reversion strategies, the transaction costs degraded the performance of the GMR. However, it achieved relatively good results by significantly reducing its turnover ratio and showed the best results on seven datasets, achieving the highest average earning and a win ratio of 0.9.
Table 5 compares GMR with
when the transaction cost rate was set to 0.25%. Again, GMR had higher risks than
, but produced better annual returns and risk-adjusted returns on all datasets except SP500(5). On the nine datasets, GMR had positive excess daily returns, but they were statistically significant on three datasets in the presence of transaction costs.
We also tested the performance of each strategy with transaction costs of 0.5%.
Table 6 lists the cumulative wealth achieved by the various strategies. The performance of
barely changed. At this transaction cost rate, the UP and the previous mean reversion strategies did not exceed
on all datasets. However, the GMR outperformed the benchmarks on all datasets by maintaining a good population of portfolio vectors and adaptively reducing the turnover ratio.
Table 7 shows that the risk-adjusted returns of GMR are overall higher than those of
with transaction costs of 0.5%.
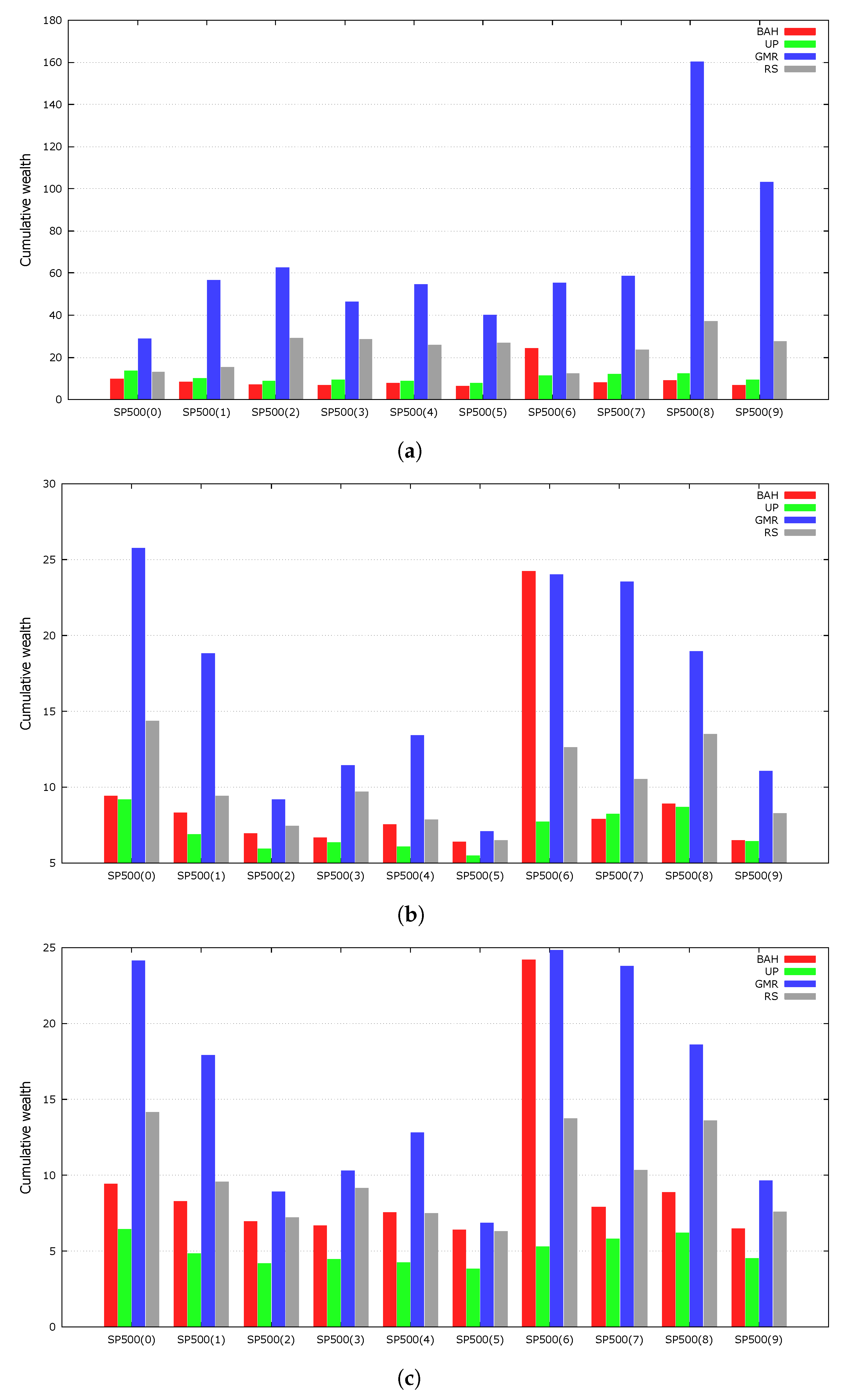
4.5. Comparisons of GA and Random Sampling
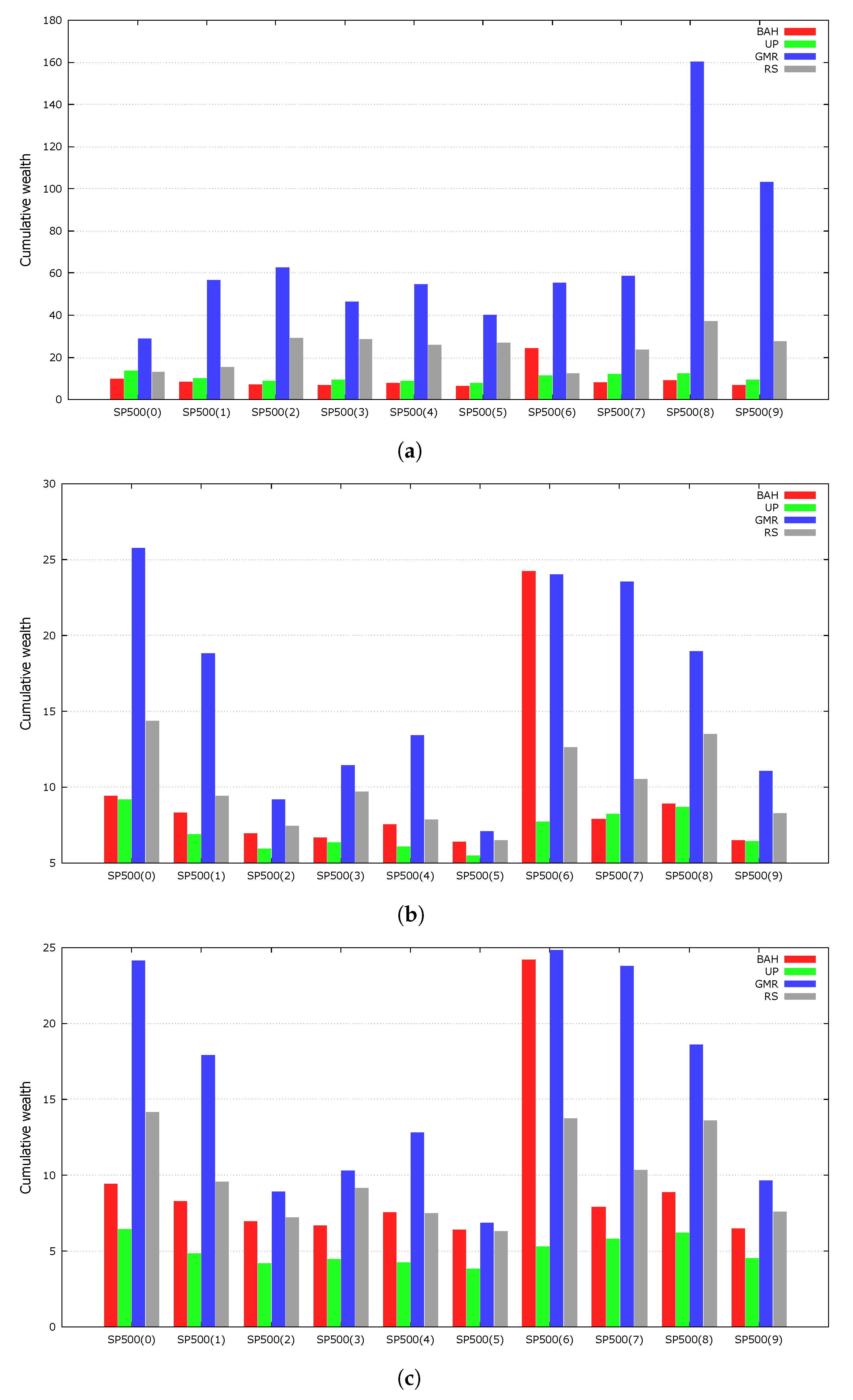
We compare a random sampling (RS) with a GA to examine how much the genetic framework contributes to the quality of the solutions. An RS is a population-based heuristic that produces a solution through random sampling. Instead of selecting two promising parents from the population, two individuals were uniformly sampled from the simplex. These individuals are processed through a local search, and the best solution replaces a random individual of the population. The RS results were averaged over 100 independent runs. The RS started with the same initial population as the GMR because it used the same random seed numbers as the GMR.
Figure 2 presents the experimental results. The GMR outperformed the RS on every dataset, indicating that the GA successfully evolved the population of portfolio vectors.
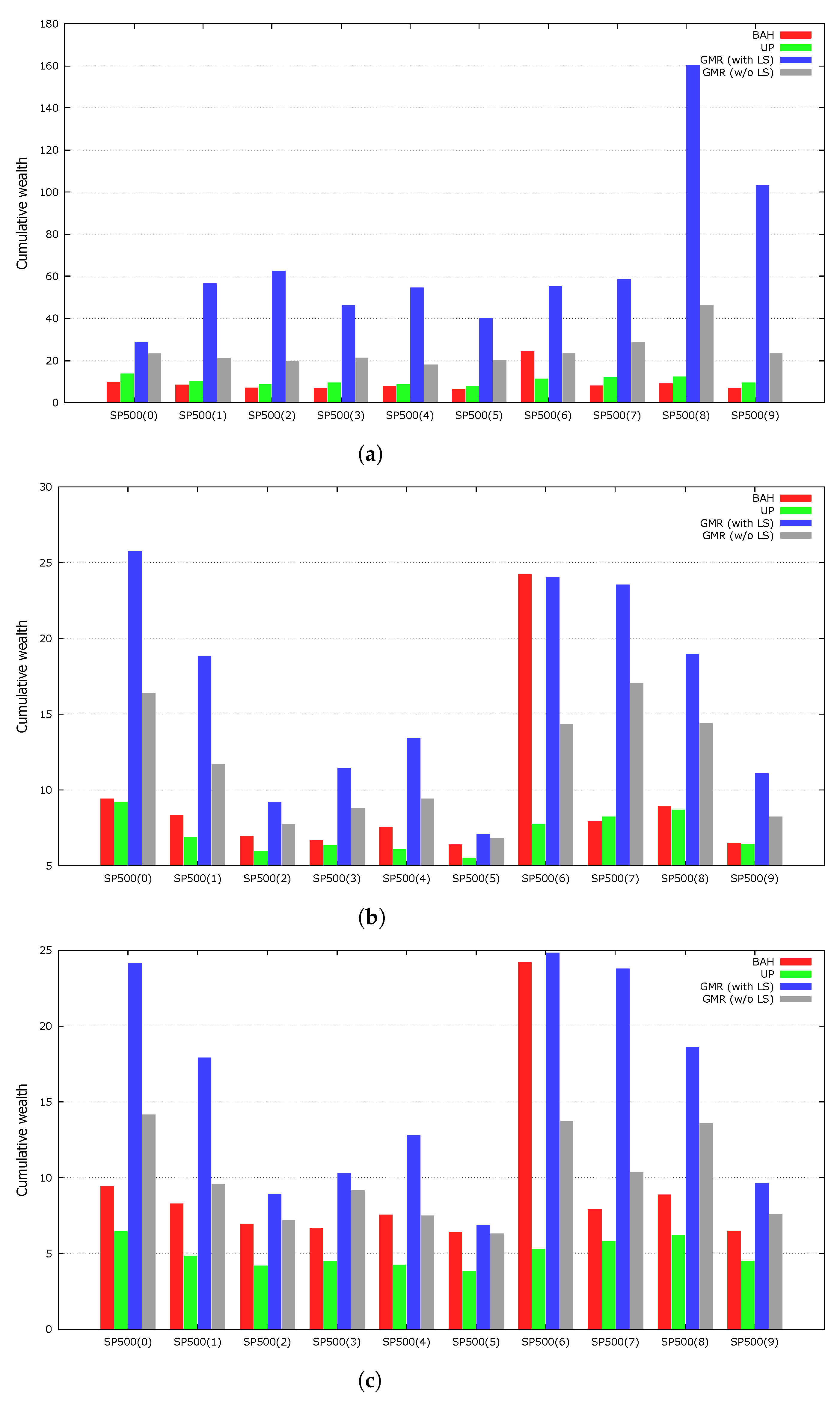
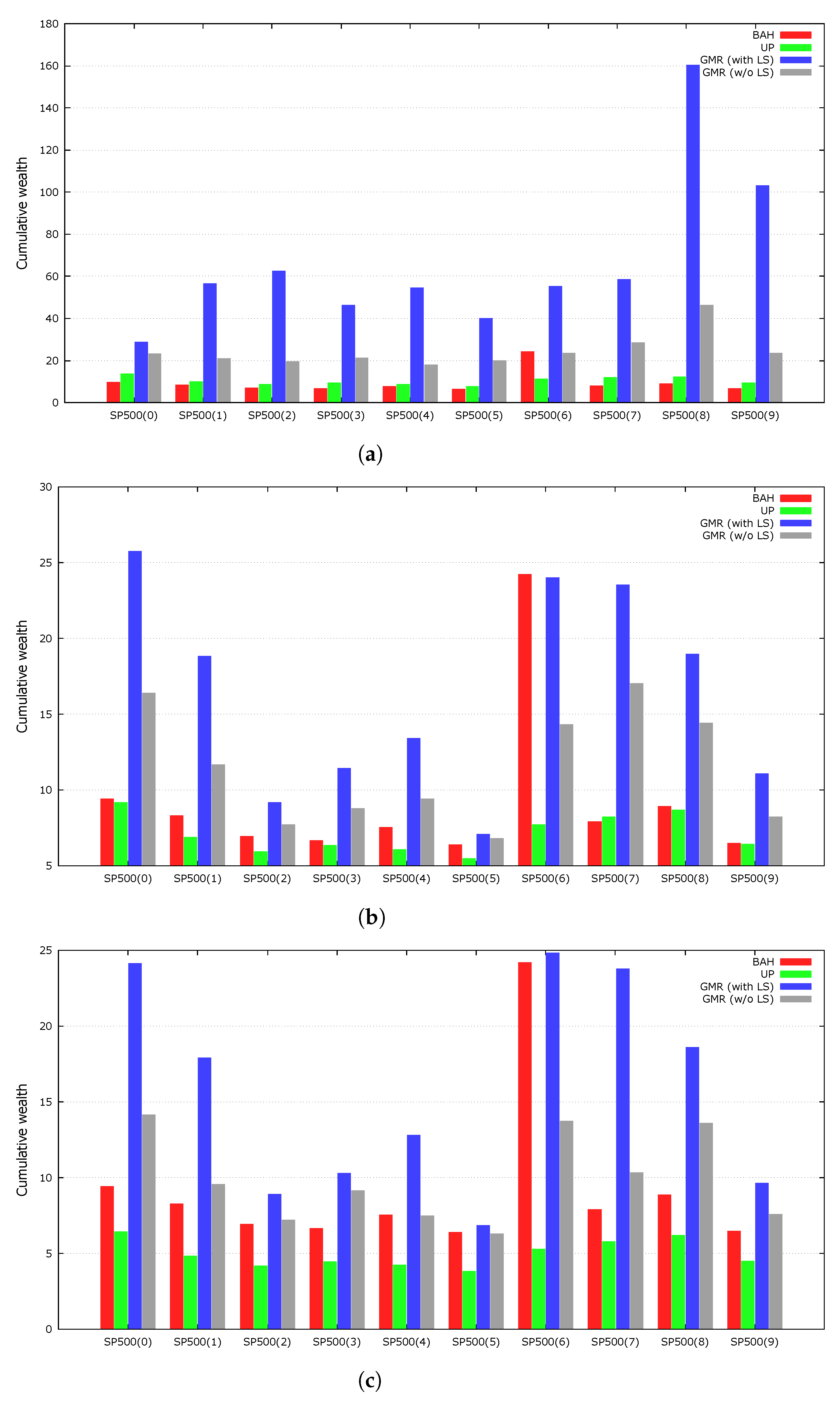
4.6. Local Search Heuristic
The GMR embeds a local search heuristic to improve the fine-tuning capability of the GA. To determine the effects of the local search, we tested the performance of GMR when not employing the local search heuristic. We averaged the results of the experiments over 100 independent runs using the same random seed numbers as the original GMR.
Figure 3 shows the results of the experiments. The local search heuristic improved the performance of our genetic framework for every dataset.
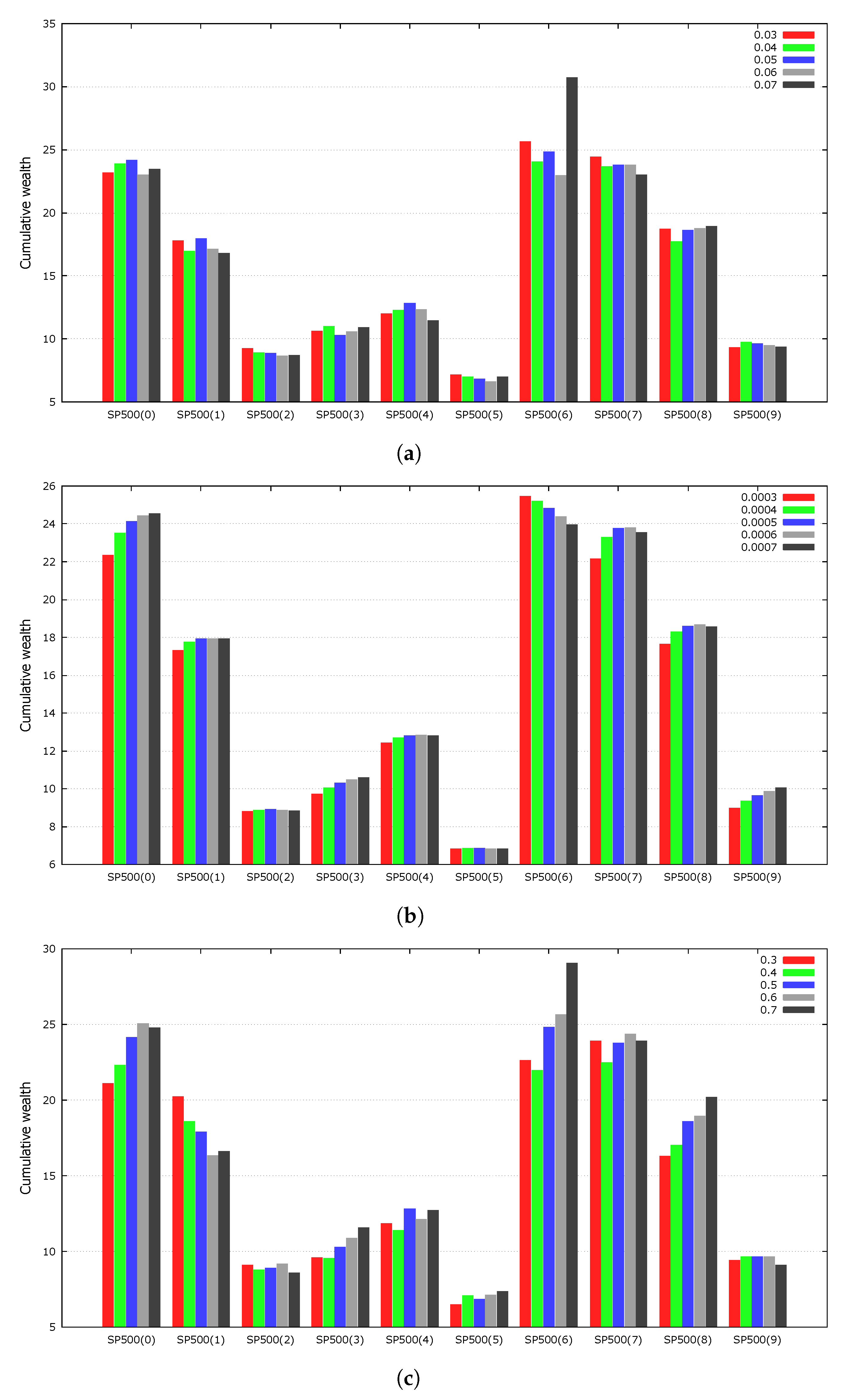
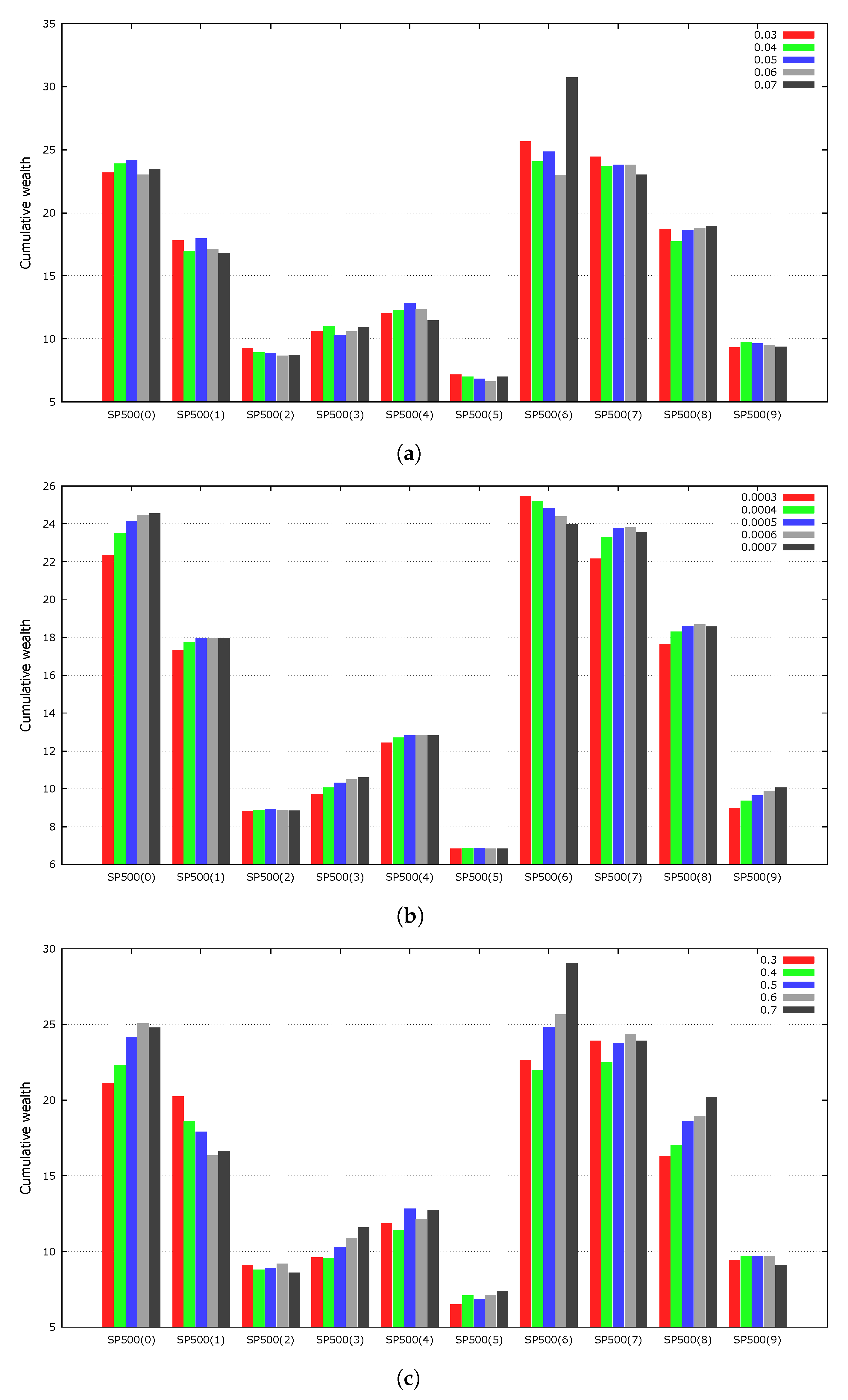
4.7. Parameter Sensitivity
Strategies that are highly sensitive to their parameters are not likely to perform well on unseen data. Experiments were conducted to determine the effect of the GMR parameters on the experimental results. We varied
,
, and
, which mutation, portfolio vector calculation, and local search, respectively. For simplicity, we fixed the rate of transaction costs to 0.5% and averaged the results of the experiments over 100 independent runs.
Figure 4 shows the experimental results. Overall, the value of each parameter did not significantly affect the experimental results. As OLPS is used for online algorithms, we deliberately did not fine-tune the parameters.
5. Conclusions
In this paper, we proposed a mean reversion strategy that evolves a population of portfolio vectors through the HGA. To exploit the mean reversion property, a local search heuristic was devised and embedded in the GA. The experimental results obtained for the S&P500 datasets revealed that our genetic framework and local search heuristic were able to improve the performance of our strategy.
We also investigated the performance of various mean reversion strategies on the S&P500 datasets. When there were no transaction costs, previous mean reversion strategies performed extremely well. However, they showed poor results with respect to the transaction costs. As our strategy limited the turnover ratio to an appropriate level based on the transaction costs, it outperformed the benchmarks on most of the datasets.
In the future, it would be worthwhile to develop a new strategy that incorporates both trend following and mean reversion disciplines. On the SP500(6) dataset, outperformed most of the mean reversion strategies; it might therefore, be helpful to adopt a trend following strategy by identifying the market conditions.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}