
Network Embedding Algorithm Taking in Variational Graph AutoEncoder




Abstract
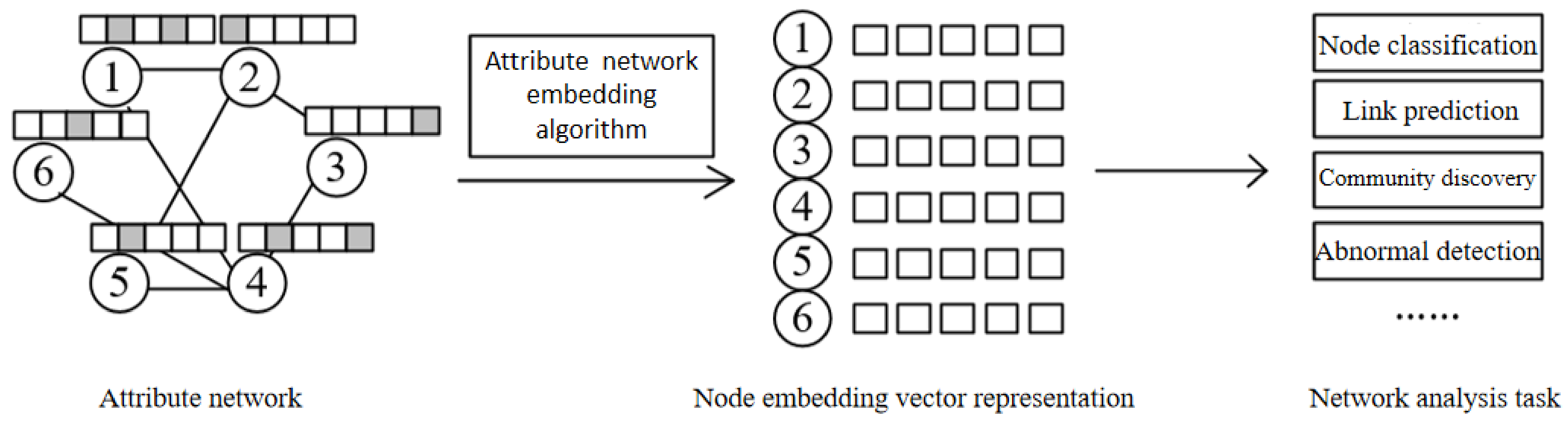
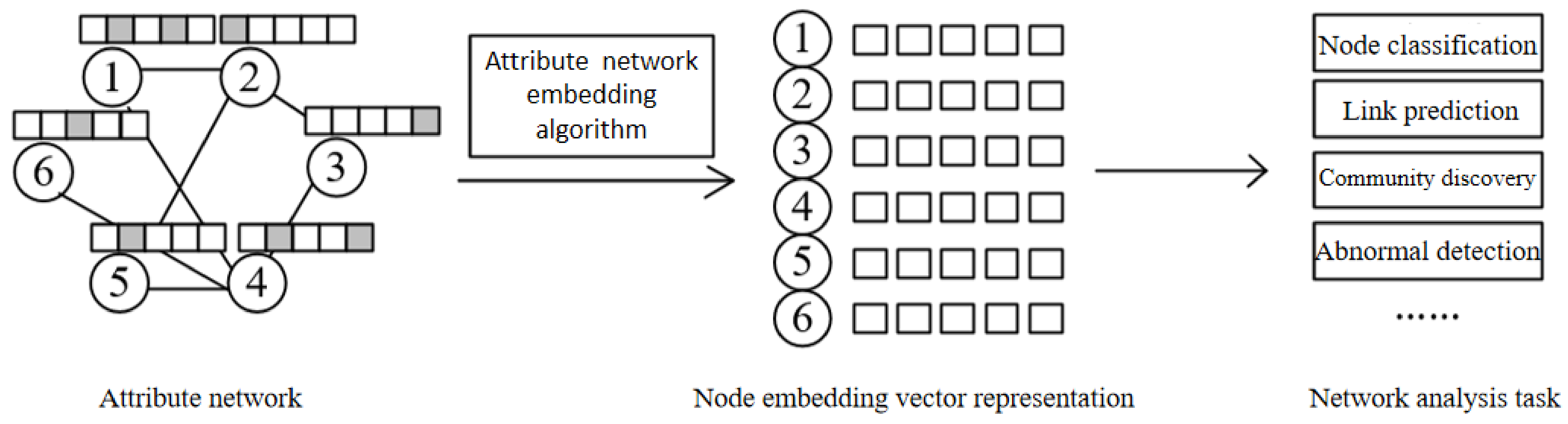
:1. Introduction
2. Related Works
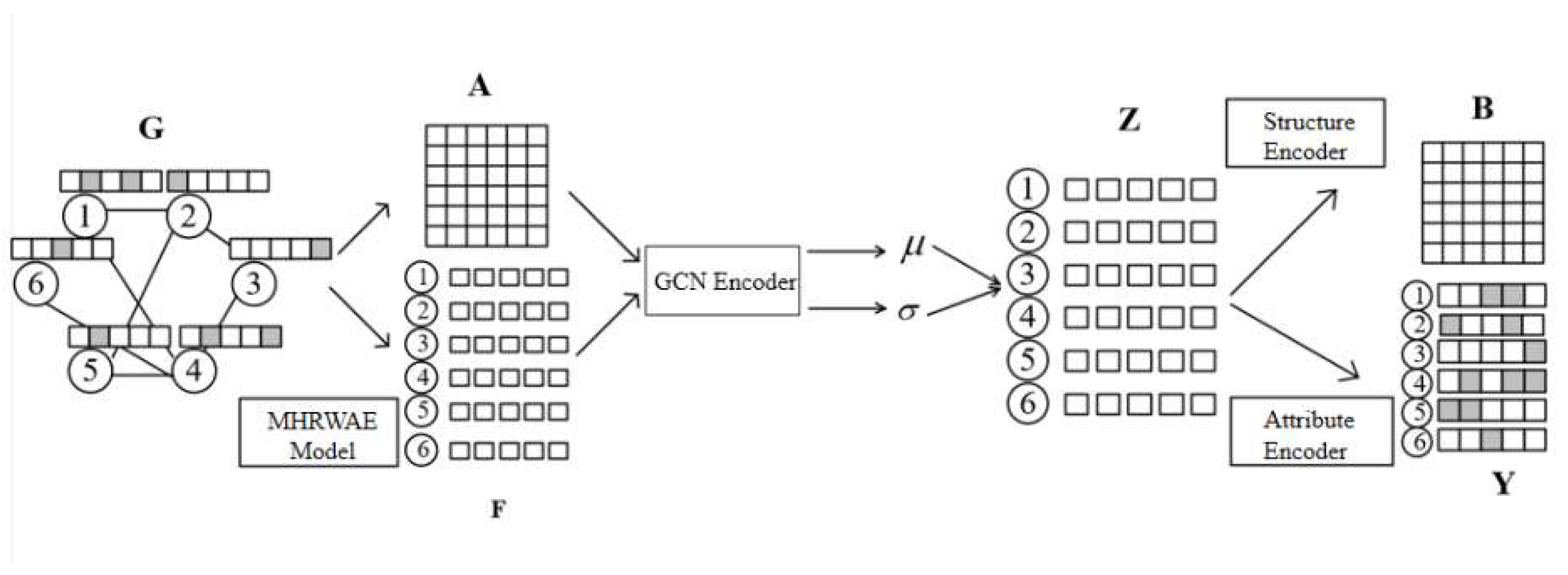
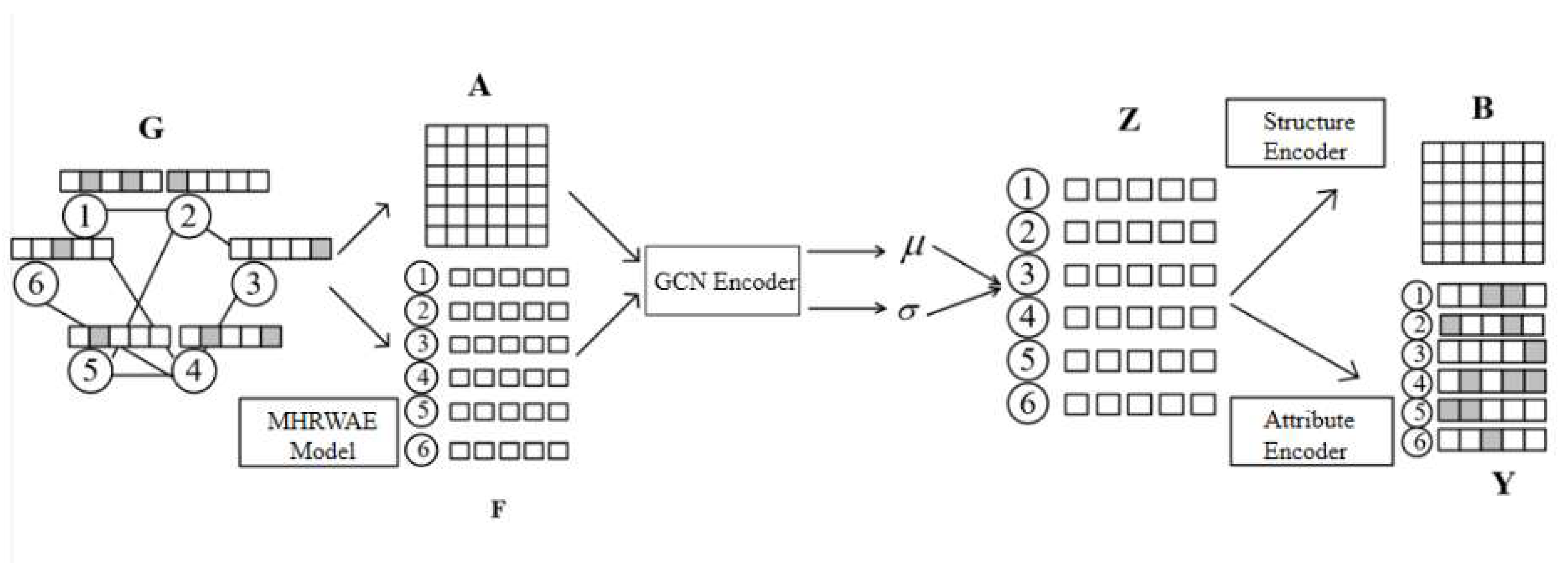
3. Methodology
- (1)
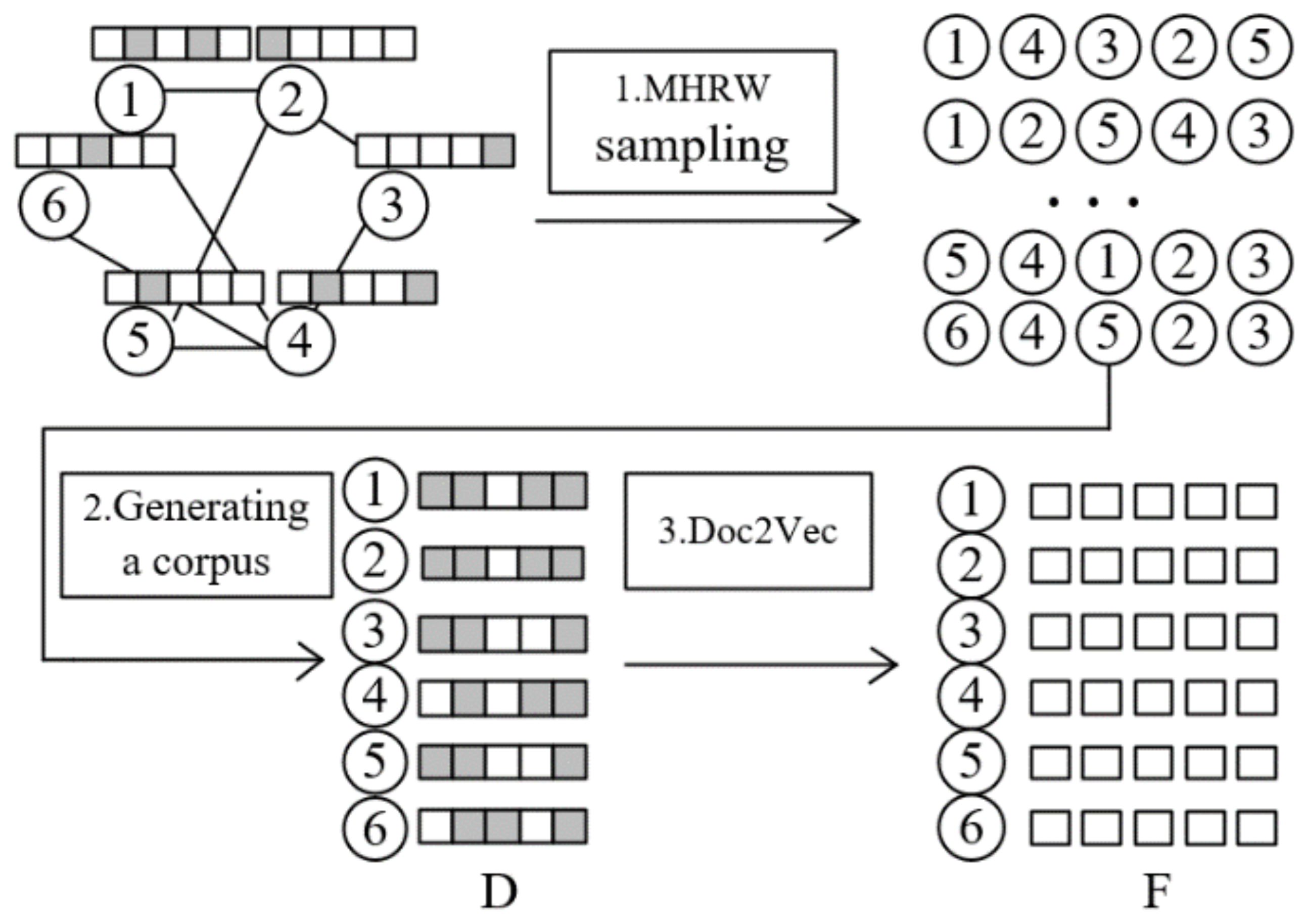
- Node Attribute Feature Learning: We employ the Metropolis–Hastings random walk (MHRW) algorithm [27] sampling, node sequence generation corpus, and Doc2Vec [28] model training to preprocess the attribute information, which is the attribute feature learning, named the MHRWAE algorithm. High-dimensional sparse attribute feature matrix learning can obtain low-dimensionality and better reflect the attribute feature learning matrix.
- (2)
- Attribute Network Encoder: The adjacency matrix and the attribute feature learning matrix are employed as input to the variational graph autoencoder, which takes GCN for encoding and maps the attribute network to a Gaussian distribution.
- (3)
- Structure Reconstruction Decoder: Sampling the Gaussian distribution to obtain a vector representation of the nodes, the structure decoder is employed to reconstruct the adjacency matrix of the network, i.e., the structural information of the network.
- (4)
- Attribute Reconstruction Decoder: Sampling the Gaussian distribution to obtain a vector representation of the nodes and using the attribute decoder to reconstruct the attribute feature learning matrix of the encoder input.
- (5)
- Loss Function Definition: We define a novel loss function, and the matrix reconstructed by the decoder is compared with the input information of the variogram autoencoder to construct the loss function, considering the effects of structural and attribute reconstruction. The final learning yields vector representations that are as good as possible in low-dimensional space for both structure and attributes.
3.1. Preliminaries
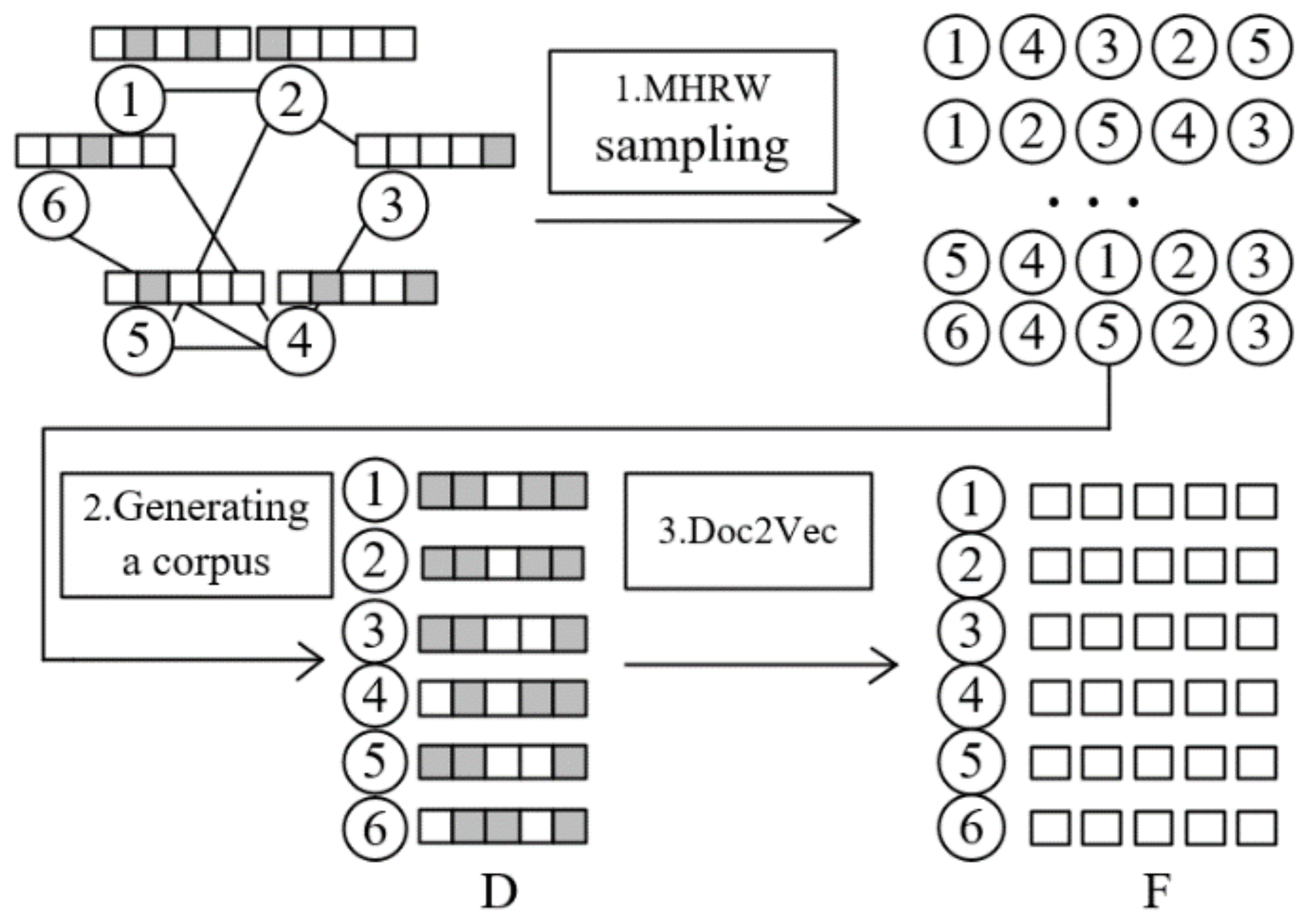
3.2. Aggregation-MHRWAE
- (1)
- The unbiased random wandering is performed with the MHRW algorithm to generate a sequence of nodes. the MHRW algorithm samples nodes without bias towards nodes of a larger degree, and the node sequences generated by the sampling reflect the connectivity between nodes, i.e., the structural information of the network. The MHRW algorithm sampling process is where the transfer probability of the MH algorithm is employed in the Random Walk algorithm to determine the transfer probability when the current node is sampled to a neighboring node. We assume that the probability distribution given in the MH algorithm is , and the election probability, , is assumed to be , then the transition probability of sampling from node i to its neighbor node j, as shown in Equation (1), as follows:where , and respectively, represent the degrees of nodes i and j. indicates the probability of node i staying at the current node.
- (2)
- Corpus generation: In the process of corpus generation by the MHRWAE algorithm, unlike DeepWalk, which employs multiple sets of nodes and node context nodes as a corpus, it employs multiple sets of nodes and node neighborhood node attributes as the corpus for SGNS training. The corpus is generated employing neighborhood node attribute aggregation, in which a sequence of nodes of a given length is generated, and for each node in the sequence, the attributes of the node and its neighborhood nodes are paired and added to the multiset, with each node in the sequence completing an iterative node attribute aggregation operation to form the final corpus.
- (3)
- The Doc2Vec model trains the corpus: Doc2Vec is a model that generates vector representations of documents, and the PV-DBOW method in the model enables SGNS. using the corpus as input, the Doc2Vec model is employed to train the corpus and generate a vector representation of each document, i.e., a vector representation of each node is obtained.
3.3. NEAT-VGA
| Algorithm 1. NEAT-VGA |
| Input: Attribute network G = (V, E, X), parameterα, m, g, l, b, t, n, p, q, a1, a2. Output: Attribute network node embedding vector Z
|
3.3.1. Node Attribute Feature Learning
3.3.2. Attribute Network Encoder
3.3.3. Structure Reconstruction Decoder
3.3.4. Attribute Reconstruction Decoder
3.3.5. Loss Function Definition
4. Experiments
4.1. Experimental Setting
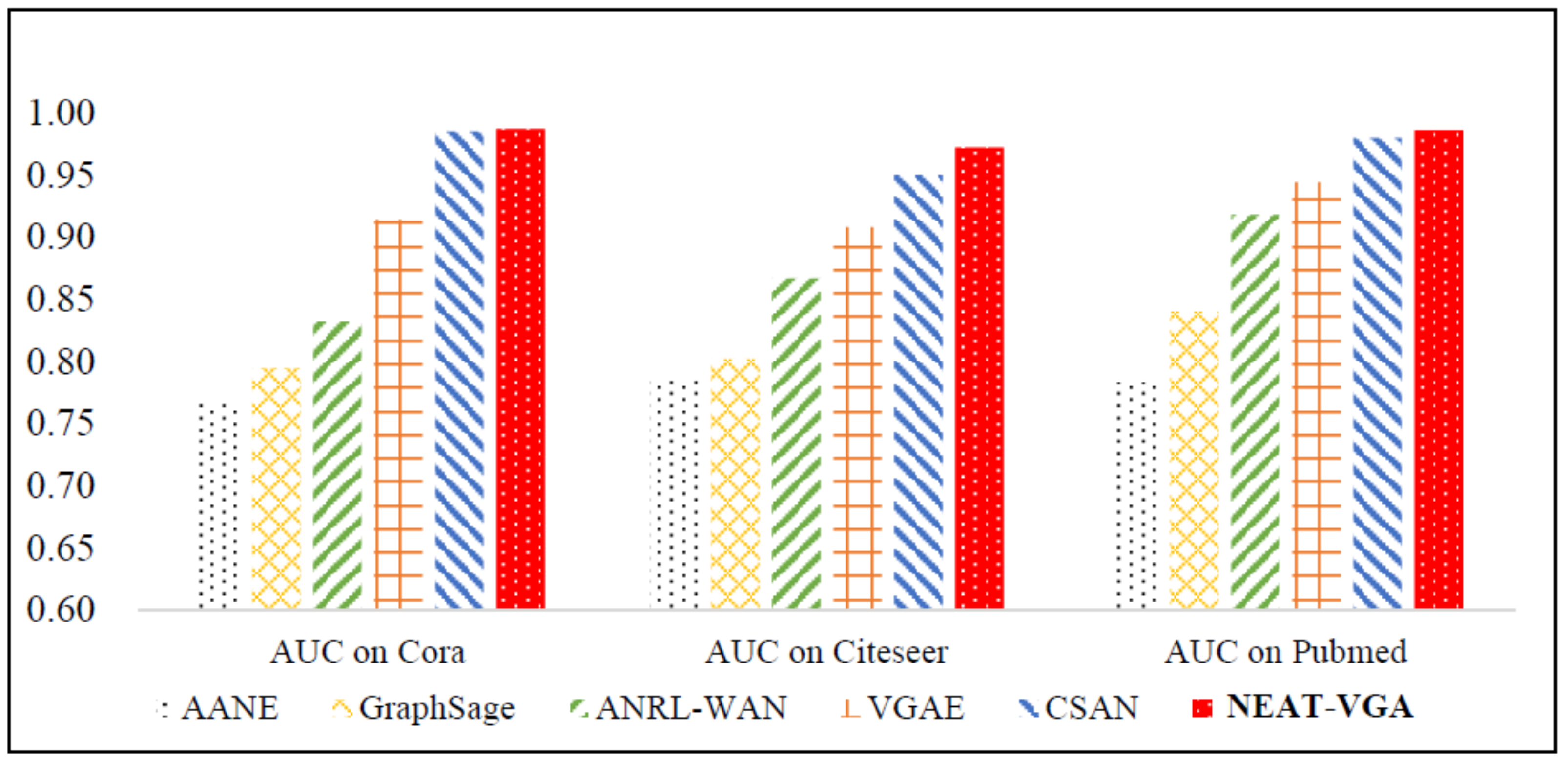
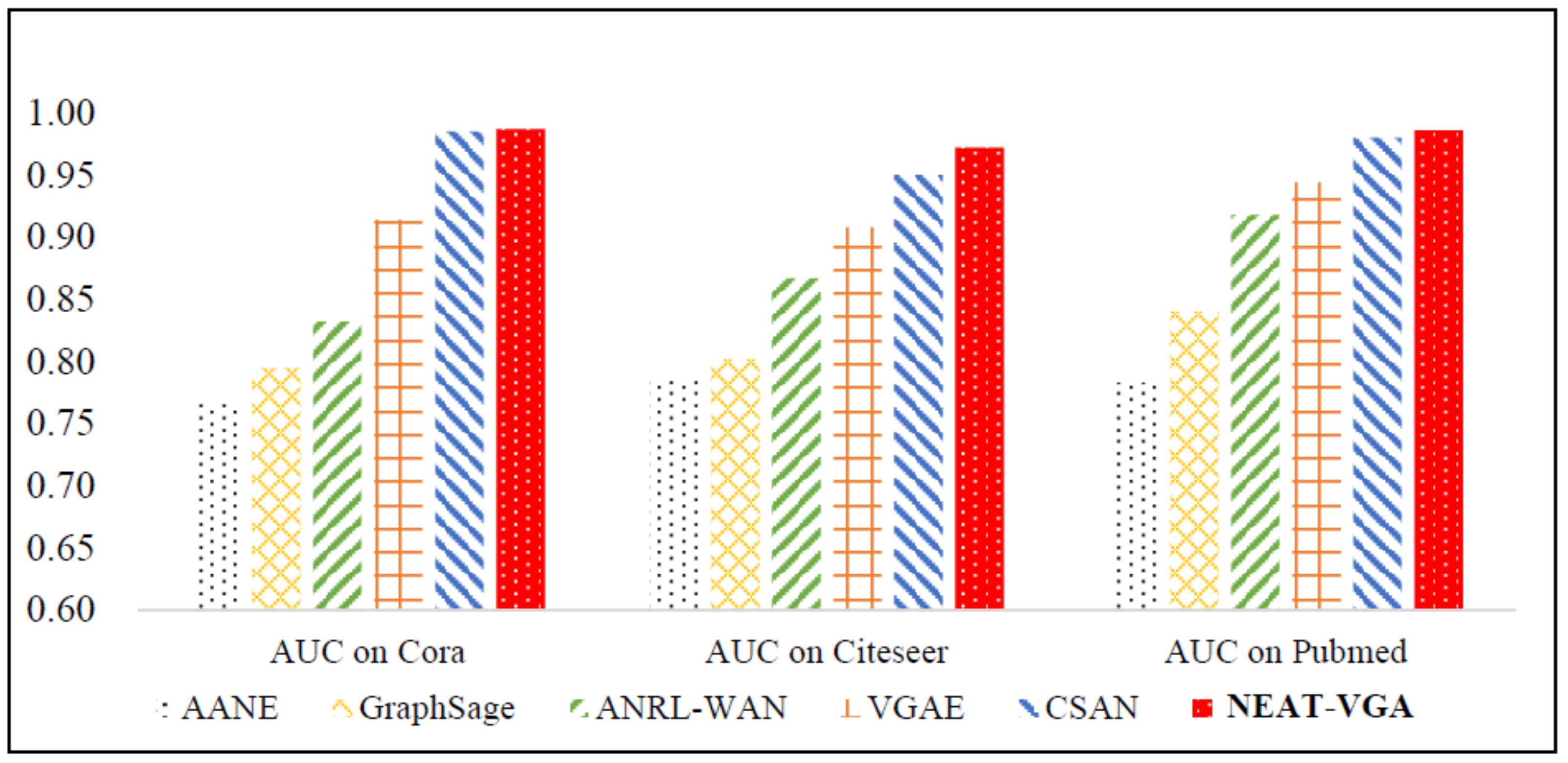
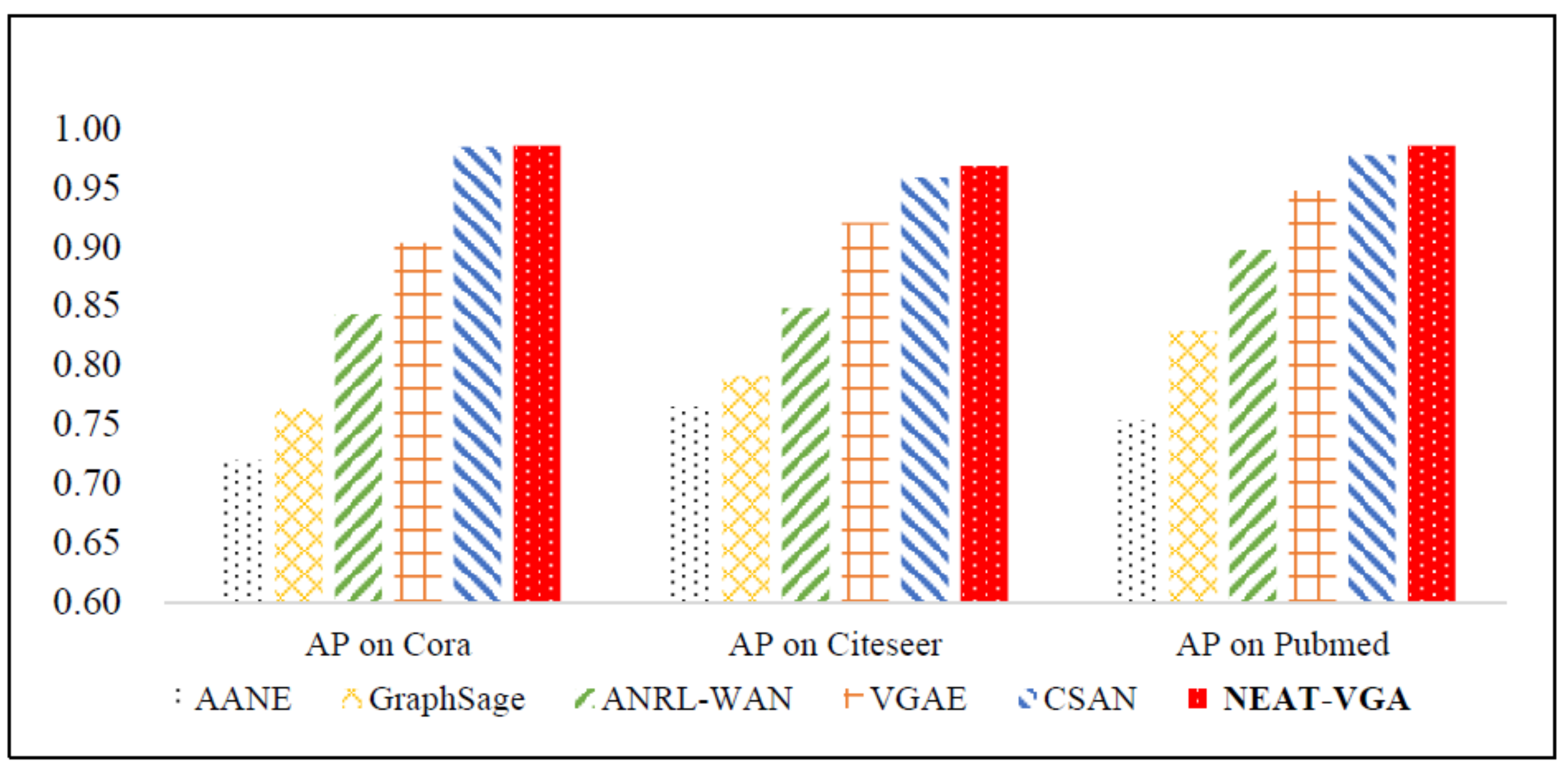
4.2. Results and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Asatani, K.; Mori, J.; Ochi, M.; Sakata, I. Detecting trends in academic research from a citation network using network representation learning. PLoS ONE 2018, 13, e0197260. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, L.; Jiang, B.; Lv, S.; Liu, Y.; Li, D. Survey on deep learning based recommender systems. Chin. J. Comput. 2018, 41, 1619–1647. [Google Scholar]
- Su, S.; Sun, L.; Zhang, Z.; Li, G.; Qu, J. MASTER: Across Multiple social networks, integrate Attribute and STructure Embedding for Reconciliation. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI-18), Stockholm, Sweden, 13–19 July 2018; pp. 3863–3869. [Google Scholar]
- Wu, X.D.; Li, Y.; Li, L. Influence analysis of online social networks. Jisuanji Xuebao/Chin. J. Comput. 2014, 37, 735–752. [Google Scholar] [CrossRef]
- Haiyan Hong, W.L. Link Prediction Algorithm in Protein-Protein Interaction Network Based on Spatial Mapping. Comput. Sci. 2016, S1, 413–417, 434. [Google Scholar]
- Wang, X.; Cui, P.; Wang, J.; Pei, J.; Zhu, W.; Yang, S. Community preserving network embedding. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-2017), San Francisco, CA, USA, 4–9 February 2017; pp. 203–209. [Google Scholar]
- Rozemberczki, B.; Davies, R.; Sarkar, R.; Sutton, C. Gemsec: Graph embedding with self clustering. In Proceedings of the 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM-2019), Vancouver, BC, Canada, 27–30 August 2019; pp. 65–72. [Google Scholar]
- Blondel, V.D.; Guillaume, J.-L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef] [Green Version]
- Chen, D.; Nie, M.; Wang, J.; Kong, Y.; Wang, D.; Huang, X. Community Detection Based on Graph Representation Learning in Evolutionary Networks. Appl. Sci. 2021, 11, 4497. [Google Scholar] [CrossRef]
- Huang, X.; Chen, D.; Ren, T.; Wang, D. A survey of community detection methods in multilayer networks. Data Min. Knowl. Discov. 2021, 35, 1–45. [Google Scholar] [CrossRef]
- Gao, S.; Denoyer, L.; Gallinari, P. Temporal link prediction by integrating content and structure information. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management (CIKM-2011), Glasgow, UK, 24–28 October 2011; pp. 1169–1174. [Google Scholar]
- Wang, D.; Nie, M.; Chen, D.; Wan, L.; Huang, X. Node Similarity Index and Community Identification in Bipartite Networks. J. Internet Technol. 2021, 22, 673–684. [Google Scholar]
- Bhuyan, M.H.; Bhattacharyya, D.K.; Kalita, J.K. Network anomaly detection: Methods, systems and tools. IEEE Commun. Surv. Tutor. 2013, 16, 303–336. [Google Scholar] [CrossRef]
- Bandyopadhyay, S.; Lokesh, N.; Murty, M.N. Outlier aware network embedding for attributed networks. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI-2019), Honolulu, HI, USA, 27 January–1 February 2019; pp. 12–19. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS-2017), Long Beach, CA, USA, 4–9 December 2017; pp. 1025–1035. [Google Scholar]
- Kipf, T.N.; Welling, M. Variational graph auto-encoders. arXiv 2016, arXiv:1611.07308. [Google Scholar]
- Meng, Z.; Liang, S.; Zhang, X.; McCreadie, R.; Ounis, I. Jointly learning representations of nodes and attributes for attributed networks. ACM Trans. Inf. Syst. 2020, 38, 1–32. [Google Scholar] [CrossRef] [Green Version]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD-2014), New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems (NIPS-2013), Lake Tahoe, CA, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; Mei, Q. Line: Large-scale information network embedding. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 1067–1077. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD-2016), San Francisco, CA, USA, 24–27 August 2016; pp. 855–864. [Google Scholar]
- Liu, J.; He, Z.; Wei, L.; Huang, Y. Content to node: Self-translation network embedding. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1794–1802. [Google Scholar]
- Liao, L.; He, X.; Zhang, H.; Chua, T.-S. Attributed social network embedding. IEEE Trans. Knowl. Data Eng. 2018, 30, 2257–2270. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Yang, H.; Bu, J.; Zhou, S.; Yu, P.; Zhang, J.; Ester, M.; Wang, C. ANRL: Attributed Network Representation Learning via Deep Neural Networks. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI-18), Stockholm, Sweden, 13–19 July 2018; pp. 3155–3161. [Google Scholar]
- Gjoka, M.; Kurant, M.; Butts, C.T.; Markopoulou, A. Walking in facebook: A case study of unbiased sampling of osns. In Proceedings of the 2010 Proceedings IEEE Infocom, San Diego, CA, USA, 14–19 March 2010; pp. 1–9. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the 31st International Conference on International Conference on Machine Learning (ICML-2014), Beijing, China, 21–26 June 2014; pp. 1188–1196. [Google Scholar]
- Sen, P.; Namata, G.; Bilgic, M.; Getoor, L.; Galligher, B.; Eliassi-Rad, T. Collective classification in network data. AI Mag. 2008, 29, 93. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; Li, J.; Hu, X. Accelerated attributed network embedding. In Proceedings of the 2017 SIAM International Conference on Data Mining (SIAM-2017), Houston, TX, USA, 27–29 April 2017; pp. 633–641. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| Attribute network diagram | |
| Node set, edge set | |
| Number of nodes, number of edges | |
| The adjacency matrix of the topological structure of the attribute network graph | |
| Attribute vector dimension of each node | |
| Attribute matrix | |
| Attribute feature learning vector dimension | |
| Node attribute feature learning matrix | |
| The number of sample node sequences | |
| The length of each sample node sequence | |
| Neighborhood size when node attributes are aggregated | |
| The vector dimension represented by each node embedding | |
| Node embedding represents the mean of Gaussian distribution | |
| Node embedding represents the variance of Gaussian distribution | |
| Training times of the node attribute feature learning part | |
| The number of training times of the image autoencoder attribute network embedding | |
| Attribute network embedding representation matrix |
| Dataset | Nodes | Edges | Features | Classes |
|---|---|---|---|---|
| Cora | 2708 | 5429 | 1433 | 7 |
| CiteSeer | 3327 | 4732 | 3703 | 6 |
| PubMed | 19,717 | 44,338 | 500 | 3 |
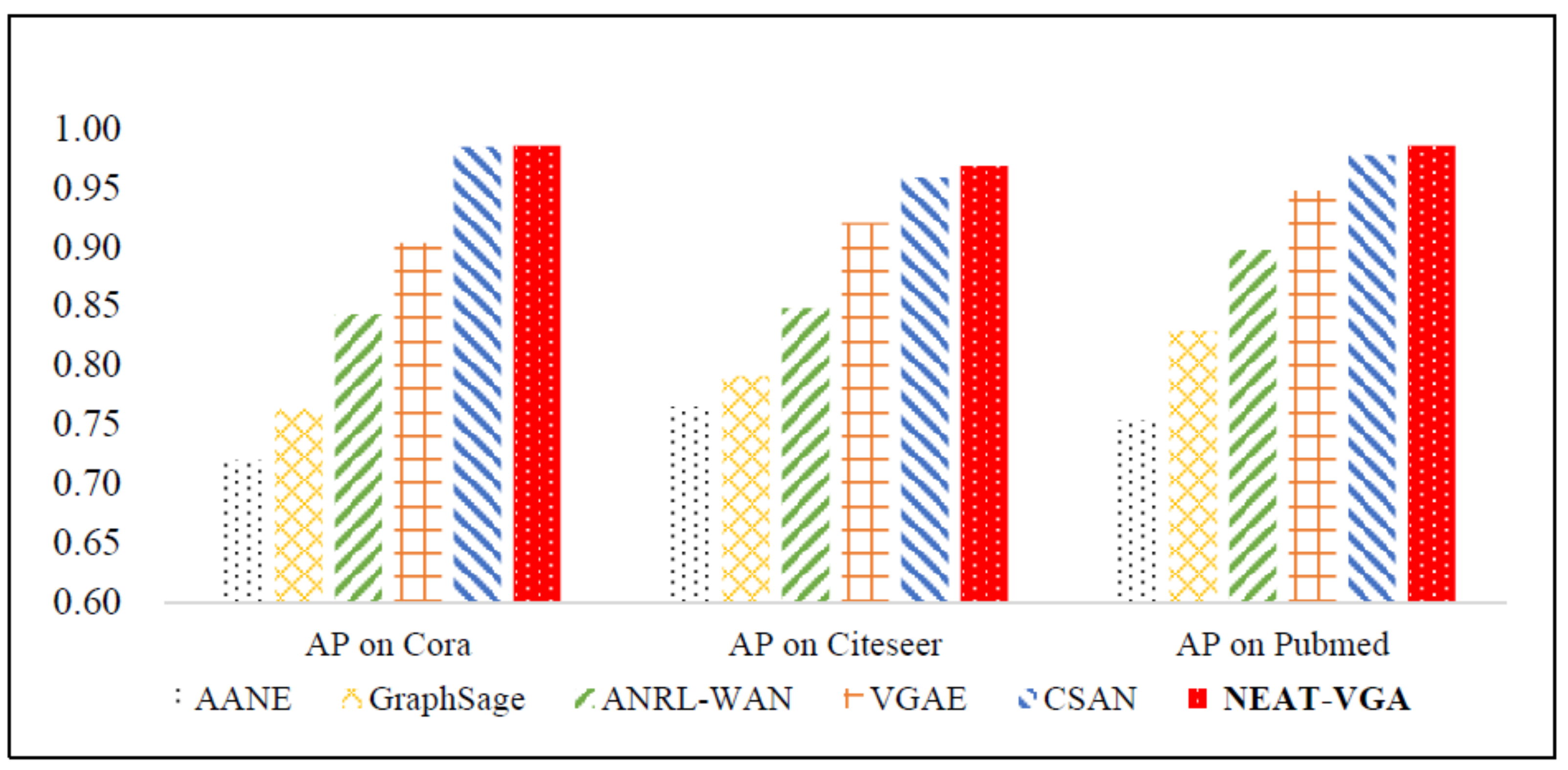
| Method | Cora | CiteSeer | PubMed | |||
|---|---|---|---|---|---|---|
| AUC | AP | AUC | AP | AUC | AP | |
| AANE | 0.767 | 0.720 | 0.785 | 0.765 | 0.783 | 0.754 |
| GraphSAGE | 0.795 | 0.763 | 0.802 | 0.791 | 0.840 | 0.829 |
| ANRL-WAN | 0.832 | 0.843 | 0.867 | 0.848 | 0.918 | 0.897 |
| VGAE | 0.914 | 0.903 | 0.908 | 0.920 | 0.944 | 0.947 |
| CSAN | 0.985 | 0.984 | 0.950 | 0.958 | 0.980 | 0.977 |
| NEAT-VGA(Ours) | 0.987 | 0.985 | 0.972 | 0.968 | 0.986 | 0.985 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, D.; Nie, M.; Zhang, H.; Wang, Z.; Wang, D. Network Embedding Algorithm Taking in Variational Graph AutoEncoder. Mathematics 2022, 10, 485. https://doi.org/10.3390/math10030485
Chen D, Nie M, Zhang H, Wang Z, Wang D. Network Embedding Algorithm Taking in Variational Graph AutoEncoder. Mathematics. 2022; 10(3):485. https://doi.org/10.3390/math10030485
Chicago/Turabian StyleChen, Dongming, Mingshuo Nie, Hupo Zhang, Zhen Wang, and Dongqi Wang. 2022. "Network Embedding Algorithm Taking in Variational Graph AutoEncoder" Mathematics 10, no. 3: 485. https://doi.org/10.3390/math10030485
APA StyleChen, D., Nie, M., Zhang, H., Wang, Z., & Wang, D. (2022). Network Embedding Algorithm Taking in Variational Graph AutoEncoder. Mathematics, 10(3), 485. https://doi.org/10.3390/math10030485