1. Introduction
The last decades have seen the significant rise of interest to the time-fractional differential equations [
1,
2,
3,
4,
5]. This is due to possibility to use these equations for modeling the multiple phenomena of anomalous diffusion and other processes with memory effects. Multiple experimental researches [
6,
7,
8] showed that the assumption of the Brownian motion in the diffusion processes may not be sufficient for the accurate description of some physical processes. The fractional differential equations are the powerful mathematical tool for adequate description of many real physical processes, and their application field still grows. The qualitive and quantitative aspects of analysis of these nonlocal models are quite complex for researching.
Thus, development of the efficient numerical algorithms for solving the direct and inverse problems for fractional differential equations is of considerable theoretical and practical interest today.
For solving approximately the initial-boundary problems for the time-fractional diffusion equation, one can use various numerical techniques. The sufficient review is presented in works [
9,
10,
11]. The most popular methods are: the finite difference method, finite element method, spectral methods, and meshless techniques. The numerical methods for solving the fractional differential equations are quite expensive due to nonlocal properties of the fractional derivatives. Thus, development of the efficient numerical algorithms is a crucially important problem. The promising way to solve various compute-intensive problems is parallel computing [
12,
13,
14,
15,
16,
17,
18]. Several parallel algorithms has been developed specifically for the fractional differential equations and anomalous diffusion problems [
19,
20].
In work [
21], for solving the SLAE with tridiagonal matrix, the parallel direct algorithm was implemented. It is based on: partitioning the matrix into blocks, processing the blocks separately on different processors, and obtaining the final solution by solving the reduced system.
In work [
22], the parallel algorithms were constructed for solving a two-dimensional partial differential equation with the Riemann–Liouville time derivatives. For solving the SLAEs arising in this problem, the iterative Krylov subspace methods were used, namely, the generalized method of minimal residuals, quasiminimal residual method, and induced dimension reduction method. Parallelization was performed by distributing the computation between threads.
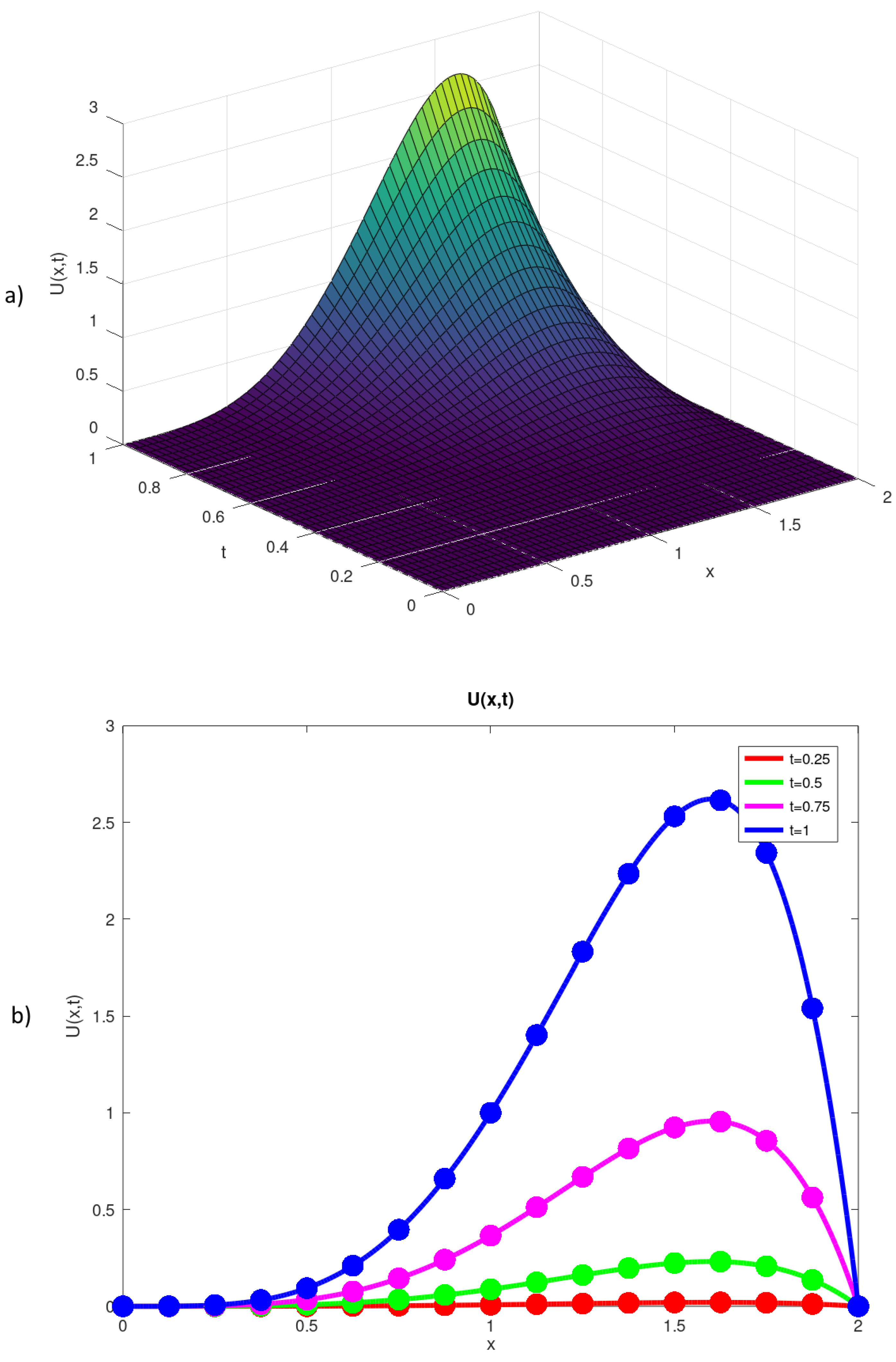
In our work, we construct the parallel algorithm for solving the one-dimensional time-fractional diffusion equation (TFDE). The implicit finite difference approximation reduces the equation to a large system of linear algebraic equations. Three algorithms are applied to solving this system, namely, the direct Thomas algorithm, the direct parallel sweep method, and the iterative accelerated over-relaxation method. The parallel algorithms are implemented on the multicore processors using the OpenMP technology. To assess the efficiency of the developed parallel algorithms, the numerical experiments are carried out.
The classic Thomas algorithm is widely used for solving the tridiagonal systems arising in various fields. Its main drawback is the limited potential of parallelization. The iterative over-relaxation method was implemented for solving the time-fractional diffusion equation as a serial program in work [
23].
In our work, the parallel sweep method is used for the first time to solve the initial boundary problem for the time-fractional diffusion equation. Its main advantage is in reducing the computing time in comparison with the classic Thomas algorithm. It also provides more accurate solution than both Thomas algorithm and the iterative over-relaxation method.
The article is organized as follows. In
Section 2, we present: the considered problem, the definitions of fractional-order operators used in the work, construct a discretization of the problem, and show that it can be reduced to solving systems of linear algebraic equations. In
Section 3, we describe the numerical algorithms and their convergence properties. In
Section 4, we construct and implement the parallel algorithms and present the results of numerical experiments. In
Section 5, we discuss these results and highlight the future research directions.
Section 6 concludes our work.
3. Numerical Methods for Solving the Problem
There is a wide variety of numerical methods for solving SLAEs. In this work, for solving the tridiagonal SLAE (
9) we will use the direct Thomas algorithm, direct parallel sweep method, and iterative accelerated over-relaxation method.
3.1. Thomas Algorithm
Thomas algorithm (in Russian literature also known as sweep method) [
26] for solving the tridiagonal systems was elaborated and investigated independently by many researchers (I. M. Gelfand and O. V. Lokutsievskii in USSR, and L. H. Thomas in USA).
It is a direct method, that is a simplified form of Gaussian elimination for a systems with a special matrices. For the system (
9) the algorithm may be written as follows:
The forward elimination phase
The backward substitution phase
The algorithm is applicable to the diagonally dominant systems. In our case, this means that the following property must hold:
This property holds in the numerical experiments presented below.
While the Thomas algorithm is extremely simple to implement and is very cache-friendly (since data is read and stored sequentially), it is essentially a serial algorithm. The flow dependency (meaning that the next coefficient must be calculated using the previous one) does not permit to use most forms of parallelization or vectorization. Thus, the parallel tridiagonal solvers are usually based on other methods [
27].
3.2. Parallel Sweep Method
In our work, we implement the parallel direct sweep method. It was proposed and researched in works [
28,
29].
The idea of parallelization consists in decomposing the interval
into
L equal subintervals split by the points
. Let us denote
,
for convenience. Then, the subintervals are
Let us introduce the operator
The auxillary subtasks may be solved independently for each subinterval
To solve them, the sweep method may be used in the following form:
The forward elimination phase
The backward substitution phase
The values
in the inner points the interval may be found by superposition
If we substitute the Formula (
15) into the system (
9) for points
, we will obtain the reduced system for the values
The parallel sweep algorithm for solving system (
9) is summed up in
Listing 1.
Listing 1.
Parallel sweep algorithm for solving SLAE.
Listing 1.
Parallel sweep algorithm for solving SLAE.
Solve the auxillary subtasks ( 13) on individual subintervals using method ( 14). This step may be executed in parallel. Construct the reduced system ( 16). This step may by executed in parallel, but requires synchronization or communications because the coefficients of the reduced systems require values from two adjacent subintervals. Solve the reduced system. Note that its dimension L is much lower than dimension of the basis system. Thus, we can solve it by the classic serial Thomas algorithm. After this step, another synchronization or communication is needed to store or transfer the computed values at the boundary points of the subintervals. Compute the solution of the basis system using Formula ( 15). This step may also be executed in parallel.
|
Essentially, steps 1 and 4 of the algorithm may be performed independently in parallel, while steps 2 and 3 require communications and synchronization.
3.3. Correctness and Stability of the Parallel Sweep Method
The sufficient correctness and stability conditions for the parallel sweep methods are
Note that .
The following theorem is valid.
Theorem 2. If either condition A or B (17) holds for the basis system (9), then both conditions A and B are satisfied for the reduced system (16): If condition A holds for (9) for some θ, then condition A holds for (16) with larger . If condition B holds for (9), then stronger condition A holds for (16).
Proof. The proof is constructed in work [
29]. □
3.4. Accelerated Over-Relaxation Iterative Method
The accelerated over-relaxation (AOR) iterative method was developed for the systems with the general dense matrices [
30,
31].
To formulate this method for Equation (
9), let us represent the matrix
A as a sum of three matrices
where
D is the diagonal matrix,
L is the lower triangular matrix, and
V is the upper triangular matrix. Then, the iterative process is defined as follows:
where
is the acceleration parameter,
is the over-relaxation parameter, and
is the sought vector at the
l-th iteration.
Specific values of this parameters reduce the AOR method to other well-known methods:
is the Jacobi method;
is the Gauss-Seidel method;
is the successive over-relaxation method.
The algorithm for solving system (
9) by the AOR method is executed as in
Listing 2.
Listing 2.
AOR algorithm for solving SLAE.
Listing 2.
AOR algorithm for solving SLAE.
3.5. Convergence of the AOR Method
The necessary condition for convergence of AOR method is formulated in work [
32].
Let us rewrite method (
18) in the form
where
is the iteration matrix of method.
The following theorem is true:
Theorem 3. If the AOR method (19) converges (i.e., the spectral radius ) for some , then exactly one of the following statements holds: and ,
and .
Proof. The proof is constructed similarly as in works [
23,
32]. □
Thus, in the numerical experiments, we select the values of parameters to satisfy these neccessary conditions.
5. Discussion
The experiments show that for both problems, the iterative AOR method is clearly inferior to the much simpler direct methods, such as Thomas algorithm and parallel sweep method, in terms of both accuracy and computing time. For Problem 1, the AOR method with tuned parameters requires less iterations and shorter computing time that the Gauss-Seidel and SOR methods. But its computing time is still 15 to 25 times lower than the direct methods.
For coarser spatial grids, such as for Problem 1 and for Problem 2, the parallel sweep method is slightly slower than the serial Thomas algorithm. This is caused by too much parallel overhead (time required for synchronizing the threads) for the small sizes of the SLAE. The results are more indicative for the large spatial grid (roughly 32 millions) in the last experiment. Here, the parallel sweep algorithm for solving the SLAE shows better time than the classic serial Thomas algorithm.
We also note that the percentage of computing the right-hand parts for each time step is up to two times larger than for solving the SLAE when we use the full memory approach (see
Table 3). The computation complexity of the right-hand parts computing is quadratic, while direct methods for SLAE are linear. Using the logarithmic memory approach (see
Table 4) reduces the time of computing the right-hand parts 3 to 4 times. Total computing time reduces up to twofold. The error of the solution remain of the same order than for the full memory.
Now, the SLAE solver takes more time than right-hand computation. This makes the effect of using the parallel solver more prominent. The parallel implementation on the basis of the parallel sweep method reduces the total computing time from 19 to 9.4 s. In contrast, the implementation which uses the classic serial Thomas algorithm reduces the computing time from 18 to 15.5 s. Thus, the parallel implementations run on 8 threads, gives the computing times of 15.5 and 9.4 s for the classic Thomas algorithms and the parallel sweep method, respectively, a speedup of 1.65 times.
Let us investigate the performance of the procedure of computing the right-hand parts deeper.
Table 5 presents the memory bandwidth utilization for the parallel implementation of this procedure (for the full memory approach) for various number of the OpenMP threads measured by the Intel VTune Profiler for the grid size
.
The table shows that even two threads saturate the memory bandwidth and further increase of the number of the threads produces miniscule improvement. This is confirmed by the results in
Table 2,
Table 3 and
Table 4. The largest speedup is about 2 times, regardless of using the full or logarithmic memory. This is caused by the fact that the calculating the right-hand parts by Formulas (
7) and (
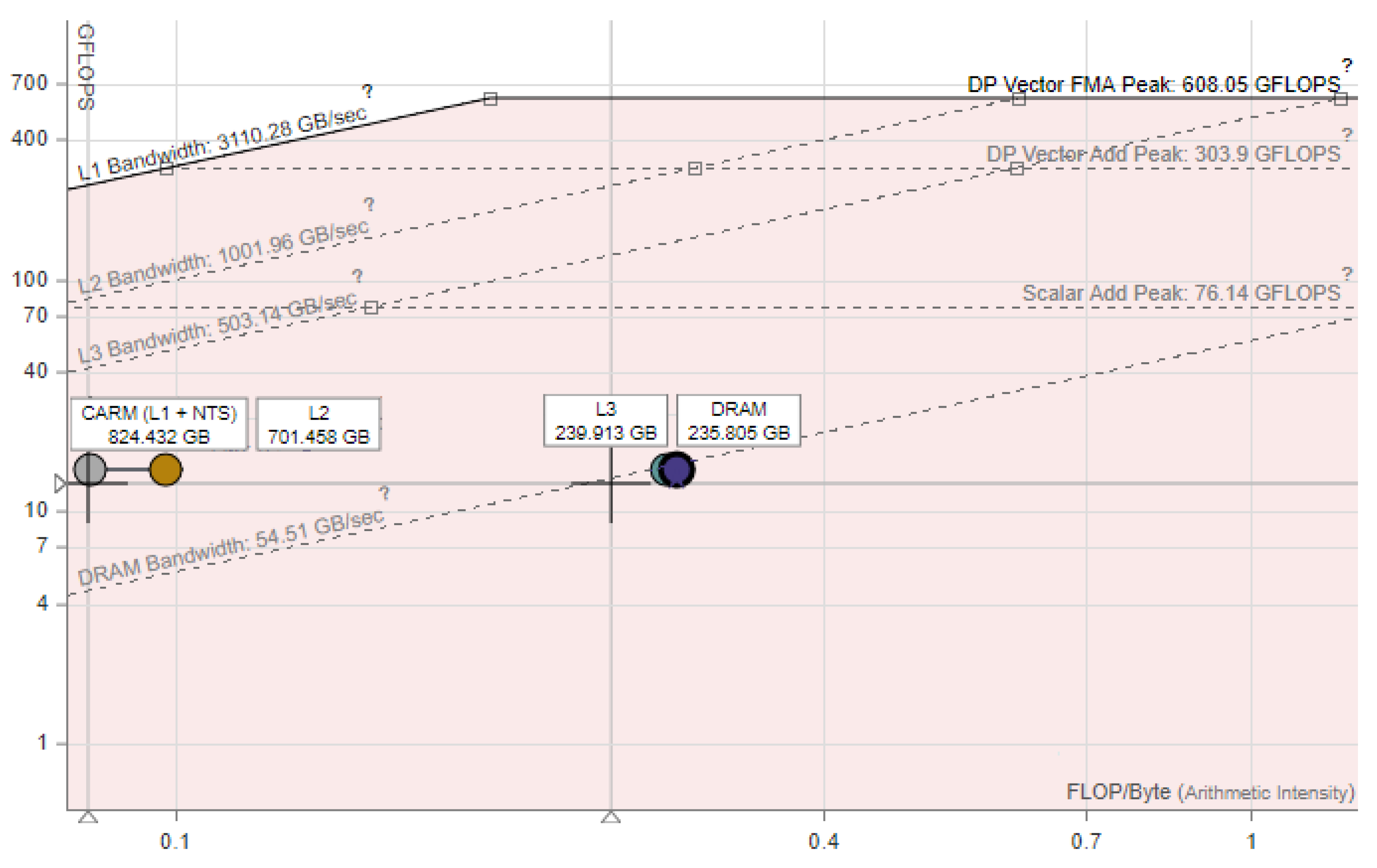
21) has low arithmetical intensity. Essentially, we perform one multiplication and one addition per 3 numbers read from memory. The roofline analysis by the Intel Advisor [
38] confirms that this implementation is memory bound (see
Figure 3).
There are several ways to get around this problem. One way is to use the hardware with higher memory bandwidth. Modern GPUs’ memory bandwidth is dozens of times higher than CPUs. For example, the NVIDIA RTX 3080 has memory bandwidth of 760 GB/s in comparison with the Intel i7-10700k with DDR4-4133 used in our experiments, which has 57 GB/s (with a comparable performance in the double precision arithmetic of about 450–500 GFLOPS).
The computing cluster systems with distributed memory allow the effective summation of the memory bandwidthes of the individual nodes. It also allows one to solve much larger problems when the total data would not fit into a memory of a single node. This makes the parallel sweep algorithm more viable for such systems.
The other way is to increase the arithmetic intensity and efficiency of memory access. Reusing the data in caches or shared memory can significantly improve the performance. Several methods for optimizing the computational procedures for fractional derivatives are proposed in works [
39,
40]. An algorithm for automatical optimization of the similar procedure of the matrix-vector multiplication for a multicore processor is presented in work [
41].
In future, the Authors plan to develop the efficient numerical algorithms for the forward and inverse 2D and 3D problems for TFDEs. This would require a larger amount of computations, as well as, larger memory requirements. To obtain more efficient parallelization, various techniques may be implemented, such as using red-black partitioning, conjugate gradient type methods, preconditioning, higher-order schemes, etc. One of the promising ways to solve large time-fractional problems is the Parareal method [
42]. Currently, it is widely used for numerical solving the initial boundary problems for classical differential equations with integer orders. Its main idea is the time domain decomposition using two grids (a coarse one and a fine one). The coarse grid is used to construct the initial approximations for the subtasks solved on a fine grid and for correcting the solution of the subtasks. The subtasks on a fine grid may be solved independently for each time subinterval. This allows one to implement the efficient parallel algorithms for various high-performance architectures.





{kind=link}
{kind=link}
{kind=link}


