1. Introduction
In this paper we study fair resource allocation for distributed job execution over multiple sites, where resources are not infinitely divisible. This problem arises from cloud computing and big data analytics, where we notice two significant features. One is that running data analysis jobs often requires a large amount of data that is usually stored at geo-distributed sites. Collecting all data needed from different sites and then executing jobs at a central location would involve unacceptable time costs in data transmission. Hence, distributed data analysis jobs that could execute close to the input data receive attention recently [
1,
2]. Job execution requires system resources. If multiple jobs need to execute at the same site but there are not enough system resources to meet their demands, fair resource allocation becomes a critical problem. On the other hand, in cloud computing, resources are usually allocated as a virtual machine. Although the amount of resources of a virtual machine is usually configurable, cloud providers often use a basic service to require the minimum amount of resources that a virtual machine must have. Thus, when studying fair resource allocation, we consider the constraint that resources are not infinitely divisible.
Resource allocation is a classical combinatorial optimization problem in many fields like computer science, manufacturing, and economics. In the past decades, fair resource allocation receives a lot of attention [
3,
4,
5]. To study fair allocation, providing a reasonable scheme to define fairness is critical. In the literature, max-min fairness is a popular scheme to define fair allocation when meeting competing demands [
6]. B. Radunovic et al. [
7] proved that in a compact and convex sets max-min fairness is always achievable. Meanwhile, the authors studied algorithms to achieve max-min fairness whenever it exists. However, they do not consider distributed job execution which is different from our work.
Max-min fairness has been generalized aiming at fair allocation of multiple types of resources. A. Ghodsi et al. [
8] proposed Dominant Resource Fairness (DRF). By defining dominant share for each user, they proposed an algorithm to maximize the minimum dominant share across all users. As a different option of DRF, D. Dolev et al. [
9] proposed “no justified complaints” which focuses on the bottleneck resource type. DRF could sacrifice the efficiency of job execution. In order to achieve a better tradeoff between fairness and efficiency, T. Bonald et al. [
10] proposed Bottleneck Max Fairness. By considering different machines could have different configurations, W. Wang et al. [
11] extended DRF to handle heterogeneous machines. All the above studies are interested in multi-resource allocation. Different from them, our problem arises from a distributed scenario where data cannot be migrated and resources allocated to jobs are not infinitely divisible. Hence, none of the schemes on fairness defined by them can be applied to handle our problem.
Y. Guan et al. [
12] considered fair resource allocation in distributed job executions. By considering fairness towards aggregate resources allocated, they defined max-min fairness under distributed settings. This work is close to our work. The key difference is that resources are assumed to be infinitely divisible. Nevertheless, we consider that the assumption does not make sense in many practical scenarios. Furthermore, it is worth noting that their fair scheme cannot be applied in our scenario, due to max-min fairness even may not exist under our settings. Hence, aiming at the new problem addressed in this paper, it is still necessary to study a new reasonable scheme on fairness.
To handle fair resource allocation in distributed setting with a minimum indivisible resource unit, we set up the model in the integral field and propose a novel fair resource allocation scheme named Distributed Lexicographical Fairness (
DLF) to specify the meaning of fairness. If an allocation satisfies
DLF, the aggregate resource allocation across all sites (machines or datacenters) of each job should be lexicographical optimal. To verify a new defined fair scheme is self-consistent or not, a usual way [
8,
9,
12] is to study whether it well satisfies critical economic properties such as Pareto efficiency, envy-freeness, strategy-proofness, maximin share and sharing incentive, and whether there exist efficient algorithms to achieve a fair allocation.
To conduct our study, we leverage a creative idea that transforms
DLF equivalently into a network flow model. Such transformation facilitates us to not only study economic properties but also to design new algorithms based on efficient max flow algorithms. More precisely, we first generalize basic properties of
DLF based on network flow theories and then use them to further prove that
DLF satisfies Pareto efficiency, envy-freeness, strategy-proofness,
-maximin share, and relaxed sharing incentive. On the other hand, to get a
DLF allocation, we proposed two algorithms based on max flow theory. One is named Basic Algorithm, which simulates a water-filling procedure. However, the time complexity is not strongly polynomial as it is affected by of the capacity of sites. To further improve the efficiency, we proposed a novel iterative algorithm leveraging parametric flow techniques [
13] and the push-relabel maximal flow algorithm. The complexity of the iterative algorithm decreases to
where
is the number of jobs and sites, and
is the number of edges in the flow network graph.
The contribution of this paper is summarized as follows.
We address a new distributed fair resource allocation problem, where resources are composed of indivisible units. To handle the problem, we propose a new scheme named Distributed Lexicographical Fairness (DLF).
We creatively transform DLF into a model based on network flow and generalize its basic properties.
By proving DLF satisfies critical economic properties and proposing efficient algorithms to get a DLF allocation, we confirm that DLF is self-consistent and is reasonable to define fairness in the scenario considered.
The rest of this paper is organized as follows.
Section 2 introduces the system model and gives a formal definition of distributed lexicographical fairness.
Section 3 remodels distributed lexicographical fairness by using network flow theories.
Section 4 proves basic properties, based on which proofs in
Section 5 show that distributed lexicographical fairness satisfies five critical economic properties.
Section 6 presents two algorithms and analyzes their time complexities. Finally,
Section 7 brings our concluding remarks and discusses future work.
3. Problem Transformation
Network flow is a well-known topic in Combinatorial Optimization. Transforming DLF equivalently to a network flow problem gives us good opportunity to apply knowledge in network flow, i.e., based on the existing network flow theories, we shall not only prove that DLF has good economic properties but also propose efficient algorithms to output a DLF allocation.
Transforming
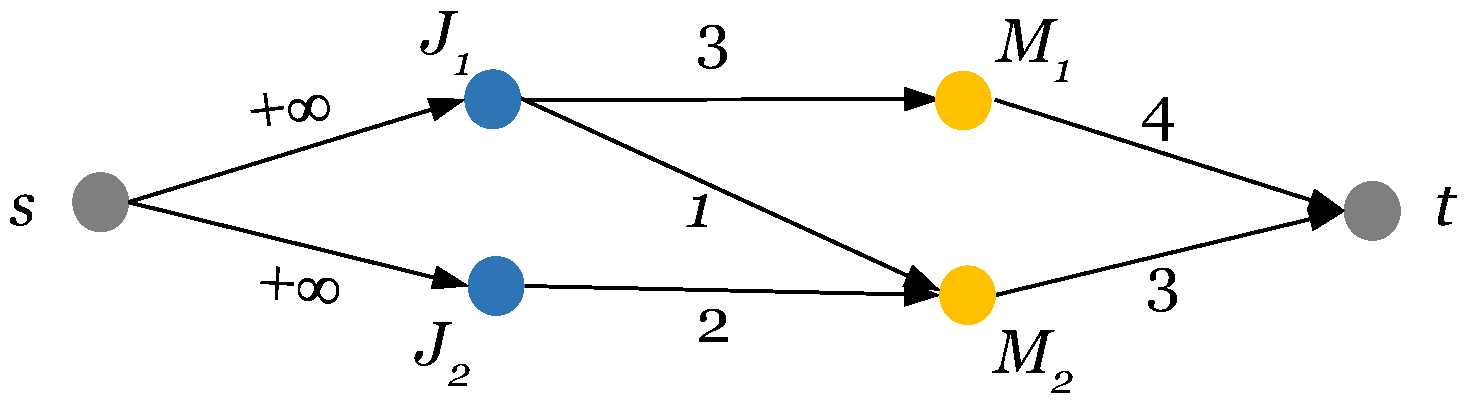
DLF means that we should build a flow network that could well model jobs, sites, capacity constraint, rational constraint, and the integral requirements. Before giving a formal description, we perform a concrete case study first. Consider there are two jobs
,
executed over two sites
,
. The demands of the two jobs are respectively
and
, while the capacity of
is 4 and the capacity of
is 3.
Figure 1 depicts the flow network built for the case. We can see that
,
and
,
all appear as nodes in the graph. We use directly edges between jobs and sites to express the demands (by edge capacity).
s and
t in the graph represent respectively the source and sink node which are essential for any flow network. We add directed edges between
s and the two jobs, where the capacity has no special constraint (expressed by
). We also add directed edges from every site to
t, where the capacity of edge is set to the corresponding capacity of site. Our general idea is to use the amount of flow passing by
and
to model the corresponding allocations. It is well-known that a feasible flow never breaks the capacity of any edge in the flow network. With the above settings, any feasible flow satisfies the capacity and rational constraints. If we further require that the flow is in integral field (i.e., for any feasible flow, the amount of flow on any edge is an integer), a feasible allocation actually corresponds to a feasible flow and vice versa.
Now let us give a formal description on problem transformation. Necessary notations are introduced first. We consider graph
with a capacity function
, where
.
s and
t represent the source node and the sink node, respectively, in a flow network.
is the set of nodes representing jobs and
is the set of nodes corresponding to sites. Each edge
is denoted as a pair of ordered nodes, i.e.,
. The capacity function
c is defined in the following.
By removing the edges that have an empty capacity, the flow network graph that we obtained for problem transformation is given in
Figure 2.
In the flow network constructed, we can also provide a formal definition on feasibility. A flow
f on
G is called feasible if it satisfies two conditions that the amount of flow over any edge
is a positive integer
and never exceeds the capacity
. For ease of representation, we use
to express the total amount flow of
f. Clearly,
is an integer too. Based on
, we have two inequalities given below:
By considering
as
, it is easy to verify that the above inequalities actually refer to the feasible and rational allocation constraints, respectively. Consequently, a feasible flow
f on
G corresponds to a feasible resource allocation
, and vice versa. For each job
, its aggregate resource allocation is the amount of flow passing by node
in graph
G:
To avoid redundant notations, we also write to mean f is feasible and let be the corresponding nondecreasing order. A DLF allocation corresponds to a lexicographically optimal flow whose definition is given below.
Definition 4. A flow is lexicographically optimal if and only if there is .
4. Basic Properties
In network flow theory, maximum flow is a well-known problem [
14]. One of the classic theorems is the augmenting path theorem [
15,
16], which plays an important role in many related algorithms [
17]. A well-known property is that maximum flow algorithm is also suitable for the integral setting where the amount of flow can only be formulated by an integer. N. Megiddo [
18,
19] studied multisource and multisink lexicographically optimal flow, the algorithm proposed in [
19] is a natural extension of Dinic maximum flow algorithm [
20]. In our paper, we also leverage maximum flow theories to carry out the key proofs. Note that if
is maximal then
, there is
.
Lemma 1. If f is a maximal flow on G, then , .
By combining (
5) and (
6), we have
. If the inequality is strictly satisfied, there must exist two successive edges
and
such that
and
. Clearly,
can be increased, which contradicts with
f being maximal.
In our model, if a flow is lexicographically optimal, it is easy to verify that f is also a maximal flow but not vice versa, i.e., a lexicographically optimal flow is a special maximal flow. Given a feasible flow f on G, an augmenting path is a directed simple path from s to t (e.g., ) on the residual graph . Similarly, an adjusting cycle on is a directed simple cycle from s to s (does not pass by t). The capacity of a given path (or a given cycle) is defined to be the capacity of the corresponding bottleneck edge, e.g., for a path , and for a cycle , . For ease of representation, we consider augmenting path or adjusting cycle to only contain edges with positive capacity, i.e., and .
In our context, performing an augmentation means increasing the original flow f by ( and ) along an augmenting path in and performing an adjustment means adjusting the original flow f by ( and ) along an adjusting cycle in . By performing an augmentation or an adjustment on a flow f, we can get a new feasible flow. The difference is that only the augmentation increases .
Claim 1. For a given feasible flow f on G, if there does not exist any augmenting path passing by in , then for any feasible augmented from f, there is also no augmenting path passing by in .
Proof. We prove by contradiction: assume there exists a feasible flow augmented from f and in the residual graph , however, there is an augmenting path passing by (denoted by in the following). In our model, , which implies is an edge existing in any residual graph. Therefore, we only need to consider where the first two nodes are s and .
As is augmented from f, we can perform successive augmentations on f to get . Note that each augmentation is performed along an augmenting path. Hence, assume the successive augmentations are performed on a sequence of augmenting paths which are respectively in the intermediate residual graphs obtained by augmentations. Here is exactly , is obtained by perform an augmentation along on , et al. Next, we perform a recursive analysis to gradually reduce and finally prove that in there also exists an augmenting path passing by , which leads to a contradiction.
Finding the last path in which has common nodes (except s, and t) with : . A special case is that we cannot find such . It means that starting from by performing augmentations along all the augmenting paths in , there is no influence on the existence of , i.e., is already an augmenting path in .
If such exists, it implies that after the augmentation is performed along in , the follow-up augmentations along , , …, do not affect the existence of any more, i.e., exists in , , …, . Now let us focus on finding an augmentation path passing by which appears in (before the augmentation along is performed). Assume is the first node not only passing by but also appearing in . We know that the augmentation along does not affect the existence of the first part of : . The remaining part of may not exist in . However, we can replace it with the part that appears in . By concatenating the above two parts together, we actually find another augmentation path in passing by . If is exactly of , we already find an augmentation path passing by in . Otherwise, let us denote the new found augmentation path by too, reduce to and restart the whole process. As is not infinite, the process will be stopped after finite times, which implies must include an augmentation path passing by . □
In our model, if a maximal flow is also lexicographically optimal, it must satisfy a special condition. In a residual graph , we name a simple path is a path if it starts at , ends at , and does not pass by s and t. Note that any path only contains edges with positive capacity.
Theorem 2. A maximal flow f on G is lexicographically optimal if and only if for all and , if , then there is no path on the residual graph .
Proof. First, proving the “only if” side. Assume there exist and , where and a path exists in . As the existence of and , we can perform an adjustment by 1-unit from s to , then along the path and along the edge to reach s again. Note that by the above adjustment, we obtain a new maximal flow where . Therefore, is lexicographically larger than f, i.e., , which contradicts with f is lexicographically optimal.
Second, proving the “if” side by contradiction. Suppose that flow
f is maximal on
G and satisfies the condition. However, it is not lexicographically optimal. Assume
is a lexicographically optimal flow such that
and
. By comparing
f with
, the set of jobs
can be naturally divided into three parts
,
and
. Next, we construct a special graph
[
21] to differentiate
and
f.
Let us denote , where . We also define a capacity function for the edges of :
if , then and ;
otherwise, and .
According to Lemma 1, we know for any site there is . Therefore, in the graph , for each , we have .
In , there could exist “positive cycles” (denoted by ): for each edge e of , there is . For a positive cycle , we let be the minimum capacity of all the edges contained in . We shall eliminate all these cycles by capacity reductions. For each edge e of , we perform . Clearly, after the reduction, is no more a positive cycle. Note that once we eliminate a positive cycle on , it is equivalent to perform an adjustment by on . For example, assume is a node included in the cycle . The adjustment is starting from s, along the edge , then along the cycle back to , and finally along the edge back to s. We can eliminate all the positive cycles to get a new by performing a sequence of capacity reduction operations. Compared with , corresponds to another maximal flow , where , there is . Hence, is not lexicographically optimal either. Moreover, , and are always kept during the capacity reductions. In the following, we turn to focus on .
In , there must exist positive paths (for each edge in the path, the capacity is a positive integer), otherwise the flow is exactly , which implies both f and are also lexicographically optimal. As there are no positive cycles in , we can extend any positive paths to be a maximal positive path, where there are no edges with positive capacity entering the starting point and no edges with positive capacity leaving the ending point. The minimum capacity of edges in a maximal positive path is also denoted by . Next, we shall demonstrate that for any maximal positive path in , the starting point must belong to and the ending point must belong to . Clearly, cannot belong to due to every node in having positive entering edges. On the other hand, cannot belong to nor , since for each node in or in , the total capacity of the positive entering edges is equal to the total capacity of the positive leaving edges. Consequently, can only belong to . Similarly, we can infer that the ending point can only belong to . Now we show that the maximal positive path in corresponds to a path in . First, note that from to , we only decrease the capacity of some edges, such that if a maximal positive path appears in , it is also a path in (not necessarily maximal).
Suppose
is a directed edge in the maximal positive path.
is also an edge having positive capacity in
. Then,
the capacity of the edge
inside
satisfies:
Similarly, assume
is a directed edge in the maximal positive path.
is also an edge with positive capacity in
.
the capacity of the edge
inside
satisfies:
The above two formulas together indicate that for each edge of a maximal positive path in , the capacity of the corresponding edge in is also positive. Without loss of generality, assume a maximal positive path that starts at and ends at . Then we get the corresponding path in . According to the assumption on f, we can easily infer that as the existence of the path. Next, we show that f must be lexicographically optimal.
First, let us assume . Together with the existence of the maximal positive path from to , we can infer that . By considering that the problem is defined in integral field, we can obtain . Note that as the maximal path exists, there is a path (a reversed path from to ) in the residual graph . As the sufficiency of this theorem is already proven, we can get that . Above all, we can obtain . A contradiction is identified, which means only can happen.
Consider
. Note that in this case we still have the
path in
and such that
. Next, we focus on the maximal positive path from
to
in
and do capacity reductions by
along such maximal path. Remember that the capacity reductions correspond to do an adjustment in
, which results in a new maximal flow
that satisfies
,
and
. Together with
, we have
. The new difference graph
is obtained by capacity reductions. Hence, in
, for node
there are no positive edges entering in and for node
there are no positive edges leaving out. Therefore, we have
and
. Above all, we have
Let us assume . According to the above inequality, we have , which also results in a contraction.
Now we can conclude that for any maximal path existing in (w.l.o.g, and represents respectively the starting point and the ending point), we must have and . We perform capacity reductions by along such maximal positive path. The adjustment corresponding to such capacity reductions is to increase by 1 and meanwhile to decrease by 1. Note that for the flow got after the adjustment, there is . It means that the adjustment cannot make f be better in terms of lexicographical order. Finally, we continue to perform capacity reductions along maximal positive paths one by one until no positive edges remains in the difference graph (i.e., is obtained). As no adjustment can make f be better, f is already lexicographically optimal. □
Corollary 1. If both f and are lexicographically optimal, they are interchangeable.
The above corollary is straightforward by the proof of Theorem 2. One can construct the different graph between f and . Then, capacity reductions can be performed to eliminate all positive cycles and maximal positive paths, which is indeed a process of transformation between the two optimal flows.
Lexicographically optimal flow is not unique. Let be the set including all lexicographically optimal flows. Next, we study the variation of aggregate resource obtained by a job among different optimal flows.
Definition 5. For any , the value interval is defined as the value range of the aggregate resource in all .
Remember that our problem is discussed in such that each value interval we defined only includes integers. The following theorem shows that the length of any value interval is at most 1.
Theorem 3. , , there is .
Proof. We prove by contradiction. Assume there exists a pair of flows and there exists a job which satisfies . Based on the proof of Theorem 2, we construct the difference graph between f and and target to transform f to . As needs to be increased, we have . Moreover, during the transformation, there must exist a time that becomes a starting point of a maximal positive path. Suppose the ending point of such path is . We have (such that ) and . On the other hand, the reverse of such maximal path is a path on the residual graph . According to Theorem 2, there is . Above all, we can show that , which is a contradiction as is obtained. □
Based on the Theorem 3, we provide a more specified definition of value interval.
Definition 6. A job ’s value interval is if and only if for all . A job ’s value interval is if and only if there exist a pair of flows such that and .
Theorem 4. For a job , suppose of a given flow . ’s value interval is if and only if there exists a path in the residual graph where .
Proof. For the “if” side, since one could obtain a new flow by performing an adjustment along the edge , then along the path and along the edge back to s. In the new flow , there is , which implies .
For the “only if” side, there exists a flow with . Based on the proof of Theorem 2, we transform f to . We first eliminate all positive cycles and then eliminate maximal positive path one by one. During the transformation process, we can find a maximal positive path which starts at and ends at another node satisfying . By such maximal path, we can identify the corresponding path on . □
By Theorem 4, we directly have the following two corollaries.
Corollary 2. For a job , suppose under a given flow . ’s value interval is if and only if there exists a path in the residual graph where .
Corollary 3. For a job , suppose under a given flow . ’s value interval is if and only if in the residual graph there neither exists a path where nor exists a path where .
We define binary relations on value intervals in order to make the comparison. Let and be the two value intervals of and respectively. if and only if or . Symmetrically, if and only if or . Finally, if and only if and .
Theorem 5. Suppose and in the residual graph there exists a path where . Let denote the set of jobs passed by the path, then , there is .
Proof. The value intervals of and can be obtained directly by Theorem 4 and Corollary 2, respectively. Both of them are equal to . Suppose and is not nor . Clearly, we have a path and a path in the residual graph . Assume ’s value interval , i.e., under the current flow f. Then we can perform an adjustment by 1 along the edge , then along the path and along the edge back to s. After the adjustment, we obtain a new flow , where and . However, it implies that satisfies which contradicts with f is lexicographically optimal. Symmetrically, we can prove that is not true too due to the existence of the path in . Above all, we can conclude . □
Definition 7. A feasible flow f on G is lexicographically feasible if and only if , if , then no path exists in the residual graph .
Definition 8. A lexicographically feasible flow f on G is called v-strict if and only if , there is and if , then in there is no augmenting path passing by .
For any given lexicographically optimal flow, we can get one unique value:
From Definitions 7 and 8, we can easily see that a lexicographically optimal flow is -strict. Additionally, we consider the empty flow () as 0-strict. Starting from the empty flow, a lexicographically optimal flow could be obtained after a sequence of water-filling stages are carried out.
Definition 9. A water-filling stage is performed on any v-strict () flow: performing augmentation by 1 for each job node in the set .
Note that by a water-filling stage, it is not necessarily that , is increased by 1, as there may already be no augmentation path passing by in . According to Claim 1, we know that if fails to be increased, then it will no more be increased during the following water-filling stages. That is also the reason that for a v-strict flow a water-filling stage only needs to focus on nodes in .
Lemma 6. A lexicographically optimal flow is obtained after water-filling stages.
Proof. This lemma is true if during all water-filling stages there is no flow obtained breaks lexicographic feasibility (Definition 7).
Without loss of generality, let us focus on one water-filling stage which will be performed on a v-strict flow, where . In such stage, we know there are a sequence of augmentations that will be performed for each node in the set . Clearly, before any augmentations are performed, the v-strict flow is lexicographically feasible. We need to prove that after any augmentation is successfully performed, the new flow obtained is still lexicographically feasible.
Suppose after a sequence augmentations the flow f obtained is still lexicographically feasible. In the current state, we can divide jobs into three parts: , and . Consider that the next augmentation will be executed along an augmenting path (denoted by ) that passes by node and assume that after the augmentation the new flow is not lexicographically feasible, i.e., in , there exists a path where . Since , we have which implies will not be increased during the current water-filling stage. There are two cases. First, in , and the path have no intersections (share common nodes in the path). In this case, we can infer that the path also exists in , as the augmentation does not affect the existence of the path. On the other hand, we can infer that under the flow f there is also . The reason is that from f to both and are kept. However, it violates the assumption that f is lexicographically feasible. Second, in , and the path have intersections. Along the two paths, let us assume node x is the first common node where the two paths intersect. Note that the sub-path (from to x) of is not affected by the augmentation such that it also exists in . On the other hand, has a sub-path from x to t in . Therefore, we can find an augmenting path from s to , then from to x and finally from x to t. However, it violates f is v-strict. Above all, we get the proof. □
Theorem 7. Suppose ’s value interval is . Under any L-strict flow f, if , then there exists a path on where . Symmetrically, if , then there exists a path on where .
Proof. Since f is L-strict, we can perform a sequence of water-filling stages on f to get a lexicographically optimal flow . Clearly, is no more increased during the following water-filling stages such that . First, consider currently . According to Corollary 2, we know in there exists a path where . Next, we prove that the path existing in also appears in . From f to , successive water-filling stages on f are performed. Every water-filling stage is composed of a sequence of augmentations each of which corresponds to an augmenting path. Thus, we could use an ordered set to include all augmenting paths (of all water-filling stages) used for augmenting f to . Suppose is the last element in which shares common nodes with the path and suppose the first common node of the two paths is . Let denote the flow before the augmentation along is processed. Note that is lexicographically feasible according to the proof of Lemma 6. We can infer that the path (sub-path of ) already appears in . On the other hand, there is a path from to t in , which is the sub-path of . Together with the edge , we find an augmenting path passing by in . Remember that f is L-strict such that in there is no augmenting path passing by . By Claim 1, we know that in there should also be no augmenting path passing by , i.e., a contradiction is identified. Therefore, for any path , it shares no common nodes with the path, which implies the path also exists in . The proof for the second case is symmetric where we can find an augmenting path passing by (with ) in an intermediately obtained residual graph, which also concludes a contradiction. □
Corollary 4. For any L-strict flow f on G, if there exists a path in where , then the same path also exists in any lexicographically optimal flow that could be augmented from f.
Corollary 4 is actually the inverse proposition of Theorem 7. The proof can be obtained by applying the proof of Theorem 7 in a reversed direction.
6. Algorithms
In this section, we shall propose two network flow-based algorithms to achieve a distributed lexicographically fair allocation (or equivalently get a lexicographically optimal flow). We use the techniques of parametric flow which is a flow network where the edge capacities could be functions of a real-valued parameter. A special case of parametric flow was studied by G. Gallo et al. [
13], who extended their push-relabel maximum flow algorithm [
23] to the parametric setting. In this paper, the techniques used are based on the work of [
13,
23].
Generally, the capacity of each edge in a parametric flow network is a function of parameter where belongs to the real value set . The capacity function is represented by and the following three conditions hold:
is a non-decreasing function of for all ;
is a non-increasing function of for all ;
is constant for all and .
The parametric flow graph in our problem can be formulated by setting the capacity of each edge
(
) in Formula (
4) to
.
Figure 3 depicts an example of parametric flow graph in our problem. Compared with the example drawn in
Figure 2, we can see that each edge taking
s as one endpoint has a parametric capacity
rather than infinity. A flow graph
G with capacity function
is called parametric flow graph
. Clearly, with the above settings, the three conditions are all satisfied, since
is an increasing function of
and
is a constant. Furthermore, we restrict
to be non-negative integers which is used to adapt the integral solution area.
It is well known that maximum flow algorithm is also applicable in discrete setting, the following lemma is directly from Lemma
in [
13].
Lemma 15. For a given online sequence of discrete parameter values and corresponding parametric graphs , any maximum flow algorithm can correctly get the maximum flows and the corresponding minimum cuts , , ⋯, , where .
The key insight of parametric flow is to represent the capacity of minimum cut (or the amount of maximal flow) as a piece-wise linear function of
, denoted by
. For a given
and the corresponding flow graph
, we let
and
be respectively the maximum flow and minimum cut, where
and
. Here
(
) denotes the set of job nodes (site nodes) in
,
(
) denotes the set of job nodes (site nodes) in
such that
,
. The cut function
for the minimum cut
is given in the following:
is the slope of . Clearly, the slope is decided by the minimum cut. The minimum cut is often not unique for , however, it is always possible to find the maximal (minimal) minimum cut such that is maximized (minimized). Let and be the minimal and maximal minimum cut of such that we have . For each job , we have . Moreover, , always belongs to , the part including s such that there is . We can also infer that the maximum slope of cut function corresponding to is not larger than the minimum slope of cut function corresponding to , i.e., the slope of the piece-wise function is non-increasing when increases. In the following, for a given , we shall use and to denote respectively the maximum and the minimum slope of the function .
6.1. Basic Algorithm
Based on the water-filling stages introduced in
Section 4, we first propose a basic algorithm which implements a sequence of water-filling stage until a lexicographically optimal flow is obtained.
Theorem 16. A L-strict flow f on graph G is also a maximum flow on the parametric graph , where .
The feasibility of f on is straightforward. As L-strict ensures that there is no augmenting path on , f is maximal on .
The basic algorithm aims to solve a sequence of parametric flows where
. Although
cannot be foreknown, the process will be stopped until no job can get more aggregate allocation by continuing to increase
. The complexity of the basic algorithm depends on the concrete maximum flow algorithm selected. If augmentation used in Ford–Fulkerson is directly taken, the complexity of implementing each water-filling is
. Overall, the complexity is
as there are
water-filling stages. If the push-relabel algorithm (implemented with queue [
13]) is take for implementing each water-filling stage, then the overall complexity decreases to
as only the first water-filling stage costs
operations. However, no matter which way is selected for implementing water-filling stage, the overall complexity is not strongly polynomial of
, since
is related to the input capacities which are upper-bounded by
.
6.2. Iterative Algorithm
The basic algorithm is time-costly due to the algorithm being performed each time the parameter
is increased. However, increasing
by one does not necessarily mean the slope of
decreases immediately. Indeed, the slope of the piece-wise function
only decreases at a few special points (called breakpoints in the following). To understand breakpoints, let us consider the first example where
and
execute over two sites
and
. The flow network is built in
Figure 1. Let us explain the breakpoints by calculating a
DLF allocation for this example. The capacity of
and
is now expressed by a variable
.
Figure 4 depicts what happens when
increases, and the dash line denotes the minimum cut. When
(
Figure 4a), the slope of
is equal to 2, i.e., for both
and
, their capacity expansion contributes to the increasing of
. Note that
is the first breakpoint. When
(
Figure 4b), only the capacity expansion of
contributes to the increasing of
such that the slope of
decreases to 1.
is the second breakpoint. When
(
Figure 4c), the increasing of
will no more increase
such that the slope decreases to 0. In
Figure 4d, we depict the two breakpoints and show the curve of
.
Generally once the slope decreases, it means there exist some jobs whose aggregate allocation stops increasing. Consequently, we only need to focus on every breakpoint: we first set the parameter , then perform push-relabel maximum flow algorithm to get a -strict flow and finally compute a new slope for . When the computation of all breakpoints is finished, we obtain a lexicographically optimal flow which corresponds to a DLF allocation.
Based on the above idea, we propose a more efficient iterative algorithm. The pseudo-code is presented in Algorithm 1. The general idea is to maintain a parametric flow with in an increasing order and identify each breakpoint sequentially. For a given , if (which means there at least exists one job whose aggregate allocation cannot be further increased), is a breakpoint. Remember that our problem is considered in . When a breakpoint identified is not an integer, we need to perform necessary rounding operations.
| Algorithm 1: Iterative Algorithm |
 |
In the first two lines of Algorithm 1, we set the parameter and run a push-label algorithm to get a 1-strict flow. Lines (4–11) contain the main iterative procedure where the key idea is using the Newton method to identify every breakpoint. More specifically, we first set a big enough value for ensuring that the slope of at is 0. At line 8 and line 9 we have two line functions which are all part of but have difference slopes. Lines 10–20 are the Newton method, by which we decrease to find the breakpoint (when the condition at line 10 is satisfied). Note that if the breakpoint identified is not an integer, we first round down and update by the push-relabel maximum flow algorithm. The result of line 13 is a -strict flow. Then at line 14 we continue to update to be -strict. If is an integer, we directly update to be -strict (line 17). Finally, we set to be and start to find the next breakpoint. Note that in the above process the slope of is decreasing such that the push-relabel maximum flow algorithm is performed on a reversed graph (reverse the direction of each edge) such that the three conditions of parametric flow still hold.
The correctness of algorithm mainly comes from Lemma 6 and Theorem 16, and also from the non-increasing slope of
, which leads to a correct application of the Newton method. The time complexity of the algorithm comes from two parts: one is update
and the other is finding breakpoints though decreasing
. The time complexity of computing
depends on the maximum flow algorithm and the number of breakpoints. The simplest way is to perform maximum flow algorithm at each breakpoint to update
. If so, the time complexity is
where
is the cost of maximum flow algorithm and
is the upper bound of the number of breakpoints. If we implement the push-relabel algorithm together with dynamic tree [
13], the time complexity can decrease to
as at each time when we update
, it is not necessarily to redo a complete push-relabel maximum flow algorithm. On the other hand, finding each breakpoint, we need to decrease
iteratively by the Newton method. The iterative times is bounded by the number of breakpoints. Note that once
decreases, we also perform the push-relabel maximum flow algorithm (line 21) to get a new function
. The complexity of the push-relabel algorithm is
. Combining with dynamic tree, the time complexity for finding one breakpoint is
. Clearly, to identify all breakpoints, the time complexity is
. By adding the time costs of the two parts together, the overall time complexity is
.


{kind=link}
{kind=link}
{kind=link}
{kind=link}




