1. Introduction
Organisations from different sectors and domains often face problems with multiple conflicting objectives to optimise. The scientific literature classifies these problems according to the number of objectives as Multi-objective Optimisation Problems (MOPs) for problems with 2–4 objectives and Many-objective Optimisation Problems (MaOPs) for problems with more than four objectives. Typically, MOPs and MaOPs are addressed through the so-called a posteriori approach, which consists of the following two phases:
Metaheuristic algorithms are promising alternatives to address Phase 1. Multi-objective Evolutionary Algorithms (MOEAs) and Multi-objective Swarm Intelligence Algorithms (MOSIAs) are quite popular because their application does not demand particular mathematical properties on the objective functions, the geometry of the Pareto frontier or the constraints of the problem [
1,
2,
3].
Even though MOEAs and MOSIAs have been widely used in addressing MOPs, most of them cannot adequately approximate the Pareto frontier for MaOPS. They have to cope with severe difficulties as the number of objectives increases; remarkably, the number of dominance resistant solutions, the high cost to ensure diversity, and the low effectiveness of the genetic operators. Studies on the difficulties and challenges found by MOEAs in addressing MaOPs are discussed by Bechikh et al. [
4], López Jaimes and Coello Coello [
5], Sudeng and Wattanapongsakorn [
6], and Ikeda et al. [
7]. One of the main criticisms of the a posteriori approaches is that they require reaching a sufficiently representative approximation of the complete Pareto front before the multi-criteria decision making.
Even supposing a good approximation of the Pareto frontier, the DM has to solve a multi-criteria selection problem in this set to address Phase 2. An alternative is to make a heuristic selection; the DM is supposed to consistently compare solutions on the approximated Pareto frontier until the best compromise is identified. This task is likely to become pretty hard and impractical in problems with many objective functions because of the human mind cognitive limitations (as stated by Miller [
8]). Another alternative is to apply a Multi-Criteria Decision Analysis (MCDA) method that articulates the preferences of the DM. Again, this approach assumes that the solution set effectively contains the most preferred solutions, which is questionable under the presence of many objective functions.
As a consequence of the above discussion, there has been an increasing interest in combining MOEAs and MCDA methods in recent years. One way is to consider the preferences to bias the search toward the Region of Interest (RoI). The RoI is the region of the Pareto frontier with the solutions that best match the DM’s preferences; accordingly, the best compromise is a solution belonging to the RoI.
The preference incorporation requires considering non-trivial aspects such as defining the model of the DM’s preferences, characterising the RoI, and determining the relevance of the solutions [
9]. Most methods for preference incorporation admit at least one of the following kinds of information on the preferences [
10,
11]: weights, e.g., [
12]; ranking of solutions, e.g., [
13]; ranking of objective functions, e.g., [
14]; reference points, e.g., [
15]; trade-offs between objective functions, e.g., [
16]; desirability thresholds, e.g., [
17]; solution classification, e.g., [
18]; and pairwise comparisons based on preference relations, e.g., [
19,
20].
The two alternatives to incorporate the above strategies are the interactive approach and the a priori approach, and both have advantages over the a posteriori one. On the one hand, better solutions are found because there is an increment in the selective pressure toward the RoI [
21]. On the other hand, preference incorporation can alleviate the DM’s cognitive effort to select the best compromise because the number of candidate solutions is relatively short. Still, the interactive approaches are strongly criticised because they require preference relations with full comparability and transitivity (as the dimensionality increases, these properties become unlikely) [
22]. Contrastingly, the a priori preference incorporation does not mandatorily require such properties. However, it demands a model that reflects the DM’s preferences about the solutions.
In many real-world MaOPs, the models should support imprecision and vagueness in the DM’s preferences. For instance, if the DM is a heterogeneous group (e.g., a board of directors) or an ill-defined entity (e.g., a community in social networks). In those circumstances, the task of eliciting the parameters of a preference model is highly difficult and is only reachable with some level of imprecision. If such imperfect knowledge is not considered, the best compromise could hardly be identified among the existing alternatives. Interval mathematics is a straightforward but effective way to express imprecision [
23].
Fernandez et al. [
24] introduced an extension of the outranking method by incorporating interval numbers in the preference parameters. This MCDA method can handle incomparability, veto situations, and non-transitive preferences. These properties become critical to address real-world MaOPs because many DMs have non-transitive and non-compensatory preferences. Additionally, the DM feels more comfortable eliciting the values of the parameters as interval numbers than as precise values. If the DM cannot (or not want to) directly give a value for some required parameters, they may use an indirect elicitation method to infer them, e.g., [
25].
In light of the above discussions, this paper presents a further analysis to observe how incorporating interval outranking in MOSIAs impacts the performance. We propose embedding multi-criteria ordinal classification based on interval outranking (strictly speaking, the INTERCLASS-nC method [
26]) into many-objective optimisation algorithms. Similar to previous approaches based on ordinal classification, e.g., [
11], our proposal also requires representative samples of solutions classified by the DM as ‘Satisfactory’ or ‘Dissatisfactory’. However, we extended this notion with two artificial classes (for internal use of the algorithms) that increase the selective pressure toward the RoI. By applying this strategy, we introduce the a priori versions of two relevant a posteriori algorithms based on swarm intelligence; specifically, Multi-objective Grey Wolf Optimisation (MOGWO) [
27] and Indicator-based Multi-objective Ant Colony Optimisation for continuous domains (
) [
28]. The a priori preference incorporation significantly increased the performance of the MOSIAs according to a non-parametric test (Mann–Whitney–Wilcoxon).
The remainder of this paper is organised as follows.
Section 2 includes some preliminaries on multi-objective optimisation, interval outranking, ordinal classification, and the MOSIAs taken as baseline.
Section 3 details the proposed algorithms with preference incorporation.
Section 4 shows the experimental results. Lastly,
Section 5 discusses the conclusions and provides some directions for future research.
2. Background
This section presents an overview of the theoretical foundations.
Section 2.1 presents some preliminaries on optimisation with multiple objectives.
Section 2.2 briefly describes the baseline versions of the MOSIAs used in this paper. Lastly,
Section 2.3 presents the model for multi-criteria ordinal classification based on interval outranking.
2.1. Preliminaries on Multi-Objective Optimisation
Optimisation refers to finding the values in the decision variables (independent variables) that provoke extreme values of one or more objective functions (dependent variables). It is called ‘mono-objective’ optimisation if a single function is treated. In contrast, it is called ‘multi-objective’ optimisation if a few objective functions are treated (typically, up to four). Farina and Amato [
29] recognised that most MOEAs are severely affected when they address problems with more than four objective functions, named them ‘many-objective’ optimisation problems.
Real-world applications often involve optimising several functions that are essentially conflicting [
30]. As a consequence, no point is simultaneously optimal in all objective functions.
Here,
represents a solution of a MOP/MaOP: a vector of decision variables that optimises a vector function
whose components represent the values of the objectives. Equation (
1) defines
, where
m is the number of objectives (dimensionality of the problem), and
n is the number of decision variables. Applied optimisation models usually add constraints to Equation (
1) to reflect real situations.
Pareto dominance is widely accepted to compare two solutions, determining which of them is better. Thus, Pareto dominance discriminates between solutions by comparing their
. Without loss of generality, let us consider minimising the
m objectives; the Pareto dominance relation, represented by the symbol ≼, may be expressed as [
31]
The non-dominated solutions make up the Pareto set, expressed as
where
is the feasible region.
The Pareto frontier, , is the image of the Pareto set. In the absence of information on the preferences of the DM, a sufficiently representative sample of the Pareto frontier should be calculated.
Identifying a set of Pareto efficient solutions is indeed necessary to solve MOPs and MaOPS. Still, it is not sufficient since the DM must select the best compromise (the solution to implement). The DM chooses the best compromise according to their personal preferences about the objective functions. In practice, the best compromise is the ultimate solution to the problem.
2.2. An Overview of Two Swarm Intelligence Algorithms to Address MaOPs
In this section, we provide a brief description of MOGWO [
27] and
[
28].
2.2.1. Multi-Objective Grey Wolf Optimisation
Mirjalili et al. [
27] proposed MOGWO—Multi-Objective Grey Wolf Optimiser—which extends the mono-objective algorithm Grey Wolf Optimiser (GWO) [
32] to treat multiple objectives. This swarm intelligence algorithm is inspired by nature, specifically by the behaviour of grey wolves in tracking and hunting their prey. By analogy, the solution with the best value in the objective function is named the
wolf. The second-best and the third-best solutions are named
and
wolves, respectively. The remaining solutions are known as Ω wolves. The leaders (
,
, and
) guide the optimisation process, and the Ω wolves follow the leaders in the search for the global optimum.
Let
n be the number of decision variables,
be the number of the current iteration,
be the
n-dimensional location point of the
ith wolf during the
th iteration, and
be the positions of a pack with
ℏ wolves. The following equation simulates how the Ω wolves are relocated to siege their prey during hunt following the social leadership:
where
,
, and
are
n-dimensional vectors reflecting the influence of the three leader wolves during the
th iteration. Each component of them is calculated as
In Equations (
4)–(
7),
,
and
are the positions of the leader wolves at the
jth coordinate,
is the number of the next iteration, and
A and
are coefficient vectors modelling the encircling behaviour of wolves as
and
In Equations (
8) and (
9),
a is an
n-dimensional vector whose elements linearly decrease from two to zero throughout the run of the algorithm, and
and
are random
n-dimensional vectors with values in
. The components of
and
are similarly calculated as those of
in Equation (
9).
Exploration is promoted by
A with values greater than one (or less than –1); with that setting, the Ω wolves diverge from the leaders.
C is another component of GWO that favours exploration, whose components represent weights and are generated at random to emphasise (
) or de-emphasise (
) the influence of the
,
and
wolves in defining the distance in Equations (
5)–(
7). According to Mirjalili et al. [
27], p. 109: “
C is not linearly decreased in contrast to
A. The
C parameter was deliberately required to provide random values at all times in order to emphasise exploration not only during initial iterations but also final iterations”.
GWO exploits the search space if because, when the components of A are in , the position of the ith wolf in the next iteration will be located between its current position and the position of the leader. This setting assists Ω wolves to converge toward an estimated position of their prey, provided by , and .
GWO starts the optimisation process by generating solutions at random during the first population. Then, the three best solutions so far are considered as the
,
and
wolves. In the next iteration, each Ω wolf updates its position by applying Equations (
4)–(
7). Simultaneously, the components of
a are linearly decreased in each iteration. Therefore, the pack of wolves tends to widely explore the search space during the first iterations and intensively exploit it during the last iterations. The algorithm stops when a maximum number of iterations is reached, and
is returned as the best solution obtained throughout the optimisation process.
To treat MOPs via GWO, MOGWO integrates the following two extensions into GWO: (i) an archive with the Pareto optimal solutions obtained so far, and (ii) a criterion for picking the leaders (, and ) from the archive.
If the archive is full of non-dominated solutions (note that there is a predefined size) and there is a new solution to be entered; then, a grid technique determines the region in the Pareto frontier that is the most crowded by the archive. A solution is removed from this region at random; then, the new solution may be added to the archive. Thus, the probability of a solution being deleted is proportional to the number of points in each hypercube (region).
Complementarily, the criterion to select
,
and
favours the least crowded regions in the Pareto front. The selection is based on a roulette-wheel method with the following probability for each hypercube:
where
is a constant (
), and
is the number of solutions in the
lth hypercube. The two extensions of MOGWO jointly promote the representativeness in the sample of the Pareto frontier.
2.2.2. Indicator-Based Multi-Objective Ant Colony Optimisation for Continuous Domains
Socha and Dorigo [
33] proposed
, an extension of Ant Colony Optimisation (ACO) [
34] to optimise mono-objective problems with continuous decision variables. In
, the pheromone matrix (
) is an archive that stores the best-so-far solutions. Here, a vector
represents a solution of a problem with
n decision variables, and
is the objective function to minimise. The
best-evaluated solutions are stored in
, following the implicit order given by
. The position in
of each
determines a weight (
) that measures the quality of
, defined in Equation (
11).
Equation (
11) defines
as a value of the Gaussian function with standard deviation
, mean 1.0, and argument
l. Here,
is the number of solutions in
, and
is a parameter (
). The effect of
is to establish the proper balance between the pressures exerted by the best-so-far solution (with values close to one) and the iteration-best solutions (with values close to zero).
Furthermore, a Gaussian kernel (
) is calculated for each decision variable
as
where
According to Equation (
13),
is a normal distribution, where
is the standard deviation, and
is the mean. The former is calculated in each iteration as ants construct solutions. Then,
in Equation (
12) is a weighted sum of
, which defines the one-dimensional Gaussian function for the
jth decision variable of the
lth solution in
.
Ants construct solutions by performing
n steps. The
ith ant sets the value for the variable
at the
jth step. Here, only
—the resulting Gaussian kernel—is needed. Then, the weights
are computed through Equation (
11) and used to sample, by following two phases:
2.3. Multi-Criteria Ordinal Classification Based on Interval Outranking
The notion behind outranking is that the credibility of the proposition ‘
x is at least as good as
y’—represented as
—may be calculated by analysing each pair of their criteria scores [
35]. ELECTRE is the most representative MCDA method of the outranking approaches. Typically, ELECTRE defines
, where
, the concordance index, cumulates the weights of the criteria in favour of the statement ‘x is at least as good as y’; and
, the discordance index, assesses the combined strength of the criteria against ‘x is at least as good as y’.
Both indexes are calculated in function of a series of parameters that must be appropriately inferred so that models the preferences of the DM. Interval outranking generalises the classic outranking to the framework of interval numbers, providing support when the values of the preference parameters are imprecisely known.
If the reader is be unfamiliar with interval mathematics,
Appendix A compiles the basic notions to understand interval outranking. Note that interval numbers in this paper are written in boldface italic letters.
Let O be a set of alternatives (solutions). Each is evaluated with an m-dimensional objective function . Without loss of generality, we suppose that each is a minimising objective and, consequently, the preference of the DM increases as the value of decreases. The parameters of the outranking model are:
The vector of weights, , where and ;
The vector of veto thresholds, ;
The majority threshold, , where ; and
The credibility threshold, , where .
The concordance coalition of two solutions
, denoted as
, is the subset of objectives favouring the statement ‘
x is at least as good as
y’. The concordance index for the statement ‘
x is at least as good as
y’ is the interval number
, defined as
and
Moreover, the discordance coalition consists of the objectives that are not in the concordance coalition, defined as
. These objectives justify arguments invalidating the outranking relation ‘
x is at least as good as
y’. The value
models the degree of credibility of the proposition ‘the
kth criterion alone vetoes the statement
x outranks y’. The discordance index,
, is calculated appraising the credibility of veto of each objective in
, and is expressed as
Accordingly,
is redefined as
By following Equation (
20), Fernandez et al. [
24] introduced a pair of binary preference relations. First, the crisp outranking relation (
) is presented in Equation (
21), where
is a threshold on the credibility of ‘
x is at least as good as
y’. Lastly, Equation (
22) presents the crisp relation ‘
x is preferred to
y’.
Fernandez et al. [
26] proposed INTERCLASS-nC, an extension of ELECTRE TRI-nC [
36] in the framework of interval outranking to multi-criteria ordinal classification. INTERCLASS-nC is applicable in circumstances in which other MCDA methods fail, specifically when the DM does not want to (or cannot) set precise values for the model parameters (majority threshold, veto thresholds, and weights). INTERCLASS-nC is especially advantageous if the DM has only a vague idea about the boundaries between adjacent classes; nonetheless, they can quickly identify one representative solution at least in each category, which may be characterised by intervals.
INTERCLASS-nC considers the array of classes
, increasingly sorted by preference (
), and the subset of reference solutions introduced to characterise each
,
(where
, and
). Additionally,
is the array of all reference solutions sorted by preference, where
is the anti-ideal point and
is the ideal point. Following the interval outranking, the following condition is true for
:
Then, Equations (
24) and (
25) are used to define the categorical credibility indices between an alternative
x and the category
.
The crisp relation of interval outranking is extended to compare actions with the sets of characteristic actions as
;
.
To suggest a class for a new alternative x, INTERCLASS-nC uses the selection function and two heuristics—the ascending rule and the descending rule—that are conjointly used. Each one of these heuristics proposes a class for an alternative x. If the classes do not coincide, they define a range of assignments for x (any category within such a range is admissible as the class of x).
The steps of the ascending rule are the following
Compare x to for until the first ℓ such that ;
If , select as a possible class for x;
If , select as a possible class for x if ; otherwise, select .
If , select as a possible class for x.
The descending rule has the following steps
Compare x to for until the first ℓ such that ;
If , select as a possible class for x;
If , select as a possible class for x if ; otherwise, select .
If , select as a possible class for x.
3. Proposed Algorithms
In this section, we describe how ordinal classification based on interval outranking was embedded in MOGWO and
to incorporate the preferences of the DM. The primary strategy is to measure the quality of the solutions in terms of the class suggested by INTERCLASS-nC. Consequently, the selective pressure increases toward the solutions the DM is highly satisfied with. Note that both proposed algorithms are not intended for searching representative approximations of the complete Pareto frontier; instead, they search for the RoI: a relatively short subset of Pareto optimal solutions that best match the DM’s preferences. Here, we propose that the RoI is made of solutions classified as ‘Highly Satisfactory’, and the best compromise—the final prescription chosen by the DM—should be a solution belonging to the RoI.
Section 3.1 introduces the Grey Wolf Optimiser with Interval outranking-based ordinal Classification, abbreviated as GWO-InClass.
Section 3.2 introduces Ant Colony Optimisation with Interval outranking-based ordinal Classification, abbreviated as ACO-InClass.
3.1. The GWO-InClass Algorithm
GWO-InClass extends MOGWO by classifying the solutions in each iteration utilising INTERCLASS-nC before picking the leaders from the archive, keeping the solutions ranked in the following order: ‘Highly Satisfactory’, ‘Satisfactory’, ‘Dissatisfactory’, and ‘Strongly Dissatisfactory’.
We suggest using an ordinal classifier that has already been validated in an evolutionary algorithm for many-objective optimisation [
37]. In this approach, the DM should classify the reference solutions (input) in two classes, ‘Dissatisfactory’ and ‘Satisfactory’ (respectively,
and
), the minimum number of classes to apply INTERCLASS-nC. Then, the model is extended by artificially adding the classes ‘Highly Satisfactory’ and ‘Strongly Dissatisfactory’. Each new solution
x generated during the evolutionary search is classified according to the following assumptions:
If , then the DM is highly satisfied with x; otherwise, the DM is satisfied with x.
If , then the DM is strongly dissatisfied with the solution x; otherwise, the DM is dissatisfied with x.
Algorithm 1 presents an outline of the ordinal classifier proposed by Balderas et al. [
37].
A crucial process of GWO-InClass is to update the archive and select the , and wolves; this process is presented in Algorithm 2. Here, Lines 1–2 initialise the variables; Lines 3–12 rank the solutions according to the class suggested by Algorithm 1; Lines 13–15 make sure that the archive () is not larger than the maximum size allowed by the parameter ℏ; and, lastly, Lines 16–20 pick three different solutions from the non-empty best-evaluated class to be the leader wolves.
Algorithm 3 provides an algorithmic outline of GWO-InClass. Unlike MOGWO, GWO-InClass needs information about the preferences of the DM, which is exploited to become closer to the RoI. The preferences of the DM are articulated through an interval outranking model. We suggest using the proposal by Fernandez et al. [
25] to infer the model parameters that reflect the preferences of the DM. Furthermore, GWO-InClass also needs the reference sets with solutions labelled by the DM as ‘Satisfactory’ or ‘Dissatisfactory’. Initially, synthetic solutions are helpful to perform this task; however, if the DM is not confident about those initial sets, they may additionally have some interactions with GWO-InClass throughout the optimisation process and directly classify the solutions in the archive, updating the reference sets. Binary classification of solutions is one of the least cognitively demanding ways to interact with the DM.
| Algorithm 1 Ordinal classifier based on interval outranking |
Input: Number of objectives (m), parameters of the outranking model (, , , ), a solution x, representative sets and Output: The class for x ()
- 1:
▹ Descending and ascending rules - 2:
if
then - 3:
if then - 4:
- 5:
else - 6:
if then - 7:
- 8:
return
|
| Algorithm 2 Selection of the leader wolves |
Input: Archive ( ), solutions of the current iteration (), maximum size of the archive (ℏ) Output: The leader wolves () - 1:
- 2:
▹ Filtering only Pareto efficient solutions, see Equation (3)- 3:
for do ▹ Main loop for ranking solutions - 4:
▹ Classifying by Algorithm 1 - 5:
if then - 6:
- 7:
if then - 8:
- 9:
if then - 10:
- 11:
if then - 12:
- 13:
if
then - 14:
Remove the worst solutions according to the ranking - 15:
- 16:
- 17:
for do ▹ Main loop for picking the leaders - 18:
▹ Choosing the best evaluated set that is not empty - 19:
▹ Probabilities calculated by Equation (10) - 20:
Remove from ▹ To avoid selecting the same solution as , or - 21:
return
|
In Algorithm 3, Lines 1–5 initialise the parameters and generate the initial positions of the wolves. Line 6 picks the first leader wolves. Lines 7–12 present the iterated process of GWO-InClass; here, Line 8 applies Equations (
4)–(
9) to update the positions of the Ω wolves, following the social leadership of the
,
and
wolves; Line 10 updates the archive and obtains the latest positions of the leader wolves; and lastly, Lines 11–12 update the parameters and variables to perform the next iteration.
| Algorithm 3 The Grey Wolf Optimiser with Interval outranking-based ordinal Classification |
Input Number of objectives (m), number of decision variables (n), parameters of the outranking model (, , ), reference solution sets (, ), maximum size of the archive (ℏ) Output: An approximation of the RoI ()
- 1:
Initialise the parameters of MOGWO (a, A, and C) - 2:
▹ Generating the initial pack of wolves at random - 3:
Calculate ▹ Getting the values of the objective functions for each wolf - 4:
- 5:
- 6:
▹ Algorithm 2 - 7:
while do ▹ Main loop of the optimisation process - 8:
▹ Updating the pack of wolves by applying Equations (4)–(9) - 9:
Calculate - 10:
▹ Algorithm 2 - 11:
Update a, A, and C - 12:
- 13:
return
|
3.2. The ACO-InClass Algorithm
Like GWO-InClass, ACO-InClass stores the best solutions in the pheromone matrix
—its archive—considering the class suggested by Algorithm 1.
Figure 1 depicts the pheromone representation used in ACO-InClass; here,
is the size of the archive,
n is the number of decision variable,
is the vector of the
lth solution in the archive,
is the value of the
jth decision variable of
,
is the Gaussian kernel for the
jth decision variable, and
is the weight of the
lth solution.
The chief difference between
and ACO-InClass is the criteria to sort
. Falcón-Cardona and Coello Coello [
28] suggested
scores [
38] as the primary criterion to rank the solutions in
. Contrarily, in this paper, we propose the class indicated by Algorithm 1 as the primary criterion, and
scores as the secondary criterion (intra-class solutions are sorted using the
metric). The archive is set to store the
top-ranked solutions.
Algorithm 4 provides an algorithmic outline of ACO-InClass. Lines 1 and 7 initialise the parameters and variables of the algorithm; Lines 2–6 generate and evaluate the initial random solutions of the colony. Lines 8–16 present the iterated process of ACO-InClass; here, Lines 9–10 generate the solutions of the colony by following the equations provided in
Section 2.2.2, particularly Equations (
14)–(
16); Lines 11–14 evaluate and rank the solutions; and, lastly, Lines 15–16 update the data structures to perform the next iteration.
| Algorithm 4 Ant Colony Optimisation with Interval outranking-based ordinal Classification |
Input Number of objectives (m), number of decision variables (n), parameters of the outranking model (, , ), reference solution sets (, ), maximum size of the archive () Output: An approximation of the RoI ()
- 1:
Initialise the parameters of ( and ) - 2:
▹ Generating the initial solutions of the pheromone trail at random - 3:
Calculate ▹ Getting the values of the objective functions for each ant - 4:
▹ Filtering only Pareto efficient solutions, see Equation (3) - 5:
) - 6:
Rank solutions in ▹ See Algorithm 1 - 7:
- 8:
while do ▹ Main loop of the optimisation process - 9:
for do ▹ is the colony (with ants) - 10:
Generate a new solution based on ▹ Applying Equation (16)- 11:
Calculate ▹ Getting the values of the objective functions for each ant - 12:
▹ Filtering only Pareto efficient solutions, see Equation (3) - 13:
) - 14:
Rank solutions in ▹ See Algorithm 1 - 15:
Copy into the first solutions of - 16:
- 17:
return
|
4. Experimental Validation
We implemented GWO-InClass and ACO-InClass in Java using OpenJDK 11.0.10, on a computer with an Intel Core i7-10510U CPU 1.80 GHz, 16 GB of RAM, and Manjaro 5.10 as operating system. This computer setting applies to all experiments reported in this section.
GWO-InClass has three main parameters to be adjusted:
a,
C, and
ℏ. The components of the vector
a are initially set in two, and are linearly decreased to reach zero in the last iteration. The vector
C is dynamically generated during each iteration, providing random numbers (cf. [
27]). The parameter setting of ACO-InClass is
and
(cf. [
28]). The parameter settings of the reference algorithms—NSGA-III, MOGWO and
—are also those originally published by the authors in the articles [
27,
28,
39]. A particular case is the size of the population (
ℏ in GWO-InClass and
in ACO-InClass), which depends on the number of objective functions (
m):
for
,
for
, and
for
. These values were inspired by the discussion of Deb and Jain [
39] on suitable population sizes for evolutionary algorithms. The maximum number of iterations for all the algorithms reported in this section is
for
and
for
.
The adjective ‘significant’ is used in this section if a non-parametric
U test (also know as Mann–Whitney test or Wilcoxon rank-sum test) with a 0.95-confidence level validates the difference as statistically significant. Furthermore, we performed all tests for statistical significance through STAC [
40].
The rest of this section is organised as follows.
Section 4.1 presents the test suite used to validate the results, as well as the indicators to measure the quality of the solutions.
Section 4.2 describes the results obtained by GWO-InClass. Lastly,
Section 4.3 presents the results by ACO-InClass.
4.1. Benchmark Problems and Performance Indicators
DTLZ [
41] has become the standard test suite most broadly accepted to assess the performance of MOEAs and MOSIAs. Accordingly, we ran our algorithms on the nine problems in the DTLZ suite, named DTLZ1–DTLZ9. These problems have continuous decision variables, and are scalable regarding the number of decision variables and objective functions, offering Pareto frontiers with challenging properties (e.g., bias, concavity, convexity, degeneration, multi-frontality, and separability). We explored the dimensionality of each DTLZ problem by considering 3, 5, and 10 objective functions (
m); accordingly, there are 27 different instances to validate our algorithms. The numbers of position-related variables (
k) and decision variables (
n) for each problem are the following:
DTLZ1: and .
DTLZ2–DTLZ6: and .
DTLZ7: and .
DTLZ8 and DTLZ9: and .
As GWO-InClass and ACO-InClass consider the DM’s preferences, each of the 27 test instances was validated using ten interval outranking models, representing different DMs. Some state-of-the-art studies [
42,
43,
44] have proposed and used these synthetic DMs to validate a priori optimisation methods run on the DTLZ suite. The primary motivation behind this choice is that an acceptable approximation to the true RoI is known for these synthetic DMs, and these Approximated RoIs (abbreviated as ‘A-RoI’ from hereon) are in compliance with the interval outranking model described in
Section 2.3, which is the keystone of the interval ordinal classifier GWO-InClass and ACO-InClass use (see Algorithm 1).
The A-RoI should contain the most preferred solutions in terms of interval outranking; Rivera et al. [
44] followed this underlying principle to calculate the A-RoI as follows (cf. [
42,
43]):
The proposed algorithms ran 30 times on each test instance using each synthetic DM (as a consequence, each algorithm was run 300 times per instance). The benchmark algorithms—NSGA-III, MOGWO and —were also run 300 times.
There are several indicators for evaluating the performance of a multi-objective optimiser that approximates the complete Pareto frontier (e.g., hypervolume, spacing, spread, and inverted generational distance). However, these indicators are inadequate for assessing the performance of preference-based multi-objective algorithms because no metric can be directly applied when only a partial Pareto frontier is considered [
45]. Furthermore, some attempts to assess the quality of a preferred solution adapt these indicators in an oversimplified way, making the assessments misleading. In line with this notion, we measured the performance via three indicators that consider the solutions that maximise the preferences of the DM. Let
be the latest set of solutions of an algorithm, the following three indicators are utilised:
Minimum Euclidian distance. The distance from the A-RoI to the closest point in .
Average Euclidian distance. The average distance from the points in the A-RoI to those in .
Satisfaction. The proportion of solutions in belonging to the class ‘Highly Satisfactory’.
On the one hand, the distance-based indicators measure the quality in terms of the similarity between and the A-RoI; the minimum distance considers the best solution alone, and the average distance considers the overall trend. For these indicators, the lower the values, the closer the approximation. On the other hand, the satisfaction-based indicator measures the quality of the algorithm considering the number of solutions that could potentially become the best compromise solution. For this indicator, greater values are preferred.
4.2. On the Performance of GWO-InClass
Table 1 shows the results of GWO-InClass in comparison with MOGWO. Given a number of objectives (Column 1),
Table 1 presents the average performance in terms of the indicators (referred to in Column 2) obtained by each algorithm (referred to in Column 3) on each DTLZ problem (referred to in Columns 4–12); here, the cells were shaded if the difference is statistically significant: in blue if it is in favour of GWO-InClass, in yellow if it is in favour of MOGWO.
The information in
Table 1 may be summarised in the following points:
Considering the satisfaction-based indicator: The results of GWO-InClass were significantly better than those of MOGWO in DTLZ1, DTLZ2, and DTLZ6 regardless of the number of objectives. In other problems (DTLZ3, DTLZ5, and DTLZ7), the advantage of including ordinal classification only became significant when m increased. On the whole, our strategy had a greater impact on the ‘satisfaction’ indicator in many-objective optimisation () than in multi-objective optimisation ().
Considering the Euclidean indicators: The results on DTLZ1–3 were particularly encouraging because the averages of GWO-InClass were consistently lower than those of MOGWO, having statistical significance in the great majority of the instances. In DTLZ5 and DTLZ6, GWO-InClass became closer to the RoI only in many-objective instances. Contrastingly, when , our strategy was inconvenient to treat DTLZ4 and DTLZ6.
Considering DTLZ8 and DTLZ9: The embedding of ordinal classification in MOGWO does not yield any significant benefit. It is worth noting that they are the only problems with side constraints in this benchmark [
46].
As a partial conclusion, we would recommend using GWO-InClass instead of MOGWO to address MaOPS. GWO-InClass was at least as good as MOGWO; what is more, it was significantly better on a regular basis. A test for statistical significance supports this hypothesis on the DTLZ test suit.
Additionally, we compared the results of GWO-InClass with NSGA-III, which has been widely accepted by the scientific community as a benchmark algorithm for evolutionary many-objective optimisation.
Table 2 presents the results of both algorithms on the DTLZ test suit. Again, the three indicators—the average Euclidean distance, the minimum Euclidean distance, and satisfaction—are considered, and the cells with significant differences are shaded (blue in favour of GWO-InClass, yellow in favour of NSGA-III).
According to
Table 2, the worst performance was observed when
. Contrarily, GWO-InClass approximated the RoI significantly better than NSGA-III in most of the 10-objective instances. Considering the satisfaction-based indicator, DTLZ1, DTLZ7, and DTLZ9 are especially challenging for GWO-InClass. To conclude, the performance of GWO-InClass becomes competitive as the number of objectives increases according to this standard of the literature.
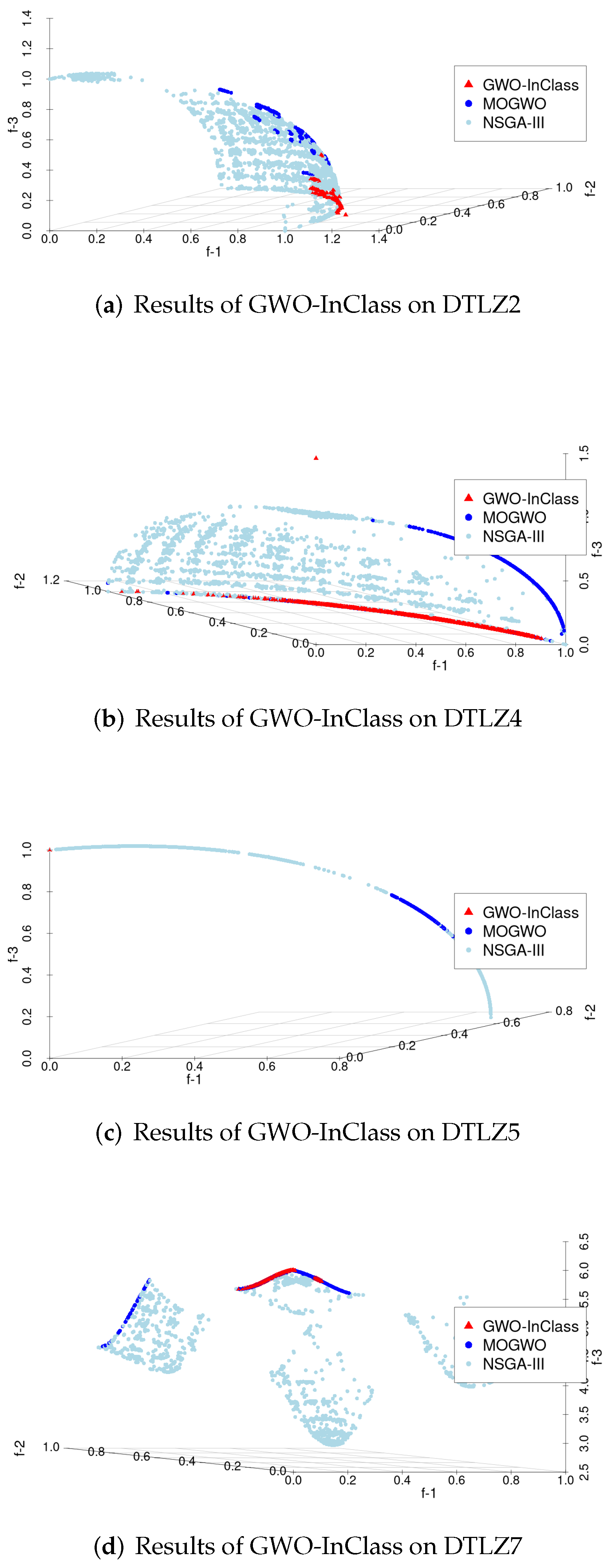
Lastly, we plotted the results of some single runs of GWO-InClass in
Figure 2. We took those runs on the three-objective problems with the results closest to the A-RoI. Although such runs are not representative, they clearly depict how GWO-InClass biases the search toward a privileged region in the Pareto frontier. The best compromise would be a solution belonging to such region (coloured in red in
Figure 2).
4.3. On the Performance of ACO-InClass
Table 3 presents the results of ACO-InClass in comparison with
; its columns should be interpreted with the same meaning provided for
Table 1. As a summary of the information provided, let us discuss the following remarks:
Considering ten objective functions: The advantage of embedding ordinal classification became statistically significant only when . Taking DTLZ1–4 and DTLZ6–8, ACO-InClass outperformed in at least one indicator, performing especially well in DTLZ1, DTLZ3, DTLZ6, and DTLZ8.
Considering three and five objective functions: With the only exception of a specific setting (DTLZ6, average Euclidean distance, and ), ACO-InClass was at least as good as regardless of the number of objectives.
Considering DTLZ5 and DTLZ9: Like in the case of GWO-InClass, no advantage was observed in DTLZ9. Additionally, this situation also occurred in DTLZ5.
We would strongly recommend using ACO-InClass instead of to address MaOPS with about ten objective functions. This insight is relevant because the efficiency of MOSIAs and MOEAs is degraded as the number of objectives increases. The strategy proposed in this paper could become a viable means of mitigating this severe drawback. Still, the DM should be prepared to devote the necessary time to express their preferences.
Furthermore,
Table 4 shows the results of ACO-InClass in comparison with those of NSGA-III. The columns of
Table 4 should be analogously interpreted as in
Table 2. These results together with the statistical tests allow concluding that ACO-InClass is competitive to address 10-objective problems according to the standard established by NSGA-III; in fact, ACO-InClass outperformed NSGA-III in the vast majority of these instances. As a welcome side effect, ACO-InClass can also support the a posteriori decision analysis; this feature would reduce the DM’s cognitive effort invested in identifying the best compromise. Adversely, these results clearly imply that ACO-InClass was unsuitable for treating three-objective instances.
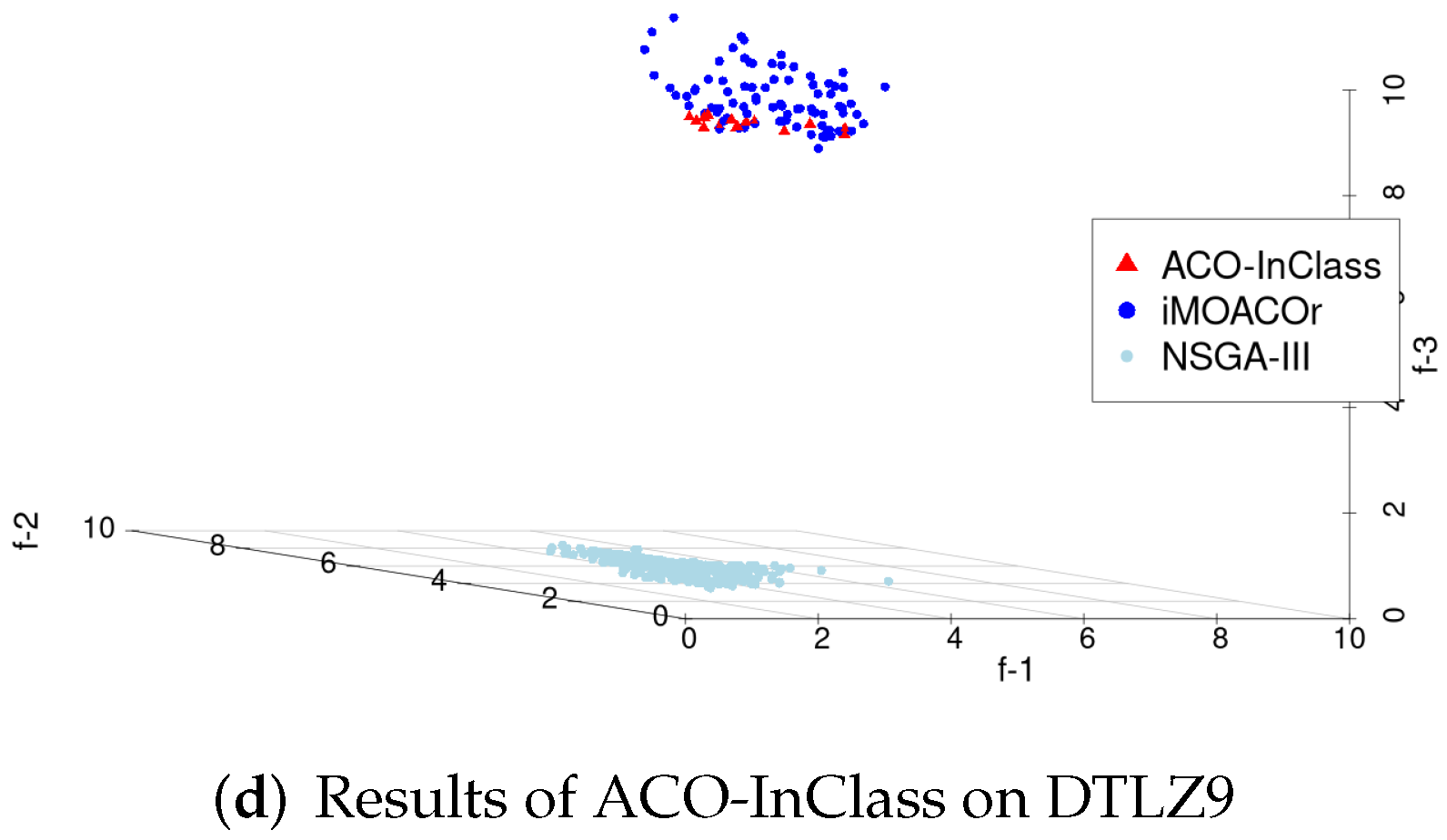
Again, we plotted the results of some runs of ACO-InClass, which are shown in
Figure 3. These runs presented the best results on the three-objective instances and clearly depicted how ACO-InClass biases the search toward the A-RoI. Here, the best compromise would be a solution obtained by ACO-InClass (coloured in red in
Figure 3).
5. Conclusions and Directions for Future Research
This paper introduces a novel strategy to incorporate preferences into swarm intelligence algorithms. Following the taxonomy of Bechikh et al. [
4], the proposed strategy falls into the category of ‘solution classification’. Initially, the DM should express their preferences about the solutions by classifying them as ‘Satisfactory’ or ‘Dissatisfactory’. The proposed strategy is one of the least cognitively demanding in the framework of solution classification because the DM must merely classify solutions into just two categories.
Then, we suggest that the optimisation algorithms additionally identify two artificial classes—‘Highly Satisfactory’ and ‘Strongly Dissatisfactory’—through an ordinal classifier based on interval outranking to model different levels of intensity in the DM’s preferences. Consequently, the classifier increases its ability to discriminate. Here, we hypothesised that swarm intelligence algorithms can obtain the edge by increasing the selective pressure toward the region of the Pareto frontier containing ‘Highly Satisfactory’ solutions. A straightforward way to achieve it is to consider ordinal classification as the major criterion to rank the solutions in the archive.
Typically, swarm intelligence algorithms use an archive with the best so-far approximation of the Pareto frontier. These solutions are sorted to pick the solution(s) whose patterns will be exploited in the next iteration, hence its relevance.
By applying this strategy, ordinal classification was embedded in two swarm intelligence algorithms, expressly Multi-objective Grey Wolf Optimisation and Indicator-based Multi-objective Ant Colony Optimisation for continuous domains. The extended versions were called Grey Wolf Optimiser with Interval outranking-based ordinal Classification (GWO-InClass) and Ant Colony Optimisation with Interval outranking-based ordinal Classification (ACO-InClass). We used ten synthetic DMs to validate the results; we also considered each problem in the DTLZ test suite and explored different numbers of objective functions (three, five, and ten). The algorithms ran 30 times for each setting.
The impact of our strategy depended on several factors: the number of objectives, the baseline algorithm, and the properties of the test problem. Despite this, our strategy conferred marked benefits when many objective functions were treated. In the case of GWO-InClass, such benefits became significant in six of the nine DTLZ problems when the number of objectives was at least five. In the case of ACO-InClass, the ordinal classifier impacted the performance in seven DTLZ problems only when ten objective functions were considered.
Although our strategy requires that the DM is well-disposed to spend the necessary time to elicit their preferences, such an effort can be favourably compensated when problems with many objective functions are treated; especially, keeping in mind that these problems are still highly challenging for a posteriori algorithms (that approximate the complete Pareto frontier). The embedding of ordinal classification based on interval outranking contributed to coping with these difficulties. Numerical results and tests for statistical significance supported these conclusions.
Perhaps, the major criticism of our approach is that it is only applicable when the preferences of the DM are compatible with the underlying principles of outranking. That is, the DM admits veto effects and has a non-compensatory preference about the objectives.
Further research is needed to draft conclusions with a greater generalisation. First, it is necessary to know the impact of this strategy on other swarm intelligence algorithms (e.g., particle swarm optimisation, artificial bee colony, and elephant herding optimisation). Second, it is also necessary to conduct more experimentation with a deeper analysis to connect the performance with the properties of the problem, providing plausible explanations for those problems in which no advantage was observed (e.g., DTLZ9).


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}