
Optimising Energy Management in Hybrid Microgrids


Abstract
:1. Introduction
2. Management of Hybrid Microgrids
- Power flows. In contrast to conventional grids, the integration of DGs in low voltage can result in bi-directional power flows and lead to difficulties in protection systems or undesirable flow patterns.
- Stability. Local oscillations may occur as a result of the interaction of DG management systems and problematic transitions between stand-alone and grid-connected mode.
- Network model. The generally accepted assumptions of three balanced phases, inductive transmission lines and constant loads become meaningless in this type of network, leading to the need to adapt the models to the new situation. A hybrid microgrid is intrinsically subject to load unbalance by the DGs themselves.
- Low inertia. The dynamic characteristics of DG equipment, fundamentally those that are electronically coupled, are different from those based on large generation turbines. If appropriate monitoring and management measures are not implemented, the low inertia of the system can lead to considerable frequency deviations in the isolated mode of operation.
- Uncertainty. In hybrid microgrids there is greater uncertainty regarding demand and, above all, generation, as the use of renewable energies means that generation is linked to environmental conditions. Therefore, reliable and economic operation must take into account weather forecasting.
- Control of voltages and currents in the various DGs, according to the standards and adequately reducing oscillations.
- Frequency and voltage regulation in both stand-alone and grid-connected modes.
- Power balancing, when changes are produced in both generation and load, while maintaining voltage and frequency within acceptable limits.
- Demand Side Management (DSM) mechanisms that allow some fluctuation in the demand of a part of the loads to adapt to the requirements of the hybrid microgrid.
- Smooth transition between operating modes, using the most appropriate strategy for each of them and promptly identifying the situations that produce the switching. Resynchronization with the main network.
- Economic dispatch, distributing the load between the different DGs and storage systems in such a way as to reduce the cost of operation, while maintaining reliability. Optimization of the cost of operation will include maximizing the economic benefit in the case of grid connection.
- Management of power flows between the microgrid and the main network and, where appropriate, with other microgrids.
3. Energy Management System (EMS)
4. Mathematical Modeling
4.1. Power Flow Equations
- The voltage values, expressed in per unit (pu), are very close to l.
- The difference between the angles of two interconnected buses is a small number close to 0.
4.2. Generation of Electrical Energy
4.3. Electrical Energy Storage
4.4. Power Converters
4.5. Energy Consumption
4.6. CO2 Emissions and Other Factors
5. Heuristic Methods
5.1. Hysteresis Band Control
- in case of lack of power, it will be the fuel cell that will give up power; and
- in case of reaching the maximum state of SOC, it will be the turn of the electrolyzer, which will start to operate at that moment of excess power.
5.2. Control by Means of Fuzzy Logic
- It provides an orderly and efficient working structure from information given orally and fuzzily by human experts.
- Due to its simplicity, it is easy to understand and simplifies the design of the problem, which gives it a quick implementation and a lower cost compared to other methods.
- It is capable of generating numerous output signals from any reasonable number of inputs.
- It does not require a model to find approximate solutions to the control problem and provides non-linear controllers.
6. Machine Learning Methods
- Supervised learning: this type of algorithm is based on prior learning, usually related to a system of labels associated with the data. This allows them to make decisions based on the previous data or even make predictions from these data. An example could be a spam detector, that is, a system that thinks it detects spam and labels an email as spam based on the patterns it has learned from the email history (keywords in the subject line, sender, text/image ratio, etc.).
- Unsupervised learning: unlike the previous type, these algorithms do not use prior knowledge. What they use is all the available data with the aim of finding patterns among them. If they find such patterns, they try to organize them in some way. For example, unsupervised learning is applied when you want to extract patterns from massive social media data, to recommend products or create advertising campaigns
- Reinforcement learning: in this less common case, an algorithm learns from its own experience. A trial-and-error process is normally used in which correct decisions are rewarded in some way (with reinforcement factors). In this way, the aim is to make the best decision in different situations. Examples include: DNA classifications, facial recognition, etc.
6.1. Operation with Machine Learning Models
- Classification problems: They try to predict the classification of objects on a set of prefixed classes. For example, classifying whether a news is about sports, entertainment, politics, etc.
- Regression problems: They try to predict a real value. For example, predict the value of the stock market tomorrow from the stock market behavior that is stored (past).
6.2. Decision Trees
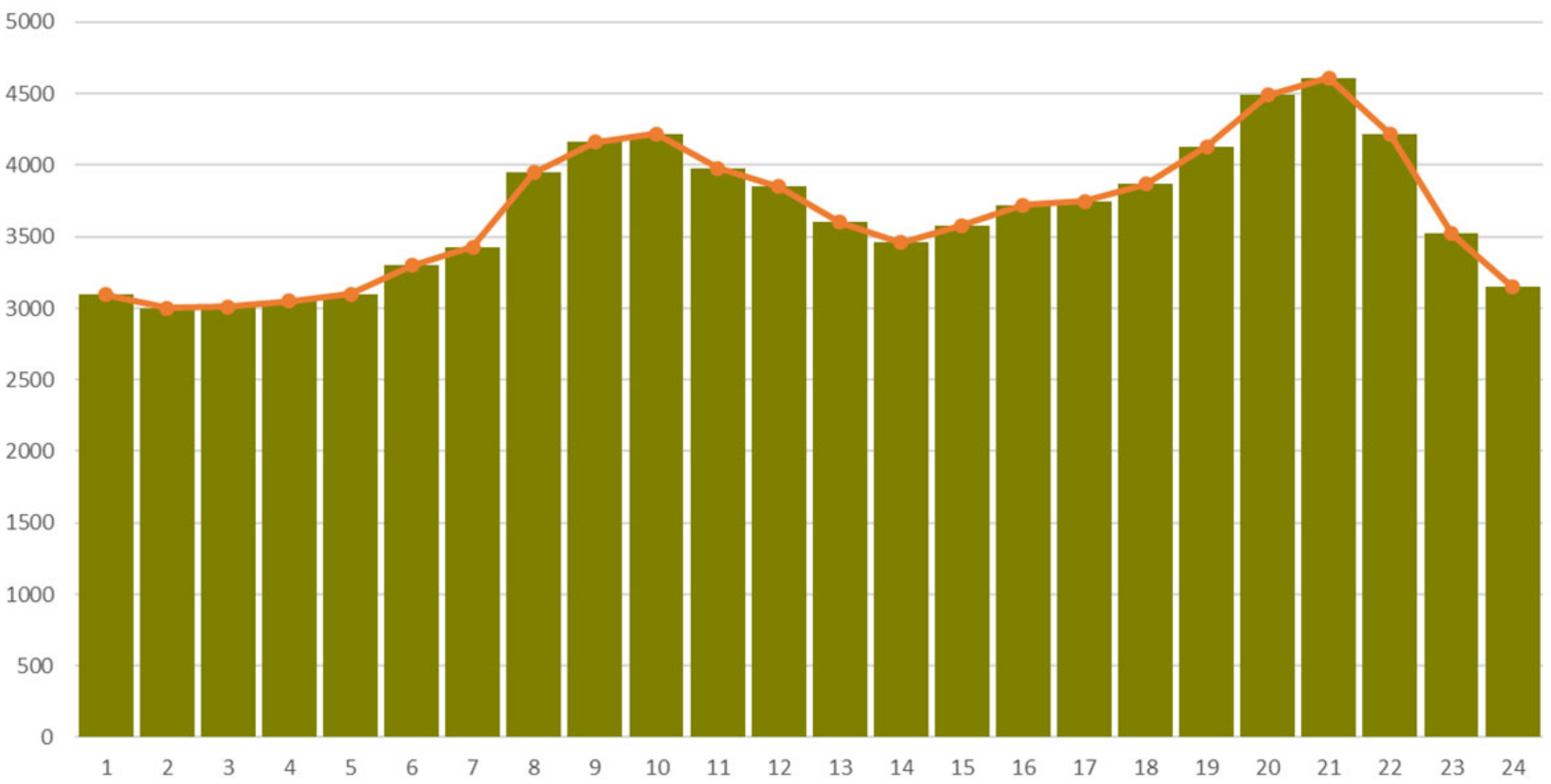
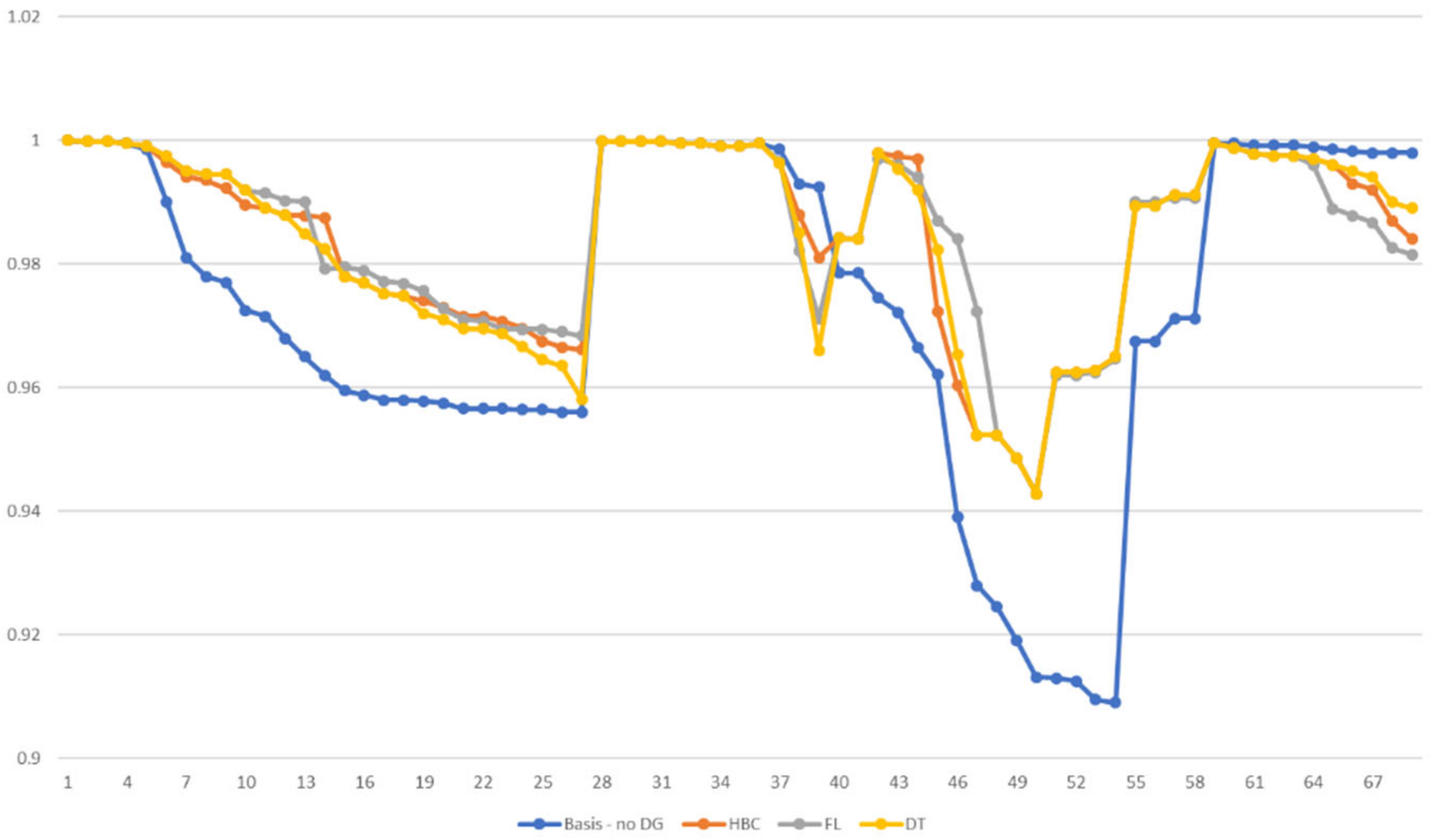
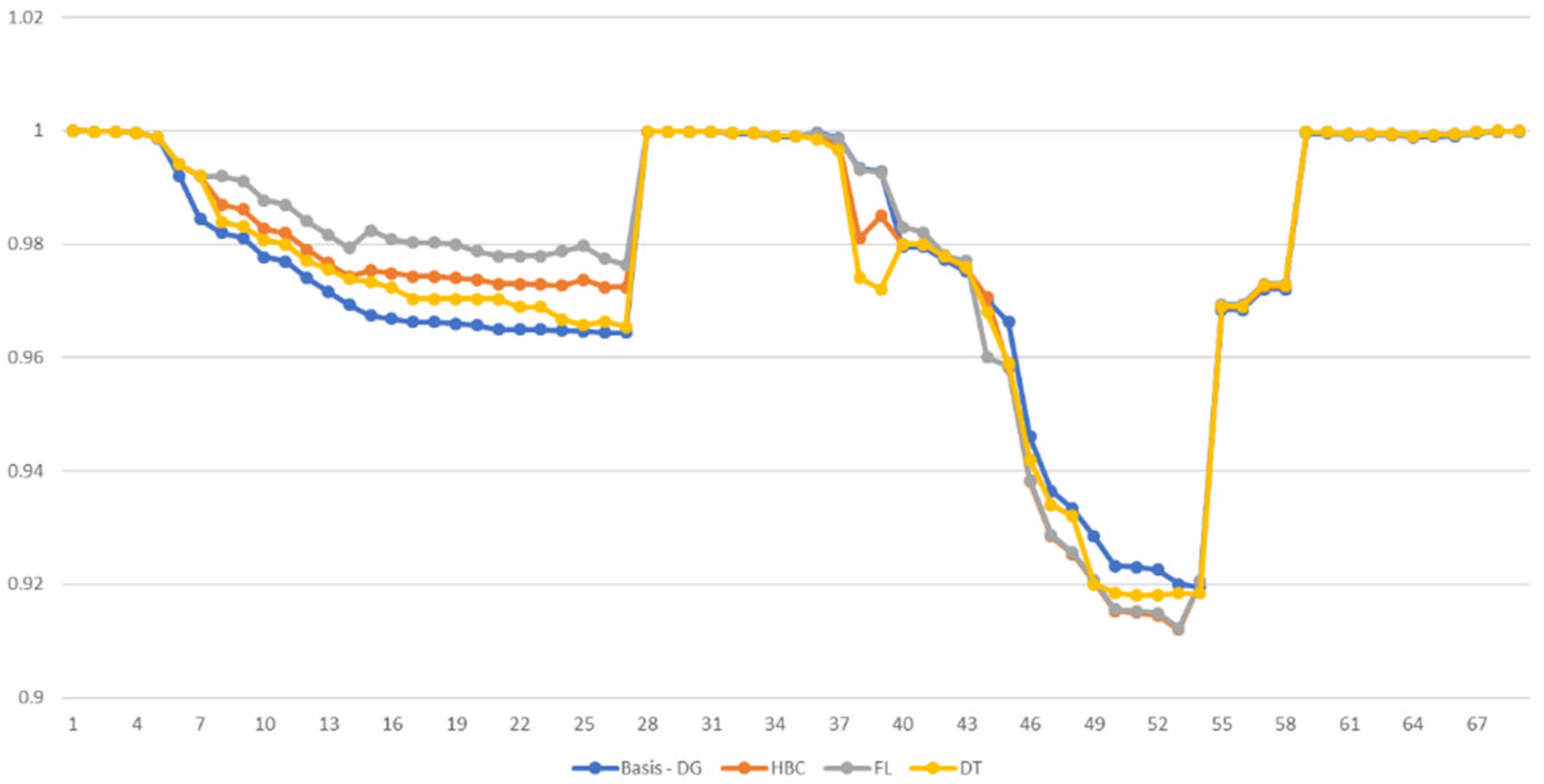
7. Results
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lasseter, R.H. Microgrids. In Proceedings of the 2002 IEEE Power Engineering Society Winter Meeting (Conference Proceedings (Cat. No.02CH37309)), New York, NY, USA, 27–31 January 2002; pp. 305–308. [Google Scholar]
- Piagi, P.; Lasseter, R.H. Autonomous Control of Microgrids. In Proceedings of the 2006 IEEE Power Engineering Society General Meeting, Montreal, QC, Canada, 18–22 June 2006; p. 8. [Google Scholar] [CrossRef]
- Lopes, J.; Moreira, C.; Madureira, A. Defining Control Strategies for Microgrids Islanded Operation. IEEE Trans. Power Syst. 2006, 21, 916–924. [Google Scholar] [CrossRef] [Green Version]
- Baghaee, H.R. Real-Time Verification of New Controller to Improve Small/Large-Signal Stability and Fault Ride-Through Capability of Multi-DER Microgrids. IET Gener. Transm. Distrib. 2016, 10, 3068–3084. [Google Scholar] [CrossRef]
- Hirsch, A.; Parag, Y.; Guerrero, J. Microgrids: A Review of Technologies Key Drivers and Outstanding Issues. Renew. Sustain. Energy Rev. 2018, 90, 402–411. [Google Scholar] [CrossRef]
- Farrokhabadi, M.; Cañizares, C.A.; Simpson-Porco, J.W.; Nasr, E.; Fan, L. Microgrid Stability Definitions, Analysis, and Examples. IEEE Trans. Power Syst. 2019, 35, 13–29. [Google Scholar] [CrossRef]
- Ullah, S.; Khan, L.; Jamil, M.; Jafar, M.; Mumtaz, S.; Ahmad, S. A Finite-Time Robust Distributed Cooperative Secondary Control Protocol for Droop-Based Islanded AC Microgrids. Energies 2021, 14, 2936. [Google Scholar] [CrossRef]
- Moazeni, F.; Khazaei, J. Optimal Operation of Water-Energy Microgrids; A Mixed Integer Linear Programming Formulation. J. Clean. Prod. 2020, 275, 122776. [Google Scholar] [CrossRef]
- Bidram, A.; Lewis, F.L.; Davoudi, A. Distributed Control Systems for Small-Scale Power Networks: Using Multiagent Cooperative Control Theory. IEEE Control Syst. Mag. 2014, 34, 56–77. [Google Scholar] [CrossRef]
- Majumder, R. A Hybrid Microgrid with DC Connection at Back to Back Converters. IEEE Trans. Smart Grid 2014, 5, 251–259. [Google Scholar] [CrossRef]
- Tabar, V.S.; Ghassemzadeh, S.; Tohidi, S. Energy Management in Hybrid Microgrid with Considering Multiple Power Market and Real Time Demand Response. Energy 2019, 174, 10–23. [Google Scholar] [CrossRef]
- Minchala-Avila, L.I.; Garza-Castañón, L.E.; Vargas-Martín, A.; Zhang, Y. A Review of Optimal Control Techniques Applied to the Energy Management and Control of Microgrids. Procedia Comput. Sci. 2015, 52, 780–787. [Google Scholar] [CrossRef] [Green Version]
- Gómez Sánchez, M.; Macia, Y.M.; Fernández Gil, A.; Castro, C.; Nuñez González, S.M.; Pedrera Yanes, J. A Mathematical Model for the Optimization of Renewable Energy Systems. Mathematics 2021, 9, 39. [Google Scholar] [CrossRef]
- Olivares, D.E.; Mehrizi-Sani, A.; Etemadi, A.H.; Canizares, C.A.; Iravani, R.; Kazerani, M.; Hajimiragha, A.H.; Gomis-Bellmunt, O.; Saeedifard, A.; Palma-Behnke, R.; et al. Trends in Microgrid Control. IEEE Trans. Smart Grid 2014, 5, 1905–1919. [Google Scholar] [CrossRef]
- Nguyen, T.-L.; Guillo-Sansano, E.; Syed, M.H.; Nguyen, V.-H.; Blair, S.M.; Reguera, L.; Tran, Q.-T.; Caire, R.; Burt, G.M.; Gavriluta, C.; et al. Multi-Agent System with Plug and Play Feature for Distributed Secondary Control in Microgrid—Controller and Power Hardware-in-the-Loop Implementation. Energies 2018, 11, 3253. [Google Scholar] [CrossRef] [Green Version]
- Bazmohammadi, N.; Anvari-Moghaddam, A.; Tahsiri, A.; Madary, A.; Vasquez, J.C.; Guerrero, J.M. Stochastic Predictive Energy Management of Multi-Microgrid Systems. Appl. Sci. 2020, 10, 4833. [Google Scholar] [CrossRef]
- Díaz, N.L.; Vasquez, J.C.; Guerrero, J.M. A Communication-Less Distributed Control Architecture for Islanded Microgrids with Renewable Generation and Storage. IEEE Trans. Power Electron. 2018, 33, 1922–1939. [Google Scholar] [CrossRef] [Green Version]
- Lin, P.; Jin, C.; Xiao, J.; Li, X.; Shi, D.; Tang, Y.; Wang, P. A Distributed Control Architecture for Global System Economic Operation in Autonomous Hybrid AC/DC Microgrids. IEEE Trans. Smart Grid 2019, 10, 2603–2617. [Google Scholar] [CrossRef]
- Llaria, A.; Terrasson, G.; Curea, O.; Jiménez, J. Application of Wireless Sensor and Actuator Networks to Achieve Intelligent Microgrids: A Promising Approach towards a Global Smart Grid Deployment. Appl. Sci. 2016, 6, 61. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Duan, S.; Cai, T.; Liu, B.; Hu, G. Smart energy management system for optimal microgrid economic operation. IET Renew. Power Gener. 2011, 5, 258–267. [Google Scholar] [CrossRef]
- Ahmad, A.; Khan, A.; Javaid, N.; Hussain, H.M.; Abdul, W.; Almogren, A.; Alamri, A.; Azim Niaz, I. An Optimized Home Energy Management System with Integrated Renewable Energy and Storage Resources. Energies 2017, 10, 549. [Google Scholar] [CrossRef] [Green Version]
- Bergen, A.R.; Vittal, V. Power Systems Analysis, 2nd ed.; Pearson: Upper Saddle River, NJ, USA, 2000. [Google Scholar]
- Nagrath, I.; Kothari, D. Modern Power System Analysis; McGraw-Hill: New Delhi, India, 1982. [Google Scholar]
- Akbari, T.; Bina, M.T. Linear Approximated Formulation of AC Optimal Power Flow Using Binary Discretisation. IET Gener. Transm. Distrib. 2016, 10, 1117–1123. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Vittal, V.; Heydt, G.; Quintero, J. A Relaxed AC Optimal Power Flow Model Based on a Taylor Series. In Proceedings of the 2013 IEEE Innovative Smart Grid Technologies-Asia (ISGT Asia), Bangalore, India, 10–13 November 2013. [Google Scholar] [CrossRef]
- Yang, Z.; Zhong, H.; Xia, Q.; Kang, C. A Novel Network Model for Optimal Power Flow with Reactive Power and Network Losses. Electr. Power Syst. Res. 2017, 144, 63–71. [Google Scholar] [CrossRef]
- Akbari, T.; Bina, M.T. A Linearized Formulation of AC Multi-Year Transmission Expansion Planning: A Mixed-Integer Linear Programming Approach. Electr. Power Syst. Res. 2014, 114, 93–100. [Google Scholar] [CrossRef]
- Attarha, A.; Amjady, N.; Conejo, A.J. Adaptive Robust AC Optimal Power Flow Considering Load and Wind Power Uncertainties. Int. J. Electr. Power Energy Syst. 2018, 96, 132–142. [Google Scholar] [CrossRef]
- Yang, J.; Zhang, N.; Kang, C.; Xia, Q. A State-Independent Linear Power Flow Model with Accurate Estimation of Voltage Magnitude. Trans. Power Syst. 2017, 32, 5. [Google Scholar] [CrossRef]
- Koster, A.M.C.A.; Lemkens, S. Designing AC Power Grids Using Integer Linear Programming. In INOC 2011, Lecture Notes in Computer Science; Pahl, J., Reiners, T., Voß, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6701, pp. 478–483. [Google Scholar] [CrossRef]
- Taylor, J.; Hover, F. Linear Relaxations for Transmission System Planning. IEEE Trans. Power Syst. 2011, 26, 4, 2533–2538. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Zhong, H.; Bose, A.; Zheng, T.; Xia, Q.; Kang, C. A Linearized OPF Model with Reactive Power and Voltage Magnitude: A Pathway to Improve the MW-Only DC OPF. IEEE Trans. Power Syst. 2018, 33, 2, 1734–1745. [Google Scholar] [CrossRef]
- Morvaj, B.; Evins, R.; Carmeliet, J. Optimization Framework for Distributed Energy Systems with Integrated Electrical Grid Constraints. Appl. Energy 2016, 171, 296–313. [Google Scholar] [CrossRef]
- Kothari, D.P. Power System Optimization. In Proceedings of the 2012 2nd National Conference on Computational Intelligence and Signal Processing (CISP), Guwahati, India, 2–3 March 2012; pp. 18–21. [Google Scholar] [CrossRef]
- Patel, N.; Porwal, D.; Bhoi, A.K.; Kothari, D.P.; Kalam, A. An Overview on Structural Advancements in Conventional Power System with Renewable Energy Integration and Role of Smart Grids in Future Power Corridors. In Green Energy and Technology; Bhoi, A., Sherpa, K., Kalam, A., Chae, G.S., Eds.; Springer: Singapore, 2020; pp. 1–15. [Google Scholar]
- Barsali, S. Benchmark Systems for Network Integration of Renewable and Distributed Energy Resources; Technical Brochure, TF C6.04.02; CIGRE: Paris, France, 2014. [Google Scholar]
- Rocha, R.C.C.; Berredo, R.C.; Bernis, R.A.O.; Gomes, E.M.; Nishimura, F.; Cicarelli, L.D.; Soares, M.R. New Technologies, Standards, and Maintenance Methods in Spacer Cable Systems. IEEE Trans. Power Deliv. 2002, 17, 2, 562–568. [Google Scholar] [CrossRef]
- Van den Brom, H.E.; van Leeuwen, R.; Rietveld, G.; Houtzager, E. Voltage Dependence of the Reference System in Medium- and High-Voltage Current Transformer Calibrations. IEEE Trans. Instrum. Meas. 2021, 70, 1502908. [Google Scholar] [CrossRef]
- Pantic, L.S.; Pavlović, T.M.; Milosavljević, D.D.; Radonjic, I.S.; Radovic, M.K.; Sazhko, G. The Assessment of Different Models to Predict Solar Module Temperature, Output Power and Efficiency for Nis, Serbia. Energy 2016, 109, 38–48. [Google Scholar] [CrossRef]
- Sun, V.; Asanakham, A.; Deethayat, T.; Kiatsiriroat, T. A New Method for Evaluating Nominal Operating Cell Temperature (NOCT) of Unglazed Photovoltaic Thermal Module. Energy Rep. 2020, 6, 1029–1042. [Google Scholar] [CrossRef]
- DFIG 2.1 MW—114. 2021. Available online: https://www.siemensgamesa.com/en-int/products-and-services/onshore/wind-turbine-sg-2-1-114 (accessed on 29 September 2021).
- Bilbao, J.; Torres, E.; Saenz, J. Load Curve Estimation by Means of Prediction Intervals. In Proceedings of the 2000 10th Mediterranean Electrotechnical Conference. Information Technology and Electrotechnology for the Mediterranean Countries. Proceedings. MeleCon 2000 (Cat. No.00CH37099), Lemesos, Cyprus, 29–31 May 2000; Volume 3, pp. 970–972. [Google Scholar] [CrossRef]
- Grandjean, A.; Adnot, J.; Binet, G. A Review and an Analysis of the Residential Electric Load Curve Models. Renew. Sustain. Energy Rev. 2012, 16, 9, 6539–6565. [Google Scholar] [CrossRef]
- Ranaboldo, M.; Ferrer-Martí, L.; García-Villoria, A.; Pastor Moreno, R. Heuristic Indicators for the Design of Community Off-Grid Electrification Systems Based on Multiple Renewable Energies. Energy 2013, 50, 501–512. [Google Scholar] [CrossRef]
- Borghei, M.; Ghassemi, M. Optimal Planning of Microgrids for Resilient Distribution Networks. Int. J. Electr. Power Energy Syst. 2021, 128, 106682. [Google Scholar] [CrossRef]
- Devarapalli, R.; Sinha, N.K.; Rao, B.V.; Knypinski, Ł.; Lakshmi, N.J.N.; García Márquez, F.P. Allocation of Real Power Generation Based on Computing over All Generation Cost: An Approach of Salp Swarm Algorithm. Arch. Electr. Eng. 2021, 70, 2, 337–349. [Google Scholar] [CrossRef]
- Muhammad, M.; Mokhlis, H.; Naidu, K.; Amin, A.; Franco, F.; Othman, M. Distribution Network Planning Enhancement via Network Reconfiguration and DG Integration Using Dataset Approach and Water Cycle Algorithm. J. Mod. Power Syst. Clean Energy 2020, 8, 86–93. [Google Scholar] [CrossRef]
- Helmi, A.; Carli, R.; Dotoli, M.; Ramadan, H. Efficient and Sustainable Reconfiguration of Distribution Networks via Metaheuristic Optimization. IEEE Trans. Autom. Sci. Eng. 2021, 19, 82–98. [Google Scholar] [CrossRef]
- Orosz, T.; Rassõlkin, A.; Kallaste, A.; Arsénio, P.; Pánek, D.; Kaska, J.; Karban, P. Robust Design Optimization and Emerging Technologies for Electrical Machines: Challenges and Open Problems. Appl. Sci. 2020, 10, 6653. [Google Scholar] [CrossRef]
- Yang, X.S. Nature-Inspired Optimization Algorithms: Challenges and Open Problems. J. Comput. Sci. 2020, 46, 101104. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.; Peng, G.-H.; He, X.-S.; Yang, X.-S. Global Convergence Analysis of the Bat Algorithm Using a Markovian Framework and Dynamic System Theory. Expert Syst. Appl. 2018, 114, 173–182. [Google Scholar] [CrossRef] [Green Version]
- Wolpert, D.H.; Macready, W.G. No Free Lunch Theorems for Optimization. IEEE Trans. Evolut. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef] [Green Version]
- Capitanescu, F. Critical Review of Recent Advances and Further Developments Needed in AC Optimal Power Flow. Electr. Power Syst. Res. 2016, 136, 57–68. [Google Scholar] [CrossRef]
- Bai, X.; Wei, H.; Fujisawa, K.; Wang, Y. Semidefinite Programming for Optimal Power Flow Problems. Int. J. Electr. Power Energy Syst. 2008, 30, 383–392. [Google Scholar] [CrossRef]
- Yuan, Z.; Hesamzadeh, M.R. Second-Order Cone AC Optimal Power Flow: Convex Relaxations and Feasible Solutions. J. Mod. Power Syst. Clean Energy 2019, 7, 268–280. [Google Scholar] [CrossRef] [Green Version]
- Garces, A. A Quadratic Approximation for the Optimal Power Flow in Power Distribution Systems. Electr. Power Syst. Res. 2016, 130, 222–229. [Google Scholar] [CrossRef] [Green Version]
- Hosseini, S.M.; Carli, R.; Dotoli, M. Robust Day-Ahead Energy Scheduling of a Smart Residential User under Uncertainty. In Proceedings of the 18th European Control Conference (ECC), Naples, Italy, 25–28 June 2019; pp. 935–940. [Google Scholar] [CrossRef]
- Barbato, A.; Capone, A. Optimization Models and Methods for Demand-Side Management of Residential Users: A Survey. Energies 2014, 7, 5787–5824. [Google Scholar] [CrossRef]
- Ipsakis, D.; Voutetakis, S.; Seferlis, P.; Stergiopoulos, F.; Elmasides, C. Power Management Strategies for a Stand-Alone Power System Using Renewable Energy Sources and Hydrogen Storage. Int. J. Hydrogen Energy 2009, 34, 16, 7081–7095. [Google Scholar] [CrossRef]
- Singh, S.; Zindani, D.; Kumar Roy, A.; Kumar, K. Application of Renewable Energy System with Fuzzy Logic. In Advanced Fuzzy Logic Approaches in Engineering Science; Ram, M., Ed.; IGI-Global: Hershey, PA, USA, 2019. [Google Scholar] [CrossRef]
- Tao, S.; Si-jia, Y.; Guang-yi, C.; Xi-jian, Z. Modelling and Control PEMFC Using Fuzzy Neural Networks. J. Zheijang Univ.-Sci. A 2005, 6, 1084–1089. [Google Scholar] [CrossRef]
- Parisio, A.; Rikos, E.; Glielmo, L. A Model Predictive Control Approach to Microgrid Operation Optimization. IEEE Trans. Control Syst. Technol. 2014, 22, 5, 1813–1827. [Google Scholar] [CrossRef]
- Nelson, J.R.; Johnson, N.G. Model Predictive Control of Microgrids for Real-Time Ancillary Service Market Participation. Appl. Energy 2020, 269, 114963. [Google Scholar] [CrossRef]
- Edwards, H. How Machines Learn; Koru Ventures LLC: Bend, OR, USA, 2016. [Google Scholar]
- Krohn, J. Deep Learning Illustrated; Pearson Education: Boston, MA, USA, 2020. [Google Scholar]
- Kourou, K.; Exarchos, T.P.; Exarchos, K.P.; Karamouzis, M.V.; Fotiadis, D.I. Machine Learning Applications in Cancer Prognosis and Prediction. Comput. Struct. Biotechnol. J. 2015, 13, 8–17. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Malhotra, R. A Systematic Review of Machine Learning Techniques for Software Fault Prediction. Appl. Soft Comput. 2015, 27, 504–518. [Google Scholar] [CrossRef]
- Mosavi, A.; Ozturk, P.; Chau, K.-W. Flood Prediction Using Machine Learning Models: Literature Review. Water 2018, 10, 1536. [Google Scholar] [CrossRef] [Green Version]
- Johnson, A.E.W.; Ghassemi, M.M.; Nemati, S.; Niehaus, K.E.; Clifton, D.A.; Clifford, G.D. Machine Learning and Decision Support in Critical Care. Proc. IEEE 2016, 104, 444–466. [Google Scholar] [CrossRef] [Green Version]
- Mitchell, T. Machine Learning; McGraw Hill: New York, NY, USA, 1997; p. 2. [Google Scholar]
- Batista, G.E.A.P.A.; Prati, R.C.; Monard, M.C. A Study of the Behavior of Several Methods for Balancing Machine Learning Training Data. SIGKDD Explor. Newsl. 2004, 6, 1, 20–29. [Google Scholar] [CrossRef]
- Bilbao, J.; Bilbao, I.; Feniser, C. Generalized Delta Rule with Entropy Error Function. Acta Tech. Napoc. Ser. Appl. Math. Mech. Eng. 2017, 60, 165–170. [Google Scholar]
- Belkin, M.; Hsu, D.; Ma, S.; Mandal, S. Reconciling Modern Machine-Learning Practice and the Classical Bias—Variance Trade-off. Proc. Natl. Acad. Sci. USA 2019, 116, 15849–15854. [Google Scholar] [CrossRef] [Green Version]
- Bilbao, I.; Bilbao, J.; Feniser, C. Adopting Some Good Practices to Avoid Overfitting in the Use of Machine Learning. WSEAS Trans. Math. 2018, 17, 274–279. [Google Scholar]
- Sharma, A.; Bhuriya, D.; Singh, U. Survey of Stock Market Prediction Using Machine Learning Approach. In Proceedings of the 2017 International conference of Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 20–22 April 2017; pp. 506–509. [Google Scholar] [CrossRef]
- Bilbao, J.; Bravo, E.; Garcia, O.; Varela, C.; Rebollar, C. Particular Case of Big Data for Wind Power Forecasting: Random Forest. Int. J. Tech. Phys. Probl. Eng. 2020, 12, 25–30. [Google Scholar]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Rostami, M.-A.; Kavousi-Fard, A.; Niknam, T. Expected Cost Minimization of Smart Grids with Plug-In Hybrid Electric Vehicles Using Optimal Distribution Feeder Reconfiguration. IEEE Trans. Ind. Inform. 2015, 11, 388–397. [Google Scholar] [CrossRef]
- Lan, T.; Jermsittiparsert, K.; Alrashood, S.T.; Rezaei, M.; Al-Ghussain, L.; Mohamed, M.A. An Advanced Machine Learning Based Energy Management of Renewable Microgrids Considering Hybrid Electric Vehicles’ Charging Demand. Energies 2021, 14, 569. [Google Scholar] [CrossRef]
- Kavousi-Fard, A.; Khodaei, A. Efficient Integration of Plug-in Electric Vehicles via Reconfigurable Microgrids. Energy 2016, 111, 653–663. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RMSE | |
|---|---|
| HBC | 0.1781 |
| FL | 0.1563 |
| DT | 0.1471 |
| Initial | HBC | FL | DT | |
|---|---|---|---|---|
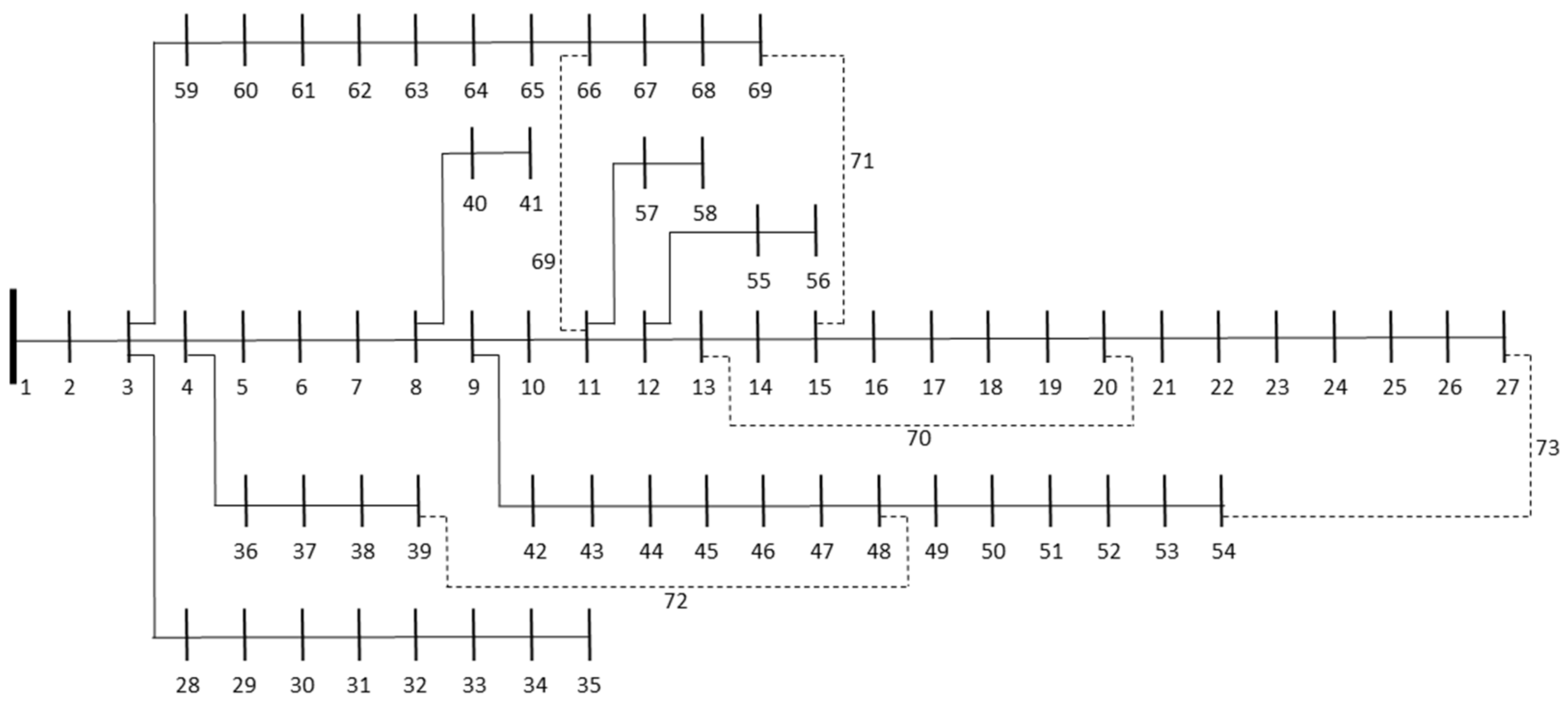
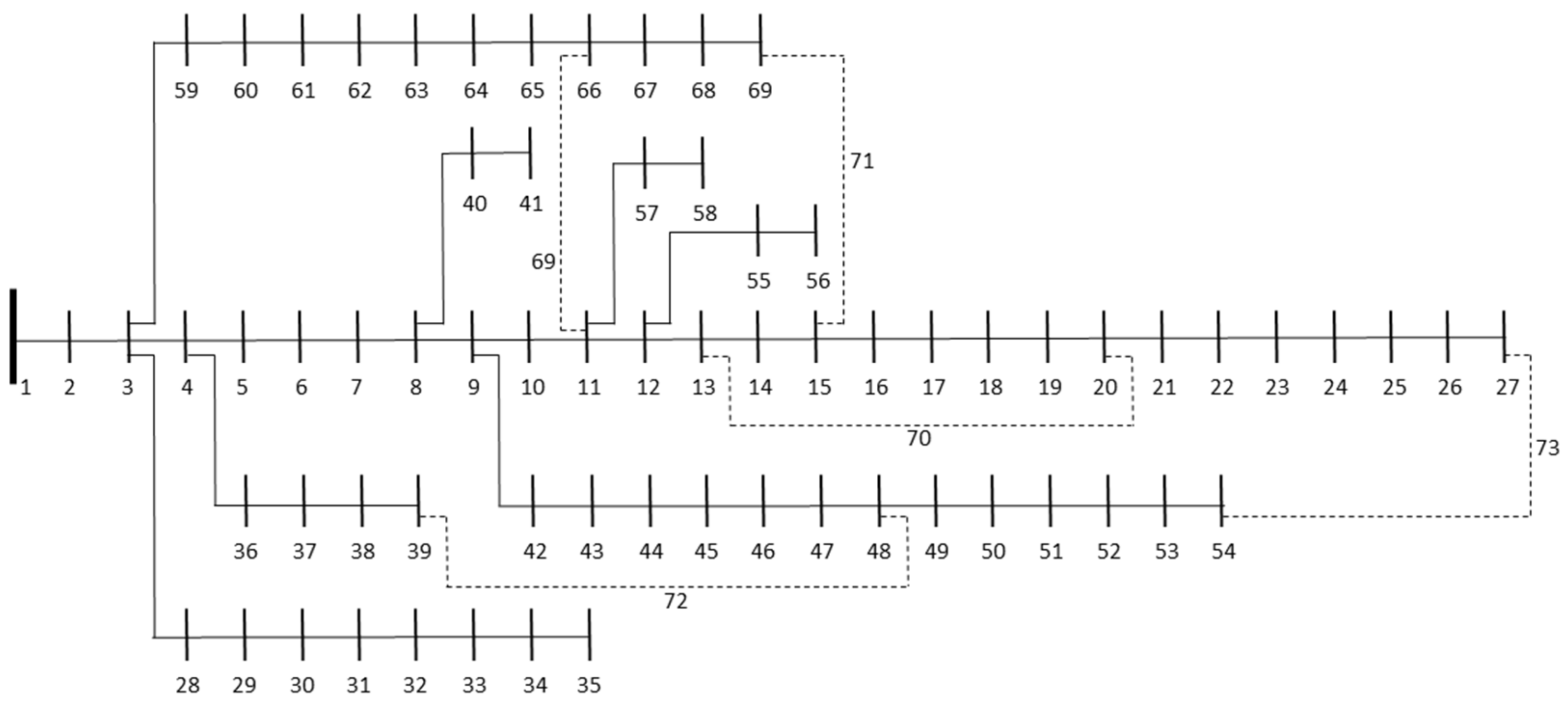
| Tie-switches | 69, 70, 71, 72, 73 | 14, 55, 61, 69, 70 | 13, 57, 61, 69, 70 | 13, 57, 61, 69, 70 |
| Initial | HBC | FL | DT | |
|---|---|---|---|---|
| Tie-switches | 69, 70, 71, 72, 73 | 13, 55, 64, 69, 70 | 13, 58, 64, 69, 70 | 13, 58, 64, 69, 70 |
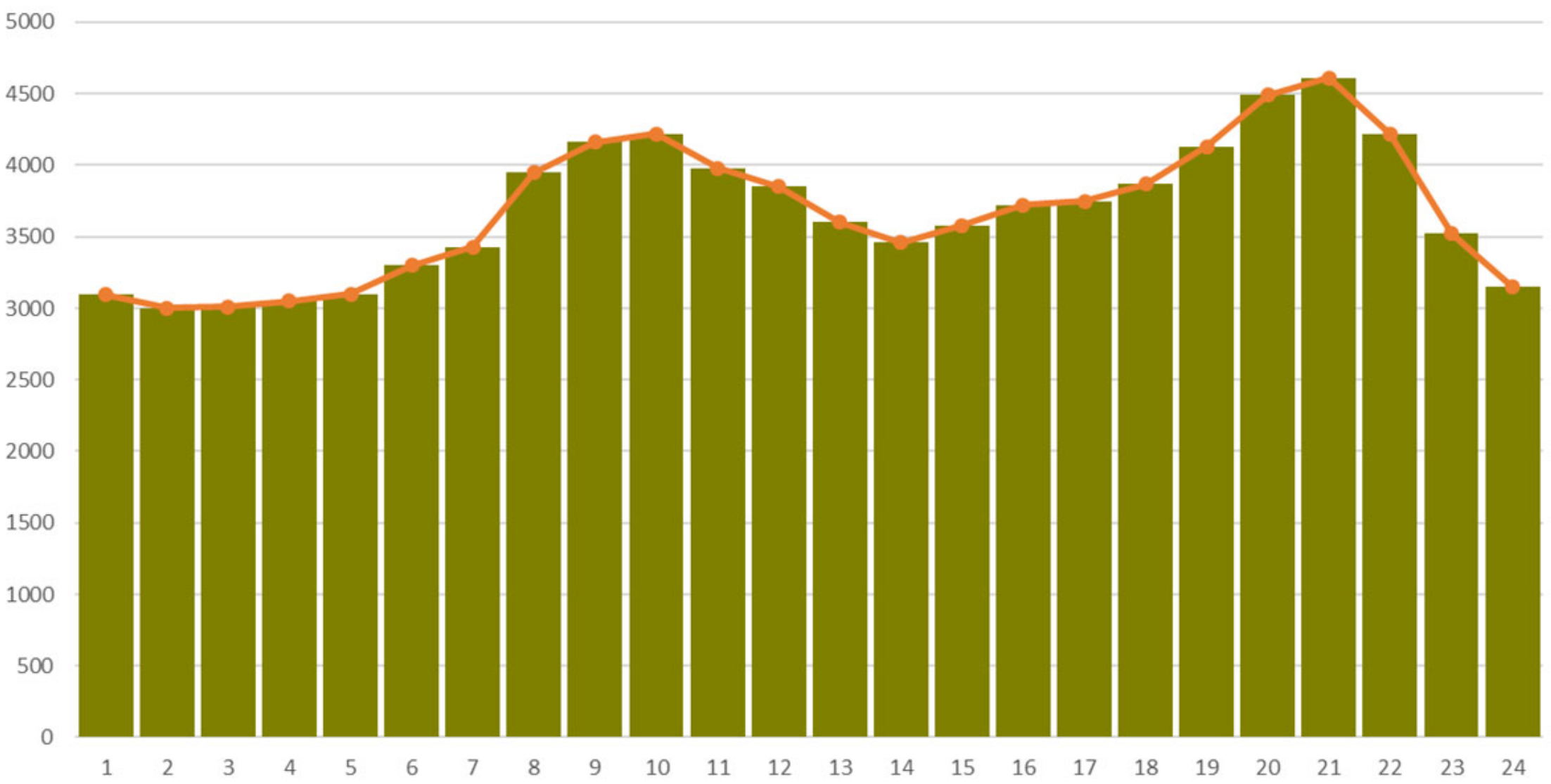
| P (kW) | 6–27.52 | 6–27.52 | 6–27.52 | 6–27.52 |
| 25–30.45 | 25–30.45 | 25–30.45 | 25–30.45 | |
| 50–30.45 | 50–30.45 | 50–30.45 | 50–30.45 | |
| 68–342.05 | 68–342.05 | 68–342.05 | 68–342.05 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bilbao, J.; Bravo, E.; García, O.; Rebollar, C.; Varela, C. Optimising Energy Management in Hybrid Microgrids. Mathematics 2022, 10, 214. https://doi.org/10.3390/math10020214
Bilbao J, Bravo E, García O, Rebollar C, Varela C. Optimising Energy Management in Hybrid Microgrids. Mathematics. 2022; 10(2):214. https://doi.org/10.3390/math10020214
Chicago/Turabian StyleBilbao, Javier, Eugenio Bravo, Olatz García, Carolina Rebollar, and Concepción Varela. 2022. "Optimising Energy Management in Hybrid Microgrids" Mathematics 10, no. 2: 214. https://doi.org/10.3390/math10020214
APA StyleBilbao, J., Bravo, E., García, O., Rebollar, C., & Varela, C. (2022). Optimising Energy Management in Hybrid Microgrids. Mathematics, 10(2), 214. https://doi.org/10.3390/math10020214