1. Introduction
The optimal operation and control (or optimal operation performance) of industrial processes has been a hot topic in recent control strategy designs, where the optimal operation performance refers to the optimal global performance of the whole system, and this optimal global performance is usually defined by economic objectives [
1]. One cornerstone of the optimal operation and control of industrial processes is calculating the optimal operating conditions and maintaining them, despite the presence of different kinds of uncertainties and disturbances [
2]. Thus, it is typical to first calculate the optimal steady-state operating condition via a real-time optimization (RTO) layer (calculating the optimal operating conditions), and then, this calculated optimal steady state is passed to the lower advanced control layer (maintaining optimal operating conditions) [
3].
Specifically, RTO is an optimization layer that aims to obtain optimal steady states based on an updated rigorous steady-state model at certain intervals [
4]. These updated optimal steady-state setpoints are sent to the lower supervisory control layer, which is usually model predictive control [
5,
6]. Model predictive control (MPC) refers to a class of computer control algorithms that utilize an explicit process model to predict the future responses of a plant [
7], and the main advantage of MPC is its explicit constraint handling ability [
8,
9].
Optimal operation and control are realized by the separation of optimization and control in RTO, but it also has some drawbacks resulting from this separation [
10]: (1) before implementing RTO, the controlled system has to be steady enough, which means there is a steady-state waiting time in RTO [
11]; (2) there is a model mismatch between the RTO layer and the MPC layer; thus, the MPC may track unreachable setpoints optimized by RTO [
12]; (3) the RTO layer focuses only on the steady-state operation, and there may exist better dynamic operations [
13].
In order to further improve the global operation performance of the processes, researchers proposed dynamic real-time optimization (DRTO) [
14]. As its name implies, DRTO uses a dynamic model to replace the steady-state model used in the RTO layer, and this high-fidelity dynamic model gives DRTO the ability to optimize the transient operation performance [
15,
16]. Unlike RTO, which only passes the steady states as setpoints to the lower MPC layer, DRTO optimizes a dynamic trajectory based on the global performance of the whole system and then transmits this optimal trajectory to the lower advanced control layer. In this way, the model mismatch problem is fixed in DRTO, and DRTO can directly optimize the optimal dynamic operation rather than the optimal steady-state operation considered in RTO [
17]. In other words, DRTO can obtain a better global operation performance than that obtained by RTO.
However, DRTO still preserves the two-layer structure, and the lower control layer, such as nonlinear model predictive control (NMPC), minimizes the tracking errors with respect to the optimized trajectory obtained in the upper DRTO layer [
18]. Since there is still a time-scale separation problem between the DRTO layer and the control layer, the real-time disturbances in the processes will make the optimized trajectory sub-optimal during the control, and the NMPC has to track this outdated trajectory until the tracking trajectory is re-optimized at the next DRTO sample instant.
Recently, researchers proposed economic model predictive control (EMPC), which combines the DRTO layer and the control layer into one framework to avoid the time-scale separation problem [
19,
20]; in this way, EMPC focuses on how to address economic optimization (the operation performance in industrial processes) directly in real time [
21]. Unlike the quadratic objective function used in tracking MPC, EMPC incorporates a general cost function that directly accounts for process economics such as process yield or production rate, and this process economics-oriented general objective function gives EMPC the ability to generate optimal dynamic operation performance [
22]. In other words, EMPC can determine the operating conditions leading to the optimal operation performance, and the safe operating conditions of the processes can also be guaranteed [
23].
The direct responses to the dynamic economic optimization resulting from the general objective function in EMPC will inevitably bring stability issues to the controlled processes [
24]. Additional conditions are required for EMPC to guarantee closed-loop stability, and there are mainly two types of common approaches to ensuring stability in the EMPC community: one is the use of the dissipativity condition, and the other is the additional terminal constraints. Dissipativity-based EMPC is terminal-free EMPC, which relies on the turnpike property [
25,
26], but the turnpike property and dissipativity both have strict requirements on the controlled plant; thus, we mainly focus on the terminal constraint-based EMPC in this paper. Terminal constraints in EMPC can be categorized into three common types: terminal equality-based EMPC [
27], terminal region-based EMPC [
28], and Lyapunov-based EMPC [
29]. However, Lyapunov-based EMPC needs to construct a Lyapunov function, terminal equality-based EMPC needs to steer the terminal state into a pre-determined steady state, which makes the feasible region small, and terminal region-based EMPC ignores the operation performance within the terminal region.
Thus, terminal constraint-based EMPC loses some optimality of the global operation performance because of the terminal conditions, and a better control strategy that can realize a better optimal dynamic operation performance is desired.
To summarize, given a general economic objective function defined in the operational layer, the global operation performance of the whole system can be evaluated (which will be discussed in detail in
Section 2). The advantage of RTO is that it separates the optimizing control of the global operation performance into two layers: the upper RTO layer calculates the optimal steady-state operation first, and then the lower control layer tracks this optimized setpoint. In this way, the optimization of the global operation performance in RTO is easy to realize. However, RTO cannot optimize the transient operation performance. DRTO, on the other hand, uses a dynamic model in the RTO layer, which can optimize the transient operation performance, and the global operation performance can thus be improved. However, the time-scale separation of DRTO makes the optimized trajectory sub-optimal in real-time control. EMPC integrates DRTO and the MPC layer to address the time-scale separation problem to further increase the global operation performance, but the additional terminal conditions restrict the improvements of the global operation performance. Thus, the main aim of this study is to address the drawbacks of EMPC to further improve the global operation performance of the controlled system.
In view of the above issues, the main contribution of this paper is to propose a new kind of control strategy named efficiency-oriented model predictive control (EfiMPC), which can further improve the global operation performance of industrial processes. Specifically, EfiMPC is a nested optimization structure where the outer layer mainly focuses on the global performance of the whole system, and the inner layer mainly focuses on the control performance to guarantee the closed-loop stability of the processes. Ideal EfiMPC is first proposed, where the inner layer is the offline construction of an efficiency-oriented terminal region, and then a practical EfiMPC is constructed, where the inner layer is the online optimization of the dynamic operation performance, and the efficiency-oriented terminal region needs not to be explicitly defined in practical EfiMPC. With this nested optimization structure, EfiMPC can realize a better global dynamic operation performance by optimizing control.
The rest of this article is organized as follows.
Section 2 presents the problem that efficiency-oriented model predictive control (EfiMPC) tries to address. In
Section 3, the details of the proposed EfiMPC are given, and ideal EfiMPC, where the inner layer is calculated offline, and practical EfiMPC, where the inner layer is optimized online, are discussed. The recursive feasibility, as well as the closed-loop stability of practical EfiMPC, is also discussed briefly.
Section 4 demonstrates the superiority of the proposed EfiMPC strategy compared to the other three control strategies in a CSTR application. Finally,
Section 5 concludes this article.
2. Problem Statement
The problem considered in this paper is the optimization of the operation performance of industrial processes, namely the global performance of the whole system, and to obtain optimal operation performance results from the optimal operation and control of plants with the help of the ideal control strategy. This operation performance is usually evaluated by a general economic objective function
defined in the operational layer. Mathematically speaking, the ideal optimizing control problem, which aims to achieve the optimal operation performance, has the following form:
where
is the initial state of the system,
is the decision variable of the optimization problem (1),
is the economic objective function defined in the operational layer representing the instantaneous global performance of the whole system,
is the nonlinear dynamics of the industrial process, and
and
are the constraints of the system states and control inputs, respectively.
In Equation (1), is the starting instant of the process operation, and is the ending instant of the process operation. is the global operation performance function of the controlled process over the entire operation interval from to , is the optimal global operation performance, and is the corresponding optimal input trajectory.
However, optimizing control problem (1) is too idealistic to implement in practice. The main issues are: (1) the optimal solution to Equation (1) is an offline optimal solution, and thus, the optimality of will be degraded when disturbances or uncertainties exist during the process operation; (2) the optimization horizon of Equation (1) is the entire operation interval from to , which is too large to solve this optimization problem successfully.
In view of these issues, researchers prefer to use a receding horizon strategy to approximate this idealistic optimizing control problem (1). To be specific, short-horizon-based online optimization problems can be used to solve this global optimizing control problem at every sample instant
, and it is usually denoted as (nonlinear) model predictive control (MPC) with the following typical definition:
where
represents the current sample instant,
represents the system state at time instant
for brevity,
represents a finite prediction horizon and
represents the terminal state at the end of the online optimization problem (2);
is a terminal cost and
is a terminal constraint, and they are added mainly to guarantee the closed-loop stability of the controlled process;
is a stage cost function of the controller aiming to guide the control actions. Usually, this stage cost
is typically a penalty function of the tracking error with respect to the setpoint
, and this setpoint is obtained from a real-time optimization (RTO) layer implementing the optimization of the steady-state operation performance
.
However, unlike the idealistic problem (1), which directly optimizes the global operation performance, the approximation problem (2) focuses only on optimizing the control performance with respect to the optimal steady state within the prediction horizon , and the local operation performance is a byproduct of maintaining the optimal steady-state operation.
Specifically, in Equation (2),
is an open-loop control performance function,
is the optimal control performance, and
is the corresponding optimal control action. At every sample instant
, MPC will solve the online optimization problem (2) repeatedly, and then the first control action
will be implemented in the plant. The resulting implicit closed-loop input profile is defined as follows:
The closed-loop system controlled by
has a corresponding global operation performance
evaluated by the economic objective function
defined in the operational layer, and its specific value is calculated as follows:
Since this operation performance is realized by the online optimization of problem (2), which aims to optimize the control performance , the degree of the approximation of towards the ideal optimal operation performance is disappointing. Thus, it is desired to construct a control strategy that can realize optimizing control with a better operation performance , and the efficiency-oriented model predictive control (EfiMPC) proposed in this paper is a promising control strategy that aims to better approximate by . The term efficiency-oriented can be understood as EfiMPC improving the efficiency of this approximation , where is determined by the controlled industrial process itself.
3. Efficiency-Oriented Model Predictive Control
3.1. Motivations for Efficiency-Oriented MPC
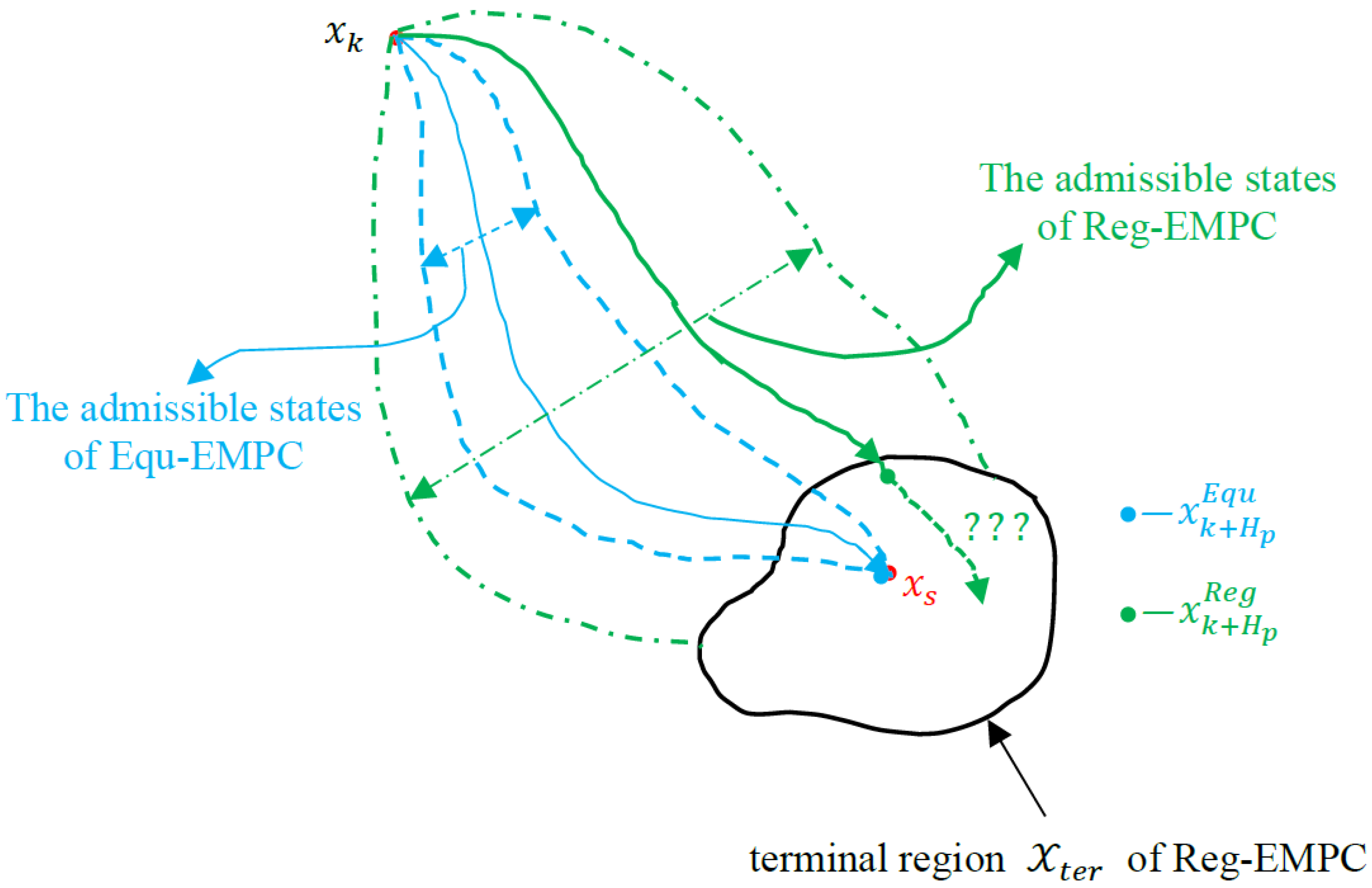
The recently proposed economic MPC (EMPC) strategies, for example, terminal-equality-based EMPC (Equ-EMPC) and terminal-region-based EMPC (Reg-EMPC), can improve the global operation performance of the process operation to some extent, but they have their own limitations that result from their structures. The advantages and disadvantages of Equ-EMPC and Reg-EMPC are briefly illustrated in
Figure 1.
In
Figure 1,
is the system state at the current sample instant
, and
is the optimal steady state in the interior of a terminal region
, which means
. This optimal steady state
is obtained from the following sub-optimization problem:
where
is the economic objective defined in the operational layer,
is the dynamic model of the industrial process, and
and
are the constraints of the system states and control inputs, respectively. This optimal steady state
can be used as the terminal equality constraint to guarantee the closed-loop stability of the controlled system, and the resulting Equ-EMPC is defined as follows:
where
is the current sample instant,
is the prediction horizon of the online optimization problem,
is the dynamic model of the controlled process, and
and
are the constraints of system states and control inputs, respectively.
is the terminal state at the end of the optimization horizon, and it is steered into the optimal steady state
.
Equ-EMPC can optimize the transient operation performance before steady-state operation, and the global operation performance has thus been improved accordingly. However, for the general economic objective function
considered in this paper, it is assumed that a better dynamic state
exists that satisfies
; thus, the optimal dynamic operation is more desirable than the steady-state operation defined by
. On the other hand, this hard equality constraint
restricts the feasible searching space of the control input, and the range of the corresponding admissible control trajectories are reduced accordingly. These admissible states constrained by
are denoted by the region within the dashed-blue lines in
Figure 1, and the optimization of the transient operation performance is degraded because of this smaller feasible region.
To summarize, the limitations of Equ-EMPC with respect to the operation performance are mainly twofold: (1) it cannot lead to the optimal dynamic operation based on a general objective function ; (2) the transient operation performance before stabilizing into the optimal steady state is also degraded because of a smaller feasible region.
As for Reg-EMPC, the terminal region
illustrated in
Figure 1 helps to enlarge the feasible space of the admissible trajectories denoted by the region within the dashed-green lines; thus, the transient operation performance of Reg-EMPC is better than that of the Equ-EMPC. The detailed definition of Reg-EMPC is as follows:
where the definitions of most parameters are the same as those defined in Equation (4), and
is the terminal region where
.
In Reg-EMPC, it is assumed that there exists a local control policy
within the terminal region
such that any states
can be controlled to stay within this terminal region. This local control policy is used mainly for the considerations of the recursive feasibility and the closed-loop stability, while the operation performance within this terminal region has been ignored. As shown in
Figure 1, Reg-EMPC will steer the terminal state
into the terminal region
, but the future behaviors of the system with respect to the operation performance are uncertain; thus, it is not safe to say that the closed-loop operation performance of Reg-EMPC is definitely better than that of Equ-EMPC. Instead, it can only be concluded that the open-loop transient operation performance of Reg-EMPC is better than that of Equ-EMPC.
To summarize, Reg-EMPC can guarantee a better open-loop transient operation performance than Equ-EMPC, but the closed-loop operation performance of Reg-EMPC is uncertain because of the use of the terminal region . In other words, Reg-EMPC can directly optimize the local operation performance, but it is unable to directly optimize the global operation performance.
Drawbacks, on the other hand, always mean there are chances for improvement. The newly proposed control strategy in this paper mainly aims to address the limitations that exist in Equ-EMPC and Reg-EMPC. Briefly speaking, efficiency-oriented model predictive control (EfiMPC) tries to (1) improve the open-loop operation performance, which means enlarging the admissible state region for optimization, and (2) improve the closed-loop operation performance, which means guaranteeing the operation performance within the terminal region to generate a better global operation performance.
3.2. Ideal Efficiency-Oriented Model Predictive Control
Ideal efficiency-oriented MPC (ideal EfiMPC) is defined as follows:
where the definitions of most parameters are the same as those defined in Equation (5),
is an efficiency-oriented terminal region, which is a subset of the control forward-invariant set
, and the optimal steady state
is in the interior of this
. A corresponding local control policy
as defined in Reg-EMPC can also guarantee stabilization within this efficiency-oriented terminal region
.
The specific definition of
is as follows:
where
is a feasible control sequence that can steer the state
into the optimal steady state
. In other words,
is in the interior of
, and
can be reached from any state within this efficiency-oriented terminal region.
is the average dynamic operation performance of the system dynamics controlled by
, and it satisfies:
This inequality condition guarantees that the dynamic operation performance controlled by ideal EfiMPC is at least no worse than the optimal steady-state operation (minimum implies optimum in this paper).
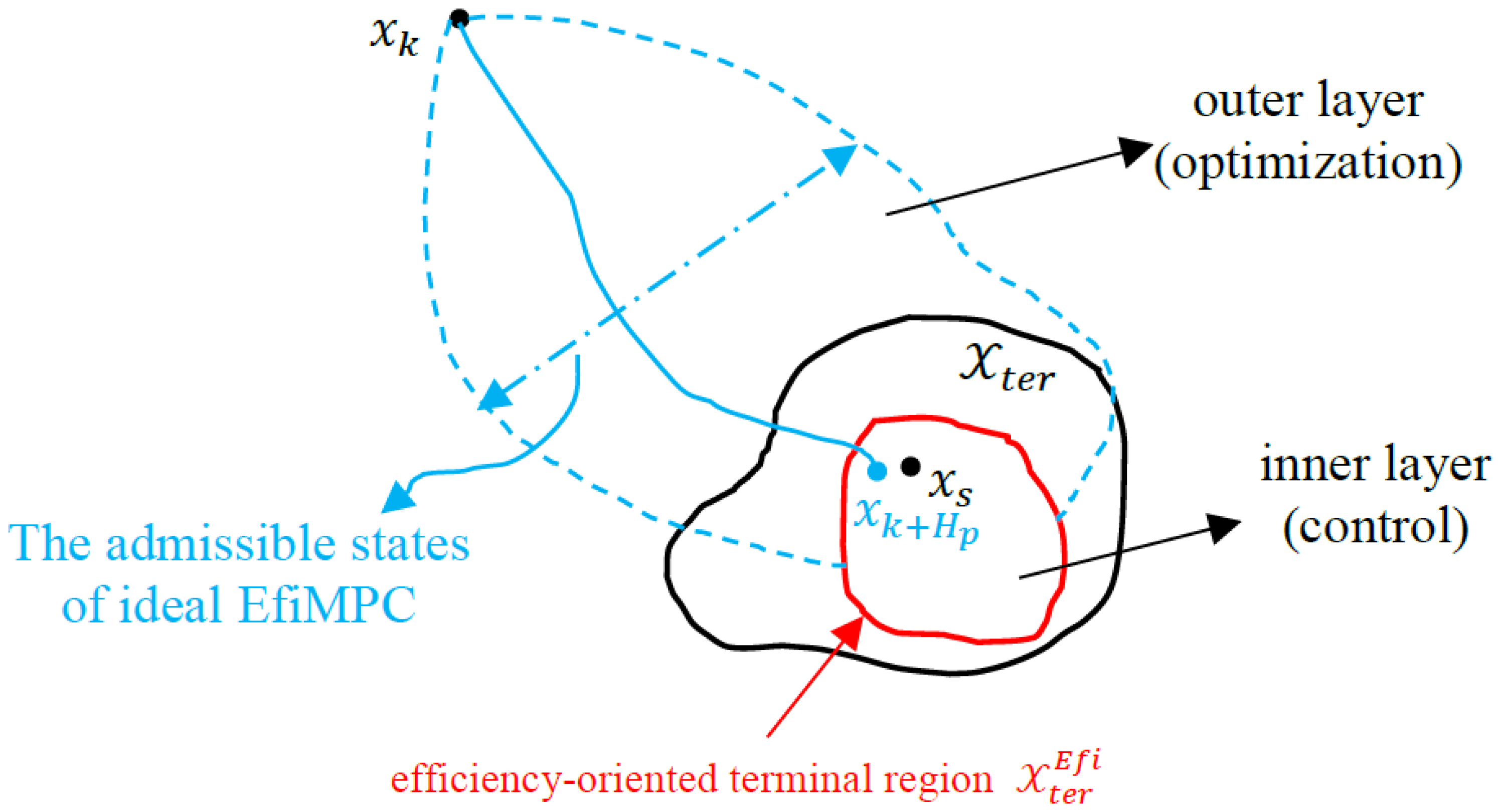
The brief ideas of ideal EfiMPC are illustrated in
Figure 2, and its superiorities over Equ-EMPC and Reg-EMPC are as follows:
- (1)
Since , the feasible region of the admissible states of ideal EfiMPC is greater than that of Equ-EMPC; thus, the transient operation performance of ideal EfiMPC evaluated by the economic objective is better than that of Equ-EMPC. In addition, because the average dynamic performance of is at least no worse than the optimal steady-state operation, ideal EfiMPC can also realize a better dynamic operation, and the closed-loop operation performance is thus better than that of Equ-EMPC.
- (2)
Reg-EMPC focuses mainly on the improvement of the local operation performance within the prediction horizon , and the global operation performance of Reg-EMPC cannot be guaranteed. On the contrary, ideal EfiMPC can guarantee the global operation performance within the efficiency-oriented terminal region with the help of the average dynamic performance condition ; thus, the closed-loop performance of Reg-EMPC evaluated by the economic objective cannot be guaranteed, while ideal EfiMPC can definitely generate a better dynamic operation performance.
The performance of ideal EfiMPC is heavily dependent on the construction of the efficiency-oriented terminal region
. As shown in
Figure 2, the state trajectory from
to
aims to improve the transient operation performance within the prediction horizon
, and it can be regarded as an outer layer focusing on the optimization perspective; the terminal state
is controlled into an efficiency-oriented terminal region
which relates the local operation performance with the global operation performance, and it can be regarded as an inner layer focusing on the control perspective.
In essence, ideal EfiMPC can be regarded as a nested optimization structure based on the construction of an efficiency-oriented terminal region
in its inner layer as follows:
where the inner layer is an offline construction of
in ideal EfiMPC, and
is defined in Equation (7). This nested structure integrates the optimization and control into one framework, where the outer layer aims to optimize the transient operation performance by
, and the inner layer aims to control the closed-loop system while guaranteeing the dynamic operation performance, which is at least no worse than the optimal steady-state operation.
Remark 1. When, ideal EfiMPC will be degraded into Equ-EMPC, and when, ideal EfiMPC will be degraded into Reg-EMPC. Thus, it is not surprising that ideal EfiMPC can outperform both Equ-EMPC and Reg-EMPC because they can be regarded as two extremes of ideal EfiMPC.
Ideally, if one can obtain an optimal by offline construction, ideal EfiMPC can generate the optimal dynamic operation performance as expected. However, this is a problem-dependent subset that has to be constructed for every control problem, and the construction itself is not a simple task. Indeed, we do not need such an optimal efficiency-oriented terminal region where every element in it can generate a promising dynamic operation; instead, we only need to find one feasible dynamic operation that outperforms steady-state operation. Of course, we want this “feasible” dynamic operation to perform as best as possible, and this leads to an online optimization of the dynamic operation within . Thus, the offline construction of in the inner layer in ideal EfiMPC can be realized by an online optimization problem. This kind of nested control strategy is denoted as “practical efficiency-oriented MPC” (practical EfiMPC), and it is discussed in detail in the following subsection.
3.3. Practical Efficiency-Oriented Model Predictive Control
Practical efficiency-oriented MPC (practical EfiMPC) is defined as follows:
where the definitions of most parameters are the same as those defined in Equation (8),
is the prediction horizon of the outer level optimization problem,
is the decision variable of the outer level,
is the terminal state of the outer level, which plays the role of a connecting parameter transmitting the information between the outer level and the inner level, and
is the optimizing control parameter indicating whether a better dynamic operation exists. Its specific value depends on
, which is the average dynamic operation performance of the inner level. Specifically, if the value of
is better (smaller in this paper) than the optimal steady-state operation
, then
is set to be zero to accept this promising dynamic operation performance; otherwise,
is set to infinity to indicate that the local performance resulting from
is not acceptable from the perspective of the global operation performance, and this disappointing dynamic operation has to be rejected.
is the prediction horizon of the inner level optimization problem, and
is the decision variable of the inner level that can steer the system state into the optimal steady state
.
In practical EfiMPC, is an implicitly defined efficiency-oriented terminal region: if the optimizing control parameter , it implies that falls into an efficiency-oriented terminal region, and the dynamic operation performance is better than the optimal steady-state operation; otherwise, it implies that does not belong to any efficiency-oriented terminal region, and the performance of the optimized dynamic operation is poor. In addition, the control actions and in practical EfiMPC are both piece-wise constant control sequences, which means .
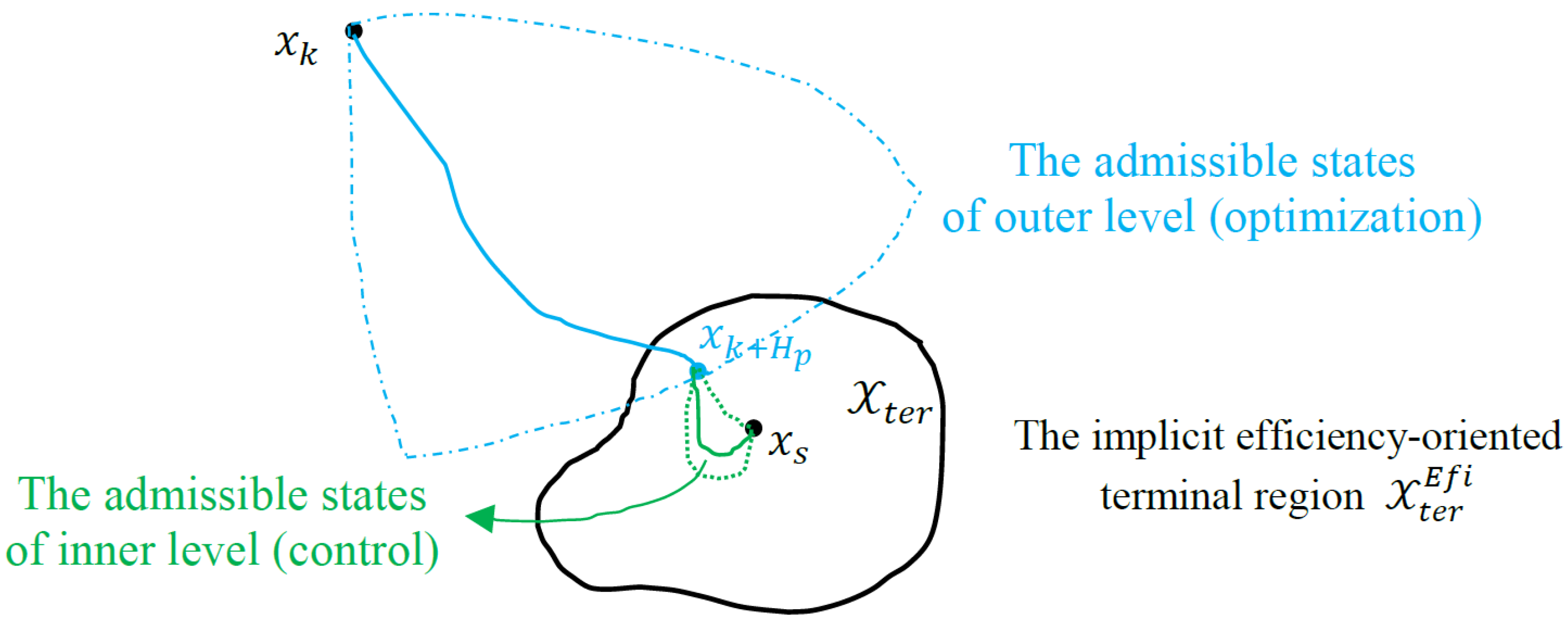
The brief ideas of practical EfiMPC are illustrated in
Figure 3. As shown in
Figure 3, the admissible states of the outer level are not constrained by the control-oriented equality constraint
; thus, practical EfiMPC can optimize the transient operation performance to a larger extent. While in the inner level, the control-oriented equality constraint
will shrink the range of the admissible states, and the operation performance suffers as a result. In this sense, the main functions of these two levels are different: the outer level focuses mainly on improving the operation performance within the prediction horizon
, while the inner level focuses mainly on satisfying the control performance to steer the system into
. The terminal state
at the outer level is the connecting parameter between the two nested levels; it is the result of the operation performance optimization of the outer level, and then it becomes the starting point of the inner level. At the inner level, the system state is steered into
, and the dynamic operation performance is also optimized along the system trajectory.
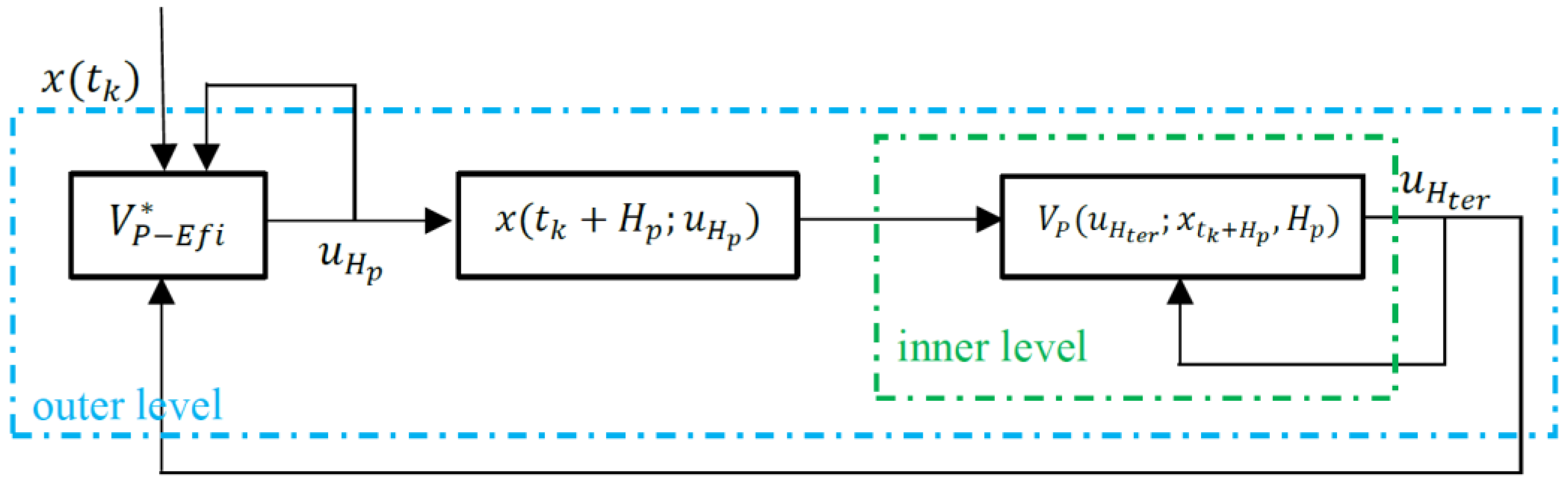
The nested structure of practical EfiMPC is illustrated in
Figure 4. The dynamic operation performance of the inner level sends feedback information to the outer level: if the average dynamic operation performance is better than the optimal steady-state operation, it is implied that the controller finds a better dynamic operation; otherwise, the steady-state operation is the best operation for the controlled process. If the optimal solution to practical EfiMPC (9) is
, which means that a better dynamic operation does not exist, then practical EfiMPC will update the terminal region
to execute the optimal steady-state operation. The update mechanism is as follows:
Remark 2. With the help of the update mechanism of the terminal region, practical EfiMPC can intelligently distinguish whether the controlled process has a better dynamic operation than the optimal steady-state operation. If such a better dynamic operation based on the current system state does not exist, practical EfiMPC will be degraded into Equ-EMPC, and the online optimization problem will be re-optimized with the updated terminal region; otherwise, practical EfiMPC will obtain an optimal dynamic operation to generate the optimal global dynamic operation performance.
The recursive feasibility and the closed-loop stability of practical EfiMPC are discussed briefly as follows. At the current sample instant
, assume that the practical EfiMPC problem (9) has an optimal solution
, where
and
At the next sample instant
, there must exist a feasible solution
such that
and
where
is the optimal steady-state control action satisfying
.
Since feasibility at sample instant guarantees the feasibility at the next sample instant and by backward recursion and induction, practical EfiMPC is recursively feasible if it is initially feasible.
The recursive feasibility of practical EfiMPC guarantees that there always exists a feasible solution to the problem Equation (9); thus, it is implied that the system states can be steered into within steps. These steerable states form a reachable set , where the optimal steady state is reachable from any state in it. Let the initial state satisfy , then ; thus, the system states controlled by practical EfiMPC will be kept in this reachable set , and the closed-loop stability with respect to is guaranteed.
4. Results and Discussion
4.1. Application to a Chemical Process Example
In this section, a chemical process example from [
30] is used to demonstrate the effectiveness of the proposed practical efficiency-oriented model predictive control (practical EfiMPC or just EfiMPC for brevity in this simulation section), and the simulation results of practical EfiMPC are compared with traditional tracking MPC (TMPC), equality-constraint-based economic MPC (Equ-EMPC), and region-constraint-based economic MPC (Reg-EMPC) control strategies.
Specifically, the chemical process considered in this paper is the oxidation of ethylene to ethylene oxide in a non-isothermal continuously stirred tank reactor (CSTR). The CSTR process is defined by the following three complex reactions:
The dimensionless equation representing this CSTR application is
, which has the following specific definitions [
31,
32]:
In Equation (11), the constant parameters and their specific values are as follows [
30]:
,
,
,
,
,
,
,
,
,
and
. In addition, the dimensionless state variables
, and
represent the dimensionless gas density, ethylene concentration, ethylene oxide concentration, and temperature in the reactor, respectively;
are control inputs, where
represents the feed volumetric flow rate, and
represents the concentration of ethylene in the feed.
The aim of this CSTR application is to maximize the global operation performance
over the whole process operation from the starting instant
to the ending instant
, and it can be defined by the minimization problem as follows:
where
represents the amount of the reactant feedstock during the CSTR process operation, and it is limited by the inventory constraint
.
is the instantaneous operation performance defined in the operational layer that represents the yield of oxide, and it has the following form as defined in [
30]:
Due to the actuator limitations, the control actions are constrained by , . The CSTR process is assumed to be initialized at the initial state , and a sample interval is used in this simulation. The first-order Runge–Kutta numerical integration method was used to obtain the discrete model from Equation (11), and the integration step used here is . The feedstock constraint defined in Equation (12) satisfies . In addition, represents the optimal steady state, and is the corresponding optimal control input.
The practical EfiMPC strategy for this CSTR application is defined as follows:
where most of the parameters are defined the same as those in Equation (9), Equation (11) is the dynamic model of the CSTR process,
is a
-neighborhood of the optimal steady state
, and
is a norm computation satisfying
.
The comparative control strategies TMPC, Equ-EMPC, and Reg-EMPC for controlling this CSTR application are defined as follows:
where
and
are symmetric positive semi-definite weighting matrices, and
is a positive scalar value. In Equation (15), the setpoint
is optimized and passed by the real-time optimization (RTO) layer; thus, the TMPC strategy (15) also represents an RTO algorithm.
Remark 3. Some readers may be confused that the comparative control strategies (14)–(17) target different behaviors by their corresponding objective functions and constraints. However, indeed, comparisons among these control strategies are fair because the controlled system dynamics were used to calculate the same closed-loop operation performancein the simulation. In addition, the values ofindicate the superiorities of the comparative control strategies.
4.2. Simulation Results
The parameters of the simulations in this paper are defined as follows: , , , , , , , , , and , where represents the diagonal matrix, and the superscript represents the transpose of the vector.
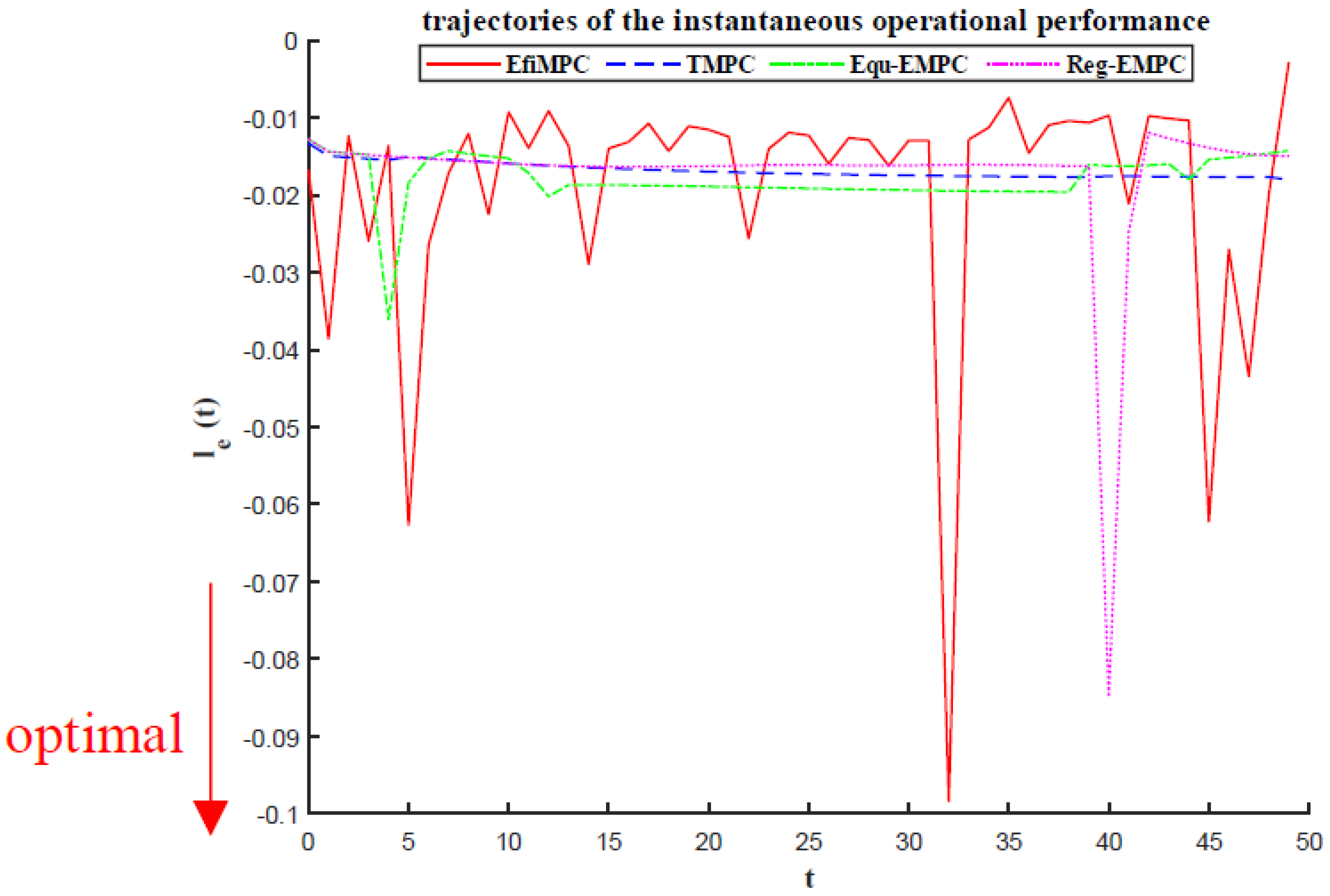
The instantaneous operation performances of the comparative control strategies are illustrated in
Figure 5, and the minimum value of the instantaneous operation performance implies the optimal objective function value
. As shown in the figure, the instantaneous operation performance controlled by the TMPC strategy is almost steady. This is because the aim of the TMPC is to control the system into steady-state operation, and the operation performance is only a byproduct of this stabilization control performance; thus, a steady-state control performance will lead to a stable operation performance.
The instantaneous operational performances controlled by Equ-EMPC and Reg-EMPC are a little bit more dynamic than that controlled by TMPC, and some of the instantaneous operation performances can perform better than steady-state operation; this better dynamic operation performance mainly results from the transient operation performance optimization that exists in Equ-EMPC and Reg-EMPC.
The instantaneous operation performance controlled by EfiMPC has the best dynamic operation performance, which is better than that of Equ-EMPC and Reg-EMPC. EfiMPC also has the best instantaneous operation performance with the minimum value . This optimal dynamic operation performance of EfiMPC is realized by the outer level of the nested structure, where the dynamic operation of the operation performance is directly optimized at the control layer online. However, this transient superiority of EfiMPC resulting from the instantaneous operation performance alone does not mean the superiority of the optimal global performance of the whole system; thus, the closed-loop operation performances are required to further compare the global performances of the comparative control strategies.
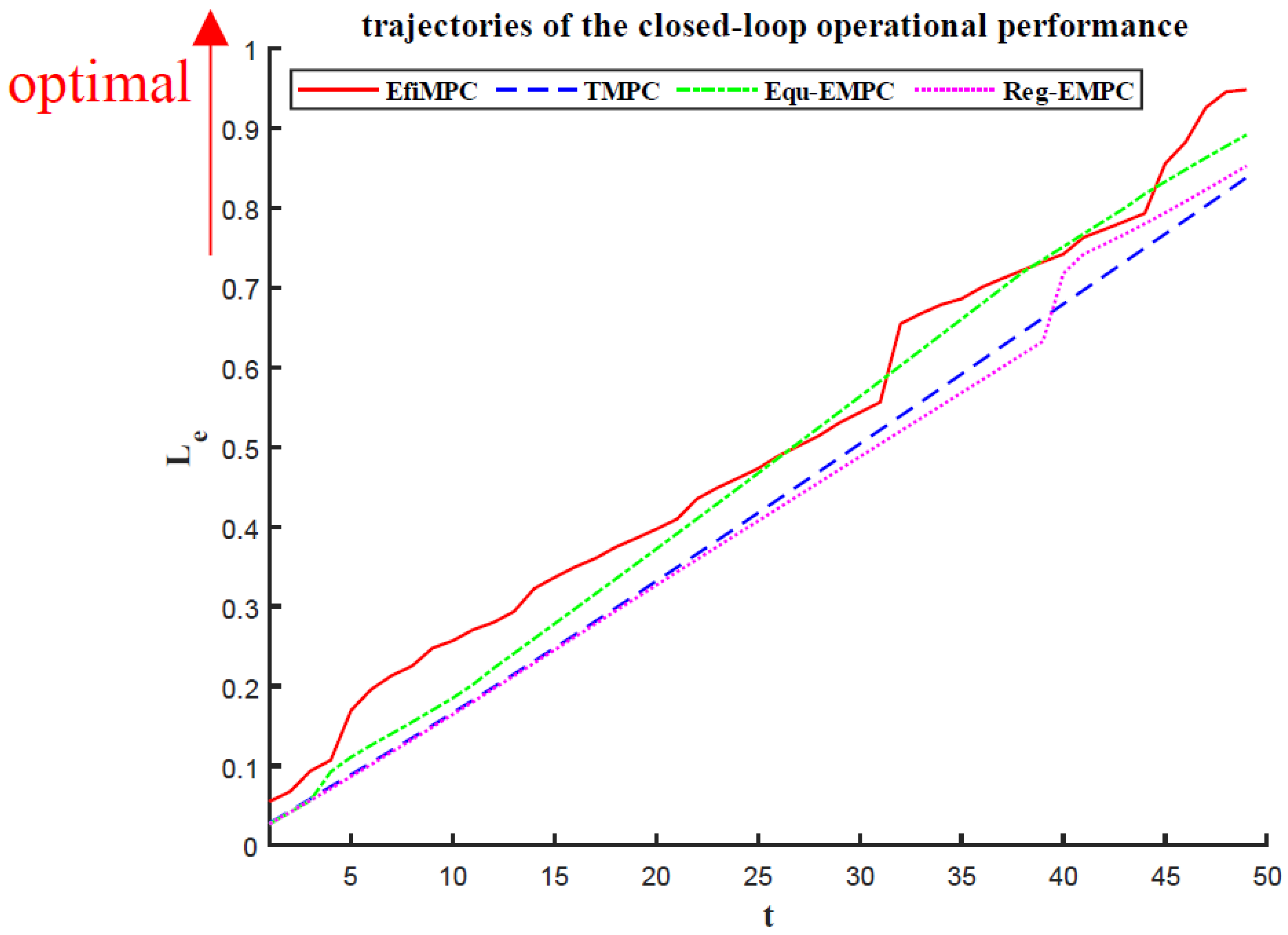
The closed-loop operation performances of the comparative control strategies are illustrated in
Figure 6, and it is calculated as follows, where the maximum value of the closed-loop operation performance implies the optimum:
where
represents the instantaneous operation performance, and
and
represent the starting instant of the CSTR process and the ending instant of the CSTR process, respectively.
As shown in
Figure 6, it is clear that EfiMPC can generate the best closed-loop operation performance with the value of
(the maximum value implies the optimum), and the closed-loop operation performances controlled by TMPC, Equ-EMPC, and Reg-EMPC are
,
and
, respectively.
The Equ-EMPC strategy and the Reg-EMPC strategy can both outperform the TMPC strategy. This is because Equ-EMPC and Reg-EMPC both can optimize the transient operation performance, while TMPC only optimizes the control performance, and the operation performance of TMPC is heavily dependent on the steady-state operation.
The reason that EfiMPC can outperform Equ-EMPC and Reg-EMPC is that EfiMPC can not only optimize the transient operation performance in a wider search space but also guarantee that the optimized dynamic operation performance is better than the steady-state operation in the closed-loop perspective.
Thus, the effectiveness of the proposed EfiMPC has been demonstrated by the best closed-loop operation performance
as reported in
Table 1.
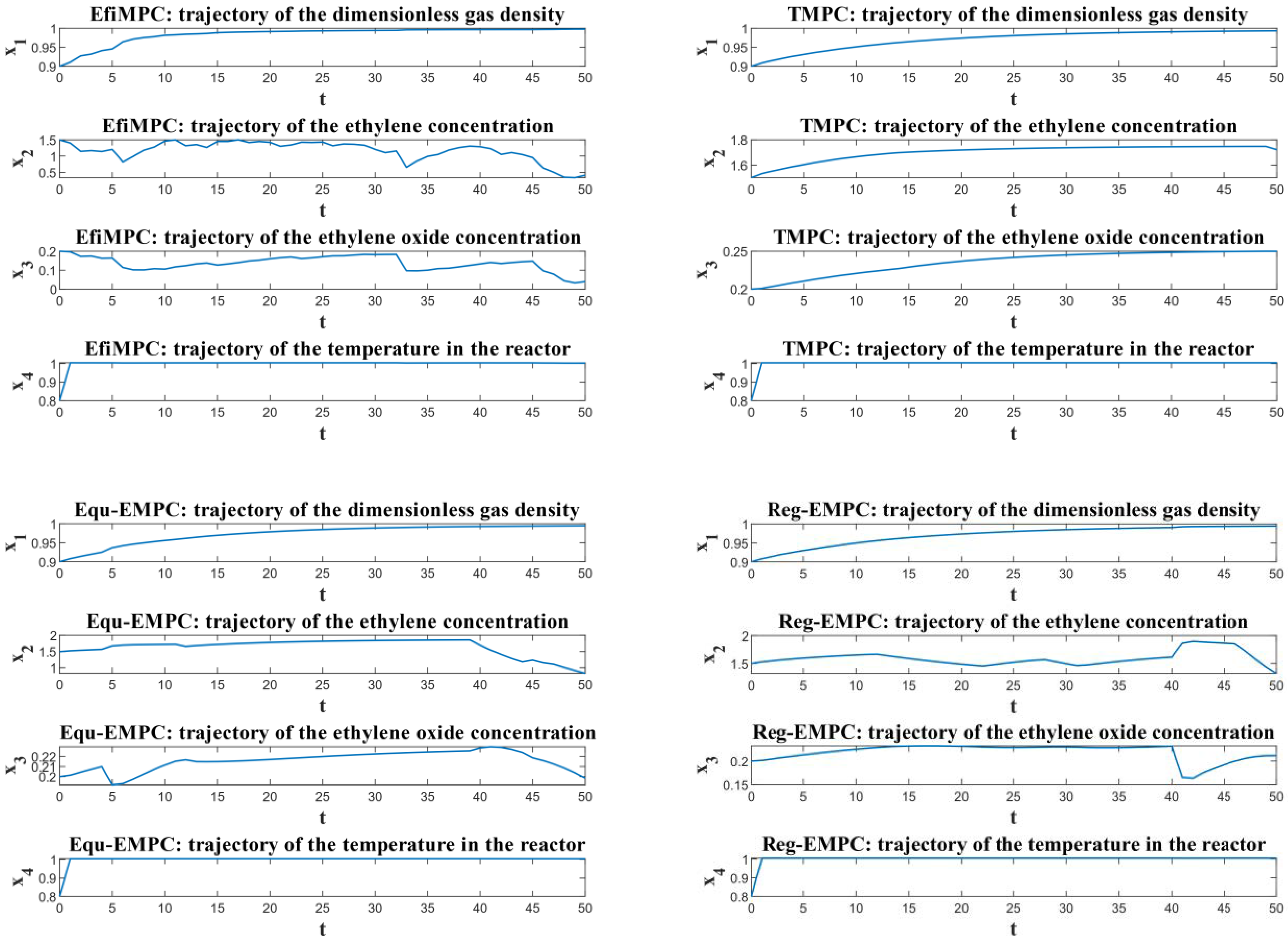
To further investigate the performances of the comparative control strategies, the state trajectories of these four comparative control strategies are illustrated in
Figure 7, and the control inputs of these four comparative control strategies are illustrated in
Figure 8. As shown in these two figures, after a short transient behavior period, the control actions, as well as the corresponding state trajectories controlled by TMPC, become steady, which indicates that TMPC leads to steady-state operation in this CSTR process.
Unlike TMPC, which focuses only on the control performance with respect to the optimal steady state, Equ-EMPC and Reg-EMPC both can optimize the transient operation performance before steady state, and the resulting control actions and the corresponding state trajectories thus have dynamic behaviors. However, limited by the small search space of Equ-EMPC and by the uncertain operation performance within the terminal region of Reg-EMPC, Equ-EMPC and Reg-EMPC can only optimize the dynamic operation to a small extent.
On the other hand, thanks to the nested structure of EfiMPC, it can obtain a better dynamic operation performance compared to the optimal steady-state operation online, and the control actions can perform a much more dynamic behavior with a higher frequency compared to Equ-EMPC and Reg-EMPC, as shown in
Figure 8. More flexible movements of the control actions imply a higher optimization potential for closed-loop operation performance.
4.3. Discussion
Although TMPC aims only to optimize the control performance with respect to the optimal steady state , it can also generate an acceptable closed-loop operation performance with , and this operation performance is mainly guaranteed by the optimal steady state optimized by the upper RTO layer. To be specific, the upper RTO layer optimizes the global objective of the whole system based on a steady-state model of the controlled process. The lower advanced control layer receives this optimized set point and tries its best to stabilize the system into this steady state. Although the objective of the control layer is the control performance with respect to the given set point, the operation performance can be guaranteed in a neighborhood of the optimal steady-state operation by this control performance. Thus, although the operation performance is a byproduct of the TMPC strategy, its operation performance can be guaranteed to some extent.
Since TMPC can only guarantee the operation performance near the optimal steady-state operation, the optimization of the transient operation performance has the potential to lead to a better closed-loop operation performance, and Equ-EMPC and Reg-EMPC are introduced by researchers for this purpose. Take this CSTR process for example, and indicate that Equ-EMPC and Reg-EMPC can find a better dynamic operation than that of TMPC. However, it is necessary to mention that the improvements in Equ-EMPC and Reg-EMPC can only be achieved for the control applications where the steady-state operation is not the optimal operation and better dynamic operations exist in the controlled problem; otherwise, the superiorities of Equ-EMPC and Reg-EMPC will deteriorate.
As for the proposed EfiMPC strategy, the nested structure gives it the ability to recognize whether better dynamic operations based on the current system state exist, and it can find the optimal dynamic operation if it exists; otherwise, EfiMPC will lead to the optimal steady-state operation instead. Thus, EfiMPC can be applied to general control applications, and the operation performance can be optimized no matter if the optimal operation mode is steady-state operation or dynamic operation. In this CSTR application, EfiMPC finds the best global dynamic operation performance with .
One interesting phenomenon that appeared in the simulation is that TMPC performed a steady-state operation for most of the processing time as expected, but it led to an obvious dynamic behavior that deviated from the steady state at the end of the process operation. For example, the control action
of TMPC had a sudden change at the end of the operation, as shown in
Figure 8. This phenomenon reveals the main limitation of the TMPC strategy: since TMPC focuses only on the control performance, it ignores the transient operation behavior during the period before the steady state, and it has to compensate for this transient operation behavior at the end of the control process. On the other hand, EfiMPC takes the transient operation performance into consideration online at every sample instant; thus, EfiMPC can take advantage of these transient operation performances, leading to optimal dynamic operation.
In addition, as shown in
Figure 8, the control actions of EfiMPC change frequently with large values, and the control actions of TMPC are stable most of the time. This implies that the better dynamic operation controlled by EfiMPC is realized by the dynamic control actions, which means EfiMPC sacrifices some control performance to achieve a better dynamic operation performance. If we put some constraints on the variation of the control actions, the control actions will change less frequently and to a smaller extent, but the improvements in the operation performance will suffer accordingly.
Finally,
Table 2 illustrates the online computation times of the comparative control strategies, and their values are all smaller than the sample interval
. As shown in
Table 2, EfiMPC has the largest computation burden, and TMPC spends the least time on computation. This indicates that although the nested structure of EfiMPC can heavily improve the global operation performance, it has a larger computation burden for this improvement. In order to make EfiMPC more applicable to fast applications, future research should investigate how to reduce the computational burden of EfiMPC.
5. Conclusions
A novel control strategy that aims to improve global operation performance to realize optimal operation and control is proposed in this paper. First, the ideal EfiMPC strategy with a nested structure was proposed, where the inner layer is the offline construction of an efficiency-oriented terminal region and the outer layer is the direct optimization of the transient operation performance. This efficiency-oriented terminal region can guarantee a dynamic operation performance in the closed-loop perspective, and a better global operation performance can thus be obtained.
In order to avoid the construction of the optimal efficiency-oriented terminal region, a practical EfiMPC strategy in which the efficiency-oriented terminal region needs not to be defined explicitly is then proposed. Specifically, the inner layer in practical EfiMPC is the online optimization of the average dynamic operation performance, and it is guaranteed to perform better than the optimal steady-state operation. The inner layer in practical EfiMPC focuses mainly on the control performance to guarantee the closed-loop stability, and the outer layer focuses mainly on the free optimization of the transient operation performance; thus, practical EfiMPC integrates optimization and control into a nested structure to realize optimal control. The recursive feasibility and the closed-loop stability of practical EfiMPC were also discussed.
A CSTR process application was used to test the superiority of the proposed practical EfiMPC. Compared with the TMPC, Equ-EMPC, and Reg-EMPC strategies, practical EfiMPC generated the best global operation performance, as expected; thus, the effectiveness of the proposed EfiMPC has been demonstrated.
This paper introduces the initial idea of nested structure-based EfiMPC. For future studies, the offline construction of the optimal efficiency-oriented terminal region in ideal EfiMPC can be investigated. In addition to the average dynamic operation used in the inner layer in practical EfiMPC, other types of inner optimization problems aiming to guarantee closed-loop operation can be researched. Finally, the effectiveness of EfiMPC in applications with disturbances can be studied.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}