
Large Language Model and Traditional Machine Learning Scoring of Evolutionary Explanations: Benefits and Drawbacks

Abstract
1. Introduction
2. Materials and Methods
2.1. Data Corpus and Human Scoring
2.2. ML-Based Scoring of Scientific Explanations
2.3. Large Language Model Selection and Prompt Engineering
2.4. Programming and Data Extraction
2.5. Statistical Comparisons of LLM and ML Scoring Accuracy Relative to Human Raters
2.6. Model Run Time
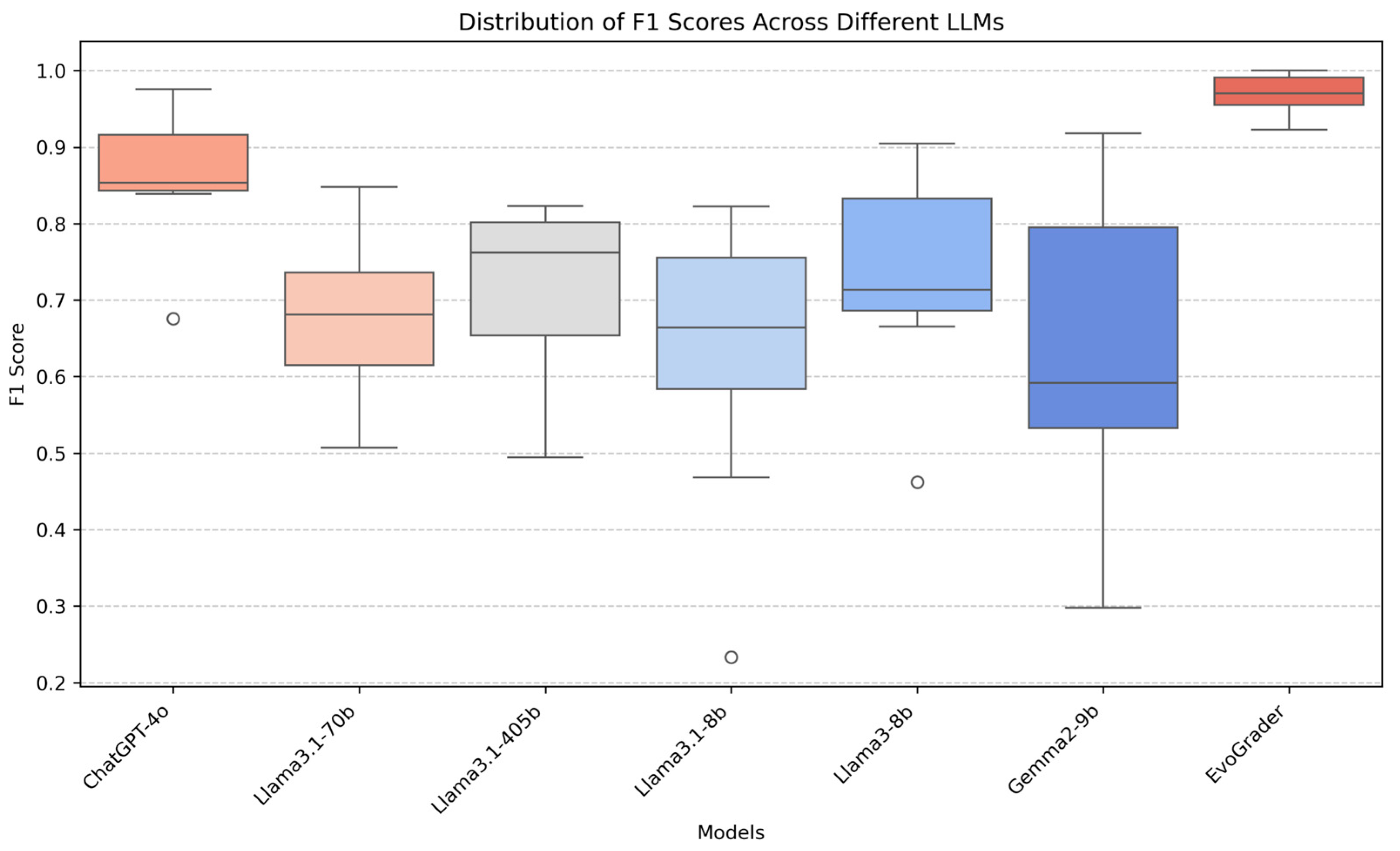
3. Results
4. Discussion
4.1. Training Corpora
4.2. Linguistic Features of the Knowledge Domain
5. Study Limitations
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| API | Application Programming Interface |
| LLM | Large Language Models |
| ML | Machine Learning |
| NCATE | National Council for Accreditation of Teacher Education |
| COT | Chain of Thought |
| 1 | See Supplementary Materials for equations. |
References
- American Association for the Advancement of Science. (2011). Vision and change in undergraduate biology education: A call to action. American Association for the Advancement of Science. [Google Scholar]
- Beggrow, E. P., Ha, M., Nehm, R. H., Pearl, D., & Boone, W. J. (2014). Assessing scientific practices using machine-learning methods: How closely do they match clinical interview performance? Journal of Science Education and Technology, 23(1), 160–182. [Google Scholar] [CrossRef]
- Brittain, B. (2025, February 20). OpenAI must face part of Intercept lawsuit over AI training. Reuters. Available online: www.reuters.com (accessed on 22 May 2025).
- Cohen, C., Hutchins, N., Le, T., & Biswas, G. (2024). A Chain-of-thought prompting approach with LLMs for evaluating students’ formative assessment responses in science. arXiv, arXiv:2403.14565v1. [Google Scholar]
- Dann, R. (2014). Assessment as learning: Blurring the boundaries of assessment and learning for theory, policy and practice. Assessment in Education: Principles, Policy & Practice, 21(2), 149–166. [Google Scholar] [CrossRef]
- Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., Yang, A., Fan, A., Goyal, A., Hartshorn, A., Yang, A., Mitra, A., Sravankumar, A., Korenev, A., Hinsvark, A., Rao, A., … Ganapathy, R. (2024). The llama 3 herd of models. arXiv, arXiv:2407.21783. [Google Scholar]
- Gemma Team. (2024). Gemma 2: Improving open language models at a practical size. arXiv, arXiv:2408.00118. [Google Scholar]
- Gerard, L., & Linn, M. C. (2022). Computer-based guidance to support students’ revision of their science explanations. Computers & Education, 176, 104351. [Google Scholar] [CrossRef]
- Ha, M., Nehm, R. H., Urban-Lurain, M., & Merrill, J. E. (2011). Applying computerized scoring models of written biological explanations across courses and colleges: Prospects and limitations. CBE-Life Sciences Education, 10(4), 379–393. [Google Scholar] [CrossRef]
- Han, A., Zhou, X., Cai, Z., Han, S., Ko, R., Corrigan, S., & Peppler, K. A. (2024, May 11–16). Teachers, parents, and students’ perspectives on integrating generative AI into elementary literacy education [Paper presentation]. CHI Conference on Human Factors in Computing Systems (CHI’24) (, 17p), Honolulu, HI, USA. [Google Scholar] [CrossRef]
- Harris, Z. (1954). Distributional structure. Word, 10, 146–162. [Google Scholar] [CrossRef]
- Haudek, K., Kaplan, J., Knight, J., Long, T., Merrill, J., Munn, A., Smith, M., & Urban-Lurain, M. (2011). Harnessing technology to improve formative assessment of student conceptions in STEM: Forging a national network. CBE-Life Sciences Education, 10, 149–155. [Google Scholar] [CrossRef]
- Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., & Steinhardt, J. (2020). Measuring massive multitask language understanding. arXiv, arXiv:2009.03300. [Google Scholar]
- Huebner, P. A., Sulem, E., Cynthia, F., & Roth, D. (2021, November 10–11). BabyBERTa: Learning more grammar with small-scale child-directed language [Paper presentation]. 25th Conference on Computational Natural Language Learning (pp. 624–646), Online. [Google Scholar]
- Karran, A. J., Charland, P., Martineau, J. T., de Arana, A., Lesage, A. M., Senecal, S., & Leger, P. M. (2024). Multi-stakeholder perspective on responsible artificial intelligence and acceptability in education. arXiv, arXiv:2402.15027. [Google Scholar]
- Kizilcec, R. F. (2024). To advance AI use in education, focus on understanding educators. International Journal of Artificial Intelligence in Education, 34, 12–19. [Google Scholar] [CrossRef] [PubMed]
- Kundu, A., & Barbosa, D. (2024). Are large language models good essay graders? arXiv. [Google Scholar] [CrossRef]
- Landis, J. R., & Koch, G. G. (1977). The measurement of observer agreement for categorical data. Biometrics, 33, 1159–1174. [Google Scholar] [CrossRef]
- Latif, E., & Zhai, X. (2024). Automatic scoring of students’ science writing using hybrid neural network. Proceedings of Machine Learning Research, 257, 97–106. [Google Scholar]
- Lee, G.-G., Latif, E., Wu, X., Liu, N., & Zhai, X. (2024). Applying large language models and chain-of-thought for automatic scoring. Computers and Education: Artificial Intelligence, 6, 100213. [Google Scholar] [CrossRef]
- Li, W. (2025). Applying natural language processing adaptive dialogs to promote knowledge integration during instruction. Education Sciences, 15(2), 207. [Google Scholar] [CrossRef]
- Liu, Z., He, X., Liu, L., Liu, T., & Zhai, X. (2023). Context matters: A strategy to pre-train language model for science education. arXiv, arXiv:2301.12031. [Google Scholar]
- Magliano, J. P., & Graesser, A. C. (2012). Computer-based assessment of student-constructed responses. Behavior Research Methods, 44(3), 608–621. [Google Scholar] [CrossRef]
- McCoy, R. T., Yao, S., Friedman, D., Hardy, M. D., & Griffiths, T. L. (2024). Embers of autoregression show how large language models are shaped by the problem they are trained to solve. Proceedings of the National Academy of Sciences of the United States of America, 121(41), e2322420121. [Google Scholar] [CrossRef]
- Moharreri, K., Ha, M., & Nehm, R. H. (2014). EvoGrader: An online formative assessment tool for automatically evaluating written evolutionary explanations. Evolution: Education and Outreach, 7, 15. [Google Scholar] [CrossRef]
- Moore, S., Nguyen, H. A., Chen, T., & Stamper, J. (2023). Assessing the quality of multiple-choice questions using GPT-4 and rule-based methods. In European conference on technology enhanced learning (pp. 229–245). Springer. [Google Scholar]
- Myers, M. C., & Wilson, J. (2023). Evaluating the construct validity of an automated writing evaluation system with a randomization algorithm. International Journal of Artificial Intelligence in Education, 33(3), 609–634. [Google Scholar] [CrossRef]
- National Research Council (NRC). (2012). A framework for K-12 science education: Practices, crosscutting concepts, and core ideas. National Academies Press. [Google Scholar]
- Nehm, R. H. (2024, November 21). AI in biology education assessment: How automation can drive educational transformation. In X. Zhai, & J. Krajcik (Eds.), Uses of artificial intelligence in STEM education (online ed.). Oxford Academic. [Google Scholar] [CrossRef]
- Nehm, R. H., Beggrow, E. P., Opfer, J. E., & Ha, M. (2012b). Reasoning about natural selection: Diagnosing contextual competency using the ACORNS instrument. The American Biology Teacher, 74(2), 92–98. [Google Scholar] [CrossRef]
- Nehm, R. H., Ha, M., & Mayfield, E. (2012a). Transforming biology assessment with machine learning: Automated scoring of written evolutionary explanations. Journal of Science Education and Technology, 21(1), 183–196. [Google Scholar] [CrossRef]
- Nehm, R. H., Ha, M., Rector, M., Opfer, J. E., Perrin, L., Ridgway, J., & Mollohan, K. (2010). Scoring guide for the open response instrument (ORI) and evolutionary gain and loss test (ACORNS) (Unpublished Technical Report of National Science Foundation REESE Project 0909999). National Science Foundation. [Google Scholar]
- Nyaaba, M., Zhai, X., & Faison, M. Z. (2024). Generative AI for culturally responsive science assessment: A conceptual framework. Education Sciences, 14(12), 1325. [Google Scholar] [CrossRef]
- Oli, P., Banjade, R., Chapagain, J., & Rus, V. (2023). Automated Assessment of Students’ Code Comprehension using LLMs. arXiv, arXiv:2401.05399. [Google Scholar]
- OpenAI. (2024). Hello gpt-4o. Available online: https://openai.com/index/hello-gpt-4o/ (accessed on 22 May 2025).
- OpenAI. (2025). Tactic: Ask the model to adopt a persona. OpenAI Platform. Available online: https://platform.openai.com/docs/guides/prompt-engineering#tactic-ask-the-model-to-adopt-a-persona (accessed on 31 March 2025).
- Opfer, J. E., Nehm, R. H., & Ha, M. (2012). Cognitive foundations for science assessment design: Knowing what students know about evolution. Journal of Research in Science Teaching, 49(6), 744–777. [Google Scholar] [CrossRef]
- Pack, A., Barrett, A., & Escalante, J. (2024). Large language models and automated essay scoring of English language learner writing: Insights into reliability and validity. Computers and Education: Artificial Intelligence, 6, 100234. [Google Scholar] [CrossRef]
- Platt, J. (1999). Fast training of support vector machines using sequential minimal optimization. In B. Schölkopf, C. J. C. Burges, & A. J. Smola (Eds.), Advances in kernel methods—Support vector learning (pp. 185–208). MIT Press. [Google Scholar]
- Rector, M. A., Nehm, R. H., & Pearl, D. (2013). Learning the language of evolution: Lexical ambiguity and word meaning in student explanations. Research in Science Education, 43, 1107–1133. [Google Scholar] [CrossRef]
- Riordan, B., Bichler, S., Bradford, A., Chen, J. K., Wiley, K., Gerard, L., & Linn, M. C. (2020, July 10). An empirical investigation of neural methods for content scoring of science explanations. Fifteenth Workshop on Innovative Use of NLP for Building Educational Applications (pp. 135–144), Seattle, WA, USA. [Google Scholar]
- Sbeglia, G. C., & Nehm, R. H. (2024). Building conceptual and methodological bridges between SSE’s diversity, equity, and inclusion statement and educational actions in evolutionary biology. Evolution, 78(5), 809–820. [Google Scholar] [CrossRef]
- Shiroda, M., Doherty, J., Scott, E., & Haudek, K. (2023). Covariational reasoning and item context affect language in undergraduate mass balance written explanations. Advances in Physiology Education, 47, 762–775. [Google Scholar] [CrossRef] [PubMed]
- Simpson, G. G. (1959). On Eschewing teleology. Science, 129(3349), 672–675. [Google Scholar] [CrossRef] [PubMed]
- Sripathi, K. N., Moscarella, R. A., Steele, M., Yoho, R., You, H., Prevost, L. B., Urban-Lurain, M., Merrill, J., & Haudek, K. C. (2024). Machine learning mixed methods text analysis: An illustration from automated scoring models of student writing in biology education. Journal of Mixed Methods Research, 18(1), 48–70. [Google Scholar] [CrossRef]
- Stahl, M., Biermann, L., Nehring, A., & Wachsmuth, H. (2024, June 20). Exploring LLM prompting strategies for joint essay scoring and feedback generation [Paper presentation]. 19th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2024) (pp. 283–298), Mexico City, Mexico. [Google Scholar]
- Stribling, D., Xia, Y., Amer, M. K., Graim, K. S., & Mulligan, C. J. (2024). The model student: GPT-4 performance on graduate biomedical science exams. Scientific Reports, 14, 5670. [Google Scholar] [CrossRef]
- Wang, H., Haudek, K. C., Manzanares, A. D., Romulo, C. L., & Royse, E. A. (2024). Extending a pretrained language model (BERT) using an ontological perspective to classify students’ scientific expertise level from written responses. Research Square. [Google Scholar] [CrossRef]
- Wei, J., Garrette, D., Linzen, T., & Pavlick, E. (2021, November 7–11). Frequency effects on syntactic rule learning in transformers. 2021 Conference on Empirical Methods in Natural Language Processing (pp. 932–948), Online and Punta Cana, Dominican Republic. [Google Scholar]
- Wu, X., Saraf, P. P., Lee, G. G., Latif, E., Liu, N., & Zhai, X. (2024). Unveiling scoring processes: Dissecting the differences between LLMs and Human graders in automatic scoring. arXiv, arXiv:2407.18328. [Google Scholar] [CrossRef]
- Yan, L., Sha, L., Zhao, L., Li, Y., Martinez-Maldonado, R., Chen, G., Li, X., Jin, Y., & Gašević, D. (2024). Practical and ethical challenges of large language models in education: A systematic scoping review. British Journal of Educational Technology, 55, 90–112. [Google Scholar] [CrossRef]
- Zhai, X. (2023). Chatgpt and AI: The game changer for education. In X. Zhai (Ed.), ChatGPT: Reforming education on five aspects (pp. 16–17). Shanghai Education. [Google Scholar]
- Zhai, X., & Nehm, R. H. (2023). AI and formative assessment: The train has left the station. Journal of Research in Science Teaching, 60(6), 1390–1398. [Google Scholar] [CrossRef]
- Zhai, X., Neumann, K., & Krajcik, J. (2023). AI for tackling STEM education challenges. Frontiers in Education, 8, 1183030. [Google Scholar] [CrossRef]
- Zhai, X., Shi, L., & Nehm, R. H. (2021). A meta-analysis of machine learning-based science assessments: Factors impacting machine-human score agreements. Journal of Science Education and Technology, 30(3), 361–379. [Google Scholar] [CrossRef]
- Zhai, X., Yin, Y., Pellegrino, J. W., Haudek, K. C., & Shi, L. (2020). Applying machine learning in science assessment: A systematic review. Studies in Science Education, 56(1), 111–151. [Google Scholar] [CrossRef]
- Zhu, M., Liu, O. L., & Lee, H.-S. (2020). The effect of automated feedback on revision behavior and learning gains in formative assessment of scientific argument writing. Computers & Education, 143, 103668. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| “To explain the presence of pulegone in later generations of a plant that had not previously contained pulegone in ancestral plants, biologists could consider the changes in the environment that may have taken place over the time period that led to the development of pulegone in plants. Possible environmental influences may have prompted a need for adaptation by the labiatae that would require pulegone in order to thrive. Biologists could use human development and disruption, climate changes, predation, and other such influences to explain the current presence of pulegone in plants. Biologists could explain a slow process of evolution that took place over an extended period of time leading up to the addition of pulegone. Biologists could also explain that genetic variation may have resulted in pulegone. Over time, some of the plants may have had mutated genetic material that caused for the [sic] presence of pulegone. If these plants were then able to survive better in the conditions of their environment rather than those of plants without the mutation, this would yield favorable genetic variation that would become more prevalent in surviving plants. With time, the plants with the mutated genes that cause pulegone to occur would out-live the ancestral plants lacking the gene and through generations of reproduction, the new labiatae all contain this material.” | |||||||||
| Student Explanation Scoring | KC1 (Presence/Causes of Variation) | KC2 (Heritability) | KC3 (Competition) | KC5 (Limited Resources) | KC6 (Differential Survival/Reproduction) | NI1 (Inappropriate Teleology) | NI2 (Use-Disuse) | NI3 (Adaptation as Acclimation) | NAR (Non-Adaptive Causation) |
| True Label | T | F | F | T | T | T | F | F | F |
| EvoGrader | TRUE | FALSE | FALSE | TRUE | TRUE | TRUE | FALSE | FALSE | FALSE |
| ChatGPT-4o | TRUE | TRUE | TRUE | TRUE | TRUE | TRUE | FALSE | TRUE | FALSE |
| Llama 3.1-405b | TRUE | TRUE | TRUE | TRUE | TRUE | TRUE | FALSE | TRUE | FALSE |
| Llama 3.1-70b | TRUE | TRUE | TRUE | TRUE | TRUE | TRUE | FALSE | TRUE | FALSE |
| Llama 3.1-8b | TRUE | TRUE | FALSE | TRUE | TRUE | TRUE | FALSE | TRUE | TRUE |
| Llama 3-8b | TRUE | TRUE | TRUE | TRUE | TRUE | TRUE | FALSE | TRUE | TRUE |
| Gemma 2-9b | TRUE | FALSE | TRUE | TRUE | TRUE | TRUE | FALSE | TRUE | TRUE |
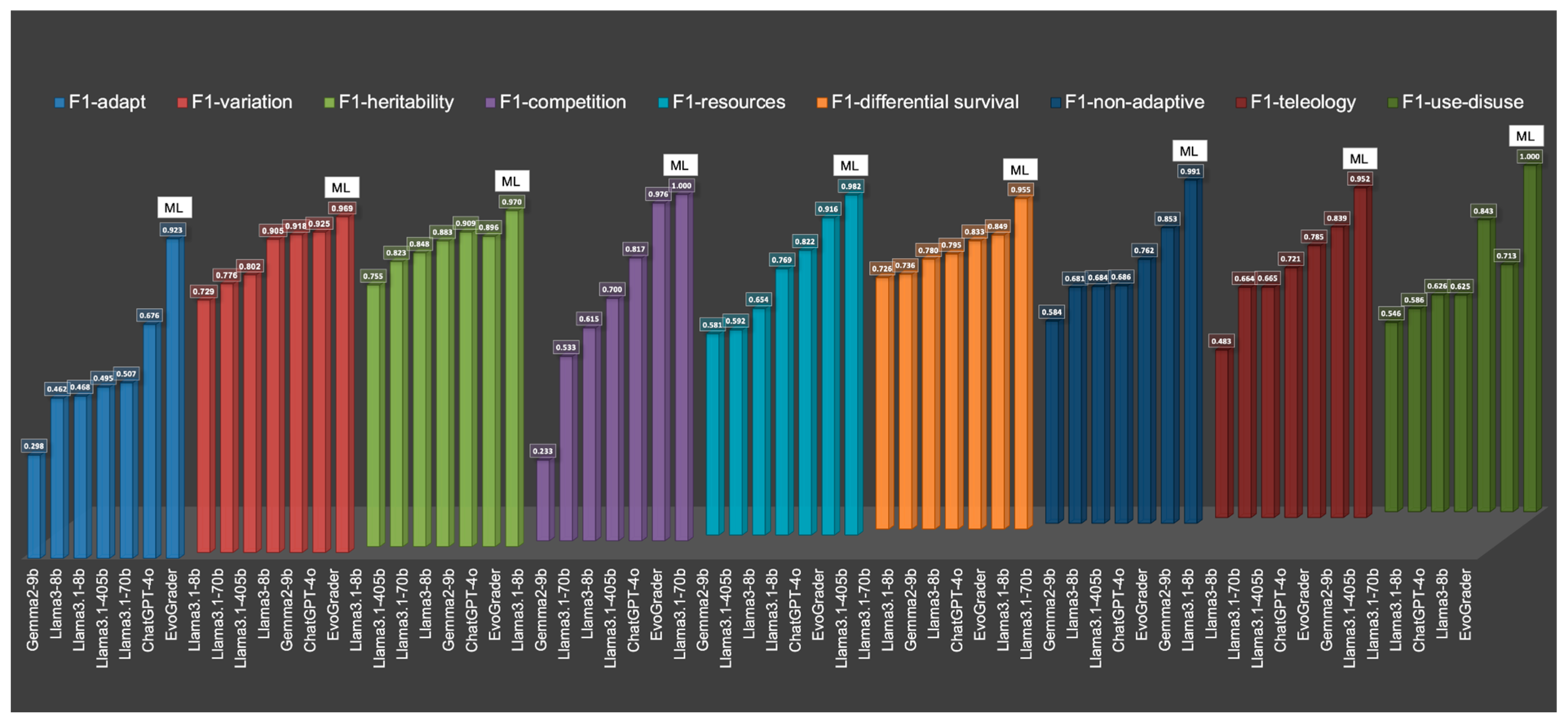
| Model | Time (h/m) | Concept | Kappa | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|---|---|
| Gemma2-9b | 0:44′ | Adapt = acclimate | 0.048 | 0.307 | 0.552 | 0.597 | 0.298 |
| Llama3-8b | 0:51′ | Adapt = acclimate | 0.129 | 0.526 | 0.571 | 0.692 | 0.462 |
| Llama3.1-8b | 0:45′ | Adapt = acclimate | 0.106 | 0.553 | 0.553 | 0.646 | 0.468 |
| Llama3.1-405b | 2:17′ | Adapt = acclimate | 0.155 | 0.571 | 0.579 | 0.718 | 0.495 |
| Llama3.1-70b | 0:46′ | Adapt = acclimate | 0.171 | 0.586 | 0.585 | 0.735 | 0.507 |
| ChatGPT-4o | 0:12′ | Adapt = acclimate | 0.367 | 0.830 | 0.647 | 0.780 | 0.676 |
| EvoGrader | 0:04′ | Adapt = acclimate | 0.846 | 0.972 | 0.923 | 0.923 | 0.923 |
| Llama3.1-8b | 0:50′ | KC1 Variation | 0.481 | 0.730 | 0.755 | 0.771 | 0.729 |
| Llama3.1-70b | 0:20′ | KC1 Variation | 0.569 | 0.777 | 0.800 | 0.820 | 0.776 |
| Llama3.1-405b | 1:11′ | KC1 Variation | 0.615 | 0.804 | 0.815 | 0.840 | 0.802 |
| Llama3-8b | 0:55′ | KC1 Variation | 0.810 | 0.916 | 0.932 | 0.889 | 0.905 |
| Gemma2-9b | 0:40′ | KC1 Variation | 0.836 | 0.924 | 0.917 | 0.919 | 0.918 |
| ChatGPT-4o | 0:12′ | KC1 Variation | 0.850 | 0.933 | 0.925 | 0.926 | 0.925 |
| EvoGrader | 0:04′ | KC1 Variation | 0.939 | 0.972 | 0.975 | 0.965 | 0.969 |
| Llama3.1-8b | 0:53′ | KC2 Heritability | 0.526 | 0.818 | 0.730 | 0.860 | 0.755 |
| Llama3.1-405b | 0:48′ | KC2 Heritability | 0.652 | 0.876 | 0.786 | 0.914 | 0.823 |
| Llama3.1-70b | 0:14′ | KC2 Heritability | 0.700 | 0.897 | 0.810 | 0.929 | 0.848 |
| Llama3-8b | 1:09′ | KC2 Heritability | 0.766 | 0.936 | 0.895 | 0.872 | 0.883 |
| Gemma2-9b | 0:40′ | KC2 Heritability | 0.818 | 0.945 | 0.885 | 0.939 | 0.909 |
| ChatGPT-4o | 0:11′ | KC2 Heritability | 0.792 | 0.950 | 0.915 | 0.880 | 0.896 |
| EvoGrader | 0:04′ | KC2 Heritability | 0.941 | 0.984 | 0.991 | 0.953 | 0.970 |
| Llama3.1-8b | 0:58′ | KC3 Competition | 0.013 | 0.277 | 0.513 | 0.632 | 0.233 |
| Gemma2-9b | 0:41′ | KC3 Competition | 0.140 | 0.814 | 0.546 | 0.905 | 0.533 |
| Llama3.1-70b | 0:15′ | KC3 Competition | 0.257 | 0.903 | 0.582 | 0.951 | 0.615 |
| Llama3-8b | 0:44′ | KC3 Competition | 0.409 | 0.949 | 0.636 | 0.974 | 0.700 |
| Llama3.1-405b | 0:18′ | KC3 Competition | 0.635 | 0.979 | 0.738 | 0.989 | 0.817 |
| ChatGPT-4o | 0:11′ | KC3 Competition | 0.951 | 0.998 | 0.955 | 0.999 | 0.976 |
| EvoGrader | 0:04′ | KC3 Competition | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| Llama3.1-70b | 0:16′ | KC5 Limited resources | 0.279 | 0.596 | 0.663 | 0.738 | 0.581 |
| Gemma2-9b | 0:40′ | KC5 Limited resources | 0.289 | 0.610 | 0.663 | 0.742 | 0.592 |
| Llama3.1-405b | 1:23′ | KC5 Limited resources | 0.374 | 0.680 | 0.691 | 0.791 | 0.654 |
| Llama3-8b | 0:45′ | KC5 Limited resources | 0.541 | 0.829 | 0.749 | 0.807 | 0.769 |
| Llama3.1-8b | 0:38′ | KC5 Limited resources | 0.646 | 0.893 | 0.859 | 0.797 | 0.822 |
| ChatGPT-4o | 0:11′ | KC5 Limited resources | 0.832 | 0.940 | 0.892 | 0.949 | 0.916 |
| EvoGrader | 0:04′ | KC5 Limited resources | 0.963 | 0.988 | 0.989 | 0.975 | 0.982 |
| Llama3.1-405b | 1:51′ | KC6 Differential survival | 0.484 | 0.738 | 0.807 | 0.746 | 0.726 |
| Llama3.1-70b | 0:20′ | KC6 Differential survival | 0.502 | 0.747 | 0.817 | 0.755 | 0.736 |
| Llama3.1-8b | 1:28′ | KC6 Differential survival | 0.570 | 0.783 | 0.811 | 0.788 | 0.780 |
| Gemma2-9b | 0:41′ | KC6 Differential survival | 0.600 | 0.798 | 0.828 | 0.803 | 0.795 |
| Llama3-8b | 0:40′ | KC6 Differential survival | 0.666 | 0.833 | 0.834 | 0.834 | 0.833 |
| ChatGPT-4o | 0:09′ | KC6 Differential survival | 0.701 | 0.850 | 0.862 | 0.852 | 0.849 |
| EvoGrader | 0:04′ | KC6 Differential survival | 0.910 | 0.955 | 0.955 | 0.955 | 0.955 |
| Llama3.1-8b | 0:32′ | Non-Adaptive reasoning | 0.188 | 0.896 | 0.564 | 0.721 | 0.584 |
| Llama3.1-70b | 0:16′ | Non-Adaptive reasoning | 0.376 | 0.923 | 0.628 | 0.926 | 0.681 |
| Gemma2-9b | 0:50′ | Non-Adaptive reasoning | 0.377 | 0.932 | 0.631 | 0.878 | 0.684 |
| Llama3-8b | 0:52′ | Non-Adaptive reasoning | 0.373 | 0.957 | 0.656 | 0.735 | 0.686 |
| Llama3.1-405b | 2:36′ | Non-Adaptive reasoning | 0.527 | 0.960 | 0.698 | 0.910 | 0.762 |
| ChatGPT-4o | 0:13′ | Non-Adaptive reasoning | 0.707 | 0.981 | 0.806 | 0.921 | 0.853 |
| EvoGrader | 0:04′ | Non-Adaptive reasoning | 0.982 | 0.999 | 0.983 | 1.000 | 0.991 |
| Gemma2-9b | 0:42′ | Need (teleology) | 0.180 | 0.485 | 0.642 | 0.666 | 0.483 |
| Llama3.1-8b | 0:35′ | Need (teleology) | 0.370 | 0.699 | 0.678 | 0.760 | 0.664 |
| Llama3-8b | 0:38′ | Need (teleology) | 0.357 | 0.712 | 0.666 | 0.735 | 0.665 |
| Llama3.1-70b | 0:15′ | Need (teleology) | 0.471 | 0.754 | 0.723 | 0.821 | 0.721 |
| Llama3.1-405b | 1:35′ | Need (teleology) | 0.580 | 0.824 | 0.765 | 0.856 | 0.785 |
| ChatGPT-4o | 0:14′ | Need (teleology) | 0.678 | 0.875 | 0.820 | 0.867 | 0.839 |
| EvoGrader | 0:04′ | Need (teleology) | 0.904 | 0.968 | 0.962 | 0.943 | 0.952 |
| Gemma2-9b | 0:42′ | Use/disuse inheritance | 0.177 | 0.763 | 0.565 | 0.840 | 0.546 |
| Llama3.1-405b | 0:31′ | Use/disuse inheritance | 0.226 | 0.817 | 0.579 | 0.856 | 0.586 |
| Llama3.1-70b | 0:14′ | Use/disuse inheritance | 0.283 | 0.861 | 0.598 | 0.866 | 0.626 |
| Llama3.1-8b | 0:31′ | Use/disuse inheritance | 0.274 | 0.876 | 0.596 | 0.813 | 0.625 |
| ChatGPT-4o | 0:12′ | Use/disuse inheritance | 0.687 | 0.963 | 0.796 | 0.913 | 0.843 |
| Llama3-8b | 0:40′ | Use/disuse inheritance | 0.427 | 0.965 | 0.779 | 0.674 | 0.713 |
| EvoGrader | 0:04′ | Use/disuse inheritance | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| Topic | Machine Learning | Large Language Models |
|---|---|---|
| Scoring accuracy | Excellent; comparable to or exceeding expert human inter-rater agreement. Useful for higher-stakes assessment contexts or cases where high accuracy is required (e.g., high quality feedback). | Very good in the case of GPT-4. It does not match expert human raters. May be appropriate for lower-stakes assessment contexts or intermediate quality feedback. |
| Scoring replication over time and across samples | Results are replicable (i.e., deterministic) and stable over time, facilitating robust comparisons across samples and over time (e.g., many years) for evaluation and research purposes. | Results may not be replicable because of LLM evolution and the probabilistic nature of model outputs (unless random seed is used). Direct comparisons across samples and over time may be limited. |
| Hardware, software, and technology expertise | Desktop computers can easily perform rapid model building and testing; no need for high-end computational resources (e.g., APIs) or personnel with specialized computer science (CS) knowledge. | Large datasets (e.g., thousands of student responses) require significant computational resources or substantial processing time. Multiple applications and complex workflows need to be used to perform scoring (see Section 2). Specialized CS knowledge is required. |
| Economics and time | Human scoring for ML training and model building is costly and time-consuming. Model deployment does not incur any costs for large-scale scoring and has no recurring costs, given that it can be executed on inexpensive hardware. | Prompt engineering can be costly in terms of technology and personnel; it may never yield scores at the needed levels of accuracy. Using LLMs requires monthly payments. LLM run time is substantially longer (see Table 2 Run Time data). |
| Ethical considerations | Clear consent procedures can be used to gather data with the option of declining to release information. Data need not be stored. | Consent is complex or implied when using “free” proprietary versions of LLMs. Information submitted to proprietary LLMs may be stored and used by corporations in profit-generating efforts. Ownership of digital property, including copyrighted material, may be disputed. Use of the LLMs involves participation in disputed copyright infringement by content creators. |
| Service | Models | Privacy Policy |
|---|---|---|
| Azure | Llama 3, Llama 3.1 and Gemma (LLM) | “With Azure, you are the owner of the data that you provide for storing and hosting…We do not share your data with advertiser-supported services, nor do we mine them for any purposes like marketing research or advertising…We process your data only with your agreement, and when we have your agreement, we use your data to provide only the services you have chosen.” (https://azure.microsoft.com/en-us/explore/trusted-cloud/privacy, accessed on 22 May 2025) |
| OpenAI API | ChatGPT-4o (LLM) | “We collect personal data that you provide in the input to our services…including your prompts and other content you upload, such as files, images, and audio.” “How we use personal data: to improve and develop our services and conduct research, for example, to develop new product features.” (https://openai.com/policies/row-privacy-policy/, accessed on 22 May 2025) |
| AWS | EvoGrader (ML) | Files uploaded to EvoGrader are not retained, and no personal information is collected by the EvoGrader system. (www.evograder.org, accessed on 22 May 2025) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, Y.; Nehm, R.H. Large Language Model and Traditional Machine Learning Scoring of Evolutionary Explanations: Benefits and Drawbacks. Educ. Sci. 2025, 15, 676. https://doi.org/10.3390/educsci15060676
Pan Y, Nehm RH. Large Language Model and Traditional Machine Learning Scoring of Evolutionary Explanations: Benefits and Drawbacks. Education Sciences. 2025; 15(6):676. https://doi.org/10.3390/educsci15060676
Chicago/Turabian StylePan, Yunlong, and Ross H. Nehm. 2025. "Large Language Model and Traditional Machine Learning Scoring of Evolutionary Explanations: Benefits and Drawbacks" Education Sciences 15, no. 6: 676. https://doi.org/10.3390/educsci15060676
APA StylePan, Y., & Nehm, R. H. (2025). Large Language Model and Traditional Machine Learning Scoring of Evolutionary Explanations: Benefits and Drawbacks. Education Sciences, 15(6), 676. https://doi.org/10.3390/educsci15060676