
Artwork Style Recognition Using Vision Transformers and MLP Mixer

 ,
,  ,
,  ,
,  and
and 
Abstract
:1. Introduction
1.1. Motivation
1.2. Contribution
- We propose Vision Transformers as the main ML method to classify artistic style.
- We train Vision Transformers from scratch in the task of artwork style recognition, achieving over 39% prediction accuracy for 21 style classes on the WikiArt paintings dataset.
- We conduct a comparative study between the most common optimizers obtaining useful information for future studies.
- We compare the results compared with MLP Mixer’s performance on the same task, examining in this way two very different DL architectures on a complex pattern recognition framework.
1.3. Organization of the Paper
2. Related Work

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Advantages | Disadvantages |
|---|---|---|
| Elgammal A., et al. [4] | • Study of many CNN architectures | No comparison |
| • Interpretation and representation | with previous works | |
| Lecoutre A., et. al. [8] | • Comprehensive methodology | Full analysis is |
| • Plenty techniques used | provided only for Alexnet | |
| Bar Y., et. al. [21] | • Combination of | test only one |
| low level descriptors and CNNs | CNN architecture | |
| Cetinic E., et. al. [10] | • Fine-tuning | No interpretation |
| • Analysing image similarity | ||
| Huang X., et. al. [11] | • Two channels used; the RGB channel | No interpretation |
| and the brush stroke information | ||
| Sandoval C., et al. [12] | • Novel two stage approach | Only pre-trained models |
3. Materials and Methods
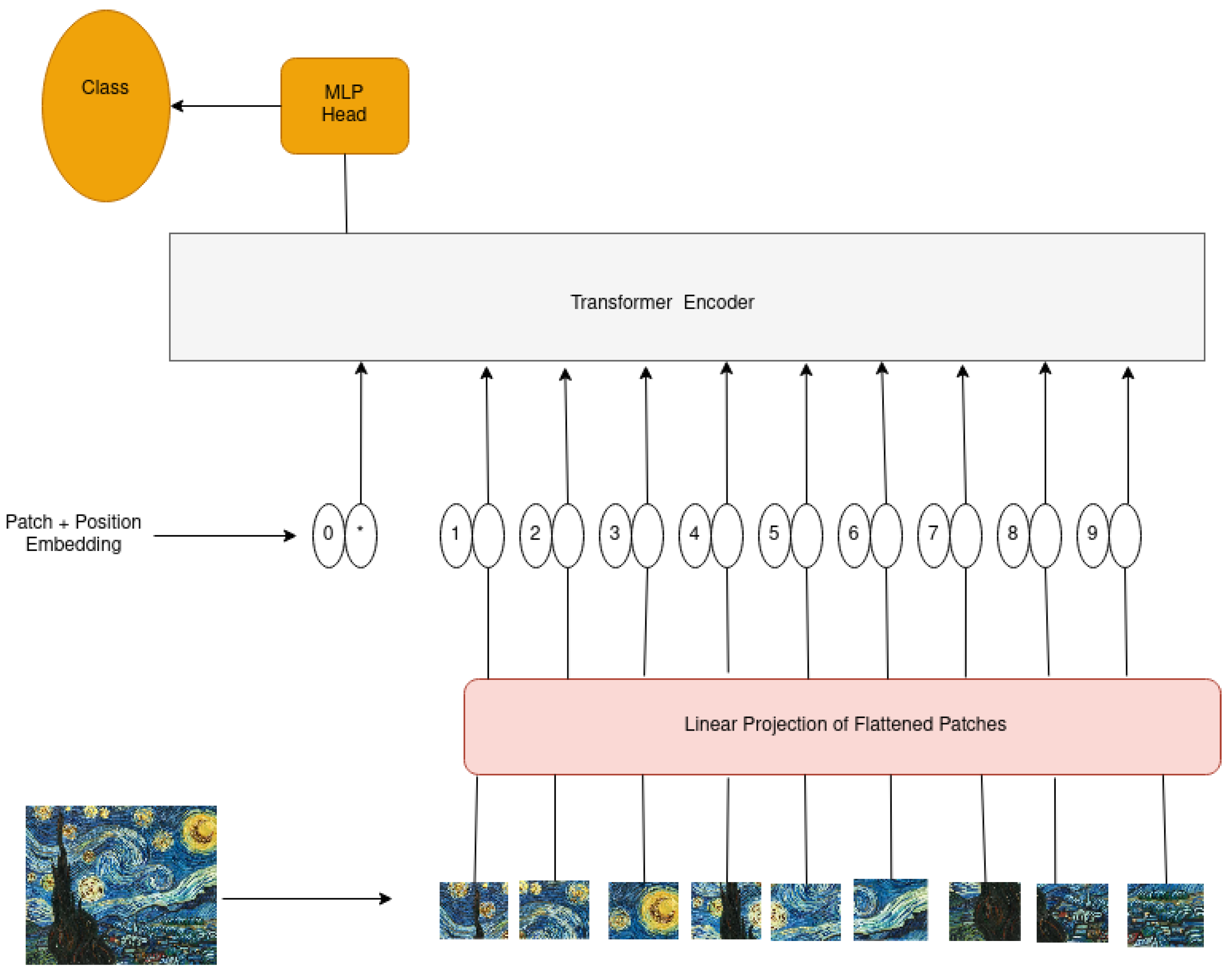
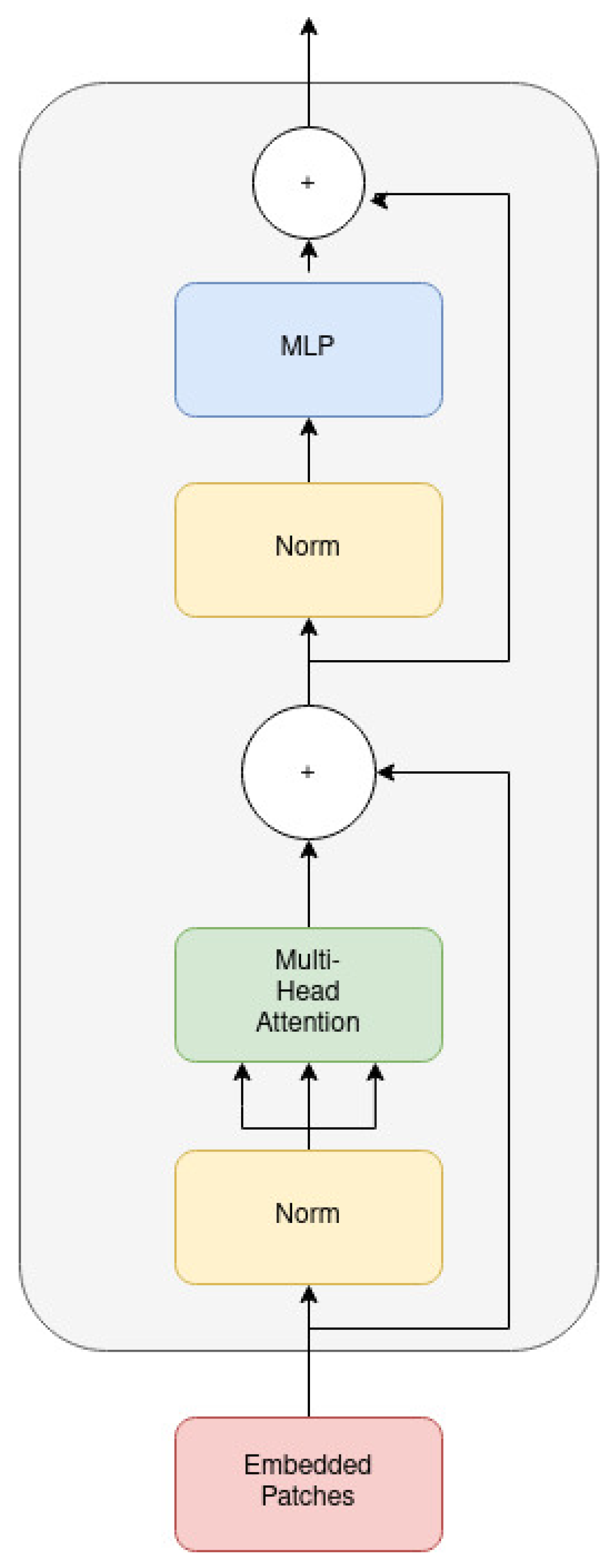
3.1. Vision Transformers
3.2. MLP Mixer
- The token-mixing MLP: it acts on columns of X and is shared across all columns.
- The channel-mixing MLP: it acts on rows of X and is shared across all rows.
3.3. Optimizers
- Stochastic Gradient Descent: Stochastic Gradient Descent (SGD) is one of the most used optimizers. SGD allows to update the network weights per each training image (online training).
- Momentum Gradient Descent: SGD may lead to oscillations during training. The best way to avoid them is the knowledge of the right direction for the gradient. This information is derived from the previous position, and, when considering the previous position, the updating rule adds a fraction of the previous update, which gives the optimizer the momentum needed to continue moving in the right direction. The weights in the Momentum Gradient Descent (MGD) are updated as
- Adam: Adam has been introduced as an algorithm for the first-order gradient-based optimization of stochastic objective functions, based on adaptive estimates of lower-order moments [25]. Adam has been established as one of the most successful optimizers in DL.
- AdaMax: AdaMax is a generalisation of Adam from the norm to the norm [25].
- Optimistic Adam: Optimistic Adam (OAdam) optimizer [26] is a variant of the ADAM optimizer. The only difference between OAdam and Adam is the weight update,
- RMSProp: Using some Adaptive Gradient Descent Optimizers leads, in some cases, the learning rate to decrease monotonically because every added term is positive. After many epochs, the learning rate is so small that it stops updating the weights. The RMSProp method proposes
3.4. WikiArt Dataset
4. Results and Discussion
4.1. Experiments
4.1.1. ViT: Optimizers’ Performance
4.1.2. MLP Mixer Performance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Networks |
| CV | Computer Vision |
| DL | Deep Learning |
| GAN | Generative Adversarial Network |
| MLP | Multi-Layered Perceptron |
| NLP | Natural Language Processing |
| ViT | Visual Transformer |
References
- Waseem, R.; Zenghui, W. Deep Convolutional Neural Networks for Image Classification: A Comprehensive Review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- Olejnik, A.; Borecki, M.; Rychlik, A. A simple detection method of movement of clouds at the sky. In Proceedings of the SPIE 11581, Photonics Applications in Astronomy, Communications, Industry, and High Energy Physics Experiments, Wilga, Poland, 14 October 2020; p. 1158111. [Google Scholar] [CrossRef]
- Stabinger, S.; Rodríguez-Sánchez, A. Evaluation of Deep Learning on an Abstract Image Classification Dataset. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 2767–2772. [Google Scholar] [CrossRef] [Green Version]
- Elgammal, A.; Liu, B.; Kim, D.; Elhoseiny, M. The Shape of Art History in the Eyes of the Machine. In Proceedings of the AAAI, Palo Alto, CA, USA, 2–7 February 2018. [Google Scholar]
- Johnson, C.R.; Hendriks, E.; Berezhnoy, I.J.; Brevdo, E.; Hughes, S.M.; Daubechies, I.; Li, J.; Postma, E.; Wang, J.Z. Image processing for artist identification. IEEE Signal Process. Mag. 2008, 25, 37–48. [Google Scholar] [CrossRef]
- Altenburgera, P.; Kämpferb, P.; Makristathisc, A.; Lubitza, W.; Bussea, H.-J. Classification of bacteria isolated from a medieval wall painting. J. Biotechnol. 1996, 47, 39–52. [Google Scholar] [CrossRef]
- Li, C.; Chen, T. Aesthetic Visual Quality Assessment of Paintings. IEEE J. Sel. Top. Signal Process. 2009, 3, 236–252. [Google Scholar] [CrossRef]
- Lecoutre, A.; Negrevergne, B.; Yger, F. Recognizing Art Style Automatically in Painting with Deep Learning. In Proceedings of the Ninth Asian Conference on Machine Learning, Seoul, Korea, 15–17 November 2017; pp. 327–342. [Google Scholar]
- Bar, Y.; Levy, N.; Wolf, L. Classification of Artistic Styles Using Binarized Features Derived from a Deep Neural Network. In Lecture Notes in Computer Science Proceedings of the ECCV Workshops, Zurich, Switzerland, 6–7 September 2014; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Cetinic, E.; Lipic, T.; Grgic, S. Fine-tuning Convolutional Neural Networks for Fine Art Classification. Expert Syst. Appl. 2018, 114, 107–118. [Google Scholar] [CrossRef]
- Huang, X.; Zhong, S.; Zhijiao, X. Fine-Art Painting Classification via Two-Channel Deep Residual Network. In Lecture Notes in Computer Science, Proceedings of the Advances in Multimedia Information Processing, Harbin, China, 28–29 September 2017; Springer: Cham, Switzerland, 2017. [Google Scholar] [CrossRef]
- Sandoval, C.; Pirogova, E.; Lech, M. Two-Stage Deep Learning Approach to the Classification of Fine-Art Paintings. IEEE Access 2019, 7, 41770–41781. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Lecture Notes in Computer Science, Proceedings of the Computer Vision – ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer: Cham, Switzerland, 2020; Volume 12346. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Gelly, S. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the ICLR 2021: The Ninth International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Tolstikhin, I.O.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Keysers, D.; Uszkoreit, J.; Lucic, M.; et al. MLP-Mixer: An all-MLP Architecture for Vision. arXiv 2021, arXiv:2105.01601. [Google Scholar]
- Amin, F.; Choi, G.S. Advanced Service Search Model for Higher Network Navigation Using Small World Networks. IEEE Access 2021, 9, 70584–70595. [Google Scholar] [CrossRef]
- Amin, F.; Ahmad, A.; Sang Choi, G. Towards Trust and Friendliness Approaches in the Social Internet of Things. Appl. Sci. 2019, 9, 166. [Google Scholar] [CrossRef] [Green Version]
- Gatys, L.; Ecker, A.; Bethge, M. Image Style Transfer Using Convolutional Neural Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2414–2423. [Google Scholar] [CrossRef]
- Gatys, L.A.; Ecker, A.S.; Bethge, M.; Hertzmann, A.; Shechtman, E. Controlling Perceptual Factors in Neural Style Transfer. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 June 2017; pp. 3730–3738. [Google Scholar] [CrossRef] [Green Version]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Lecture Notes in Computer Science, Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; Volume 9906. [Google Scholar] [CrossRef] [Green Version]
- Tan, W.R.; Chan, C.S.; Aguirre, H.E.; Tanaka, K. ArtGAN: Artwork synthesis with conditional categorical GANs. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3760–3764. [Google Scholar] [CrossRef] [Green Version]
- Tan, W.R.; Chan, C.S.; Aguirre, H.E.; Tanaka, K. Improved ArtGAN for Conditional Synthesis of Natural Image and Artwork. IEEE Trans. Image Process. 2019, 28, 394–409. [Google Scholar] [CrossRef] [PubMed]
- Choi, D.; Shallue, C.; Nado, Z.; Lee, J.; Maddison, C.; Dahl, G. On Empirical Comparisons of Optimizers for Deep Learning. arXiv 2020, arXiv:1910.05446. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Daskalakis, C.; Ilyas, A.; Syrgkanis, V.; Zeng, H. Training GANs with optimism. In Proceedings of the International Conference on Learning Representations, Vancuver, BC, Canada, 30 April–3 May 2018; Available online: https://openreview.net/forum?id=SJJySbbAZ (accessed on 20 September 2021).


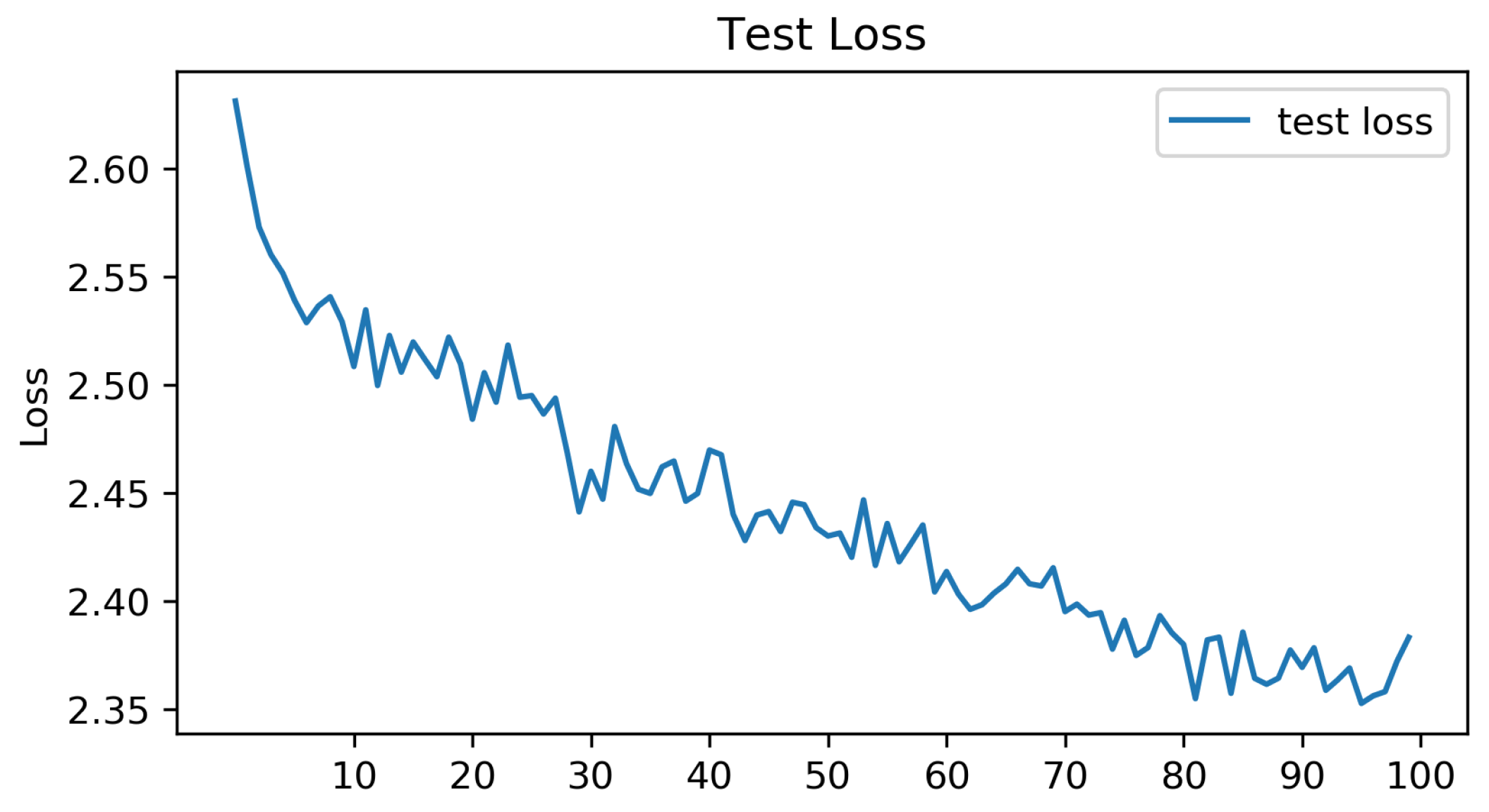
| Optimizer | Accuracy |
|---|---|
| Adam | 39.89% |
| Adamax | 39.42% |
| Optimistic Adam | 39.71% |
| SGD | 39.28% |
| MGD | 39.31% |
| RMSProp | 38.97% |
| Class | Accuracy % |
|---|---|
| Abstract Expressionism | 29.6 |
| Art Nouveau | 25.3 |
| Baroque | 48.3 |
| Color Field Painting | 65.5 |
| Cubism | 21.3 |
| Early Renaissance | 34.1 |
| Expressionism | 28.0 |
| Fauvism | 17.5 |
| High Renaissance | 8.5 |
| Impressionism | 65.0 |
| Mannerism Late Renaissance | 18.1 |
| Minimalism | 49.4 |
| Naive Art / Primitivism | 15.4 |
| Northern Renaissance | 6.1 |
| Pop Art | 14.6 |
| Post Impressionism | 30.6 |
| Realism | 57.7 |
| Rococo | 45.3 |
| Romanticism | 37.4 |
| Symbolism | 28.4 |
| Ukiyo-e | 68.3 |
| Model | Accuracy |
|---|---|
| MLP Mixer | 39.59% |
| Class | Accuracy % |
|---|---|
| Abstract Expressionism | 29.0 |
| Art Nouveau | 34.3 |
| Baroque | 46.2 |
| Color Field Painting | 64.9 |
| Cubism | 20.4 |
| Early Renaissance | 34.1 |
| Expressionism | 28.0 |
| Fauvism | 16.8 |
| High Renaissance | 23.1 |
| Impressionism | 62.0 |
| Mannerism Late Renaissance | 15.1 |
| Minimalism | 46.6 |
| Naive Art / Primitivism | 25.5 |
| Northern Renaissance | 5.3 |
| Pop Art | 22.1 |
| Post Impressionism | 30.4 |
| Realism | 44.3 |
| Rococo | 44.4 |
| Romanticism | 36.2 |
| Symbolism | 28.2 |
| Ukiyo-e | 60.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Iliadis, L.A.; Nikolaidis, S.; Sarigiannidis, P.; Wan, S.; Goudos, S.K. Artwork Style Recognition Using Vision Transformers and MLP Mixer. Technologies 2022, 10, 2. https://doi.org/10.3390/technologies10010002
Iliadis LA, Nikolaidis S, Sarigiannidis P, Wan S, Goudos SK. Artwork Style Recognition Using Vision Transformers and MLP Mixer. Technologies. 2022; 10(1):2. https://doi.org/10.3390/technologies10010002
Chicago/Turabian StyleIliadis, Lazaros Alexios, Spyridon Nikolaidis, Panagiotis Sarigiannidis, Shaohua Wan, and Sotirios K. Goudos. 2022. "Artwork Style Recognition Using Vision Transformers and MLP Mixer" Technologies 10, no. 1: 2. https://doi.org/10.3390/technologies10010002
APA StyleIliadis, L. A., Nikolaidis, S., Sarigiannidis, P., Wan, S., & Goudos, S. K. (2022). Artwork Style Recognition Using Vision Transformers and MLP Mixer. Technologies, 10(1), 2. https://doi.org/10.3390/technologies10010002