

After Self-Imitation Prosodic Training L2 Learners Converge Prosodically to the Native Speakers


Abstract
1. Introduction
2. Learning L2 Prosody with CAPT
- Prosodic deviations may be even more detrimental to the perceived intelligibility and nativeness of L2 speech than segmental deviations (Derwing and Munro 2005; Jilka 2000; Munro and Derwing 2006; Chun 2013).
- L2 speech typically gains in perceived nativeness and intelligibility when manipulated to align with the prosodic characteristics of L1 speech. For studies on foreign-accented English, see, a.o., Winters and Grantham O’Brien (2013); Ulbrich and Mennen (2015); Rognoni and Busà (2013); Polyanskaya et al. (2017); and Tajima et al. (1997). For research on Swiss German-accented Italian, cf. Pellegrino et al. (2021), and on Polish-accented Dutch, cf. Quené and Van Delft (2010).
2.1. Self-Imitation Prosodic Training
2.2. Self-Imitation Prosodic Training in L2 Italian
2.2.1. Previous Research on Japanese Learners of Italian
3. The Present Study
3.1. Participants
3.2. Speech Material
- -
- (Request) Accendi la radio?/eng. Can you turn on the radio?
- -
- Command) Accendi la radio!/eng. Turn on the radio!
- -
- (Granting) Accendi la radio./eng. Ok, you can turn on the radio.
- -
- (Request) Chiudi la finestra?/eng. Can you close the window?
- -
- (Command) Chiudi la finestra!/eng. Close the window!
- -
- (Granting) Chiudi la finestra./eng. Ok, you can close the window.
- A total of 42 utterances in L2 Italian (7 L2 speakers * 2 sentences * 3 communicative intentions) (henceforth pre-training corpus);
- A total of 12 utterances in L1 Italian (2 L1 speakers * 2 sentences * 3 communicative intentions) (henceforth L1 Italian corpus).
- The donors’ and receivers’ utterances were manually segmented into consonantal and vocalic portions in Praat textgrids.
- Duration and pitch contour were transferred from donors’ to receivers’ utterances interval-wise by means of a Praat script automatizing the prosodic transplantation.
3.3. Acoustic and Statistical Analyses
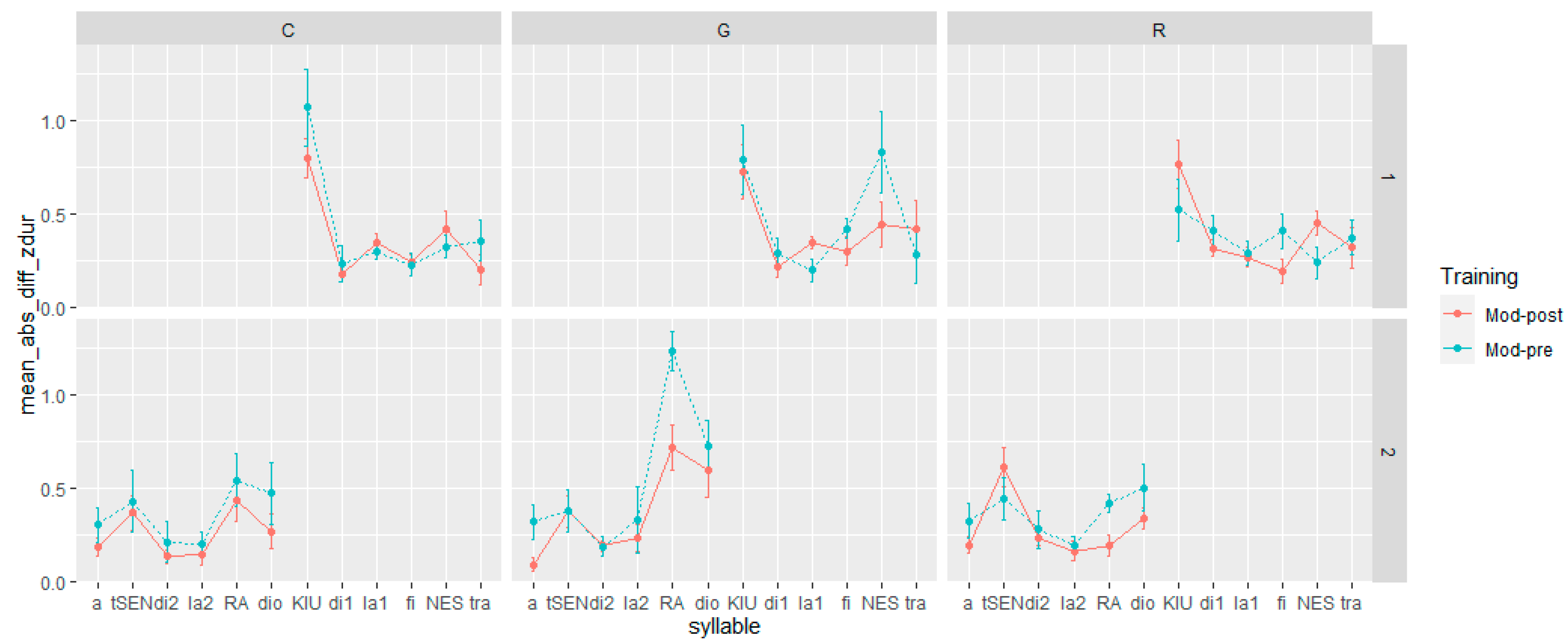
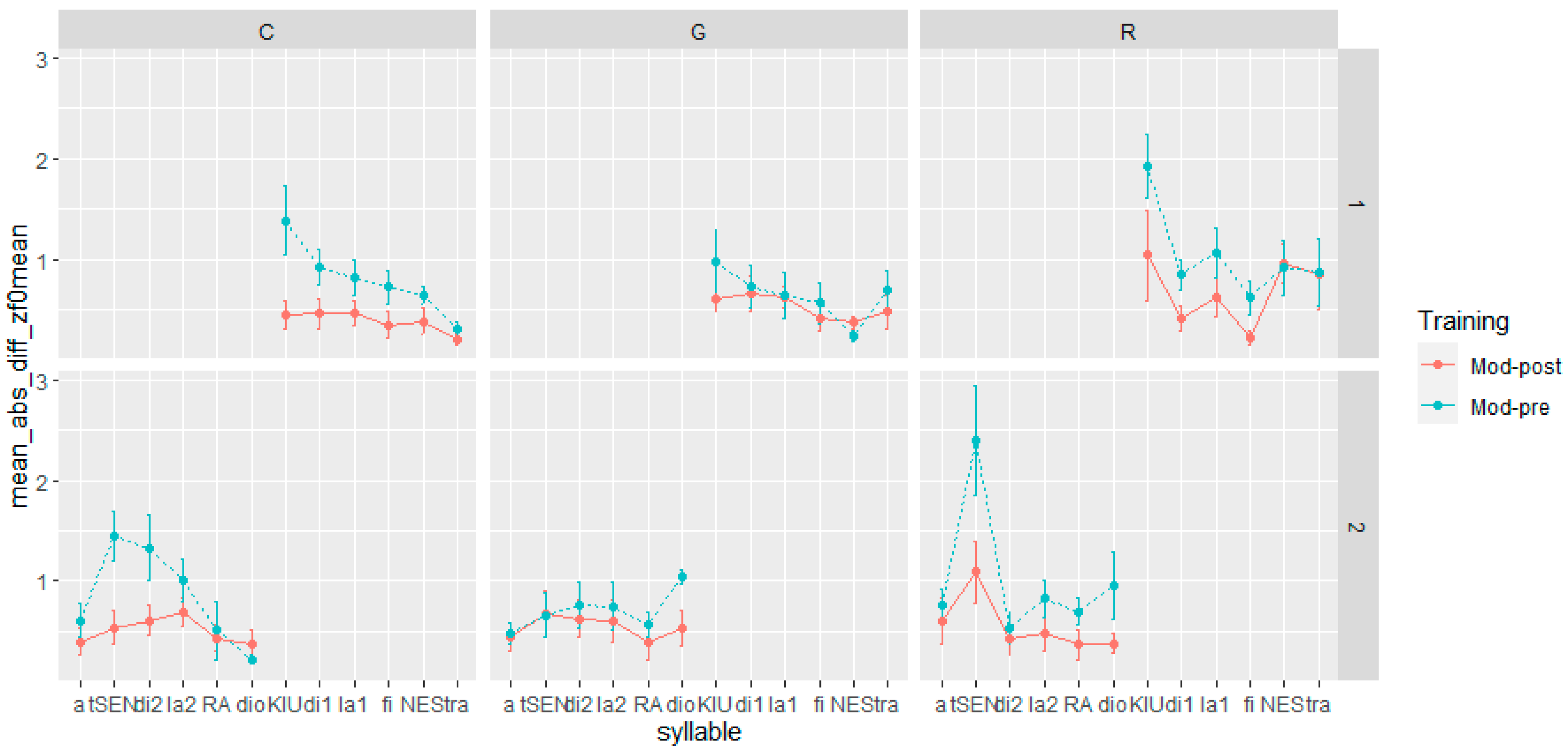
- Step 1: We manually segmented and labeled in syllables the utterances of the L1 speakers and those of the L2 learners in the pre- and post-training corpora using Praat textgrids.
- Step 2: For each syllable of the L1 corpus, pre- and post-training corpora, we automatically extracted duration, F0 mean, and F0 max. The measurements were extracted from a total number of 576 syllables, of which 504 were in L2 Italian ((6 syllables * 2 utterances * 3 speech acts * 2 recording sessions (pre- and post-training) * 7 speakers) and 72 were in L1 Italian (6 syllables * 2 utterances * 3 speech acts * 2 speakers).
- Step 3: For each syllable in every corpus, we normalized the syllable duration, F0 max, and F0 mean using z-score transformation (z = (x − μ)/σ), computed per speaker, sentence, and speech act.
- Step 4: We calculated the absolute difference in duration, F0 mean, and F0 max between the syllables in the L1 Italian corpus and the corresponding syllables in the pre- and post-training corpora (henceforth Mod-Pre and Mod-Post). In the calculation of the distance between the L1 and L2 productions, we adhered to the gender-matching criterion applied in prosodic transplantation and self-imitation training. Hence, in the computation of Mod-Pre and Mod-Post, we matched the syllables of the female L1 speaker with those produced by the female L2 learners and, likewise, the syllables of the male L1 speaker with those of the male L2 learners.
- Mod-Pre (i.e., the acoustic distance between the model and the pre-training productions syllable by syllable).
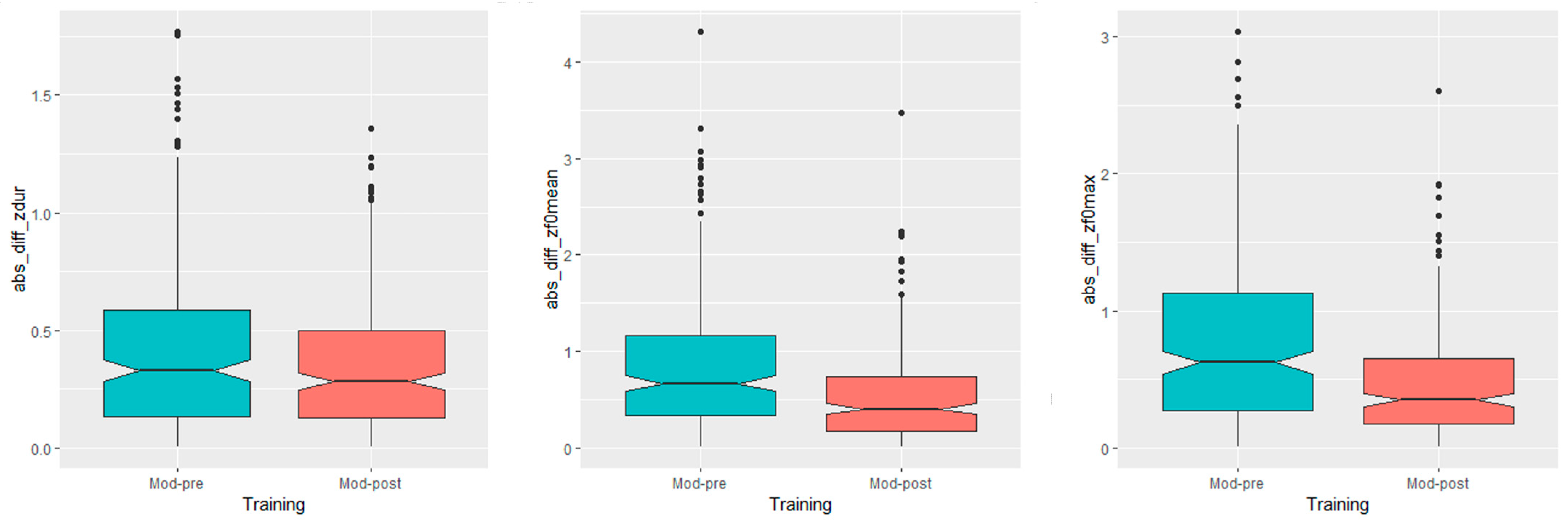
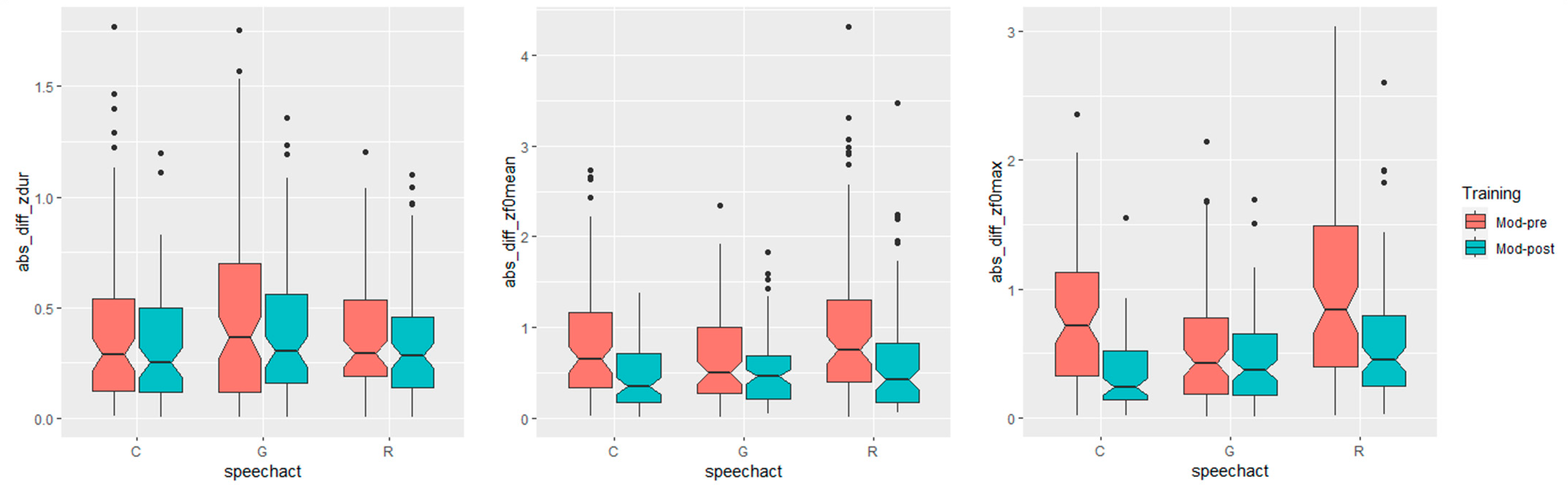
- Degree of convergence, quantified as the difference in the distance (henceforth DID) between Mod-Post (i.e., the acoustic distance between the model and the post-training productions syllable-wise) and Mod-Pre. Negative DID values indicate that Mod-Post is lower than Mod-Pre, providing evidence of convergence. Conversely, positive DID values signify that Mod-Post is higher than Mod-Pre, suggesting divergence. DID values centered around zero indicate maintenance.
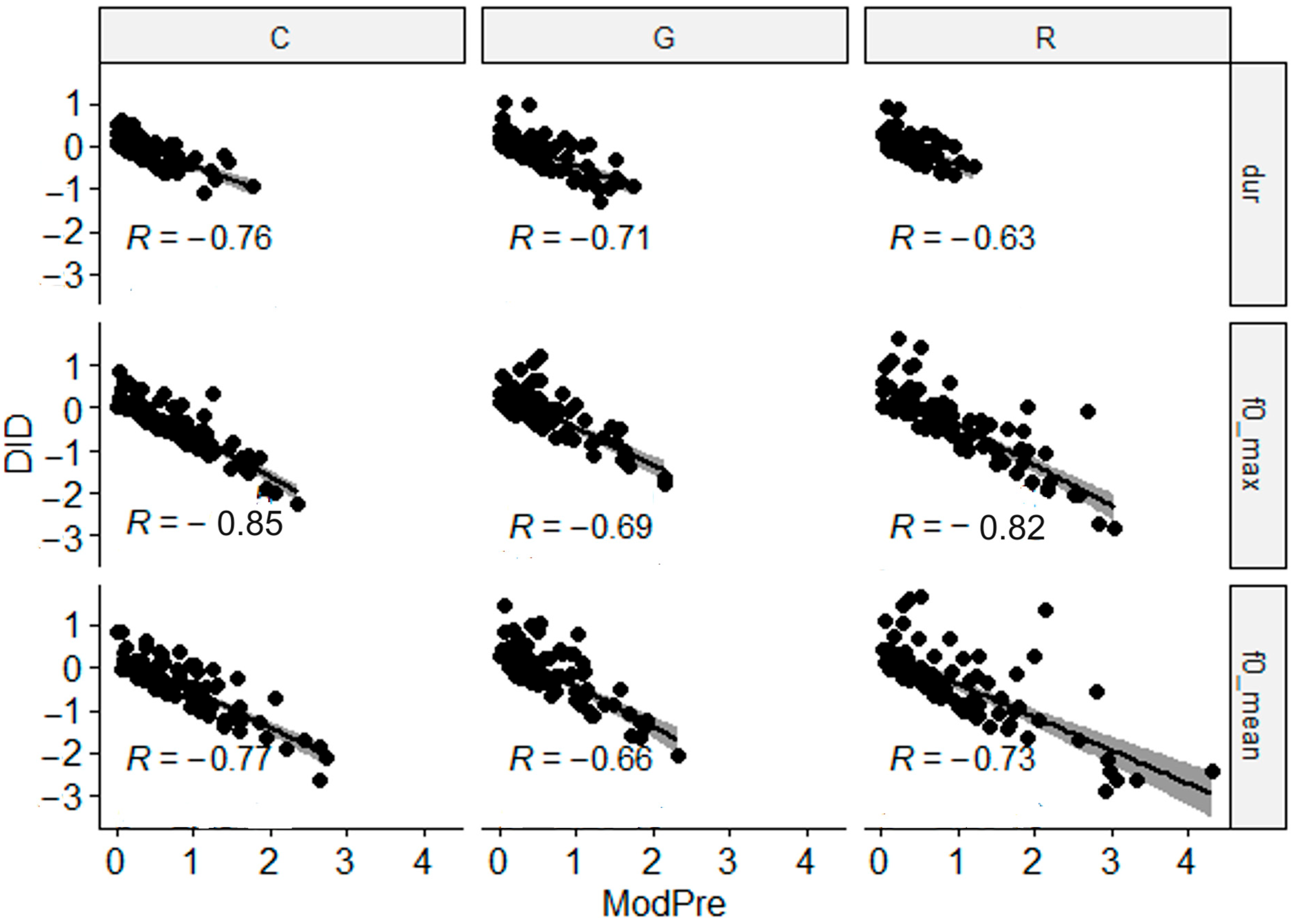
4. Results
- For duration, the distance to the model from pre- to post-training productions did not change significantly for any speech act (Table 1).
5. Discussion
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Contrast—Distance in Duration | Estimate | SE | df | t.Ratio | p Value |
|---|---|---|---|---|---|
| (Mod-postC)-(Mod-preC) | −0.07873 | 0.0433 | 493 | −1.82 | 0.454 |
| (Mod-postC)-(Mod-postG) | −0.07807 | 0.0433 | 493 | −1.805 | 0.464 |
| (Mod-postC)-(Mod-preG) | −0.18938 | 0.0433 | 493 | −4.378 | <0.001 |
| (Mod-postC)-(Mod-postR) | −0.02797 | 0.0433 | 493 | −0.646 | 0.987 |
| (Mod-postC)-(Mod-preR) | −0.05722 | 0.0433 | 493 | −1.323 | 0.772 |
| (Mod-preC)-(Mod-postG) | 0.000657 | 0.0433 | 493 | 0.015 | 1.000 |
| (Mod-preC)-(Mod-preG) | −0.11066 | 0.0433 | 493 | −2.558 | 0.110 |
| (Mod-preC)-(Mod-postR) | 0.050758 | 0.0433 | 493 | 1.173 | 0.850 |
| (Mod-preC)-(Mod-preR) | 0.021506 | 0.0433 | 493 | 0.497 | 0.996 |
| (Mod-postG)-(Mod-preG) | −0.11132 | 0.0433 | 493 | −2.573 | 0.106 |
| (Mod-postG)-(Mod-postR) | 0.050101 | 0.0433 | 493 | 1.158 | 0.856 |
| (Mod-postG)-(Mod-preR) | 0.020849 | 0.0433 | 493 | 0.482 | 0.997 |
| (Mod-preG)-(Mod-postR) | 0.161416 | 0.0433 | 493 | 3.731 | 0.003 |
| (Mod-preG)-(Mod-preR) | 0.132164 | 0.0433 | 493 | 3.055 | 0.029 |
| (Mod-postR)-(Mod-preR) | −0.02925 | 0.0433 | 493 | −0.676 | 0.984 |
| Contrast—Distance in F0 Mean | Estimate | SE | df | t.Ratio | p Value |
|---|---|---|---|---|---|
| (Mod-postC)-(Mod-preC) | −0.3819 | 0.0873 | 493 | −4.375 | 0.0002 |
| (Mod-postC)-(Mod-postG) | −0.089 | 0.0873 | 493 | −1.02 | 0.9112 |
| (Mod-postC)-(Mod-preG) | −0.2287 | 0.0873 | 493 | −2.62 | 0.0943 |
| (Mod-postC)-(Mod-postR) | −0.1764 | 0.0873 | 493 | −2.021 | 0.3315 |
| (Mod-postC)-(Mod-preR) | −0.5896 | 0.0873 | 493 | −6.756 | <0.0001 |
| (Mod-preC)-(Mod-postG) | 0.2929 | 0.0873 | 493 | 3.355 | 0.011 |
| (Mod-preC)-(Mod-preG) | 0.1532 | 0.0873 | 493 | 1.755 | 0.496 |
| (Mod-preC)-(Mod-postR) | 0.2054 | 0.0873 | 493 | 2.353 | 0.175 |
| (Mod-preC)-(Mod-preR) | −0.2077 | 0.0873 | 493 | −2.38 | 0.1652 |
| (Mod-postG)-(Mod-preG) | −0.1397 | 0.0873 | 493 | −1.6 | 0.5987 |
| (Mod-postG)-(Mod-postR) | −0.0874 | 0.0873 | 493 | −1.002 | 0.9173 |
| (Mod-postG)-(Mod-preR) | −0.5006 | 0.0873 | 493 | −5.736 | <0.0001 |
| (Mod-preG)-(Mod-postR) | 0.0523 | 0.0873 | 493 | 0.599 | 0.9911 |
| (Mod-preG)-(Mod-preR) | −0.3609 | 0.0873 | 493 | −4.135 | 0.0006 |
| (Mod-postR)-(Mod-preR) | −0.4132 | 0.0873 | 493 | −4.733 | <0.0001 |
| Contrast—Distance in F0 Max | Estimate | SE | df | t.Ratio | p Value |
|---|---|---|---|---|---|
| (Mod-post C)-(Mod-pre C) | −0.43251 | 0.0759 | 493 | −5.701 | <0.0001 |
| (Mod-post C)-(Mod-post G) | −0.11198 | 0.0759 | 493 | −1.476 | 0.6799 |
| (Mod-post C)-(Mod-pre G) | −0.22987 | 0.0759 | 493 | −3.03 | 0.0307 |
| (Mod-post C)-(Mod-post R) | −0.23658 | 0.0759 | 493 | −3.118 | 0.0235 |
| (Mod-post C)-(Mod-pre R) | −0.6631 | 0.0759 | 493 | −8.74 | <0.0001 |
| (Mod-pre C)-(Mod-post G) | 0.32053 | 0.0759 | 493 | 4.225 | 0.0004 |
| (Mod-pre C)-(Mod-pre G) | 0.20264 | 0.0759 | 493 | 2.671 | 0.083 |
| (Mod-pre C)-(Mod-post R) | 0.19592 | 0.0759 | 493 | 2.582 | 0.1036 |
| (Mod-pre C)-(Mod-pre R) | −0.2306 | 0.0759 | 493 | −3.039 | 0.0299 |
| (Mod-post G)-(Mod-pre G) | −0.11789 | 0.0759 | 493 | −1.554 | 0.6294 |
| (Mod-post G)-(Mod-post R) | −0.12461 | 0.0759 | 493 | −1.642 | 0.5708 |
| (Mod-post G)-(Mod-pre R) | −0.55113 | 0.0759 | 493 | −7.264 | <0.0001 |
| (Mod-pre G)-(Mod-post R) | −0.00672 | 0.0759 | 493 | −0.089 | 1 |
| (Mod-pre G)-(Mod-pre R) | −0.43324 | 0.0759 | 493 | −5.71 | <0.0001 |
| (Mod-post R)-(Mod-pre R) | −0.42652 | 0.0759 | 493 | −5.621 | <0.0001 |
| 1 | The concept of phonetic convergence typically refers to interspeaker adjustments that occur during interactions or as a result of increased exposure to a conversation partner. Nonetheless, extensive research has explored this phenomenon in non-interactive contexts as well, such as shadowing or imitation tasks. In these scenarios, participants are tasked with replicating words or phrases after hearing them from a model speaker (cf. Pardo et al. 2022; Wynn and Borrie 2022 for recent overviews). Some studies have even compared phonetic convergence between conversational interactions and non-interactive speech shadowing tasks, involving a substantial number of speakers who participated in both types of tasks (Pardo et al. 2018). |
| 2 | As clarified in Pellegrino and Vigliano (2015), the rationale behind the choice of the three speech acts was to integrate directives (requests and commands), which are frequently used in classroom interactions and therefore appear in the early phases of interlanguage development, with the less commonly encountered act of granting. This selection aimed to mirror the natural progression of speech acts in language development, where directives are prominent in the initial stages whereas granting receives less emphasis in advanced-level language courses. |
References
- Abe, Isamu. 1998. Intonation in Japanese. In Intonation Systems—A Survey of Twenty Languages. Edited by Daniel Hirst and Albert Di Cristo. Cambridge, MA: Cambridge University Press, pp. 363–78. [Google Scholar]
- Anderson-Hsieh, Janet, Johnson Ruth, and Kenneth Koehler. 1992. The relationship between native speaker judgments of nonnative pronunciation and deviance in segmentals, prosody, and syllable structure. Language Learning 42: 529–55. [Google Scholar] [CrossRef]
- Babel, Molly. 2010. Dialect divergence and convergence in New Zealand English. Language in Society 39: 437–56. [Google Scholar] [CrossRef]
- Babel, Molly. 2012. Evidence for phonetic and social selectivity in spontaneous phonetic imitation. Journal of Phonetics 40: 177–89. [Google Scholar] [CrossRef]
- Bissiri, Maria Paola, and Hartmut R. Pfitzinger. 2009. Italian speakers learn lexical stress of German morphologically complex words. Speech Communication 51: 933–47. [Google Scholar] [CrossRef]
- Bradford, Barbara. 1988. Intonation in Context. Cambridge, MA: Cambridge University Press. [Google Scholar]
- Brazil, David, Malcom Coulthard, and Catherine Johns. 1980. Discourse Intonation and Language Teaching. London: Longman. [Google Scholar]
- Chapman, Mark. 2007. Theory and practice of teaching discourse intonation. English Language Teaching Journal 61: 3–11. [Google Scholar] [CrossRef]
- Chun, Dorothy M. 2013. Computer-assisted pronunciation teaching. In Encyclopedia of Applied Linguistics. Edited by Carol A. Chapelle. Malden: Wiley-Blackwell, pp. 823–34. [Google Scholar]
- Cole, Jennifer. 2015. Prosody in context: A review. Language, Cognition and Neuroscience 30: 1–31. [Google Scholar] [CrossRef]
- D’Imperio, Maria Paola. 2002. Italian intonation: An overview and some questions. Probus 14: 37–69. [Google Scholar] [CrossRef]
- Dahmen, Silvia, Martine Grice, and Simon Roessig. 2023. Prosodic and Segmental Aspects of Pronunciation Training and Their Effects on L2. Languages 8: 74. [Google Scholar] [CrossRef]
- Dalton, Christiane, and Barbara Seidlhofer. 1994. Pronunciation. Oxford: Oxford University Press. [Google Scholar]
- De Meo, Anna, Marilisa Vitale, and Elisa Pellegrino. 2016. Tecnologia della voce e miglioramento della pronuncia in una L2: Imitazione e autoimitazione a confronto. Uno studio su cinesi apprendenti di italiano L2. In Studi AItLA 4. Linguaggio e Apprendimento Linguistico. Metodi e Strumenti Tecnologici. Edited by Francesca Bianchi and Paola Leone. Milano: AItLA, pp. 13–25. [Google Scholar]
- De Meo, Anna, Marilisa Vitale, Massimo Pettorino, Franco Cutugno, and Antonio Origlia. 2012. Imitation/self-imitation in computer-assisted prosody training for Chinese learners of L2 Italian. Pronunciation in Second Language Learning and Teaching Proceedings 4: 90–100. [Google Scholar]
- Derwing, Tracey M., and Murray J. Munro. 2005. Second language accent and pronunciation teaching: A research-based approach. TESOL Quarterly 39: 379–97. [Google Scholar] [CrossRef]
- Derwing, Tracey M., and Murray J. Munro. 2015. Pronunciation Fundamentals: Evidence-Based Perspectives for L2 Teaching and Research. Amsterdam: John Benjamins Publishing Company. [Google Scholar]
- Ding, Shaojin, Christopher Liberatore, Sinem Sonsaat, Ivana Lučić, Alif Silpachai, Guanlong Zhao, Evgeny Chukharev-Hudilainen, John Levis, and Ricardo Gutierrez-Osuna. 2019. Golden speaker builder—An interactive tool for pronunciation training. Speech Communication 115: 51–66. [Google Scholar] [CrossRef]
- Donaldson, Jonan P. 2009. Literature Review: Computer Aided Pronunciation Training. Available online: https://people.wou.edu/~donaldsj/TestWebsitePortfolio2/TestWebsitePortfolio2/portfolioartifacts/ResearchWriting/Jonan%20Donaldson%20ED%20633%20Final%20Literature%20Review.pdf (accessed on 1 October 2023).
- Felps, Daniel, Heather Bortfeld, and Ricardo Gutierrez-Osuna. 2009. Foreign accent conversion in computer assisted pronunciation training. Speech Communication 51: 920–32. [Google Scholar] [CrossRef] [PubMed]
- Flege, James Emil, Ocke-Schwen Bohn, and Sunyoung Jang. 1997. Effects of experience on non-native speakers’ production and perception of English vowels. Journal of Phonetics 25: 437–70. [Google Scholar] [CrossRef]
- Fouz-González, Jonas. 2015. Trends and directions in computer assisted pronunciation training. In Investigating English Pronunciation: Trends and Directions. Edited by Jose Mompean and Jonas Fouz-González. Basingstoke: Palgrave Macmillan, pp. 314–42. [Google Scholar]
- Gilbert, Judy. 2014. Myth 4: Intonation is hard to teach. In Pronunciation Myths: Applying Second Language Research to Classroom Teaching. Edited by Linda Grant. Ann Arbor: University of Michigan Press, pp. 107–36. [Google Scholar]
- Giles, Howard, and Patricia Johnson. 1987. Ethnolinguistic Identity Theory: A Social Psychological Approach to Language Maintenance. International Journal of the Sociology of Language 68: 69–99. [Google Scholar] [CrossRef]
- Goldman, Jean-Philippe, and Sandra Schwab. 2018. MIAPARLE: Online training for the discrimination of stress contrasts. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018). Miyazaki: European Language Resources Association (ELRA). [Google Scholar]
- Gut, Ulrike. 2007. Foreign Accent. In Speaker Classification I. Lecture Notes in Computer Science 4343. Edited by Christian Müller. Berlin/Heidelberg: Springer, pp. 75–87. [Google Scholar]
- Hismanoglu, Murat. 2011. Computer Assisted Pronunciation Teaching: From the Past to the Present with its Limitations and Pedagogical Implications. In Frontiers of Language and Teaching, Proceedings of the 2011 IOLC. Parkland: Universal-Publishers, vol. 2, pp. 193–202. [Google Scholar]
- Hoque, Mohammed E., Mohammad S. Sorower, Mohammed Yeasin, and Max M. Louwerse. 2007. What Speech Tells Us About Discourse: The Role of Prosodic and Discourse Features in Speech Act Classification. Paper presented at the 2007 International Joint Conference on Neural Networks, Orlando, FL, USA, August 12–17; pp. 2999–3004. [Google Scholar]
- Jilka, Matthias. 2000. The contribution of intonation to the perception of foreign accent: Identifying intonational deviations by means of F0 generation and resynthesis. In Arbeitspapiere des Instituts für Maschinelle Sprachchverarbeitung [Working Papers of the Institute for Machine Language Processing]. Stuttgart: Universität Stuttgart, vol. 6. [Google Scholar]
- Kang, Okim. 2010. Relative salience of suprasegmental features on judgments of L2 comprehensibility and accentedness. System 38: 301–15. [Google Scholar] [CrossRef]
- Kim, Midam, William S. Horton, and Ann R. Bradlow. 2011. Phonetic convergence in spontaneous conversations as a function of interlocutor language distance. Laboratory Phonology 2: 125–56. [Google Scholar] [CrossRef]
- Kusz, Ewa. 2022. Effects of imitation and self-imitation practice on L2 pronunciation progress. Topics in Linguistics 23: 1–17. [Google Scholar] [CrossRef]
- Lengeris, Angelos. 2012. Prosody and Second Language Teaching: Lessons from L2 Speech Perception and Production Research. In Pragmatics and Prosody in English Language Teaching. Educational Linguistics. Edited by J. Romero Trillo. Dordrecht: Springer, vol. 15, pp. 25–40. [Google Scholar]
- Levis, John. 2007. Computer technology in teaching and researching pronunciation. Annual Review of Applied Linguistics 27: 184–202. [Google Scholar] [CrossRef]
- Li, Peng, Florence Baills, Lorraine Baqué, and Pilar Prieto. 2023. The effectiveness of embodied prosodic training in L2 accentedness and vowel accuracy. Second Language Research 39: 1077–105. [Google Scholar] [CrossRef]
- Lin, Yuhan, Yao Yao, and Jin Luo. 2021. Phonetic accommodation of tone: Reversing a tone merger-in-progress via imitation. Journal of Phonetics 87: 101060. [Google Scholar] [CrossRef]
- Medgyes, Péter. 2001. When the Teacher Is a Non-Native Speaker. Teaching English as a Second or Foreign Language. Boston: Heinle & Heinle, vol. 3, pp. 429–42. [Google Scholar]
- Moulines, Eric, and Francis Charpentier. 1990. Pitch-synchronous waveform processing techniques for text-to-speech synthesis using diphones. Speech Communication 9: 453–67. [Google Scholar] [CrossRef]
- Moyer, Alene. 2013. Foreign Accent: The Phenomenon of Non-Native Speech. Cambridge: Cambridge University Press. [Google Scholar]
- Munro, Murray J., and Tracey M. Derwing. 2006. The functional load principle in ESL pronunciation instruction: An exploratory study. System 34: 520–31. [Google Scholar] [CrossRef]
- Nagano, Keiko, and Kazunori Ozawa. 1990. English speech training using voice conversion. Paper presented at the First International Conference on Spoken Language Processing (ICSLP 90), Kobe, Japan, November 18–22; pp. 1169–72. [Google Scholar]
- Neri, Ambra, Ornella Mich, Matteo Gerosa, and Diego Giuliani. 2008. The effectiveness of computer assisted pronunciation training for foreign language learning by children. Computer Assisted Language Learning 21: 393–408. [Google Scholar] [CrossRef]
- Pardo, Jennifer S. 2006. On phonetic convergence during conversational interaction. Journal of the Acoustical Society of America 119: 2382–93. [Google Scholar] [CrossRef] [PubMed]
- Pardo, Jennifer S., Elisa Pellegrino, Volker Dellwo, and Bernd Möbius. 2022. Special issue: Vocal accommodation in speech communication. Journal of Phonetics 95: 101196. [Google Scholar] [CrossRef]
- Pardo, Jennifer S., Kelly Jordan, Rolliene Mallari, Caitlin Scanlon, and Eva Lewandowski. 2013. Phonetic convergence in shadowed speech: The relation between acoustic and perceptual measures. Journal of Memory and Language 69: 183–95. [Google Scholar] [CrossRef]
- Pardo, Jennifer S., Adelya Urmanche, Sherilyn Wilman, Jaclyn Wiener, Nicholas Mason, Keagan Francis, and Melanie Ward. 2018. A comparison of phonetic convergence in conversational interaction and speech shadowing. Journal of Phonetics 69: 1–11. [Google Scholar] [CrossRef]
- Pellegrino, Elisa, and Debora Vigliano. 2015. Self-imitation in prosody training: A study on Japanese learners of Italian. In Proceedings of the Workshop on Speech and Language Technology in Education. Edited by Stefan Steidl, Anton Batliner and Oliver Jokisch. Leipzig: ISCA Special Interest Group SLaTE, pp. 53–57. [Google Scholar]
- Pellegrino, Elisa, Sandra Schwab, and Volker Dellwo. 2021. Listeners pay attention to rhythmic cues when deciding on the nativeness of speech. The Journal of the Acoustical Society of America 150: 2836–53. [Google Scholar] [CrossRef]
- Polyanskaya, Leona, Mikhail Ordin, and Maria Grazia Busa. 2017. Relative salience of speech rhythm and speech rate on perceived foreign accent in a second language. Lang Speech 60: 333–55. [Google Scholar] [CrossRef]
- Probst, Katharina, Yan Ke, and Maxime Eskenazi. 2002. Enhancing foreign language tutors—In search of the golden speaker. Speech Communication 37: 161–73. [Google Scholar] [CrossRef]
- Quené, Hugo, and L. E. Van Delft. 2010. Non-native durational patterns decrease speech intelligibility. Speech Commun 52: 911–18. [Google Scholar] [CrossRef]
- R Core Team. 2023. R: A Language and Environment for Statistical Computing (R Foundation for Statistical Computing). Available online: https://www.R-project.org/ (accessed on 1 September 2023).
- Rogerson-Revell, Pamela M. 2021. Computer-Assisted Pronunciation Training (CAPT): Current Issues and Future Directions. RELC Journal 52: 189–205. [Google Scholar] [CrossRef]
- Rognoni, Luca, and Maria Grazia Busà. 2013. Testing the Effects of Segmental and Suprasegmental Phonetic Cues in Foreign Accent Rating: An Experiment Using Prosody Transplantation. Proceedings International on the Acquisition of Second Language Speech 5: 547–60. [Google Scholar]
- Ross, Jory, Kevin D. Lilley, Cynthia Clopper, Jennifer Pardo, and Susannah V. Levi. 2021. Effects of dialect-specific features and familiarity on cross-dialect phonetic convergence. Journal of Phonetics 86: 101041. [Google Scholar] [CrossRef]
- Seferoglu, Gölge. 2005. Improving students’ pronunciation through accent reduction software. British Journal of Educational Technology 36: 303–16. [Google Scholar]
- Sztahó, David, Gábor Kiss, and Klára Vicsi. 2018. Computer based speech prosody teaching system. Comput. Speech Lang 50: 126–40. [Google Scholar] [CrossRef]
- Tajima, Keiichi, Robert Port, and Jonathan Dalby. 1997. Effects of temporal correction on intelligibility of foreign-accented English. Journal of Phonetics 25: 1–24. [Google Scholar] [CrossRef]
- Trofimovich, Pavel, and Wendy Baker. 2006. Learning second language suprasegmentals: Effect of L2 experience on prosody and fluency characteristics of L2 speech. Studies in Second Language Acquisition 28: 1–30. [Google Scholar] [CrossRef]
- Ulbrich, Christine, and Inneke Mennen. 2015. When prosody kicks in: The intricate interplay between segments and prosody in perceptions of foreign accent. International Journal of Bilingualism 20: 1–28. [Google Scholar] [CrossRef]
- Vigliano, Debora, Elisa Pellegrino, and Massimo Pettorino. 2016. L’apprendimento della prosodia dell’italiano in contesto LS: Uno studio su apprendenti giapponesi. In La Fonetica Nell’apprendimento Delle Lingue. Studi AISV 2. Edited by Renata Savy and Iolanda Alfano. Milano: AISV, pp. 101–15. [Google Scholar]
- Vitale, Marilisa, and Anna De Meo. 2020. Aspetti Prosodici Dell’acquisizione Dell’italiano da Parte di Sinofoni. Roma: Aracne. [Google Scholar]
- Walker, Abby, and Kathryn Campbell-Kibler. 2015. Repeat what after whom? Exploring variable selectivity in a cross-dialectal shadowing task. Frontiers in Psychology 6: 546. [Google Scholar] [CrossRef]
- Winters, Stephen, and Mary Grantham O’Brien. 2013. Perceived accentedness and intelligibility: The relative contributions of F0 and duration. Speech Communication 55: 486–507. [Google Scholar] [CrossRef]
- Wrembel, Magdalena. 2007. Metacompetence-based approach to the teaching of L2 prosody: Practical implications. In Non-Native Prosody: Phonetic Description and Teaching Practice. Edited by Jürgen Trouvain and Ulrike Gut. Berlin and New York: De Gruyter Mouton, pp. 189–210. [Google Scholar]
- Wynn, Camille J., and Stephanie A. Borrie. 2022. Classifying conversational entrainment of speech behavior: An expanded framework and review. Journal of Phonetics 94: 101173. [Google Scholar] [CrossRef] [PubMed]
- Yoon, Kyuchul. 2007. Imposing native speakers’ prosody on non-native speakers’ utterances: The technique of cloning prosody. Journal of the Modern British & American Language & Literature 25: 197–215. [Google Scholar]
- Zuengler, Jane. 1982. Applying Accommodation Theory to Variable Performance Data in L2. Studies in Second Language Acquisition 4: 181–92. [Google Scholar] [CrossRef]

| Contrast—Distance in Duration | Estimate | SE | df | t.Ratio | p Value |
|---|---|---|---|---|---|
| (Mod-postC)-(Mod-preC) | −0.07873 | 0.0433 | 493 | −1.82 | 0.454 |
| (Mod-postG)-(Mod-preG) | −0.11132 | 0.0433 | 493 | −2.573 | 0.106 |
| (Mod-postR)-(Mod-preR) | −0.02925 | 0.0433 | 493 | −0.676 | 0.984 |
| Contrast—Distance in F0 Mean | Estimate | SE | df | t.Ratio | p Value |
|---|---|---|---|---|---|
| (Mod-postC)-(Mod-preC) | −0.3819 | 0.0873 | 493 | −4.375 | 0.0002 |
| (Mod-postG)-(Mod-preG) | −0.1397 | 0.0873 | 493 | −1.6 | 0.5987 |
| (Mod-postR)-(Mod-preR) | −0.4132 | 0.0873 | 493 | −4.733 | <0.0001 |
| Contrast—Distance in F0 Max | Estimate | SE | df | t.Ratio | p Value |
|---|---|---|---|---|---|
| (Mod-post C)-(Mod-pre C) | −0.43251 | 0.0759 | 493 | −5.701 | <0.0001 |
| (Mod-post G)-(Mod-pre G) | −0.11789 | 0.0759 | 493 | −1.554 | 0.6294 |
| (Mod-post R)-(Mod-pre R) | −0.42652 | 0.0759 | 493 | −5.621 | <0.0001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pellegrino, E. After Self-Imitation Prosodic Training L2 Learners Converge Prosodically to the Native Speakers. Languages 2024, 9, 33. https://doi.org/10.3390/languages9010033
Pellegrino E. After Self-Imitation Prosodic Training L2 Learners Converge Prosodically to the Native Speakers. Languages. 2024; 9(1):33. https://doi.org/10.3390/languages9010033
Chicago/Turabian StylePellegrino, Elisa. 2024. "After Self-Imitation Prosodic Training L2 Learners Converge Prosodically to the Native Speakers" Languages 9, no. 1: 33. https://doi.org/10.3390/languages9010033
APA StylePellegrino, E. (2024). After Self-Imitation Prosodic Training L2 Learners Converge Prosodically to the Native Speakers. Languages, 9(1), 33. https://doi.org/10.3390/languages9010033