

Visible Vowels as a Tool for the Study of Language Transfer


Abstract
1. Introduction
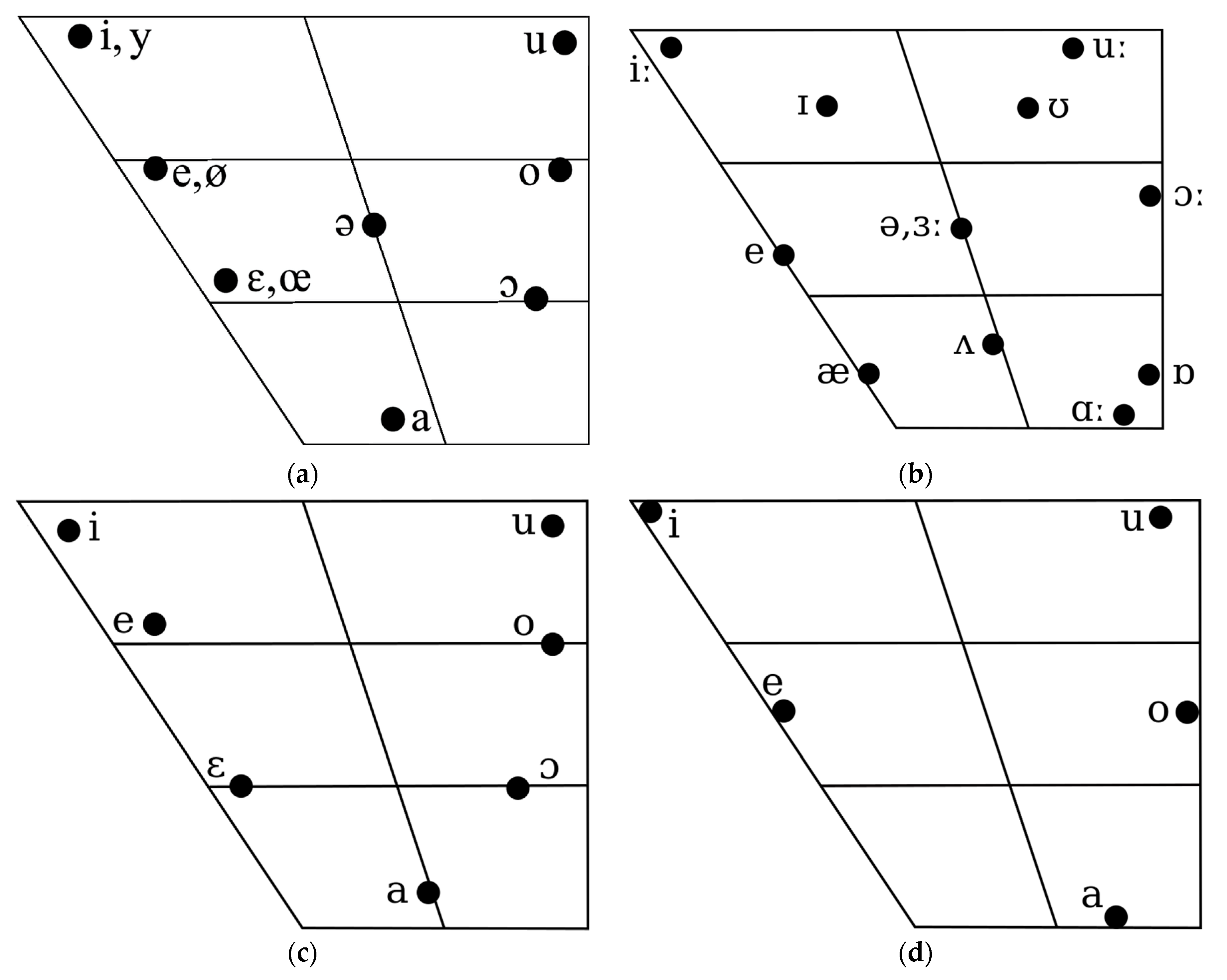
1.1. Acquisition of Sounds
“During L1 acquisition, speech perception becomes attuned to the contrastive phonic elements of the L1. Learners of an L2 may fail to discern the phonetic differences between pairs of sounds in the L2, or between L2 and L1 sounds, either because phonetically distinct sounds in the L2 are “assimilated” to a single category (see Best this volume), because the L1 phonology filters out features (or properties) of U sounds that are important phonetically but not phonologically, or both.”
“A model reflecting this developmental sequence from universal perception to language-specific perception, called the Native Language Magnet model, proposes that infants’ mapping of ambient language warps the acoustic dimensions underlying speech, producing a complex network, or filter, through which language is perceived (39, 40, 82). The language-specific filter alters the dimensions of speech we attend to, stretching and shrinking acoustic space to highlight the differences between language categories. Once formed, language-specific filters make learning a second language much more difficult because the mapping appropriate for one’s primary language is completely different from that required by other languages.”(p. 11854)
1.2. Existing Software for Vowel Visualization
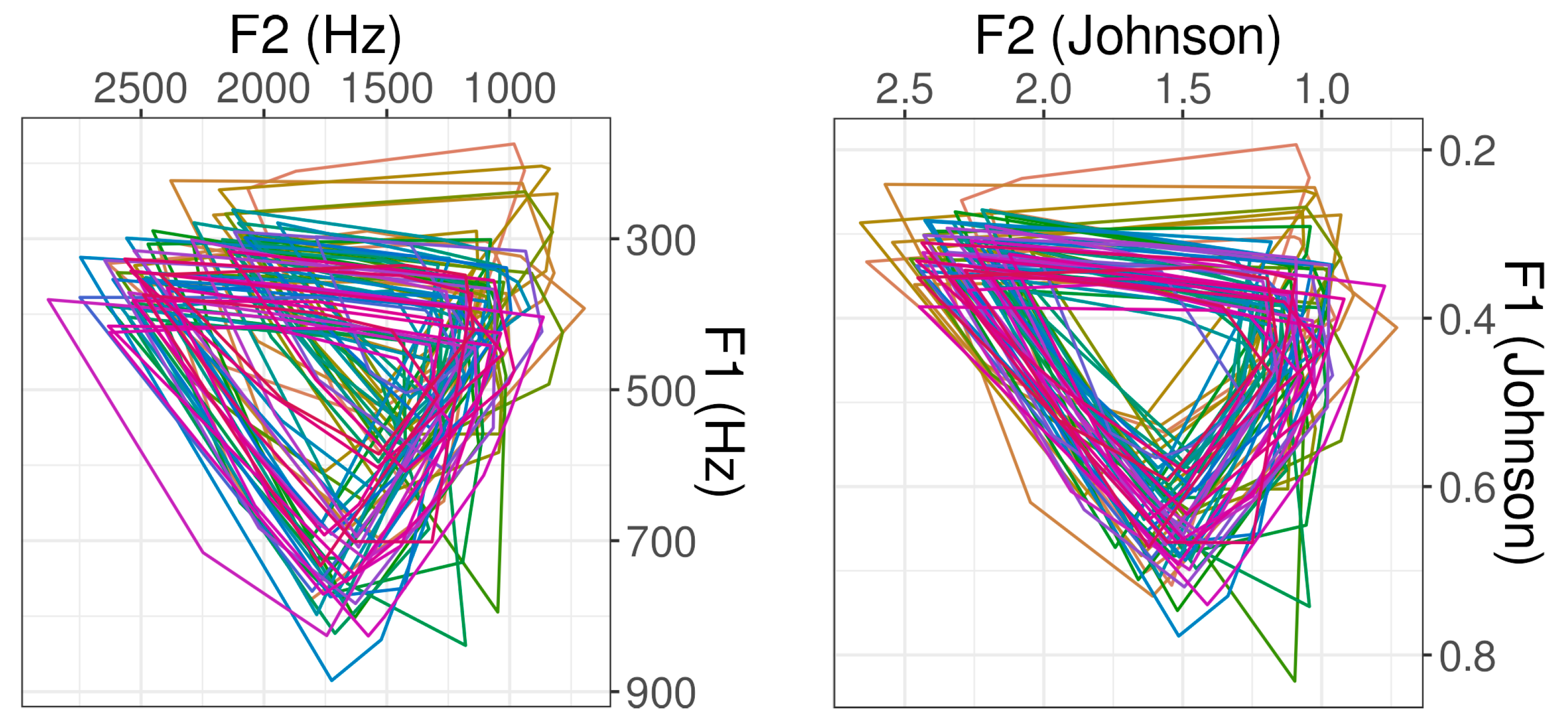
1.3. Visible Vowels
1.4. Case Study
- What are the differences in F1 and F2 between the French vowels of Italian, Spanish and English L2 speakers and French L1 speakers?
- Do the vowel spaces of Italian, Spanish and English L2 speakers of French differ from the vowel space of French L1 speakers?
- How do the vowel systems of the French L2 speaker groups relate to the vowel system of the French L1 speaker group, and to each other, regarding the inter-vowel relationships?
- What are the differences in duration between the French vowels of Italian, Spanish and English L2 speakers and French L1 speakers?
2. Methodology
2.1. Data Set
2.2. Scale Conversion and Normalization
3. Results
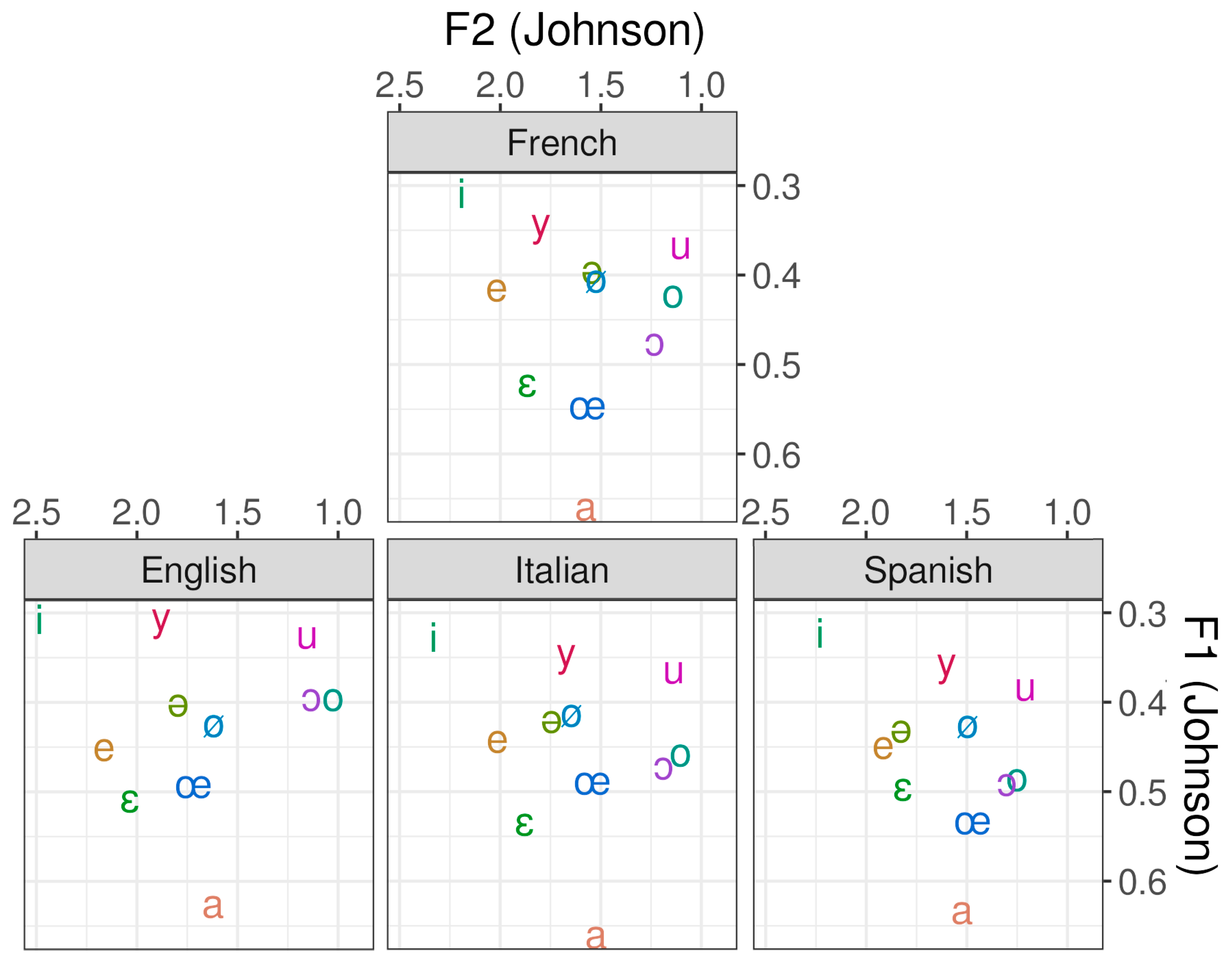
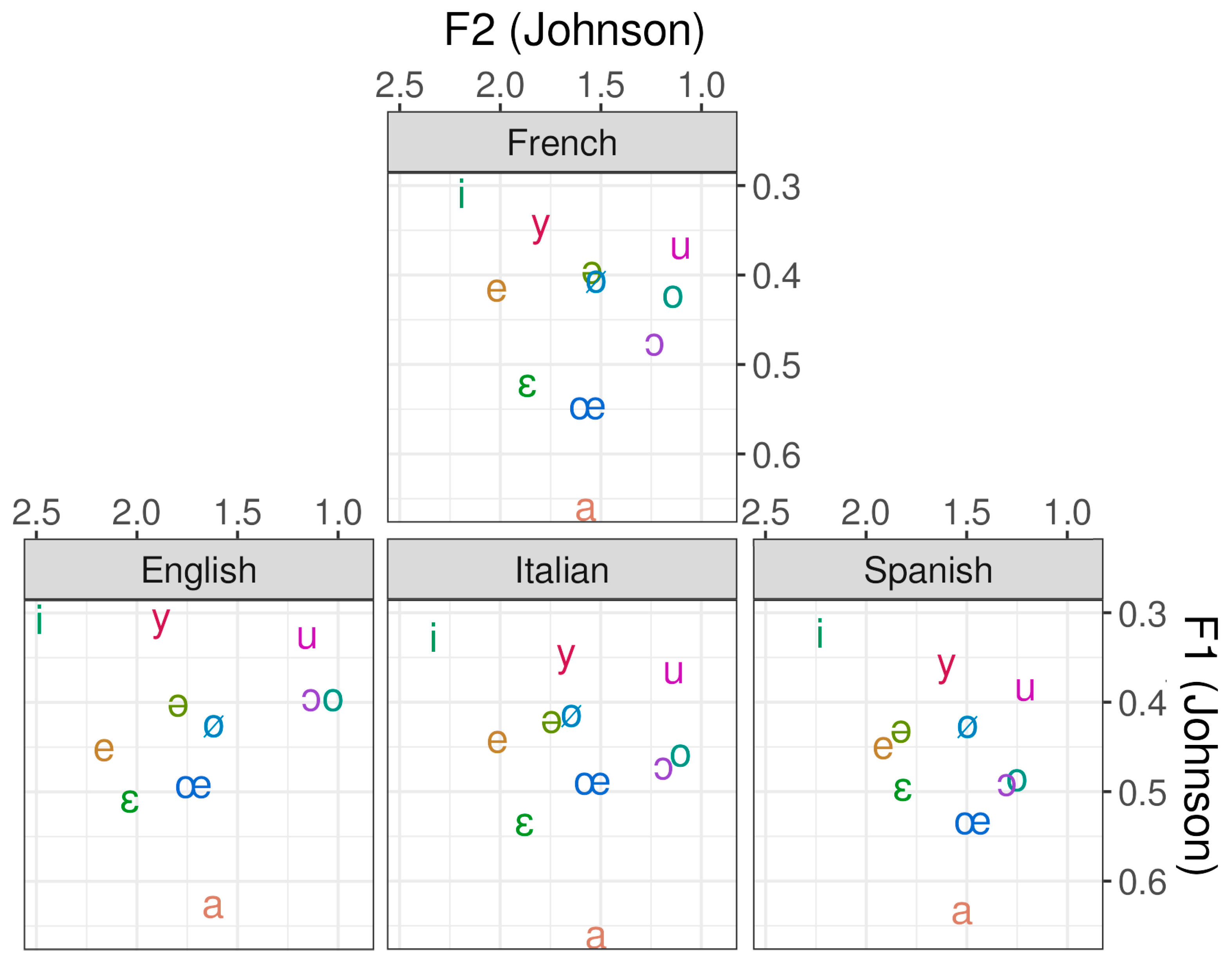
3.1. What Are the Differences in F1 and F2 between the French Vowels of Italian, Spanish and English L2 Speakers and French L1 Speakers?
3.1.1. Comparing Vowel Plots
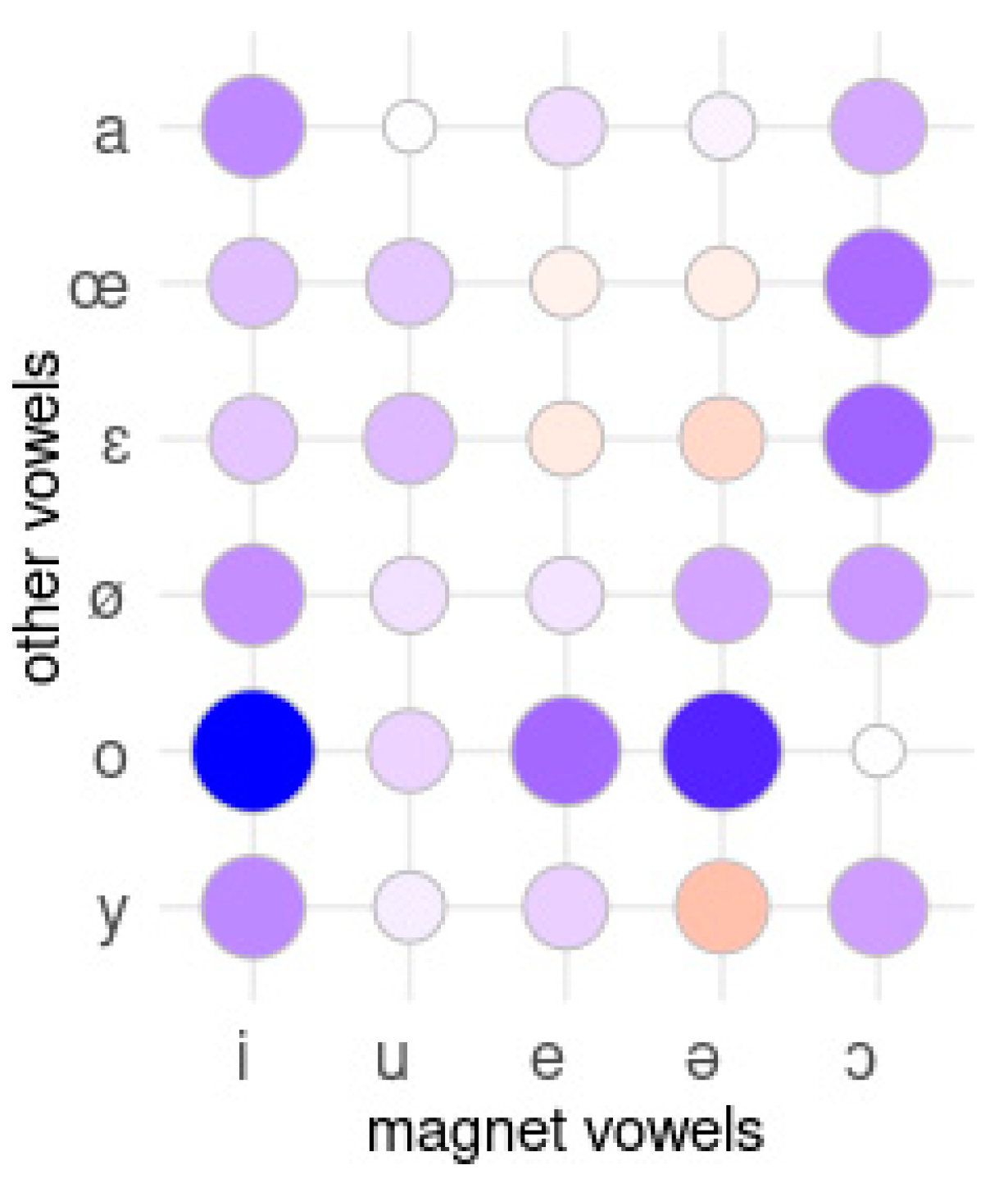
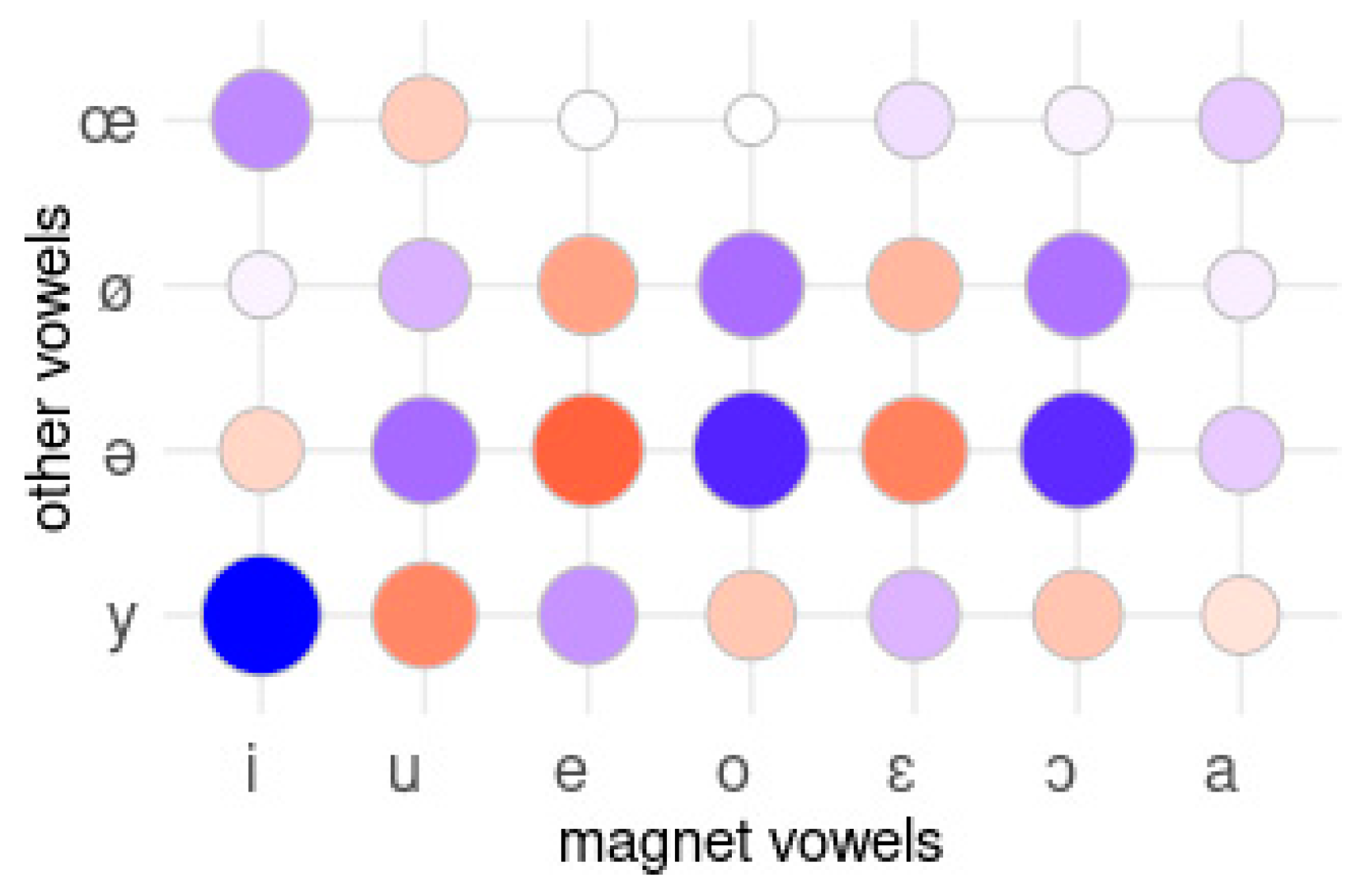
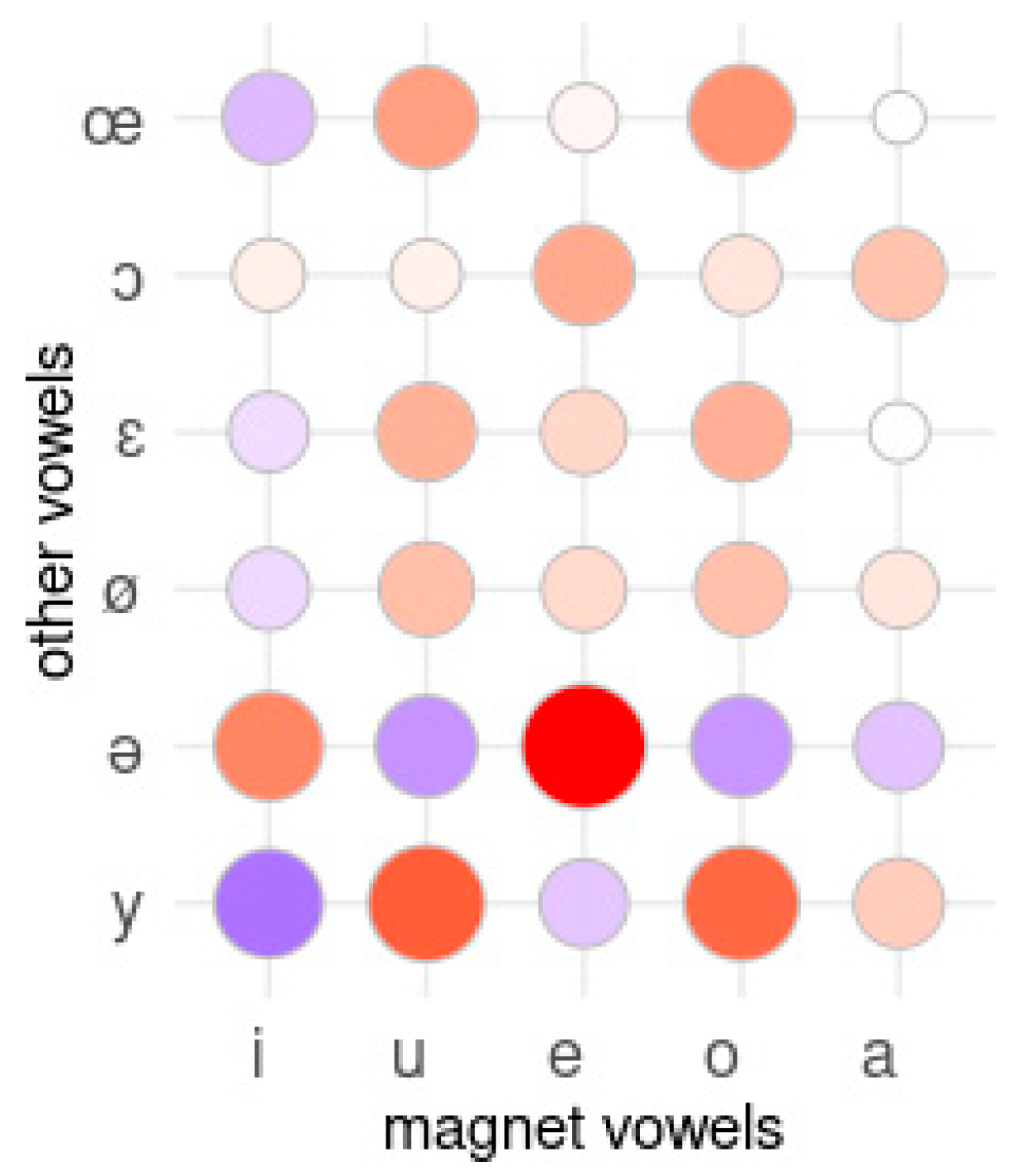
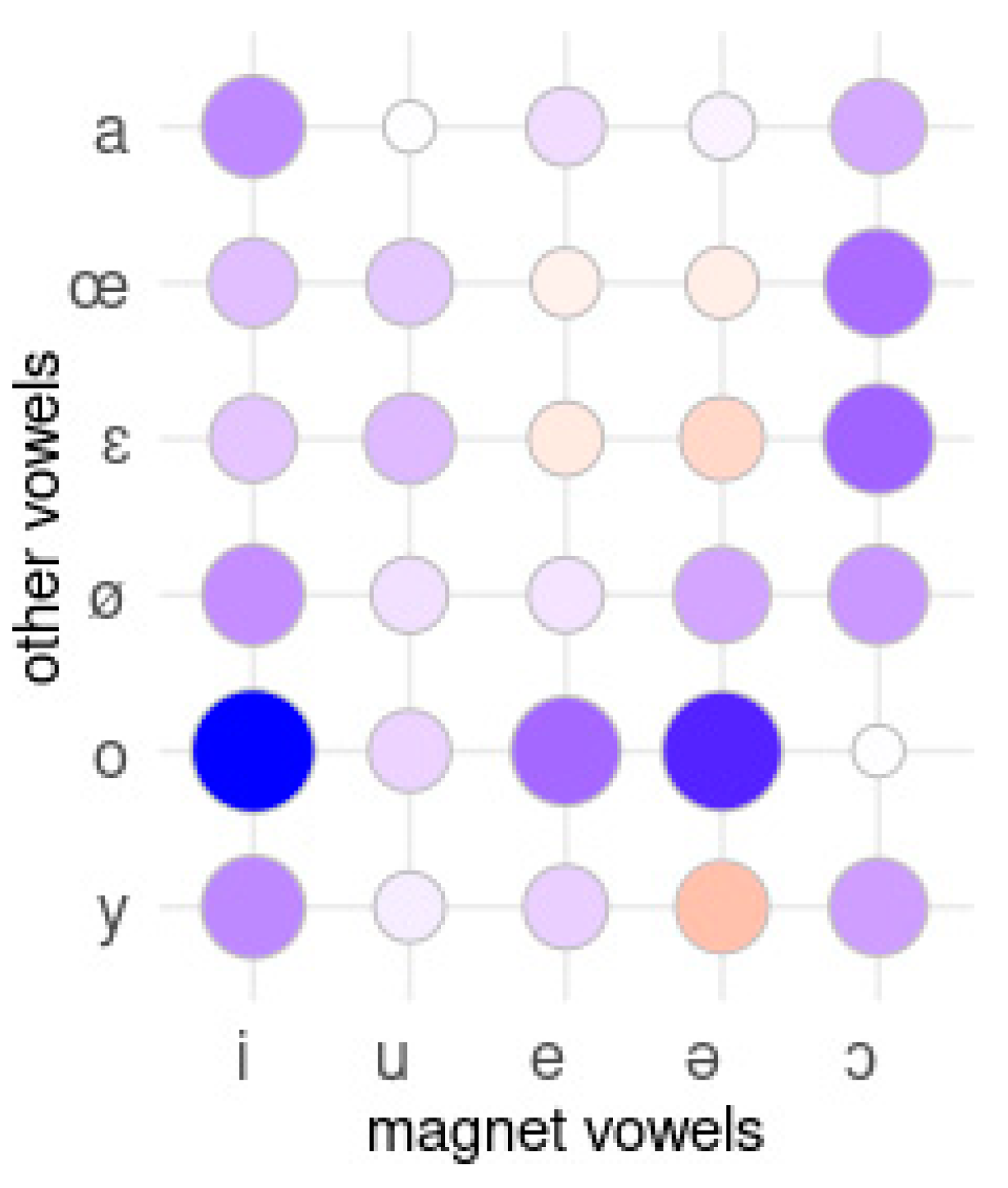
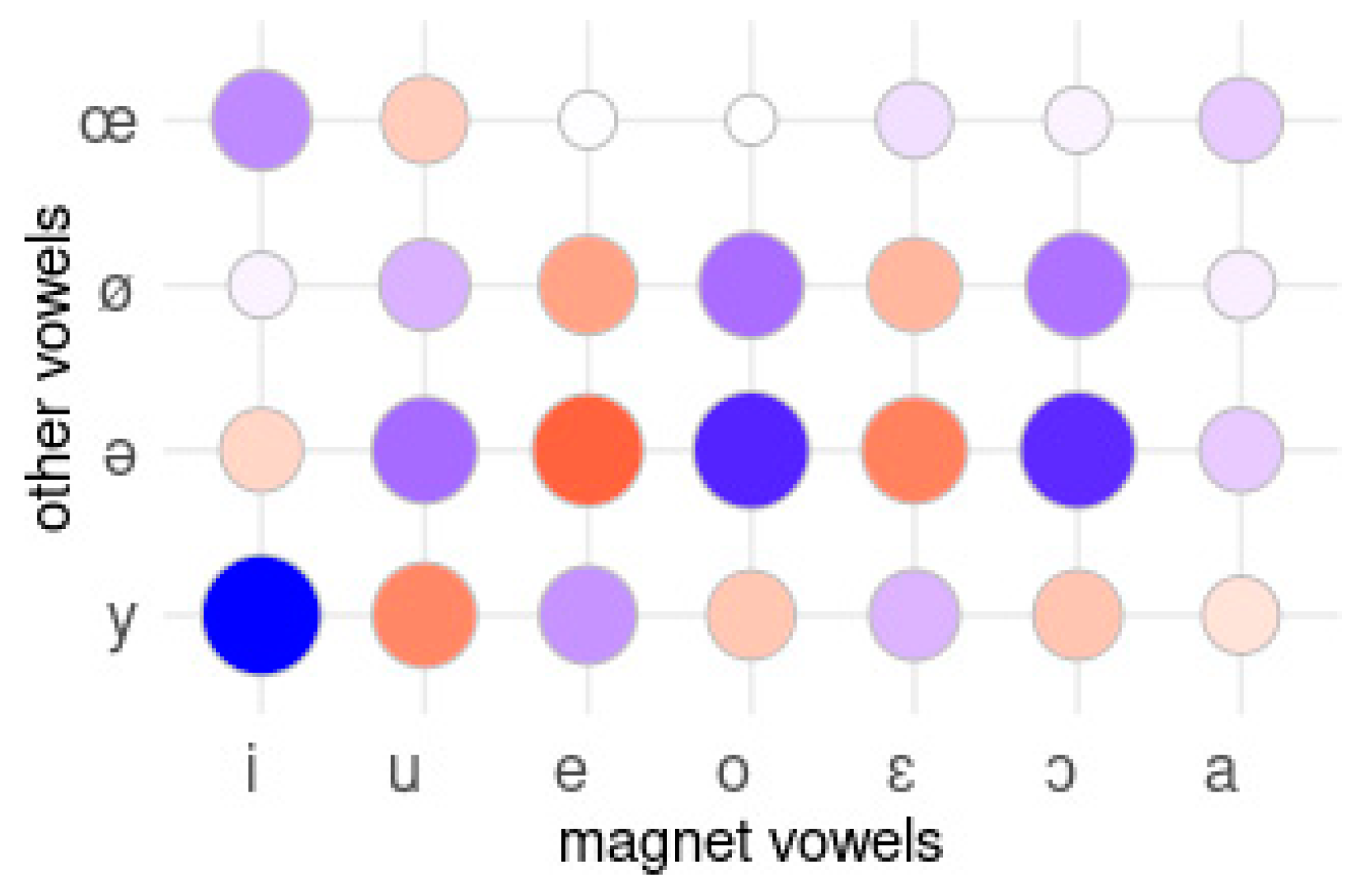
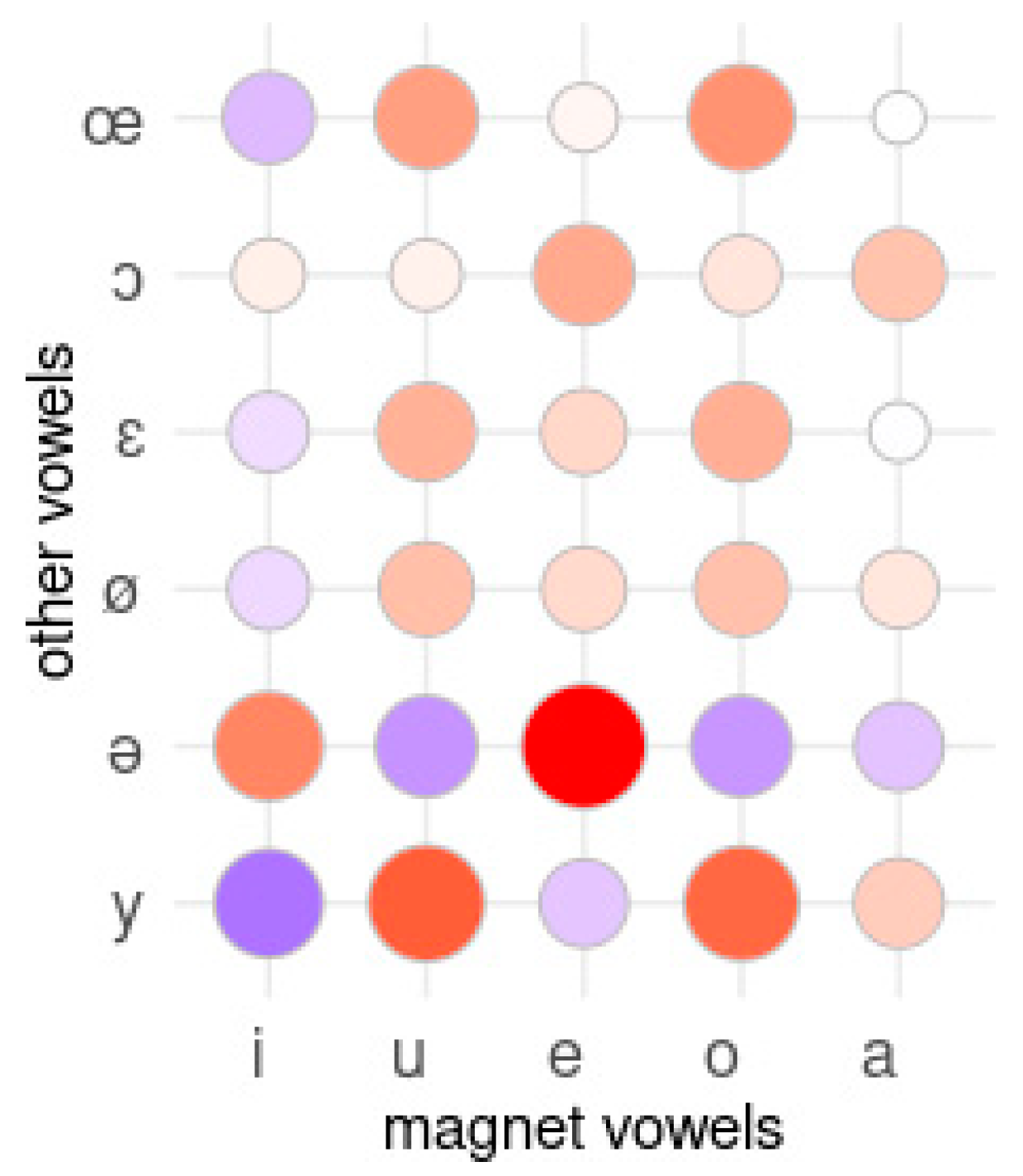
3.1.2. Detecting Magnet Vowels
3.2. Do the Vowel Spaces of Italian, Spanish and English L2 Speakers of French Differ from the Vowel Space of French L1 Speakers?
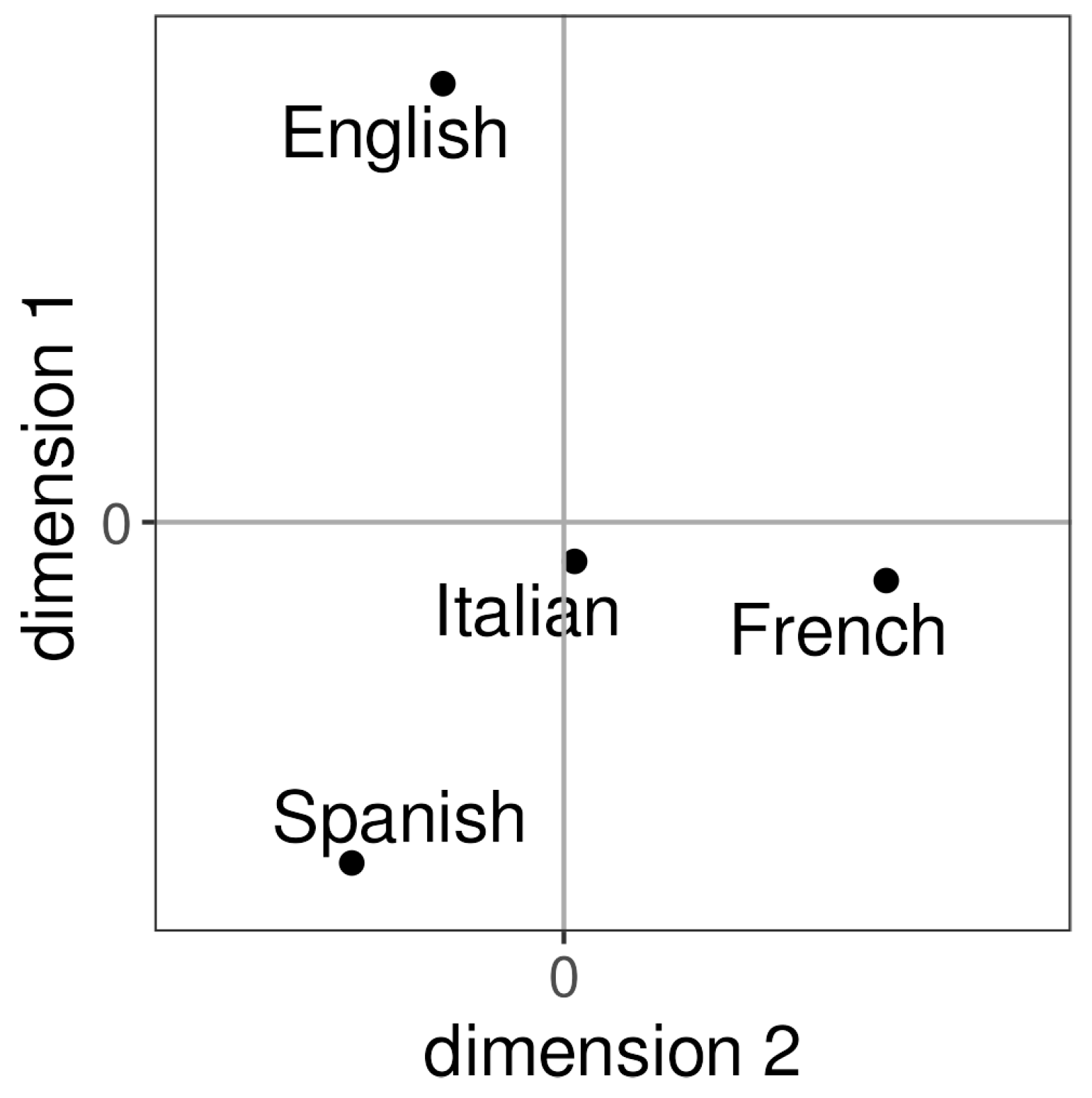
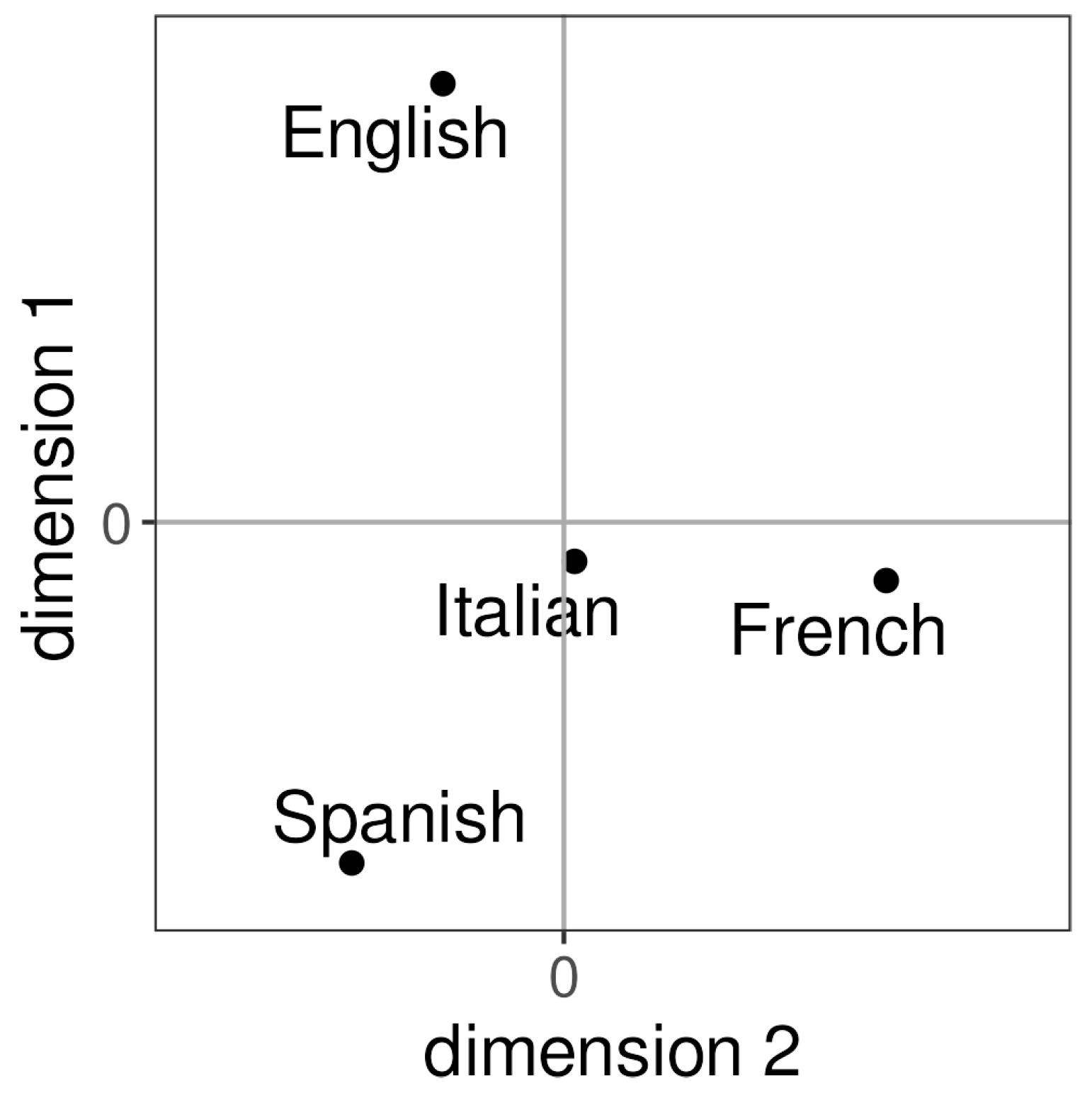
3.3. How Do the Vowel Systems of the French L2 Speaker Groups Relate to the Vowel System of the French L1 Speaker Group and to Each Other Regarding the Inter-Vowel Relationships?
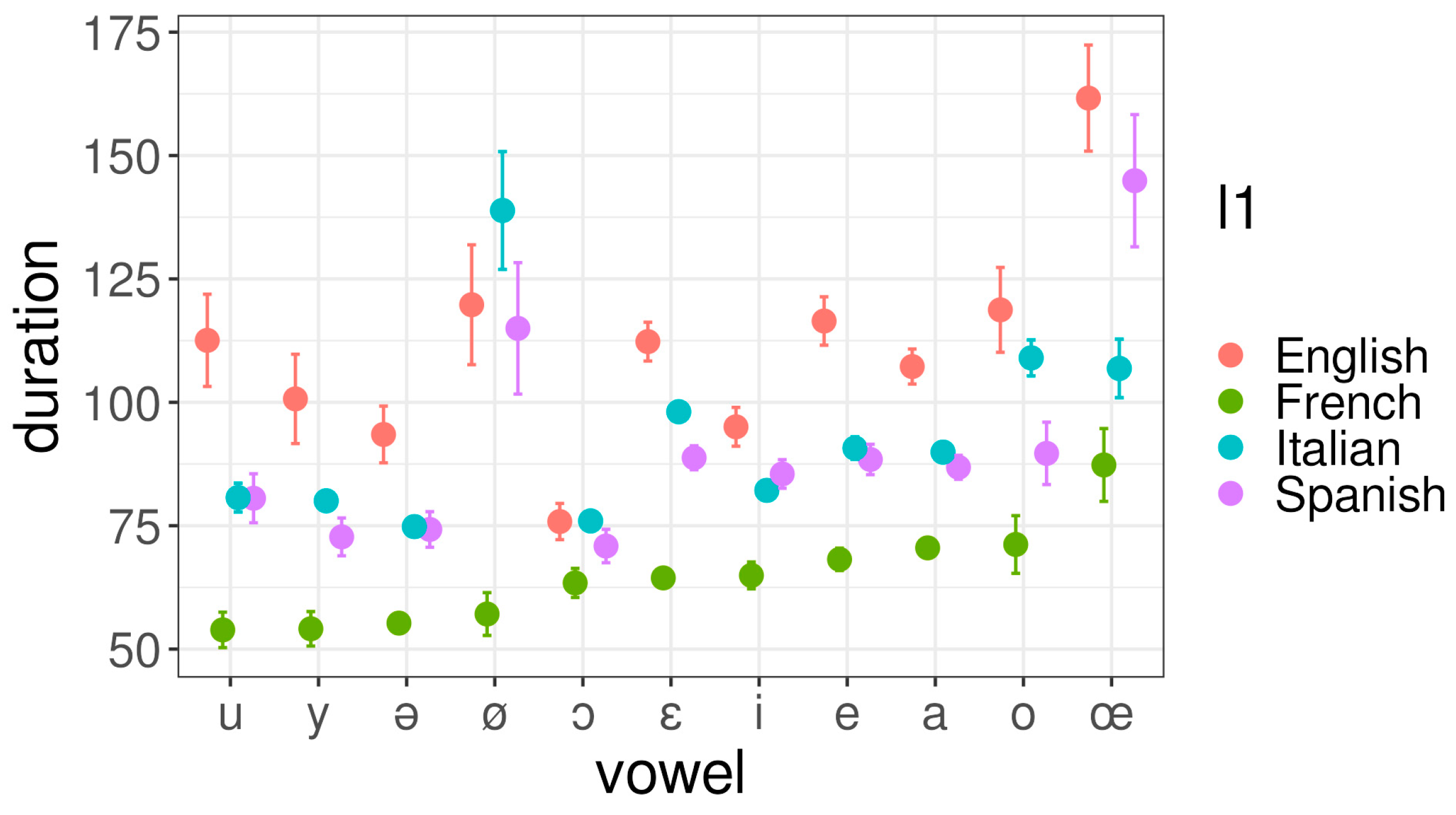
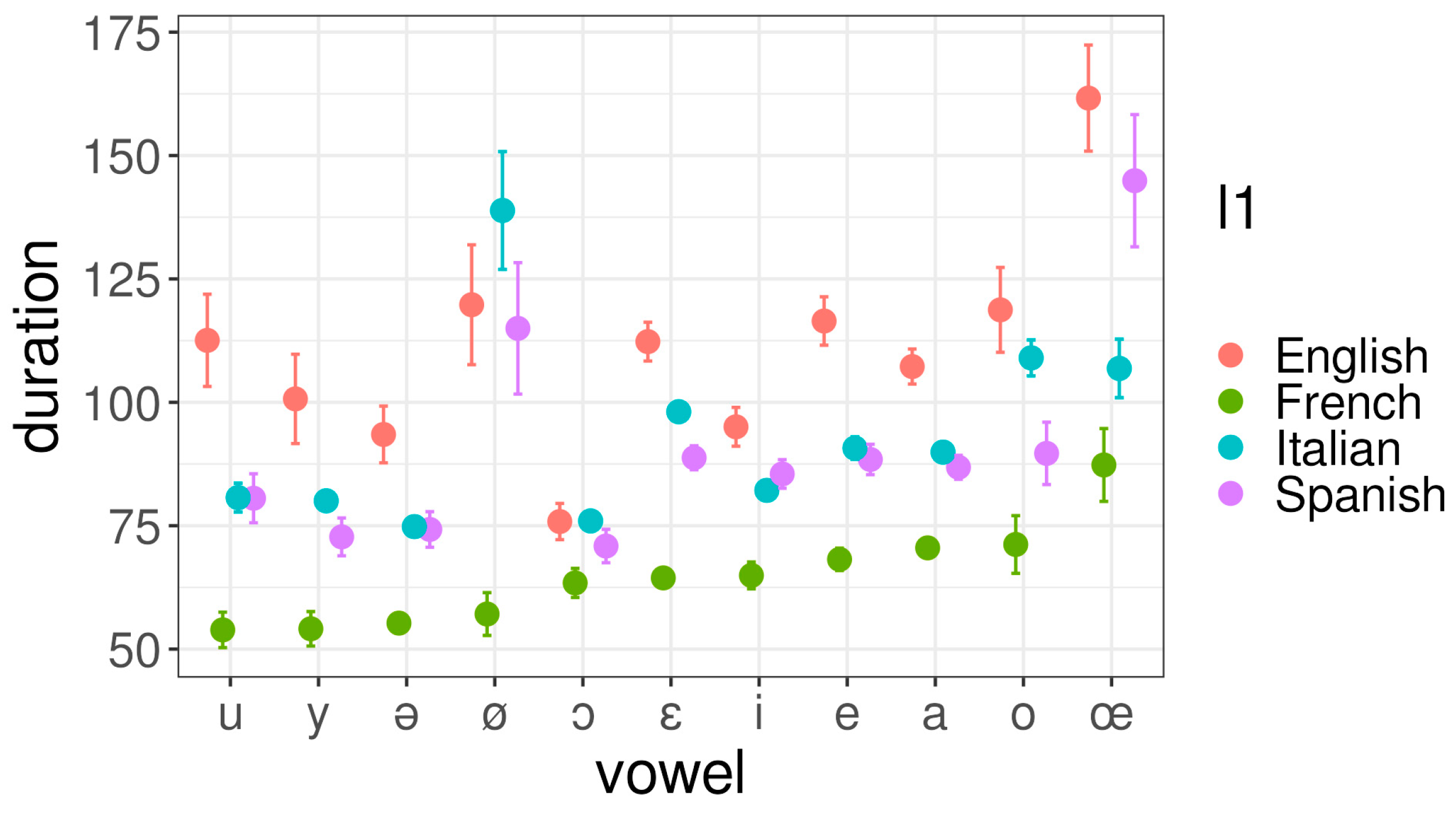
3.4. What Are the Differences in DURATION between the French Vowels of Italian, Spanish and English L2 Speakers and French L1 Speakers?
4. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
| 1 | Available at: https://github.com/BYU-ODH/apeworm (accessed on 18 October 2023). |
| 2 | Available at: https://github.com/BYU-ODH/VowelCat (accessed on 18 October 2023). |
| 3 | See: https://www.ivanarehman.com/l2-tech-portfolio (accessed on 18 October 2023). |
| 4 | See: http://lingtools.uoregon.edu/norm/norm1.php (accessed on 18 October 2023). |
| 5 | See: https://depts.washington.edu/sociolab/VOIS3D/ (accessed on 18 October 2023). |
| 6 | In the formant tab of Visible Vowels this method can be found as ‘Labov et al. (2006) log-geomean II’. In the evaluation tab the method is labeled as ‘LABOV II’. The implementation is described in Voeten et al. (2022). |
References
- Adank, Patricia Martine. 2003. Vowel Normalization: A Perceptual-Acoustic Study of Dutch Vowels. Nijmegen: Catholic University of Nijmegen. [Google Scholar]
- Adank, Patricia Martine, Roel Smits, and Roeland Van Hout. 2004. A comparison of vowel normalization procedures for language variation research. The Journal of the Acoustical Society of America 116: 3099–107. [Google Scholar] [CrossRef] [PubMed]
- Best, Catherine T., and Michael D. Tyler. 2007. Nonnative and second-language speech perception: Commonalities and complementarities. In Language Experience in Second Language Speech Learning; in Honour of James Emil Flege. Edited by Ocke-Schwen Bohn and Murray J. Munro. Amsterdam: John Benjamins Publishing Company, pp. 13–34. [Google Scholar]
- Boersma, Paul, and David Weenink. 2021. Praat: Doing Phonetics by Computer [Computer Program]. Version 6.4.01. Available online: http://www.praat.org/ (accessed on 18 October 2023).
- Delais-Roussarie, Elisabeth, and Hiyon Yoo. 2010. The COREIL Corpus: A Learner Corpus Designed for Studying Phrasal Phonology and Intonation. Paper presented at 6th New Sounds, Poznan, Poland, May 1–3; pp. 100–5. [Google Scholar]
- Delais-Roussarie, Elisabeth, Fabián Santiago, and Hi-Yon Yoo. 2015. The extended COREIL corpus: First outcomes and methodological issues. Paper presented at Workshop on Phonetic Learner Corpora, Glasgow, UK, August 12; pp. 57–59. [Google Scholar]
- Delais-Roussarie, Elisabeth, Tanja Kupisch, Paolo Mairano, Fabian Santiago, and Frida Splendido. 2018. ProSeg: A Comporable Corpus of Spoken L2 French. Paper presented at EuroSLA 2018, Münster, Germany, September 5–8. [Google Scholar]
- Derwing, Tracey M., and Murray J. Munro. 1997. Accent, intelligibility, and comprehensibility: Evidence from four L1s. Studies in Second Language Acquisition 19: 1–16. [Google Scholar] [CrossRef]
- Flege, James E. 1995. Second language speech learning theory, findings, and problems. In Speech Perception and Linguistic Experience: Issues in Cross-Language Research. Edited by Winifred Strange. Timonium: York Press, pp. 233–77. [Google Scholar]
- Fougeron, Cécile, and Caroline L. Smith. 1999. French. In Handbook of the International Phonetic Association: A Guide to the Use of the International Phonetic Alphabet. Cambridge: Cambridge University Press, pp. 78–81. [Google Scholar]
- Frostel, Harald, Andreas Arzt, and Gerhard Widmer. 2011. The vowel worm: Real-time mapping and visualisation of sung vowels in music. Paper presented at 8th Sound and Music Computing Conference, Padova, Italy, July 6–9; Padova: Padova University Press, pp. 214–19. [Google Scholar]
- Goldman, Jean-Philippe. 2011. EasyAlign: An automatic phonetic alignment tool under Praat. Paper presented at 12th Annual Conference of the International Speech Communication Association 2011 (INTERSPEECH 2011), Florence, Italy, August 27–31; pp. 3233–36. [Google Scholar] [CrossRef]
- Herment, Sophie, Anne Tortel, Brigitte Bigi, Daniel J. Hirst, and Anastassia Loukina. 2014. AixOx, a Multi-Layered Learners Corpus: Automatic Annotation. In Specialisation and Variation in Language Corpora. Edited by Francisco Javier Diaz-Pérez and Ana Díaz-Negrillo. Bern: Peter Lang, pp. 41–76. [Google Scholar]
- Huckvale, Mark. 2004. ACCDIST: A Metric for Comparing Speakers’ Accents. Paper presented at International Conference on Spoken Language Processing, Jeju, Republic of Korea, October 4–8; pp. 29–32. [Google Scholar]
- Huckvale, Mark. 2007. ACCDIST: An accent similarity metric for accent recognition and diagnosis. In Speaker Classification II: Selected Projects. Berlin and Heidelberg: Springer, pp. 258–75. [Google Scholar]
- Johnson, Keith. 2018. Vocal tract length normalization. In UC Berkeley PhonLab Annual Report. Berkeley: UC Berkeley PhonLab, vol. 14. [Google Scholar] [CrossRef]
- Johnson, Keith. 2020. The ∆F method of vocal tract length normalization for vowels. Laboratory Phonology 11: 10. [Google Scholar] [CrossRef]
- Kendall, Tyler, and Erik R. Thomas. 2018. Vowels: Vowel Manipulation, Normalization, and Plotting. R Package Version 1.2-2. Available online: https://CRAN.R-project.org/package=vowels (accessed on 18 October 2023).
- Kisler, T., U. Reichel, and F. Schiel. 2017. Multilingual processing of speech via web services. Computer Speech & Language 45: 326–47. [Google Scholar]
- Kruskal, Joseph B., and Myron Wish. 1978. Multidimensional Scaling. In Sage University Paper Series on Quantitative Applications in the Social Sciences. Newbury Park: Sage Publications, pp. 7–11. [Google Scholar]
- Krzonowski, J., F. Pellegrino, and E. Ferragne. 2018. Étude acoustique de la production de voyelles de l’anglais par des apprenants francophones. Paper presented at Actes des XXXIIe Journées d’Études sur la Parole, Aix-en-Provence, France, June 4–8; pp. 525–31. [Google Scholar]
- Kuhl, Patricia K. 2000. A new view of language acquisition. Proceedings of the National Academy of Sciences 97: 11850–57. [Google Scholar] [CrossRef]
- Kuhl, Patricia K., Barbara T. Conboy, Sharon Coffey-Corina, Denise Padden, Maritza Rivera-Gaxiola, and Tobey Nelson. 2008. Phonetic learning as a pathway to language: New data and native language magnet theory expanded (NLM-e). Philosophical Transactions of the Royal Society B: Biological Sciences 363: 979–1000. [Google Scholar] [CrossRef] [PubMed]
- Labov, William, Sharon Ash, and Charles Boberg. 2006. The Atlas of North American English: Phonetics, Phonology and Sound Change. Berlin: Mouton de Gruyter. [Google Scholar]
- Ladefoged, Peter, and Keith Johnson. 2010. A Course in Phonetics, 6th ed. Boston: Wadsworth Publishing. [Google Scholar]
- Mairano, Paolo, Fabián Santiago, and Leonardo Contreras-Roa. 2023. Can L2 pronunciation be evaluated without reference to a native model? Pillai scores for the intrinsic evaluation of L2 vowels. Languages 8: 280. [Google Scholar] [CrossRef]
- McCloy, Daniel R. 2016. phonR: Tools for Phoneticians and Phonologists. R package Version 1.0-7. Available online: https://CRAN.R-project.org/package=phonR (accessed on 18 October 2023).
- Rehman, Ivana. 2021. Real-Time Formant Extraction for Second Language Vowel Production Training. Ph.D. dissertation, Iowa State University, Ames, IA, USA. [Google Scholar]
- Roach, Peter. 2004. British English: Received Pronunciation. Journal of the International Phonetic Association 34: 239–45. [Google Scholar]
- Rogers, Derek, and Luciana d’Arcangeli. 2004. Italian. Journal of the International Phonetic Association 34: 117–21. [Google Scholar] [CrossRef]
- Torgerson, Warren S. 1952. Multidimensional scaling. I. Theory and method. Psychometrika 17: 401–19. [Google Scholar] [CrossRef]
- Torgerson, Warren S. 1958. Theory and Methods of Scaling. New York: Wiley. [Google Scholar]
- Voeten, Cesko, Wilbert Heeringa, and Hans Van de Velde. 2022. Normalization of nonlinearly time-dynamic vowels. The Journal of the Acoustical Society of America 152: 2692–710. [Google Scholar] [CrossRef] [PubMed]
- Wassink, Alicia Beckford. 2006. A geometric representation of spectral and temporal vowel features: Quantification of vowel overlap in three linguistic varieties. The Journal of the Acoustical Society of America 119: 2334–50. [Google Scholar] [CrossRef] [PubMed]
- Wikipedia Contributors. 2023. Convex Hull—Wikipedia, the Free Encyclopedia. Available online: https://en.wikipedia.org/wiki/Convex_hull (accessed on 4 August 2023).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| L2 English (AixOx) | L2 Italian (ProSeg) | L2 Spanish (COREIL) | L1 French (AixOx) | |
|---|---|---|---|---|
| male speakers | 7 | 4 | 8 | 4 |
| female speakers | 3 | 21 | 6 | 6 |
| Total | Total | L1 French | L2 English | L2 Italian | L2 Spanish | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Incl. | Excl. | Incl. | Excl. | Incl. | Excl. | Incl. | Excl. | Incl. | Excl. | |
| a | 524 | 480 | 128 | 123 | 135 | 110 | 145 | 137 | 116 | 110 |
| e | 343 | 311 | 87 | 82 | 86 | 70 | 86 | 81 | 84 | 78 |
| ə | 356 | 327 | 71 | 68 | 90 | 75 | 104 | 97 | 91 | 87 |
| ɛ | 388 | 365 | 98 | 92 | 102 | 92 | 95 | 91 | 94 | 90 |
| i | 314 | 285 | 76 | 64 | 78 | 69 | 86 | 82 | 75 | 70 |
| o | 79 | 71 | 17 | 16 | 20 | 16 | 28 | 26 | 15 | 13 |
| ø | 55 | 51 | 13 | 13 | 16 | 14 | 14 | 13 | 12 | 11 |
| œ | 41 | 38 | 11 | 10 | 16 | 14 | 9 | 9 | 5 | 5 |
| ɔ | 145 | 137 | 33 | 33 | 36 | 31 | 50 | 48 | 26 | 25 |
| u | 110 | 101 | 28 | 27 | 29 | 23 | 26 | 25 | 27 | 26 |
| y | 123 | 114 | 24 | 23 | 29 | 24 | 47 | 45 | 23 | 22 |
| 2478 | 2280 | |||||||||
| F1 + F2 | F1 + F2 + F3 | |||
|---|---|---|---|---|
| Best Prediction | Highest Explained Variance | Best Prediction | Highest Explained Variance | |
| phonemic | Lobanov Hz | Johnson Hz | Lobanov Hz/bark I/mel II | Nearey I Hz |
| anatomic | Heeringa & Van de Velde II bark II | Heeringa & Van de Velde II bark II | Gerstman bark I/ERB II | Lobanov bark I |
| socioling. | Heeringa & Van de Velde II ln | Nearey I Hz | Nearey II Hz | LABOV II Hz6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Heeringa, W.; Velde, H.V.d. Visible Vowels as a Tool for the Study of Language Transfer. Languages 2024, 9, 35. https://doi.org/10.3390/languages9020035
Heeringa W, Velde HVd. Visible Vowels as a Tool for the Study of Language Transfer. Languages. 2024; 9(2):35. https://doi.org/10.3390/languages9020035
Chicago/Turabian StyleHeeringa, Wilbert, and Hans Van de Velde. 2024. "Visible Vowels as a Tool for the Study of Language Transfer" Languages 9, no. 2: 35. https://doi.org/10.3390/languages9020035
APA StyleHeeringa, W., & Velde, H. V. d. (2024). Visible Vowels as a Tool for the Study of Language Transfer. Languages, 9(2), 35. https://doi.org/10.3390/languages9020035