Sound Symbolism Facilitates Long-Term Retention of the Semantic Representation of Novel Verbs in Three-Year-Olds



Abstract
1. Introduction
2. Experiment 1
2.1. Method
2.1.1. Participants
2.1.2. Stimuli
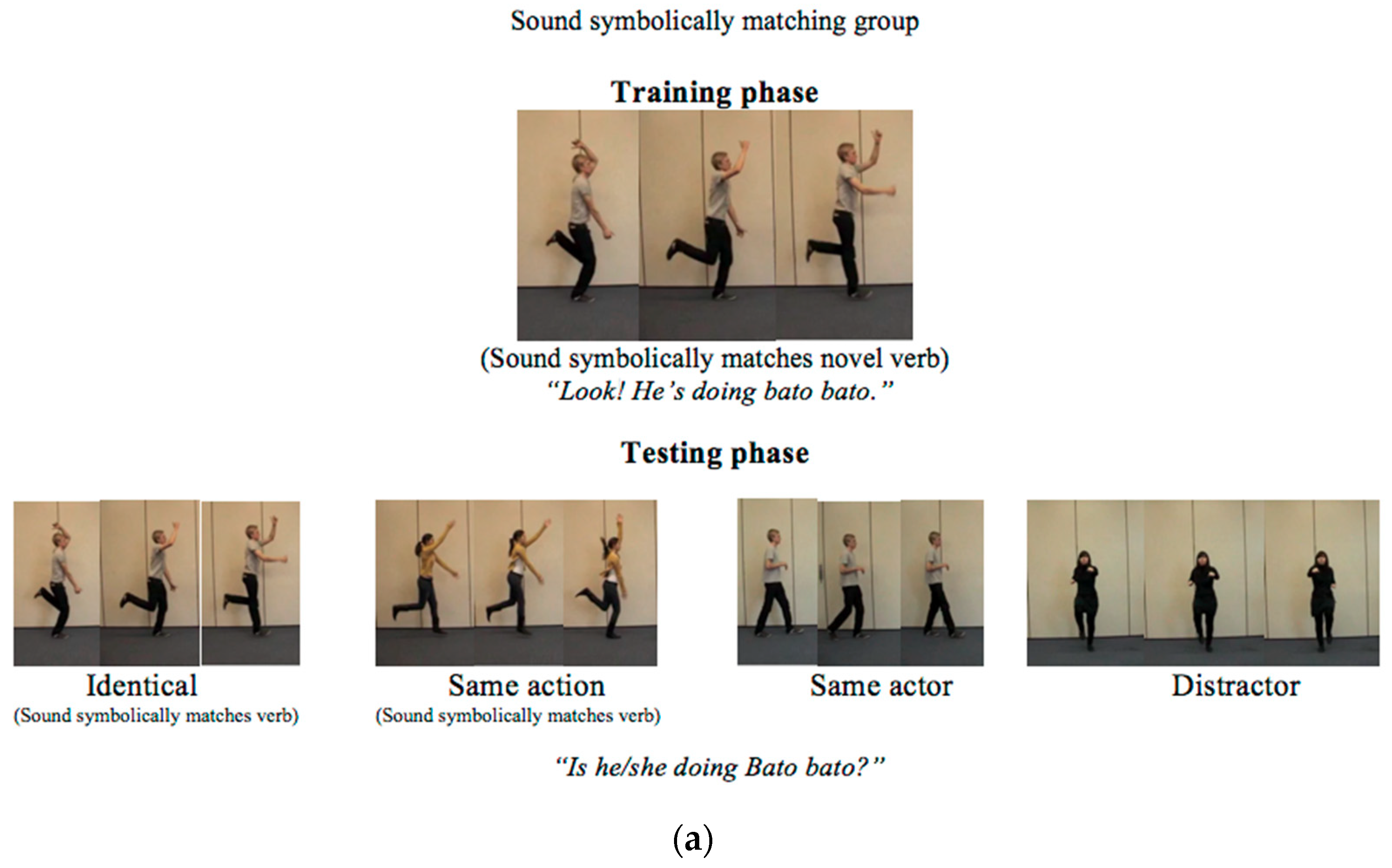
2.1.3. Condition
2.1.4. Procedure
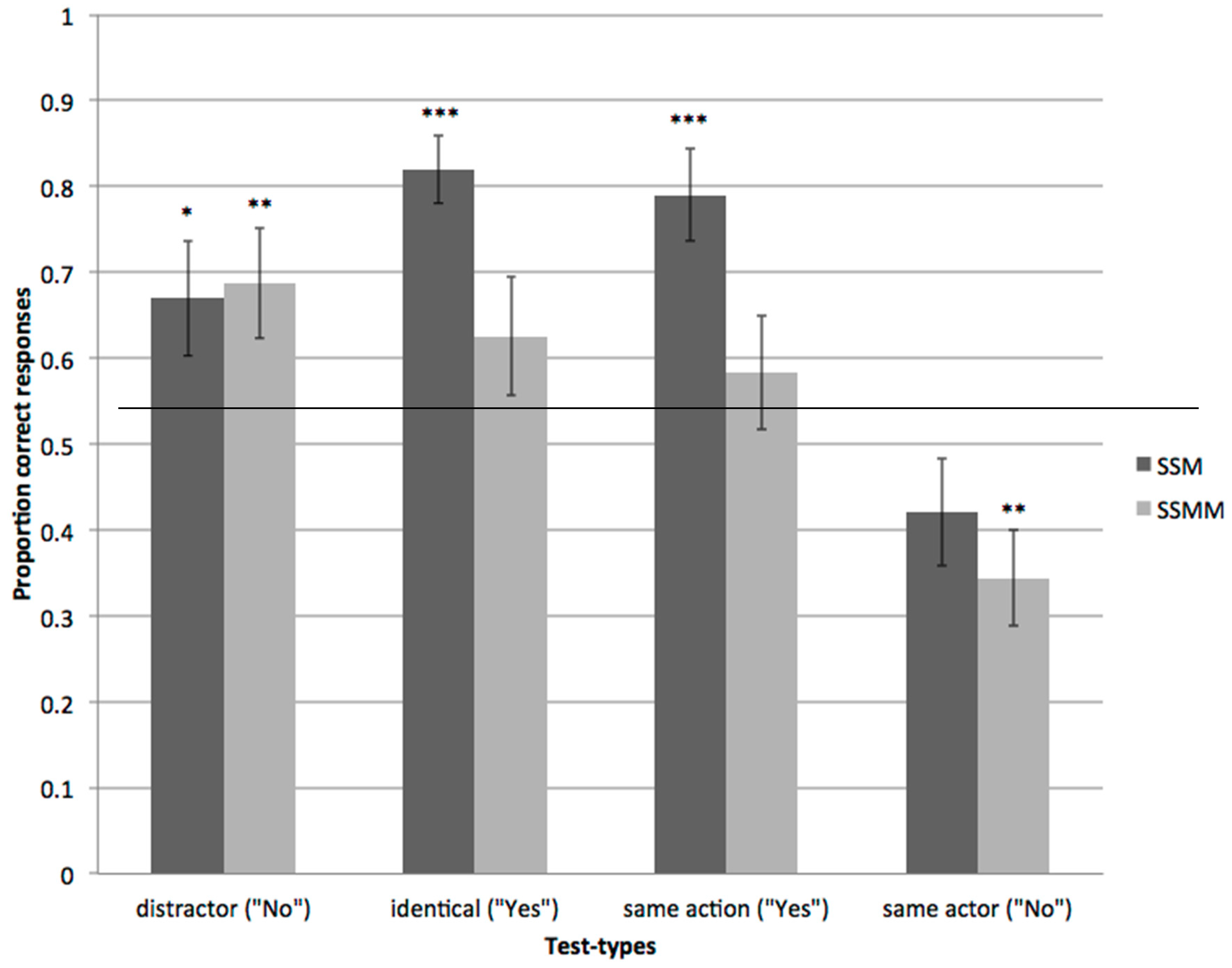
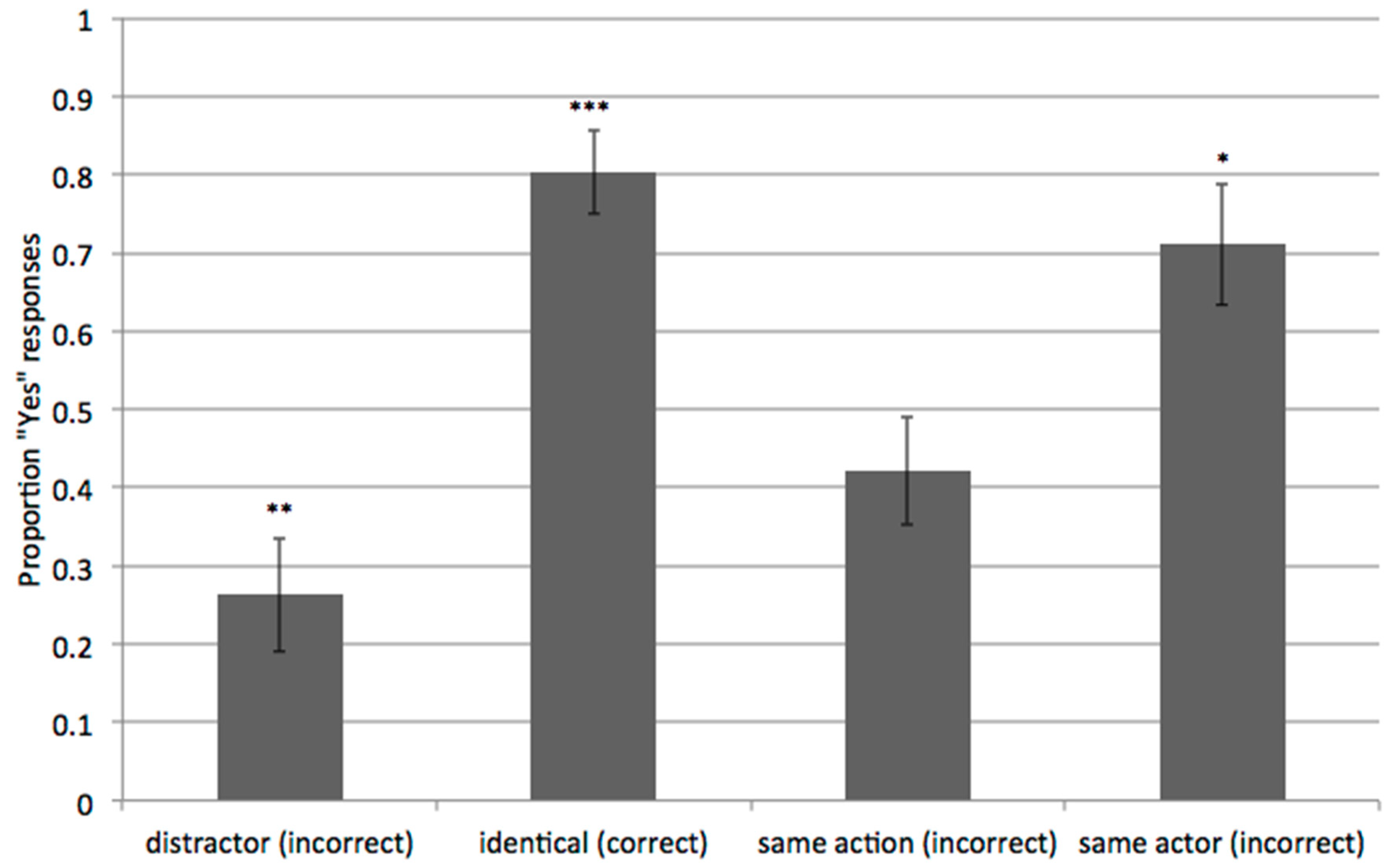
2.2. Results and Discussions
3. Experiment 2
3.1. Method
3.1.1. Participants
3.1.2. Stimuli
3.1.3. Procedure
3.2. Results and Discussions
4. General Discussion
Author Contributions
Conflicts of Interest
References
- Abbot-Smith, Kirsten, Mutsumi Imai, Samantha Durrant, and Erika Nurmsoo. 2017. The role of timing and prototypical causality on how preschoolers fast-map novel verb meanings. First Language 37: 186–204. [Google Scholar] [CrossRef]
- Asano, Michiko, Mutsumi Imai, Sotaro Kita, Keiichi Kitajo, Hiroyuki Okada, and Guillaume Thierry. 2015. Sound symbolism scaffolds language development in preverbal infants. Cortex 63: 196–205. [Google Scholar] [CrossRef] [PubMed]
- Aussems, Suzanne, and Sotaro Kita. 2017. Seeing iconic gestures while encoding events facilitates children’s memory of these events. Child Development. [Google Scholar] [CrossRef] [PubMed]
- Brown, Roger, and Ronald Nuttall. 1959. Methods in phonetic symbolism experiments. Journal of Abnormal and Social Psychology 59: 441–45. [Google Scholar] [CrossRef] [PubMed]
- Brown, Roger W., Abraham H. Black, and Arnold E. Horowitz. 1955. Phonetic symbolism in natural languages. The Journal of Abnormal and Social Psychology 50: 388–93. [Google Scholar] [CrossRef]
- Childers, Jane B. 2011. Attention to multiple events helps two-and-a-half-year-olds extend new verbs. First Language 31: 3–22. [Google Scholar] [CrossRef]
- Childers, Jane B., and Michael Tomasello. 2002. Two-year-olds learn novel nouns, verbs, and conventional actions from massed or distributed exposures. Developmental Psychology 38: 967–78. [Google Scholar] [CrossRef] [PubMed]
- Davis, Roger. 1961. The fitness of names to drawings: A cross-cultural study in Tanganyika. British Journal of Psychology 52: 259–68. [Google Scholar] [CrossRef]
- Deloache, Judy S. 1995. Early Understanding and Use of Symbols—The Model Model. Current Directions in Psychological Science 4: 109–13. [Google Scholar] [CrossRef]
- Deloache, Judy S., and Tanya Sharon. 2005. Symbols and Similarity: You Can Get Too Much of a Good Thing. Journal of Cognition and Development 6: 33–49. [Google Scholar] [CrossRef]
- Dingemanse, Mark. 2013. Ideophones and gesture in everyday speech. Gesture 13: 143–65. [Google Scholar] [CrossRef]
- Fort, Mathilde, Weiß Alexa, Martin Alexander, and Peperkamp Sharon. 2013. Looking for the bouba–kiki effect in prelexical infants. In Proceedings of the 12th International Conference on Auditory–Visual Speech Processing, Annecy, France, 29 August–1 September 2013. Edited by Slim Ouni, Frédéric Berthommier and Alexandra Jesse. Le Chesnay Cedex: Inria, pp. 71–76. [Google Scholar]
- Fort, Mathilde, Imme Lammertink, Sharon Peperkamp, Adriana Guevara-Rukoz, Paula Fikkert, and Sho Tsuji. 2018. SymBouki: A meta-analysis on the emergence of sound symbolism in early language acquisition. Developmental Science. [Google Scholar] [CrossRef]
- Gebels, Gustav. 1969. An investigation of phonetic symbolism in different cultures. Journal of Verbal Learning and Verbal Behavior 8: 310–12. [Google Scholar] [CrossRef]
- Gentner, Dedre. 1982. Why nouns are learned before verbs: Linguistic relativity versus natural partitioning. In Language development: Vol. 2. Language, thought, and Culture. Edited by Stan A. Kuczaj. Hillsdale: Erlbaum, pp. 301–34. [Google Scholar]
- Golinkoff, Roberta Michnick, and Kathy Hirsh-Pasek. 2008. How toddlers begin to learn verbs. Trends in Cognitive Science 12: 397–403. [Google Scholar] [CrossRef]
- Goodrich, Whitney, and Carla L. Hudson Kam. 2009. Co-speech gesture as input in verb learning. Developmental Science 12: 81–87. [Google Scholar] [CrossRef] [PubMed]
- Holland, Morris K., and Michael Wertheimer. 1964. Some physiognomic aspects of naming, or maluma and takete revisited. Perception of Motor Skills 19: 111–17. [Google Scholar] [CrossRef] [PubMed]
- Imai, Mutsumi, and Sotaro Kita. 2014. The sound symbolism bootstrapping hypoethiesis afor language acquisition and language evolution. Philosophical Transactions of the Royal Society B: Biological Sciences 369: 20130298. [Google Scholar] [CrossRef]
- Imai, Mutsumi, Etsuko Haryu, and Hiroyuki Okada. 2005. Mapping novel nouns and verbs on to dynamicaction events: Are verb meanings easier to learn than noun meanings for Japanese children? Child Development 76: 340–55. [Google Scholar] [CrossRef]
- Imai, Mutsumi, Sotaro Kita, Miho Nagumo, and Hiroyuki Okada. 2008a. Sound-symbolism between a word and an action facilitates early verb learning. Cognition 109: 54–65. [Google Scholar] [CrossRef]
- Imai, Mutsumi, Lianjing Li, Etsuko Haryu, Hiroyuki Okada, Kathy Hirsh-Pasek, Roberta Michnick Golinkoff, and Jun Shigematsu. 2008b. Novel noun and verb learning in Chinese-, English-, and Japanese-speaking children. Child Development 79: 979–1000. [Google Scholar] [CrossRef]
- Imai, Mutsumi, Michiko Miyazaki, H. Henny Yeung, Shohei Hidaka, Katerina Kantartzis, Hiroyuki Okada, and Sotaro Kita. 2015. Sound symbolism facilitates word learning in 14 month olds. PLoS ONE 10: e0116494. [Google Scholar] [CrossRef]
- Iwasaki, Noriko, David P. Vinson, and Gabriella Vigliocco. 2007a. How does it hurt, "kiri-kiri" or "siku-siku"? Japanese mimetic words of pain perceived by Japanese speakers and English speakers. In Applying Theory and Research to Learning Japanese as a Foreign Language. Edited by Masahiko Minami. Newcastle upon Tyne: Cambridge Scholars Publishing, pp. 2–19. [Google Scholar]
- Kantartzis, Katerina, Mutsumi Imai, and Sotaro Kita. 2011. Japanese sound-symbolism facilitates wordlearning in English-speaking children. Cognitive Science 35: 575–86. [Google Scholar] [CrossRef]
- Kersten, Alan W., and Linda B. Smith. 2002. Attention to novel objects during verb learning. Child Development 73: 93–109. [Google Scholar] [CrossRef]
- Kita, Sotaro. 1997. Two-dimensional semantic analysis of Japanese mimetics. Linguistics 35: 379–415. [Google Scholar] [CrossRef]
- Kita, Sotaro. 2001. Semantic schism and interpretive integration in Japanese sentences with a mimetic: A reply to Tsujimura. Linguistics 39: 419–36. [Google Scholar] [CrossRef]
- Kita, Sotaro, Asli Özyürek, Shanley Allen, Tomoko Ishizuka, and Mihoko Fujii. Forthcoming. The role of iconicity in symbolic development: Children’s preference for sound symbolic words and their early coupling with iconic gestures. Under review.
- Klank, Linda J. K., Yau-Huang Huang, and Ronald C. Johnson. 1971. Determinants of success in matching word pairs in tests of phonetic symbolism. Journal of Verbal Learning and Verbal Behavior 10: 140–48. [Google Scholar] [CrossRef]
- Köhler, Wolfgang. 1947. Gestalt Psychology, 2nd ed.Liverlight: New York. First published in 1929. [Google Scholar]
- Kunihara, Shirou. 1971. Effects of the expressive voice on phonetic symbolism. Journal of Verbal Learning and Verbal Behavior 10: 427–29. [Google Scholar] [CrossRef]
- Maguire, Mandy J., Elizabeth A. Hennon, Kathy Hirsh-Pasek, Roberta Michnick Golinkoff, Carly B. Slutzky, and Jennifer Sootsman. 2002. Mapping words to actions and events: How do 18-month-olds learn a verb? Paper presented at 26th Annual Boston University Conference on Language Development, Boston, MA, USA, November 2–4; Edited by Paola Escudero, P. Boersma, B. Skarabela, S. Fish and A. H. J. Do. , vols. 1 and 2, pp. 369–82. [Google Scholar]
- Maguire, Mandy J., Kathy Hirsh-Pasek, Roberta Michnick Golinkoff, and Amanda C. Brandone. 2008. Focusing on the relation: Fewer exemplars facilitate children’s initial verb learning and extension. Developmental Science 11: 628–34. [Google Scholar] [CrossRef]
- Marentette, Paula, and Elena Nicoladis. 2011. Preschoolers’ interpretations of gesture: Label or action associate? Cognition 121: 389–99. [Google Scholar] [CrossRef] [PubMed]
- Maurer, Daphne, Thanujeni Pathman, and Catherine J. Mondloch. 2006. The shape of boubas: Sound-shape correspondences in toddlers and adults. Developmental Science 9: 316–22. [Google Scholar] [CrossRef] [PubMed]
- McGregor, Karla K., Katharina J. Rohlfing, Allison Bean, and Ellen Marschner. 2009. Gesture as a support for word learning: The case of under. Journal of Child Language 36: 807–28. [Google Scholar] [CrossRef] [PubMed]
- McNeill, David. 1992. Hand and Mind. Chicago: University of Chicago Press. [Google Scholar]
- Mumford, Katherine H., and Sotaro Kita. 2014. Children use gesture to interpret novel verb meanings. Child Development 85: 1181–89. [Google Scholar] [CrossRef]
- Namy, Laura L. 2008. Recognition of iconicity doesn’t come for free. Developmental Science 11: 841–46. [Google Scholar] [CrossRef]
- Namy, Laura L., Aimee L. Campbell, and Michael Tomasello. 2004. The changing role of iconicity in non-verbal symbol learning: A U-shaped trajectory in the acquisition of arbitrary gesture. Journal of Cognition and Development 5: 37–57. [Google Scholar] [CrossRef]
- Ohala, John J. 1994. The frequency code underlies the sound-symbolic use of voice pitch. In Sound Symbolism. Edited by Leanne Hinton, Johanna Nichols and John J. Ohala. Cambridge: Cambridge University Press, pp. 325–47. [Google Scholar]
- Quine, Willard Van Orman. 1960. Word and Object. Cambridge: MIT Press. [Google Scholar]
- Ramachandran, Vilayanur S., and Edward M. Hubbard. 2001. Synaesthesia—A window into perception, thought, and language. Journal of Consciousness Studies 8: 3–34. [Google Scholar]
- Sapir, Edward. 1929. A study in phonetic symbolism. Journal of Experimental Psychology 12: 225–39. [Google Scholar] [CrossRef]
- Siegel, Allen, Irwin Silverman, and Norman N. Markel. 1965. On the effects of mode of presentation on phonetic symbolism. Journal of Verbal Learning and Verbal Behavior 6: 171–73. [Google Scholar] [CrossRef]
- Snape, Simon, and Andrea Krott. 2018. The benefit of simultaneously encountered exemplars and of exemplar variability to verb learning. Journal of Child Language 45: 1412–22. [Google Scholar] [CrossRef]
- Tomasello, Michael, Tricia Striano, and Phillippe Rochat. 1999. Do young children use objects as symbols? British Journal of Developmental Psychology 17: 563–84. [Google Scholar] [CrossRef]
- Tsuru, Shigeto, and H. S. Fries. 1933. Sound and meaning. Journal of General Psychology 8: 281–84. [Google Scholar] [CrossRef]
- Werner, Heinz, and Bernard S. Kaplan. 1963. Symbol Formation: An Organismic-Developmental Approach to Language and the Expression of Thought. London: Wiley. [Google Scholar]
- Yoshida, Hanako. 2012. A cross-linguistic study of sound symbolism in children’s verb learning. Journal of Cognition and Development 13: 232–65. [Google Scholar] [CrossRef] [PubMed]
- Yoshida, Hanako, and Linda B. Smith. 2003. Sound symbolism and early word learning in two languages. In Proceedings of the Twenty-Fifth Annual Conference of the Cognitive Science Society. Edited by Richard Alterman and David Kirsh. Boston: Cognitive Science Society, pp. 1287–92. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Word | Sound-Symbolic Matching Action | Sound-Symbolic Mismatching Action |
|---|---|---|
| Bato bato | A large energetic movement, arms are swinging back and forth outstretched, whereas legs are making large leaping movement | Walking slowly, with arms loosely bent and hands touching in the front |
| Choka choka | Walking quickly in very small steps with the arms swinging quickly with bent elbows | Legs slightly bent, walking slowly and in a controlled fashion, with arms bent and held out in front of body (as if carrying a tray); |
| Nosu nosu | Walking slowly in large steps with bent knees and hands on knees | Legs making large steps forward, with a bounce, arms swinging freely from side to side |
| Toku toku | A small shuffling movement, with straight arms rigidly at the side and legs moving very slightly and rigidly. | Creeping-type walk with medium sized steps, with arms bent and held closely in front of body |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kantartzis, K.; Imai, M.; Evans, D.; Kita, S. Sound Symbolism Facilitates Long-Term Retention of the Semantic Representation of Novel Verbs in Three-Year-Olds. Languages 2019, 4, 21. https://doi.org/10.3390/languages4020021
Kantartzis K, Imai M, Evans D, Kita S. Sound Symbolism Facilitates Long-Term Retention of the Semantic Representation of Novel Verbs in Three-Year-Olds. Languages. 2019; 4(2):21. https://doi.org/10.3390/languages4020021
Chicago/Turabian StyleKantartzis, Katerina, Mutsumi Imai, Danielle Evans, and Sotaro Kita. 2019. "Sound Symbolism Facilitates Long-Term Retention of the Semantic Representation of Novel Verbs in Three-Year-Olds" Languages 4, no. 2: 21. https://doi.org/10.3390/languages4020021
APA StyleKantartzis, K., Imai, M., Evans, D., & Kita, S. (2019). Sound Symbolism Facilitates Long-Term Retention of the Semantic Representation of Novel Verbs in Three-Year-Olds. Languages, 4(2), 21. https://doi.org/10.3390/languages4020021