Gaze as a Window to the Process of Novel Adjective Mapping


Abstract
1. Introduction
Study
2. Materials and Methods
2.1. Subjects
2.2. Procedure
2.3. Adjective Task
Video Processing and Annotation of Looking Behavior
2.4. Analytic Approach
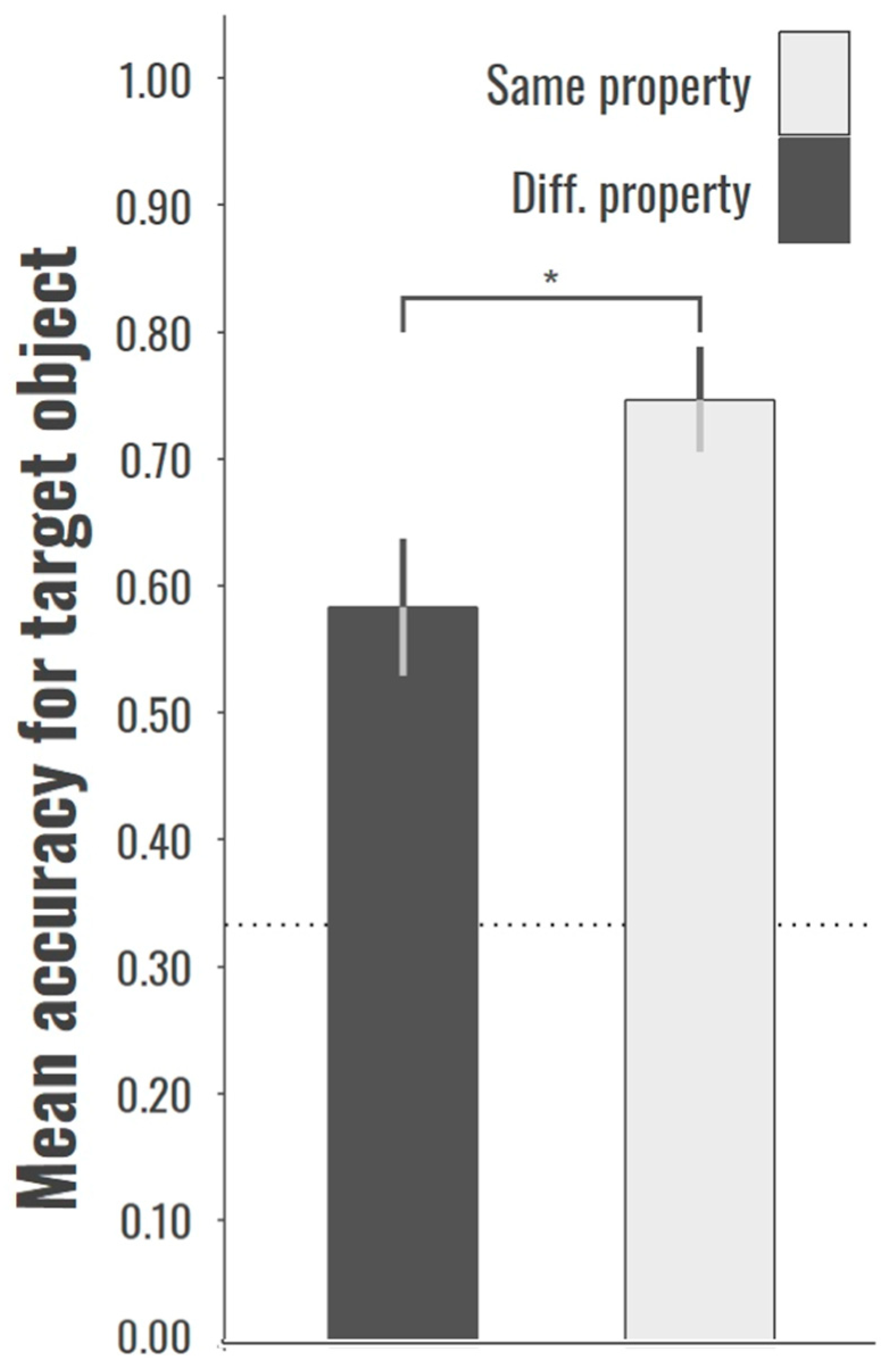
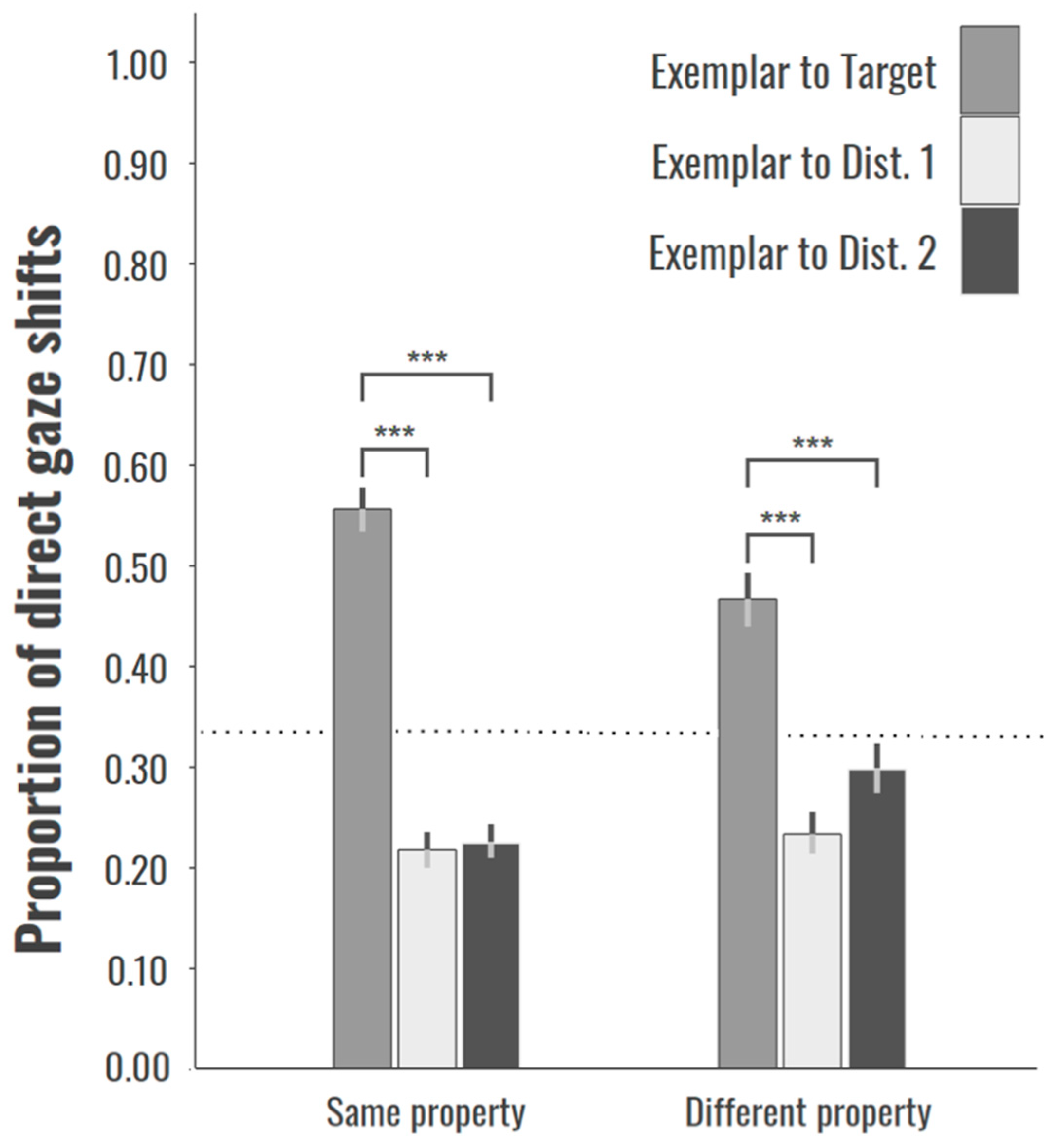
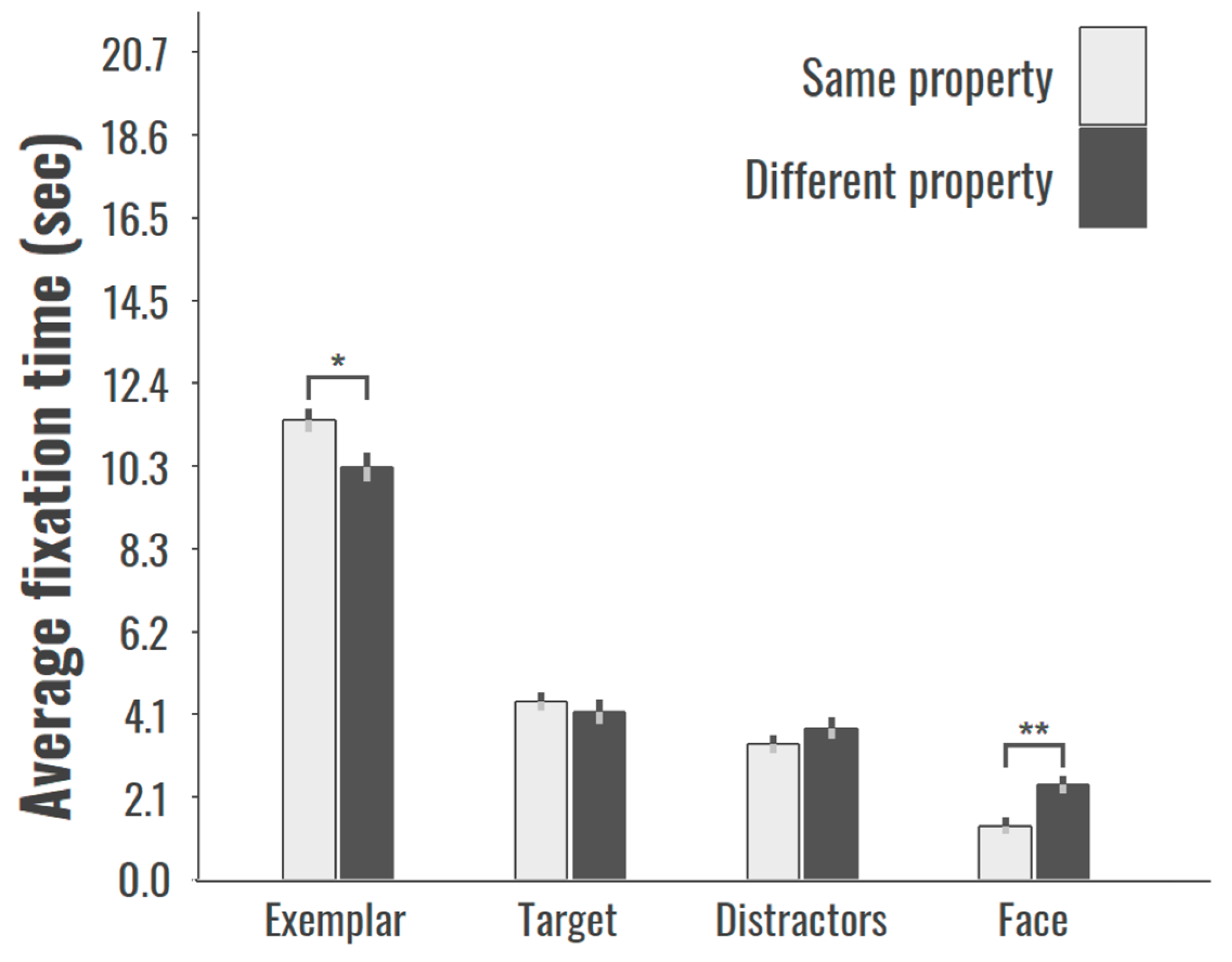
3. Results
4. General Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

References
- Aslin, Richard N., and Linda B. Smith. 1988. Perceptual Development. Annual Review of Psychology 39: 435–73. [Google Scholar] [CrossRef] [PubMed]
- Baldwin, Dare. A., and Ellen M. Markman. 1989. Establishing word-object relations: A first step. Child Development 60: 381–98. [Google Scholar] [CrossRef] [PubMed]
- Bergelson, Elika, and Daniel Swingley. 2012. At 6–9 months, human infants know the meanings of many common nouns. Proceedings of the National Academy of Sciences of the United States of America 109: 3253–58. [Google Scholar] [CrossRef] [PubMed]
- Biedinger, Nicole. 2011. The influence of education and home environment on the cognitive outcomes of preschool children in Germany. Child Development Research 2011: 916303. [Google Scholar] [CrossRef]
- Birch, S. A., Nazanin Akmal, and Kristen L. Frampton. 2010. Two-year-old are vigilant of others’ non-verbal cues to credibility. Developmental Science 13: 363–69. [Google Scholar] [CrossRef]
- Borovsky, Arielle, Jeffrey L. Elman, and Anne Fernald. 2012. Knowing a lot for one’s age: Vocabulary skill and not age is associated with anticipatory incremental sentence interpretation in children and adults. Journal of Experimental Child Psychology 112: 417–36. [Google Scholar] [CrossRef]
- Bradley, Robert H., and Robert F. Corwyn. 2002. Socioeconomic status and child development. Annual Review of Psychology 53: 371–99. [Google Scholar] [CrossRef]
- Brockmole, James R., Monica S. Castelhano, and John M. Henderson. 2006. Contextual cueing in naturalistic scenes: Global and local contexts. Journal of Experimental Psychology: Learning, Memory, and Cognition 32: 699–706. [Google Scholar] [CrossRef]
- Burling, Joseph, and Hanako Yoshida. 2016. Highlighting in Early Childhood: Learning Biases through Attentional Shifting. Cognitive Science 41: 96–119. [Google Scholar] [CrossRef]
- Chun, Marvin M., and Yuhong Jiang. 1998. Contextual cueing: Implicit learning and memory of visual context guides spatial attention. Cognitive Psychology 36: 28–71. [Google Scholar] [CrossRef]
- Clark, A. 1997. Being There: Putting Mind, Body, and World Together Again. Cambridge: The MIT Press. [Google Scholar]
- Colunga, Eliana, and Linda B. Smith. 2005. From the lexicon to expectations about kinds: A role for associative learning. Psychological Review 112: 347–82. [Google Scholar] [CrossRef] [PubMed]
- Dahan, Delphine, and Michael K. Tanenhaus. 2005. Looking at the rope when looking for the snake: Conceptually mediated eye movements during spoken-word recognition. Psychonomic Bulletin & Review 12: 453–59. [Google Scholar]
- Darby, Kevin, Joseph Burling, and Hanako Yoshida. 2014. The role of search speed in contextual cueing of children’s attention. Cognitive Development 29: 17–29. [Google Scholar] [CrossRef][Green Version]
- Davis-Kean, Pamela E. 2005. The influence of parent education and family income on child achievement: The indirect role of parental expectations and the home environment. Journal of Family Psychology: Journal of the Division of Family Psychology of the American Psychological Association 19: 294–304. [Google Scholar] [CrossRef]
- Desimone, Robert, and John Duncan. 1995. Neural mechanisms of selective visual attention. Annual Review of Neuroscience 18: 193–222. [Google Scholar] [CrossRef] [PubMed]
- Dixon, Robert M. W. 1982. ‘Where Have All the Adjectives Gone?’ and Other Essays in Semantics and Syntax. Berlin: Mouton de Gruyter. [Google Scholar]
- Dromi, Esther. 1996. Early Lexical Development. San Diego: Singular Publishing Group. [Google Scholar]
- Eimas, Peter D., and Paul C. Quinn. 1994. Studies on the formation of perceptually based basic-level categories in young infants. Child Development 65: 903–17. [Google Scholar] [CrossRef] [PubMed]
- Elman, Jeffrey L. 1993. Learning and development in neural networks: The importance of starting small. Cognition 48: 71. [Google Scholar] [CrossRef]
- Fecteau, Jillian H., and Douglas P. Munoz. 2006. Salience, relevance, and firing: A priority map for target selection. Trends in Cognitive Sciences 10: 382–90. [Google Scholar] [CrossRef]
- Fenson, Larry, Philip S. Dale, J. Steven Reznick, Elizabeth Bates, Donna J. Thal, and Stephen J. Pethick. 1994. Variability in early communicative development. Monographs of the Society for Research in Child Development 59: 85. [Google Scholar] [CrossRef]
- Fisher, József, and Richard N. Aslin. 2002. Statistical learning of new visual feature combinations by infants. Proceedings of the National Academy of Sciences USA 99: 15822–26. [Google Scholar] [CrossRef]
- Fontenot, Kayla, Jessica Semega, and Melissa Kollar. 2018. Census Bureau, Current Population Reports. In Income and Poverty in the United States: 2017; Washington: U.S. Government Printing Office, pp. 60–263. [Google Scholar]
- Franchak, John M., Kari S. Kretch, Kasey C. Soska, and Karen E. Adolph. 2011. Head-mounted eye tracking: A new method to describe infant looking. Child Development 82: 1738–50. [Google Scholar] [CrossRef] [PubMed]
- Gasser, Michael, and Linda B. Smith. 1998. Learning nouns and adjectives: A connectionist account. Language and Cognitive Processes 13: 269–306. [Google Scholar] [CrossRef]
- Gelman, Susan A., and Ellen M. Markman. 1986. Categories and induction in young children. Cognition 23: 183–209. [Google Scholar] [CrossRef]
- Gentner, Dedre. 1982. Why nouns are learned before verbs: Linguistic relativity vs. natural partitioning. In Language Development. Language, Thought and Culture. Hillsdale: Erlbaum, vol. 2, pp. 301–34. [Google Scholar]
- Gentner, Dedre, and Arthur B. Markman. 1994. Structural alignment in comparison: No difference without similarity. Psychological Science 5: 152–58. [Google Scholar] [CrossRef]
- Goldstone, R. L., and Douglas L. Medin. 1994. Time course of comparison. Journal of Experimental Psychology: Learning Memory and Cognition 20: 29–50. [Google Scholar] [CrossRef]
- Golinkoff, Roberta Michnick, Carolyn B. Mervis, and Hirsh-K. Pasek. 1994. Early object labels: The case for a developmental lexical principles framework. Journal of Child Language 21: 125–55. [Google Scholar] [CrossRef]
- Griffin, Zenzi M., and Kathryn Bock. 2000. What the eyes say about speaking. Psychological Science 11: 274–79. [Google Scholar] [CrossRef] [PubMed]
- Hall, D. Geoffrey, Sandra R. Waxman, and Wendy M. Hurwitz. 1993. How two- and four-year-old children interpret adjectives and count nouns. Child Development 64: 1651–64. [Google Scholar] [CrossRef]
- Hayhoe, Mary, and Dana Ballard. 2005. Eye movements in natural behavior. Trends in Cognitive Sciences 9: 188–94. [Google Scholar] [CrossRef]
- Henderson, John M., and Fernanda Ferreira. 2004. Scene Perception for Psycholinguists: The Interface of Language, Vision, and Action: Eye Movements and the Visual World. New York: Psychology Press, pp. 1–58. [Google Scholar]
- Henderson, John, and Andrew Hollingworth. 1999. High-level scene perception. Annual Review of Psychology 50: 243–71. [Google Scholar] [CrossRef]
- Huettig, Falk, and Gerry T. M. Altmann. 2007. Visual-shape competition during language-mediated attention is based on lexical input and not modulated by contextual appropriateness. Visual Cognition 15: 985–1018. [Google Scholar] [CrossRef]
- Hutchinson, Jean E. 1984. Constraints on Children’s Implicit Hypotheses about Word Meanings. Ph.D. dissertation, Stanford University, Stanford, CA, USA. [Google Scholar]
- Imai, Mutsumi, and Dedre Gentner. 1997. A cross-linguistic study of early word meaning: Universal ontology and linguistic influence. Cognition 62: 169–200. [Google Scholar] [CrossRef]
- Jackson-Maldonado, Donna, D. Thal, Virginia Marchman, Elizabeth Bates, and Vera Gutierrez-Clellen. 1993. Early lexical development in Spanish-speaking infants and toddlers. Journal of Child Language 20: 523–49. [Google Scholar] [CrossRef] [PubMed]
- Kemler, Deborah G. 1983. Exploring and reexploring issues of integrality, perceptual sensitivity, and dimensional salience. Journal of Experimental Child Psychology 36: 365. [Google Scholar] [CrossRef]
- Klibanoff, Raquel S., and Sandra R. Waxman. 2000. Basic level object categories support the acquisition of novel adjectives: Evidence from preschool-aged children. Child Development 71: 649–59. [Google Scholar] [CrossRef]
- Kooiker, Marlou J., Johan J. Pel, Sanny P. van der Steen-Kant, and Johannes van der Steen. 2016. A Method to Quantify Visual Information Processing in Children Using Eye Tracking. Journal of Visualized Experiments JoVE 113: 54031. [Google Scholar] [CrossRef] [PubMed]
- Krippendorf, K. 2004. Reliability in Content Analysis—Some Common Misconceptions and Recommendations. Human Communication Research 30: 411–33. [Google Scholar] [CrossRef]
- Krummenacher, Joseph, Hermann J. Muller, and Dieter Heller. 2001. Visual search for dimensionally redundant pop-out targets: Evidence for parallel-coactive processing of dimensions. Perception & Psychophysics 63: 901–17. [Google Scholar]
- Kruschke, John K. 1996. Base rates in category learning. Journal of Experimental Psychology: Learning, Memory and Cognition 22: 3–26. [Google Scholar] [CrossRef][Green Version]
- Kruschke, John K. 2009. Highlighting: A canonical experiment. The Psychology of Learning and Motivation 51: 153–85. [Google Scholar]
- Landau, Barbara, Linda Smith, and Susan Jones. 1998. Object shape, object function, and object name. Journal of Memory and Language 38: 1. [Google Scholar] [CrossRef]
- Lupyan, Gary, and Michael J. Spivey. 2010. Making the invisible visible: Verbal but not visual cues enhance visual detection. PLoS ONE 5: e11452. [Google Scholar] [CrossRef]
- MacArthur, J. D., and C. T. MacArthur. 2013. MacArthur Foundation Research Network on Socioeconomic Status and Health. Available online: http://www.macses.ucsf.edu (accessed on 24 May 2019).
- Mandler, Jean M. 2000. Perceptual and conceptual processes in infancy. Journal of Cognition and Development 1: 3–36. [Google Scholar] [CrossRef]
- Mandler, Katherine, and D. Geoffery Hall. 2002. Comparison, basic-level categories, and the teaching of adjectives. Journal of Child Language 29: 923–37. [Google Scholar]
- Medin, Douglas L., and Edward J. Shoben. 1988. Context and structure in conceptual combination. Cognitive Psychology 20: 158–90. [Google Scholar] [CrossRef]
- Merriman, William E. 1999. Competition, Attention, and Young Children’s Lexical Processing: The Emergence of Language. Mahwah: Lawrence Erlbaum Associates Publishers, pp. 331–58. [Google Scholar]
- Mintz, Toben. 2005. Linguistic and conceptual influences on adjective acquisition in 24- and 36-month-olds. Developmental Psychology 41: 17–29. [Google Scholar] [CrossRef]
- Mintz, Toben H., and Lila R. Gleitman. 2002. Adjectives really do modify nouns: The incremental and restricted nature of early adjective acquisition. Cognition 84: 267–93. [Google Scholar] [CrossRef]
- Nappa, Rebecca, Allison Wessell, Katherine McEldoon, Lila Gleitman, and John Trueswell. 2009. Use of speaker’s gaze and syntax in verb learning. Language Learning and Development 5: 203–34. [Google Scholar] [CrossRef]
- Neider, Mark B., and Gregory J. Zelinsky. 2006. Scene context guides eye movements during visual search. Vision Research 46: 614–21. [Google Scholar] [CrossRef]
- Nelson, Katherine. 1973. Structure and strategy in learning to talk. Monographs of the Society for Research in Child Development 38: 1–135. [Google Scholar] [CrossRef]
- Plunkett, Kim, and Virginia Marchman. 1991. U-shaped learning and frequency effects in a multi-layered perception: Implications for child language acquisition. Cognition 38: 43–102. [Google Scholar] [CrossRef]
- Quinn, J. G. 1994. Towards a clarification of spatial processing. The Quarterly Journal of Experimental Psychology, Section A 47: 465–80. [Google Scholar] [CrossRef]
- Regier, Terry. 2005. The emergence of words: Attentional learning in form and meaning. Cognitive Science 29: 819–65. [Google Scholar] [CrossRef]
- Sandhofer, Catherine, and Linda B. Smith. 2007. Learning adjectives in the real world: How learning nouns impedes learning adjectives. Language Learning and Development 3: 233–67. [Google Scholar] [CrossRef]
- Shipley, Elizabeth F., and Ivy F. Kuhn. 1983. A constraint on comparisons: Equally detailed alternatives. Journal of Experimental Child Psychology 35: 195–222. [Google Scholar] [CrossRef]
- Smith, Linda B. 1984. Young children’s understanding of attributes and dimensions: A comparison of conceptual and linguistic measures. Child Development 55: 363–80. [Google Scholar] [CrossRef] [PubMed]
- Smith, Linda. 1993. The concept of same. In Advances in Child Development and Behavior. Edited by H. Reese. San Diego: Academic Press, pp. 215–52. [Google Scholar]
- Smith, Linda B. 2005. Cognition as a dynamic system: Principles from embodiment. Developmental Review; Development as Self-Organization: New Approaches to the Psychology and Neurobiology of Development 25: 278–98. [Google Scholar] [CrossRef]
- Smith, Linda, and Diana Heise. 1992. Perceptual similarity and conceptual structure. In Percepts, Concepts and Categories. Edited by B. Burns. Amsterdam: Elsevier Science Publishers B. V., pp. 233–72. [Google Scholar]
- Smith, Linda B., Michael Gasser, and Catherine M. Sandhofer. 1997. Learning to talk about the properties of objects: A network model of the development of dimensions. In Perceptual Learning, The Psychology of Learning and Motivation 36. San Diego: Academic Press, pp. 219–55. [Google Scholar]
- Smith, Linda B., Susan S. Jones, Barbara Landau, Lisa Gershkoff-Stowe, and Larissa Samuelson. 2002. Object name learning provides on-the-job training for attention. Psychological Science 13: 13–19. [Google Scholar] [CrossRef] [PubMed]
- Tincoff, Ruth, and Peter W. Jusczyk. 2012. Six-month-olds comprehend words that refer to parts of the body. Infancy 17: 432–44. [Google Scholar] [CrossRef]
- Torralba, Antonio, Aude Oliva, Monica S. Castelhano, and John M. Henderson. 2006. Contextual guidance of eye movements and attention in real-world scenes: The role of global features in object search. Psychological Review 113: 766–86. [Google Scholar] [CrossRef]
- Turk-Browne, Nicholas B., Justin Junge, and Brian J. Scholl. 2005. The automaticity of visual statistical learning. Journal of Experimental Psychology: Learning, Memory, and Cognition 34: 399–407. [Google Scholar] [CrossRef] [PubMed]
- Twomey, Katherine E., Jessica S. Horst, and Anthony F. Morse. 2013. An embodied model of young children’s categorization and word learning. In Theoretical and Computational Models of Word Learning: Trends in Psychology and Artificial Intelligence. Hershey: IGI Globa, pp. 172–96. [Google Scholar]
- Vales, Catarina, and Linda B. Smith. 2015. Words, shape, visual search and visual working memory in 3-year-old children. Developmental Science 18: 65–79. [Google Scholar] [CrossRef] [PubMed]
- Waxman, Sandra, and Amy Booth. 2003. The origins and evolution of links between word learning and conceptual organization. Developmental Science 6: 128–35. [Google Scholar] [CrossRef]
- Waxman, Sandra R., and Raquel S. Klibanoff. 2000. The role of comparison in the extension of novel adjectives. Developmental Psychology 36: 571–81. [Google Scholar] [CrossRef] [PubMed]
- Waxman, Sandra R., and Toby D. Kosowski. 1990. Nouns mark category relations: Toddlers’ and preschoolers’ word-learning biases. Child Development 61: 1461–73. [Google Scholar] [CrossRef] [PubMed]
- Wolfe, Jeremy M., Todd S. Horowitz, and Kristin O. Michod. 2007. Is visual attention required for robust picture memory? Vision Research 47: 955–64. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Yoshida, Hanako, and Joseph M. Burling. 2012. Highlighting: A mechanism relevant for word learning. Frontiers in Psychology 3: 1–12. [Google Scholar] [CrossRef] [PubMed]
- Yoshida, Hanako, and Rima Hanania. 2013. If it’s red, it’s not vap: How competition among words may benefit early word learning. First Language 33: 3–19. [Google Scholar] [CrossRef] [PubMed]
- Yoshida, Hanako, and Linda B. Smith. 2005. Linguistic cues enhance the learning of perceptual cues. Psychological Sciences 16: 90–95. [Google Scholar] [CrossRef]
- Yoshida, Hanako, Duc N. Tran, Viridiana Benitez, and Megumi Kuwabara. 2011. Inhibition and adjective learning in bilingual and monolingual children. Frontiers in Psychology 2: 210. [Google Scholar] [CrossRef]
| 1. | Noun object categories were selected from the MacArthur Communicative Developmental Inventory (MCDI) toddler form (Fenson et al. 1994). |







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Condition | Same | Different |
|---|---|---|
| Mean Age (months) | 44.40 (SD 5.06) | 46.99 (4.00) |
| Highest Education Earned | 6.12 (SD 0.90) | 5.93 (SD 1.10) |
| Mean Income | $64,708 (SD 30,539) | $66,000 (SD 29,472) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoshida, H.; Patel, A.; Burling, J. Gaze as a Window to the Process of Novel Adjective Mapping. Languages 2019, 4, 33. https://doi.org/10.3390/languages4020033
Yoshida H, Patel A, Burling J. Gaze as a Window to the Process of Novel Adjective Mapping. Languages. 2019; 4(2):33. https://doi.org/10.3390/languages4020033
Chicago/Turabian StyleYoshida, Hanako, Aakash Patel, and Joseph Burling. 2019. "Gaze as a Window to the Process of Novel Adjective Mapping" Languages 4, no. 2: 33. https://doi.org/10.3390/languages4020033
APA StyleYoshida, H., Patel, A., & Burling, J. (2019). Gaze as a Window to the Process of Novel Adjective Mapping. Languages, 4(2), 33. https://doi.org/10.3390/languages4020033