


Phonetically Based Corpora for Anglicisms: A Tijuana–San Diego Contact Outcome

 ,
,  and
and 
Abstract
1. Introduction
- (a)
- What are the acoustic characteristics in terms of F1 and F2 formants of the vowels within the Anglicisms from this study?
- (b)
- How do the vowel realizations in spontaneous speech present a gradient continuum between Spanish and English phonological categories in a language contact setting?
- (c)
- To what extent can the development of two phonetically grounded corpora, based on the acoustic properties of vowels in monosyllabic Anglicisms, contribute to a more empirically robust typology of loanword integration?
2. Materials and Methods
2.1. Corpus Design
2.1.1. Data Collection and Participants
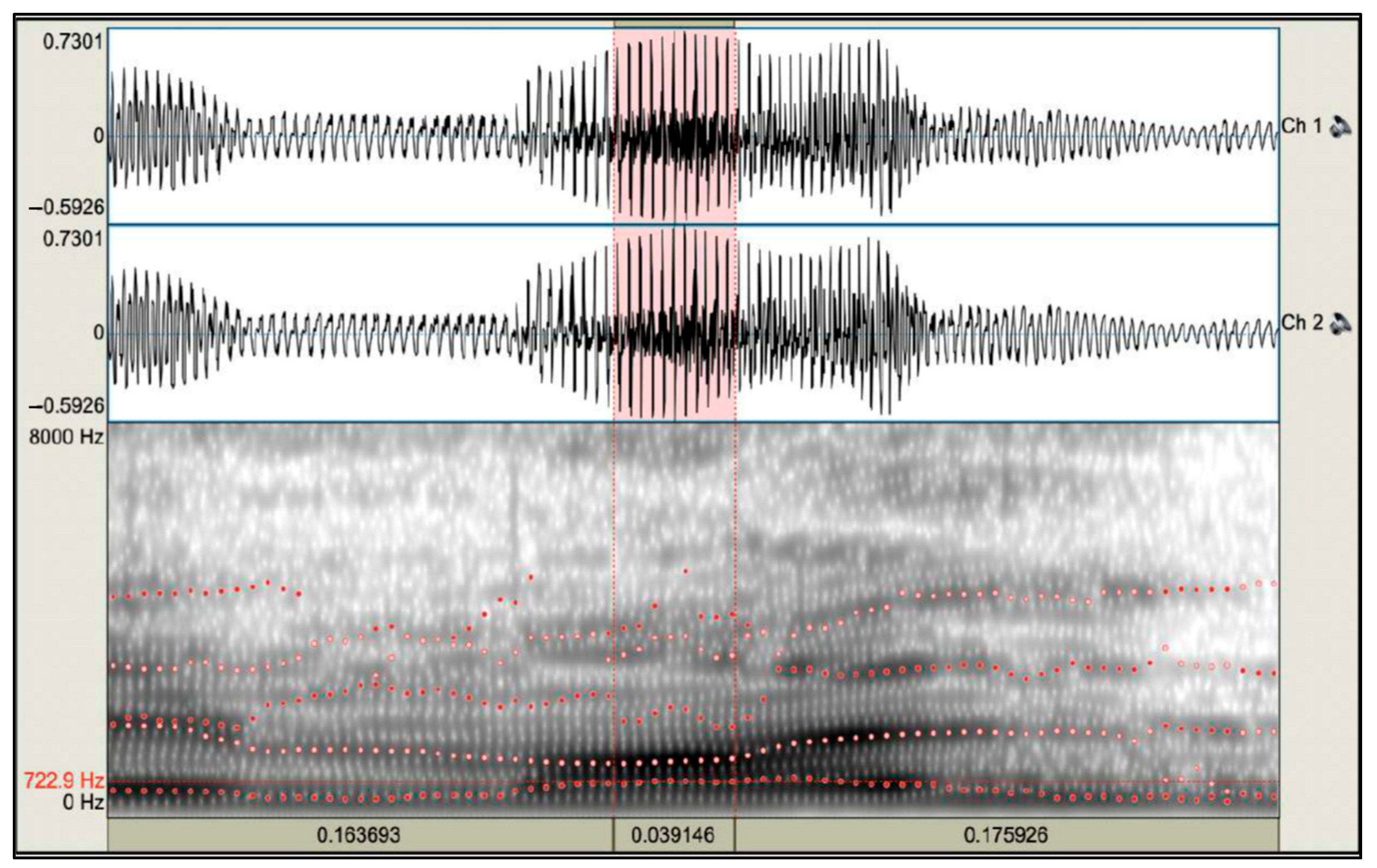
2.1.2. Acoustic Analyses
3. Results
3.1. The Distance Margin Between Spanish and English Target Tokens
3.2. The Frequency of the Anglicisms and the Vowels
3.3. The Vowel Plotting
4. The Importance of Proposing Two Phonetically Grounded Corpora
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
| Token ID | Anglicism | F1_T | F2_T | F1_S | F2_S | F1_E | F2_E | D_S | D_E | Differences | Classification |
| 1 | blend | 586 | 2078 | 585 | 2115 | 655 | 1844 | 37.013511046643494 | 243.9610624669437 | 206.94755142030021 | PAA |
| 2 | blend | 571 | 2100 | 585 | 2115 | 655 | 1844 | 20.518284528683193 | 269.4290259047826 | 248.9107413760994 | PAA |
| 3 | blend | 568 | 2053 | 585 | 2115 | 655 | 1844 | 64.28841264178172 | 226.38462845343543 | 162.0962158116537 | PAA |
| 4 | cash | 846 | 1483 | 839 | 1558 | 814 | 1666 | 75.32595834106593 | 185.776747737708 | 110.45078939664208 | PAA |
| 5 | cash | 780 | 1555 | 839 | 1558 | 814 | 1666 | 59.07622195096772 | 116.09048195265622 | 57.0142600016885 | PAA |
| 6 | cash | 864 | 1578 | 839 | 1558 | 814 | 1666 | 32.01562118716424 | 101.21264743103995 | 69.19702624387571 | PAA |
| 7 | dark | 776 | 1576 | 839 | 1558 | 762 | 1209 | 65.52098900352466 | 367.26693289758606 | 301.7459438940614 | PAA |
| 8 | dark | 832 | 1497 | 839 | 1558 | 762 | 1209 | 61.40032573203501 | 296.3848849047468 | 234.98455917271178 | PAA |
| 9 | dark | 827 | 1565 | 839 | 1558 | 762 | 1209 | 13.892443989449804 | 361.8853409576022 | 347.99289696815237 | PAA |
| 10 | dude | 389 | 1135 | 451 | 836 | 357 | 1481 | 305.3604427557702 | 347.476617918386 | 42.11617516261583 | Both |
| 11 | dude | 378 | 1149 | 451 | 836 | 357 | 1481 | 321.4000622277475 | 332.66349363884217 | 11.263431411094643 | Both |
| 12 | dude | 388 | 1133 | 451 | 836 | 357 | 1481 | 303.608300281794 | 349.3780187705002 | 55.76971848870619 | Ambiguous |
| 13 | gym | 359 | 2551 | 371 | 2581 | 317 | 2546 | 32.31098884280702 | 42.2965719651132 | 9.985583122306181 | Both |
| 14 | gym | 363 | 2602 | 371 | 2581 | 317 | 2546 | 22.47220505424423 | 72.47068372797375 | 49.99847867372952 | Both |
| 15 | gym | 336 | 2591 | 371 | 2581 | 317 | 2546 | 36.40054944640259 | 48.84669896727925 | 12.44614952087666 | Both |
| 16 | gym | 382 | 2560 | 371 | 2581 | 317 | 2546 | 23.706539182259394 | 66.49060083951716 | 42.784061657257766 | Both |
| 17 | gym | 388 | 2552 | 371 | 2581 | 317 | 2546 | 33.61547262794322 | 71.25307010929424 | 37.63759748135102 | Both |
| 18 | gym | 389 | 2560 | 371 | 2581 | 317 | 2546 | 27.65863337187866 | 73.348483283569 | 45.68984991169033 | Both |
| 19 | hack | 864 | 1549 | 839 | 1558 | 814 | 1666 | 26.570660511172846 | 127.23600119463045 | 100.6653406834576 | PAA |
| 20 | hack | 793 | 1572 | 839 | 1558 | 814 | 1666 | 48.08326112068523 | 96.317184344228 | 48.23392322354277 | Ambiguous |
| 21 | hack | 802 | 1584 | 839 | 1558 | 814 | 1666 | 45.221676218380054 | 82.87339742040264 | 37.651721202022586 | Ambiguous |
| 22 | nerd | 594 | 2033 | 585 | 2115 | 655 | 1844 | 82.49242389456137 | 198.600100704909 | 116.10767681034764 | PAA |
| 23 | nerd | 624 | 2097 | 585 | 2115 | 655 | 1844 | 42.95346318982906 | 254.8921340488953 | 211.93867085906624 | PAA |
| 24 | nerd | 528 | 2205 | 585 | 2115 | 655 | 1844 | 106.53168542738823 | 382.6878623630491 | 276.1561769356608 | PAA |
| 25 | nerd | 564 | 2149 | 585 | 2115 | 655 | 1844 | 39.96248240537617 | 318.2860348805772 | 278.323552475201 | PAA |
| 26 | plus | 464 | 912 | 451 | 836 | 663 | 1512 | 77.10382610480494 | 632.140016135666 | 555.036190030861 | PAA |
| 27 | plus | 410 | 857 | 451 | 836 | 663 | 1512 | 46.06517122512408 | 702.163798554155 | 656.0986273290309 | PAA |
| 28 | plus | 408 | 879 | 451 | 836 | 663 | 1512 | 60.81118318204309 | 682.432414236018 | 621.6212310539748 | PAA |
| 29 | plus | 433 | 814 | 451 | 836 | 663 | 1512 | 28.42534080710379 | 734.917682465186 | 706.4923416580822 | PAA |
| 30 | plus | 428 | 931 | 451 | 836 | 663 | 1512 | 97.74456506629922 | 626.7264155913647 | 528.9818505250655 | PAA |
| 31 | plus | 508 | 847 | 451 | 836 | 663 | 1512 | 58.05170109479997 | 682.8250141873832 | 624.7733130925833 | PAA |
| 32 | sad | 734 | 1540 | 839 | 1558 | 814 | 1666 | 106.53168542738823 | 149.25146565444507 | 42.719780227056845 | Ambiguous |
| 33 | sad | 820 | 1492 | 839 | 1558 | 814 | 1666 | 68.6804193347711 | 174.1034175425629 | 105.4229982077918 | PAA |
| 34 | sad | 791 | 1560 | 839 | 1558 | 814 | 1666 | 48.041648597857254 | 108.4665847162157 | 60.42493611835845 | PAA |
| 35 | sad | 805 | 1516 | 839 | 1558 | 814 | 1666 | 54.037024344425184 | 150.26975743641833 | 96.23273309199314 | PAA |
| 36 | sad | 793 | 1511 | 839 | 1558 | 814 | 1666 | 65.76473218982953 | 156.41611170208776 | 90.65137951225823 | PAA |
| 37 | sad | 779 | 1481 | 839 | 1558 | 814 | 1666 | 97.6165969494942 | 188.2817038376273 | 90.66510688813311 | PAA |
| 38 | shot(s) | 628 | 1114 | 606 | 1012 | 762 | 1209 | 104.34557968596465 | 164.2589419179364 | 59.913362231971746 | PAA |
| 39 | shot(s) | 623 | 1025 | 606 | 1012 | 762 | 1209 | 21.400934559032695 | 230.6013876801265 | 209.2004531210938 | PAA |
| 40 | shot(s) | 688 | 996 | 606 | 1012 | 762 | 1209 | 83.54639429682169 | 225.48835890129672 | 141.94196460447503 | PAA |
| 41 | staff | 818 | 1395 | 839 | 1558 | 814 | 1666 | 164.34719346554112 | 271.02951868754076 | 106.68232522199963 | Ambiguous |
| 42 | staff | 821 | 1574 | 839 | 1558 | 814 | 1666 | 24.08318915758459 | 92.26592003551474 | 68.18273087793014 | PAA |
| 43 | staff | 872 | 1488 | 839 | 1558 | 814 | 1666 | 77.38862965578342 | 187.21111078138497 | 109.82248112560156 | PAA |
| 44 | tip(s) | 362 | 2602 | 371 | 2581 | 317 | 2546 | 22.847319317591726 | 71.84010022264724 | 48.99278090505551 | Both |
| 45 | tip(s) | 370 | 2570 | 371 | 2581 | 317 | 2546 | 11.045361017187261 | 58.180752831155424 | 47.13539181396816 | Both |
| 46 | tip(s) | 322 | 2599 | 371 | 2581 | 317 | 2546 | 52.20153254455275 | 53.23532661682466 | 1.0337940722719097 | Both |
| 47 | tip(s) | 355 | 2567 | 371 | 2581 | 317 | 2546 | 21.2602916254693 | 43.41658669218482 | 22.156295066715522 | Both |
| 48 | tip(s) | 363 | 2604 | 371 | 2581 | 317 | 2546 | 24.351591323771842 | 74.02702209328699 | 69.675430769515145 | Ambiguous |
| 49 | tip(s) | 341 | 2612 | 371 | 2581 | 317 | 2546 | 43.139309220245984 | 70.22819946431775 | 27.08889024407177 | Both |
| 50 | top | 650 | 1094 | 606 | 1012 | 762 | 1209 | 93.05912099305473 | 160.52725625263767 | 67.46813525958294 | PAA |
| 51 | top | 526 | 1030 | 606 | 1012 | 762 | 1209 | 82.0 | 296.2043213729334 | 214.2043213729334 | PAA |
| 52 | top | 609 | 1002 | 606 | 1012 | 762 | 1209 | 10.44030650891055 | 257.40629362935164 | 246.9659871204411 | Ambiguous |
| 53 | top | 590 | 989 | 606 | 1012 | 762 | 1209 | 28.0178514522438 | 279.25615481131297 | 251.23830335906916 | PAA |
| 54 | trip | 355 | 2570 | 371 | 2581 | 317 | 2546 | 19.4164878389476 | 44.94441010848846 | 25.527922269540863 | Both |
| 55 | trip | 333 | 2584 | 371 | 2581 | 317 | 2546 | 38.118237105091836 | 41.23105625617661 | 3.1128191510847714 | Both |
| 56 | trip | 344 | 2590 | 371 | 2581 | 317 | 2546 | 28.460498941515414 | 51.62363799656123 | 23.163139055045814 | Both |
| 57 | trip | 351 | 2611 | 371 | 2581 | 317 | 2546 | 36.05551275463989 | 73.35529974037323 | 37.299786985733334 | Both |
| 58 | trip | 289 | 2708 | 371 | 2581 | 317 | 2546 | 151.17208737065187 | 164.40194646049662 | 13.229859089844751 | Both |
| 59 | bleach | 505 | 2454 | 371 | 2581 | 317 | 2546 | 184.6212338816963 | 209.30360723121808 | 24.682373349521782 | Ambiguous |
| 60 | bleach | 326 | 2518 | 371 | 2581 | 317 | 2546 | 77.42092740338364 | 29.410882339705484 | 48.01004506367816 | Both |
| 61 | bleach | 377 | 2508 | 371 | 2581 | 317 | 2546 | 73.24616030891995 | 71.02112361825881 | 2.225036690661142 | Both |
| 62 | boss | 721 | 1219 | 606 | 1012 | 762 | 1209 | 236.799493242701 | 42.20189569201838 | 194.59759755068262 | PNAA |
| 63 | boss | 714 | 1301 | 606 | 1012 | 762 | 1209 | 308.5206638136253 | 103.76897416858277 | 204.75168964504252 | PNAA |
| 64 | boss | 788 | 1224 | 606 | 1012 | 762 | 1209 | 279.4065138825507 | 30.01666203960727 | 249.38985184294344 | PNAA |
| 65 | boss | 726 | 1179 | 606 | 1012 | 762 | 1209 | 205.6428943581567 | 46.861498055439924 | 158.78139630271676 | PNAA |
| 66 | boss | 802 | 1328 | 606 | 1012 | 762 | 1209 | 371.8494318941472 | 125.54282137979854 | 246.30661051434865 | PNAA |
| 67 | bun | 589 | 1487 | 839 | 1558 | 663 | 1512 | 259.88651369395836 | 78.10889834071403 | 181.77761535324433 | PNAA |
| 68 | bun | 611 | 1502 | 839 | 1558 | 663 | 1512 | 234.77648945326703 | 52.952809179494906 | 181.82368027377214 | PNAA |
| 69 | bun | 632 | 1622 | 839 | 1558 | 663 | 1512 | 216.6679487141557 | 114.28473213863697 | 102.38321657551873 | PNAA |
| 70 | bun | 571 | 1575 | 839 | 1558 | 663 | 1512 | 268.5386378158644 | 111.50336317797773 | 157.03527463788663 | PNAA |
| 71 | bundle | 623 | 1432 | 839 | 1558 | 663 | 1512 | 250.06399181009647 | 89.44271909999159 | 160.62127271010488 | PNAA |
| 72 | bundle | 710 | 1491 | 839 | 1558 | 663 | 1512 | 145.3616180427282 | 51.478150704935004 | 93.88346733779319 | PNAA |
| 73 | bundle | 686 | 1580 | 839 | 1558 | 663 | 1512 | 154.5736070614903 | 71.78439941937245 | 82.78920764211784 | PNAA |
| 74 | cheers | 322 | 2549 | 371 | 2581 | 317 | 2546 | 58.52349955359813 | 5.830951894845301 | 52.69254765875283 | Ambiguous |
| 75 | cheers | 351 | 2525 | 371 | 2581 | 317 | 2546 | 59.464274989274024 | 39.96248240537617 | 19.501792583897853 | Both |
| 76 | cheers | 340 | 2534 | 371 | 2581 | 317 | 2546 | 56.302753041036986 | 25.942243542145693 | 30.360509498891293 | Both |
| 77 | clean | 301 | 2482 | 371 | 2581 | 317 | 2546 | 121.24768039018313 | 65.96969000988257 | 55.277990380300565 | Ambiguous |
| 78 | clean | 301 | 2577 | 371 | 2581 | 317 | 2546 | 70.11419257183242 | 34.88552708502482 | 35.2286654868076 | Both |
| 79 | clean | 324 | 2479 | 371 | 2581 | 317 | 2546 | 112.30761327710601 | 67.36467917239716 | 44.942934104708854 | Both |
| 80 | cool | 488 | 1191 | 451 | 836 | 357 | 1481 | 356.9229608753127 | 318.2153358969363 | 38.70762497837637 | Both |
| 81 | cool | 451 | 1188 | 451 | 836 | 357 | 1481 | 352.0 | 307.7092783781471 | 44.290721621852924 | Both |
| 82 | cool | 382 | 1175 | 451 | 836 | 357 | 1481 | 345.950863563021 | 307.01954335188503 | 38.93132021113598 | Both |
| 83 | cool | 381 | 1454 | 451 | 836 | 357 | 1481 | 621.951766618602 | 36.124783736376884 | 585.8269828822251 | Ambiguous |
| 84 | cool | 333 | 1479 | 451 | 836 | 357 | 1481 | 653.737714989735 | 24.08318915758459 | 629.6545258321504 | Both |
| 85 | cool | 404 | 1099 | 451 | 836 | 357 | 1481 | 267.1666146808018 | 384.88050093503045 | −117.71388625422867 | Ambiguous |
| 86 | core | 611 | 1360 | 606 | 1012 | 632 | 1172 | 348.0359176866664 | 189.16923639957952 | 158.86668128708686 | PNAA |
| 87 | core | 646 | 1125 | 606 | 1012 | 632 | 1172 | 119.87076374162301 | 49.040799340956916 | 70.82996440066609 | PNAA |
| 88 | core | 644 | 1201 | 606 | 1012 | 632 | 1172 | 192.78226059469267 | 31.38470965295043 | 161.39755094174225 | PNAA |
| 89 | core | 722 | 1144 | 606 | 1012 | 632 | 1172 | 175.72706109191037 | 94.25497334358543 | 81.47208774832494 | PNAA |
| 90 | crush | 681 | 1501 | 839 | 1558 | 663 | 1512 | 167.96725871431016 | 21.095023109728988 | 146.87223560458116 | PNAA |
| 91 | crush | 625 | 1818 | 839 | 1558 | 663 | 1512 | 336.7432256185713 | 308.3504499753487 | 28.392775643222592 | PNAA |
| 92 | crush | 656 | 1623 | 839 | 1558 | 663 | 1512 | 194.20092687729377 | 111.22050170719426 | 82.98042517009951 | PNAA |
| 93 | crush | 623 | 1517 | 839 | 1558 | 663 | 1512 | 219.85677155821242 | 40.311288741492746 | 179.54548281671967 | PNAA |
| 94 | flush | 665 | 1490 | 839 | 1558 | 663 | 1512 | 186.81541692269406 | 22.090722034374522 | 164.72469488831953 | PNAA |
| 95 | flush | 719 | 1572 | 839 | 1558 | 663 | 1512 | 120.81390648431164 | 82.07313811473277 | 38.74076836957887 | PNAA |
| 96 | flush | 744 | 1528 | 839 | 1558 | 663 | 1512 | 99.62429422585637 | 82.56512580987206 | 17.059168415984317 | PNAA |
| 97 | fuck | 643 | 1497 | 839 | 1558 | 663 | 1512 | 205.27298896834918 | 25.0 | 180.27298896834918 | PNAA |
| 98 | fuck | 619 | 1506 | 839 | 1558 | 663 | 1512 | 226.06193841511666 | 44.40720662234904 | 181.65473179276762 | PNAA |
| 99 | fuck | 690 | 1532 | 839 | 1558 | 663 | 1512 | 151.25144627407698 | 33.60059523282288 | 117.6508510412541 | PNAA |
| 100 | loop | 486 | 1191 | 451 | 836 | 357 | 1481 | 356.72117963473937 | 317.3972274611106 | 39.323952173628754 | Both |
| 101 | loop | 465 | 1188 | 451 | 836 | 357 | 1481 | 352.27829907617075 | 312.27071588607214 | 40.007583190098615 | Both |
| 102 | loop | 344 | 1224 | 451 | 836 | 357 | 1481 | 402.48354003611126 | 257.3285837212804 | 145.15495631483088 | Ambiguous |
| 103 | mall(s) | 668 | 1125 | 606 | 1012 | 632 | 1172 | 128.89142717807107 | 59.20304046246274 | 69.68838671560833 | PNAA |
| 104 | mall(s) | 645 | 1217 | 606 | 1012 | 632 | 1172 | 208.67678356731494 | 46.84015371452148 | 161.83662985279346 | PNAA |
| 105 | mall(s) | 789 | 1222 | 606 | 1012 | 632 | 1172 | 278.54802099458544 | 164.76953601925328 | 113.77848497533216 | PNAA |
| 106 | mall(s) | 722 | 1136 | 606 | 1012 | 632 | 1172 | 206.6204249342257 | 47.07440918375928 | 159.5460157504664 | PNAA |
| 107 | mall(s) | 606 | 1347 | 606 | 1012 | 632 | 1172 | 335.0 | 176.92088627406318 | 158.07911372593682 | PNAA |
| 108 | match | 795 | 1667 | 839 | 1558 | 814 | 1666 | 117.5457357797381 | 19.026297590440446 | 98.51943818929765 | PNAA |
| 109 | match | 790 | 1740 | 839 | 1558 | 814 | 1666 | 188.48076824970764 | 77.79460135510689 | 110.68616689460075 | PNAA |
| 110 | match | 825 | 1681 | 839 | 1558 | 814 | 1666 | 123.79418403139947 | 18.601075237738275 | 105.1931087936612 | PNAA |
| 111 | mood | 445 | 1171 | 451 | 836 | 357 | 1481 | 335.0537270349339 | 322.2483514310042 | 12.80537560392969 | Both |
| 112 | mood | 481 | 1185 | 451 | 836 | 357 | 1481 | 350.28702516650543 | 320.92366693654736 | 29.363358229958067 | Both |
| 113 | mood | 495 | 1202 | 451 | 836 | 357 | 1481 | 368.63532115086315 | 311.26355392175293 | 57.37176722911022 | Both |
| 114 | mood | 394 | 1621 | 451 | 836 | 357 | 1481 | 787.0667061945893 | 144.80676779764127 | 642.259938396948 | Ambiguous |
| 115 | mood | 312 | 1476 | 451 | 836 | 357 | 1481 | 654.9206058752466 | 45.27692569068709 | 609.6436801845595 | Ambiguous |
| 116 | must | 699 | 1509 | 839 | 1558 | 663 | 1512 | 148.32734070291963 | 36.124783736376884 | 112.20255696654274 | PNAA |
| 117 | must | 615 | 1412 | 839 | 1558 | 663 | 1512 | 267.3798795721174 | 110.92339699089638 | 156.456482581221 | PNAA |
| 118 | must | 644 | 1492 | 839 | 1558 | 663 | 1512 | 205.86646157157313 | 27.586228448267445 | 178.2802331233057 | PNAA |
| 119 | spot(s) | 711 | 1288 | 606 | 1012 | 762 | 1209 | 295.29815441346733 | 94.03190947758107 | 201.26624493588628 | PNAA |
| 120 | spot(s) | 678 | 1327 | 606 | 1012 | 762 | 1209 | 323.12381527829234 | 144.84474446799925 | 178.2790708102931 | PNAA |
| 121 | spot(s) | 784 | 1255 | 606 | 1012 | 762 | 1209 | 301.21918929576844 | 50.99019513592785 | 250.2289941598406 | PNAA |
| 122 | spot(s) | 743 | 1198 | 606 | 1012 | 762 | 1209 | 231.00865784641059 | 21.95449840010015 | 209.05415944631045 | PNAA |
| 123 | weed | 366 | 2403 | 371 | 2581 | 317 | 2546 | 178.07021087200408 | 151.16216457830973 | 26.908046293694355 | Both |
| 124 | weed | 363 | 2470 | 371 | 2581 | 317 | 2546 | 111.28791488746656 | 88.83692925805124 | 22.450985629415314 | Both |
| 125 | weed | 356 | 2529 | 371 | 2581 | 317 | 2546 | 54.120236510939236 | 42.5440947723653 | 11.576141738573938 | Both |
| 126 | weed | 347 | 2333 | 371 | 2581 | 317 | 2546 | 249.15858403835898 | 215.10230124292022 | 34.05628279543876 | Both |
| 127 | weird | 371 | 2481 | 371 | 2581 | 317 | 2546 | 100.0 | 84.50443775329198 | 15.495562246708019 | Both |
| 128 | weird | 294 | 2518 | 371 | 2581 | 317 | 2546 | 99.48869282486326 | 36.235341863986875 | 63.25335096087639 | Ambiguous |
| 129 | weird | 360 | 2441 | 371 | 2581 | 317 | 2546 | 140.4314779527724 | 113.46365056704283 | 26.967827385729578 | Both |
| 130 | weird | 288 | 2509 | 371 | 2581 | 317 | 2546 | 109.87720418721983 | 47.01063709417264 | 62.866567093047195 | Ambiguous |
| 131 | weird | 329 | 2548 | 371 | 2581 | 317 | 2546 | 53.41348144429457 | 12.165525060596439 | 71.24795638369813 | Ambiguous |
| 1 | Several studies have provided their own definitions and typologies depending on the linguistic nature of the receipt language. |
| 2 | The subjects declared having an English language certification (e.g., TOEFL or IELTS); others completed six semesters from an English course offered by the Centro de Educación Continua. The link provides more information about the English course: https://centrodeeducacioncontinua.uabc.mx/ingles/ (accessed on 2 November 2024). |
| 3 | Hagiwara (1997) and Aiello (2010) included northern and southern areas of California as well as both speaker’s sexes. Therefore, they provided sufficient information to ground average formants of this English dialect, suitable at least for the present study, despite the variation in sex among the subjects that crucially influences the average of both formants. |
| 4 | Other studies (Zeldin, 2023) advocated for the use of Euclidean metrics to measure interphonemic distance. The studies emphasized its utility in quantifying phonetic similarity—even with limited data—across languages and applications like hearing assessments. Therefore, this measurement fits ideally for this limited dataset. |
| 5 | This consideration is based on Usage-Based Phonology (Bybee, 1999, pp. 225–227) that suggests that phonetic and phonological patterns arise through the frequency or productive repetitive use of structures. |
| 6 |
References
- Aiello, A. (2010). A phonetic examination of California [Master’s thesis, University of California]. [Google Scholar]
- Aubanel, V., Davis, C., & Kim, J. (2015, August 10–14). Syllabic structure and informational content in English and Spanish. 18th International Congress of Phonetic Sciences (ICPhS 2015), Glasgow, UK. Available online: https://hal.science/hal-02068860v1 (accessed on 14 October 2024).
- Baigorri, M., Campanelli, L., & Levy, E. S. (2018). Perception of American-English vowels by early and late Spanish-English bilinguals. Language and Speech, 62(4), 681–700. [Google Scholar] [CrossRef] [PubMed]
- Bäumler, L. (2024). Loanword phonology of Spanish anglicisms: New insights from corpus data. Languages, 9(9), 294. [Google Scholar] [CrossRef]
- Best, C. T. (1995). A direct realistic view of cross-language speech perception. In W. Strange (Ed.), Speech perception and linguistic experience: Issues in cross-language research (pp. 171–204). York Press. [Google Scholar]
- Best, C. T., & Tyler, M. D. (2007). Nonnative and second-language speech perception: Commonalities and complementarities. In O.-S. Bohn, & M. J. Munro (Eds.), Language experience in second language speech learning: I honor of james emil flege (pp. 13–34). John Benjamins. [Google Scholar]
- Boersma, P., & Weenink, D. (2023). Praat: Doing phonetics by computer (Version 6.1.40) [Computer Software]. Available online: https://www.fon.hum.uva.nl/praat/ (accessed on 25 November 2024).
- Bybee, J. L. (1999). Usage-based phonology. In M. Darnell, F. J. Newmeyer, M. Noonman, & E. A. Moravcsik (Eds.), Functionalism and formalism in linguistics (Vol. 1, pp. 211–242). John Benjamins Publishing Company. [Google Scholar]
- Calabrese, A., & Wetzels, L. (2009). Loan phonology: Issues and controversies. In A. Calabrese, & L. Wetzels (Eds.), Loan phonology (pp. 1–10). John Benjamins Publishing Company. [Google Scholar]
- Council of Europe. (2001). Common European framework of reference for languages: Learning, teaching, assessment. Cambridge University Press. [Google Scholar]
- Duběda, T. (2020). The phonology of anglicisms in French, German and Czech: A contrastive approach. Journal of Language Contact, 13(1), 327–350. [Google Scholar] [CrossRef]
- El Colegio de México. (2010). Diccionario del Español de México. Available online: https://dem.colmex.mx (accessed on 10 January 2025).
- Escandón, A. (2019). Linguistic practices and the linguistic landscape along the US-Mexico border: Translanguaging in Tijuana [Ph.D. dissertation, University of Southampton]. Available online: http://eprints.soton.ac.uk/id/eprint/438663 (accessed on 11 June 2023).
- Escudero, P. (2005). Linguistic perception and second language acquisition: Explaining the attainment of optimal phonological categorization [Ph.D. dissertation, University of Utrecht]. [Google Scholar]
- Escudero, P. (2006). The phonological and phonetic development of new vowel contrasts in Spanish learners of English. In B. O. Baptista, & M. A. Watkins (Eds.), English with a Latin beat: Studies in Portuguese/Spanish English interphonology (pp. 41–55). John Benjamins. [Google Scholar] [CrossRef]
- Flege, J. E. (1995). Second-language speech learning: Theory, findings, and problems. In W. Strange (Ed.), Speech perception and linguistic experience: Issues in cross-language research (pp. 233–277). York Press. [Google Scholar]
- Flege, J. E., Bohn, O.-S., & Jang, S. (1997). Effects of experience on non-native speakers’ production and perception of English vowels. Journal of Phonetics, 25(4), 437–470. [Google Scholar] [CrossRef]
- Gottlieb, H. (2005). Anglicisms and translation. In G. Anderman, & M. Rogers (Eds.), In and out of English: For better, for worse? (pp. 161–184) Multilingual Matters. [Google Scholar] [CrossRef]
- Grijalva, C., Piccinini, E., & Arvaniti, A. (2013). The vowels spaces of southern Californian English and Mexican Spanish as produced by monolinguals and bilinguals. The Journal of the Acoustical Society of America, 133(5), 3340. [Google Scholar] [CrossRef]
- Hagiwara, R. (1997). Dialect variation and formant frequency: The American English vowels revisited. The Journal of the Acoustical Society of America, 102(1), 655–658. [Google Scholar] [CrossRef]
- Harrington, J. (2010). The phonetic analysis of speech corpora. Wiley-Blackwell. [Google Scholar]
- Haspelmath, M. (2009). Lexical borrowings: Concepts and issues. In M. Haspelmath, & U. Tadmor (Eds.), Loanwords in the world’s languages: A comparative handbook (pp. 35–54). De Gruyter Mouton. [Google Scholar] [CrossRef]
- Jeske, A. (2012). The perception of English vowels by native Spanish speakers [Unpublished Master’s thesis, University of Pittsburgh]. Available online: http://d-scholarship.pitt.edu/13199/ (accessed on 19 October 2024).
- Labov, W., Ash, S., & Boberg, C. (2006). The atlas of North American English: Phonetics, phonology and sound change. Mouton de Gruyter. [Google Scholar]
- Lallier, M., Valdois, S., Lassus-Sangosse, D., Prado, Chloé, & Kandel, S. (2014). Impact of orthographic transparency on typical and atypical reading development: Evidence in French-Spanish bilingual children. Research in Developmental Disabilities, 35(5), 1177–1190. [Google Scholar] [CrossRef] [PubMed]
- Lanz, L. (2020). Actitudes lingüísticas frente al inglés en Tijuana. Gloss, 9(9), 47–61. Available online: https://glosas.anle.us/site/assets/files/1286/07_lanz_vallejo.pdf (accessed on 25 June 2023).
- Lanz, L. (2022). Mixed feelings en Tijuana: Bilingüismo, sentimiento y consumo. McGraw Hill. [Google Scholar]
- Liberman, M. Y. (2019). Corpus phonetics. Annual Review of Linguistics, 5(1), 91–107. [Google Scholar] [CrossRef]
- McCloy, R. (2016/2023). Normalizing and plotting vowels with phonR 1.0.7. Available online: https://drammock.github.io/phonR/ (accessed on 22 December 2024).
- Milroy, L., & Gordon, M. (2003). Style-shifting and code-switching. In Sociolinguistics: Method and interpretation (pp. 188–222). Wiley & Sons. [Google Scholar] [CrossRef]
- Nuñez-Nogueroles, E. E. (2017). Typographical, orthographic and morphological variation of Anglicisms in a corpus of Spanish newspaper texts. Revista Canaria de Estudios Ingleses, (75), 175–190. Available online: http://riull.ull.es/xmlui/handle/915/6972 (accessed on 22 November 2024).
- Paradis, C., & LaCharité, D. (2008). Apparent phonetic approximation: English loanwords in Old Quebec French. Journal of Linguistics, 44(1), 87–128. [Google Scholar] [CrossRef]
- Pols, L. C. W., Tromp, H. R. C., & Plomp, R. (1973). Perceptual and physical space of vowels. The Journal of the Acoustical Society of America, 54(1), 92–105. [Google Scholar] [CrossRef]
- R Core Team. (2023). R: A language and environment for statistical computing. R Foundation for Statistical Computing. Available online: https://www.R-project.org/ (accessed on 12 November 2024).
- Real Academia Española. (2001). Nuevo tesoro lexicográfico de la lengua española. Espasa Calpe. Available online: https://www.rae.es/obras-academicas/diccionarios/nuevo-tesoro-lexicografico-0 (accessed on 10 January 2025).
- Recasens, D. (2015). The effect of stress and speech rate on vowel coarticulation in catalan vowel-consonant-vowel sequences. Journal of Speech, Language, and Hearing Research, 58(5), 1407–1424. [Google Scholar] [CrossRef] [PubMed]
- Shea, C. (2021). Spanish speaker’s English schwar production: Does orthography play a role? Applied Psycholinguistics, 42(6), 1377–1401. [Google Scholar] [CrossRef]
- Silva-Corvalán, C. (2017). Variación y cambio. In C. Silva-Corvalán, & A. Enrique-Arias (Eds.), Sociolingüística y pragmática del español (2nd ed., pp. 262–297). Georgetown University Press. [Google Scholar]
- Strange, W. (2005). Cross-language comparisons of contextual variation in the production and perception of vowels. The Journal of the Acoustical Society of America, 117, 2399. [Google Scholar] [CrossRef]
- Thomas, E. R. (2011). Sociophonetics: An introduction. Palgrave Macmillan. [Google Scholar]
- Toledo, D., & García, L. (2018). Escenarios lingüísticos emergentes en la frontera Tijuana-San Diego. Káñiña, Revista Artes y Letras-Universidad de Costa Rica, 42(2), 87–111. [Google Scholar] [CrossRef]
- Zeldin, A. (2023). The Euclidean metrics applied to the interphonemic distance measurements. Philology and Culture, 71(1), 10–13. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic | Description |
|---|---|
| Nationality | Mexico/United States |
| Age | 20–29 |
| Sex | Female/male |
| First language | Spanish |
| Proficiency level (English) | Intermediate/advanced |
| Education level | High school/university |
| Place of residence | Tijuana |
| Current interaction with English | Yes (work or leisure) or no |
| English F1 F2 | /ɑ/ F1: 762 F2: 1209 | /æ/ F1: 814 F2: 1666 | /i/ F1: 317 F2: 2546 | /ʌ/ F1: 663 F2: 1512 | /ɔ/ F1: 632 F2: 1172 | /u/ F1: 357 F2: 1281 | /ɛ/ F1: 655 F2: 1844 |
| Spanish F1 F2 | /a/ F1: 839 F2: 1558 | /e/ F1: 585 F2: 2115 | /i/ F1: 371 F2: 2581 | /o/ F1: 606 F2: 1012 | /u/ F1: 451 F2: 836 |
| Vocalic Sound | Anglicism and Frequency | Frequency Total |
|---|---|---|
| [ɑ] | boss (5), spot(s) (4) | 9 |
| [ʌ] | bun (4), bundle (3), crush (4), flush (3), fuck (3), must (3) | 20 |
| [ɔ] | core (4), mall(s) (5) | 9 |
| [æ] | match (3) | 3 |
| [a] | cash (3), dark (3), (to) hack (3), sad (6), staff (3) | 18 |
| [e] | blend (3), nerd (4) | 7 |
| [i] | bleach (3), cheers (3), clean (3), gym (6), tip(s) (6), trip (5), weed (4), weird (5) | 35 |
| [o] | shot(s) (3), top (4) | 7 |
| [u] | cool (6), dude (3), loop (3), mood (5), plus (6) | 23 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peralta-Rivera, R.R.; Gil-Burgoin, C.I.; Valenzuela-Miranda, N.E. Phonetically Based Corpora for Anglicisms: A Tijuana–San Diego Contact Outcome. Languages 2025, 10, 143. https://doi.org/10.3390/languages10060143
Peralta-Rivera RR, Gil-Burgoin CI, Valenzuela-Miranda NE. Phonetically Based Corpora for Anglicisms: A Tijuana–San Diego Contact Outcome. Languages. 2025; 10(6):143. https://doi.org/10.3390/languages10060143
Chicago/Turabian StylePeralta-Rivera, Ruben Roberto, Carlos Ivanhoe Gil-Burgoin, and Norma Esthela Valenzuela-Miranda. 2025. "Phonetically Based Corpora for Anglicisms: A Tijuana–San Diego Contact Outcome" Languages 10, no. 6: 143. https://doi.org/10.3390/languages10060143
APA StylePeralta-Rivera, R. R., Gil-Burgoin, C. I., & Valenzuela-Miranda, N. E. (2025). Phonetically Based Corpora for Anglicisms: A Tijuana–San Diego Contact Outcome. Languages, 10(6), 143. https://doi.org/10.3390/languages10060143