The controller design is a requirement for the generic helicopter model because the open loop system can sometimes lead to unpractical trajectories that contain chattering, and random sampling can result in infeasible trajectories when lateral and longitudinal dynamics of the helicopter are not uncoupled with an appropriate control structure. Another challenge originates from the parameter uncertainties. Because it may be required to estimate some of the model parameters, the designed controller should be robust against the uncertainties in the model parameters.
3.1. Control Structure
This study benefits from the successive loop closure approach and nonlinear dynamic inversion to design the control system. Successive loop closure is a concept based on creating several sequential feedback loops around the original open-loop system instead of designing a single complex control structure. It eases the process when it is required to control the inertial position and attitude of a vehicle at the same time. While an inner loop is used to control the attitude, the outer loop manages the position. However, when there are nonlinearities in the system dynamics, it cannot be expected to obtain the desired performance by applying the classical linear control techniques in a successive loop closure frame. To overcome this limitation, the technique of nonlinear dynamic inversion can be utilized. The basic idea of nonlinear dynamic inversion is to perform a variable transformation to unwrap a nonlinear system into a simple linear system [
14]. Let us consider the following system:
where
Z is the vector of state variables and
u is the control input. The system (
6) can be presented in an input–output linear form by defining a new control input as:
After substituting
u defined in (
7) into the system (
6), the system dynamics become:
This new system can easily be controlled with the conventional linear control techniques when the is considered as the new control input.
In this study, the control of the longitudinal motion of the helicopter is separated from the lateral motion to ease the trajectory generation process. In the control structure, the vertical and horizontal motion are managed by the thrust level
and the rotor roll angle
, respectively. Additionally, the speed of the helicopter is adjusted by setting the rotor pitch angle
. The proposed control structure is presented in
Figure 1.
The rotor roll command
and rotor pitch command
are utilized to set the rotor roll angle
and rotor pitch angle
, respectively. The relation between the commanded target values and the real angles is presented using first-order equations as follows:
For the vertical motion, two commanded target values are defined, i.e., the target altitude
and the target vertical speed
. Both altitude and vertical speed are managed by adjusting the thrust level
via the successive loop closure approach. While the inner loop in
Figure 1 is used to set the vertical speed, the outer loop is designed to manage the altitude. Because there is a natural integrator in the system when controlling the altitude and the open-loop system is fast enough, a proportional controller (P-controller) is sufficient for the outer loop. For the inner loop, a PID controller is proposed to improve both transition and steady-state performance of the closed-loop system. A new control signal
is defined, benefiting from the nonlinear dynamic inversion approach, to create a new input–output linear system that makes the linear control techniques usable without any chattering. The function that is derived via nonlinear dynamic inversion is presented as follows:
When the defined function is written into the fifth equation of the system model (i.e., (
1) or (
3)), it can easily be seen that the new equation will be
, which makes the new system input–output linear and easily controlled using the linear control techniques.
In the proposed control structure, the horizontal and vertical motions are uncoupled. When there are changes to the rotor roll angle or rotor pitch angle, the P-PID controller compensates for the impact of the changes on the vertical motion by modifying the thrust level . This makes the closed-loop system appropriate for feasible trajectory generation with random sampling.
3.2. Reinforcement Learning (RL)-Based Robust PID Tuning
When the model parameters are not known precisely and obtained based on an estimation, the control performance can be affected by deviations in the model parameters. A robust PID design can be proposed to mitigate this impact. As illustrated in
Figure 1, an RL-based PID tuner is developed to obtain robust PID parameters.
Reinforcement learning (RL) is an approach based on a trial and error process. By interacting with its environment, the RL agent receives rewards and uses these rewards to calculate the overall return for the defined task. When the environment is fully observable, the focused problem can be described as a Markov decision process (MDP).
A Markov decision process (MDP) is a tuple , where:
S is a set of states;
A is a set of actions;
T is a state transition probability function, ;
r is a reward function, ;
is a discount factor, which represents the difference in importance between future rewards and present rewards, .
The core problem of MDPs is to find a policy
for the decision-maker by maximizing the long-term future reward. A policy is a mapping from states to actions that defines the behavior of an agent:
and long-term reward is presented as:
However, the calculation of
contains the rewards in the future, which must be calculated with a strategy that is different from the direct calculation. The expected long-term reward can be used in this process. For this purpose, two different functions are defined. The state-value function
of an MDP is the expected return starting from state
s, and the following policy
:
The action-value function
is the expected return starting from state
s, taking action
a, and the following policy
:
Bellman [
15] shows that value functions can be decomposed into two parts, namely, immediate rewards and the discounted value of the successor:
Using this property, value functions can be calculated with recursive algorithms. Then, optimal value functions can also be calculated to generate optimal policy. For example, an optimal policy can be generated by using the Bellman optimality equation [
15,
16], also known as value iteration. However, finding an optimal policy using the Bellman optimality equation requires a huge amount of space and time when the number of states and actions is high. These kinds of recursive methods, such as value iteration and policy iteration [
17], make calculations for all of the state-action pairs in working space, so the computation is hard in real implementations. To overcome this computational inefficiency, an alternative strategy called reinforcement learning (RL) comes from the machine learning domain.
Reinforcement learning consists of an active decision-making agent that interacts with its environment to accomplish a defined task by maximizing the overall return. The future states of the environment are also affected by the agent’s actions. This process is modeled as an MDP when there is a fully observable environment. There are various RL methods that can be utilized to provide a solution for an MDP [
17]. RL methods define how the agent changes its policy as a result of its experience. The learning process is based on a sampling-based simulation.
In this study, we benefit from the Proximal Policy Optimization (PPO) algorithm [
18] as the RL method. It is based on an actor–critic framework in which two different neural networks are used: actor and critic. While the critic estimates the value function, the actor modifies the policy according to the direction suggested by the critic.
The main idea behind the PPO is to improve the training stability of the policy by limiting the policy change at each training epoch. This is achieved by measuring how much the policy changed with respect to the previous policy using a ratio calculation between the current and previous policy and then clipping this ratio in the range to prevent the current policy from going too far from the former one.
In the PPO, the objective function that the algorithm tries to maximize in each iteration is defined as follows:
where
refers to the set of policy parameters.
S is the entropy bonus that is used to ensure sufficient exploration. This term encourages the algorithm to try different actions. It can be tuned by setting the constant
to achieve the balance between exploration and exploitation.
and
are constants.
is the squared-error value loss,
. The term
regulates how large the gradient steps can be through gradient clipping. It restricts the range that the current policy can vary from the old one, which is defined as follows:
where
is a hyperparameter. The estimated advantage
refers to the difference between the discounted sum of rewards and the state-value function. Additionally,
symbolizes the probability ratio between the new and the old policy. This ratio measures the difference between the two policies, and it is defined as follows:
where
is the old policy.
The PPO algorithm [
18] is given below (Algorithm 1). In each iteration, the parallel actors collect the data to compute the average estimates. Additionally, the objective
L (
17) is maximized via the obtained information by modifying the set of policy parameters
based on the stochastic gradient descent. In this way, the policy network is trained iteratively.
| Algorithm 1: PPO Algorithm |
For iteration = 1, 2, … do: For actor = 1, 2, …, N do: Run old policy for T timesteps Compute advantage estimates Optimize L ( 17) with respect to with K epochs and minibatch size Update the old policy
|
The PID tuner is considered to be the RL agent by defining a policy neural network (NN) with a single neuron. The states or the inputs of the policy NN are defined as the error, the derivative of the error, and the error’s integral. Because there is only one layer with a single neuron, each signal is multiplied by a coefficient, i.e.,
and
, when the bias unit is discarded. Additionally, the reward is defined as the negative of the absolute error. The concept of domain randomization [
19] is utilized to consider the variability and create a robust structure during the training. In domain randomization, the different aspects of the domain are randomized in the samples used during the training to ensure simulation variability and address the reality gap. In this study, we benefit from domain randomization by giving random deviations to the model parameters during the training. After completing the training process, the coefficients in the policy NN are assigned as the corresponding PID parameters. In this way, a robust set of parameters for the PID controller is obtained by considering random model parameter uncertainties during the training process.
3.3. Simulation Results
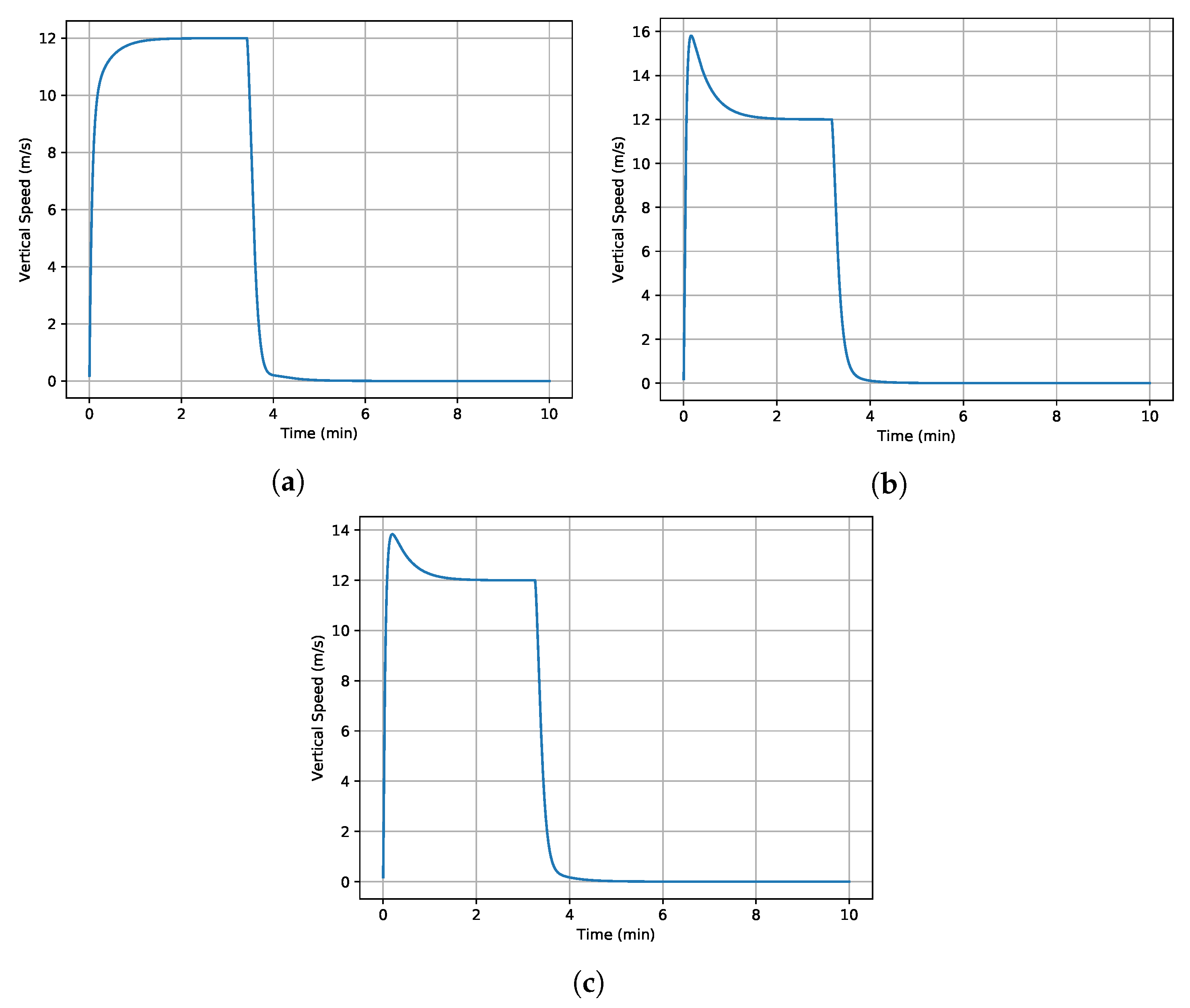
Many different scenarios have been assessed to analyze the performance of the proposed control architecture against the model parameter uncertainty. Parameters
and
in Equation (
10) are considered during the robustness assessment. As illustrative examples, the results of three case studies are presented in
Figure 2 and
Figure 3. In these case studies, the initial speed of the helicopter is set to zero, and the maximum rotor pitch angle is applied. While the helicopter is in hover at the beginning of the simulation, it accelerates and switches from hover to forward flight. Then, it continues accelerating to a speed of
in forward flight. In this way, it experiences both hover and forward flight during simulations. In the first case study, all parameters are considered with
deviation, and
deviation is applied to all parameters in the second case. The third case study gives different deviations to the
with respect to others to show that it is the main parameter that drives the system’s robustness.
Overall, the altitude can be controlled without any overshoot or steady-state error. The deviations in the model parameters have almost no impact on the performance of the altitude control, as illustrated in
Figure 2. However, there could be an overshoot on the vertical speed, which is controlled without a steady-state error. Especially, the uncertainty in
can lead to an overshoot with almost no impact on the settling time.






{kind=link}
{kind=link}
{kind=link}
{kind=link}