

Design and Simulation of a Neuroevolutionary Controller for a Quadcopter Drone



Abstract
1. Introduction
2. Literature Review and Motivation
3. Drone Control with a Neuro-Evolutionary Algorithm
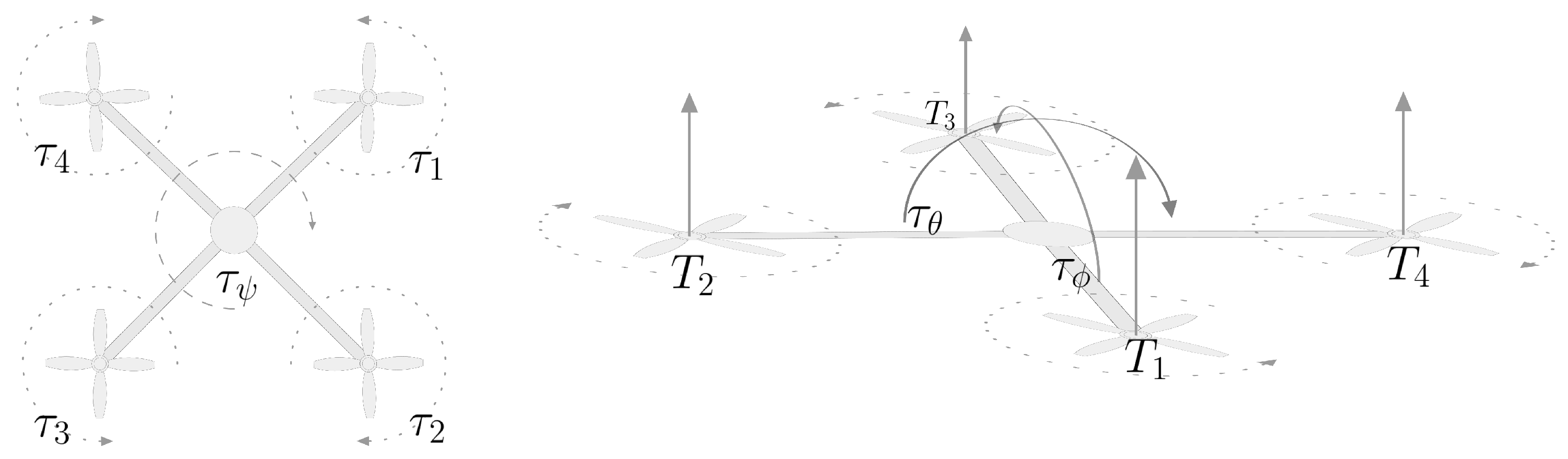
3.1. Mathematical Model of a Quadcopter Drone
- From the current state (including the initial conditions), the torque and the thrust intensity T along the z-axis relative to the body frame are computed aswhere the constant l denotes the length of the drone’s arms, the constant k denotes the lift constant and the parameter b denotes the ‘drag’ constant of a single rotor. The above equations account for the spinning directions of the rotors as well as the efficiency of the rotors’ blades. The drag effect refers to the fact that the collective spinning of the rotors tends to make the body of the quadcopter spin as well along the vertical axis.
- On the basis of the torque vector , the angular acceleration of the quadcopter’s body relative to the body frame is calculated aswhere , and denote the moments of inertia of the quadcopter with respect to the principal axes of inertia, which are supposed to coincide to those of the reference frame, while denotes the moment of inertia of each rotor along the z-axis (which is the only inertia value of interest). Since the structure is—in good approximation—geometrically symmetrical, it is commonly assumed that . To compute the angular velocity vector in a computer-based implementation, the differential Equation (6) will be solved using numerical recipes.
- By using the transformation matrix , the attitude-change rate of the quadcopter relative to the ground can be obtained by a transformation of the angular velocity vector relative to the body frame :By numerically solving such a further differential equation, the attitude of the quadcopter is obtained at every time-step of the simulation.
- The center of mass’s acceleration relative to the earth frame is then obtained by applying the gravity acceleration directly and by applying the thrust force vector (divided by the drone’s mass and rotated using the attitude matrix ). The acceleration obeys Newton’s law:where m denotes the mass of the quadcopter, denotes the gravitational force (weight) directed towards the negative direction of the earth frame’s z-axis, namely, , where c denotes the gravitational acceleration constant and . In addition, the quantity denotes a friction matrix. Notice that since the force is only applied to the z-axis of the drone, only the third column of plays a role in such an equation. The relationship (8) may be cast in plain form aswhere and are the friction coefficients for the velocities in the x-, y- and z-direction, respectively, of the earth frame of reference.
3.2. Proposed Control Strategy
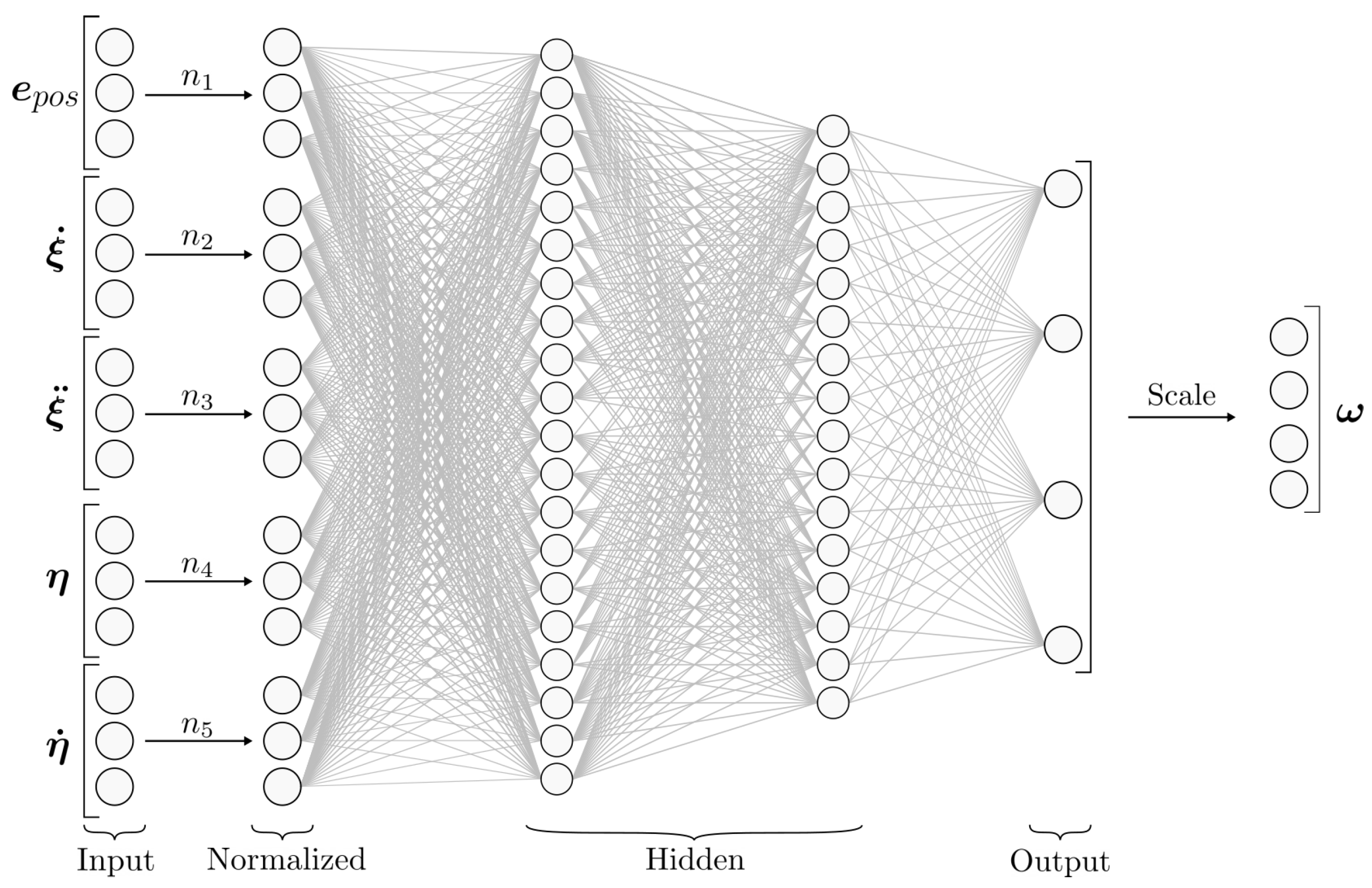
3.3. Neural-Network-Type Controller Structure
3.4. Evolutionary Training Algorithm
3.4.1. Initialization
3.4.2. Starting State Definition
3.4.3. Population Evaluation
3.4.4. Next Population Generation with an Evolutionary Algorithm
| Algorithm 1 Next-population-generation algorithm |
|
4. Implementation
4.1. Numerical Implementation
4.2. Software Implementation
4.2.1. Program Functionality
- The program defines the simulation parameters in a configuration file;
- The code applies the evolutionary algorithm with the specified configuration, while a virtual 3D environment is showing the evolution of the generations;
- The program supplies the evolutionary algorithm without the 3D environment to increase the training speed;
- The software loads and saves the neural networks of a population produced by the algorithm in a JSON file;
- The program simulates (from a neural network file) and shows in 3D the best individual in that population while it runs along a randomly generated spatial path.
4.2.2. Exemplary Screenshots
5. Computer-Based Simulated Experiments
- Parameters regarding the quadcopter model and its numerical simulation: , , , , , , , , , .
- Parameters of the evolutionary-type learning algorithm: , , , , , , , , , , , , , .
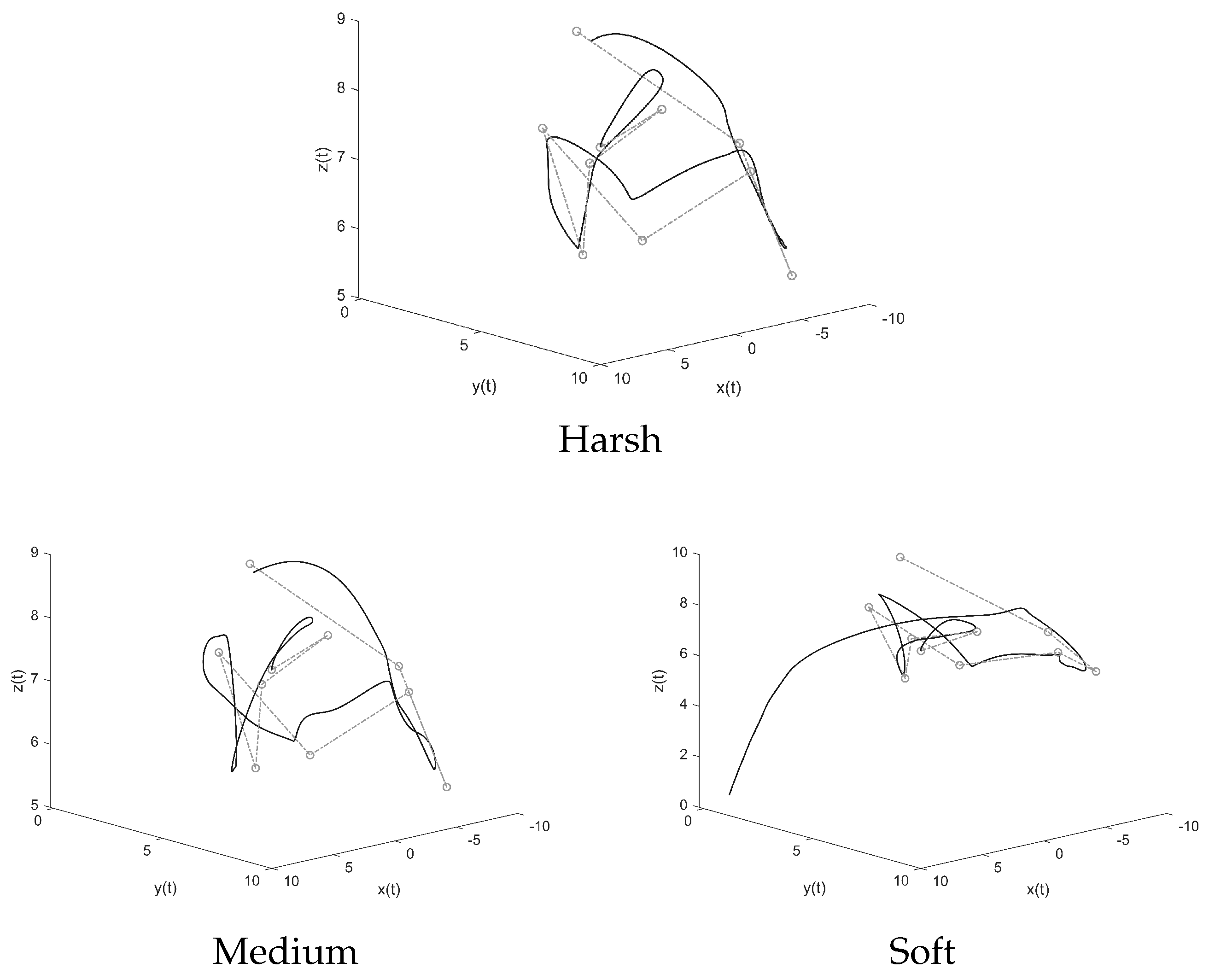
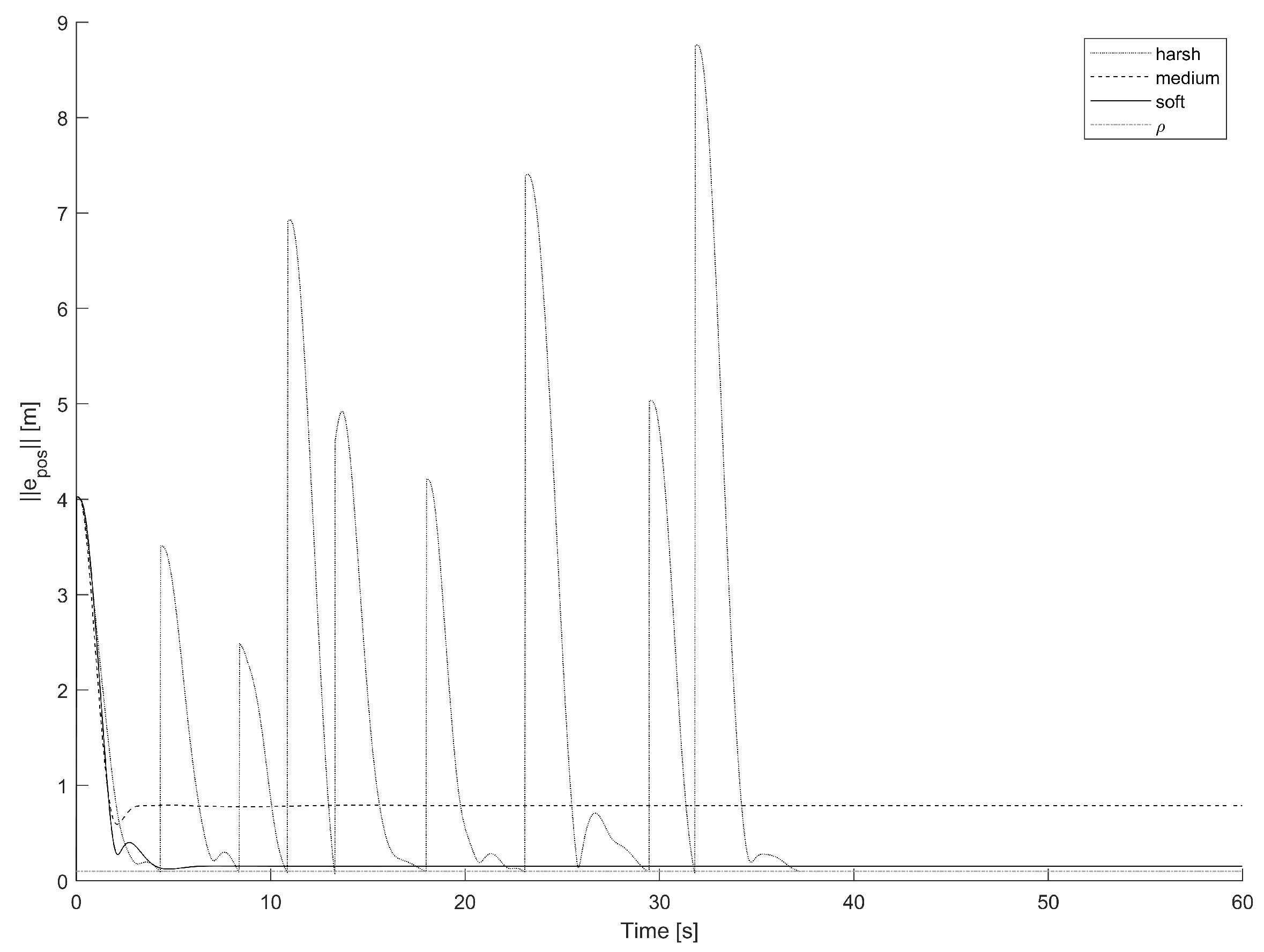
5.1. General Performance Assessment and Harshness Configuration Testing
5.1.1. Loose Path-Following
- The harsh training produces more stable and more ‘careful’ controllers that are not prone to make a quadcopter crash, at the cost of some slowdown along the trajectory.
- The soft training yields faster and more ‘reckless’ individuals, at the cost of occasional crashes where the quadcopter visits a state that it was not evolved to cope with.
- The medium-harshness training causes deplorable effects compared to the harsh and the soft training in terms of speed and reliability. Such a result is due to the fact that the training conditions are not harsh enough to produce reliable individuals, yet they are harsh enough to hinder the training process in evolving fast individuals.
5.1.2. Tight Path-Following
5.1.3. Additional Precision Tests
5.2. Experiments on Different Network Topologies
- Complex topology: (which will be referred to as ‘complex’),
- Medium-size topology: (which will be referred to as ‘medium’),
- Simple topology: (which will be referred to as ‘simple’).
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Barbedo, J. A review on the use of unmanned aerial vehicles and imaging sensors for monitoring and assessing plant stresses. Drones 2019, 3, 40. [Google Scholar] [CrossRef]
- Budiharto, W.; Chowanda, A.; Gunawan, A.; Irwansyah, E.; Suroso, J. A Review and Progress of Research on Autonomous Drone in Agriculture, Delivering Items and Geographical Information Systems (GIS). In Proceedings of the 2019 2nd World Symposium on Communication Engineering (WSCE), Nagoya, Japan, 20–23 December 2019; pp. 205–209. [Google Scholar]
- Hassanalian, M.; Rice, D.; Abdelkefi, A. Evolution of space drones for planetary exploration: A review. Prog. Aerosp. Sci. 2018, 97, 61–105. [Google Scholar] [CrossRef]
- Lee, S.; Choi, Y. Reviews of unmanned aerial vehicle (drone) technology trends and its applications in the mining industry. Geosystem Eng. 2016, 19, 197–204. [Google Scholar] [CrossRef]
- Rao Mogili, U.; Deepak, B. Review on application of drone systems in precision agriculture. Procedia Comput. Sci. 2018, 133, 502–509. [Google Scholar] [CrossRef]
- Morris, K.C.; Schlenoff, C.; Srinivasan, V. Guest Editorial: A remarkable resurgence of artificial intelligence and its impact on automation and autonomy. IEEE Trans. Autom. Sci. Eng. 2017, 14, 407–409. [Google Scholar] [CrossRef]
- Erginer, B.; Altug, E. Modeling and PD control of a quadrotor VTOL vehicle. In Proceedings of the 2007 IEEE Intelligent Vehicles Symposium, Istanbul, Turkey, 13–15 June 2007; pp. 894–899. [Google Scholar]
- Bolandi, H.; Rezaei, M.; Mohsenipour, R.; Nemati, H.; Smailzadeh, S. Attitude control of a quadrotor with optimized PID controller. Intell. Control. Autom. 2013, 4, 335–342. [Google Scholar] [CrossRef]
- Li, J.; Li, Y. Dynamic analysis and PID control for a quadrotor. In Proceedings of the 2011 IEEE International Conference on Mechatronics and Automation, Beijing, China, 7–10 August 2011; pp. 573–578. [Google Scholar]
- Salih, A.L.; Moghavvemi, M.; Mohamed, H.A.F.; Gaeid, K.S. Modelling and PID controller design for a quadrotor unmanned air vehicle. In Proceedings of the 2010 IEEE International Conference on Automation, Quality and Testing, Robotics (AQTR), Cluj-Napoca, Romania, 28–30 May 2010; Volume 1, pp. 1–5. [Google Scholar]
- Szafranski, G.; Czyba, R. Different approaches of PID control UAV type quadrotor. In Proceedings of the International Micro Air Vehicles Conference 2011 Summer Edition, ’t Harde, The Netherlands, 12–15 September 2011; pp. 70–75. [Google Scholar] [CrossRef]
- Saif, A.W.; Dhaifullah, M.; Al-Malki, M.; El Shafie, M. Modified backstepping control of quadrotor. In Proceedings of the International Multi-Conference on Systems, Signals & Devices, Chemnitz, Germany, 20–23 March 2012; pp. 1–6. [Google Scholar]
- Argentim, L.M.; Rezende, W.C.; Santos, P.E.; Aguiar, R.A. PID, LQR and LQR-PID on a quadcopter platform. In Proceedings of the 2013 International Conference on Informatics, Electronics and Vision (ICIEV), Dhaka, Bangladesh, 17–18 May 2013; pp. 1–6. [Google Scholar]
- Besnard, L.; Shtessel, Y.; Landrum, B. Quadrotor vehicle control via sliding mode controller driven by sliding mode disturbance observer. J. Frankl. Inst. 2012, 349, 658–684. [Google Scholar] [CrossRef]
- Siti, I.; Mjahed, M.; Ayad, H.; El Kari, A. New trajectory tracking approach for a quadcopter using genetic algorithm and reference model methods. Appl. Sci. 2019, 9, 1780. [Google Scholar] [CrossRef]
- Grzonka, S.; Grisetti, G.; Burgard, W. A fully autonomous indoor quadrotor. IEEE Trans. Robot. 2011, 28, 90–100. [Google Scholar] [CrossRef]
- Rodić, A.; Mester, G.; Stojković, I. Qualitative evaluation of flight controller performances for autonomous quadrotors. In Intelligent Systems: Models and Applications; Springer: Berlin/Heidelberg, Germany, 2013; pp. 115–134. [Google Scholar]
- Leal, I.S.; Abeykoon, C.; Perera, Y.S. Design, Simulation, Analysis and Optimization of PID and Fuzzy Based Control Systems for a Quadcopter. Electronics 2021, 10, 2218. [Google Scholar] [CrossRef]
- Pham, T.; Ichalal, D.; Mammar, S. LPV and nonlinear-based control of an autonomous quadcopter under variations of mass and moment of inertia. IFAC-PapersOnLine 2019, 52, 176–183. [Google Scholar] [CrossRef]
- Bai, Y.; Gururajan, S. Evaluation of a Baseline Controller for Autonomous “Figure-8” Flights of a Morphing Geometry Quadcopter: Flight Performance. Drones 2019, 3, 70. [Google Scholar] [CrossRef]
- Bakar, A.; Ke, L.; Liu, H.; Xu, Z.; Wen, D. Design of low altitude long endurance solar-powered UAV using genetic algorithm. Aerospace 2021, 8, 228. [Google Scholar] [CrossRef]
- Kaufmann, E.; Loquercio, A.; Ranftl, R.; Dosovitskiy, A.; Koltun, V.; Scaramuzza, D. Deep drone racing: Learning agile flight in dynamic environments. In Proceedings of the 2nd Annual Conference on Robot Learning, CoRL 2018, Zürich, Switzerland, 29–31 October 2018; Volume 87, pp. 133–145. [Google Scholar]
- Lambert, N.; Drew, D.; Yaconelli, J.; Levine, S.; Calandra, R.; Pister, K. Low-level control of a quadrotor with deep model-based reinforcement learning. IEEE Robot. Autom. Lett. 2019, 4, 4224–4230. [Google Scholar] [CrossRef]
- Dierks, T.; Jagannathan, S. Neural network control of quadrotor UAV formations. In Proceedings of the 2009 American Control Conference, St. Louis, MO, USA, 10–12 June 2009; pp. 2990–2996. [Google Scholar]
- Pham, H.; Soriano, T.; Ngo, V.; Gies, V. Distributed adaptive neural network control applied to a formation tracking of a group of low-cost underwater drones in hazardous environments. Appl. Sci. 2020, 10, 1732. [Google Scholar] [CrossRef]
- Loquercio, A.; Kaufmann, E.; Ranft, R.; Müller, M.; Koltun, V.; Scaramuzza, D. Learning high-speed flight in the wild. Sci. Robot. 2021, 6. [Google Scholar] [CrossRef] [PubMed]
- Perez, R.; Arnal, J.; Jansen, P. Neuro-evolutionary control for optimal dynamic soaring. In Proceedings of the AIAA Scitech 2020 Forum, Orlando, FL, USA, 6–10 January 2020. [Google Scholar] [CrossRef]
- Stanley, K.; Miikkulainen, R. Evolving Neural Networks through Augmenting Topologies. Evol. Comput. 2002, 10, 99–127. [Google Scholar] [CrossRef]
- Shepherd, J.; Tumer, K. Robust neuro-control for a micro quadrotor. In Proceedings of the 12th Annual Conference on Genetic and Evolutionary Computation, GECCO’10, New York, NY, USA, 7–10 July 2010; pp. 1131–1138. [Google Scholar] [CrossRef]
- Alhmoud, L.; Al Dairy, A.R.; Faris, H.; Aljarah, I. Prediction of Hysteresis Loop of Barium Hexaferrite Nanoparticles Based on Neuroevolutionary Models. Symmetry 2021, 13, 1079. [Google Scholar] [CrossRef]
- Xu, J.; Chen, J.; Chen, S. Efficient Opponent Exploitation in No-Limit Texas Hold’em Poker: A Neuroevolutionary Method Combined with Reinforcement Learning. Electronics 2021, 10, 2087. [Google Scholar] [CrossRef]
- Ullah, Q.Z.; Khan, G.M.; Hassan, S.; Iqbal, A.; Ullah, F.; Kwak, K.S. A Cartesian Genetic Programming Based Parallel Neuroevolutionary Model for Cloud Server’s CPU Usage Prediction. Electronics 2021, 10, 67. [Google Scholar] [CrossRef]
- Giernacki, W. Minimum energy control of quadrotor UAV: Synthesis and performance analysis of control system with neurobiologically inspired intelligent controller (BELBIC). Energies 2022, 15, 7566. [Google Scholar] [CrossRef]
- Mendívez Vásquez, B.L.; Barca, J.C. Adversarial scenarios for herding UAVs and counter-swarm techniques. Robotica 2023, 41, 1436–1451. [Google Scholar] [CrossRef]
- Luukkonen, T. Modelling and Control of Quadcopter. Independent Research Project in Applied Mathematics, Aalto University, School of Science, 2011. Available online: https://sal.aalto.fi/publications/pdf-files/eluu11_public.pdf (accessed on 11 October 2018).
- Gambier, A.; Badreddin, E. Multi-objective optimal control: An overview. In Proceedings of the 2007 IEEE International Conference on Control Applications, Singapore, 1–3 October 2007; pp. 170–175. [Google Scholar] [CrossRef]
- Srinivas, M.; Patnaik, L. Learning neural network weights using genetic algorithms-improving performance by search-space reduction. In Proceedings of the 1991 IEEE International Joint Conference on Neural Networks, Singapore, 18–21 November 1991; Volume 3, pp. 2331–2336. [Google Scholar]
- Xue, Z.; Gonsalves, T. Vision based drone obstacle avoidance by deep reinforcement learning. AI 2021, 2, 366–380. [Google Scholar] [CrossRef]
- Chithapuram, C.; Jeppu, Y.; Kumar, C.A. Artificial Intelligence guidance for Unmanned Aerial Vehicles in three dimensional space. In Proceedings of the 2014 International Conference on Contemporary Computing and Informatics (IC3I), Mysore, India, 27–29 November 2014; pp. 1256–1261. [Google Scholar] [CrossRef]
- Whitley, D. A genetic algorithm tutorial. Stat. Comput. 1994, 4, 65–85. [Google Scholar] [CrossRef]
- Bäck, T.; Hoffmeister, F. Extended selection mechanisms in genetic algorithms. In Proceedings of the 4th International Conference on Genetic Algorithms, San Diego, CA, USA, 13–16 July 1991; Morgan Kaufmann: Burlington, MA, USA, 1991; pp. 92–99. [Google Scholar]
- Miller, B.; Goldberg, D. Genetic algorithms, tournament selection, and the effects of noise. Complex Syst. 1995, 9, 193–212. [Google Scholar]
- Črepinšek, M.; Liu, S.H.; Mernik, M. Exploration and exploitation in evolutionary algorithms: A survey. ACM Comput. Surv. 2013, 45. [Google Scholar] [CrossRef]
- Poon, P.; Carter, J. Genetic algorithm crossover operators for ordering applications. Comput. Oper. Res. 1995, 22, 135–147. [Google Scholar] [CrossRef]
- Bäck, T. Optimal mutation rates in genetic search. In Proceedings of the Fifth International Conference on Genetic Algorithms, San Francisco, CA, USA, 1 June 1993. [Google Scholar]
- Fiori, S.; Bigelli, L.; Polenta, F. Lie-group type quadcopter control design by dynamics replacement and the virtual attractive-repulsive potentials theory. Mathematics 2022, 10, 1104. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Configuration | ||
|---|---|---|---|
| Harsh | Medium | Soft | |
| 1.2 | 0.6 | 0.2 | |
| 1.5 | 0.75 | 0.1 | |
| 4 | 2 | 0.1 | |
| 1 | 0.5 | 0.0 | |
| Configuration | No. of Crashes | No. of Stalls | |||
|---|---|---|---|---|---|
| Harsh | 14.64 | 19.98 | 25.06 | 0 | 0 |
| Medium | 17.54 | 24.28 | 32.64 | 749 | 0 |
| Soft | 12.24 | 17.59 | 24.00 | 101 | 0 |
| Configuration | No. of Crashes | No. of Stalls | |||
|---|---|---|---|---|---|
| Harsh | 29.18 | 42.49 | 54.74 | 0 | 0 |
| Medium | - | - | - | 31 | 969 |
| Soft | - | - | - | 5 | 995 |
| Path Parameters | Travel Times | Paths Not Completed | |||||
|---|---|---|---|---|---|---|---|
| ℓ | No. of Crashes | No. of Stalls | |||||
| 200 | 0.3 | 0.15 | 177.94 | 202.24 | 223.5 | 0 | 0 |
| 200 | 0.2 | 0.1 | 212.92 | 247.09 | 277.06 | 0 | 0 |
| 150 | 0.18 | 0.09 | 179.06 | 208.92 | 240.52 | 0 | 0 |
| 150 | 0.18 | 0.085 | 194.32 | 236.13 | 268.4 | 0 | 0 |
| 200 | 0.2 | 0.08 | - | - | - | 0 | 10,000 |
| 150 | 0.18 | 0.075 | - | - | - | 0 | 10,000 |
| 200 | 0.15 | 0.075 | - | - | - | 0 | 10,000 |
| Path Parameters | Topology | Travel Times | Paths Not Completed | |||||
|---|---|---|---|---|---|---|---|---|
| ℓ | No. of Crashes | No. of Stalls | ||||||
| 20 | 10 | 1 | Complex | 56.80 | 71.93 | 86.72 | 27 | 0 |
| Medium | 41.08 | 52.41 | 60.64 | 8 | 0 | |||
| Simple | - | - | - | 500 | 0 | |||
| 20 | 10 | 0.5 | Complex | - | - | - | 6 | 494 |
| Medium | 54.26 | 67.98 | 82.26 | 3 | 0 | |||
| Simple | - | - | - | 500 | 0 | |||
| 100 | 0.2 | 0.1 | Complex | - | - | - | 0 | 500 |
| Medium | - | - | - | 0 | 500 | |||
| Simple | - | - | - | 0 | 500 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mariani, M.; Fiori, S. Design and Simulation of a Neuroevolutionary Controller for a Quadcopter Drone. Aerospace 2023, 10, 418. https://doi.org/10.3390/aerospace10050418
Mariani M, Fiori S. Design and Simulation of a Neuroevolutionary Controller for a Quadcopter Drone. Aerospace. 2023; 10(5):418. https://doi.org/10.3390/aerospace10050418
Chicago/Turabian StyleMariani, Manuel, and Simone Fiori. 2023. "Design and Simulation of a Neuroevolutionary Controller for a Quadcopter Drone" Aerospace 10, no. 5: 418. https://doi.org/10.3390/aerospace10050418
APA StyleMariani, M., & Fiori, S. (2023). Design and Simulation of a Neuroevolutionary Controller for a Quadcopter Drone. Aerospace, 10(5), 418. https://doi.org/10.3390/aerospace10050418